
Abstract
Randomised benchmarking is a widely used experimental technique to characterise the average error of quantum operations. Benchmarking procedures that scale to enable the characterisation of n-qubit circuits rely on efficient procedures for manipulating those circuits and, as such, have been limited to subgroups of the Clifford group. However, universal quantum computers require additional, non-Clifford gates to approximate arbitrary unitary transformations. We define a scalable randomised benchmarking procedure over n-qubit unitary matrices that correspond to protected non-Clifford gates for a class of stabiliser codes. We present efficient methods for representing and composing group elements, sampling them uniformly and synthesising corresponding poly(n)-sized circuits. The procedure provides experimental access to two independent parameters that together characterise the average gate fidelity of a group element.
Similar content being viewed by others

Introduction
A key step to realising a large-scale universal quantum computer is demonstrating that decoherence and other realistic imperfections are small enough to be overcome by fault-tolerant quantum computing protocols.1,2 Randomised benchmarking (RB)3–6 has become a standard experimental technique for characterising the average error of quantum gates partly because of its insensitivity to state preparation and measurement errors. Benchmarking provides robust estimates of average gate fidelity6,7 and it can characterise specific interleaved gate errors,8,9 addressability errors10 and leakage errors.11–13
RB techniques that efficiently scale to many qubits have been limited to subgroups of gates in the Clifford group, as computations with this group are tractable.6 However, the Clifford group is not enough for general quantum computations.14 Previous work generalises RB to groups that include non-Clifford gates,15,16 but only on single qubits, a significant limitation. Methods for bounding the average fidelity of specific types of non-Clifford gates have also been considered.17
We present a scalable RB procedure that includes important non-Clifford circuits, such as circuits composed from and controlled-NOT (CNOT) gates that naturally occur in fault-tolerant quantum computations. The n-qubit matrix groups we study are a generalisation of the standard dihedral group and coincide in some cases with protected gates in stabiliser codes, such as k-dimensional colour codes.18 Circuits built from these gates cannot be universal but do constitute significant portions of magic state distillation protocols,19,20 repeat-until-success circuits21 and the vital quantum Fourier transform.22 We show that there are efficient methods for representing and composing group elements, sampling them uniformly and synthesising corresponding circuits whose size grows polynomially with the number of qubits n. The benchmarking procedure provides experimental access to two independent noise parameters through exponential decays of average sequence fidelities.
Results
The quantum circuits we consider are products of CNOT gates , bit-flip gates and single-qubit m-phase gates , where . More concisely, the circuits of interest are given by the group
We call this group a CNOT-dihedral group, as it is generated by CNOTs and a single-qubit dihedral group. Although we prove certain results for general m, we focus mainly on the case of m=2k. This case affords efficient benchmarking and contains non-Clifford gates of interest, such as , controlled- (defined as ) and controlled–controlled–Z (defined as ), which is locally equivalent to a Toffoli gate.
Our interest in the dihedral group was motivated by symmetries of stabiliser codes. However, another group that may have similar properties is where Λ(p)(X) is a p-controlled-NOT gate. Not all entangling gates are suitable for randomised benchmarking though. Our arguments imply that the group does not yield an efficient benchmarking procedure, as twirling over this group produces a map with exponentially many parameters.
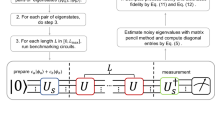
The benchmarking procedure we present here both generalises16 and extends naturally to interleaving gates to estimate individual gate fidelities.8,9 The procedure closely follows10 but we describe it in some detail for completeness. Choose a sequence of ℓ+1 unitary gates in which the first ℓ gates are uniformly random elements , , …, of and the (ℓ+1)st gate is where jℓ denotes the ℓ-tuple (j1, … jℓ) labelling the sequence. We show later that elements of can be efficiently sampled and can be efficiently computed. For each sequence, we prepare an input state ρ, apply and measure an operator E.
Assuming each gate gi has an associated error , the sequence is implemented as
where each . The overlap with E is . Averaging this overlap over K independent sequences of length ℓ gives an estimate of the average sequence fidelity where is the average quantum channel.
Defining to be the average of errors and assuming for all i that is small, the average quantum channel is
where is the -twirl of (see Materials and Methods). The error operator is attributed to measurement error and perturbs E to a new operator E′. We decompose the input state and this final measurement operator in the Pauli basis to give and . Neglecting the term, the average sequence fidelity is
where and .
