
Abstract
Nighttime light remote sensing has been an increasingly important proxy for human activities. Despite an urgent need for long-term products and pilot explorations in synthesizing them, the publicly available long-term products are limited. A Night-Time Light convolutional LSTM network is proposed and applied the network to produce a 1-km annual Prolonged Artificial Nighttime-light DAtaset of China (PANDA-China) from 1984 to 2020. Assessments between modeled and original images show that on average the RMSE reaches 0.73, the coefficient of determination (R2) reaches 0.95, and the linear slope is 0.99 at the pixel level, indicating a high confidence in the quality of generated data products. Quantitative and visual comparisons witness PANDA-China’s superiority against other NTL datasets in its significantly longer NTL dynamics, higher temporal consistency, and better correlations with socioeconomics (built-up areas, gross domestic product, population) characterizing the most relevant indicator in different development phases. The PANDA-China product provides an unprecedented opportunity to trace nighttime light dynamics in the past four decades.
Similar content being viewed by others


Background & Summary
Spaceborne sensors with nighttime light (NTL) capabilities have served as an effective measure of various human activities over the past years1,2,3. In recent years, the NTL data has provided a unique perspective on the intensity of lighting, which is related to the dynamics of socioeconomic activities and urban development. The availability of long-term NTL data has triggered extensive efforts in multiple long-term research frontiers1,2,3. For instance, mapping long-term urbanization processes benefits from the unique advantage of the NTL observations spanning a relatively long period, including urban extent4,5, urban boundary6,7, impervious surface areas8,9, urban land use8,10,11, and built-up infrastructure12,13,14. Furthermore, long-term NTL datasets have proved to successfully estimate the population15,16, the gross domestic product (GDP)17 and income18,19,20, but also the poverty21,22,23 and freight traffic24.
NTL datasets supporting the application above mainly derive from two groups. The first group is a primary NTL data source from the Defense Meteorological Satellite Program - Operational Linescan System (DMSP-OLS), which provides valuable records of global nightscape from 1992 to 2013. It has been widely used in socioeconomic fields even though suffering from the brightness saturation in urban centers1,25 and the blooming effect near the urban-rural transitions26,27 regarding its relatively long-term historical records. However, it is no longer available after 2013, which defines its time period as permanent 1992 ~ 20132,28,29,30,31. The second group of NTL dataset derived from satellites on track mostly started working since then, including Suomi National Polar-Orbiting Partnership-Visible Infrared Imaging Radiometer Suite (NPP-VIIRS), Luojia 1-01 satellite32, and Jilin1-03b (Jilin-1) satellite33 and SDGSAT34. As new generations of global NTL composites, they provided higher spatial resolution and fewer over-glow effects of the recorded radiance of NTL data compared to that of DMSP28,35,36. However, their time spans are only available since 2012 at the earliest, resulting in a relatively short period for mapping the dynamics of human activities8,9,27,37,38.
In all, even usable satellite NTL data has been publicly available since 1992, there is, unfortunately, no such dataset with high temporal consistency that spans from 1992 till now. The quality39 and the available time span3 of existing NTL datasets limited their capability to reflect long-term spatiotemporal dynamics of human behaviour. Per these shortcomings and urgent needs, several attempts have been made to synthesize consistent nightlight time series across different platforms and sensors, which can be classified into a new third group. Li et al.37 proposed an inter-calibration model to simulate DMSP/OLS composites from the VIIRS day-and-night band (DNB) composites by using a power function for radiometric degradation and a Gaussian low pass filter for spatial degradation (RMSE:5.00, R2:0.92). Zhao et al.40 conducted a sigmoid function model for generating a temporally consistent NTL dataset from 1992 to 2018 in Southeast Asia (R2: 0.91 in 2012, 0.94 in 2013). Li et al.3 generated an integrated and consistent NTL dataset using a sigmoid function at the global scale (1992-2018). Despite similar pilot efforts39,41,42, it still lacks comprehensive and systematic evaluation frameworks for assessing the quality and reliability of the generated NTL dataset. Although statistical errors have been calculated, the temporal consistency of these datasets has been seldom checked and assumed in good accordance by default, which is not the case. Neither DMSP-OLS nor NPP-VIIRS has high temporal accordance owing to its manual-like pre-process recorded in official documents43, let alone that of a synthesized dataset deriving from these satellite datasets with different passing times.
To produce a longer-period NTL dataset as well as develop higher temporal consistency, we recommend the potential of historical records of DMSP be fully explored, with the help of newly adopted deep learning methods followed with a temporal consistency correction model. The recent rapid development of deep learning approaches44,45,46 has provided a targeted and promising method in modeling the dependencies between the spatiotemporal dynamics of the DMSP-OLS. The LSTM architecture hereby has proved its capability in several spatiotemporally dependent applications47,48,49, which is promisingly helpful in modeling the spatial and temporal dependencies of NTL data.
Considering the abilities of existing deep learning approaches in capturing the long-range spatial and temporal dependencies of NTL data remain to be improved50,51, in this study, we propose a space- and time-aware approach named nighttime light convolutional long short-term memory network (NTLSTM) for modeling the relationship between dynamic changes of the long-term DMSP data followed with a temporal consistency correction method adapted from Robust LOcally WEighted Scatterplot Smoothing (RLOWESS) (Cleveland 1979). With the newly proposed method, we achieve the time series of NTL data in China spanning 1984 to 2020 for the first time, affirm its temporal consistency, name it a prolonged artificial nighttime-light dataset of China (PANDA-China), and analyze the spatiotemporal urbanization process at both national and regional scales using PANDA-China.
