
Abstract
Post-acute pancreatitis diabetes mellitus (PPDM-A) is the main component of pancreatic exocrine diabetes mellitus. Timely diagnosis of PPDM-A improves patient outcomes and the mitigation of burdens and costs. We aimed to determine risk factors prospectively and predictors of PPDM-A in China, focusing on giving personalized treatment recommendations. Here, we identify and evaluate the best set of predictors of PPDM-A prospectively using retrospective data from 820 patients with acute pancreatitis at four centers by machine learning approaches. We used the L1 regularized logistic regression model to diagnose early PPDM-A via nine clinical variables identified as the best predictors. The model performed well, obtaining the best AUC = 0.819 and F1 = 0.357 in the test set. We interpreted and personalized the model through nomograms and Shapley values. Our model can accurately predict the occurrence of PPDM-A based on just nine clinical pieces of information and allows for early intervention in potential PPDM-A patients through personalized analysis. Future retrospective and prospective studies with multicentre, large sample populations are needed to assess the actual clinical value of the model.
Similar content being viewed by others


Introduction
Acute pancreatitis (AP) is one of the most common gastrointestinal diseases characterized by acute pancreas inflammation and acinar cell destruction. The global incidence of AP is increasing dramatically worldwide1,2,3. AP was originally thought to be a self-limiting disease. Most patients recover completely, but only about 20% may develop severe acute pancreatitis (SAP), with a mortality rate of around 30%4,5. However, diabetes, as a sequela of AP, has drawn attention in recent years. National Population-Based cohort studies reveal that the risk of PPDM-A is twofold higher than those without AP, and the occurrence of PPDM-A is observed across the spectrum of severity in AP6,7,8. Its prevalence has tripled in the past decade and is expected to reach 13.6 per 100,000 by 20509. PPDM-A has gained more and more attention in the field of diabetes.
Pancreas contains both exocrine and endocrine parts. The exocrine pancreatic disease can lead to diabetes of the exocrine pancreas (DEP), the second most common type of new-onset diabetes in adults (surpassing type 1 diabetes)10. Furthermore, AP is considered the most common cause of DEP, and about 80% of pancreatitis-related DEP is due to AP11. This type of diabetes is characterized by impaired endocrine and exocrine functions, including significant glycemic drift, frequent episodes of hypoglycemia (fragile diabetes)10, and impaired digestion and absorption of nutrients12,13. It seriously threatens human health and places a heavy burden on health care14,15.
However, PPDM-A has not drawn sufficient attention and has often been misdiagnosed as T2DM12,16. Diabetes mellitus is highly heterogeneous and requires fine diagnostic staging for precise treatment. Therefore, screening high-risk patients is essential for developing PPDM-A prevention guidelines, delaying islet function damage, avoiding adverse outcomes, and improving the prognosis of PPDM-A.
In this study, we used a machine learning model to screen the most important clinical features for predicting PPDM-A and used these clinical features to construct a logistic regression model with L1 regularisation, obtaining good AUC and F1 values. In addition, we interpreted the predictions of the model using nomograms and Shapley values and provided personalized early prevention protocols. This study provides a valuable guide to the occurrence and prevention of PPDM-A.
Results
Study cohort and baseline characteristics
Between 1 October 2016 and 31 October 2021, 3477 admissions for AP were screened in hospital information system (HIS). After using the exclusion criteria described (Supplementary Fig. 1), 820 patients with AP without known diabetes were included in our study. Of these, two-thirds (n = 574) were randomly assigned to the training set, with the remaining one-third (n = 246) assigned to a validation cohort. Table 1 shows the baseline characteristics of the patients. The median age was 50 (38, 63) years. The proportion of males was 61.3% (n = 503). Biliary was the most common cause of AP. 484 (59%) patients presented with mild AP, 280 (34.1%) with moderate AP, and 56 (6.8%) with severe AP; 68 (8.3%) patients had PPDM-A, and they were more likely to be obese (20.7% vs. 9.2%, P = 0.005), presenting with hyperlipidemia and tending to have combined non-alcoholic fatty liver disease (NAFLD) (75% vs. 45.2%, P < 0.001). Smoking rates were higher in patients with PPDM-A than in those without DM.
