
Abstract
Nanomaterials (NMs) have the potential to be hazardous owing to their unique physico-chemical properties. Therefore, the need for Health Risk Assessment (HRA) of NMs is expanding. In this study, a novel HRA was developed by the Pythagorean Fuzzy Health Risk Assessment (PFHRA) approach. Risk is considered to be the outcome of parameters including Occurrence Likelihood (OL), Potential Exposure (PE) and Toxic Effects (TE). In our proposed method, priority weights of sub-factors in Pythagorean Fuzzy-Analytical Hierarchical Process (PF-AHP) were determined by pairwise comparison based on expert judgment. After determining parameter scores, both RM and risk class (i.e., negligible, minor, major and critical) were reported as Fuzzy Inference System (FIS) output. Ultimately, a risk management strategy is presented for NMs manufacturing workplaces. This proposed method provides experts with more flexibility to express their opinions. The PFHRA approach was applied for two scenarios. The production scenario for SiNPs can create minor (5%) and major (95%) occupational health risks; the production scenario for ZnONPs can create minor (100%) concerns. However, the production SiNPs and ZnONPs utilizing the CB Nanotool technique had a major and minor risk class, respectively. The results of the present study confirmed the reliability and applicability of this approach.
Similar content being viewed by others
Introduction
According to the definition of the European Commission, "Nano matter is any natural, incidental, or manufactured substance that contains particles, in a non-connected state or as identifiable constituent particles in aggregates or agglomerates. Nanomaterials must have at least one dimension that is less than approximately 100 nm"1,2. Numerous studies have convincingly demonstrated that nanomaterials have unique physicochemical characteristics that lead to toxic effects. Creating these adverse effects cannot possible by larger particles3,4. Previous studies on ambient or natural nanoparticles have faced doubts regarding their possible toxic health effects5,6,7,8,9,10.
Nowadays, the use of nanomaterials in a various industrial processing, products, and healthcare applications has widely spread11,12. Due to the lack of a clear toxicological basis for setting nanomaterial-specific occupational exposure limits13,14,15, it is necessary to assess the risk of nanomaterial hazards16,17,18.
On the other hands, the rapid growth of nanotechnology has led to an increased production and use of nanomaterials19, which may pose potential risks to the health and safety of workers involved in their manufacturing20. Occupational health risk assessments are crucial in identifying and mitigating these occupational risks21,22. Control Banding (CB) methods such as CB Nanotool, Stoffenmanager Nano created in The Netherlands, and CB Tool from the French Agency for Food and Act, are employed as categories criteria, or "bands," for occupational and health risk assessment, which combined with parameters to determine desired levels of control measures18,23.
Nanotechnology has emerged as a promising field with numerous applications in various industries, including manufacturing. However, the use of nanomaterials in the workplace poses potential health risks to workers. Therefore, it is essential to assess and manage these risks effectively. However, traditional methods are uncertain and ambiguous due to the lack of safety materials datasheets or information from a literature review. In addition, there is variability and incomplete knowledge24,25,26,27. In this paper, we present an integrated approach to occupational health risk assessment using Pythagorean Fuzzy AHP and Fuzzy Inference System. This approach allows for a more flexible and nuanced assessment of risk factors and their interactions, providing a more comprehensive understanding of overall occupational health risk. Our approach highlight the importance of considering uncertainty and imprecision in risk assessments for nanomaterials, and the need for more sophisticated and adaptable methods in this field.
In our proposed method, the HRA for NMs was carried out in the following phases:
-
I.
To hierarchically identify and determine the sub-factors that relate to the Occurrence Likelihood (OL) of NMs in the ambient, their Potential Exposure (PE), and the Toxic Effects (TE).
-
II.
Assessing each sub-factor regarding its contribution to health risk using expert judgments and calculating priority weights by the Pythagorean fuzzy Analytical Hierarchy Process (PF-AHP) method for these factors that can overcome uncertainty and ambiguous data.
-
III.
Merging all factors and determining RM and risk class by Fuzzy Inference System (FIS).
Literature review
Many studies have used integrated AHP and FIS methods for risk assessment in mines28 and different project29,30. In this regard, a novel integrated approach, Pythagorean Fuzzy Proportional Risk Assessment, was perfectly developed by Ilbahar et al. that was integrated Fine Kinney method, Pythagorean Fuzzy Analytic Hierarchy Process (PFAHP) method, and a Fuzzy Inference System that is used for risk assessment in the risk assessment of occupational health and safety16. In addition, integrating AHP and FIS methods in various fields, was applied such as prioritizing of suppliers on sustainability factors31 and ranking environmental issues in offshore oil and gas operations32, Production planning33, and act. However, unlike the literature, this study uses the PFAHP method and a fuzzy inference system for nanomaterials health risk assessment. Topuz et al34. proposed an environmental risk assessment approach for engineered nanoparticles using integrated AHP and fuzzy inference rules, which systematically evaluate related risk factors and reduce uncertainty about data and information. In this study, the proposed approach was precise and helpful in determining the risk management strategies. Moreover, many studies have focused on the environmental risk assessment of various nanoparticles that is used using fuzzy logic35,36. Based on our research, none of the MCDM techniques in literature has been used to assess occupational and health risks of nanomaterials. Different from the literature, this study is the first to suggest a fuzzy method for the NMs' occupational and health risk assessment. Moreover, the present study has developed an accurate approach to assess occupational health risk in the manufacture of nanomaterials using PFAHP and FIS. PFAHP determines the weight of each sub-factor, considering its contribution to HRA. Finally, after determining the weight of the main factors of OL, TE, and PE, the risk class of the nanomaterial production process, including Negligible (N), Minor (Mi), Major (Ma), and Critical (C), is determined using a fuzzy inference system.