Methods
Study area and used data
In this work, we focus on China as the study area, which has experienced different levels of fast urban development in different regions over the past four decades. The relatively different levels of development in China are suitable for assessing both the proposed method as well as the newly generated PANDA-China.
DMSP-OLS time-series data from 1992 to 2012 is retrieved from the National Geophysical Data Center (NGDC) at the National Oceanic and Atmospheric Administration (NOAA) website (https://www.ncei.noaa.gov/products/dmsp-operational-linescan-system). In brief, DMSP-OLS sensors have a unique capability to detect visible lights from country-sides, towns, cities, and other sites with persistent lighting and exclude the effect of accidental noise such as stray light, lightning, lunar illumination, and cloud cover. Their digital number (DN) values range from 0 to 63. Before the experiments, the temporal consistency has been improved through ridgeline regression, and DMSP-2013 is excluded considering its quality50,51.
As for the training and evaluation period of deep learning, the training and evaluation material is generated by randomly cropping the raw DMSP NTL images into patches with the size of 1,024 × 1,024 pixels. The generated patches are divided into training, validating, and testing materials in a proportion of 7:2:1.
Nine ancillary data sets are collected to help validate the accuracy or performance of PANDA-China, including six other existing global nighttime-light products, and Population (POP), Gross Domestic Products (GDP), built-up areas (BUA), as shown in Table 1.
Implementation tasks
Two targets for PANDA-China are longer-period and higher consistency. The first part, aiming at target one, is to demonstrate NTLSTM routes and illustrates its process and components. The second part, aiming at target two, is to adapt RLOWESS to correct the temporal consistency of PANDA-China and systematically describes the assessments of NTLSTM and PANDA-China.
As illustrated in Fig. 1(a), we develop a stepwise method to achieve the extended NTL datasets consisting of the following five steps:
-
Step 1: The raw DMSP NTL data is preprocessed by inter-calibration using methods proposed by41, followed by normalization. Then NTL training datasets and validation datasets are generated by randomly cropping and spatially splitting.
-
Step 2: A nighttime light convolutional long short-term memory network (NTLSTM) is developed to model the inherent mechanism of dynamic changes of NTL datasets.
-
Step 3: We utilize several assessment criteria for evaluating the performance of the proposed model in validation datasets.
-
Step 4: The simulated NTL images of China (1984-2020) are generated using our properly trained NTLSTM.
-
Step 5: The generated NTL data is temporally adjusted into a more consistent version of PANDA-China using MODEST (an adapted RLOWESS method).

The proposed stepwise method. (a) The overall workflow of the proposed approach. (b) The two tasks designed in this study.
We design two tasks in the training period (Fig. 1(b)). One is to backtrack the NTL data of the year 1984-1991, and the other is to forecast the NTL data of the year 2013-2020. The year 1984 is chosen as the end point of the backtracking task because Landsat-5, one of the most commonly used remote sensing imageries for early-year research, is mostly considered usable since circa 1984. The year 2020 is chosen as the end point of the forecasting task for the availability of other NTL datasets. The NTL data of 1992-2012 is split into two periods, 13 years of data for input and 8 years of data for supervision. Specifically, for the backtracking task, the deep learning network is supposed to be capable of utilizing the NTL data of the year 2000-2012 as input and backtracking the NTL data of the year 1992-1999. On the contrary, in the forecasting task, the deep learning network is designed to use the NTL data of the year 1992-2004 as input and to forecast the NTL data of the year 2005-2012.
Nighttime light convolutional long short-term memory network
We apply tensor \({{\bf{T}}}_{y}^{1}\) with shape y × h × w to represent the input NTL patch sequence and tensor \({{\bf{T}}}_{y+z}^{y+1}\) with shape z × h × w to represent the target NTL patch sequence, where y denotes the length of inputted years, z represents the length of target year sequence, h and w denote the height and weight of each patch respectively:
The In represents the NTL image patch at the n-th year, which is a h × w tensor:
Our ultimate goal is to learn a mapping function F(•) that can forecast the corresponding NTL sequence \({{\bf{T}}}_{y+z}^{y}\) via taking full use of the inputted \({{\bf{T}}}_{y}^{1}\). As illustrated in Fig. 2(a), we propose a nighttime light convolutional long short-term memory network (NTLSTM), which is regarded as our target mapping function F(•), consists of two main components: the spatiotemporal attention module and the convolutional LSTM unit. Other details of NTLSTM can be found in the supplementary material.

The overall methodology. (a) The structure of the proposed NTLSTM network. (b) The proposed spatiotemporal attention module. (c) The sketch of MODEST, of which 1) shows randomly generated time series, 2) shows the first-order difference of raw time-series (in magenta) and the RLOWESSed results (in green), and 3) cumulative sum time-series when replacing abrupt changing point value with RLOWESSed values.
The spatiotemporal attention module
The attention module has been proposed to enhance the inherent feature representation capability of the networks and proved to be effective in quantities of previous studies52,53,54. Considering the information provided by the input NTL patches at different times and regions are unequally important for prediction performance, we propose a spatiotemporal attention module to implicitly learn spatiotemporal matrixes, which worked as weighting masks for further prediction. As illustrated in Fig. 2(2), the proposed spatiotemporal attention module consists of a spatial attention submodule and a temporal attention submodule, which automatically exploit different levels of importance of each NTL image patch sequence to generate spatiotemporally weighted feature maps Y.
