
Abstract
Sparse decomposition technique is a new method for nonstationary signal extraction in a noise background. To solve the problem of accuracy and efficiency exclusive in sparse decomposition, the bat algorithm combined with Orthogonal Matching Pursuits (BatOMP) was proposed to improve sparse decomposition, which can realize adaptive recognition and extraction of nonstationary signal containing random noise. Two general atoms were designed for typical signals, and dictionary training method based on correlation detection and Hilbert transform was developed. The sparse decomposition was turned into an optimizing problem by introducing bat algorithm with optimized fitness function. By contrast with several relevant methods, it was indicated that BatOMP can improve convergence speed and extraction accuracy efficiently as well as decrease the hardware requirement, which is cost effective and helps broadening the applications.
Similar content being viewed by others

Introduction
Background information
Signal extraction and signal–noise separation are always two of the research focuses in modern signal processing1, which are commonly used in biomedical signal features extraction, vibration signal analysis, seismic signal detection2, sound signals recognition3. In practical applications, such signals are often submerged in a variety of vibration or electromagnetic noise, and the occurrence times of the target signals are random, which are typical nonstationary signals. Fourier transform is one of the most classic signal analysis and extraction method, but it cannot accurately describe nonstationary signals4. In recent years, new theories and technologies continue to appear in signal extraction. For example, wavelet decomposition (WD)5,6, empirical mode decomposition7, Hilbert–Huang Transform (HHT), variational mode decomposition (VMD) algorithm8. These methods need to meet certain conditions to work, for example the decomposition levels, modal number, and termination thresholds.
To achieve a more flexible, concise and adaptive signal decomposition, researchers proposed sparse decomposition. This method represents the signal with as few atoms as possible in a given redundant dictionary by matching pursuit (MP) algorithm9, which is a greedy algorithm for sparse decomposition. Various new evaluation criteria and basis pursuit, orthogonal matching pursuit algorithm (OMP)10, and time–frequency spectrum segmentation methods11 were generated to select a set of optimal atoms from the constructed over-complete dictionary. In principle, if the dictionary redundancy is high enough and the iterations is large enough, the target signal can be perfectly extracted by OMP. On this basis, some general improved algorithms were proposed for example Regularized Orthogonal MP (ROMP)12 and Compressive Sampling MP (CoSaMP)13. These methods require the signal Sparsity K for efficient execution, but K is generally unknown in practice. Sparsity Adaptive MP (SAMP) was proposed for signal reconstruction without prior information of the sparsity, but it is more complex than other greedy algorithms under large sparsity level14. And improper initial step size will lead to excessive decomposition for SAMP. The accuracy of signal sparse decomposition mainly depends on the redundancy and refinement accuracy of the redundant dictionary. Over or under estimation as well as long-time running will appear in these algorithms under the condition of large sparsity. Generally, the greater the redundancy and refinement, the greater the probability of accurate signal decomposition. However, for the greedy algorithm mentioned above, these are at the cost of algorithm efficiency. The accuracy and efficiency are exclusive.
Aiming at two main research hotspots including sparse decomposition algorithm and over-complete atom dictionary of signal sparse decomposition15, we designed two typical universal atoms, and proposed an adaptive feature-based atom construction method for the extraction of non-stationary signals with unknown sparsity. Redundant dictionary is obtained by extending the feature-based atoms, which can balance the completeness and redundancy. A signal matching tracking extraction algorithm was developed based on the bat algorithm and OMP, which successfully combined the accuracy and efficiency and could effectively realize nonstationary time domain signal extraction.
Classical signal sparse decomposition algorithms
Signal sparse decomposition represents a signal by specific combinations of some atoms in a dictionary. For a given dictionary, the optimal combination can be accurately determined when all possible combinations were calculated. However, exhausting all combinations in a dictionary is a non-deterministic polynomial problem that is almost impossible to achieve for large dictionary bases. So, the requirement was changed to finding a suboptimal combination from the dictionary with the lowest possible number of atoms and the smallest possible extraction error. This will reduce the computational complexity significantly, and the MP algorithm is one of the algorithms that can achieve this requirement.
Assume that the represented signal is x with length of N. Let ℝ denote the Hilbert space in which a dictionary matrix D composed of a set of vectors {g1, g2,…,gn}. Each vector is an atom with the same length N and these vectors have been treated as normalized as \(\left\| g \right\|_{2}^{{}} = 1\).
With ξ1 = x, the MP algorithm selects one atom at a time from the dictionary matrix D that best matches x, satisfying (1),
where ibest is the index of the best matching atom in D. \(\left\langle \cdot \right\rangle\) is the inner product function.
The signal x is then decomposed into two parts, a sparse approximation \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{x}\) and an approximation residual ξ2:
Continues to select the atoms that best matches ξ2, iterating repeatedly and eventually the signal x can be approximated as a linear sum of these atoms:
For MP algorithm, the non-orthogonality between the vertical projection of the signal (or residuals) on the selected atoms and the residuals will lead to suboptimal iterative results instead of the best optimal, and convergence requires many iterations. The OMP algorithm is the orthogonalization of all selected atoms at each step of the decomposition, which makes the convergence faster with the same accuracy requirement. The convergence process of MP and OMP are described by a dictionary D with length of three, as shown in Fig. 1. However, although the OMP algorithm reduced iterations to some extent, it had to calculate the current residual and the inner product of all atoms within the current dictionary during each iteration, resulting in unsatisfied effectiveness. Therefore, this paper introduced the bat algorithm (BA) to optimize the matching tracking algorithm.

