
Abstract
Cauliflower (Brassica oleracea L. var. botrytis) is a distinctive vegetable that supplies a nutrient-rich edible inflorescence meristem for the human diet. However, the genomic bases of its selective breeding have not been studied extensively. Herein, we present a high-quality reference genome assembly C-8 (V2) and a comprehensive genomic variation map consisting of 971 diverse accessions of cauliflower and its relatives. Genomic selection analysis and deep-mined divergences were used to explore a stepwise domestication process for cauliflower that initially evolved from broccoli (Curd-emergence and Curd-improvement), revealing that three MADS-box genes, CAULIFLOWER1 (CAL1), CAL2 and FRUITFULL (FUL2), could have essential roles during curd formation. Genome-wide association studies identified nine loci significantly associated with morphological and biological characters and demonstrated that a zinc-finger protein (BOB06G135460) positively regulates stem height in cauliflower. This study offers valuable genomic resources for better understanding the genetic bases of curd biogenesis and florescent development in crops.
Similar content being viewed by others

Main
Brassica oleracea, the CC-genome diploid in the Triangle of U1, is characterized by its remarkable morphological diversity, bearing specialized leafy, stem or floral organs represented by Chinese kale (B. oleracea var. alboglabra), kohlrabi (var. gongylodes), Brussels sprouts (var. gemmifera), cabbage (var. capitata), broccoli (var. italica) and cauliflower (var. botrytis). However, the great variety of wild species, intraspecific crossability2 and strong self-incompatibility3 raise serious challenges for investigating the domestication history of B. oleracea, the authentic relationships among its subspecies and its bona fide ancestral source. Recently, multiple pieces of evidence have indicated that the Aegean-endemic Brassica cretica might be the closest wild relative of the currently cultivated B. oleracea4.
Among the B. oleracea subspecies, cauliflower is an economically important vegetable crop possessing unique flavor, high nutritional value and anticancer activity2. The global production of cauliflower and broccoli is continuously increasing and reached over 25.5 million tons with a net value of 14.1 billion US dollars in 2020 (http://faostat.fao.org/). Cauliflower and broccoli, regarded as the ‘arrested inflorescence’ lineage, are speculated to have been domesticated ~2,500 years ago5. Cultivated cauliflower is generally divided into loose-curd and compact-curd classes according to its curd solidity6, although the detailed population structure of cauliflower has not been well clarified owing to its short evolutionary history and narrow genetic background7,8. Until recently, three ecotypes with different maturity levels had been roughly determined in cauliflower, excluding Romanesco cauliflower5. Now, two draft genome sequences of cauliflower have been reported9,10. These have expanded our understanding of modern cauliflower demography and the phenotypic variation that has occurred during differentiation and domestication. However, owing to the low contiguity of the genome sequence, the lack of high-density markers, and the limited sampling of cauliflower and ancestral wild accessions in previous studies4,5,10,11, the genome-wide effects of selection and the genetic mechanisms underlying important agronomic traits in cauliflower remain poorly understood.
Curd biogenesis is a complex process regulated by multiple developmental signals and environmental factors10,12,13, involving vernalization14, photoperiod15, gibberellin16, and autonomous17 flowering-related pathways. In cauliflower and Arabidopsis, several important curd-biogenesis-related genes have been identified, including MADS-box genes CAULIFLOWER (CAL/AGL10), APETALA1 (AP1/AGL7)18, FRUITFULL (FUL/AGL8)19, SUPPRESSOR OF OVEREXPRESSION OF CO 1 (SOC1/AGL20)20, AGAMOUSLIKE 24 (AGL24)21 and XAANTAL2 (XAL2/AGL14)22, as well as phosphatidylethanolamine-binding protein TERMINAL FLOWER 1 (TFL1)23 and a plant-specific transcription factor gene, LEAFY (LFY)24. The nested-spiral pattern of cauliflower curd has been preliminarily deciphered using a three-dimensional computational model13. However, our knowledge is still segmental and the underlying genetic mechanisms remain elusive.
In this study, we have updated the high-quality reference genome assembly of cauliflower C-8 (V2) and present a comprehensive genomic variation map derived from the resequencing of 971 diverse cauliflower accessions and their relatives. Using these data, we performed population genomic analyses to genetically dissect the evolutionary relationships among B. oleracea subspecies and explored the molecular mechanism of curd biogenesis and seven important agronomic traits. Further functional experiments demonstrated that a zinc-finger protein (BOB06G135460) positively regulates SH and three significantly associated biomass traits in cauliflower. This work provides information to better understand the nature of cauliflower and lays a solid foundation for future germplasm utilization and improvements in cauliflower breeding.
Results
De novo assembly and annotation of the cauliflower genome
We updated a highly contiguous and complete genome sequence of the cauliflower inbred line C-8 (V2) using an integrated approach including PacBio SMRT sequencing, Bionano optical mapping and Hi-C technologies, supplemented with Illumina whole-genome shotgun data9 (Supplementary Fig. 1a). As a result, we achieved a high-quality assembly comprising 557 contigs with a contig N50 of 10.57 Mb and a total genome size of 568.52 Mb that anchors and orients 557.11 Mb (approximately 98%) onto nine pseudochromosomes. Compared with the previously published C-8 genome9, this updated version is markedly improved with better completeness and contiguity. Moreover, the C-8 (V2) genome exhibits greater advantages in terms of contig N50 and genome quality (higher BUSCO value and lower gap numbers) compared with the recently released cauliflower genome ‘Korso’10 (Supplementary Fig. 2 and Table 1).
By integrating evidence from ab initio predictions, RNA sequencing (RNA-seq) data and homology searching, a total of 57,983 protein-coding genes were functionally annotated. Approximately 331.36 Mb (58.30%) of the updated genome was identified as consisting of repeat sequences. Of these, Gypsy-type (13.42%) and Copia-type (10.14%) long terminal repeats were the predominant repetitive elements in the entire genome (Supplementary Table 2). In addition, nine potential centromeric regions were distinguished across the entire genome, ranging from 1.9 to 6.9 Mb (Supplementary Fig. 1b). These findings demonstrate the high quality and coverage of the C-8 (V2) genome sequence and indicate that it provides an ideal model system for studying curd organ development and a preferred resource for cauliflower breeding.
Genomic variation of cauliflower and its relatives
To achieve a comprehensive genomic variation map, we collected a total of 820 diverse cauliflower and B. oleracea accessions for whole-genome resequencing and downloaded 151 additional accessions derived from up-to-date data available from previous studies11,25. In total, we acquired 726 cauliflower accessions representing broad genetic and phenotypic diversity, as well as 43 accessions for broccoli, 50 for cabbage, 13 for Brussels sprouts, 28 for kohlrabi, 59 for Chinese kale, and 30 for wild relatives and other B. oleracea subspecies (Supplementary Table 3). Resequencing of these accessions yielded 7.59 Tb of sequencing data, with an average depth of 7.8× and coverage of 90.55% of the C-8 (V2) genome. After alignment with the cauliflower reference genome, we detected a final set of 17,917,317 single-nucleotide polymorphisms (SNPs) and 10,831,040 insertions and deletions (InDels), much more than previously reported for B. oleracea11. Among these variants, 1,872,979 (3.11%) nonsynonymous SNPs and 720,309 (1.47%) frameshift InDels were located within coding regions of 55,927 (96.45%) annotated genes. In addition, 903,486 variants in 53,491 (92.25%) genes showed potentially large effects, leading to truncated or elongated transcripts, frameshift mutations or other disruptions of protein-coding capacity (Supplementary Tables 4 and 5). These variants provide a valuable resource for functional genomic researches and marker-assisted breeding in B. oleracea.
Evolutionary relationships among B. oleracea subspecies
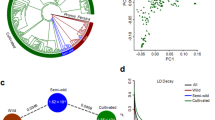
Although the representative B. oleracea subspecies are easily distinguished based on their specialized edible organs, the exact evolutionary relationships among B. oleracea subspecies remain uncertain because of their frequent genetic exchanges4,10,11. To explore the phylogenetic relationships among these plants, we used a subset of 69,275 SNPs at fourfold degenerate sites (4d-SNPs) among 971 B. oleracea accessions to build a maximum-likelihood (ML) tree. Evidence from the ML tree, model-based clustering and principal component analysis (PCA) supported four major clades: clade 1, solely composed of Chinese kale; clade 2, mainly including kohlrabi, Brussels sprouts and cabbage; and clade 3 and clade 4, corresponding to broccoli and cauliflower, respectively (Fig. 1a,b and Supplementary Fig. 3). These results are mostly in agreement with those of previous studies4,5,10,11, but they are more informative with respect to the identity of B. cretica and Chinese kale, as well as the classification of B. oleracea subspecies.

