
Abstract
Meta-heuristic algorithms distinguish themselves from conventional optimization methods owing to their intrinsic adaptability and straightforward implementation. Among them, the sine cosine algorithm (SCA) is lauded for its ability to transition seamlessly between exploration and exploitation phases throughout the optimization process. However, there exists potential for enhancing the balance that SCA maintains between exploration and exploitation. To augment the proficiency in global optimization of SCA, an innovative strategy—nSCA—that integrates the roulette wheel selection (RWS) with opposition-based learning was formulated. The robustness of nSCA was rigorously evaluated against leading-edge methods such as the genetic algorithm (GA), particle swarm optimization, moth-flame optimization, ant lion optimization, and multi-verse optimizer, as well as the foundational SCA. This evaluation included benchmarks set by both CEC 2019 and CEC 2021 test functions. Additionally, the performance of nSCA was confirmed through numerous practical optimization problems, emphasizing its effectiveness in applied settings. In all evaluations, nSCA consistently showcased superior performance compared to its evolutionary algorithm counterparts, delivering top-tier solutions for both benchmark functions and real-world optimization challenges. Given this compelling evidence, one can posit that nSCA serves as a strong candidate for addressing intricate optimization challenges found in real-world contexts, regardless of whether they are of a discrete or continuous nature.
Similar content being viewed by others


Introduction
Evolutionary algorithm
In recent years, the scholarly community has increasingly turned its attention to nature-inspired optimization algorithms, recognizing their efficacy in addressing complex optimization challenges. Holland1 was among the pioneers, utilizing genetic algorithms (GA) to explore complex adaptive systems. He drew a compelling parallel between biological evolution and computational problem-solving. Kennedy and Eberhart2 put forth the particle swarm optimization (PSO), a method tailored for nonlinear function optimization. They detailed its evolution, tested it against benchmarks, applied it in neural network training, and explored its intersections with artificial life and GA. Rezaei et al.3 introduced the geometric mean optimizer (GMO). This new meta-heuristic technique leverages the capabilities of the geometric mean operator. When compared to other contemporary algorithms, GMO consistently exhibited superior performance in various optimization challenges. Mirjalili4 introduced the sine cosine algorithm (SCA), a unique population-based optimization approach. This technique, which utilizes sine and cosine functions to guide solution candidates, demonstrated its versatility in multiple tests, notably in the optimization of an aircraft wing’s cross-section. Such applications underscore its capacity to navigate challenges with constrained and unfamiliar search domains. Mirjalili et al.5 presented the multi-verse optimizer (MVO). Drawing inspiration from cosmological phenomena, the MVO was proficient in outperforming other well-regarded optimization methods across diverse benchmark tasks and real-world challenges. Gandomi6 put forth the interior search algorithm (ISA), a novel technique inspired by principles of interior design. With its efficacy pitted against other popular algorithms, ISA yielded promising results and featured a straightforward single-parameter tuning approach. Mirjalili7 rolled out the moth-flame optimization (MFO) algorithm. Inspired by the navigation techniques of moths, the MFO asserted its dominance across a gamut of benchmark functions and tangible engineering quandaries, such as marine propeller optimization. Mirjalili8 proffered the ant lion optimizer (ALO). Rooted in the predatory dynamics of antlions, this method underscored its pre-eminence across diverse test environments, spanning mathematical functions to intricate engineering challenges, such as ship propeller formulation, further solidifying its stature vis-à-vis other established algorithms.
In population-based evolutionary algorithms, the optimization technique is commonly divided into exploration and exploitation stages, irrespective of the algorithm’s specific characteristics9,10. The exploration phase focuses on investigating promising regions within the search area, where significant changes in directions can have a substantial impact. Conversely, the exploitation stage enables gradual adjustments in options and demonstrates the algorithm’s convergence by utilizing the solutions obtained during exploration. Finding the optimal trade-off between the exploration and exploitation phase is crucial to ensure the effectiveness of the algorithm in achieving global optimization.
Optimization techniques have wide applications across various fields. Xi et al.11 utilized advanced machine learning algorithms combined with novel optimization techniques to forecast the compressive strength of recycled aggregate concrete (RAC). Their findings highlighted the superior performance of the LGBM-based hybrid model and underlined the crucial role of factor interactions in shaping the mechanical properties of RAC. In another study, Zhou et al.12 applied three optimization algorithms to fine-tune the hyper-parameters of the support vector machine. Their aim was to predict the progress rate of tunnel-boring machines in hard rock conditions. Data from a water transfer tunnel project in Malaysia revealed that the MFO hybrid model surpassed other models in accuracy. Li et al.13 used support vector regression along with five optimization algorithms to estimate the mean fragment size (MFS) during blasting operations. Their analyses identified the grey wolf optimization (GWO) variant as the top performer. Additionally, their research found that the uniaxial compressive strength was the most significant factor influencing the prediction of blasting MFS. Son and Nguyen Dang14 introduced the MVO as a potent tool designed for time–cost optimization challenges in construction project management. Evaluations, especially on smaller benchmarks, reinforced the effectiveness of MVO over other stochastic optimization methods. In another insightful study, Son and Hieu15 developed a detailed model for logistics costs associated with precast concrete structures. This model, based on the activity-based costing method, also incorporated an enhanced ALO algorithm that combined OBL, mutation, and crossover strategies for optimal cost solutions. When compared to earlier models, this new approach demonstrated better performance in terms of convergence speed, accuracy, and overall cost reduction.
