
Abstract
Failure mode and effects analysis (FMEA) has been widely used for potential risk modeling and management. Expert evaluation is used to model the risk priority number to determine the risk level of different failure modes. Dempster–Shafer (D–S) evidence theory is an effective method for uncertain information modeling and has been adopted to address the uncertainty in FMEA. How to deal with conflicting evidence from different experts is an open issue. At the same time, different professional backgrounds of experts may lead to different weights in modeling the evaluation. How to model the relative weight of an expert is an important problem. We propose an improved risk analysis method based on triangular fuzzy numbers, the negation of basic probability assignment (BPA) and the evidence distance in the frame of D–S evidence theory. First, we summarize and organize the expert’s risk analysis results. Then, we model the expert’s assessments based on the triangular fuzzy numbers as BPAs and calculate the negation of BPAs. Third, we model the weight of expert based on the evidence distance in the evidence theory. Finally, the Murphy’s combination rule is used to fuse the risk assessment results of different experts and calculate the new risk priority number (RPN). At the end of this paper, we apply the proposed method to analyze seventeen failure modes of aircraft turbine blades. The experimental results verify the rationality and effectiveness of this method.
Similar content being viewed by others

Introduction
Failure Mode and Effects Analysis (FMEA) was first proposed by NASA in 1960s. It is a tool of risk analysis and management, which aims at allocating limited resources to the projects with the highest risk1,2,3,4,5. FMEA can improve the quality, safety and reliability of the products. Due to its remarkable advantages, FMEA has been widely used in various fields, such as steel production6,7, fishing boat propulsion system8, sewage treatment9 and so on10,11. The most commonly used tool for FMEA is the risk priority number (RPN), which is expressed as the product of occurrence (O), severity (S) and detection(D). Although FMEA has significant advantages12, as the assessment system becomes more and more complex, the results of the assessment are subject to great uncertainty, which greatly influences the final risk analysis. Firstly, different risk factors will produce the same RPN value. For example, (O: 9, S: 2, D: 5) and (O:2, S:9, D:5), the final RPN value is same, but the occurrence and severity of the two are quite different. Secondly, traditional risk priority number treats O, S and D as equally crucial, but in fact their weights may vary. Finally, the rating of each risk factor is rated as [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], so that the final RPN value will be between 1 and 1000, but not all the numbers between them can represent RPN values, in fact, there are only 120 discrete values13,14. When we do FMEA, we need to deal with uncertain information. At present, there are many methods to study uncertain information, such as fuzzy set theory15,16,17,18, D numbers theory19, Dempster–Shafer (D–S) evidence theory20,21, grey theory22,23, analytic hierarchy process24,25 and so on. Because D–S evidence theory has significant advantages in dealing with uncertain information and independent evidence fusion, Ma et al.26 applied D–S evidence theory to the gender analysis. In addition, Liu et al.27 applied D–S evidence theory to supplier selection, Perez et al.28 applied D–S evidence theory to 3D human motion recognition. In this study, we also choose D–S evidence theory as our research method to figure out uncertain information.
Motivations
-
In application of D–S evidence theory, how to generate basic probability assignment (BPA) is an open issue. For FMEA, we propose a novel method of generating BPAs for modeling the risk priority number in this paper.
Quite a few scholars have put forward their own solutions to this problem. Jiang et al. proposed using fuzzy set theory to solve evidence conflict29, Su et al. used Gaussian function to construct BPAs30. Tang et al. used triangular distribution to construct BPAs for incomplete and uncertain information31. Mendonca et al. used game theory to solve data conflicts32. The base BPAs is an option in generating BPAs considering potential conflict information33. In this paper, we firstly construct BPAs through triangular fuzzy numbers to reduce the evidence conflict, and then consult the negation34,35 of BPAs to study the uncertainty of uncertain information from another angle.
-
Due to the different professional backgrounds of different experts, the assessment weight of each risk factor for the same failure mode may be different.
As an important reference in the field, expert knowledge plays a vital role in FMEA36. However, the evaluation of each failure mode by experts is based on their own subjective evaluation, which aggravates the uncertainty and ambiguity of the evaluation results37. Based on this consideration, we calculate expert weight by the evidence distance38,39, and finally fuse the evidence with expert weight. Other solutions for conflict data fusion can be belief entropy-based methods40,41.
