
Abstract
Timely detection of anomalies and automatic interpretation of an electrocardiogram (ECG) play a crucial role in many healthcare applications, such as patient monitoring and post treatments. Beat-wise segmentation is one of the essential steps in ensuring the confidence and fidelity of many automatic ECG classification methods. In this sense, we present a reliable ECG beat segmentation technique using a CNN model with an adaptive windowing algorithm. The proposed adaptive windowing algorithm can recognise cardiac cycle events and perform segmentation, including regular and irregular beats from an ECG signal with satisfactorily accurate boundaries.The proposed algorithm was evaluated quantitatively and qualitatively based on the annotations provided with the datasets and beat-wise manual inspection. The algorithm performed satisfactorily well for the MIT-BIH dataset with a 99.08% accuracy and a 99.08% of F1-score in detecting heartbeats along with a 99.25% of accuracy in determining correct boundaries. The proposed method successfully detected heartbeats from the European S-T database with a 98.3% accuracy and 97.4% precision. The algorithm showed 99.4% of accuracy and precision for Fantasia database. In summary, the algorithm’s overall performance on these three datasets suggests a high possibility of applying this algorithm in various applications in ECG analysis, including clinical applications with greater confidence.
Similar content being viewed by others

Introduction
A typical electrocardiogram (ECG) depicts the heart’s electrical activity and is a well-established cardiology technique for analysing the heart’s medical state and diagnosing heart anomalies. Careful examination of an ECG by an expert cardiologist or a physician is one of the standard practices in routine clinical procedures as ECG is recognised as a primary vital signal that ties with the physiology of the human body. The ECG beats’ regularity is also used as a diagnostic tool in specific topics such as evaluating mental stress1,2. However, the traditional diagnosis is becoming inefficient because, large amounts of heterogeneous data generated with the rapid spread of heart-related disorders in modern society. ECG inspection is essential to detect severe cases and perform close inspections after treatments, due to high prevalence of heart related complications3,4.
Various techniques have been proposed and implemented to perform automatic computer-based ECG classification in the past decades. Many follow three phases to perform the detection; (i) pre-processing, (ii) heartbeat segmentation (iii) beat-wise classification5,6,7. Automatic detection and segmentation of the ECG beat with R-peak (the critical event when detecting a single beat) is one of the essential steps in many ECG-based algorithms, including cardiac diagnosing8,9, heart rate variability analysis, and ECG-based authentication10,11. The importance of heartbeat segmentation becomes more pronounced in ECG analysis, where the classification phase strictly relies on the separated heartbeat5. Misdetections occur in the segmentation phase can propagate the error to the subsequent stages causing malfunction in the classification algorithms. Generally, these algorithms are designed based on digital filters12,13,14,15,16, signal processing techniques17, linear prediction, wavelet transforms18,19,20,21,22,23, derivatives, mathematical morphology24,25, geometrical matching, neural networks and hybrid approaches26,27. This article proposes two ECG beat segmentation methods using a CNN model and an adaptive windowing technique which can potentially employed as a preprocessing tool in beat-wise ECG analysing algorithms.
Methods
In this section, the methodology for training the CNN to distinguish ECG heartbeats and the concept of the adaptive windowing algorithm are presented. Table 1 shows the symbols and definitions used in this article.
Implementation of the CNN
Dataset, pre-processing, and augmentation
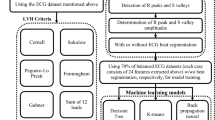
The main steps followed for implementing the proposed adaptive windowing algorithm are shown in Fig. 1. Mainly it consists of two phases, (A). Implementation and validation of the CNN model based on k-fold cross-validation (B). Implementation and validation of the adaptive windowing (see Fig. 2). ECG data from the MIT-BIH arrhythmia database28,29 was employed to assess the proposed technique. The MIT-BIH arrhythmia database comprises diverse beat types derived from 48 recordings of 47 subjects, with each record containing a 30-min long ECG segment sampled at 360 Hz and band-pass filtered at 0.1–100 Hz. The dataset includes an annotation file for each record, specifying each R peak position and the heartbeat label. Each record contains an upper and lower lead signal acquired by placing the electrodes on the chest.
Adding random perturbation based on a meaningful augmentation strategy can increase the diversity of the dataset (variance). Data augmentation is employed not only as a potential method for improving performances in the speech and vision domains30,31 but also in ECG classification32,33,34.
Before starting the CNN training, data augmentation was carried out as explained in Figs. 3, 4, and 5. The term QRS-like is used in the rest of the article to denote a typical or atypical cardiac cycle event, as QRS patterns may be distorted or not perfectly presented in abnormal ECG beats. Generally, CNN requires a specific fixed input size, considering the worst-case scenario, we set the input segment size as 512 samples ( \(\approx 1.4\,s\) for signals sampled at 360 Hz).

The method flow for the implementation of the proposed approach.
