
Abstract
Given the limitation of current routine approaches for pancreatic cancer screening and detection, the mortality rate of pancreatic cancer cases is still critical. The development of blood-based molecular biomarkers for pancreatic cancer screening and early detection which provide less-invasive, high-sensitivity, and cost-effective, is urgently needed. The goal of this study is to identify and validate the potential molecular biomarkers in white blood cells (WBCs) of pancreatic cancer patients. Gene expression profiles of pancreatic cancer patients from NCBI GEO database were analyzed by CU-DREAM. Then, mRNA expression levels of three candidate genes were determined by quantitative RT-PCR in WBCs of pancreatic cancer patients (N = 27) and healthy controls (N = 51). ROC analysis was performed to assess the performance of each candidate gene. A total of 29 upregulated genes were identified and three selected genes were performed gene expression analysis. Our results revealed high mRNA expression levels in WBCs of pancreatic cancer patients in all selected genes, including FKBP1A (p < 0.0001), PLD1 (p < 0.0001), and PSMA4 (p = 0.0002). Among candidate genes, FKBP1A mRNA expression level was remarkably increased in the pancreatic cancer samples and also in the early stage (p < 0.0001). Moreover, FKBP1A showed the greatest performance to discriminate patients with pancreatic cancer from healthy individuals than other genes with the 88.9% sensitivity, 84.3% specificity, and 90.1% accuracy. Our findings demonstrated that the alteration of FKBP1A gene in WBCs serves as a novel valuable biomarker for patients with pancreatic cancer. Detection of FKBP1A mRNA expression level in circulating WBCs, providing high-sensitive, less-invasive, and cost-effective, is simple and feasible for routine clinical setting that can be applied for pancreatic cancer screening and early detection.
Similar content being viewed by others
Introduction
According to GLOBOCAN 2020, pancreatic cancer is the seventh leading cause of cancer mortality worldwide. Mortality is estimated to continue rising over the next few decades, becoming the second most common cancer-related death by 20401. Pancreatic cancer is an aggressive malignancy with very poor prognosis, represented by an mortality-to-incidence ratio (MIR) of about 94%2. Patients with pancreatic cancer are commonly diagnosed at an advanced stage, with only 10% detected at an early stage3. This is due to patients with pancreatic cancer having obscure symptoms with most cases asymptomatic at the early stage, leading to tumor progression and subsequent non-responsiveness to curative treatment4,5. Compared to other tumors, the five-year survival rate of pancreatic tumors is very low at less than 10%. However, if patients can be detected at early-stage and undergo surgical resection, they would have a 5-year survival rate more than ten-fold higher compared to patients with advanced stage or metastasis6,7,8,9,10. At the present time, there are no clinical approaches to screen or diagnose early pancreatic cancer, especially in asymptomatic patients11. As a result, the discovery of potential methods or biomarkers for screening and early detection is crucial to improve cancer prognosis, reduce mortality, and enhance the chance for effective treatment.
The diagnosis of pancreatic cancer is mainly operated by biopsy and imaging tests such as endoscopy, computed tomography (CT) scan, and magnetic resonance imaging (MRI). Although these examinations play important roles in clinical practice, they are invasive and possess unsatisfied sensitivity in the early stage12,13,14. The identification of a blood-based biomarker can offer critical information in pancreatic cancer detection. Currently, serum carbohydrate antigen 19‐9 (CA19‐9) is the only biomarker approved by United States Food and Drug Administration for pancreatic cancer diagnosis and monitoring15. However, CA19‐9 lacks tumor specificity. High CA19-9 levels can also be indicative of different types of cancer such as esophageal, stomach, colon, liver, bile duct, and ovary16,17,18,19,20. CA19-9 is not currently considered as a screening test for pancreatic cancer patients due to its low positive predictive value21,22.
