
Abstract
Standard enzyme-linked immunosorbent assays based on microplates are frequently utilized for various molecular sensing, disease screening, and nanomedicine applications. Comparing this multi-well plate batched analysis to non-batched or non-standard testing, the diagnosis expenses per patient are drastically reduced. However, the requirement for rather big and pricey readout instruments prevents their application in environments with limited resources, especially in the field. In this work, a handheld cellphone-based colorimetric microplate reader for quick, credible, and novel analysis of digital images of human cancer cell lines at a reasonable price was developed. Using our in-house-developed app, images of the plates are captured and sent to our servers, where they are processed using a machine learning algorithm to produce diagnostic results. Using FDA-approved human epididymis protein of ovary IgG (HE4), prostate cancer cell line (PC3), and bladder cancer cell line (5637) ELISA tests, we successfully examined this mobile platform. The accuracies for the HE4, PC3, and 5637 tests were 93%, 97.5%, and 97.2%, respectively. By contrasting the findings with the measurements made using optical absorption EPOCH microplate readers and optical absorption Tecan microplate readers, this approach was found to be accurate and effective. As a result, digital image colorimetry on smart devices offered a practical, user-friendly, affordable, precise, and effective method for quickly identifying human cancer cell lines. Thus, healthcare providers might use this portable device to carry out high-throughput illness screening, epidemiological investigations or monitor vaccination campaigns.
Similar content being viewed by others
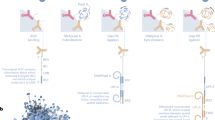


Introduction
The first rapid detection method, point of care (POC), was based on lateral flow assays (LFA) for pregnancy tests back in the 1970s1,2. LFAs rely on the color change caused by the reaction between the target biomolecule and its biomarker using labels such as gold nanoparticles, fluorescence particles, etc.3. The color change created in LFAs is visible to the naked eye. However, LFAs have disadvantages, including low accuracy, the need for large volumes of biomolecules and biomarkers to receive the faintest eye-detectable signal, qualitative responses instead of quantitative or quasi-quantitative outputs, and the inaccuracy of naked-eye detection, or in other words, the fallacy of interpretative subjectivity4,5,6.
The aforementioned method, limited to single-use, is expensive and has a tedious procedure6. To resolve the challenges associated with the LFAs, an enzyme-linked immunosorbent assay (ELISA) was proposed. This method of diagnosis can detect multiple samples simultaneously via all 96 plates, making laboratory diagnosis swifter and less expensive. In addition, it uses a color-changing mechanism based on enzymatic reactions that reduces the volume of biomarkers required for the minimum detectable signal7.
The application of the optical absorption mechanism in ELISA readers dramatically increases the detection accuracy compared to the LFA1,6,8,9. Despite the numerous diagnostic advantages of ELISA, the ELISA reader’s reliance on large light absorption equipment as well as its non-portability present drawbacks which limits availability of ELISA-based diagnostics in well-equipped modern laboratories. As the gold standard in various tests, the FDA-approved 96-well plates’ structure cannot be altered in order to enhance their performance. Replacing the optical absorption system with alternative mechanisms, such as a digital ELISA system with smaller device’s dimensions and highly accurate detection at the femtomolar scale, or amplification of the color change signal through the surface plasmon enhancement effect, offers a solution to reduce the size of the ELISA while improving accuracy10,11. Recently, several POC ELISA methods have been created based on microfluidic platforms or paper-based devices to increase accessibility in resource-constrained or rural places12,13,14,15,16,17,18. One of the most advanced innovations involves the integration of a microfluidic ELISA platform with a smartphone dongle capable of performing multiple functions, including pumping and imaging of a sandwich ELISA’s silver precipitation readout19. Widely used in clinical labs, various multi-well plate ELISA test implementations have already received FDA approval, which reduces the cost of future regulatory requirements for modifications. The conventional ELISA reading methods use expensive and bulky scanning-based spectrophotometry and requires a stable power supply to scan each individual well, severely restricting its use in resource-constrained or remote locations. Additionally, image processing techniques, utilizing digital cameras or scanners, provide an alternative method to measure color and read the concentration of all 96 ELISA plate wells, analyzing them in one image. Alternatively, other imaging-based detection techniques involve scanners20 or charge-coupled device (CCD) cameras21,22,23 to take one picture of the 96-wells. The challenge of miniaturization of these rapid optical imaging methods into a self-contained, reliable hand-held unit with minimal optical aberrations arises from the necessitation of large fields of view (FOV) images covering the full extent of the plate’s surface (127 \(\times\) 85 mm2) simultaneously. The ideal POC well plate reader platform would feature a smart user-friendly interface, real-time on-site image processing, wireless connectivity, instant reporting and sharing, spatiotemporal labeling and archiving, and the incorporation of visualization of diagnostic outcomes for applications such as telemedicine and POC screening. While the aforementioned imaging devices increase the dimensions of the devices which fail to relate to their portability, smartphones equipped with cameras and processors have revolutionized image processing capabilities and spawned a new generation of diagnostic systems, offer portability, affordability, real-time image processing, processing and interpretation of the images, and increased accessibility and availability of diagnostic amenities. With the integration of cameras into smartphones, professionals in the healthcare industry can conveniently take images for diagnostic goals, eliminating the requirement of specialized equipment, thereby reducing the overall expenses. This portability also enables telemedicine applications by allowing professionals to remotely diagnose patients based on the captured images, providing immediate feedback, and providing swift choices.