a, Clades and groups including wild and major subspecies of B. oleracea, along with their relationships, illustrated using a phylogenetic tree. Different colors represent different groups as follows: gray, outgroup (B. rapa and B. nigra); black, wild and feral-type; cyan, Chinese kale; red, kohlrabi; dark green, lacinato kale; gold, curly kale; yellow, Brussels sprouts; dark blue, savoy cabbage; pink, kale; dark cyan, cabbage; green, broccoli; dark purple, purple cauliflower; magenta, ROM; blue, ELMC, purple, LMC; orange, EMC-1; brown, EMC-2. White and gray bars indicate 5 cm. b, Results of model-based clustering when K = 3, 4 and 5. Red dashed lines indicate three categories as labeled: Curdless, Green-curd and White-curd. c, PCA analysis based on 1,564 4d-SNPs. d, Summary of nucleotide diversity (π) and population divergence (FST) among major B. oleracea subspecies and each cauliflower group. e, LD decay. Dashed lines and colored dots indicate the half-maximum distance and corresponding r2 values, respectively.
Clade 1 was closest to the phylogenetic root and occupied a distinct position in the PCA results (Fig. 1a,c). Clade 1 had a relatively lower level of nucleotide diversity (πclade1 = 1.08 × 10−3) than clade 2 (πclade2 = 1.29 × 10−3), implying that infrequent genetic exchange occurred, perhaps owing to its early geographic isolation (Fig. 1d). This is consistent with the historical record in which clade 1 was introduced to China from Europe during the Northern and Southern Dynasties ~ad 420–589)26 and evolved as an independent population. Our analysis assigned kohlrabi, lacinato kale, curly kale, Brussels sprouts, savoy cabbage, kale and cabbage into clade 2. We found that these subspecies shared closer relationships among the B. oleracea subspecies, suggesting that they may have undergone widespread gene exchange during their differentiation (Fig. 1a,b). Notably, eight wild accessions within clade 2 might be feral plants derived from intraspecific hybridization or escape from domestication4,27. Compared with the 22 wild relatives at the base of the phylogenetic tree (πwild = 2.31 × 10−3), these feral accessions had lower nucleotide diversity (πferal = 1.52 × 10−3), but higher than that of the entire clade 2 (πclade2 = 1.29 × 10−3), indicating a substantial genetic difference between feral and authentic wild relatives (Fig. 1d and Supplementary Table 6). This speculation was also supported by the values of the inbreeding coefficient, which differed markedly between the feral and wild accessions (Supplementary Fig. 4).
The phylogenetic tree and model-based analysis showed that the floral-organ-specialized clade 4 probably directly evolved from clade 3 rather than from wild relatives, consistent with previous speculations28,29. Compared with the clade 1, clade 2 and clade 3 accessions, the clade 4 accessions showed the lowest nucleotide diversity (πClade4 = 0.73 × 10−3) and an intimate relationship with clade 3 (FST = 0.186) (Supplementary Fig. 5 and Table 6). The linkage disequilibrium (LD) decay indicated that clade 4 had moderate physical distance between SNPs (27.9 kb) compared with the other clades, in which it ranged from 11.6 to 37.6 kb (Fig. 1e). Notably, when K = 3, model-based clustering showed a clear and gradual tendency from clade 3 (hereafter ‘broccoli’) to clade 4 (hereafter ‘cauliflower’), suggesting the evolutionary pathway of cauliflower (Fig. 1b).
Stepwise domestication of cauliflower
Cauliflower has undergone a short evolutionary history (~2,500 years), and strong bottlenecks may have occurred during its domestication5. To date, the population structure of cauliflower has remained unclear. Based on the phylogenetic tree, plant architecture and maturity levels, we assigned the 726 cauliflower accessions into five groups: ROM (Romanesco cauliflower), ELMC (extremely late-maturing cultivars), LMC (late-maturing cultivars), EMC-1 (early-maturing cultivars) and EMC-2. The ROM group was the nearest phylogenetic neighbor and showed the lowest level of genetic differentiation (FST = 0.121) from the broccoli accessions (Fig. 1a,d). Among these groups, the ROM group bears light green and pyramidal shaped curds, making its appearance different from that of the other cauliflower groups. Moreover, ROM displayed the highest level of nucleotide diversity (πROM = 1.30 × 10−3) among the five cauliflower groups, suggesting that it may be the predecessor of cauliflower cultivars and may have had a transitional role during cauliflower differentiation.
The ELMC accessions are regarded as valuable germplasms for cauliflower breeding, owing to their excellent properties of cold hardiness and disease resistance. Among the five cauliflower groups, the lowest FST value was that between the ROM and ELMC groups (0.112), followed by that between the ELMC and LMC groups (0.118) (Fig. 1d). In addition, genetic diversity decreased from the ROM (πROM = 1.30 × 10−3) to the ELMC (πELMC = 0.92 × 10−3) group, and then to the LMC and EMC groups (πaverage(LMC+EMCs) = 0.58 × 10−3) (Fig. 1d and Supplementary Table 6). The PCA plots also supported the transitional roles of the ROM and ELMC groups, which occupied bridging positions between broccoli and the majority of the cauliflower groups (LMC, EMC-1 and EMC-2) (Fig. 1c and Supplementary Fig. 3). Notably, the LMC, EMC-1 and EMC-2 groups (hereafter ‘LEE’ groups) were tightly clustered in the PCA results (Fig. 1c), suggesting their highly similar genetic backgrounds and the strong bottlenecks that cauliflower experienced. Taken together, these results indicate that cauliflower has undergone a one-way and stepwise domestication route that yielded the ROM and ELMC groups from broccoli and further improved into the early-maturity cauliflower cultivars.
Genomic evidence for the wild ancestor of B. oleracea
The ‘C9’ wild relatives of B. oleracea contain nine chromosome pairs and are generally considered to be the ancestral origin. They are mainly located in the Mediterranean region and are able to produce fertile hybrids through crossing with B. oleracea subspecies30,31. To identify the authentic progenitor of cauliflower and B. oleracea, we inferred potential identical genomic regions by comparing each B. oleracea subspecies with 22 ‘C9’ wild relatives (Brassica insularis, Brassica macrocarpa, Brassica villosa, Brassica rupestris, Brassica hilarionis and B. cretica). Our data showed that B. cretica made an extensive genetic contribution to all clades and groups in B. oleracea, ranging from 3.78% in LEE groups of cauliflower to 5.56% in cabbage, whereas B. macrocarpa contributed about 1.53% and other wild relatives contributed 0.94% on average (Fig. 2a). The distribution of these identical regions indicated that they are scattered across the entire genome, with short fragments of 5 kb in length occupying the majority of homologous sequences (Fig. 2b,c and Supplementary Figs. 6 and 7). Notably, genomic contributions varied among different wild accessions, ranging from 2.16% to 9.75% in B. cretica and from 0.92% to 2.47% in B. macrocarpa. The B. cretica accessions possessed the greatest number of identical regions with all B. oleracea subspecies (Supplementary Table 7). These results support B. cretica as the closest wild ancestor of cauliflower and suggest that it might be the origin of all B. oleracea subspecies4. To characterize the landscape of synteny within the cauliflower genome, we compared the genotype of the most similar B. cretica accession C0_0162 to the pseudo-ancestral genotype derived from a consensus of the LEE groups. We detected 4,996 candidate identical regions, ranging from 5 kb to 260 kb and harboring 5,980 genes. Gene ontology (GO) analysis revealed that these genes were overrepresented in lipid and fatty acid metabolism, including lipid transport (biological process (BP), GO:0006869), long-chain fatty acid metabolic process (BP, GO:0001676), long-chain fatty acid-CoA ligase activity (molecular function (MF), GO:0004467) and lipid transporter activity (MF, GO:0005319) (Fig. 2d).

a, Average length of identical windows between wild accessions and B. oleracea subspecies. b, Histograms of identical fragments. A single representative accession was selected for each wild species as follows: SRR6453800, B. insularis; C0_0166, B. macrocarpa; SRR6453822, B. villosa; SRR6453618, B. rupestris; SRR6453871, B. hilarionis; SRR9331105, B. cretica. c, Diagram of inferred syntenic regions between the LEE groups of cauliflower and 22 wild accessions in chromosome 3. d, GO enrichment analysis of genes from identical regions between B. cretica C0_0162 and the LEE groups. P values were adjusted using the Benjamini–Hochberg false discovery rate correction.
