
Abstract
Paleoclimatic data are used in eco-evolutionary models to improve knowledge of biogeographical processes that drive patterns of biodiversity through time, opening windows into past climate–biodiversity dynamics. Applying these models to harmonised simulations of past and future climatic change can strengthen forecasts of biodiversity change. StableClim provides continuous estimates of climate stability from 21,000 years ago to 2100 C.E. for ocean and terrestrial realms at spatial scales that include biogeographic regions and climate zones. Climate stability is quantified using annual trends and variabilities in air temperature and precipitation, and associated signal-to-noise ratios. Thresholds of natural variability in trends in regional- and global-mean temperature allow periods in Earth’s history when climatic conditions were warming and cooling rapidly (or slowly) to be identified and climate stability to be estimated locally (grid-cell) during these periods of accelerated change. Model simulations are validated against independent paleoclimate and observational data. Projections of climatic stability, accessed through StableClim, will improve understanding of the roles of climate in shaping past, present-day and future patterns of biodiversity.
Measurement(s) | climate change • climate • temperature of air • volume of hydrological precipitation |
Technology Type(s) | computational modeling technique • digital curation |
Factor Type(s) | timing of temperature and precipitation estimates |
Sample Characteristic - Environment | climate system |
Sample Characteristic - Location | Earth (planet) |
Machine-accessible metadata file describing the reported data: https://doi.org/10.6084/m9.figshare.12831935
Similar content being viewed by others


Background & Summary
A stronger understanding of the relationships between past climatic change and contemporary geographic distributions, and abundances of species, and ecosystem structure and function, can improve capacities to anticipate, and potentially manage responses of biodiversity to rapid future climate change, and global change more generally1,2. Interdisciplinary approaches that combine macroecological models with inferences from paleoclimate simulations, paleoecology, and paleogenomics are opening windows into climate–biodiversity dynamics during the late Quaternary3,4. This research has shown that a primary factor constraining the distributions and diversity of species at macro-scales is climate stability5,6,7, with hotspots of biodiversity often occurring in regions that have experienced stable temperatures and variable rates of precipitation during the late Pleistocene and Holocene8,9,10,11.
Unravelling the mechanisms that have shaped ancient and current-day patterns of biodiversity requires spatially detailed and temporally consistent datasets of paleo climatic change4. While there is a growing library of high spatial and temporal resolution paleo climate datasets available to researchers12,13,14, issues relating to spatiotemporal coverage and continuity persist. Furthermore, a lack of paleo climate simulations harmonised (i.e., consistently spatially and temporally blended to) with independently derived future projections is preventing a wider integration of paleo-archives and paleo perspectives in model projections of future biodiversity change. Missed opportunities include providing the context and tools needed to guide conservation decisions regarding desired states of ecological systems under global warming15,16. Although there have been attempts to overcome this problem17,18,19, a lack of spatial and temporal continuity in simulations that extend from the past into the future remains14.
Blended data on centennial trends and variability of temperature and precipitation are needed to calculate consistent spatiotemporal changes in climatic stability from the Last Glacial Maximum to the end of the 21st century, enabling the eco-evolutionary impacts of climate change to be quantified8. Here we provide continuous gridded global-scale estimates of centennial trend, variability, and signal-to-noise ratio (SNR) in temperature and precipitation between 21,000 B.P. and 2100 C.E. We do this by harmonising, at 2.5° spatial resolution (~278 km at the equator), three distinct data sets: paleoclimate simulations from the TraCE-21ka coupled atmosphere-ocean-general-circulation-model (AOGCM)20,21, historical runs from 19 CMIP5 AOGCMs, and future projections from the same CMIP5 19 AOGCMs under 4 Representative Concentration Pathways (RCPs)22,23.
We use pre-industrial control runs from CMIP5 AOGCMs to define thresholds that can be used to identify centuries of past and future rapid high magnitude temperature change at global and regional scales. We do this separately for terrestrial and ocean realms, for distinct IPCC AR5 climatic regions24, and for terrestrial zoogeographic realms25. These thresholds enable users to subset StableClim to periods of rapid warming (or cooling) at global and/or regional scales25, allowing rapid climate change events26 that occurred in the past to be identified in space and time and compared directly with those projected for the future. Regions that experienced past climate shifts that are of similar magnitude to future forecasts provide locations where geohistorical data can be used to better derive and strengthen conservation management and policy through improved knowledge of biotic responses to climatic stressors2, and for connecting theory to the on-ground design and implementation of effective measures to protect biodiversity27.
StableClim also includes continuous coverage of gridded monthly-mean temperature and total monthly precipitation between 1850 and 2100 at monthly time-step with 2.5° × 2.5° spatial resolution. When combined with PaleoView28 this provides users with more than 21,100 years of harmonised monthly temperature and precipitation climatic data. This feature, allows end-users to generate alternative measures of climate stability, including climate velocity29, for the past and the future at temporal scales different to those provided in StableClim.
Methods
Overview
An overview of the design of StableClim is provided in Fig. 1. Broadly, 19 Atmosphere-Ocean General Circulation Models (AOGCMs), from the Coupled Model Inter-comparison Project phase 5 (CMIP5)30 were used to calculate continuous estimates of trend, variability, and signal-to-noise ratios (SNR) in pre-industrial control, historical, and future climates under four different emissions scenarios. Simulated climate data from the TraCE-21ka20 experiment was used to calculate the same metrics for paleo climates since the Last Glacial Maximum. Global and regional estimates of trend for pre-industrial control temperatures can be used to identify past and future extreme centennial conditions.

Overview of the StableClim database. Simulated climate data for temperature and precipitation for pre-industrial, past, historical, and future climates come from 19 CMIP5 climate models (a). Paleo climatic conditions come from the TRaCE-21ka simulation. One-hundred-year trends in mean temperature for the past, historical, and future climates are provided at global and regional scales (b). Gridded datasets (n = 10,368 cells) of trend, variability, and signal to noise-ratio for the past, historical, and future climates are provided at global scales (c). Thresholds are used to identify past and future periods of rapid warming and cooling and stable climatic periods based on natural variability from the pre-industrial control runs (d). Thresholds are applied to the continuous grid-based trends, variability, and signal-to-noise ratio (21,000 B.P. to 100 C.E.), allowing estimates of climatic stability during specific periods in Earth’s history and potential future (e).
