
Abstract
Purpose:
Screening multiple genes for inherited cancer predisposition expands opportunities for cancer prevention; however, reports of variants of uncertain significance (VUS) may limit clinical usefulness. We used an expert-driven approach, exploiting all available information, to evaluate multigene panels for inherited cancer predisposition in a clinical series that included multiple cancer types and complex family histories.
Methods:
For 1,462 sequential patients referred for testing by BROCA or ColoSeq multigene panels, genomic DNA was sequenced and variants were interpreted by multiple experts using International Agency for Research on Cancer guidelines and incorporating evolutionary conservation, known and predicted variant consequences, and personal and family cancer history. Diagnostic yield was evaluated for various presenting conditions and family-history profiles.
Results:
Of 1,462 patients, 12% carried damaging mutations in established cancer genes. Diagnostic yield varied by clinical presentation. Actionable results were identified for 13% of breast and colorectal cancer patients and for 4% of cancer-free subjects, based on their family histories of cancer. Incidental findings explaining cancer in neither the patient nor the family were present in 1.7% of subjects. Less than 1% of patients carried VUS in BRCA1 or BRCA2. For all genes combined, initial reports contained VUS for 10.5% of patients, which declined to 7.5% of patients after reclassification based on additional information.
Conclusions:
Individualized interpretation of gene panels is a complex medical activity. Interpretation by multiple experts in the context of personal and family histories maximizes actionable results and minimizes reports of VUS.
Genet Med 18 10, 974–981.
Similar content being viewed by others


Introduction
In the past few years, massively parallel (or “next-generation”) sequencing has enabled simultaneous capture and multiplexed sequencing of many cancer-predisposing genes, thus increasing the efficiency of testing and reducing its cost.1,2,3,4 Analysis indicates that panel testing for colorectal cancer and polyposis with current technology is very likely to be cost-effective.5 However, early approaches to simultaneous sequencing of many genes have yielded many reports of “variants of uncertain significance” (VUS),6,7,8,9,10,11,12 which again leave clinicians and patients uncertain about how to proceed.
Strategies and data sources used for variant classification in cancer panel testing have been improving rapidly. We report our experience of applying a rigorous and practical approach to classify genetic variation identified by multigene testing for cancer predisposition. We applied the guidelines of the International Agency for Research on Cancer (IARC),13 with individual scrutiny of every variant in every patient in the context of their personal and family histories. Multiple experts reviewed every case by taking into account the a priori likelihood of variant pathogenicity, features, and predicted consequences of the variant (all known functional information) and the personal and family histories of the patient.14 Expert review of each variant was first independent and then in consensus conference. We report here the application of this approach to 1,462 sequential patients with a wide variety of simple and complex clinical presentations who were tested using our multigene panels BROCA and ColoSeq.1,3
Materials and Methods
Subjects
Subjects were 1,462 sequential patients referred for testing of germline DNA with the BROCA or ColoSeq gene panels between November 2011 and June 2014. Clinicians ordered one of the two gene panels based on their judgment. Clinicians also had the option to order targeted sequencing of individual genes or subsets of genes, but this study included only patients for whom either the entire ColoSeq panel or the entire BROCA panel was ordered. Patient and family histories were requested from the providers but were not required for inclusion in this analysis. After removing identifiers, data from patients were extracted from the laboratory database. The analysis and publication plan were discussed with the University of Washington Human Subjects Division and were determined to be consistent with ongoing quality assurance and improvement activities for clinical genetic testing.
Gene capture panel design
In 2009, we developed the BROCA multigene panel for testing inherited predisposition to breast cancer and ovarian cancer in the research laboratory.1,2 In November 2011, we developed the ColoSeq panel, modeled on BROCA, for testing inherited predisposition to colon cancer and polyposis in the clinical setting.3 Beginning in July 2012, genetic testing using BROCA was offered as a clinical service in addition to its research role, with BRCA1 and BRCA2 included in clinical testing in June 2013. At the conclusion of the study, the BROCA panel included 48 genes15 and the ColoSeq panel included 20 genes.16 Levels of evidence for inclusion varied between genes and between different classes of variants within genes. For both panels, capture includes all exons, 5′ and 3′ untranslated regions, and nonrepetitive portions of introns. Including the intronic sequence enables identification of all sizes of genomic deletions and duplications and of complex genomic events. Total targeted genomic DNA is 1.1 MB.
