
Abstract
Deep vein thrombosis (DVT) is a common complication in patients with lower extremity fractures. Once it occurs, it will seriously affect the quality of life and postoperative recovery of patients. Therefore, early prediction and prevention of DVT can effectively improve the prognosis of patients. This study constructed different machine learning models to explore their effectiveness in predicting DVT. Five prediction models were applied to the study, including Extreme Gradient Boosting (XGBoost) model, Logistic Regression (LR) model, RandomForest (RF) model, Multilayer Perceptron (MLP) model, and Support Vector Machine (SVM) model. Afterwards, the performance of the obtained prediction models was evaluated by area under the curve (AUC), accuracy, sensitivity, specificity, F1 score, and Kappa. The prediction performances of the models based on machine learning are as follows: XGBoost model (AUC = 0.979, accuracy = 0.931), LR model (AUC = 0.821, accuracy = 0.758), RF model (AUC = 0.970, accuracy = 0.921), MLP model (AUC = 0.830, accuracy = 0.756), SVM model (AUC = 0.713, accuracy = 0.661). On our data set, the XGBoost model has the best performance. However, the model still needs external verification research before clinical application.
Similar content being viewed by others

Introduction
DVT is a common perioperative complication in fracture patients and the incidence of postoperative DVT is significantly higher than that before the operation1. It is the third leading cause of cardiovascular death worldwide and a major complication limiting recovery in patients with lower extremity fractures2. Moreover, it can cause symptoms such as limb swelling, pain, and limitations in motor function3. As the disease progresses, DVT can even lead to the occurrence of pulmonary embolism, increasing the risk of death4.
More and more studies have been dedicated to finding the relevant factors for the occurrence and development of DVT in patients with lower extremity fractures during hospitalization, including age, underlying diseases, fracture types, operation time, bed rest time, coagulation function, etc.5,6,7. These studies promoted a better understanding of the factors associated with increased risk of DVT. However, whether to take measures to prevent DVT is usually up to doctors’ experience and patients’ symptoms. This approach, although clinically feasible, may delay the prevention of and treatment for DVT. Therefore, the identification of high-risk patients with DVT and timely prevention can avoid its occurrence.
Determining the important predictors of DVT is the key to accurately identify high-risk patients. However, the occurrence and development of DVT is influenced by many factors8. The occurrence of DVT is characterized by diversity and instability, and its influencing factors are still in the stage of continuous exploration. As a quantitative tool for disease risk assessment, the disease prediction model is an important auxiliary tool for identifying high-risk groups in the current clinical diagnosis, treatment and nursing process9. An in-depth analysis of the interaction mechanism of disease-related factors is the core of accurate disease prediction.
Machine learning is a scientific discipline that studies how computers learn from data. Through the computer algorithm, it automatically learns knowledge and rules from the data, so as to simulate human intelligent behavior and then achieve a certain purpose of technology and methods. Although there are currently scoring scales for predicting the risk of venous thrombosis in clinical practice, Mooney et al.10 demonstrated that machine learning is superior to traditional scoring methods in the accuracy of prediction. Shohat et al.11 also demonstrated that machine learning can predict venous thrombosis risk in hospitalized patients more accurately than scoring models developed in the past. Furthermore, Danilatou et al.12 considered machine learning as a method suitable for venous thromboembolism (VTE) risk prediction and believed that it has great advantages in finding the best predictors of VTE. At present, machine learning, as a new risk assessment and prediction tool, has been used by many researchers in clinical research and practice.
Ferroni et al.13 selected 1179 outpatient cancer patients who received chemotherapy but did not receive thrombus prophylaxis, and used the SVM model and randomized optimized multi-core learning model to predict DVT risk factors in these patients. The area under the Precision-Recall curve (AUCPR) of the model was 0.212. This study confirmed the possibility and effectiveness of machine learning method for DVT risk prediction. Ferroni et al.14 compared machine learning with Khorana score (KS) risk assessment scale, and the results showed that the predictive model was better than KS. The study conducted by James et al.15 aimed to measure the accuracy of the machine learning classifier for predicting DVT in cancer inpatients, and found that the RF model could correctly classify DVT and non-DVT patients with an accuracy of 74%. The study suggests that machine learning classifiers could be incorporated into electronic medical record systems that could provide an effective blood clot risk assessment for patients.
Although there are several prediction models for DVT, these prediction models have limitations16,17. Firstly, the inclusion and exclusion criteria of patients in the model were strict, and the population representative needed to be improved. Secondly, most machine learning algorithms were compared with traditional analysis methods, and the performance of multiple machine learning classifiers was not compared. Therefore, in this study, we compared the DVT prediction performance with several machine learning algorithms, such as XGB, LR, RF, MLP, and SVM models. Finally, we obtained the optimal model based on the comprehensive score.
