
Abstract
We introduce a new approach for finding high accuracy, free and closed-form expressions for the gravitational waves emitted by binary black hole collisions from ab initio models. More precisely, our expressions are built from numerical surrogate models based on supercomputer simulations of the Einstein equations, which have been shown to be essentially indistinguishable from each other. Distinct aspects of our approach are that: (i) representations of the gravitational waves can be explicitly written in a few lines, (ii) these representations are free-form yet still fast to search for and validate and (iii) there are no underlying physical approximations in the underlying model. The key strategy is combining techniques from Artificial Intelligence and Reduced Order Modeling for parameterized systems. Namely, symbolic regression through genetic programming combined with sparse representations in parameter space and the time domain using Reduced Basis and the Empirical Interpolation Method enabling fast free-form symbolic searches and large-scale a posteriori validations. As a proof of concept we present our results for the collision of two black holes, initially without spin, and with an initial separation corresponding to 25–31 gravitational wave cycles before merger. The minimum overlap, compared to ground truth solutions, is 99%. That is, 1% difference between our closed-form expressions and supercomputer simulations; this is considered for gravitational (GW) science more than the minimum required due to experimental numerical errors which otherwise dominate. This paper aims to contribute to the field of GWs in particular and Artificial Intelligence in general.
Similar content being viewed by others
Introduction
The surge of direct detections of the gravitational waves (GWs) emitted by the collision of two black holes, neutron stars, and mixed pairs through laser interferometer laboratories1 stresses even more the need for fast evaluation of the GWs emitted by these processes, as predicted by Einstein’s theory of gravity (or alternative ones2). High accuracy numerical simulations of the Einstein equations are the gold standard for these predictions. The problem is that they are computationally very expensive. As an example, if one considers the case of two black holes, initially far away and in quasi-circular orbit, the usual rationale is that due to the no-hair theorem each black hole can be uniquely described by its mass and spin. Which results in eight degrees of freedom. The total time of computation (wall time) elapsed for each of these simulations depends, among other factors, on the initial separation of the two black holes, resolution, etc. For the sake of definiteness, let’s say that each simulation takes 10,000 hours of wall time, which is a lower bound for cases of interest. Assuming that one samples each parameter dimension with, say, 100 points, this gives \(10^{16}\) years of computing time, which is orders of magnitude larger than the age of the universe. Even using the top 10 supercomputers3 this time would be reduced to \(\sim 10^8\) years. Worse, for Bayesian parameter estimation, a catalog/bank of templates cannot be constructed a priori since each new waveform needs to be computed on demand without a priori knowledge of which ones those will be4. All these are consequences of the curse of dimensionality combined with an already computationally very expensive High Performance Computing problem (numerically solving the Einstein field equations) even for any fixed parameter tuple.
This bottleneck cannot be overcome through software optimization or specialized hardware (such as Graphics Processing Units, for example), which gave rise to the introduction of Phenomenological5 and Effective One Body (EOB)6 models for the prediction of GWs. These do not correspond to solutions of the Einstein field equations but, instead, physically inspired fits and/or “stitches” of approximate models for binary systems. We will not review these approaches here—except some remarks in the final section—since our take is to represent the emitted GWs using Einstein’s theory of gravity without any physical approximation.
The GWs emmitted by binary systems can be seen as a parameterized problem, the parameters being for example the masses and spins of the binary components, initial separation, equations of state in the case of neutron stars, and so on. For each value of the parameter tuple, the GW consists of two degrees of polarization which can be encapsulated in a single complex-valued time (or, equivalently, frequency) series.
Over the last decade surrogate models for GWs based on modern frameworks such as Reduced Basis (RB) and the Empirical Interpolation Method (EIM)7,8,9,9,10,11,12,13,14,15,16 have been developed. For a recent and detailed review and any doubts in what follows in this article regarding reduced order and surrogate modeling see Ref.17. The RB framework provides a sparse representation in the parameter domain while the EIM does so in the dual one, here being time. Both make use of the smooth dependence on parameter variation to achieve fast—usually exponential in the case of GWs—convergence of the representation with respect to the number of basis elements (which by construction equals the number of EIM time nodes). The resulting surrogate models predict GWs which are essentially indistinguishable from numerical relativity (NR) simulations, but with a speedup of evaluation of around eight orders of magnitude9, being evaluated in less than a second on a standard laptop instead of using supercomputers as in NR. A relatively small number of NR simulations are still needed in the offline (training) stage, though, but with a fast, highly accurate, surrogate, predictive model to evaluate for any parameter and time in the intervals considered in the online stage. This is referred to as an offline-online decomposition strategy.
In this article we build upon these efforts for what we consider a natural next step: a methodology for finding high accuracy free and closed-form representations of GWs, as opposed to numerical surrogates. As a proof of concept we present our results for the collision of two black holes, initially without spin, and with an initial separation corresponding to about 25–31 GW cycles before merger. The minimum overlap obtained, compared to ground truth solutions, is 99%. That is, 1% difference between our closed-form expressions and supercomputer simulations.