Method
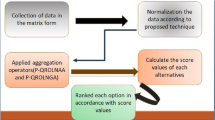
The overall framework for HRA using PFHRA is presented in Fig. 1. To obtain RM, two distinct procedures, namely the Mamdani-FIS and the PF-AHP are integrated into this proposed method. In this proposed method, factors in CB Nanotool were scored using Pythagorean fuzzy numbers, and then membership degrees of the main factors were used as input for FIS. This section, lists each technique employed in our proposed integrated method. Finally, a detailed description of the proposed integrated method is mentioned.

Framework of health risk assessment using PFHRA approach.
CB nanotool
The conventional CB Nanotool 2.0 technique, the most popular and effective among CBs, uses probability and severity parameters directly obtained from expert opinions to establish risk classes. Zalk et al. modified this tool and presented CB Nanotool 2.0 by lowering the severity scale's maximum points23. The risk level is obtained using a four by four matrix shown in Table 1. The severity of the impact on human health is determined by adding scores from 13 factors (Table 2). These factors relate to the physicochemical properties and toxic effects of the parent material or the nanomaterial under study. The results of the five factors (Table 3) are summed together to get the final probability score, which considers the worker's interactions with the engineered nanomaterials under study.
Analytical hierarchy process
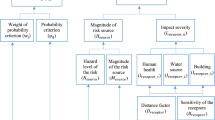
A hierarchy of factors is presented in Fig. 2 for the HRA of NMs. AHP can consider all the factors in a hierarchical framework for their orderly arrangement. This framework clarifies their relative weights concerning health hazards. Owing to the weighting of the factors in a hierarchy, the factors demanded by experts not considered in this study can also simply be added to such an HRA approach. The main factors affecting NM health risks are addressed at the second level. Based on the comparison, the sub-factors are located at the same level in the hierarchy. This approach reduces ambiguity and uncertainty in factors by transforming expert judgments' linguistic terms into fuzzy numbers.

Hierarchy to evaluate sub factors of parameter in terms of their contribution to the risk of NMs.
Preliminaries of the Pythagorean fuzzy sets
Atanassov developed intuitionistic fuzzy sets37, which numerous researchers use in various fields to overcome uncertainty. In these fuzzy sets, the degree of membership and non-membership should be less than 1. Therefore38, has been introduced to Pythagorean fuzzy sets. Pythagorean fuzzy sets are, under some conditions, the extension of intuitionistic fuzzy sets. Pythagorean fuzzy sets are now more capable and adaptable to solving uncertainty-related issues. While the sum of membership and non-membership degrees in Pythagorean fuzzy sets can exceed 1, the sum of squares cannot, unlike intuitionistic fuzzy sets. Definition (1) expresses the following situation16:
Definition 1
Envision X as a fixed set. A Pythagorean fuzzy set \(\widetilde{{\text{P}}}\) is an object with the properties of:
where the function \({\mu }_{\widetilde{p}}\left(x\right)\to \left[\mathrm{0,1}\right]\) defines the degree of membership and \({\vartheta }_{\widetilde{p}}\left(x\right)\to \left[\mathrm{0,1}\right]\) defines the degree of non-membership of the element \(x \in X to P\), respectively, and, for every \(x \in X\), it holds:
Here, also the degree of hesitancy condition is as follows:
Definition 2
Let \(\widetilde{{\text{A}}}=\langle {\upmu }_{1},{\mathrm{\vartheta }}_{1}\rangle ,\widetilde{{\text{B}}}=\langle {\upmu }_{1},{\mathrm{\vartheta }}_{1}\rangle \) be two PFNs, and λ > 0, then the operations on these two PFNs are defined as follows:
Definition 3
Let \(\widetilde{{\text{A}}}=\langle {\upmu }_{1},{\mathrm{\vartheta }}_{1}\rangle ,\mathrm{ i}=\left(\mathrm{1,2},\dots ,{\text{n}}\right)\) be a collection of PFNs and \({\text{w}}={\left({{\text{w}}}_{1},{{\text{w}}}_{2},\dots ,{{\text{w}}}_{{\text{n}}} \right)}^{{\text{T}}}\) be the weight vector \({\text{w}}={\left({{\text{w}}}_{1},{{\text{w}}}_{2},\dots ,{{\text{w}}}_{{\text{n}}} \right)}^{{\text{T}}}\) of \({\widetilde{{\text{A}}}}_{{\text{i}}},{\text{i}}=\left(\mathrm{1,2},\dots ,{\text{n}}\right)\) with \(\sum {w}_{i} = 1\), then the Pythagorean fuzzy weighted power geometric (PFWPG) operator is:
Pythagorean Fuzzy Analytical Hierarchy Process (PFAHP)
The PFAHP steps are explained in this subsection.
