
Abstract
The effective meta-heuristic technique known as the grey wolf optimizer (GWO) has shown its proficiency. However, due to its reliance on the alpha wolf for guiding the position updates of search agents, the risk of being trapped in a local optimal solution is notable. Furthermore, during stagnation, the convergence of other search wolves towards this alpha wolf results in a lack of diversity within the population. Hence, this research introduces an enhanced version of the GWO algorithm designed to tackle numerical optimization challenges. The enhanced GWO incorporates innovative approaches such as Chaotic Opposition Learning (COL), Mirror Reflection Strategy (MRS), and Worst Individual Disturbance (WID), and it’s called CMWGWO. MRS, in particular, empowers certain wolves to extend their exploration range, thus enhancing the global search capability. By employing COL, diversification is intensified, leading to reduced solution stagnation, improved search precision, and an overall boost in accuracy. The integration of WID fosters more effective information exchange between the least and most successful wolves, facilitating a successful exit from local optima and significantly enhancing exploration potential. To validate the superiority of CMWGWO, a comprehensive evaluation is conducted. A wide array of 23 benchmark functions, spanning dimensions from 30 to 500, ten CEC19 functions, and three engineering problems are used for experimentation. The empirical findings vividly demonstrate that CMWGWO surpasses the original GWO in terms of convergence accuracy and robust optimization capabilities.
Similar content being viewed by others
Introduction
Optimization is described as the process of determining the most suitable values for the parameters of a problem with the goal to obtain the ideal solution1. Optimization Algorithms have gained acknowledgment as effective instruments for improving various types of single-objective, multi-objective, and many-objective problems2. The effectiveness of these algorithms has resulted in the creation of a large number of swarm intelligence algorithms and their extensive use in numerous applications across numerous fields3. Swarm intelligence algorithms are developed by studying the interactions of self-organized living beings in nature and are a subset of Metaheuristic Algorithms (MAs)4. Examples of recent MAs include Gannet Optimization Algorithm (GOA)5, African Vultures Optimization Algorithm (AVOA)6, Material Generation Algorithm (MGA)7, Beluga Whale Optimization (BWO)8, Archimedes Optimization Algorithm (AOA)9, Artificial Gorilla Troops Optimizer (GTO)10, Dandelion Optimizer (DO)11, Golden Eagle Optimizer (GEO)12, Chaos Game Optimization (CGO)13, Fire Hawk Optimizer (FHO)14 and Honey Badger Algorithm (HBA)15. It is also worthwhile to explore certain modified algorithms that exhibit exceptional performance, such as Modified Social Group Optimization (MSGO)16, Chaotic Vortex Search Algorithm (VSA)17, Modified Marine Predators Algorithm (MMPA)18, and Hybrid Binary Dwarf Mongoose Optimization Algorithm (BDMSAO)19. They have found practical applications in various domains, including parameter identification20, feature selection21,22, Antenna Optimization23, Image Segmentation24,25, demand prediction26, Reliability-Based Design27,28, constrained optimization problems21,22. These algorithms, however, share several challenges, such as a propensity to get trapped in local optimal solutions, sluggish convergence rate, and limited precision in identifying the optimal solution29.
The Grey Wolf Optimizer (GWO) is a Swarm intelligence metaheuristic algorithm developed by Mirjalili et al. that emulates the leadership structure and hunting behaviour of grey wolves in the wild30. The GWO algorithm has been successfully used to address different optimization problems, including numerical optimization31, feature subset selection32, engineering design33, image analysis34, and other real-world applications35. Researchers have attempted to improve the original GWO by creating various variants, which can be categorized into two groups. The first group focuses on implementing distinct optimization strategies to overcome GWO's limitations. The second group includes variants that combine GWO with other algorithms to enhance its optimization capabilities by leveraging the advantages of these combined algorithms.
In the first group, Nadimi-Shahraki et al.36 introduced the Improved Grey Wolf Optimizer (I-GWO) that incorporates a novel movement strategy called dimension learning-based hunting (DLH) search strategy, modelled after the solitary hunting tactics used by wolves in the wild. DLH establishes wolf neighbourhoods in a way to facilitate the exchange of neighboring information among them. The incorporation of dimension learning in the DLH search strategy improves the equilibrium between local and global search and diversity preservation in the optimization process. The proposed I-GWO algorithm's efficacy was assessed using the CEC 2018 test set and four real-world problems. I-GWO is contrasted across many tests to six other algorithms. Friedman and Mean Absolute Error (MAE) statistical tests are also used to assess the results. In comparison to the algorithms employed in the studies, the I-GWO algorithm was highly efficient and frequently outstanding. Mirjalili et al. proposed a Multi-Objective Grey Wolf Optimizer (MOGWO) to address multi-objective problems’ optimization37. For that purpose, a fixed-sized external archive was incorporated into the GWO, serving as a repository to store and retrieve the best solutions. The incorporated archive influences the definition of social ranking and the emulation of grey wolves’ hunting patterns in multi-objective search areas. To assess its performance, the novel MOGWO was evaluated on ten multi-objective standard problems and benchmarked against two other popular MAs. The outputs of the assessments indicate that the MOGWO algorithm surpassed the other MAs under consideration in terms of performance. Bansal and Singh suggested an improved grey wolf optimizer to enhance the exploration and exploitation capabilities of the traditional GWO38. Opposition-based learning (OBL) and the explorative equation were used to make this improvement. The explorative equation contributed to improving GWO's capacity for exploration. The OBL sped up convergence and prevented the GWO from stagnating. 23 popular standard functions were used to evaluate the suggested IGWO. The results have been contrasted against some recent GWO versions along with additional well-known MAs. The results confirmed that the IGWO has better exploration capabilities while yet retaining an excellent speed of convergence. Meidani et al. presented another variant called Adaptive GWO (AGWO) that tackles the non-automated variable adjustment and absence of precise stopping conditions that frequently result in wasteful consumption of computing resources39. The optimization process was carried out by incorporating an adaptive calibration of the intensification/diversification variables depending on the fitness records of the potential solutions. A satisfactory optimal solution can be reached by AGWO within a brief period by regulating the stopping criteria depending on the importance of fitness increase in the optimization. Through a comprehensive comparative study, they demonstrated that AGWO is significantly more efficient than the original GWO and a number of GWO variations that were already in use. AGWO achieved this by lowering the number of iterations necessary to arrive at similar solutions to those of GWO. Lei et al. introduced Levy Flight to the GWO (LFGWO) to tackle the challenges of premature convergence and inadequate results40. By conducting experiments with eight common algorithms and 23 common benchmark functions from CEC 2005, the overall performance of LFGWO was assessed. The findings showed that LFGWO performs better than the competing algorithms. Gutpa and Deep introduced a revised RWGWO employing a random walk in an effort to enhance the grey wolf's search capabilities41. The algorithm's performance is demonstrated by comparing it with GWO and other advanced algorithms using IEEE CEC 2014 benchmark problems. To gauge the effect of enhancing the leaders in the proposed algorithm, a non-parametric test, Wilcoxon, and Performance Index Analysis were used to analyze outcomes. The findings show that the suggested algorithm offers grey wolves greater leadership when searching for prey. Nasrabadi et al. introduced parallelism and opposition-based learning methods in an attempt to enhance the basic GWO’s outcomes42. The setup and execution of the revised method on renowned benchmark functions yielded results that showed improvements in convergence and accuracy.
In the second group also, noteworthy outcomes were achieved by researchers. By integrating the Elephant Herding Optimization (EHO) algorithm with the Grey Wolf Optimizer (GWO), the exploitation and exploration performances, as well as the speed of convergence, of the GWO were significantly enhanced by Hoseini et al.43. To confirm the effectiveness of the proposed Grey Wolf Optimizer Elephant Herding Optimization (GWOEHO), a set of twenty-three benchmark functions and six engineering problems were employed for testing. The performance of GWOEHO was compared to that of the GWO and EHO, along with several other popular MAs. The statistical analysis using Wilcoxon's rank-sum test demonstrates that GWOEHO consistently performed better than the other algorithms in the majority of function minimization tasks. With the merging of Particle Swarm Optimization and Grey Wolf Optimizer, Singh and Singh formed a Hybrid Particle Swarm Optimization and Grey Wolf Optimizer (HPSOGWO)44. The major goal was to increase the exploration and exploitation capacities of the two algorithms to boost their strengths. A few unimodal, multimodal, and fixed-dimension multimodal testing functions were employed to evaluate the effectiveness and efficacy of the HPSOGWO. The hybrid algorithm greatly exceeded the PSO and GWO versions in terms of outcome effectiveness, robustness, speed, and capacity to reach the global optimum. Zhao et al. presented another hybrid variant of the grey wolf optimizer that integrates opposition-based learning, reinforcement learning, and sine cosine search strategy45. The novel algorithm was employed for scheduling and resource allocation. To validate its effectiveness, six sets of realistic data related to space debris tracking were selected. The proposed algorithm's performance was evaluated in comparison with that of other algorithms. The experimental results demonstrate that the proposed algorithm successfully tackles the resource allocation and scheduling challenges associated with space debris tracking. Fadheel et al. proposed the Sparrow Search Algorithm-Grey Wolf Optimizer (SSAGWO), which is designed for the precise tuning of controllers used in frequency regulation46. The authors succeeded in enhancing the original algorithms' capabilities for exploration and exploitation. SSAGWO was applied to regulate frequency in a two-area Hybrid Power System (HPS) simulated in Simulink. To validate the efficacy of the hybrid SSAGWO in controlling the frequency of the HPS model, its performance is first evaluated using common benchmark functions. The results clearly demonstrate that the hybrid SSAGWO significantly outperforms other state-of-the-art algorithms. J and Priya also recently introduced another variant of the GWO, known as the Hybrid Grey Wolf and Improved Particle Swarm Optimization Algorithm with Adaptive Inertial Weight-based multi-dimensional Learning Strategy (HGWIPSOA) to improve the precision and efficiency of task scheduling and resource allocation for Virtual Machines (VMs) in cloud environments47. The algorithm begins by integrating the Grey Wolf Optimization Algorithm (GWOA) into the Particle Swarm Optimization (PSO), treating the highest fitness particle as the alpha wolf search agent. This integration effectively achieves the task allocation objective for VMs. Additionally, the suggested method combines PSO with chaos, Adaptive Inertial Weight, and Dimensional Learning. These additional features rely on the best experiences decided by particles to support efficient Load Balancing, with the goals of preventing early convergence, improving convergence pace, and enhancing overall search capabilities. The HGWIPSOA 's higher performance was demonstrated in simulation trials, and significant advancements were seen. Large tasks were presented in the cloud environment, improvements are constantly seen, putting the proposed HGWIPSOA on a level with benchmarked Load Balancing methods.
While these improved GWO variants address the limitations of GWO to a certain degree, there remains potential for further enhancement, especially in terms of population diversity, which affects convergence speed, precision, and vulnerability to getting trapped in local optima. The original Grey Wolf Optimizer operates by utilizing the three most successful wolves in each iteration to guide the search process, resulting in significant convergence towards these wolves. However, there are instances where these leading wolves become trapped in local extreme points or fail to locate the global optimal solution, particularly in problems with multiple locally optimal solutions. Consequently, when the leading wolves encounter local optima, other individuals in the population also become susceptible to local extremes. This phenomenon contributes to a decrease in population diversity as the wolves converge toward the leaders. Although authors have demonstrated significant progress in improving the conventional Grey Wolf Optimizer (GWO) through various enhancement techniques and hybridization approaches, the literature review reveals a lack of consideration for utilizing physics-inspired techniques and leveraging information from the worst wolf to escape local optima and address population diversity. These fundamental issues pose challenges to the traditional GWO and serve as the primary motivation for this research. This research aims to address these issues by introducing a novel approach called Chaotic Opposition Learning with Mirror Reflection and Worst Individual Disturbance Grey Wolf Optimizer (CMWGWO). The CMWGWO incorporates three distinct search strategies with unique characteristics to generate and enhance candidate solutions. One of these strategies is Chaotic Opposition learning, which draws inspiration from the concept that the opposite of a current solution may yield a superior solution. By leveraging this strategy, population diversity is improved throughout the search space, facilitating better escape from local optima. However, since opposition learning may lead to suboptimal trapping, chaotic randomness is introduced through chaotic Map functions to introduce more randomness to the opposition solution, thereby enabling the algorithm to discover additional potential solutions. Additionally, the Mirror Reflection Strategy which is a physics-inspired phenomenon is integrated into the updating process to amplify population exploration and expand the search space. This enables the population to broaden their search range and approach the optimal solution more closely. Furthermore, the Worst individual disturbance strategy is implemented to disrupt the dominance of the leading wolves. This approach allows wolves to update their positions based on the worst-performing wolf with a certain probability, enabling them to break free from local optima even when the three best-performing wolves are trapped. It also promotes better trapping of prey. By incorporating this strategy, the proposed CMWGWO achieves a balance between exploration and exploitation by exchanging and merging information between the best and worst wolves, ultimately leading to the discovery of the global optimum. CMWGWO distinguishes itself from the recently proposed state of art optimizers such as Bonbo Optimizer (BO)48, Quantum-based Avian Navigation optimizer Algorithm (QANA)49, and Starling Murmuration Optimizer (SMO)50 by combining the hunting hierarchy of GWO, Chaotic Opposition learning, Mirror Reflection Strategy, and Worst Individual Disturbance for enhanced exploration and escape from local optima. BO relies on a fission–fusion social strategy inspired by Bonobos, QANA integrates quantum principles for navigation, and SMO emphasizes dynamic multi-flock construction for effective exploration. Each algorithm has unique features tailored to specific inspirations, making them suitable for different optimization challenges. The research presented in this study contributes in the following ways:
-
(1)
A novel Grey Wolf Optimizer (GWO) approach is introduced, incorporating Chaotic Opposition learning, Mirror Reflection Strategy, and Worst Individual Disturbance. This innovative GWO variant is specifically designed for Global Numerical Optimization problems.
-
(2)
By incorporating Chaotic Opposition learning into GWO, the algorithm mitigates stagnation and enhances diversification, leading to improved solution accuracy.
-
(3)
The integration of the Mirror Reflection Strategy into the GWO updating process amplifies population exploration and expands the search space. This enables the algorithm to explore a wider range of potential solutions.
-
(4)
The proposed worst individual disturbance strategy reduces the probability of the algorithm getting stuck in local optima. By exchanging information between the best and worst wolves, it enhances population diversity and improves the algorithm’s ability to trap prey.
-
(5)
The performance of the proposed algorithm is thoroughly evaluated by comparing it to nine other algorithms across twenty-three test functions. This evaluation provides insights into its effectiveness and efficiency.
-
(6)
In addition to numerical optimization problems, the proposed algorithm is also evaluated on three engineering design issues, demonstrating its applicability and effectiveness in solving practical problems.
The subsequent sections of this paper are organized as follows: “Grey wolf optimizer (GWO)” section provides an introduction to the background of GWO. In “Proposed CMWGWO” section, the proposed algorithm’s mechanism is explained and the proposed CMWGWO is presented. The complexity of the new CMWGWO is discussed in “Computational complexity of CMWGWO” section, The experimental results are discussed and displayed in “Experiments and result analysis” section. Lastly, “Conclusion” section concludes the paper and outlines future research directions.
Grey wolf optimizer (GWO)
GWO, an optimization algorithm inspired by the hierarchical structure and hunting dynamics of grey wolves30, employs a population division into four levels denoted as \(\alpha ,\beta ,\delta\) and \(\omega\). The uppermost level comprises the \(\alpha\) wolf, followed by the \(\beta\) wolf in the subsequent tier, and the \(\delta\) wolf in the third tier. The remaining wolves, situated in the lowermost layer, are known as \(\omega\) wolves or search wolves as seen in Fig. 1. The \(\alpha ,\beta\) and \(\delta\) wolves serve as leaders, each with a count of one. In GWO, the objective is for the \(\omega\) wolves, representing the search wolves, to update their position and attain the optimal solution. Meanwhile, the \(\alpha ,\beta ,\) and \(\delta\) wolves represent the best, Second best, and third-best Solutions, respectively. The hunting behavior of grey wolves is primarily directed by the leading wolves (\(\alpha ,\beta ,\) and \(\delta\)), guiding the iterative position updates of the search wolves (\(\omega\)) based on the leaders’ locations. This iterative process can be mathematically described as the formula governing the movement of the grey wolves in pursuit of their prey
where \(t\) represents the current iteration count, \(*\) denotes the product operation, \({\text{X}}_{p}\) represents the position vector of the prey, \({\text{X}}\) represents the position vector of a grey wolf, and the calculation formulas for random vectors \({\text{A}}\) and \({\text{C}}\) are expressed as follows:

Hierarchical model of GWO.
The utilization of random vectors and linearly decreasing values to optimize the position updates in GWO is discussed below. Figure 2 illustrates the potential areas that the \(\omega\) wolf can occupy around the prey by adjusting the parameters \({\text{A}}\) and \({\text{C}}\). The random variables \({\text{r}}_{1}\) and \({\text{r}}_{2}\) aid the search wolves in reaching different points depicted in Fig. 2, both variables are within [0, 1], \({\text{a}}\) decrease from 2 to 0 over the increment of iteration number. The parameters \({\text{A}}\) and \({\text{C}}\) play a crucial role in the exploration and exploitation behaviour of GWO. \({\text{A}}\) takes on a random value within the range of [− \({\text{a}}\), \({\text{a}}\)]. When \({\text{A}} > 1\) and \({\text{C}} > 1\), the population demonstrates a preference for exploration. Conversely, when \({\text{A}} < 1\) and \({\text{C}} < 1\), the population exhibits a tendency towards exploitation. The formulas governing the tracking of the grey wolves to target their prey are as follows:

Illustration of search wolf during exploration and exploitation.
The distances between the lead wolves and search wolves in this situation are represented by the symbols \({\text{D}}_{a}\), \({\text{D}}_{\beta }\), and \({\text{D}}_{\delta }\), respectively. The locations of the lead wolves are shown by the symbols \({\text{X}}_{\alpha }\), \({\text{X}}_{\beta }\), and \({\text{X}}_{\delta }\). While \({\text{X}}_{1}\), \({\text{X}}_{2}\), and \({\text{X}}_{3}\) represent the step size and direction of the \(\omega\) wolf towards the lead wolves, respectively, \({\text{C}}_{1}\), \({\text{C}}_{2}\), and \({\text{C}}_{3}\) are random vectors. Equation (6) is used to determine the wolf’s ultimate location. Algorithm 1 shows the iterative process of GWO.