Pre-industrial, paleo, historical, and future climate data
Data access
Pre-industrial, historical, and future climate datasets with global coverages of modelled monthly-mean surface temperature, and monthly precipitation were extracted from the CMIP5 Earth System Grid Federation data portal (https://esgf-node.llnl.gov/projects/esgf-llnl/) using customised bash scripts (available from https://github.com/GlobalEcologyLab/ESGF_ClimateDownloads). Paleoclimate data from the TraCE-21ka experiment was extracted from PaleoView28 at a monthly time-step for the period 21,000 B.P. to 100 B.P. (1850 C.E.).
We used four different modelled climate datasets to generate the climate data compiled in StableClim (Fig. 1):
-
(1)
Pre-industrial control runs for 19 AOGCMs from CMIP5 were used to quantify natural climate variability,
-
(2)
Paleoclimate simulations from the TraCE-21ka experiment were used. TraCE-21ka simulations were done with the Community Climate System Model ver. 3 (CCSM3)31,32,
-
(3)
Historical simulations (1850–2005 generally) from the same 19 CMIP5 AOGCM’s that were used to generate the pre-industrial control climates25,
-
(4)
Representative Concentration Pathway (RCP)22,23 2.6, 4.5, 6.0, and 8.5 runs for the same 19 CMIP5 AOGCM’s used to generate pre-industrial control climates.
While the chosen RCP scenarios are four of hundreds of future climate scenarios currently available, they span a wide range of possibilities. RCP 8.5 and RCP 6.0 are commonly thought to represent “Business As Usual” scenarios (i.e., with no new mitigation policies), whilst RCP 4.5 and RCP 2.6 are within the spectrum of mitigation policy scenarios.
Pre-industrial climate
Pre-industrial control runs are multi-century unforced climate simulations, where the initial model conditions are set based on atmospheric gas concentrations prior to large-scale industrialisation25. They have non-evolving boundary conditions (e.g. non-evolving land use and greenhouse gas concentrations) relevant to the chosen start year25 and ignore natural forcing effects such as those caused by variations in the Sun’s output, and relatively short-term cooling of explosive volcanic eruptions. They therefore capture only internally-generated variability. We elected to use only the first realisation (r1i1p1) from each model for the pre-industrial control runs as all models, with the exception of the Community Climate System Model ver. 4 (CCSM4)33, only had a single realisation (i.e. a single set of initial conditions). The additional pre-industrial realisations (r2i1p1 and r3i1p1) for the CCSM4 model were too short to be used. The shortest duration pre-industrial control run used in this analysis was 240 years (HadGEM2-CC; see Online-only Table 1).
Paleoclimate
The TraCE-21ka experiment was chosen to represent paleo-climate conditions because (i) the data are available at a high temporal (monthly) and moderate spatial (2.5° × 2.5°) resolution with global coverage28; and (ii) the model has been independently validated at multiple temporal and spatial scales28,34,35,36. These independent validations have shown that the TraCE-21ka model effectively reconstructs important regional-to-global paleoclimatic fluctuations during the last deglaciation event28,34,35,36 and accurately simulates present-day climate patterns28.
Historical climate
The historical simulations cover the period 1850–2005 (in some extended cases they continue to 2012), with the beginning of the modelling period occurring before significant anthropogenic forcing and climate change. The historical climate simulations allow simulated climatic conditions to be validated against observed datasets25. The historical simulations differ from the pre-industrial control conditions as they are forced by observed atmospheric composition changes and aerosol emissions (for both anthropogenic and natural sources) and include the effects of solar irradiance variations and major volcanic eruptions, and time-evolving land and sea-ice cover. All available model realisations were used for the historical period as there can be significant differences in trends due to internal climate variability in the models37. We chose to include all model realisations, as there is no way to determine which of the realisations should be preferred over others, and each realisation will lead to a slightly different climate state38. For example, all members within an ensemble of historical runs (e.g. CCSM4 r1i1p1, r2i1p1, r3i1p1) are forced in the same way, but each is initiated at a different point in the pre-industrial control run25. The differences in initial conditions result in different trajectories, and multi-realisation averaging reduces this “noise”39.
Future climate
The RCP scenarios describe a set of possible climate outcomes as a result of changes in emissions, land use, and sea-ice developed specifically to allow assessment of future climates over a wide range of warming scenarios23. The RCP numerical designation indicates the radiative forcing level reached at the end of the century (e.g. RCP 8.5 is a high emissions warming scenario with radiative forcing level reaching approximately 8.5 W/m2 by 2100)23. The two intermediate scenarios feature a peak-and-stabilise scenario, whereby the radiative warming peaks at the given level before stabilising by 2100 (RCP 4.5) or shortly thereafter (RCP 6.0). The low emissions RCP 2.6 scenario has radiative forcing peaking in the middle of the 21st century before decreasing to an eventual nominal level of 2.6 W/m2 23. As with the historical climate simulations, assessment of the RCP scenarios utilised all available model realisations to reduce inter-model noise in the ensemble average.
Pre-processing of climate data
To address the different temporal extents and spatial resolutions of the AOGCMs used to generate StableClim, a number of pre-processing steps were required to ensure that the different datasets were consistently blended to have an adjoining timeframe for the period of interest, and that the data were on a spatially consistent grid. Pre-processing was performed using the Climate Data Operators (version 1.9.3) software40.
Modelled years for TraCE-21ka simulations were constrained to the period 21,000 B.P. to 100 B.P. (1850 C.E.) to limit the influence of wide scale industrialisation on the paleoclimate simulations41. The start-date for the CMIP5 historical simulations is 1850. An end-date of 2005 was chosen because of the low number of models (n = 3; BCC-CSM1.1, CNRM-CM5, and MIROC5) with simulations extending beyond this time period. The RCP scenarios simulate possible future climates between 2005 and 2100 and are initialised using the climate conditions at the end of the historical period (2005). As the RCP simulations are essentially continuations of the historical simulations23 and we needed to have continuous centennial trends between the paleo, historical, and future periods, we temporally harmonised the historical and RCP simulations. Following Santer, et al.42 we spliced the historical simulations to the beginning of the RCP simulations ensuring that the realisations matched so that there were no differences in simulation forcings (e.g. CCSM-4 historical r1i1p1 was matched to CCSM-4 RCP r1i1p1). To account for intra-model variability, each model (e.g. CCSM-4) was then averaged across all realisations within that model to produce a multi-realisation model average.
