
Abstract
The study aimed to identify critical factors associated with the surgical stability of pogonion (Pog) by applying machine learning (ML) to predict relapse following two-jaw orthognathic surgery (2 J-OGJ). The sample set comprised 227 patients (110 males and 117 females, 207 training and 20 test sets). Using lateral cephalograms taken at the initial evaluation (T0), pretreatment (T1), after (T2) 2 J-OGS, and post treatment (T3), 55 linear and angular skeletal and dental surgical movements (T2-T1) were measured. Six ML modes were utilized, including classification and regression trees (CART), conditional inference tree (CTREE), and random forest (RF). The training samples were classified into three groups; highly significant (HS) (≥ 4), significant (S) (≥ 2 and < 4), and insignificant (N), depending on Pog relapse. RF indicated that the most important variable that affected relapse rank prediction was ramus inclination (RI), CTREE and CART revealed that a clockwise rotation of more than 3.7 and 1.8 degrees of RI was a risk factor for HS and S groups, respectively. RF, CTREE, and CART were practical tools for predicting surgical stability. More than 1.8 degrees of CW rotation of the ramus during surgery would lead to significant Pog relapse.
Similar content being viewed by others


Introduction
Orthognathic surgery is performed to overcome skeletal discrepancies, obtain esthetics, and achieve normal occlusion. However, unstable outcomes often require dental compensation during postoperative orthodontic treatment and other surgical procedures1. Surgical instability, including hierarchy in post-surgical stability, is well established based on the surgical direction. Changes > 2 mm or 2° were defined as moderately unstable, and 4 > mm or 4° were highly unstable2,3,4. A comprehensive report on hierarchy5 indicated that post-surgical instability after mandibular setback was related to "A technical problem," which meant that the chin occasionally underwent clockwise (CW) rotation during the operation, and later the pterygomassetreic sling induced the opposite direction even with rigid fixation. The quantity of CW rotation of the proximal segment was correlated with the linear measurement of pogonion (Pog)6. Although two-jaw orthognathic surgery(2 J-OGS) was expected to overcome this situation, the proximal segment counter CW rotation after surgery, measured as ramus inclination (RI), was significantly associated with the amount of mandibular relapse7. Based on the literature above, the major relapse occurred during CW rotation of the ramus (proximal segment) during surgery, which was related to the forward movement of the Pog after surgery. Therefore, training a dataset by including pre-operative (T1) and post-operative RI change (T2, and six to eight weeks later) to a machine learning (ML) algorithm may lead to predicting the change in Pog during retention in the testing set.
Artificial intelligence (AI) refers to the development of computer systems that can perform tasks that require human intelligence. ML is a subfield of AI that focuses on devising algorithms and statistical models that computers can use to "learn" from data without explicit programming. Deep learning is a subset of ML that uses artificial neural networks inspired by the structure and function of the human brain to process and analyze large amounts of data8. Studies on ML and deep learning in the field of temporomandibular joint (TMJ) in the dental orthodontic department have been reported9,10,11,12,13. Jung stated that it is possible to classify extraction versus non-extraction with a 93% success rate using ML9. Etemd reported the ranking factors determining the extraction using random forest (RF)10. Li suggested that the K-Nearest Neighbors (KNN) method was the best model for distinguishing between extraction and non-extraction, extraction patterns, and anchorage determination11. Fang used multivariate logistic regression to detect cephalometric variables associated with degenerative joint disease12. Lee et al.13 adopted RF to determine the rank of the risk factors related to temporomandibular disorders. ML has demonstrated the potential for predicting surgical outcomes14.
To our knowledge, stability prediction of 2 J-OGS surgery using ML has not been reported. Since the obvious clinical expression in patients with skeletal class III is the sagittal chin projection (Pog), the quantitative change in Pog was selected for investigation. The purpose of the present study was to identify the critical factors associated with the surgical stability of Pog by applying ML to predict relapse following 2 J-OGS.