Steps of GWO
Proposed CMWGWO
Chaotic opposition learning (COL)
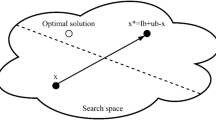
Opposition-based learning (OBL) stands as a robust Optimizer improvement methodology in the domain of intelligence computation, initially introduced by Tizhoosh51. Generally, MAs begin with random initial solutions and iteratively strive to move closer to the global best solution. The termination of the search process occurs when specific predetermined requirements are met. In the absence of pertinent advance information about the solution, convergence might require a considerable amount of time. To address this, OBL incorporates a novel approach, depicted in Fig. 3, which involves assessing the fitness values of the current solution and the matching opposing solution at the same time. The superior individual is then retained for the next iteration, thereby promoting population diversity effectively. Notably, the opposite candidate solution has nearly a 50% higher chance of being closer to the global optimum compared to the current solution52. Consequently, OBL has gained widespread adoption as it significantly enhances the optimization performance of various MAs53,54. The mathematical representation of OBL is as follows:

Graphical illustration of opposition learning.
The opposite solution is denoted by \(\hat{X}\), while X represents the current solution. \(lb\) and \(ub\) correspond to the lower and upper limits of the search area. As evidenced by Eq. (7), OBL has the limitation of producing the opposite solution at a given position55. This approach proves effective during the initial optimization phases. However, as the search process advances, there is a possibility that the opposite solution may end up close to a local optimum. Consequently, other individuals in the population might rapidly gravitate towards this area, leading to premature convergence and reduced solution accuracy. In response to this issue, the random opposition-based learning (ROBL) strategy which incorporates random perturbations to modify Eq. (7) as follows was introduced in this work:
rand is an arbitrary value taken from the interval [0, 1]. While ROBL demonstrates some improvement in population diversity and is efficient in mitigating local optima, its convergence speed remains unsatisfactory. Chaos is the unpredictability observed in nonlinear structures, which possess dynamic, random, and ergodic properties. Incorporating chaos theory in algorithms facilitates the acceleration of convergence and strengthens the capability to maintain diversity. The CMWGWO includes a hybrid approach that combines normal OBL with chaotic maps, referred to as the chaotic opposition learning (COL) strategy. The mathematical expression for COL is provided below:
\(\widehat{{X^{CO} }}\) represents the inverse solution of X, and φ denotes the value of the chaotic map. The chaotic Map introduced in this work is calculated as given in Eq. (10)
The visual representation of the COL implemented in this work is displayed in Fig. 4. The illustration depicts that with the introduction of Chaos, the opposition solution, instead of falling in the same position can avoid getting trapped in the local Optimal by falling in random positions.

Graphical illustration of chaotic opposition learning.
Mirror reflection strategy (MRS)
The mirror reflection principle describes the phenomena that occur when light comes into contact with the boundary between two different media56. This principle comes into play when a portion of the incident light returns to the original medium. There are two basic rules that govern mirror reflection. Firstly, the angle at which the light is reflected (angle of reflection) is equivalent to the angle at which it strikes the surface (angle of incidence). Secondly, the reflected and the incident ray lie on opposite sides of an imaginary line denoted the "normal" that is perpendicular to the surface at the point of reflection. Drawing inspiration from these well-established principles, the proposed CMWGWO includes a Mirror Reflection Learning (MRL) strategy. In the MRL strategy, we represent the incident angle direction of a potential solution on the x-axis to denote its location. Simultaneously, the reflected angle direction on the x-axis represents the mirrored version of the solution. The MRL method explores both the potential solutions and their mirror reflections, to choose the best solution thereby expanding the search area. Figure 5 gives a visual demonstration of the concept of mirror-reflection learning. The potential answers are chosen within the \(\left[ {lb,ub} \right]\) interval. The halfway between \(lb\) and \(ub\) is denoted by \(O = \left( {X_{0} ,0} \right)\) and \(X\left( {a,0} \right)\) denotes an arbitrary variable inside the same interval, \(\left( {b,0} \right)\) is the location of \(X_{m}\), the mirror reflection of \(X\). The following Eqs. (11) to (14) define the relationship between incident and reflection angles and subsequently provide a method for determining the mirror-reflected solution. They are based on the first law of mirror reflection previously mentioned in the subsection: The angle of reflection is equal to the angle of incidence. Equation (11) and (12) establishes the relationship between the incident angle (α) and the reflection angle (β) using the tangent function:

Illustration incident reflected light on a mirror surface.
By considering \(\alpha\) as the incident angle and \(\beta\) as the reflection angle, Eq. (13) can be derived following the first rule of reflection.
To simplify Eq. (14), a variable \(\lambda_{m}\) is introduced such that \(B_{0} = \lambda_{m} A_{0}\), resulting in the following expression:
Equation (16) provides the expression of \(\uplambda _{{\text{m}}}\).
Here, µ and Q are the elasticity coefficients and neighborhood radius, both occurring inside the interval of [0,1], and r1 and r2 are arbitrary values between 0 and 1. The inverse solution's updated equation is expressed as follows:
In this work, we have uniquely incorporated the levy mechanism into Eq. (17). This incorporation is motivated by its potential to significantly contribute to the exploration–exploitation balance, which is a crucial aspect in improving the performance of CMWGWO. The Levy flight, inspired by the Levy distribution, possesses unique characteristics that facilitate long-range exploration in the search space57. By leveraging this feature, MRS can effectively escape local optima, thus promoting the exploration of promising regions that may lead to superior solutions. Moreover, the Levy flight mechanism enhances the algorithm's capability to diversify the search process, which helps maintain population diversity and mitigate premature convergence issues.
Worst individual disturbance (WID)
Majority of the improved variants of the GWO algorithm focus on increasing the chances of population individuals converging towards the best wolf. For example, the Grey Wolf Optimizer based on a new Weighted Distance (GWO-WD) introduced by Yan et al. eliminates and repositions several of the worst individuals58. However, it is important to reflect on the natural laws that Grey wolves must adhere to while hunting. During the process of surrounding their prey, Grey wolves encounter both the chance of successfully encircling the prey and the potential risk of the prey evading capture. This phenomenon is accurately modelled in the HHO algorithm that mimics the hunting behaviour of Harris hawks when they catch rabbits59. In HHO, there is a probability that the rabbit being chased by the hawk may escape. In that case, while the global optimal individual guides the entire population towards the best solution, there is a risk of getting stuck in a local optimum, leading to stagnation and failure to escape the local optimal space. Based on this idea, the proposed CMWGWO incorporates a worst individual disturbance strategy to escape local optima in case of unsuccessful encircling leading to a greater and more dynamic exploration of the search area as illustrated in Fig. 6, thus increasing the chances of finding better solutions. Equation (18) represents the encirclement phase, taking into account the global worst wolf:

Information exchange between alpha wolf and worst wolf.
In the equation, \(X_{{\text{w }}}^{t}\) represents the global worst wolf, and \({\text{rand}}\) is a randomly generated number from the interval [0,1]. \({\text{rand}}\) and (1–\({\text{ rand}}\)) are assigned randomly to \(X_{{\alpha { }}}^{t}\) and \(X_{{\text{w }}}^{t}\). Due to the uncertainty introduced by \({\text{rand}}\) and its random variation between 0 and 1, the search process is influenced not only by the global optimal individual but also by \(X_{{\text{w}}}^{t}\). A higher value of \({\text{rand}}\) implies a more pronounced impact of the optimal individual on the formula, bringing the wolves closer to the target, effectively simulating a successful prey encirclement scenario. In contrast, if \({\text{rand}}\) is small, the impact of the worst individual on the formula becomes prominent, replicating the situation where wolves fail to encircle their prey effectively.
CMWGWO is an improved variant of the GWO algorithm, incorporating three novel techniques (WID, COL, and MRS) to enhance its performance. The algorithm starts by initializing a population of grey wolves as eventual solutions to an optimization problem. Each wolf's fitness is evaluated, and the best-performing wolves (\(\alpha ,\beta ,{ }\delta\)) and \(Worst\) the Worst wolf are identified. The main loop iteratively updates wolf positions using calculated parameters \(A,a,{\text{ and }}C\). The WID technique is applied with a probability of a random number less than \(p_{1}\) and when |A|< 1 to some wolves. |A|< 1 implies the exploitation phase in other words, during this phase, if the best wolf gets trapped in suboptimal or the prey evades capture, the population can weaken the leadership of the best wolf to avoid convergence towards local optimal by using the information exchange between the best wolf and worst to break out of local optimal, furthermore the population is able to keep track of the prey effectively, followed by COL with a probability of \(p_{3}\), and MRS with a probability of \(p_{2}\) to improve diversity and amplify population exploration by expanding the search space respectively, all these improvements are subject to boundary constraints. The process continues until a termination condition is met. These newly introduced techniques aim to improve the exploration and exploitation abilities of the original GWO, potentially leading to improved optimization results. The step-by-step procedure of CMWGWO is expressed in Algorithm 2 and the graphical illustration is given in Fig. 7.

CMWGWO flow chart.