The proposed spatial attention submodule is designed to adjust the input spatial features via calculating an attention matrix βs. This operation enhances or attenuates certain regions of the feature map based on their estimated attention weight. Here, we use two convolutional layers to learn the spatial attention matrix βs. Specifically, given the kth patch feature, the spatially weighted feature \({\widetilde{{\bf{I}}}}_{k}\) is computed as a weighted summation using Ik and attention matrix \({\beta }_{s}^{k}\) as follows:
where the ρ represents the softmax function, ΦS1 and ΦS2 are feed-forward neural networks with trainable parameters. Note that the learned spatial attention matrix βs has the same height and width of the size of the input feature Ik. While each input feature is attended over spatially via the spatial attention module, the temporal attention module is designed to calculate the temporal weight matrix βt at each year. This temporal weight matrix βt decides which year of the NTL patch sequence to pay attention to. Given spatially attended frames \(\widetilde{{{\bf{T}}}_{y}^{1}}=[\widetilde{{{\bf{I}}}_{1}},\,\widetilde{{{\bf{I}}}_{2}},\widetilde{{{\bf{I}}}_{3}},\,\ldots ,\,\widetilde{{{\bf{I}}}_{y}}]\) and corresponding hidden state at (k − 1)th of ConvLSTM Hk−1, the temporal weight matrix at k-th \({\beta }_{t}^{k}\) is calculated as follows:
where the ρ represents a softmax function, ΦH and ΦI are feed-forward neural networks that are jointly trained with all other components of the proposed NTLSTM. Note that the temporal attention matrix βt has the same length of input \(\widetilde{{{\bf{T}}}_{y}^{1}}\).
The convolutional LSTM unit
The convolutional LSTM (ConvLSTM)48 captures spatiotemporal dependency in each NTL data sequence. Given the kth spatiotemporally attended NTL patch features \(\overline{{\widetilde{{\bf{I}}}}_{k}}\) in the inputted NTL feature maps Y, the input gate \({G}_{k}^{i}\), forget gate \({G}_{k}^{f}\) and output gate \({G}_{k}^{o}\) of the Convolutional LSTM (ConvLSTM) (please refer to the supplementary material for more details and illustrations) are calculated using following equations:
where σ is the sigmoid function, (*) represents convolutional operator, and (•) is the Hadamard product. The W represents the weight matrix, each subscript has an obvious meaning. For example, Whi is the hidden-input gate matrix, and Who is the input-output gate matrix, etc. The bi, bf, bo and bc are bias terms.
As shown in the above formulas, the ConvLSTM is a modification of LSTM, which replaces the fully-connected operators with convolutional operators. A ConvLSTM unit contains several ConvLSTM layers, each of which can extract the spatiotemporal features of certain frame \(\overline{{\widetilde{{\bf{I}}}}_{k}}\). Thus, the ConvLSTM unit is capable to handle the inputted NTL sequence Y.
The proposed NTLSTM consists of two subnetwork structures: one is the encoding subnetwork fenc (left part of Fig. 2(a)), and the other is the decoding subnetwork fdec (right part of Fig. 2(a)), both of which are formed by stacking three ConvLSTM units. The initial states and cell outputs of the decoding subnetwork are copied from the last state of the encoding subnetwork. As shown in Fig. 2(a), the encoding subnetwork of NTLSTM extracts and compresses the spatiotemporal features from the input tensor \({{\bf{T}}}_{y}^{1}=[{{\bf{I}}}_{1},\,{{\bf{I}}}_{2},{{\bf{I}}}_{3},\,\ldots ,\,{{\bf{I}}}_{y}]\); the decoding subnetwork of NTLSTM unfolds the extracted features and predicts the final sequence \({{\bf{T}}}_{y+z}^{y+1}=[{{\bf{I}}}_{y+1},\,{{\bf{I}}}_{y+2},{{\bf{I}}}_{y+3},\,\ldots ,\,{{\bf{I}}}_{y+z}]\).
Adjustment of outlier phases
Maximum-selection Of the Difference Enlarged by Smoothed Timeseries (MODEST) is proposed to adjust the inconsistency in marginal years between backward, original, and forward phases in raw PANDA-China. The challenge is to smooth the raw time-series while maintaining potentially helpful signals without ground truth. Therefore, MODEST is applied to PANDA-China pixel-by-pixel, followed by a spatially median smoothing window after its successful experiments on the basis of randomly generated time series data with a known shift up or down.
In general, MODEST includes two parts: detection and correction. To maintain potential valuable signals of raw PANDA-China (Fig. 2c-1), RLOWESS is applied to its first-order difference (in pink in Fig. 2c-2) instead of its raw time series and gets an RLOWESSed time series (in green dashed line in Fig. 2c-2). Values exceeding the three-standard deviation range are labeled as outliers (examples in black dashed line in Fig. 2c-2), where the highest and lowest values are detected as the start and end timestamp of the first outlier phase. It is then corrected by replacing values on detected start and end time with respective RLOWESSed values, and cumulatively summing the corrected first-order difference time series. This can be accepted as the final adjusted time series when the standard deviation of the corrected time series is lower than the results from the previous loop (Fig. 2c-3); otherwise, proceed to select the second pair of outliers and repeat the previous progress above. Further detailed processes and illustrations of MODEST and its results can be found in the supplementary information.
Model assessment and product evaluation
Technical validation of PANDA-China mainly focuses on three parts: model assessment, product comparison with other existing datasets, and taking product correlation with socioeconomics as both the application and the assessment of PANDA-China.
We first assess the model based on the testing material, which can be divided into two phases: 1992-1999 from the backtracking task, and 2005-2012 from the predicting task. Widely adopted Root Mean Square Error (RMSE), linear regression determination coefficient R2 and its slope k are adopted to assess the accuracy, accordance, and over-/under-estimation, respectively. Multiple RMSE, R2, and k can be calculated between each pair of modeled and original patches, where temporal trend and annual uncertainties can be obtained and visualized. Secondly, our assessment focuses on differences between modeled and original summed values in the built-up areas (including both urban and rural areas). Temporally, 34 values are recorded in each year so that the accuracy of modeled results in previously and newly built-up areas can be measured annually. Spatially, differences in 1992-1999 and 2005-2012 in each China province are also used to evaluate the results of the model.
