
Abstract
This paper deals with a class of nonparametric two-sample location-scale tests. The purpose of this paper is to approximate the exact p-value of the considered class under a randomized block design. The exact p-value of the considered class is approximated by the saddlepoint approximation method, also by the traditional method which is the normal approximation method. The saddlepoint approximation method is more accurate than the normal approximation method in approximating the exact p-value, and does not take a lot of time like the simulation method. This accuracy is proved by applying the mentioned methods to two real data sets and a simulation study.
Similar content being viewed by others

Introduction
The tests for location-scale problem have many uses in many fields, especially when studying spatial and variations in streamflow, Zhang et al.1 and Yang et al.2, also in monsoon circulation, see Kwoon et al.3. In addition, these tests arise very often in bioinformatics in the case of comparing two groups such as control and treatment in order to detect differentially expressed genes, see Neuhäuser and Senske4. There is also an importance for location-scale tests in the field of biomedical and clinical trials, when the drug or the treatment is given for the treatment group causes changes in location and scale parameters between the two groups, see Mulccioli et al.5, Rice et al.6, Lunde and Timmermann7 and Marozzi8. This paper presents some location-scale linear rank tests that can form the proposed class. Lepage9 test “LP1”, was the first test that combines both, the location test which is the Wilcoxon test and the scale test which is the Ansari-Bradley test. In addition, Büning and Thadewald10 presented LP2, LP3 and LP4 tests which are known as modified tests for LP1. Furthermore, Rublik11 proposed a test statistic consisting of a linear combination of the location test which is the Wilcoxon test and the scale test which is the Mood test. Rousson12 discussed the location-scale test in case of a multivariate two-sample problem. All the aforementioned tests can be used when all observations in the population or selected samples are determined. Therefore, these tests belong to classical statistics. While if the data to be analyzed or a part of it is indeterminate, we can resort to neutrosophic statistics. For more information on this context, a number of references can be referred to, namely Smarandache13, Aslam14,15,16, Afzal et al.17, Albassam et al.18 and Sherwani et al.19. If you interested in location shift only, you could see Hollander et al.20. They suggested many location problems and tests, with one sample and two samples.
In clinical trials, consider we have \(N\) patients will be distributed into two groups, control group and treatment group. To guarantee no selection bias in the randomization assignment for the subjects, and to achieve a certain degree of balance between the control and treatment groups, randomization designs must be used. Complete randomization design is one of the easiest ways to assign the subject into two groups using a fair coin, if the head, it goes to the control but if the tail, it goes to the treatment group, and so on until we finish all subjects. There is also a random allocation design, which depends on one of the \(\left(\begin{array}{c}N\\ \frac{N}{2}\end{array}\right)\) permutations to assign the \(N\) patients to the groups. The randomized block design is an important design that reduces selection bias and control the imbalance of group sizes. In this paper, we tend to use randomized block design, which contains \(k\) blocks of even sizes \({n}_{i}\), such that \(\frac{{n}_{i}}{2}\) patients are for control group and the same number for treatment group, and within each block the random allocation design is applied to assign the patients to the two groups. For more randomization designs, see Rosenberger and Lachin21.
To calculate the exact p-value of the proposed class, an accurate method is used, which is saddlepoint approximation method “SPA” that depends on the permutation distribution of the considered class. The SPA method discovered by Daniels22 who investigated an approximate formula for any probability mass or density function based on its moment generating function. The theory of SPA expansions and multidimensional generalizations were presented in Good23,24 and Barndorff-Nielsen and Cox25. Further developed by Lugannani and Rice26 who proposed an approximate formula for the cumulative distribution function, CDF. Saddelpoint approximations to randomization distributions and permutation distributions were treated by Robinson27 and Davison and Hinkley28. Skovgaard29 introduced an approximate formula for the conditional distribution function which is a generalization of the Lugannani and Rice26 formula, for more details, see Booth and Butler30 and Butler31. The SPA has many advantages, first, the SPA has a correction term equal to \(O({n}^{-\frac{3}{2}} )\), in contrast the central limit theorem has \(O({n}^{-\frac{1}{2}} )\), Daniels32. Second, the SPA often leads to a uniformly bounded error, in contrast, the errors of the normal approximation method generally increase in the tail of the distribution. Daniels33 was the first who suggested the major advantages of the SPA method and its general power and scope. Many papers were interested in approximating the exact p-value for various classes using SPA method with different randomization designs, such as, Abd-Elfattah and Butler34,35 Abd-Elfattah36,37,38,39, Abd EL-Raheem and Abd-Elfattah40,41, Kamal et al.42,43 and Abd El-Raheem et al.44,45.