To see this, it is convenient to express in a corresponding Liouville representation (see Methods). In this representation, is diagonal with three distinct diagonal elements corresponding to sets of Pauli operators: the identity I has value 1, the Z-type Pauli operators have value αZ and the remaining Pauli operators have value αR. The Pauli operator P then contributes ePxPαℓ to Fseq(ℓ, E, ρ), where α is one of 1, αZ or αR depending on P.
In a spirit similar to simultaneous RB,10 each of the two exponential decays and can be observed by choosing appropriate input states. For example, if we choose the input state , then where . On the other hand, if we choose , then where . State preparation errors may lead to deviation from a single exponential decay, but this is detectable. The channel parameters αZ and αR can be extracted by fitting the average sequence fidelity. The corresponding depolarising channel parameter is a weighted average , and the average gate error is given by (see ref. 6).
The Materials and Methods section is devoted to proving the technical results that enable the benchmarking procedure such as a canonical decomposition of Gm, efficient computation within and twirling over to obtain the averaged quantum channel.
Discussion
Our results enable scalable benchmarking of a natural family of non-Clifford circuits related to quantum error-correcting codes. In principle, our procedure allows efficient benchmarking of isolated non-Clifford gates, as well as large sub-circuits for state distillation19,20 or repeat-until-success protocols.21 These sub-circuits can be characterised with our procedure using physical gates or logical gates on protected qubits. Altogether with standard Clifford benchmarking, our procedures enable characterisation of the full range of gates used in the leading fault-tolerant quantum computing protocols. As multi-qubit benchmarking is well within experimental reach,9,23,24 we expect an optimised implementation of our procedure to be quite practical.
Several natural questions arise from this work. First, one might address the asymptotically optimal cost of circuit synthesis for elements of the CNOT-dihedral groups, as well as the practical question of finding optimal circuit decompositions for elements of the smallest groups. We expect optimal circuits are computationally hard to find as n grows, but experimentally it is important to minimise the number of gates. Second, unlike the Clifford group, the CNOT-dihedral group is not a 2-design.5 It would be interesting to find a group (or set) containing a non-Clifford gate and that is a 2-design, and in which benchmarking can be done efficiently. Third, our results show that we can efficiently perform RB. However, we have not addressed the precise sense in which quantum computations over the CNOT-dihedral group can be efficiently simulated. This may be a subtle problem.25,26 Last, there are generalised stabiliser formalisms, such as,27 and it is natural to ask whether one of these describes how this group acts on some set of states.
Materials and methods
This section is devoted to proving the various results used in the benchmarking procedure: canonical decomposition of Gm, efficient computation in Gm and twirling over Gm, each of which is interesting in its own right. Let m be general and let us briefly set some notation. The matrix representation of Gm is set by identifying g∈Gm to the matrix that maps to with unit phase. We define the phase-flip gates and controlled-Z gates . The support of a bit string v∈{0, 1}n is . We refer to v and its support interchangeably, treating v as a set and vice versa. Let U be a single-qubit gate and U(v) denote the gate acting as U only on qubits in the support of v. Given J⊆[n] or elements i, j, … ∈[n], we also use the shorthand U(J) and U(i, j, …). denotes the n-qubit Pauli group and we define , , and .
Canonical form of Gm
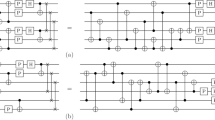
Our first goal will be to put Gm in a canonical form (the main result is contained in Theorem 1). The rewriting identities shown in Figure 1 allow us to commute diagonal elements of Gm through Λij(X) and X(j) gates. The rules for bit-flip gates are a special case of the CNOT rules. The following Lemma follows directly from definitions and formalises the role of the rewriting identities in understanding the group’s structure.

Rewriting identities. Controlled-phase gate notation carrying the label a denotes a controlled-(Zm)a gate. (a) This is the only identity that increases the number of controls. (b) This identity preserves the number of controls.
Lemma 1: Let Wm denote the subgroup of diagonal matrices of Gm and let denote the subgroup of permutation matrices. Then, Gm is isomorphic to a semi-direct product of groups Gm≃Wm⋊Π.
The proof of Lemma 1 is given in the Supplementary Material. Note that by definition . As and , each element π∈Π can be associated with an n-bit string and an n by n invertible 0–1 linear transformation such that . Here denotes the field with two elements. Furthermore, .
It remains to better understand Wm (see Lemma 3 for the main result). Let Dm denote the group of 2n by 2n diagonal unitary matrices D with elements . Here is a function that assigns mth roots of unity to the diagonal and is the ring of integers modulo m. Since Gm is generated by permutation matrices and products of m-phase gates, Wm⊆Dm.