On the other hand, PANDA-China is compared with similar products by Li et al.3 and Zhang et al.41, on their spatiotemporal performance. Visual interpretation and correlation between NTL products and socioeconomic metrics are compared. More comparisons with other datasets can be found in the supplementary information.
Correlations between PANDA-China and socioeconomic variables are also calculated, as an assessment and an application. Since there is no ground truth for DMSP in 1984-1991 and 2013-2020, Pearson’s correlation R is calculated between PANDA-China and built-up areas (BUA), GDP, and population (POP) respectively, to build a consistent evaluation during the whole study period. For a better command of data performance, spatiotemporal evaluations are based on three manually selected phases: 1984-1991 (backtracked), 1992-2012 (modeled and original), and 2013-2020 (predicted).
Data Records
PANDA-China is a prolonged artificial nighttime-light dataset of China ranging from 1984 to 2020, which has been produced using the developed Night-Time light convolutional Long Short-Term Memory network on the basis of DMSP-OLS. Model assessment shows the low error (RMSE: 0.73) and high accordance (R2: 0.95, linear slope: 0.99) at the pixel level, and well captures the temporal trends at newly-built urban areas while it slightly underestimates the intensity within older core urban areas. Pearson’s Rs are calculated between socioeconomic variables (BUA, GDP, POP) and PANDA-China in three phases, where reasonable values are presented and explained by history. PANDA-China provides consistent temporal trends, shows high accordance with socioeconomics, delineates road network, and thus is precious especially before 1992 and after 2013. PANDA-China helps to better demonstrate the dynamics of human activities in the long run and offers unprecedented opportunities to investigate economic or energy-related topics since 1984. PANDA-China is freely accessible at https://doi.org/10.11888/Socioeco.tpdc.27120255.
The data is stored in independent TIF format, each representing the night-time light data for a specific year, named PANDA_China_Year.tif. These files are organized in the following folder structure and are compatible with software such as ArcGIS. 
Technical Validation
Analysis of NTLSTM results
Temporal error distribution of modeled results
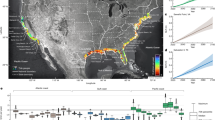
Temporally, the annual average RMSE of cropped patches reaches 0.47 with original data ranging from 0 to 63. By excluding the patches that contain only zero values, the average RMSE notably rises to 0.73. Inter-annual dynamics of RMSE, R2, and k with their uncertainty of backtracking and predicting models are visualized in boxplots in Fig. 3a1–a3 respectively, and the dots indicate the data distribution. These trends fluctuate with uncertainty in each period, but variances are still quite small. Data for each cropped patch are visualized in Fig. 3b1–b3. Note that different numbers of cropped patches here in predicting (126) and backtracking model (79) result from different numbers of cropped patches with all zero values.

Temporal assessment of modeled results in randomly sampled cropped patches. The temporal trend of statistics of 79 and 126 cropped patches with all-zero ones excluded are shown: (a1) RMSE, (a2) R2, (a3) k; dots in each panel indicate data distribution. Statistic values from patch to patch: (b1) RMSE, (b2) R2, (b3) k, where colors indicate different years; note that the different numbers of cropped patches in backtracking and predicting model results from different patches with all zero values.
Spatial error distribution of modeled results
To further test the model’s ability to depict night-time light variances, we investigate the built-up areas, known as the ad hoc areas of the NTL study. Temporally, the average of simple differences in all built-up areas throughout the whole of China is calculated annually, as shown in Fig. 4b2. Apparently, backtracking modeled results generally outperform predicting modeled results in highly developed areas, with the former within 0 to -1 and the latter exceeding -2 in 2011. Spatially, deeply investigating into areas with different built-up areas, we found older built-up areas are much underestimated (painted as deeper blue), while simple differences of newly-built areas or areas to be built keep closer to zero, as Fig. 4a shows. The results indicate that models are more powerful in describing the decreasing or increasing trend but limited in depicting variances in the established built-up areas. Apart from the underestimation in Fig. 4a, b2, there are still some slight overestimations when referring to spatial heterogeneity, such as that in Guizhou and Hunan provinces, as shown in Fig. 4b1. North-western China undergoes higher underestimation, while south-eastern China shows less underestimation.

Spatiotemporal assessment of modeled results in urban areas. (a) Annual average of simple differences in areas with different built-up years. The upper one indicates older built-up areas and deeper blue indicates higher underestimation. (b) temporal and spatial heterogeneity of the averaged simple difference: (b1) spatial pattern of both underestimation and overestimation at the provincial level, and (b2) trend of averaged simple difference throughout the whole of China within built-up areas only.
Comparison between PANDA-China and previous NTL datasets
Statistic comparison between seven datasets
Direct comparisons are posted in Fig. 5. It provides two kinds of temporal dynamics of seven datasets, one is the averaged value of province-wise time-series with its temporal variance (Fig. 5b1), and the other is the summed value of the whole country (Fig. 5b2), both of which share the same figure legend. Besides, we also visualize the dynamics of POP, GDP, and BUA (Fig. 5a1–a3) for further indirect comparison. Black bold lines show the summed value of the whole country, and red bold ones show their respective averages, with pink areas indicating its temporal variance. Grey dashed lines in the background represent variable values in different provinces.

PANDA-China comparison with different socioeconomic variables and other datasets. Temporal dynamics of POP, GDP, and BUA have been shown in a1–a3, where black and red bold lines indicate their respective sum and average time-series, and grey dashed lines represent variables of each province. Seven NTL datasets have been summarized into province-wise average time-series (b1) and sum time-series (b2).