Increasing studies are focusing on a cancer biomarker derived from circulating blood cells which can be an effective and less-invasive method23,24,25. Our recent studies have revealed a mechanism by which cancer cells leave cytokine-like secretions in the surrounding WBCs which result in the alteration of WBC’s epigenetic and gene expression profiles. This mechanism has appeared in several types of cancer, including breast cancer, hepatocellular carcinoma, head and neck squamous cell carcinoma, and colon cancer26,27,28,29. Based on this knowledge, this study aimed to evaluate promising novel biomarkers for pancreatic cancer screening and detection by identifying differences in gene expression profiles of WBCs. The results of this study would be beneficial for future screening or for diagnostic purposes in pancreatic cancer patients.
Results
Bioinformatics
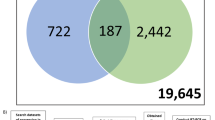
The expression profiling microarray corresponding to pancreatic cancer was extracted to screen for upregulated genes. Data from the GEO dataset including GSE172103, GSE125158, and GSE151945 were analyzed by the CU-DREAM program. By intersecting data across the 3 datasets, a total number of 29 upregulated genes were obtained (Fig. 1A). The functions of identified genes were then classified according to their biological functions as shown in Fig. 1B. Three candidate genes with the highest significant p-values in cell signaling and transport, immunological process, as well as protein degradation process were selected, consisting of FKBP1A (p = 2.88 × 10–6), PLD1 (p = 2.82 × 10–5), and PSMA4 (p = 4.5 × 10–4). The details of the biological function of the genes are provided in supplement information 1.

Summary of the experiment. Each gene expression from each dataset including GSE172103, GSE125158, and GSE151945 was analyzed by a “Connection Up and Down-Regulation Expression Analysis of Microarrays (CU-DREAM) to evaluate the intersection genes. (a) Venn diagram based on the overlapping number of upregulated genes among microarray data groups indicated 29 genes indicating upregulated differentially expressed genes (DEG); (b) Total 29 candidate genes determined by biological process from gene ontology as represented in the table according to function of mechanism.
Upregulation of FKBP1A, PLD1, and PSMA4 gene expression
To investigate gene expression in WBC-associated pancreatic cancer, mRNA expression levels of three selected genes including FKBP1A, PLD1, and PSMA4 were evaluated using qRT-PCR. We found that these genes were differentially expressed in cancer. The quantification showed that mRNA levels of all candidate genes were significantly higher in pancreatic cancer samples compared to controls (p < 0.0001 in FKBP1A, p < 0.0001 in PLD1, and p = 0.0002 in PSMA4). Interestingly, the mRNA expression levels of FKBP1A in some pancreatic cancer patients were a thousand-fold higher than in control samples (Fig. 2).

qRT-PCR results were performed in cDNA from all blood samples. The relative mRNA expression value of each gene was compared to the housekeeping gene (GAPDH) within the healthy control group and pancreatic cancer group and shown as mean ± SD. The Ct values in the pancreatic group were significantly increased compared to the healthy controls with p-value < 0.0001 in FKBP1A (a) and PLD1 (b), and p-value = 0.0002 in PSMA4 (c).
Comparison of gene expression and stages of tumor
Next, we assessed whether the expression of selected genes (FKBP1A, PLD1, and PSMA4) was correlated to the tumor stage. The mRNA expression level of the indicated gene was compared between control and pancreatic cancer samples in each stage (I-IV). As shown in Fig. 3, significant increases in mRNA levels of all indicated genes were detected at all stages of the tumor, however; there was no statistical significance between tumor stages. In the early stage, FKBP1A exhibited the highest significant increase when compared to controls (p < 0.0001). In addition, the mRNA expression level of FKBP1A and PSMA4 revealed statistically significant increases in the late stage (p < 0.0001).

Additional analysis in stages of mRNA expression in FKBP1A (a), PLD1 (b), and PSMA4 (c) genes. The figures show the statistically significance (p-value) of all gene expressions when pairing between stage I, II, III, and IV compared with normal control (all using t-test).