Steps of CMWGWO
Computational complexity of CMWGWO
To analyze the computational complexity of the CMWGWO algorithm, we need to assess the complexity of each individual step and the number of iterations performed in the while loop. The breakdown of the steps and analysis of complexity is given below:
-
1.
Random initialization: Initializing the grey wolf population \(X_{i} \left( {i = 1,2,3 \ldots n} \right)\) involves generating random values for each individual wolf's position in the search space. The complexity of this step is \(O\left( n \right)\), where \(n\) is the size of the population and big \(O\) denotes CMWGWO’s complexity60,61.
-
2.
Fitness evaluation: Evaluating the fitness of each grey wolf requires evaluating the objective function of each individual. The computational complexity of this step depends on the complexity of the objective function and how it scales with the problem size. The complexity of evaluating the objective function as \(O\left( {fitness} \right)\).
-
3.
Finding the \(\alpha ,\beta ,{ }\delta and Worst\): This step involves identifying the best, second-best, third-best, and worst grey wolves based on their fitness values. The complexity of finding these wolves is \(O\left( n \right)\).
-
4.
The main loop (While loop): The main optimization loop iterates until the termination condition is met \((t < {\text{Maxit}})\). The number of iterations is determined by \({\text{Maxit}}\), so we can denote the complexity of the while loop as \(O\left( {{\text{Maxit}}} \right)\).
-
5.
Calculations within the loop: Within each iteration of the while loop, there are three separate techniques included in traditional GWO. The complexity of each of these techniques can be denoted as \(O\left( 1 \right)\) since they involve basic arithmetic operations and comparisons.
-
6.
Boundary checks are carried out once each wolf's new position has been determined to make sure that it remains inside the bounds of the search area. The dimension of the search area and the effectiveness of the boundary-checking method determine how complicated these boundary checks are. Boundary check complexity is expressed as \(O\left( {\text{d}} \right)\), where d is the search area 's dimensionality. The computational complexity of the CMWGWO algorithm can be approximated as expressed in Eq. (19), due to the introduction of these new techniques it is evident that the complexity of CMWGWO is higher than that of the original GWO:
$$O\left( n \right) + O\left( {fitness} \right) + O\left( n \right) + O\left( {{\text{Maxit}}} \right) + {\text{Maxit}}*\left( {3*O\left( 1 \right) + n*\left( {O\left( 1 \right) + O\left( d \right)} \right)} \right).$$(19)
Experiments and result analysis
In this part, we will carry out tests to verify CMWGWO's efficacy while highlighting the improvement it offers. To confirm their effectiveness, each mechanism’s analysis will be used to comprehensively assess the improvement techniques used. To support the validity of CMWGWO's superiority, studies will also be undertaken to evaluate the optimization performance of CMWGWO with various improved versions of GWO. The enhanced GWO in this work will also be put up against original algorithms, further demonstrating the optimization value of GWO. Benchmarking the performance of several algorithms using a variety of complex tasks is an important step62. Therefore we will put CMWGWO through 23 benchmark functions, 10 CEC 2019 functions, and 3 real-world engineering situations to show its supremacy. The 23 benchmark functions are specifically described in Table 1, together with their mathematical formulations, dimensions, and theoretically ideal values. Researchers have carefully chosen these test functions from a list of frequently used CEC functions63. Table 1 displays a set of 7 unimodal functions (F1-F7), each containing a single minimum value. These functions are ideal for evaluating the algorithm's exploitation performance, as they test its ability to converge to the global minimum. Additionally, Table 1 includes 6 multimodal functions (F8-F13), which differ from F1-F7 by having numerous local optimal. These functions assess the algorithm's exploration capability64, as they require it to search for multiple optimal solutions. Their expressions are provided in Table 1. Moreover, F14-F23 are multimodal functions as well, but they have a fixed dimensionality. In addition to 23 functions, CEC 2019 functions (C1–C10) are employed. The intricacy of this test suite has been increased by shifting and rotating them relative to the usual functions. Table 2 includes the details of the test suite. Throughout this work we will carry out 500 iterations with a population size of 50, in order to preserve the validity of the studies 30 repeated runs will be carried out to lessen the effects of population randomness and population concentration brought on by randomness, and the average value (AVG), standard deviation (STD) and Best will indicate the outcomes of each algorithms optimization.
Statistical and non-parametric analysis of each improvement technique contribution
Three strategies WID, COL, and MRS, are used by the CMWGWO algorithm to improve optimization performance. Three GWO variations were evaluated on 23 functions to show the impact of various techniques on GWO. Each variant denotes the employment of a single strategy: WIDGWO denotes the only application of the WID strategy, COLGWO denotes the sole application of the COL strategy, and MRSGWO denotes the sole application of the MRS approach. CMWGWO stands for the entire combination of all three methodologies. By contrasting the AVG, STD, and Best of the outcomes attained by each method across several functions, as shown in Table 3, the impacts of these techniques on GWO's search capability can be investigated. The average and best values provided by the COLGWO, WIDGWO, and MRSGWO algorithms are typically better than those of the conventional GWO, demonstrating that these three optimization techniques significantly enhance the algorithm's optimization accuracy in both exploration and exploitation. Additionally, CMWGWO surpasses COLGWO, WIDGWO, and MRSGWO in the majority of functions when considering average values, best values, and standard deviations of their results, outperforming all three optimization procedures. This shows that using all three of these procedures together enhances GWO's optimization speed and guarantees stable optimization capability.
The nonparametric Wilcoxon signed-rank test was used across the 23 functions to compare the differences between the 4 distinct GWOs and CMWGWO in Table 3 at a significance threshold of 5% recorded as a P Value in Table 3. Table 3 also shows the contrast between CMWGWO and various GWOs. The symbols “+”, “−”, and “=” denote that CMWGWO is more superior to, less superior than, and identical to the comparison algorithm. According to the results, CMWGWO performs better than the original GWO in 17 out of 23 functions and is inferior to GWO in just 2 of them. Using the three strategies, CMWGWO exceeds COLGWO, CIGWO, and MRSGWO in 16 functions, 17 functions, and 14 functions, respectively. This indicates that the three strategies employed in CMWGWO complement each other, compensating for the shortcomings of GWO and significantly enhancing its performance across different test functions that test both the diversification and intensification capacity of CMWGWO. Notably, when comparing CMWGWO to other variants of GWO, including the traditional GWO in Table 3, the difference is less than 0.05 as indicated by the P Value, implying significant improvements in performance. The exception is MRSGWO, where CMWGWO shows no significant difference because it achieves similar results to MRSGWO in some functions, this also shows that the MRS being part of CMWGWO contributes to its exceptional performance. The Friedman Average (FRD-AVG) of CMWGWO is 1.80, ranking first among the five algorithms, and the FRD-AVG of the GWOs with other strategies is also smaller than that of the original GWO. This highlights that CMWGWO's overall performance surpasses other GWO variants and the traditional GWO in the comprehensive ranking using the Friedman Rank.
Figure 8 presents the convergence paths of CMWGWO and other variants based on different techniques, with the goal of evaluating the distinct performance of CMWGWO in achieving convergence while dealing with optimization functions. The study involves comparing CMWGWO with other algorithms derived from different techniques and the traditional GWO. The outcomes clearly demonstrate that CMWGWO outperforms the traditional GWO and other variants developed from different techniques in terms of convergence precision, particularly on all unimodal functions except F5. Remarkably, CMWGWO showcases exceptional convergence rates and successfully reaches the best optimal solution for F10, F11, F14-19, F21, and F23, showcasing its proficiency in handling multimodal functions. Comparatively, CMWGWO exhibits better convergence efficiency than GWO and other counterparts. These findings provide compelling evidence that the population diversification adjustments and the introduction of enhanced exploration techniques have significantly contributed to the success of CMWGWO. The experimental data strongly support the notion that CMWGWO has greatly improved its optimization capability and convergence performance.