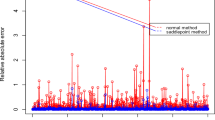
The exact distribution of the considered class of tests is unknown. Then, we cannot obtain the exact p-values for such tests. Therefore, we resort to the saddlepoint approximation method to approximate the exact p-values for such tests. In all previous studies related to the considered class of tests, the normal approximation method was used to approximate the exact p-values of such tests. In the current study, we use the saddlepoint approximation method to approximate the exact p-value for the considered tests. From the results of simulation study and real data analysis, it will be seen that saddlepoint approximation p-values are almost always closer to the simulated (permutation) p-values than the normal approximation. The degree of greater accuracy is readily apparent in small and intermediate size samples for which the asymptotic normality has not been attained. Thus, the saddlepoint method is a more accurate approximation method than the normal approximation method and computationally less demanding than the simulation method (permutation based, so time consuming).
This paper is partitioned as follows: “Class of location-scale tests” presents the class of non-parametric location-scale tests. The saddlepoint approximation is presented in “Saddlepoint approximation”. Section “Simulation study and real data examples” proves the accuracy of SPA in approximating the exact p-value by performing a simulation study and analyzing three real data sets. Moreover, the time consumed for calculating the SPA p-values, normal approximation p-values and simulated mid-p-values is calculated in minutes and presented in “Simulation study and real data examples”. Furthermore, the 95% and 99% confidence intervals for location and scale parameters are constructed in “Confidence intervals for location and scale parameters”. Finally, the conclusion and discussion are presented in “Conclusion”.
Class of location-scale tests
Consider two independent samples \(X\) which is the control group and \(Y\) is the treatment group are drawn from populations with CDF \(F\) and \(G\), with means \({\mu }_{1}\) and \({\mu }_{2}\) and standard deviations \({\sigma }_{1}\) and \({\sigma }_{2}\), respectively. Under the randomized block design, the location-scale class is given by
where \(k\) is the number of blocks with even sizes \({n}_{i}\), \(N=\sum_{i=1}^{k}{n}_{i}\), and \({b}_{i}=\frac{1}{{n}_{i}+1}\) is the optimum weight of block \(i\), Elteren46. The location and scale scores of each observation \(j\) in each block \(i\) are donated by the linear combination \({(a}_{{L}_{ij}}+{a}_{{S}_{ij}} )\), where \({a}_{{L}_{ij}}\) is for location score and \({a}_{{S}_{ij}}\) is for scale score, and \({Z}_{ij}\) is the group indicator takes the value 1 if the observation \(j\) in the block \(i\) is from the treatment group \(Y\) and takes the value 0 otherwise. The permutation distribution of the observations assignments within the blocks, is done under random allocation rule with \(\left(\begin{array}{c}{n}_{i}\\ {m}_{i}\end{array}\right)\) possible permutations, where \({m}_{i}\) is the number of the treatment observations inside the block \(i\). The asymptotic distribution of \({H}_{B}\) is \(N\left( {\mu }_{L}+{\mu }_{S},{\sigma }_{L}+{\sigma }_{S}\right)\), where \({\mu }_{L}\) and \({\mu }_{S}\) are the means of the location and scale tests, respectively. Also, \({\sigma }_{L}\mathrm{ and }{\sigma }_{S}\) are the standard deviations of the location and scale tests, respectively.