Recent developments in wireless communication technology and consumer electronics have sparked a revolution in biomedical imaging, sensing, and diagnostics3,24,25. Mobile cellphone-based devices have evolved into microscopy and sensing platforms for various applications3,24,25,26,27,28,29,30,31,32,33,34, including blood analysis35,36,37,38, bacterium identification39,40,41, single-virus imaging42,43, DNA imaging and sizing44,45, chemical sensing46,47,48,49, and biomarker detection18,33,34,50,51. These methods use the mobile internet platform to transfer and share data, analyze results, etc. These features provide an attractive context for introducing ELISA readers which are based on image processing on the mobile platform52,53,54,55,56.
Herein, we demonstrate a cost-effective and portable ELISA reader for microtiter plate (MTP) reading. This ELISA reader is based on colorimetry using images captured by a smartphone and then processed on a server. At the same time, similar tests were performed using an FDA-certified calibrated ELISA reader, Optical absorption EPOCH microplate readers and Optical absorption TECAN microplate readers for comparison.
Results and discussions
In order to develop a portable and miniaturized version of an Enzyme-linked Immunosorbent Assay (ELISA) for applications in telemedicine, underdeveloped areas, and rapid clinical test evaluation, we constructed a 3D printed device. By utilizing a smartphone and the custom-built opto-mechanical platform mentioned earlier, we captured images of a typical 96-well plate while testing PC3, 5637, and HE4 cell-lines. These findings demonstrated that our portable and cost-effective device can deliver performance on par with a traditional FDA-approved ELISA reader, providing users with precise diagnostic outcomes within minutes. Our system exhibited comparable findings for various illnesses typically assessed using conventional ELISA methods. Our study utilizes a learning-based model to correlate cancer cell lines' concentration with R, G, and B parameters. The Lab-on-a-phone device we developed offers advantages such as high sensitivity, accuracy, user-friendly operation, and ubiquitous detection capabilities. We maintain uniform irradiance conditions in colorimetry through the use of a TFT LCD. Employing adaptive boosting-based machine learning algorithms enhances our methodology by focusing on significant features, ensuring accurate and reliable results.
The workflow begins by filling the 96-well plate with the test samples mentioned previously. Subsequently, the ELISA plate is inserted into the device, and images are captured in three wavelengths: green, blue, and red, as depicted in Fig. 1. Next, three RGB values are obtained for each well, representing the average pixel intensity within the cropped circle of each well. To ensure accurate evaluation of the RGB values, it is crucial to maintain consistent test conditions, and carefully assess and consider the effects of light interferences and differences in light paths. Figure 2 depicts the RGB input values and their corresponding Epoch Optical Densities.

Images of a 96-well plate container using a smartphone camera (A) optical image under normal light, optical image while the LCD was adjusted to (B) red light Red, (C) Green light, and (D) Blue light.

RGB Intensities Compared to Epoch Optical Density (A) R (r, g, b), (B) G (r, g, b), (C) B (r, g, b) and (D) All Inputs.
Table 1 compares the results taken from our mobile phone-based ELISA reader with two commercially available ELISA readers. One of these commercially available readers is the EPOCH, which measures 32 \(\times\) 32.3 \(\times\) 39.54 cm3 with a weight of 11.34 kg. In comparison, our device’s design reduces the overall volume of the reader instrument (141 × 222 × 250 mm3) and the weight considerably.
