
Abstract
Clifford group lies at the core of quantum computation—it underlies quantum error correction, its elements can be used to perform magic state distillation and they form randomized benchmarking protocols, Clifford group is used to study quantum entanglement, and more. The ability to utilize Clifford group elements in practice relies heavily on the efficiency of their circuit-level implementation. Finding short circuits is a hard problem; despite Clifford group being finite, its size grows quickly with the number of qubits n, limiting known optimal implementations to n = 4 qubits. For n = 6, the number of Clifford group elements is about 2.1 × 1023. In this paper, we report a set of algorithms, along with their C++ implementation, that implicitly synthesize optimal circuits for all 6-qubit Clifford group elements by storing a subset of the latter in a database of size 2.1TB (1kB = 1024B). We demonstrate how to extract arbitrary optimal 6-qubit Clifford circuit in 0.0009358 and 0.0006274 s using consumer- and enterprise-grade computers (hardware) respectively, while relying on this database. We use this implementation to establish a new example of quantum advantage by Clifford circuits over CNOT gate circuits and find optimal Clifford 2-designs for up to 4 qubits.
Similar content being viewed by others
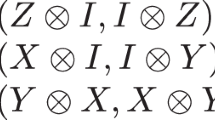


Introduction
Quantum computations are studied for their promise to outperform classical counterparts for certain kinds of computations1. The Clifford group is an important finite subgroup of the full unitary group, describing the set of quantum computations. Despite being possible to simulate classically2,3 by a low degree polynomial and having a simple structure4 (admitting efficient parametrization and being possible to compute by linear depth circuits), the group is most famous for lying at the core of quantum error correction1, which is believed to be necessary for scalable quantum computation. Restricted to the study of fault-tolerance, Clifford group plays multiple roles still. To illustrate, all (standard) encoding circuits are Clifford1, and so are the circuits for state distillation5,6, necessary for fault-tolerant implementation of non-Clifford gates. Clifford circuits lie at the core of randomized benchmarking protocols7,8. Other use cases include shadow tomography9,10, the study of entanglement1,11, and quantum data hiding12. It is perhaps fair to regard the Clifford group as one of the most visible and important subgroups of the group of all quantum computations.
Superconducting circuits and trapped ions are two technological frameworks that produced a stream of (universal prototype) programmable quantum computers, publicly available since the year 2016. Each technology comes in a range of flavors: e.g., superconducting circuits can be based on phase, charge, or flux qubits (or even hybrid kinds), and rely on various qubit coupling mechanisms, and trapped ions can be based on various ion species and rely on different approaches to the two-qubit gates (e.g., stationary vs mobile qubits). However, no matter the specific flavor, all prototype quantum computers based on these two approaches share one property13,14: the two-qubit gate has notably lower fidelity than a single-qubit gate. Thus, to the first degree of approximation, the fidelity of an entire quantum computation depends on the number of two-qubit gates it uses. To make a more subtle point, since the single-qubit gates are most frequently implemented by pulses with real-valued control parameters, the number of two-qubit gates in a circuit upper bounds the number of the single-qubit gates (up to a constant factor), meaning the reduction of the two-qubit gate count likely leads to the reduction in the number of single-qubit gates. We further note that the CNOT gates are available natively (i.e., requiring the minimal number of one two-qubit physical-level interaction) in both superconducting circuits and trapped ions technologies. Finally, recall that the physical-level entangling pulses frequently take the form of XX, ZX, and ZZ, requiring single-qubit corrections to turn those interactions into commonly used CNOT or CZ gates. This means that minimizing single-qubit gate count in an abstract circuit may not directly minimize the number of single-qubit physical pulses, since the single-qubit gates will be reshuffled during technology mapping. This justifies our focus on minimizing the CNOT gate count, selected as the optimization criterion in this paper.
In this paper, we study the problem of optimal synthesis of Clifford circuits. Since the problem of optimal circuit synthesis is hard, we restrict our attention to a small number of qubits, at most 6. The number of Clifford group elements over 6 qubits, 2.1 × 1023, is still very large, and we employ a range of techniques to make the search tractable using modern computers. At the core of our approach is a mechanism to break down the set of Clifford unitaries into a set of classes containing unitaries sharing a similar optimal circuit structure, efficient computation of the canonical representative of each class, and efficient manipulation of class members and the database of canonical representatives.
We define the n-qubit Clifford group \({{{{\mathcal{C}}}}}_{n}\) as the group of 2n × 2n symplectic matrices M over the two-element field \({{\mathbb{F}}}_{2}\), \({{{\rm{Sp}}}}(2n,{{\mathbb{F}}}_{2})\,:=\,\{M:\,{M}^{T}{{{\Omega }}}_{n}M\,=\,{{{\Omega }}}_{n}\}\), where MT denotes the transpose matrix, Ωn is the matrix \(\left(\begin{array}{ll}0&{I}_{n}\\ {I}_{n}&0\end{array}\right)\), and In is the n × n identity matrix. Symplectic matrices are equivalent to and alternatively known as the tableaux3. The size of the symplectic group is \(| {{{\rm{Sp}}}}(2n,{{\mathbb{F}}}_{2})| ={2}^{{n}^{2}}\mathop{\prod }\limits_{j=1}^{n}({2}^{2j}-1)\), which for the purpose of this paper implies \(| {{{{\mathcal{C}}}}}_{6}| \,=\,208,\,114,\,637,\,736,\,580,\,743,\,168,\,000\,\approx \,2.1\times 1{0}^{23}\) and assigns the numeric value to the size of the search space we are exploring.
Tableau representation is particularly useful since it allows to define quantum gates and circuits directly without the need to resort to standard definitions in quantum information that employ 2n × 2n unitary matrices1. Indeed,
-
the Hadamard gate H on qubit k can be defined as the 2n × 2n identity matrix with swapped columns k and n + k,
-
the Phase gate P on qubit k can be defined as the addition of column k to column n + k in the 2n × 2n identity matrix,
-
the CNOT gate with control qubit k and target j performs simultaneous addition of column k to column j and column n + j to column n + k in the 2n × 2n identity matrix,
and circuits are matrix multiplications. The computational completeness of the {H, P, CNOT} library is readily exposed by the ability to apply Gaussian elimination to obtain arbitrary symplectic matrix as a product of gates. An additional advantage of such a definition of gates and circuits comes from displaying the capacity to implement transformations by Clifford gates efficiently by a computer program.
As a side note, we highlight that each element of the Clifford group \({{{{\mathcal{C}}}}}_{n}\) defines an equivalence class of 2n × 2n unitary matrices realizable by the circuits over H, P, and CNOT gates (defined, in turn, via unitary matrices1). A pair of unitary matrices is considered equivalent if they can be mapped to each other by the left (or right) multiplication with single-qubit Pauli gates and overall phase factors. Since we focus on the minimization of the two-qubit gate count, Pauli gates and phase factors can be safely factored out. Had Pauli gates been included in the Clifford group, the search space size for n = 6 would read 8.5 × 1026.
Results
6-qubit optimal Clifford circuits
The distribution of the number of equivalence classes across CNOT gate costs is shown in Table 6. For the number of qubits 2 through 5 the most complex function to implement is unique (within the equivalence class definition), and it is equivalent to a cyclic permutation of qubits. For n = 6, the cyclic permutation is one of three such functions; the other two are illustrated in Fig. 1. The small number of equivalence classes for a small number of qubits implies an efficient formula (based on ReduceU) to compute the CNOT cost of a small Clifford unitary.

a left: a compact representation in the form (U ⊗ U)SWAP, right: its optimal implementation. b left: a compact representation in the form \((U^{\prime} \otimes V^{\prime} )\,{{\mbox{SWAP}}}\,\), right: its optimal implementation. Not illustrated is the cyclic SWAP of all 6 qubits, that also requires 15 entangling gates.
We ran a script to calculate the distribution of the number of Clifford group elements across optimal CNOT gate costs. Given the database, it took a few days to collect the data using an HPC system. This computation is highly parallelizable, and the runtime can be reduced significantly with many processors, e.g., GPUs; we have not pursued those reductions. The results are reported in Table 1.
We used the database to look for examples of quantum Clifford advantage over classical reversible CNOT circuits, meaning optimal CNOT circuits that can be implemented with fewer entangling gates as a Clifford circuit. We found one such example, illustrated in Fig. 2, that gives a reduction of 14 gates into 12, improving the 8 to 7 reduction seen earlier4\(\left(\,{{\mbox{indeed,}}}\,\frac{14}{12} > \frac{8}{7}\right)\).

An optimal CNOT gate circuit (left) can be implemented with fewer entangling gates as an optimal Clifford circuit (right).
The compiler was benchmarked using both consumer-grade and enterprise-grade systems for a test set with 10, 000 elements of the Clifford group \({{{{\mathcal{C}}}}}_{6}\). Each element was generated by a Clifford circuit with 600 randomly chosen gates over the library {H, P, CNOT}. The number of gates was selected to be high enough to effect a close to random uniform distribution over the elements of the group \({{{{\mathcal{C}}}}}_{6}\). We observed that such random test set is dominated by the elements with costs 11 and 12. The compiler runtime reported below is the time required to obtain optimal circuits for all test set elements divided by the size of the test set. We observed the runtime of 0.0009358 s for a laptop with Intel® i7-1068NG7 2.3 GHz CPU and 16GB RAM with USB-C-attached consumer-grade SSD. The search relies on the database stored on SSD, and a 2.5GB index in RAM, see the section “Software tricks” for details. The time reported measures hot cache performance, cold cache performance reads 0.003708 s per an optimal circuit, on average. The compiler performance improves when the entire database can be stored in RAM. We observed the hot cache runtime of approximately 0.0006274 s for a server with Intel® Xeon® 128-CPU E7-4850 v4 @ 2.10GHz and 6TB RAM. The process of loading the full database into RAM took approximately 2 h.