Methods
Study population
The retrospective study was conducted according to STROBE guidelines and all methods were performed in accordance with the relevant guidelines and regulations. STROBE guidelines for an international, collaborative initiative of epidemiologists, methodologists, statisticians, researchers, and journal editors involved in the conduct and dissemination of observational studies, with the common aim of strengthening the reporting of observational studies in epidemiology. The Ethics Committee of the Second Affiliated Hospital of Nanchang University approved the study, without patient informed consent due to the anonymous nature of the data. Two specialists used the hospital digital medical record system to retrieve information about patients after lower limb fracture surgery in the Second Affiliated Hospital of Nanchang University from July 1, 2017 to July 1, 2023. Eligible patients were screened by checking medical records, doctor orders, and nursing records in the hospital’s digital medical record system. The results of patients with deep venous thrombosis of lower limbs were obtained through imaging examination reports in the hospital’s digital medical record system. All the obtained data were recorded into Excel software for sorting.
In this study, patients with lower extremity fractures who met the following criteria were included as eligible subjects: patients aged 18 years and older, with less than 20% missing items. Exclusion criteria are pathological fractures, fractures in other parts (such as sternum, and vertebrae), history of venous thromboembolism, oral contraceptives (nearly 1 month), pregnancy, and blood system diseases.
Data preprocessing
With the occurrence or absence of DVT as the outcome index, all patients underwent color Doppler ultrasonography of both lower limbs. The sensitivity and specificity of color Doppler ultrasonography for DVT is more than 90%, which can determine the location and type of thrombus, determine the degree of embolization and collateral circulation, as well as evaluate the therapeutic effect18. DVT ultrasound diagnosis includes the following signs: enlarged lumen below the thrombus obstruction site, thickened vessel wall, solid echo in the lumen, filling defect of blood flow signal in the lumen, loss of phasic changes in blood flow spectrum, extrusion of the distal end increased blood flow to extremities disappears or weakens.
The multiple imputation (MI) was used for subjects with missing values. The basic idea of the MI is to infer multiple estimated fill values for missing values and generate multiple complete data sets for comprehensive analysis to determine the final estimated fill value19. The method modelled the actual posterior distribution of missing values through multiple estimates20. For outliers, they are reconfirmed by the data source and treated as null if they are still outliers after reconfirmation. The StandardScaler is used for standardization processing. The mean value of the data features processed by StandardScaler is 0, while the standard deviation is 1.
Data in the no-thrombosis cases outnumbered those in the thrombosis cases by a ratio of approximately 20:1. The Synthetic Minority Oversampling Technique (SMOTE) was applied to balance no-thrombosis and thrombosis groups. The SMOTE created new minority data by interpolation within the available minority data via bootstrap sampling and data generation via the k-nearest neighbors algorithm21. The K parameter, which determines the number of closest neighbors considered with each SMOTE iteration, was set to 5. To achieve an approximate balance between the no-thrombosis and thrombosis groups, 4010 new data for the thrombosis group were created.
Selection of predictors
Based on a search of relevant literature and clinical judgment, we compiled a list of potential predictors of DVT. There are 36 predictors including sex, rh blood type, ABO blood type, smoking, alcohol consumption, operation time, hypoalbuminemia, kidney disease, cerebrovascular disease, atrial fibrillation, heart disease, cancer, chronic obstructive pulmonary disease (COPD), osteoporosis, hypertension, diabetes, lung infection, fracture type, surgical grade, age, total cholesterol (mmol/L), T triacylglycerol (mmol/L), free fatty acid (mmol/L), albumin (g/L), globulin ratio, calcium (mmol/L), potassium (mmol/L), platelets (1012/L), red blood cells (1012/L), white blood cells (109/L), fibrinogen (g/L), D-dimer (mg/lFEU), international normalized ratio(INR), plasma prothrombin time (s), hospital stay (days) and C-reactive protein (mg/L). The fracture site was divided into hip, femur, tibia, and multiple fractures. Besides, the operation grade was divided into first-level operation, second-level operation, third-level operation, and fourth-level operation. The operation time was categorized into two subsets: those within three hours and the others above.
Ranking of important predictors
Before building the models, we used the XGBoost model to calculate the average contribution value of each predictor, and listed the top 10 important predictors. Based on the study22, and in order to improve efficiency, we skipped the hyperparameter tuning that requires a lot of computational resources, and chose a set of relatively reasonable hyperparameter values in a more balanced way. The model parameters are: learning_rate = 0.1, maximum tree depth = 8, minimum fork weight sum = 4, L2 regularization coefficient = 0.5. The 10 most important variables in the XGBoost model (from high to low) are age, hypertension, fibrinogen, surgical grade, platelets, T triacylglycerol, free fatty acid, D-dimer, globulin ratio, and diabetes. See Table 1 for details.