Regression is an effective and supervised learning technique for modeling and creates a rational, mathematical relation between inputs called features, their impacts, and an output to be able to later make approximate and accurate predictions based on the same relation. Accordingly, we extracted RGB values from each image and the outputs are their corresponding optical densities. 72 cancer cell lines were used as sample images. Consequently, their corresponding extracted RGB values create the training set matrix; in other words, each RGB value is a training example, and the whole stack is the training set. R, G, and B are each a feature in the training set. Xi, j refers to the ith training example and the jth feature. The values of the training example and features are 1 ≤ i ≤ 71 and 1 ≤ j ≤ 3, which both are -1 shifted since in Python indices start from 0. Also, according to the hypothesis formula, there needs to be a bias, so a column of 1 s needs to be added.
The input matrix is as below:
The output matrix is as follows:
The hypothesis or the predicted output array is:
Accordingly, the coefficient matrix is:
So, in order to acquire the coefficient matrix, the algorithm is as follows:
Moreover, for estimating the coefficients in Θ, the Root Mean Square Error (RMSE) loss function needs to be optimized. By minimizing the RMSE, the coefficients are estimated.
An RMSE solver was used to minimize the loss function. For the regression algorithm, a machine learning code was written using Python libraries. Primarily, the Θ matrix was gathered by using the known values of optical densities, the “Epoch Optical Densities” and when the matrix was created, other data were then predictable.
To check the accuracy, two different correlation techniques were implemented. Firstly, Pearson’s Correlation (r) followed by Spearman’s Correlation (ρ). The first one indicates the linear correlation between the predicted result and the Epoch optical density, while the other measures the trends or, as it is called, ranks. The results were 0.993 and 0.834, respectively. When Pearson’s Correlation is near 1 (or − 1), it indicates a total linear correlation, and when it is more than 0.5, it means that there is a robust linear correlation and accordingly 0.993 is almost a solid linear correlation. 0.834 for Spearman’s correlation means that 0.834 of the trends are followed, meaning that either increasing or decreasing one results in the same transformation in the other. The more the input, the more the optical density and vice versa.
where θ1, θ2, and θ3 are the coefficients of Red, Green, and Blue, respectively which, as explained, were the unknown quantities of the hypothesis equation. By carrying out the regression algorithm as stated above, the coefficients were figured out. However, for a more accurate result, more data were created from the given data before the regression was implemented.
The feature engineering was carried out and for each new feature, the engineering was implemented by a newly given formula, and then the columns with ‘all-zero’ elements were deleted, and the number of features was boosted from the initial 3 (R, G, and B) to 12. Figure 3A is the demonstration of the same matrix, with 12 features and 72 data examples. Looking at the picture, row-wise, the heatmap visualization depicts that row 0 has an R and G near 0.2 and a B near 0.3, and the rest in a similar manner.

(A) Extracted features of images, (B) Representation of the regression coefficients.
Furthermore, a column of 1 s was added to the left side of the matrix (Column 0) for the bias, and post-regression, the now-known coefficients were as the bars displayed in Fig. 3 Image (B).
Cross-validation
K-fold cross-validation is an effective method for assessing a model's predictive capacity. Utilizing this technique, datasets are divided into K subsets, allowing the model to undergo training K times, each with a distinct training set. In the context of the Cross-Validation section, a k-fold validation approach was employed, iterating through the dataset 72 times (k = 72), resulting in 72 testing instances and 5184 training instances. During each iteration, one example set was strategically excluded from the entire matrix. This systematic approach involves designating one fold as the testing set, while the remaining k-1 folds function as the training model, a process repeated k times to ensure each fold acts as the testing set once. This careful cycling through various subsets for the training and testing sets provides a thorough and accurate assessment of the model's performance. The test data set was as Fig. 4.

K-Fold validation used for cross-validation.
The RMSE, an essential metric measuring the disparity between actual experimental data and the predicted values (as denoted by Eq. (7)) to determine the accuracy of the predictive abilities of the model, was computed for each training and testing set, yielding values of 0.0817 and 0.0877, respectively. A model with smaller RMSE fits the data better. Figure 5 displays a graphical representation of the predicted values from the training and testing sets compared to the actual experimental data, revealing the presence of a good harmony between them. Our model shows precise prediction as evidenced by the low RMSE values for train and test predictions. In other words, the predicted values were relevant to the actual experimental data, showcasing the model’s accuracy and reliability. Figure 5 both demonstrates and confirms the relatively low RMSE and proves that since the training and testing errors are approximately close as well as not being exactly on the experimental data, there is no overfitting or high variance involved. In other words, the model is a balanced model when comparing the training and testing errors since the proximity of these errors which are roughly similar but not exactly equal to the experimental values which is evidence of the absence of high variance or overfitting. The results of the k-fold cross-validation coupled with the RMSE are satisfactory, valid, and have the ability to become generalized so that the model can extend beyond the training set and effectively handle the un-trained data.