This performance allows to use our implementation to obtain individual circuits and entire randomized benchmarking schedules in mere seconds using consumer-grade hardware as well as online via a web interface. For the use in demanding applications such as peep-hole optimization of large circuits, we suggest relying on large-RAM commercial-grade servers and note that it takes roughly half the time to look up the cost without computing the optimal circuit (the procedure that would likely get called most frequently during peep-holing).
The average runtime of our compiler for random n-qubit Clifford operators with n ≤ 5 is shown in Table 2.
Optimal 2-designs
Unitary designs15 are probability distributions on the unitary group that reproduce low-order moments of the Haar (uniform) distribution. Of particular interest are unitary designs that can be efficiently implemented by quantum circuits16. Such designs can serve as a substitute for the Haar distribution in certain randomized quantum protocols such as data hiding12, estimating fidelity of quantum operations8,17, and quantum state tomography10. In this section, we leverage the database of reduced Clifford elements to construct optimal unitary designs that have the minimum average cost, subject to the constraint that all elements of the design are Clifford operators.
Let U(2n) be the group of unitary complex matrices of size 2n × 2n. Suppose \({{{\mathcal{D}}}}\,\subseteq \,U({2}^{n})\) is a finite subset and \(\mu :\,{{{\mathcal{D}}}}\,\to \,{{\mathbb{R}}}_{+}\) is a probability distribution on \({{{\mathcal{D}}}}\). The pair \(({{{\mathcal{D}}}},\mu )\) is called a unitary 2-design18 if
for any complex matrices \(\hat{A}\) and \(\hat{B}\). Here the tensor product separates two n-qubit registers and the integral in the right-hand side of Eq. (1) is the average over the Haar distribution on the unitary group U(2n). We reserve the hat notation for complex unitary matrices to avoid confusion with binary symplectic matrices considered in the rest of the paper. Below we choose \({{{\mathcal{D}}}}\) to be the n-qubit Clifford group and construct a probability distribution μ that minimizes the average cost
subject to the constraint that \(({{{\mathcal{D}}}},\mu )\) is a unitary 2-design. Here \({{{\rm{cost}}}}(\hat{U})\) is the minimum number of the CNOT gates required to implement \(\hat{U}\) by a quantum circuit composed of the Hadamard, Phase, and CNOT gates.
Since Pauli operators have zero cost, we can assume wlog that the optimal solution μ is Pauli-invariant, i.e., \(\mu (\hat{U})\,=\,\mu (\hat{U}\hat{O})\) for all n-qubit Pauli operators \(\hat{O}\). As defined earlier, the unitary version of the n-qubit Clifford group is isomorphic to \({{{{\mathcal{C}}}}}_{n}\,\times \,{\{I,X,Y,Z\}}^{n}\). Here we ignore the overall phase factors. Define the probability distribution \(\pi :\,{{{{\mathcal{C}}}}}_{n}\,\to \,{{\mathbb{R}}}_{+}\) such that π(U) = 4nμ(U × P) for all \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) and P ∈ {I, X, Y, Z}n. The distribution π is well-defined whenever μ is Pauli-invariant. In the section “Pauli mixing constraint”, we show that μ is a Clifford 2-design iff π obeys the so-called Pauli mixing constraint16
Furthermore, μ has the average cost
Thus it suffices to minimize the average cost Eq. (4) over variables π(U) ≥ 0 subject to the normalization constraint \({\sum }_{U\in {{{{\mathcal{C}}}}}_{n}}\pi (U)\,=\,1\) and the Pauli mixing constraint, Eq. (3). This gives a linear program with \(| {{{{\mathcal{C}}}}}_{n}|\) variables.
The next step is to reduce the number of variables and the number of constraints in the linear program. Suppose π is a Pauli mixing distribution on \({{{{\mathcal{C}}}}}_{n}\), that is, π obeys Eq. (3). Define a symmetrized version of π as follows. First, sample \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) from the distribution π. Second, sample W ∈ Sn and \(L,R\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\) from the uniform distribution on the respective groups. Finally, output \(U^{\prime} \,=\,L{W}^{-1}UWR\). The probability distribution of \(U^{\prime}\) is given by
Since the cost is invariant under a qubit relabeling and left/right multiplications by the elements of local subgroup \({{{{\mathcal{C}}}}}_{n}^{0}\), the distributions π and \(\pi ^{\prime}\) have the same average cost. We claim that \(\pi ^{\prime}\) is Pauli mixing. Indeed, pick any non-zero vectors x, y ∈ {0, 1}2n, a qubit permutation W ∈ Sn, and local Cliffords \(L,R\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\). Then
where \(x^{\prime} \,=\,WRx\,\ne \,0\) and \(y^{\prime} \,=\,W{L}^{-1}y\,\ne \,0\). The last equality in Eq. (5) follows from the assumption that π is Pauli mixing. Thus \(\pi ^{\prime}\) is a convex linear combination of Pauli mixing distributions, that is, \(\pi ^{\prime}\) itself is Pauli mixing.
The above shows that an optimal Clifford 2-design can be found by minimizing the average cost Eq. (4) over symmetric Pauli mixing distributions π such that the probability π(U) depends only on the equivalence class [U] that contains U. Such distribution π can be compactly specified by considering the set of reduced elements
Given a reduced element \(U\,\in \,{{{{\mathcal{R}}}}}_{n}\), define the probability distribution
Note that η is a probability distribution on \({{{{\mathcal{R}}}}}_{n}\) since each equivalence class [U] contains a unique reduced element, see the section “Computation of ReduceU”. For brevity, we will refer to η as a reduced distribution. The average cost of the original distribution π depends only on η and can be computed using the formula
It remains to express the Pauli mixing constraint in terms of the reduced distribution η. Given a reduced element \(U\,\in \,{{{{\mathcal{R}}}}}_{n}\) and non-zero vectors x, y ∈ {0, 1}2n, define the quantity
In words, g(U, x, y) is the probability that a random uniformly distributed element of the equivalence class [U] maps x to y. Then π is Pauli mixing iff
for all non-zero vectors x, y ∈ {0, 1}2n. It remains to note that some constraints Eq. (7) are redundant. Indeed, since the equivalence class [U] is invariant under the left/right multiplications of U by the elements of the local subgroup \({{{{\mathcal{C}}}}}_{n}^{0}\), one has g(U, x, y) = g(U, Lx, Ry) for all \(L,R\in {{{{\mathcal{C}}}}}_{n}^{0}\). Suppose (xj, xn+j) ≠ (0, 0) for some qubit j. Then one can choose \(L\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\) acting non-trivially only on the jth qubit such that (Lx)j = 0 and (Lx)n+j = 1, see the section “Computation of ReduceU”. Applying this transformation to all qubits we conclude that the Pauli mixing constraint Eq. (7) has to be imposed only for vectors
Minimizing the average cost Eq. (6) over variables η(U) ≥ 0 with \(U\,\in \,{{{{\mathcal{R}}}}}_{n}\), subject to the normalization \({\sum }_{U\in {{{{\mathcal{R}}}}}_{n}}\eta (U)\,=\,1\) and the Pauli mixing constraints Eqs. ((7), (8)), gives a linear program with \(| {{{{\mathcal{R}}}}}_{n}|\) variables and \(1\,+\,{({2}^{n}-1)}^{2}\) equality constraints. We were able to find an optimal solution of this linear program numerically for n = 2, 3, 4 qubits. The optimal reduced distributions η presented in Table 3, Table 4, and Table 5 are compactly represented by a list of reduced elements \({U}_{1},{U}_{2},\ldots,{U}_{m}\in {{{{\mathcal{R}}}}}_{n}\) along with their probabilities η(Uj). Only reduced elements that appear with non-zero probability are shown. The tables display an optimal circuit implementation of each reduced element Uj. To avoid clutter, we omit single-qubit gates on the left and on the right. The actual 2-design has the form LW−1UjWR, where the index j ∈ {1, 2, …, m} is sampled with the probability η(Uj), the qubit permutation W is sampled uniformly from Sn, and L, R are sampled uniformly from the local subgroup \({C}_{n}^{0}\).
Comparison to prior work
Similar-spirited prior work includes the synthesis of 4-qubit optimal Clifford circuits19, the synthesis of 4-bit optimal reversible circuits20, and optimal solution of Rubik’s cube puzzle21,19 is most closely related to our work, given the focus on Clifford circuits; the difference is we chose to study the two-qubit gate cost, which better reflects the constraints of the existing quantum computers than the total gate count. The search space size comparison is 4.7 × 1010 in19 to 2.1 × 1023 in our work—an almost 13 orders of magnitude difference20 study reversible circuits, being a highly relevant type of computations. Their search space size is 2.1 × 1013, meaning we solved a problem with 10 orders of magnitude higher search space size. Finally21, studies Rubik’s cube, which is also a finite group. Their search space size is 4.3 × 1019, meaning ours is almost 4 orders of magnitude higher.
Discussion
In this paper, we reported algorithms and their C++ implementation that compute all two-qubit gate count optimal 6-qubit Clifford circuits. There are about 2.1 × 1023 different Clifford functions. The large search space required us to employ server-class machines to make the computation possible. In particular, we used HPC to break down the set of canonical representatives of Clifford group elements sharing similar optimal circuit structure, and store them in a database of size 2.1TB. Given this database on an SSD and a 2.5GB index file in RAM, the time to extract an optimal circuit using a consumer-grade laptop is 0.0009358 s—10 times faster than the typical access time for a spindle drive. The time to extract an optimal circuit using an enterprise-level system while storing the database in RAM is 0.0006274 s—15 times faster than the typical HDD access time. We used the database to establish the maximal gate count needed to implement an arbitrary 6-qubit Clifford unitary and showed the distribution of the number of Clifford functions across their required gate counts. We established a new example of quantum advantage by Clifford circuits over CNOT gate circuits and found optimal Clifford 2-designs for the number of qubits up to, and including, 4.
