
Abstract
Clustering of earthquake magnitudes is still actively debated, compared to well-established spatial and temporal clustering. Magnitude clustering is not currently implemented in earthquake forecasting but would be important if larger magnitude events are more likely to be followed by similar sized events. Here we show statistically significant magnitude clustering present in many different field and laboratory catalogs at a wide range of spatial scales (mm to 1000 km). It is universal in field catalogs across fault types and tectonic/induced settings, while laboratory results are unaffected by loading protocol or rock types and show temporal stability. The absence of clustering can be imposed by a global tensile stress, although clustering still occurs when isolating to triggered event pairs or spatial patches where shear stress dominates. Magnitude clustering is most prominent at short time and distance scales and modeling indicates >20% repeating magnitudes in some cases, implying it can help to narrow physical mechanisms for seismogenesis.
Similar content being viewed by others


Introduction
Clustering in time and space is a well-recognized feature of earthquakes, with prominent examples being spatial clustering of aftershocks around a mainshock and Omori–Utsu decay in the temporal productivity1,2. These patterns are consistent with universal scaling laws for the temporal and spatial patterns between successive earthquakes3,4. However, the existence of clustering in earthquake magnitudes is still a matter of active debate. Other than the power-law characterization of the frequency-magnitude distribution (Gutenberg-Richter law)5, magnitudes were thought to be independent until a set of studies reported magnitude correlations between sequential cataloged earthquakes6,7,8. However, these results could be influenced by catalog incompleteness, questioning the significance of the observed correlations9,10. If magnitude clustering does exist, it has practical applications in the form of short-term forecasting, particularly if larger magnitude events can be clustered in short time windows11,12,13,14. Typical forecasting approaches, such as the epidemic-type aftershock sequence (ETAS) approach, utilize a methodology for simulating seismicity with spatial and temporal clustering but without magnitude clustering13,15,16. Determining whether magnitude clustering exists is also paramount to understanding fault behavior considering proposed magnitude correlations appear to be more apparent when earthquakes occur close-in-time and space17,18. If magnitude clustering is a universal feature of seismic behavior, it provides a new opportunity to evaluate physical mechanisms for seismogenesis.
In this study, we evaluate the existence of magnitude clustering extensively in a variety of field and lab settings.
Results
Prior studies and the Southern California catalog
Much of the prior work on magnitude clustering has focused on the Southern California catalog (e.g., ref. 19). Prior work found the magnitude of a given event may depend on the magnitude of the previous event20, the correlations between consecutive magnitudes are restricted to recurrence times <30 min6, and the next earthquake tends to have a magnitude similar but smaller than the previous one18. However, the limited observation of magnitude correlations to short recurrence times suggested it may be a spurious effect due to short-term aftershock incompleteness (STAI), and that overall catalog incompleteness associated with seismic network density increased the probability for the magnitudes of subsequent earthquakes to be similar10.
To address this debate, we performed a similar analysis on the same high precision Southern California catalog from 1985 to 2001 with more than 400,000 events19, (Fig. 1A). To test for magnitude clustering, we followed the approach of prior work in comparing the probabilistic distribution (P) of magnitude differences (\(\triangle m\)) of successive events between the real catalog and a randomly shuffled catalog using the equation \(\delta p\left({m}_{0}\right)=P\left(\triangle m=\,{m}_{0}\right)-P(\triangle {m}^{*}=\,{m}_{0})\), where \(\triangle {m}^{*}\) represents the magnitude differences after randomly shuffling the order of the cataloged events. If magnitude clustering is present, \(\delta p\left({m}_{0}\right)\) should significantly deviate from zero for a given magnitude difference \({m}_{0}\). In a catalog with randomly arranged magnitudes, \(\delta p\left({m}_{0}\right)\) would not deviate from zero. Our findings show that these statistically significant deviations do indeed occur, and they occur at several different magnitude thresholds (Fig. 1B). The largest probability occurs at the small magnitude differences. These deviations were most strongly observed in the cumulative distribution of magnitude differences: \(\delta P\left({m}_{0}\right)=P\left(\triangle m < \,{m}_{0}\right)-P(\triangle {m}^{*} < \,{m}_{0})\) (Fig. 1C), which were the specific target of Davidsen and Green10.

