
Abstract
Efficient and rapid auxiliary diagnosis of different grades of lung adenocarcinoma is conducive to helping doctors accelerate individualized diagnosis and treatment processes, thus improving patient prognosis. Currently, there is often a problem of large intra-class differences and small inter-class differences between pathological images of lung adenocarcinoma tissues under different grades. If attention mechanisms such as Coordinate Attention (CA) are directly used for lung adenocarcinoma grading tasks, it is prone to excessive compression of feature information and overlooking the issue of information dependency within the same dimension. Therefore, we propose a Dimension Information Embedding Attention Network (DIEANet) for the task of lung adenocarcinoma grading. Specifically, we combine different pooling methods to automatically select local regions of key growth patterns such as lung adenocarcinoma cells, enhancing the model's focus on local information. Additionally, we employ an interactive fusion approach to concentrate feature information within the same dimension and across dimensions, thereby improving model performance. Extensive experiments have shown that under the condition of maintaining equal computational expenses, the accuracy of DIEANet with ResNet34 as the backbone reaches 88.19%, with an AUC of 96.61%, MCC of 81.71%, and Kappa of 81.16%. Compared to seven other attention mechanisms, it achieves state-of-the-art objective metrics. Additionally, it aligns more closely with the visual attention of pathology experts under subjective visual assessment.
Similar content being viewed by others

Introduction
The grading of invasive pulmonary adenocarcinoma (hereinafter referred to as lung adenocarcinoma) can guide physicians in developing treatment plans and patient prognosis1,2,3,4. The specific criteria of the grading system for invasive lung adenocarcinoma, as described in the latest publication of the 2021 edition of the WHO classification of chest tumors, are shown in Table 15. This criterion was proposed by the pathology committee of the International Association for Study of Lung Cancer (IASLC)6 and was also adopted by the Chinese Medical Association. As pathological images become increasingly important and abundant, pathologists face growing pressure in diagnosis. The demand for computer-aided diagnostic models in the medical system continues to rise. Therefore, the use of computer-assisted diagnostic models to assist pathologists in diagnosing lung adenocarcinoma grades that have small interclass and large intraclass differences has an important application value.
However, research on lung adenocarcinoma tissue pathological images7,8,9 primarily focuses on intelligent classification of pathological types, while overlooking the study of pathological grading tasks, which to some extent hinders the formulation of personalized treatment plans for physicians. Currently, there is often a problem of large intra-class differences and small inter-class differences between pathological images of lung adenocarcinoma tissues under different grades. If attention mechanisms such as Coordinate Attention (CA)10 are directly used for lung adenocarcinoma grading tasks, two issues may arise: CA only extracts global features through average pooling, thus risking excessive compression of feature information, affecting the model's ability to compare local features of lung adenocarcinoma; CA processes too few operations within the same dimension, lacking the process of embedding interactions within the same dimension, thus affecting the model's perception of global information in lung adenocarcinoma tissue pathological images. Therefore, to address the challenge of difficulty in grading lung adenocarcinoma, we propose Dimension Information Embedding Attention Net (DIEANet), which enables the model to focus on the local growth morphology of individual cells while also considering the overall growth pattern of cell clusters. Specifically, our contributions are as follows:
-
(1)
We integrate different pooling techniques to automatically select local regions representing key growth patterns of lung adenocarcinoma cells, enhancing the model's attention to local information.
-
(2)
We employ an interactive fusion approach to focus on feature information within the same dimension and across dimensions, improving the model's capacity to incorporate dimension information and extract remote dependency relationships. This enables the model to better consider the overall growth patterns of cell clusters.
-
(3)
In terms of objective metrics, DIEANet achieved an accuracy of 88.19%, an AUC of 96.61%, an MCC of 81.71%, and a Kappa of 81.16%. Compared to other 7 attention mechanisms, DIEANet achieved state-of-the-art objective metrics, and it aligns better with the visual attention of pathologists under subjective observation.
The following sections are structured as follows: In Section “Related work”, we delve into the evolution of deep learning techniques for lung cancer diagnosis in recent years, and the application and development of Coordinate Attention (CA). Section “Methods” describes the structure of DIEANet in detail. Section “Experiments” shows the lung adenocarcinoma dataset and experimental setup, including comparison experiments and ablation experiments. Section “Summary and outlook” makes some summary and outlook.