Genomic selection for curd formation in cauliflower
In B. oleracea, cauliflower has its own morphological and biological characteristics, including curd derived from specialized inflorescence meristems, plant height, biomass, and tolerance to biotic and abiotic stresses. Since cauliflower has been domesticated and cultivated worldwide, the genomic regions associated with its agronomic traits have changed substantially through continuous artificial selection, especially for the edible high-nutrient curd. To investigate the mechanism of curd biogenesis during cauliflower domestication, we merged clades 1 and 2 as an assumed ‘Curdless’ category, and clade 3 and the ROM group from clade 4 as a ‘Green-curd’ category, as well as the ELMC, LMC, EMC-1 and EMC-2 groups from clade 4 as a ‘White-curd’ category. In total, we identified 211 highly divergent genomic regions between the Curdless and Green-curd categories (defined as Curd-emergence) using the FST method, and 185 between the Green-curd and White-curd categories (Curd-improvement). These divergent regions covered 50.7 Mb (8.92%; Curd-emergence) and 50.2 Mb (8.83%; Curd-improvement) of the C-8 (V2) genome, comprising 5,136 and 5,664 protein-coding genes, respectively (Supplementary Tables 8–11). GO analysis showed that the Curd-emergence genes were involved in maturation of 5.8S ribosomal RNA (BP, GO:0000460), cleavage involved in ribosomal RNA processing (BP, GO:0000469), ATP metabolic process (BP, GO:0046034) and preribosome (cellular component, GO:0030684). The Curd-improvement genes were enriched in protein maturation (BP, GO:0051604), plant epidermis development (BP, GO:0090558) and negative regulation of phosphorus metabolic process (BP, GO:0010563) (Supplementary Table 12).
Curd development occurs at the initial stage of flowering, during which the emerging primordia are transformed into curd-shaped inflorescences instead of floral organs32. To elucidate the underlying mechanisms of curd formation, we first collected all known flowering-related genes in Arabidopsis and then identified 519 homologs in the C-8 (V2) genome (Supplementary Table 13). Of these homologs, 55 and 61 flowering-related candidate genes resided in the significantly divergent genomic regions during the Curd-emergence and Curd-improvement processes, respectively (Fig. 3a,b and Supplementary Tables 14 and 15). The discrimination capacities of these genes showed successive declines in the above two processes, indicating that continuous artificial selection may have occurred throughout cauliflower domestication (Fig. 3c). Further investigation revealed that the upstream regulatory regions of three MADS-box genes, CAL1, CAL2 (AP1) and FUL2 (AGL8.2), varied between the Curdless and Green-curd categories (Fig. 3d), potentially affecting their function through transcriptional regulation. These findings are consistent with those of a previous study in Arabidopsis showing that CAL and AP1 control the ‘curd-like’ phenotype, which arises from an abnormal inflorescence meristem18. More informatively, we found that the promoter region of FUL2, a gene controlling meristem arrest and lifespan in Arabidopsis19, further differed between the Green-curd and White-curd categories. Tissue-specific transcriptome analysis showed that CAL1, CAL2 and FUL2 were indeed mainly expressed in cauliflower curd and floral organs (bud and flower) (Supplementary Fig. 8 and Table 16). To further verify divergent genomic regions related to curd formation, we performed bulked segregant analysis in two F2 segregating populations derived from crossing of the Curdless and White-curd lines, each consisting of approximately 1,000 individuals. The differences (∆SNP index) between the Curdless and White-curd bulks showed eight previously identified divergent genomic regions contributing to curd formation, containing SEP3.3, CAL1, RPL18.2, TFL1.1 and RPL3 on chromosome 3; SEP3.1 on chromosome 5; NAC071.1 and FUL2 on chromosome 7; and LIP1.2, FVE2, ABI2.1 and WOX12.1 on chromosome 9 (Fig. 3e,f). To summarize, we propose a stepwise domestication of curd biogenesis containing two different sets of loci that may jointly give rise to cultivated White-curd.

a,b, Genome-wide screening of FST differentiated signals for Curd-emergence (a) and Curd-improvement (b) during cauliflower domestication. Red dashed lines indicate the top 5% threshold set to select highly differentiated regions. Overall, 55 (Curd-emergence) and 61 (Curd-improvement) flowering-related genes located in the highly differentiated regions are indicated by gray arrows. The 21 genes showing altered expression profiles during curd development are labeled with their names. c, The discrimination capacity of differentiated flowering-related genes in the Curdless, Green-curd and White-curd categories (centerline, median; box limits, first and third quartiles; whiskers, 1.5× interquartile range). d, Nucleotide diversity (π) and read mapping diagrams for CAL1, CAL2 and FUL2 in each category. Red boxes indicate the promoter regions of target genes. e,f, Bulked segregant analysis (BSA) with F2 populations developed by crossing the Curdless versus White-curd lines PQ409 (e) and PQ432 (f). Black dotted lines indicate the thresholds at 95% confidence level. Light purple blocks indicate BSA intervals overlapping with important FST signals. g, Gene expression heatmap of differentially expressed genes at different stages of curd development. S0, vegetative; S1, curd initiation; S2, curd expansion; S3, curd premature; S4, curd mature. h, Integrated regulatory network showing potential mechanisms underlying curd biogenesis. This network covers the 21 candidate genes identified in this study as well as interacting genes, key flowering-related genes, phytohormones, microRNAs and environmental factors. White bars indicate 5 cm.
We further analyzed the expression levels of these genes at the vegetative, curd initiation, curd expansion, curd premature and curd mature stages of curd furmation10 and identified 21 potential curd-biogenesis-related genes that were differentially expressed during the Curd-emergence and Curd-improvement stages. In addition to the well-known genes CAL1, CAL2, FUL2, TFL1.1, SEP3.1 and SEP3.3, whose homologs regulate floral organ development in Arabidopsis13,19,33, we identified 15 genes comprising homologs of auxin-induced growth-related genes34,35,36 (WOX12.1, ARF9.1, HTA9.3 and NAC071.1), a circadian period-related gene37 (LIP1.2), vernalization/autonomous-related genes38,39,40 (AGL19.2, FVE2 and AGL6.1), cytokinin- and abscisic acid-responsive genes41 (CYCD3;2.1, ABI1.2, ABI2.1 and HB53.2), housekeeping-related genes42 (RPL16B.4 and RPL18.2) and a regulatory-related gene (RPL3) (Fig. 3g and Supplementary Table 17). To understand the regulatory network responsible for curd formation, we constructed a panoramic view of regulatory events by integrating circadian clock, vernalization and autonomous pathways, as well as environmental signals, microRNAs and phytohormones including auxin, cytokinin, abscisic acid, brassinosteroids and gibberellic acid (Fig. 3h). In this analysis, multiple molecular interactions and environmental responses indicated that regulatory events during curd formation might be more complex than previously expected. However, the mechanisms and causal variations of these genes need to be further validated functionally.
Genome-wide association studies of important agronomic traits
After continuous improvement, the cauliflower LEE groups have been bred into various edible varieties with diverse characteristic traits such as curd properties, resistance to pathogens, maturity and biomass. However, the genetic basis of most traits has not yet been elucidated in cauliflower. Therefore, to identify potential target genes or loci, we measured seven agronomic traits—stem height (SH), curd diameter (CD), curd height (CH), whole-plant mass (WPM), black rot resistance (BRR), color of curd branch (CCB) and insect resistance (IR)—and performed genome-wide association studies (GWAS) using 1.87 million SNPs from a panel composed of 691 cauliflower accessions. A total of nine dominant association signals were identified in the C-8 (V2) genome, and several candidate genes were speculated to be significantly associated with seven agronomic traits in cauliflower. These included BOB04G169050 (encoding an ENT domain-containing protein) and BOB06G135460 (RING-type zinc-finger protein) for SH; BOB03G039150 (elongation factor) and BOB03G039160 (nonspecific serine/threonine protein kinase) for CD; BOB04G016240 (unknown), BOB04G016250 (ATP-dependent zinc metalloprotease FtsH) and BOB08G004150 (TATA-box-binding protein) for CH, BOB02G184480 (transcription repressor) for WPM; BOB03G053850 (prokaryotic RING finger family 4) for BRR; BOB03G161490 (DnaJ molecular chaperone) for CCB; and BOB09G004730 (protein kinase) for IR (Table 1 and Supplementary Fig. 9).