Methods
Algorithm and its implementation: an overview
Our approach relies on the use of pruned breadth-first search (BFS) to generate a number of databases containing Clifford unitaries that can be implemented by equal cost optimal circuits, and augment it by a set of tools that extract useful statistics (e.g., distribution of the number of unitaries by entangling gate cost, average cost, largest cost) as well as individual optimal circuits. BFS is a strategy that relies on taking optimal implementations of cost up to k, modifying them by applying cost-1 transformations to cost-k elements, and recording the result as a cost k + 1 element if it is not yet found in the database. BFS is initiated with the identity operator costing zero and ends when all elements in the target set were explored. While our algorithm can be applied to obtain optimal 2-, 3-, 4-, 5-, and 6-qubit Clifford circuits using modern computers, we focus the rest of the description on the most difficult but still amenable to classical computers 6-qubit case.
Since the database we are synthesizing contains Clifford unitaries, the first order of business is to choose a suitable data structure to store those. The data structure must be both compact and allow quick application of gates; this is because BFS boils down to a series of gate applications and memory lookups. We start with the tableau, which is naturally suited for quick gate application, and modify it to remove two last rows corresponding to X and Z stabilizers each3. As described in the section “Data structure”, these rows can be quickly restored. However, removing them allows to reduce the storage from 4n2∣n=6 = 144 bits to 2 × 2n(n − 1)∣n=6 = 120 bits. Each unitary is thus stored across two 64-bit machine words (each half corresponding to X and Z parts), with 4 bits per machine word of (yet) unused space. While information-theoretic minimum storage requirement, \(\lceil {\log }_{2}(| {{{{\mathcal{C}}}}}_{6}| )\rceil \,=\,78\), implies that more compact storage exists, BFS imposes the requirement of quick gate application and we furthermore rely on canonicity (discussed in next paragraph) to reduce the size of the database; thus, it is not obvious if more efficient storage is possible.
Should each Clifford element require storage, the search would not be possible to execute on modern computers since \(| {{{{\mathcal{C}}}}}_{6}| \,\approx \,2\times 1{0}^{23}\). We, therefore, break Clifford group elements into classes of equivalence such that class members share the same optimal circuit structure, a canonical representative exists, and it is efficient to compute. In our approach, a class of equivalence can be thought of as containing unitaries with optimal circuits equivalent up to left- and right-hand multiplication by single-qubit Clifford unitaries, and qubit relabeling; the canonical representative is chosen to be the one with the least lexicographic order across all elements in its equivalence class. This means that we can pack up to \(| {{{{\mathcal{C}}}}}_{1}{| }^{2n}\cdot | {S}_{n}| {| }_{n = 6}={6}^{12}\cdot 6!=1,567,283,281,920\) unitaries into one class. More precisely, the number of unitaries contained in each equivalence class may vary between \(| {{{{\mathcal{C}}}}}_{1}{| }^{n}\) and \(| {{{{\mathcal{C}}}}}_{1}{| }^{2n}\cdot | {S}_{n}|\). The former case is realized for the identity operator which is invariant under all qubit relabelings and does not differentiate between left- and right-hand multiplications by single-qubit Clifford unitaries. The latter case is realized for a generic element of the Clifford group without any special symmetries. Here, \(| {{{{\mathcal{C}}}}}_{1}|\) is the size of the single-qubit Clifford group \({{{{\mathcal{C}}}}}_{1}\) raised to the power 2n to represent one-qubit operators on each qubit in the beginning and end of the circuit, and Sn is the permutation group. However, the computation of canonical representative must be efficient, as otherwise, complexity moves from storage to computation. We utilized a Pareto-efficient definition of the equivalence class, as determined by ReduceU, the function computing the canonical representative, to be most practical. Our computationally-defined canonical representative is at most factor 14 storage inefficient, but it allows a quick computation of the canonical representative, taking on average 0.000003 s (using Intel Core i7-10700K processor). The computation of ReduceU turns out to be the runtime-level bottleneck of our implementation since other operations that are applied with a comparable frequency (such as tableau restoration and gate application) are faster. Further details about ReduceU may be found in the section “Computation of ReduceU”.
The restriction to equivalence classes helps not only to dramatically reduce the storage requirement, but also to minimize the number of CNOT-equivalent transformations that we need to apply to a Clifford unitary requiring k gates to explore Clifford unitaries requiring k + 1 entangling gates. Specifically, the number of transformations is only \(9\frac{n(n-1)}{2}{\left|\right.}_{n = 6}=135\), as illustrated in Fig. 3.

It suffices to apply these gates to a pair of qubits in an arbitrary fixed order, since the application of a gate in the other order is enabled by some other gate among those listed. For instance, the CNOT with flipped controls with respect to (a) is accomplished by (h), noting that the single-qubit gates on the right side do not matter due to the choice to work with equivalence classes.
The 15-part (one part per a fixed gate count ranging from 1 to 15, with 15 turning out to be the maximum) sorted database with canonical representatives of equal cost is 2.1TB in size, and it took roughly 6 months to synthesize it on a small cluster of Intel® server-class machines. Since we made software updates as the search progressed, and improved the performance in doing so, we believe it may take about 2 months to rerun it from scratch. We store the database on an SSD (2 + TB RAM was expensive at the time of this writing). Given the database, an optimal circuit for a given 6-qubit Clifford unitary U may be found as follows: compute ReduceU(U), find it in part of the database containing size k unitaries, apply each of \(9\frac{n(n-1)}{2}\) gates, compute the resulting canonical element and look it up in the size k − 1 database; once found repeat for k : = k − 1 until k = 0. Our implementation of the above algorithm takes an average of 0.1 s to extract an optimal circuit. The bottleneck is the database search on the SSD, since the average number of times an element needs to be searched is at most \(\frac{135}{2}=67.5\), the databases for large k are large, and search needs to make multiple queries that add up quickly given SSD’s limited access time. Instead, recall that 4 + 4 = 8 bits of the original data structure are unused, and note that 8 bits suffice to store the gate information, since \(\lceil {\log }_{2}(135)\rceil \,=\,8\). We thus augment the database by loading these 8 bits with the last gate information, allowing to select the correct gate right away during the circuit restoration. This modification reduces the runtime by roughly a factor of 67.5. We further optimize the performance by storing an index with each 1024th element of the database in RAM. This allows finding an optimal circuit implementation of an arbitrary 6-qubit Clifford unitary in as little as 0.0009358 s on a MacBook Pro® (2.3 GHz Quad-Core Intel® Core i7-1068NG7 CPU, 16GB RAM) with a USB-C attached SSD (4TB VectoTech Rapid® 540MB/s 3D NAND Flash), and 0.0006274 s on a high-performance server (Quad Intel® Xeon E7-4850 v4 16-Core/2.1GHz, 6TB RAM). These performance figures were established by averaging out the time to synthesize optimal circuits for 10,000 random uniformly distributed Clifford unitaries while relying on kernel-owned memory to cache files with the use of mmap and using a supplementary index for the laptop version of the search.
In the following subsections we report further details of our implementation.
Database generation
Let \({{{{\mathcal{C}}}}}_{n}^{k}\,\subseteq \,{{{{\mathcal{C}}}}}_{n}\) be the set of all Clifford group elements with the CNOT cost k. Here k = 0, 1, …, kmax(n) for some a-priori unknown maximum cost kmax(n). For example, \({{{{\mathcal{C}}}}}_{n}^{0}\) is the local subgroup of \({{{{\mathcal{C}}}}}_{n}\), i.e., one generated by the single-qubit Clifford gates. Suppose \({\mathsf{ReduceU}}:\,{{{{\mathcal{C}}}}}_{n}\to {{{{\mathcal{C}}}}}_{n}\) is a function such that ReduceU(U) = ReduceU(V) if and only if U and V are equivalent up to left and right multiplications by single-qubit gates and a qubit relabeling. In other words, ReduceU(U) is a canonical representative of the equivalence class
Here and below \({S}_{n}\,\subseteq \,{{{{\mathcal{C}}}}}_{n}\) is the subgroup of qubit permutations. A specific implementation of the function ReduceU, which we refer to the section “Computation of ReduceU”, does not matter at this point. Let \({{{{\mathcal{R}}}}}_{n}^{k}\) be the set of all reduced cost-k Clifford group elements,
Our database consists of kmax(n) + 1 parts, such that the k-th part contains all elements of \({{{{\mathcal{R}}}}}_{n}^{k}\). The elements are furthermore stored in the lexicographic order to enable binary search.
Let \(I\,\in \,{{{{\mathcal{C}}}}}_{n}\) be the identity matrix and CNOTi,j be the CNOT gate with the control qubit i and the target qubit j. Since any cost-0 and cost-1 element is equivalent to I and CNOT1,2 respectively, we have
Suppose we have the sets \({{{{\mathcal{R}}}}}_{n}^{0},{{{{\mathcal{R}}}}}_{n}^{1},\ldots,{{{{\mathcal{R}}}}}_{n}^{k-1}\) for some k ≥ 2 (initially k = 2). The rest of this section explains how to compute \({{{{\mathcal{R}}}}}_{n}^{k}\). First, we need to choose a set of cost-1 generators that obey certain technical conditions. Let m = 9n(n − 1)/2 and \({G}_{1},{G}_{2},\ldots,{G}_{m}\in {{{{\mathcal{C}}}}}_{n}^{1}\) be the generators shown in Fig. 3. By definition, each generator has the form AiBjCNOTi,j for some pair of qubits i < j and A, B ∈ {I, PH, HP}. We will use the following properties of the generator set.
Lemma 1
Any cost-k element \(U\,\in \,{{{{\mathcal{C}}}}}_{n}^{k}\) can be written as \(U={G}_{{a}_{1}}{G}_{{a}_{2}}\cdots {G}_{{a}_{k}}L\) for some \(L\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\) and some a1, a2, …, ak ∈ {1, 2, …, m}.
The proof is deferred to the section “Proof of Lemma 1”. This lemma has the following simple corollaries.
Corollary 1
Suppose W ∈ Sn is a qubit permutation and \(L\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\). For any generator Ga there exist a generator Gb and \(M\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\) such that WLGa = GbWM.