Methods
Subjects
The study sample consisted of 319 adult Korean patients diagnosed with skeletal class III malocclusion who underwent combined surgical orthodontic treatment and 2 J-OGS surgery at Seoul National University Dental University Hospital or Ajou University Dental Hospital, located in Republic of Korea, between 2006 and 2017. The inclusion criteria were as follows; (1) patients who had undergone 2 J-OGS surgery, Le Fort I osteotomy in the maxilla, and bilateral sagittal split osteotomy in the mandible, (2) patients who underwent rigid fixation with a metal plate and monocortical screws for fixation of the osteotomized bony segments, (3) patients for whom photographs and lateral cephalograms were taken at the initial visit (T0), at least one month before the surgery (T1), at least one month after the surgery (T2), and at debonding (T3), and (5) patients who faculty orthodontists treated with more than 30 years of experience (SHB and YHK). The exclusion criteria were (1) patients who had cleft lip and/or palate or congenital craniofacial deformities, (2) patients who had a history of trauma in the craniofacial area, and (3) patients who had severe facial asymmetry (menton deviation > 5 mm), and (4) patients who underwent vertical genioplasty. Supplementary Table 1 describes the age, sex, and Pog posterior movement (1.59 ± 2.76 mm). Consequently, the final study sample included 227 patients (110 males and 117 females). This retrospective case–control study was reviewed and approved by the Institutional Review Board of Seoul National University Dental Hospital (IRB no. ERI20022) and Ajou University Hospital (IRB no. AJIRB-MED-MDB-19–039). All experimental protocols were approved by the two institutional committees. Seoul National University Dental Hospital and Ajou University Hospital IRB committees waived the need of patient informed consent. Previous studies have indicated that the major relapse after 2 J-OGS surgery occurred within 8 weeks7 to 1 year5. Thus, 1 year of follow-up was sufficient to examine relapse.
Sample size calculation
Power analyses were conducted using Cohen's effective sample size15 with a significance level (α) of 0.05 and a power (1-β) of 0.9. Based on the mean and standard deviation (SD) values of postsurgical linear change in Pog from a previous study7, which were reported as 1.87 and 2.6 mm, respectively, sample size calculations were performed using R software (ver. 4.0.3, Vienna, Austria). The results indicated that a minimum of 20 individuals were required to achieve the desired statistical power for the study. According to Rajput's suggestion16, a suitable sample size in machine learning algorithms should have an effective size greater than 0.5 and an ML accuracy of over 80%. Additionally, Rajput indicated that increasing the sample size beyond the threshold point would not significantly improve performance. In this study, the standardized effect size was 1.14, which exceeds the threshold of 0.5, indicating a substantial effect size. Therefore, among the machine learning algorithms used in this study, those that demonstrate an accuracy of more than 80% can be considered acceptable in terms of their performance.
Landmarks and variables used in this study
Figures 1 and 2 illustrated the definitions of the landmarks and linear and angular variables. Fifty-five linear and angular skeletal and dental surgical movements (T2-T1) were measured, of which 16 were calibrated relative to the horizontal and vertical reference planes for further analysis of linear changes to assess the magnitude of surgical movement. Postoperative relapse was estimated by measuring Pog movement (T3-T2). The identification of landmarks and measurement of variables were performed by a single operator (YHK).

Landmarks, reference lines, and definitions of linear and angular measurements. Linear measurements: 1. A_x (mm), the horizontal distance from point A to VRP. 2. PNS_x (mm), the horizontal distance from PNS to VRP. 3. U1_x (mm), the horizontal distance from U1E to VRP. 4. U6_x (mm), the horizontal distance from U6MBC to VRP. 5. A_y (mm), the vertical distance from point A to HRP. 6. PNS_y (mm), the vertical distance from PNS to HRP. 7. U1_y(mm), the vertical distance from U1E to HRP. 8. U6_y (mm), the vertical distance from U6MBC to HRP. 9. B_x (mm), the horizontal distance from point B to VRP. 10. Pog_x (mm), the horizontal distance from Pog to VRP. 11. L1_x (mm), the horizontal distance from L1E to VRP. 12. L6_x (mm), the horizontal distance from L6MBC to VRP. 13. B_y (mm), the vertical distance from point B to HRP. 14. Pog_y(mm), the vertical distance from Pog to HRP. 15. L1_y (mm), the vertical distance from L1E to HRP. 16. L6_y (mm), the vertical distance from L6MBC to HRP.