ROC analysis
To evaluate the pancreatic cancer detection efficiency of the candidate genes in terms of sensitivity, specificity, and accuracy, receiver operating characteristic (ROC) curve analysis was performed as presented in Fig. 4. The results showed that the mRNA expression level of the FKBP1A gene in WBCs provided excellent accuracy (AUC = 0.901) with a sensitivity of 88.9% and a specificity of 84.3%. For PLD1 and PSMA4 genes, the sensitivity was 66.7% and 44.4%, and the specificity was 72.5% and 80.4%, respectively.

The ROC graph and the result of sensitivity and specificity in each gene including; FKBP1A (a), PLD1 (b), and PSMA4 (c). The sensitivity and specificity of FKBP1A gene showed the greatest value compared to other genes with 88.9% sensitivity, 84.3% specificity and AUC data = 0.901.
FKBP1A validation
We further tested other 18 WBC samples (April 2021 to April 2022), including 7 cases of pancreatic cancers (1 case for stage 1, 1 case for stage 2, and 5 cases for stage 3), and 11 cases of healthy normal. All samples were examined by double-blind test to validate the predictive ability of FKBP1A expression. With relative expression of 103.7467, the accuracy rate of FKBP1A in detecting the presence of pancreatic cancer was 88.89%. The result was presented in supplement information 2.
FKBP1A expression is tumor specific
We also tested the specificity of the FKBP1A gene by comparing mRNA levels with other cancer-related digestive systems, including pancreatic cancer (N = 8), esophageal cancer (N = 5), stomach cancer (N = 5), colon cancer (N = 5), and liver cancer (N = 5). In pancreatic cancer, the results revealed a significant increase of FKBP1A mRNA expression (p = 0.0073), while in other cancers, except liver cancer (p = 0.0022), the mRNA level was unchanged (Fig. 5).

The specification of FKBP1A gene expression in pancreatic cancer. mRNA level of FKBP1A gene was significantly increased in pancreatic cancer compared with to normal controls and other cancer-related digestive system including of colon, esophageal, stomach, and liver cancer (p = 0.0073). The mRNA level, however, was highly expressed in liver cancer (p = 0.0022) compared to normal control.
Discussion
Pancreatic cancer is typically found during the late stage and is difficult to diagnosis early due to unspecified symptoms and the inability to identify through MRI imaging. Currently, the screening marker CA19-9 delivers unsatisfactory efficiency prompting the need for a new molecular biomarker for pancreatic cancer. In this current work, we integrated bioinformatics analysis (CU-DREAM) with a molecular approach (RT-qPCR) to demonstrate the FKBP1A gene as a novel molecular biomarker for pancreatic cancer detection. At the mRNA level, FKBP1A gene expression in WBCs of pancreatic cancer patients was significantly higher than normal and showed satisfactory sensitivity (88.9%) and specificity (84.3%) with an AUC of 0.901. Multiple studies have postulated about the ability of cancer cells to produce cytokine and chemokine-like secretion molecules which affect gene expression changes in blood circulating immune cells, including WBCs, contributing to the progression of various forms of cancer and impacting outcomes31,32,33,34. Recent works have shown that the levels of mRNA and protein expression of PBMCs exhibited changes in both hepatocellular carcinoma and non-small cell lung cancer27,35. In line with this previous work, our findings also described the mechanism of cancer cytokine signaling in molecule-regulated gene expression of immune cells in pancreatic cancer. In addition, co-culture studies revealed that secretion molecules from cancer cells could alter epigenetics via DNA methylation in blood immune cells in several types of cancers such as head and neck, colorectal, and breast26,28,29.
In our comparison between the normal and early-stage cancer groups, FKBP1A showed the highest significant p-value (p < 0.0001) among all candidate genes (PLD1, p = 0.0078, PSMA4, p = 0.0165). Although a small amount of tumor cells was present in the early stage, thousands of blood-circulating immune cells which consist of WBCs and PBMCs can be activated through cancer secretion28,29. This interaction between cancer and immune cells increases the opportunity and sensitivity for cancer detection, especially at an early stage. Our results suggested that FKBP1A, which showed the best performance, could be applied for early detection of pancreatic cancer. Moreover, FKBP1A and PSMA4 mRNA expression levels tended to be higher in advanced pancreatic cancer stages. This might be due to increased cancer cell growth and proliferation during advanced tumor stages which results in an increase in cancer immune cells interaction. Therefore, these increased levels of gene expression in the immune cells are promising in developing highly predictive cancer biomarkers.