Model building
The working principle of the XGBoost model is to re-adjust the training samples of the decision tree obtained from the initial training set, especially after further adjustment of the training samples that the decision tree got wrong, and then use them to train the next decision23. The max_depth was 6 and the learning_rate was 0.01 in the XGBoost model. The LR model is a generalized linear regression analysis model that can be extended to assess the correlation between various types of observed data and certain predictors24. The LR model used L2 loss for regularization, the liblinear solver as the optimizer, and the one-vs.-rest scheme as the loss function. The model was trained for 100 iterations and had a C-index of 1. The RF model is an algorithm that combines multiple decision trees through ensemble learning25. The RF model was trained with 20 decision trees with maximum tree depth of 10. The quality of split was measured using Gini impurity. The construction principle of the MLP model is to imitate the human brain, which consists of an input layer, an output layer, and hidden layers of 20 and 1026. The MLP model was trained with 20 iterations and ReLU activation. The SVM model maps the original data to a high-latitude space through a nonlinear function, in which the original data can be separated by a line called a separating hyperplane, and the distance from the data point to this line represents the prediction result of the model confidence (the farther the distance, the more confident the model is about the accuracy of the prediction)27. The hyperparameters of five models are as Table 2.
The 10 most important predictors used to train the models were encoded into the machine learning models. We then divided all the data into five equal parts and chose one of them as the test set. The remaining four parts were used as the training set and repeated five times. Five machine learning models, including XGBoost model, LR model, RF model, MLP model, and SVM model, were used for model construction by using fivefold cross-validation. Model building was done in R version 3.6.3 and python version 3.7. This work was supported by the Extreme Smart Analysis platform (https://www.xsmartanalysis.com/).
Model evaluation
The confusion matrix is a cross-tabulation of real values through which multiple evaluation indexes of the model can be constructed. True Positive (TP) means that the true classification of the sample is positive, and the identification result of the model is also positive; False Negative (FN) means that the true classification of the sample is positive, but the model serves as a negative class. False Positives (FP) means that the true classification of the sample is a negative class, but the model will regard it as a positive class. True Negative (TN) means that the true classification of the sample is negative, and the identification result of the model is also negative.
The size of the area under the receiver operating characteristic (ROC) curve is AUC. AUC reflects the overall predictive performance of the model. The closer the AUC is to 1, the better the predictive performance of the model will be; Accuracy is used to describe the accuracy of the model, that is, the accurate number/total number of samples that the model can identify. The higher the accuracy of the model is, the better the effectiveness of the model will be. Sensitivity represents the ratio of the number of positive patients correctly identified in the model to the total number of positive patients. Specificity refers to the proportion of the number of correctly predicted negative patients in the number of true negative cases. The F1 score is the harmonic mean of accuracy and sensitivity and its value ranges from 0 to 1. The higher the F1 value is, the better the efficiency will be. The Kappa is used for consistency testing and measuring the effectiveness of classification. Consistency refers to whether the predicted results are consistent with the actual results. The calculation of the Kappa is based on the confusion matrix, with values ranging from − 1 to 1, usually greater than 0. When we obtained the AUC, accuracy, sensitivity, specificity, F1 score, and Kappa of five machine learning algorithms on the test set, the optimal model was selected by comprehensive score.
Statistical analysis
Using DVT as the outcome indicator, the data were divided into two groups. The continuous variables such as age, were expressed as median and interquartile range (IQR). Gender and other variables were expressed as percentages (%). For classified variables, if the sample size > 40 and the expected frequency > 5, the Chi-square test would be used. For continuous variables, if the distribution is normal and the variance is homogeneous, the t-test would be used. The Welch’s t-test would be used when the normal distribution was met but the variance was not homogeneous. For non-normal distributions, the Mann–Whitney U test would be used. All Statistical analyses were performed using R version 3.6.3 and python version 3.7. P < 0.05 was considered to be statistically significant. This work was supported by the Extreme Smart Analysis platform (https://www.xsmartanalysis.com/).
Ethical approval
The present research was approved by the Biomedical Research Ethics Committee of the Second Affiliated Hospital of Nanchang University (BR/AFISG-04/1.0). The informed consent was waived by the approving ethics committee due to the retrospective nature of the study.