The continuous evolution and improvement of algorithms have piqued the interest of numerous researchers16. This interest arises from the acknowledgment that there is no universally applicable algorithm competent in addressing diverse optimization problems. This understanding compels researchers either to enhance the current algorithms to cater to novel challenges or to devise new ones that can competently rival their predecessors. Son and Nguyen Dang17 introduced the hybrid multi-verse optimizer model (hDMVO), a synthesis of the MVO and the SCA. This model is explicitly crafted to navigate discrete time–cost trade-off dilemmas encountered in construction project management. Its efficacy is particularly pronounced in large-scale projects, where it outstrips many established algorithms. Zhen et al.18 proposed a novel WPA-PSO hybrid algorithm. By harnessing the collective strengths of both methodologies, this amalgamated solution boasts enhanced prediction accuracy and stability, particularly when operating with sparse data, as opposed to its individual counterparts. Pham et al.19 ventured into logistics with an innovative hybrid swarm intelligence algorithm. The chief aim of this model is to refine dispatch schedules for ready-mix concrete trucks, fostering improved coordination between batching plants and construction locales. Teng et al.20 launched the grey wolf grasshopper hybrid algorithm (GWGHA). This algorithm targets the optimization of traffic light cycles, with a vision to curtail vehicle waiting durations and bolster on-time arrivals. The efficacy of this model is underpinned by the simulation of urban mobility (SUMO), which employed data from an assortment of global cities. Qiao et al.21 introduced a groundbreaking hybrid algorithm, fusing the lion swarm optimizer with the GA. Tasked with amplifying the stability and accuracy of carbon dioxide emission predictions, this model was rigorously tested using data spanning 1965 to 2017. Its performance in terms of optimization, convergence speed, and forecasting precision outshone other prevalent models. Long et al.22 brought forth the GWOCS, a hybrid algorithm blending the GWO with the cuckoo search (CS). Augmented with an OBL strategy, this algorithm adeptly extracts parameters from various solar PV models, utilizing experimental data across heterogeneous conditions. It achieves a harmonious interplay between exploration and exploitation, as evinced by its superior benchmark test outcomes. Dhiman and Kaur23 championed the hybrid particle swarm and spotted hyena optimizer (HPSSHO). This avant-garde optimization technique marries the PSO with the spotted hyena optimizer (SHO). It seeks to augment the hunting strategy of the SHO by integrating PSO dynamics. Its performance, as evidenced across thirteen benchmark functions and a nuanced 25-bar engineering design challenge, stands as a testament to its prowess over other metaheuristic approaches. Şenel et al.24 unveiled a hybrid algorithm that seamlessly integrates the robustness of both PSO and GWO. Notably, it shines in benchmark evaluations and real-world applications alike, consistently eclipsing other traditional and hybrid optimization techniques.
Sine cosine algorithm
Since its introduction in 2016, the SCA has gained considerable popularity as an optimization method widely utilized in various domains to address a broad spectrum of problems. For instance, Zhao et al.25 developed a discrete version of SCA to overcome the challenge of community detection, while Banerjee and Nabi 26 proposed an SCA model to optimize the return trajectory phase of a reusable launch vehicle. Fatlawi et al.27 used SCA to determine camera positions for monitoring systems. Reddy et al. 28 presented a binary adaptation of SCA to determine the optimal commitment and dispatch of power-generating units while considering operational constraints. Tawhid and Savsani29 developed an enhanced SCA for the optimization of engineering design tasks with multiple objectives. Finally, Raut and Mishra30 proposed an advanced SCA modification that incorporates a load flow methodology leveraging data structures to optimize power distribution network reconfiguration tasks.
Given the diverse nature of optimization problems, it is widely acknowledged that there is no universally applicable optimization algorithm competent in addressing diverse optimization problems16. Cheng and Duan31 proposed a hybrid version that combines SCA and the cloud model to handle benchmark test functions with different dimensions. Bureerat and Pholdee32 developed a hybrid model that combines SCA and DE for detecting structural damage. Turgut33 proposed a model that integrates the SCA with the backtracking search algorithm to effectively address multi-objective problems in heat exchanger design. Bairathi and Gopalani34 improved SCA by integrating the opposition-based mechanism to instruct multi-layer neural networks. Qu et al.35 introduced an upgraded version of the SCA by incorporating a neighborhood search technique and a greedy Levy mutation. Finally, Pham and Nguyen36 proposed an integrated SCA version with tournament selection, OBL, and mutation and crossover methods to handle cement transport routing.
The motivation of this study
The SCA, recognized for its simplicity, has carved a niche for itself as a preferred stochastic optimization technique across various scientific domains. Nonetheless, a prominent drawback associated with the SCA is its inclination to converge prematurely. This can be attributed to its undefined exploitation mechanism within the search area37. Such a limitation has spurred researchers to suggest a refined SCA framework, envisaged as a panacea to the intricacies intertwined with optimization issues.
In the subsequent section, the development and evolution of the nSCA are detailed. In “Analysis of performance” section, a thorough examination of the algorithm’s convergence properties is provided. Here, its behavior and efficacy are evaluated using benchmarks from CEC 2019 and CEC 2021. In “Practical application of nSCA” section, the robustness of the model is validated by subjecting the nSCA to a range of real-world optimization challenges, including the cantilever beam design, truss structure design, and the capacity vehicle routing problems. In “Conclusion” section, pivotal research insights are compiled, and potential avenues for future research are suggested. “Limitations” section presents the limitations identified in the nSCA.
Novel version of sine cosine algorithm
Roulette wheel selection (RWS)
The Roulette wheel selection (RWS) mechanism has been widely employed in the realm of optimization, being incorporated into numerous algorithms because of its inherent flexibility and adaptability. This mechanism is fundamentally based on the principle of selection probability, where entities are selected according to their performance metrics, most commonly their fitness values in genetic algorithms (GA). The visualization of RWS is likened to a roulette wheel, with slots assigned in proportion to an individual’s fitness. Individuals with higher fitness values are allocated larger slots, thereby augmenting their likelihood of selection for the subsequent generation. The dynamic character of RWS has prompted several refinements to its core structure. Efforts have been made to sharpen the selection criteria, while others have aimed to evade the issue of premature convergence. For example, the challenge of the well-known traveling salesman problem (TSP) was addressed by Yu et al.38, who instilled adaptability into RWS. A mechanism was introduced that dynamically modified the selection pressure, bolstering genetic diversity and ensuring continued exploration. Differential evolution (DE) has also been influenced by RWS. It was integrated into DE by Qian et al.39 for the purpose of mutation strategy selection, enhancing its convergence behaviour. In the domain of sentiment analysis, RWS was utilized by Pandey et al.40 to bolster the performance of the CS algorithm, leading to improved outcomes. The capabilities of RWS extend beyond traditional algorithms. A multi-dimensional strategy was advocated by Asghari et al.41, merging RWS with the whale-PSO algorithm. Their objective was to address intricate optimization challenges. The subject of parallelism in optimization has gained traction, and a significant contribution to this field was made by Lloyd and Amos42. Their research cantered on the efficacy of an autonomous RWS mechanism within parallel ant colony optimization (ACO). In the realm of power dispatching, a complex endeavour, a novel approach was proposed by Cheng et al.43. RWS was amalgamated with PSO to adeptly handle equality constraints.
