
Abstract
Febrile seizures (FS) are the most prevalent type of seizures in children. Existing predictive models for FS exhibit limited predictive ability. To build a better-performing predictive model, a retrospective analysis study was conducted on febrile children who visited the Children's Hospital of Shanghai from July 2020 to March 2021. These children were divided into training set (n = 1453), internal validation set (n = 623) and external validation set (n = 778). The variables included demographic data and complete blood counts (CBCs). The least absolute shrinkage and selection operator (LASSO) method was used to select the predictors of FS. Multivariate logistic regression analysis was used to develop a predictive model. The coefficients derived from the multivariate logistic regression were used to construct a nomogram that predicts the probability of FS. The calibration plot, area under the receiver operating characteristic curve (AUC), and decision curve analysis (DCA) were used to evaluate model performance. Results showed that the AUC of the predictive model in the training set was 0.884 (95% CI 0.861 to 0.908, p < 0.001) and C-statistic of the nomogram was 0.884. The AUC of internal validation set was 0.883 (95% CI 0.844 to 0.922, p < 0.001), and the AUC of external validation set was 0.858 (95% CI 0.820 to 0.896, p < 0.001). In conclusion, the FS predictive model constructed based on CBCs in this study exhibits good predictive ability and has clinical application value.
Similar content being viewed by others


Introduction
Febrile seizures (FS) are the most common type of convulsions in childhood, primarily affecting children between the ages of 6 months and 6 years1. FS often induce panic in parents, leading them to employ unnecessary or excessive management measures due to concerns about potential neurological damage, asphyxia, or even death during these episodes. Consequently, FS are common conditions in the pediatric emergency department2. The exact pathogenesis of FS is unknown, although some researchers suggest that it may be associated with factors such as infections, particularly viral infections, genetic susceptibility, and certain vaccinations3,4. While it is previously widely believed that most FS are harmless5, recent studies have revealed a correlation between FS and neurological, cognitive, and memory deficits6,7,8. Furthermore, research has demonstrated that individuals with FS are at an increased risk of developing epilepsy or psychiatric disorders compared to children without FS, with the risk escalating with each occurrence of FS9,10. Reports have also indicated an elevated risk of sudden death in patients with FS11. Therefore, further exploration of methods for predicting FS is still necessary.
For the prediction of FS, Cokyaman et al. conducted a study utilizing serum Brain-derived neurotrophic factor levels to predict FS, yielding the area under the curve (AUC) of 0.72312. Bakri et al. discovered that neurotrophin-3 predicted FS with an AUC of 0.67813. In Baek et al.'s study, hypomagnesemia was identified as an independent risk factor for FS, and when used to predict FS, it achieved an AUC of 0.73114. Liu et al.'s study employed neutrophil to lymphocyte ratio (NLR) and mean platelet volume (MPV)/platelet count (PLT) ratio (MPR) to predict FS, resulting in AUC values of 0.768 and 0.689, respectively15. On one hand, the existing FS predictive models demonstrated limited predictive ability, with AUC values below 0.8. On the other hand, complete blood counts (CBCs) have shown potential in predicting FS, such as the NLR single indicator with an AUC value of 0.768, which was close to 0.815. By incorporating additional CBCs, the model's predictive ability could be significantly enhanced. Therefore, our study aims to establish an FS predictive model using CBCs that significantly improves predictive ability and holds practical value.
Materials and methods
Study design and patients
The study protocol was approved by the Ethics Committee of Children’s Hospital of Shanghai (approval number 2022R132). All methods were carried out in accordance with the relevant guidelines and regulations. Informed consent was obtained from the legal guardian(s) of each child.
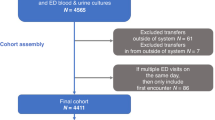
We collected demographic data and CBCs of 3031 febrile children (328 children with FS and 2703 febrile children without seizures) who visited the emergency department of Children's Hospital of Shanghai from July 2020 to March 2021. All the children were aged between 6 months and 6 years old. The diagnosis of FS was performed according to the clinical practice guideline for the long-term management of the child with simple febrile seizures by the Subcommittee on FS American Academy of Pediatrics16. The exclusion criteria consisted of the following: (1) the presence of central nervous system infection; (2) the presence of underlying diseases or conditions such as epilepsy, gastroenteritis, perinatal abnormalities, delayed psychomotor development, chromosomal abnormalities, congenital metabolic disorders, brain tumors, or history of intracranial surgery; (3) history of seizures unrelated to fever; (4) cases with missing values (missing demographic variables or missing CBCs). Through screening, a total of 2854 children were included in the study, consisting of 299 children with FS and 2555 febrile children without seizures. The 2020 data was randomly divided into training set and internal validation set in a 7:3 ratio. 1453 children were included in the training set, and 623 children were included in the internal validation set. Data from January to March 2021 were used as the external validation set, with a sample size of 778. Data exclusion and data splitting were shown in Fig. 1.