To enable spatially consistent comparisons with the TraCE-21ka simulation, the CMIP5 data were re-gridded to a 2.5° × 2.5° (latitude/longitude) global grid using bilinear interpolation. Re-gridding of the CMIP5 datasets to match the resolution of the TraCE-21 data using bilinear interpolation was chosen because (i) the source and destination grids were rectilinear, (ii) precipitation and temperature in the climate models varies smoothly spatially, and (iii) bilinear interpolation (more or less) retains the integrity and limitations of the original model output data, where orography is highly smoothed relative to the real-world28. Furthermore, the 2.5° × 2.5° grid cell resolution corresponds to the resolution of the TraCE-21ka data as documented in PaleoView28, (bilinearly downscaled to 2.5° × 2.5° from its nominal original resolution of ~3.75°28), and the resolution of projections from MAGICC/SCENGEN43. Surface temperatures and precipitation were then converted to °C (from Kelvin) and mm/year (from kg m2 s1) respectively.
Calculating trends in global mean temperature
Continuous estimates of trends in global-mean temperature through time allow comparisons of rates of change during key periods in Earth’s history and those projected for the future (Fig. 2). Pre-industrial control-runs can be used as a baseline for identifying high magnitude and rapid changes in global mean temperature (“extreme” events) that occurred in the past and likely to occur in the future8,44 Accordingly, we determined linear trends in area-weighted global-mean surface temperature associated with natural variability45 for maximally overlapping century long windows for each of the CMIP5 pre-industrial control runs. This means that for a time series 1,2,3 … N, the 100-year windows would be years 1–100, 2–101, 3–103, etc. We calculated weighted global mean temperature for each year using the cosine of the latitude of the grid-cell centroids as weights.

Annual global mean temperature and trend in global mean temperature from the Last Glacial Maximum to the end of the 21st century. The Global mean temperature during the past as simulated by TraCE-21ka (a), and spliced historical/future climate simulations to 2100 (b). Trends in global mean temperature for past (c), historical to 2005 (d), and for the future under four different RCP scenarios (e). The individual lines in b show the multi-realisation model averages, with the bolder lines showing the multi-model ensemble average for the respective scenario. The shaded areas in b and d show the multi-model variability in global mean temperatures and trend estimates (±1 S.D.). The timesteps in c and d, show the end-year of the century window (e.g. 1950 = window from 1851:1950 C.E.). Values in e show slopes for 2006 to 2100 C.E. Note that the y-axis differs between all plots.
Trends for annual area-weighted global-mean temperatures were then calculated using Generalised Least Squares (GLS) regression with AR(1) errors. The GLS models were calculated using the ‘nlme’ package46 for R (version 3.5.1)47. GLS regression with an AR(1) error structure was chosen to minimise any effect of temporal auto-correlation in the model residuals46. The resulting global natural trends (i.e., the slope of the regression) for surface temperature were used to generate a multi-model, pre-industrial cumulative distribution function (CDF) using signed slopes.
Because the number of years varied between pre-industrial control runs from different AOGCMs (Online-only Table 1) we used a bootstrap procedure to ensure that all models had equal weights in the CDF (i.e. we did not want to bias the CDF towards models that had longer simulations, or higher/lower modelled global-mean temperatures). The bootstrap procedure for each model involved first selecting the slopes for all overlapping windows for a given model, and then randomly selecting slopes from that model (with replacement) equal to the difference between the number of overlapping windows for the model, and the maximum number of overlapping windows across all models (n = 952). For example, for model ACCESS 1.3 which has 500 years of simulated pre-industrial control conditions, the maximum number of overlapping centennial windows is 401. For the bootstrap procedure, slopes for the 401 overlapping windows were first selected, before 551 slopes were then selected randomly with replacement, giving 952 slope values. The bootstrap procedure was repeated 1000 times for each of the 19 models before building the CDF. This process ensured that all intra-model variability was accounted for, while the effect of longer simulation runs was eliminated.
For the past (21k B.P. – 1850 C.E.) and spliced historical/future climate (1850–2100 C.E.) we calculated trends in global-mean temperature using the methods described above (Fig. 2). However, we did not use a bootstrap approach because for the paleo period we only had a single simulation (TraCE-21ka), and the historical and future simulations were a multi-model ensemble average, subset to a consistent temporal window which negated the need for a bootstrap. Multi-model averages for the spliced historical/future climate were calculated by averaging across all multi-realisation model averages (n = 19, see Pre-processing of climate data). Whilst this approach may bias the results of models that have multiple realisations (as the intra-model variability is effectively reduced by averaging across realisations), it has been shown that the performance of multi-model ensemble averages improves with an increase in models, not realisations48. This process allowed us to effectively calculate robust measures of global mean temperature that accounted for intra- and inter-model variability37,42,49.
Calculating trends in regional mean temperature
We quantified linear trends in area-weighted regional-mean surface temperature associated with natural variability for maximally overlapping century long windows for each of the CMIP5 pre-industrial control runs. As for trends in global mean temperature (see above), we also calculated trends in regional-mean temperature for the past (21k B.P.–1850 C.E.) and spliced historical/future climate (1850–2100 C.E.). The regions were defined by 18 distinct IPCC AR5 climatic regions24, 19 Wallace Zoogeographic zones25, and 11 zoogeographic realms25. Temperatures were extracted for grid-cells inside the boundary of the region. Weights for the regions were calculated as above. The 18 IPCC AR5 climatic regions are an amalgamation of the terrestrial regions defined by Working Group 1 for the IPCC Fifth Assessment Report50. The Wallace Zoogeographic zones and realms follow Holt, et al.25 although the Polynesian zone was removed due to its small size (average island size in the Polynesian zone is ~118 km2, or approximately 0.15% of the area of our grid-cells). A geopackage of the IPCC regions, the Wallace zones, and the zoogeographic realms we used is available in StableClim.
Identifying thresholds of extreme climate change
To identify periods of rapid, medium and slow climate change at global and regional scales, we used the ensemble averaged bootstrapped pre-industrial CDF of trends in global/regional mean temperature at 1, 2.5, and 5% increments (e.g. 1%, 2.5%, 5%, 10%, 15%…90, 95%, 97.5%, 99%) to identify rates of change that correspond to different “thresholds” of stable climate (at lower thresholds) or rapid climate change (at higher thresholds)8,44. Based on Fordham, et al.44, we define a stable climate as having low rates of centennial change (i.e. low trend values), and an unstable climate as having high rates of centennial change. Notably, these definitions do not however preclude high inter-annual variability (i.e. high frequency climate instability) in ‘stable’ conditions or low inter-annual variability for ‘unstable’ conditions. The 90th percentile of the pre-industrial CDF has previously been used to identify periods of change in global mean temperature that had high absolute (i.e. unsigned) rates of climate change since 21,000 B.P.8,44,51.