Feature extraction
Lasso regression (L1 regularized logistic regression) can be used for feature extraction in classification models. We performed 1000 randomly perturbed lasso regressions to extract the weights of 38 clinical features. By ranking the mean weights of these 38 features and using a threshold of 0.01, we obtained the nine most influential indicators on the classification of the model (Fig. 1), in order of Admission glucose, obesity (BMI > 28 kg/m2), cardiovascular disease (CVD), Age, NAFLD, alanine transaminase (ALT), uric acid (UA), HDL-C < 1.03 mmol/l, Smoking. In addition, indicators with a residual range above 0 included several features, drinking, organ failure, acute peripancreatic fluid collection (APFC), blood urea nitrogen (BUN), creatinine, hypertension, amylase, Ca. The results show that the two most influential factors in PPDM-A are still Admission glucose and obesity. These two indicators are also those associated with type 2 diabetes. It suggests that type 2 diabetes and PPDM-A share common risk factors.

Core influencing factor screening. The mean values of the weights of the features were ranked by 1000 lasso regressions. Of these, nine features with Feature Importance Score > 0.01 were selected as core genes considered to be associated with PPDM-A.
Algorithm performance
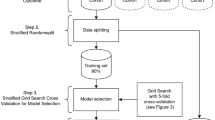
Multiple machine learning algorithms were used to construct the classification models. Following the same approach, we constructed a classification model based on the core nine features. We validated the performance of the model on the training set using fivefold cross-validation (Fig. 2A,B; Supplementary Table 1). Additionally, we performed internal validation on the training set (Fig. 2C,D; Supplementary Table 2). We then tested these models in validation data (Fig. 2E,F; Supplementary Tables 3, 4). The results showed that the best model was obtained with LR L1(C = 1) at the average level (AUC = 0.819, CA = 0.927, F1 = 0.912, Precision = 0.912, Recall = 0.927; Fig. 2E, Supplementary Table 3). For the prediction of positive events, LR L1(C = 1) also achieved the best results (AUC = 0.819, CA = 0.927, F1 = 0.357, Precision = 0.625, Recall = 0.250; Fig. 2F, Supplementary Table 4). The previous analysis showed that the prognostic model constructed using the core nine features had the best predictive effect.

Model performance. Fivefold cross-validation was used to evaluate model performance in the training set. ROC curves and calibration curves were used to compare the strengths and weaknesses of the models. (A,B) ROC andibration curves of the five machine learning models on the training set using fivefold cross-validation. (C,D) internal validation on the training set. (E,F) ROC andibration curves of the five machine learning models in the test set. From Supplementary Table 4, we can find that the model obtained by Logistic Regression (L1 regularization) performs best with AUC = 0.819, F1 = 0.357 in the validation set.
Assessing the interpretability of model predictions
We constructed a nomogram based on LR L1(C = 1) for nine features. HDL-C < 1.03, CVD, and ALT were predicted to contribute to PPDM-A (Fig. 3A) negatively. To gain insight into the features that contributed most to the model prediction results, we used Sharply Values to assess the importance of core features for model evaluation (Fig. 3B). The factors that most impacted the model predictions included HDL-C < 1.03 mmol/l, BMI > 28 kg/m2, and Admission glucose. HDL-C < 1.03 = TRUE made the most significant contribution to predicting positive events. The contribution of BMI >28 = FALSE in predicting positive events was the opposite of BMI > 28 = TRUE. It suggests that obesity is also a causal factor for disease.

Model interpretation. We have used two methods of model interpretation. (A) Nomogram. The trend and magnitude of the effect of the nine core factors on the prediction of positive events can be observed in the figure. Admission glucose, BMI > 28, Age, NAFLD, UA and Smoking are the risk factors for PPDM-A. In contrast, Cardiovascular disease, ALT, HDL-C < 1.03 are negative predicted factors. (B) Sharpley value was used to explain the effect of the model on prediction. HDL-C < 1.03, BMI > 28 and Admission Glucose were the main factors affecting prediction. BMI > 28, Cardiovascular disease, HDL-C < 1.03 and Smoking are logistic variables, with 0 being FALSE and 1 being TRUE.