Opposition-based learning (OBL)
The opposition-based learning (OBL) approach has been widely recognized and utilized in diverse optimization applications, underscoring its versatility and efficacy. First introduced by Tizhoosh44 in 2005, OBL was presented as an innovative framework for computational intelligence, devised to generate complementary solutions for existing ones. Later, Wang et al.45 put forth a generalized OBL method, aiming to augment the efficiency of the PSO. In the context of construction project management, a balance in optimizing time, cost, and quality in multi-mode projects was achieved by Luong et al.46 through the application of opposition multiple objective DE. Further, a two-phase DE algorithm was developed by Cheng and Tran47 for multi-criteria decision-making, primarily targeting the equilibrium between time and cost in resource-constrained projects. The power systems sector has not been untouched by OBL’s influence. Shaw et al.48 formulated an algorithm that harnesses OBL principles and integrates a gravitational search strategy, aiming to optimize both economic and emission objectives simultaneously. Furthermore, the integration of OBL into various other optimization algorithms has been witnessed. This includes its incorporation into the grasshopper optimization algorithm (GOA) by Ewees et al.49, and into the salp swarm algorithm (SSA) by Tubishat et al.50. Surveying the literature reveals a clear trend: the integration of OBL can notably elevate the relative performance of numerous optimization algorithms across varied sectors. This positions OBL as a potent avenue warranting further exploration in upcoming research.
Novel version of SCA (nSCA)
In the nSCA, each solution position is defined by a series of variables, which collectively form sets of solutions. These sets, together with their associated positions, are systematically organized into a matrix configuration, as illustrated in Eq. (1). In a similar manner, the matrix of opposite solutions, which are produced during the exploration phase, is delineated in Eq. (2). Such matrix formulations aid in proficient handling and assessment of solutions within the algorithm, thereby promoting efficient exploration and optimization of the search space.
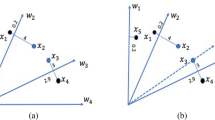
During the initial population generation phase, the OBL method, shown in Fig. 1, is employed to produce opposite solutions from those randomly generated, as illustrated in the pseudocode for nSCA in Table 1. The fitness function is subsequently applied to both the randomly generated solutions and their corresponding opposite solutions to identify the superior and inferior solutions. The superior solution is retained, while the inferior one is discarded, maintaining a consistent population size.

The OBL concept.
The opposite solution \({s}^{*}\) of the solution \(s\in [{b}_{l},{b}_{u}]\) can be identified by:
where bl and bu denote the lower and upper boundary of alternative s.
For a solution S with d dimensions, where each dimension is within the range of \([{b}_{l,j},{b}_{u,j}]\), an opposition solution \({S}^{*}=({s}_{1}^{*},{s}_{2}^{*},{s}_{3}^{*},\dots ,{s}_{d}^{*})\) can be characterized by:
where bl,j and bu,j show the minimum and maximum limits of the jth dimension, respectively.
Following the update of the new solution set during the initial population generation phase, the solutions are sorted, and the current optimal solution is identified. Subsequently, the normalized fitness score for each solution is determined, playing a crucial role in the RWS mechanism, as depicted in Fig. 2. The normalized fitness score is derived using Eq. (5), and the RWS mechanism is mathematically expressed in Eq. (6). These computations and mechanisms play pivotal roles in selecting and advancing the exploration of solutions within the algorithm.

The RWS concept.
The terms NF(Si) and F(Si) represent the normalized fitness score and fitness score of solution Si, respectively. The notation \({s}_{i}^{j}\) indicates the jth parameter of the ith solution, and \({s}_{1}^{j}\) represents the jth parameter of the best solution achieved so far. The variable σ2 corresponds to a stochastic number ranging between 0 and 1. Distinctive categorization of the optimization process into exploration and exploitation stages has emerged as a focal point in earlier studies. Such a division is characteristic of many population-based stochastic methods9. Within the exploration phase, the optimization method employs a heightened degree of randomness, facilitating the amalgamation of solutions and quickening the identification of promising areas within the search domain. On the other hand, the exploitation phase witnesses subtle adjustments in the stochastic solutions, characterized by notably reduced stochastic fluctuations compared to the exploration phase. With regard to the SCA, mathematical formulas, encapsulated by Eq. (7), are outlined to update positions during both the exploration and exploitation phases. The value of these formulas stems from their role in directing the search trajectory of the SCA, ensuring an effective survey and utilization of the solution domain.
In Eq. (7), the location of current solution in the ith dimension at the tth iteration is represented by \({s}_{j}^{t}\). The movement direction is determined by σ1, while σ3 is a uniformly distributed random variable between 0 and 1. Additionally, σ4 is a stochastic variable that governs the magnitude of displacement towards or away from the destination, and σ5 is a random number used as the weight for the destination. The location of the target solution in the ith dimension is denoted by \({D}_{j}^{t}\), and the absolute value is indicated by ||.
Figure 3 presents a comprehensive model that illustrates the effectiveness of sine and cosine functions within the range of [− 2, 2]. These functions facilitate an alternative to navigate within the area bounded by them or extend beyond it, facilitating flexible movement toward the desired objective. The figure highlights the dynamic nature of the sine and cosine ranges, which are instrumental in updating the solution positions. Moreover, the inclusion of a stochastic variable, σ4, in the range of 0 to 2π, as defined in Eq. (7), introduces a stochastic element into the process. This mechanism enhances exploration within the search space, enabling a more extensive exploration of potential solutions.

The exploration and exploitation mechanisms of the SCA.
Within each iteration, the range of the sine and cosine functions in Eq. (7) is dynamically adjusted to strike an optimal trade-off between exploitation and exploration (Fig. 4). This adaptive modification aims to efficiently identify fruitful spaces within the search area, ultimately enabling the attainment of the optimal solution. The adaptation process is governed by Eq. (8), where the constant value v is set to 2, Icur represents the current iteration number, and Imax denotes the maximum iteration number.

The range of sine and cosine exhibits a decreasing pattern.
During the exploitation phase, as illustrated in the pseudocode of nSCA in Table 1, the solutions are updated using Eq. (7). Subsequently, a jumping condition, denoted as JC in Eq. (9), is employed to dynamically generate the opposite solution using Eq. (10). This procedure stands in contrast to the method adopted during the initial population generation phase. The objective equation evaluates both the original solution and its opposite, preserving the more optimal of the two and eliminating the less optimal. Such a practice guarantees the consistency of the population size, as articulated by Eq. (11).
where Si represents the ith solution; σ6 is a uniformly distributed random variable between 0 and 1; \({S}_{i}^{*}\) represents the opposite solution of the ith solution created by OBL.
