
Abstract
Failure mode and effects analysis (FMEA) is an effective model that identifies the potential risk in the management process. In FMEA, the priority of the failure mode is determined by the risk priority number. There is enormous uncertainty and ambiguity in the traditional FMEA because of the divergence between expert assessments. To address the uncertainty of expert assessments, this work proposes an improved method based on the belief divergence measure. This method uses the belief divergence measure to calculate the average divergence of expert assessments, which is regarded as the reciprocal of the average support of assessments. Then convert the relative support among different experts into the relative weight of the experts. In this way, we will obtain a result with higher reliability. Finally, two practical cases are used to verify the feasibility and effectiveness of this method. The method can be used effectively in practical applications.
Similar content being viewed by others


Introduction
Risk assessment and prevention have drawn more and more attention in modern management. Risk represents the probability of an adverse event which will breach security and pose a threat. Assessments of risk are largely dependent on an analysis of the uncertainty. Failure mode and effects analysis (FMEA), a risk assessment method widely used in engineering and management1, was first proposed by the Department of Defense, USA in 19492 and used to solve quality and reliability problems in military products. FMEA has been gradually applied to all walks of life, including aerospace3, automobile manufacturing4, the medical field5, food safety6, and supplier selection7. The main purpose of FMEA is to identify potential failure modes and assess their causes and influences8. The core parameter of FMEA is risk priority number (RPN)9, which is the product of three risk factors, which are the occurrence (O), severity (S), and detection (D) of a failure mode. The failure modes are ranked according to their RPN, and the failure mode with the highest RPN has the higher priority.
The traditional FMEA model can be roughly described as the following steps. (1) Identifying all failure modes in the target system. (2) Assessing the risk factors of these failure modes by experts. (3) Calculating the RPN value of failure modes according to the result of assessments. (4) Ranking the failure modes on the basis of RPN value. However, in practice, there is a great deal of uncertainty in assessing potential risks in systems with the traditional FMEA model, often yielding imprecise results. Because it is difficult to reach an agreement on the assessment of failure mode by different experts10, coupled with the inaccurate cognition of the real problem by experts, the assessment of risk is inaccurate and uncertain11. For example, if a very authoritative expert gives an assessment of a failure mode is (5,6,7) (assuming that his assessment is very close to the truth), the RPN value is 210. And another expert gives an assessment is (3,1,4). The RPN value is 12. Obviously, due to the second expert’s subjective opinion or incomplete understanding of the problem, their assessment has great ambiguity and uncertainty. The average RPN value is 111. It is very different from the real situation. In addition, the traditional FMEA has some defects12,13. First, the traditional FMEA model ignored the relative importance between the three risk factors named O, S, and D. Different risk factors should have different weights, so there is no way to unify the weights of the three risk factors. Second, the traditional FMEA model divides ratings of O, S, and D into non-linear scales of grades [1, 2, 3, ..., 10]. It will eventually produce many repeated and intermittent values that will affect the ability of the management personnel to make effective decisions. Third, there are some subjective assumptions about the assessments of the failure mode by experts. Enough attention should be given to the weighting of each expert.
For the above problems, some existing studies propose many methods to deal with the uncertainty in risk assessments by adopting existed theories such as fuzzy sets theory14,15, Dempster-Shafer evidence theory16, evidence reasoning17, prospect theory18, D-number theory19, Z-number theory20, R-number theory21, fairness-oriented consensus approach22, grey relation analysis method23, and best-worst method24. Among them, Liu et al. propose a method combining the fuzzy theory and technique for order preference by similarity to ideal solution (TOPSIS)25, which achieves the calculation of weights of expert decisions based on similarity. Wang et al. capture the experts’ diverse assessments on the risk of failure modes and the weights of risk factors by interval two-tuple linguistic variables and develop a ranking method for failure modes based on the regret theory and TODIM26. In27, the authors use the ambiguity measure(AM) to quantify the degree of uncertainty assessed by each expert for each risk item. An AM-based weighting method for weighted risk priority number is proposed in28. A FMEA method based on rough set and interval probability theories is proposed in29, which converts the assessment values of risk factors into interval numbers, and the interval exponential RPN is proposed to overcome the discontinuity problem of traditional RPN values. In30, the authors propose a FMEA method based on Deng entropy under the Dempster-Shafer evidence theory framework, where the uncertainty of expert assessments is measured by Deng entropy and converted into the relative weights of experts and weights of risk factors. In addition to the above studies, some researchers have done some studies based on similarity measure in FMEA . In31, Zhou et al. use the Similarity Measure Value Method (SMVM) to model the failure modes and their correlations. This method gains similarity among assessments based on the concept of medium curve and fuzzy number. Pang et al. propose a method to weight the experts based on the similarity of their assessments, which is calculated by fuzzy Euclidean distance32. Furthermore, Jin et al.’s research introduce the Dice similarity and the Jaccard similarity33. However, little research is conducted to improve FMEA from the standpoint of divergence measure, despite the fact that divergence measure and similarity measure share some characteristics, while Song and Wang use the form of “\(1-D(A,B)\)” (D(A, B) represents the divergence of evidence) to measure the similarity34. Most previous researches have improved the FMEA in view of the process of assessment. Those methods are able to effectively model the experts’ assessments as accurate data and deal with them with some appropriate methods. But for the data that has been modeled, it is necessary to measure the uncertainty among them by some methods, such as the divergence measure. Due to the fact that there is little research which combines the divergence measure and FMEA, the effectiveness of the method that introduces divergence measure into FMEA is necessary to verify. It’s also the motivation of this paper.