The considered class includes many of location-scale tests, such as, Lepage’s statistic which can be written according to the Eq. (1) as
where \({W}_{{L}_{ij}}\) is the score of the Wilcoxon location test with mean \({\mu }_{L}=\frac{1}{2}{\sum_{i=1}^{k}{b}_{i}m}_{i}\left({n}_{i}+1\right)\) and variance \({\sigma }_{L}^{2}=\frac{1}{12}{\sum_{i=1}^{k}{b}_{i}}^{2}{m}_{i}^{2}\left({n}_{i}+1\right).\) Also, \({R}_{{S}_{ij}}\) is the score of Ansari-Bradley scale test that takes the form
with mean
and variance
with asymptotic distribution \(N\left( {\mu }_{L}+{\mu }_{S},{\sigma }_{L}+{\sigma }_{S}\right)\). In addition, \(LP2\), also called Gastwirth47 test, can be written in the form of Eq. (1), as follows:
where the location score is
and the scale score
where
and \(Z_{{i(j)}}\) is the j-th order statistic of the combined two samples \(X\) and \(Y\) in the block \(i\).
\(LP3\) test takes the form of \(LP2\) in Eq. (3) and follows the form of location-scale class in Eq. (1) with location score of Van der Waerden test
and Klotz scale score
where \({\varphi }^{-1}\) is the inverse cumulative distribution function of standard normal distribution.
\(LP4\) test also takes the same form of \(LP2\) and \(LP3\) but with location score
and with Mood scale score
where [a] denotes the greatest integer less than or equal to a.
All Lepage’s types, \(LP2, LP3,{\text{and}} LP4\) are asymptotically distributed \(N\left( \mu ,\sigma \right),\) where
and
In addition, Rublik11 investigated the location-scale problem with test statistic contains a combination between the Wilcoxon location score and the Mood scale score, that can take the same form of (1) as follows:
with location mean \({\mu }_{L}=\frac{1}{2}\sum_{i=1}^{k}{b}_{i}{m}_{i} \left({n}_{i}+1\right),\) and variance \({\sigma }_{L}^{2}=\frac{1}{12}{{\sum_{i=1}^{k}{b}_{i}}^{2}m}_{i}^{2}\left({n}_{i}+1\right)\), and scale mean \({\mu }_{S}=\frac{1}{12}\sum_{i=1}^{k}{b}_{i}{m}_{i}\left({n}_{i}^{2}-1\right)\) and variance \({\sigma }_{S}^{2}=\frac{1}{180 }{{\sum_{i=1}^{k}{b}_{i}}^{2}m}_{i}^{2}\left({n}_{i}+1\right)\left({n}_{i}^{2}-4\right).\) The asymptotic distribution of \(T\) is \(N\left( {\mu }_{L}+{\mu }_{S},{\sigma }_{L}+{\sigma }_{S}\right)\).
In this paper, we are interested in working with three test statistics only, which are \(LP1\) test, \(LP3\) test and Rublik test. For more location-scale tests, see Duran et al.48 who investigated a class of location-scale nonparametric tests. Also see, Fueda and \(\widehat{{\text{O}}}\)hori49 who designed a two-sample rank test based on the Wilcoxon test.
Saddlepoint approximation
For simplicity, let the class (Eq. 1) be in the form
where \({{{A}_{ij}=b}_{i}(a}_{{L}_{ij}}+{a}_{{S}_{ij}})\), as we noted before, that the patients within the blocks distributed under random allocation design, this means that the random variables \({Z}_{ij}\) and \({Z}_{ib}\) for all \(i=1,\dots ,k\) and \(j\ne b\) are dependent but independent with \({Z}_{aj}\) where \(a\ne i\).
To avoid the problem of the dependence, we constructed a conditional distribution as follow:
where \({V}_{i1}, \dots , {V}_{i{n}_{i}}\) are independent and identically Bernoulli (\({\theta }_{i}\)) random variables for each \(i=1,\dots ,k\).
