
Abstract
Besides achieving high quality products, statistical techniques are applied in many fields associated with health such as medicine, biology and etc. Adhering to the quality performance of an item to the desired level is a very important issue in various fields. Process capability indices play a vital role in evaluating the performance of an item. In this paper, the larger-the-better process capability index for the three-parameter Omega model based on progressive type-II censoring sample is calculated. On the basis of progressive type-II censoring the statistical inference about process capability index is carried out through the maximum likelihood. Also, the confidence interval is proposed and the hypothesis test for estimating the lifetime performance of products. Gibbs within Metropolis–Hasting samplers procedure is used for performing Markov Chain Monte Carlo (MCMC) technique to achieve Bayes estimation for unknown parameters. Simulation study is calculated to show that Omega distribution's performance is more effective. At the end of this paper, there are two real-life applications, one of them is about high-performance liquid chromatography (HPLC) data of blood samples from organ transplant recipients. The other application is about real-life data of ball bearing data. These applications are used to illustrate the importance of Omega distribution in lifetime data analysis.
Similar content being viewed by others

Introduction
To guarantee the precision, dependability, and utility of data, quality control is an essential procedure. In order to detect and reduce biases, errors, and inconsistencies in data collection, processing, and interpretation, a variety of methods and instruments are used. To achieve quality control, a variety of methods and instruments are available, including process control charts and capability analysis. The three key process variables that control charts track are mean, range, and standard deviation. Any significant deviations from normal patterns indicate potential issues requiring investigation and corrective action. There are many articles related to this point. Conditional mean- and median-based cumulative sum control charts were calculated for Weibull data by Raza et al.1. Ali et al.2 showed the effect of estimation error for the risk-adjusted Charts,(see also Refs.3,4,5 and Ref.6). Rather than assessing the process's overall quality, a control chart tracks the consistency of the product quality generated inside a certain manufacturing process. Although control charts are widely used in the industry, real-time process capability estimation and quality monitoring are not possible with them.
Because products differ in terms of specifications and units, managers must first determine target values and associated tolerances in order to assess process capabilities. Process capability indices are essential instruments for evaluating a process's capacity to produce a good that complies with requirements. The industry's most popular method for evaluating process quality is these indicators. This paper dealt with one of the process capability indices to test its conformity with quality specifications, which is the lifetime performance index.
Many services under certain specifications (desired level) are desired from customers. Modern institutes assess the quality performance of items to provide special needs to their customers. Statistical methods are used to control and promote the quality performance of items. Therefore, process capability indices (PCIs) are employed to detect whether the quality performance of an item reaches the desired level. Montgomery7 and Kane8 illustrate various PCIs in literature. \({C}_{L}\) is utilized by assessing the performance of electronic components lifetime, where \(L\) is the lower specification limit. The performance of electronic components lifetimes is determined by employing the larger-the-better process capability index \({C}_{L}\).
Recently, the lifetime performance index \({C}_{L}\) is used in many research for various fields. Using data from High-Performance Liquid Chromatography (HPLC) of blood samples from organ transplant recipients, Rady et al. 9 investigated the statistical inference of the lifetime performance index for the Topp Leone Alpha power exponential distribution based on first failure progressive censoring schemes. El-sagheer et al.10 provide an assessment for the lifetime performance index of power hazard function distribution. Ahmadi and Doostparast11 evaluate \({C}_{L}\) for Pareto distribution with a new Bayesian approach. Inference of \({C}_{L}\) for Power Rayleigh distribution is provided by Mahmoud et al.12 on progressive first failure censored sample. Hassan and Assar13 evaluate the lifetime performance index of Burr type III distribution under progressive type II censoring. Hassanein14 measured \({C}_{L}\) for Lindley distribution on progressive first failure censoring data. Assessing the lifetime performance index of Weighted Lomax distribution under progressive type-II censoring scheme for bladder cancer is presented by Ramadan15. Wu and Hsieh16 assess \({C}_{L}\) with Gompertz distribution on Progressive type-I interval censored sample. Wu et al.17 calculate the lifetime performance index for Weibull products. Inference of \({C}_{L}\) of Gamma distribution by point and interval estimation is constructed by Shaabani and Jafari18. A credible interval for \({C}_{L}\) of Rayleigh products based on Bayesian estimation is calculated by Lee et al.19. Also, see Laumen and Cramer20. Statistical inference for the lifetime performance index of products with Pareto distribution under general progressive type-II censored sample is measured by Zhang and Gui21. Ahmad et al.22 investigate the lifetime performance index under Ishita distribution based on progressive type II censored data with applications. The lifetime performance index for Stacy distribution applied to medical and engineering data by Elhaddad et al.23.
Moreover, institutes strive to save costs and time of testing. Censored data can be used for solving these problems. In survival analysis, many censoring schemes are proposed. Progressive type-II censoring is the most fundamental type in survival analysis. Progressive type-II censored sample can be described as follows,
-
Assume that \(n\) randomly specified items are set at time zero on a test and at the time of the \(m-th\) failure, the test finished.
-
\({R}_{i}\) of the surviving items are removed randomly from the test, when the \(i-th\) product fails \((i=1,\dots . ,m-1).\)
-
At the end of the test, all \({R}_{m}\)(items which are still surviving) are ejected from the test when the \(m-th\) failure occurs.