To produce positive and negative samples, we exploited three critical points and other points as described in Fig. 3. Here, a positive sample means an ECG beat where elementary cardiac cycle attributes are seated vaguely in the centre [a segment \((\le 1.4\,s)\) comprised of rudimentary QRS characteristics where a normal or an abnormal cardiac beat event is presented]. Slightly shifted versions of the main QRS-like pattern were extracted to produce such alternative ECG-beat segments. The amounts of the shift to the right and left are 4, 8, and 12% of the relative length s, respectively (where s is the length of the main QRS-like ECG segment as shown in Fig. 3). These shifted versions are adequately off-centred versions of the main QRS-like pattern and adequately off from being positioned too close to the rightmost or leftmost corners. Additionally, five end-trimmed versions around the main critical point were also created to ensure that the CNN can identify distorted versions of the main QRS-like pattern. 12 positive versions (11 augmented versions) of QRS-like patterns were created, including the main QRS morphology which is illustrated in Fig. 4. Having a robust CNN which can detect off-centred and shifted versions makes it easier to locate the ECG beat even if the window is not perfectly aligned with the main points.
A negative sample means an ECG segment where attributes of a complete cardiac cycle are not entirely presented or partially accommodated (segments \((\le 1.4\,s)\) which do not represent a normal or an abnormal cardiac beat event completely). Generating 12 negative samples using an ECG segment is shown in Fig. 5. Here, incomplete parts of QRS-like shapes, extremely left or right-shifted versions, and segments containing two critical points were extracted using consecutive critical points.
Any alternative positive or negative segment (separated according to Figs. 4 and 5) can be represented as signal \(v_{i,j}(m)\) after separating ECG segment \(u_{j}(t)\) (see Fig. 6a) with the main heartbeat \((H_j)\) using the adjacent critical points \((cp_{j-1},cp_{j},cp_{j+1})\). Here \(v_{i,j}(m)\) is the \(i^{th}\) alternative example from \(j^{th}\) heartbeat with sample points designated as m as illustrated in Fig. 6a. The length of each segment is shown as \(L_{i,j}\). As the \(L_{i,j}\) can vary from segment to segment, all \(v_{i,j}(m)\) are homogenised to have \(M (=512)\) samples and aligned to form \(w_{i,j}(n)\) as shown in Fig. 6b and in Eq. (1) to represent VBs and NVBs.
where, \(x_{i,j}, \{ n, L, M\in \mathbb {Z}, n \ge 0,M \ge L_{i,j} >0 \}\)
After the centring alignment strategy was carried out, all \(w_{i,j}\) were min-max normalised to the range [0, 1] to form vector \(x_{i,j}\) with length \(M(=512)\) as depicted in Eq. (2). As the original sampling rate \(f_s\) is 360 Hz, the maximum length of the ECG segment is \(\approx\)1422 ms \((\frac{512}{360})\). The set of feature vectors in the dataset \(\chi\) can be denoted as in Eq. (4)
where, \((i,j \in \mathbb {Z}, I \ge i> 1, J > j \ge 0, I = 24)\), \(J-\) total heartbeats, \(j=0\) is undefined in the training phase, \(I-\) total alternatives per beat.

The overview of the proposed windowing approach.

An ECG segment contains a triplet of critical points, cpl left critical point, cpr right critical point, cpm main critical point, bl left margin of the main beat, br right margin of the main beat, tl - left trimming point (cpl offset), tr right trimming point (cpr + offset), s length of the main ECG beat \((s = 0.5d1 + 0.6d2)\)).

Creating 12 alternative positive ECG beat segments based on the main ECG beat in the middle of a triplet of ECG beats shown in Fig. 3, all the shifts and scale down are calculated reference to length s.

Creating 12 negative ECG beat segments based on adjacent critical points of a triplet of ECG beats shown in Fig. 3.
In this study, an input segment \(x_{i,j}\) (see Eq. (3)) from the training dataset \(\chi\) can be denoted by \(x_{i,j} \in \mathbb {R}_{M*1}\) with its label \(y_{i,j} \in Y\), and \(Y=\{VB, NVB\}\). Then, the proposed CNN model can be defined by a function \(\hat{f}:x_{i,j}\rightarrow y_{i,j}\), which is later used to derive the function \(f^{p}(\Theta ^{cnn}, \zeta _{temp})\).
CNN training and evaluation
The CNN model architecture comprises five convolutional layers followed by rectified linear unit (ReLU) activation and max pooling layers. Finally, a fully-connected layer is followed by a dropout layer and a SoftMax layer for binary classification.

Homogenising the length of clipped ECG to a fixed length (512 samples), centralising the main ECG event and scale to [0,1] range. (a) Examples of the positive and negative sample (b) Examples of positive and negative samples after aligning (c). Example of the process applied to positive and negative samples from a record.