Convergence plot of different improvement techniques.
Dimension impact statistical analysis and non-parametric test of 23 test functions
CMWGWO is compared with several variants of GWO and Original algorithms, namely GWO30, Adaptive GWO (AdGWO)39, GWO based on Aquila exploration (AGWO)65, Augmented GWO & Cuckoo Search (AGWOCS)66, Random Walk GWO (RWGWO) 41, Hybrid-Flash Butterfly Optimization Algorithm (HFBOA) 67, Chimp Optimization Algorithm (CHOA)68, Particle Swarm Optimization (PSO)69 and Sine Cosine Algorithm 70 in this section on 23 functions while varying the dimension of each function. The parameters of this algorithm can be found in Table 4. Other parameters like iteration, population, and number of runs are set to 50, 500, and 30, respectively.
By raising the dimension (Dim) of functions F1–F13 in the benchmark suite to 30, 100, 200, and 500, the effectiveness of CMWGWO in tackling high-dimensional optimization problems was assessed in this section. Tables 5, 6, 7 and 8 showcase the statistical experiment findings based on AVG (average), STD (standard deviation) and Best results for each function on the benchmark suite with Dim = 30, 100, 200, and 500, respectively, CMWGWO got remarkable FRD-AVG ranking values of 2.11, 1.73, 1.79, and 1.67, demonstrating that CMWGWO consistently ranks top across all dimensions it can be inferred that CMWGWO show robustness in complex problem handling as it maintain superior performance compared to other algorithm. The data shown in Tables 5, 6, 7 and 8 confirms the efficacy of each technique introduced to this variant of GWO.
For functions F1–F7, in Table 5 (functions F1–F6), Table 6 (functions F1–F3, F5–F7), Table 7 (Functions F1–F3, F5–F7) and Table 8 (Functions F1–F7) CMWGWO obtained the best solution in these functions as the complexity of problem increased with the dimension. This suggests that CMWGWOO has the ability to converge to the global optimal value. This observation demonstrated that the CMWGWO has a high exploitative ability while solving unimodal functions compared to the original GWO. In addition, GWO variations such as AdGWO and AGWOCS produced competitive results. Moving on to F8-F13 in Tables 5, 6, 7 and 8, CMWGWO consistently outperforms other competitors and GWO variants, in functions F8, F11-F13. Furthermore, in Table 5, F21-F23, which are fixed-dimension functions, CMWGWO maintains superior performance in F14-F19, F21, and F23. The superior performance of CMWGWO can be attributed to the improvement strategies. COL maintains high diversity during optimization, MRS improves population exploration capacity, and WID enhances the population's ability to approach the optimal solution while reducing the dominance of the best wolf in order to escape local optima in multi-peaked problems (F13-F24). The P Value results from the Wilcoxon signed-rank test on the 23 benchmark suite at Dim = 30, 100, 200, and 500, shown in Tables 5, 6, 7 and 8, confirm that CMWGWO is significantly superior to other competitors. The statistical analysis further verifies that CMWGWO effectively enhances optimization performance in the search process.
Statistical and non-parametric analysis of CEC 2019 functions
To evaluate the proposed optimizers performance in intricate objective functions, the AVG, STD, and Best were used as assessment metrics to gauge the precision as well as the reliability of the CMWGWO and other optimizers. It is evident from the statistics in Table 9 that CMWGWO obtains the most optimum solution for five out of ten functions. It is extremely crucial to highlight that the effectiveness of CMWGWO is a substantial advancement beyond the traditional GWO as well as other methods in C1, C4, C6, C7, C8, and C9 in terms of AVG. This significant enhancement is anticipated as a result of the addition of improvement strategies to enhance CMWGWO’s capacity to enhance local and global search while preserving variety. As a consequence, CMWGWO’s overall performance has significantly improved. Based on the Wilcoxon signed-rank test the P Values in Table 9, CMWGWO shows statistically significant improvement compared to AdGWO, AGWO, CHOA, HFBOA, GWO, AGWOCS, RWGWO, PSO, and SCA (P < 0.05). The Friedman test ranks CMWGWO as the best-performing algorithm among the ten, indicating its overall superiority in terms of these metrics. This shows that with MRS, COL, and WID, CMWGWO is able to maintain stability in overcoming local optimal and keeping population diversity consistent throughout the iteration process in challenging problems.
Convergence and box plot analysis on 23 functions and CEC 2019 functions
Figures 9, 10, 11 and 12 compare the CMWGWO method with nine different cutting-edge algorithms using convergence curves and box plots on 23 functions (30 dim) and CEC 2019 respectively. These charts show how each algorithm's average accuracy changes as the number of iterations rises, as shown in Figs. 9 and 10. The distribution of the final optimal solutions attained by each method is shown by the box plots. The minimum, maximum, lower quartile (Q1), median, upper quartile (Q3), and any outliers can all be viewed clearly inside the box plots in Figs. 11 and 12. The best set of solutions from each iteration of 30 iterations is displayed by a box plot, while the orange line inside the box denotes the median. Notably, an outlier is a data point that deviates significantly from the norm and is identified by a red “+” sign. This comparison's goal is to illustrate and assess the variations in optimization performance between CMWGWO and other cutting-edge algorithms. The convergence curves provide information on how the best solution values change when the search process of each approach is performed. A low value representing the best solution found indicates that the approach is more capable of optimization. The box plots, on the other hand, give details about how the best results from each approach are distributed. A technique is more stable and hence more resistant to changes in the search space if the approach's box sizes in the box plots are smaller. To put it another way, the box plots illustrate how consistently each approach finds the ideal answer while the convergence curves show how effectively each method achieves that goal.


Convergence trajectory of CMWGWO and nine compared optimizers on 23 functions.

Convergence trajectory of CMWGWO and nine compared optimizers on CEC 2019.


Box plot of CMWGWO and nine compared optimizers on 23 functions.

Box plot of CMWGWO and nine compared optimizers on CEC 2019 functions.
The CMWGWO technique displays quick convergence in its early phases, as seen in Fig. 9. It's interesting to note that the CMWGWO approach continues to explore high-quality regions while other algorithms tend to have a flattened curve meaning they can easily be stuck in local optimal. Furthermore, according to the findings, CMWGWO demonstrates quicker convergence for all functions other than F7 in uni-modal functions (F1-F7). The suggested technique, however, performs better for multimodal functions than current approaches, with better results for functions F8, F11, F12, and F13. Additionally, the suggested method exhibits admirable and exceptional convergence for functions F14–F19, F21, and F23, categorized as fixed-dimension functions. Notably, the CMWGWO outperforms AGWO, AdGWO, and AGWOCS in establishing a balance between convergence and divergence. Figure 9’s comparison further demonstrates that CMWGWO maintains higher convergence accuracy than other techniques. These findings confirm that, in comparison to the traditional GWO approach, the modifications made in this work not only improve the trade-off between exploration and exploitation, it also demonstrate the method's capacity to avoid local optima and get close to the overall best outcome. Three crucial strategies WID, COL, and MRS were incorporated into the CMWGWO technique to increase its effectiveness in this area. While the COL technique increases population variation throughout the search process, the MRS strategy enables the wolf agent to keep investigating the optimum solution. The WID tactic also effectively traps prey, all these add to the efficiency of CMWGWO. Furthermore, the CMWGWO approach is able to find probable solutions inside the problem domain characterized by shifted, rotated, and hybrid in CEC 2019 functions in Fig. 10 because of the combination of various tactics, which finally results in improved diversity and more accurate solutions in functions C1, C4, C6, C7, C8, and C9. The boxplot analysis of each function also makes it quite evident that CMWGWO has strong stability as seen in Figs. 11 and 12. This suggests that the CMWGWO’s approach to exploration and exploitation capabilities is well-balanced.
Exploration and exploitation analysis
Exploration and exploitation stages are often two essential phases in optimization algorithms. The Algorithm prioritizes exploration in the first stage with the goal of identifying areas of the feasible domain space that have promising prospects for improved candidate solutions. The algorithm then progressively moves from the exploration to the exploitation , putting more effort into looking for better candidate solutions close to the existing best solution. An algorithm's optimization efficiency is largely influenced by how well its exploration and exploitation capabilities are balanced. The chances of discovering improved candidate solutions may increase with more exploration capabilities, but the speed of convergence may be slowed. On the other hand, increasing the exploitation capabilities might hasten convergence but increase the chance of being stuck in local optima. To establish a delicate balance between the exploration and exploitation phases, we enhanced CMWGWO’s exploitation and exploration. This balance is essential since it affects the effectiveness of optimization as a whole. In order to locate high-quality solutions quickly while avoiding premature convergence to local optima, The algorithm must ideally balance exploration and exploitation. To enhance the algorithm's efficacy and resilience in tackling optimization issues.
In this part, the exploration and exploitation stages of the CMWGWO are numerically investigated and compared to the traditional GWO. We use Eqs. (20) to (23) to determine the proportion of these two phases in order to more accurately characterize the algorithm's exploration and exploitation process while it is running.
The percentages of the algorithm's exploration and exploitation stages are shown by the symbols \({\text{\% }}EPR\) and \({\text{\% }}EPL\), respectively. The diversity of all population members in the technique is denoted by \(Div\) and \(Div_{max}\) denotes the highest diversity value thus far observed among the population members. Furthermore, \(Div_{j}\) stands for the diversity of the \(jth\) dimension throughout the whole population. The algorithm's parameters \(n\) and \(dim\) correspond to the population's size and the problem's dimension, respectively. While \({\text{median}}\left( {x^{j} } \right)\) designates the median value of the \(jth\) dimension across all population members, \(x^{j}\) specifies the \(jth\) dimension of the \(ith\) member in the technique.
Specific illustrations depicting unimodal and multimodal functions selected from the functions utilized in the previous experiment are used to analyze the algorithm's exploration and exploitation levels during their search process, as shown in Fig. 13. The first column compares the convergence curves of CMWGWO and GWO, while the second and third columns show the exploration and exploitation phases of CMWGWO and GWO, respectively. F1, F3, and F5 are categorized as unimodal functions, whereas F10 and F23 are categorized as multimodal. The balance of the suggested CMGWO and GWO for unimodal and multimodal functions is shown in Fig. 13 by the convergence and diversity patterns. It is clear that when compared to the original GWO approach, the CMWGWO method shows enhanced exploration of optimum solutions. Additionally, CMWGWO outperforms GWO in terms of striking a balance between the algorithm's exploitation and exploration stages.

Exploration and exploitation comparison of CMWGWO and GWO.
The percentage of exploration length (\({\text{\% }}EPR)\) attained by the CMWGWO approach is as follows when looking at the second column of Fig. 13: 1.1164% for F1, 1.5338% for F3, 1.2949% for F5, 3.4933% for F10, and 32.4377% for F23. Furthermore the \({\text{\% }}EPL\) is 98.8836% for F1, 98.4662% for F3, 98.7051% for F5, 96.5067% for F10, and 67.5623% for F23. The suggested CMWGWO approach exhibits an increase of around 2.1% on the unimodal functions F1, F3, and F5 in the exploration phase when compared to the \({\text{\% }}EPR\) attained by GWO in the unimodal functions. Additionally, there is an increase of around 19% in the exploration phase compared to GWO for the multimodal functions F10 and F23. It can be concluded that the proposed CMWGWO more efficiently divides the execution time between the exploitation and exploration phases of the algorithm based on the convergence curves of CMWGWO and GWO on F1, F3, F5, F10, and F23. To put it another way, it shows a greater balance between the two stages, which enhances performance.
Computation time analysis
Tables 10 and 11 present a comparison of the average computation time of CMWGWO and its competitors. A detailed analysis of CMWGWO highlights that it generally necessitates more CPU time when compared to other methods. This can be attributed to CMWGWO's incorporation of MRS, COL, and WID, wherein each method is independently executed in the course of the optimization process. Consequently, the CPU time of CMWGWO does not consistently outperform the compared methods due to its inherent complexity, as elucidated in Eq. 19. In Figs. 14 and 15, it becomes evident that CMWGWO requires greater computational time than the original GWO and other GWO variants such as AdGWO, AGWO, AGWOCS, and RWGWO. Nonetheless, despite its increased computational demands, CMWGWO exhibits remarkable efficiency, surpassing these algorithms in terms of performance. Taking into consideration the substantial contributions of CMWGWO, a harmonious balance can be achieved between attaining high accuracy and effectively managing the time required to solve problems.