Method
Reduced order and surrogate models
In general, surrogate models for GWs have followed reduced order modeling (ROM) for parameterized systems and/or “standard” machine learning regression techniques18. Here we focus on the former, we will not delve into reviewing them but instead, as mentioned, refer to17. In this work we focus on RB19,20 and the EIM21,22,23. Briefly, RB collocates parameter points according to their relevance, which are used to build a hierarchical, nearly optimal basis in a rigorous mathematical sense with respect to the Kolmogorov n-width24,25. The framework of RB takes advantage of any regularity with respect to parameter variation to achieve fast convergence in the accuracy of the representation with the number of basis elements; it is usually referred to as an application-based spectral expansion. In fact, in the case of gravitational waves it can be easily argued that the parameter dependence is smooth (\(C^{\infty }\)) and RB has been shown to achieve asymptotic exponential convergence7,8,10,13,14,15,26 in practice, as expected with any spectral-type method. Similarly, the EIM achieves a subsampling in the space dual to that one of parameters (time in the case here considered) which is also nearly optimal. For a detailed discussion on the optimality of the EIM see27 and references therein. On top of that, high accuracy predictive models (prediction as opposed to projection) can be built once one has a reduced basis and an empirical interpolant13. These predictive models are essentially indistinguishable from numerical relativity supercomputer simulations of the Einstein equations but can be evaluated in less than a second on a laptop. The availability of high accuracy, fast to evaluate, numerical predictive models and a sparse subsampling in time are key components upon we build on in the approach presented in this article for finding and validating ab initio symbolic expressions for GWs.
Symbolic regression using genetic programming
Symbolic regression (SR) is the general procedure of finding closed-form expressions representing data. Unlike more conventional regression approaches, when SR is free-form it means precisely that: no specific form is specified. This eliminates any possible bias or human knowledge gap when postulating specific forms to fit for; it also contemplates completely data-driven cases, in which there is no underlying fundamental model or if there is one it is (still) unknown28.
Genetic programming (GP) is, in brief, an area of Artificial Intelligence (AI) whose goal is the evolution of programs or tasks through computer means. The techniques of GP emulate those of Nature; that is, algorithms are modeled following the process of natural evolution. A thorough book on GP is29, and a shorter field guide30.
Unlike perhaps more conventional Machine Learning (ML) deterministic regression approaches, GP-SR uses genetic algorithms to find free, closed-form expressions, either algebraic or differential. GP-SR can be described through the following general tree-structured algorithm tracing genetic programming principles:
1. | Create stochastically an initial population of programs (e.g. mathematical expressions and operations); |
2. | Repeat |
3. | Execute each program and compute their quality or fitness; |
4. | Select one or two programs from the population with a probability based on their fitness to participate in genetic operations; |
5. | Create new programs through the application of genetic operations (e.g. mutation or crossover); |
6. | Until an acceptable solution is found or some other stopping condition is met; |
7. | Return the best-so-far individual/s. |
GP-SR algorithms do not find a unique representation of data but a number of them with different levels of complexity (roughly speaking and for simplicity, cost of evaluation) and fitness with respect to training and validation sets. So, depending on the criteria used to find expressions via SR, the final symbolic forms can be shorter or larger with variable accuracy. In this work we prioritize accuracy. We used Eureqa31 for GP-SR, although there are open source alternatives such as gplearn32 and Glyph33. As a fitness criteria we used the Hybrid Correlation and the \(R^2\)-Goodness-of-fit metric errors to fit symbolic models for amplitude and phase, respectively. Our contribution is not actually on the area of GP-SR but on how to address its high computational cost by means of modern ROM and show that it actually works through the case study of the gravitational waves emitted by the collision of two black holes (a highly non-trivial system to model). For the details on the GP side of Eureqa see the original works of Lipson, Schmidt and Bongard28,34,35,36,37,38,39.
An example: a robot discovering Newton’s second law. As an example of the power of GP-SR we present results for the following system: the simple pendulum. In polar coordinates, Newton’s second law is
where \(\lambda =g/l\), g is the gravitational acceleration and l the length of the pendulum. The variable \(\theta\) represents the angle with respect to the point of stable equilibrium (the pendulum at rest). We set \(\lambda =0.5 s^{-2}\) and performed GP-SR on a dataset with initial conditions \(\theta (t=0) = \pi /2\) and \({{\dot{\theta }}}(t=0) = 0\). The time interval for the training set was set to be [0, 22] s with grid size \(\Delta t = 0.1\) s, which roughly corresponds to 2 cycles of the pendulum. That is, a single stream of data was used for training. We solved the above ordinary differential equation (ODE) with the integrate.odeint solver from the Scipy Python library40, and used the resulting data (with intrinsic noise, due to the numerical errors of the ODE solver) to find symbolic expressions for the underlying differential equation, searching for expressions of the form
The representation with highest fitness —found in the order of seconds— was exactly, not a numerical approximation of, Newton’s second law for this system, Eq. (1). Furthermore, for initial conditions close to the stable equilibrium state, one of the symbolic expressions found was exactly the harmonic oscillator equation.