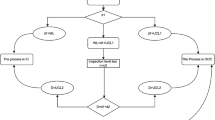
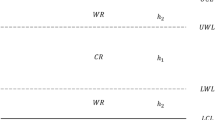
Note that, \(m\) and \(R= ({R}_{1}, \dots \dots , {R}_{m})\) are pre-defined and \(\sum_{i=1}^{m}{R}_{i}=n-m\). Also, if \({R}_{i}=0\) for \(\left(i=1,\dots . ,m-1\right)\) and thus \({R}_{m}=n-m,\) the progressive Type-II censoring scheme is abbreviated to the Type-II censoring scheme and if \({R}_{i}=0\) for \(i=1,\dots . ,m-1\), this censoring scheme is simplified to the complete sample; see Balakrishnan24. Figure 1 shows the mechanism of progressive type-II censored data.

The framework of a progressive type-II censoring scheme.
In this paper, the items lifetime distribution may not obey the normal distribution. The omega distribution is a relatively new probability distribution with three parameters \((\alpha , \beta , and \gamma )\) that can be used to model various hazard function shapes, including the bathtub shape. We compare the omega distribution's performance with other models to show its effectiveness and potential advantages in modeling bathtub-shaped hazard function. Omega distribution introduced by Dombi et al.25 is used to measure \({C}_{L}\) to detect if the quality of the item meets the desired level or not. Assume that \(X\) be random variable which satisfy omega model with three parameters \(\alpha ,\beta ,\gamma >0\). The probability density function (pdf) and the cumulative distribution function (cdf) of the Omega distribution are constructed as follows,
The rest of this paper, Sect. "The lifetime performance index of Omega distribution" represented the lifetime performance index of Omega distribution. The conforming rate is calculated for the items in Sect. "The conforming rate". Section "Maximum likelihood estimator of lifetime performance index" introduced the maximum likelihood estimation of the \({C}_{L}\). Section "Bayesian estimator of the lifetime performance index" introduce Bayesian estimation for unknown parameters and \({C}_{L}\). Section "The testing procedure for the lifetime performance index" involved testing procedure of the \({C}_{L}\). Simulation study is done in Sect. "Simulation study". Two real data sets HPLC data and Ball Bearing data are given in Sect. "Applications".
The lifetime performance index of Omega distribution
In order to satisfy customers' demands, the lifetime of products should exceed the lower specification limit known as \(L,\) since the products lifetime exhibit the larger-the-better quality characteristic. Suppose that \(X\) the product lifetime and \(X\) constitute by the Omega model with the pdf and cdf shown in Eqs. (1) and (2). Then, \({C}_{L}\) is defined on the next equation,
where \(L\) is the lower specification limit, \(\mu\) is the process mean and \(\sigma\) is the process standard deviation, which given by
where \(B\left(n,m\right)\) and \({2F}_{1} (n,m;z ;x)\) denote the beta function and the hypergeometric function, respectively. To assess the lifetime performance of products,\({C}_{L}\) for Omega distribution, we can use Eqs. (4) and (5) as,
where
The hazard function \(h(x)\) of the Omega distribution is defined as
Figure 2 shows plots of the Omega distribution hazard function. If \(\beta <1\), then \(h(x)\) is bathtub shaped.

Bathtub-shaped omega hazard function plots.
The conforming rate
When the lifetime of the product \(X\) is greater than the lower specification limit \(L\) , the product is referred to as a conforming product. The conforming rate is the realization of the ratio of the conforming product, which is described as
Table 1 show the \({C}_{L}\) values v.s. the conforming rate \({P}_{r}\) values with \(\left(\alpha ,\beta ,\gamma \right)\)=\((\mathrm{4.28,2.61,57.79}).\) Clearly, there is a relation between the \({C}_{L}\) and the \({P}_{r}\). If the lifetime performance index \({C}_{L}\) increases, the conforming rate \({P}_{r}\) increases for given \(\alpha , \beta\) and \(\gamma\). The lifetime performance index \({C}_{L}\) is given as \(2.3\) then, \({P}_{r}\) is equal to \(1\). On the other hand, Table \(1\) support for evaluating the lifetime performance of products in real example of Sect. "Testing process for the lifetime performance index"\(.\)
Maximum likelihood estimator of lifetime performance index
Consider the progressive type II censored sample is denoted by \({X}_{1:m:n}, {X}_{2:m:n},\dots \dots .,{X}_{m:m:n}\) with survival products \({R}_{1}, {R}_{2},\dots \dots .,{R}_{m}\) ejected from the life test. The likelihood function of this sample is given as (Casella and Berger26)
where \(C=n(n-{R}_{1}-1).....(n-{R}_{1}-{R}_{2}-......-{R}_{m-1}-m+1),\)
\({f}_{X}\left({x}_{i:m;n}|\theta \right)\) and \({F}_{X}\left({x}_{i:m;n}|\theta \right)\) are the pdf and cdf of \(X\) given in Eqs. (1) and (2).