Comparison of optimizer average computation time on 23 functions.

Comparison of optimizer average computation time on CEC 2019 functions.
Engineering problem application
Based on the constraints and particular needs of the optimization method they are employing, researchers must take thorough and well-founded assessments. They need efficient tools that provide them the ability to make wise decisions within a logical framework in order to do this 71,72. By using it to solve three traditional engineering constraint issues, the performance of CMWGWO is carefully assessed in this context. The purpose of this inquiry is to confirm the useful and practical uses of the CMWGWO approach. The three issues under consideration are as follows: Welded Beam Design Problem (WBDP)73, Three Truss Bar (TTB)74,75 and I-Beam Design Problem(IBDP)76,77.
Welded beam design (WBDP)
In the welded beam problem, a stiff support member needs to be welded to a beam. The ideal cost problem, depicted in Fig. 16, is used to estimate the beam's ideal dimensions in order to reduce costs78. Four main factors, namely, weld seam thickness (h(\({\text{x}}_{1} )\)), steel bar length (l \(\left( {{\text{x}}_{2} } \right)\)), steel bar height (t \(\left( {{\text{x}}_{3} } \right)\)) and steel bar thickness (b \(\left( {{\text{x}}_{4} } \right)\)), have an impact on the production cost. Additionally, the model is subject to four constraints: buckling load (Pc), shear stress (τ), beam internal bending stress (σ), and end deflection rate (δ). The mathematical expression of this problem can be stated as in Fig. 16.

Welded beam design problem.
Objective function
Subject to:
where
Based on the data shown in Table 12, the results reveal that the CMWGWO method attains the smallest cost for WBDP, measuring 1.670217726. This outcome highlights a significant advantage over the GWO, RWGWO, and AGWOCS algorithms. Clearly, CMWGWO effectively meets the requirements of the design problem with the lowest cost, leading to reduced engineering consumption. These findings demonstrate the practical superiority of CMWGWO in achieving optimal solutions, resulting in cost-effective designs and resource savings in engineering applications.
Three truss bar (TTB)
Firstly introduced by Ray and Saini, the three bar truss design optimization problem is a classic engineering optimization problem in structural mechanics79. The problem consists of two variables and three constraints. It involves finding the optimal dimensions of a truss made of three bars to achieve certain design objectives while respecting constraints such as buckling, stress, and bending, as presented in Fig. 17.

Three bar truss design problem.
Objective function:
Subject to by:
where \(l = 100\;{\text{cm}};\;P = \frac{{2\;{\text{kN}}}}{{{\text{cm}}^{2} }};\;\sigma = \frac{{2\;{\text{kN}}}}{{{\text{cm}}^{2} }}\).
The information in Table 13 makes it readily apparent that the CMWGWO approach earns the top spot in terms of best costs. This result shows that the CMWGWO, works remarkably well for this particular situation. It verifies the suggested algorithm's superiority over competing approaches and shows that it can produce cost-optimization solutions that are both highly competitive and superior.
I-beam design problem (IBDP)
The I-beam design problem, as shown in Fig. 18, involves a beam subjected to two pressures80. The goal is to design an I-beam with minimal vertical deflection. The structural parameters of the problem consist of height, length, and two thicknesses. The mathematical representation of this problem is presented below:

I-beam design problem.
Objective function:
Subject to:
where \(10 \le z_{1} \le 50\), \(10 \le z_{2} \le 80\), \(0.9 \le z_{3} ,z_{4} \le 5\).
The CMWGWO is compared to a number of optimization techniques as seen in Table 14, Table 14 displays the experimental results. It is evident from observing the data that CMWGWO obtains the smallest vertical deflection, measuring 0.013074119. This outstanding outcome demonstrates that, when compared to other optimization techniques, CMWGWO provides the best answer for this particular problem design type.
Conclusion
This paper introduces CMWGWO with the primary objective of addressing the limitations of the original GWO. These limitations include premature convergence, insufficient diversity within the population, subpar global search capabilities, and susceptibility to be trapped in local optimum due to convergence towards the best wolf. CMWGWO employs three strategies to overcome these limitations. Firstly, the WID strategy is employed to enhance population diversity by facilitating better information exchange between the best and worst wolves. This improvement enables the algorithm to escape stagnation and explore a more extensive range of solutions. Secondly, the algorithm incorporates the embedded COL search mechanism to increase the likelihood of individuals approaching the global optimum. By doing so, it elevates the optimization accuracy and alleviates stagnation issues. Lastly, the integration of MRS amplifies population exploration and significantly expands the search space. As a result, CMWGWO is able to effectively explore a wider range of potential solutions, enhancing its overall performance in optimization tasks.
The experiments in this study involve the testing of 23 functions and 10 CEC 2019 with distinct characteristics. The initial comparison includes WID_GWO, COL_GWO, MRS_GWO, GWO, and CMWGWO to confirm the effectiveness of the optimization mechanisms introduced in this paper. Furthermore, CMWGWO is pitted against well-known GWO variants, namely RWGWO, AGWO, AdGWO, and AGWOCS. The results clearly demonstrate that CMWGWO outperforms these competitive algorithms significantly, a fact that becomes evident when examining the convergence curves of these algorithms. In contrast to the original algorithms, such as CHOA, SCA, HFBOA, and PSO, CMWGWO exhibits a robust exploration ability and improves solution accuracy substantially. Extensive testing on high-dimensional problems, coupled with exploitation and diversity analysis, further confirms its capability to achieve higher-quality solutions. Lastly, the application of CMWGWO to WBDP, TTB, and IBDP problems showcases its effectiveness in effectively solving these typical engineering constraint problems, thereby highlighting its potential for practical applications.
Although CMWGWO can surpass the original GWO and other rival algorithms, its optimization performance can yet be enhanced. Tables 5, 6, 7 and 9 display the results of such functions i.e. F7 and F9 functions. This proves the No Free Lunch theorem that no single optimizer is efficient for all problems. To attain greater solution accuracy, we intend to improve CMWGWO's exploration and exploitation capabilities going forward. This will need combining more modification approaches, such as applying novel population initializing strategies, hybridizing with other algorithms, and adaptively lowering some parameters in a nonlinear way. Additionally, CMWGWO has difficulties when tackling large-scale and complicated issues; therefore, future work will entail extensive tests on complex problems and comparison with more state-of-the-art algorithms. CMWGWO requires more time than the original GWO, making it necessary to take into account parallel computing in the next research stage to speed up the procedure. A fascinating research path also involves merging CMWGWO with machine learning. Furthermore, the applicability of CMWGWO can be extended to various real-world optimization problems across different fields. For instance, it can be effectively utilized in optimal power flow problems 81, classification of neuroimaging82, heat removal systems83, and water distribution systems84. Expanding CMWGWO’s potential, it would be reasonable to explore the development of a multi-objective version of the algorithm, catering to complex multi-objective challenges that require simultaneous optimization of multiple criteria.
Data availability
The data obtained through the experiments are available upon request from the corresponding author.
References
Xu, W. et al. Evolutionary process for engineering optimization in manufacturing applications: Fine brushworks of single-objective to multi-objective/many-objective optimization. Processes https://doi.org/10.3390/pr11030693 (2023).
Bao, C., Gao, D., Gu, W., Xu, L. & Goodman, E. D. A new adaptive decomposition-based evolutionary algorithm for multi- and many-objective optimization. Expert Syst. Appl. 213, 119080. https://doi.org/10.1016/j.eswa.2022.119080 (2023).
Tang, J., Liu, G. & Pan, Q. A review on representative swarm intelligence algorithms for solving optimization problems: Applications and trends. IEEECAA J. Autom. Sin. 8(10), 1627–1643. https://doi.org/10.1109/JAS.2021.1004129 (2021).
Angadi, B. M., Kakkasageri, M. S. & Manvi, S. S. Chapter 2—Computational intelligence techniques for localization and clustering in wireless sensor networks. In Recent trends in computational intelligence enabled research (eds Bhattacharyya, S. et al.) 23–40 (Academic Press, 2021). https://doi.org/10.1016/B978-0-12-822844-9.00011-6.
Pan, J.-S., Zhang, L.-G., Wang, R.-B., Snášel, V. & Chu, S.-C. Gannet optimization algorithm : A new metaheuristic algorithm for solving engineering optimization problems. Math. Comput. Simul. 202, 343–373. https://doi.org/10.1016/j.matcom.2022.06.007 (2022).
Abdollahzadeh, B., Gharehchopogh, F. S. & Mirjalili, S. African vultures optimization algorithm: A new nature-inspired metaheuristic algorithm for global optimization problems. Comput. Ind. Eng. 158, 107408. https://doi.org/10.1016/j.cie.2021.107408 (2021).
Talatahari, S., Azizi, M. & Gandomi, A. H. Material generation algorithm: A novel metaheuristic algorithm for optimization of engineering problems. Processes https://doi.org/10.3390/pr9050859 (2021).
Zhong, C., Li, G. & Meng, Z. Beluga whale optimization: A novel nature-inspired metaheuristic algorithm. Knowl. Based Syst. 251, 109215. https://doi.org/10.1016/j.knosys.2022.109215 (2022).
Hashim, F. A., Hussain, K., Houssein, E. H., Mabrouk, M. S. & Al-Atabany, W. Archimedes optimization algorithm: A new metaheuristic algorithm for solving optimization problems. Appl. Intell. 51(3), 1531–1551. https://doi.org/10.1007/s10489-020-01893-z (2021).
Abdollahzadeh, B., Soleimanian Gharehchopogh, F. & Mirjalili, S. Artificial gorilla troops optimizer: A new nature-inspired metaheuristic algorithm for global optimization problems. Int. J. Intell. Syst. 36(10), 5887–5958. https://doi.org/10.1002/int.22535 (2021).
Zhao, S., Zhang, T., Ma, S. & Chen, M. Dandelion optimizer: A nature-inspired metaheuristic algorithm for engineering applications. Eng. Appl. Artif. Intell. 114, 105075. https://doi.org/10.1016/j.engappai.2022.105075 (2022).
Mohammadi-Balani, A., Dehghan Nayeri, M., Azar, A. & Taghizadeh-Yazdi, M. Golden eagle optimizer: A nature-inspired metaheuristic algorithm. Comput. Ind. Eng. 152, 107050. https://doi.org/10.1016/j.cie.2020.107050 (2021).
Talatahari, S. & Azizi, M. Chaos Game Optimization: A novel metaheuristic algorithm. Artif. Intell. Rev. 54(2), 917–1004. https://doi.org/10.1007/s10462-020-09867-w (2021).
Azizi, M., Talatahari, S. & Gandomi, A. H. Fire Hawk Optimizer: A novel metaheuristic algorithm. Artif. Intell. Rev. 56(1), 287–363. https://doi.org/10.1007/s10462-022-10173-w (2023).
Hashim, F. A., Houssein, E. H., Hussain, K., Mabrouk, M. S. & Al-Atabany, W. Honey Badger Algorithm: New metaheuristic algorithm for solving optimization problems. Math. Comput. Simul. 192, 84–110. https://doi.org/10.1016/j.matcom.2021.08.013 (2022).
Naik, A., Satapathy, S. C. & Abraham, A. Modified Social Group Optimization—A meta-heuristic algorithm to solve short-term hydrothermal scheduling. Appl. Soft Comput. 95, 106524. https://doi.org/10.1016/j.asoc.2020.106524 (2020).
Gharehchopogh, F. S., Maleki, I. & Dizaji, Z. A. Chaotic vortex search algorithm: Metaheuristic algorithm for feature selection. Evol. Intell. 15(3), 1777–1808. https://doi.org/10.1007/s12065-021-00590-1 (2022).
Fan, Q. et al. A modified self-adaptive marine predators algorithm: Framework and engineering applications. Eng. Comput. 38(4), 3269–3294. https://doi.org/10.1007/s00366-021-01319-5 (2022).
Akinola, O. A., Ezugwu, A. E., Oyelade, O. N. & Agushaka, J. O. A hybrid binary dwarf mongoose optimization algorithm with simulated annealing for feature selection on high dimensional multi-class datasets. Sci. Rep. https://doi.org/10.1038/s41598-022-18993-0 (2022).
Yang, B. et al. Comprehensive overview of meta-heuristic algorithm applications on PV cell parameter identification. Energy Convers. Manag. 208, 112595. https://doi.org/10.1016/j.enconman.2020.112595 (2020).
Askarzadeh, A. A novel metaheuristic method for solving constrained engineering optimization problems: Crow search algorithm. Comput. Struct. 169, 1–12. https://doi.org/10.1016/j.compstruc.2016.03.001 (2016).
Wu, D. et al. Modified sand cat swarm optimization algorithm for solving constrained engineering optimization problems. Mathematics https://doi.org/10.3390/math10224350 (2022).
Adegboye, O. R. et al. Antenna S-parameter optimization based on golden sine mechanism based honey badger algorithm with tent chaos. Heliyon https://doi.org/10.1016/j.heliyon.2023.e21596 (2023).
Abualigah, L., Almotairi, K. H. & Elaziz, M. A. Multilevel thresholding image segmentation using meta-heuristic optimization algorithms: Comparative analysis, open challenges and new trends. Appl. Intell. 53(10), 11654–11704. https://doi.org/10.1007/s10489-022-04064-4 (2023).
Chouksey, M., Jha, R. K. & Sharma, R. A fast technique for image segmentation based on two meta-heuristic algorithms. Multimed. Tools Appl. 79(27), 19075–19127. https://doi.org/10.1007/s11042-019-08138-3 (2020).
Goli, A. et al. An integrated approach based on artificial intelligence and novel meta-heuristic algorithms to predict demand for dairy products: A case study. Netw. Comput. Neural Syst. 32(1), 1–35. https://doi.org/10.1080/0954898X.2020.1849841 (2021).
Kaveh, A. & Zaerreza, A. A new framework for reliability-based design optimization using metaheuristic algorithms. Structures 38, 1210–1225. https://doi.org/10.1016/j.istruc.2022.02.069 (2022).
Meng, Z., Rıza Yıldız, A. & Mirjalili, S. Efficient decoupling-assisted evolutionary/metaheuristic framework for expensive reliability-based design optimization problems. Expert Syst. Appl. 205, 117640. https://doi.org/10.1016/j.eswa.2022.117640 (2022).
Chou, Y.-H., Kuo, S.-Y., Yang, L.-S. & Yang, C.-Y. Next Generation metaheuristic: Jaguar algorithm. IEEE Access 6, 9975–9990. https://doi.org/10.1109/ACCESS.2018.2797059 (2018).
Mirjalili, S., Mirjalili, S. M. & Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007 (2014).
Long, W., Cai, S., Jiao, J. & Tang, M. An efficient and robust grey wolf optimizer algorithm for large-scale numerical optimization. Soft Comput. 24(2), 997–1026. https://doi.org/10.1007/s00500-019-03939-y (2020).
Feda, A. K. et al. S-shaped grey wolf optimizer-based FOX algorithm for feature selection. Heliyon 10(2), e24192. https://doi.org/10.1016/j.heliyon.2024.e24192 (2024).