(A) Predicted Optical Density and (B) Validation Curve.
To conclude Table 2 represents the general characteristics of the optical device:
In comparison to previous studies that utilized paper strips or achieved 89.5% and 84.2% accuracy, the same device exhibited superior accuracy and eco-friendliness due to the absence of third-party utilization and its reusability15,57. Furthermore, its direct utilization of samples, without the need for labeling with nanoparticles or other materials, provided a competitive advantage over similar systems with comparable objectives15. The absence of third-party involvement allowed each 96-well plate to accommodate different biomarkers or cancer cell lines, enabling simultaneous detection of every well. Also being cost-effective is a major advantage.
In a related study by Berg et al., Light Emitting Diodes (LEDs) were employed as the light source. However, in this paper, a Liquid Crystal Display (LCD) was used, offering the advantage of controlled and homogeneous illumination, thus enhancing the system's performance9.
The simultaneous detection of multiple samples, a notable advantage, facilitates efficiency and time savings in diagnostics. This approach is label-free, eliminating the need for additional markers or labels. The low-cost nature of the method makes it accessible for widespread use. Another advantage is portability, which enables on-site testing in various environments.
There are, however, drawbacks that come with it. The quality of the camera used becomes a crucial factor, influencing the accuracy of results. There could be problems with connectivity that affect data transfer. Dependency on smartphone batteries poses a potential drawback, requiring a stable power source. These systems could be susceptible to outside influences because of their delicate design. Additionally, there might be inconsistency among different smartphone models, affecting the reliability, standardization, and accuracy of the results. Also, a drawback of colorimetry lies in its potential lack of sensitivity when detecting substances present in low concentrations.
The use of Digital Image Colorimetry Systems introduces some challenges. These encompass the necessity for precise color measurement and calibration across diverse devices and environments and the complexity of adapting color measurements to fluctuating environmental conditions such as lighting and temperature. This poses difficulties in maintaining consistent and reliable colorimetry. Efforts to address these challenges have seen notable advancements, mainly through integrating AI-driven algorithms, leveraging machine learning to compensate for environmental variations, and thereby enhancing the robustness of colorimetric measurements.
Material and methods
Smartphone-based colorimetric device
A schematic of the smartphone-based colorimetric device is shown in Fig. 6. To protect the system from outside light, a black box with dimensions of 141 × 222 × 250 mm3 was made by 3D printing. Digital images are taken through the mobile cellphone (Samsung A71) via a hole contrived at the top of the box. Solutions containing the cancer cell lines are placed in a 96-well microplate on a microplate holder made of MDF with 2.8 mm black bases placed on top of the LCD (see Fig. 6). A 7-inch LCD with specifications; 1024 × 600, HDMI, IPS Panel was connected to electrical circuits and placed under the microplate holder. The reason for choosing this type of display is its accuracy and large angle of view. The Raspbian operating system was installed on the mainboard and connected to the monitor via the mentioned HDMI cable. The filter renders the LCD light, which then passes through the 96-well ELISA plate, and reaches the smartphone camera lens. The LCD light is set in the visible light wavelength range, and for each ELISA plate, three images with red, blue, and green lights are captured by the smartphone camera and transmitted to a computing server (Fig. 1). The processing program extracts a three-digit (RGB) code for each well from each green, blue, and red image. Then, the linear regression model is used for the image processing and machine learning stages.

Schematic view and optical density detection for different Cancer cells of the cell phone-based ELISA colorimetric reader.