FKBP1A, belonging to FKBPs family, is a cis–trans prolyl isomerase (PPIase) enzyme36. This protein functions as a receptor of immunosuppressive drugs which can bind to the immunosuppressants FK506 and rapamycin. It plays an essential role in immune cell signaling. It can also interact with many intracellular signal transduction proteins including type I TGF-beta receptor37,38. Evidence has shown that FKBP1A participates in multiple malignancies such as head and neck, breast, lung, and liver39,40,41. In this study, the higher FKBP1A gene expression level was identified in WBCs of pancreatic cancer patients compared to controls, indicating that FKBP1A is involved in the cell-to-cell communication between immune cells and pancreatic cancer. Moreover, our experiments revealed that the tumor specific property that elevated FKBP1A gene expression was not only found in pancreatic cancer WBCs but also in hepatic cancer. Consistent with our results, a recent study revealed that protein expression of FKBP1A was found in hepatocellular carcinoma tissues and its expression was correlated with stage, grade, and metastasis of the tumor. In addition, a positive correlation between FKBP1A expression and immune cells such as B cells, CD8+ T cells, and CD4+ T cells was observed41. In contrast, downregulated FKBP1A in breast cancer tissues is associated with poor prognosis and increased resistance to chemotherapy40. Upregulation of FKBP1A was found to diminish cancer cell growth in glioblastoma, a type of brain tumor42. The limitations of this research included the absence of in vitro study such as co-cultured techniques because the interaction between cancer and the immune cell process occurs from multiple factors that cannot reproduced by in vitro studies. Another limitation is the small sample population that did not include subjects with pancreatitis. Due to the nature characteristics of pancreatic cancer, the most of patients were diagnosed at very late stage. However, the result from our study demonstrated FKBP1A as a clinically validated biomarker in early and advanced stage.
In summary, our study is the first to document mRNA expression levels of FKBP1A in WBCs as a potential biomarker for pancreatic cancer detection and show that elevated FKBP1A mRNA expression can distinguish early-stage pancreatic cancer patients from healthy controls. These findings also shed light on the pathogenesis involving immunological regulation in pancreatic cancer. Utilizing the differential FKBP1A gene expression in circulating WBCs of pancreatic cancer patients is simple, less invasive, and exhibited high sensitivity in our study, when compared to the conventional serum biomarker CA19-9 and imaging methods (MRI). This approach is feasible in clinical practice and can be applied for mass screening and early detection for pancreatic cancer in the near future.
Materials and methods
Bioinformatics analysis
Three Gene Expression Omnibus (GEO) datasets were selected from the National Center for Biotechnology Information (NCBI) database (https://www.ncbi.nlm.nih.gov/geo/), including GSE172103, GSE125158 and GSE151945. The GSE125158 gene expression microarray, which included blood samples from pancreatic cancer patients, was compared with GSE172103 which is the expression profile of activated macrophages in pancreatic cancer tissues and GSE151945 which is the expression profile of endothelial cells in pancreatic cancer tissues. GEO datasets were analyzed for the gene expression levels using the CU-DREAM (Connection Up- or Down-Regulation Expression Analysis of Microarrays Extra, website: http://pioneer.netserv.chula .ac) program and calculated p-values and odds ratios. All upregulated genes from GSE125158, GSE172103, and GSE151945 were analyzed. We manually observed the gene function of all upregulated genes (Fig. 1). Three candidate genes with significant p-values were then selected from the list of upregulated genes to observe gene expression in WBCs of pancreatic cancer patients.