- Step 1.:
-
The pairwise comparison matrix \(R={\left({r}_{ik}\right)}_{m\times m}\) is constructed using the linguistic terms specified by experts and presented in Table 416.
Table 4 Linguistic terms and weighting scale for PF-AHP method (retrieved from16). - Step 2::
-
Using Eqs. (8) and (9) to calculate the differences matrix \({\text{D}}={\left({{\text{d}}}_{{\text{ik}}}\right)}_{{\text{m}}\times {\text{m}}}\) using the lower and upper values of the membership and non-membership functions:
$${{\text{d}}}_{{{\text{ik}}}_{{\text{U}}}}={\upmu }_{{{\text{ik}}}_{{\text{U}}}}^{2}-{\mathrm{\vartheta }}_{{{\text{ik}}}_{{\text{L}}}}^{2}$$(8)$${{\text{d}}}_{{{\text{ik}}}_{{\text{L}}}}={\upmu }_{{{\text{ik}}}_{{\text{L}}}}^{2}-{\mathrm{\vartheta }}_{{{\text{ik}}}_{{\text{U}}}}^{2}$$(9) - Step 3::
-
Using Eqs. (10) and (11) to determine the interval multiplicative matrix \(={\left({{\text{s}}}_{{\text{ik}}}\right)}_{{\text{m}}\times {\text{m}}}\) .
$${{{\text{S}}}_{{\text{ik}}}}_{{\text{l}}}=\sqrt{{1000}^{{{\text{d}}}_{{\text{l}}}}}$$(10)$${{{\text{S}}}_{{\text{ik}}}}_{{\text{u}}}=\sqrt{{1000}^{{{\text{d}}}_{{\text{u}}}}}$$(11) - Step 4::
-
Using Eq. (12) to calculate the determinacy value \(\uptau ={\left({\uptau }_{{\text{ik}}}\right)}_{{\text{m}}\times {\text{m}}}\) of the \({{\text{r}}}_{{\text{ik}}}\).
$${\uptau }_{{\text{ik}}}=1-\left({{{\upmu }_{{\text{ik}}}}_{{\text{u}}}}^{2}-{{{\upmu }_{{\text{ik}}}}_{{\text{L}}}}^{2}\right)-\left({{{\mathcal{V}}_{{\text{ik}}}}_{{\text{u}}}}^{2}-{{{\mathcal{V}}_{{\text{ik}}}}_{{\text{L}}}}^{2}\right)$$(12) - Step 5::
-
To obtain the weights matrix \(T={\left({\tau }_{ik}\right)}_{m\times m}\), before normalizing using Eq. (13), multiply the determinacy degrees with the \(S={\left({s}_{ik}\right)}_{m\times m}\) matrix.
$${t}_{ik}=\left(\frac{{{S}_{ik}}_{u}+ {{S}_{ik}}_{l}}{2}\right){\tau }_{ik}$$(13) - Step 6::
-
Using Eq. (14) to determine the priority weight \({\upomega }_{i}\).
$${\upomega }_{i}=\frac{{\sum }_{k=1}^{m}{t}_{ik}}{{\sum }_{i=1}^{m}{\sum }_{k=1}^{m}{t}_{ik}}$$(14)
Fuzzy Inference System (FIS)
Instead of putting several risk variables into one equation and depending on multiple assumptions to determine RM with "if…then…" rules, the fuzzy inference system allows expert judgment to be combined with causal factors. The Mamdani and Sugeno types of FIS have been used in various technical and scientific applications. One of the first and most well-known algorithms in the literature is the Mamdani fuzzy model. Mamdani FIS model as shown in Fig. 3 employed in this proposed method. The FIS consists of four phases: fuzzification, knowledge base, fuzzy inference system, and defuzzification.

Schematic of three main factors as crisp inputs, two outputs and two fuzzy rules in FIS by MATLAB software. OL occurrence likelihood, PE potential exposure, TE toxic effects.
Fuzzification
Fuzzification, the initial phase in the FIS process, converts crisp values into membership functions for linguistic terms of fuzzy sets. In other words, linguistic terms including very high (VH), high (H), medium (M), low (L), and very low (VL), are used to translate crisp input numbers. Membership degrees are entered into fuzzy If–Then rules.
Knowledge base
The knowledge base is comprised of a database and rule base. The database defines the membership functions of the fuzzy sets used to generate fuzzy rules and the fuzzy if–then rules create the rule base. Fuzzy "if–then" rules, called fuzzy conditional functions, define the relationships between input and output. The following are the general if–then rule structures for the Mamdani FIS:
Where \({A}_{in}\) and \({B}_{i}\) are linguistic terms for membership function of input variable (\({x}_{i}\)) and linguistic terms (\({x}_{i}\)) for output (z), respectively, in rth rule.