Thresholds were calculated at a range of scales and for different regions and realms. For climate focused studies, thresholds are provided at regional scales using the IPCC AR5 climatic regions described above. For biogeographical or ecological focussed work, thresholds are provided at two scales: (i) 19 smaller scale Wallace Zoogeographic zones and (ii) 11 broader scale terrestrial zoogeographic realms, both described above.
Calculating local trends, variability, and SNR
Trend and the variability around the trend are the primary components of climate stability44, and they provide a distinction between low frequency (long term trend) and high frequency (inter-annual) climate stability. For both temperature and precipitation, we calculated ‘local’ measures of centennial linear trend (i.e. inter-centennial variability; low frequency climate in/stability) for each grid-cell (n = 10,368 cells) for the paleo, and the spliced historical/RCP simulations (Fig. 3). We also calculated grid-cell estimates of variability (i.e. inter-annual variability; high frequency climate in/stability), where variability was defined as the standard deviation of the residuals about the local trend52.

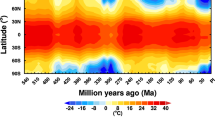
Maps of trend, variability, and signal to noise ratio (SNR) for temperature during periods of extreme global warming in the ocean and on land (≥90th percentile from pre-industrial conditions). Maps of centennial trend (a), inter-annual variability (b), and SNR (c). Rows represent rapid global warming events at different time periods/climate scenarios. Past = Bølling–Allerød (14.7-14.2k B.P.69); Historical = 1850 C.E.–2005 C.E.; RCP 2.6 & 4.5 = Representative Concentration Pathways 2.6 and 4.5 for 2001 C.E.–2100 C.E. Maps of the past and historical conditions are mean estimates for overlapping century windows during the relevant periods.
We also calculated a signal-to-noise ratio (SNR = abs(trend)/variability)53, for both temperature and precipitation. We opted to consider SNR in addition to trend and variability, because the SNR is a composite measure of the trend given background variability (Fig. 3). Furthermore, the SNR can be useful in comparing climate stability as a function of long-term trend and inter-annual variability at different locations and times8. For the spliced historical/future climates, estimates of trend, variability, and SNR were determined by averaging across all multi-realisation model averages.
Ensemble estimates of monthly temperature and precipitation
While our estimates of trend, variability, and SNR provide continuous global coverages for air temperature and precipitation from the Last Glacial Maximum to the end of the 21st Century at centennial time scales, we recognise that some researchers may want to work with datasets that cover different time periods, e.g. seasonal or decadal trends. Therefore, we also provide ensemble mean estimates of monthly temperature (°C) and precipitation (mm/day) for the historical and future climates at the same spatial resolution of our continuous trend, variability, and SNR estimates. These ensembles allow end users to create their own estimates of trend, variability, and SNR at time scales suitable for their purposes (e.g. seasonal or decadal). These ensemble means are provided only for the spliced historical/future climate period (1850–2100 C.E.). We opted not to provide ensemble means for the pre-industrial control runs as these simulations are not reconstructions of temporally explicit pre-industrial climate (unlike, e.g., TraCE-21ka), but are used to simulate internal model variability, which can be used as a proxy for natural (unforced) climate variability. When combined with the data in PaleoView, the historical/future ensemble means provide a spatiotemporally harmonised monthly temperature and precipitation climate dataset from 21,000 B.P. to 2100 C.E. Monthly ensembles were generated using CDO40, by averaging across all realisations within each model, and then across models, for each of the RCP scenarios.
Data Records
Access to StableClim is through figshare54. Dataframes for the results of the global and regional regressions under pre-industrial, past, and historical/RCP conditions are stored as data.tables47 in named lists in a compressed RDS format55. These are also provided as CSV files inside a tar.gz archive within StableClim. The gridded datasets have been created as NetCDF files. A geopackage containing the aggregated IPCC regions and the Wallace zoogeographic regions and realms can also be found in the ‘gpkg’ folder within StableClim. A tutorial showing how to extract and subset the data is also provided.
The naming convention for the results of the global and regional regressions is:
StableClim_ < scenario > _ < var > .RDS
where scenario is the name of the scenario (piControl, past, spliced historical), and var represent either global and regional regression thresholds for the pre-industrial control simulation, or the slopes for global/regional temperature regressions for the past and historical/RCP data.
The naming convention for the ensemble mean monthly data is:
StableClim_MonthlyEnsemble_ < scenario > _ < var > .nc
and for the regression files:
StableClim_Regression_ < scenario > _ < var > .nc
where scenario is the name of the scenario (past, spliced historical RCP 2.6–RCP 8.5), and var is pr (precipitation) or ts (air temperature).
The monthly ensemble temperature and precipitation have the following dimensions – 72 × latitude, 144 × longitude, 3012 × months. The units for the monthly ensembles are pr = mm/day, ts = °C. Each of the regression files contains three record variables: (1) = Trend, (2) = Variability, (3) = Signal:Noise ratio. These record variables have the following dimensions – 72 × latitude, 144 × longitude, and year [20,902 for the past, 251 for the historical/RCP]. Units for the regressions are pr = mm/year, ts = °C/year.
Multi-model median estimates of trend, variability, and SNR can be easily generated using the provided code. Likewise, regressions on bias corrected datasets for the past and historical/RCP simulations, can be easily generated by applying anomalies/bias corrections to the data as appropriate, before using the provided regression code.
Technical Validation
The TraCE-21ka simulation has previously been well validated across multiple spatial and temporal scales with regards to its ability to simulate known rapid climate change events28,34,35,36, and to accurately model contemporary climates28. As such, we have done no additional technical validation on the raw temperature or precipitation data extracted from the TraCE-21ka simulation. Validations have, however, been done on estimates of SNR (see below for details).
The CMIP5 pre-industrial and RCP simulations are built using the same model structure as for the historical simulations but with altered forcing and boundary conditions25. An assessment of agreement between historical multi-model ensemble-averaged projections of temperature and precipitation, and observed temperature and precipitation provides confidence that trends, variability, and SNR measures provided in StableClim are an accurate representation of recent and future climates28.