Although the following conclusion could be somewhat debatable, the point is that a robot could find Newton’s fundamental second law in seconds. One could argue that this was for a particular system but, though not presented in these terms, this is the process of scientific induction. In data science (DS), ML or AI, this process is called validation, whereas in physics it is called verification (as in verifying Newton’s or Einstein’s theory of gravity). In fact, with more computational power, the authors of Eureqa remarkably rediscovered Newton’s second law for the double pendulum28, which is known in physics as a classical example of a chaotic system.
Complexity: searches and validations
Genetic programming symbolic regression algorithms are known for their scalability issues with the amount and dimensionality of data41,42. Although it is not unusual for deterministic ML algorithms to suffer from the curse of dimensionality, scaling in GP-SR is nevertheless an issue. For our domain application, as described later on in this article, it resulted in no signs of convergence whatsoever after \({\mathcal {O}}(10^3-10^4)\) core hours (total number of hours with all cores running in parallel). The problem was not so much the number of hours but the lack of any progress in the fitness.
Our approach to overcome this problem is intuitive and conceptually simple: it uses a set of sparse data for fast training and later high-accuracy surrogate models for large scale validations. Here we use the RB and EIM frameworks combined with the surrogate approach developed in Ref.13. If, as in our case, the surrogate models are essentially indistinguishable from supercomputer simulations of the Einstein equations, they can be considered as ground truth solutions, with the advantage of very fast evaluations. The steps of validation for building surrogate models based on RB and the EIM are described in9, 10,13,15. So here we focus on the ones related to GP-SR. In this processes we used a fraction of our catalog for training and another one for validation so as to avoid overfitting; typically we used 50% for each (training and validation). We then compared the symbolic time series with the ground truth solutions using dense sampling in parameter and time. This validation instance was achieved by computing the overlap integral \(S(h^{1},h^{2})(q)\) between surrogate and symbolic normalized waveforms in the time domain, defined as
where
and \({\bar{h}}^{1}\) stands for the complex conjugate of \(h^1\). The overlap S gives a measure of the match between two waveforms and is commonly used in GW science. For training issues we have normalized time by a factor of 1,000; this has to be taken account for.
Results
Gravitational waves setup
As a proof of concept we tackled the problem of two black holes initially in quasi-circular orbit and without spin, for about 25–31 GW cycles before merger. More precisely, for the time interval \(t\in [-2,750: 100]M\), where M is the total mass of the system and the waveforms are aligned so that \(t=0\) corresponds to the peak of their amplitudes, which is around the time the two black holes merge. Due to the scale invariance of General Relativity, the only free parameter then is the mass ratio
here chosen to be in the range \(q\in [1,10]\), with \(m_i\) the mass of each black hole. Furthermore, for definiteness we restrict our discussion to the dominant multipolar mode, the \(\ell =m = 2\) one.
A surrogate for this problem was constructed in Ref.9, and is publicly available as part of the GWSurrogate Python package43. This surrogate model consists of only 22 basis elements and, by construction, only 22 EIM time nodes. These are the only pieces of information needed to predict with high accuracy any waveform in the parameter and time domains considered. The surrogate model can be considered —and we do— as ground truth solutions of the EE, since it was shown in9 that it is essentially indistinguishable from NR simulations up to the numerical errors of the latter, performed by SpEC44, the most accurate code in the NR community to date for modeling GWs from sources without shocks (such as binary black holes).
The two polarizations of GWs can be encoded in a single complex parameterized function,
where \(\varvec{\lambda }\) represents a tuple in parameter dimension; here, it corresponds to the mass ratio q defined in Eq. (3). The waveforms for the collision of two black holes in initial quasi-circular orbit have an apparent complexity, but they are simply oscillatory functions with an increasing amplitude until the time of coalescence, followed by a damped exponentially decaying profile, the quasinormal modes of the final black hole. It is therefore convenient to consider the amplitude \(A(t,\varvec{\lambda })\) and phase \(\phi (t,\varvec{\lambda })\) separately,
find closed-form expressions for them, later reconstruct the symbolic waves and compare them with their ground truth counterparts for a large number of validation cases.
For both amplitude and phase our symbolic expressions have an \(R^2\)-goodness-of-fit of at least \(R^2 \sim 0.999\) with respect to the validation members of the catalog used in the symbolic regression searches. We discuss more thorough and large-scale validation results below.