High throughput sequencing and sequence data analysis
Sequencing, alignment, and variant identification for ColoSeq and BROCA are described in detail elsewhere.1,3 Briefly, germline genomic DNA is extracted from blood or tissue samples provided for clinical testing. DNA is fragmented, purified, and ligated to Illumina sequencing adapters (Illumina, San Diego, CA). These libraries are amplified and hybridized to a custom library of cRNA capture probes (SureSelect, Agilent Technologies, Santa Clara, CA). After washing and additional PCR amplification, equimolar portions of DNA from each patient are pooled, cluster amplified, and sequenced on a HiSeq2500 (Illumina). Variants (single nucleotide polymorphisms, insertions and deletions, and structural variants) are called against human genome reference sequence hg19 as described elsewhere (see Pritchard et al.17, Figure 1 for diagram of informatics pipeline).1,3 The accuracy of high-depth variant calls has been extensively validated and calls are confirmed using alternate methods only in specific situations when there is a question about the validity about variant calls, such as in the pseudogenized region of PMS2.3,18
Interpretation of variants
Variant interpretation was based on the IARC guidelines, which emphasize the importance of information from multiple sources to calculate probabilities of pathogenicity and estimate these probabilities if it is impossible to quantify all relevant information.13 The IARC suggests that, in interpreting estimated probability of pathogenicity (P), variants with P > 0.99 should be considered pathogenic, those with 0.95 < P < 0.99 likely pathogenic, those with 0.05 < P < 0.95 of uncertain clinical significance, those with 0.01 < P < 0.05 likely benign, and those with P < 0.01 benign.
We used all available sources of primary information on variants to inform variant classification. Estimates of probabilities of pathogenicity depend on multiple features of variant type and gene, and the definition of pathogenicity itself is arbitrary. We focused on variants that yield at least a twofold increase in lifetime cancer risk. (The exceptions to this rule are a small number of variants extensively documented to convey real increases in risk of approximately 1.5-fold, such as CHEK2 p.I157T.) Thus, for BROCA and ColoSeq genes already established as predisposing to cancer, we classified as pathogenic all newly encountered variants with effects likely to be equivalent to previously characterized pathogenic variants. This class included truncating mutations, with the exception of truncations in the same exon as, or in 3′ of, a known polymorphic stop (e.g., BRCA2 p.3326X). Pathogenic truncating mutations could be the result of frameshift or nonsense mutations or of large genomic deletions or duplications leading to stops.
Similarly, splice site variants shown experimentally to lead to truncations in cancer-predisposing genes were classified as pathogenic. Variants within 10 bp of splice junctions were evaluated using NNsplice, and exonic synonymous and nonsynonymous variants were evaluated using NNsplice and Rescue ESE. Variants predicted to have no effect on splicing were classified as benign. Variants predicted to lead to splicing errors on initial analysis combined with follow-up analysis with Spliceman, SKIPPY, or ESE finder (Supplementary Table S2 online), but without experimental evidence, were classified as being of uncertain significance. In-frame deletions, as a result of either genomic deletion or splicing alteration, that were known to occur as alternate naturally occurring transcripts were classified as benign.