Results
Patient demographic features
A total of 4424 patients were included in this study, including 4217 patients without DVT and 207 patients with DVT, the incidence rate of DVT was 4.68%. The average age was 61 years old, mainly between 45 and 76 years old. There were 2353 male patients included, accounting for 53.187% of the total, and 2071 females accounting for 46.813%. The incidence of DVT in patients with different parts of lower limb fractures was different (P < 0.001), and the incidence of DVT in patients with femoral fractures and multiple fractures was significantly higher than that of tibial and pelvic fractures. Since the number of first-level surgery patients in the no-thrombosis group was 0, the statistical result of the final surgery level was nan. Between the thrombosis group and the no-thrombosis group, the gender (P < 0.001), age (P < 0.001), ABO blood type (P < 0.001), hypoalbuminemia (P < 0.001), atrial fibrillation (P < 0.001), Total cholesterol (P < 0.001), T triacylglycerol (P = 0.002), albumin (P < 0.001), white blood cell ratio (P < 0.001), calcium ion (P < 0.001), platelets (P = 0.003), red blood cells (P < 0.001), fibrinogen (P < 0.001), d-dimer (P = 0.027), International Normalized Ratio (P = 0.036), C-reactive protein (P = 0.007) were statistically significant. There were no statistically significant differences in the remaining variables (see Supplementary Information).
Model performance
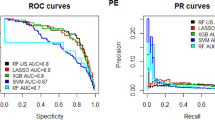
In the test set, the AUC, accuracy, sensitivity, specificity, F1 score, and Kappa of the XGBoost model are 0.979, 0.931, 0.956, 0.911, 0.942, and 0.862. The AUC, accuracy, sensitivity, specificity, F1 score, and Kappa of the LR model are 0.821, 0.758, 0.803, 0.722, 0.764, and 0.516, respectively. The AUC, accuracy, sensitivity, specificity, F1 score, and Kappa of the RF model are 0.970, 0.921, 0.922, 0.921, 0.921, and 0.842. The AUC, accuracy, sensitivity, specificity, F1 score, and Kappa of the MLP model are 0.830, 0.756, 0.828, 0.704, 0.783, and 0.512, respectively. The AUC, accuracy, sensitivity, specificity, F1 score, and Kappa of the SVM model are 0.713, 0.661, 0.691, 0.642, 0.668, and 0.322. By comparing multiple indicators such as AUC, accuracy, sensitivity, specificity, F1 score, and Kappa, the XGBoost model performs best (see Table 3).
Figure 1 shows the ROC curves of the test set for these five models. The AUC values of the ROC curves of different models are the XGBoost model (0.979), LR model (0.821), RF model (0.970), MLP model (0.830), and SVM model (0.713). The XGBoost model and RF model are better than the other models on the test set.

The ROC curve of test set for 5 models.
Discussion
By comparing the characteristic factors between the two groups for different thrombotic outcomes in patients with lower extremity fractures, we found sex, age, ABO blood type, hypoalbuminemia, atrial fibrillation, total cholesterol, T triacylglycerol, albumin, white blood cell ratio, calcium ion, platelets, red blood cells, fibrinogen, d dimer, international normalized ratio, C-reactive protein and fracture types were significantly different between the two groups (P < 0.05). The importance ranking (from high to low) of 10 predictors are age, hypertension, fibrinogen, surgical grade, platelets, T triacylglycerol, free fatty acid, d-dimer, globulin ratio, and diabetes. By comparing multiple indicators such as AUC, accuracy, sensitivity, specificity, F1 score, and Kappa, the XGBoost model has the best performance.
DVT is a common complication in patients with lower extremity fractures and may lead to fatal pulmonary embolism. The incidence of DVT in this study was 4.68%. Surgery is an independent risk factor for DVT in previous studies28. This is mainly because, during the operation, the long-term inability of the body to actively move and the trauma caused by the operation will lead to slow blood flow and damage to the blood vessel wall resulting in the formation of venous thrombosis. In addition, advanced age is also an independent risk factor for DVT29. For the elderly, not only the aging of vascular endothelial cells is accelerated, but also the vascular tension, permeability, and the regulation ability of the vascular wall are reduced, making vascular homeostasis difficult to maintain and more prone to thrombosis30,31.
Blood hypercoagulability is one of the mechanisms of thrombus formation, so coagulation function tests are closely related to thrombus formation. Previous studies have found a correlation between fibrinogen, INR, d-dimer, and thrombus32,33, which is consistent with our research results. High blood lipids and cholesterol will keep the body in a low-inflammatory state for a long time and increase blood viscosity34. Serum albumin, which has the function of inhibiting platelet aggregation and anticoagulation, has been found to be closely related to nutritional status and inflammatory response35,36. Studies found that serum albumin level was a predictor of left atrial thrombus in elderly patients with nonvalvular atrial fibrillation37,38. However, no research has found its correlation with DVT so far, and the relationship between them needs further verification by higher-quality research.