Proof
Let U = WLGaW−1. Note that \(U\,\in \,{{{{\mathcal{C}}}}}_{n}^{1}\) since U is equivalent to a cost-1 element Ga. Lemma 1 with k = 1 implies that \(U\,=\,{G}_{b}M^{\prime}\) for some generator Gb and some \(M^{\prime} \,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\). Thus \(WL{G}_{a}={G}_{b}M^{\prime} W={G}_{b}WM\), where \(M={W}^{-1}M^{\prime} W\in {{{{\mathcal{C}}}}}_{n}^{0}\).
Corollary 2
For any generator Ga and \(L\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\) there exists a generator Gb such that \({G}_{a}L{G}_{b}\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\).
Proof
Let \(U\,=\,{({G}_{a}L)}^{-1}\). Note that \(U\,\in \,{{{{\mathcal{C}}}}}_{n}^{1}\) since the cost is invariant under taking the inverse. Lemma 1 with k = 1 implies that U = GbM for some generator Gb and \(M\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\). Thus \({G}_{a}L{G}_{b}={M}^{-1}\in {{{{\mathcal{C}}}}}_{n}^{0}\).
We claim that the following algorithm outputs the set \(S\,=\,{{{{\mathcal{R}}}}}_{n}^{k}\).
Algorithm 1
\(S\leftarrow {{\emptyset}}\)
for \(V\in {{{{\mathcal{R}}}}}_{n}^{k-1}\) do
for b ∈ {1, 2, . . . . , m} do
U ← ReduceU(VGb)
if \(U\notin {{{{\mathcal{R}}}}}_{n}^{k-2}\cup {{{{\mathcal{R}}}}}_{n}^{k-1}\) then
S ← S ∪ {U}.
end if
end for
end for
Let us first check that \({{{{\mathcal{R}}}}}_{n}^{k}\,\subseteq \,S\). Consider any element \(U\,\in \,{{{{\mathcal{R}}}}}_{n}^{k}\). Then \(U\,=\,{\mathsf{ReduceU}}(\tilde{U})\) for some \(\tilde{U}\,\in \,{{{{\mathcal{C}}}}}_{n}^{k}\). By Lemma 1, we can write \(\tilde{U}\,=\,{G}_{{a}_{1}}{G}_{{a}_{2}}\cdots {G}_{{a}_{k}}M\) for some \(M\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\). Define
Note that \(\tilde{V}\,\in \,{{{{\mathcal{C}}}}}_{n}^{k-1}\) (if \(\tilde{V}\in {{{{\mathcal{C}}}}}_{n}^{\ell }\) for some ℓ < k − 1 then \(\tilde{U}\,=\,\tilde{V}{G}_{{a}_{k}}M\) would have cost less than k). Accordingly, \(V\,\in \,{{{{\mathcal{R}}}}}_{n}^{k-1}\). By definition of the function ReduceU, we have \(\tilde{V}=K{W}^{-1}VWL\) for some \(K,L\in {{{{\mathcal{C}}}}}_{n}^{0}\) and some qubit relabeling W ∈ Sn. Thus
Commuting \({G}_{{a}_{k}}\) through WL next to V using Corollary 1 we obtain \(\tilde{U}=K{W}^{-1}(V{G}_{b})WM^{\prime}\) for some generator Gb and some \(M^{\prime} \,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\). This shows that \(\tilde{U}\) is equivalent to VGn and thus \({\mathsf{Reduce}}(V{G}_{b})={\mathsf{Reduce}}(\tilde{U})=U\) for some \(V\in {{{{\mathcal{R}}}}}_{n}^{k-1}\) and some generator Gb. Thus U ∈ S. We have proved that \({{{{\mathcal{R}}}}}_{n}^{k}\,\subseteq \,S\).
Conversely, suppose U ∈ S. Then U is a reduced element obtained from some cost-(k − 1) element V by adding a single generator, relabeling the qubits, and left/right multiplications by the single-qubit gates. Since adding a single generator can change the cost by at most one, we conclude that \(U\in {{{{\mathcal{R}}}}}_{n}^{k-2}\cup {{{{\mathcal{R}}}}}_{n}^{k-1}\cup {{{{\mathcal{R}}}}}_{n}^{k}\). The cost cannot grow by more than 1 for an obvious reason. It cannot decline by d > 1 since this would imply that V can be implemented with cost (k − 1 − d) + 1 = k − d < k − 1 as the circuit (Vg). g−1, where g is the generator, which contradicts the notion that V is a cost-(k − 1) element. Thus the algorithm adds U to S only if \(U\,\in \,{{{{\mathcal{R}}}}}_{n}^{k}\). We have proved that \(S\,\subseteq \,{{{{\mathcal{R}}}}}_{n}^{k}\).
By sorting the elements of each set \({{{{\mathcal{R}}}}}_{n}^{\ell }\) and using the binary search to check set membership, the above algorithm requires \(\tilde{O}(| {{{{\mathcal{R}}}}}_{n}^{k-1}| m)\) calls to the function ReduceU, where the \(\tilde{O}\) notation hides factors logarithmic in the size of \({{{{\mathcal{R}}}}}_{n}^{k-2}\), \({{{{\mathcal{R}}}}}_{n}^{k-1}\), and \({{{{\mathcal{R}}}}}_{n}^{k}\). The database generation terminates as soon as \({{{{\mathcal{R}}}}}_{n}^{k}\,=\,{{\emptyset}}\). This determines the maximum cost kmax(n) as k − 1.
As discussed in the section “Methods”, the generation of the 6-qubit database spans a few CPU months and involves manipulations with terabytes of data. How can we be confident that this computation is error-free? Our correctness tests included the verification that the size of the Clifford group inferred from the database agrees with the analytic formula \(| {{{{\mathcal{C}}}}}_{n}| ={2}^{{n}^{2}}\mathop{\prod }\nolimits_{j = 1}^{n}({4}^{j}-1)\). In more detail, the number of cost-k Clifford group elements can be inferred from the identity
where ∣[U]∣ is the size of the equivalence class [U] that contains U, see Eq. (9). Furthermore,
where Aut(U) is the automorphism group of U that consists of all triples \(K\times L\times W\in {{{{\mathcal{C}}}}}_{n}^{0}\times {{{{\mathcal{C}}}}}_{n}^{0}\times {S}_{n}\) such that U = KW−1UWL. We have checked that the counts \(| {{{{\mathcal{C}}}}}_{n}^{k}|\) inferred from Eqs. ((10), (11)) indeed obey \(\mathop{\sum }\nolimits_{k = 0}^{{k}_{max}(n)}| {{{{\mathcal{C}}}}}_{n}^{k}| =| {{{{\mathcal{C}}}}}_{n}|\). Thus our database passed the self-consistency test. Table 6 and Table 1 display the counts \(| {{{{\mathcal{R}}}}}_{n}^{k}|\) and \(| {{{{\mathcal{C}}}}}_{n}^{k}|\) can be found in the section “Results”.
In order to speed up the synthesis of optimal circuits, we augmented each database entry \(U\,\in \,{{{{\mathcal{R}}}}}_{n}^{k}\) with 8 auxiliary bits specifying a generator Gb that reduces the cost of U by one, such that \(U{G}_{b}\,\in \,{{{{\mathcal{C}}}}}_{n}^{k-1}\). Here we assume k ≥ 1. Let us prove that such cost-reducing generator Gb exists for any \(U\,\in \,{{{{\mathcal{R}}}}}_{n}^{k}\). Indeed, use Lemma 1 to write \(U={G}_{{a}_{1}}{G}_{{a}_{2}}\cdots {G}_{{a}_{k}}L\) for some \(L\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\). By Corollary 2, there exists a generator Gb such that \(F\equiv {G}_{{a}_{k}}L{G}_{b}\in {{{{\mathcal{C}}}}}_{n}^{0}\). Now \(U{G}_{b}={G}_{{a}_{1}}{G}_{{a}_{2}}\cdots {G}_{{a}_{k-1}}F\) for some \(F\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\), that is, UGb has cost k − 1.
To augment a given element U of the cost-k database \({{{{\mathcal{R}}}}}_{n}^{k}\) we find the first cost-reducing generator b ∈ {1, 2, …, m} such that \({\mathsf{ReduceU}}(U{G}_{b})\,\in \,{{{{\mathcal{R}}}}}_{n}^{k-1}\). This requires at most m calls to ReduceU and binary searches in \({{{{\mathcal{R}}}}}_{n}^{k-1}\) (computing the group multiplication takes a negligible time). Once a cost-reducing generator Gb is found, its index b is recorded in the database using the unused bits of U. The augmentation step is applied to all \(U\,\in \,{{{{\mathcal{R}}}}}_{n}^{k}\) and for all k = 1, 2, …, kmax(n).
Synthesis of optimal circuits
The optimal compiler takes as input an element of the Clifford group \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) and outputs a Clifford circuit (a list of the primitive gates H, P, and CNOT) implementing U with the smallest possible CNOT gate count, equal to the cost of U. The cost can be computed by making a single call to ReduceU and performing at most kmax(n) database searches. Below we assume that the database is augmented with the cost-reducing generators, as discussed in the section “Database generation”. Thus the database search returns the cost k element V such that \(V\,\equiv \,{\mathsf{Reduce}}(U)\in {{{{\mathcal{R}}}}}_{n}^{k}\) and a cost-reducing generator Ga such that \(V{G}_{a}\,\in \,{{{{\mathcal{C}}}}}_{n}^{k-1}\). The next step is to convert Ga into a cost-reducing generator for U. To this end, write V = KW−1UWL for some \(K,L\in {{{{\mathcal{C}}}}}_{n}^{0}\) and some qubit permutation W. The group elements K, L, and W that transform U into the reduced form are readily available by adding appropriate bookkeeping steps to the implementation of ReduceU described in the section “Computation of ReduceU”. At this point we have
Commute Ga through WL next to U using Corollary 1. This gives
for some generator Gb and some \(M\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\). The generator Gb can be computed in time O(1) using the standard commutation rules of the Clifford group. Thus \(U{G}_{b}\,\in \,{{{{\mathcal{C}}}}}_{n}^{k-1}\), that is, Gb is a cost-reducing generator for U. Replacing U by UGb and applying the above step recursively, one constructs a k-tuple of generators such that \(M=U{G}_{{a}_{1}}{G}_{{a}_{2}}\cdots {G}_{{a}_{k}}\in {{{{\mathcal{C}}}}}_{n}^{0}\) is a product of single-qubit gates. This gives \({U}^{-1}={G}_{{a}_{1}}{G}_{{a}_{2}}\cdots {G}_{{a}_{k}}{M}^{-1}\). Decomposing each generator and M−1 into a product of primitive gates H, P, and CNOT gives an optimal circuit implementing U−1. Since all primitive gates are self-inverse, an optimal circuit implementing U is obtained simply by reversing the order of gates. If needed, the number of single-qubit gates in the compiled circuit can be optimized by commuting single-qubit gates to the last time step (whenever possible) and merging them using optimal lookup of \({{{{\mathcal{C}}}}}_{1}\) elements.