For missense variants and in-frame deletions of conserved residues, we assessed probabilities of pathogenicity using the following multiple sources of information: predicted cancer predisposing effects; published genetic, epidemiologic, and biological evidence for individual alleles; in silico prediction tools SIFT, PolyPhen, and GERP; and allele frequencies from public sequence databases. We also considered variation profiles of the protein or protein domain harboring each missense and applied assessments of tolerance of functional variation that have been developed for BRCA1, BRCA2, ATM, and CHEK2 (refs. 19,20) and more generally (refs. 21,22). We postulated that the great majority of amino acid variation that already exists in the general population is neutral or close to neutral. Thus, if in a protein domain there is no evidence for a functional effect of any existing amino acid variation, the likelihood is very low that a newly encountered amino acid substitution in the same domain that disrupts protein conservation to a similar extent will have a functional effect. By contrast, if a protein domain harbors little variation in the general population, and some previously encountered variants are known to be damaging, then the likelihood that a similar newly encountered missense will have a functional effect is much higher. For example, newly encountered missense mutations in PTEN, CHEK2, and PALB2 have very different probabilities of pathogenicity. The same logic applies to different domains within the same protein. When classifying missenses, it is important to consider these profiles because, in the absence of such considerations, uncharacterized missenses may be declared VUS by default. Because an average of two rare exonic variants per individual are expected in the 1.1 MB of sequence captured for each of our patients,10,23 a very large proportion of reports could include VUS that would more accurately be considered likely benign.
Missenses with experimental evidence for loss of gene function or epidemiologic evidence for cancer predisposition were classified as likely pathogenic. Based on the approach described above, missenses predicted to be damaging by either PolyPhen or SIFT, but without functional or epidemiologic characterization, were classified as of uncertain significance if located at a highly conserved residue in a domain harboring at least one known damaging missense. By contrast, missenses consistently predicted by bioinformatics tools to be benign, or located at nonconserved sites, or located in domains or regions with considerable polymorphic variations and no known damaging mutations were classified as likely benign. For example, the BRCA1 RING domain is highly conserved, with several documented pathogenic missense changes, consistent with comprehensive functional analysis.24 However, exon 11 of BRCA1 is not highly conserved, has few pathogenic missense changes, and has more than 300 benign missense variants. The estimated likelihood that a missense variant in exon 11 of BRCA1 is pathogenic is on the order of 1 in a 100. Thus, without additional data, a novel missense in the BRCA1 RING domain is classified as VUS, but a novel missense in BRCA1 exon 11 is classified as likely benign.
Consensus review and reporting process
A review of variants was performed in two steps by experts from medical genetics, cancer genetics, and molecular pathology, each with extensive experience with a subset of the BROCA or ColoSeq genes. In the first step, each of two to four reviewers independently evaluated primary calls for all variants, flagging any that were potentially pathogenic. All reviewers had access to all variant calls and to the aligned sequence. In the second step, three to five reviewers discussed all flagged variants and developed a consensus classification for each one. Variants classified as pathogenic or likely pathogenic were reported to clinicians and patients as positive results, VUS were reported as such, and benign or likely benign variants were not reported. Positive results and VUS will be added to the ClinVar database. Variants are reviewed continuously as they appear in new patients and when database upgrades are released.
Results
Patient characteristics
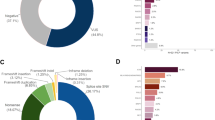
The study sample consisted of 1,462 patients; 396 underwent ColoSeq testing and 1,066 underwent BROCA testing. For more than 95% of patients, tests were ordered by medical geneticists or genetic counselors, with the remainder ordered by oncologists or primary-care physicians. At least some family-history information was available for 1,455 (99%) of patients. More than 80% of patients had a personal history of cancer or a cancer-associated lesion ( Table 1 ), with 12% of patients reporting a personal history of more than one type of cancer. A complex family cancer history—defined by multiple cancer types in proband and first-degree relatives that would not be explained by a single genetic mutation in an established cancer gene—was present in 44% of patients.
Positive results
Of the 1,462 patients, 179 (12.2%) carried a pathogenic or likely pathogenic mutation in a known cancer gene. These patients included 134 (9.2%) with a mutation in a gene predisposing to their clinical condition. The proportion of patients with positive results varied by presenting clinical indication ( Table 2 ). Of patients with a personal history of breast cancer and no previous genetic testing, 13% had a positive result. Of patients with a personal history of breast cancer and previous commercial testing of BRCA1 and BRCA2, 7% had a pathogenic or likely pathogenic mutation in CHEK2, PALB2, ATM, BRIP1, TP53, or PTEN ( Table 2 ), consistent with previous reports that a substantial portion of inherited predisposition to breast cancer is due to genes other than BRCA1 and BRCA2.1,25,26,27 Of patients with a personal history of ovarian cancer, 13% had a positive result in any one of 9 different genes. Of patients with a personal history of colorectal cancer, 13% had a positive result in any one of 10 different genes, and approximately half were in Lynch syndrome genes. Of patients with endometrial cancer, 21% (9/43) had a positive result, as did 21% (4/21) of patients with pancreatic cancer; both occurred in any one of multiple genes ( Table 2 ).