Convergence process of MP and OMP.
Bat algorithm presentation
The basic flow of bat algorithm is as follows:
-
(1)
Initialization: the best fitness Fitbest, bat population number Npop,, the max bat generation Ngen,, the current generation n = 0, initial flight frequency f0 = {fi0|i = 1,2,…, Npop}, acoustic loudness A0 = {Ai0|i = 1,2,…, Npop} and pulse emission frequency r0 = {ri0|i = 1,2,…, Npop}. The initial location of the bat colony is randomly generated according to (4):
$$ P^{0} { = }\left\{ {P_{i}^{0} \left| {i = 1,2,...,N_{pop} } \right.} \right\},\quad P_{i}^{0} \in \left( {P_{\min } \,P_{\max } } \right), $$(4) -
(2)
The best position Pnbest is determined by the fitness function Fitn.
$$ Fit^{n} \left( {P_{best}^{n} } \right){\text{ = arg }}\mathop {{\text{min}}}\limits_{{N_{pop} }} \left( {Fit^{n} } \right). $$(5) -
(3)
Update the velocity and position of the individual bat:
$$ \left\{ \begin{array}{*{20}l} f_{i} = f_{\min } + r_{1} \times \left( {f_{\max } - f_{\min } } \right) \\ v_{i}^{n} = v_{i}^{n - 1} + \left( {P_{best} - P_{i}^{n - 1} } \right) \cdot f_{i} \\ P_{i}^{n} = P_{i}^{n - 1} + v_{i}^{n} \\ \end{array} \right., $$(6)where r1 was a random number, satisfying r1∈[0,1]; fi was the search pulse frequency of the i-th bat; vin denoted the velocity of the i-th bat in the n-th igeneration, Pin denoted the position of the i-th bat in the n-th igeneration; and Pnbest is the current global optimal solution.
-
(4)
Generate a random number r2i ∈ [0,1] for each bat and update bat position according to (7).
$$ \left\{ \begin{array}{*{20}l} global optimization:P_{i}^{n + 1} { = }P_{i}^{n} + v_{i}^{n + 1} ,r_{2i}^{{}} \le r_{i}^{n} \\ local optimization:P_{i}^{n + 1} { = }P_{i}^{n} + \lambda_{ri} \mathop {A^{n} }\limits^{\_\_} * \left( {P_{\max }^{{}} - P_{\min }^{{}} } \right),r_{2i}^{{}} > r_{i}^{n} \\ \end{array} \right., $$(7)where: η was a random number, satisfying η ∈ [− 1; 1] and Ān was the mean fitness of the bat population.
-
(5)
Update the fitness
$$ Fit^{n + 1} \left( i \right){ = }Fit\left( {P_{i}^{n + 1} } \right). $$(8) -
(6)
For each bat, a random number r3i is generated, and update the position:
$$ \left\{ {\begin{array}{*{20}l} {P_{i}^{n + 1} { = }P_{i}^{n + 1} ,} & {r_{3i} > A_{i}^{n} \& \& Fit_{i}^{n + 1} < Fit_{i}^{n} } \\ {P_{i}^{n + 1} = P_{i}^{n} ,} & {Fit_{i}^{n + 1} = Fit_{i}^{n} ,\;otherwise} \\ \end{array} } \right.. $$(9) -
(7)
The fitness and pulse emission frequency are updated:
$$ \left\{ \begin{array}{*{20}l} r_{i}^{n + 1} { = }r_{i}^{0} \left( {1 - e^{ - \gamma n} } \right) \\ A_{i}^{n + 1} = \lambda A_{i}^{n} \\ \end{array} \right.. $$(10)where, λ ∈ (0,1), γ > 0, when \(n \to \infty\), \(A_{i}^{n} \to 0\), \(r_{i}^{n} \to r_{0}\).
-
(8)
Find the current matching atom based on the optimal solution.
-
(9)
The random perturbation of the current optimal solution in step 4 can effectively avoid the iterative result from falling into a local optimal solution, which helped to find the global optimal solution fast and accurate.
-
(10)
The Ackley function iss used to test the BA. The expression of the Ackley function is as follows:
$$ f(x) = - c_{1} \exp \left( { - 0.2\sqrt {\frac{1}{n}\sum\limits_{j = 1}^{n} {x_{j}^{2} } } } \right) - \exp \left( {\frac{1}{n}\sum\limits_{j = 1}^{n} {\cos \left( {2\pi x} \right)} } \right) + e. $$(11)
In this study, n = 2, c1 = 20, e = 2.71289. the Ackley function was taken as the fitness function and the global minimum of this function was searched by the above methods. The particle swarm optimization (PSO)16, artificial fish school algorithm (AFSA)17 and Cuckoo Search (CS)18 are used for comparison. The population size and iteration numbers of these intelligent algorithms are the same to ensure rigorous comparison. The search paths and results are shown in Fig. 2.