First, the most eye-catching advantage of PANDA-China is the time range prolonged by NTLSTM, compared to the other six sets of NTL datasets. It provides unique resources to understand social activities at night. Second, PANDA-China achieves high temporal consistency throughout its whole time-range both in average time-series and sum time-series, and its temporal trend cohorts with that of most datasets. Significant fluctuation mainly occurs around 2012 in other NTL datasets, like DE, DVNL, and Li’s, due to sensor degradation or the incorporation of cross-sensor information. Note that although the DN range of Chen’s seems much lower than DMSP-like datasets including PANDA-China in both average and sum time-series, its trend also shapes alike. Comparison of NTL temporal trends would be more helpful in comparing or applying NTL datasets since DN of DMSP-like NTL changes represents no explicit physical meaning (unitless).
To quantitatively compare NTL datasets against different socioeconomic variables, Pearson’s correlation analysis has been conducted on their same period, from 2000 to 2012, where seven datasets were further reduced to five types here since DE and DVNL share the same value with DMSP during this period. Major results have been summarized in Table 2. Two kinds of comparison are conducted. In the first type, the correlation between summed NTL and socioeconomic parameters (SOEC Param.) among all provinces has been calculated every year; and the results have been reported in Table 2 “By Year”. In the other type, the temporal correlation has been calculated in each province from various NTL sources, as listed in Table 2 “By Province” row. The average correlation of each and both types were calculated and reported as AVG shows.
Judging from the reported correlation, different kinds of NTL datasets emphasize various connections between night-time activities and socioeconomic development. From the profile’s view ("By Year” row), local night-time light mostly represents GDP and BUA in Chen’s and Li’s datasets, while it correlates well with all three parameters in DMSP, Zhang’s, and our PANDA-China datasets. From the perspective of time-series correlation ("By Province” row), it correlates higher with GDP and BUA than with POP in Chen’s and Zhang’s datasets, higher with POP and GDP than with BUA in DMSP, and higher with POP and BUA than with GDP in Li’s and our PANDA-China. Generally, an agreement would be reached on their correlation extent, no matter from the profile’s view or from time-series’ view; that is its stronger correlation with POP in the profile should persist in time-series. Chen’s, DMSP, and our PANDA-China meet this principle. PANDA-China also reaches the second-highest average correlation. More and thorough comparisons in detail can be found in the supplementary information.
Apart from the comparison of NTL values, that of spatial pattern should also be uncovered. Zhang’s and Li’s NTL datasets are selected as examples to be compared with the PANDA-China hereafter, since they share the same spatial resolution, and represent DMSP-based information and VIIRS-incorporated information, respectively.
Spatiotemporal comparison between representative datasets
Temporal consistent products derived from Li’s and Zhang’s methods are compared to PANDA-China in Shanghai- and Beijing-centred regions visually and throughout the whole China statistically. PANDA-China outperforms both of them in proper estimation and the description of road networks.
In 1992, the earliest year of DMSP-OLS, our back-modeled result well captures the spatial pattern and the light intensity in both Shanghai and Beijing as Li’s (Fig. 6a1–a3,e1–e3). In contrast, slight overestimation exists at the fringe of urban areas resulting from the blooming in Zhang’s products. In 2012, which is a fast-developing period in both Shanghai and Beijing, PANDA-China delineates the road network much clearer than both Li’s and Zhang’s products. Specifically, the connection between Hangzhou and the city west to it is well reflected in the lower-left corner in Fig. 6b1, but not shown explicitly in Li’s and Zhang’s results, as shown in Fig. 6b2–b3. Similar situations can be seen in upper left corner of Fig. 6f1–f3.

Comparison between PANDA-China and products from Li’s and Zhang’s methods (Li’s and Zhang’s hereafter) in Shanghai-centred and Beijing-centred regions. (a1–a3) and (e1–e3) show the spatial pattern of PANDA-China, Li’s and Zhang’s in 1992, the first year of published DMSP-OLS data; (b1–b3) and (f1–f3) show that in 2012, the last year of Zhang’s products. (c1–c2), (g1–g2) and (d1–d2), (h1--h2) compare PANDA-China and Li’s in 2013 and 2018, respectively.
Compared to adjustment of observations in Li’s and Zhang’s products, PANDA-China is not good at foreseeing light change. However, if we include such changes in the training process, such a capability to foresee light change can be maintained. As the lower-right corner of Fig. 6b1,c2 show, for the year of 2012, PANDA-China fails to predict the expressway between Shanghai and Hangzhou, while for the year of 2013, PANDA-China succeeds in bridging them. Similar phenomenon occurs in the west of Beijing (upper-left corner) in Fig. 6f1–g2. Surprisingly, Li’s product disconnects this road in Fig. 6g2 compared to Fig. 6g1. Besides, PANDA-China also shows a good capability to maintain the increasing spatial pattern, i.e. spatial consistency. As Fig. 6d1–d2,h1–h2 show, urban areas expanding from north-east to south-west in Shanghai-centred region, and from north to south in Beijing-centred region, inherit the pattern from Fig. 6c1–c2,d1–d2. In contrast, observations in Li’s product tend to underestimate the light intensity surrounding the urban areas, to overestimate at distant regions, and to obscure the road networks, as Fig. 6d1–d2,h1–h2 show. As Li’s product is considered to be better than Zhang’s in the literature2, we only perform the whole-China quantitative comparison between PANDA-China and Li’s product. As listed in Table 3, statistics of PANDA-China and Li’s product in these four years show close performance from 1992 to 2013, but PANDA-China outperforms Li’s product since then, which agrees with visual validation in Fig. 6. Please refer to the supplementary material for detailed annual statistics of the whole study period.