Comparison of machine learning models (Dependent: RANK—HS/S/N). Scale 1.00 indicates the best metric performance.
Intra-examiner reliability assessment
To evaluate intra-examiner reliability, the same investigator (YHK) re-evaluated all variables from 20 randomly selected subjects one month after the initial measurement. After conducting paired t-tests, no significant differences were observed between the first and second measurements. As a result, the first set of variables was used for subsequent statistical analyses.
Statistical analyses
The normality of the data distribution for each variable was assessed using the Shapiro–Wilk test. Statistical analysis was conducted among groups using a one-way analysis of variance and the Kruskal–Wallis test. A Bonferroni post-hoc analysis was performed. Statistical analysis was performed using R version 4.2.2. A significance level of p < 0.05 was established for all statistical tests.
ML algorithms
Six ML approaches were utilized to identify factors contributing to Pog relapse, and these algorithms were compared to determine the optimal method for prediction, classification, and regression trees (CART)17, conditional inference tree (CTREE)18, linear discriminant analysis19, support vector machine20, KNN21, RF22. A tenfold cross-validation was performed, repeating the process ten times to further reduce the variance in the results. The literature23 supporting k-fold cross-validation indicates that it is an effective resampling technique to mitigate overfitting in machine learning models. Cross-validation is particularly useful when dealing with limited data samples. In the k-fold cross-validation process, the dataset is partitioned into k subsets, or "folds," with equal sizes. During the evaluation phase, the model is trained and tested k times. In each iteration, one fold is held out as the test set, while the remaining (k-1) folds are used for training the model. This procedure ensures that the model is assessed on different subsets of data, which helps to provide a more robust evaluation of its performance24,25. The primary advantage of k-fold cross-validation is that it allows the model to be trained and tested on various data partitions, thereby reducing the risk of overfitting. Overfitting occurs when a model becomes too specialized to the training data and performs poorly on new, unseen data. By repeatedly evaluating the model on different data subsets, k-fold cross-validation helps to identify whether the model generalizes well across various data distributions. This technique provides a more reliable estimate of the model's performance metrics, such as accuracy, precision, recall, and F1 score, compared to a single train-test split evaluation. Moreover, it aids in optimizing hyperparameters and selecting the best model architecture that yields better generalization to unseen data. In summary, k-fold cross-validation is a valuable tool for machine learning model evaluation, particularly when dealing with limited data and aiming to avoid overfitting. Its implementation can lead to more robust and accurate models by ensuring better generalization across different data samples. The training and testing set consisted of 207 and 20 samples, respectively.
Metrics
The metric evaluation included accuracy, kappa, mean balanced accuracy, mean F1 score, mean recall, mean sensitivity, and mean specificity.
Ethics declaration
The study design followed the Declaration of Helsigki principles and was approved by SNUDH and Ajou University Hospital. his retrospective case–control study was reviewed and approved by the Institutional Review Board of Seoul National University Dental Hospital (IRB no. ERI20022) and Ajou University Hospital (IRB no. AJIRB-MED-MDB-19–039). The IRB Committee waived the requirement for obtaining patient consent from both institutions.