Contributions
Compared with a large number of FMEA methods, the main contributions of the method proposed in this paper are as follows:
-
To reduce the evidence conflict, we introduce triangular fuzzy numbers to construct BPAs. In fact, different scholars have proposed many methods to reduce the evidence conflict. Bi et al.42 proposed a method to reduce the evidence conflict based on Tanimoto measure. Miao et al.43 achieved the goal of reducing the evidence conflict by modifying the D–S combination rule. Hu et al.44 used feature fusion method to solve this problem. Generally speaking, there are two main methods to reduce evidence conflict. One is to modify the preliminary test information, and the other is to modify the combination rule. Our research integrates these two methods. And then the idea of construct the negation45,46 is firstly applied to the failure mode and effects analysis.
-
The evidence distance is used to calculate the weight of the experts participating in the risk assessment, which reduces the uncertainty and ambiguity of the assessment results caused by the subjectivity of the expert assessment. As a matter of fact, there are many ways to get the weight of experts, including Deng entropy47, AMWRPN48, Ambiguity Measure49 and so on50,51,52. These methods show good characteristics in some attributes. Compared with these methods, the evidence distance can accurately calculate the distance between two bodies of evidence, so as to provide a reliable guarantee for calculating similarity, which is why we choose evidence distance to calculate expert weight.
Organization
In this paper, the rest of the content is arranged as follow. In “Basic concepts” section, we briefly reviewed the basic concepts. “Improved method based on the negation of basic probability assignment and the evidence distance” section proposed the new FMEA method. “Application” section provided the application of the proposed method. “Discussion” section discussed the experimental results. “Conclusions” section made the conclusion of the whole paper.
Basic concepts
In this part, we introduce some basic concepts, including D–S evidence theory, the negation of BPA, Murphy combination rule, the evidence distance, triangular fuzzy numbers and risk priority number(RPN).
Dempster–Shafer evidence theory20,21
Definition 1
Frame of discernment \(\Theta \) is defined as a non-empty set \(\Theta =\left\{ \theta _{1}, \theta _{2}, \ldots , \theta _{i}, \ldots , \theta _{m}\right\} \) , it contains m mutually exclusive events. The power set \(\theta \) of the frame of discernment contains \(2^{m}\) elements, it is shown as follows:
Definition 2
Within the frame of discernment, the basic evidence function is defined to represent uncertain information, mass function m is the mapping of set \(2^\Theta \) on [0, 1], the mapping satisfies the following relationship:
m(A) is the mass function value of proposition subset A, also known as Basic Probability Assignment (BPA), the sum of all mass functions is 1. We call A fatal element if m(A)>0.
Definition 3
Under the framework of evidence theory, two groups of independent mass functions \(m_{1},m_{2}\) can be fused by the following Dempster’s combination rule53,54:
We call k the conflict coefficient.
Definition 4
For n groups of independent mass functions \(m_{1},m_{2}...m_{n}(n>2)\), Murphy calculates the average of n groups of mass as \(m_{avg}\), then iterate (n-1) times to get the new mass function. Murphy combination rule is defined as follows:
where \(F_{DS}\) represents the Dempster’s combination rule.
The negation of BPAs55,56
Definition 5
In the evidence theory,Yagar proposed a concept of negation for probability distribution. The main ideas are as follows:
where n is the amount of fatal element, and \({{\bar{m}}_{i}}\) satisfies:
Evidence distance57
Definition 6
In order to measure the similarity between evidences, we use the distance function. In the frame of discernment \(\Theta \) where has N elements, the evidence distance between two bodies of evidence(\(m_{1}\),\(m_{2}\)) can be defined as:
where \({\underline{D}} \) is a matrix that has \({2^N}\) rows and \({2^N}\) columns. The elements in the matrix are:
Triangular fuzzy numbers58,59
In the fuzzy set theory, the probability that the element x belongs to a set A can be represented by a value \(f_{A}(x)\) in the interval [0, 1], the membership function \(f_{A}(x)\in [0,1]\).
Definition 7
Let X be the domain of discourse, set \(A=\left\{ \left( x, f_{A}(x) \mid x \in X\right\} \right. \), the generalized fuzzy number is a fuzzy set defined on the real number, it can be expressed as \({\tilde{A}}=\left( a_{1}, a_{2}, a_{3}, a_{4} ; \omega \right) \) , of which \(0 \le \omega \le 1\) , \(a_{1}, a_{2}, a_{3}, a_{4}\) are real numbers. If the membership function of fuzzy number \({\tilde{A}}\) can be expressed as
then, fuzzy numbers \({\tilde{A}}\) is called triangular fuzzy numbers.