The thresholds of extreme change we provide to subset continuous estimates of global-mean temperature trend, variability, and SNR to periods of rapid climate change have been validated recently. Brown, et al.8 identified past centuries of rapid change in global-mean temperature, over the period 21,000 B.P. to 100 B.P. as those having absolute global-mean temperature trends greater than the 90th percentile of the pre-industrial control CDF. To check that their definition of rapid climate change was appropriate, they ran two tests: 1) Brown, et al.8 calculated the CDF for trends from the TraCE-21ka model and compared these to the CDF based on periods of rapid climate change from the pre-industrial control simulations; and 2) they determined the amount of time a calendar millennium was considered to be experiencing rapid rates of climate change by calculating the % of time that a millennium was characterised by trends ≥90th percentile of the pre-industrial control run trends. This confirmed that known large-scale climatic events during the last deglaciation (e.g. Bølling–Allerød) were being correctly identified as periods of rapid climate change in their analysis (see Supplementary Fig. 6 in Brown, et al.8). The tacit assumption made here is that changes in grid-cell temperatures (and variability) scale approximately linearly with changes in global-mean temperature.
Signal to noise ratio
To validate our method of calculating signal-to-noise ratio (SNR), we calculated estimates of SNR for Antarctica and Greenland using latitudinally weighted temperatures and compared these to estimates based on the Vostok56 and NGRIP57,58 ice-cores. The temporal resolution and timing of temperature estimates was matched between the TraCE-21 simulation and the ice-core data by sub-setting the (annual) TraCE-21 data to the same time steps as the Vostok (~150 years) and NGRIP data (~20 years). This allowed us to calculate estimates of SNR at centennial timescales between observed (ice-core) and simulated (TraCE-21) datasets that were directly comparable. Boxplots of SNR values for four different windows during which high and low magnitude climate fluctuations occurred at the poles (21-15k B.P.; 15-11k B.P.; 11-3k B.P.; >3k B.P.) were constructed for visual interpretation, before the SNR values were statistically compared using PERMDISP59 and PERMANOVA60 on a Euclidean distance matrix in PRIMER61 with the PERMANOVA+ addon62. The four different windows were chosen as there are known major rapid climate change events that occur within at least the first three windows: the oldest Dryas and the H1 Heinrich events occur in the period 21-15k63,64,65,66,67,68, the Bølling–Allerød, Antarctic Cold Reversal, Younger Dryas, and the 11.7 event occur in the period 15-11k63,64,67,69, and the 8.2k event occurs within the 11-3k window70. Both procedures had data source (TraCE-21 or ice-core) nested within window and used 999 permutations to generate P-values.
The PERMDISP results suggest there were significant differences in the dispersion of SNR values between sources (i.e. between the ice-core and simulated data) within windows for the Vostok core. However, after accounting for multiple comparisons71, only one of the results was considered significant (15-11k comparison, adj. P = 0.01). Likewise, unadjusted P-values were significant for comparisons between the NGRIP core and our simulated estimate of SNR, but after adjusting for multiple comparisons none of the results were considered significant (all P ≥ 0.45). These results suggest there were only significant differences in the dispersion of observed (Vostok) and simulated (TraCE-21) SNR during the period 15-11k B.P. The PERMANOVA results suggested significant differences between sources within window for the Vostok core (pseudo-F4,670 = 11.82, P = 0.001; Fig. 4), with pairwise comparisons confirming differences in the 15-11k (t = 3.16, adj. P = 0.008) and the 11-3k window (t = 2.81, adj. P = 0.013). There were no differences in the NGRIP ice core comparison (pseudo-F3,4 = 1.64, P = 0.188; Fig. 4). These results suggest significant differences in mean SNR values between the observed and simulated datasets only for the Antarctic region in the 15-11k and 11-3k windows. In other words, for the NGRIP-TraCE21 comparisons there were no statistically significant SNR differences, while for the comparisons with Vostok data, and in particular the 15-11k window, the results were more equivocal.

Validation of our modelled Signal-to-Noise ratio (SNR) against SNR calculated for the Vostok (a–d) and NGRIP (e–h) ice-cores56,57,58. Differences between the shape of the distributions and the SNR values were significant in b, with significant differences in mean SNR for b and c, but non-significant in all other windows based on PERMDISP and PERMANOVA results.
Multi-model temperature and precipitation ensembles
Our multi-model ensemble climate data was validated at global and regional scales for land surfaces only, at a spatial resolution of 2.5°. To validate our ensemble mean historical temperature and precipitation datasets, we extracted gridded high resolution (0.5° × 0.5°, monthly time step) data between 1901 and 2018 from the Climatic Research Unit (CRU) time-series database72. The data were re-gridded to the same 2.5 × 2.5° grid of our ensemble monthly estimates and converted to annual average temperature and average total monthly precipitation. Annual average climatologies for temperature and precipitation were then calculated for both the CMIP5 ensemble-mean historical dataset and the re-gridded CRU dataset, for a 50-yr period centered on 1980, globally and for a range of different regions.
To quantify the skill of our ensemble model to recreate observed temperature and precipitation conditions we used a combination of visual and statistical approaches. Figure 5 shows the relatively high pattern correlations and low standard deviations between our ensemble estimates and the re-gridded CRU data at a global scale73. The spread in inter-model correlations and standard deviations was, as expected, much higher for simulated precipitation than for temperature74. We also calculated a range of statistical metrics to quantify the relationship between our ensembled data and the CRU data, namely: Percentage bend correlation75, M-statistic76, latitudinally weighted Root-Mean-Square-Error, ratio-of-standard-deviations, modified index of agreement77, and percentage bias. These metrics were calculated globally and for four latitudinal bands: High-North (50°N–90°N), Mid-North (20°N–50°N), Mid-South (50°S–20°S) and the High-Tropics (20°S–20°N)8,28. Five IPCC AR5 regions24 and 4 biogeographic realms25 were also included in the validation (Table 1). All correlations were significant at P < 0.001 with correlation coefficient ranging between 0.67 (Neotropical realm) and 0.99 (Table 1, Fig. 6). The M-statistic ranged between 40.5 and 91.3, with no clear relationship between scale and the resultant score indicating the ensemble estimate of climate has varying capacities to simulate observed conditions independent of scale. Percentage bias in precipitation varied between −3.4 and 31.5% with the lowest values occurring in the tropics and the Mediterranean (Table 1). The ensemble mean precipitation was shown to over-estimate precipitation across all latitudinal bands. On average, over a range of spatial scales, precipitation was overestimated by ~11%.

Taylor diagram showing the relationship between ensemble estimates of temperature (green points), precipitation (blue points), and the CRU TS v. 4.03 dataset (orange point) for a 50-yr period centered on 1980 calculated at global extent. Each circle represents a different model, with ensemble means shown by the triangles. The reference (CRU) climatology is shown by the orange circle, with SD values normalised to 1.