This transfers the distribution of the statistic (Eq. 4) to equivalent conditional distribution as follows:
Now, to approximate exact p-value of \({H}_{B}\) in (Eq. 4), we need to approximate the following conditional probability
where \({h}_{o}\) is the observed value of \({H}_{B}\), using the double saddlepoint approximation of Skovgaard29, the conditional probability in (Eq. 5) can be approximated as follows:
where
where \(M=({m}_{1},\dots , {m}_{k})\), the two saddlepoints are \(\left(\widehat{t},\widehat{S}\right)=\left(\widehat{t},{\widehat{s}}_{1},\dots , {\widehat{s}}_{k}\right)\) and \({\widehat{S}}_{0}=({\widehat{s}}_{10},\dots ,{\widehat{s}}_{k0})\).
The joint cumulant generating function of \(\left\{\sum_{i=1}^{k}\sum_{j=1}^{{n}_{i}}{A}_{ij}{V}_{ij}, \sum_{j=1}^{{n}_{1}}{V}_{1j}={m}_{1}, \dots ,\sum_{j=1}^{{n}_{k}}{V}_{kj}={m}_{k}\right\}\) is
where \(Q\left(\widehat{t},\widehat{S}\right)\) is \((k+1)\times (k+1)\) Hessian matrix and \({Q}_{ss}^{{\prime}{\prime}}\) is the second derivative of \(Q\left(0,{\widehat{S}}_{0}\right)\) with respect to \(S\). To calculate \(\widehat{\omega }\) and \(\widehat{u}\), we first calculate the numerator saddlepoints \(\left(\widehat{t},\widehat{S}\right)=\left(\widehat{t},{\widehat{s}}_{1},\dots , {\widehat{s}}_{k}\right)\), by solving the following equations
and to find the value of \({\widehat{S}}_{0}=\left({\widehat{s}}_{10},\dots ,{\widehat{s}}_{k0}\right),\) we solve the following equation
Each of \(\widehat{\omega }\) and \(\widehat{u}\) dose not depend on \({\theta }_{i}\), so for explicitly in solving the SPA equations, we can choose \({\theta }_{i}=\frac{{m}_{i}}{{n}_{i}}\), then \({\widehat{S}}_{0}=(0,\dots ,0)\) for all \(i=1,\dots ,k\).
Simulation study and real data examples
Simulation study
The main aim of using a simulation study is to prove that the saddlepoint approximation method is closer to the simulated mid-p-value than the normal approximation method. The exact p-values of Lepage test, LP3 test and Rublik test are approximated using the two methods, saddlepoint approximation and normal approximation methods. To illustrate the accuracy of SPA p-value, we compare the p-values for the two previously methods with the simulated mid-p-value, which can be calculated from simulation of one million random permutations of the treatment and control indicator \({Z}_{ij}\). The simulated mid-p-value is obtained as \([\sum I(H>{h}_{0})+0.5\sum I(H={h}_{0})]/{10}^{6}\), and its donated here as “exact” p-value. The benefit of using mid-p-value instead of the p-value is that the mid-p-value is convenient in case of discrete test statistics and not conservative compared to the ordinary p-value, for more details, see Agresti50, Butler31 and Delanchy et al.51. The simulated data in this section is generated from extreme value and logistic distributions with six cases which are (1): \(N=24,k=4,m=3\), case (2): \(N=30,k=3,m=5\), case (3): \(N=40, k=4, m=5\), case (4): \(N=60, k=6, m=5\), case (5): \(N=80, k=5, m=8\) and case (6): \(N=90, k=5, m=5,\) each with \({n}_{i}=\frac{N}{k}\), and \({m}_{i}=m.\) Different location \(({\mu }_{1},{\mu }_{2}\)) and scale (\({\sigma }_{1}, {\sigma }_{2}\)) parameters are used to generate the data according to the previous scenarios. To prove our aim this process is repeated 1000 times based on 1000 generated samples. Tables 1, 2 and 3 present the mean of the SPA p-values, normal approximation p-values, simulated mid-p-values and the percentage of approaching the SPA method to the simulated method “P.SPA”. Also, the average relative absolute error for SPA “R.E.SPA” and the average relative absolute error for normal approximation method “R.E.NA” are calculated and presented in Tables 1, 2 and 3.