Let denote the polynomial ring whose elements are where α=α1 … αn is a multi-index, and is a monomial. The multi-index takes values in {0, 1}n as a convenient notation, as we will evaluate p(x) on binary strings, so . The degree of a monomial is denoted . We mainly consider ℛ as an additive group. The next Lemma follows from the definition of group isomorphism and the fact that each function f(b) can be expressed as a polynomial in ℛ.
Lemma 2: Let p(b) denote evaluation of p on the n-bit binary string b=b1 … bn with operations in . The function given by is a group isomorphism.
The proof of Lemma 2 is given in the Supplementary Material. The rewriting identities give the action of Π on Wm by conjugation. Let . On the basis of a similar application of the rewriting identities as in Lemma 1, . As , Φ−1 associates a polynomial in ℛ to each element of Wm. By our chosen convention, matrices representing elements w∈Wm are given modulo a global phase factor such that . Therefore, the preimages Φ−1(w) have zero constant term—i.e., pα=0 when . Through Φ, the rewriting identities define an action of Π on ℛ that, respectively, takes x1x2 … xpxj to
and x1x2…xpxixj to
Equation (6) increments the degree of a monomial and multiplies its coefficient by −2, whereas Equation (7) does not change the degree. Another way to understand iterated applications of Equation (6) is to observe that
This fact relates how single qubit Zm gates acting on mod 2 linear combinations of input bits are equivalent to products of certain controlled-phase gates.
There is an element of Wm corresponding to each monomial term of non-zero degree, and the coefficient of this term has the form , as we will now see (see Supplementary Materials for further details.). We choose a subset of qubits J, fix any j∈J and define a permutation gate and corresponding polynomial
By Equation (8), ; i.e., this circuit has a polynomial with one term of degree . As Φ(Zm(j))=xj, scaled monomials of successive degrees |α| and with coefficients in can be generated inductively by composing these circuits. Take all linear combinations of these over to find
Lemma 3: Wm is isomorphic to the subgroup given by
We can now directly compute .
Corollary 1
Proof: Let om(a)=LCM(a, m)/a denote the order of a in . Observe that as additive groups. Therefore, Wm is isomorphic to a direct product of additive cyclic groups . This shows that .
Putting everything together, we have
Theorem 1: Any element of Gm can be written in canonical form as the composition of a sequence of phase gates (comprising an element of Wm whose form is given in Lemma 3), a sequence of CNOT gates and a sequence of bit-flip gates.
Efficient computation in
Our next goal is to present efficient methods for computing with Gm. Suppose we fix value of m so that it is not a function of n. Any labelling of group elements will have length proportional to . If m is odd, then , whereas if m=2k then . Therefore, s=Ω(2n) whenever m is odd (see Supplementary Materials for further details.), and in general we cannot efficiently represent elements of Gm as the number of qubits grows. However, s=O(nk) for the special case m=2k, and the story is different. We focus on this special case for the remainder of this article.
An element g∈Gm can be written as a product g=uvw where w∈Wm is a diagonal matrix, is a CNOT circuit and is a tensor product of bit-flips. This transforms n-qubit quantum states as where , and . Group elements are in bijective correspondence with the triples (p, B, c). The polynomial p has maximum degree k and at most nonzero coefficients, each contained in .
The product of group elements g1, g2∈Gm,
is given by the triple
The products B2B1 and B2c1⊕c2 can be computed in O(n3) time, and polynomials in can be added in O(nk) ring operations. We need to show that p2(B1x⊕c1) can also be computed efficiently.
Consider a triple (p, B, c) and let Bj denote the jth row of B and Jj=supp(Bj). Define x′=Bx⊕c. Then, for any j∈[n], using Equations (8) and (9),
has maximum degree k. When we substitute into the degree k polynomial p(x), computations occur with coefficients in . We compute each monomial (x′)α with O(k) multivariate polynomial multiplications, each of which can be done term-by-term in O(n2k+1) ring operations. We compute the term pα(x′)α with an additional O(nk) ring operations to multiply each term of (x′)α by a and accumulate the result. There are O(nk) terms in p(x), so the total number of ring operations to compute p(x′) is O(n3k+1). If c ≠ 0n, then it is possible that p(x′) has a non-zero constant term. With additional O(nk) ring operations, p(x′) can be mapped to an equivalent polynomial in .