The proposed CNN was implemented in MATLAB 2021a using record-wise 10-fold cross-validation. Before implementing the 10-fold configuration, several architectures were tested to ensure satisfactory performance. In each fold, the network was trained for 15 epochs resulting in 10 models (one epoch covers approximately 2.3 million equally distributed positive and negative training samples as well as 0.26 million test samples).
Implementation of adaptive windowing algorithm
Motivation
Figure 2 shows the elementary operation of the proposed windowing algorithm. A window runs along the ECG signal to extract an arbitrary ECG segment consecutively. Then the ECG segment is passed through the trained CNN to calculate the probability P(B), where B is the event containing a full heartbeat-related pattern in an ECG segment (length \(\le 1.4\) s). If the CNN predict the relevant ECG segment is a Non-valid heartbeat segment, the window is moved forward a step and repeats the same processes until a valid heartbeat ECG segment is met. However, this approach arouses some challenges, as depicted below.
-
multiple detections (False Positives) of the same beat can be expected if the step size is too small.
-
a larger number of misdetections can be expected if the step size is too long
-
none or significantly fewer detections (False Negatives) can be expected if the window size is too long or too short
Therefore, using a fixed window with a fixed step size may cause numerous misdetections, over-detections and malperformance. In addition, after detecting a Valid Heartbeat segment, the boundaries should be defined so that,
-
the most appropriate features are preserved
-
the main morphology is aligned to the centre (because the CNN detects valid heartbeat segments which are inexplicitly seated around the centre of the segment)
-
minimised or zeroed morphological parts integrated into the segmented part from neighbouring heartbeats
All things considered, the facts suggest that the window size, step size and boundary should be meticulously calculated by exploiting the local characteristics and behaviour of the interested region of the signal.
Adaptive windowing algorithm, setting boundaries, and beat segmentation
After the \(j\)th heartbeat detection, the length of the window, and the step size, are denoted as \(\omega _j\) and \(s_j\) respectively (see Fig. 8a). Initial parameters such as starting window length \(\omega _0\), step size \(s_0\) etc. are calculated in a separate process (demonstrated later in this article) before executing the segmentation process. Assume that the \(({j-1})^{th}\) beat is detected, and then the window is moved forward with \(s_{j-1}\) step. Then an ECG segment \({\zeta }_{tmp}\) with a length of \(\omega _{j-1}\) is separated, preprocessed, aligned and passed through the CNN to calculate the probability P(B) (B is the event \({\zeta }_{tmp}\) being a valid heartbeat). If \(P(B) > p_b\), where \(p_b(=0.9)\) is a predefined confidence level, then it can be safely inferred that most of \({\zeta }_{tmp}\) fully or partially contain a QRS-like segment. However, it is obvious that the main morphology may not align with the centre of \({\zeta }_{tmp}\) because the window does not cover the entire event. Therefore, a cp is calculated to approximate the point where the main event is centred around. The boundaries can then be calculated based on it. As shown in Fig. 7, the cp of the \({\zeta }_{tmp}\) is computed based on the central tendency (here, we chose the median as the central tendency measure) of the segment and the local maximum and the minimum. If the central tendency is closer to the local maximum, the cp is considered as the maximum and if it is closer to the local minimum then the cp is selected as the local minimum. In the rest of the article, we refer to the horizontal component (sample index) of the cp as cp.
If \(P(B) \le p_b\), the window is forwarded without updating window parameters. When \(P(B) > p_b\) and \(cp_{j}\) is not too close to the previous \(cp_{j-1}\), the new window size \(\omega _{j}\) and step \(s_{j}\) is calculated as a ratio of mean cp interval \({\bar{{\textbf {C}}}_{j}}\) resulting \((\eta _w\cdot {\bar{{\textbf {C}}}_{j}}\) and \(\eta _s\cdot {\bar{{\textbf {C}}}_{j}})\) respectively, where \(\eta _w(=0.9)\) and \(\eta _s(=\frac{3\cdot \eta _w}{11})\) are predefined constants. Equation (8) shows how \({\bar{{\textbf {C}}}_{j}}\) is calculated.
Subsequently, left and right boundaries are calculated. Here we propose two cases to calculate the boundaries (method I and II). In method I, the boundaries of the \(j{th}\) beat are calculated with reference to the \(cp_{j}\), and predefined constants, centre align ratio \(\eta _{ar}(=\frac{5}{11})\), safe margin constant \(\eta _{\delta } (=\frac{9}{10})\) and \(\overline{{{\textbf {C}}}_{j}}\) resulting the segmentation length being \(\eta _{\delta }\cdot {\bar{{\textbf {C}}}_{j}}\). Here, the current critical event is aligned so that the cp lies in a 5 : 6 ratio within the segmented ECG beat. In method II, the boundaries of \((j-1){th}\) are calculated based on the locations of adjacent (left \(cp_{j-2}\) , right \(cp_{j}\)) and predefined arbitrary constants \(\eta _l (e.g., 0.5)\) and \(\eta _r (e.g., 0.5)\). Once the segmentation is executed, the new window \(\omega _{j}\) starts from a point beyond the current critical point to save iterations and avoid multiple detections. The length of the offset is calculated proportionally to window \(\omega _j\) length using a constant \(\eta _{of}(=0.1)\).