Flow diagram of participants selection.
Variables
Demographic information, including age and gender, as well as CBCs were collected. The CBCs encompassed the following indicators: absolute neutrophil count (ANC), absolute lymphocyte count (ALC), absolute monocyte count (AMC), absolute eosinophil count (AEC), absolute basophil count (ABC), red blood cell count (RBC), hematocrit (Hct), mean corpuscular volume (MCV), hemoglobin (Hb), mean corpuscular hemoglobin (MCH), mean corpuscular hemoglobin concentration (MCHC), platelet count (PLT), mean platelet volume (MPV), red blood cell distribution width (RDW), platelet distribution width (PDW), and C-reactive protein (CRP). Additionally, the neutrophil to lymphocyte ratio (NLR) was calculated.
Statistical analysis
Statistical analysis was performed using SPSS (version 25.0), STATA (version 17) and R language (version 4.2.3). Continuous variables were described using means and standard deviations (SD), while categorical variables were described using frequencies and percentages. The training set was utilized for model development, while the internal validation set, and external validation set was used for testing the model.
The least absolute shrinkage and selection operator (LASSO) method was used to select the predictors of FS. Variables with non-zero coefficients were selected in the LASSO regression model. Multivariate logistic regression model was used to predict FS. The coefficients obtained from the multivariate logistic regression were used to create a nomogram that predicts the probability of FS.
The receiver operating characteristic curve (ROC) was utilized to evaluate the predictive performance. The AUC was calculated for three sets to assess the model's discriminatory capacity. The discriminatory capacity was categorized as poor (AUC: 0.6–0.69), adequate (AUC: 0.7–0.79), good (AUC: 0.8–0.89), or excellent (AUC: 0.9–1.0)17. The validation of the nomogram involved assessing its discrimination (C-statistic) and calibration (calibration plot). Generally, a C-statistic value greater than 0.75 was considered indicative of relatively good discrimination.
Finally, we measured the applicability of the nomogram to clinical practice through decision curve analysis (DCA) and clinical impact curve (CIC). A significance level of p < 0.05 was considered statistically significant in all analyses.
The reporting of this study followed the guidelines of Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD)18.
Results
Analysis of clinical profiles and laboratory variables in the training set
Within the training set, patients were divided into two groups: 152 (7.3%) in the FS group, with a mean age of 28 ± 15 months, and 1301 (62.7%) in the control group, with a mean age of 38 ± 16 months. Table 1 presents a comparison of variables between the FS group and the control group in the training set. In comparison to the control group, the FS group exhibited a higher proportion of males (p < 0.001). Furthermore, the FS group demonstrated significantly higher levels of ANC, AMC, RDW, and NLR compared to the control group (all p < 0.05). Conversely, the FS group had significantly lower levels of ALC, MCV, Hb, MCH, MCHC, PLT, and CRP compared to the control group (all p < 0.05). No significant differences in other laboratory variables were observed between the two groups (all p > 0.05).
Selection of predictors using the LASSO logistic regression model
Since we have many covariates, we used LASSO regression for variable selection to simplify the model. Optimal parameter (lambda) selection in the LASSO model used fivefold cross-validation via minimum criteria, optimal lambda (λ = 0.0032). Do LASSO regression based on this lambda. The optimal lambda resulted in 13 variables with non-zero coefficients. These variables were Age, Gender, ANC, ALC, AMC, MCV, Hb, MCH, PLT, RDW, PDW, CRP, NLR (Fig. 2).