Study population
This cross-sectional case–control study was performed at the Faculty of Medicine, Chulalongkorn University. All samples were recruited from King Chulalongkorn Memorial Hospital composed of the experimental set collected during March 2017 to March 2021 including 51 healthy normal and 27 pancreatic cancer patients, and the validation set collected during April 2021 to April 2022 including 11 healthy normal and 7 pancreatic cancer patients. All cancer cases were staged according to the revised Tumor, Node and Metastasis (TNM) classification criteria by a pathologist. Healthy normal samples were collected from the patients without a family history of cancer, immune disorders, jaundice and chronic diseases. The demographic data of all samples is presented in Table 1. All participants in this study were of Asian descent and provided their written informed consent to participate in this study.
Sample size calculation
We used the preliminary results from GSE172103, GSE125158 and GSE151945 to find the appropriate sample size with the following formula26,27:
N = sample size, d = Different of value in each group, \({\bar{\text{x}}_{\text{d}}}\) = Different of mean in each group, σ2d = Different of variance in each group, Zα/2 = Standard normal variate for level of significance, Zβ = Standard normal variate for power.
We calculated and found that the sample size for our study was 12.51 samples, confirming that this study has recruited enough samples for the experimentation.
Blood sample collection
Two ml of EDTA blood was extracted from all patients. All samples were collected in 4 × 6 ml K3 EDTA tubes (VACUETTE, Greiner Bio-One GmbH, Kremsmünster, Austria) and provided by King Chulalongkorn Memorial Hospital. All samples were centrifuged for 15 min at 3000 rpm to separate the WBC layer (buffy coat). Then, 100 μl of the WBC layer was transferred to a 1.5 ml Eppendorf tube. The cells were washed with 1 ml PBS for 15 min at 1700 rpm 16 °C. All subjects participating in blood collection were given a self-administered questionnaire to collect their medical history, which was carefully recorded. All samples were obtained under a research protocol approved by the Ethics Committee, Faculty of Medicine, Chulalongkorn University, Thailand (approval number: IRB 034/59. The collection of blood samples from all participants was performed based on the World Health Organization (WHO) guidelines. This study was conducted in accordance with the Declaration of Helsinki. Signed informed consent was obtained.
RNA extraction
The WBC pellets were mixed with 500 μl of TRIzol reagent (ThermoFisher Scientific, MA, USA) and incubated at room temperature for 10 min, then 200 μl of chloroform was added and incubated at room temperature for 3 min. The sample was then separated into three phases by centrifugation at 8500 rpm at 4 °C for 15 min. The colorless upper aqueous phase was transferred to a new RNA 1.5 ml Eppendorf tube, supplemented with 4 μl of glycogen (20 mg/mL) and 500 μl of 100% isopropanol, incubated for 10 min at room temperature, then centrifuged at 8500 rpm at 4 °C for 10 min. Supernatants of the centrifuged tubes were discarded. The RNA pellets were washed with 1 ml of 75% ethanol and mixed by vortexing. The samples were then centrifuged at 7000 rpm at 4 °C for 5 min. The supernatants were discarded and the RNA pellets were dried by vacuum for 8 min. The RNA pellets were resuspended with 20 μl of DEPC water. Finally, RNA concentration and integrity were evaluated by Nanodrop and bioanalyzer.
Complementary DNA (cDNA) synthesis
The cDNA was synthesized using RevertAid First Strand cDNA Synthesis (Thermo Scientific) following the manufacturer’s protocol. Briefly, the amount of RNA templates was adjusted into 0.5–1 μg in each reaction. The samples were added to the 1 μl of oligo dT and incubated at 65 °C for 5 min. The following solutions including primer 1 μl, nuclease-free water up to 12 μl, 5X reaction buffer 4 μl, Ribolock RNAse inhibitor 1 μl, 10 mM dNTP mix 2 μl, RevertAid M-MuLV RT 1 μl were added to the samples. After mixing and brief centrifuging, the samples were incubated for 60 min at 42 °C followed by 5 min at 70 °C. The product of the first strand cDNA synthesis can be used directly in PCR or quantitative real-time PCR.