Because of the influence of subjective opinion and historical experience, expert assessments are often inaccurate. The uncertainty among the assessments by different experts needs to be measured by some appropriate methods. Processing data with imprecise information can be done using the Dempster-Shafer evidence theory35,36. In Dempster-Shafer evidence theory, how to measure the divergence and conflicts between the evidence remains an open issue37. There are many uncertainty measurement methods38, such as ambiguity measure39, total uncertainty measure40, divergence measure41, the correlation coefficient42, and the fractal-based belief entropy43. Recently, Xiao44 proposed the belief divergence measure (BJS) on the basis of the Jensen-Shannon divergence measure45. By replacing the probability assignment function with the mass function, BJS is able to effectively measure the divergence between different pieces of evidence. Therefore, this work propose an expert assessment uncertainty analysis method based on BJS.
The new method models the belief structure of expert assessment results, calculate the divergence among BPAS with BJS, and construct the divergence degree matrix. Since the divergence degree and the support degree of assessments are opposite concepts, the divergence degree of other BPAS to the current BPA is regarded as the reciprocal of the support degree. This theory is used to convert the average divergence degree into the average support degree, which is used to represent the weight of experts. By bringing the weight of experts into the calculation of RPN, a more accurate analysis of expert assessments will be obtained and the risk of the system will be reduced. Compared with other improved methods, BJS calculates the reliability by combining all the evidence rather than calculating the credibility of each piece of evidence in isolation, so the results calculated in this way have higher reliability. In addition, the method considers the relative importance of different experts, reduces the uncertainty caused by divergence that is produced by the subjectivity of different experts, and is more in line with the actual situation.
This paper’s contribution is that the new method proposed solutions in view of the traditional FMEA defects, in this way, provide a new idea to improve the FMEA method. In addition, this paper provides some new theoretical support for the research combining divergence and FMEA. The rest of this work is organized as follows: in Preliminaries" section reviews the theoretical basis of this work. In "FMEA method based on belief divergence measure" section, aiming at FMEA, an expert assessment uncertainty measurement method based on the belief divergence measure is proposed. Then, an actual case is used to verify the application of this method in "Applications and discussion" section. Finally, "Conclusion" section summarizes the content of this work.
Preliminaries
Dempster-Shafer evidence theory
The D-S evidence theory (DST) is a very effective tool to process the data with uncertainty. From data modeling to uncertainty measurement and data fusion, every step has useful methods to finish. Research on the DST has made great progress in recent years. Accordingly, the FMEA method in DST has great advantages. The DST was first proposed by Dempster in 1967 and further developed by Shafer46,47. DST is a generalization of Bayesian subjective probability theory and also an extension of classical probability theory. As a mathematical framework for representing uncertainty, DST combines the degree of belief from independent evidence items. DST is defined as below:
Supposing \(\Omega \) is a fixed, exhaustive set of mutually exclusive events whose probability of occurrence does not interfere with each other. \(\Omega \) is expressed by the following formula:
where \(\Omega \) is called the frame of discernment, and the set of all subsets of \(\Omega \)(such as formula (2)) is called the power set of \(\Omega \), which is recorded as \(2^\Omega \).
where \(\varnothing \) is an empty set, and the elements in \(2^\Omega \) are called propositions.