Risk priority number (RPN)
FMEA method is used for risk analysis based on the RPN number. RPN is expressed as the product of three risk factors: occurrence (O), severity (S) and detection (D).
Definition 8
RPN is defined as follows:
Generally speaking, for each failure mode item, the risk level of each risk factor is divided into ten grades. The rating standard of occurrence, severity and detection can be found in60.
Improved method based on the negation of basic probability assignment and the evidence distance
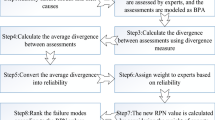
The flow chart of the improved FMEA method based on triangular fuzzy numbers, the negation of BPAs and the evidence distance in D–S evidence theory is shown in Fig. 1.

Flow chart of improved FMEA method based on triangular fuzzy numbers, the negation of BPAs and the evidence distance.
Step 1: Simplify the frame of discernment. Suppose there are J experts in an FMEA, and N failure modes: \(E_{1}, \ldots E_{J}; FM_{1}, \ldots FM_{N}\). In this case, the frame of discernment of the ith risk factor of the nth failure mode can be written as follows:
Obviously, we can observe that the number of recognition frames is 3N. Because the evaluation of the ith risk factor by different experts on the nth failure mode is not very different, in practical applications, the frame of discernment can be simplified into the following form:
Among them, \(\left. \min X\right| _{X \subseteq \Theta _{i}^{n}} \) represents the lowest level of evaluation by L experts on the ith risk factor of the nth failure mode. And, the following constraints are also satisfied:
Step 2: Construct BPAs using triangular fuzzy numbers. In this step, in order to solve the conflict of combined evidence, we use triangular fuzzy numbers to construct more flexible BPAs, and fully consider the uncertainty of experts in evaluation. Since the evaluation of risk factor i by different experts on the nth failure mode is not very different, we can select two adjacent setting values to construct the BPAs function. An illustration of constructing new BPAs with triangular fuzzy numbers is shown in Fig. 2.

Construct new BPAs with triangular fuzzy numbers.
Based on the above discussion, we construct a trigonometric fuzzy number that fits this description well. In this example, we define \(\omega =2 / 3, a_{2}- a_{1}= 1, a_{4}- a_{3}= 2\). There are two reasons: (1) The triangular fuzzy numbers cover the two adjacent tuning values, and the corresponding function value of the other tuning values is 0. (2) The sum of these two adjacent setting values is 1, which conforms to the basic definition of mass function.
Suppose we use X to represent the single possible rating of the ith risk coefficient of the nth failure mode, the new BPAs will be expressed in the following form:
where the frame of discernment can be expressed as \(\left[ \left. \min X\right| _{X \subseteq \theta _{i}^{n}},\left. \max X\right| _{X \subseteq \theta _{i}^{n}}+1\right] \).
Example 1
Suppose that the severity(S) results of two experts(\(E_1, E_2\)) for nth failure mode are \(m_{S1}^{n}=1\) and \(m_{S2}^{n}(4)=1\) respectively, using Eq. (5) we can get the conflict coefficient \(k=1\). But judging from our experience, level 3 and level 4 are not completely in conflict. Then using triangular fuzzy numbers we can get new BPAs:
Using Eq. (5) again, we can get \(k=0.78\). Obviously, the use of triangular fuzzy numbers can effectively reduce the evidence conflict.
Step 3: Calculate the negation of BPAs. In order to study the probability distribution from another point of view, we use the method of finding the negation of mass function. For these new BPAs that constructed with triangular fuzzy numbers, using Eq. (8) to calculate the negation of them.
Step 4: Calculate the evidence distance. Murphy combination rule is just a simple averaging process for BPAs, the difference between information is not considered. In our modified combination rule, we use the evidence distance to calculate weight when combining different evidences. In this step, we need to get the evidence distance between experts. Then, use these distances, we construct a distance matrix. For 3 experts, the distance matrix of ith risk factor and nth failure mode can be defined as follows:
Step 5: Find out the support degree and credibility between the evidences.
Definition 9
Because we have performed the inverse operation on BPAs, the greater the evidence distance, the smaller the similarity. Similarity represents the degree of similarity between two bodies of evidence, the similarity matrix is defined as follows:
Definition 10
The degree of support reflects the extent to which a certain body of evidence is supported by other bodies of evidence. The following equtaion shows the extent to which the ith body of evidence is supported by other bodies of evidence.