The likelihood function of \({X}_{1:m:n}, {X}_{2:m:n},\dots \dots .,{X}_{m:m:n}\) is given as,
where \(C=n\left(n-{R}_{1}-1\right).....\left(n-{R}_{1}-{R}_{2}-......-{R}_{m-1}-m+1\right).\)
The form of the log-likelihood function of this sample can be presented as,
By taking the first derivative of the Eq. (11) with respect to parameters \(\alpha , \beta\) and \(\gamma\) and be equal them to zero. Then we have these equations,
The invariance property of the MLE is used to obtain the MLE of \({C}_{L}\)(Zehan27). The MLE of \({C}_{L}\) can be constructed as follows,
Moreover, the asymptotic normal model for the MLEs is stated in the following technique (see Soliman28). From Eq. (12) we have
From Eqs. (13) and (14) we have,
The asymptotic normality results of the MLE of \(\theta\) can be represented as,
where, \(I\left(\theta \right)\) is the Fisher information matrix. The approximate information matrix \({I}_{0}\left(\widehat{x}\right)\) is given by,
The variance–covariance matrix \({I}_{0}{(\widehat{\theta })}^{-1}\) is utilized to estimate \({I}_{0}{(\theta )}^{-1}.\) Assume that \({C}_{L}\equiv C(\theta )\), and the multivariate delta method identified that the asymptotic normal distribution of \(C(\widehat{\theta })\) is
The approximate asymptotic variance–covariance matrix \({\psi }_{\widehat{\theta }}\) of \(C\left(\theta \right)\) is utilized to estimate \({\psi }_{\theta }\) and it given by
Bayesian estimator of the lifetime performance index
Bayes estimation is a powerful and versatile technique in statistics that uses prior knowledge and observed data to estimate the value of unknown parameters. It’s based on Bayes' theorem, which provides a framework for updating beliefs based on new evidence. The gamma prior density function is shown as
where \({b}_{i}\) and \({c}_{i} ,i=\mathrm{1,2},3\) are hyper-parameters which represents our initial beliefs about the possible values of the parameters.
By combining the prior distribution with the likelihood function using Bayes' theorem, you obtain the posterior distribution. The posterior is denoted by \({h}^{*}\left(\alpha ,\beta ,\gamma |x\right)\). When we combine Eqs. (10) and (26), we get posterior function as following,
Square error loss (SEL) function is crucial for guiding model training towards better performance. We used the SEL for \(\theta =(\alpha ,\beta ,\gamma )\) which is given by,
Hence, the Bayes estimate of a function of \(\alpha ,\beta ,\gamma\), say \(g\left(\alpha ,\beta ,\gamma \right)\) under the SEL function in Eq. (28).
And,
In statistical analysis and prediction problems, a symmetric loss function, the linear exponential (LINEX) loss function is very helpful in many respects see Ref.29. It is derived as,
where \(\epsilon\) is a loss function scale parameter. LINEX loss function penalizing overestimation only linearly. This makes it suitable for situations where underestimation is considered more harmful than overestimation. The LINEX loss function can take positive or negative values for \(\epsilon\) and it is close to zero.
The Bayesian estimate for \(\alpha ,\beta ,\gamma\) is denoted by \(\pi (\alpha ,\beta ,\gamma )\) under the LINEX function. \(\pi (\alpha ,\beta ,\gamma )\) is derived as the following equation.
And,
Markov chain Monte Carlo (MCMC) is a powerful and versatile technique used in statistics and computational physics to sample from probability distributions. It is particularly useful for complex distributions where direct sampling is difficult or impossible. In this paper, the calculation of likelihood function is impossible. Hence, we must construct the joint posterior density function in order to the Bayesian estimation for \({C}_{L}\) by applying MCMC approach. The implementation of MCMC, a specific approach called Gibbs sampling within Metropolis is chosen. The joint posterior is computed from Eq. (27)
The conditional posterior densities of \(\alpha ,\beta\) and \(\gamma\) is calculated as follows:
The methodology of M-H is shown in the following steps,
-
Step 1: Start with the first proposal \({(\alpha }^{(0)}, {\beta }^{\left(0\right)},{\gamma }^{(0)})\),
-
Step 2: Assign j = 1.
-
Step 3: Produce \({\alpha }^{(j)},{\beta }^{(j)}\) and \({\gamma }^{(j)}\) from \({{h}_{1}}^{*}\left({\alpha }^{j-1}|{\beta }^{j-1},{\gamma }^{j-1},x\right), {{h}_{2}}^{*}\left({\beta }^{j-1}|{\alpha }^{j-1},{\gamma }^{j-1},x\right)\) and \({{h}_{3}}^{*}\left({\gamma }^{j-1}|{\alpha }^{j-1},{\beta }^{j-1},x\right)\) from the M-H method with the normal distribution
\(N\left({\alpha }^{j-1}|var(\alpha )\right), N\left({\beta }^{j-1}|var(\beta )\right)\) and \(N\left({\gamma }^{j-1}|var(\gamma )\right).\)
-
(1)
Derive \({\alpha }^{*}\) from \(N\left({\alpha }^{j-1}|var(\alpha )\right), {\beta }^{*}\) from \(N\left({\beta }^{j-1}|var(\beta )\right)\) and \({\gamma }^{*}\) from \(N\left({\gamma }^{j-1}|var(\gamma )\right).\)
-
(2)
Detect the probability of acceptance,
$$\left\{\begin{array}{c}{\rho }_{\alpha }={\text{min}}\left[1,\frac{{{h}_{1}}^{*}\left({\alpha }^{*}|{\beta }^{\left(j-1\right)},{\gamma }^{\left(j-1\right)},x\right)}{{{h}_{1}}^{*}\left({\alpha }^{\left(j-1\right)}|{\beta }^{\left(j-1\right)},{\gamma }^{\left(j-1\right)},x\right)}\right]\\ {\rho }_{\beta }={\text{min}}\left[1,\frac{{{h}_{2}}^{*}\left({\beta }^{*}|{\alpha }^{\left(j-1\right)},{\gamma }^{\left(j-1\right)},x\right)}{{{h}_{2}}^{*}\left({\beta }^{\left(j-1\right)}|{\alpha }^{\left(j-1\right)},{\gamma }^{\left(j-1\right)},x\right)}\right]\\ {\rho }_{\gamma }={\text{min}}\left[1,\frac{{{h}_{3}}^{*}\left({\gamma }^{*}|{\alpha }^{\left(j-1\right)},{\beta }^{\left(j-1\right)},x\right)}{{{h}_{3}}^{*}\left({\gamma }^{\left(j-1\right)}|{\alpha }^{\left(j-1\right)},{\beta }^{\left(j-1\right)},x\right)}\right]\end{array}\right.$$ -
(3)
Generate \({u}_{1}, {u}_{2}\) and \({u}_{3}\) from a uniform \((\mathrm{0,1})\) distribution.