In Table 1, 2 and 3, the SPA approximation is more accurate than the normal approximation method. This can be seen through the R.E.SPA, which is much smaller than R.E.NA, for all considered cases.
Real data examples
To support the aim of this paper, three real data sets are analyzed. The first data set is from Rosenberger and Lachin21. They analyzed cholesterol rate for 50 patients. The results of the cholesterol rate for 50 patients can be found in Table 7.4 in the reference Rosenberger and Lachin21. The 50 patients were assigned randomly to control and treatment group by generating the vector of the group indicator \({Z}_{ij}\), such that 25 assign to control and 25 assign to treatment, where each block contains 5 from each group, i.e. (\(N=50,{n}_{i}=10 ,k=5, m=5\)). The second data set is from a survey of household expenditure for 20 single men” treatment group” and 20 single women ”control group”. For this data set, (\(N=40,{n}_{i}=8, k=5, m=4)\). The second data is presented in Büning and Thadewald10. The third data set was presented on page 39 of Hand et al.52. This data set consists of 40 measurements of cholesterol levels for 40 men were divided into two groups A and B according to two types of behaviors. The type A behavior “treatment group” is characterized by urgency and aggression. While type B behavior “control group” is relaxed. For this data set, (\(N=40,{n}_{i}=8, k=5, m=4)\). Table 4 presents the p-values of \(LP1\) test, \(LP3\) test and Rublik test using simulated, SPA and normal approximation methods.
From Table 4, we can see that SPA p-value is closer to the exact p-value than the normal p-value, and this result gives more evidence that SPA method is more accurate than the normal method in approximating the p-value. It remains for us to explain the reason for considering the saddlepoint approximation method as an alternative to the simulation method. The reason is that the saddlepoint approximation method requires much less computing time compared to the simulation method. To clarify this, the computing time for the different methods is calculated and this is summarized in Tables 5, 6 and 7.
From the result of the simulation study, we can see that the SPA method is more accurate than the normal approximation methods compared to the simulated exact p-value. Moreover, from Tables 5, 6 and 7 it is clear that the SPA method is faster than simulated method which needs a lot of time to approximate the exact p-value.
Confidence intervals for location and scale parameters
The estimated confidence intervals for location parameter \({\mu }_{2}\) and scale parameter \({\upsigma }_{2}\), are the set of all values \({\mu }_{{2}_{o}}\) and \({\upsigma }_{{2}_{{\text{o}}}}\) of the parameters \({\mu }_{2}\) and \({\upsigma }_{2}\), respectively, which if formulated in the claim \({H}_{o}: {\mu }_{2}={\mu }_{{2}_{o}}\) and \({\upsigma }_{2 }={\upsigma }_{{2}_{{\text{o}}}}\), would not be rejected at α significant level. Accordingly, if \(p\left({\mu }_{{2}_{o}}, {\upsigma }_{{2}_{{\text{o}}}}\right)\) is the one-sided p-value for the location-scale test, then a \(\left(1-\alpha \right)100\%\) confidence intervals of \({\mu }_{2}\) and \({\upsigma }_{2}\) can be constructed as \(\left\{{\mu }_{{2}_{o}}:\frac{\alpha }{2}\le p\left({\mu }_{{2}_{o}}, {\upsigma }_{{2}_{{\text{o}}}}\right)\le 1-\frac{\alpha }{2}\right\}\) and \(\left\{{\upsigma }_{{2}_{{\text{o}}}}:\frac{\alpha }{2}\le p\left({\mu }_{{2}_{o}}, {\upsigma }_{{2}_{{\text{o}}}}\right)\le 1-\frac{\alpha }{2}\right\}\), respectively, see34. Assume \({D}_{o }\left({\mu }_{{2}_{o}}, {\upsigma }_{{2}_{{\text{o}}}}\right)\) be the observed test statistic with location parameter \({\mu }_{{2}_{o}}\) and scale parameter \({\upsigma }_{{2}_{{\text{o}}}}\), using a satisfactory grid of \({\mu }_{{2}_{o}}\) and \({\upsigma }_{{2}_{{\text{o}}}}\) values with suitable increasing, the cutoff \({D}_{o }\left( ., .