Cell lines and cell culture sample preparation
Human cancer cell lines58, HE4 (Human Epididymis Protein of Ovarian Cancer), PC3 (Bone Metastasis of Grade IV of Prostate Cancer), LNCap (an epithelial cell line derived from a human prostate carcinoma was first isolated from a human metastatic prostate adenocarcinoma found in a lymph node), 5637 (Primary Tumor of the Bladder), and ACHN (Metastatic Renal Adenocarcinoma) were obtained from Pishtaz Teb Zaman Diagnostics and the National Cell Bank of the Pasteur Institute of Iran. The PC3 cells were cultured in RPMI-1640 medium complemented with 10% fetal bovine serum (FBS), streptomycin (100 Ig/mL) (Gibco BRL; Thermo Fisher Scientific, Waltham, MA, USA), and penicillin–streptomycin (100 IU/mL). LNCaP cell lines were cultured in RPMI-1640 medium with 10% FBS and penicillin/streptomycin (100 U/ml) in 100 × 20 mm2 cell culture dishes in a humidified incubator with 5% CO2 at 37 °C. Four human cancer cell lines were cultured in RPMI-1640 Medium (Gibco, Carlsbad, CA), with 10% fetal bovine serum (Gibco, Carlsbad, CA), 1000 units/ml Penicillin, and 100 μg/ml streptomycin (Gibco BRL, Grand Island, NY) (Fig. 7).

Photographs of human prostate cancer cell line, LNCaP (B) and PC3 (A) cells were photographed at magnification, × 400.
The cells in the exponential growth phase with approximately 70%–80% confluences were cultured for experimental purposes in a humidified atmosphere using a 5% CO2 incubator at 37 °C. The cultured cells were screened for Mycoplasma species using the GenProb detection kit (Gen-Probe, San Diego, CA, USA) according to the manufacturer’s instructions.
Cell viability assay and cell counting through tetrazolium test (MTT)
The MTT Cell Proliferation Assay is employed for assessing the rate of cellular proliferation and, conversely, when metabolic events lead to apoptosis or necrosis, the reduction in cell viability. The number of assay steps has been minimized as much as possible to expedite sample processing. To measure the metabolic activity of prostate cancer cell lines, we used the MTT Assay test59 (3-[4,5-dimethylthiazol-2-yl]-2,5 diphenyl Tetrazolium Bromide, Sigma-Aldrich, St. Louis, MO, USA). At first, both prostate cancer cell lines and their normal cell lines were seeded at three counts, 100, 250, and 500 per well in 96-well plates treated for 48 h at 37 °C with 5% CO2 saturation. For the MTT solution, 5 mg of MTT powder was dissolved in 10 ml RPMI-1640 without any serums to make a solution with a 0.5 mg/mL concentration. 100 μl of MTT solution was added to the cells and incubated for 4 h at 37 °C to metabolize this solution.
Next, 100 µl of Dimethyl Sulfoxide was used to dissolve the formed Formazan crystals, which then formed a purple-colored solution. The optical density was afterwards read with an ELISA microplate reader ((MPR4 +), Hyperion, Medizintechnik GmbH & Co.KG, Germany)) at 570 nm wavelength (Fig. 8).

A microliter plate after an MTT assay. Increasing amounts of cells resulted in increased purple coloring.
The %Viable cells % Death cells are calculated using as in trypan blue stain assay with following formulas:
%Viable cells = Total number of viable cells per milliliter of aliquot/Total number of cells per milliliter of aliquot × 100.
% Death cells = Total number of Dead cells per milliliter of aliquot/Total number of cells per milliliter of aliquot × 100.
%Viability = Mean OD sample / Mean OD control × 100.
Conclusions and future prospective
We have developed a handheld, reasonably priced smartphone-based colorimetric microplate reader for immediate, simultaneous testing of multiple subjects, and portable determination of enzyme-linked immunosorbent assays. It uses a 3D-printed grip to illuminate a 96-well plate using an LCD array. Red, green, and blue color space images were processed to extract the appropriate colors, and the RGB values were utilized to assess the concentrations of human cancer cell lines. By integrating an Image Processing application and incorporating machine learning regression algorithms, the sensitivity of the portable ELISA was significantly enhanced and the optical density was successfully estimated. To evaluate its performance, the results were compared to those obtained from benchtop FDA-certified clinical plate readers: Epoch and Tecan.
We obtained an overall accuracy of 93.580%, 97.580%, and 97.288% for the HE4, PC3, and 5637 tests, respectively.
Although the specific focus of this research lies in cancer detection, there is potential for its application in a broader context. By incorporating samples from different viruses, bacteria, or any clinical or laboratory tests currently conducted using ELISA, the research can be expanded to encompass a wider range of applications. Furthermore, conducting actual clinical tests and implementing them on cancer-free samples would contribute to establishing its clinical validity.