Avoiding false detections caused in exceptional scenarios
If the ECG signal is too noisy or anomalous, multiple detections can be expected in the neighbourhood of current cp for Non-heartbeat segments which morphologically appear as QRS-like segments (e.g., wider QRS or T wave, deformed T wave etc.). As the window size directly depends on the moving average of the cp interval \(\overline{{\textbf {C}}}_j\) and updated at each jth detection, the adaptive window parameters can be erroneous (may cause the window to be very small) causing many iterations to auto-correct. Figure 8a,b show a double-checking procedure introduced to tackle the trade-off between maintaining the adaptability of the window parameters and avoiding false detection near the main cp.

Determination of critical points and window relocation after segmentation.

Detailed overview of the adaptive windowing process.
If the newly detected \(\tilde{cp}_j\) is too close to the \(cp_j\), the same window is run starting from a slightly different point beyond the faulty \(\tilde{cp}_j\) with tiny steps until it detects the next cp. The faulty \(\tilde{cp}_j\) does not take into account when calculating the mean cp interval. The faulty \(\tilde{cp}_j\) is detected based on adaptively changing thresholds \(\overline{cp}_{{min}_{j}}\) and \(\overline{cp}_{{max}_{j}}\) where \(\overline{cp}_{{min}_{j}} = \eta _{cmin}\cdot \overline{{\textbf {C}}}_{j}, (\eta _{cmin} = 0.45)\) and \(\overline{cp}_{{max}_{j}} =\eta _{cmax}\cdot \overline{{\textbf {C}}}_{j}, (\eta _{cmax} = 1.45)\). If a \(\tilde{cp}_j\) is detected within 45% of \(\overline{{\textbf {C}}}_{j-1}\) or beyond 145% of \(\overline{{\textbf {C}}}_{j-1}\), it infers that the \(\tilde{cp}_j\) is too close or too far to the \({cp}_{j-1}\). Therefore, all \(\tilde{cp}_j\) that do not satisfy these constraints are omitted when calculating the new mean cp interval \(\overline{{\textbf {C}}}_j\). On the other hand, if the current cp is too far away from the last detected \({cp}_{j-1}\), it also causes the window to be too large resulting in no detections or faulty detection. Therefore, an adaptively changing threshold is calculated \(\overline{cp}_{{max}_{j}} = \eta _{cmax}\cdot {\bar{{\textbf {C}}}_{j}} (\eta _{cmax} = 1.4\) means that if there is a cp within 145% of mean cp interval \(\overline{{\textbf {C}}}_{j-1}\), then \(\tilde{cp}_j\) is omitted when calculating the new mean cp interval \({\bar{{\textbf {C}}}_{j}})\). As a result, abruptly emerging false QRS-Like events within reach of the main cp or too far away from the cp have no major influence on miscalculating the window parameters. However, the cps found too far are segmented using current window parameters.
Equation (5) shows how the window parameters are updated in occurrences of valid beat detection and how the boundaries are calculated for method I. Equation (6) shows how the boundaries are calculated for \({(j-1)}{th}\) beat after the detection of j th beat (method II). Similarly Eq. (7) shows how the parameters get updated when a valid beat is not detected. Algorithm 1 (see Fig. 9) shows the pseudo-code for computing the initial window parameters before starting the segmentation, as the window is not yet adapted. Here we run the algorithm for the first 16 beats without performing segmentation. The initial window size \(\omega _0\) is set as \(\frac{1}{2}\cdot f_s\) (0.5 s) where \(f_s\) is the sampling rate. Then the window size is updated in each detection. If the window is not correctly adapted after the 16th beat, the initial window size \(\omega _0\) is increased by multiples of \(e^{0.01}\). Algorithm 2 (see Fig. 9) shows the pseudo-code of how the window parameters are updated during each iteration.
where, \(c_r\) is the interval between \(c_r\) and \(c_{r-1}\), \(\kappa = K (=16)\), \(j=k\) in initialising phase (when \(\kappa \le K\))

Pseudo-codes for the proposed algorithms.
For quantitative analysis, the proposed method is evaluated using the MIT-BIH arrhythmia database, the European ST-T database, and Fantasia database. The CNN model was trained, tested and tuned since the MIT-BIH arrhythmia database contains numerous anomalous QRS complexes, irregular rhythmic patterns, significant baseline drifts, and rapid changes. The performance is evaluated in several steps as follows.
-
1.
Performance evaluation for trained CNN based on 10-fold configuration for MIT-BIH arrhythmia database
-
2.
Performance evaluation for adaptive windowing algorithm on MIT-BIH arrhythmia database
-
(a)
Evaluation of the accuracy of locating critical points
-
(b)
Conformity of the boundaries of each beat based on manual inspection
-
(a)
-
3.