The mass function, also known as basic probability assignment (BPA), represents the mapping relationship between an element in \(2^\Omega \) and interval [0,1]. It is defined as follows:
Mass function also satisfy the condition as follows:
For a focus element A of \(\Omega \), its Belief function bel (A) is defined as follows:
The plausibility function pl (A) of A is defined as follows:
The bel(A) is the lower bound function of proposition A, and the pl(A) is the upper bound function of proposition A.
Assuming that \(m_1\) and \(m_2\) are two BPAS under the frame of discernment \(\Omega \), B and C are the focus elements of \(m_1\) and \(m_2\), respectively. By using the Dempster’s combination rule, the two groups of BPAS are fused to obtain a new set of probabilities. Dempster’s combination rule is defined as follows:
where k represents the degree of conflict between two evidence bodies, which is called the conflict coefficient, k is defined as follows:
FMEA
FMAE is a management tool for system reliability with a highly structured approach that provides a set of effective technologies for risk assessment and prevention11,48, and has been widely used in product quality monitoring, decision-making, other fields. FMEA mainly relies on experts to assess different failure modes so as to determine the priority of each failure mode. Those failure modes with a high RPN value often get focused attention to reduce the risk of the system effectively. The calculation of RPN is an important step in FMEA, and the definition of RPN is as follows:
The RPN consists of the probability of failure occurrence (O), the severity of failure occurrence (S), and the probability of failure being detected (D). The traditional RPN model multiplies the three risk factors (O, S, and D) to obtain the RPN value, as shown in formula 9:
In tradition, the grades of O, S, and D are often divided into 10 levels, in which each level of assessment is given different explanations. The assessment level for O is shown in Table 1, and the assessment levels for S and D can be found in49.
Divergence measure
The divergence measure can effectively measure the divergence and conflict between evidence. The divergence, like the similarity, measures the conflict from a distance perspective, but the divergence and similarity are diametrically opposed concepts.There are many existing divergence measurements, summarized below.
For two probability distributions \(A={a_1,a_2,\dots ,a_n}\) and \(B={b_1,b_2,\dots ,b_n}\). The JS divergence measure is denoted as45:
The BJS divergence measure was proposed by Xiao based on the JS divergence measure. Supposing that there are two BPAS, \(m_1\) and \(m_2\), the BJS divergence measure between them is denoted as44:
where,
BJS is also defined as the following formula:
where, H(\(m_j\)) represents Shannon entropy, and H (\(m_j\)) is defined as:
The Reinforced belief divergence measure (RB divergence measure) was proposed by Xiao in 2019. It mainly measures the divergence among belief functions. For two belief functions in the frame of discernment, m1 and m2, the RB divergence measure is denoted as50:
where
The divergence measure proposed by Wang et al. between m1 and m2 is denoted as51:
Compared with Wang et al. divergence, the BJS represents the divergence directly from the view of entropy without calculating the pl function. As for RB divergence, most assessments in FMEA are regarded as propositions with a single element, so the RB divergence will be complex and inefficient in FMEA. The BJS is based on the JS divergence measure and is the extent of the JS divergence measure. BJS is widely used in belief functions. When all the hypothesis of belief functions are assigned to a single element, the BBA will transform into probability. At this time, the BJS will degenerate into JS44.
FMEA method based on belief divergence measure
This work proposed a method for calculating RPN value based on the divergence measure, which uses BJS under the framework of Dempster-Shafer evidence theory to measure the divergence between evidence. In FMEA, the expert’s assessment is regarded as a piece of evidence. The divergence between different assessments will be converted into uncertainty of assessment and relative weight of experts. The specific conversion will be carried out according to the following process:
Step 1: Identify potential failure modes in the target system based on past experience.
Step 2: The risk factors of these failure modes are assessed by experts, and the assessments are modeled as BPA. Assume that the ith expert’s assessments of a risk factor are modeled as a mass function \(m_i=\)(\(m(1), m(2),\dots , m(10)\)), the \(m(\theta )\) represent that the probability of the expert gives the level as \(\theta \). m\((\theta )\) satisfy that \(\sum _{\theta =1}^{10}m(\theta )=1\).
Step 3: BJS is used to measure the divergence between each expert’s assessment, and the divergence matrix (DMM) is constructed. The DMM is defined as follows:
where \(BJS_{ij}\) represents the divergence between \(m_i\) and \(m_j\). Obviously, the DMM has the following two characteristics:
-
1.