Fuzzy inference engine
The fuzzy inference unit creates a map from fuzzy inputs to fuzzy outputs based on fuzzy logic. It uses membership functions, logical operations, and if-then rules. This phase is the main section of a fuzzy system, which conducts the modeling process. It combines the facts obtained through the fuzzification phase with the rule base created in the previous phase. The Mamdani fuzzy model can be created using various fuzzy composition techniques. The most popular strategy, maximal composition, is applied in this essay. This method is described mathematically by Eq. (15).
where \({{\upmu }_{{\text{C}}}}_{{\text{r}}}\left({\text{Z}}\right)\) is membership of output (Z) for rth rule, \({{\upmu }_{{\text{A}}}}_{{\text{r}}}\) \(, {{\upmu }_{{\text{B}}}}_{{\text{r}}}\) are membership functions input “x” and “y”, respectively.
Defuzzification
Finally, the defuzzification process converts fuzzy sets into crisp values in Mamdani-FIS. Centroid of area (COA) is one of the most widely used defuzzification process. In Mamdani- FIS uses the defuzzification to convert fuzzy sets into crisp values. The COA technique benefit from all active rules participating in defuzzification process. Using Eq. (16), fuzzy sets in the COA approach are transformed into crisp values.
Step of proposed integrated method
- Step 1.:
-
Before the analytical phase, an expert group of occupational health engineers, workers, operators, and research engineers for NMs and ENP-based products should be established. In the first, this group should be gathering information regarding the nanoparticle effects of and their parent materials, the production of NPs products, NM characteristics, and potential release paths to the ambient workplace. Next, a worksheet that resembles Table 7 needs being prepared. The expert group, as referred to in step 2, fills the pairwise comparison matrix with linguistic terms by consensus. Steps 3 to 11 of the proposed approach must be carried out by a specialist in PFAHP and FIS techniques to estimate risk magnitude based on pairwise comparison by expert group.
- Step 2.:
-
Form a pairwise comparison matrix and compare factors pairwise. Each factor is compared with others at in the same level based on their relative contribution to parameters.
- Step 3.:
-
Convert Linguistic terms into IVPF by employing the scale shown in Table 4. Then, using PF-AHP, whose processes are thoroughly discussed in "Pythagorean Fuzzy Analytical Hierarchy Process (PFAHP)" section, computes the priority weight of each factor (\({\upomega }_{{\text{i}}}\)).
- Step 4.:
-
Determine priority weight of sub-factors in the hierarchy (\({\mathrm{\omega ^{\prime}}}_{{\text{i}}}\)). While \({\upomega }_{{\text{i}}}\) is the weight of sub-factors in its own level, \({\mathrm{\omega ^{\prime}}}_{{\text{i}}}\) which is given in Eq. (17), displays the weight of sub-factors in the hierarchy. \({\upomega }_{{\text{i}}}\) section indicates the priority weight of i. section that is above factors in the case of being t level above it39.
$${\mathrm{\omega^ {\prime}}}_{{\text{i}}}={\upomega }_{{\text{i}}} \times \prod_{{\text{i}}}^{{\text{t}}}{\upomega }_{{\text{i}}} \; \mathrm{ section}$$(17) - Step 5.:
-
Obtain normalized priority weight of sub-factors. Obtain normalized sub-factors weight by dividing \({\mathrm{\omega ^{\prime}}}_{{\text{i}}}\) with their maximum in the same level.
- Step 6.:
-
Calculate OL, PE and TE score. It is obtained from sum of all their normalized weight of sub-factors by Eq. (18). n indicates the number of their sub-factors in the hierarchy.
$$parameter \; score= \sum_{i}^{n}{{\omega }^{\prime}}_{i} \; criterions \; in \; its \; sub \; level \quad i=\mathrm{1,2},\dots ,n$$(18) - Step 7.:
-
Convert normalized parameter scores to membership degrees (MD). To use OL, PE and TE scores as inputs for the FIS, they should be transformed to Trapezoidal fuzzy sets using Fig. 5 and Fig. 6.
- Step 8.:
-
In order to achieve RM, take the minimum of membership degree of OL, PE and TE of a NPs production process to obtain \({X}_{ijk}\) values as in following Eq. (19).
$${X}_{ijk}=min\left({\mu }_{OL},{\mu }_{TE},{\mu }_{PE}\right)$$(19)where i, j, and k represent OL, PE and TE, respectively; \({\mu }_{OL},{\mu }_{TE},{\mu }_{PE}\) represent MD of OL, TE and PE of NPs, respectively.
- Step 9.:
-
Find the values of N, Mi, Ma, and C. As part of the defuzzification technique, take the maximum of the \({X}_{ijk}\) values using Eqs. (20)–(22) that are members of the same class is shown in Table 5.