Results not apparently related to personal cancer history
In the 20 (1.4%) patients with a mutation predisposing to cancer in their family but not related to their personal history, positive results were distributed both across multiple types of cancer ( Table 1 and Supplementary Table S1 online) and across multiple genes ( Table 2 ). Of the 258 patients without personal cancer history who were tested only because of family cancer history, we identified 10 (4%) individuals with positive results related to their family cancer history. For the 25 (1.7%) patients with positive results that were incidental to both personal history and family history, positive results were also distributed across multiple genes ( Table 3 ). Several patients with incidental findings had little or no known family history. It is possible that some apparently incidental findings were in fact related to history not reported to us.
VUS
Initial reports contained VUS for 157 (10.5%) of the 1,462 patients. After reclassification based on additional information that became available during the course of the project, 109 persons (7.5%) carried VUS. These events were distributed across 15 genes ( Table 4 and Supplementary Table S1 online). VUS in colon cancer genes were more frequently missenses, whereas VUS in breast cancer genes were more frequently at splice sites. These differences reflect both gene-specific differences in biology and differences in the extent of experimental characterization. The evolving nature of VUS assignments was also reflected in our experience with follow-up review. For 45 patients, variants originally reported as VUS were later reclassified as likely benign. Seven of these were splice variants, 36 were missenses, and two were initiator codon variants. For three patients with mutations affecting splicing, VUS were reclassified as pathogenic after experimental evaluation of patient RNA (Supplementary Table S2 online). Of the 109 remaining VUS, 22 (20% of VUS and 1.5% of 1,462 patients) were unambiguously damaging mutations in any of 11 different “emerging genes” (ATR, CHEK1, FAM175A, GALNT12, GEN1, MRE11A, POLE, POLD1, RAD51B, RAD51D, and XRCC2). Reports of these mutations indicated the present status of information about these genes with respect to inherited predisposition to cancer.
Splice effects
Seventeen patients harbored variants that were predicted by in silico tools to alter splicing but that had not been characterized experimentally (Supplementary Table S2 online). For 7 of these 17 patients, we were able to obtain RNA and test splicing directly. Of these seven variants, three led to exon deletions and stops, one led to an in-frame deletion, and three led to normal splicing. These were reported as positive, VUS, and benign, respectively. Predicted splice variants with no experimental analyses were reported as VUS.
Structural variants
Fourteen patients carried structural genomic changes, identified by BROCA and ColoSeq, that led to truncation or complete gene deletion. These positive results were in nine different genes and represented 8% of all damaging mutations. Several of these alterations are unlikely to have been detected by less comprehensive sequencing approaches, as we previously reported.28
Discussion
A multi-institution consensus process is the ideal solution for definitive classification of variants, and efforts to develop consensus classification of variants in critical disease-predisposing genes are presently in progress.29,30,31 The present report represents our experience with multigene panel testing for inherited cancer risk in the clinical setting in the interim period during the development of consensus classification for all possible variants. Our results indicate that multigene testing need not be overwhelmed by reports of VUS, even in the context of panels that include genes with emerging evidence about pathogenicity and mechanisms of action.