The optimal trajectory of different methods. (a,b) Show the 3D view and contour attempt of the optimal trajectory, respectively. Colors: black: the merit-seeking trajectories of PSO, blue: the merit-seeking trajectories of AFSA, green: the merit-seeking trajectories of CS, red: the merit-seeking trajectories of BA.
The detailed values are shown in Table 1. The comparison of the tracking trajectory and the optimization results show that BA has advantage of high convergence speed and computational accuracy because the gradient of the optimization deviation is the largest and the optimization results are closest to the true value.
Methods
BatOMP sparse decomposition
General atomics designed for typical signals
For sinusoidal-like and one-sided decaying oscillatory signals, g-atoms are constructed:
where c is the normalization factor to ensure that the original signal has the same energy as its sparse decomposition results; d: the attenuation factor; t: the sampling time; t1: start point of atomic appearance; t2: the ending point; f: signal frequency and ϕ: phase. The time domain waveforms of g-atoms with different parameters are shown in Fig. 3.

Time domain waveforms of g-atoms with different parameters.
When the attenuation factor d = 0, the g-atom degenerates to standard sine wave; when d increases, the g-atom performs sinusoidal damped oscillation. Therefore, this atom has a strong match with sinusoidal signals, and single-sided oscillatory decay signals.
For kind of triangle waves, charge–discharge waves, and bilateral decay oscillation signals, tr atoms are constructed:
where d1 and d2 are the bilateral damping factors; t0 is the bilateral boundary of the atomic; [t1, t2] is the atomic time range; and η is the bilateral scaling factor.
The time domain waveforms of tr-atoms with different parameters are shown in Fig. 4. When the bilateral scaling factor η = 0, the tr-atom degenerates to single-sided oscillating atom (reverse-order g-atom); when 0 < η < 1 and the atomic frequency is low enough, the tr-atom behaves as a charge–discharge triangle wave; when η = 1, the tr-atom with low-frequency behaves as a triangle-like wave, and behaves as bilateral oscillating decay signal with high-frequency.