In the end, we normalize the degree of support and call it credibility.
Definition 11
The purpose of normalization is to make the final result more accurate. The calculation method is as follows:
Step 6: Use the modified combination rule to fuse the evidence. Using credibility as weight to average BPAs. For proposition subset A, we can get
where A represents the rating standard and the value range of A is from 1 to 10. Then, after two rounds of iterations using Murphy combination rules, we can get the fused BPA value(\({\tilde{m}}_i^n(A)\)).
Step 7: Get the new RPN value based on the improved method. RPN is a discrete random variable. In the nth failure mode, it is assumed that RPN has several different levels, each of which corresponds to different probabilities. The mean value of RPN can be used to compare the overall risk of each failure mode. The specific definition is as follows:
Application
This section adopts a structure similar to literature60.
In the FMEA for aircraft compressor rotor blades, according to literature60, the evaluation results of the O risk factors of the first failure mode by three experts are as follows: \(O_{1}(3, 40\%; 4, 60\%), O_{2}(3, 90\%; 4, 10\%), O_{3}(3, 80\%; 4, 20\%)\). This means that “the operation of the system can continue, but the performance of the system or product will be affected.”
Firstly, for the risk factor O of the first failure mode in60, the frame of discernment of risk level can be simplified as:
According to Eq. (4), the new BPAs constructed from the data in literature60 is shown in Table 1. As for the risk factor O of the first failure mode, the results are shown in Table 2. By using Eq. (8), we can get the negation of the BPAs. The results are shown in Table 3.
Then, we start to calculate the evidence distance between 3 experts. By using Eqs. (11) and (12), we get the evidence distance. Next we construct the distance matrix using Eq. (19):
The smaller the distance between the two evidences, the higher their similarity. By using Eq. (20) we get the similarity matrix between 3 experts:
The support degree reflects the degree of mutual support between evidence. We get the support degree by using the similarity matrix and Eq. (21), the results are shown in Table 4. Then we use the Eq. (22) to normalize the results to get the credibility, as shown in the Table 5. The more evidence is supported by other evidence, the more credible the evidence is.
Then, we use credibility as the weight of BPAs to calculate the \({\tilde{m}}_O^1\). The specific calculation process of \(m_O^1(3)\) is shown as follows:
Next we use Murphy combination rule to get the final mass function, as shown in Table 6. Use Eq. (24) to get the average value of O risk factor. The specific calculation process is shown as follows:
In the same way, we can find out the average value of S and D risk factor. We put the results in Table 7.
Finally, we can get the improved RPN value:
Discussion
After the same calculation process for 17 failure modes, using Eq. (25) we get the RPN value of each failure mode. The results (\(RPN_{avg}\)) are listed in the Table 8, as well as the results of some other methods. AMWRPN48 uses the method of Ambiguity Measurement to calculate the weight of experts. MVRPN60 averages the obtained RPN values. Improved MVRPN30 further improves the combination rule of MVRPN60. As described in the literature, \(FM1 \thicksim FM8\) describe the failure mode of compressor rotor blades and \(FM9 \thicksim FM17\) describe the failure mode of turbo rotor blades. Experimental results show that, for compressor rotor blades: \(FM2\succ FM6\succ FM1\succ FM3\succ FM7\succ FM8\succ FM4\succ FM5\), for turbo rotor blades: \(FM9 \succ FM10\succ FM14\succ FM12\succ FM11\succ FM13\succ FM15\succ FM17 \succ FM16\), \(\succ \) indicates that the previous item has a higher priority. For compressor rotor blades and turbo rotor blades respectively, FM2 and FM9 have the highest priority, indicates that more resources should be allocated to it. In Fig. 3, we can know that our ranking result is nearly the same with others. In Fig. 4, we can find that the results calculated by different methods are slightly different, but this is acceptable. Because the calculation results of several groups in \(FM9-FM17\) are very close, this brings some impact to our sorting results. The experimental results verify the rationality of our method.

The ranking result of FM1–FM8.

The ranking result of FM9–FM17.