We conducted testing for this article before the 2014 American College of Medical Genetics and Genomics (ACMG) guidelines for variant classification were published.32 We did not compare the IARC and ACMG variant-interpretation frameworks using our sample because appropriate application of either requires substantial judgment at multiple steps, and because parsing differences in guidelines from the judgment of experts applying those guidelines was outside the scope of our study. Variations in classification in previous reports of multigene panel testing indicate that differences in the application of guidelines probably contribute more to variability in reporting than to differences in the guidelines themselves.6,7,8,9,10,11,12
The proportion of our patients with positive results is similar to that in previous reports.9,10,11 However, earlier studies of clinical testing using multigene panels reported higher VUS rates (between 15 and 88% of results6,7,8,9,10,11,12), in contrast to the 7.5% in our series. Variant classification for multigene panel testing is rapidly improving, so it is not possible to directly compare methodologies. Improved reporting or duplicate testing would be needed to directly compare performances between diagnostics laboratories. No previous reports have included detailed lists of variants classified as being of “uncertain significance” or detailed data from efforts to resolve these VUS, making it impossible to evaluate the classification of specific variants or collate preliminary information regarding potentially causative mutations in emerging genes. This is a major limitation of previous studies that prevents the accurate evaluation of diagnostic panel performance and slows potential improvement in clinical diagnostics that may come from expanded genetic screening. Reporting in public databases, such as ClinVar, is important, but it does not obviate the need for more complete reporting in the scientific literature.
Some VUS that we have reported are clearly deleterious variants in emerging genes where the uncertainty is at the level of the gene, not at the level of the variant. These might be identified as a separate category because the nature of uncertainly is different. For example, in POLE, few variants have been convincingly associated with colorectal and endometrial cancer, but most types of variants in many domains have not been evaluated ( Table 4 ). For emerging genes, algorithm-based variant classification runs the risk of overcalling pathogenic variants when evidence in the scientific literature does not support altering clinical management;33,34 however, not testing runs the risk of missing findings that are clearly actionable. Careful reporting of data for rare variants in these genes is critical for optimal patient care. Given the intensity of research on genes suspected to be associated with cancer predisposition, uncertainty for many emerging genes is likely to be resolved soon.23
Risk assessment that integrates potentially complex clinical history with genetic findings is a form of medical practice. It requires expert judgment that incorporates information from multiple sources at the laboratory interpretation stage and at the patient evaluation stage. This medical judgment ideally starts with laboratory-based clinicians drafting clinical reports tailored to individual patients in consultation with ordering physicians. Automated algorithms are not an adequate substitute.8 Expert interpretation will become more efficient with the development of freely accessible and well-curated databases of consensus classifications for thousands of variants in hundreds of critical genes. Such databases will further resolve the extreme variation in VUS rates among laboratories and reduce the cost of screening. However, medical judgment by diagnostic and genetic experts will be necessary until databases classify all possible human genetic variations.
This study adds to the evidence that simultaneous testing of multiple genes is the most effective approach for identifying clinically actionable mutations predisposing to cancer in many patients.1,2,25,26,27 Pathogenic mutations were identified in multiple genes for every common cancer type. We have shown that careful application of classification methods by multiple experts can minimize the number of VUS.14 Our experience reflects rapid improvements in testing for hereditary predisposition to cancer. This experience may inform future guidelines and policy decisions about testing for cancer predisposition in the genomic era.
Disclosure
Several authors are employees of the University of Washington; these authors declare no financial stake in the genetic testing described in this manuscript because their compensation is not based on the genetic tests described. All authors not associated with the University of Washington declare no financial interest.
References
Walsh T, Lee MK, Casadei S, et al. Detection of inherited mutations for breast and ovarian cancer using genomic capture and massively parallel sequencing. Proc Natl Acad Sci USA 2010;107:12629–12633.
Walsh T, Casadei S, Lee MK, et al. Mutations in 12 genes for inherited ovarian, fallopian tube, and peritoneal carcinoma identified by massively parallel sequencing. Proc Natl Acad Sci USA 2011;108:18032–18037.
Pritchard CC, Smith C, Salipante SJ, et al. ColoSeq provides comprehensive lynch and polyposis syndrome mutational analysis using massively parallel sequencing. J Mol Diagn 2012;14:357–366.
Hall MJ, Forman AD, Pilarski R, Wiesner G, Giri VN. Gene panel testing for inherited cancer risk. J Natl Compr Canc Netw 2014;12:1339–1346.