Time domain waveforms of tr-atoms with different parameters. ‘ita’ represents η.
The above analysis shows that the constructed g-atoms and tr-atoms are very flexible and could match almost typical testing signals by parameter adjustment.
Dictionary training algorithm
A dictionary training algorithm based on feature parameters was studied to determine the key parameters of feature base-atom and to balance the completeness and redundancy for redundant dictionary library construction.
When constructing the redundancy dictionary, we firstly use the short-time Fourier transform to initially determine the frequency fs and phase ϕs of the target signal in the original data x. Then, standard sine atom s0 = sin(2πfst + ϕs) is constructed. The correlation detection technique is used by calculating the correlation function of the original data and the sine atom, and the upper and lower envelopes of the correlation function are obtained by searching the positive and negative peaks of the correlation function. The points of the maximum positive gradient between the positive and negative peaks are the extracted range of the target signal. Thus, the signal sample Ei in the original observation sequence is extracted. The time information section obtained by the above calculation determines the time domain parameters such as t0, t1 and t2 of the characteristic atom.
Accurate time and frequency domain parameters are obtained by Hilbert transform of Ei.
where: h(t) is the Hitch transform factor.
Complex analytic signal as follows is constructed:
where, A(t) is the amplitude function:
and, ϕ(t) is the phase function:
The instantaneous frequency of Ei is given by (18):
The base-atom is obtained with the time information gained by the correlation detection and localization algorithm and the time–frequency parameter information obtained by Hilbert transform as the reference. And the redundant dictionary of this feature atom is constructed by performing equal-step discrete expansion of the time–frequency parameters on both sides of the reference values.
where, D(:, j) = {gji|i = 1,2,…,N}, denoting the set of atoms consisting of extensions of the characteristic base-atom gi0. Atoms has the same length N as x.
BatOMP improved sparse decomposition algorithm
The optimization-seeking process can be viewed as a global optimization problem. In order to solve the problems of large computation and low efficiency of existing matching tracking algorithms, the adaptive matching tracking algorithm, BatOMP, with fast convergence and accurate approximation is studied by combining BA into the OMP algorithm.
For BatOMP, the bat individual positions Pi represent the atoms column index in the redundant dictionary D, thus: gi = D(:,Pi). And for noise-containing signal extraction, the fitness function of the traditional sparse decomposition is improved to take the ratio of the ℓ-2 norm of the residual and the inner product as the fitness function. The target signal tends to be regular signals and most random noises obeys Gaussian distributions with zero mean error. So, the ℓ-2 norm of the former is greater than the latter. In consequence, the smaller the fitness indicates that the residual sequence contains smaller effective signal components and higher signal-to-noise separation. In addition, the larger the inner product, the better matchs between the atom and the residual. So, the optimal individual bat position Pb is determined and saved according to (20).
and
where A is the matched dictionary, composed by the selected best matching atoms.
The flow chart of BatOMP is as follows:

The overall flow chart of the proposed signal extraction algorithm is shown in Fig. 5. The flow of sparse decomposition based on BA and MP (BatMP), CoSaMP and SAMP are also presented for comparison. Different algorithms are distinguished by different border colors. All of the four methods consist of four main modules: 1. redundant dictionary construction, 2. algorithm initialization, 3. circulative iteration and optimization, and 4. result output. In this paper, module 1 and 4 are almost same for the different methods, module 2 is slightly different, and the differences are mainly reflected in module 3.

The overall flow chart of signal extraction algorithms.
Experiments
We constructed a nonstationary signal x to test the methods described above:
where s is nonstationary target signal including pulse signal s1 and partial discharge signal s2 distributed in different regions, and ns is background noise subjecting to Gauss distribution. The sampling rate fs = 1500 Hz, sampling time T = 1 s, and SNR is 7.402 dB. Thus, the sequence length N is 1500.
The PC for the testing features a i7-8550U CPU Core(TM) @ 1.80 GHz with 16.0 GB RAM, 4 cores and 8 Logic processors, running the 64 bit operating system.
Time–frequency parameter calculation
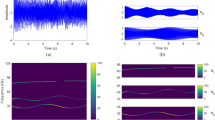
First, time and frequency analysis was performed, and results were shown in Fig. 6. From Fig. 6, after 0.4 s, s1 decreases to zeros with the action of attenuation term.

Waveform of the testing signal. The upper and lower subplot denote the time domain and frequency domain waveforms, respectively; red and blue lines in the upper subplot denote the original signal x and the target signal s = s1 + s2, respectively.
Secondly, time information of the target signal was calculated by the correlation detection and localization algorithm described above, shown in Fig. 7. L1 and L2 are the calculated start and end indexes of the target segments, and L is the length of the segmentations. Accordingly, t1 = L1/fs ≈ 0 s, t2 = L2/fs ≈ 0.415 s for ŝ1, and t1 = L1/fs ≈ 0.501 s, t2 = L2/fs ≈ 0.671 s for ŝ2.