\right)\) is a step function in \({\mu }_{{2}_{o}}\) and \({\upsigma }_{{2}_{{\text{o}}}}\) that leads to incremental increases with increasing \({\mu }_{{2}_{o}}\) and \({\upsigma }_{{2}_{{\text{o}}}}\). Here, the 3rd real data set is used to illustrate the procedure for creating confidence intervals for the location and scale parameters. We use the “gofTest” R package to estimate the location \({\mu }_{2}\) and scale \({\upsigma }_{2}\) parameters for the 3rd real data set and to test the suitability of the extreme value distribution for the considered real data set. The maximum likelihood estimations for the location and scale parameters are 227.9 and 31.17, respectively. Furthermore, the p-value of the goodness of fit test, is p-value = 0.887. We evaluate the values of \({D}_{o }\left({\mu }_{{2}_{o}}, {\upsigma }_{{2}_{{\text{o}}}}\right)\) using a large range of the possible values of \({\mu }_{{2}_{o}}{\text{and}} {\upsigma }_{{2}_{{\text{o}}}}\), then for each value of \({D}_{o }\left({\mu }_{{2}_{o}}, {\upsigma }_{{2}_{{\text{o}}}}\right)\) the corresponding exact, saddlepoint and normal p-values are calculated. Table 8 includes the exact, saddlepoint and normal confidence intervals for LP1 test.
From Table 8, we can see that the estimated 99% confidence interval using SPA method is more accurate than the corresponding estimated confidence interval using the normal approximation method as compared to the simulated (Exact) confidence interval. For the 95% confidence interval, both methods have the same accuracy as the simulated method.
Conclusion
In this article, various nonparametric tests for location and scale problem have been discussed and rewritten as a common linear rank class. The exact p-value of the considered class is approximated by SPA method and the normal approximation method. According to our results in the simulation study and the two real data sets, SPA performs well and achieves high accuracy in approximating the exact p-value instead of the normal method. This article can be applied in different designs, such as random allocation design, Wei’s urn design, complete design and truncated binomial design. Also, the proposed study can be extended to neutrosophic statistics, see Afzal et al.17, Albassam et al.18 and Sherwani et al.19.
Data availability
The datasets used and/or analyzed during the current study available from the corresponding author on reasonable request.
References
Zhang, Q., Xu, C. Y. & Yang, T. Variability of water resource in the yellow river basin of past 50 years. Water Resource Manag. 23, 1157–1170 (2009).
Yang, T., Chen, X. & Zhang, Z. C. Spatio-temporal changes of hydrological processes and underlying driving forces in Guizhou region, Southwest China. Stoch. Env. Res. Risk Assess. 23, 1071–1087 (2009).
Kwoon, M., Jhun, J. G. & Ha, K. J. Decadal change in east Asian summer monsoon circulation in the mid-1990s. Geophys. Res. Lett. 34, L21706 (2007).
Neuhäuser, M. & Senske, R. The Baumgartner-Weiss-Schindler test for the detection of differentially expressed genes in replicated microarray experiments. Bionformatics 20, 3553–3564 (2004).
Muccioli, C. et al. The diagnosis of intraocular inflammation and cytomegalovirus retinitis in HIV-infected patients by laser flare photometry. Ocul. Immunol. Inflamm. 4(2), 75–81 (1996).
Rice, K. L. et al. Withdrawal of chronic systemic corticosteroids in patients with COPD. Am. J. Respir. Crit. Care Med. 162, 174–178 (2000).