For both phase and amplitude our dictionary is composed of the following functions and operations:
Amplitude
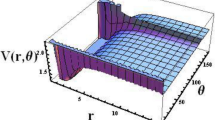
In our experience, naively sampling both in parameter (mass ratio q) and physical dimension (time) resulted in days or weeks of no convergence while searching for symbolic expressions for the amplitude of the GWs. The reason for this is the need to resolve with high accuracy the region around the peak of the amplitude (see Fig. 1), for which we tried using a dense sampling in time, which led to substantial computation with no signs of convergence.

Amplitude for the surrogate waveform \(q=2\); the red diamonds denote the EIM time nodes, which are by construction the same for all \(q\in [1,10]\). Their adaptive nature, leading to a resolution improvement around the peak of the amplitude, can be noticed.
One could attempt to manually collocate time nodes where needed. This approach is not only tedious but also not guaranteed to work. Instead, here we resorted to subsampling in time using only the 22 EIM nodes, shown in Fig.1, and 90 equally spaced values in the mass ratio. The rationale for this approach is that the EIM time nodes are the only relevant ones for recovering the whole time series and thus the only representative ones; this intuition proved to be correct, as we discuss below. Using only the EIM nodes in a few minutes we were able to find the following closed-form expression for all \(q \in [1,10]\) (we discuss validation using a dense set of time nodes below):
where \(\text {gauss}(x):= e^{-x^2}\), \(\text {atan2}(x,y)\) is the arctangent of two parameters and
Figure 2 shows the symbolic amplitude (5) as a function of the mass ratio q and time. The ground truth values are not shown because they are indistinguishable by eye.

Symbolic amplitude (5) as a function of the mass ratio \(q=m_1/m_2\) and time.
As a mode of illustration, we show in Fig. 3 the error curve as a function of time for the amplitude. Although the complete range of convergence included several hours, the plateau of the curve is achieved in the order of minutes, dedicating most of the time to fine tuning of parameters for improving the accuracy of the model. There are several reasons for the formation of this plateau, for example the finiteness of the dictionary, which serves as a constraint for the search space of functions; and the penalization for large formulas (high complexity) in the GP algorithm, which prevents from finding extremely high complex functions with little or no gain in accuracy. One could say that an important reason for the plateau is the stagnation in local optima, but actually the algorithm softens this problem by implementing a protocol that allows to promote population diversity in the evolutionary search without impacting the fitness performance. For details, see36,37.

Error curve in time for symbolic regression corresponding to the amplitude. Note the error in a few seconds reaches a plateau. We stopped our search when the symbolic waveforms reached a 99% overlap with respect to the surrogate model.
Phase
Although we were able to find high accuracy symbolic expressions for the phase in the considered interval of \(q \in [1,10]\) (see Fig. 4 for a symbolic model that is continuous in the whole interval), they resulted in large propagation errors in the reconstruction of the waveforms. The reason is different from phase accumulation errors in numerical relativity, since here we are dealing with global optimization errors and is simply the following: a change in phase \(\phi \rightarrow \phi + \delta \phi\) in (4) leads to an error in the waveforms of the form
so \(|\delta h|/A=\delta \phi\). In order to get a relative error of 1% at least, we must have an order of 0.01 in the phase error \(\delta \phi\). For the whole \(q\in [1,10]\) phase symbolic model, in the results here obtained \(\delta \phi\) is of order 1 (with a relative error less than \(10^{-2}\)), leading to large errors when reconstructing the waveforms.
A simple domain decomposition to solve this issue worked out for us: we subdivided the domain \(q \in [1,10]\) into 9 equally spaced subdomains of the form
We have not tried using a different number of domains, or of different relative sizes, since the point of this paper is to show how to build a sparse training set to avoid the high computational cost of symbolic regression through genetic programming, and that it works in practice in a highly non-trivial application.
For simplicity, we have not imposed boundary conditions between the subdomain boundaries, although this could in principle be done. Domain decompositions are standard when solving partial differential equations (PDEs). In fact, it is possible that in more complex scenarios or even in this case a more elaborate scheme such as an hp-greedy domain decomposition45,46,47,48 (where the hp term is actually borrowed from domain decomposition and refinement in finite elements when solving partial PDEs) might be more efficient in terms of decreasing the number of subdomains and improve our results. As an analogy, it is well known that when solving PDEs through a domain decomposition numerical solutions are not continuous across domain boundaries at fixed resolution (either in space, time, or both); this is usually addressed through weak enforcement of the solution across boundaries, usually in the form of penalty terms For a detailed discussion on these topics in the context of Einstein’s equations see, for example49,50,51. In this article we focus on showing that, as a proof of concept, closed- and free-form expressions can be obtained without resorting to physical approximations. It might be possible to obtain accurate symbolic expressions without a domain decomposition, for example by enriching the dictionary through physically inspired functions, but this is left for future work. Here we focus on the basic elements of eliminating the curse of dimensionality in symbolic regression using modern approaches to reduced order modeling for parametrized systems.
When searching for symbolic expressions for the phase we used 20 values in mass ratio and 285 time nodes for each domain, with all points equally spaced. Due to the simple structure of the phase (see. Fig. 4), subsampling was not necessary.