Primer design and preparation
Primers were designed using reference gene sequences from NCBI database including CR542168.1 for FKBP1A, NM_001130081.3 for PLD1 and NM_001330675.2 for PSMA4. The primers were synthesized by U2Bio. The details of the primer sequence, melting temperature, and product length are described in Table 2. Prior to quantitative PCR, conventional PCR and electrophoresis for finding optimal temperature for each primer was conducted.
Quantitative real-time PCR (qRT-PCR)
The quantitative real-time PCR contained 10 µl SensiFast Lo-ROX reagent (Bioline), 0.8 µl of forward and reverse mixture primers, 1 µl of cDNA sample, 0.1 µl of Taq polymerase, and 8.1 µl distilled water in a total volume of 20 µl. The reactions were operated by QuantStudio 5 (Thermo Fisher Scientific) following with the manufacturer’s protocol. The amplification conditions were as follows: denaturation at 95 °C for 2 min with 40 cycles, annealing at 60 °C, respectively for 30 s. The positive signals from the amplified product were detected at the end of the annealing step. Duplications were in all samples. In this study, glyceraldehyde 3-phosphate dehydrogenase (GAPDH) was selected as the housekeeping gene or the reference gene. GAPDH gene was analyzed alongside all candidate genes.
The amplification results were calculated with the following formula:
The results were then represented in the folds of change (the equation is in the form of 2−ΔΔCt) of the candidate gene expression in the sample against the reference sample30.
ROC analysis
The Receiver Operating Characteristic (ROC) curves were calculated with MedCalc program version 22.009 (Belgium). Ct values of each candidate gene were entered into the dataset. The sensitivity, specificity, and area under curve (AUC) were calculated for all the datasets.
Statistical analysis
The box plot graph and summary of the dataset (including t-test results of Ct mean of candidate gene) were analyzed with GraphPad Prism version 8.4.3. (MA, USA). The p-value < 0.05 was the cut-off for each analysis calculated by unpaired t-tests.
Ethics approval
All samples were obtained under a protocol approved by the Ethics Committee, Faculty of Medicine, Chulalongkorn University, Thailand (approval number: IRB 034/59). The blood sample collection from all participants was performed in accordance with the WHO guidelines. This study was conducted in accordance with the Declaration of Helsinki. The participants provided their written informed consent to participate in this study.
Data availability
Data analyzed and calculated in this study are available from the corresponding author upon reasonable request.
Abbreviations
- cDNA:
-
Complementary DNA
- qRT-PCR:
-
Quantitative Real-time PCR
- PBS:
-
Phosphate buffer saline
- ROC:
-
Receiver operating characteristic
- WBC:
-
White blood cell
- EDTA:
-
Ethylene diamine tetraacetic acid
- MRI:
-
Magnetic resonance imaging
- CT:
-
Computed tomography
- WHO:
-
World Health Organization
- GEO:
-
Gene Expression Omnibus
- DEPC:
-
Diethyl pyrocarbonate
- CD:
-
Cluster of differentiation
References
Rahib, L., Wehner, M. R., Matrisian, L. M. & Nead, K. T. Estimated projection of US cancer incidence and death to 2040. JAMA Netw. Open 4(4), e214708–e214708 (2021).
Sung, H. et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 71(3), 209–249 (2021).
Siegel, R. L., Miller, K. D. & Jemal, A. Cancer statistics, 2018. CA Cancer J. Clin. 68(1), 7–30 (2018).
Kleeff, J. et al. Pancreatic cancer. Nat. Rev. Dis. Primers 2(1), 1–22 (2016).
Mizrahi, J. D., Surana, R., Valle, J. W. & Shroff, R. T. Pancreatic cancer. The Lancet 395(10242), 2008–2020 (2020).
Conroy, T. et al. Current standards and new innovative approaches for treatment of pancreatic cancer. Eur. J. Cancer 57, 10–22 (2016).
Gudjonsson, B. Survival statistics gone awry: Pancreatic cancer, a case in point. J. Clin. Gastroenterol. 35(2), 180–184 (2002).
Matsubayashi, H., Ishiwatari, H., Sasaki, K., Uesaka, K. & Ono, H. Detecting early pancreatic cancer: Current problems and future prospects. Gut Liver 14(1), 30 (2020).