Target segment extraction based on correlation detection technique. The upper and lower subplot denoted the segmentation result of signal components s1 and s2, respectively. In the upper subplots, the black solid lines are cross-correlation functions; red and blue scatters describe the envelopes of the effective correlated windows; and red dotted line are calculated time range. The green cycles indicate the start–end of the target segments.
Different dictionaries construction and testing
After determining the key parameters of s, the redundant dictionary GT consisting of the two new atoms was created by dictionary training algorithm. And two typical redundant dictionaries were built by Discrete Cosine Transformation (DCT) and Gabor dictionary for comparison. The dictionaries’ sizes are shown in Table 2.
Since the OMP method will iterate over the whole dictionary repeatedly, the extraction results are relatively accurate. In view of this, we take the results of OMP from statistical analyses to illustrate the performance of the different dictionaries, as shown in Fig. 8. The vertical axis represents the deviation between the extracted signal ŝ and actual signal s:

Dictionary testing.
We quantified the errors by RMS, the root mean square value of Amperr. The time–frequency parameters were not considered when building the DCT dictionary by MATLAB, so there was the maximum deviation in the correlative results. The atom expression of Gabor dictionary is as follows:
We can see the lack of unilateral oscillation atoms by contrast with g-atom and tr-atom. Relatively, GT dictionary is completer and more accurate, so OMP based on GT dictionary gave minimum errors and the shortest optimizing time.
Algorithm performance testing
The algorithms involved in the article including MP, OMP, SAMP, CoSaMP, BatMP and the proposed BatOMP were carried out for performance comparison.
The extraction results and corresponding errors obtained by different methods were shown in Fig. 9. Figure 9a,c,e display the extracted signals ŝ by different methods based on DCT, Gabor and GT dictionary respectively. And Fig. 9b,d,f presente corresponding errors obtained by Eq. (26).

Signal extraction results. Colors: jasper: the target signal s; red: result of BatOMP; black: result of BatMP; bule: result of CoSaMP; green: result of SAMP; pink: result of OMP; skyblue: result of MP.
The efficiency analysis of different algorithms and dictionaries are shown in Fig. 10 and Table 3.

Quantitative analysis of experimental results. Blue bares mark the running time (the left axis) and red bars indicate the extraction errors (the right axis). For each method, the three bars of a sort from left to right represent the result of DCT, Gabor and GT dictionary respectively.
Because that the MP and OMP method traversed through the whole dictionary, the accuracies are relatively high and the latter is superior to the former.
The step length l of SAMP and sparsity q of CoSaMP were determined by expert experience. Because a certain amount atoms have to choose every time, there are clearly overextraction for these two methods. It’s important to note that better parameters may be obtained by trial and error, but it is not suitable for real-time data processing.
For BatOMP, the best match atoms are determined by bat colony optimization. Every time before the searching, the bat individuals randomly scattered over the whole dictionary, and then gradually gather to the optimum solution through local optimization and global optimization. The optimal trajectories of ten bat individuals were randomly selected to show the convergence process, as shown in Fig. 11. The optimum solution is the index of the optimum matching atom in the redundant dictionary.