SH is an important agronomic trait that influences light capture, curd yield and the efficiency of mechanical picking of cauliflower (Fig. 4a). Phenotypic data of SH exhibited normal distributions in 2019 and 2020 (Fig. 4b,c). Correlation analysis indicated that SH has significant positive correlations with CD, CH and WPM traits (Supplementary Fig. 10). Our GWAS identified a strong association signal at the end of chromosome 6 for SH (2019, P = 2.8 × 10−7; 2020, P = 1.1 × 10−7) and CH (2020, P = 2.5 × 10−7) (Fig. 4d). Further analysis narrowed this interval to approximately 72 kb between 47.88 and 47.95 Mb; 12 protein-coding genes were located in this region based on the threshold value (P = 1.0 × 10−5) (Fig. 4e). Functional annotation and variant analysis revealed a RING-type zinc-finger gene (BOB06G135460) harboring one nonsynonymous SNP and a 3-bp deletion within its sixth exon that were present in most short-stem accessions (Fig. 4f). Haplotype analysis of this gene showed significant differences for SH, CD, CH and WPM traits in both 2019 and 2020 (Fig. 4g and Supplementary Fig. 11). The orthologs of this gene are widespread among monocots and dicots but exhibit divergent functions (Supplementary Fig. 12). For instance, a RING-type protein with E3 ubiquitin ligase activity (DA2) controls seed size by restricting cell proliferation in the maternal integuments in Arabidopsis43, and another ortholog (GW2) regulates seed size44 and leaf senescence45 in rice. The expression of BOB06G135460 dramatically increased at the vegetative and curd harvest stages in nine tall-stem accessions compared with nine short-stem accessions (Fig. 4h).

a, Morphology of short-stem and tall-stem cauliflower. Scale bar, 5 cm. b,c, Histograms of SH data in 2019 (b) and 2020 (c). Red boxes indicate the data of short-stem and tall-stem cauliflower, respectively, with thresholds set to ≤15 cm for short-stem and ≥30 cm for tall-stem. d, Overlapping Manhattan plots of SH, CD, CH and WPM traits. The red arrow indicates overlapping signals from SH and CH (Bonferroni correction). e, Schematic view of the target 72-kb region and candidate gene BOB06G135460. f, Statistics of haplotypes based on the nonsynonymous SNP and 3-bp deletion located in the sixth exon of BOB06G135460. g, Proportions of different haplotypes in SH in 2019 (nHap1 = 125, nHap2 = 244) and 2020 (nHap1 = 172, nHap2 = 391) (centerline, median; box limits, first and third quartiles; whiskers, 1.5× interquartile range). h, Expression analysis of BOB06G135460 for two haplotypes at the vegetative (84-day-old) and harvest (119-day-old) stages. Data are presented as means ± s.d. i, CRISPR–Cas9-induced mutations in BOB06G135460 in T0 plants. j, Plant morphologies of three knockout (KO) lines. White bars indicate 5 cm. k, Horizontal and vertical sections of stem tissues in short-stem and tall-stem accessions. Red scale bar, 500 μm. Red boxes indicate the regions of thin-walled cortical cells used for calculating cell numbers. l,m, Quantitative analysis of cell density for horizontal (l) and vertical (m) sections. Data are presented as mean ± s.e.m. (n = 4). In g, h, l and m, statistical significance was determined by two-sided Student’s t-tests.
To further validate the function of BOB06G135460, we used a CRISPR–Cas9 editing strategy and generated three T0 independently transformed lines (Fig. 4i). We found that the knockout lines (2.35–2.45 cm) had significantly shorter SH than the wild-type line (5.52 cm) (Fig. 4j). By contrast, the overexpression lines displayed obvious elongated SH (Supplementary Fig. 13). Microscopic observation showed that the thin-walled cortical cells in tall-stem accessions were significantly larger than those in short-stem accessions (Fig. 4k). Further analysis showed that the cell density (cell number per 500 μm2) in tall-stem accessions was approximately three times lower than that in short-stem accessions (Fig. 4l,m), indicating that SH is mainly determined by the size of cells in the cauliflower stem. Taken together, these results demonstrate that BOB06G135460 positively regulates SH through affecting cell size during stem development, simultaneously affecting curd size and plant biomass in cauliflower.
Discussion
Brassica oleracea has rich morphological diversity represented by highly specialized inflorescence, leaf, lateral bud and stem organs in its subspecies. Despite the attempts of numerous studies to untangle the origin and genetic relationships of B. oleracea populations, these details have remained unclear because of the frequent crossing and fully fertile progeny among wild and domesticated accessions. Taking advantage of large-scale sampling and high-density SNP markers, we carried out a comprehensive population genetic analysis and obtained a reasonable classification of B. oleracea composed of four major clades.
We confirmed that Chinese kale (clade 1) is the earliest divergent lineage, consistent with the fact that its cultivation history in China spans more than 1,000 years. Feral samples in clade 2 reflected the complicated nature of B. oleracea and made it difficult to clarify the evolutionary relationships. In addition, our results confirmed that the Aegean-endemic B. cretica is the closest wild ancestor of B. oleracea, although B. cretica individuals have unequal contributions owing to intraspecific diversity. Cauliflower (clade 4) is thought to possess a very narrow genetic background and have diverged less than 2,500 years ago5. However, its evolutionary history has never been thoroughly investigated because of the lack of wild germplasm resources and geographical origin information5,6,7,8. Herein, benefiting from large-scale sampling (726 accessions of cauliflower) and a whole-genome resequencing strategy, we divided the cauliflower population into five groups based on morphotypes and curd maturity levels. Among these, the ROM group has been traditionally classified as a type of cauliflower and displays a distinct curd morphotype, which is clearly different from broccoli and cauliflower curds in terms of color and shape. Our results also support the speculation that cauliflower directly evolved from broccoli. Importantly, we discovered the stepwise evolutionary route of cauliflower, from broccoli (clade 3) to the ROM group and next to the ELMC group, finally evolving into early-maturing cauliflower cultivars.
Curd development is a key concern in cauliflower breeding, as it affects yield and quality. Recent research in Arabidopsis has shown that Curd-emergence can be attributed to the combination of a few floral meristem determinants including TFL1, LFY, CAL, AP1, SOC1 and AGL24 (ref. 13). Cauliflower curd biogenesis was further illustrated using a batch of genes containing structural variants between the cauliflower and cabbage genomes10. In this study, we explored two steps of cauliflower domestication (Curd-emergence and Curd-improvement) and identified 21 candidate genes and their potential regulatory network based on expression profiles during curd development and found that CAL1, CAL2/AP1 and FUL2 might be key causal genes for curd formation. Our dataset will provide new routes for research into the genetic mechanisms of curd biogenesis and important resources for better understanding florescent development in crops.
In cauliflower, we found that SH was closely correlated with curd size and plant biomass. Previous studies had identified four quantitative trait loci (QTLs)46 and multiple factors, including endogenous hormones47 and gibberellin-related genes (DELLA48 and SOC1 (ref. 49)), that influenced stem elongation in Brassica plants. Nevertheless, no causal gene for stem elongation had been identified. Based on GWAS analysis, we discovered a RING-type zinc-finger protein-encoding gene, BOB06G135460, that controls stem elongation by influencing cell size. Its orthologous genes have been demonstrated to regulate seed size in Arabidopsis43 and rice44, suggesting that BOB06G135460 could have versatile roles in regulating SH and associated traits in cauliflower. Notably, ~72–83% of haplotypes in short-stem cultivars could be explained, and another GWAS peak on chromosome 4 (2019, P = 2.4 × 10−7) was detected, suggesting a minor quantitative trait locus (QTL) associated with SH (Fig. 4e). These results offer useful information for studying stem development and biomass regulation in Brassica plants. In addition, a few GWAS-identified loci and candidate genes responsible for important agronomic traits will facilitate cauliflower improvement in the future.
Collectively, we updated a high-quality and highly contiguous reference genome C-8 (V2) and implemented large-scale whole-genome resequencing in cauliflower, providing resources for gene mining and genome-guided breeding. Our findings shed light on the population structure and evolutionary history of B. oleracea. Moreover, candidate genes identified in this study related to curd formation and important agronomic traits will facilitate germplasm innovation in cauliflower.