Lunde, A. & Timmermann, A. Duration dependence in stock prices: An analysis of bull and bear markets. J. Business Econ. Stat. 22, 253–273 (2004).
Marozzi, M. Nonparametric simultaneous tests for location and scale testing: A comparison of several methods. Commun. Stat. Simulat. Comput. 42(6), 1298–1317 (2013).
Lepage, Y. A combination of Wilcoxon’s and Ansari-Bradley’s statistics. Biometrika 58, 213–217 (1971).
Büning, H. & Thadewald, Th. An adaptive two-sample location-scale test of Lepage-type for symmetric distributions. J. Stat. Comput. Simul. 65, 287–310 (2000).
Rublik, F. Critical values for testing location-scale hypothesis. Meas. Sci. Rev. 9, 9–15 (2009).
Rousson, V. On distribution-free tests for the multivariate two sample location scale model. J. Multivar. Anal. 80, 43–57 (2002).
Smarandache F. (2014). Introduction to neutrosophic statistics. Infinite Study.
Aslam, M. Retracted article: Neutrosophic statistical test for counts in climatology. Sci. Rep. 11, 17806 (2021).
Aslam, M. Clinical laboratory medicine measurements correlation analysis under uncertainty. Ann. Clin. Biochem. 58(4), 377–383 (2021).
Aslam, M. Neutosophic analysis of variance: Application to university students. Complex Intell. Syst. 5, 403–407 (2019).
Afzal, U., Alrweili, H., Ahamd, N. & Aslam, M. Neutrosophic statistical analysis of resistance depending on the temperature variance of conducting material. Sci. Rep. 11, 23939 (2021).
Albassam, M., Khan, N., Aslam, M. (2020). The W/S test for data having neutrosophic numbers: An application to USA village population. Complexity. 3690879.
Sherwani, R.A.K., Shakeel, H., Saleem, M., Awan, W.B., Aslam, M. & Farooq, M. (2021). A new neutrosophic sign test: An application to COVID-19 data. Plos One. 16(8).
Hollander, M., Wolfe, D. A. & Chicken, E. Nonparametric Statistical Methods (Wiley, 2013).
Rosenberger, W. F. & Lachin, J. M. Randomization in Clinical Trials: Theory and Practice (Wiley, 2002).
Daniels, H. E. Saddlepoint approximations in statistics. Ann. Math. Stat. 25, 631–650 (1954).
Good, I. J. Saddlepoint methods for the multinomial distribution. Ann. Math. Stat. 28, 861–880 (1957).
Good, I. J. The multivariate saddlepoint method and chi-squared for the multinomial distribution. Ann. Math. Stat. 32, 535–548 (1957).
Barndorff-Nielsen, O. E. Edgeworth and saddlepoint approximations with statistical applications. J. R. Stat. Soc. B 41, 279–312 (1979).
Lugannani, R. & Rice, S. Saddle point approximation for the distribution of the sum of independent random variables. J. Appl. Probability 12, 475–490 (1980).
Robinson, J. Saddlepoint approximations for permutation tests and confidence intervals. J. R. Stat. Soc. 44, 91–101 (1982).
Davison, A. C. & Hinkley, D. V. Saddlepoint approximations in resampling methods. Biometrika 75, 417–431 (1988).
Skovgaard, I. M. Saddlepoint expansions for conditional distributions. J. Appl. Probability 24, 875–887 (1987).
Booth, J. G. & Butler, R. W. Randomization distributions and saddlepoint approximations in generalized linear models. Biometrika 77, 787–796 (1990).
Butler, R. W. Saddlepoint Approximations with Applications (Cambridge University Press. UK, 2007).
Daniels, H. E. The approximate distribution of serial correlation coefficients. Biometrika 43, 169–185 (1956).
Daniels, H. E. Discusssion of paper by D. R. Cox. J. R. Stat. Soc. Biometrika 20, 236–238 (1958).