Table 5 Rules of fuzzy inference system. $$N={\max}\left({x}_{ijk}\right) \forall {x}_{ijk}\epsilon N$$(20)$$Mi={\max}\left({x}_{ijk}\right) \forall {x}_{ijk}\epsilon Mi$$(21)$$Ma={\max}\left({x}_{ijk}\right) \forall {x}_{ijk}\epsilon Ma$$(22)$$C={\text{max}}\left({x}_{ijk}\right) \forall {x}_{ijk}\epsilon C$$ - Step 10.:
-
Determine RM. Defuzzify the N, Mi, Ma, and C values using Eq. (23) to obtain RM.
$$RM=\frac{1\times N+4\times Mi+7\times Ma+10\times C}{N+Mi+Ma+C}$$(23) - Step 11.:
-
Find the corresponding membership degrees (MD) of the NMs production process. Figure 6 is used to find the corresponding membership degrees of N, Mi, Ma, and C by RM. Finally, based on the risk class of the NMs production process, control approaches, including General ventilation, Fume hoods or local exhaust ventilation, containment and seek specialist advice is suggested for N, Mi, Ma and C class risk, respectively.
Results and discussions
The PFHRA method is applied to two case studies with two different NPs. Table 6 summarizes the overall results. CB Nanotool technique has already been introduced in “CB nanotool section”, which is then applied to case studies I and II. Their results are compared with the PFHRA method after the proposed method has been applied to assess health risks in case studies. Since information on NM production and data on OL, EP and TE parameters is still fairly limited for health risk, case studies with accessible data from the literature has been served to validate the proposed HRA method. The same assumptions as case Study I fuzzy conditional functions, define the relationships between apply to case Study II, the except that ZnONPs are produced. This manuscript does not present case Study II data due to space constraints. The scenario for case Study I involved making SiNPs into solid powder suspensions summarized in Table 7. First, the main factors at the first level are compared in pairs. Experts compare the sub-factors at the same level in pairs according to their contribution to health risk. The consistency ratios (CR) of the pairwise comparison matrices were less than 0.1, indicating the reliability of pairwise comparison by expert judgments based on the corresponding numerical values in the Classic AHP technique for the linguistic scale40. Table a.1–a.6 in Appendix A provide pairwise comparisons and the weights (ω) for the factors from a case study I (i.e., the main factor and sub-factors) besides their CR. Using the scale shown in Table 4, the linguistic values in these grids are transformed into IVPF numbers. PFAHP is applied to OL, TE and PE scores. The priority weight of sub-factors in the hierarchy is calculated by multiplying the weight by the weight of each factor above it. After finding the OL score, the sub-factor weights belonging to the OL factor are added together. TE and PE scores are calculated the same. OL, TE and PE scores for case study I are demonstrated in Figs. 4 and 5. Moreover, Figs. 4 and 5 are applied to determine OL, PE and TE membership degrees. After calculating N, Mi, Ma, and C values, defuzzification uses Eq. (22) to determine RM. As a result of FIS, the contribution of risk class and RM of the case studies is shown in Fig. 6.

Membership functions of OL and PE inputs with OL and PE score indicators for case study I. OL occurrence likelihood, PE potential exposure, VH very high, H high, M medium, L low, VL very low.

Membership functions of TE input with TE score indicator for case study I. TE toxic effects, VH very high, H high, M medium, L low, VL very low.

Membership functions of output with class risk indicators for case studies I and II. MD membership degree, RM risk magnitude, N negligible, Mi minor, Ma major, C critical.
The SiNPs production was estimated to cause minor (5%) and major (95%) occupational health concerns. In regard to ZnONPs production, it was minor (100%) (Table 6 and Fig. 6). Therefore, Manufacturing ZnoNPs and SiNPs require local exhaust ventilation and containment devices, respectively. While, using the CB Nanotool technique, were determined major and minor for a case study I and II, respectively. Compared to the CB Nanotool, the proposed method uses fuzzy sets to scale the RM and allows the results to report membership degrees for each risk class.
The main sub-factors of the TE, PE, and OL factors based on their weight are carcinogenicity (0.41), surface chemistry and shape features (0.37), and estimated amount (0.51), respectively. Among the factors related to SiNPs, the toxic effect (score = 5.3) is highly contributive to health risk because of its high carcinogenicity. The results of the health risk assessment of our proposed method involving ZNO and SiNP nanoparticles demonstrated that SiNP poses much more serious risk to occupational health than ZnO. In this regard, previous studies have confirmed that SiNPs manufacturing is more crucial than ZnONPs41,42. In addition, Numerous studies have demonstrated that the production process for SiNPs carries a high level of occupational health risk43,44. On the other hand, the risk of exposure to ZnO is regarded as low in numerous pieces of research on risk analysis45,46.
These results are demonstrated that our proposed method is reliable and informative. Since the risk assessment precedes risk management applications, risk magnitude must be properly addressed to decide what to do afterward. Therefore, the results provided by the proposed approach can facilitate decision-making related to risk management strategies. This proposed integrated method answers to essential questions regarding HRA for NMs. I) What is the significance of each factor for risk; II) What are the risk class and their membership degrees; and III) What risk management strategies should be employed?
Conclusion
Occupational health and safety require systematic analysis to protect employees from dangers that might be caused by nanomaterial exposure in the workplace. In this study, PFHRA, a combination of PF-AHP and FIS, is proposed and then PFHRA method applied for the HRA of ZnONPs and SiNPs. On the other hand, a comparison with CB Nanotool is conducted revealing that the proposed method provides reliable outcomes containing more information about uncertainty of decision makers. This should be very handy for risk managers to establish their strategies to reduce the risk.