Our highest accuracy results are the following:

Symbolic phase as a function of the mass ratio \(q=m_1/m_2\) and time.
Validation and accuracy of symbolic waveforms
From the symbolic amplitude and phases we reconstructed the time series for the two polarizations of the GWs and compared them with the ground truth solutions using \(10^5\) GWs per each subdomain \([q_i,q_{i+1}]\) \(i=1, \ldots , 9\), and the whole 28, 501 time samples provided by GWSurrogate, leading to \(\sim 10^6\) validation waveforms.
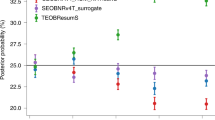
The result is that the overlap \(S=S(q)\) (2) in our approach gives values above 99% for all cases. The main reason that we could do this a posteriori dense validation is due to the fact that ground truth solutions using surrogate models can be evaluated very quickly. The results are shown in Fig. 5. One should not reach any conclusion from the dependence of the overlap S as a function of the mass ratio q, since these are representations, much as in domain decomposition approaches in NR (though usually in physical space, not in parameters). For example, we could have chosen to show results for symbolic expressions with a more uniform error distribution, though it is worth emphasizing that the differences in the figure are in the order of 0.1%, which is below the accuracy required by Laser Interferometer GW detectors. Put differently, although not perhaps known for non-numerical relativists, this non-smooth behavior across boundaries is always present (though in a different sense) in numerical solutions to the Einstein equations when using state of the art domain decomposition or adaptive mesh refinement: continuity is only imposed within a given numerical resolution49. There are always “numerical jumps” and at any fixed resolution the numerical solution to Eintein’s equations is non-smooth; the idea is that these discontinuities are below an acceptable numerical error. The analogue in our approach is that across boundaries the symbolic phases are not smooth but they result in waveforms with overlaps with respect to the ground truth solutions which are below an acceptable error tolerance. As a remark, in GW science, this acceptable discrepancy is of 97%, while our results guarantee at least 99%.

Overlap S(q) for the symbolic waveforms vs the mass ratio q, when compared to ground truth solutions, using \(q \sim 10^6\) values. The minimum and maximum overlaps are \(S=0.9905\) and \(S=0.9986\), respectively. The dotted lines delimit each subdomain \([q_i,q_{i+1}]\) for \(i=1 \ldots 9\).
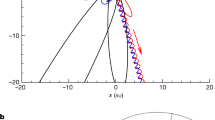
As an example, in Fig. 6 we show the ground truth solution on top of its symbolic expression for \(h_+\), corresponding to the worst match in the validation space for the whole interval \(q \in [1,10]\). Results for \(h_{\times }\) are similar since both modes are related simply by a \(\pi /2\) phase difference.

Symbolic and surrogate waveforms corresponding to the worst match in a posteriori validation with respect to the surrogate model. Top: the whole waveforms, with the vertical redline prior to merger, at \(t/M=-60\). Bottom: zoom in of the waveforms in the range \(t/M\in [-60,100]\). The differences near the merger are noticeable, but the overlap is still \(S=0.9905\).
Discussion
In perspective, having high accuracy, closed-form (symbolic) expressions for the emitted gravitational waves as predicted by a theory as complex as Einstein’s one of gravity, for a process as complex as the collision of two black holes, without any simplification in the theory (thus the ab initio-based emphasis), in a completely autonomous way, cannot be overemphasized.
The standard procedure in GW phenomenological modeling is that one of “stitching” GWs from post-Newtonian (PN) expansions or Effective One Body approximations, ringdown, and a merger regime in between from numerical relativity in some way (there are many of them) and in this sense they do carry physical approximations and therefore are not ab initio-based in the sense here used. Similarly with hybrid models, where early in the inspiral stage some physical approximant is stitched to a numerical relativity solution. Here we have concentrated for training data on a model that is completely indistinguishable from high accuracy numerical relativity supercomputer simulations of the full Einstein equations. In this sense our results can be considered truly ab initio-based, since in the absence of exact solutions (except for those with high degrees of symmetry) high accuracy NR simulations of the Einstein equations are considered the true gold-standard.
Another point to emphasize is that, unlike most —if not all— phenomenological models, our closed-form expressions do not distinguish between inspiral, merger and ringdown, but model all regimes at once. One could have chosen to find symbolic expressions for the different regimes just mentioned, but in order to show the power of our approach we have chosen to model the whole inspiral-merger-ringdown case at once. The domain decomposition here presented is very simple. Having different models in parameter space is not unusual. In fact, it has allowed (among many other ingredients) to find new signals from public LIGO data52.
Our approach is one of the many trends in the gravitational wave science community to incorporate tools from DS, ML and AI, but to our knowledge it is the first of its kind. Because of this, and because genetic programming symbolic regression is meant to provide insights from data, it is difficult to anticipate the full impact and ramifications of our approach. It might be useful, for example, for other ones combining ROM with Deep Learning for GW inference53, which produce, and start from closed-form expressions.