Computation of ReduceU
In this section we introduce reduced forms of Clifford group elements and give algorithms for computing these forms. A given matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) is transformed into a reduced form by applying a sequence of elementary reductions from the following list:
-
1.
Multiplication of U on the left by single-qubit Clifford gates.
-
2.
Multiplication of U on the right by single-qubit Clifford gates.
-
3.
Relabeling of qubits.
Depending on which type of reductions is considered, there are three different reduced forms: a left-reduced form (reductions of type 1 only), a locally reduced form (reductions of types 1 and 2), and a fully reduced form (reductions of types 1, 2, and 3). Each form comes with an algorithm specifying the sequence of reductions to be applied. We define the reduced forms inductively starting from the left-reduced form. The function ReduceU used in the sections “Database generation” and “Synthesis of optimal circuits” computes the fully reduced form.
We begin by defining convenient notations. Let \({e}^{1},{e}^{2},\ldots,{e}^{2n}\in {{\mathbb{F}}}_{2}^{2n}\) be the standard basis of \({{\mathbb{F}}}_{2}^{2n}\): the basis vector ej has a single non-zero at the jth position. We consider ej as column vectors. Let \({e}_{j}:={({e}^{j})}^{T}\) be the corresponding row vector. For example, if n = 1 then
We write u ⊕ v to denote the addition of binary vectors u and v modulo 2. Elements of the Clifford group \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) are treated as binary symplectic matrices of the size 2n × 2n. A matrix U has the jth column and the jth row Uej and ejU, respectively.
Recall that \({{{{\mathcal{C}}}}}_{n}^{0}\,\subseteq \,{{{{\mathcal{C}}}}}_{n}\) is the local subgroup generated by the single-qubit gates (H and P). Define a subgroup \({{{{\mathcal{C}}}}}_{n,j}\,\subseteq \,{{{{\mathcal{C}}}}}_{n}^{0}\) generated by the single-qubit gates acting on the jth qubit, where j = 1, 2, …, n. Equivalently, \(U\,\in \,{{{{\mathcal{C}}}}}_{n,j}\) iff Uei = ei for all i ∉ {j, n + j}, whereas Uej = aej ⊕ ben+j and Uen+j = cej ⊕ den+j for some coefficients \(a,b,c,d\in {{\mathbb{F}}}_{2}\) such that
Note that the subgroups \({{{{\mathcal{C}}}}}_{n,j}\) pairwise commute.
A matrix \(U\in {{{{\mathcal{C}}}}}_{n}\) is said to be left-reduced if
Here and below the bit strings are compared using the lexicographic order (i.e., 00 < 01 < 10 < 11 in the case n = 1). The following lemma shows that left-reduced elements of \({{{{\mathcal{C}}}}}_{n}\) can serve as canonical representatives of cosets \({{{{\mathcal{C}}}}}_{n}^{0}U\). In other words, \({{{{\mathcal{C}}}}}_{n}\) is a disjoint union of cosets \({{{{\mathcal{C}}}}}_{n}^{0}U\) and each coset contains a unique left-reduced element, which can be efficiently computed. We refer to the unique left-reduced element of a coset \({{{{\mathcal{C}}}}}_{n}^{0}U\) as the left-reduced form of U and denote it leftReduce(U). Our symplectic matrix data structure described in the section “Data structure” enables the computation of leftReduce(U) for a randomly picked matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) in time less than 2 × 10−8 s for any n ≤ 6 on a server-class CPU, in this case an Intel® Xeon® CPU E7-4850 v4 @ 2.10GHz.
Lemma 2
Each coset \({{{{\mathcal{C}}}}}_{n}^{0}U\) with \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) contains a unique left-reduced element that can be computed in time O(n2), given symplectic matrix representation of U.
Proof
First note that the rows of a symplectic matrix are linearly independent. Thus for each qubit j the bit strings xj : = ejU, zj : = en+jU, and yj : = (ej ⊕ en+j)U are all distinct: xj ≠ yj ≠ zj. It follows directly from the above definitions that multiplying U on the left by the elements of the subgroup \({{{{\mathcal{C}}}}}_{n,j}\) we can implement any permutation of the bit strings xj, yj, and zj. For example, the Hadamard gate swaps xj and zj, the Phase gate swaps xj and yj. Since \(| {{{{\mathcal{C}}}}}_{n,j}| \,=\,6\), there is a one-to-one correspondence between elements of \({{{{\mathcal{C}}}}}_{n,j}\) and permutations of xj, yj, zj. Multiply U on the left by the unique element of \({{{{\mathcal{C}}}}}_{n,j}\) that permutes the bit strings such that xj < zj < yj. Now Eq. (12) is satisfied for the jth qubit. Repeating this for all n qubits and noting that \({{{{\mathcal{C}}}}}_{n}^{0}\) is generated by the subgroups \({{{{\mathcal{C}}}}}_{n,j}\) proves that the coset \({{{{\mathcal{C}}}}}_{n}^{0}U\) contains a unique left-reduced element. All above steps can be efficiently implemented. Indeed, given a matrix U, one can compute the bit strings xj, yj, and zj and sort all three in time O(n). Repeating this for all n qubits gives the total runtime of O(n2).
Given a matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) define a double coset
It includes all elements of the Clifford group obtained from U by adding single-qubit Clifford gates on the left and on the right. Clearly, the full Clifford group \({{{{\mathcal{C}}}}}_{n}\) is a disjoint union of double cosets [U]loc and the cost of the matrix U depends only on the double coset that contains U. The next step is to choose an efficiently computable canonical representative of each double coset. First define the map \(\chi \,:\,{{\mathbb{F}}}_{2}^{2n}\to {{\mathbb{F}}}_{2}^{n}\) as
where ∨ stands for the logical OR operation. The jth component of χ(v) is non-zero iff vj = 1 or vn+j = 1 (the bit string χ(v) can be interpreted as the support of an n-qubit Pauli operator parameterized by v, according to the standard binary parameterization of Pauli operators3). We claim that the map χ is invariant under left multiplications by the elements of the local subgroup, in the sense that
Indeed, it suffices to check Eq. (13) for the special case \(L\,\in \,{{{{\mathcal{C}}}}}_{n,j}\) (since the local subgroup is generated by matrices \(L\,\in \,{{{{\mathcal{C}}}}}_{n,j}\) with j = 1, 2, …, n). As discussed above, the action of \(L\,\in \,{{{{\mathcal{C}}}}}_{n,j}\) on v is equivalent to applying a 2 × 2 binary invertible matrix to the components vj and vn+j while all other components of v remain unchanged. Since an invertible matrix maps non-zero vectors to non-zero vectors, (Lv)j ∨ (Lv)n+j = 1 iff vj ∨ vn+j = 1. This implies Eq. (13).
A matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) is said to be locally ordered if U is left-reduced and
Here bit strings are compared using the lexicographic order. Let \({{{\mathcal{L}}}}(U)\,\subseteq \,{[U]}^{{\mathsf{loc}}}\) be the set of all locally ordered elements of the double coset [U]loc. Define a locally reduced form of the matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\), denoted localReduce(U), as the lexicographically smallest element of the set \({{{\mathcal{L}}}}(U)\). The following lemma shows that locally reduced elements of \({{{{\mathcal{C}}}}}_{n}\) can serve as canonical representatives of the double cosets [U]loc. In other words, \({{{{\mathcal{C}}}}}_{n}\) is a disjoint union of the double cosets [U]loc and each double coset contains a unique locally reduced element that can be efficiently computed (albeit slightly less efficiently than leftReduce). The symplectic matrix data structure described in the section “Data structure” enables the computation of localReduce(U) for a randomly picked matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) in time less than 4 × 10−7 s for all n ≤ 6 on a server-class CPU, in this case an Intel® Xeon® CPU E7-4850 v4 @ 2.10GHz.
Lemma 3
Each double coset \({[U]}^{{\mathsf{loc}}}\,=\,{{{{\mathcal{C}}}}}_{n}^{0}U{{{{\mathcal{C}}}}}_{n}^{0}\) contains a unique locally reduced element that can be computed in time O(n26n), given the symplectic matrix U.