Personalized diagnosis
We used the RL L1 (C = 1) model constructed with nine features to assess the main influences on the predictions of the six samples using Sharp Value. The results showed that the main contribution to an optimistic prediction for sample 1 came from (BMI > 28 = 0) = FALSE, (HDL-C < 1.03 = 0) = FALSE, with contributions of 0.68, 0.06 in order (Fig. 4A). The probability of an optimistic prediction for sample 1 was 0.83. The main contribution to an optimistic prediction for sample 2 came from (BMI > 28 = 0) = FALSE, (HDL-C < 1.03 = 1) = FALSE, with contributions of 0.62, 0.22 in order (Fig. 4B). The probability that this sample was predicted to be positive was 0.74. For sample 3, (BMI > 28 = 0) = FALSE, (HDL-C < 1.03 = 1) = FALSE contributed a positive predictive likelihood of 0.65, 0.21. Thus BMI > 28 kg/m2 was the leading risk factor for this sample (Fig. 4C). Multiple clinical information in samples 4, 5, and 6 contributed less to the positive prediction (Fig. 4D,E,F). The probability of predicting the occurrence of PPDM-A in each of these samples was less than 0.13.

Personalized diagnosis. The risk factors for the three positive and three negative predicted samples in the prediction set were studied. (A) Patient 1 had a BMI > 28 kg/m2 as the main risk factor and a predicted probability of developing diabetes of 0.83. (B) Patient 2 had a BMI > 28 kg/m2, HDL-C > 1.03 mmol/l as the main factor and a predicted probability of developing diabetes of 0.74. (C) Patient 3 had a BMI > 28 kg/m2 as the main risk factor and a predicted probability of developing diabetes of 0.89. (D,E,F) Patient 4, Patient 5, Patient 6 have no factors that make a major contribution to predicting a positive event and all have a predicted probability of developing diabetes of less than 0.13. The contribution of risk factors to this patient can be observed in the graph. Red represents the positive contribution and blue represents the negative contribution.
Discussion
PPDM-A is the most common sequela of pancreatitis11,17,18, and is characterized by poorer glycaemic control, a higher risk of developing cancer, and a higher risk of mortality10,19,20,21. However, the pathogenesis of diabetes secondary to acute pancreatitis is convoluted, which makes early clinical identification challenging. In addition, there is still no good classification model to predict PPDM-A in advance. Our feature contribution analysis prompted us to try to build a simpler predictive model based on a minimum number of the most influential features. To this end, we could fully evaluate the model’s performance using only nine pieces of information obtained about the patient. This study examined the ability to use nine clinical features to predict PPDM-A, leading to early intervention and effective PPDM-A screening.
Our results suggest that clinical features can accurately predict the risk of PPDM-A after the onset of acute pancreatitis, although none of the nine clinical features we included directly reflected islet cell function. The findings reveal that indicators related to pancreatic injury (APFC, PPC, ANC, WON, amylase) affected the predicted outcome during the feature selection process, consistent with previous studies22,23. However, growing evidence compels a reconsideration of the dogma: “β-cell destruction is the only underlying mechanism of diabetes after acute pancreatitis”. Our study reveals that age, BMI, metabolic status, and comorbidities play different roles in individuals and may lead to opposite outcomes. It may be due to the mutual influence of organs on each other in the case of imbalanced glucose metabolism24,25,26. We assessed the characteristics that had the most profound impact on the model's predictions by Shapley value. We found that admission glucose, obesity (BMI > 28 kg/m2), and HDL-C < 1.03 mmol /l were the three factors that had the most significant impact on the outcome, and this result is consistent with the results of feature extraction. Prior studies also have demonstrated that hyperglycemia during hospitalization of acute critical illness is associated with emergent diabetes and identifying patients for subsequent diabetes screening. In a Scottish retrospective cohort study, 2.3% of patients with an emergency admission to a hospital without previously known diabetes were newly diagnosed with diabetes within 3-years27. In a nationwide national cohort of consecutive patients with acute myocardial infarction without known diabetes, hyperglycemia at admission was significantly associated with subsequent diabetes (odds ratio: 2.56; 95% CI 2.15–3.06)28. Furthermore, changes in lipid metabolism and abnormal distribution of abdominal adipose tissue are significantly associated with PPDM-A.