We presented a proof of concept for a novel approach. A next natural, conceptually straightforward, step might be to apply it to the other multipole modes of9, and more complex systems such as the case of spinning, precessing black holes using, for example, the surrogate models of11,12,54. It is possible that for these cases, and higher dimensionality ones in parameter space in general, it would be beneficial when training GP-SR to use not only the EIM time nodes but also the greedy parameter values to increase sparseness and avoid the curse of dimensionality of SR searches. Another line of future research would be to use an hp-greedy refinement approach at the surrogate level to minimize the number of domains. The question of what is the optimal minimum number of subdomains and how it increases with parameter dimensionality is outside the scope of this work but remains as an interesting question. Making touch again with numerical relativity, the equivalent would be asking how the number of domains or levels of adaptive mesh refinement changes with resolution. Even in an established field such as NR, where there is little to no theory for equations as complicated as the Einstein ones, one usually proceeds through numerical experiments.
Even though here we have focused on symbolic expressions based on surrogates built from high accuracy numerical relativity simulations, our approach can be applied to other surrogates based on RB and the EIM, for example those based on EOB or PN ones13,55.
The sparse yet near-optimal subsampling in time using the EIM is a key ingredient in our approach for finding closed-form expressions, so it is not clear that other surrogate models (say based on Gaussian regression, see, e.g. Ref.56) can do so. There might be potential in enriching the dictionary here used for GP-SR (composed of elementary functions and basic arithmetic operations) using phenomenological or other physically based symbolic models. In this sense, using GP-SR should outperform any other kind of physics-based fits by design being free-form. Also, any other fits can be used as a bootstrap to enrich the dictionary of GP-SR; this can also be done as more dimensions and physics complexity are added28.
Anyone willing to qualitatively reproduce or extend the results of this paper can apply for a free academic license of DataRobot57, an Automated Machine Learning framework, which integrates the GP algorithm used in this work. Our results can be easily accesible through a Jupyter notebook at https://github.com/aaronuv/SymbolicGWs.
In general terms, our approach should be applicable to other disciplines beyond gravitational wave science since computational complexity is a common problem in genetic programming.
References
LIGO-detection-papers. https://www.ligo.caltech.edu/page/detection-companion-papers.
Cornish, N., Sampson, L., Yunes, N. & Pretorius, F. Gravitational wave tests of general relativity with the parameterized post-Einsteinian framework. Phys. Rev. D 84, 062003. https://doi.org/10.1103/PhysRevD.84.062003 (2011).
Top500 the list. https://www.top500.org/lists/2019/06/ (2019).
Smith, R. et al. Fast and accurate inference on gravitational waves from precessing compact binaries. Phys. Rev. D 94, 044031. https://doi.org/10.1103/PhysRevD.94.044031 (2016).
Ajith, P. et al. Phenomenological template family for black-hole coalescence waveforms. Class. Quant. Grav. 24, S689–S700. https://doi.org/10.1088/0264-9381/24/19/S31 (2007).
Buonanno, A. & Damour, T. Effective one-body approach to general relativistic two-body dynamics. Phys. Rev. D 59, 084006. https://doi.org/10.1103/PhysRevD.59.084006 (1999).
Rifat, N.-E.-M., Field, S., Khanna, G. & Varma, V. Surrogate model for gravitational wave signals from comparable and large-mass-ratio black hole binaries. Phys. Rev. D.https://doi.org/10.1103/PhysRevD.101.081502 (2020).
Varma, V. et al. Surrogate model of hybridized numerical relativity binary black hole waveforms. Phys. Rev. D 99, 064045. https://doi.org/10.1103/PhysRevD.99.064045 (2019).
Blackman, J. et al. Fast and accurate prediction of numerical relativity waveforms from binary black hole coalescences using surrogate models. Phys. Rev. Lett. 115, 121102. https://doi.org/10.1103/PhysRevLett.115.121102 (2015).
Caudill, S., Field, S. E., Galley, C. R., Herrmann, F. & Tiglio, M. Reduced basis representations of multi-mode black hole ringdown gravitational waves. Class. Quantum Gravity 29, 095016. https://doi.org/10.1088/0264-9381/29/9/095016 (2012).
Blackman, J. et al. A surrogate model of gravitational waveforms from numerical relativity simulations of precessing binary black hole mergers. Phys. Rev. D 95, 104023. https://doi.org/10.1103/PhysRevD.95.104023 (2017).
Varma, V. et al. Surrogate models for precessing binary black hole simulations with unequal masses. Phys. Rev. Res. 1, 033015. https://doi.org/10.1103/PhysRevResearch.1.033015 (2019).
Field, S. E., Galley, C. R., Hesthaven, J. S., Kaye, J. & Tiglio, M. Fast prediction and evaluation of gravitational waveforms using surrogate models. Phys. Rev. X 4, 031006. https://doi.org/10.1103/PhysRevX.4.031006 (2014).