Methods
Genome assembly and annotation
In our previous study, a draft genome assembly and its annotation were reported using the elite cauliflower inbred line C-8 (ref. 9). Here, on the basis of existing raw data derived from PacBio (121×), Illumina (81×) and RNA-seq, we used complementary Hi-C library sequencing and Bionano optical mapping approaches to achieve a chromosomal-level genome assembly. Ten-day-old seedlings grown under greenhouse conditions were harvested and stored at −80 °C for subsequent experiments. The Hi-C library was constructed following the Proximo Hi-C plant protocol (Phase Genomics) with HindIII digestion, producing ~50.6 Gb raw reads (89×). To generate Bionano single-molecule maps, high-molecular-weight DNA with fragment distribution greater than 150 kb was isolated. Then, 300 ng of isolated DNA was incubated for 2 h at 37 °C with the Nt.BspQI enzyme for DNA nicking. After labeling of nicks using an IrysPrep Reagent Kit (Bionano Genomics) according to the manufacturer’s instructions, the labeled DNA sample was loaded and imaged using the Bionano Saphyr platform (Bionano Genomics), producing ~98.4 Gb raw data with an average length of 270 kb.
Canu (v.2.2)50 and the HERA pipeline (v.1.0)51 were used for de novo genome assembly by producing contigs and merging repetitive regions with PacBio long reads and Illumina paired-end reads. During this process, Minimap2 (v.2.23)52 and BWA (v.0.7.10-r789)53 were employed for sequence alignment and overlap identification. Then, optical-map alignment and hybrid scaffolding were performed using the IrysView package (v.2.4.0.15879, Bionano Genomics) with a minimum length of 150 kb. Subsequently, scaffolds were further clustered by Hi-C data and 3D-DNA54 with default parameters. After three rounds of base polishing with Pilon55, the integrity of the final genome assembly (C-8, V2) was assessed with BUSCO (v.4.1.4)56. Analysis of genome-wide synteny was performed using SyRI (v.1.4)57.
Before genome annotation, repeat analysis was accomplished by integrating de novo and homology-based methods and using RepeatModeler (v.2.0.1)58, LTR_retriever (v.2.9.0)59 and RepeatMasker (v.4.1.0)60; this included identification of interspersed transposable elements. A comprehensive pipeline for genome annotation was established by combining evidence from ab initio predictions, transcript mapping and cross-genome protein homology. In brief, tissue-specific RNA-seq data of cauliflower C-8 was cleaned and mapped onto the repeat-masked genome using HISAT2 (v.2.2.1)61. Coding sequences were assembled and recognized with TopHat2 (v.2.1.5)62, Trinity (v.2.13.2)63 and the PASA pipeline (v.2.4.1)64. Augustus (v.3.4.0)65 and GeneMark-ES (v.3.67)66 were used for ab initio gene predictions. Last, high-confidence gene models were integrated and summarized using the MAKER pipeline (v.2.31.11)67.
Plant materials and whole-genome resequencing
For whole-genome resequencing, 820 inbred lines of cauliflower and B. oleracea relatives were collected, and developed and stored in the Tianjin Kernel Vegetable Research Institute, Tianjin Academy of Agricultural Sciences. These lines included three wild accessions (one each of B. macrocarpa, B. cretica and B. oleracea), 53 Chinese kale accessions (var. alboglabra), nine kohlrabi accessions (var. gongylodes), two lacinato kale accessions (var. palmifolia), three curly kale accessions (var. sabellica), 11 Brussels sprouts accessions (var. gemmifera), two savoy cabbage accessions (var. capitata), three kale accessions (var. acephala), five cabbage accessions (var. capitata), 20 broccoli accessions (var. italica), 16 Romanesco cauliflower accessions (var. botrytis) and 693 cauliflower accessions (var. botrytis) (Supplementary Table 3). This collection had widespread origins and diverse genetic backgrounds, exhibiting abundant biological and morphological variations in traits such as maturity, biomass, disease resistance and curd characteristics.
Young leaves from 25-day-old seedlings of these accessions were subjected to genomic DNA isolation using a modified cetyltrimethylammonium bromide method68. The PE150 strategy was used for library construction and deep sequencing on an Illumina NovaSeq 6000 platform at Novogene (Beijing, China), producing ~6.5 Tb raw reads corresponding to approximately 14× genomic depth for each sample. In addition, 151 sets of genome resequencing raw data were downloaded from the NCBI Sequence Read Archive (SRA) database (PRJNA217459, PRJNA301390, PRJNA312457, PRJNA320480, PRJNA428769, PRJNA470925 and PRJNA516907) (Supplementary Table 3).
Sequence alignment and variant calling
First, raw reads were filtered using the Fastp program (v.0.12.4)69 with default parameters. Clean reads for each sample were aligned onto the C-8 (V2) genome with the ‘mem’ algorithm in BWA (v.0.7.10-r789)53. SAMtools (v.1.14)70 was then used to convert the format of SAM files, sort BAM files and filter mapping quality with the ‘-q 30’ parameter. The Genome Analysis Toolkit (GATK, v.4.1.4.1)71 modules MarkDuplicates and ValidateSamFile were used to remove duplicates and validate the file integrity, respectively. To improve variant calling efficiency, the genome was split into individual chromosomes for parallel calculation. For each chromosome of each sample, GATK HaplotypeCaller was used in -ERC GVCF mode to generate original GVCF files. Subsequently, the CombineGVCFs, GenotypeGVCFs, SelectVariants and VariantFiltration modules were applied in turn for SNP and InDel calling (SNPs: –filter-expression ‘QD < 2.0 || MQ < 40.0 || FS > 60.0 || MQRankSum < −12.5 || ReadPosRankSum < −8.0’ –cluster-size 3 –cluster-window-size 10; InDels: –filter-expression ‘QD < 2.0 || FS > 200.0 || ReadPosRankSum < −20.0’). The SNPs or InDels that passed the screening criteria were extracted and gathered as high-confidence variants. Finally, the whole set of variants was annotated using SnpEff (v.4.3t)72 with default parameters.
Phylogenetic and population structure analyses
Considering that 4d-SNPs are under less selective pressure and can reliably reflect population structure and demography, we selected 4d-SNPs with a minor allele frequency greater than 0.05 and missing rate less than 20% as neutral or near-neutral SNPs. As a result, 69,275 4d-SNPs were obtained and subjected to construction of an ML phylogenetic tree using FastTree (v.2.1.11)73. Population structure was analyzed using the ADMIXTURE (v.1.3.0)74 program with the same set of SNPs. For PCA, PLINK (v.1.90b5.3)75 was utilized with parameters –geno 0.05, –hwe 0.0001 and –maf 0.05 for SNP filtration. PCA was performed on a subset of 1,564 SNPs using genome-wide complex trait analysis (GCTA, v.1.26.0)76. Population fixation statistics (FST) and genetic diversity (π) were calculated using VCFtools (v.0.1.16)77 based on the whole set of SNPs. The π levels were measured for each 100-kb window, and FST values were estimated for 50-kb sliding windows with a step size of 5 kb. The average values of π and FST across the whole genome were designated as the final values for each clade or group. LD decay was calculated for all pairs of SNPs within 1000 kb using PopLDdecay (v.3.41)78 with parameters -MaxDist 1000, -Het 0.1 and -Miss 0.1. Average r2 values in a bin of 100 bp against the physical distance of pairwise bins were illustrated. Inbreeding coefficients were computed using PLINK75 and GCTA software76 with the command ‘-ibc’.
Ancestral inference
Synteny analysis was carried out between the 22 wild accessions at the root of the phylogenetic tree and each B. oleracea subspecies. Briefly, the consensus genotype of a specified clade or group was reconstructed by selecting the most common allele composition across each individual. Consecutive 5-kb sliding windows were set to compare the identity between a wild accession and the inferred ancestral genotype at each SNP site. Only the windows with at least five shared SNPs and similarity greater than 96% were defined as syntenic regions and reserved for visualization with the RIdeogram package (v.0.2.2)79.
Identification of differentiated regions
With the aid of a variance component approach using the Hierfstat R package (v.0.5.10)80, FST values were estimated for 100-kb sliding windows with a step size of 10 kb. Sliding windows with the top 5% FST values were initially selected. After merging neighboring windows, fragments were further merged into one region if the distance between two fragments was less than 100 kb. The final merged regions were considered to be highly diverged regions between different groups.
Identification of flowering-related genes and genotype analysis
A comprehensive literature review was carried out to identify flowering-related genes in plants10,13,81. Following specific BLASTP thresholds (mutual coverage >70%, sequence identity >75% and mismatches/coverage <25%), 519 homologous genes with potential roles in curd development were identified in the cauliflower genome C-8 (V2). For each target gene, SNPs located in the gene body were connected into an assumed sequence, which was deemed to be its own genotype. For each group, the most abundant genotype was regarded as the representative genotype. Discrimination capacity was calculated by dividing the number of different genotypes by the total number of individuals in a certain group. GO enrichment analysis of the sweep genes was carried out using R package topGO (v.2.36.0)82.