Proof
For each qubit j define the bit strings xj : = χ(Uej), zj : = χ(Uen+j), and yj : = χ(Uej ⊕ Uen+j). Same as before, multiplying U on the right by the elements of the subgroup \({{{{\mathcal{C}}}}}_{n,j}\) one can implement any permutation of the bit strings xj, yj, and zj. Define a subset \({{{{\mathcal{S}}}}}_{j}\,\subseteq \,{{{{\mathcal{C}}}}}_{n,j}\) as the one including all elements \({R}_{j}\,\in \,{{{{\mathcal{C}}}}}_{n,j}\) such that the right multiplication U ← URj permutes the bit strings xj, yj, and zj into the non-decreasing order xj ≤ zj ≤ yj. Note that \({{{{\mathcal{S}}}}}_{j}\) is non-empty since the right multiplication by the elements of \({{{{\mathcal{C}}}}}_{n,j}\) can implement any permutation of xj, yj, and zj. Recall that the set \({{{\mathcal{L}}}}(U)\) includes all locally ordered elements of the double coset [U]loc. We claim that
Indeed, \({{{\mathcal{L}}}}(U)\subseteq {[U]}^{{\mathsf{loc}}}\) since any matrix \(W\,\in \,{{{\mathcal{L}}}}(U)\) has the form W = LUR for some \(L,R\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\). Furthermore, \({{{\mathcal{L}}}}(U)\) is non-empty since each subset \({{{{\mathcal{S}}}}}_{j}\) is non-empty. Let us check that any element \(W\,\in \,{{{\mathcal{L}}}}(U)\) is locally ordered. Indeed, pick any matrices \({R}_{j}\,\in \,{{{{\mathcal{S}}}}}_{j}\) and let R = R1R2 ⋯ Rn. By construction, the matrix V = UR satisfies Eq. (14) with U replaced by V. Let W = leftReduce(V). Then W = LV for some \(L\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\). The invariance of the map χ under left multiplications by the elements of the local subgroup, see Eq. (13), implies that W satisfies Eq. (14) with U replaced by W. Thus W is locally ordered. Conversely, suppose W ∈ [U]loc is locally ordered. Then W = LUR for some \(L,R\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\) and leftReduce(W) = W. The invariance of the map χ under left multiplications by the elements of the local subgroup and the local ordering condition imply that the matrix V = UR satisfies Eq. (14) with U replaced by V. Thus R = R1R2 ⋯ Rn for some \({R}_{j}\,\in \,{{{{\mathcal{S}}}}}_{j}\). This proves that \(W\,\in \,{{{\mathcal{L}}}}(U)\). The uniqueness follows from the ability to encode the elements of the sets considered by distinct integers and the existence of the smallest integer in any finite set of integers.
It remains to check that the set \({{{\mathcal{L}}}}(U)\) can be computed in time O(n26n). Indeed, for any given qubit j one can compute the bit strings xj, yj, and zj and the subset \({S}_{j}\,\subseteq \,{{{{\mathcal{C}}}}}_{n,j}\) in time O(n). Note that \(| {{{{\mathcal{S}}}}}_{j}| \,\le \,| {{{{\mathcal{C}}}}}_{n,j}| \,=\,6\). Thus the number of matrices R = R1R2 ⋯ Rn with \({R}_{j}\,\in \,{{{{\mathcal{S}}}}}_{j}\) is at most 6n. Since the right multiplication by the elements of the subgroup \({{{{\mathcal{C}}}}}_{n,j}\) changes at most two rows of a matrix, we can compute UR in time O(n2). By Lemma 2, computing the left reduced form of UR takes time O(n2). Thus the overall runtime of computing \({{{\mathcal{L}}}}(U)\) is O(n26n). Once the set \({{{\mathcal{L}}}}(U)\) is computed, finding its lexicographically smallest element takes time \(O(n| {{{\mathcal{L}}}}(U)| )\,=\,O(n{6}^{n})\).
Comment 1: Our implementation of localReduce(U) relies on a streamlined version of the above algorithm with a modified definition of the subsets \({{{{\mathcal{S}}}}}_{j}\). Namely, we define \({{{{\mathcal{S}}}}}_{j}\) as a set of all elements \({R}_{j}\,\in \,{{{{\mathcal{C}}}}}_{n,j}\) such that the right multiplication U ← URj permutes the bit strings xj, yj, and zj into the non-decreasing order and leftReduce(URj) ≠ leftReduce(U). The last condition rules out the possibility that the right multiplication of U by Rj is equivalent to a left multiplication of U by some element of the local subgroup (for example, this is the case if U is the identity matrix). Since leftReduce(U) depends only on the coset \({{{{\mathcal{C}}}}}_{n}^{0}U\), the left multiplication of U by any element of the local subgroup does not change leftReduce(U). Thus the set of locally ordered elements \({{{\mathcal{L}}}}(U)\) can be computed using Eq. (15) with the modified definition of \({{{{\mathcal{S}}}}}_{j}\).
Comment 2: We empirically observed that the average-case runtime of the above algorithm is much better than the worst case upper bound of O(n26n). Indeed, a direct inspection shows that the runtime scales as O(n2M), where \(M\,=\,| {{{{\mathcal{S}}}}}_{1}| \cdot | {{{{\mathcal{S}}}}}_{2}| \cdot \ldots \cdot | {{{{\mathcal{S}}}}}_{n}|\). For randomly picked matrices \(U\,\in \,{{{{\mathcal{C}}}}}_{6}\) we observed that M ≈ 5 on average even though \(M\,=\,| {{{{\mathcal{C}}}}}_{6}^{0}| \,=\,{6}^{6}\,=\,46,656\) in the worst case. We leave it as an open question whether the average-case runtime of the above algorithm scales polynomially with n.
Recall that we consider the symmetric group Sn that includes all qubit permutations as a subgroup of \({{{{\mathcal{C}}}}}_{n}\). If w is a permutation of integers {1, 2, …, n}, then the corresponding symplectic matrix W ∈ Sn acts on the basis vectors as Wej = ew(j) and Wen+j = en+w(j) for all j = 1, 2, …, n. Given a matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\), define the equivalence class
The rest of this section is devoted to choosing an efficiently computable canonical representative of each class [U]. Let \({{\mathbb{Z}}}^{n\times n}\) be the set of n × n matrices with integer entries. Define the map \(\kappa \,:\,{{{{\mathcal{C}}}}}_{n}\,\to \,{{\mathbb{Z}}}^{n\times n}\) such that the matrix element of κ(U) located at the ith row and the jth column is the rank of the 2 × 2 submatrix of U formed by the intersection of rows i and i + n and columns j and j + n. The rank is computed over the binary field \({{\mathbb{F}}}_{2}\). In other words, each matrix element of κ(U) has the form
By definition, κ(U) contains entries from the set {0, 1, 2} and the full matrix κ(U) can be computed in time O(n2). We claim that the left and right multiplications of U by the single-qubit Clifford gates leave κ(U) invariant, that is,
Indeed, suppose first that L = I and \(R\,\in \,{{{{\mathcal{C}}}}}_{n,j}\). Right multiplication U ← UR applies an invertible linear transformation to the pair of columns Uej and Uen+j, and acts trivially on the remaining columns. Since the matrix rank is invariant under applying an invertible linear transformation, we conclude that κ(UR) = κ(U) for all \(R\,\in \,{{{{\mathcal{C}}}}}_{n,j}\). Same argument shows that κ(LU) = κ(U) for all \(L\,\in \,{{{{\mathcal{C}}}}}_{n,j}\). This proves Eq. (16) since the local subgroup \({{{{\mathcal{C}}}}}_{n}^{0}\) is generated by the subgroups \({{{{\mathcal{C}}}}}_{n,j}\).
Let κmin(U) be the lexicographically smallest matrix in the set of matrices {κ(W−1UW) : W ∈ Sn}. Define a set of qubit permutations
and a set of matrices
Note that \({{{\mathcal{R}}}}(U)\,\subseteq \,[U]\) since
for some \(L,R\in {{{{\mathcal{C}}}}}_{n}^{0}\). Define a fully reduced form of a matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\), denoted ReduceU(U), as the lexicographically smallest element of the set \({{{\mathcal{R}}}}(U)\). The following lemma shows that the fully reduced elements of \({{{{\mathcal{C}}}}}_{n}\) can serve as canonical representatives of the equivalence classes [U]. In other words, \({{{{\mathcal{C}}}}}_{n}\) is a disjoint union of the equivalence classes [U] and each class contains a unique fully reduced element that can be efficiently computed (albeit slightly less efficiently than localReduce). The symplectic matrix data structure enables the computation of ReduceU(U) for a randomly picked matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) in time less than 3 × 10−6 s for n = 6 and time less than 10−6 s for all n ≤ 5 on a server-class CPU, in this case an Intel® Xeon® CPU E7-4850 v4 @ 2.10GHz.
Lemma 4
Each equivalence class [U] with \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) contains a unique fully reduced element that can be computed in time \(O({n}^{2}\cdot n!+{t}_{n}\cdot | {{{\mathcal{S}}}}(U)| )\), given the symplectic matrix representation of U. Here tn is the runtime of localReduce for elements of \({{{{\mathcal{C}}}}}_{n}\).
Proof
Consider a matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\). It follows directly from the definitions that ReduceU(U) ∈ [U]. Thus it suffices to check that
Indeed, this equation implies \({\mathsf{ReduceU}}(U)\,=\,{\mathsf{ReduceU}}(U^{\prime} )\) for all \(U^{\prime} \,\in \,[U]\), that is, the equivalence class [U] contains a unique reduced element. Let us prove Eq. (17). Write \(U^{\prime} \,=\,L{W}^{-1}UWR\) for some \(L,R\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\) and W ∈ Sn. Then
Here \(L^{\prime} \,:=\,{\tilde{W}}^{-1}L\tilde{W}\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\) and \(R^{\prime} \,:=\,{\tilde{W}}^{-1}R\tilde{W}\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\). In the third equality we noted that localReduce is invariant under left/right multiplications by the elements of the local subgroup \({{{{\mathcal{C}}}}}_{n}^{0}\), see Lemma 3. Finally, the invariance of the map κ under the left and right multiplications by the elements of the local subgroup, see Eq. (16), implies \({\kappa }_{{\rm{min}}}(U^{\prime} )={\kappa }_{{\rm{min}}}(U)\). Thus \(\tilde{W}\,\in \,{{{\mathcal{S}}}}(U^{\prime} )\) iff \(W\tilde{W}\,\in \,{{{\mathcal{S}}}}(U)\). Combining this and Eq. (18) gives \({{{\mathcal{R}}}}(U^{\prime} )\,=\,{{{\mathcal{R}}}}(U)\), as claimed.