Gupta, S., Deep, K., Moayedi, H., Foong, L. K. & Assad, A. Sine cosine grey wolf optimizer to solve engineering design problems. Eng. Comput. 37(4), 3123–3149. https://doi.org/10.1007/s00366-020-00996-y (2021).
Sathiyabhama, B. et al. A novel feature selection framework based on grey wolf optimizer for mammogram image analysis. Neural Comput. Appl. 33(21), 14583–14602. https://doi.org/10.1007/s00521-021-06099-z (2021).
Preethi, P., Asokan, R., Thillaiarasu, N. & Saravanan, T. An effective digit recognition model using enhanced convolutional neural network based chaotic grey wolf optimization. J. Intell. Fuzzy Syst. 41(2), 3727–3737. https://doi.org/10.3233/JIFS-211242 (2021).
Nadimi-Shahraki, M. H., Taghian, S. & Mirjalili, S. An improved grey wolf optimizer for solving engineering problems. Expert Syst. Appl. 166, 113917. https://doi.org/10.1016/j.eswa.2020.113917 (2021).
Mirjalili, S., Saremi, S., Mirjalili, S. M. & Coelho, L. D. S. Multi-objective grey wolf optimizer: A novel algorithm for multi-criterion optimization. Expert Syst. Appl. 47, 106–119. https://doi.org/10.1016/j.eswa.2015.10.039 (2016).
Bansal, J. C. & Singh, S. A better exploration strategy in Grey Wolf Optimizer. J. Ambient Intell. Humaniz. Comput. 12(1), 1099–1118. https://doi.org/10.1007/s12652-020-02153-1 (2021).
Meidani, K., Hemmasian, A., Mirjalili, S. & Barati Farimani, A. Adaptive grey wolf optimizer. Neural Comput. Appl. 34(10), 7711–7731. https://doi.org/10.1007/s00521-021-06885-9 (2022).
Lei, W., Jiawei, W. & Zezhou, M. Enhancing grey wolf optimizer with levy flight for engineering applications. IEEE Access https://doi.org/10.1109/ACCESS.2023.3295242 (2023).
Gupta, S. & Deep, K. A novel random walk grey wolf optimizer. Swarm Evol. Comput. 44, 101–112. https://doi.org/10.1016/j.swevo.2018.01.001 (2019).
Nasrabadi, M. S., Sharafi, Y. & Tayari, M. A parallel grey wolf optimizer combined with opposition based learning. In 2016 1st Conference on Swarm Intelligence and Evolutionary Computation (CSIEC) 18–23. https://doi.org/10.1109/CSIEC.2016.7482116 (2016).
Hoseini, Z., Varaee, H., Rafieizonooz, M. & Jay Kim, J.-H. A new enhanced hybrid grey wolf optimizer (GWO) combined with elephant herding optimization (EHO) algorithm for engineering optimization. J. Soft Comput. Civ. Eng. 6(4), 1–42. https://doi.org/10.22115/scce.2022.342360.1436 (2022).
Singh, N. & Singh, S. B. Hybrid algorithm of particle swarm optimization and grey wolf optimizer for improving convergence performance. J. Appl. Math. 2017, e2030489. https://doi.org/10.1155/2017/2030489 (2017).
Zhao, M., Hou, R., Li, H. & Ren, M. A Hybrid Grey Wolf Optimizer Using Opposition-Based Learning, Sine Cosine Algorithm and Reinforcement Learning for Reliable Scheduling and Resource Allocation (Rochester, 2023). https://doi.org/10.2139/ssrn.4374576.
Fadheel, B. A. et al. A hybrid grey wolf assisted-sparrow search algorithm for frequency control of RE integrated system. Energies https://doi.org/10.3390/en16031177 (2023).
Janakiraman, S. & Priya, D. Hybrid grey wolf and improved particle swarm optimization with adaptive intertial weight-based multi-dimensional learning strategy for load balancing in cloud environments. Sustain. Comput. Inform. Syst. 38, 100875. https://doi.org/10.1016/j.suscom.2023.100875 (2023).
Das, A. K. & Pratihar, D. K. Bonobo optimizer (BO): An intelligent heuristic with self-adjusting parameters over continuous spaces and its applications to engineering problems. Appl. Intell. 52(3), 2942–2974. https://doi.org/10.1007/s10489-021-02444-w (2022).
Zamani, H., Nadimi-Shahraki, M. H. & Gandomi, A. H. QANA: Quantum-based avian navigation optimizer algorithm. Eng. Appl. Artif. Intell. 104, 104314. https://doi.org/10.1016/j.engappai.2021.104314 (2021).
Zamani, H., Nadimi-Shahraki, M. H. & Gandomi, A. H. Starling murmuration optimizer: A novel bio-inspired algorithm for global and engineering optimization. Comput. Methods Appl. Mech. Eng. 392, 114616. https://doi.org/10.1016/j.cma.2022.114616 (2022).
Tizhoosh, H. R. Opposition-based learning: A new scheme for machine intelligence. In International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC’06) 695–701. https://doi.org/10.1109/CIMCA.2005.1631345 (2005).
Bo, Q., Cheng, W. & Khishe, M. Evolving chimp optimization algorithm by weighted opposition-based technique and greedy search for multimodal engineering problems. Appl. Soft Comput. 132, 109869. https://doi.org/10.1016/j.asoc.2022.109869 (2023).
Si, T., Miranda, P. B. C. & Bhattacharya, D. Novel enhanced Salp Swarm Algorithms using opposition-based learning schemes for global optimization problems. Expert Syst. Appl. 207, 117961. https://doi.org/10.1016/j.eswa.2022.117961 (2022).
Khishe, M. Greedy opposition-based learning for chimp optimization algorithm. Artif. Intell. Rev. 56(8), 7633–7663. https://doi.org/10.1007/s10462-022-10343-w (2023).
Chen, H. et al. Slime mould algorithm: A comprehensive review of recent variants and applications. Int. J. Syst. Sci. 54(1), 204–235. https://doi.org/10.1080/00207721.2022.2153635 (2023).
Zhang, Y. Backtracking search algorithm with specular reflection learning for global optimization. Knowl. Based Syst. 212, 106546. https://doi.org/10.1016/j.knosys.2020.106546 (2021).
He, Q., Liu, H., Ding, G. & Tu, L. A modified Lévy flight distribution for solving high-dimensional numerical optimization problems. Math. Comput. Simul. 204, 376–400. https://doi.org/10.1016/j.matcom.2022.08.017 (2023).
Yan, F., Xu, X. & Xu, J. Grey wolf optimizer with a novel weighted distance for global optimization. IEEE Access 8, 120173–120197. https://doi.org/10.1109/ACCESS.2020.3005182 (2020).
Qiao, S. et al. Individual disturbance and neighborhood mutation search enhanced whale optimization: Performance design for engineering problems. J. Comput. Des. Eng. 9(5), 1817–1851. https://doi.org/10.1093/jcde/qwac081 (2022).
Adegboye, O. R. & Deniz Ülker, E. Gaussian mutation specular reflection learning with local escaping operator based artificial electric field algorithm and its engineering application. Appl. Sci. https://doi.org/10.3390/app13074157 (2023).
Long, W. et al. A novel grey wolf optimizer algorithm with refraction learning. IEEE Access 7, 57805–57819. https://doi.org/10.1109/ACCESS.2019.2910813 (2019).
Shen, Y., Zhang, C., Soleimanian Gharehchopogh, F. & Mirjalili, S. An improved whale optimization algorithm based on multi-population evolution for global optimization and engineering design problems. Expert Syst. Appl. 215, 119269. https://doi.org/10.1016/j.eswa.2022.119269 (2023).
Peng, L., Cai, Z., Heidari, A. A., Zhang, L. & Chen, H. Hierarchical Harris hawks optimizer for feature selection. J. Adv. Res. https://doi.org/10.1016/j.jare.2023.01.014 (2023).
Adegboye, O. R. & Deniz Ülker, E. Hybrid artificial electric field employing cuckoo search algorithm with refraction learning for engineering optimization problems. Sci. Rep. https://doi.org/10.1038/s41598-023-31081-1 (2023).
Ma, C. et al. Grey wolf optimizer based on Aquila exploration method. Expert Syst. Appl. 205, 117629. https://doi.org/10.1016/j.eswa.2022.117629 (2022).
Sharma, S., Kapoor, R. & Dhiman, S. A novel hybrid metaheuristic based on augmented grey wolf optimizer and cuckoo search for global optimization. In 2021 2nd International Conference on Secure Cyber Computing and Communications (ICSCCC) 376–381. https://doi.org/10.1109/ICSCCC51823.2021.9478142 (2021).
Zhang, M., Wang, D. & Yang, J. Hybrid-flash butterfly optimization algorithm with logistic mapping for solving the engineering constrained optimization problems. Entropy https://doi.org/10.3390/e24040525 (2022).
Khishe, M. & Mosavi, M. R. Chimp optimization algorithm. Expert Syst. Appl. 149, 113338. https://doi.org/10.1016/j.eswa.2020.113338 (2020).
Kennedy, J. & Eberhart, R. Particle swarm optimization. In Proceedings of ICNN’95—International Conference on Neural Networks, Vol. 4, 1942–1948. https://doi.org/10.1109/ICNN.1995.488968 (1995).
Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 96, 120–133. https://doi.org/10.1016/j.knosys.2015.12.022 (2016).
Trojovský, P. & Dehghani, M. Pelican optimization algorithm: A novel nature-inspired algorithm for engineering applications. Sensors https://doi.org/10.3390/s22030855 (2022).
Gharehchopogh, F. S. An improved tunicate swarm algorithm with best-random mutation strategy for global optimization problems. J. Bionic Eng. 19(4), 1177–1202. https://doi.org/10.1007/s42235-022-00185-1 (2022).
Dalirinia, E., Jalali, M., Yaghoobi, M. & Tabatabaee, H. Lotus effect optimization algorithm (LEA): A lotus nature-inspired algorithm for engineering design optimization. J. Supercomput. https://doi.org/10.1007/s11227-023-05513-8 (2023).
Etaati, B., Dehkordi, A. A., Sadollah, A., El-Abd, M. & Neshat, M. A comparative state-of-the-art constrained metaheuristics framework for TRUSS optimisation on shape and sizing. Math. Probl. Eng. 2022, e6078986. https://doi.org/10.1155/2022/6078986 (2022).
Öztürk, H. T. & Kahraman, H. T. Meta-heuristic search algorithms in truss optimization: Research on stability and complexity analyses. Appl. Soft Comput. 145, 110573. https://doi.org/10.1016/j.asoc.2023.110573 (2023).
Yang, X. et al. An adaptive quadratic interpolation and rounding mechanism sine cosine algorithm with application to constrained engineering optimization problems. Expert Syst. Appl. 213, 119041. https://doi.org/10.1016/j.eswa.2022.119041 (2023).
Che, Y. & He, D. An enhanced seagull optimization algorithm for solving engineering optimization problems. Appl. Intell. 52(11), 13043–13081. https://doi.org/10.1007/s10489-021-03155-y (2022).
Coello Coello, C. A. Use of a self-adaptive penalty approach for engineering optimization problems. Comput. Ind. 41(2), 113–127. https://doi.org/10.1016/S0166-3615(99)00046-9 (2000).
Ray, T. & Saini, P. Engineering design optimization using a swarm with an intelligent information sharing among individuals. Eng. Optim. 33(6), 735–748. https://doi.org/10.1080/03052150108940941 (2001).
Wang, G. G. Adaptive response surface method using inherited latin hypercube design points. J. Mech. Des. 125(2), 210–220. https://doi.org/10.1115/1.1561044 (2003).
Papazoglou, G. & Biskas, P. Review and comparison of genetic algorithm and particle swarm optimization in the optimal power flow problem. Energies https://doi.org/10.3390/en16031152 (2023).
Dar, S. A. & Imtiaz, N. Classification of neuroimaging data in Alzheimer’s disease using particle swarm optimization: A systematic review. Appl. Neuropsychol. Adult https://doi.org/10.1080/23279095.2023.2169886 (2023).
Xia, G., Bi, Y. & Wang, C. Optimization design of passive residual heat removal system based on improved genetic algorithm. Ann. Nucl. Energy 189, 109859. https://doi.org/10.1016/j.anucene.2023.109859 (2023).
Parvaze, S. et al. Optimization of water distribution systems using genetic algorithms: A review. Arch. Comput. Methods Eng. https://doi.org/10.1007/s11831-023-09944-7 (2023).
Funding
Open access funding provided by Linköping University.
Author information
Authors and Affiliations
Contributions
All authors contributed equally to this paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Adegboye, O.R., Feda, A.K., Ojekemi, O.S. et al. Chaotic opposition learning with mirror reflection and worst individual disturbance grey wolf optimizer for continuous global numerical optimization. Sci Rep 14, 4660 (2024). https://doi.org/10.1038/s41598-024-55040-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-55040-6
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