Transcriptomic analysis
A total of 132 sets of B. oleracea tissue-specific RNA-seq data were downloaded from the SRA database (PRJNA183713, PRJNA227258, PRJNA231628, PRJNA289196, PRJNA292848, PRJNA297049, PRJNA428769, PRJNA489323, PRJNA516113, PRJNA525713, PRJNA546441, PRJNA548819, PRJNA633027, PRJNA683970). These datasets included RNA-seq data from root, stem, leaf, bud, flower and silique, as well as from curd organs (Supplementary Table 16). Transcriptome data of different curd developmental stages were also downloaded from the SRA database (PRJNA546441) (Supplementary Table 17). Fastq-dump (v.2.11.2) in the SRA Toolkit83 and the Fastp program (v.0.12.4)69 were used for format conversion and read cleaning. HISAT2 (v.2.2.1)61 and the Cufflinks suite (v.2.2.1)84 were used to estimate fragments per kilobase of transcript per million mapped reads (FPKM) values for each gene. Heatmaps were constructed using the R package pheatmap (v.1.0.12)85 with log2 (FPKM + 1) values of selected genes.
Planting and phenotyping
Curd is the specialized organ composed of enlarged and developmentally arrested inflorescence or floral meristems in cauliflower and broccoli. In this study, seven important agronomic traits were analyzed, comprising SH, CD, CH, WPM, BRR, CCB and IR. These traits were measured in two successive years from plants grown in two separate geographic locations: from the Baodi district of Tianjin municipality, China, in 2019, and from Hebei province, China, in 2020. The recording standards for the phenotype data refer to the description guidelines for germplasm resources of cauliflower and broccoli in China86. A scatterplot matrix with correlation values was produced using the ggpairs function in the GGally R package.
Genome-wide association studies
SNP filtration was set as major allele frequency >0.05 and missing rate <0.2. As a result, 1,873,097 SNPs were qualified across cauliflower populations and used for GWAS with GAPIT3 (v.3.1.0)87 with a mixed linear model. The significance threshold was set as P = 1 × 10−5. For phenotypic data, 450 accessions in 2019 and 607 accessions in 2020 were successfully collected. Downy mildew resistance was assessed using at least 20 individuals per accession. Other traits were measured in duplicate on five individuals per accession.
Quantitative real-time PCR
To verify the expression of the target gene BOB06G135460, main stem tissues of 18 accessions and corresponding genotypes were sampled at the vegetative (84-day-old) and harvest (119-day-old) stages. Total RNA was isolated with an Eastep Super Total RNA Extraction Kit (Promega, LS1040) and used to synthesize first-strand cDNA with a PrimeScript RT Reagent Kit (TaKaRa, RR037A) according to the manufacturer’s protocols (Supplementary Table 18). All quantitative real-time PCR reactions were performed using a TB Green Premix Ex Taq II kit (Takara, RR820A) in a LightCycler 480 II system (Roche Diagnostics) with reference gene Actin (BOB02G179850) as an internal control. The relative expression levels were calculated as 2−(CT target−CT control) × 1,000 in arbitrary units.
Cytological analysis
Phloem tissues were fixed in FAA (50% ethanol/formaldehyde/glacial acetic acid, 90:5:5) for 24 h then subjected to paraffin embedding and slicing as previously described88. Slices were stained with 0.5% tolonium chloride and photographed using a fluorescence microscope (VIYEE V5800, China). Three biological replicates derived from different cultivars (62 days old) were used for both short-stem and tall-stem samples. For each microscopic picture, four 500 × 500 μm2 squares were randomly selected to calculate the number of cortical thin-walled cells.
Bulked segregant analysis
We created two F2 populations, each consisting of about 1,000 individuals, using Chinese kale (PQ435) × cauliflower (PQ409) and Chinese kale (PQ435) × cauliflower (PQ432), planted in the spring of 2023 in the experimental bases of Zhangjiakou Academy of Agricultural Sciences (Zhangbei, Hebei province, China) and Tianjin Academy of Agricultural Sciences (Wuqing district, Tianjin municipality, China). Bulk DNA samples were collected by mixing equal amounts of DNA from 20 individuals with cauliflower-like phenotypes and 20 individuals with Chinese kale-like phenotypes, respectively. Roughly 20× raw data for each parent and 50× for each bulk sample were generated on the Illumina NovaSeq 6000 platform. BWA53, SAMtools70 and BCFtools were used for genome mapping and SNP calling. Only high-quality SNPs with base quality value >30 and mapping quality value >30 were retained for further analysis. SNP index and ∆(SNP index) parameters were calculated to identify candidate regions using a 1,000 kb sliding window with a step size of 10 kb. Combined with the statistical confidence intervals of the ΔSNP index under the null hypothesis of no QTLs, 95% confidence intervals of the ΔSNP index were finally extracted for each position89.
Vector construction and plant transformation
Overexpression and CRISPR/Cas9-mediated knockout were performed for functional validation of BOB06G135460. The full-length cDNA clone was integrated into the pCAMBIA3301 vector through RNA isolation and reverse transcription using the stem tissue of a high-stem genotype accession. The highly specific guide RNAs located in the exonic regions of BOB06G135460 were integrated into the pCBC-DT1T2 and pKSE401 vectors for gene editing. Agrobacterium tumefaciens-mediated hypocotyl transformation was conducted as previously described90. The FQ-38 inbred line was used as the transformation receptor.
Statistical analysis
Statistical significance was determined by two-sided Student’s t-tests.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Hi-C raw reads (SRR18307894 and SRR18307895) and Bionano CMAP file PRJNA516113 have been deposited in the NCBI SRA database. The genome assembly of cauliflower C-8 (V2) has been deposited at DDBJ/ENA/GenBank (https://www.ncbi.nlm.nih.gov/nucleotide) under accession JAMKOK000000000 and at the Genome Warehouse of the National Genomics Data Center (NGDC, https://ngdc.cncb.ac.cn/gwh) under accession GWHBJSH00000000. Resequencing raw reads derived from 820 accessions of cauliflower and B. oleracea relatives have been deposited in the SRA database under BioProject accession PRJNA794342. The raw reads of bulked segregant sequencing have been deposited in the SRA database under BioProject accession PRJNA1082923 and at the Genome Sequence Archive NGDC database (CRA012694).
Code availability
Custom scripts and codes used in this study are provided at Zenodo (https://doi.org/10.5281/zenodo.10824481)91 and GitHub (https://github.com/ChenRui-TAAS/Cauliflower_Resequencing). Software and tools used are described in the Methods and Reporting Summary.
References
Nagaharu, U. Genome-analysis in Brassica with special reference to the experimental formation of B. napus and peculiar mode of fertilization. Jpn. J. Bot. 7, 389–452 (1935).
Fang, Z. in Vegetable Breeding in China (ed. Fang, Z.) (China Agriculture Press, 2016).
Kusaba, M. & Nishio, T. The molecular mechanism of self-recognition in Brassica self-incompatibility. Plant Biotechnol. 16, 93–102 (1999).
Mabry, M. E. et al. The evolutionary history of wild, domesticated, and feral Brassica oleracea (Brassicaceae). Mol. Biol. Evol. 38, 4419–4434 (2021).
Cai, C., Bucher, J., Bakker, F. T. & Bonnema, G. Evidence for two domestication lineages supporting a middle-eastern origin for Brassica oleracea crops from diversified kale populations. Hortic. Res. 9, uhac033 (2022).
Zhao, Z. et al. Genetic diversity and relationships among loose-curd cauliflower and related varieties as revealed by microsatellite markers. Sci. Hortic. 166, 105–110 (2014).
Rakshita, K. N. et al. Agro-morphological and molecular diversity in different maturity groups of Indian cauliflower (Brassica oleracea var. botrytis L.). PLoS ONE 16, e0260246 (2021).
Zhu, S. et al. The genetic diversity and relationships of cauliflower (Brassica oleracea var. botrytis) inbred lines assessed by using SSR markers. PLoS ONE 13, e0208551 (2018).
Sun, D. et al. Draft genome sequence of cauliflower (Brassica oleracea L. var. botrytis) provides new insights into the C genome in Brassica species. Hortic. Res. 6, 82 (2019).
Guo, N. et al. Genome sequencing sheds light on the contribution of structural variants to Brassica oleracea diversification. BMC Biol. 19, 93 (2021).