Conclusions
In the frame of D–S evidence theory, this paper proposes an improved failure mode and effects analysis method based on triangular fuzzy numbers, negation of BPAs and evidence distance. Firstly, the new BPAs was constructed by fuzzy modeling of expert evaluation results, then calculate the negation of BPAs, next BPAs weight was calculated by evidence distance, and finally, a new RPN value was calculated by fusion of Murphy combination rule. In short, the method considers how to fuse conflicting evidence from experts and also considers the relative weight inconsistency caused by the uncertainty of experts’ evaluation. We apply the proposed method to the failure mode analysis of compressor rotor blades and turbo rotor blades. The experimental results verify the effectiveness and rationality of this method. In the future research, we can broaden our approach to other fields. Moreover, we can consider the relative importance of each risk factor to enrich our study.
Data availability
All data generated or analysed during this study are included in this published article.
References
Liu, H.-C., Wang, L.-E., Li, Z. W. & Yu-Ping, H. Improving risk evaluation in FMEA with cloud model and hierarchical Topsis method. IEEE Trans. Fuzzy Syst. 27(1), 84–95 (2018).
Huang, J., Liu, H.-C., Duan, C.-Y. & Song, M.-S. An improved reliability model for FMEA using probabilistic linguistic term sets and Todim method. Ann. Oper. Res. 1–24, 2019 (2019).
Liu, H.-C., Chen, X.-Q., Duan, C.-Y. & Wang, Y.-M. Failure mode and effect analysis using multi-criteria decision making methods: A systematic literature review. Comput. Ind. Eng. 135, 881–897 (2019).
Huang, J., You, J. X., Liu, H. C. & Song, M. S. Failure mode and effect analysis improvement: A systematic literature review and future research agenda. Reliab. Eng. Syst. Saf. 199, 106885 (2020).
Tang, M. & Liao, H. Failure mode and effect analysis considering the fairness-oriented consensus of a large group with core-periphery structure. Reliab. Eng. Syst. Saf. 215, 107821 (2021).
Kang, J., Sun, L., Sun, H. & Chunlin, W. Risk assessment of floating offshore wind turbine based on correlation-FMEA. Ocean Eng. 129, 382–388 (2017).
Shaker, F., Shahin, A., & Jahanyan, S. Developing a two-phase QFD for improving FMEA: An integrative approach. Int. J. Quality Reliab. Manag. (2019).
Certa, A., Hopps, F., Inghilleri, R. & Fata, C. M. L. A Dempster–Shafer theory-based approach to the failure mode, effects and criticality analysis (FMECA) under epistemic uncertainty: Application to the propulsion system of a fishing vessel. Reliab. Eng. Syst. Saf. 159, 69–79 (2017).
Nie, R., Tian, Z., Wang, X., Wang, J. & Wang, T. Risk evaluation by FMEA of supercritical water gasification system using multi-granular linguistic distribution assessment. Knowl. Based Syst. 162, 185–201 (2018).
Chi, C.-F., Sigmund, D. & Astardi, M. O. Classification scheme for root cause and failure modes and effects analysis (FMEA) of passenger vehicle recalls. Reliab. Eng. Syst. Saf. 200, 106929 (2020).
Dongdong, W. & Tang, Y. An improved failure mode and effects analysis method based on uncertainty measure in the evidence theory. Qual. Reliab. Eng. Int. 36(5), 1786–1807 (2020).
Selim, H., Yunusoglu, M. G., Şebnem, C. & Balaman, Y. A dynamic maintenance planning framework based on fuzzy Topsis and FMEA: Application in an international food company. Quality Reliab. Eng. Int. 32(3), 795–804 (2016).
Wang, Y.-M., Chin, K.-S., Poon, G. K. K. & Yang, J.-B. Risk evaluation in failure mode and effects analysis using fuzzy weighted geometric mean. Expert Syst. Appl. 36(2), 1195–1207 (2009).
Liu, H.-C., Liu, L. & Liu, N. Risk evaluation approaches in failure mode and effects analysis: A literature review. Expert Syst. Appl. 40(2), 828–838 (2013).
Chanamool, N. & Naenna, T. Fuzzy FMEA application to improve decision-making process in an emergency department. Appl. Soft Comput. 43, 441–453 (2016).
Liang, W., Liu, J., Wang, J. & Zhuang, Y. Pricing for a basket of LCDS under fuzzy environments. Springerplus 5(1), 1–12 (2016).
Kang, B., Chhipi-Shrestha, G., Deng, Y., Hewage, K. & Sadiq, R. Stable strategies analysis based on the utility of z-number in the evolutionary games. Appl. Math. Comput. 324, 202–217 (2018).