-
I.
If \({u}_{1}<{\rho }_{\alpha },\) accept the suggestion and put \({\alpha }^{(j)}={\alpha }^{*}\) otherwise put \({\alpha }^{j}={\alpha }^{j-1}\).
-
II.
If \({u}_{2}<{\rho }_{\beta },\) accept the suggestion and put \({\beta }^{(j)}={\beta }^{*}\) otherwise put \({\beta }^{j}={\beta }^{j-1}\).
-
III.
If \({u}_{1}<{\rho }_{\gamma },\) accept the suggestion and put \({\gamma }^{(j)}={\gamma }^{*}\) otherwise.
Put \({\gamma }^{j}={\gamma }^{j-1}\).
-
Step 4: Count the \({{C}_{LBS}}^{(j)}as following\),
$${{C}_{LBS}}^{(j)}=\frac{{\alpha }^{(j)}{{k}^{(j)}\gamma }^{(j)({\beta }^{(j)}+1)}-L}{\sqrt{{\alpha }^{(j)}{\gamma }^{(j)({\beta }^{(j)}+2)}B\left(\frac{2}{{\beta }^{(j)}}+1,\frac{{\alpha }^{(j)}{\gamma }^{(j)({\beta }^{(j)})}}{2}+1\right){ }_{2}{F}_{1}\left(\frac{{\alpha }^{(j)}{\gamma }^{{\beta }^{(j)}}}{2}+1,\frac{2}{{\beta }^{(j)}}+1,\frac{2}{{\beta }^{(j)}}+\frac{{\alpha }^{(j)}{\gamma }^{(j){\beta }^{(j)}}}{2}+1,-1\right)-{\alpha }^{2(j)}{{k}^{2(j)}\gamma }^{(j)(2{\beta }^{(j)}+2)}}}$$(38) -
Step 5: Suppose that \(j=j+1.\)
-
Step 6: Repeat N times steps from step 3 to step 5 to have \({\alpha }^{(i)},{\beta }^{(i)},{\gamma }^{(i)}\) and \({{{C}_{L}}^{(BS)}}^{(i)}, i=\mathrm{1,2},\dots ,N.\)
-
Step 7: Assess the credible interval of \(\alpha ,\beta ,\gamma\) and \({C}_{L}\) order \({\alpha }^{(i)},{\beta }^{(i)},{\gamma }^{(i)}\) and \({{{C}_{L}}^{(BS)}}^{(i)}, i=\mathrm{1,2},..,N\) as \({\alpha }_{(1)}<{\alpha }_{(2)}<\dots <{\alpha }_{\left(N\right)}, {\beta }_{\left(1\right)}<{\beta }_{\left(2\right)}<\dots <{\beta }_{\left(N\right)}, {\gamma }_{(1)}<{\gamma }_{(2)}<\dots <{\gamma }_{\left(N\right)}\) and \({{C}_{L}}_{(1)}<{{C}_{L}}_{(2)}<\dots <{{C}_{L}}_{(N)}\) . Then, the \(100(1-\rho )\%\) credible intervals of,
\(\vartheta =\left(\alpha ,\beta ,\gamma \right)\) be \(\left(\varphi \left(N\left({\rho }_{\vartheta }/2\right)\right),\varphi \left(N\left(1-{\rho }_{\vartheta }/2\right)\right)\right)\).
The testing procedure for the lifetime performance index
The testing procedure allows us to measure the behavior of the lifetime of the product. In this section, a statistical testing process is submitted to evaluate whether the lifetime performance index achieves the pre-specified desired level \({c}^{*}\)(target value). If the \({C}_{L}\) is larger than \({c}^{*}\), the product is categorized as reliable. The attitude of the lifetime test process is executed as follows.