Analysis of performance
In the realm of optimization, particularly in the exploration of evolutionary algorithms and metaheuristics, the efficacy of these algorithms is required to be validated to ensure their applicability in addressing real-world challenges. The performance of these optimization techniques is often benchmarked using specific test cases or established benchmark problems. Such benchmarks are provided to allow for a consistent platform, thereby facilitating an objective and uniform comparison across various algorithms. For the purposes of this research, the CEC 2019 and CEC 2021 test functions have been employed. These functions have been utilized to gauge the performance of nSCA in comparison to other well-established metaheuristic techniques.
CEC 2019 test functions
The CEC 2019 dataset consists of ten complex composition functions within the suite51. For addressing large-scale optimization problems, these functions have been employed. The first three functions, F1 to F3, are characterized by various dimensions, as depicted in Table 2. In contrast, the functions F04 to F10 are set as 10-dimensional minimization challenges within the scope of [− 100, 100], and they have undergone shifts and rotations. Every function within the CEC 2019 is scalable, with the global optimum of these functions established at 1.
Results for the CEC 2019 test functions of nSCA, along with six other established metaheuristic algorithms (GA, PSO, MFO, ALO, MVO, and the original SCA), are provided in Tables 3 and 4. Each of the test functions was solved 30 times, with 50 search agents being utilized over 300 iterations. For the evaluation of nSCA’s performance, two essential statistical metrics, the average value (avg) and standard deviation (std), were determined.
In Tables 3 and 4, superiority in the majority of the CEC 2019 test cases was demonstrated by nSCA. An average value smaller than that of SCA, MFO, PSO, and GA in all 10 CEC 2019 test functions was attained by nSCA. In 9 of the CEC 2019 test functions, a smaller average value than that of MVO was achieved by nSCA. In 8 of the CEC 2019 test functions, a smaller average value than that of ALO was recorded by nSCA. The benefits of combining the RWS and OBL mechanisms were observed, as they aided in the initial exploration and contributed to the final convergence of the solutions identified early in the exploration phase.
CEC 2021 test functions
For a comprehensive assessment, the effectiveness of nSCA was benchmarked against an array of state-of-the-art algorithms, utilizing the sophisticated functions delineated in the IEEE CEC 2021 test suite. The performance of nSCA was scrutinized based on shifted, rotated, and biased functions within this suite, spanning 10 dimensions, as detailed in Table 5. This methodology was employed to offer a deeper understanding of the capabilities of nSCA by setting it in direct comparison with other renowned algorithms such as GA, PSO, MFO, ALO, MVO, and the foundational SCA. In-depth insights into the IEEE CEC 2021 test suite can be found in Ref.52.
Results of the CEC 2021 test functions for nSCA, alongside six other well-regarded metaheuristic algorithms (GA, PSO, MFO, ALO, MVO, and the original SCA), are elucidated in Tables 6 and 7. Following the approach used in the CEC 2019 test function assessment, each function underwent 30 trials, with the deployment of 50 search agents throughout 300 iterations. For the purpose of gauging the performance of nSCA, two statistical metrics, namely the average value (avg) and standard deviation (std), were extracted.
Tables 6 and 7 reveal the dominance of nSCA across a significant portion of the CEC 2021 test cases. Specifically, nSCA secured an average value lower than those of MFO, PSO, and GA across all 10 CEC 2021 test functions. Moreover, in 9 out of these 10 functions, nSCA surpassed the original SCA. In a comparison with ALO, nSCA managed to record a lower average in 8 functions, whereas MVO achieved this distinction in 6 functions.
Figure 5 offers a visual depiction of the convergence trajectories of both nSCA and its original version, SCA, across the CEC 2021 test functions. From Fig. 5, it is clear that nSCA significantly excels over the original SCA in terms of identifying superior solutions. Additionally, as evidenced in Fig. 5, the effectiveness of nSCA in locating the global optimal solution and avoiding local optima is attributed to its integration of the RWS and OBL mechanisms. These mechanisms not only enable nSCA to induce sudden shifts in solution vectors but also, through the juxtaposition of fitness values between original and OBL-generated solutions, facilitate the retention of more favorable options. This capability equips nSCA to discern promising zones within the search landscape, ensuring a thorough exploration and the subsequent identification of optimal outcomes.

Convergence behavior of nSCA and SCA on CEC 2021 test functions.
Practical application of nSCA
The primary objective of this section is to evaluate the effectiveness of nSCA in addressing a range of practical technical optimization challenges characterized by multiple inequality constraints. The emphasis lies in understanding the ability of nSCA to adeptly manage these constraints during the optimization procedure.
Cantilever beam design problem
Figure 6 presents a visual depiction of five parameters that define the cross-sectional geometry of cubes within the beam. This particular beam is assembled from five distinct square blocks. While the foremost block remains fixed, the fifth one is subjected to a vertical load. The central objective of this optimization task is to minimize the weight of a cantilever beam composed of hollow square blocks. Subsequent equations elaborate on the mathematical underpinnings that frame this complex challenge. Within the nSCA framework, any solution that fails to satisfy the constraints is penalized by assigning it an exceptionally large fitness value. The incorporation of OBL and RWL techniques, which facilitate abrupt adjustments to the non-conforming solution, primes the algorithm to generate an improved, compliant solution from its predecessor. Such methodologies empower the nSCA to channel its search in the direction of solutions that comply with the established constraints.

Cantilever beam design problem.
Consider:
Minimize:
Subject to:
Variable range:
Table 8 provides a detailed evaluation of the results pertaining to the problem. Evidently, nSCA consistently produces solutions that either match or surpass the performance of advanced optimization techniques such as SCSO, PSO53, RCGO54, ERHHO55, GSA56, GCA_I57, GCA_II57 and MMA57. This observation underscores the formidable capability of the algorithm in adeptly addressing and optimizing complex constrained challenges. Furthermore, these outcomes highlight the practical utility of nSCA in sectors like engineering and related fields, emphasizing its competence in navigating challenging problem landscapes.
Truss structure design problem using continuous variables
Truss optimization represents a complex facet of structural engineering and design, focused primarily on discerning the most resource-efficient configurations for truss structures. Defined as skeletal assemblies composed of straight members intersecting at joints, trusses are foundational in both architectural and civil engineering realms. They play a crucial role in supporting various types of loads, especially in the contexts of buildings, bridges, and other diverse structural entities.