Abd-Elfattah, E. F. & Butler, R. W. The weighted log-rank class of permutation tests: P-values and confidence intervals using saddlepoint methods. Biometrika 94, 543–551 (2007).
Abd-Elfattah, E. F. & Butler, R. W. Log-rank permutation tests for trend: Saddlepoint p-values and survival rate confidence intervals. Can. J. Stat. 37, 5–16 (2009).
Abd-Elfattah, E. F. The weighted log-rank class under truncated binomial design: Saddlepoint p-values and confidence intervals. Lifetime Data Anal. 18, 247–259 (2012).
Abd-Elfattah, E. F. Saddlepoint p-values and confidence intervals for the class of linear rank tests for censored data under generalized randomized block design. Comput. Stat. 30, 593–604 (2015).
Abd-Elfattah, E. F. Saddlepoint p-values for two-sample bivariate tests. J. Stat. Plan. Inference 171, 92–98 (2016).
Abd-Elfattah, E. F. Saddlepoint p-values for group of linear rank tests. Commun. Stat. Simulat. Comput. 46, 4274–4280 (2017).
Abd El-Raheem, A. M. & Abd-Elfattah, E. F. Weighted log-rank tests for clustered censored data: Saddlepoint p-values and confidence intervals. Stat. Method Med. Res. 29, 2629–2636 (2020).
Abd El-Raheem, A. M. & Abd-Elfattah, E. F. Log-rank tests for censored clustered data under generalized randomized block design: Saddlepoint approximation. J. Biopharm. Stat. 31, 352–361 (2021).
Kamal, K.S., Abd El-Raheem, A.M. & Abd-Elfattah, E.F. (2021). Weighted log-rank tests for left-truncated data: Saddlepoint p-values and confidance intervals. Commun. Stat.-Theory Methods.
Kamal, K. S., Abd El-Raheem, A. M. & Abd-Elfattah, E. F. Weighted log-rank tests for left-truncated data under Wei’s urn design: Saddlepoint p-values and confidence intervals. J. Biopharm. Stat. 32(5), 641–651 (2022).
Abd El-Raheem, A. M., Hosny, M. & Abd-Elfattah, E. F. Statistical inference of the class of non-parametric tests for the panel count and current status data from the perspective of the saddlepoint approximation. J. Math. 2023, 1–8 (2023).
Abd El-Raheem, A.M., Kamal, K.S., & Abd-Elfattah, E.F. (2023b). P-values and confidence intervals of linear rank tests for left-truncated data under truncated binomial design. https://doi.org/10.1080/10543406.2023.2171431
Elteren, P. H. On the combination of independent two-sample tests of Wilcoxon. Bull. Int. Stat. Inst. 37, 351–361 (1960).
Gastwirth, J. L. Percentile modifications of two sample rank tests. J. Am. Stat. Assoc. 60, 1127–1141 (1965).
Duran, B. S., Tsai, W. S. & Lewis, T. O. A class of location-scale nonparametric tests. Biometrika 63, 173–176 (1976).
Fueda, K. & Ohori, K. Versatile two-sample rank tests based on Wilcoxon test. Bull. Inform. Cybernet. 27, 159–164 (1995).
Agresti, A. A survey of exact inference for contingency tables. Stat. Sci. 7(1), 131–153 (1992).
Delanchy, P. R., Heard, N. A. & Lawson, D. J. Meta-analysis of mid-p-values: Some new results based on the convex order. J. Am. Stat. Assoc. 114(527), 1105–1112 (2018).
Hand, D. J., Daly, F., Lunn, A. D., McConway, K. J. & Ostrowski, E. A Handbook of Small Data Sets (Chapman and Hall, 1994).
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
All authors participated equally in all tasks.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mohamed, H.N., Abd-Elfattah, E.F., Abd-El-Monem, A. et al. Saddlepoint p-values for a class of location-scale tests under randomized block design. Sci Rep 14, 3092 (2024). https://doi.org/10.1038/s41598-024-53451-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-53451-z
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