Related work
Currently, research in computer-aided diagnosis of lung cancer mainly focuses on the classification tasks of subtypes such as adenocarcinoma (LUAD), squamous carcinoma (LUSC), and large cell carcinoma. In 2017, Teramoto et al.11 correctly classified 71% of cytological pictures of lung cancer into the three lung cancer subtypes LUAD, LUSC, and small cell carcinoma using triple cross-validation to train Deep Convolution Neural Network (DCNN). In 2018, Coudray et al.12 and Khosravi et al.13 both published a paper on deep learning-based classification for LUAD and LUSC, where the former demonstrated that deep learning can effectively help pathologists detect lung cancer subtypes and even genetic mutations, and the latter investigated the effect of fine-tuning pre-trained CNN models on classification. In 2020, Moitra et al.14 used a one-dimensional CNN model to study the staging and grading of non-small cell carcinoma (NSCLC) based on CT images and clinical data, and they achieved good results but did not collect important histopathological images. In addition to improving model performance, in 2022, Civit-Masot et al.9 turned their attention to the interpretability aspect, and the proposed system can output the diagnostic results, as well as the image regions focused by the model, which can be used to provide more supporting information to physicians. This inspires us to enhance the model's focusing ability on the most densely populated regions of cancer cells with the highest malignancy level through attention mechanisms.
The aforementioned studies only consider the task of classifying different types of lung cancer, but overlook the significance of different grading of lung adenocarcinoma for personalized treatment and prognosis management. Identifying different grades of lung adenocarcinoma requires models to discern the growth patterns of cells more intricately, focusing on both the local growth morphology of individual cells and the overall growth pattern of cell clusters. We found that Coordinate Attention (CA) proposed by Hou et al.10 not only captures inter-channel information but also includes directional and dimensional information, which can enhance the network's vision and performance. This aligns with our approach; hence, we have organized and summarized CA as well as its applications and developments in recent years, as shown in Table 2.
Different from the above studies, we are concerned with the problems of severely compressed information and insufficient calculation of information relevance within the same dimension in CA. These problems somewhat reduce the degree of dimensional information embedding, and cannot be well solved by the problem of large intra-class differences and small inter-class differences that exist in lung adenocarcinoma histopathology images. Therefore, this paper proposes the DIEANet structure for lung adenocarcinoma grading, starting from two aspects: extracting more effective feature information and embedding dimensional information more comprehensively. In the following, we will provide a detailed description of DIEANet.
Methods
Overview
The complete structure of DIEANet is illustrated in Fig. 1, which can be divided into three stages. The first stage is the data preprocessing stage, including color normalization and random cropping of histopathological images, which will be detailed in Section “Preprocessing”. The second stage is the feature extraction stage, where ResNet34 is utilized for feature extraction. The specific code uses the ResNet34 code provided by the torchvision library in the Pytorch platform. The third stage is the attention evaluation stage, consisting of Dimension Information Embedding Attention (DIEA), a classifier, and Grad_Cam, which will be elaborated on in Section “Dimension information embedding attention (DIEA)”. This stage validates the performance of DIEANet through both quantitative metrics and visualization.

Dimension Information Embedding Attention Net (DIEANet).
Dimension information embedding attention (DIEA)
To boost the model's efficacy and elevate focus on lesion sites, we propose the DIEA structure. Within DIEA, it specifically includes operations such as feature compression decomposition, feature fusion embedding processing, and restored feature map operations. The detailed structural diagram is shown in Fig. 2.

Dimension information embedding attention (DIEA).
Feature compression decomposition stage
First, the formula for the feature compression decomposition operation is expressed as follows:
where \({\mathbf{x}}\) denotes the input features, \(h\) and \(w\) the indexes of feature map height and width, respectively. \(a_{c}^{h} (h)\), \(a_{c}^{w} (w)\) denote the features obtained by strip average pooling in horizontal and vertical dimension, respectively. \(m_{c}^{h} (h)\), \(m_{c}^{w} (w)\) denote the features obtained by strip max pooling in horizontal and vertical dimension, respectively. After that, the four 1D feature tensors are combined two by two according to the pooling method to obtain two 1D feature description tensors of length \((H + W)\):
where \(T\) denotes the transpose operation and [*,*] denotes the splicing operation. In this stage, \({\mathbf{a}}\) containing the remote dependencies of features, \({\mathbf{m}}\) highlighting the features of the key growth morphology of cancer cells, and the combination of the two can provide more effective feature information for the feature embedding operation later in the model. The experimental results in Section “Experimental results and comparison experiments” demonstrate this point.