Blood type is an important characteristic of DVT in patients with lower extremity fractures. Li et al.39 found that patients with blood type B had a higher risk of DVT. Differently, Haddad et al. claimed that O blood type does not increase the chance of DVT. However, a higher-quality systematic review suggests that ABO blood type is closely related to the occurrence of DVT in cancer patients. The reason may be that ABO blood type is closely related to vWF level, which acts as a protective carrier of coagulation factor VIII and can promote the formation of thrombus40.
At present, more and more evidence has shown that there is a close relationship between inflammatory immune response and DVT41,42. In addition, the C-reactive protein, platelets, and neutrophils play an important role in the development of DVT43. However, it has been expounded in many relevant researches that severe trauma, stress sepsis and blood loss can all lead to systemic inflammatory response syndrome, which increases the reactivity of neutrophils and platelets in the body44,45,46. Neutrophils provide the original stimulation of DVT and recruit other cells in the coagulation process. Platelets produce circulating microparticles that accelerate blood coagulation47. Over the past few years, many scholars have investigated the association between inflammation and venous thrombosis. Kyril et al.48 analyzed all thrombosis patients in their Thrombosis Research Center and found that a high platelet-to-lymphocyte ratio would increase the risk of inducing DVT by 3 times.
In the past, most machine learning algorithms were compared with traditional analysis methods, and the performance of multiple machine learning classifiers was not compared. Therefore, we compare and analyze the prediction effects of five machine learning classifiers, and search for the optimal model by integrating AUC, accuracy, specificity, and other indicators. James et al.15 used the RF model to predict patients with venous thrombosis, and the accuracy rate was 74%, which was lower than that of the XGBoost model in this study. Liu et al.49 also used RF as a classifier to identify patients at high risk of thrombosis, and the AUC obtained by this method was between 0.77 and 0.79, which was also lower than the AUC obtained by the XGBoost model in this study. However, it is noteworthy that predictive factors varied in researches above, thus extra attention is required in this respect when comparing those models. Besides, the data is unavailable from the previous machine learning studies, so we cannot directly evaluate other machine learning methods. Several pivotal problems still require to be emphasized again including irregular data management, inappropriate data sources, and deficiency in algorithm details, which largely depends on the researchers' awareness and level of scientific research.
Overall, we analyzed various possible predictors of DVT and compared the predictive performance of various machine-learning methods. AUC is a performance measure of the ROC curve: the higher the AUC is, the higher the predictive power of the model is. By comparing multiple indicators such as AUC, accuracy, sensitivity, specificity, F1 score, and Kappa, the XGBoost model has the best performance. The XGBoost model is an optimized distributed gradient boosting library designed to be efficient, flexible, and portable. The XGBoost model fully considers the regularization problem by introducing the number of subtrees and the value of subtree leaf nodes in the loss function. In terms of efficiency, the XGBoost model has greatly improved the modeling efficiency by using the unique approximate regression tree bifurcation point estimation and sub-node parallelization, coupled with the characteristics of second-order convergence. So, its application is becoming more and more widespread, including prognosis and diagnosis of diseases, prediction of disease risk, etc. For example, Trakadis et al.50 used XGBoost analysis to identify people at risk of schizophrenia and found it to be the best performer in comparison with other algorithms, obtaining a better model efficacy (accuracy = 85.7, specificity = 86.6, sensitivity = 84.9, and AUC = 0.95). It can be seen that XGBoost as an efficient algorithm in machine learning is able to construct risk warning models well and achieve higher prediction accuracy.
The occurrence and development of DVT in the actual clinical environment is the result of the long-term interaction of multiple risk factors. The progress of disease is complex as well. The impact of predictors on the occurrence of DVT is judged solely by whether there is a statistical difference, which is different from the clinical situation and the pathophysiology of DVT. The machine learning algorithm can present the degree of influence of all predictors51,52. Therefore, the prediction model based on machine learning can fully reflect the impact of all predictors on DVT, and its results are closer to the actual clinical diagnosis and treatment.
We included variables possibly associated with DVT in the current algorithm to obtain accurate predictions. However, some limitations need to be considered when interpreting the findings of this study. First, there is a lack of detailed description of the variables regarding medication and lifestyle during hospitalization, such as antiplatelet, anticoagulant, antihypertensive, hypoglycemic, chemotherapy, antibiotics, diets, and physical activity, which may lead to some confounding effects. Second, we are unable to obtain symptoms and signs such as pain, cramping, heaviness, pruritus, and varicose veins at the site of DVT, which can hinder a more comprehensive analysis. Although vascular ultrasonography has gradually replaced venous angiography and is widely used, this method is not the “golden standard”. As a result, the possibility of a false positive or false negative in DVT diagnoses cannot be ruled out in this study. In addition, it was difficult for us to include all variables that may affect the statistical results. The relationship between variables and DVT is correlation, not causation. Therefore, the findings should be interpreted in the context of the clinical situation. Furthermore, no external datasets were used for validation in this study and all models were validated only with cross-validation and a test set during training. Finally, this study lacks comparability with previous studies due to the high variability and lack of sharing of medical data across hospitals. Therefore, the creation of large-scale databases that can be freely accessed plays a vital role in future research and attention should be paid to standardised data management.