Gallego CJ, Shirts BH, Bennette CS, et al. Next-generation sequencing panels for the diagnosis of colorectal cancer and polyposis syndromes: a cost-effectiveness analysis. J Clin Oncol 2015;33:2084–2091.
Yorczyk A, Robinson LS, Ross TS. Use of panel tests in place of single gene tests in the cancer genetics clinic. Clin Genet 2014;16:12488.
Cragun D, Radford C, Dolinsky JS, Caldwell M, Chao E, Pal T. Panel-based testing for inherited colorectal cancer: a descriptive study of clinical testing performed by a US laboratory. Clin Genet 2014;86:510–520.
Dewey FE, Grove ME, Pan C, et al. Clinical interpretation and implications of whole-genome sequencing. JAMA 2014;311:1035–1045.
Laduca H, Stuenkel AJ, Dolinsky JS, et al. Utilization of multigene panels in hereditary cancer predisposition testing: analysis of more than 2,000 patients. Genet Med 2014;24:40.
Kurian AW, Hare EE, Mills MA, et al. Clinical evaluation of a multiple-gene sequencing panel for hereditary cancer risk assessment. J Clin Oncol 2014;14:14.
Tung N, Battelli C, Allen B, et al. Frequency of mutations in individuals with breast cancer referred for BRCA1 and BRCA2 testing using next-generation sequencing with a 25-gene panel. Cancer 2014;3:29010.
Maxwell KN, Wubbenhorst B, D’Andrea K, et al. Prevalence of mutations in a panel of breast cancer susceptibility genes in BRCA1/2-negative patients with early-onset breast cancer. Genet Med 2014;11:176.
Plon SE, Eccles DM, Easton D, et al.; IARC Unclassified Genetic Variants Working Group. Sequence variant classification and reporting: recommendations for improving the interpretation of cancer susceptibility genetic test results. Hum Mutat 2008;29:1282–1291.
Shirts BH, Walsh T, Jacobson A, et al. Performance characteristics of collaborative, multiple-director sign-out for next-generation sequencing tests. J Mol Diagn 2013;15:845G08.
University of Washington. UW Laboratory Medicine Clinical Test Information. Previous Versions of BROCA—Cancer Risk Panel. http://web.labmed.washington.edu/tests/genetics/BROCA_VERSIONS. Accessed 28 January 2014.
University of Washington. UW Laboratory Medicine Clinical Test Information. Previous Versions of ColoSeq™—Lynch and Polyposis Panel. http://web.labmed.washington.edu/tests/genetics/COSEQ_VERSIONS. Accessed 28 January 2014.
Pritchard CC, Salipante SJ, Koehler K, et al. Validation and implementation of targeted capture and sequencing for the detection of actionable mutation, copy number variation, and gene rearrangement in clinical cancer specimens. J Mol Diagn 2014;16:56–67.
Baudhuin LM, Lagerstedt SA, Klee EW, Fadra N, Oglesbee D, Ferber MJ. Confirming variants in next-generation sequencing panel testing by Sanger sequencing. J Mol Diagn 2015;17:456–461.
Tavtigian SV, Byrnes GB, Goldgar DE, Thomas A. Classification of rare missense substitutions, using risk surfaces, with genetic- and molecular-epidemiology applications. Hum Mutat 2008;29:1342–1354.
Le Calvez-Kelm F, Lesueur F, Damiola F, et al.; Breast Cancer Family Registry. Rare, evolutionarily unlikely missense substitutions in CHEK2 contribute to breast cancer susceptibility: results from a breast cancer family registry case-control mutation-screening study. Breast Cancer Res 2011;13:R6.
Petrovski S, Wang Q, Heinzen EL, Allen AS, Goldstein DB. Genic intolerance to functional variation and the interpretation of personal genomes. PLoS Genet 2013;9:e1003709.
Fu W, Gittelman RM, Bamshad MJ, Akey JM. Characteristics of neutral and deleterious protein-coding variation among individuals and populations. Am J Hum Genet 2014;95:421–436.