Selection of predictors using the LASSO logistic regression model. (A) Optimal parameter (lambda) selection in the LASSO model used fivefold cross-validation via minimum criteria. The mean-squared error curve was plotted versus lambda. Dotted vertical lines were drawn at the optimal values by using the minimum criteria and the 1 SE of the minimum criteria (the 1-SE criteria). (B) LASSO coefficient profiles of the 20 features. LASSO least absolute shrinkage and selection operator, SE standard error.
Logistic regression and nomogram
The 13 variables selected through LASSO regression entered the logistic regression model. The expression was: logit (p) = 3.707 − 0.060*Age – 0.299*Gender + 0.095*ANC – 0.404*ALC + 0.633*AMC – 0.029*MCV – 0.022*Hb −0.092*MCH – 0.006*PLT + 0.091*RDW + 0.064*PDW – 0.052*CRP + 0.159*NLR. Among these variables, ANC, AMC, RDW, and NLR demonstrated significant positive effects on FS, while age, ALC, Hb, MCH, PLT, and CRP exhibited negative effects on FS (p < 0.05). The effects of gender, MCV, and PDW were not significant (p > 0.05). Based on the coefficients obtained from the logistic regression model, which identified risk factors for FS, a novel nomogram was developed to predict the risk of FS (Fig. 3). In the nomogram, "Points" correspond to the risk value of a single variable, which was then summed up to calculate the "Total Points". The "FS Risk" was determined based on the "Total Points". For instance, a boy with 55 months (points 20), ANC of 10 × 109/L (points 15), ALC of 5 × 109/L (points 50), AMC of 2 × 109/L (points 20), MCV of 70 fL (points 20), Hb of 100 g/L (points 30), MCH of 30 pg (points 10), PLT of 200 × 109/L (points 30), RDW of 40 fl (points 50), CRP of 50 mg/L (points 60), and NLR of 2 (points 5), would have a total of 315 points, corresponding to a risk of FS of less than 1%.

FS risk assessment tool by nomogram. "Points" correspond to the risk value of a single variable; "Total Points" is the sum of the risk values of all variables; “Risk” is determined by “Total points”.
Predictive model validation
The ROC curves of training set, internal validation set, and external validation set were presented in Fig. 4.A. In the training set, the AUC was 0.884 (95% CI 0.861 to 0.908, p < 0.001), with a sensitivity of 0.908 and a specificity of 0.725. In the internal validation set, the AUC was 0.883 (95% CI 0.844 to 0.922, p < 0.001), with a sensitivity of 0.862 and a specificity of 0.783. In the external validation set, the AUC was 0.858 (95% CI 0.820 to 0.896, p < 0.001), with a sensitivity of 0.829 and a specificity of 0.774. The Sensitivity, Specificity, PPV, NPV, LR+ and LR− at four suggested thresholds (100%, 95%, 90% and 85%) were summarized in Table 2.

(A) ROC analysis. AUC = 0.884 (95% CI 0.861 to 0.908, p < 0.001) in training set; AUC = 0.883 (95% CI 0.844 to 0.922, p < 0.001) in internal validation set; AUC = 0.858 (95% CI 0.820 to 0.896, p < 0.001) in external validation set. Calibration curves of the nomogram to predict the probability of FS in training set (B), internal validation set (C), and external validation set (D). The “Ideal” represents the ideal reference line, the “Apparent” represents the model calibration curve, and the “Bias-corrected” represents the 1000 Bootstrap results.
Calibration measurements was performed with C-statistic and calibration plot. In the training set (Fig. 4B), C-statistic was 0.884 (95% CI 0.861 to 0.908); calibration intercept (calibration-in-the-large) was 0.000 (95% CI −0.197 to 0.197); calibration slope was 1.000 (95% CI 0.852 to 1.148). In the internal validation set (Fig. 4C), C-statistic was 0.883 (95% CI 0.844 to 0.922); calibration intercept was 0.000 (95% CI −0.306 to 0.306); calibration slope was 1.000 (95% CI 0.779 to 1.221). In the external validation set (Fig. 4D), C-statistic was 0.858 (95% CI 0.820 to 0.896); calibration intercept was 0.000 (95% CI −0.261 to 0.261); calibration slope was 1.000 (95% CI 0.791 to 1.209). The predictive model, the internal validation set, and the external validation set showed a very good degree of fit from the calibration curves.