Field, S. E., Galley, C. R. & Ochsner, E. Towards beating the curse of dimensionality for gravitational waves using reduced basis. Phys. Rev. D 86, 084046. https://doi.org/10.1103/PhysRevD.86.084046 (2012).
Field, S. E. et al. Reduced basis catalogs for gravitational wave templates. Phys. Rev. Lett. 106, 221102. https://doi.org/10.1103/PhysRevLett.106.221102 (2011).
Canizares, P. et al. Accelerated gravitational-wave parameter estimation with reduced order modeling. Phys. Rev. Lett. 114, 071104. https://doi.org/10.1103/PhysRevLett.114.071104 (2015).
Tiglio, M. & Villanueva, A. Reduced order and surrogate models for gravitational waves (2021). arXiv:2101.11608.
Setyawati, Y. E., Puerrer, M. & Ohme, F. Regression methods in waveform modeling: a comparative study. Class. Quantum Gravity. https://doi.org/10.1088/1361-6382/ab693b (2020).
Hesthaven, J. S., Rozza, G. & Stamm, B. Certified Reduced Basis Methods for Parametrized Partial Differential Equations 1st edn. (Springer, Bern, 2015).
Quarteroni, A., Manzoni, A. & Negri, F. Reduced Basis Methods for Partial Differential Equations: An Introduction (Springer International Publishing, Berlin, 2015).
Maday, Y., Nguyen, N. C., Patera, A. T. & Pau, S. H. A general multipurpose interpolation procedure: the magic points. Commun. Pure Appl. Anal. 8, 383–404. https://doi.org/10.3934/cpaa.2009.8.383 (2009).
Barrault, M., Maday, Y., Nguyen, N. C. & Patera, A. T. An ‘empirical interpolation’ method: application to efficient reduced-basis discretization of partial differential equations. C. R. Math. 339, 667–672 (2004).
Chaturantabut, S. & Sorensen, C. D. Nonlinear model reduction via discrete empirical interpolation. SIAM J. Sci. Comput. 32, 2737–2764. https://doi.org/10.1137/090766498 (2010).
Pinkus, A. n-Widths in Approximation Theory. Ergebnisse der Mathematik und ihrer Grenzgebiete. 3. Folge/A Series of Modern Surveys in Mathematics (Book 7) (Springer, 1985).
Binev, P. et al. Convergence rates for greedy algorithms in reduced basis methods. SIAM J. Math. Anal. 43, 1457–1472 (2011).
Blackman, J., Szilagyi, B., Galley, C. R. & Tiglio, M. Sparse representations of gravitational waves from precessing compact binaries. Phys. Rev. Lett. 113, 021101. https://doi.org/10.1103/PhysRevLett.113.021101 (2014).
Tiglio, M. & Villanueva, A. On the stability and accuracy of the empirical interpolation method and gravitational wave surrogates. arXiv:2009.06151 (2020).
Schmidt, M. & Lipson, H. Distilling free-form natural laws from experimental data. Science 324, 81–85. https://doi.org/10.1126/science.1165893 (2009).
Koza, J. R. Genetic Programming: On the Programming of Computers by Means of Natural Selection (MIT Press, Cambridge, 1992).
RiccardoPoli, W. B. L. & Nicholas, F. M. A Field Guide to Genetic Programming (Lulu.com, London, 1992).
Eureqa webpage. https://www.nutonian.com/products/eureqa/ (2009).
gplearn webpage. https://gplearn.readthedocs.io/en/stable/.
Quade, M., Gout, J. & Abel, M. Glyph: symbolic regression tools. J. Open Res. Softw.https://doi.org/10.5334/jors.192 (2019).
Bongard, J. C. & Lipson, H. Nonlinear system identification using coevolution of models and tests. IEEE Trans. Evol. Comput. 9, 361–384. https://doi.org/10.1109/TEVC.2005.850293 (2005).
Bongard, J. & Lipson, H. Automated reverse engineering of nonlinear dynamical systems. Proc. Natl. Acad. Sci. 104, 9943–9948. https://doi.org/10.1073/pnas.0609476104 (2007).
Schmidt, M. & Lipson, H. Co-evolving fitness predictors for accelerating evaluations and reducing sampling. Genetic Programming Theory and Practice IV 5, (2006).
Schmidt, M. D. & Lipson, H. Coevolution of fitness predictors. IEEE Trans. Evol. Comput. 12, 736–749. https://doi.org/10.1109/TEVC.2008.919006 (2008).
Schmidt, M. & Lipson, H. Symbolic Regression of Implicit Equations 73–85 (Springer, Boston, 2010).
Schmidt, M. & Lipson, H. Age-Fitness Pareto Optimization 129–146 (Springer, New York, 2011).
Scipy webpage. https://www.scipy.org/.