A Map of southern California study area. B Non-cumulative distribution of difference in probability between the observed catalog and a randomized version, \(\delta P\left({m}_{0}\right)\), as a function of magnitude difference (\({m}_{0}\)), for the southern California catalog. \({m}_{c}=\) magnitude of completeness, n = number of events. Error bars correspond to the 1 standard deviation confidence interval. C Cumulative distribution of the difference in probability, \(\delta P\left({m}_{0}\right)\), for the southern California catalog before applying filters. D Same as C but after applying filters to address potential issues from catalog incompleteness. E Cumulative distribution for 3 areas of 10×10 km2 in southern California with pronounced seismicity, represented by solid black boxes in the southern California map.
Demonstrating magnitude clustering despite catalog incompleteness
We investigated Davidsen and Green’s10 claims that magnitude incompleteness caused the apparent magnitude clustering by applying two standard approaches to estimate the magnitude of completeness via the frequency-magnitude distribution of the catalog21 (Fig. S1). The maximum curvature method generally produces a lower, more inclusive estimate22, while the b-value stability method produces a higher, more conservative estimate23,24. We also followed the Davidsen and Green10 approach to correct for STAI by removing magnitude differences during periods following larger mainshocks and excluding all event pairs separated by less than 2 min to address smaller mainshocks. Fig. 1D shows the signature of the magnitude clustering remains prominent even when strategies for addressing incompleteness are implemented. We also investigated the claim that spatial variability of the magnitude of completeness could contribute to magnitude clustering by focusing on smaller (10×10 km2) areas of the California catalog with the most productive seismicity. Although the uncertainties are larger for the smaller datasets, the magnitude clustering patterns remain statistically significant at these spatial scales along several different faults (Figs. 1E and S2). These findings are similar to Lippiello et al.17 that used two regions with different magnitude of completeness thresholds to argue that magnitude correlations do not depend on catalog incompleteness.
To further demonstrate the statistical significance of magnitude clustering in spite of potential incompleteness that could proportionally influence smaller magnitude events, we developed a new approach to compare successive events based on their positions in the empirical cumulative density function (ECDF) of the magnitudes (see “Methods”). Figure 2A shows the results from calculating the number of event comparisons that fall into each bin. To help establish true variations from the catalog magnitude distribution, ECDF values were also calculated on the catalog randomized by time (Fig. 2B). Subsequent events with the same ECDF bin value (diagonal line) occurred at significantly higher rates than randomized catalogs. The biggest difference (+26%) occurred for the largest magnitude bin, highlighting that magnitude clustering is not restricted to small magnitude comparisons. We found a >99.9999% confidence level that the increased number of events along the 1:1 diagonal line for the real catalog were statistically different from that of 1000 randomly shuffled realizations of the catalog (Table S1).

Comparisons are for A the real, filtered southern California catalog and B this catalog randomized by event time. Color scale shows the number of event comparisons that fall into each 0.2 × 0.2 bin by illustrating the difference relative to the expected mean (total number of comparisons divided by total number of bins). Diagonal line highlights cases where an event has the same ECDF bin value as the subsequent event.
Application to Injection Induced Seismicity Catalogs
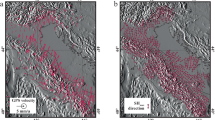
Although many of the studies investigating magnitude clustering have focused on California, some have not9,11,12. A noteworthy study is that of hydraulic fracturing induced seismicity that identified prominent magnitude clustering and interpreted it as a consequence of the specific geometrical constraints of finely laminated shale gas and tight oil reservoirs25. To investigate this idea, we turned our attention to a variety of field-scale human induced seismicity catalogs (Fig. 3). Two catalogs are from hydraulic fracturing well pads a few km apart in Harrison County, Ohio (Ryser and Hamilton)26,27. The other two catalogs are from wastewater disposal cases near Guthrie in central Oklahoma and the Delaware Basin in west Texas, which are about 10 km and 50 km wide, respectively28,29,30.

A Map of Harrison County, Ohio study area. Seismicity on the left side of the map is associated with the Ryser well pad, and seismicity on the right associated with Hamilton well pad. B Map of the Logan County, Oklahoma study area near the town of Guthrie. C Map of the west Texas study area. D Comparison of the cumulative distribution of difference in probability between the observed catalog and a randomized version, \(\delta P\left({m}_{0}\right)\), as a function of magnitude difference (\({m}_{0}\)), for each catalog before any filters are applied. E Same as D but after applying filters to address potential issues from catalog incompleteness. Same labeling conventions as Fig. 1.
We find that all of these seismicity catalogs have significant magnitude clustering, with several nearly identical to results from the California catalog. Fig. 3D shows this after limiting to the conservative magnitude of completeness threshold, but the significance can be seen at even higher magnitude thresholds (Figs. S3 and S5). Perhaps the most noteworthy difference is the larger signature from the Hamilton catalog, which is intriguing, considering the similar conditions to the nearby Ryser catalog26,27, although Hamilton was stimulated 2 years after Ryser. While most of the catalogs in this comparison are from strike-slip environments (California, Ohio, Oklahoma), the West Texas catalog is dominated by normal faulting31, demonstrating that magnitude clustering is not restricted to a particular fault type at the field scale.
A key advantage of induced sequences is that they are swarms instead of aftershock sequences32,33, so it removes the concern about STAI when evaluating magnitude clustering. The induced sequences show the same degree of magnitude clustering as the California tectonic seismicity catalog (Fig. 3D), further supporting the notion that STAI is not artificially causing magnitude clustering observations17,18.
Time dependency of magnitude clustering
The Guthrie catalog is noteworthy for its high seismicity rate28,29,30, and we determined that a shorter 10-s interevent time filter was still appropriate for this catalog given the advanced subspace detection technique. Even after implementing this shorter interevent time restriction, the size of the magnitude clustering signature was reduced by more than half in the Guthrie catalog (cf. Fig. 3D, E), indicating that magnitude clustering in this case is prominent among events with time separations less than 10 s. To further explore the effect of interevent time on magnitude clustering, we split each catalog into interevent time intervals (Fig. S11). Figure 4 shows how the Guthrie, Oklahoma wastewater disposal catalog has significant variation in magnitude clustering with different interevent times while the California tectonic catalog does not. This result provides intriguing clues that something about the wastewater disposal process is enabling magnitude clustering over shorter time scales but disrupting it over longer time scales.