Xue Y, Chen Y, Ayub Q, et al.; 1000 Genomes Project Consortium. Deleterious- and disease-allele prevalence in healthy individuals: insights from current predictions, mutation databases, and population-scale resequencing. Am J Hum Genet 2012;91:1022–1032.
Starita LM, Young DL, Islam M, et al. Massively parallel functional analysis of BRCA1 RING domain variants. Genetics 2015;200:413–422.
Chong HK, Wang T, Lu HM, et al. The validation and clinical implementation of BRCAplus: a comprehensive high-risk breast cancer diagnostic assay. PLoS One 2014;9:e97408.
Kuusisto KM, Bebel A, Vihinen M, Schleutker J, Sallinen SL. Screening for BRCA1, BRCA2, CHEK2, PALB2, BRIP1, RAD50, and CDH1 mutations in high-risk Finnish BRCA1/2-founder mutation-negative breast and/or ovarian cancer individuals. Breast Cancer Res 2011;13:R20.
Couch FJ, Hart SN, Sharma P, et al. Inherited mutations in 17 breast cancer susceptibility genes among a large triple-negative breast cancer cohort unselected for family history of breast cancer. J Clin Oncol 2015;33:304–311.
Shirts BH, Salipante SJ, Casadei S, et al. Deep sequencing with intronic capture enables identification of an APC exon 10 inversion in a patient with polyposis. Genet Med. 2014;27:30.
Plazzer JP, Sijmons RH, Woods MO, et al. The InSiGHT database: utilizing 100 years of insights into Lynch syndrome. Fam Cancer 2013;12:175–180.
International Agency for Research on Cancer. IARC TP53 Database. http://p53.iarc.fr/. Accessed 19 January 2015.
Landrum MJ, Lee JM, Riley GR, et al. ClinVar: public archive of relationships among sequence variation and human phenotype. Nucleic Acids Res 2014;42:D980–D985.
Richards S, Aziz N, Bale S, et al. Standards and guidelines for the interpretation of sequence variants: a joint consensus recommendation of the American College of Medical Genetics and Genomics and the Association for Molecular Pathology. Genet Med 2015;5:30.
Richards CS, Bale S, Bellissimo DB, et al.; Molecular Subcommittee of the ACMG Laboratory Quality Assurance Committee. ACMG recommendations for standards for interpretation and reporting of sequence variations: revisions 2007. Genet Med 2008;10:294–300.
Dorschner MO, Amendola LM, Turner EH, et al.; National Heart, Lung, and Blood Institute Grand Opportunity Exome Sequencing Project. Actionable, pathogenic incidental findings in 1,000 participants’ exomes. Am J Hum Genet 2013;93:631–640.
Acknowledgements
Some of the funding for this study was from internal funds of the Department of Laboratory Medicine, University of Washington, which provides the genetic tests described on a fee-for-service basis.
Author information
Authors and Affiliations
Corresponding author
Supplementary information
Supplementary Table S1
(XLS 104 kb)
Supplementary Table S2
(XLS 39 kb)
Rights and permissions
About this article

Cite this article
Shirts, B., Casadei, S., Jacobson, A. et al. Improving performance of multigene panels for genomic analysis of cancer predisposition. Genet Med 18, 974–981 (2016). https://doi.org/10.1038/gim.2015.212
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/gim.2015.212
Keywords
This article is cited by
-
A novel founder MSH2 deletion in Ethiopian Jews is mainly associated with early-onset colorectal cancer
Familial Cancer (2022)
-
Collaborative Group of the Americas on Inherited Gastrointestinal Cancer Position statement on multigene panel testing for patients with colorectal cancer and/or polyposis
Familial Cancer (2020)
-
Evaluation of a 27-gene inherited cancer panel across 630 consecutive patients referred for testing in a clinical diagnostic laboratory
Hereditary Cancer in Clinical Practice (2018)
-
A comparison of cosegregation analysis methods for the clinical setting
Familial Cancer (2018)
-
Screening of over 1000 Indian patients with breast and/or ovarian cancer with a multi-gene panel: prevalence of BRCA1/2 and non-BRCA mutations
Breast Cancer Research and Treatment (2018)