In conclusion, the integrated approach of Pythagorean Fuzzy AHP and Fuzzy Inference System provides a more comprehensive and accurate assessment of health risks associated with the use of nanomaterials in manufacturing. The results of this study demonstrate the potential benefits of using this approach in occupational health risk assessments. However, the practical challenges and limitations of implementing this approach in real-world settings need to be addressed to ensure its successful adoption. Overall, this study highlights the importance of considering multiple factors and utilizing advanced techniques in occupational health risk assessments to protect the health and safety of workers in the manufacturing industry.
Strengths of the study
Health Risk Assessment of NMs in the workplace is crucial because NMs might be dispersed in the work environment. In this regards, the proposed method provides a comprehensive and systematic method for assessing the occupational health risks associated with the manufacturing of nanomaterials. The use of Pythagorean Fuzzy AHP allows for the consideration of uncertainty and imprecision in the decision-making process, while the Fuzzy Inference System enables the integration of multiple risk factors and their interactions. PFHRA method can be applied to assess risk of the different NMs production in laboratories and industrial workplaces. Output of the proposed approach suggests control strategy should be used for the workplace. The control strategy is ultimately realized based on risk class by this method.
This is important for risk management of work environment. Therefore, our proposed method can be used with high reliability and correctly to assess the risk of the workplace. This proposed method is used in all workplaces where nanomaterials are produced, such as laboratories, industrial for nanomaterial production, etc.
Moreover, the results of the present study can create a novel scientific perspective in the field of health risk assessment due to occupational exposure to nanomaterials.
Limitations of the study
Although the PFHRA method in this work provides several of the advantages listed above, there are still some limitations and a need for additional research in the following claims. However, further research is needed to validate the proposed approach using additional case studies and to refine the methodology based on feedback from industry experts. On the other hands, three parameters, OL, PE, and TE, were considered in this method to determine the RM. However, there are additional sub-factors for these parameters that are likely to influence the RM for NMs. In this regard, the study of Nina Elizabeth Landvik and et al. might be used47. In this manuscript, criteria for grouping NMs have been comprehensively introduced in order to facilitate hazard and risk assessment of NMs. They could be taken into account in the risk assessment for further study. To lessen uncertainty in HRA, more data (e.g., NMs data) must be collected, and another approach must be developed (e.g., incorporating dynamic techniques machine learning for example fuzzy neural network model). The expansion of the proposed approach with other fuzzy set types, such as neutrosophic sets, Fermatean fuzzy sets, circular intuitionistic fuzzy sets and Decomposed fuzzy sets. These viewpoints may be employed in future work for a more comprehensive quantitative and qualitative HRA for NMs.
While the Pythagorean Fuzzy AHP and Fuzzy Inference System offer a more comprehensive and accurate assessment of health risks associated with the use of nanomaterials in manufacturing, there may be practical challenges in implementing these methods in a workplace environment. For example, there may be limitations in data availability or accessibility, or challenges in communicating complex risk assessment results to decision-makers in the industry. Addressing these challenges and developing strategies to overcome them will be critical to ensuring the successful implementation and adoption of this integrated approach in real-world settings.
References
Ali, I. A. M., Ahmed, A. B. & Al-Ahmed, H. I. Green synthesis and characterization of silver nanoparticles for reducing the damage to sperm parameters in diabetic compared to metformin. Sci. Rep. 13, 2256 (2023).
Rauscher, H. et al. An overview of concepts and terms used in the European Commission’s definition of nanomaterial. (2019) https://doi.org/10.2760/459136.
Shatkin, J. A. et al. Nano risk analysis: Advancing the science for nanomaterials risk management. Risk Anal. 30, 1680–1687. https://doi.org/10.1111/j.1539-6924.2010.01493.x (2010).
Li, X. et al. Effects of physicochemical properties of nanomaterials on their toxicity. J. Biomed. Mater. Res. A 103, 2499–2507. https://doi.org/10.1002/jbm.a.35384 (2015).
Quadros, M. E. & Marr, L. C. Environmental and human health risks of aerosolized silver nanoparticles. J. Air Waste Manag. Assoc. 60, 770–781. https://doi.org/10.3155/1047-3289.60.7.770 (2010).
De Jong, W. H. & Borm, P. J. Drug delivery and nanoparticles: Applications and hazards. Int. J. Nanomedicine 3, 133. https://doi.org/10.2147/ijn.s596 (2008).
Drobne, D. Nanotoxicology for safe and sustainable nanotechnology. Arhiv za higijenu rada i toksikologiju 58, 471–478 (2007).
Fernández-Pampin, N. et al. Toxicology assessment of manganese oxide nanomaterials with enhanced electrochemical properties using human in vitro models representing different exposure routes. Sci. Rep. 12, 20991 (2022).
Vajhadin, F., Mazloum-Ardakani, M., Hemati, M. & Moshtaghioun, S. M. Facile preparation of a cost-effective platform based on ZnFe2O4 nanomaterials for electrochemical cell detection. Sci. Rep. 13, 4962 (2023).