Comparison of simulated and observed historical temperatures and precipitation. Simulated data are ensemble mean estimates and observed data are from the CRU TS v. 4.03 dataset. Comparisons are shown for different latitudes for a 50-yr period centered on 1980. High-north (50°:90°; a,b), Mid-north (20°:50°; c,d), High-tropics (−20°:20°; e,g), and Mid-south (−20°:−50°; g,h). All percentage bend correlations are significant at P < 0.001.
Usage Notes
To further account for the large inter-model differences in spatial resolution, forcings, physics, and sensitivities within each of the AOGCMS43, we recommend using pattern scaling approaches78 where local (cell-based) “raw” trends in temperature and precipitation are standardised by the trend in global-mean temperature for the matching window. This technique has been applied previously8,44,51. Due to the method of calculating Signal-to-Noise ratio we recommend inspecting the individual trend and variability components when interpreting analyses on SNR (Fig. 3). See Brown, et al.8 for an analysis which classifies trend and variability into a range of classes representing different qualitative levels of climate stability. See Supplementary File 1 for an example analysis which involves subsetting the data to periods of regionally rapid climate change, pattern scaling the trends and producing maps of trend, variability, and SNR.
Code availability
Code used to generate and validate StableClim is available at https://github.com/GlobalEcologyLab/StableClim, with bash scripts to download the CMIP5 data from ESGF available at https://github.com/GlobalEcologyLab/ESGF_ClimateDownloads.
References
Fordham, D. A., Brook, B. W., Moritz, C. & Nogues-Bravo, D. Better forecasts of range dynamics using genetic data. Trends Ecol. Evol. 29, 436–443, https://doi.org/10.1016/j.tree.2014.05.007 (2014).
Fordham, D. A. et al. Using paleo-archives to safeguard biodiversity under climate change. Science, https://doi.org/10.1126/science.abc5654 (2020).
Nogués-Bravo, D. et al. Cracking the code of biodiversity responses to past climate change. Trends Ecol. Evol. 33, 765–776, https://doi.org/10.1016/j.tree.2018.07.005 (2018).
Fordham, D. A. & Nogues-Bravo, D. Open-access data is uncovering past responses of biodiversity to global environmental change. PAGES 26, 77–77, https://doi.org/10.22498/pages.26.2.77 (2018).
Fine, P. V. A. Ecological and evolutionary drivers of geographic variation in species diversity. Annu. Rev. Ecol. Evol. Syst. 46, 369–392, https://doi.org/10.1146/annurev-ecolsys-112414-054102 (2015).
Rangel, T. F. et al. Modeling the ecology and evolution of biodiversity: biogeographical cradles, museums, and graves. Science 361, eaar5452, https://doi.org/10.1126/science.aar5452 (2018).
Lister, A. M. & Stuart, A. J. The impact of climate change on large mammal distribution and extinction: Evidence from the last glacial/interglacial transition. C. R. Geosci. 340, 615–620, https://doi.org/10.1016/j.crte.2008.04.001 (2008).
Brown, S. C., Wigley, T. M. L., Otto-Bliesner, B. L., Rahbek, C. & Fordham, D. A. Persistent quaternary climate refugia are hospices for biodiversity in the anthropocene. Nat. Clim. Change., https://doi.org/10.1038/s41558-019-0682-7 (2020).
Fjeldså, J. & Lovett, J. C. Geographical patterns of old and young species in African forest biota: The significance of specific montane areas as evolutionary centres. Biodivers. Conserv. 6, 325–346, https://doi.org/10.1023/A:1018356506390 (1997).
Haffer, J. Speciation in Amazonian forest birds. Science 165, 131–137, https://doi.org/10.1126/science.165.3889.131 (1969).
Harrison, S. & Noss, R. Endemism hotspots are linked to stable climatic refugia. Ann. Bot. 119, 207–214, https://doi.org/10.1093/aob/mcw248 (2017).
Armstrong, E., Hopcroft, P. O. & Valdes, P. J. A simulated northern hemisphere terrestrial climate dataset for the past 60,000 years. Sci. Data 6, 265, https://doi.org/10.1038/s41597-019-0277-1 (2019).
Brown, J. L., Hill, D. J., Dolan, A. M., Carnaval, A. C. & Haywood, A. M. Paleoclim, high spatial resolution paleoclimate surfaces for global land areas. Sci. Data 5, 180254, https://doi.org/10.1038/sdata.2018.254 (2018).
Lorenz, D. J., Nieto-Lugilde, D., Blois, J. L., Fitzpatrick, M. C. & Williams, J. W. Downscaled and debiased climate simulations for north america from 21,000 years ago to 2100 AD. Sci. Data 3, 160048, https://doi.org/10.1038/sdata.2016.48 (2016).
Barnosky, A. D. et al. Merging paleobiology with conservation biology to guide the future of terrestrial ecosystems. Science 355, https://doi.org/10.1126/science.aah4787 (2017).
Nogués-Bravo, D. et al. Amplified plant turnover in response to climate change forecast by late quaternary records. Nat. Clim. Change. 6, 1115–1119, https://doi.org/10.1038/nclimate3146 (2016).
Maiorano, L. et al. Building the niche through time: Using 13,000 years of data to predict the effects of climate change on three tree species in Europe. Global Ecol. Biogeogr. 22, 302–317, https://doi.org/10.1111/j.1466-8238.2012.00767.x (2013).
Blois, J. L., Zarnetske, P. L., Fitzpatrick, M. C. & Finnegan, S. Climate change and the past, present, and future of biotic interactions. Science 341, 499, https://doi.org/10.1126/science.1237184 (2013).
Lima-Ribeiro, M. S. et al. Ecoclimate: A database of climate data from multiple models for past, present, and future for macroecologists and biogeographers. Biodiversity Informatics 10, 1–21, https://doi.org/10.17161/bi.v10i0.4955 (2015).
Liu, Z. et al. Transient simulation of last deglaciation with a new mechanism for Bølling–Allerød warming. Science 325, 310–314, https://doi.org/10.1126/science.1171041 (2009).
Otto-Bliesner, B. L. et al. Coherent changes of southeastern equatorial and northern African rainfall during the last deglaciation. Science 346, 1223, https://doi.org/10.1126/science.1259531 (2014).