The primary goal of truss optimization is to conceive a truss design capable of bearing the stipulated loads with the least material consumption. This efficiency is attained by fine-tuning the section of each truss member. The aim is to ensure that every member endures minimal stress while abiding by specific design constraints. Within truss optimization, the design variables encompass the cross-sectional areas of the truss members, the precise locations of the joints, and a myriad of geometric parameters delineating the truss’s shape and configuration. The mathematical representations pertinent to this optimization challenge can be delineated as follows:
Consider:
Objective function:
Subject to:
In Eq. (17), W denotes the total weight of the truss structure. γi represents the material density of the ith truss member, while Ai and Li signify the cross-sectional area and length of the ith member, respectively. N stands for the total number of members in the truss structure. Equation (18) is imperative for ensuring that the truss design complies with the stress constraints. Within this equation, σi refers to the stress experienced by the ith member. σmin and σmax are, respectively, the minimum and maximum permissible stresses. Equation (19) is formulated to ascertain that the truss design adheres to the deflection constraints. In this context, δj is the deflection at the jth node, and δmin and δmax correspond to the minimum and maximum allowable deflections, respectively. Lastly, Eq. (20) ensures that the truss design remains within the geometric constraints. For this equation, Ai is the cross-sectional area of the ith member, and Amin and Amax represent the smallest and largest permissible cross-sectional areas for the truss members, respectively.
To provide an unbiased comparison among truss design problems, the necessity of multiple independent evaluations was emphasized. Consequently, ten independent runs were undertaken. In each instance, a group of 50 search agents was utilized, with each agent progressing through 250 iterations.
10-Bar truss structure design problem
In order to benchmark the performance of the nSCA in comparison with other optimization techniques tailored for continuous variables, an augmented 10-bar truss design is introduced, as illustrated in Fig. 7. This design specification permits the truss’s cross-sectional areas to vary between a range of 0.1 in2 and 35.0 in2.

10-Bar truss structure problem.
The material selected for this truss possesses distinctive characteristics. Specifically, it carries a unit weight of 0.1 lb/in3 and is characterized by a modulus of elasticity set at 107 psi.
The design of the truss is governed by certain predefined conditions:
-
The stress magnitudes in any given truss member must not surpass an acceptable range of ± 25 ksi.
-
All nodal deflections, be they vertical or horizontal, must be confined within a limit of ± 2.0 in.
These predetermined conditions aim to guarantee the truss’s peak performance, ensuring it is consistent with its established design criteria and operational requirements.
Table 9 presents a comparative analysis of the optimal solution obtained using nSCA alongside results from various other optimization techniques. It is significant to highlight that the results derived from PSO62 and HS61 are characterized by constraint violations. When utilizing nSCA, the design records a weight of 5061.0548 lb after 10,950 equation evaluations and presents a standard deviation (SD) of 0.5491. Such performance is superior to that of both EHS59 and SAHS59. Although the design from ABC-AP60 has a weight of 5060.88 lb and emerges as the most optimal on the scale, it necessitates an extensive 500,000 function evaluations. Conversely, the design from TLBO58 with a weight of 5060.973 lb, aligns closely with the outcome from ABC-AP60 but necessitates 13,767 function evaluations. From the data collated in Table 9, nSCA not only produces a solution comparable to those of other renowned algorithms but also excels in terms of computational efficiency.
25-Bar truss structure design problem
The 25-bar truss problem, as illustrated in Fig. 8, encompasses two distinct load scenarios, detailed in Table 10. This truss structure is divided into eight symmetrical segments, with each segment subject to its own stress limitations as outlined in Table 11.

25-bar truss structure problem.
The selected material for the truss structure possesses the following attributes:
-
A density of 0.1 lb/in3.
-
A modulus of elasticity of 10,000 ksi.
Constraints on nodal movements have been enforced, ensuring displacements do not exceed ± 0.35 inches in any x, y, or z direction. These constraints are grounded in the findings presented in Ref.63.
In this problem, the design variables are continuous. Moreover, the bars within the truss can have cross-sectional areas ranging from a minimum of 0.01 in2 to a maximum of 3.40 in2. This range facilitates the optimization of the truss within the prescribed constraints and stipulations.
Table 12 offers a comprehensive comparison between the designs produced using nSCA and those generated by other optimization techniques. Notably, the most efficient 25-bar truss configuration realized by nSCA weighs 545.1630 lb, ascertained following 10,350 evaluation equations, accompanied by a standard deviation (SD) of 0.1820. From the information provided in Table 12, it becomes evident that nSCA surpasses several other techniques, including PSO64, MSPSO64, HSPSO65, IRO66, TLBO58, ACO 67 and STA68. This assessment underscores the capability of nSCA in achieving superior performance and computational efficiency, particularly in the context of the 25-bar truss problem with continuous variables, thereby solidifying its edge over other metaheuristic methodologies.
Capacity vehicle routing problem
The capacitated vehicle routing problem (CVRP), inherently discrete in nature, holds a foundational topic within the realms of operations research and logistics, as evidenced by a comprehensive body of research69. Essentially, the CVRP seeks to identify the most efficient strategy for distributing goods from a singular depot to a predetermined set of customers. This task is accomplished by deploying a fleet of vehicles, each of which returns to the depot after its delivery. This concept can be succinctly captured in a mathematical formulation:
Consider:
Objective function:
where xijt is a binary variable that indicates the selection of a route. Specifically, xijt is set to 1 if the route between customer i and customer j is chosen by the tth vehicle, and 0 otherwise. cij denotes the cost associated with traveling from customer i to customer j.
As outlined by Shan and Wang70, the CVRP operates under two principal constraints:
-
Single visit requirement Each customer must be serviced exactly once, ensuring not just efficiency, but also punctuality in deliveries.
$$\sum_{i=0}^{k}{x}_{ijt}={y}_{jt};j=\mathrm{1,2},\dots ,k;t=\mathrm{1,2},\dots ,h,$$(22)$$\sum_{i=0}^{k}{x}_{ijt}={y}_{it};j=\mathrm{1,2},\dots ,k;t=\mathrm{1,2},\dots ,h,$$(23)$$\sum_{t=1}^{h}{y}_{it}=\left\{\begin{array}{c}1; i=\mathrm{1,2},3,\dots ,k\\ h;i=0\end{array}\right\}.$$(24)Equations (22) and (23) collaboratively ensure that each vehicle follows a unique route to serve every customer. Specifically, Eq. (22) mandates that each customer is visited only once, while Eq. (23) dictates that every vehicle must cater to at least one customer. In the context of Eq. (24), it is stipulated that a given customer can only be served by a single vehicle. However, an exception is carved out for the central depot or warehouse, which may be accessed by h vehicles, signifying the total fleet allocated for the operation.