Conclusions
Age, hypertension, fibrinogen, surgical grade, platelets, T triacylglycerol, free fatty acid, d-dimer, globulin ratio, and diabetes are potentially important predictors of DVT. On our data set, the XGBoost model is the most effective in predicting the occurrence of DVT in patients with lower extremity fractures during hospitalization while it still needs external verification research before clinical application.
Data availability
The source code is available at https://doi.org/10.5072/zenodo.31925, and the source data is available at https://doi.org/10.5072/zenodo.31921.
References
Bartlett, M. A. et al. Perioperative venous thromboembolism prophylaxis. Mayo Clin. Proc. 95(12), 2775–2798. https://doi.org/10.1016/j.mayocp.2020.06.015 (2020).
Lutsey, P. L. & Zakai, N. A. Epidemiology and prevention of venous thromboembolism. Nat. Rev. Cardiol. 20(4), 248–262. https://doi.org/10.1038/s41569-022-00787-6 (2022).
Jaff, M. R. et al. Management of Massive and submassive pulmonary embolism, iliofemoral deep vein thrombosis, and chronic thromboembolic pulmonary hypertension. Circulation 123(16), 1788–1830. https://doi.org/10.1161/CIR.0b013e318214914f (2011).
Di Nisio, M., van Es, N. & Büller, H. R. Deep vein thrombosis and pulmonary embolism. Lancet 388(10063), 3060–3073. https://doi.org/10.1016/s0140-6736(16)30514-1 (2016).
Xing, F. et al. Admission prevalence of deep vein thrombosis in elderly Chinese patients with hip fracture and a new predictor based on risk factors for thrombosis screening. BMC Musculoskelet. Dis. https://doi.org/10.1186/s12891-018-2371-5 (2018).
Luksameearunothai, K. et al. Usefulness of clinical predictors for preoperative screening of deep vein thrombosis in hip fractures. BMC Musculoskelet. Disord. https://doi.org/10.1186/s12891-017-1582-5 (2017).
Silveira, P. C. et al. Performance of wells score for deep vein thrombosis in the inpatient setting. JAMA Int. Med. https://doi.org/10.1001/jamainternmed.2015.1687 (2015).
Tøndel, B. G. et al. Risk factors and predictors for venous thromboembolism in people with ischemic stroke: A systematic review. J. Thromb. Haemost. 20(10), 2173–2186. https://doi.org/10.1111/jth.15813 (2022).
Price, E. L. & Minichiello, T. The wells deep vein thrombosis score for inpatients. JAMA Int. Med. https://doi.org/10.1001/jamainternmed.2015.1699 (2015).
Mooney, S. J. & Pejaver, V. Big data in public health: Terminology, machine learning, and privacy. Annu. Rev. Public. Health. 39(1), 95–112. https://doi.org/10.1146/annurev-publhealth-040617-014208 (2018).
Shohat, N. et al. Using machine learning to predict venous thromboembolism and major bleeding events following total joint arthroplasty. Sci. Rep. https://doi.org/10.1038/s41598-022-26032-1 (2023).
Danilatou, V. et al. Outcome prediction in critically-ill patients with venous thromboembolism and/or cancer using machine learning algorithms: External validation and comparison with scoring systems. Int. J. Mol. Sci. https://doi.org/10.3390/ijms23137132 (2022).
Ferroni, P. et al. Risk assessment for venous thromboembolism in chemotherapy-treated ambulatory cancer patients. Med. Decis. Mak. 37(2), 234–242. https://doi.org/10.1177/0272989x16662654 (2016).
Ferroni, P. et al. Validation of a machine learning approach for venous thromboembolism risk prediction in oncology. Dis. Mark. 2017, 1–7. https://doi.org/10.1155/2017/8781379 (2017).
James, S. L., Mody, K. & Shatzel, J. J. Novel algorithms to predict the occurrence of in-hospital venous thromboembolism in cancer patients: Machine learning classifiers developed from the 2012 national inpatient sample. J. Clin. Oncol. https://doi.org/10.1200/jco.2015.33.15_suppl.1582 (2015).