Feature fusion embedding processing
In the second stage, in order to better fuse the features with each other, we stitch \({\mathbf{a}},{\mathbf{m}}\) together to form a one-dimensional feature description tensor of length \((2H + 2W)\), which is separated after nonlinear processing. The process is represented as follows:
\(F_{1} (),F_{2} (),F_{3} ()\) denotes the \(1 \times 1\) convolution kernel, \(BN()\) denotes Batch-Normalization, and \(\delta ()\) denotes the h_swish activation function. H_swish is proposed by MobileNetV319 and is a combination of ReLU and linear functions. The convolution operation of \(F_{1} ()\) uses the squeeze operation of the SE block to perform channel dimensionality reduction using the \(1 \times 1\) convolution kernel, and the resulting tensor is \({\mathbf{h}} \in {\mathbb{R}}^{C//r \times (2H + 2W) \times 1}\). \({\mathbf{h}}^{a} \in {\mathbb{R}}^{C \times (H + W) \times 1} ,{\mathbf{h}}^{m} \in {\mathbb{R}}^{C \times 1 \times (H + W)}\) denote two one-dimensional feature description tensor of length \((H + W)\).
Recovery feature map processing
In the third stage, in order to recover the feature map, we multiply \({\mathbf{h}}^{a}\) and \({\mathbf{h}}^{m}\) to obtain the feature map \({\mathbf{h}}^{am} \in {\mathbb{R}}^{C \times (H + W) \times (H + W)}\) containing dimensional embedding information, and this part of the operation is expressed as:
where \({\mathbf{h}}^{a}\) and \({\mathbf{h}}^{m}\) contain the transformed features \(\left[ {{\mathbf{a}}^{h} ,({\mathbf{a}}^{w} )^{T} } \right]\) and \(\left[ {({\mathbf{m}}^{h} )^{T} ,{\mathbf{m}}^{w} } \right]\), respectively, and after multiplying them, the feature map \({\mathbf{h}}^{am}\) will contain four kinds of information, i.e., \(({\mathbf{a}}^{h} \times ({\mathbf{m}}^{h} )^{T} )\), \(({\mathbf{a}}^{h} \times {\mathbf{m}}^{w} )\), \((({\mathbf{a}}^{w} )^{T} \times ({\mathbf{m}}^{h} )^{T} )\), and \((({\mathbf{a}}^{w} )^{T} \times {\mathbf{m}}^{w} )\). In contrast, CA generates only one kind of information \(({\mathbf{a}}^{h} \times {\mathbf{a}}^{w} )\) when recovering the feature map, and although it achieves the inter-embedding of features in both horizontal and vertical dimensions, it ignores the inter-embedding of features within the same dimension, such as between horizontal and horizontal and between vertical and vertical. To better distinguish between DIEA and CA, the structure of CA is shown in Fig. 3.

Coordinate attention (CA).
Finally, \({\mathbf{h}}^{am}\) is downsampled and embedded in the input feature \({\mathbf{x}}\). The equation is expressed as follows:
where \(F \downarrow ()\) denotes a convolutional kernel with kernel size of 3 × 3, stride of 2, and padding of 1. \(\sigma\) represents the sigmoid, and \({\mathbf{g}} \in {\mathbb{R}}^{C \times H \times W}\) is the same size as the input feature \({\mathbf{x}}\). \({\mathbf{y}}\) is the final attention-enhanced feature map.
Ethics approval
This study was approved by the Medical Ethics Committee of the Key Laboratory of Kelamayi Central Hospital on February 10th, 2023.The the ethics approval number is "K202302-29". The informed consent was obtained from the subjects.
Experiments
Dataset
We utilized two datasets to assess the model's performance. A private dataset was employed for a thorough examination within the paper's core application domain, while a publicly accessible dataset was utilized to validate the model's effectiveness and its capacity for generalization.