Decision curve analysis and clinical impact curve
DCA is an advanced method used to analyze the net clinical benefits of predictive models. In this study, we evaluated the clinical applicability of established FS nomograms through DCA (Fig. 5A). The results showed that the most favorable threshold probabilities for predicting FS in the training set with the nomogram were 0.1–0.4. As demonstrated by the favorable threshold probability, it indicated that the nomogram had a satisfactory clinical benefit and can assist clinicians to predict FS accurately. Figure 5B showed the CIC of the predict model and indicated that as the predicted probability increases, the population predicted by the model to have a high risk becomes increasingly consistent with the population of individuals who actually experience the outcome event.

(A) Decision curve analysis (DCA) of the predictive model for FS. X-axis and Y-axis represent threshold probability and net benefit. The most favorable threshold probabilities for predicting FS are 0.1–0.4. (B) Clinical impact curve of the predictive model for FS. The red line represents the number of people judged as high risk by the model at different probability thresholds; The blue line represents the number of true positives judged as high risk by the model at different probability thresholds. The cost benefit ratio represents the proportion of cost and benefit at different probability thresholds. The Y-axis is measured in units of 1000 people.
Discussion
Predictive models are currently receiving increasing attention in various clinical fields, including malignant tumors, sepsis, and Kawasaki disease, with a growing number of publications in these areas19,20,21,22. However, existing predictive models for FS demonstrate limited predictive ability12,13,14,15. Consequently, our study aims to explore the predictive value of CBCs in FS and construct a highly effective predictive model based on these indicators. In this retrospective analysis, a multivariable logistic regression model was constructed to predict FS. The model's results were visually presented and interpreted using a nomogram, and the predictive performance was assessed using ROC and DCA. Key findings of the study were as follows: (1) The multivariable logistic regression analysis identified four variables, ANC, AMC, RDW, and NLR, that positively influenced the likelihood of FS. Conversely, six variables including age, ALC, Hb, MCH, PLT, and CRP had a negative impact on FS. (2) The nomogram results highlighted the significant contributions of the CRP, ALC and RDW. C-statistic, a measure of discrimination and calibration, was calculated to be 0.884, indicating good predictive accuracy. (3) In the training set, the AUC was 0.884 ((95% CI 0.861 to 0.908, p < 0.001), sensitivity and specificity were 0.908 and 0.725, respectively. In the internal validation set, the AUC was 0.883 (95% CI 0.844 to 0.922, p < 0.001), sensitivity and specificity were 0.862 and 0.783, respectively. In the external validation set, the AUC was 0.858 (95% CI 0.820 to 0.896, p < 0.001), sensitivity and specificity were 0.829 and 0.774, respectively. These findings suggested that the developed predictive model exhibits favorable predictive value.
Our study revealed that ANC, AMC, RDW, and NLR had a positive influence on FS, aligning with the findings of Liu et al., who also observed significantly elevated levels of ANC and NLR in the FS group compared to the control group15. Similarly, other studies such as Aziz et al. and Sharawat et al. demonstrated higher RDW levels in the FS group and lower Hb and MCH levels compared to the non-seizure group23,24. However, it's worth noting that Liu et al. did not find a statistically significant difference in AMC levels between the FS and control groups15, which diverges from our study. This discrepancy may be attributed to the use of univariate analysis in their study, whereas our study employed multivariable logistic regression analysis for a more comprehensive assessment. Furthermore, our study identified age, ALC, Hb, MCH, PLT, and CRP as negative influencers of FS. Previous studies have shown that FS were most common in children between the ages of 6 months and 3 years, with a peak incidence at around 18 months3. Liu et al. observed significantly reduced levels of ALC, PLT, and CRP in the FS group compared to the control group15. Similarly, Gontko-Romanowska et al. found significantly lower ALC, PLT, and CRP levels in the FS group compared to the control group25. In summary, our study's findings regarding the impact of these variables on FS were in line with previous research.
It should be noted that CRP, ALC and RDW were the three indicators that showed the highest values in the nomogram, indicating their significant contributions to the predictive model. This highlights the importance of CRP and RDW in influencing FS. In a previous study conducted by Liu et al.15, the AUC value of NLR in predicting FS was 0.768, suggesting its predictive value was sufficient. However, in our study, when considering the nomogram, the contribution of NLR was relatively lower compared to age, CRP, RDW, and ALC. We speculate that this could be due to the inclusion of ANC and ALC in our predictive model, which partly replaced the contribution of NLR.