Ilic, M. & Ilic, I. Epidemiology of pancreatic cancer. World J. Gastroenterol. 22(44), 9694 (2016).
Latenstein, A. E. et al. Conditional survival after resection for pancreatic cancer: A population-based study and prediction model. Ann. Surg. Oncol. 27, 2516–2524 (2020).
Yang, J. et al. Early screening and diagnosis strategies of pancreatic cancer: A comprehensive review. Cancer Commun. 41(12), 1257–1274 (2021).
Kato, S. & Honda, K. Use of biomarkers and imaging for early detection of pancreatic cancer. Cancers 12(7), 1965 (2020).
Elbanna, K. Y., Jang, H.-J. & Kim, T. K. Imaging diagnosis and staging of pancreatic ductal adenocarcinoma: A comprehensive review. Insights Imaging 11(1), 1–13 (2020).
Wu, H. et al. Advances in biomarkers and techniques for pancreatic cancer diagnosis. Cancer Cell Int. 22(1), 1–12 (2022).
Ballehaninna, U. K. & Chamberlain, R. S. The clinical utility of serum CA 19–9 in the diagnosis, prognosis and management of pancreatic adenocarcinoma: An evidence based appraisal. J. Gastrointest. Oncol. 3(2), 105 (2012).
Tuncer, İ et al. Comparison of serum cytokeratin-18, CEA and CA 19–9 levels in esophageal and gastric cancers. Eastern J. Med. 9(2), 72 (2004).
Vukobrat-Bijedic, Z. et al. Cancer antigens (CEA and CA 19–9) as markers of advanced stage of colorectal carcinoma. Med. Arch. 67(6), 397 (2013).
Chen, Y.-L., Chen, C.-H., Hu, R.-H., Ho, M.-C. & Jeng, Y.-M. Elevated preoperative serum CA19-9 levels in patients with hepatocellular carcinoma is associated with poor prognosis after resection. Sci. World J. 2013, 1–6 (2013).
Coelho, R. et al. CA 19-9 as a marker of survival and a predictor of metastization in cholangiocarcinoma. GE-Port. J. Gastroenterol. 24(3), 114–121 (2017).
Lertkhachonsuk, A. A. et al. Serum CA19-9, CA-125 and CEA as tumor markers for mucinous ovarian tumors. J. Obstet. Gynaecol. Res. 46(11), 2287–2291 (2020).
Kim, B. et al. How do we interpret an elevated carbohydrate antigen 19-9 level in asymptomatic subjects?. Digest. Liver Dis. 41(5), 364–369 (2009).
Kim, J. E. et al. Clinical usefulness of carbohydrate antigen 19-9 as a screening test for pancreatic cancer in an asymptomatic population. J. Gastroenterol. Hepatol. 19(2), 182–186 (2004).
Mosallaei, M. et al. PBMCs: A new source of diagnostic and prognostic biomarkers. Arch. Physiol. Biochem. 128(4), 1081–1087 (2022).
Hamm, A. et al. Tumour-educated circulating monocytes are powerful candidate biomarkers for diagnosis and disease follow-up of colorectal cancer. Gut 65(6), 990–1000 (2016).
Kaur, S., Baine, M. J., Jain, M., Sasson, A. R. & Batra, S. K. Early diagnosis of pancreatic cancer: Challenges and new developments. Biomark. Med. 6(5), 597–612 (2012).
Puttipanyalears, C. et al. Quantitative STAU2 measurement in lymphocytes for breast cancer risk assessment. Sci. Rep. 11(1), 1–11 (2021).
Patarat, R. et al. The expression of FLNA and CLU in PBMCs as a novel screening marker for hepatocellular carcinoma. Sci. Rep. 11(1), 1–13 (2021).
Arayataweegool, A. et al. Head and neck squamous cell carcinoma drives long interspersed element-1 hypomethylation in the peripheral blood mononuclear cells. Oral Dis. 25(1), 64–72 (2019).