The values on the main diagonal of DMM are 0, because when the two pieces of evidence are exactly the same, i.e., \(m_1 = m_2\), BJS (\(m_1 , m_2\)) = 0, indicating that there is no divergence between the two pieces of evidence, which also conforms to the definition of BJS.
-
2.
DMM is a symmetric square matrix because BJS satisfies symmetry.
Step 4: Calculate the average divergence among assessments, which is defined as follows:
It means that summing all data in column i of DMM and dividing it by n-1. The result is the average divergence between \(m_i\) and other mass functions.
Step 5: The weight of experts is defined as follows:
where the \(Sup(m_i)\) represents the support degree,and \(Sup(m_i)\) is defined as:
When the \(\tilde{BJS_i}=0\). It means that all of assessments are same, there is no divergence among them, so the the weights will be equally distributed. When the \(\tilde{BJS_i}\ne 0\). The average divergence is converted into the degree of support, and the weight of experts is obtained by support degree weighting.
Step 6: Since the risk assessments by experts are divided into multiple levels (i.e., \(m_i = (m(1),m(2),\dots ,m(10)\)), the comprehensive value of risk factors needs to be calculated before calculating the RPN value. The comprehensive value of risk factors is defined as follows:
In tradition, the expert divides his or her assessments into 10 levels, and each level corresponds to a risk value (represented by \(\theta _j\) and \(\theta _j\in [1,10]\)). For example, an expert’s assessment of the severity (s) of a failure mode is \((m(1)=0.8, m(2)=0.1, m(3)=0.1)\), which means that 80\(\%\) of people think that the failure is not serious, 10\(\%\) think that the failure is moderately serious, and 10\(\%\) think that the failure is very serious. Then the comprehensive value of the risk factor S is: S=0.8\(\times \)1+0.1\(\times \)2+0.1\(\times \)3=1.3.
Step 7: The new RPN value is calculated according to the comprehensive value of risk factors and the weighted results of expert evaluation, which is defined as follows:
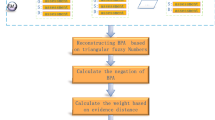
Finally, all failure modes are ranked according to RPN values. We will know which failure modes have a higher priority and focus on them. The specific execution flow of the new method is shown in Fig. 1. It is worth noting that the weight of experts is considered in the calculation of the new RPN, and the weight is obtained by combining all assessments, not obtained independently from one piece of evidence. In other words, when the assessment of one expert changes, the weight of other experts will also be affected.

Flow chart of calculating RPN value with the proposed method.
Applications and discussion
Application 1
Experiment process
To verify the feasibility of the new method in this work, the application example in52 was referenced to conduct an experiment in this work, and the experimental results are compared with the other four methods. In the end, the effectiveness of this method has been verified. The experimental steps are as follows:
-
1.
Find all the failure modes in the target system. As shown in Table 2, this is an application example of a steel plate production process with 10 failure modes.
-
2.
Collect those assessments of the risk factor from experts. Taking the first failure mode as an example, the assessment results are shown in Table 3 (the rest of the assessment results can be found in52). Three experts assessed the risk factors, and these assessments were divided into 3 levels, from which the comprehensive value of risk factors can be calculated by formula 21, and the result is shown in Table 4.
-
3.
Calculate the divergence between two assessments using formula 12, and structure the divergence matrix using formula 17. In \(FM_1\), the divergence matrix was structured as follows according to the values in Table 3.
$$\begin{aligned} DMM(O)= & {} \begin{bmatrix} 0 &{}0.0773 &{}0.0366\\ 0.0773 &{}0 &{}0.0533\\ 0.0366 &{}0.0533 &{}0 \end{bmatrix} \\ DMM(S)= & {} \begin{bmatrix} 0 &{}0.0902 &{}0.0623\\ 0.0902 &{}0 &{}0.2524\\ 0.0623 &{}0.2524 &{}0 \end{bmatrix} \\ DMM(D)= & {} \begin{bmatrix} 0 &{}0.0113 &{}0\\ 0.0113 &{}0 &{}0.0113\\ 0 &{}0.0113 &{}0 \end{bmatrix} \end{aligned}$$ -
4.
Using formulas 18 and 20 to calculate the average divergence and the support degree between assessments, the results are shown in Tables 5 and 6.
-
6.