Cheng, F. et al. Subgenome parallel selection is associated with morphotype diversification and convergent crop domestication in Brassica rapa and Brassica oleracea. Nat. Genet. 48, 1218–1224 (2016).
Duclos, D. V. & Björkman, T. Meristem identity gene expression during curd proliferation and flower initiation in Brassica oleracea. J. Exp. Bot. 59, 421–433 (2008).
Azpeitia, E. et al. Cauliflower fractal forms arise from perturbations of floral gene networks. Science 373, 192–197 (2021).
Amasino, R. M. Vernalization and flowering time. Curr. Opin. Biotechnol. 16, 154–158 (2005).
Song, Y. H., Shim, J. S., Kinmonth-Schultz, H. A. & Imaizumi, T. Photoperiodic flowering: time measurement mechanisms in leaves. Annu. Rev. Plant Biol. 66, 441–464 (2015).
Hedden, P. & Sponsel, V. A century of gibberellin research. J. Plant Growth Regul. 34, 740–760 (2015).
Simpson, G. G. The autonomous pathway: epigenetic and post-transcriptional gene regulation in the control of Arabidopsis flowering time. Curr. Opin. Plant Biol. 7, 570–574 (2004).
Kempin, S. A., Savidge, B. & Yanofsky, M. F. Molecular basis of the cauliflower phenotype in Arabidopsis. Science 267, 522–525 (1995).
Balanzà, V. et al. Genetic control of meristem arrest and life span in Arabidopsis by a FRUITFULL-APETALA2 pathway. Nat. Commun. 9, 565 (2018).
Samach, A. et al. Distinct roles of constans target genes in reproductive development of Arabidopsis. Science 288, 1613–1616 (2000).
Yu, H., Xu, Y., Tan, E. L. & Kumar, P. P. AGAMOUS-LIKE 24, a dosage-dependent mediator of the flowering signals. Proc. Natl Acad. Sci. USA 99, 16336–16341 (2002).
Garay-Arroyo, A. et al. The MADS transcription factor XAL2/AGL14 modulates auxin transport during Arabidopsis root development by regulating PIN expression. EMBO J. 32, 2884–2895 (2013).
Hanano, S. & Goto, K. Arabidopsis terminal flower1 is involved in the regulation of flowering time and inflorescence development through transcriptional repression. Plant Cell 23, 3172–3184 (2011).
Siriwardana, N. S. & Lamb, R. S. The poetry of reproduction: the role of LEAFY in Arabidopsis thaliana flower formation. Int. J. Dev. Biol. 56, 207–221 (2012).
An, H. et al. Transcriptome and organellar sequencing highlights the complex origin and diversification of allotetraploid Brassica napus. Nat. Commun. 10, 2878 (2019).
Zhou, Y. et al. Taxonomic relationship between Chinese kale and other varieties in Brassica oleracea L. Acta Hortic. Sin. 37, 1161–1168 (2010).
Gering, E. et al. Getting back to nature: feralization in animals and plants. Trends Ecol. Evol. 34, 1137–1151 (2019).
Branca, F. Cauliflower and Broccoli. In Vegetables I (eds Prohens, J. et al.) 151–186 (Springer, 2007).
Stansell, Z. et al. Genotyping-by-sequencing of Brassica oleracea vegetables reveals unique phylogenetic patterns, population structure and domestication footprints. Hortic. Res. 5, 38 (2018).
von Bothmer, R., Gustafsson, M. & Snogerup, S. Brassica sect. Brassica (Brassicaceae). Genet. Resour. Crop Evol. 42, 165–178 (1995).
Kianian, S. F. & Quiros, C. F. Trait inheritance, fertility, and genomic relationships of some n = 9 Brassica species. Genet. Resour. Crop Evol. 39, 165–175 (1992).
Quiros, C. F. & Farnham, M. W. The Genetics of Brassica oleracea. In Genetics and Genomics of the Brassicaceae (eds Schmidt, R. et al.) 261–289 (Springer, 2011).
Pan, Z. J. et al. Flower development of Phalaenopsis orchid involves functionally divergent SEPALLATA-like genes. N. Phytol. 202, 1024–1042 (2014).
Jarillo, J. A. & Piñeiro, M. H2A.Z mediates different aspects of chromatin function and modulates flowering responses in Arabidopsis. Plant J. 83, 96–109 (2015).
Liu, J. et al. WOX11 and 12 are involved in the first-step cell fate transition during de novo root organogenesis in Arabidopsis. Plant Cell 26, 1081–1093 (2014).
Pitaksaringkarn, W. et al. XTH20 and XTH19 regulated by ANAC071 under auxin flow are involved in cell proliferation in incised Arabidopsis inflorescence stems. Plant J. 80, 604–614 (2014).
Kevei, É. et al. Arabidopsis thaliana circadian clock is regulated by the small GTPase LIP1. Curr. Biol. 17, 1456–1464 (2007).
Ausín, I., Alonso-Blanco, C., Jarillo, J. A., Ruiz-García, L. & Martínez-Zapater, J. M. Regulation of flowering time by FVE, a retinoblastoma-associated protein. Nat. Genet. 36, 162–166 (2004).
Yoo, S. K., Wu, X., Lee, J. S. & Ahn, J. H. AGAMOUS-LIKE 6 is a floral promoter that negatively regulates the FLC/MAF clade genes and positively regulates FT in Arabidopsis. Plant J. 65, 62–76 (2011).
Kang, M. J., Jin, H. S., Noh, Y. S. & Noh, B. Repression of flowering under a noninductive photoperiod by the HDA9-AGL19-FT module in Arabidopsis. New Phytol. 206, 281–294 (2015).
Pan, W. et al. The UBC27–AIRP3 ubiquitination complex modulates ABA signaling by promoting the degradation of ABI1 in Arabidopsis. Proc. Natl Acad. Sci. USA 117, 27694–27702 (2020).
Wang, B. et al. Cre-miR914-regulated RPL18 is involved with UV-B adaptation in Chlamydomonas reinhardtii. J. Plant Physiol. 232, 151–159 (2019).
Xia, T. et al. The ubiquitin receptor DA1 interacts with the E3 ubiquitin ligase DA2 to regulate seed and organ size in Arabidopsis. Plant Cell 25, 3347–3359 (2013).
Song, X. J., Huang, W., Shi, M., Zhu, M. Z. & Lin, H. X. A QTL for rice grain width and weight encodes a previously unknown RING-type E3 ubiquitin ligase. Nat. Genet. 39, 623–630 (2007).
Shim, K. C. et al. A RING-type E3 ubiquitin ligase, OsGW2, controls chlorophyll content and dark-induced senescence in rice. Int. J. Mol. Sci. 21, 1704 (2020).
Sebastian, R. L., Kearsey, M. J. & King, G. J. Identification of quantitative trait loci controlling developmental characteristics of Brassica oleracea L. Theor. Appl. Genet. 104, 601–609 (2002).
Guo, D. P., Ali Shah, G., Zeng, G. W. & Zheng, S. J. The interaction of plant growth regulators and vernalization on the growth and flowering of cauliflower (Brassica oleracea var. botrytis). Plant Growth Regul. 43, 163–171 (2004).
Zhao, B. et al. Brassica napus DS-3, encoding a DELLA protein, negatively regulates stem elongation through gibberellin signaling pathway. Theor. Appl. Genet. 130, 727–741 (2017).
Wang, Y. et al. BcSOC1 promotes bolting and stem elongation in flowering Chinese cabbage. Int. J. Mol. Sci. 23, 3459 (2022).
Koren, S. et al. Canu: scalable and accurate long-read assembly via adaptive k-mer weighting and repeat separation. Genome Res. 27, 722–736 (2017).
Du, H. & Liang, C. Assembly of chromosome-scale contigs by efficiently resolving repetitive sequences with long reads. Nat. Commun. 10, 5360 (2019).
Li, H. Minimap2: pairwise alignment for nucleotide sequences. Bioinformatics 34, 3094–3100 (2018).
Li, H. & Durbin, R. Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics 25, 1754–1760 (2009).
Dudchenko, O. et al. De novo assembly of the Aedes aegypti genome using Hi-C yields chromosome-length scaffolds. Science 356, 92–95 (2017).
Walker, B. J. et al. Pilon: an integrated tool for comprehensive microbial variant detection and genome assembly improvement. PLoS ONE 9, e112963 (2014).
Seppey, M., Manni, M. & Zdobnov, E. M. BUSCO: assessing genome assembly and annotation completeness. Methods Mol. Biol. 1962, 227–245 (2019).