Our work has several clinical applications. Firstly, it can facilitate early intervention in patients at high risk of diabetes. Early intervention for the development of diabetes is not currently studied. However, based on the health management knowledge of type 2 diabetes29,30,31,32, we can assume that a combination of diet and exercise can significantly decrease the incidence of diabetes. Due to the low prevalence of PPDM-A, early analysis of the effectiveness of prevention strategies can present some challenges. Our model can identify and recruit people at high risk of developing PPDM-A above 70%. Therefore, the current study paves the way for future randomized controlled trials to investigate further the effectiveness of using the model for early prediction of PPDM-A and possible prevention interventions. Another influential application is to help construct effective screening methods for PPDM-A. The prevalence of PPDM-A can already be confirmed considerably by admission glucose, BMI metrics, and HDL-C at the onset of acute pancreatitis. This staged risk assessment model can be used in subsequent studies to construct more rational design protocols for prospective studies of PPDM-A. Finally, by using the Sharpely Value, we can predict the likelihood of PPDM-A occurring in patients and identify key causative factors that can be targeted to give personalized treatment recommendations.
Limitations
Our study has several limitations. Firstly, our model collected HIS data with inherent bias retrospectively from a small number of centers in urban China. Although we have tried to make use of existing knowledge about diabetes and AP in the selection of features in the HIS data, there are additional clinical features that may have been overlooked. These features may have better predictive effects. In addition, our overall data volume was inadequate. Although the sample size requirements for making inferences about the occurrence of PPDM-A using nine clinical information may be reduced, our model obtained low F1 and recall rates in predicting positive events, and these may have led to the under-recording of positive samples. Finally, the population to which the study applies is limited to HIS data information from the Chinese population, and the predictive value of its findings on other populations requires more data accumulation.
In conclusion, our work shows that it is possible to make accurate predictions of PPDM-A early in the onset of AP through nine clinical variables. These results may have many implications for the health of patients with PPDM-A. Our predictive model could form the basis for diagnosis and selective screening for PPDM-A and allow for personalized advice to patients on PPDM-A prevention. Future prospective studies, as well as multicentre, multicohort prospective studies, are needed to assess the clinical value of the model.
Methods
Study design and participants
This multicentre cross-sectional follow-up study included all consecutive patients with first-episode AP admitted to Zhongda Hospital of Southeast University, Yixing Second People’s Hospital, First Affiliated Hospital of Xinjiang Medical University, and Hunan Provincial People’s Hospital from 1 October 2016 to 31 October 2021. The study was approved by the ethics committee of Zhongda Hospital, affiliated with Southeast University, and performed according to the Declaration of Helsinki and relevant regulations. Informed consent was obtained orally from all participants.
Inclusion criteria were as follows:
-
1.
Diagnosis of AP based on international guidelines33;
-
2.
Age ≥ 18 years;
-
3.
Admitted with abdominal pain for < 48 h.
Exclusion criteria were as follows:
-
1.
Recurrent AP;
-
2.
Chronic pancreatitis;
-
3.
History of diabetes, HbA1c ≥ 6.5% or hypoglycemic drugs diagnosed before AP attack;
-
4.
History of malignant tumor;
-
5.
Severe heart, liver, kidney and other organ dysfunction;
-
6.
History of immune system diseases or hormone use;
-
7.
Mental illness, unable to cooperate with research;
-
8.
Pregnancy and lactation;
-
9.
Data missing > 10%
-
10.
Death during admission.
Data collection
Date of demographic parameters (gender, age), Family history of diabetes, smoking, drinking, Clinical comorbidities (CVD, NAFLD, and hypertension), vital signs (systolic blood pressure, diastolic blood pressure, body mass index (BMI)), laboratory studies (amylase, admission glucose, serum calcium, hepatic and renal functions, lipid profiles), severity and etiology of AP, length of stay, infection condition, local complications and systemic complications of AP were extracted through HIS.