Using formula 22 to calculate the RPN value of \(FM_1\) in combination with the data in Table 4 and Table 7, the result is 0.2735. Repeat all the above steps to calculate the RPN value of other FMs. RPN values and the ranking result according to RPN values are shown in Table 8. The ranking result is \(FM_4> FM_7> FM_3> FM_8> FM_1> FM_{10}> FM_2> FM_5> FM_6 > FM_9\). Because \(FM_4\) is ranked first, in practice, the managers should pay more attention to the monitoring and management of \(FM_4\), followed by \(FM_7\). \(FM_9\) has the lowest RPN value, ranks last, and will be given the least attention. In addition, it should be noted that for the two groups of failure modes with very close or even the same RPN values, such as \(FM_5\) and \(FM_6\), although they have the sequence based on RPN, they should be given the same attention as much as possible.
Experimental result of application 1
In order to verify the correctness of the method proposed in this work, the experimental results are compared with the results in papers27,28,52,53. In52, Li and Chen used the grey correlation projection method to deal with the uncertainty between expert assessments. In53, Vahdani et al. combined the fuzzy belief TOPSIS method with FMEA to improve the traditional FMEA model. The correctness of the other methods has been well verified in their articles. The comparison results between the method proposed in this work and the other methods are shown in Fig. 2.

Ranking of failure modes with different methods.
It shows that the ranking result obtained by this method has the same trend as those obtained by the other methods (that is, the relative position of ranking between failure modes does not change much), especially the \(FM_4\) ranked first, which is completely consistent with the results of other three methods, which ensure that in the practical application, focus is on the failure mode with the highest risk initially. The results indicate there is a certain amount of distinction through different methods. We considered that this distinction may be caused by the RPN value, so we compared the RPN values with Li and Chen’s method. The results are shown in Fig. 3. It indicates that the RPN values produced by Li and Chen’s method and the proposed method are very close.

RPN values of Li and Chen’s method and the proposed method.
Application 2
Experiment process
In order to better verify the application of this method in FMEA, we used another example in54 to verify it. There are 17 failure modes in this example, and the data was processed more accurately in48. Some of the assessments are shown in Table 9.
The calculation is similar to the application one, due to space, the calculation process will not be described here. Table 10 shows the RPN values and the ranking result. The ranking result is \(FM_9>FM_2> FM_{14}> FM_6> FM_{10}> FM_{12}> FM_{11}> FM_{13}> FM_1> FM_{15}> FM_{17}> FM_3> FM_7> FM_{16}> FM_4> FM_8 > FM_5\). The result is consistent with the preliminary assessment.
Experimental result of application 2
The comparison of the ranking result with other methods( MVRPN54, Improved MVRPN48, GERPN55, Zhou et al.’s method56) is shown in Fig. 4. The ranking result is very close to the other methods, especially exactly the same as Zhou et al.’s method, which makes the usability of the method further verified. As for the comparison of the RPN values, it is shown in Table 11. The RPN values of this method are generally smaller than other RPN values. In case where all the assessments are different, other methods produces 5 same RPN values (\(FM_6\) and \(FM_{10}\), \(FM_{11}\), \(FM_{12}\) and \(FM_{13}\)), and this method produces only 2 same RPN values(\(FM_6\) and \(FM_{10}\)). The reason for this gap is the way experts are assigned weight.

Ranking of failure modes with different methods.
Discussion
In general, the feasibility of the new method is verified by the above cases. One characteristic of this method is that the RPN value generated is small, but it does not affect the final sorting result. Compared with other methods, the new method is less likely to produce the same RPN values, which can better overcome the defects of the traditional FMEA and make the evaluation more accurate. In addition, this method also has some issues that need to be improved. The uncertainty between assessments of the same risk factor can represent the weights of the experts, but the uncertainty between assessments of different risk factors cannot represent the weights of different risk factors. Other uncertainty measures can be introduced into this method to measure the weight between different risk factors.
Conclusion
The uncertainty of expert assessment has always been an inevitable problem in risk management. Due to the effectiveness of FMEA in risk assessment, managers pay more and more attention to the accuracy of FMEA in failure mode assessment to ensure the safe operation of the target system. Therefore, the traditional FMEA has great limitations. At the same time, effective methods are also needed to improve the problems of the traditional FMEA.