Goel, M., Sun, H., Jiao, W. B. & Schneeberger, K. SyRI: finding genomic rearrangements and local sequence differences from whole-genome assemblies. Genome Biol. 20, 277 (2019).
Bao, Z. & Eddy, S. R. Automated de novo identification of repeat sequence families in sequenced genomes. Genome Res. 13, 1269–1276 (2003).
Ou, S. & Jiang, N. LTR_retriever: a highly accurate and sensitive program for identification of long terminal repeat retrotransposons. Plant Physiol. 176, 1410–1422 (2018).
Chen, N. Using RepeatMasker to identify repetitive elements in genomic sequences. Curr. Protoc. Bioinformatics 5, 4–10 (2004).
Kim, D., Paggi, J. M., Park, C., Bennett, C. & Salzberg, S. L. Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype. Nat. Biotechnol. 37, 907–915 (2019).
Kim, D. et al. TopHat2: accurate alignment of transcriptomes in the presence of insertions, deletions and gene fusions. Genome Biol. 14, R36 (2013).
Haas, B. J. et al. De novo transcript sequence reconstruction from RNA-seq using the Trinity platform for reference generation and analysis. Nat. Protoc. 8, 1494–1512 (2013).
Haas, B. J. et al. Improving the Arabidopsis genome annotation using maximal transcript alignment assemblies. Nucleic Acids Res. 31, 5654–5666 (2003).
Stanke, M. et al. AUGUSTUS: ab initio prediction of alternative transcripts. Nucleic Acids Res. 34, W435–W439 (2006).
Lomsadze, A., Burns, P. D. & Borodovsky, M. Integration of mapped RNA-seq reads into automatic training of eukaryotic gene finding algorithm. Nucleic Acids Res. 42, e119 (2014).
Cantarel, B. L. et al. MAKER: an easy-to-use annotation pipeline designed for emerging model organism genomes. Genome Res. 18, 188–196 (2008).
Allen, G. C., Flores-Vergara, M. A., Krasynanski, S., Kumar, S. & Thompson, W. F. A modified protocol for rapid DNA isolation from plant tissues using cetyltrimethylammonium bromide. Nat. Protoc. 1, 2320–2325 (2006).
Chen, S., Zhou, Y., Chen, Y. & Gu, J. fastp: an ultra-fast all-in-one FASTQ preprocessor. Bioinformatics 34, i884–i890 (2018).
Li, H. et al. The sequence alignment/map format and SAMtools. Bioinformatics 25, 2078–2079 (2009).
McKenna, A. et al. The Genome Analysis Toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res. 20, 1297–1303 (2010).
Cingolani, P. et al. A program for annotating and predicting the effects of single nucleotide polymorphisms, SnpEff: SNPs in the genome of Drosophila melanogaster strain w1118; iso-2; iso-3. Fly 6, 80–92 (2012).
Price, M. N., Dehal, P. S. & Arkin, A. P. FastTree 2 – approximately maximum-likelihood trees for large alignments. PLoS ONE 5, e9490 (2010).
Peter, B. M. Admixture, population structure, and F-statistics. Genetics 202, 1485–1501 (2016).
Purcell, S. et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 81, 559–575 (2007).
Yang, J., Lee, S. H., Goddard, M. E. & Visscher, P. M. GCTA: a tool for genome-wide complex trait analysis. Am. J. Hum. Genet. 88, 76–82 (2011).
Danecek, P. et al. The variant call format and VCFtools. Bioinformatics 27, 2156–2158 (2011).
Zhang, C., Dong, S. S., Xu, J. Y., He, W. M. & Yang, T. L. PopLDdecay: a fast and effective tool for linkage disequilibrium decay analysis based on variant call format files. Bioinformatics 35, 1786–1788 (2019).
Hao, Z. et al. RIdeogram: drawing SVG graphics to visualize and map genome-wide data on the idiograms. PeerJ Comput. Sci. 6, e251 (2020).
Goudet, J. HIERFSTAT, a package for R to compute and test hierarchical F-statistics. Mol. Ecol. Notes 5, 184–186 (2005).
Blümel, M., Dally, N. & Jung, C. Flowering time regulation in crops – what did we learn from Arabidopsis? Curr. Opin. Biotechnol. 32, 121–129 (2015).
Alexa, A. & Rahnenfuhrer, J. topGO: enrichment analysis for gene ontology. R package version 2.32.0 (2016).
Leinonen, R., Sugawara, H. & Shumway, M. The sequence read archive. Nucleic Acids Res. 39, D19–D21 (2011).
Trapnell, C. et al. Differential gene and transcript expression analysis of RNA-seq experiments with TopHat and Cufflinks. Nat. Protoc. 7, 562–578 (2012).
Kolde, R. Pheatmap: pretty heatmaps. R package version 1.0.10 (2015).
Li, X. & Fang, Z. Description Guidelines and Data Standards for Germplasm Resources of Cauliflower and Broccoli (China Agriculture Press, 2008).
Wang, J. & Zhang, Z. GAPIT Version 3: boosting power and accuracy for genomic association and prediction. GPB 19, 629–640 (2021).
Yeung, E. C. T., Stasolla, C., Sumner, M. J. & Huang, B. Q. In Plant Microtechniques and Protocols (eds Yeung, E. C. T. et al.) (Springer, 2015).
Takagi, H. et al. QTL‐seq: rapid mapping of quantitative trait loci in rice by whole genome resequencing of DNA from two bulked populations. Plant J. 74, 174–183 (2013).
Dai, C. et al. An efficient Agrobacterium-mediated transformation method using hypocotyl as explants for Brassica napus. Mol. Breed. 40, 96 (2020).
Lin, T. & Chen, R. Codes and scripts for cauliflower genome resequencing project. Zenodo https://doi.org/10.5281/zenodo.10824481 (2024).
Acknowledgements
We thank X. Wang (Institute of Vegetables and Flowers, Chinese Academy of Agricultural Sciences) for critical comments, and M. Avramakis (University of Crete, Greece) for the pictures of B. cretica. This work was supported by funding from the Modern Agro-Industry Technology Research System of China (CARS-23-A-04 to D.S.), the National Key Research and Development Program of China (2022YFF1003000 to X.Z. and 2023YFF1000100 to T.L.), the 111 Project (B17043 to T.L.), the Construction of Beijing Science and Technology Innovation and Service Capacity in Top Subjects (CEFF-PXM2019_014207_000032 to T.L.), Hunan Youth Science and Technology Talent Project (2022RC1017 to K.C.), ‘131’ innovative team construction project of Tianjin (201923 to X.Y.), the Vegetable Modern Agro-Industry Technology Research System of Tianjin (ITTVRS2017004 to X.Y.), the National Natural Science Foundation of China (31671964 to R.C., 32002042 to X.Z. and 32302579 to Yingxia Yang), the Natural Science Foundation of Tianjin (22JCYBJC00190 to Yingxia Yang, 23JCYBJC00770 to M.L. and 23JCQNJC01040 to Q.W.) and the Innovation Research and Experiment Program for Youth Scholar of Tianjin Academy of Agricultural Sciences (2021023 to Q.W. and 2022017 to Yingxia Yang).
Author information
Authors and Affiliations
Contributions
T.L., R.C. and D.S. designed studies and initiated this project. D.S., X.Y., X.Z., X.G. and P.F.S. contributed to the collection of B. oleracea accessions. X.Y., X.Z., G.Z., M.W., L.D. and T.X. planted accessions, prepared the samples and performed phenotyping. T.L., K.C. and X.S. assembled and annotated the genome. T.L., R.C., K.C., Yingxia Yang, X.S., M.L., Q.W., G.Z., Yuyao Yang and G.J. performed the bioinformatics analyses. R.C., Yingxia Yang, M.W., H.L., H.Z. and Y.G. designed and performed the molecular experiments. Y.L. and T.X. performed the cytological experiments. T.L., R.C., D.S., K.C., X.Y. and X.Z. wrote and/or revised the manuscript. All authors read and approved the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Genetics thanks Longjiang Fan, Alisdair Fernie and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information
Supplementary Figs. 1–13.
Supplementary Table 1
Supplementary Tables 1–18.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, R., Chen, K., Yao, X. et al. Genomic analyses reveal the stepwise domestication and genetic mechanism of curd biogenesis in cauliflower. Nat Genet (2024). https://doi.org/10.1038/s41588-024-01744-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41588-024-01744-4
This article is cited by
-
How the cauliflower got its curlicues
Nature (2024)