Zheng, H., Deng, Y. & Yong, H. Fuzzy evidential influence diagram and its evaluation algorithm. Knowl. Based Syst. 131, 28–45 (2017).
Zhou, X., Deng, X., Deng, Y. & Mahadevan, S. Dependence assessment in human reliability analysis based on d numbers and ahp. Nucl. Eng. Des. 313, 243–252 (2017).
Dempster, A. P. Upper and lower probabilities induced by a multi-valued mapping. Ann. Math. Stat. 38(2), 325–339 (1967).
Shafer, G. A Mathematical Theory of Evidence (Princeton University Press, Princeton, 1976).
Yang, C.-C. & B.-S. Chen. Supplier selection using combined analytical hierarchy process and grey relational analysis. J. Manuf. Technol. Manag. (2006).
Pitchipoo, P., Venkumar, P. & Rajakarunakaran, S. Grey decision model for supplier evaluation and selection in process industry: A comparative perspective. Int. J. Adv. Manuf. Technol. 76(9–12), 2059–2069 (2015).
Deng, X. & Deng, Y. D-AHP method with different credibility of information. Soft. Comput. 23(2), 683–691 (2019).
Zhou, X., Hu, Y., Deng, Y., Chan, F. T. S. & Ishizaka, A. A dematel-based completion method for incomplete pairwise comparison matrix in AHP. Ann. Oper. Res. 271(2), 1045–1066 (2018).
Ma, J., Liu, W., Miller, P. & Zhou, H. An evidential fusion approach for gender profiling. Inf. Sci. 333, 10–20 (2016).
Liu, T., Deng, Y. & Chan, F. Evidential supplier selection based on dematel and game theory. Int. J. Fuzzy Syst. 20(4), 1321–1333 (2018).
Perez, A., Tabia, H., Declercq, D. & Zanotti, A. Using the conflict in Dempster–Shafer evidence theory as a rejection criterion in classifier output combination for 3d human action recognition. Image Vis. Comput. 55, 149–157 (2016).
Jiang, W., Xie, C., Zhuang, M. & Tang, Y. Failure mode and effects analysis based on a novel fuzzy evidential method. Appl. Soft Comput. 57, 672–683 (2017).
Xiaoyan, S., Deng, Y., Mahadevan, S. & Bao, Q. An improved method for risk evaluation in failure modes and effects analysis of aircraft engine rotor blades. Eng. Fail. Anal. 26, 164–174 (2012).
Tang, Y., Wu, D. & Liu, Z. A new approach for generation of generalized basic probability assignment in the evidence theory. Pattern Anal Appl. 24(3), 1007–23 (2021).
Mendonca, D., Beroggi, G. E. G., Van Gent, D. & Wallace, W. A. Designing gaming simulations for the assessment of group decision support systems in emergency response. Saf. Sci. 44(6), 523–535 (2006).
Jing, M. & Tang, Y. A new base basic probability assignment approach for conflict data fusion in the evidence theory. Appl. Intell. 51(2), 1056–1068 (2021).
Yager, R. R. On the maximum entropy negation of a probability distribution. IEEE Trans. Fuzzy Syst. 23(5), 1899–1902 (2014).
Yin, L., Deng, X. & Deng, Y. The negation of a basic probability assignment. IEEE Trans. Fuzzy Syst. 27(1), 135–143 (2018).
Peeters, J. F. W., Basten, R. J. I. & Tinga, T. Improving failure analysis efficiency by combining FTA and FMEA in a recursive manner. Reliab. Eng. Syst. Saf. 172, 36–44 (2018).
Zheng, H. & Tang, Y. Deng entropy weighted risk priority number model for failure mode and effects analysis. Entropy 22(3), 280 (2020).
Mo, H., Xi, L. & Deng, Y. A generalized evidence distance. J. Syst. Eng. Electron. 27(2), 470–476 (2016).
Dong, Y., Zhang, J., Li, Z., Yong, H. & Deng, Y. Combination of evidential sensor reports with distance function and belief entropy in fault diagnosis. Int. J. Comput. Commun. Control 14(3), 329–343 (2019).
Deng, Y. Uncertainty measure in evidence theory. Sci. China Inf. Sci. 63(11), 1–19 (2020).
Chen, Y., Tang, Y. & Lei, Y. An improved data fusion method based on weighted belief entropy considering the negation of basic probability assignment. J. Math.https://doi.org/10.1155/2020/1594967 (2020).