González, J. et al. Limited diagnostic workup for deep vein thrombosis after major joint surgery. Thromb. Haemost. 99(06), 1112–1115. https://doi.org/10.1160/th08-02-0115 (2017).
Rogers, M. A. M. et al. Triggers of hospitalization for venous thromboembolism. Circulation 125(17), 2092–2099. https://doi.org/10.1161/circulationaha.111.084467 (2012).
Rose, S. C. et al. Symptomatic lower-extremity deep venous thrombosis—Accuracy, limitations, and role of color duplex flow imaging in diagnosis. Radiology 175(3), 639–644. https://doi.org/10.1148/radiology.175.3.2188293 (1990).
Schafer, J. L. & Olsen, M. K. Multiple imputation for multivariate missing-data problems: A data analyst’s perspective. Multivar. Behav. Res. 33(4), 545–571. https://doi.org/10.1207/s15327906mbr3304_5 (1998).
Hughes, R. A. et al. Accounting for missing data in statistical analyses: Multiple imputation is not always the answer. Int. J. Epidemiol. 48(4), 1294–1304. https://doi.org/10.1093/ije/dyz032 (2019).
Chawla, N. V. et al. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 16, 321–357. https://doi.org/10.1613/jair.953 (2002).
Zhu, J. et al. Application of machine learning algorithms to predict central lymph node metastasis in T1–T2, non-invasive, and clinically node negative papillary thyroid carcinoma. Front. Med. https://doi.org/10.3389/fmed.2021.635771 (2021).
Mitchell, R. & Frank, E. Accelerating the XGBoost algorithm using GPU computing. PeerJ Comput. Sci. https://doi.org/10.7717/peerj-cs.127 (2017).
Liu, Y. & Hannig, J. Generalized fiducial inference for logistic graded response models. Psychometrika 82(4), 1097–1125. https://doi.org/10.1007/s11336-017-9554-0 (2017).
Amaratunga, D., Cabrera, J. & Lee, Y.-S. Enriched random forests. Bioinformatics 24(18), 2010–2014. https://doi.org/10.1093/bioinformatics/btn356 (2008).
Tran, D. T. et al. Heterogeneous multilayer generalized operational perceptron. IEEE Trans. Neural Netw. Learn. Syst. 31(3), 710–724. https://doi.org/10.1109/tnnls.2019.2914082 (2020).
Wang, H. et al. Support vector machine classifier via soft-margin loss. IEEE Trans. Pattern Anal. Mach. Intell. 44(10), 7253–7265. https://doi.org/10.1109/tpami.2021.3092177 (2022).
Chopra, V. et al. Risk of venous thromboembolism associated with peripherally inserted central catheters: A systematic review and meta-analysis. Lancet 382(9889), 311–325. https://doi.org/10.1016/s0140-6736(13)60592-9 (2013).
Tick, L. W. et al. Risk factors for post-thrombotic syndrome in patients with a first deep venous thrombosis. J. Thromb. Haemost. 6(12), 2075–2081. https://doi.org/10.1111/j.1538-7836.2008.03180.x (2008).
Strijkers, R. H. W., de Wolf, M. A. F. & Wittens, C. H. A. Risk factors of postthrombotic syndrome before and after deep venous thrombosis treatment. Phlebol. J. Venous Dis. 32(6), 384–389 (2016).
Stain, M. et al. The post-thrombotic syndrome: Risk factors and impact on the course of thrombotic disease. J. Thromb. Haemost. 3(12), 2671–2676. https://doi.org/10.1111/j.1538-7836.2005.01648.x (2005).
Menéndez, J. J. et al. Incidence and risk factors of superficial and deep vein thrombosis associated with peripherally inserted central catheters in children. J. Thromb. Haemost. 14(11), 2158–2168. https://doi.org/10.1111/jth.13478 (2016).
Jeraj, L., Jezovnik, M. K. & Poredos, P. insufficient recanalization of thrombotic venous occlusion—risk for postthrombotic syndrome. J. Vasc. Interv. Radiol. 28(7), 941–944. https://doi.org/10.1016/j.jvir.2017.03.031 (2017).
Ye, C. et al. Prediction of incident hypertension within the next year: Prospective study using statewide electronic health records and machine learning. J. Med. Int. Res. https://doi.org/10.2196/jmir.9268 (2018).
Soaita, I., Yin, W. & Rubenstein, D. A. Glycated albumin modifies platelet adhesion and aggregation responses. Platelets 28(7), 682–690. https://doi.org/10.1080/09537104.2016.1260703 (2017).
Lam, F. W. et al. Histone induced platelet aggregation is inhibited by normal albumin. Thromb. Res. 132(1), 69–76. https://doi.org/10.1016/j.thromres.2013.04.018 (2013).