Results
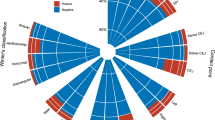
Based on previous studies2,3,4, the training set was classified into three subgroups based on the rank of relapse; highly significant (HS, n = 19) relapse, which was defined as greater than 4 mm of relapse; significant (S, n = 62) relapse, which was defined as a relapse ranging between 2 and 4 mm, and insignificant (N, n = 126) relapse, which was < 2 mm. The evaluation involved calculating the position of the Pog between T3 (debonding) and T2 (surgery). The differences in cephalometric variables among the three groups in the training set (n = 207) are presented in Supplementary Table 2. Bjork sum, articular angle, gonial angle, lower anterior–posterior height ratio (ANS-Me/N-Me), FMA, SN to MP, SNA, FM_UOP, and A-point to vertical reference plane VRP displayed statistically significant differences (Fig. 1). The metrics evaluation among the ML models was shown in Fig. 2 and summarized in Table 1. A scale close to 1.0 indicated a higher prediction level. The significance of the differences between the metric distributions of the different ML algorithms was shown in Table 2. Each number indicated the difference between the algorithms, and p-values were described. For example, in accuracy, the mean difference between CART and CTREE was 0.008, obtained by subtracting them in Table 2 (|0.966–0.958|= 0.008). In general, RF presented the most significant difference. The performance metrics of the ML algorithms in the testing set (n = 20) were compared in Table 3. CART, CTREE, and RF displayed better prediction results. For example, RF predicted a sagittal chin point (Pog) surgical relapse of more than 2 mm 95% (19/20), and considering the classification between HS and S, 90% (18/20) was the same as the actual outcomes (Supplementary Table 2). In RF, "VarImp" stands for "variable importance." The variable importance measures the relative importance of each predictor variable in the RF model. The six important head variables were RI, articular angle, Bjork sum, gonial angle, Sn to MP, and FMA. (Supplementary Fig. 1). Although RF predicted the rank of relapse and found critical variables, quantitative critical points can be obtained from Decision Tree models, which also visualize the prediction process to understand the process easily (CTREE, Fig. 3a and CART, Fig. 3b). In Fig. 3a, the prediction model of CTREE was illustrated. The first step was evaluating the amount of CW rotation of the ramus to predict the Pog relapse rank, N, S, and HS. No significant relapse was forecasted if it was less than 1.86 degrees (− 1.86). When more than 1.86°of CW rotation occurred during surgery, the next step was to evaluate whether it was more or less than 3.72. The third step was determining whether the articular angle changed by more than 9.25°in the same direction. If so, the fifth step estimated the increased vertical position of point A (Apoint_y). An HS relapse was anticipated if it was more than 1.12 mm. CART (Fig. 3b) revealed that the CW rotation of the ramus with critical points of 1.8° and 3.7° was essential for forecasting the relapse rank.

Decision Tree of Conditional Inference (CTREE). (A) Decision Tree of Conditional Inference (CTREE). RI, Articular angle, Bjork sum, Apoint_y (A_y), and Saddle angle were chosen for the classification. (B) Critical values of Classification and Regression Trees (CART) (Complexity parameter = 0.176).
Discussion
This study aimed to predict the stability of sagittal chin projection (Pog) following 2 J-OGS surgery using ML. The changes in Pog during surgery between the preoperative (T1) and postoperative (T2) stages were used to predict the change in Pog at the debonding stage (T3). This study employed ML algorithms to identify the critical factors associated with the surgical stability of Pog. In agreement with earlier research6,7, our study emphasizes the significance of changes in Pog relapse between the pre-operative and post-operative stages as indicators of surgical instability. This supports the idea that alterations in the proximal segment of the mandible in the clockwise (CW) direction during surgery and counterclockwise (CCW) direction in the retention period are crucial factors in determining the stability of Pog. The application of ML algorithms to predict surgical stability in orthodontics and dental orthognathic surgery has been gaining interest in recent years. In this context, our study builds upon previous work by Jung9, Etemd10, and Li11 successfully utilized AI techniques to classify extraction versus non-extraction cases, rank factors determining extraction, and distinguish between extraction patterns, respectively. The current study expands this research with a comparable performance by employing ML algorithms to predict Pog stability following 2 J-OGS surgery, which has not been previously explored.