Bi, W., Zhang, A. & Yuan, Y. Combination method of conflict evidences based on evidence similarity. J. Syst. Eng. Electron. 28(3), 503–513 (2017).
Miao, Y. Z., Zhang, H. X., Zhang, J. W., & Ma, X. P. Improvement of the combination rules of the ds evidence theory based on dealing with the evidence conflict. In 2008 International Conference on Information and Automation, 331–336, IEEE (2008).
Hu, D., Wang, L., Zhou, Y., Zhou, Y., Jiang, X., & Ma, L. Ds evidence theory based digital image trustworthiness evaluation model. In 2009 International Conference on Multimedia Information Networking and Security, Vol. 1, 85–89, IEEE (2009).
Dongdong, W., Liu, Z. & Tang, Y. A new classification method based on the negation of a basic probability assignment in the evidence theory. Eng. Appl. Artif. Intell. 96, 103985 (2020).
Xie, K. & Xiao, F. Negation of belief function based on the total uncertainty measure. Entropy 21(1), 73 (2019).
Deng, Y. Deng entropy. Chaos Solitons Fractals 91, 549–553 (2016).
Tang, Y., Zhou, D. & Chan, F. T. S. Amwrpn: Ambiguity measure weighted risk priority number model for failure mode and effects analysis. IEEE Access 6, 27103–27110 (2018).
Jousselme, A. L., Liu, C., Grenier, D. & Bossé, E. Measuring ambiguity in the evidence theory. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 36(5), 890–903 (2006).
Denoeux, T. Maximum likelihood estimation from uncertain data in the belief function framework. IEEE Trans. Knowl. Data Eng. 25(1), 119–130 (2011).
Klir, G. J. & Ramer, A. Uncertainty in the Dempster–Shafer theory: A critical re-examination. Int. J. Gener. Syst. 18(2), 155–166 (1990).
Song, Y., Wang, X., Lei, L. & Yue, S. Uncertainty measure for interval-valued belief structures. Measurement 80, 241–250 (2016).
Ma, W., Jiang, Y. & Luo, X. A flexible rule for evidential combination in Dempster–Shafer theory of evidence. Appl. Soft Comput. 85, 105512 (2019).
Shafer, G. Dempster’s rule of combination. Int. J. Approx. Reason. 79, 26–40 (2016).
Luo, Z. & Deng, Y. A matrix method of basic belief assignment’s negation in Dempster–Shafer theory. IEEE Trans. Fuzzy Syst. 28(9), 2270–2276 (2019).
Deng, X. & Jiang, W. On the negation of a Dempster–Shafer belief structure based on maximum uncertainty allocation. Inf. Sci. 516, 346–352 (2020).
Jousselme, A.-L., Grenier, D. & Bossé, É. A new distance between two bodies of evidence. Inf. Fusion 2(2), 91–101 (2001).
Tseng, M.-L., Lim, M., Kuo-Jui, W., Zhou, L. & Bui, D. T. D. A novel approach for enhancing green supply chain management using converged interval-valued triangular fuzzy numbers-grey relation analysis. Resour. Conserv. Recycl. 128, 122–133 (2018).
Dong, J., Wan, S., & Chen, S. M. Fuzzy best-worst method based on triangular fuzzy numbers for multi-criteria decision-making. Inf. Sci. (2020).
Yang, J., Huang, H.-Z., He, L.-P., Zhu, S.-P. & Wen, D. Risk evaluation in failure mode and effects analysis of aircraft turbine rotor blades using Dempster-Shafer evidence theory under uncertainty. Eng. Fail. Anal. 18(8), 2084–2092 (2011).
Acknowledgements
The work is partially supported by National Key Research and Development Project of China (Grant No. 2020YFB1711900) and NWPU Research Fund for Young Scholars (Grant No. G2022WD01010).
Author information
Authors and Affiliations
Contributions
Y.Y. and Y.T. designed and performed the research work.
Corresponding author
Ethics declarations
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yuan, Y., Tang, Y. Fusion of expert uncertain assessment in FMEA based on the negation of basic probability assignment and evidence distance. Sci Rep 12, 8424 (2022). https://doi.org/10.1038/s41598-022-12360-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-12360-9
This article is cited by
-
Failure mode and effects analysis using an improved pignistic probability transformation function and grey relational projection method
Complex & Intelligent Systems (2023)
-
The maximum entropy negation of basic probability assignment
Soft Computing (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