The null hypothesis \({H}_{0}:{C}_{L} \le {c}^{*}\) is performed against an alternative hypothesis \({H}_{a}:{C}_{L}>{c}^{*} .\) The MLE for \({C}_{L}\) is applied as a test statistic. The rejection region can be represented as \(\{\widehat{{C}_{L}} |\widehat{ {C}_{L}}>{C}_{0}\}\), when \({C}_{0}\) is a critical value. We can obtain the value of \({C}_{0}\) for assigned specified significance level \(\alpha\) as follows,
where, \(\frac{\widehat{{C}_{L}}-{C}_{L}}{\sqrt{{\psi }_{\widehat{\theta }}}}\sim N(\mathrm{0,1})\) and \({\psi }_{\widehat{\theta }}\) is the approximate asymptotic variance–covariance matrix given in Eq. (25)\(.\) Then, the percentile of the standard normal distribution \({z}_{\alpha }=\frac{{C}_{0}-{c}^{*} }{\sqrt{{\psi }_{\widehat{\theta }}}}\) with right-tail probability \(\alpha\) and the critical value can be performed as,
Moreover, the level \(100\left(1-\alpha \right)\%\) one-sided confidence interval of \({C}_{L}\) is obtained as follows,
As a result, the \(100\left(1-\alpha \right)\%\) ower confidence bound for \({C}_{L}\) can be performed as,
The methodology of the proposed testing procedure about \({C}_{L}\) can be employed in the next steps.
-
Step \(1\): Calculate the estimation of three parameters \(\alpha , \beta\) and \(\gamma\) of the Omega distribution. From Eqs. (12), (13) and (14) we can determine the MLE under progressive type-II censored sample \({X}_{1:m:n}, {X}_{2:m:n},\dots \dots .,{X}_{m:m:n}\) which is \(\widehat{\alpha }=4.28\),\(\widehat{\beta }=2.61\) and \(\widehat{\gamma }=57.79.\)
-
Step 2: Detect the lower lifetime limit \(L\) for the product and the target value \({c}^{*}.\)
-
Step \(3\): Applying \({H}_{0}:{C}_{L} \le {c}^{*}\) which called the null hypothesis and the alternative hypothesis \({H}_{a}:{C}_{L}>{c}^{*}.\)
-
Step 4 : Detect a significance level \(\alpha .\)
-
Step 5 : Conclude the \(100\left(1-\alpha \right)\%\) one-sided confidence interval \([LB,\infty )\) for \({C}_{L}\) as,
$$LB=\widehat{ {C}_{L}}-{z}_{\alpha }\sqrt{{\psi }_{\widehat{\theta }}},$$(44)
where the number of observed failures before termination \(m\) is determined also, the lower lifetime limit \(L,\) the censoring scheme \(R=\left({R}_{1}, {R}_{2},\dots \dots .,{R}_{m}\right)\) and the significance level.
-
Step 6: The conclusion is detected as \({c}^{*}\notin [LB,\infty )\) then we will reject \({H}_{0}\). This indicates that the desired level for the performance of the product is reached.
Clearly, the hypothesis test process not only can assess the performance of products lifetime but also detect the customers' demands. In the following section two numerical examples obvious this concept.
Simulation study
This section shows our simulation study involves generating data under various sample sizes.
-
Number of samples: N = 1000.
-
Sample sizes: n = 30, 50, 70, 90, 100, 200.
The equation \(F\left(x\right)-u=0\), where \(u\) is an observation from the Omega distribution and \(F(x)\) is a cumulative distribution function of Omega distribution, is used to create this study. The following measures are assessed:
-
Average bias of \(\widehat{\alpha }, \widehat{\beta }\) and \(\widehat{\gamma }\) of the parameters \(\alpha , \beta\) and \(\gamma\) are respectively:
$$\frac{1}{N}\sum_{i=1}^{N}\left(\widehat{\alpha }-\alpha \right), \frac{1}{N}\sum_{i=1}^{N}\left(\widehat{\beta }-\beta \right) \,\,and\,\, \frac{1}{N}\sum_{i=1}^{N}\left(\widehat{\gamma }-\gamma \right) .$$ -
The mean square error (MSE) of \(\widehat{\alpha }, \widehat{\beta }\) and \(\widehat{\gamma }\) of the parameters \(\alpha , \beta\) and \(\gamma\) are respectively:
$$\frac{1}{N}\sum_{i=1}^{N}{\left(\widehat{\alpha }-\alpha \right)}^{2}, \frac{1}{N}\sum_{i=1}^{N}{\left(\widehat{\beta }-\beta \right)}^{2} \,\,and\,\, \frac{1}{N}\sum_{i=1}^{N}{\left(\widehat{\gamma }-\gamma \right)}^{2}.$$
From Table 2, we can know that the estimates have small bias and that the MSE decreases as the sample size increases. This suggests that the estimator is relatively consistent and that increasing the sample size can improve the accuracy of the estimates.
Applications
In this section we construct the testing procedure for the lifetime performance index on two applications. These two applications obviously show the importance of the Omega distribution on detecting the quality of products. One of them is about HPLC data and the other is about Ball Bearing data.
HPLC data
High-performance liquid chromatography (HPLC) is an important mechanism for separating, identifying, and quantifying each component in the blood. Under large samples, Omega distribution fit to data set which is taken over 56 blood samples from an organ transplant recipient and analyzing an aliquot of each sample by a standard approved method high performance liquid chromatography (HPIC) (see Dube et. al.30).