With an unprecedented long time-span, PANDA-China helps to witness the connection between cities and villages during early years and project future expansion types. Taking the Guangzhou-centred region as an example, villages are nearly singly located around Guangzhou-centred urban agglomeration in 1984, and connections are gradually built between villages and between villages and cities during 1984 to 1992, as shown in the northern part of Fig. 7. Besides, PANDA-China manages to identify the major characteristics of the urban expansion. The urban area generally expands from urban fringe in Guangzhou during 1984 to 2020, but sometimes leaves a “hole” behind, mainly due to demographic reasons, such as mountainous or estuary regions, as shown in the southern part of Guangzhou from 2013 to 2020. Also, the comparison between PANDA-China with Landsat composites in this same area are shown (Figs. S7 ~ S8) in supplementary information.

Spatial pattern of PANDA-China in the Guangzhou-centred region from 1984 to 2020.
Spatiotemporal analysis of 37-year China nighttime light using PANDA-China
Three phases are selected accordingly: 1984-1991, 1992-2012, and 2013-2020, to excavate the controlling socioeconomic parameters of night-time light in different periods. Generally, PANDA-China is capable of characterizing the dynamics of BUA, GDP, and POP in each phase although their correlation varies in different provinces and phases.
In the first phase (1984-1991), NTL intensity is positively correlated with BUA, GDP, and POP to a large extent in all provinces (no GDP and POP statistical data available in Hongkong, Macau and Taiwan). This also indicates that urbanization, economic development and population increase all contribute to NTL in this phase throughout the whole China (Fig. 8a). While in the second phase (1992-2012), the situation changed. Generally, BUA and GDP still correlate well with NTL in all provinces except some in Hongkong, Macau, and Taiwan due to lack of statistic data. However, interaction between POP and NTL in each province varies largely. In Guizhou and Hunan provinces, their correlations reach a lower level (<0.5); and most notably, in Sichuan and Chongqing, there even exists negative correlation in the second phase (Fig. 8b). Most variances occur in the third phase. In this phase, NTL in each province results from different contributions. In south-eastern China, the relationships between BUA, GDP, POP, and NTL reach similar strong intensity as in first phase. In western China, NTL correlates well with GDP development and POP variances but shows lower relationship with BUA, especially in Xinjiang and Tibet. Not surprisingly, NTL correlates negatively to GDP and POP in north-eastern China, whose major contribution is BUA, as Fig. 8c shows.

Spatiotemporal correlation between NTL and BUA, GDP, POP by provinces in each phase. 1984 to 2020 are divided into three phases according to model setting: (a) 1984-1991; (b) 1992-2012; (c) 2013-2020. The colors of provinces indicate the average value of three Pearson’s R.
Code availability
The programs used to generate all the results were Python 3.7, MATLAB (R2018b), and ArcGIS (10.4). The code and scripts used for training, testing, and predicting the NTL data are available in the open GitHub repository “https://github.com/xian1234/NTLSTM”, and the code for calibrating and validating the data is available at “https://www.mathworks.com/matlabcentral/fileexchange/119308-modest”.
References
Elvidge, C. D., Baugh, K. E., Kihn, E. A., Kroehl, H. W. & Davis, E. R. Mapping city lights with nighttime data from the dmsp operational linescan system. Photogrammetric Engineering and Remote Sensing 63, 727–734, https://doi.org/10.1016/S0924-2716(97)00008-7 (1997).
Li, X. & Zhou, Y. Urban mapping using dmsp/ols stable night-time light: a review. International Journal of Remote Sensing 38, 6030–6046, https://doi.org/10.1080/01431161.2016.1274451 (2017).
Li, X., Zhou, Y., Zhao, M. & Zhao, X. A harmonized global nighttime light dataset 1992-2018. Sci Data 7, 168, https://doi.org/10.1038/s41597-020-0510-y (2020).
Small, C., Pozzi, F. & Elvidge, C. D. Spatial analysis of global urban extent from dmsp-ols night lights. Remote Sensing of Environment 96, 277–291, https://doi.org/10.1016/j.rse.2005.02.002 (2005).
Zhou, Y. et al. A global map of urban extent from nightlights. Environmental Research Letters 10, 054011, https://doi.org/10.1088/1748-9326/10/5/054011 (2015).
Feng, Z., Peng, J. & Wu, J. Using dmsp/ols nighttime light data and k-means method to identify urban-rural fringe of megacities. Habitat International 103, 102227, https://doi.org/10.1016/j.habitatint.2020.102227 (2020).
Henderson, M., Yeh, E. T., Gong, P., Elvidge, C. & Baugh, K. Validation of urban boundaries derived from global night-time satellite imagery. International Journal of Remote Sensing 24, 595–609, https://doi.org/10.1080/01431160304982 (2003).
Zhang, Q. & Seto, K. C. Mapping urbanization dynamics at regional and global scales using multi-temporal dmsp/ols nighttime light data. Remote Sensing of Environment 115, 2320–2329, https://doi.org/10.1016/j.rse.2011.04.032 (2011).
Zhao, M. et al. Mapping urban dynamics (1992-2018) in southeast asia using consistent nighttime light data from dmsp and viirs. Remote Sensing of Environment 248, 111980, https://doi.org/10.1016/j.rse.2020.111980 (2020).
Huang, X., Schneider, A. & Friedl, M. A. Mapping sub-pixel urban expansion in china using modis and dmsp/ols nighttime lights. Remote Sensing of Environment 175, 92–108, https://doi.org/10.1016/j.rse.2015.12.042 (2016).