n = number of events, \({m}_{c}\) = magnitude of completeness. The filtered Guthrie catalog shows a decay in the magnitude clustering signature as the events are further separated in time.
Application to laboratory catalogs
Based on the verification of magnitude clustering in a variety of field environments, we turned our attention to the laboratory environment to see whether these patterns would persist at even smaller scales and to probe the physical mechanisms. The wider variability and controlled conditions of environments in the laboratory provides an opportunity to explore the necessary conditions and the potential controlling factors for magnitude clustering. The fundamental similarities between laboratory rock fracture processes and seismogenic processes are well documented34,35,36,37. The investigated tests cover more than a decade of effort of different academic and industrial research laboratories, but all the laboratory catalogs display scale-invariance features in that they obey Gutenberg–Richter magnitude–frequency power–law and even can exhibit universal scaling laws for interevent times and distances35,38,39,40,41,42,43,44. The lab catalog spans of absolute magnitude difference (M0) are variable due to the differences of rock types and data acquisition systems used at different industrial and research institutes but are generally smaller than the field studies. These tests also cover a wide range of different loading protocols and stress conditions in multiple rock types (see “Methods”), so we found it useful to divide into those generating rock fracture under shear stress, either under extending35 or confined39 conditions (Fig. 5C), and those causing rock fractures under dominatingly tensile stress, including tensile bending and hydraulic fracturing40,41,42,43 (Fig. 5D, E).

A Normalized magnitude clustering phenomena for various types of rock fractures on different rock types. Absolute M0 spans of the curves are varied as tests are conducted on different rock types with different data acquisition systems. B The non-clustering observations on the whole catalogs of the rock fractures under dominatingly tensile stress. Catalogs are on tests conducted at University of Minnesota (left), and Halliburton (right), respectively. C–E The induced rock fractures under extending and shear stress35 conditions (left of C), confined and shear stress39 conditions (right of C), tensile stress42,43 conditions (D), and hydraulic fracturing (E)40,41.
Magnitude clustering in laboratory catalogs
We found magnitude clustering in rock fracture under shear stress occurs regardless of loading protocols, rock types, and observable magnitude ranges imposed by different data acquisition systems. As in the field-scale investigations, we addressed potential issues of catalog incompleteness in our processing of the laboratory catalogs. Figure 5a illustrates how prominent magnitude clustering occurs under both extending35 and confined39 shear rock fractures. Significant magnitude clustering occurs regardless of whether the magnitude of completeness is met (Figs. S12a and S15b). In fact, magnitude clustering appears to be “unconditional” in shear rock fracture tests as it can be observed regardless of temporal, spatial, loading protocol, or magnitude conditioning (Supplementary Note 2). The lack of influence of spatial condition indicates geometric constraints are not a first order control for magnitude clustering under shear stress. The energy input for these tests is also not the artificial factor for imposing magnitude clustering, as the energy input for most of the tests is progressively decreasing during the fracture processes, and unconditional clustering for shear rock fractures can be observed under both increasing and decreasing energy input conditions (Figs. S12, S16, and S17). The clustering became more significant as we progressively removed the AE events of the early testing time from the analysis and kept only the last several-hundred events (Fig. S14a). Such observation suggests the rock fracture evolution can amplify the magnitude clustering phenomena in shear rock fractures, but this influence is secondary as it did not alter the statistical significance of magnitude clustering.
Effects of stress condition and interevent distance
For rock fracture under dominatingly tensile stress (tensile bending and hydraulic fracturing), the overall catalogs did not show statistically significant magnitude clustering (Fig. 5B). However, we were able to find significant magnitude clustering in these catalogs when we restricted the interevent distance (Figs. 5A and S12b). Specifically, the non-clustering pattern changed to significant clustering when the inter-event distance was conditioned to the range of the tests’ characteristic length (i.e., the influence of geometric constraints). For the hydraulic fracturing test this characteristic length is the distance between the fracturing wellbore and the pre-cut fault (Fig. S13), and for the tensile bending tests this length is the thickness of the specimens (Fig. S12b). The increase of statistical significance in magnitude clustering are also most clear when interevent distance conditioning approaches the characteristic length of the specimen. Some clues to why this restriction is necessary to observed magnitude clustering come from additional observations during tests that generated both tensile and shear rock fracture in the same sample38 (Fig. S17). Non-clustering occurred when the wing-shaped rock fractures were developing under tensile stress, but the later developing shear fracture shifted the magnitude clustering behavior to significant clustering. This indicates the remarkable finding that significant (i.e., exceeding 3-standard deviations) magnitude clustering appears to be universal when a shear rock fracture condition is met.
Lack of magnitude clustering in synthetic catalogs
We investigated whether magnitude clustering exists in synthetics catalogs generated with a variety of techniques to identify whether magnitude clustering arises from existing knowledge of earthquake patterns (see “Methods”). None of these approaches, including several ETAS strategies and random draws from a FMD45,46,47, produced any statistically significant signature of magnitude clustering (Figs. 6 and S10). This includes when catalog incompleteness is artificially included or when the ETAS parameters are tuned to earthquake catalogs with magnitude clustering in them. These findings indicate that current strategies for modeling earthquake magnitudes, and the forecasting strategies that result, are unable to account for the temporal-based magnitude relationships demonstrated in this study.