Performance analysis of detecting critical points on the European ST-T database and Fantasia database (unseen data for the CNN)
It is practically impossible to formulate a coherent criterion to assess the accuracy of the boundaries. So, the segmented ECG beats were manually inspected to ensure that the boundaries were satisfactorily defined in accordance to a checklist (qualitative analysis) as follows. qualifying criterion
-
1.
the critical point (main ECG event) is sufficiently aligned to the centre of the segmented ECG beats
-
2.
the left and right margins are lied on the isoelectric line without overlapping the nearby ECG beats when applicable
-
3.
slightly overlapped or trivially truncated versions of ECG beats were passed as correct when,
-
(a)
the margin of a beat is not straightforward or ambiguous
-
(b)
the isoelectric line is not presented clearly due to the irregular nature of abnormal patterns, missing QRS patterns or possible intermingling between adjacent cardiac cycles
-
(a)
disqualifying criterion
-
1.
when multiple critical points are observed in a segmented portion
-
2.
when there is substantial overlap, and the boundaries are unambiguous
-
3.
When a clear QRS-Like morphology is not observed in a segmented portion
-
4.
when QRS-Like morphology is substantially aligned towards left or right corners
The European ST-T database and Fantasia database were used as a validation dataset, to verify the algorithm’s ability to locate critical points accurately. However, a subjective inspection was not performed as the dataset is too large.
Results
Performance of the CNN model
The average accuracy for the whole dataset is determined based on the average accuracy of the test dataset of each fold. The average accuracy of the CNN is determined to be 99.11%. The fold wise accuracies showed almost consistent test accuracy for each fold, proving that the CNN is robust. According to Table 2, CNN has accurately classified 1,299,606 valid ECG beats and 1,307,380 Non-valid ECG beats. Here, we evaluated all alternative ECG segments when calculating the matrices, as they are not subject to any alterations other than shifting and trimming. However, there is no overlap between the training and test datasets as the folds are configured record-wise. The sensitivity, accuracy, specificity , and the F1 score for the proposed model were calculated as 99.03%, 99.08%, 99.12%, and 99.08%, respectively.

Segmentation of heartbeats from (a) a good quality signal comprised with normal heartbeats (record 113) (b) a noisy signal comprised of right bundle branch block beats (record 108) (c) a signal which has a baseline wander comprised with normal heartbeats (record 116) (d) a noisy signal comprised with normal heartbeats (record 104) (e) a signal comprised with premature ventricular contraction and fusion of the ventricular and normal beat (record 208) (f) a signal comprised with premature ventricular contraction (record 200) (g) a signal comprised with right bundle branch block beats and premature ventricular contraction (record 207) (h) a signal comprised with abnormal heartbeats (record 208).

Adapting window parameters in each detection (a) record 208 (b) record 212 (c) record 207 (d) record 200.
Performance of the ECG segmentation
In evaluating the segmentation, some parts of record 207 were discarded as we decided that the critical points were too ambiguous. Similarly, seven records (e0112, e0129, e0133, e0304, e0305, e0415, e0604) were not considered, as some annotations seem inconsistent. Whole segmentation algorithm was also evaluated based on the criteria explained in this article. Table 3 shows the number of True Positives and False Positives, the precision and the accuracy for each record. As this algorithm focuses on segmenting the ECG beat, we used the term critical point, to separate the main ECG event accurately. Therefore, some detected critical points, match the given annotated locations within a range. However, the majority of annotated locations exactly match the detected location. Even though this study does not focus on finding precise R-peaks, we decided to compare the peak locations with our critical points as tabulated in Table 3 for the sake of relating our research to similar studies. In Table 3, we illustrated the performance of locating the critical points and the segmentation performance.
The average agreement of detecting a critical point and an annotated location is 96.93, 98.41 and 98.94% within \(\pm 25, \pm 50\), and \(\pm 75\) (ms) margins, respectively. The study in16 also used this kind of margin criteria to evaluate the performance. 108,633 beats out of 109,473 have been correctly identified and appropriately segmented in this study. The average of correctly identified and segmented beats is 99.25%, and the precision for correctly segmented beats is 99.62%. Figure 10 shows an assortment of examples which proves the robustness of the proposed algorithm against various scenarios of ECG signals. In each sub-figure, in Fig. 10, the top figure shows the detected ECG beat and the boundaries calculated based on method I and method II, and the bottom two figures show the segmented ECG beats (last two beats). Two green vertical lines show the size of the next window and its position. For demonstration purposes, we indicated the annotated points with a blue dot provided by the original database. Figure 12 shows an instance of heartbeat segmentation from the European ST-T database. Here, red vertical lines indicate the given annotation location, and green vertical lines indicate the window size and position. The proposed algorithm perfectly detects and segments the ECG beats even when the signals are heavily affected by practical issues such as noise, baseline wander, abnormally larger or smaller S-T waves, morphological disparities, abnormally larger or smaller RR intervals, abnormally suppressed QRS patterns or irregular wave patterns which are illustrated in Figs. 10 and 12. Figure 11 shows how the windowing parameters such as window size, step size, windowing start offset, and expected maximum/ minimum cp interval, adaptively follow the fluctuations of mean critical point interval in different ratios.