Dataset for lung adenocarcinoma histopathological image grading: This dataset was provided by the Karamay Central Hospital of Xinjiang and approved by the Medical Ethics Committee of the Key Laboratory of Kelamayi Central Hospital, and contains three labels of low-grade, intermediate-grade, and high-grade lung adenocarcinoma. All experiments adhered to pertinent guidelines and regulations. All cases were diagnosed between November 2016 and August 2019, and were confirmed by histopathological examination and informed consent was obtained from the participants. The dataset contains a total of 107 cases, including 30 cases of low grade, 38 cases of intermediate grade, and 39 cases of high grade. The dataset was all stained by hematoxylin–eosin staining (HE staining), and the grading labels of the images were retrieved from the hospital's data system. Since cancer cells coexist in multiple growth patterns in lung adenocarcinoma, for example, there may be a small number of low grade growth patterns in intermediate grade lung adenocarcinoma, we asked two experienced pathologists from the Karamay Central Hospital to draw a finer representative lesion area with the highest and most intensive malignancy for each case as a way to obtain more accurate images of the lesions. The digital slice scanning system PRECICE 500b was then used to scan within the range marked by the physicians. Depending on the size of the lesion area marked by the physicians in the section, we scanned 2–10 random images in jpg format from each case, each with a size of 1665 × 1393 px. A total of 893 images were obtained, including 260 low grade, 316 intermediate grade, and 317 high grade images.
PCam20020: This dataset is derived from the Camelyon2016 challenge dataset21 by sliding window extraction, used to train models to detect the presence of lymph node metastasis. Tumor patches and normal patches are respectively cropped from annotated regions of tumor slides and tissue regions of normal slides. Subsequently, the cropped patch sizes are adjusted to 512 × 512 pixels using bicubic interpolation. After balancing the number of tumor and normal samples, a total of 56,703 images are randomly split into training, validation, and testing sets, where patches from the same slide are placed in the same set (slide-level splitting). Detailed information about the dataset is shown in Table 3.
Preprocessing
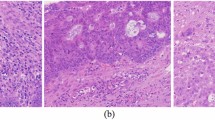
We observed excessive color differences between the HE-stained histopathology images and therefore used the currently more popular Vahadane22 method for stain normalization of the dataset, the results of which are shown in Fig. 4.

Stain normalization effect. The top row is the original image, the bottom row is the image after Vahadane processing.
We referenced common processing methods for histopathological image datasets as well as the training approach of cross-validation23,24. Initially, at the case level, we utilized five-fold cross-validation to partition the dataset into five folds. Then, we extracted 3 images per normalized image through random cropping, ensuring that all images from the same case are used only for training or validation. Besides, in order to ensure experimental rigor, we removed the images with blank parts accounting for more than 75% of the overall. The final number of images in each category is shown in Table 4.
Experimental setup details
The experiments were taken with Python version 3.7.13, torch version 1.10.2 + cu102, and GPU V100-PCIE-16 GB. The batch size of the experiment is set to 16, the input image size is set to 256 × 256 px, the optimizer adopts AdamW, the learning rate is 1e-4, while the weight decay is set to 1e−2. The learning rate adjustment strategy is set to use linear learning rate warm-up at the first epoch, and cosine annealing strategy is used for 1–200 epoch to gradually reduce the learning rate to 0 according to cosine function. Cross Entropy Loss, which is commonly used in classification model, is used for training to converge the model.
For the lung adenocarcinoma grading dataset, we employed stratified five-fold cross-validation during model training, with each fold trained for 200 epochs. At the case level, we randomly divided patients into five folds, and when reading images, we determined their belonging to each fold based on their pathological identification number. This approach ensures both balanced data in training and validation sets and independence between them, thereby ensuring the authenticity of the experimental results.
For the PCam200 dataset, we train 200 epochs according to the training, validation, and test sets that have been divided by the authors.
Experimental results and comparison experiments
We selected three backbone frequently used in cancer pathology image classification tasks to validate the performance of DIEA, namely ResNet3425,26,27, MobileNetV228,29, and EfficientNet30,31. The pre-trained weights obtained from ImageNet training provided in torchvision.models were used in all training.