For the training set, the nomogram results showed a C-statistic of 0.884, indicating good predictive value. Additionally, the ROC analysis of the internal validation set yielded an AUC of 0.883 (95% CI 0.844 to 0.922, p < 0.001), further confirming the predictive capability of the model. These results suggest that the predictive model developed in this study is highly accurate, approaching an excellent level of prediction. External validation was also performed, and the ROC analysis of the external validation set showed that the AUC was 0.858 (95% CI 0.820 to 0.896, p < 0.001). This external validation further supports the good predictive value of the multivariate logistic regression model established in our study. Moreover, the minimal differences in AUC values among the training set, internal validation set, and external validation set indicate that high accuracy and consistent performance of our predictive model in predicting FS. Notably, the sensitivity in the training set reached 0.908, suggesting a high probability of accurately identifying individuals with FS among fever patients using this model. This highlights the significant clinical utility of the model.
On one hand, our study holds academic value as the AUC values achieved 0.884, 0.883 and 0.858 in the training set, internal validation set and external validation sets respectively, indicating the strong predictive performance of the regression model. This contributes to a deeper understanding of FS and enables clinicians to identify patients at risk of developing FS within the population, advancing FS prediction research. The high consistency in the three datasets suggests the generalizability of the predictive model, making it suitable for practical extension and application in clinical practice. On the other hand, in terms of practical significance and clinical value, our study exhibited remarkable sensitivity, indicating that the model effectively distinguishes patients who are likely to progress to FS. This highlights its potential clinical utility. Additionally, the nomogram, which visually represents complex regression equations, is location-independent and can be easily understood and utilized by healthcare professionals at all levels, as well as the public without medical backgrounds, with simple training. It enables personalized risk prediction and has gained increasing attention and utilization in medical research20,21,22. Furthermore, the demographic variables (age, gender) and blood indicators used in this study are readily accessible in hospitals of all levels, do not require advanced medical equipment, have high acceptance, and have low economic burden. This makes the regression model highly applicable in clinical settings, emphasizing its clinical value.
One of the limitations of our study was its single-center design, which lacks validation in diverse populations. It remains unclear whether our results can be generalized to different regions and races. To improve the accuracy and representativeness of the predictive model, multicenter studies with larger sample sizes are needed. While the validation sets' AUC values in this study were high, the scarcity of studies on FS predictive models calls for further research to validate our model. Moreover, the specificity of the constructed model in this study was not sufficiently high, which may limit its ability to identify febrile children without seizures. Strengthening the predictive ability and practical clinical application value of the model by achieving higher specificity and sensitivity is an avenue for future research. Another aspect for improvement in this study could be the inclusion of additional demographic variables and laboratory indicators. However, it should be noted that in most cases, the additional laboratory indicators may lead to unnecessary medical interventions, causing discomfort for children and financial burdens for families. Additionally, adding more variables may significantly increase the complexity of the model, hindering its widespread clinical application. In conclusion, further research is warranted to enhance the prediction of FS in children, with future advancements in testing techniques and algorithms.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Change history
15 December 2023
A Correction to this paper has been published: https://doi.org/10.1038/s41598-023-47491-0
References
Subcommittee on Febrile Seizures, & American Academy of Pediatrics. Neurodiagnostic evaluation of the child with a simple febrile seizure. Pediatrics 127, 389–394 (2011).
Patterson, J. L. et al. Febrile seizures. Pediatr. Ann. 42, 249–254 (2013).
Leung, A. K., Hon, K. L. & Leung, T. N. Febrile seizures: An overview. Drugs Context 7, 212536 (2018).
Ye, M. et al. Differential roles of NaV1.2 and NaV1.6 in regulating neuronal excitability at febrile temperature and distinct contributions to febrile seizures. Sci. Rep. 8, 753 (2018).
Paul, S. P. et al. Management of febrile convulsion in children. Emerg. Nurse 23, 18–25 (2015).
Martinos, M. M. et al. Recognition memory is impaired in children after prolonged febrile seizures. Brain 135, 3153–3164 (2012).
Patterson, K. P. et al. Enduring memory impairments provoked by developmental febrile seizures are mediated by functional and structural effects of neuronal restrictive silencing factor. J. Neurosci. 7, 3799–3812 (2017).