Roller, M. In vitro genotoxicity data of nanomaterials compared to carcinogenic potency of inorganic substances after inhalational exposure. Mutat. Res./Rev. Mutat. Res. 727, 72–85 (2011).
Kuhlbusch, T. A., Wijnhoven, S. W. & Haase, A. Nanomaterial exposures for worker, consumer and the general public. NanoImpact 10, 11–25 (2018).
Pietroiusti, A. & Magrini, A. Engineered nanoparticles at the workplace: Current knowledge about workers’ risk. Occup. Med 64, 319–330. https://doi.org/10.1002/jbm.a.35384 (2014).
Ghafari, J., Moghadasi, N. & Shekaftik, S. O. Oxidative stress induced by occupational exposure to nanomaterials: A systematic review. Ind. Health 58, 492–502 (2020).
Starost, K., Sachse, S. & Njuguna, J. Measurement, testing, and characterization of airborne nanoparticles released from machining of nanoreinforced composites. In Health and Environmental Safety of Nanomaterials 99–127 (2021).
Omari Shekaftik, S. et al. Academic nanotechnology laboratories: Investigating good practices and students’ health status. J. Nanoparticle Res. 24, 177 (2022).
Ilbahar, E., Karaşan, A., Cebi, S. & Kahraman, C. A novel approach to risk assessment for occupational health and safety using Pythagorean fuzzy AHP & fuzzy inference system. Saf. Sci. 103, 124–136. https://doi.org/10.1016/j.ssci.2017.10.025 (2018).
Omari Shekaftik, S., Ashtarinezhad, A., Shirazi, F. H., Hosseini, A. & Yarahmadi, R. Assessing the risk of main activities of nanotechnology companies by the NanoTool method. Int. J. Occup. Saf. Ergon. 27, 1145–1153 (2021).
Omari Shekaftik, S., Moghadasi, N. & Nasirzadeh, N. National (Iranian) and global use of control banding-based methods for assessing the risks of activities involved with nanomaterials: A comparative review. J. Nanoparticle Res. 25, 145 (2023).
Leso, V., Fontana, L., Chiara Mauriello, M. & Iavicoli, I. Occupational risk assessment of engineered nanomaterials: Limits, challenges and opportunities. Curr. Nanosci. 13, 55–78. https://doi.org/10.2174/1573413712666161017114934 (2017).
Grieger, K. et al. Best practices from nano-risk analysis relevant for other emerging technologies. Nat. Nanotechnol 14, 998–1001. https://doi.org/10.1038/s41565-019-0572-1 (2019).
Ahmadi Kanrash, F. et al. Comparative risk assessment of tasks involved with nanomaterials using nanotool & guidance methods. J. Chem. Health Risks 12, 371–378 (2022).
Omari Shekaftik, S. et al. Investigation of recommended good practices to reduce exposure to nanomaterials in nanotechnology laboratories in Tehran, Iran. J. Nanoparticle Res. 22, 1–8 (2020).
Zalk, D. M., Paik, S. Y. & Swuste, P. Evaluating the control banding nanotool: A qualitative risk assessment method for controlling nanoparticle exposures. J. Nanoparticle Res. 11, 1685–1704 (2009).
Möller, B. & Beer, M. Engineering computation under uncertainty–capabilities of non-traditional models. Comput. Struct. 86, 1024–1041. https://doi.org/10.1016/j.compstruc.2007.05.041 (2008).
Yazdi, M., Kabir, S. & Walker, M. Uncertainty handling in fault tree based risk assessment: State of the art and future perspectives. Process Saf. Environ. Prot. 131, 89–104. https://doi.org/10.1016/j.psep.2019.09.003 (2019).
Shi, L., Shuai, J. & Xu, K. Fuzzy fault tree assessment based on improved AHP for fire and explosion accidents for steel oil storage tanks. J. Hazard. Mater. 278, 529–538. https://doi.org/10.1016/j.jhazmat.2014.06.034 (2014).
Nasirzadeh, N., Golbabaei, F. & Shekaftik, S. O. Laboratory activities involving nanomaterials: Risk assessment and investigating researchers symptoms. Nanoscale 15, 2674–2689 (2023).
Cinar, U. & Cebi, S. A hybrid risk assessment method for mining sector based on QFD, fuzzy inference system, and AHP. J. Intell. Fuzzy Syst. 39, 6047–6058 (2020).
Khan, O. et al. Experimental investigation and multi-performance optimization of the leachate recirculation based sustainable landfills using Taguchi approach and an integrated MCDM method. Sci. Rep. 13, 19102 (2023).
Kim, M.-S., Lee, E.-B., Jung, I.-H. & Alleman, D. Risk assessment and mitigation model for overseas steel-plant project investment with analytic hierarchy process—fuzzy inference system. Sustainability 10, 4780. https://doi.org/10.3390/su10124780 (2018).
Omair, M. et al. The selection of the sustainable suppliers by the development of a decision support framework based on analytical hierarchical process and fuzzy inference system. Int. J. Fuzzy Syst. 23, 1986–2003. https://doi.org/10.1007/s40815-021-01073-2 (2021).