A progressive type II censoring scheme was performed with \(m=24\) and \({R}_{i}=\left({R}_{1}, {R}_{2},\dots \dots .,{R}_{m}\right) =(\mathrm{7,4}*\mathrm{2,0}* \mathrm{2,3},0*\mathrm{7,1},\mathrm{5,2},0*\mathrm{2,3}*\mathrm{2,0}*4).\) Table 3 clarify the HPLC data.
We fitted the omega model to the data by employing maximum likelihood method. For determination stability with fitting of the model, we divided each observation by 980.
The Omega distribution is a relatively new lifetime distribution that has been shown to be a good fit for a variety of data sets, including HPLC data. The Omega distribution was compared to four other lifetime distributions, namely the Exponential31, Lindley32, gamma33, and TLAPE34 distributions, for their ability to fit HPLC data. K-S values and its p-values are shown in Table 4. The results of the study showed that the Omega distribution provided a better fit to the HPLC data than the other four distributions.
Then, the life test procedure is constructed for \({C}_{L}\) of Omega distribution in the next steps.
-
Step 1: Compute the MLE for parameters \(\alpha , \beta\) and \(\gamma\) of the Omega model under progressive type-II censoring sample. Table 5 shows censoring scheme under progressive type-II scheme.
-
Step 2: Detect the lower limit specification L = 0.0191. The conforming rate of products should exceed 0.80306. The target value \({c}^{*}\) is equal to 0.9.
-
Step 3: Constructing \({H}_{0}:{C}_{L} \le 0.9\) (null hypothesis) and the \({H}_{a}:{C}_{L}>0.9\) (alternative hypothesis).
-
Step 4: Specify \(\alpha =0.05\) significance level for calculating \({C}_{L}.\)
-
Step 5: Employing Eq. (43), the lower confidence interval bound.
$$LB=2.64-1.645\sqrt{0.1115}=2.09237$$
So that, the 95% one-sided confidence interval for \({C}_{L}\) is \([LB,\infty )=[2.09237,\infty ).\)
-
Step 6: The performance index \({c}^{*}=0.9\notin [LB,\infty )=[2.09237,\infty )\) so we make a decition that null hypothesis \({H}_{0}:{C}_{L} \le 0.9\) is rejected. Moreover, \(\widehat{{C}_{L}}=2.64>{c}^{*}+{z}_{\alpha }\sqrt{{\psi }_{\widehat{\theta }}}=0.9+1.645 \sqrt{0.1115 }\approx 1.44943\) So that, we accept the \({H}_{a}\) and the \({C}_{L}\) of the item adhere the desired level.
In Tables 6 and 7, it is seen that Bayes estimates outperform MLEs in the progressive type II samples. In comparison to the approximation confidence intervals, the Bayes credible intervals have the shortest confidence lengths. This study may effectively assist in the failure analysis of the HPLC dataset since the distribution of Omega distribution is well suited to the applicable data.
Ball bearing data
In a life test, ball bearing data devoted the number of millions of revolutions before failing for 23 ball bearings (see Lawless35). A progressive type II censoring scheme was presented with \(m=11\) and \({R}_{i}=({R}_{1},{R}_{2},...,{R}_{m})=(0*\mathrm{3,3},\mathrm{2,3},\mathrm{1,0}*\mathrm{3,3}).\) Table 8, show the data on the failure times of 23 ball bearing.
We fitted the omega model to the data by employing maximum likelihood method. For determination stability with fitting of the model, we divided each observation by 1.2792.
Table 9 contains critical information for a comprehensive discussion around Ball Bearing data. Statistical tests like Kolmogorov–Smirnov test are applied to show which distribution is more fit to ball bearing data.Ahmadi et al.36 constructed the lifetime performance index with Weibull distribution. The Omega distribution performed better than the Weibull distribution because the Weibull distribution is not fitted to ball bearing data.
Also, we can notice that the Omega distribution provided better than some other distribution on evaluating performance for products such as Kumaraswamy distribution37 and Power Lomax distribution38.
Then, we create life test procedure of \({C}_{L}\) for Omega distribution in the next steps.
-
Step 1: Calculate the MLE for parameters \(\alpha , \beta\) and \(\gamma\) of the Omega model under progressive type-II censoring sample. Table 10 illustrates the progressive type-II censored scheme.
-
Step 2: Determine the lower limit specification \({\text{L}}= 0.0732\). The conforming rate of products should be exceeding \(0.80306\). The target value \({c}^{*}\) is equal to \(0.9\).
-
Step 3: Applying \({H}_{0}:{C}_{L} \le 0.9\) (null hypothesis) and the \({H}_{a}:{C}_{L}>0.9\) (alternative hypothesis).
-
Step 4: Specify \(\alpha =0.05\) significance level for calculating \({C}_{L}.\)
-
Step 5: utilizing Eq. (43), the lower confidence interval bound.
$$LB=5.5-1.645\sqrt{1.50451}=3.48227$$
So that, the 95% one-sided confidence interval for \({C}_{L}\) is \([LB,\infty )=[3.48227,\infty ).\)
-
Step 6: Since, the performance index \({c}^{*}=0.9\notin [LB,\infty )=[3.48227,\infty )\) so we decide that null hypothesis \({H}_{0}:{C}_{L} \le 0.9\) is rejected. Moreover, \(\widehat{{C}_{L}}=5.5>{c}^{*}+{z}_{\alpha }\sqrt{{\psi }_{\widehat{\theta }}}=0.9+1.645 \sqrt{1.50451 }\approx 2.91773\) So that, we accept the \({H}_{a}\) and the \({C}_{L}\) of the product adhere the desired level.