This work proposed a method based on the divergence measure to deal with the uncertainty of expert assessment. This method transforms the uncertainty of experts’ subjective assessment into experts’ weight, and attempts to improve the accuracy of assessment from the perspective of experts’ weight. At the same time, the divergence measure highlights the correlation between assessments, so that the assessments are no longer isolated. Finally, a case of a steel plate production process is used to verify the practicability of this method, and excellent results are obtained.
The core idea in this work is that by using the divergence measure to obtain the divergence between assessments and converting this divergence into the support degree of assessments, the support degree will represent the weight of experts. In the following research, we can apply this method to other fields to deal with the uncertainty of subjective assessments and consider introducing information entropy to measure the quantity of information in assessments to improve this method from the perspective of the weighted risk factor. In addition, the fusion of different pieces of evidence with potential conflict has always been an open issue in the Dempster-Shafer evidence theory. Thus, we can improve this method and apply it to the fusion of conflicting assessments.
Data availability
All data generated or analysed during this study are included in this published article.
References
Wang, Z., Ran, Y., Chen, Y., Yu, H. & Zhang, G. Failure mode and effects analysis using extended matter-element model and ahp. Comput. Ind. Eng. 140, 106233 (2020).
Wu, Z., Liu, W., & Nie, W. Literature review and prospect of the development and application of fmea in manufacturing industry, Int. J. Adv. Manuf. Technol. 1–28 (2021).
Jones, M., Fretz, K., Kubota, S., Smith, & C. A. The use of the expanded fmea in spacecraft fault management, in 2018 Annual Reliability and Maintainability Symposium (RAMS), IEEE, pp. 1–6 (2018).
Gueorguiev, T., Kokalarov, M., & Sakakushev, B. Recent trends in fmea methodology, in 2020 7th International Conference on Energy Efficiency and Agricultural Engineering (EE & AE), IEEE, pp. 1–4 (2020).
Warnick, R. E., Lusk, A. R., Thaman, J. J., Levick, E. H. & Seitz, A. D. Failure mode and effects analysis (fmea) to enhance the safety and efficiency of gamma knife radiosurgery. J. Radiosurg. SBRT 7, 115 (2020).
Permana, R. A., Ridwan, A. Y., Yulianti, F., & Kusuma, P. G. A. Design of food security system monitoring and risk mitigation of rice distribution in indonesia bureau of logistics, in 2019 IEEE 13th International Conference on Telecommunication Systems, Services, and Applications (TSSA), IEEE, pp. 249–254.
Hendiani, S., Mahmoudi, A. & Liao, H. A multi-stage multi-criteria hierarchical decision-making approach for sustainable supplier selection. Appl. Soft Comput. 94, 106456 (2020).
Brun, A., & Savino, M. M. Assessing risk through composite fmea with pairwise matrix and markov chains, Int. J. Qual. Reliab. Manag. (2018).
Park, J., Park, C. & Ahn, S. Assessment of structural risks using the fuzzy weighted euclidean fmea and block diagram analysis. Int. J. Adv. Manuf. Technol. 99(9), 2071–2080 (2018).
Wu, J., Tian, J. & Zhao, T. Failure mode prioritization by improved rpn calculation method, in 2014 Reliability and Maintainability Symposium, pp. 1–6.
Zhang, H., Dong, Y., Palomares-Carrascosa, I. & Zhou, H. Failure mode and effect analysis in a linguistic context: a consensus-based multiattribute group decision-making approach. IEEE Trans. Reliab. 68, 566–582 (2018).
Subriadi, A. P. & Najwa, N. F. The consistency analysis of failure mode and effect analysis (fmea) in information technology risk assessment. Heliyon 6, e03161 (2020).
Yazdi, M. Improving failure mode and effect analysis (fmea) with consideration of uncertainty handling as an interactive approach. Int. J. Interact. Des. Manuf. (IJIDeM) 13, 441–458 (2019).
Nguyen, H. A new aggregation operator for intuitionistic fuzzy sets with applications in the risk estimation and decision making problem, in 2020 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), IEEE, pp. 1–8.
Kabir, S. & Papadopoulos, Y. A review of applications of fuzzy sets to safety and reliability engineering. Int. J. Approx. Reason. 100, 29–55 (2018).
Wei, K., Geng, J. & Xu, S. Fmea method based on fuzzy theory and ds evidence theory. J. Syst. Eng. Electron. 41, 2662–2668 (2019).