In this study, a tenfold cross-validation method was used to evaluate the predictive performance of the ML model. The performances of six popular ML algorithms were compared by adopting multiple evaluation metrics. Since the sample number of each group was different and the HS group had the smallest number (n = 19), the mean balance accuracy, precision, recall, and sensitivity were also investigated to account for the class imbalance. In the current study, the "false negative" detection was clinically critical since the prediction of relapse should not exclude those patients who will relapse. On the other hand, the "false positive" of the HS and S groups were not as significant as the "false negative." Therefore, the mean balanced precision, recall, and sensitivity, useful metrics when the cost of false-negative prediction is high, were utilized and examined (Fig. 2). CART and CTREE performed better than the others, and RF displayed the best scores. For example, RF exhibited the highest mean balanced accuracy, followed by CART, CTREE, Support Vector Machine, Linear Discriminant Analysis, and KNN (Table 1). Statistical differences were examined among the ML models (Table 2). For example, the mean balanced accuracy of RF differed from the others, except for CART. Table 3 demonstrates the testing set data results, which indicate that RF, CART, and CTREE also exhibit superior performance. Therefore, the results of these three algorithms were investigated further (Table 3).
As shown in Supplementary Table 2, RF was predicted correctly in 18/20 samples. Case number four underwent 4.78 mm relapse (HS in reality), but it was predicted to be in the S group, which was inaccurate but partially correct regarding whether relapse occurred. Case number five showed a 2 mm Pog backward movement, but that number was incorrect. A unique feature of RF is that it reveals an important variable (Supplementary Fig. 1); an essential variable that affected the rank prediction was RI, followed by the articular angle, Bjork sum, gonial angle, Sn to MP, and FMA. These variables were all related to the vertical increment during surgery, implicating the importance of maintaining the vertical dimension in the mandible. The composition of the decision-making triage is illustrated in Fig. 3. CTREE forecasted that the first and second critical numbers of RI CW rotation were 1.86 (S) and 3.72 (HS), respectively. The articular angle and Bjork sum were nominated in the next tree, followed by A point vertical and a saddle angle increment. The most crucial advantage of decision trees is that they suggest critical numbers. The exact numbers were acquired using CART regarding the RI CW rotation (Fig. 3b).
The present study has several limitations. The first is the overfitting of the ML algorithms. Overfitting is a common problem in ML. A model is trained to fit the training data so closely that it starts memorizing instead of generalizing and identifying patterns. When a model overfits, it performs very well on the training data; however, its performance on new, unseen data is poor. This phenomenon occurs when the model is overly tailored to the training dataset, leading to reduced generalizability and accuracy when making predictions on new, unseen data26. Furthermore, this study only collected samples from two universities, two oral surgeons who operated on the surgery, and two orthodontists who performed orthodontic treatment. Considering the different treatment plans, techniques, and ethnic backgrounds, other institutions may have different predictions. Nonetheless, it may be more appropriate to make predictions based on data from each institution, given that most institutions likely employ specific surgical techniques and orthodontic mechanics. The second limitation is that Pog was the only measurement. Other measurements, such as the maxillary occlusal plane27, vertical bony step28 and points A, B, etc., should be addressed in future studies.
This study provides valuable insights into ML's application of ML in predicting Pog stability after 2 J-OGS surgery. The findings of this study indicate that the ML model developed could be used to predict the relapse of Pog accurately, suggesting the critical number of variables associated with the surgical stability of Pog. The clinical implication of the current study was that ML applications could be used to identify patients at high risk of surgical relapse and develop appropriate postoperative management strategies to improve surgical stability. The model's accuracy in predicting Pog's relapse could reduce the need for further surgical procedures, reducing the treatment cost and duration.