Segmentation examples (European ST-T database record e0139).
Discussion
In this work, we proposed two ECG beat segmentation methods using a CNN model and an adaptive windowing algorithm that can serve as a preprocessing tool in beat-wise ECG analysing algorithms. This research was performed to improve the precision of ECG segmentation so that abnormal ECG beats also can be segmented. Specifically, we used a CNN model to detect critical points where the main ECG morphology is formed around to recognise an occurrence of a heartbeat cycle, unlike other methods, which employ signal quality, filters, or other signal processing techniques such as peak detection etc. Therefore a complete or incomplete heart cycle, including abnormal patterns such as arrhythmic events, could be identified more accurately. The performance matrix in Table 2 shows that the specificity, sensitivity, precision and F1-Score are close to 100%, meaning that the CNN model is very confident in classifying heartbeat and Non-heartbeat segments. As many similar studies focus on detecting accurate R peaks/ QRS detection and the proposed method focuses on adaptive segmentation via detecting critical points, this work differs from those in some aspects. So we compare our work with the study33 in Table 5 as both studies used the same database, and some techniques are comparable to each other.
In contrast to the CNN model proposed in33, our model achieved an F1-score of 99.8% whilst their model is 96% for the MIT-BIH dataset. The precision shows a slightly lower value of 99.13% to their 100%. However, it should be noted that our model can distinguish both normal and abnormal heartbeat compared to the study in33, where the model is trained only with healthy individuals (only 23 records). Furthermore, in33 the training data is prepared using fixed lengths from the annotated points, unlike ours where all the lengths are calculated locally with reference to the adjacent critical points. This makes our CNN to be more sensitive to wider or narrower variations of QRS morphology. Additionally, the proposed model demonstrates better performance in terms of sensitivity, precision, and F1-Score in comparison to the Pan-Tompkins algorithm in locating critical points.
In calculating the boundaries of the heartbeat, we used an instantaneous critical point interval which can be closely related to the RR interval. Results presented in Tables 3 and 4 show that our idea of using an adaptive window calculated based on mean cp interval to identify QRS-like patterns and determine boundaries is a success.
Figure 10b–d,f demonstrate that the proposed algorithm can successfully detect and segment regular and irregular heartbeats even if the signal comprises abrupt changes, baseline wander, or a considerable level of noise, resulting in a high number of true positive and true negative detection level whilst having very low false negative and false positive. Figure 10a,e,g,h also show the observation in detecting and segmenting atypical heartbeats such as premature ventricular contraction etc. The algorithm showed appealing average accuracy of 98.3% and a precision of 97.4% for the unseen dataset as illustrated in Fig. 12 and Table 4.
The reported results for both datasets suggest a high possibility of using this algorithm in ECG analysing as a preprocessing tool, given the notion that correct segmentation is critical for medical equipment and the arrhythmia classification algorithms.
Even though some studies35,36 performed for R peak detection and detailed ECG delineation can not be directly related to our work, we review some potentials specific to this study for comparison and discussion. High pass or low pass filtering techniques were not exploited in our work to denoise the signal in contrast to the work in37, which was performed to detect T-Wave. Unlike in37, the proposed algorithm can be directly applied to the raw signal. On the other hand, our algorithm adapts its parameters depending on the cp interval in each detection, allowing to use of this algorithm for a wide variety of ECG waves which shows different characteristics.
Getting a high positive prediction rate is important to avoid false detections in many ECG applications. As a result of using adaptive window size and step size, we could use the sliding window more efficiently to reduce the number of iterations per detection (it can be fewer steps, 1–3 depending on the nature of the ECG). In this study, we did not use any hard thresholds allowing the algorithm to be adapted to the interested region of the signal. The window parameters and other local points are always recalculated and updated in each detection allowing the algorithm to detect the next heartbeat smoothly. As we tested the algorithm with two datasets, we found that the algorithm shows outstanding performance for unseen data, proving that this algorithm can be used robustly in detecting and segmenting ECG signals. In addition, the segmentation performance is monitored manually, beat by beat, to ensure that the boundaries are reasonable. It is important to mention that the high sensitivity and positive prediction rate reported in the CNN model proposed in this study have a balanced trade-off that supports the notion that this algorithm can be used reliably and accurately as an ECG segmentation tool.