Meinshausen, M. et al. The RCP greenhouse gas concentrations and their extensions from 1765 to 2300. Clim. Change 109, 213–241, https://doi.org/10.1007/s10584-011-0156-z (2011).
van Vuuren, D. P. et al. The representative concentration pathways: An overview. Clim. Change 109, 5–31, https://doi.org/10.1007/s10584-011-0148-z (2011).
van Oldenborgh, G. J. et al. In Climate Change 2013: The Physical Science Basis. Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change (eds Stocker, T. F. et al.) 1311–1393 (Cambridge University Press, Cambridge, United Kingdom, 2013).
Holt, B. G. et al. An update of Wallace’s zoogeographic regions of the world. Science 339, 74, https://doi.org/10.1126/science.1228282 (2013).
Botta, F., Dahl-Jensen, D., Rahbek, C., Svensson, A. & Nogues-Bravo, D. Abrupt change in climate and biotic systems. Curr. Biol. 29, R1045–R1054, https://doi.org/10.1016/j.cub.2019.08.066 (2019).
Fordham, D. A. et al. Predicting and mitigating future biodiversity loss using long-term ecological proxies. Nat. Clim. Change. 6, 909–916, https://doi.org/10.1038/nclimate3086 (2016).
Fordham, D. A. et al. Paleoview: A tool for generating continuous climate projections spanning the last 21 000 years at regional and global scales. Ecography 40, 1348–1358, https://doi.org/10.1111/ecog.03031 (2017).
Fordham, D. A., Saltré, F., Brown, S. C., Mellin, C. & Wigley, T. M. L. Why decadal to century timescale palaeoclimate data are needed to explain present-day patterns of biological diversity and change. Global Change Biol. 24, 1371–1381, https://doi.org/10.1111/gcb.13932 (2018).
Taylor, K. E., Stouffer, R. J. & Meehl, G. A. An overview of CMIP5 and the experiment design. Bull. Amer. Meteor. 93, 485–498, https://doi.org/10.1175/Bams-D-11-00094.1 (2012).
Otto-Bliesner, B. L. et al. Climate sensitivity of moderate- and low-resolution versions of CCSM3 to preindustrial forcings. J. Clim. 19, 2567–2583, https://doi.org/10.1175/Jcli3754.1 (2006).
Collins, W. D. et al. The community climate system model version 3 (CCSM3). J. Clim. 19, 2122–2143, https://doi.org/10.1175/jcli3761.1 (2006).
Gent, P. R. et al. The community climate system model version 4. J. Clim. 24, 4973–4991, https://doi.org/10.1175/2011jcli4083.1 (2011).
Barker, S. et al. Interhemispheric Atlantic seesaw response during the last deglaciation. Nature 457, 1097–1102, https://doi.org/10.1038/nature07770 (2009).
Carlson, A. E. In The encyclopedia of quaternary science Vol. 3 (ed Elias, S. A.) 126–134 (Elsevier, Amsterdam, 2013).
Marsicek, J., Shuman, B. N., Bartlein, P. J., Shafer, S. L. & Brewer, S. Reconciling divergent trends and millennial variations in holocene temperatures. Nature 554, 92, https://doi.org/10.1038/nature25464 (2018).
Deser, C., Knutti, R., Solomon, S. & Phillips, A. S. Communication of the role of natural variability in future north American climate. Nat. Clim. Change. 2, 775, https://doi.org/10.1038/nclimate1562 (2012).
Lutz, A. F. et al. Selecting representative climate models for climate change impact studies: An advanced envelope-based selection approach. Int. J. Climatol. 36, 3988–4005, https://doi.org/10.1002/joc.4608 (2016).
Tebaldi, C. & Knutti, R. The use of the multi-model ensemble in probabilistic climate projections. Philos. T. R. Soc. A. 365, 2053–2075, https://doi.org/10.1098/rsta.2007.2076 (2007).
Schulzweida, U. CDO user guide (version 1.9.3). https://doi.org/10.5281/zenodo.3539275, (2019).
Kaplan, J. O. et al. Holocene carbon emissions as a result of anthropogenic land cover change. Holocene 21, 775–791, https://doi.org/10.1177/0959683610386983 (2011).
Santer, B. D. et al. Identifying human influences on atmospheric temperature. Proc. Natl. Acad. Sci. USA 110, 26–33, https://doi.org/10.1073/pnas.1210514109 (2013).
Fordham, D. A., Wigley, T. M. L., Watts, M. J. & Brook, B. W. Strengthening forecasts of climate change impacts with multi-model ensemble averaged projections using MAGICC/SCENGEN 5.3. Ecography 35, 4–8, https://doi.org/10.1111/j.1600-0587.2011.07398.x (2012).
Fordham, D. A., Brown, S. C., Wigley, T. M. L. & Rahbek, C. Cradles of diversity are unlikely relics of regional climate stability. Curr. Biol. 29, R356–R357, https://doi.org/10.1016/j.cub.2019.04.001 (2019).
Sen Gupta, A., Jourdain, N. C., Brown, J. N. & Monselesan, D. Climate drift in the CMIP5 models. J. Clim. 26, 8597–8615, https://doi.org/10.1175/Jcli-D-12-00521.1 (2013).
Pinheiro, J., Bates, D., DebRoy, S., Sarkar D. & R Core Team nlme: linear and nonliner mixed effects models, https://CRAN.R-project.org/package=nlme (2017).
R Core Team R: A language and environment for statistical computing https://www.R-project.org/ (R Foundation for Statistical Computing, Vienna, Austria, 2018).
Pierce, D. W., Barnett, T. P., Santer, B. D. & Gleckler, P. J. Selecting global climate models for regional climate change studies. Proc. Natl. Acad. Sci. USA 106, 8441, https://doi.org/10.1073/pnas.0900094106 (2009).
Hawkins, E. & Sutton, R. Time of emergence of climate signals. Geophys. Res. Lett. 39, https://doi.org/10.1029/2011gl050087 (2012).
IPCC Climate Change 2013: The Physical Science Basis. Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change (eds Stocker, T. F. et al.) 1535 (Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA, 2013).
Theodoridis, S. et al. Evolutionary history and past climate change shape the distribution of genetic diversity in terrestrial mammals. Nat. Commun., https://doi.org/10.1038/s41467-020-16449-5 (2020).
Nadeau, C. P., Urban, M. C. & Bridle, J. R. Coarse climate change projections for species living in a fine-scaled world. Globl Chang Biol 23, 12–24, https://doi.org/10.1111/gcb.13475 (2017).
Frame, D., Joshi, M., Hawkins, E., Harrington, L. J. & de Roiste, M. Population-based emergence of unfamiliar climates. Nat. Clim. Change. 7, 407, https://doi.org/10.1038/Nclimate3297 (2017).