Yang, M., Khan, F. I. & Sadiq, R. Prioritization of environmental issues in offshore oil and gas operations: A hybrid approach using fuzzy inference system and fuzzy analytic hierarchy process. Process Saf. Environ. Prot. 89, 22–34. https://doi.org/10.1016/j.psep.2010.08.006 (2011).
Bon, A. T. & Utami, S. F. An analytical hierarchy process and fuzzy inference system tsukamoto for production planning: A review and conceptual research. Bus. Manag. Rev. 5, 101. (2014).
Topuz, E. & van Gestel, C. A. An approach for environmental risk assessment of engineered nanomaterials using Analytical Hierarchy Process (AHP) and fuzzy inference rules. Environ. Int. 92, 334–347. https://doi.org/10.1016/j.envint.2016.04.022 (2016).
Ramirez Garrido, R., Martí Gregorio, V. & Darbra Roman, R. M. Environmental risk assessment of silver nanoparticles in 2 aquatic ecosystems using fuzzy logic. Water 2022, 14 (1885).
Ramirez, R., Martí, V. & Darbra, R. M. Environmental risk assessment of silver nanoparticles in aquatic ecosystems using fuzzy logic. Water 2022, 14 (1885).
Atanassov, K. Review and new results on intuitionistic fuzzy sets. presented in part at the mathematical foundations of artificial intelligence, Sofia (1988).
Yager, R. R. (2013) https://doi.org/10.1109/IFSA-NAFIPS.2013.6608375.
Topuz, E., Talinli, I. & Aydin, E. Integration of environmental and human health risk assessment for industries using hazardous materials: A quantitative multi criteria approach for environmental decision makers. Environ. Int. 37, 393–403 (2011).
Kabir, G. & Hasin, M. A. A. Comparative analysis of AHP and fuzzy AHP models for multicriteria inventory classification. Int. J. Fuzzy Syst. 1, 1–16 (2011).
Saifi, M. A., Khurana, A. & Godugu, C. Nanomaterials in Chromatography 437–465 (Elsevier, 2018). https://doi.org/10.1016/B978-0-12-812792-6.00017-0.
Forest, V. Combined effects of nanoparticles and other environmental contaminants on human health—an issue often overlooked. NanoImpact 23, 100344. https://doi.org/10.1016/j.impact.2021.100344 (2021).
Li, L. et al. Genotoxicity evaluation of silica nanoparticles in murine: A systematic review and meta-analysis. Toxicol. Mech. Methods 32, 1–17 (2022).
Malpani, S. K. & Goyal, D. Synthesis, analysis, and multi-faceted applications of solid wastes-derived silica nanoparticles: A comprehensive review (2010–2022). Environ. Sci. Pollut. Res. https://doi.org/10.1007/s11356-022-23873-1 (2022).
Kim, K.-B. et al. Risk assessment of zinc oxide, a cosmetic ingredient used as a UV filter of sunscreens. J. Toxicol. Environ. Health B Crit. Rev. 20, 155–182. https://doi.org/10.1080/10937404.2017.1290516 (2017).
Schneider, S. L. & Lim, H. W. A review of inorganic UV filters zinc oxide and titanium dioxide. Photodermatol. Photoimmunol. Photomed. 35, 442–446. https://doi.org/10.1111/phpp.12439 (2019).
Landvik, N. E., Skaug, V., Mohr, B., Verbeek, J. & Zienolddiny, S. Criteria for grouping of manufactured nanomaterials to facilitate hazard and risk assessment, a systematic review of expert opinions. Regul. Toxicol. Pharmacol. 95, 270–279. https://doi.org/10.1016/j.yrtph.2018.03.027 (2018).
Mohammadi, P., Abbasinia, M., Assari, M. J. & Oliaei, M. The toxicology of silica nanoparticles: A review. Toxicol. Environ. Chem. 100, 285–316. https://doi.org/10.1080/02772248.2018.1485921 (2018).
Liu, L. & Kong, L. Research progress on the carcinogenicity of metal nanomaterials. J. Appl. Toxicol. 41, 1334–1344. https://doi.org/10.1002/jat.4145 (2021).
Shin, J. H. et al. Subacute inhalation toxicity study of synthetic amorphous silica nanoparticles in Sprague–Dawley rats. Inhal. Toxicol. 29, 567–576. https://doi.org/10.1080/08958378.2018.1426661 (2017).
Acknowledgements
The authors express their gratitude to Tehran University of Medical Sciences due to financial supports.
Author information
Authors and Affiliations
Contributions
S.S.: performed the experiments; Contributed reagents, materials, analysis tools or data; Wrote the paper. M.S.-Y.: analyzed and interpreted the data. F.G.: conceived and designed the experiments; wrote the paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Salari, S., Sadeghi-Yarandi, M. & Golbabaei, F. An integrated approach to occupational health risk assessment of manufacturing nanomaterials using Pythagorean Fuzzy AHP and Fuzzy Inference System. Sci Rep 14, 180 (2024). https://doi.org/10.1038/s41598-023-48885-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-48885-w
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