The runtime stated in the lemma consists of two terms. The term O(n2 ⋅ n!) is the time needed to compute the set of permutations \({{{\mathcal{S}}}}(U)\). The term \(O({t}_{n}\cdot | {{{\mathcal{S}}}}(U)| )\) is the time needed to compute the set of matrices \({{{\mathcal{R}}}}(U)\) and pick the lexicographically smallest element of \({{{\mathcal{R}}}}(U)\).
Comment 3: Our implementation of ReduceU(U) relies on a streamlined version of the above algorithm with a modified definition of the set \({{{\mathcal{S}}}}(U)\). Namely, we define \({{{\mathcal{S}}}}(U)\) as the set of all permutations W ∈ Sn such that κ(W−1UW) = κmin(U) and leftReduce(W−1UW) ≠ leftReduce(U). The last condition rules out the possibility that the conjugation of U by W is equivalent to a left multiplication of U by some element of the local subgroup (for example, this is the case if U is the identity matrix). Since localReduce(U) depends only on the double coset \({{{{\mathcal{C}}}}}_{n}^{0}U{{{{\mathcal{C}}}}}_{n}^{0}\), a left multiplication of U by any element of the local subgroup does not change localReduce(U). Thus one can compute the set \({{{\mathcal{R}}}}(U)\) using the modified definition of \({{{\mathcal{S}}}}(U)\).
Comment 4: We empirically observed that \(| {{{\mathcal{S}}}}(U)| =1\) for typical a element of the Clifford group and the maximal value of \(| {{{\mathcal{S}}}}(U)|\) is 14. The mean value of \(| {{{\mathcal{S}}}}(U)|\) is approximately 1.03 for a randomly picked \(U\,\in \,{{{{\mathcal{C}}}}}_{6}\).
By a slight abuse of terminology, we refer to the computationally-defined fully reduced elements of the Clifford group as the reduced elements in the remainder of the paper. This should not lead to confusion since the left-reduced and the locally reduced forms are used only in this subsection.
Data structure
By definition, any element of the Clifford group \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) can be represented by a binary matrix of size 2n × 2n. However, if we only care about the reduced form of U, a slightly more efficient representation is possible, as given by the following lemma.
Lemma 5
Let \(U^{\prime}\) be the matrix obtained from \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) by removing the n-th and the 2n-th rows from it. Then U is uniquely determined by \(U^{\prime}\) up to left multiplication by the single-qubit Clifford gates acting on the n-th qubit.
Proof
Let \({{{\mathcal{L}}}}\,\subseteq \,{{\mathbb{F}}}_{2}^{2n}\) be the linear subspace spanned by the jth row of U with j ∉ {n, 2n} and let \({{{{\mathcal{L}}}}}^{\perp }\,\subseteq \,{{\mathbb{F}}}_{2}^{2n}\) be the linear subspace spanned by the vectors orthogonal to \({{{\mathcal{L}}}}\) with respect to the symplectic inner product. Note that \({{{\mathcal{L}}}}\) depends only on \(U^{\prime}\). The condition that U is a symplectic matrix implies \({{{{\rm{span}}}}}_{{{\mathbb{F}}}_{2}}({e}_{n}U,{e}_{2n}U)\,=\,{{{{\mathcal{L}}}}}^{\perp }\). Here we use the notations from the section “Computation of ReduceU”. The missing pair of rows enU and e2nU is uniquely defined by \({{{\mathcal{L}}}}\) up to an invertible linear transformation enU ← aenU ⊕ be2nU and e2nU ← cenU ⊕ de2nU for some
As discussed in the section “Computation of ReduceU”, there is a one-to-one correspondence between such transformations and left multiplications U ← LU, where \(L\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\) acts non-trivially only on the nth qubit.
We refer to the matrix \(U^{\prime}\) obtained from \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) by removing the pair of rows n and 2n as a thin matrix representation of U. Our C++ implementation adopts the thin matrix data format for all intermediate steps of the algorithm. The thin matrix spans 4n(n − 1) bits and can be conveniently distributed over two machine words, each of length 64 bits. The first word stores the rows e1U, e2U, …, en−1U and the second word stores the rows en+1U, en+2U, …, e2n−1U. This leaves 128 − 4n(n − 1)∣n≤6 ≥ 8 free bits that can be conveniently used to specify the cost-reducing generator in the augmented database, see the section “Database generation”. Recall that the number of generators is m = 9n(n − 1)/2∣n≤6 ≤ 135. Thus the generator can be specified using only 8 bits. Note also that storing the full matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) using only two machine words is impossible for n = 6, as it requires 4n2∣n=6 = 144 bits.
The thin matrix format enables fast left and right multiplication by the single-qubit and two-qubit Clifford gates, that require at most 24 CPU instructions per gate for all n ≤ 6 (each instruction implements a bitwise operation on a single machine word). When needed, the thin matrix \(U^{\prime}\) can be expanded into the full symplectic matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) by calculating the missing pair of rows enU and e2nU using the symplectic version of Gram–Schmidt orthogonalization. Our implementation converts the thin matrix to the full matrix in time less than 2 × 10−7 s for any n ≤ 6 on a server-class CPU, in this case an Intel® Xeon® CPU E7-4850 v4 @ 2.10GHz, which is negligible compared with the time it takes to compute the reduced form.
Software tricks
Database generation
The calculation of the reduced cost-k Clifford group set \({{{{\mathcal{R}}}}}_{n}^{k}\), as described in the section “Database generation”, lends itself to parallel processing. Specifically, each element of the set \({{{{\mathcal{R}}}}}_{n}^{k}\) can be calculated concurrently from its own data on its own processor. The implementation considerations for this run-once parallel processing job depended on factors such as:
-
i.
the cost and availability of scaled-up/scaled-out hardware, and
-
ii.
the cost-benefit for implementing, measuring, and tuning for different data-level parallel processing options, including shared memory versus distributed memory (e.g., OpenMP/MPI) and specialized processors (e.g., vector processors, GPUs, FPGAs),
not to mention the multiple software options with each, from programming languages to libraries22.
Using Flynn’s taxonomy23, the Single Program, Multiple Data (SPMD) streams model was implemented using the C++ concurrent-set template class; specifically, each reduced cost-k Clifford group set \({{{{\mathcal{R}}}}}_{n}^{k}\) is an instance of set<pair<uint64, uint64>>. This is a good choice for programmer productivity, i.e., letting the container’s semantics deal with the requirements of maintaining distinct and efficiently-searchable elements of a multi-terabyte set on SMP hardware, in this case an Intel® Xeon® 128-CPU E7-4850 v4 @ 2.10GHz with 6TB RAM.
Runtime was extrapolated to take about 100 days to complete the full database generation on a single machine, amounting to approximately 100 ⋅ 24 ⋅ 128 = 307, 200 CPU-hours that can be effectively divided among as many machines as there are available. Hardware and software measurements during database generation, using performance analysis tools such as vmstat to VTune™, exposed heavy “NUMA thrashing,” i.e., soft page faults24. To alleviate this for the final half of the run, C’s most basic systems programming mechanisms were more readily and easily used to replace the C++ set template in order to allocate, position, and search raw memory, resulting in a 5x speed-up; namely, malloc, bsearch, and qsort, along with read/write and uint128.
Synthesis of optimal circuits
With the one-time generation of the database complete and saved on secondary storage (Solid State Disk), similar systems programming mechanisms in C were exploited to optimize performance and scalability in order to read/search what is now effectively a lookup table (LUT), with the expensive runtime calculation of an optimal 6-qubit Clifford circuit completed and replaceable by a simple array indexing operation. The database can be memory-mapped with mmap25 for a greater degree of
-
i.
programmer productivity, i.e., the database can be easily referenced as memory using pointers, with no explicit file IO, and
-
ii.
operational flexibility, i.e., the database can be effectively used by any type of hardware, ranging from a single laptop to a cluster of server-class machines, with scaling solely dependent on the choice of hardware,
all without changing the code; while the OS kernel and mmap transparently and efficiently take care of
-
i.
demand paging, and
-
ii.
maintaining only a single copy of data in memory, as opposed to copies in both the file cache and user space.
In addition, to reduce the number of SSD queries, being the most time-consuming operation our search relies on, we employed the following strategy:
-
i.
we store the databases of Clifford circuits requiring 1–8, 14, and 15 gates in RAM,
-
ii.
we store an index consisting of each 1024th element of Clifford unitaries implementable with 9–13 gates in RAM, and
-
iii.
when the length-1024 chunk containing the desired element is found by the binary search, we make one long query to extract all 2048 64-bit integers in this chunk.
The above modification limits the number of SSD queries required to synthesize an optimal circuit to at most 10 (at most two queries per searches over the gate counts of 9, 10, 11, 12, and 13) at the cost of RAM memory usage of 2.5GB.
A machine with enough RAM to fit the entire database in will get the best performance as the complete database fills the file cache, and a machine with little-to-no available RAM will get the worst performance as every pointer access to a memory-mapped region (e.g., bsearch) will touch the secondary storage. A commodity machine with typical RAM sizes will get near-best performance as the “hot” parts of the database—the internal nodes of bsearch—will tend to remain in the cache hierarchy (L1-L3, file cache) and result in minimal access to secondary storage. OS-specific parameters were not explored but can also be benchmarked and tuned independently of the database and code, including page sizes and pinned memory.