In Tables 11 and 12, it is seen that Bayes estimates outperform MLEs in the progressive type II samples. In comparison to the approximation confidence intervals, the Bayes credible intervals have the shortest confidence lengths. This study may effectively assist in the failure analysis of the Ball Bearing dataset since the distribution of Omega distribution is well suited to the applicable data.
Conclusion
Evaluating the lifetime performance index is a critical point in our life to meet customers' demands. Making that assessment under censoring data allows good results in detecting the required customer level of quality. Some statistical measures are constructed to calculate \({C}_{L}\). By using the MLE method of \({C}_{L}\), we can test the \({C}_{L}\) of Omega distribution based on Progressive type-II censoring sample data with displaying the multivariate delta method. Bayes estimation based the Markov chain Monte Carlo (MCMC) method is performed for unknown parameters and \({C}_{L}\). To compare MCMC with MLE, a simulation study is provided. The simulation study is provided to compare MCMC with MLE. We compare Omega distribution with some other distributions by applying Kolmogorov–Smirnov test to show the superiority of Omega distribution. This analysis is derived for various values of \(\alpha , \beta\) and \(\gamma .\) Finally, the theoretical results are applied to two real data sets HPLC data and Ball Bearing data for specifying the desired concept of this paper.
In future research, as an alternative, Expectation–Maximization (EM) algorithm will be applied to estimate the parameters of Omega distribution. Whereas it's applied in various statistical areas, including mixture models, hidden Markov models, factor analysis, and many more. The EM algorithm is an iterative algorithm for estimating parameters. It consists of iterating the expectation step (E), which computes a bound for the loglikelihood function using the current parameter values, and the maximization step (M), where the bound is maximized with respect to parameters, we will discuss it in detail in our future research.
Data availability
The data that support the findings of this study are available within the article.
References
Raza, S. M. M., Ali, S., Shah, I. & Butt, M. M. Conditional mean- and median-based cumulative sum control charts for Weibull data. Qual. Reliab. Eng. Int. https://doi.org/10.1002/qre.2746 (2020).
Ali, S., Altaf, N., Shah, I., Wang, L. & Raza, S. M. M. On the effect of estimation error for the risk-adjusted charts. Complexity https://doi.org/10.1155/2020/6258010 (2020).
Akram, M. F., Ali, S., Shah, I. & Raza, S. M. M. Max-EWMA chart using beta and unit Nadarajah and Haghighi distributions. J. Math. https://doi.org/10.1155/2022/9374740 (2022).
Ali, S., Shah, I., Raza, S. M. M. & Tahir, M. Bayesian analysis for geometric shapes in additive manufacturing. J. Taibah Univ. Sci. 16(1), 836–853. https://doi.org/10.1080/16583655.2122261 (2022).
Hyder, M., Mahmood, T., Butt, M. M., Raza, S. M. M. & Abbas, N. On the location-based memory type control charts under modified successive sampling scheme. Qual. Reliab. Eng. Int. https://doi.org/10.1002/qre.3049 (2021).
Raza, S. M. M., Ali, S., Shah, I., Wang, L. & Yue, Z. On efficient monitoring of Weibull lifetimes using censored median hybrid DEWMA chart. Complexity https://doi.org/10.1155/2020/9232506 (2020).
Montgomery, D. C. Introduction to Statistical Quality Control (Wiley, 1985).
Kane, V. E. Process capability indices. J. Qual. Technol. 18, 41–52 (1986).
Rady, E. A., Hassanein, W. A. & Yehia, S. Evaluation of the lifetime performance index on first failure progressive censored data based on Topp Leone Alpha power exponential model applied on HPLC data. J. Biopharm. Stat. https://doi.org/10.1080/10543406.2021.1895192 (2021).
El-Sagheer, R. M., Jawa, T. M. & Sayed-Ahmed, N. Assessing the lifetime performance index with digital inferences of power hazard function distribution using progressive type-II censoring scheme. Comput. Intell. Neurosci. https://doi.org/10.1155/2022/6467724 (2022).
Ahmadi, M. V. & Doostparast, M. Evaluating the lifetime performance index of products based on progressively type-II censored pareto samples: A new Bayesian approach. Qual. Reliab. Eng. Int. https://doi.org/10.1002/qre.3040 (2021).
Mahmoud, M. A. W., Kilany, N. M. & El-Refai, L. H. Inference of the lifetime performance index with power Rayleigh distribution based on progressive first-failure censored data. Qual. Reliab. Eng. Int. https://doi.org/10.1002/qre.2643 (2020).
Hassan, A. & Assar, S. M. Assessing the lifetime performance index of burr type III distribution under progressive type II censoring. Pak. J. Stat. Oper. Res. 17(3), 633–647. https://doi.org/10.18187/pjsor.v17i3.3635 (2021).
Hassanein, W. A. Statistical inference of lifetime performance index for lindley distribution under progressive first failure censoring scheme applied to HPIC data. Int. J. Biomath. https://doi.org/10.1142/S1793524518500730 (2018).