To measure the performance of the model in multiple aspects, a total of nine metrics were used to evaluate the model performance in two aspects. First, in terms of computational complexity, Number of Parameters (Params) and Giga Floating Point Operations per Second (GFLOPs) are used. These two metrics are used to measure the computational resource requirements and computational efficiency of the model. In this paper, both Params and GFLOPs are computed with the input image size of 256 × 256 px. Second, for the performance metrics, we used Accuracy (ACC), F1-Score (F1), Precision (PRE), Recall, Area Under Curve (AUC), Matthew's Correlation Coefficient (MCC), Cohen's Kappa score (Kappa) which are seven metrics32,33. These metrics are used to assess the performance and prediction quality of the model. ACC measures the overall prediction accuracy of the model, F1 combines PRE and Recall, while PRE and Recall measure the positive case prediction accuracy and positive case prediction ability of the model, respectively. Furthermore, given that the model's task involves three-class classification, we considered two averaging methods to comprehensively showcase the model's performance. "_m" in the table indicates macro-average, where all classes are equally weighted without considering sample distribution. "_w" denotes weighted-average, providing a more accurate reflection of overall classification performance. AUC measures the performance of the classification model, and MCC and Kappa score are used to assess the prediction quality and consistency of the classification model. The experimental results display the averages and standard deviations of five-fold cross-validation.
With ResNet34 as the backbone, the comparison results of DIEANet with SimAM34, BAM35, Criss-Cross Attention (CCA) in CCNet36, CBAM37, CA, EMA38, ACmix18 which are seven types of attention, are shown in Table 5.
According to Table 5, our model achieved the highest values in 8 out of 10 objective metrics, with the remaining two ranking second, and the standard deviations generally being low. Particularly noteworthy is the five-fold average accuracy for lung adenocarcinoma grading, which reached 88.19% ± 0.0426, demonstrating outstanding performance along with good generalization and robustness.
We show the gradient-weighted class activation map generated by different attentions in Fig. 5 to analyze the spatial localization ability of DIEANet.

Gradient-weighted class activation map for each model when ResNet34 is the backbone.
As shown in Fig. 5, DIEANet focuses on a more comprehensive and accurate region, which obviously can better identify global information while paying attention to location information compared to other attention, and can assist pathologist to better locate the region of interest.
We then compared with other attentions again using MobileNetV2 and EfficientNet as backbone, respectively.
According to Table 6, when using MobileNetV2 as the backbone, DIEANet achieved the highest values in all 10 performance metrics, with low standard deviations across the board. The five-fold average accuracy for lung adenocarcinoma grading reached 87.22% ± 0.0444, demonstrating outstanding performance. Similarly, as indicated in Table 7, when employing EfficientNet as the backbone, DIEANet attained the highest values in 9 out of 10 performance metrics, with generally low standard deviations. The five-fold average accuracy for lung adenocarcinoma grading reached 87.70% ± 0.0446, also showcasing remarkable performance.
In PCam200, we compared the performance of DIEANet with seven other attention mechanisms using ResNet34 as the backbone. The results on the test set are presented in Table 8.
Based on Table 8, it is evident that our model achieved the highest values in six out of seven metrics, with accuracy reaching 93.57% and recall reaching 90.91%. The significantly higher recall value compared to other models is crucial for reducing false negatives in medical diagnosis. These results further confirm the suitability of DIEANet for processing histopathological images.
Ablation experiments
We conducted ablation experiments using alone strip average pooling or only strip max pooling to extract features to validate the efficiency of combining strip average pooling with strip max pooling to extract features. The experimental results revealed that fusing the two pooling can facilitate the model to extract more effective feature information, which is advantageous to enhance the network's performance. The experimental results are presented in Tables 9 and 10.
Summary and outlook
In this study, we proposed the Dimension Information Embedding Attention Net (DIEANet) for the task of lung adenocarcinoma histopathological image grading, building upon the improvement of Coordinate Attention (CA). Specifically, DIEANet combines different pooling techniques to automatically select local regions of critical growth patterns such as lung adenocarcinoma cells, enhancing the model's focus on local information. Furthermore, it adopts interactive fusion methods to concentrate on feature information within the same dimension and across dimensions, improving the model's capacity to embed dimensional information and thus improve its perception of global features. Ultimately, extensive experiments demonstrate that, objectively, DIEANet achieves state-of-the-art performance in the grading task of lung adenocarcinoma. Subjectively, it also aligns better with the visual attention of pathology experts. In the future, we will collect pathological images of lung adenocarcinoma tissues from different research institutions to expand our dataset. In addition, considering the significant cost of annotating medical images, we plan to introduce weakly supervised techniques. By learning features from publicly available lung adenocarcinoma pathological images without graded labels, we aim to further enlarge the dataset and enhance model performance.