-
Vehicle capacity constraint Every vehicle within the fleet possesses a predetermined carrying capacity. As a result, the cumulative volume or weight of goods allocated to a particular route must not surpass this stipulated capacity.
$$\sum_{i=0}^{k}{g}_{i}{y}_{it}\le {q}_{t}{y}_{it};t=\mathrm{1,2},\dots ,h.$$(25)Equation (25) enforces a restriction on the carrying capacity of each vehicle, ensuring that it does not surpass its predetermined volume or weight during any given trip. Within this equation, gi represents the demand of the ith client, with i varying from 1 through k—the total number of clients. The term h symbolizes the entire count of vehicles engaged in the operation. Concurrently, qt designates the capacity of the tth vehicles, with t ranging from 1 to h.
8-Customer problems
In this problem, there exists a central warehouse serving eight distinct customers. Two trucks, each boasting a carrying capacity of eight units, are deployed for this operation. Relevant data encompassing the distance matrix and individual customer demands are detailed in Table 13. The primary objective centers around optimizing the delivery routes for these trucks, aiming to minimize the total distance covered while concurrently respecting the inherent constraints of the VRP. To ensure robustness and maintain consistency in results, every algorithm was run 20 times, employing 20 search agents, and was subjected to a total of 50 iterations.
Table 14 presents a comparative analysis of results derived from various algorithms. Among them, nSCA distinguished itself by exhibiting exceptional efficiency. This superior performance becomes evident when considering its average percentage deviation (APD) from the optimal result. The most favorable solution identified for this specific problem had a total travel distance of 67.5 units. With an APD value of 0.33%, nSCA surpassed the performances of the original SCA36, DA36, ALO36, PSO36, MHPSO71, DPGA71, and SGA71. Their corresponding APD values were recorded as 0.78%, 1.81%, 2.44%, 2.15%, 2.04%, 3.04%, and 4.33%, respectively. Such data distinctly emphasize the robustness of nSCA, especially in addressing discrete problem-solving challenges.
Figure 9 features a boxplot that contrasts nSCA with other metaheuristic methods, accentuating the efficacy of nSCA. The detailed routing for the two vehicles, representing the optimal solution, can be found in Table 15. For enhanced visual comprehension, this routing is also depicted graphically in Fig. 10.

Boxplot of nSCA, SCA, DA, ALO, PSO, MHPSO, DPGA, and SGA on 8-customer problem.

Best solution of the 8-customer problem.
Real CVRP in Vietnam: 16-customer problems
In a practical application of the CVRP, delivery data from a delivery company in Vietnam was analyzed. Serving 16 customers through a hub-and-spoke distribution model, the supplier operates a fleet of three delivery vehicles, each with a carrying capacity of 70 units. Distinguished from the traditional TSP, this case introduces added complexity due to the presence of multiple vehicles and capacity constraints. Distance and demand data for the 16 customers were processed and converted into a distance matrix, as detailed in Table 16.
The core objective of this study revolves around optimizing the delivery process for a set of 16 customers using a fleet comprising three vehicles. The goal is to curtail the overall distance covered while staying within the boundaries of the CVRP constraints. This challenge was tackled using nSCA, alongside other esteemed algorithms like GA, PSO, MFO, ALO, MVO, and the original SCA. To ensure a balanced comparison, each algorithm underwent 20 runs, deploying 50 search agents, and spanning 400 iterations for all CVRP test instances. The outcomes generated by nSCA and the other methodologies are detailed in Table17.
As evident from Table 17, nSCA clearly stands out in terms of efficiency. The optimal solution for this problem, identified using nSCA, corresponded to a total travel distance of 463 units. nSCA showcased an APD value of 8.80%, which was superior to the performances of the original SCA, GA, PSO, ALO, MFO, and MVO. The APD values for these methods were observed to be 26.29%, 40.19%, 29.42%, 45.81%, 28.64%, and 33.46%, respectively. This information underscores the strengths of nSCA, particularly when confronted with large-scale discrete problem-solving scenarios.
Figure 11 provides additional evidence underscoring the superiority of nSCA, with its data distribution clearly outpacing other algorithms. The specific routing for the two vehicles, illustrating the optimal solution ascertained by nSCA, is delineated in Table 18. For an enriched visual perspective, this routing is further illustrated in Fig. 12.

Box plot of nSCA, SCA, GA, PSO, ALO, MFO and MVO on 16-customer problem.

Best solution of the 16-customer problem.
Conclusion
Combining the opposition-based learning (OBL) technique with the roulette wheel selection (RWS) strategy, this research introduces nSCA, a novel approach intended to boost the exploratory capabilities of the SCA. The effectiveness of nSCA undergoes rigorous scrutiny alongside notable algorithms such as GA, PSO, MFO, ALO, MVO, and the foundational SCA, using the benchmarks provided by CEC 2019 and CEC 2021 test functions. Furthermore, the versatility and prowess of nSCA are evident in its capability to adeptly address tangible discrete and continuous optimization challenges. Insights from the analysis position nSCA above many metaheuristic methodologies, highlighting its refined ability to produce premier solutions for benchmark situations and practical optimization tasks. These findings solidify the role of nSCA as an essential instrument in the field of engineering optimization, paving the way for advanced problem-solving and decision-making techniques. With a foundation built on compelling evidence, it becomes clear that nSCA stands as a potent, trustworthy mechanism, well-suited for navigating the myriad of optimization challenges encountered in real-world scenarios.
Limitations
The efficacy of nSCA has been substantiated by the authors through the use of contemporary benchmark test suites such as CEC 2019 and CEC 2021, and its application to various practical optimization challenges has been demonstrated. However, deeper scrutiny is still deemed necessary. Enhancement in the evaluation of the robustness of nSCA could be achieved by its integration with regression or classification techniques, notably the support vector machine (SVM). By having this integrated framework applied to real-world problems, a more intricate understanding of the adaptability and efficacy of nSCA can be obtained. Through such an exhaustive assessment, richer insight into how nSCA collaborates with established machine learning methodologies will be provided, affirming the adaptability and capability of nSCA across a wider range of challenges.
Data availability
The corresponding author is available to provide the data, model, or code underlying the findings of this study upon request, in accordance with reasonable conditions.
References
Holland, J. H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence (MIT Press, 1992).
Kennedy, J. & Eberhart, R. Particle swarm optimization. In Proc. ICNN'95-International Conference on Neural Networks (IEEE, 1995).
Rezaei, F. et al. GMO: Geometric mean optimizer for solving engineering problems. Soft Comput. 27(15), 10571–10606 (2023).
Mirjalili, S. SCA: A sine–cosine algorithm for solving optimization problems. Knowl. Based Syst. 96, 120–133 (2016).