Shi, H., Wang, L., Li, X.-Y. & Liu, H.-C. A novel method for failure mode and effects analysis using fuzzy evidential reasoning and fuzzy petri nets, Journal of Ambient Intelligence and Humanized. Computing 11, 2381–2395 (2020).
Fan, C., Zhu, Y., Li, W. & Zhang, H. Consensus building in linguistic failure mode and effect analysis: a perspective based on prospect theory. Qual. Reliab. Eng. Int. 36, 2521–2546 (2020).
Liu, B. & Deng, Y. Risk evaluation in failure mode and effects analysis based on d numbers theory. Int. J. Comput. Commun. Control 14, 672–691 (2019).
Ghoushchi, S. J., Gharibi, K., Osgooei, E., Ab Rahman, M. N. & Khazaeili, M. Risk prioritization in failure mode and effects analysis with extended swara and moora methods based on z-numbers theory. Informatica 32, 41–67 (2021).
Seiti, H., Fathi, M., Hafezalkotob, A., Herrera-Viedma, E. & Hameed, I. A. Developing the modified r-numbers for risk-based fuzzy information fusion and its application to failure modes, effects, and system resilience analysis (fmesra). ISA Trans. 113, 9–27 (2021).
Tang, M. & Liao, H. Failure mode and effect analysis considering the fairness-oriented consensus of a large group with core-periphery structure. Reliab. Eng. Syst. Saf. 215, 107821 (2021).
Nie, W., Liu, W., Wu, Z., Chen, B. & Wu, L. Failure mode and effects analysis by integrating bayesian fuzzy assessment number and extended gray relational analysis-technique for order preference by similarity to ideal solution method. Qual. Reliab. Eng. Int. 35, 1676–1697 (2019).
Gul, M., Yucesan, M. & Celik, E. A manufacturing failure mode and effect analysis based on fuzzy and probabilistic risk analysis. Appl. Soft Comput. 96, 106689 (2020).
Liu, Z., Sun, L., Guo, Y., & Kang, J. Fuzzy fmea of floating wind turbine based on related weights and topsis theory, in 2015 Fifth International Conference on Instrumentation and Measurement, Computer, Communication and Control (IMCCC), IEEE, pp. 1120–1125 (2015).
Wang, L., Hu, Y.-P., Liu, H.-C. & Shi, H. A linguistic risk prioritization approach for failure mode and effects analysis: a case study of medical product development. Qual. Reliab. Eng. Int. 35, 1735–1752 (2019).
Wu, D. & Tang, Y. An improved failure mode and effects analysis method based on uncertainty measure in the evidence theory. Qual. Reliab. Eng. Int. 36, 1786–1807 (2020).
Tang, Y., Zhou, D. & Chan, F. T. Amwrpn: Ambiguity measure weighted risk priority number model for failure mode and effects analysis. IEEE Access 6, 27103–27110 (2018).
Ouyang, L., Zheng, W., Zhu, Y. & Zhou, X. An interval probability-based fmea model for risk assessment: a real-world case. Qual. Reliab. Eng. Int. 36, 125–143 (2020).
Zheng, H. & Tang, Y. Deng entropy weighted risk priority number model for failure mode and effects analysis. Entropy 22, 280 (2020).
Zhou, H., Yang, Y.-J., Huang, H.-Z., Li, Y.-F. & Mi, J. Risk analysis of propulsion system based on similarity measure and weighted fuzzy risk priority number in fmea. Int. J. Turbo Jet-Engines 38, 163–172 (2021).
Pang, J., Dai, J., & Qi, F. A potential failure mode and effect analysis method of electromagnet based on intuitionistic fuzzy number in manufacturing systems, Math. Prob. Eng. 2021 (2021).
Jin, C., Ran, Y. & Zhang, G. An improving failure mode and effect analysis method for pallet exchange rack risk analysis. Soft. Comput. 25, 15221–15241 (2021).
Song, Y. & Wang, X. A new similarity measure between intuitionistic fuzzy sets and the positive definiteness of the similarity matrix. Pattern Anal. Appl. 20, 215–226 (2017).
Liu, Z.-G., Huang, L.-Q., Zhou, K. & Denoeux, T. Combination of transferable classification with multisource domain adaptation based on evidential reasoning. IEEE Trans. Neural Netw. Learn. Syst. 32, 2015–2029 (2021).
Liu, Z., Zhang, X., Niu, J. & Dezert, J. Combination of classifiers with different frames of discernment based on belief functions. IEEE Trans. Fuzzy Syst. 29, 1764–1774 (2021).