O’Neill, M., Vanneschi, L. & Gustafson, S. Open issues in genetic programming. Genet. Program. Evol. Mach. 11, 339–363. https://doi.org/10.1007/s10710-010-9113-2 (2010).
Icke, I. & Bongard, J. C. Improving genetic programming based symbolic regression using deterministic machine learning. In 2013 IEEE Congress on Evolutionary Computation, 1763–1770, https://doi.org/10.1109/CEC.2013.6557774 (2013).
GWSurrogate 0.9.7 webpage. https://pypi.org/project/gwsurrogate/.
Spectral Einstein Code webpage. https://www.black-holes.org/code/SpEC.html.
Eftang, J. L. & Stamm, B. Parameter multi-domain ‘hp’ empirical interpolation. Int. J. Numer. Methods Eng. 90, 412–428. https://doi.org/10.1002/nme.3327 (2012).
Eftang, J. L., Patera, A. T. & Ronquist, E. M. An hp certified reduced basis method for parametrized elliptic partial differential equations. SIAM J. Sci. Comput. 32, 3170–3200 (2010).
Eftang, J. L., Knezevic, D. J. & Patera, A. T. An HP certified reduced basis method for parametrized parabolic partial differential equations. Math. Comput. Model. Dyn. Syst. 17, 395–422. https://doi.org/10.1080/13873954.2011.547670 (2011).
Eftang, J. L., Huynh, D. B., Knezevic, D. J. & Patera, A. T. A two-step certified reduced basis method. J. Sci. Comput. 51, 28–58. https://doi.org/10.1007/s10915-011-9494-2 (2012).
Sarbach, O. & Tiglio, M. Continuum and discrete initial-boundary value problems and einstein’s field equations. Living Reviews in Relativity15, 9. https://doi.org/10.12942/lrr-2012-9 (2012).
Calabrese, G., Lehner, L., Reula, O., Sarbach, O. & Tiglio, M. Summation by parts and dissipation for domains with excised regions. Class. Quant. Grav. 21, 5735–5758. https://doi.org/10.1088/0264-9381/21/24/004 (2004).
Lehner, L., Reula, O. & Tiglio, M. Multi-block simulations in general relativity: high order discretizations, numerical stability, and applications. Class. Quant. Grav. 22, 5283–5322. https://doi.org/10.1088/0264-9381/22/24/006 (2005).
Venumadhav, T., Zackay, B., Roulet, J., Dai, L. & Zaldarriaga, M. New binary black hole mergers in the second observing run of Advanced LIGO and Advanced Virgo. Phys. Rev. D 101, 083030. https://doi.org/10.1103/PhysRevD.101.083030 (2020).
Chua, A. J. K., Galley, C. R. & Vallisneri, M. Reduced-order modeling with artificial neurons for gravitational-wave inference. Phys. Rev. Lett. 122, 211101. https://doi.org/10.1103/PhysRevLett.122.211101 (2019).
Lackey, B. D., Purrer, M., Taracchini, A. & Marsat, S. Surrogate model for an aligned-spin effective-one-body waveform model of binary neutron star inspirals using gaussian process regression. Phys. Rev. D 100, 024002. https://doi.org/10.1103/PhysRevD.100.024002 (2019).
Lackey, B. D., Bernuzzi, S., Galley, C. R., Meidam, J. & Van Den Broeck, C. Effective-one-body waveforms for binary neutron stars using surrogate models. Phys. Rev. D 95, 104036. https://doi.org/10.1103/PhysRevD.95.104036 (2017).
Lackey, B. D., Pürrer, M., Taracchini, A. & Marsat, S. Surrogate model for an aligned-spin effective one body waveform model of binary neutron star inspirals using Gaussian process regression. Phys. Rev. D 100, 024002. https://doi.org/10.1103/PhysRevD.100.024002 (2019).
DataRobot webpage. https://www.datarobot.com/.
Acknowledgements
The main ideas of this project were initiated with Rory Smith, to whom we are extremely thankful, as well as Alan Weinstein and Yanbei Chen for hospitality at Caltech. We thank Hod Lipson for introducing us to symbolic regression, the team at Nutonian for academic licenses of Eureqa (now part of DataRobot) and a steep discount on their enterprise parallel version, and Jorge Pullin for comments on a previous draft of this paper. We also thank two anonymous referees for valuable comments and feedback on a previous version of this manuscript. This project was supported in part by CONICET (Argentina).
Author information
Authors and Affiliations
Contributions
M.T. and A.V. contributed equally to the research leading to this paper, as well as its writing and review. The list of authors has been ordered alphabetically.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tiglio, M., Villanueva, A. On ab initio-based, free and closed-form expressions for gravitational waves. Sci Rep 11, 5832 (2021). https://doi.org/10.1038/s41598-021-85102-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-85102-y
This article is cited by
-
Reduced order and surrogate models for gravitational waves
Living Reviews in Relativity (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