A complete search process of the bat colony. Obviously, the bats gradually converge to the best solution from the original scattered position.
The difference between BatMP and BatOMP is similar to MP and OMP. BatOMP based on GT dictionary occupied the highest precision, probably because that MP and OMP took the inner product as the fitness function which leading to suboptimum for signal extraction. So, the results reflect the availability of the new fitness in some extent.
Moreover, the first four methods executed vast and complex matrix computations many times during the optimizing period, so they are time-consuming and require very high CPU occupancy rate compared with BatOMP. In other words, BatOMP can be widely used even on low lever machines. This is important for the occasions without algorithmic workstation and high-performance computer, i.e. field data processing or low cost testing.
Conclusion
For nonstationary signal extraction, the dictionary training algorithm based on feature parameters is firstly used to determine the key parameter range of feature atoms, which can effectively reduce the redundancy while ensuring the completeness of the redundant dictionary; the bat algorithm combined with OMP is proposed to transform the signal sparse decomposition problem into an optimization problem with ratio of the ℓ-2 norm of the residual and the inner product as the fitness, which can improve the efficiency of the sparse decomposition algorithm. The experimental results showed that compared with other methods, the BatOMP algorithm is occupied with high efficiency, which can extract nonstationary signals form noise background without over constrained prior knowledges and avoid excessive decomposition. Testing results show that the proposed algorithm outperforms previous method in speeding up the convergence procedure and meanwhile ensuring high accuracy. Compared with the existing sparse decomposition algorithm, BatOMP requires much lower levels of hardware configuration. So, the new method will be helpful for to reducing data processing cost and enlarging the application fields.
References
Bohra, P. & Unser, M. Continuous-domain signal reconstruction using Lp-norm regularization. IEEE Trans. Signal Process. 69, 1–1 (2020).
Gao, Y., Zhao, P., Li, G. & Li, H. Seismic noise attenuation by signal reconstruction: An unsupervised machine learning approach. Geophys. Prospect. 69, 1–50 (2021).
Mack, W. & Habets, E. A. P. Deep filtering: Signal extraction and reconstruction using complex time-frequency filters. IEEE Signal Process. Lett. 27, 61–65. https://doi.org/10.1109/LSP.2019.2955818 (2020).
Li, X.-L., Wang, N., Gao, D.-Z. & Li, Q. A sound field separation and reconstruction technique based on reciprocity theorem and fourier transform. Chin. Phys. Lett. 35, 114301. https://doi.org/10.1088/0256-307x/35/11/114301 (2018).
Wang, X.-L. & Wang, W.-B. Harmonic signal extraction from noisy chaotic interferencebased on synchrosqueezed wavelet transform. Chin. Phys. B 24, 080203. https://doi.org/10.1088/1674-1056/24/8/080203 (2015).
Wolf, G., Mallat, S. & Shamma, S. Rigid motion model for audio source separation. IEEE Trans. Signal Process. 64, 1822–1831 (2016).
Ukte, A., Kizilkaya, A. & Elbi, M. D. Two empirical methods for improving the performance of statistical multirate high-resolution signal reconstruction. Dig. Signal Process. 26, 36–49 (2014).
Dragomiretskiy, K. & Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 62, 531–544 (2014).
Mallat, S. G. & Zhifeng, Z. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process. 41, 3397–3415. https://doi.org/10.1109/78.258082 (1993).
Mailhé, B. & Gribonval, R. A low complexity Orthogonal Matching Pursuit for sparse signal approximation with shift-invariant dictionaries. In 2009 IEEE International Conference on Acoustics, Speech and Signal Processing.
Baokang, Y., Bin, W., Fengxing, Z., Weigang, L. & Bo, X. Sparse decomposition method based on time–frequency spectrum segmentation for fault signals in rotating machinery. ISA Trans. 83, 142–153 (2018).
Needell, D. & Vershynin, R. Signal recovery from inaccurate and incomplete measurements via regularized orthogonal matching pursuit. IEEE J. Select. Top. Signal Process. 4(2), 310–316 (2010).
Needell, D. & Tropp, J. A. CoSaMP: Iterative signal recovery from incomplete and inaccurate samples. Commun. ACM 53, 93 (2010).
Sun, G., Zhou, Y., Wang, Z., Dang, W. & Li, Z. Sparsity adaptive compressive sampling matching pursuit algorithm based on compressive sensing. J. Comput. Inf. Syst. 8, 2883–2890 (2012).
Zhu, J. & Xiaolu, L. Electrocardiograph signal denoising based on sparse decomposition. Healthcare Technol. Lett. 4, 134–137 (2017).
Clerc, M. Particle Swarm Optimization (Fractional Order Darwinian Particle Swarm Optimization, 2016).
Fei, W., Xu, X. & Jing, Z. J. Single airport ground-holding problem optimizing strategy based on artificial fish school algorithm. J. Nanjing Univ. Aeronaut. Astronaut. 41, 116–120 (2009).
Civicioglu, P. & Besdok, E. J. A conceptual comparison of the Cuckoo-search, particle swarm optimization, differential evolution and artificial bee colony algorithms. Artif. Intell. Rev. 39, 315–346 (2013).
Acknowledgements
This research was sponsored by National Natural Science Foundation of China (41904080), the Key Research and Development (R&D) Projects of Shanxi Province (201903D121118) and Scientific and Technologial Innovation Programs of Higher Education Institutions in Shanxi.
Author information
Authors and Affiliations
Contributions
S.C.G. wrote the main manuscript text, and S.D.Z. participated in the experiment. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ge, Sc., Zhou, S. Nonstationary signal extraction based on BatOMP sparse decomposition technique. Sci Rep 11, 17869 (2021). https://doi.org/10.1038/s41598-021-97431-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-97431-z
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