Deng, Y. Uncertainty measure in evidence theory, Science China. Inf. Sci. 63, 1–19 (2020).
Wang, X. & Song, Y. Uncertainty measure in evidence theory with its applications. Appl. Intell. 48, 1672–1688 (2018).
Jousselme, A.-L., Liu, C., Grenier, D. & Bossé, É. Measuring ambiguity in the evidence theory. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 36, 890–903 (2006).
Deng, Z. & Wang, J. Measuring total uncertainty in evidence theory. Int. J. Intell. Syst. 36, 1721–1745 (2021).
Xu, S. et al. A novel divergence measure in dempster-shafer evidence theory based on pignistic probability transform and its application in multi-sensor data fusion. Int. J. Distrib. Sens. Netw. 17, 15501477211031472 (2021).
Jiang, W. A correlation coefficient for belief functions. Int. J. Approx. Reason. 103, 94–106 (2018).
Zhou, Q. & Deng, Y. Fractal-based belief entropy. Inf. Sci. 587, 265–282 (2022).
Xiao, F. Multi-sensor data fusion based on the belief divergence measure of evidences and the belief entropy. Inf. Fusion 46, 23–32 (2019).
Lin, J. Divergence measures based on the shannon entropy. IEEE Trans. Inf. Theory 37, 145–151 (1991).
Dempster, A. P. Upper and lower probabilities induced by a multi-valued mapping. Ann. Math. Stat. 38, 325–339 (1967).
Shafer, G. A Mathematical Theory of Evidence (Princeton University Press, Princeton, 1976).
Su, X., Deng, Y., Mahadevan, S. & Bao, Q. An improved method for risk evaluation in failure modes and effects analysis of aircraft engine rotor blades. Eng. Fail. Anal. 26, 164–174 (2012).
Bian, T., Zheng, H., Yin, L. & Deng, Y. Failure mode and effects analysis based on d numbers and topsis. Qual. Reliab. Eng. Int. 34, 501–515 (2018).
Xiao, F. A new divergence measure for belief functions in d-s evidence theory for multisensor data fusion. Inf. Sci. 514, 462–483 (2020).
Wang, H., Deng, X., Jiang, W. & Geng, J. A new belief divergence measure for dempster-shafer theory based on belief and plausibility function and its application in multi-source data fusion. Eng. Appl. Artif. Intell. 97, 104030 (2021).
Li, Z. & Chen, L. A novel evidential fmea method by integrating fuzzy belief structure and grey relational projection method. Eng. Appl. Artif. Intell. 77, 136–147 (2019).
Vahdani, B., Salimi, M. & Charkhchian, M. A new fmea method by integrating fuzzy belief structure and topsis to improve risk evaluation process. Int. J. Adv. Manuf. Technol. 77, 357–368 (2015).
Yang, J., Huang, H.-Z., He, L.-P., Zhu, S.-P. & Wen, D. Risk evaluation in failure mode and effects analysis of aircraft turbine rotor blades using dempster-shafer evidence theory under uncertainty. Eng. Fail. Anal. 18, 2084–2092 (2011).
Zhou, D., Tang, Y. & Jiang, W. A modified model of failure mode and effects analysis based on generalized evidence theory. Math. Probl. Eng. 2016, 1–11 (2016).
Zhou, X. & Tang, Y. Modeling and fusing the uncertainty of fmea experts using an entropy-like measure with an application in fault evaluation of aircraft turbine rotor blades. Entropy 20, 864 (2018).
Funding
The work is supported by the National Key Research and Development Project of China (Grant No. 2020YFB1711900). There was no additional external funding received for this study.
Author information
Authors and Affiliations
Contributions
Y.L. and Y.T. designed the research and wrote the manuscript text. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, Y., Tang, Y. Managing uncertainty of expert’s assessment in FMEA with the belief divergence measure. Sci Rep 12, 6812 (2022). https://doi.org/10.1038/s41598-022-10828-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-10828-2
This article is cited by
-
Digitalization enhancement in the pharmaceutical supply network using a supply chain risk management approach
Scientific Reports (2023)
-
Failure mode and effects analysis using an improved pignistic probability transformation function and grey relational projection method
Complex & Intelligent Systems (2023)
-
Bridging the Industry–Academia Gap: An Experiential Learning for Engineering Students
Journal of Formative Design in Learning (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