This device can make a massive difference in rapid diagnostics, increase the level of healthcare, and provide extensive screening in disadvantaged and less developed areas.
Data availability
All data generated or analyzed during this study are included in this published article and its Supplementary Files.
References
Boteler, W. L., Luipersbeck, P. M., Fuccillo, D. A. & O’Beirne, A. J. Enzyme-linked immunosorbent assay for detection of measles antibody. J. Clin. Microbiol. 17, 814–818 (1983).
Zhou, Y., Wu, Y., Ding, L., Huang, X. & Xiong, Y. Point-of-care COVID-19 diagnostics powered by lateral flow assay. Trends Anal. Chem. 145, 116452 (2021).
Sajed, S. et al. Instant sensitive measurement of hg concentration using lab-on-a-phone colorimetry. Phys. Stat. Solidi (A) Appl. Mater. Sci. https://doi.org/10.1002/pssa.201800871 (2019).
Koczula, K. M. & Gallotta, A. Lateral flow assays. Essays Biochem. 60, 111–120 (2016).
Sajid, M., Kawde, A. N. & Daud, M. Designs, formats and applications of lateral flow assay: A literature review. J. Saudi Chem. Soc. 19, 689–705 (2015).
De Souza Campos, H. et al. Leptospira interrogans insoluble fraction as a potential antigen source for lateral flow immunochromatography. Mem. Inst. Oswaldo Cruz 118, e220265 (2023).
Aydin, S. A short history, principles, and types of ELISA, and our laboratory experience with peptide/protein analyses using ELISA. Peptides (N. Y.) 72, 4–15 (2015).
Bahadır, E. B. & Sezgintürk, M. K. Lateral flow assays: Principles, designs and labels. TrAC Trends Anal. Chem. 82, 286–306 (2016).
Berg, B. et al. Cellphone-Based Hand-Held Microplate Reader for Point-of-Care Testing of Enzyme-Linked Immunosorbent Assays. ACS Nano 9, 7857–7866 (2015).
Chen, S., Svedendahl, M., Antosiewicz, T. J. & Käll, M. Plasmon-enhanced enzyme-linked immunosorbent assay on large arrays of individual particles made by electron beam lithography. ACS Nano 7, 8824–8832 (2013).
Wu, Y., Fu, Y., Guo, J. & Guo, J. Single-molecule immunoassay technology: Recent advances. Talanta 265, 124903 (2023).
Kim, S. H. et al. Large-scale femtoliter droplet array for digital counting of single biomolecules. Lab Chip 12, 4986–4991 (2012).
Long, K. D., Yu, H. & Cunningham, B. T. Smartphone instrument for portable enzyme- linked immunosorbent assays. Biomed. Opt. Express 5, 3792 (2014).
Sun, S., Yang, M., Kostov, Y. & Rasooly, A. ELISA-LOC: Lab-on-a-chip for enzyme-linked immunodetection. Lab Chip 10, 2093–2100 (2010).
Wang, S. et al. Integration of cell phone imaging with microchip ELISA to detect ovarian cancer HE4 biomarker in urine at the point-of-care. Lab Chip 11, 3411–3418 (2011).
Wang, T., Zhang, M., Dreher, D. D. & Zeng, Y. Ultrasensitive microfluidic solid-phase ELISA using an actuatable microwell-patterned PDMS chip. Lab Chip 13, 4190–4197 (2013).
Cai, T. et al. A paper-based microfluidic analytical device with a highly integrated on-chip valve for autonomous ELISA. Proc. IEEE Int. Conf. Micro Electro Mech. Syst. (MEMS) 2022, 271–274 (2022).
Abdelbasset, W. K. et al. Smartphone based aptasensors as intelligent biodevice for food contamination detection in food and soil samples: Recent advances. Talanta 252, 123769 (2023).
Laksanasopin, T. et al. A smartphone dongle for diagnosis of infectious diseases at the point of care. Sci. Transl. Med. 7, 273re1 (2015).
Soldat, D. J., Barak, P. & Lepore, B. J. Microscale colorimetric analysis using a desktop scanner and automated digital image analysis. J. Chem. Educ. 86, 617–620 (2009).
Abriola, L., Chin, M., Fuerst, P., Schweitzer, R. & Sills, M. A. Digital imaging as a detection method for a fluorescent protease assay in 96-well and miniaturized assay plate formats. SLAS Discov. 4, 121–127 (1999).