Imhoff, M. L. et al. Using nighttime dmsp/ols images of city lights to estimate the impact of urban land use on soil resources in the united states. Remote Sensing of Environment 59, 105–117, https://doi.org/10.1016/S0034-4257(96)00110-1 (1997).
Chowdhury, P. R. & Maithani, S. Monitoring growth of built-up areas in indo-gangetic plain using multi-sensor remote sensing data. Journal of the Indian Society of Remote Sensing 38, 291–300, https://doi.org/10.1007/s12524-010-0019-5 (2010).
Ma, X., Li, C., Tong, X. & Liu, S. A new fusion approach for extracting urban built-up areas from multisource remotely sensed data. Remote Sensing 11, 2516, https://doi.org/10.3390/rs11212516 (2019).
Ma, X. et al. Optimized sample selection in svm classification by combining with dmsp-ols, landsat ndvi and globeland30 products for extracting urban built-up areas. Remote Sensing 9, 236, https://doi.org/10.3390/rs9030236 (2017).
Sutton, P. Modeling population density with night-time satellite imagery and gis. Computers, Environment and Urban Systems 21, 227–244 (1997).
Xu, H., Yang, H., Li, X., Jin, H. & Li, D. Multi-scale measurement of regional inequality in mainland china during 2005-2010 using dmsp/ols night light imagery and population density grid data. Sustainability 7, 13469–13499, https://doi.org/10.3390/su71013469 (2015).
Fu, H., Shao, Z., Fu, P. & Cheng, Q. The dynamic analysis between urban nighttime economy and urbanization using the dmsp/ols nighttime light data in china from 1992 to 2012. Remote Sensing 9, 416, https://doi.org/10.3390/rs9050416 (2017).
Ebener, S., Murray, C., Tandon, A. & Elvidge, C. C. From wealth to health: modelling the distribution of income per capita at the sub-national level using night-time light imagery. international Journal of health geographics 4, 5, https://doi.org/10.1186/1476-072X-4-5 (2005).
Elvidge, C. D., Baugh, K. E., Anderson, S. J., Sutton, P. C. & Ghosh, T. The night light development index (nldi): a spatially explicit measure of human development from satellite data. Social Geography 7, 23–35, https://doi.org/10.5194/sg-7-23-2012 (2012).
Shao, X. et al. Radiometric calibration of dmsp-ols sensor using viirs day/night band. In Earth Observing Missions and Sensors: Development, Implementation, and Characterization III, vol. 9264, 92640A, https://doi.org/10.1117/12.2068999 (International Society for Optics and Photonics).
Elvidge, C. D. et al. A global poverty map derived from satellite data. Computers and Geosciences 35, 1652–1660, https://doi.org/10.1016/j.cageo.2009.01.009 (2009).
Jean, N. et al. Combining satellite imagery and machine learning to predict poverty. Science 353, 790–794 (2016).
Wang, W., Cheng, H. & Zhang, L. Poverty assessment using dmsp/ols night-time light satellite imagery at a provincial scale in china. Advances in Space Research 49, 1253–1264, https://doi.org/10.1016/j.asr.2012.01.025 (2012).
Tian, J., Zhao, N., Samson, E. L. & Wang, S. Brightness of nighttime lights as a proxy for freight traffic: A case study of china. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 7, 206–212, https://doi.org/10.1109/JSTARS.2013.2258892 (2013).
Abrahams, A., Oram, C. & Lozano-Gracia, N. Deblurring dmsp nighttime lights: A new method using gaussian filters and frequencies of illumination. Remote Sensing of Environment 210, 242–258, https://doi.org/10.1016/j.rse.2018.03.018 (2018).
Wei, Y., Liu, H., Song, W., Yu, B. & Xiu, C. Normalization of time series dmsp-ols nighttime light images for urban growth analysis with pseudo invariant features. Landscape and Urban Planning 128, 1–13, https://doi.org/10.1016/j.landurbplan.2014.04.015 (2014).
Zhou, Y., Li, X., Asrar, G. R., Smith, S. J. & Imhoff, M. A global record of annual urban dynamics (1992-2013) from nighttime lights. Remote Sensing of Environment 219, 206–220, https://doi.org/10.1016/j.rse.2018.10.015 (2018).
Elvidge, C. D., Baugh, K. E., Zhizhin, M. & Hsu, F.-C. Why viirs data are superior to dmsp for mapping nighttime lights. Proceedings of the Asia-Pacific Advanced Network 35, 62, https://doi.org/10.7125/APAN.35.7 (2013).
Hsu, F.-C., Baugh, K. E., Ghosh, T., Zhizhin, M. & Elvidge, C. D. Dmsp-ols radiance calibrated nighttime lights time series with intercalibration. Remote Sensing 7, 1855–1876, https://doi.org/10.3390/rs70201855 (2015).
Li, X. & Zhou, Y. A stepwise calibration of global dmsp/ols stable nighttime light data (1992-2013). Remote Sensing 9, 637, https://doi.org/10.3390/rs9060637 (2017).
Yang, M., Wang, S.-x, Zhou, Y. & Wang, L.-t Review on applications of dmsp/ols night-time emissions data. Remote Sensing Technology and Application 26, 45–51, https://doi.org/10.3724/SP.J.1011.2011.00403 (2011).
Jiang, W. et al. Potentiality of using luojia 1-01 nighttime light imagery to investigate artificial light pollution. Sensors 18, 2900, https://doi.org/10.3390/s18092900 (2018).
Guk, E. & Levin, N. Analyzing spatial variability in night-time lights using a high spatial resolution color jilin-1 image-jerusalem as a case study. ISPRS Journal of Photogrammetry and Remote Sensing 163, 121–136, https://doi.org/10.1016/j.isprsjprs.2020.02.016 (2020).