Conclusions
The primary objective of this study was to utilize ML algorithms to predict sagittal chin projection (Pog) stability after 2 J-OGS surgery and identify the key factors contributing to surgical stability. Changes in Pog relapse with mandibular CW rotation during surgery served as indicators of surgical instability. RF, CART, and CTREE demonstrated the most robust predictive performances of the six ML algorithms assessed in this study. The study revealed that a CW rotation of more than 3.7 and 1.8 degrees of RI CW rotation was the most significant risk factor for HS (≥ 4) and S (≥ 2 and < 4) Pog relapse, respectively. The findings of this study suggest that ML algorithms, mainly RF and decision-tree models, are practical tools for predicting surgical stability. Additionally, decision tree models enable the visualization of the prediction process using a triage illustration.
Data availability
The test set data can be obtained via github (https://github.com/pfChae/The-prediction-of-sagittal-chin-point-relapse-following-double-jaw-surgery-using-machine-learning).
Change history
02 February 2024
A Correction to this paper has been published: https://doi.org/10.1038/s41598-024-53035-x
References
Troy, B. A., Shanker, S., Fields, H. W., Vig, K. & Johnston, W. Comparison of incisor inclination in patients with Class III malocclusion treated with orthognathic surgery or orthodontic camouflage. Am. J. Orthod. Dentofacial Orthop. 135(146), e1-146.e9 (2009).
Proffit, W. R., Turvey, T. A. & Phillips, C. Orthognathic surgery: A hierarchy of stability. Int. J. Adult Orthodon. Orthognath. Surg. 11, 191–204 (1996).
Proffit, W. R., Bailey, L. J., Phillips, C. & Turvey, T. A. Long-term stability of surgical open-bite correction by Le Fort I osteotomy. Angle Orthod. 70, 112–117 (2000).
Bailey, L., Cevidanes, L. H. & Proffit, W. R. Stability and predictability of orthognathic surgery. Am. J. Orthod. Dentofac. Orthop. 126, 273–277 (2004).
Proffit, W. R., Turvey, T. A. & Phillips, C. The hierarchy of stability and predictability in orthognathic surgery with rigid fixation: An update and extension. Head Face Med. 3, 21 (2007).
Cho, H. J. Long-term stability of surgical mandibular setback. Angle Orthod. 77, 851–856 (2007).
Al-Delayme, R., Al-Khen, M., Hamdoon, Z. & Jerjes, W. Skeletal and dental relapses after skeletal class III deformity correction surgery: Single-jaw versus double-jaw procedures. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 115, 466–472 (2013).
Sarker, I. H. Deep learning: A comprehensive overview on techniques, taxonomy, applications and research directions. SN Comput. Sci. 2, 420 (2021).
Jung, S. K. & Kim, T. W. New approach for the diagnosis of extractions with neural network machine learning. Am. J. Orthod. Dentofacial Orthop. 149, 127–133 (2016).
Etemad, L. et al. Machine learning from clinical data sets of a contemporary decision for orthodontic tooth extraction. Orthod. Craniofac. Res. 24(Suppl 2), 193–200 (2021).
Li, P. et al. Orthodontic treatment planning based on artificial neural networks. Sci. Rep. 9, 2037 (2019).
Fang, X. et al. Machine-learning-based detection of degenerative temporomandibular joint diseases using lateral cephalograms. Am. J. Orthod. Dentofacial Orthop. 163, 260-271.e5 (2023).
Lee, K. S., Jha, N. & Kim, Y. J. Risk factor assessments of temporomandibular disorders via machine learning. Sci. Rep. 11, 19802 (2021).
Elfanagely, O. et al. Machine learning and surgical outcomes prediction: A systematic review. J. Surg. Res. 264, 346–361 (2021).
Cohen, J. Statistical power analysis. Curr. Dir. Psychol. Sci. 1(3), 98–101 (1992).
Rajput, D., Wang, W.-J. & Chen, C.-C. Evaluation of a decided sample size in machine learning applications. BMC Bioinform. 24, 48 (2023).