Definitions and classification
BMI was calculated as weight (kg) divided by the square of height (m). According to the Guidelines for Prevention and Control of Overweight and Obesity in Chinese adults, obesity was defined as BMI greater than or equal to 28 kg/m2. The severity of AP was defined as mild, moderately severe, and severe according to the revised Atlanta classification33. Local complications include acute peripancreatic fluid collection(APFC), pancreatic pseudocyst(PPC), acute necrotic collection(ANC), and walled-off necrosis (WON)33. Signs of systemic inflammatory response syndrome (SIRS) defined by presence of two or more criteria: 1. Heart rate > 90 beats/min; 2. Core temperature < 36 °C or > 38 °C; 3. White blood count < 4000 or > 12,000/mm3; 4. Respirations > 20/min or PCO2 < 32 mm Hg. PPDM-A was defined as new onset diabetes more than 90 days after AP with no history of diabetes before the AP episode14,34 and absence of type 1 diabetes–associated autoimmunity. Organ failure is defined as a score of 2 or more for one of these three organ systems using the modified Marshall scoring system35.
Statistical analysis
Logistic regression L1 regularization was used to screen for appropriate features. We extracted features with weights > 0.01 as core classification features. The top 9 features were obtained for the follow-up study.
We constructed five common machine learning algorithms using Orange336: logistic regression, neural networks, random forests, catBoost37, and SVM. Fivefold cross-validation was used to evaluate the predictive power of the model. Five metrics, Area under ROC(AUC), Classification accuracy (CA), F1, accuracy, and recall, were used to evaluate the model. AUC is the area under the receiver-operating curve. The larger the AUC, the better the model effect. CA is the proportion of correctly classified samples. F1 is a weighted harmonic mean of precision and recall. F1 can be used to evaluate the model's trade-off between precision and recall metrics. Precision is the proportion of true positives among instances classified as positive. Recall is the proportion of true positives among all positive instances in the data. In assessing the model's effectiveness, we primarily used ROC and Calibration curves in the test set to assess the predictive effectiveness of the model. We analyzed the average performance of the model ground and the performance of the predicted positive events separately.
To understand the relationship between individual features and model output, we use Shapley values38, which can be used to evaluate the outcome of complex models and are particularly applicable to artificial neural networks and gradient boosting machines (CatBoost). By averaging over all samples, the Shapley values estimate the contribution of each feature to the overall model prediction. In addition, Shapley analysis allows the contribution of each individual risk factor to the diagnosis to be assessed.
Data availability
All the data are available upon request to the corresponding author.
References
Lee, P. J. & Papachristou, G. I. New insights into acute pancreatitis. Nat. Rev. Gastroenterol. Hepatol. 16, 479–496. https://doi.org/10.1038/s41575-019-0158-2 (2019).
Mederos, M., Reber, H. & Girgis, M. J. J. Acute pancreatitis: A review. JAMA 325, 382–390. https://doi.org/10.1001/jama.2020.20317 (2021).
Iannuzzi, J. P. et al. Global incidence of acute pancreatitis is increasing over time: A systematic review and meta-analysis. Gastroenterology 162, 122–134. https://doi.org/10.1053/j.gastro.2021.09.043 (2022).
Schepers, N. J. et al. Impact of characteristics of organ failure and infected necrosis on mortality in necrotising pancreatitis. Gut 68, 1044–1051. https://doi.org/10.1136/gutjnl-2017-314657 (2019).
Forsmark, C. E., Vege, S. S. & Wilcox, C. M. Acute pancreatitis. N. Engl. J. Med. 375, 1972–1981. https://doi.org/10.1056/NEJMra1505202 (2016).
Das, S. L. et al. Newly diagnosed diabetes mellitus after acute pancreatitis: A systematic review and meta-analysis. Gut 63, 818–831. https://doi.org/10.1136/gutjnl-2013-305062 (2014).
Shen, H. N., Yang, C. C., Chang, Y. H., Lu, C. L. & Li, C. Y. Risk of diabetes mellitus after first-attack acute pancreatitis: A national population-based study. Am. J. Gastroenterol. 110, 1698–1706. https://doi.org/10.1038/ajg.2015.356 (2015).