Boonsongserm, P. et al. Tumor-induced DNA methylation in the white blood cells of patients with colorectal cancer. Oncol. Lett. 18(3), 3039–3048 (2019).
Rao, X., Huang, X., Zhou, Z. & Lin, X. An improvement of the 2ˆ (–delta delta CT) method for quantitative real-time polymerase chain reaction data analysis. Biostat. Bioinform. Biomath. 3(3), 71 (2013).
Čelešnik, H. & Potočnik, U. Peripheral blood transcriptome in breast cancer patients as a source of less invasive immune biomarkers for personalized medicine, and implications for triple negative breast cancer. Cancers 14(3), 591 (2022).
Bin-Alee, F. et al. Transcriptomic analysis of peripheral blood mononuclear cells in head and neck squamous cell carcinoma patients. Oral Dis. 27(6), 1394–1402 (2021).
Hosseini, A. et al. The local and circulating SOX9 as a potential biomarker for the diagnosis of primary bone cancer. J. Bone Oncol. 23, 100300 (2020).
Denariyakoon, S., Puttipanyalears, C., Chatamra, K. & Mutirangura, A. Breast cancer sera changes in alu element methylation predict metastatic disease progression. Cancer Diagn. Progn. 2(6), 731–738 (2022).
Pakvisal, N. et al. Differential expression of immune-regulatory proteins C5AR1, CLEC4A and NLRP3 on peripheral blood mononuclear cells in early-stage non-small cell lung cancer patients. Sci. Rep. 12(1), 18439 (2022).
Wedemeyer, W. J., Welker, E. & Scheraga, H. A. Proline cis−trans isomerization and protein folding. Biochemistry 41(50), 14637–14644 (2002).
Annett, S., Moore, G. & Robson, T. FK506 binding proteins and inflammation related signalling pathways; basic biology, current status and future prospects for pharmacological intervention. Pharmacol. Therap. 215, 107623 (2020).
Wang, T. et al. The immunophilin FKBP12 functions as a common inhibitor of the TGFβ family type I receptors. Cell 86(3), 435–444 (1996).
Patel, D. et al. FKBP1A upregulation correlates with poor prognosis and increased metastatic potential of HNSCC. Cell Biol. Int. 46(3), 443–453 (2022).
Xing, M. et al. FKBP12 is a predictive biomarker for efficacy of anthracycline-based chemotherapy in breast cancer. Cancer Chemother. Pharmacol. 84, 861–872 (2019).
Li, Z. et al. The prognostic significance of FKBP1A and its related immune infiltration in liver hepatocellular carcinoma. Int. J. Mol. Sci. 23(21), 12797 (2022).
Cai, S. et al. Upregulated FKBP1A suppresses glioblastoma cell growth via apoptosis pathway. Int. J. Mol. Sci. 23(23), 14935 (2022).
Acknowledgements
The authors would like to thank the Faculty of Medicine, Chulalongkorn University for equipment, laboratory assistance, and technical support. The manuscript was proofed the English structure and Grammar by a native English speaker at the Chulalongkorn University English Editing Service.
Funding
This work was supported by the National Research Council of Thailand (NRCT) (Grant No. N35A661026), Office of the Permanent Secretary, Ministry of Higher Education, Science, Research and Innovation (Grant No. RGNS 63-004), Thailand Science Research and Innovation Fund Chulalongkorn University.
Author information
Authors and Affiliations
Contributions
The experiments were conducted and designed by P.W. and C.P. Blood samples were recruited and collected by V.A. and C.P. RNA extraction and qRT-PCR were performed by P.W., N.B. and C.P. The results were analyzed and interpreted by P.W., N.B., A.M. and C.P. P.W., N.B. and C.P. wrote the manuscript. P.W., N.B., A.M. and C.P. reviewed and edited the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Watcharanurak, P., Mutirangura, A., Aksornkitti, V. et al. The high FKBP1A expression in WBCs as a potential screening biomarker for pancreatic cancer. Sci Rep 14, 7888 (2024). https://doi.org/10.1038/s41598-024-58324-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-58324-z
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