Limitations and future works
The proposed approach intends to distinguish ECG beats from an ECG signal, including normal and pathological beats. However, the CNN model is trained based on one dataset; therefore, some pathological patterns might be new to the model, which may lead it to perform differently than intended. Possible failures of the windowing algorithm can be expected when extraordinarily high or low RR intervals are met as the CNNs maximum input is limited to 1.4 s. However, this problem rarely arises as the RR interval usually is lower than 1.4 s. There is a space to fine-tune the constants based on practical observations, domain-based knowledge and specific case studies. Safety mechanisms such as time outs, and checking signal noise levels also can be employed in serious practical cases to ensure the adaptive parameters always lie within the realistic values.
In the future, we plan to train the network with more data collected locally and use other public datasets to increase performance and robustness. Further, the windowing algorithm can be modified in multiple ways to overcome the limitations of this work mentioned in the limitation section. For example, the same CNN model can be employed repeatedly to confirm that the boundaries are reasonable. If the validation fails, a boundary re-adjusting procedure can be implemented based on the prediction score. Multiple segmentation of the same beat is also an option in heavily complicated cases such as incomplete arrhythmic episodes. In future, we aim to extend this algorithm as a vote-based detection system with multiple classification methods to be used in various ECG analysing applications such as38 patented by the same authors.
Data availability
The data used to support the findings of this study are available freely at https://physionet.org/content/mitdb/1.0.0/ , https://physionet.org/content/edb/1.0.0/, and https://physionet.org/content/fantasia/1.0.0/.
References
Castaldo, R. et al. Acute mental stress assessment via short term HRV analysis in healthy adults: A systematic review with meta-analysis. Biomed. Signal Process. Control 18, 370–377 (2015).
Aysin, B. & Aysin, E. Effect of respiration in heart rate variability (HRV) analysis. In 2006 International Conference of the IEEE Engineering in Medicine and Biology Society 1776–1779 (IEEE, 2006).
Isin, A. & Ozdalili, S. Cardiac arrhythmia detection using deep learning. Procedia Comput Sci. 120, 268–275 (2017).
Ebrahimi, Z., Loni, M., Daneshtalab, M. & Gharehbaghi, A. A review on deep learning methods for ECG arrhythmia classification. Expert Syst. Appl. X 7, 100033 (2020).
Sannino, G. & De Pietro, G. A deep learning approach for ECG-based heartbeat classification for arrhythmia detection. Future Gener. Comput. Syst. 86, 446–455 (2018).
Luz, E. J. D. S., Schwartz, W. R., Cámara-Chávez, G. & Menotti, D. Ecg-based heartbeat classification for arrhythmia detection: A survey. Comput. Methods Progr. Biomed. 127, 144–164 (2016).
Berkaya, S. K. et al. A survey on ECG analysis. Biomed. Signal Process. Control 43, 216–235 (2018).
Li, J., Si, Y., Xu, T. & Jiang, S. Deep convolutional neural network based ECG classification system using information fusion and one-hot encoding techniques. Math. Probl. Eng. 2018, 110 (2018).
Xu, X. & Liu, H. ECG heartbeat classification using convolutional neural networks. IEEE Access 8, 8614–8619 (2020).
Sufi, F., Khalil, I. & Hu, J. Ecg-based authentication. In Handbook of Information and Communication Security 309–331 (Springer, 2010).
Huang, P., Li, B., Guo, L., Jin, Z. & Chen, Y. A robust and reusable ECG-based authentication and data encryption scheme for ehealth systems. In 2016 IEEE Global Communications Conference (GLOBECOM) 1–6 (IEEE, 2016).
Arzeno, N. M., Deng, Z.-D. & Poon, C.-S. Analysis of first-derivative based GRS detection algorithms. IEEE Trans. Biomed. Eng. 55, 478–484 (2008).
Pan, J. & Tompkins, W. J. A real-time GRS detection algorithm. IEEE Trans. Biomed. Eng. 32, 230–236 (1985).
Hamilton, P. S. & Tompkins, W. J. Quantitative investigation of GRS detection rules using the MIT/BIH arrhythmia database. IEEE Trans. Biomed. Eng. 33, 1157–1165 (1986).
Bote, J. M., Recas, J., Rincón, F., Atienza, D. & Hermida, R. A modular low-complexity ECG delineation algorithm for real-time embedded systems. IEEE J. Biomed. Health Inform. 22, 429–441 (2017).
Choi, S. et al. Development of ECG beat segmentation method by combining lowpass filter and irregular r-r interval checkup strategy. Expert Syst. Appl. 37, 5208–5218 (2010).
Martinez, A., Alcaraz, R. & Rieta, J. J. Automatic electrocardiogram delineator based on the phasor transform of single lead recordings. In 2010 Computing in Cardiology 987–990 (IEEE, 2010).
Legarreta, I. R. et al. R-wave detection using continuous wavelet modulus maxima. In Computers in Cardiology 565–568 (IEEE, 2003).
Elgendi, M., Jonkman, M. & De Boer, F. R wave detection using coiflets wavelets. In 2009 IEEE 35th Annual Northeast Bioengineering Conference 1–2 (IEEE, 2009).