Data availability
The datasets generated and analyzed during the current study are not publicly available due to data privacy laws, but are available from the corresponding author on reasonable request.
References
Helpap, B. et al. The significance of accurate determination of gleason score for therapeutic options and prognosis of prostate cancer. Pathol. Oncol. Res. 22, 349–356 (2016).
Rabe, K. et al. Interobserver variability in breast carcinoma grading results in prognostic stage differences. Hum. Pathol. 94, 51–57 (2019).
Travis, W. D., Brambilla, E., Burke, A. P., Marx, A. & Nicholson, A. G. Introduction to the 2015 world health organization classification of tumors of the lung, pleura, thymus, and heart. J. Thorac. Oncol. 10, 1240–1242 (2015).
Tsao, M.-S. et al. Subtype classification of lung adenocarcinoma predicts benefit from adjuvant chemotherapy in patients undergoing complete resection. J. Clin. Oncol. 33, 3439–3446 (2015).
Nicholson, A. G. et al. The 2021 WHO classification of lung tumors: impact of advances since 2015. J. Thorac. Oncol. 17, 362–387 (2022).
Moreira, A. L. et al. A grading system for invasive pulmonary adenocarcinoma: A proposal from the international association for the study of lung cancer pathology committee. J. Thorac. Oncol. 15, 1599–1610 (2020).
Xu, R. et al. Histopathological tissue segmentation of lung cancer with bilinear CNN and soft attention. BioMed. Res. Int. 2022, 1–10 (2022).
Radhakrishnan, J. K., Aravind, K. S., Nambiar, P. R. & Sampath, N. Detection of non-small cell lung cancer using histopathological images by the approach of deep learning. in 2022 2nd International Conference on Intelligent Technologies (CONIT) 1–11 (IEEE, 2022). https://doi.org/10.1109/CONIT55038.2022.9847945.
Civit-Masot, J. et al. Non-small cell lung cancer diagnosis aid with histopathological images using explainable deep learning techniques. Comput. Methods Prog. Biomed. 226, 107108 (2022).
Hou, Q., Zhou, D. & Feng, J. Coordinate Attention for Efficient Mobile Network Design. in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 13708–13717 (IEEE, 2021). https://doi.org/10.1109/CVPR46437.2021.01350.
Teramoto, A., Tsukamoto, T., Kiriyama, Y. & Fujita, H. Automated classification of lung cancer types from cytological images using deep convolutional neural networks. BioMed Res. Int. 2017, e4067832 (2017).
Coudray, N. et al. Classification and mutation prediction from non–small cell lung cancer histopathology images using deep learning. Nat. Med. 24, 1559–1567 (2018).
Khosravi, P., Kazemi, E., Imielinski, M., Elemento, O. & Hajirasouliha, I. Deep convolutional neural networks enable discrimination of heterogeneous digital pathology images. EBioMedicine 27, 317–328 (2018).
Moitra, D. & Mandal, R. Classification of non-small cell lung cancer using one-dimensional convolutional neural network. Expert Syst. Appl. 159, 113564 (2020).
Ming, Q., Miao, L., Zhou, Z., Song, J. & Yang, X. Sparse label assignment for oriented object detection in aerial images. Remote Sens. 13, 2664 (2021).
Yang, L., Zhang, F., Wang, P.S.-P., Li, X. & Meng, Z. Multi-scale spatial-spectral fusion based on multi-input fusion calculation and coordinate attention for hyperspectral image classification. Pattern Recogn. 122, 108348 (2022).
Zhou, Z., Zhu, X. & Cao, Q. AAGDN: Attention-augmented grasp detection network based on coordinate attention and effective feature fusion method. IEEE Robot. Autom. Lett. 8, 3462–3469 (2023).
Ouyang, D. et al. Efficient multi-scale attention module with cross-spatial learning. in ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5 (IEEE, 2023). https://doi.org/10.1109/ICASSP49357.2023.10096516.
Howard, A. et al. Searching for MobileNetV3, 1314–1324 (2019).
Kawai, M., Ota, N. & Yamaoka, S. Large-scale pretraining on pathological images for fine-tuning of small pathological benchmarks. In Medical Image Learning with Limited and Noisy Data Vol. 14307 (eds Xue, Z. et al.) 257–267 (Springer, 2023).