Lee, Y. K., Huang, M. Y., Hsu, C. Y. & Su, Y. C. Bidirectional relationship between diabetes and acute pancreatitis: A population-based cohort study in Taiwan. Medicine 95, e2448. https://doi.org/10.1097/md.0000000000002448 (2016).
Cho, J. & Petrov, M. S. Pancreatitis, pancreatic cancer, and their metabolic sequelae: Projected burden to 2050. Clin. Transl. Gastroenterol. 11, e00251. https://doi.org/10.14309/ctg.0000000000000251 (2020).
Woodmansey, C. et al. Incidence, demographics, and clinical characteristics of diabetes of the exocrine pancreas (type 3c): A retrospective cohort study. Diabetes Care 40, 1486–1493. https://doi.org/10.2337/dc17-0542 (2017).
Petrov, M. S. & Yadav, D. Global epidemiology and holistic prevention of pancreatitis. Nat. Rev. Gastroenterol. Hepatol. 16, 175–184. https://doi.org/10.1038/s41575-018-0087-5 (2019).
Ewald, N. et al. Prevalence of diabetes mellitus secondary to pancreatic diseases (type 3c). Diabetes Metab. Res. Rev. 28, 338–342. https://doi.org/10.1002/dmrr.2260 (2012).
Vujasinovic, M. et al. Pancreatic exocrine insufficiency, diabetes mellitus and serum nutritional markers after acute pancreatitis. World J. Gastroenterol. 20, 18432–18438. https://doi.org/10.3748/wjg.v20.i48.18432 (2014).
Petrov, M. S. & Basina, M. Diagnosis of endocrine disease: Diagnosing and classifying diabetes in diseases of the exocrine pancreas. Eur. J. Endocrinol. 184, R151-r163. https://doi.org/10.1530/eje-20-0974 (2021).
Jivanji, C. J., Soo, D. H. & Petrov, M. S. Towards reducing the risk of new onset diabetes after pancreatitis. Minerva Gastroenterol. Dietol. 63, 270–284. https://doi.org/10.23736/s1121-421x.16.02365-5 (2017).
Hart, P. A., Andersen, D. K., Petrov, M. S. & Goodarzi, M. O. Distinguishing diabetes secondary to pancreatic diseases from type 2 diabetes mellitus. Curr. Opin. Gastroenterol. 37, 520–525. https://doi.org/10.1097/mog.0000000000000754 (2021).
Petrov, M. S. Metabolic trifecta after pancreatitis: exocrine pancreatic dysfunction, altered gut microbiota, and new-onset diabetes. Clin. Transl. gastroenterol. 10, e00086. https://doi.org/10.14309/ctg.0000000000000086 (2019).
Wynne, K., Devereaux, B. & Dornhorst, A. Diabetes of the exocrine pancreas. J. Gastroenterol. Hepatol. 34, 346–354. https://doi.org/10.1111/jgh.14451 (2019).
Cho, J., Scragg, R. & Petrov, M. S. Risk of mortality and hospitalization after post-pancreatitis diabetes mellitus vs. type 2 diabetes mellitus: A population-based matched cohort study. Am. J. Gastroenterol. 114, 804–812. https://doi.org/10.14309/ajg.0000000000000225 (2019).
Cho, J., Scragg, R. & Petrov, M. S. Postpancreatitis diabetes confers higher risk for pancreatic cancer than type 2 diabetes: Results from a nationwide cancer registry. Diabetes Care 43, 2106–2112. https://doi.org/10.2337/dc20-0207 (2020).
Cho, J., Pandol, S. J. & Petrov, M. S. Risk of cause-specific death, its sex and age differences, and life expectancy in post-pancreatitis diabetes mellitus. Acta Diabetol. 58, 797–807. https://doi.org/10.1007/s00592-021-01683-0 (2021).
Zhi, M. et al. Incidence of new onset diabetes mellitus secondary to acute pancreatitis: A systematic review and meta-analysis. Front. Physiol. 10, 637. https://doi.org/10.3389/fphys.2019.00637 (2019).
Sheikh, S. et al. Reduced β-cell secretory capacity in pancreatic-insufficient, but not pancreatic-sufficient, cystic fibrosis despite normal glucose tolerance. Diabetes 66, 134–144. https://doi.org/10.2337/db16-0394 (2017).