Abdelliche, F. & Charef, A. R-peak detection using a complex fractional wavelet. In 2009 International Conference on Electrical and Electronics Engineering-ELECO 2009 II–267 (IEEE, 2009).
Kalyakulina, A. I. et al. Finding morphology points of electrocardiographic-signal waves using wavelet analysis. Radiophys. Quantum Electron. 61, 689–703 (2019).
Li, C., Zheng, C. & Tai, C. Detection of ECG characteristic points using wavelet transforms. IEEE Trans. Biomed. Eng. 42, 21–28 (1995).
Rincón, F., Recas, J., Khaled, N. & Atienza, D. Development and evaluation of multilead wavelet-based ECG delineation algorithms for embedded wireless sensor nodes. IEEE Trans. Inf. Technol. Biomed. 15, 854–863 (2011).
Chen, Y. & Duan, H. A qrs complex detection algorithm based on mathematical morphology and envelope. In 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference 4654–4657 (IEEE, 2006).
Zhang, F. & Lian, Y. QRS detection based on multiscale mathematical morphology for wearable ECG devices in body area networks. IEEE Trans. Biomed. Circuits Syst. 3, 220–228 (2009).
Meyer, C., Gavela, J. F. & Harris, M. Combining algorithms in automatic detection of QRS complexes in ECG signals. IEEE Trans. Inf. Technol. Biomed. 10, 468–475 (2006).
Manikandan, M. S. & Soman, K. A novel method for detecting r-peaks in electrocardiogram (ECG) signal. Biomed. Signal Process. Control 7, 118–128 (2012).
Moody, G. B. & Mark, R. G. The impact of the MIT-BIH arrhythmia database. IEEE Eng. Med. Biol. Mag. 20, 45–50 (2001).
Moody, G. & Mark, R. The mit-bih arrhythmia database on cd-rom and software for use with it. In [1990] Proceedings Computers in Cardiology 185–188. https://doi.org/10.1109/CIC.1990.144205 (1990).
Bloice, M. D., Roth, P. M. & Holzinger, A. Biomedical image augmentation using augmentor. Bioinformatics 35, 4522–4524 (2019).
Bloice, M. D., Stocker, C. & Holzinger, A. Augmentor: an image augmentation library for machine learning. arXiv preprint arXiv:1708.04680 (2017).
Nonaka, N. & Seita, J. Data augmentation for electrocardiogram classification with deep neural network. arXiv preprint arXiv:2009.04398 (2020).
Silva, P. et al. Towards better heartbeat segmentation with deep learning classification. Sci. Rep. 10, 1–13 (2020).
Silva, P., Luz, E., Wanner, E., Menotti, D. & Moreira, G. QRS detection in ECG signal with convolutional network. In Iberoamerican Congress on Pattern Recognition 802–809 (Springer, 2018).
Martínez, J. P., Almeida, R., Olmos, S., Rocha, A. P. & Laguna, P. A wavelet-based ECG delineator: Evaluation on standard databases. IEEE Trans. Biomed. Eng. 51, 570–581 (2004).
Legarreta, I. R. et al. R-wave detection using continuous wavelet modulus maxima. In Computers in Cardiology, 2003 565–568 (IEEE, 2003).
Vázquez-Seisdedos, C. R., Neto, J. E., Marañón Reyes, E. J., Klautau, A. & Limão de Oliveira, R. C. New approach for t-wave end detection on electrocardiogram: Performance in noisy conditions. . Biomed. Eng. Online 10, 1–11 (2011).
Niroshana, S. M. I., Chen, W. & Kuroda, S. Bathing person monitoring system. https://www.j-platpat.inpit.go.jp/c1800/PU/JP-7126230/2530E7C7DE0FC3890D82D5D74EF9905B2623578ED13CA7E4445E3A734B77DD9B/15/en (2022).
Niroshana, S. M. I., Chen, W. & Kuroda, S. Heartbeat segmentation device and bather monitoring system. https://www.j-platpat.inpit.go.jp/c1800/PU/JP-7162232/41F85F604288832DAA340A139C1CB66C0437C9393D99B0B6B65040B30C7C06CE/15/en (2022).
Acknowledgements
This research is patented collaboratively by The University of Aizu, Japan and, Information System Engineering Inc.(ISE), Japan (Patent Number JP7162232B1, “Heart rate classification device and bather monitoring system”39), and implemented as a part of the work patented by the same authors38. This research is financially supported by Information System Engineering Inc.(ISE), Japan.
Author information
Authors and Affiliations
Contributions
S.M.I.N. and W.C. conceived and implemented the experiment(s), S.K. and K.T. analysed and assessed the results. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Niroshana, S.M.I., Kuroda, S., Tanaka, K. et al. Beat-wise segmentation of electrocardiogram using adaptive windowing and deep neural network. Sci Rep 13, 11039 (2023). https://doi.org/10.1038/s41598-023-37773-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-37773-y
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