Barry, J. M. et al. T2 relaxation time post febrile status epilepticus predicts cognitive outcome. Exp. Neurol. 269, 242–252 (2015).
Dreier, J. W. et al. Childhood seizures and risk of psychiatric disorders in adolescence and early adulthood: A Danish nationwide cohort study. Lancet Child Adolesc. Health 3, 99–108 (2019).
Jongbloets, B. C. et al. Expression profiling after prolonged experimental febrile seizures in mice suggests structural remodeling in the hippocampus. PloS one 10, e0145247 (2015).
Crandall, L. G. et al. Potential role of febrile seizures and other risk factors associated with sudden deaths in children. JAMA Netw. Open 2, e192739 (2019).
Cokyaman, T., Kasap, T. & Şehitoğlu, H. Serum brain-derived neurotrophic factor in the diagnosis of febrile seizure. Pediatr. Int. 63, 1082–1086 (2021).
Bakri, A. H. et al. Biochemical assessments of neurotrophin-3 and zinc involvement in the pathophysiology of pediatric febrile seizures: Biochemical markers in febrile seizures. Biol. Trace Elem. Res. 200, 2614–2619 (2022).
Baek, S. J. et al. Risk of low serum levels of ionized magnesium in children with febrile seizure. BMC Pediatr. 18, 297 (2018).
Liu, Z. et al. The role of mean platelet volume/platelet count ratio and neutrophil to lymphocyte ratio on the risk of febrile seizure. Sci. Rep. 8, 15123 (2018).
Steering Committee on Quality Improvement and Management, Subcommittee on Febrile Seizures American Academy of Pediatrics. Febrile seizures: Clinical practice guideline for the long-term management of the child with simple febrile seizures. Pediatrics 121, 1281–1286 (2008).
Ben Abdelkrim, M. et al. Contextual validation of the prediction of postoperative complications of colorectal surgery by the “ACS NSQIP®Risk Calculator” in a Tunisian Center. Cancer Inform. 21, 11769351221135152 (2022).
Collins, G. S. et al. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): The TRIPOD statement. BMC Med. 13, 1 (2015).
Ren, C. et al. Development and external validation of a dynamic nomogram to predict the survival for adenosquamous carcinoma of the pancreas. Front. Oncol. 12, 927107 (2022).
Zeng, W. et al. Development and validation of a nomogram for predicting postoperative distant metastasis in patients with cervical cancer. Med. Sci. Monit. 28, e933379 (2022).
Lu, B. et al. Development of a nomogram for predicting mortality risk in sepsis patients during hospitalization: A retrospective study. Infect. Drug Resist. 16, 2311–2320 (2023).
Yang, S. et al. Predictive tool for intravenous immunoglobulin resistance of Kawasaki disease in Beijing. Arch. Dis. Child 104, 262–267 (2019).
Aziz, K. T., Ahmed, N. & Nagi, A. G. Iron deficiency anaemia as risk factor for simple febrile seizures: A case control study. J. Ayub. Med. Coll. Abbottabad 29, 316–319 (2017).
Sharawat, I. K. et al. Evaluation of risk factors associated with first episode febrile seizure. J. Clin. Diagn. Res. 10, SC10–SC13 (2016).
Gontko-Romanowska, K. et al. The assessment of laboratory parameters in children with fever and febrile seizures. Brain Behav. 7, e00720 (2017).
Acknowledgements
This work was supported by the 2021 Jing'an District Medical Discipline Series Projects (Grant 2021 BR06).
Author information
Authors and Affiliations
Contributions
A.C. and Y.H. designed the research study, analyzed the data, researched, and wrote the paper. Q.X. contributed to data collection, J.W., R.W., L.S., G.Z. provided suggestions on the study and revised the manuscript. All authors read and approved the final manuscript for publication.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: In the original version of this Article, the affiliation of the authors was incorrectly given as ‘Children’s Hospital of Shanghai, Shanghai, China’. The correct affiliation is: Department of Emergency, Shanghai Children's Hospital, School of Medicine, Shanghai Jiao Tong University, Shanghai, China.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cheng, A., Xiong, Q., Wang, J. et al. Development and validation of a predictive model for febrile seizures. Sci Rep 13, 18779 (2023). https://doi.org/10.1038/s41598-023-45911-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-45911-9
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