Brown, S. C., Wigley, T. M. L., Otto-Bliesner, B. L. & Fordham, D. A., StableClim. The University of Adelaide https://doi.org/10.25909/5ea59831121bc (2020).
Dowle, M. & Srinivasan, A. data.table: extension of ‘data.frame’, https://CRAN.R-project.org/package=data.table (2019).
Petit, J. R. et al. Climate and atmospheric history of the past 420,000 years from the Vostok ice core, Antarctica. Nature 399, 429–436, https://doi.org/10.1038/20859 (1999).
Andersen, K. K. et al. The Greenland ice core chronology 2005, 15–42ka. Part 1: Constructing the time scale. Quat. Sci. Rev. 25, 3246–3257, https://doi.org/10.1016/j.quascirev.2006.08.002 (2006).
Rasmussen, S. O. et al. Synchronization of the NGRIP, GRIP, and GISP2 ice cores across MIS 2 and palaeoclimatic implications. Quat. Sci. Rev. 27, 18–28, https://doi.org/10.1016/j.quascirev.2007.01.016 (2008).
Anderson, M. J. Distance-based tests for homogeneity of multivariate dispersions. Biometrics 62, 245–253, https://doi.org/10.1111/j.1541-0420.2005.00440.x (2006).
Anderson, M. J. A new method for non-parametric multivariate analysis of variance. Austral Ecol. 26, 32–46, https://doi.org/10.1111/j.1442-9993.2001.01070.pp.x (2001).
Clarke, K. R. & Gorley, R. N. PRIMER v6: User manual/tutorial. (PRIMER-E, Plymouth, 2006).
Anderson, M. J., Gorley, R. N. & Clarke, K. R. Permanova+ for PRIMER: Guide to software and statistical methods. (PRIMER-E, Plymouth, 2008).
Clark, P. U. et al. Global climate evolution during the last deglaciation. Proc. Natl. Acad. Sci. USA 109, E1134, https://doi.org/10.1073/pnas.1116619109 (2012).
Liu, Z. et al. Younger Dryas cooling and the Greenland climate response to CO2. Proc. Natl. Acad. Sci. USA, https://doi.org/10.1073/pnas.1202183109 (2012).
McManus, J. F., Francois, R., Gherardi, J. M., Keigwin, L. D. & Brown-Leger, S. Collapse and rapid resumption of atlantic meridional circulation linked to deglacial climate changes. Nature 428, 834–837, https://doi.org/10.1038/nature02494 (2004).
Peck, V. L. et al. The relationship of Heinrich events and their European precursors over the past 60ka BP: A multi-proxy ice-rafted debris provenance study in the north east atlantic. Quat. Sci. Rev. 26, 862–875, https://doi.org/10.1016/j.quascirev.2006.12.002 (2007).
Shakun, J. D. et al. Global warming preceded by increasing carbon dioxide concentrations during the last deglaciation. Nature 484, 49, https://doi.org/10.1038/nature10915 (2012).
Carlson, A. E. & Winsor, K. Northern hemisphere ice-sheet responses to past climate warming. Nat. Geosci. 5, 607–613, https://doi.org/10.1038/ngeo1528 (2012).
Renssen, H. & Isarin, R. F. B. The two major warming phases of the last deglaciation at ∼14.7 and ∼11.5 ka cal BP in Europe: Climate reconstructions and AGCM experiments. Global Planet. Change 30, 117–153, https://doi.org/10.1016/S0921-8181(01)00082-0 (2001).
Alley, R. B. & Ágústsdóttir, A. M. The 8k event: Cause and consequences of a major holocene abrupt climate change. Quat. Sci. Rev. 24, 1123–1149, https://doi.org/10.1016/j.quascirev.2004.12.004 (2005).
Benjamini, Y. & Yekutieli, D. The control of the false discovery rate in multiple testing under dependency. Ann. Stat. 29, 1165–1188, https://doi.org/10.1214/aos/1013699998 (2001).
Harris, I., Jones, P. D., Osborn, T. J. & Lister, D. H. Updated high-resolution grids of monthly climatic observations – the CRU TS3.10 dataset. Int. J. Climatol. 34, 623–642, https://doi.org/10.1002/joc.3711 (2014).
Taylor, K. E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys. Res. Atmos. 106, 7183–7192, https://doi.org/10.1029/2000jd900719 (2001).
Wigley, T. M. MAGICC/SCENGEN 5.3: User manual (version 2). (NCAR, Boulder, Colorado, 2008).
Wilcox, R. R. The percentage bend correlation coefficient. Psychometrika 59, 601–616, https://doi.org/10.1007/BF02294395 (1994).
Watterson, I. G. Non-dimensional measures of climate model performance. Int. J. Climatol. 16, 379-391, https://doi.org/10.1002/(Sici)1097-0088(199604)16:4<379::Aid-Joc18>3.0.Co;2-U (1996).
Willmott, C. J. On the validation of models. Phys. Geogr. 2, 184–194, https://doi.org/10.1080/02723646.1981.10642213 (2013).
Santer, B. D., Wigley, T. M., Schlesinge, M. E. & Mitchell, J. F. B. Developing climate scenarios from equilibrium GCM results. (Max Planck Institute for Meteorology, Hamburg, Germany, 1990).
Acknowledgements
This research was funded by an Australian Research Council Future Fellowship (grant no. FT140101192) and Discovery grant (grant no. DP180102392) awarded to D.A.F. and a Discovery Grant (grant no. DP130103261) awarded to T.M.L.W. This material is based upon work supported by the National Center for Atmospheric Research, which is a major facility sponsored by the National Science Foundation under Cooperative Agreement No. 1852977.
Author information
Authors and Affiliations
Contributions
D.A.F. and S.C.B. conceived and led the project. S.C.B. did the analysis and produced all outputs. T.M.L.W. and B.L.O.-B. guided the analysis and interpretation of the climate data. S.C.B. drafted the manuscript and all authors commented on the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Online-only Table
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files associated with this article.
About this article

Cite this article
Brown, S.C., Wigley, T.M.L., Otto-Bliesner, B.L. et al. StableClim, continuous projections of climate stability from 21000 BP to 2100 CE at multiple spatial scales. Sci Data 7, 335 (2020). https://doi.org/10.1038/s41597-020-00663-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-020-00663-3
This article is cited by
-
Evolutionary imbalance, climate and human history jointly shape the global biogeography of alien plants
Nature Ecology & Evolution (2023)
-
Climate Stability Index maps, a global high resolution cartography of climate stability from Pliocene to 2100
Scientific Data (2022)