Ehteshami Bejnordi, B. et al. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer. JAMA 318, 2199 (2017).
Vahadane, A. et al. Structure-preserving color normalization and sparse stain separation for histological images. IEEE Trans. Med. Imaging 35, 1962–1971 (2016).
Aatresh, A. A., Alabhya, K., Lal, S., Kini, J. & Saxena, P. P. LiverNet: Efficient and robust deep learning model for automatic diagnosis of sub-types of liver hepatocellular carcinoma cancer from H&E stained liver histopathology images. Int. J. CARS 16, 1549–1563 (2021).
Kumar, A., Vishwakarma, A. & Bajaj, V. CRCCN-Net: Automated framework for classification of colorectal tissue using histopathological images. Biomed. Signal Process. Control 79, 104172 (2023).
He, K., Zhang, X., Ren, S. & Sun, J. Deep Residual Learning for Image Recognition, 770–778 (2016).
Wetstein, S. C. et al. Deep learning-based breast cancer grading and survival analysis on whole-slide histopathology images. Sci. Rep. 12, 15102 (2022).
Ding, H. et al. Deep learning-based classification and spatial prognosis risk score on whole-slide images of lung adenocarcinoma. Histopathology (2023).
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. & Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4510–4520 (IEEE, 2018). https://doi.org/10.1109/CVPR.2018.00474.
Voon, W. et al. Performance analysis of seven convolutional neural networks (CNNs) with transfer learning for invasive ductal carcinoma (IDC) grading in breast histopathological images. Sci. Rep. 12, 19200 (2022).
Tan, M. & Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. in Proceedings of the 36th International Conference on Machine Learning, 6105–6114 (PMLR, 2019).
Nishio, M., Matsuo, H., Kurata, Y., Sugiyama, O. & Fujimoto, K. Label distribution learning for automatic cancer grading of histopathological images of prostate cancer. Cancers 15, 1535 (2023).
Nassif, A. B., Talib, M. A., Nasir, Q., Afadar, Y. & Elgendy, O. Breast cancer detection using artificial intelligence techniques: A systematic literature review. Artif. Intell. Med. 127, 102276 (2022).
Ladbury, C. et al. Integration of artificial intelligence in lung cancer: Rise of the machine. Cell Rep. Med. 4, 100933 (2023).
Yang, L., Zhang, R.-Y., Li, L. & Xie, X. SimAM: A simple, parameter-free attention module for convolutional neural networks. in Proceedings of the 38th International Conference on Machine Learning, 11863–11874 (PMLR, 2021).
Park, J., Woo, S., Lee, J.-Y. & Kweon, I. S. BAM: Bottleneck attention module. https://doi.org/10.48550/arXiv.1807.06514 (2018).
Huang, Z. et al. CCNet: Criss-cross Attention for Semantic Segmentation, 603–612 (2019).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S. CBAM: Convolutional Block Attention Module, 3–19 (2018).
Pan, X. et al. On the integration of self-attention and convolution. in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 805–815 (IEEE, 2022). https://doi.org/10.1109/CVPR52688.2022.00089.
Acknowledgements
This work was supported in part by grants from Tianshan Talent-Young Science and Technology Talent Project (NO.2022TSYCCX0060) and Natural Science Foundation of Xinjiang Uygur Autonomous Region for general program (Grant No.: 2021D01A24 to Yuhua Ma.) and for prefecture lever projects (Grant No.: 2021D01F35 to Jing Gao).
Author information
Authors and Affiliations
Contributions
Zexin Wang is the experimental designer and executor of this research, completing data analysis and writing the first draft of the paper; Jing Gao, Min Li guides data organization, experimental analysis and assists in thesis writing and revision; Enguang Zuo, Chen Chen, Cheng Chen, Fei Liang participate in the experimental design and analysis of experimental results; Xiaoyi Lv for review and supervision; Yuhua Ma guides the data collection and data analysis. All authors read and agreed to the final text.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, Z., Gao, J., Li, M. et al. DIEANet: an attention model for histopathological image grading of lung adenocarcinoma based on dimensional information embedding. Sci Rep 14, 6209 (2024). https://doi.org/10.1038/s41598-024-56355-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-56355-0
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