Muttan, S., Durai Arun, P. & Sankaran, K. Image analysis system for 96-well plate fluorescence assays. 2012 3rd International Conference on Computing, Communication and Networking Technologies, ICCCNT 2012. doi:https://doi.org/10.1109/ICCCNT.2012.6395958 (2012).
Durai Arun, P., Sankaran, K. & Muttan, S. An image based microtiter plate reader system for 96-well FORMAT FLUORESCENCE ASSAYS. Eur. J. Biomed. Inform. (Praha) 9, 58–68 (2013).
Ozcan, A. Mobile phones democratize and cultivate next-generation imaging, diagnostics and measurement tools. Lab Chip 14, 3187–3194 (2014).
Hunt, B., Ruiz, A. J. & Pogue, B. W. Smartphone-based imaging systems for medical applications: A critical review. J. Biomed. Opt. 26, 1–22 (2021).
Breslauer, D. N., Maamari, R. N., Switz, N. A., Lam, W. A. & Fletcher, D. A. Mobile phone based clinical microscopy for global health applications. PLoS One 4, 1–7 (2009).
Smith, Z. J. et al. Cell-phone-based platform for biomedical device development and education applications. PLoS One 6, e17150 (2011).
Vashist, S. K., Mudanyali, O., Schneider, E. M., Zengerle, R. & Ozcan, A. Cellphone-based devices for bioanalytical sciences multiplex platforms in diagnostics and bioanalytics. Anal. Bioanal. Chem. 406, 3263–3277 (2014).
Preechaburana, P., Suska, A. & Filippini, D. Biosensing with cell phones. Trends Biotechnol. 32, 351–355 (2014).
Erickson, D. et al. Smartphone technology can be transformative to the deployment of lab-on-chip diagnostics. Lab Chip 14, 3159–3164 (2014).
Hernández-Neuta, I. et al. Smartphone-based clinical diagnostics: Towards democratization of evidence-based health care. J. Intern. Med. 285, 19–39 (2019).
Sajed, S., Kolahdouz, M. & Sadeghi, M. A. Prediction of arsenic concentration in water samples using digital imaging colorimetry and multi-variable regression. ChemistrySelect 7, e202201376 (2022).
Sajed, S., Kolahdouz, M., Sadeghi, M. A. & Razavi, S. F. High-performance estimation of lead ion concentration using smartphone-based colorimetric analysis and a machine learning approach. ACS Omega 5, 27675–27684 (2020).
Sajed, S., Arefi, F., Kolahdouz, M. & Sadeghi, M. A. Improving sensitivity of mercury detection using learning based smartphone colorimetry. Sens. Actuators B Chem. 298, 126942 (2019).
Merazzo, K. J., Totoricaguena-Gorriño, J., Fernández-Martín, E., Javier Del Campo, F. & Baldrich, E. Smartphone-enabled personalized diagnostics: Current status and future prospects. Diagnostics 11, 1–13 (2021).
Banik, S. et al. Recent trends in smartphone-based detection for biomedical applications: A review. Anal. Bioanal. Chem. 413, 2389–2406 (2021).
Aslan, M. K., Ding, Y., Stavrakis, S. & deMello, A. J. Smartphone imaging flow cytometry for high-throughput single-cell analysis. Anal. Chem. https://doi.org/10.1021/ACS.ANALCHEM.3C03213/SUPPL_FILE/AC3C03213_SI_001.PDF (2023).
Wang, B. et al. Smartphone-based platforms implementing microfluidic detection with image-based artificial intelligence. Nat. Commun. 14, 1–18 (2023).
Kumar Gunda, N. S. et al. Mobile Water Kit (MWK): A smartphone compatible low-cost water monitoring system for rapid detection of total coliform and E. coli. Anal. Methods 6, 6236–6246 (2014).
Rojas-Barboza, D. et al. Rapid, simple, low-cost smartphone-based fluorescence detection of Escherichia coli. Int. J. Agric. Biol. Eng. 14, 189–193 (2021).
Khalaf, E. M. et al. Smartphone-assisted microfluidic sensor as an intelligent device for on-site determination of food contaminants: Developments and applications. Microchem. J. 190, 108692 (2023).
Wei, Q. et al. Fluorescent imaging of single nanoparticles and viruses on a smart phone. ACS Nano 7, 9147–9155 (2013).
Zhang, S., Li, Z. & Wei, Q. Smartphone-based cytometric biosensors for point-of-care cellular diagnostics. Nami Jishu yu Jingmi Gongcheng/Nanotechnol. Precis. Eng. 3, 32–42 (2020).