Napolitano, M. et al. Optimal duration of low molecular weight heparin for the treatment of cancer-related deep vein thrombosis: The cancer-DACUS study. J. Clin. Oncol. 32(32), 3607–3612. https://doi.org/10.1200/jco.2013.51.7433 (2014).
Rana, P. & Levine, M. N. How long to treat acute venous thrombosis in cancer: Can treatment be personalized?. J. Clin. Oncol. 32(32), 3586–3587. https://doi.org/10.1200/jco.2014.55.6977 (2014).
Li, D. et al. ABO non-O type as a risk factor for thrombosis in patients with pancreatic cancer. Cancer Med. 4(11), 1651–1658. https://doi.org/10.1002/cam4.513 (2015).
Swystun, L. L. et al. Genetic determinants of VWF clearance and FVIII binding modify FVIII pharmacokinetics in pediatric hemophilia A patients. Blood 134(11), 880–891. https://doi.org/10.1182/blood.2019000190 (2019).
Budnik, I. & Brill, A. Immune factors in deep vein thrombosis initiation. Trends Immunol. 39(8), 610–623. https://doi.org/10.1016/j.it.2018.04.010 (2018).
Salemi, R. et al. Overactivation of IL6 cis-signaling in leukocytes is an inflammatory hallmark of deep vein thrombosis. Mol. Med. Rep. https://doi.org/10.3892/mmr.2022.12652 (2022).
Navarrete, S. et al. Pathophysiology of deep vein thrombosis. Clin. Exp. Med. 23(3), 645–654. https://doi.org/10.1007/s10238-022-00829-w (2022).
von Brühl, M.-L. et al. Monocytes, neutrophils, and platelets cooperate to initiate and propagate venous thrombosis in mice in vivo. J. Exp. Med. 209(4), 819–835. https://doi.org/10.1084/jem.20112322 (2012).
Zhao, Y. et al. Preoperative systemic inflammatory response index predicts long-term outcomes in type B aortic dissection after endovascular repair. Front. Immunol. https://doi.org/10.3389/fimmu.2022.992463 (2022).
Yang, M. et al. STING activation in platelets aggravates septic thrombosis by enhancing platelet activation and granule secretion. Immunity 56(5), 1013-1026.e6. https://doi.org/10.1016/j.immuni.2023.02.015 (2023).
Yan, Y. Y. et al. Kindlin-3 in platelets and myeloid cells differentially regulates deep vein thrombosis in mice. Aging-Us. 11(17), 6951–6959. https://doi.org/10.18632/aging.102229 (2019).
Cole, K. L. et al. Factors associated with venous thromboembolism development in patients with traumatic brain injury. Neurocritical. Care https://doi.org/10.1007/s12028-023-01780-8 (2023).
Liu, S. et al. Machine learning approaches for risk assessment of peripherally inserted Central catheter-related vein thrombosis in hospitalized patients with cancer. Int. J. Med. Inform. 129, 175–183. https://doi.org/10.1016/j.ijmedinf.2019.06.001 (2019).
Trakadis, Y. J. et al. Machine learning in schizophrenia genomics, a case-control study using 5,090 exomes. Am. J. Med. Genet. B Neuropsychiatr. Genet. 180(2), 103–112. https://doi.org/10.1002/ajmg.b.32638 (2019).
Liu, H. et al. Prediction of venous thromboembolism with machine learning techniques in young-middle-aged inpatients. Sci. Rep. https://doi.org/10.1038/s41598-021-92287-9 (2021).
Rinaldo, L. et al. Venous thromboembolic events in patients undergoing craniotomy for tumor resection: Incidence, predictors, and review of literature. J. Neurosurg. 132(1), 10–21. https://doi.org/10.3171/2018.7.Jns181175 (2020).
Acknowledgements
Funding supported by Project of the Science and Technology Department of Jiangxi Province, China (20224ABC03A02) and Science and Technology support project of Jiangxi Provincial Health Commission (202,130,466) are greatly appreciated. This work was supported by the Extreme Smart Analysis platform (https://www.xsmartanalysis.com/).
Author information
Authors and Affiliations
Contributions
Lingling Yu and Pengfei Yu conceived and designed the experiments; Jialiang Wang and Conghui Wei performed the experiments; Ang Li and Ziying Xiong analyzed the data; Jun Luo and Zhen Yuan contributed reagents and materials; Conghui Wei wrote the paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wei, C., Wang, J., Yu, P. et al. Comparison of different machine learning classification models for predicting deep vein thrombosis in lower extremity fractures. Sci Rep 14, 6901 (2024). https://doi.org/10.1038/s41598-024-57711-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-57711-w
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