Ramadan, D. A. Assessing the lifetime performance index of weighted Lomax distribution based on progressive type-II censoring scheme for bladder cancer. Int. J. Biomath. https://doi.org/10.1142/s1793524521500182.2150018 (2021).
Wu, S. F. & Hsieh, Y. T. The assessment on the lifetime performance index of products with Gompertz distribution based on the progressive type I interval censored sample. J. Comput. Appl. Math. 351, 66–76 (2019).
Wu, S. F., Wu, Y. C., Wu, C. H. & Chang, W. T. Experimental design for the lifetime performance index of Weibull products based on the progressive Type I interval censored sample. Symmetry 13(9), 1691. https://doi.org/10.3390/sym13091691 (2021).
Shaabani, J. & Jafari, A. A. Inference on the lifetime performance index of Gamma distribution: Point and interval estimation. Commun. Stat. Simul. Comput. https://doi.org/10.1080/03610918.2022.2045498 (2022).
Lee, W. C., Wu, J. W., Hong, M. L., Lin, L. S. & Chan, R. L. Assessing the lifetime performance index of Rayleigh products based on the Bayesian estimation under progressive type II right censored samples. J. Comput. Appl. Math. 235, 1676–1688 (2011).
Laumen, B. & Cramer, E. Likelihood inference for the lifetime performance index under progressive type-II censoring. Econ. Qual. Control https://doi.org/10.1515/eqc-2015-0008 (2015).
Zhang, Y. & Gui, W. Statistical inference for the lifetime performance index of products with Pareto distribution on basis of general progressive type II censored sample. Commun. Stat. Theory Methods 50(16), 3790–3808. https://doi.org/10.1080/03610926.2020.1801735 (2021).
Ahmad, H. H., Elnagar, K. & Ramadan, D. Investigating the lifetime performance index under Ishita distribution based on progressive type II censored data with applications. Symmetry https://doi.org/10.3390/sym15091779 (2023).
Elhaddad, T. A., Abd El-Monsef, M. M. E. & Hassanein, W. A. The lifetime performance index for stacy distribution under progressive first-failure type II right censoring scheme applied to medical and engineering data. J. Stat. Appl. Probab. 12(2), 559–569. https://doi.org/10.18576/jsap/120219 (2023).
Balakrishnan, N. Progressive censoring methodology: An appraisal. Test 16, 211–289 (2007).
Dombi, J., Jonas, T., Toth, Z. E. & Arva, G. The omega probability distribution and its applications in reliability theory. Qual. Reliab. Eng. Int. https://doi.org/10.1002/qre.2425 (2018).
Casella, G. & Berger, R. L. Statistical Inference 2nd edn. (Pacific Grove, 2002).
Zehan, P. W. Invariance of maximum likelihood estimation. Ann. Math. Stat. 37, 744–744 (1966).
Soliman, A. A. Estimation of parameters of life from progressively censored data using burr-II model. IEEE Trans. Reliab. 54, 34–42 (2005).
Varian, H. R. Bayesian approach to real estate assessment. In Studies in Bayesian Econometrics and Statistics (eds Savage, L. J. et al.) 195–208 (Amsterdam North-Holland, 1975).
Dube, M., Garg, H. & Krishna, H. On progressively first failure censored Lindley distribution. Comput. Stat. 31, 139–163 (2016).
Balakrishnan, N. & Basu, A. P. Exponential Distribution Theory, Methods and Applications (Wiley, 1995).
Ghitany, M. E., Atien, B. & Nadarajah, S. Lindley distribution and its application. Math. Comput. Simul. 78, 493–506. https://doi.org/10.1016/j.matcom.2007.06.007 (2008).
Choi, S. C. & Wette, R. Maximum likelihood estimation of the parameters of the gamma distribution and their bias. Technometrics https://doi.org/10.1080/00401706.1969.10490731 (1969).
El-Houssainy, A. R., Hassanein, W. A. & Yehia, S. Evaluation of the lifetime performance index on first failure progressive censored data based on Topp Leone alpha power exponential model applied on HPLC data. J. Biopharm. Stat. https://doi.org/10.1080/10543406.2021.1895192 (2021).
Lawless, J. F. Statistical Models and Methods for Lifetime Data 2nd edn. (Wiley, 2003).
Ahmadi, M. A., Doostparast, M. & Ahmadi, J. Estimating the lifetime performance index with Weibull distribution based on progressive first-failure censoring scheme. J. Comput. Appl. Math. 239, 93–102 (2013).
Abd El-Monsef, M. M. E. & Hassanein, W. A. Assessing the lifetime performance index for Kumaraswamy distribution under first-failure progressive censoring scheme for ball bearing revolutions. Qual. Reliab. Eng. Int. https://doi.org/10.1002/qre.2616 (2019).
Hassanein, W. A. The lifetime performance index of power lomax distribution based on progressive first-failure censoring scheme. J. Stat. Appl. Probab. 7(2), 333–341. https://doi.org/10.18576/jsap/070210 (2018).
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
All authors have equally made contributions. The authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kilany, N.M., El-Refai, L.H. Evaluating the lifetime performance index of omega distribution based on progressive type-II censored samples. Sci Rep 14, 5694 (2024). https://doi.org/10.1038/s41598-024-55511-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-55511-w
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