Wei, Q. et al. Imaging and sizing of single DNA molecules on a mobile phone. ACS Nano 8, 12725–12733 (2014).
Selck, D. A., Karymov, M. A., Sun, B. & Ismagilov, R. F. Increased robustness of single-molecule counting with microfluidics, digital isothermal amplification, and a mobile phone versus real-time kinetic measurements. Anal. Chem. 85, 11129–11136 (2013).
Coskun, A. F. et al. A personalized food allergen testing platform on a cellphone. Lab Chip 13, 636–640 (2013).
Lee, S., Oncescu, V., Mancuso, M., Mehta, S. & Erickson, D. A smartphone platform for the quantification of vitamin D levels. Lab Chip 14, 1437–1442 (2014).
Wei, Q. et al. Detection and spatial mapping of mercury contamination in water samples using a smart-phone. ACS Nano 8, 1121–1129 (2014).
Singh, G. P. & Sardana, N. Smartphone-based surface plasmon resonance sensors: A review. Plasmonics 17, 1869–1888 (2022).
Coskun, A. F., Nagi, R., Sadeghi, K., Phillips, S. & Ozcan, A. Albumin testing in urine using a smart-phone. Lab Chip 13, 4231–4238 (2013).
Oncescu, V., O’Dell, D. & Erickson, D. Smartphone based health accessory for colorimetric detection of biomarkers in sweat and saliva. Lab Chip 13, 3232–3238 (2013).
Vashist, S. K. et al. A smartphone-based colorimetric reader for bioanalytical applications using the screen-based bottom illumination provided by gadgets. Biosens. Bioelectron. 67, 248–255 (2015).
Su, K. et al. High-sensitive and high-efficient biochemical analysis method using a bionic electronic eye in combination with a smartphone-based colorimetric reader system. Sens. Actuators B Chem. 216, 134–140 (2015).
Nath, S., Sarcar, S., Chatterjee, B., Chourashi, R. & Chatterjee, N. S. Smartphone camera-based analysis of ELISA using artificial neural network. IET Comput. Vision 12, 826–833 (2018).
Bergua, J. F. et al. Low-cost, user-friendly, all-integrated smartphone-based microplate reader for optical-based biological and chemical analyses. Anal. Chem. 94, 1271–1285 (2022).
Wu, Z. et al. Smartphone-based high-throughput fiber-integrated immunosensing system for point-of-care testing of the SARS-CoV-2 nucleocapsid protein. ACS Sens. 7, 1985–1995 (2022).
Kight, E. C., Hussain, I., Bowden, A. K. & Haselton, F. R. Recurrence monitoring for ovarian cancer using a cell phone-integrated paper device to measure the ovarian cancer biomarker HE4/CRE ratio in urine. Sci. Rep. 11, 1–11 (2021).
Suzuki, T., Tsukumo, Y., Furihata, C., Naito, M. & Kohara, A. Preparation of the standard cell lines for reference mutations in cancer gene-panels by genome editing in HEK 293 T/17 cells. Genes Environ. 42, 1–12 (2020).
Präbst, K., Engelhardt, H., Ringgeler, S. & Hübner, H. Basic colorimetric proliferation assays: MTT, WST, and Resazurin. Methods Mol. Biol. 1601, 1–17 (2017).
Acknowledgements
The Urology Research Center of Tehran University of Medical Sciences generously supported and supplied Cell Lines for this research. We genuinely value their input. Furthermore, the HE4 employed in this study was provided by Pishtaz Teb Zaman Diagnostics. Their valuable contribution to this research is extremely appreciated.
Author information
Authors and Affiliations
Contributions
S.M.: Conceptualization, Investigation, Methodology, Validation, Data curation, Visualization, Writing—original draft. A.F.N.: Validation, Investigation, Software, Data curation, Visualization. F.K.: Planning and supervision, processing the experimental data, Review and Editing. A.M.: Sample preparation. S.M.K.A.: Methodology, Project administration. M.K.: Methodology, Writing—Review and Editing, Project administration. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mirhosseini, S., Nasiri, A.F., Khatami, F. et al. A digital image colorimetry system based on smart devices for immediate and simultaneous determination of enzyme-linked immunosorbent assays. Sci Rep 14, 2587 (2024). https://doi.org/10.1038/s41598-024-52931-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-52931-6
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