Uniformly sampling from G2k is equivalent to uniformly and independently sampling from , and . This can be done efficiently, as elements of have maximum degree k; see also ref. 28 (see Supplementary Materials for further details.).
Given a triple (p, B, c), we synthesise a corresponding circuit from products of CNOT gates, bit-flip gates and single-qubit m-phase gates. Our goal is to efficiently synthesise a circuit whose size (number of gates) is polynomial in n but not to optimise this circuit. We independently synthesise circuits coinciding with p, B and c. As c corresponds to X(c), and a CNOT circuit for B can be found by Gaussian elimination,14 the new part of the algorithm synthesises a circuit for p.
We describe the circuit synthesis for p informally. The algorithm proceeds in k rounds. Begin by initialising a working polynomial q(x)←p(x), set a round counter t←k and set a quantum circuit U←I. Here ‘←’ denotes assignment. In round t, we synthesise a circuit corresponding to a polynomial p(t)(x) that coincides with q(x) on its degree t terms. For each of the O(nt) degree-t terms of q(x), we apply the constant-sized circuit setting U←gαU, where J=supp(α) as in the proof of Lemma 3. The product of the gα corresponds to . Therefore, we update q(x)←q(x)−p(t)(x), which now has maximum degree t−1, decrement the round counter and proceed to the next round. The algorithm terminates when q(x)=0 and t=0. The total algorithm run-time and circuit size of the output U is O(nk).
Twirling over
A quantum channel is a completely positive trace-preserving map whose operator sum decomposition is where . The twirl of over a finite group G (G-twirl) is given by
In what follows, we use several facts about group twirls. If G=AB is a direct product of groups, then , and if A is a normal subgroup of G (denoted ), then , where the twirl over the factor group G/A is over a set of coset representatives. Twirling any map over the Pauli group produces a Pauli channel.5 Consider a Pauli channel . Twirl this channel over any finite group G that has a permutation action on the set . The orbit of P∈ is and the stabiliser is . The orbits define an equivalence relation P~Q if and only if OP=OQ. This relation partitions into a disjoint union of orbits. By the orbit-stabiliser theorem and Lagrange’s theorem,29 . Therefore, the twirl, Equation (15), can be written
where is a set of representative elements, one from each orbit.
These facts allow us to compute the twirl over when k>1 by expressing it as a sequence of twirls. We begin by decomposing the group. Let and recall that , then . As and , we form the corresponding factor groups. Therefore, an element can be written as where labels cosets , , labels cosets and . Finally, by Lemma 1, any element factors as g=uvw where , and . Therefore, we have where .
Our strategy is to use the decomposition to express the -twirl as a sequential -twirl, c-twirl, c-twirl, -twirl and -twirl. Each twirl can be computed in a straightforward manner using the facts we have described, and it reduces the number of independent parameters describing the channel until we have twirled over the whole of (see Supplementary Materials for further details.). The final twirled map is
In the Liouville representation in the Pauli basis, which has matrix elements where P and Q are n-qubit Pauli operators, this map has three diagonal blocks corresponding to I, and with elements 1, αZ:=1−4nβR and αR:=1−2nβZ−(4n−2n)βR, respectively.
References
Gottesman., D. An introduction to quantum error correction and fault-tolerant quantum computation. Preprint at http://arxiv.org/abs/0904.2557 (2009).
Raussendorf, R. & Harrington, J. Fault-tolerant quantum computation with high threshold in two dimensions. Phys. Rev. Lett. 98, 190504 (2007).
Emerson, J., Alicki, R. & Zyczkowski, K. Scalable noise estimation with random unitary operators. J. Opt. B Quantum Semiclassical Opt 7, S347 (2005).
Knill, E. et al. Randomized benchmarking of quantum gates. Phys. Rev. A 77, 012307 (2008).
Dankert, C., Cleve, R., Emerson, J. & Livine., E. Exact and approximate unitary 2-designs and their application to fidelity estimation. Phys. Rev. A 80, 012304 (2009).
Magesan, E., Gambetta, J. & Emerson, J. Robust randomized benchmarking of quantum processes. Phys. Rev. Lett. 106, 180504 (2011).
Wallman, J. & Flammia, S. Randomized benchmarking with confidence. New J. Phys. 16, 103032 (2014).
Magesan, E. et al. Efficient measurement of quantum gate error by interleaved randomized benchmarking. Phys. Rev. Lett. 109, 080505 (2012).
Gaebler, J. et al. Randomized benchmarking of multiqubit gates. Phys. Rev. Lett. 108, 260503 (2012).