Mirjalili, S., Mirjalili, S. M. & Hatamlou, A. Multi-verse optimizer: A nature-inspired algorithm for global optimization. Neural Comput. Appl. 27(2), 495–513 (2016).
Gandomi, A. H. Interior search algorithm (ISA): A novel approach for global optimization. ISA Trans. 53(4), 1168–1183 (2014).
Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 89, 228–249 (2015).
Mirjalili, S. The ant lion optimizer. Adv. Eng. Softw. 83, 80–98 (2015).
Črepinšek, M., Liu, S.-H. & Mernik, M. Exploration and exploitation in evolutionary algorithms: A survey. ACM Comput. Surv. 45(3), 1–33 (2013).
Lin, L. & Gen, M. Auto-tuning strategy for evolutionary algorithms: Balancing between exploration and exploitation. Soft Comput. 13(2), 157–168 (2009).
Xi, B. et al. LGBM-based modeling scenarios to compressive strength of recycled aggregate concrete with SHAP analysis. Mech. Adv. Mater. Struct. 1, 1–16 (2023).
Zhou, J. et al. Optimization of support vector machine through the use of metaheuristic algorithms in forecasting TBM advance rate. Eng. Appl. Artif. Intell. 97, 104015 (2021).
Li, E. et al. Prediction of blasting mean fragment size using support vector regression combined with five optimization algorithms. J. Rock Mech. Geotech. Eng. 13(6), 1380–1397 (2021).
Son, P. V. H. & NguyenDang, N. T. Optimizing time and cost simultaneously in projects with multi-verse optimizer. Asian J. Civil Eng. 24, 1–7 (2023).
Son, P. V. H. & Hieu, H. T. Logistics model for precast concrete components using novel hybrid ant lion optimizer (ALO) algorithm. Int. J. Construct. Manag. 23(9), 1560–1570 (2023).
Wolpert, D. H. & Macready, W. G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1(1), 67–82 (1997).
Son, P. V. H. & Nguyen Dang, N. T. Solving large-scale discrete time–cost trade-off problem using hybrid multi-verse optimizer model. Sci. Rep. 13(1), 1987 (2023).
Zhen, L. et al. Parameter estimation of software reliability model and prediction based on hybrid wolf pack algorithm and particle swarm optimization. IEEE Access 8, 29354–29369 (2020).
Pham, V. H. S., Trang, N. T. N. & Dat, C. Q. Optimization of production schedules of multi-plants for dispatching ready-mix concrete trucks by integrating grey wolf optimizer and dragonfly algorithm. Eng. Construct. Archit. Manag. https://doi.org/10.1108/ECAM-12-2022-1176 (2023).
Teng, T.-C., Chiang, M.-C. & Yang, C.-S. A hybrid algorithm based on GWO and GOA for cycle traffic light timing optimization. In 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC) (IEEE, 2009).
Qiao, W. et al. A hybrid algorithm for carbon dioxide emissions forecasting based on improved lion swarm optimizer. J. Clean. Prod. 244, 118612 (2020).
Long, W. et al. A new hybrid algorithm based on grey wolf optimizer and cuckoo search for parameter extraction of solar photovoltaic models. Energy Convers. Manag. 203, 112243 (2020).
Dhiman, G. & Kaur, A. A hybrid algorithm based on particle swarm and spotted hyena optimizer for global optimization. In Soft Computing for Problem Solving: SocProS 2017 Vol. 1 (eds Bansal, J. C. et al.) (Springer, 2019).
Şenel, F. A. et al. A novel hybrid PSO–GWO algorithm for optimization problems. Eng. Comput. 35, 1359–1373 (2019).
Zhao, Y., Zou, F. & Chen, D. A discrete sine–cosine algorithm for community detection. In Intelligent Computing Theories and Application: 15th International Conference, ICIC 2019, Nanchang, China, August 3–6, 2019, Proceedings, Part I 15 (Springer, 2019).
Banerjee, A. & Nabi, M. Re-entry trajectory optimization for space shuttle using sine-cosine algorithm. In 2017 8th International Conference on Recent Advances in Space Technologies (RAST) (IEEE, 2017).
Fatlawi, A., Vahedian, A. & Bachache, N. K. Optimal camera placement using sine-cosine algorithm. In 2018 8th International Conference on Computer and Knowledge Engineering (ICCKE) (IEEE, 2018).
Reddy, K. S. et al. A new binary variant of sine–cosine algorithm: Development and application to solve profit-based unit commitment problem. Arab. J. Sci. Eng. 43, 4041–4056 (2018).
Tawhid, M. A. & Savsani, V. Multi-objective sine–cosine algorithm (MO-SCA) for multi-objective engineering design problems. Neural Comput. Appl. 31, 915–929 (2019).
Raut, U. & Mishra, S. Power distribution network reconfiguration using an improved sine–cosine algorithm-based meta-heuristic search. In Soft Computing for Problem Solving: SocProS 2017 Vol. 1 (eds Bansal, J. C. et al.) (Springer, 2019).
Cheng, J. & Duan, Z. Cloud model based sine cosine algorithm for solving optimization problems. Evol. Intell. 12, 503–514 (2019).
Bureerat, S. & Pholdee, N. Adaptive sine cosine algorithm integrated with differential evolution for structural damage detection. In International Conference on Computational Science and Its Applications (Springer, 2017).
Turgut, O. E. Thermal and economical optimization of a shell and tube evaporator using hybrid backtracking search—Sine–cosine algorithm. Arab. J. Sci. Eng. 42(5), 2105–2123 (2017).
Bairathi, D. & Gopalani, D. Opposition-based sine cosine algorithm (OSCA) for training feed-forward neural networks. In 2017 13th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS) (IEEE, 2017).
Qu, C. et al. A modified sine–cosine algorithm based on neighborhood search and greedy levy mutation. Comput. Intell. Neurosci. 2018, 1–19 (2018).
Pham, V. H. S. & Nguyen, V. N. Cement transport vehicle routing with a hybrid sine cosine optimization algorithm. Adv. Civil Eng. 2023, 2728039 (2023).
Abualigah, L. & Diabat, A. Advances in sine cosine algorithm: A comprehensive survey. Artif. Intell. Rev. 54(4), 2567–2608 (2021).
Yu, F. et al. Improved roulette wheel selection-based genetic algorithm for TSP. In 2016 International Conference on Network and Information Systems for Computers (ICNISC) (IEEE, 2016).
Qian, W. et al. Differential evolution algorithm with multiple mutation strategies based on roulette wheel selection. Appl. Intell. 48, 3612–3629 (2018).