Proof of Lemma 1
We need to show that any element \(U\,\in \,{{{{\mathcal{C}}}}}_{n}^{k}\) can be written as \(U={G}_{{a}_{1}}{G}_{{a}_{2}}\cdots {G}_{{a}_{k}}L\) for some \(L\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\) and some k-tuple of generators. We use the induction in k. The base of induction is k = 0, in which case the statement is trivial. Suppose k ≥ 1 and \(U\,\in \,{{{{\mathcal{C}}}}}_{n}^{k}\). By definition, U can be implemented by a circuit composed of k CNOT gates and some number of single-qubit gates. Let CNOTi,j be the last CNOT gate in this circuit. Then
for some \(M\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\) and \(V\,\in \,{{{{\mathcal{C}}}}}_{n}^{k-1}\). We can assume without loss of generality that i < j. Indeed, if i > j, use the identity CNOTj,i = HiHjCNOTi,jHiHj to flip the control and the target qubits of the last CNOT gate. The extra H gates can be absorbed into M and V layers. By the induction hypothesis, \(V={G}_{{a}_{2}}\cdots {G}_{{a}_{k}}L\) for some \(L\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\). Furthermore, we can assume without loss of generality that M = AiBj for some \({{{\rm{A}}}},{{{\rm{B}}}}\,\in \,{{{{\mathcal{C}}}}}_{1}\). Indeed, all single-qubit gates in M that act on qubits ℓ ∉ {i, j} can be commuted through CNOTi,j and absorbed into V. If A, B ∈ {I, HP, PH}, we are done. Indeed, in this case \({{{{\rm{A}}}}}_{i}{{{{\rm{B}}}}}_{j}{{{{\rm{CNOT}}}}}_{i,j}\,=\,{G}_{{a}_{1}}\) is a generator and \(U={G}_{{a}_{1}}V={G}_{{a}_{1}}{G}_{{a}_{2}}\cdots {G}_{{a}_{k}}L\) with \(L\,\in \,{{{{\mathcal{C}}}}}_{n}^{0}\). Otherwise, transform A and B into the desired form by “borrowing" the missing single-qubit gates from V and commuting them through CNOTi,j using the Clifford group identities:
Recall that these identities only apply to elements of the binary symplectic group; the corresponding identities for unitary Clifford operators may include some extra phase factors and Pauli gates. This completes the proof.
Pauli mixing constraint
In this section, we prove that a Pauli-invariant probability distribution μ on the n-qubit Clifford group is a unitary 2-design iff μ is Pauli mixing. The fact that Pauli-invariance and Pauli mixing are sufficient for being a 2-design is known16,Appendix D]. Thus it suffices to prove that any Pauli-invariant Clifford 2-design is Pauli mixing.
The Haar integeral in Eq. (1) can be computed explicitly using Weingarten functions26,
Here SWAP is a unitary operator that swaps the two n-qubit registers separated by the tensor product. It is well-known that any complex matrix of size 2n × 2n can be expanded in the Pauli basis
Thus it suffices to impose Eq. (1) only for \(\hat{A},\hat{B}\in {{{{\mathcal{P}}}}}_{n}\). Noting that the Pauli basis is orthonormal with respect to the inner product \({{{\rm{Tr}}}}({\hat{A}}^{{\dagger} }\hat{B})/{2}^{n}\) one concludes that a pair \(({{{\mathcal{D}}}},\mu )\) is a unitary 2-design iff
where
A Pauli operator \(\hat{O}\,\in \,{{{{\mathcal{P}}}}}_{n}\) can be parameterized by a bit string v ∈ {0, 1}2n such that
where \(\hat{O}(00)\,\equiv \,\hat{I}\), \(\hat{O}(10)\,\equiv \,\hat{X}\), \(\hat{O}(01)\,\equiv \,\hat{Z}\), and \(\hat{O}(11)\,\equiv \,\hat{Y}\). The unitary version of the Clifford group, which we denote \({{\mathfrak{C}}}_{n}\), is a group of complex matrices \(\hat{U}\,\in \,U({2}^{n})\) that map Pauli operators to Pauli operators under conjugation. More formally, \(\hat{U}\in {{\mathfrak{C}}}_{n}\) iff there exists a symplectic matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) such that
for all v ∈ {0, 1}2n. Here the sign may depend on v. The symplectic matrix \(U\,\in \,{{{{\mathcal{C}}}}}_{n}\) in Eq. (20) is uniquely determined by \(\hat{U}\). Conversely, \(\hat{U}\) is uniquely determined by U up to (right) multiplications by Pauli operators and the overall phase. In other words, \({{\mathfrak{C}}}_{n}\) is isomorphic (as a set) to \({{{{\mathcal{C}}}}}_{n}\times {{{{\mathcal{P}}}}}_{n}\) if one ignores the overall phase of unitary matrices.
Suppose \(\mu :\,{{\mathfrak{C}}}_{n}\,\to \,{{\mathbb{R}}}_{+}\) is a Pauli-invariant probability distribution, that is, \(\mu (\hat{U})\,=\,\mu (\hat{U}\hat{O})\) for all \(\hat{O}\,\in \,{{{{\mathcal{P}}}}}_{n}\) and \(\hat{U}\,\in \,{{\mathfrak{C}}}_{n}\). Using the isomorphism \({{\mathfrak{C}}}_{n}\,\cong \,{{{{\mathcal{C}}}}}_{n}\times {{{{\mathcal{P}}}}}_{n}\), define a distribution \(\pi :\,{{{{\mathcal{C}}}}}_{n}\,\to \,{{\mathbb{R}}}_{+}\) such that μ(U × P) = π(U)/4n for all U ∈ Cn and \(P\,\in \,{{{{\mathcal{P}}}}}_{n}\). Suppose \(({{\mathfrak{C}}}_{n},\mu )\) is a 2-design, that is, μ obeys Eq. (19) with \({{{\mathcal{D}}}}={{\mathfrak{C}}}_{n}\). Consider the second case of Eq. (19) such that \(\hat{A}\,=\,\hat{B}\,=\,\hat{O}(x)\) for some non-zero vector x ∈ {0, 1}2n. Then it is equivalent to
Since Pauli operators are linearly independent, this is possible only if a random vector Ux with U sampled from π(U) is distributed uniformly on the set of all non-zero vectors {0, 1}2n⧹02n. This gives the Pauli mixing condition Eq. (3).
Data availability
A Python implementation of the described algorithms will be available at: https://github.com/qiskit-community/prototype-clifford-optimizer.
References
Nielsen, M. A. & Chuang, I. Quantum Computation and Quantum Information (Cambridge University Press, 2002).
Gottesman, D. The Heisenberg representation of quantum computers. Preprint at https://arxiv.org/abs/quant-ph/9807006 (1998).
Aaronson, S. & Gottesman, D. Improved simulation of stabilizer circuits. Phys. Rev. A 70, 052328 (2004).
Bravyi, S. & Maslov, D. Hadamard-free circuits expose the structure of the Clifford group. IEEE Trans. Inform. Theory 67, 4546–4563 (2021).
Bravyi, S. & Kitaev, A. Universal quantum computation with ideal Clifford gates and noisy ancillas. Phys. Rev. A 71, 022316 (2005).
Knill, E. Quantum computing with realistically noisy devices. Nature 434, 39–44 (2005).
Knill, E. et al. Randomized benchmarking of quantum gates. Phys. Rev. A 77, 012307 (2008).
Magesan, E., Gambetta, J. M. & Emerson, J. Scalable and robust randomized benchmarking of quantum processes. Phys. Rev. Lett. 106, 180504 (2011).
Aaronson, S. Shadow tomography of quantum states. SIAM J. Computing (0):STOC18–368–STOC18–394, (2020).
Huang, Hsin-Yuan, Kueng, R. & Preskill, J. Predicting many properties of a quantum system from very few measurements. Nat. Phys. 16, 1050—1057 (2020).
Bennett, C. H., DiVincenzo, D. P., Smolin, J. A. & Wootters, W. K. Mixed-state entanglement and quantum error correction. Phys. Rev. A 54, 3824 (1996).
DiVincenzo, D. P., Leung, D. W. & Terhal, B. M. Quantum data hiding. IEEE Trans. Inform. Theory 48, 580–598 (2002).
IBM. IBM Quantum Experience. https://quantum-computing.ibm.com/, last accessed 10/5/2020.
Amazon Web Services. Amazon Bracket. https://aws.amazon.com/braket/, last accessed 10/5/2020.
R. A., Low. Pseudo-randomness and learning in quantum computation. PhD Thesis, University of Bristol, UK (2010).
Cleve, R., Leung, D. W., Liu, L. & Wang, C. Near-linear constructions of exact unitary 2-designs. Quantum Inform. Comput. 16, 721–756 (2016).
Emerson, J., Alicki, R. & Życzkowski, K. Scalable noise estimation with random unitary operators. J. Opt. B: Quantum Semiclassical Opt 7, S347 (2005).
Dankert, C., Cleve, R., Emerson, J. & Livine, E. Exact and approximate unitary 2-designs and their application to fidelity estimation. Phys. Rev. A 80, 012304 (2009).
Kliuchnikov, V. & Maslov, D. Optimization of Clifford circuits. Phys. Rev. A 88, 052307 (2013).
Golubitsky, O. & Maslov, D. A study of optimal 4-bit reversible Toffoli circuits and their synthesis. IEEE Trans. Comput. 61, 1341–1353 (2011).
Rokicki, T., Kociemba, H., Davidson, M. & Dethridge, J. The diameter of the Rubik’s cube group is twenty. SIAM Rev. 56, 645–670 (2014).
Clang project. Clang version 9.0.0.
Wikipedia contributors. Flynn’s taxonomy. https://en.wikipedia.org/wiki/Flynn’s_taxonomy (2020) (accessed 20 October 2020).
Wikipedia contributors. Page fault. https://en.wikipedia.org/wiki/Page_fault (2020).
Wikipedia contributors. mmap. https://en.wikipedia.org/wiki/Mmap (2020). See Further reading for the Windows® mmap equivalent (accessed 20 October 2020).
Collins, B. & Śniady, P. Integration with respect to the Haar measure on unitary, orthogonal and symplectic group. Commun. Math. Phys. 264, 773–795 (2006).
Author information
Authors and Affiliations
Contributions
All authors contributed equally to this work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no Competing Non-Financial Interests but the following Competing Financial Interests. A provisional patent application US20220114468A1 covering this work was filed by IBM.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bravyi, S., Latone, J.A. & Maslov, D. 6-qubit optimal Clifford circuits. npj Quantum Inf 8, 79 (2022). https://doi.org/10.1038/s41534-022-00583-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-022-00583-7