Gambetta, J. et al. Characterization of addressability by simultaneous randomized benchmarking. Phys. Rev. Lett. 109, 240504 (2012).
Epstein, J., Cross, A., Magesen, E. & Gambetta, J. Investigating the limits of randomized benchmarking protocols. Phys. Rev. A 89, 062321 (2014).
Wallman, J., Barnhill, M. & Emerson, J. Characterization of leakage errors via randomized benchmarking. Phys. Rev. Lett. 115, 060501 (2015).
Chasseur, T. & Wilhelm, F. Complete randomized benchmarking protocol accounting for leakage errors. Phys. Rev. A 92, 042333 (2015).
Gottesman., D . Stabilizer Codes and Quantum Error Correction. PhD dissertation, (Caltech, 1997).
Barends, R. et al. Rolling quantum dice with a superconducting qubit. Phys. Rev. A 90, 030303, (R)) (2014).
Dugas, A., Wallman, J. & Emerson, J. Characterizing universal gate sets via dihedral benchmarking. Phys. Rev. A 92, 060302, (R) (2015).
Kimmel, S., da Silva, M. P., Ryan, C., Johnson, B. & Ohki, T. Robust extraction of tomographic information via randomized benchmarking. Phys. Rev. X 4, 011050 (2014).
Bombin, H. & Martin-Delgado, M. Topological computation without braiding. Phys.Rev.Lett. 98, 160502 (2007).
Bravyi, S. & Kitaev, A. Universal quantum computation with ideal Clifford gates and noisy ancillas. Phys. Rev. A 71, 022316 (2005).
Duclos-Cianci, G. & Poulin, D. Reducing the quantum computing overhead with complex gate distillation. Phys. Rev. A 91, 042315 (2015).
Paetznick, A. & Svore., K. Repeat-until-success: Non-deterministic decomposition of single-qubit unitaries. Quant. Inf. Comp. 14, 15/16 (2014).
Nielsen, M. & Chuang., I. Quantum Computation and Quantum Information. (Cambridge Univ. Press, 2000).
Corcoles, A. et al. Process verification of two-qubit quantum gates by randomized benchmarking. Phys. Rev. A 87, 030301, (R)) (2013).
Kelly, J. et al. Optimal quantum control using randomized benchmarking. Phys. Rev. Lett. 112, 240504 (2014).
Ni, X. & Van den Nest, M. Commuting quantum circuits: efficient classical simulations versus hardness results. Quant. Inf. Comp. 13, 54–72 (2013).
Jozsa, R. & Van den Nest, M. Classical simulation complexity of extended Clifford circuits. Quant. Inf. Comp. 14, 633–648 (2014).
Ni, X., Buerschaper, O. & Van den Nest., M. A non-commuting stabilizer formalism. J. Math. Phys. 56, 052201 (2015).
Randall, D. Efficient generation of random nonsingular matrices. Random Struct. Algorithms 4, 111–118 (1993).
Artin., M. Algebra. (Prentice Hall, 1991).
Acknowledgements
All authors acknowledge support from ARO under contract W911NF-14-1-0124.
Author information
Authors and Affiliations
Contributions
A.W.C. proved the main results with substantial contributions from E.M. and J.M.G. L.S.B. and A.W.C. implemented twirling operations and computed group orders. J.A.S. contributed significantly to early discussions. All authors contributed to writing the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no conflict of interest.
Additional information
Supplementary Information accompanies the paper on the npj Quantum Information website (http://www.nature.com/npjqi)
Supplementary information
Rights and permissions
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-nd/4.0/
About this article

Cite this article
Cross, A., Magesan, E., Bishop, L. et al. Scalable randomised benchmarking of non-Clifford gates. npj Quantum Inf 2, 16012 (2016). https://doi.org/10.1038/npjqi.2016.12
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/npjqi.2016.12
This article is cited by
-
Majorization-based benchmark of the complexity of quantum processors
Quantum Information Processing (2024)
-
Benchmarking universal quantum gates via channel spectrum
Nature Communications (2023)
-
Near-term quantum computing techniques: Variational quantum algorithms, error mitigation, circuit compilation, benchmarking and classical simulation
Science China Physics, Mechanics & Astronomy (2023)
-
Optimal two-qubit circuits for universal fault-tolerant quantum computation
npj Quantum Information (2021)
-
Multi-exponential error extrapolation and combining error mitigation techniques for NISQ applications
npj Quantum Information (2021)