Guo, H. et al. Sdgsat-1: the world’s first scientific satellite for sustainable development goals. Science Bulletin 68, 34–38, https://doi.org/10.1016/j.scib.2022.12.014 (2023).
Chen, Z. et al. An extended time-series (2000-2018) of global npp-viirs-like nighttime light data from a cross-sensor calibration. Earth System Science Data Discussions 1–34, https://doi.org/10.5194/essd-2020-201 (2020).
Jeswani, R., Kulshrestha, A., Gupta, P. K. & Srivastav, S. Evaluation of the consistency of dmsp-ols and snpp-viirs night-time light datasets. J. Geomat 13, 98–105 (2019).
Li, X., Li, D., Xu, H. & Wu, C. Intercalibration between dmsp/ols and viirs night-time light images to evaluate city light dynamics of syria’s major human settlement during syrian civil war. International Journal of Remote Sensing 38, 5934–5951 (2017).
Xie, Y. & Weng, Q. Detecting urban-scale dynamics of electricity consumption at chinese cities using time-series dmsp-ols (defense meteorological satellite program-operational linescan system) nighttime light imageries. Energy 100, 177–189, https://doi.org/10.1016/j.energy.2016.01.058 (2016).
Levin, N. et al. Remote sensing of night lights: A review and an outlook for the future. Remote Sensing of Environment 237, 111443, https://doi.org/10.1016/j.rse.2019.111443 (2020).
Zhao, M. et al. Building a series of consistent night-time light data (1992-2018) in southeast asia by integrating dmsp-ols and npp-viirs. IEEE Transactions on Geoscience and Remote Sensing 58, 1843–1856, https://doi.org/10.1109/TGRS.2019.2949797 (2019).
Zhang, Q., Pandey, B. & Seto, K. C. A robust method to generate a consistent time series from dmsp/ols nighttime light data. IEEE Transactions on Geoscience and Remote Sensing 54, 5821–5831, https://doi.org/10.1109/TGRS.2016.2572724 (2016).
Chen, Z. et al. An extended time series (2000–2018) of global npp-viirs-like nighttime light data from a cross-sensor calibration. Earth System Science Data 13, 889–906, https://doi.org/10.5194/essd-13-889-2021 (2021).
Group)., E. E. O. DMSP Documents (https://eogdata.mines.edu/products/dmsp, 2023).
LeCun, Y. & Bengio, Y. Convolutional networks for images, speech, and time series. The handbook of brain theory and neural networks 3361, 1995 (1995).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. nature 521, 436–444 (2015).
Goodfellow, I., Bengio, Y., Courville, A. & Bengio, Y.Deep learning, vol. 1 (MIT press Cambridge, 2016).
Srivastava, N., Mansimov, E. & Salakhudinov, R. Unsupervised learning of video representations using lstms. In International conference on machine learning, 843–852.
Shi, X. et al. Convolutional lstm network: A machine learning approach for precipitation nowcasting. Advances in neural information processing systems 28, 802–810, https://doi.org/10.1007/978-3-319-21233-3_6 (2015).
Lotter, W., Kreiman, G. & Cox, D. Deep predictive coding networks for video prediction and unsupervised learning. arXiv preprint arXiv:1605.08104 (2016).
Wang, Y., Long, M., Wang, J., Gao, Z. & Yu, P. S. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms. Advances in Neural Information Processing Systems 30, 879–888 (2017).
Wang, Y. et al. Memory in memory: A predictive neural network for learning higher-order non-stationarity from spatiotemporal dynamics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 9154–9162, https://doi.org/10.1109/cvpr.2019.00937.
Meng, L. et al. Interpretable spatio-temporal attention for video action recognition. In Proceedings of the IEEE international conference on computer vision workshops, 0–0.
Vaswani, A. et al. Attention is all you need. In Advances in neural information processing systems, 5998–6008, https://doi.org/10.5040/9781350101272.00000005.
Zheng, J. et al. Cross-regional oil palm tree counting and detection via a multi-level attention domain adaptation network. ISPRS Journal of Photogrammetry and Remote Sensing 167, 154–177 (2020).
Zhang, L. et al. A prolonged artificial nighttime-light dataset of china (1984-2020). National Tibetan Plateau/Third Pole Environment Data Center https://doi.org/10.11888/Socioeco.tpdc.271202 (2021).
Acknowledgements
Bing Xu, Zhehao Ren, Bin Chen, and Peng Gong were partially supported by the the Open Research Program of the International Research Center of Big Data for Sustainable Development Goals (CBAS2022ORPO2), the National Natural Science Foundation of China (No. U1839206, 41871331, 41801343), the National Key Research and Development Plan of China (No. 2022YFE0209300). Haohuan Fu and Lixian Zhang were partially supported by the National Natural Science Foundation of China (Grant No. T2125006), Jiangsu Innovation Capacity Building Program (Project No. BM2022028).
Author information
Authors and Affiliations
Contributions
Lixian Zhang: Conceptualization, Methodology, Software, Validation, Formal analysis, Visualization, Writing Zhehao Ren: Conceptualization, Methodology, Resources, Validation, Formal analysis, Writing, Visualization Bin Chen: Review & Editing Peng Gong: Review & Editing Haohuan Fu: Review, Editing, Formal analysis, Funding acquisition, Supervision. Bing Xu: Review, Editing, Formal analysis, Funding acquisition, Supervision.
Corresponding authors
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, L., Ren, Z., Chen, B. et al. A Prolonged Artificial Nighttime-light Dataset of China (1984-2020). Sci Data 11, 414 (2024). https://doi.org/10.1038/s41597-024-03223-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03223-1