Castillo-Armengol, J., Fajas, L. & Lopez-Mejia, I. C. Inter-organ communication: A gatekeeper for metabolic health. EMBO Rep. 20, e47903. https://doi.org/10.15252/embr.201947903 (2019).
Pendharkar, S. A. et al. The role of gut-brain axis in regulating glucose metabolism after acute pancreatitis. Clin. Transl. Gastroenterol. 8, e210. https://doi.org/10.1038/ctg.2016.63 (2017).
Gillies, N. A., Pendharkar, S. A., Singh, R. G., Asrani, V. M. & Petrov, M. S. Lipid metabolism in patients with chronic hyperglycemia after an episode of acute pancreatitis. Diabetes Metab. Syndr. 11(Suppl 1), S233-s241. https://doi.org/10.1016/j.dsx.2016.12.037 (2017).
McAllister, D. A. et al. Stress hyperglycaemia in hospitalised patients and their 3-year risk of diabetes: A Scottish retrospective cohort study. PLoS Med. 11, e1001708. https://doi.org/10.1371/journal.pmed.1001708 (2014).
Shore, S. et al. Association between hyperglycemia at admission during hospitalization for acute myocardial infarction and subsequent diabetes: Insights from the veterans administration cardiac care follow-up clinical study. Diabetes Care 37, 409–418. https://doi.org/10.2337/dc13-1125 (2014).
Johansen, M. Y. et al. Effect of an intensive lifestyle intervention on glycemic control in patients with type 2 diabetes: A randomized clinical trial. JAMA 318, 637–646. https://doi.org/10.1001/jama.2017.10169 (2017).
Gregg, E. W. et al. Association of an intensive lifestyle intervention with remission of type 2 diabetes. JAMA 308, 2489–2496. https://doi.org/10.1001/jama.2012.67929 (2012).
Tuomilehto, J. & Schwarz, P. E. Preventing diabetes: Early versus late preventive interventions. Diabetes Care 39(Suppl 2), S115-120. https://doi.org/10.2337/dcS15-3000 (2016).
Guasch-Ferré, M. & Willett, W. C. The Mediterranean diet and health: A comprehensive overview. J. Intern. Med. 290, 549–566. https://doi.org/10.1111/joim.13333 (2021).
Banks, P. A. et al. Classification of acute pancreatitis–2012: Revision of the Atlanta classification and definitions by international consensus. Gut 62, 102–111. https://doi.org/10.1136/gutjnl-2012-302779 (2013).
American Diabetes Association Professional Practice Committee. 2. Classification and diagnosis of diabetes: Standards of medical care in diabetes-2022. Diabetes Care 45, S17-s38. https://doi.org/10.2337/dc22-S002 (2022).
Marshall, J. C. et al. Multiple organ dysfunction score: A reliable descriptor of a complex clinical outcome. Crit. Care Med. 23, 1638–1652. https://doi.org/10.1097/00003246-199510000-00007 (1995).
Demšar, J. et al. Orange: Data mining toolbox in Python. J. Mach. Learn. Res. 14, 2349–2353 (2013).
Dorogush, A. V., Ershov, V. & Gulin, A. CatBoost: Gradient boosting with categorical features support (2018).
Kalai, E. & Samet, Dov. On weighted Shapley values. Int. J. Game Theory 16, 205–222 (1987).
Acknowledgements
The authors thank all staffs for their support.
Funding
This work was supported by National Natural Science Foundation of China (81970717 and 82170845).
Author information
Authors and Affiliations
Contributions
J.Z.: contributed to the design of the study, analyzed data, and wrote the manuscript. Y.L.: contributed to the discussion, and reviewed the manuscript. J.H., C.Z., Y.W., X.Y., T.Y., X.S.: acquired data and reviewed the manuscript. Z.Y., L.L.: contributed to the design of the study, researched data, contributed to discussion, and reviewed and edited the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, J., Lv, Y., Hou, J. et al. Machine learning for post-acute pancreatitis diabetes mellitus prediction and personalized treatment recommendations. Sci Rep 13, 4857 (2023). https://doi.org/10.1038/s41598-023-31947-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-31947-4
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