Batra, M. & Agrawal, R. Comparative analysis of decision tree algorithms. In Advances in Intelligent Systems and Computing. Nature Inspired Computing (eds Panigrahi, B. et al.) 31–36 (Springer Singapore, 2018). https://doi.org/10.1007/978-981-10-6747-1_4.
Hothorn, T., Hornik, K. & Zeileis, A. Unbiased recursive partitioning: A conditional inference framework. J. Comput. Graph Stat. 15, 651–674 (2006).
Wu, L., Shen, C. & Van Den Hengel, A. Deep linear discriminant analysis on fisher networks: A hybrid architecture for person re-identification. Pattern Recogn. 65, 238–250 (2017).
Schölkopf, B. Support Vector Learning (Oldenbourg, 1997).
Bhatia, N. Vandana. Survey of nearest neighbor techniques. Int. J. Comput. Sci. Inf. Secur. 8, 302–305 (2010).
Breiman, L., Last, M. & Rice, J. Random forests: Finding quasars. In Statistical Challenges in Astronomy (eds Breiman, L. et al.) 243–254 (Springer-Verlag, 2003). https://doi.org/10.1007/0-387-21529-8_16.
Brodeur, Z. P., Herman, J. D. & Steinschneider, S. Bootstrap aggregation and cross-validation methods to reduce overfitting in reservoir control policy search. Water Resour. Res. 56, e2020WR027184 (2020).
Nematzadeh, Z., Ibrahim, R. & Selamat, A. Comparative studies on breast cancer classifications with k-fold cross validations using machine learning techniques. In 2015 10th Asian Control Conference (ASCC) (eds Nematzadeh, Z. et al.) 1–6 (IEEE, 2015).
Prusty, S., Patnaik, S. & Dash, S. K. SKCV: Stratified K-fold cross-validation on ML classifiers for predicting cervical cancer. Front. Nanotechnol. 4, 972421 (2022).
Friedrich, S. et al. Is there a role for statistics in artificial intelligence?. Adv. Data Anal. Classif. 16, 823–846 (2021).
Kang, S. Y. et al. Stability of clockwise rotation of the maxillary occlusal plane in skeletal Class III patients treated with two-jaw surgery. Orthod. Craniofac. Res. https://doi.org/10.1111/ocr.12601 (2022).
Batbold, M. et al. Vertical bony step between proximal and distal segments after mandibular setback is related with relapse: A cone-beam computed tomographic study. Am. J. Orthod. Dentofacial Orthop. 161, e524–e533 (2022).
Acknowledgements
This research was supported by a grant from the Korea Health Technology R&D Project through the Korea Health Industry Development Institute, funded by the Ministry of Health &Welfare, Republic of Korea (Grant number: HI18C1638). The authors would like to express their sincere gratitude to Dr. Sungsu Heo for his invaluable contribution to this research through insightful illustrations of the figures presented in this article.
Author information
Authors and Affiliations
Contributions
Y.H.K. collection of data, analysis of data, interpretation of data, construction of manuscript, I.K. analysis of data, interpretation of data, conception and design of the article, Y.K. conception and design of the article, M.K. conception and design of the article, J.C. conception and design of the article, M.H. conception and design of the article, K.K. conception and design of the article, S.L. conception and design of the article, S.K. conception and design of the article, N.K. “conception and design of the article, J.W.S, conception and design of the article, S.S. conception and design of the article, S.B. collection of data, conception and design of the article, H.S.C.: conception and design of the article, collection of data, analysis of data, interpretation of data, construction of manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: The original version of this Article contained an error in the spelling of the author Minji Kim, which was incorrectly given as Minji Ki.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kim, Y.H., Kim, I., Kim, YJ. et al. The prediction of sagittal chin point relapse following two-jaw surgery using machine learning. Sci Rep 13, 17005 (2023). https://doi.org/10.1038/s41598-023-44207-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-44207-2
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