Pandey, A. C., Kulhari, A. & Shukla, D. S. Enhancing sentiment analysis using roulette wheel selection based cuckoo search clustering method. J. Ambient Intell. Hum. Comput. 13(1), 1–29 (2022).
Asghari, K. et al. Multi-swarm and chaotic whale-particle swarm optimization algorithm with a selection method based on roulette wheel. Expert Syst. 38(8), e12779 (2021).
Lloyd, H. & Amos, M. Analysis of independent roulette selection in parallel ant colony optimization. In Proc. Genetic and Evolutionary Computation Conference (2017).
Cheng, Y.-S. et al. A particle swarm optimization based power dispatch algorithm with roulette wheel re-distribution mechanism for equality constraint. Renew. Energy 88, 58–72 (2016).
Tizhoosh, H. R. Opposition-based learning: A new scheme for machine intelligence. In International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC'06) (IEEE, 2005).
Wang, H. et al. Enhancing particle swarm optimization using generalized opposition-based learning. Inf. Sci. 181(20), 4699–4714 (2011).
Luong, D.-L., Tran, D.-H. & Nguyen, P. T. Optimizing multi-mode time–cost-quality trade-off of construction project using opposition multiple objective difference evolution. Int. J. Construct. Manag. 21(3), 271–283 (2021).
Cheng, M.-Y. & Tran, D.-H. Two-phase differential evolution for the multiobjective optimization of time–cost tradeoffs in resource-constrained construction projects. IEEE Trans. Eng. Manag. 61(3), 450–461 (2014).
Shaw, B., Mukherjee, V. & Ghoshal, S. A novel opposition-based gravitational search algorithm for combined economic and emission dispatch problems of power systems. Int. J. Electr. Power Energy Syst. 35(1), 21–33 (2012).
Ewees, A. A., AbdElaziz, M. & Houssein, E. H. Improved grasshopper optimization algorithm using opposition-based learning. Expert Syst. Appl. 112, 156–172 (2018).
Tubishat, M. et al. Improved salp swarm algorithm based on opposition based learning and novel local search algorithm for feature selection. Expert Syst. Appl. 145, 113122 (2020).
Price, K. et al. Problem definitions and evaluation criteria for the 100-digit challenge special session and competition on single objective numerical optimization. In Technical Report (Nanyang Technological University, 2018).
Brest, J., Maučec, M. S. & Bošković, B. Self-adaptive differential evolution algorithm with population size reduction for single objective bound-constrained optimization: Algorithm j21. In 2021 IEEE Congress on Evolutionary Computation (CEC) (IEEE, 2021).
Seyyedabbasi, A. & Kiani, F. Sand cat swarm optimization: A nature-inspired algorithm to solve global optimization problems. Eng. Comput. 39(4), 2627–2651 (2023).
Ma, B. et al. Running city game optimizer: A game-based metaheuristic optimization algorithm for global optimization. J. Comput. Des. Eng. 10(1), 65–107 (2023).
Song, M. et al. Modified Harris Hawks optimization algorithm with exploration factor and random walk strategy. Comput. Intell. Neurosci. 2022, 4673665 (2022).
Rashedi, E., Nezamabadi-Pour, H. & Saryazdi, S. GSA: A gravitational search algorithm. Inf. Sci. 179(13), 2232–2248 (2009).
Chickermane, H. & Gea, H. C. Structural optimization using a new local approximation method. Int. J. Numer. Methods Eng. 39(5), 829–846 (1996).
Camp, C. V. & Farshchin, M. Design of space trusses using modified teaching–learning based optimization. Eng. Struct. 62, 87–97 (2014).
Degertekin, S. Improved harmony search algorithms for sizing optimization of truss structures. Comput. Struct. 92, 229–241 (2012).
Sonmez, M. Artificial bee colony algorithm for optimization of truss structures. Appl. Soft Comput. 11(2), 2406–2418 (2011).
Lee, K. S. & Geem, Z. W. A new structural optimization method based on the harmony search algorithm. Comput. Struct. 82(9–10), 781–798 (2004).
Schutte, J. F. & Groenwold, A. A. Sizing design of truss structures using particle swarms. Struct. Multidiscip. Optim. 25, 261–269 (2003).
Venkayya, V., Khot, N. & Reddy, V. Energy Distribution in an Optimum Structural Design (Air Force Flight Dynamics Laboratory, Air Force Systems Command, 1969).
Talatahari, S. et al. A multi-stage particle swarm for optimum design of truss structures. Neural Comput. Appl. 23, 1297–1309 (2013).
Li, L.-J. et al. A heuristic particle swarm optimizer for optimization of pin connected structures. Comput. Struct. 85(7–8), 340–349 (2007).
Kaveh, A., Ghazaan, M. I. & Bakhshpoori, T. An improved ray optimization algorithm for design of truss structures. Period. Polytech. Civil Eng. 57(2), 97–112 (2013).
Camp, C. V. & Bichon, B. J. Design of space trusses using ant colony optimization. J. Struct. Eng. 130(5), 741–751 (2004).
Shahrouzi, M. Switching teams algorithm for sizing optimization of truss structures. Int. J. Optim. Civil Eng. 10(3), 365–389 (2020).
Archetti, C. et al. Complexity of the VRP and SDVRP. Transp. Res. C Emerg. Technol. 19(5), 741–750 (2011).
Shan, Q. & Wang, J. Solve capacitated vehicle routing problem using hybrid chaotic particle swarm optimization. In 2013 Sixth International Symposium on Computational Intelligence and Design (2013).
Zhengchu, W. et al. Research in capacitated vehicle routing problem based on modified hybrid particle swarm optimization. In 2009 IEEE International Conference on Intelligent Computing and Intelligent Systems (2009).
Acknowledgements
The authors acknowledge Ho Chi Minh City University of Technology (HCMUT), VNU-HCM for supporting this study.
Author information
Authors and Affiliations
Contributions
All authors, including V.H.S.P., N.T.N.D., and V.N.N., jointly contributed to the writing of the main manuscript, preparation of all figures and tables, and reviewed and approved the final version prior to submission.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pham, V.H.S., Nguyen Dang, N.T. & Nguyen, V.N. Enhancing engineering optimization using hybrid sine cosine algorithm with Roulette wheel selection and opposition-based learning. Sci Rep 14, 694 (2024). https://doi.org/10.1038/s41598-024-51343-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-51343-w
This article is cited by
-
Achieving improved performance in construction projects: advanced time and cost optimization framework
Evolutionary Intelligence (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