A Comparison of cumulative distribution for synthetic catalogs generated with different approaches, including adding artificial incompleteness to the stochastic catalog and tuning the ETAS parameters to the Hamilton, OH catalog. ECDF results for the B ETAS catalog fit to Hamilton parameters, C stochastic catalog with incompleteness added, and D 22% repeating events added to the ETAS catalog. Magnitude clustering patterns observed in field (E, F) and lab (G, H) settings compared with best-fitting patterns from synthetic seismicity catalogs with varying amounts of repetitive events. A grid search over repeating percentage, magnitude uncertainty, and b-value was used to identify a range of synthetic catalogs that best fit the observed pattern (gray shading, dashed line indicates mean). Percentages of repeating events for the range of fitting catalogs are reported.
Discussion
Modeling of observations catalogs with repeating events added to synthetic catalogs
To help investigate the causes of the magnitude clustering patterns demonstrated in multiple field and laboratory environments, one possibility to explain the observed patterns of magnitude clustering is if a higher than expected portion of events in the catalog are repeated events with approximately the same magnitude. We generated synthetic seismic catalogs and added repeating events to look for similarities to observed catalogs (see “Methods”). Figure 6 shows the best-fitting curves and shaded 2σ from the synthetic catalogs compared with a pair of field and lab catalogs, along with the corresponding percentage of inserted repeating events. For the California and mixed mode catalogs, a modest amount (~10%) of the event magnitudes repetition is needed to fit the data, although the uncertainty from this approach indicates it could be as small as 2%. For the Hamilton and extending shear catalogs, a larger portion (25–40%) of event magnitudes repetition, with at least 12–21% repeating based on the 2σ. The ideal laboratory environment under shear dominant stress is best fit by including 39% repeating events. Even though insertion of repeated events into synthetically generated catalogs is a simplistic way to envision the true process, it indicates a substantial relationship between magnitudes in observed seismicity catalogs.
Potential physical mechanisms for magnitude clustering
We then used the laboratory catalogs to evaluate the potential physical mechanisms for magnitude clustering. Hypotheses we sought to evaluate were (1) whether fault patches rupture with incomplete strain release such that they can rupture again soon after to form similar size events or (2) whether there are conditions controlling event size that change slowly enough between events to produce a clustering of magnitudes. The precision of the lab catalogs allowed us to define triggered pairs (one event triggers an aftershock) based on whether they violate the null hypothesis that events occur randomly in space, time, and magnitude following well-established scaling relationships35,48,49,50,51,52 (see Supplementary Information).
Influence of triggering
Intriguingly, restricting to triggering-triggered (T-T) pairs created the most significant magnitude clustering patterns we observed in rock fracture under dominatingly tensile stress, far exceeding the increases under all other types of interevent spatial and/or temporal constraints discussed above (Fig. 7A).

A Magnitude clustering of all triggering-triggered (T-T) pairs (cyan), long T-T waiting time pairs (purple), long T-T distance pairs (red), derived from a tensile stress catalog that did not show significant magnitude clustering (whole catalog, 1 or 3 SD, yellow)42,43. B Different magnitude clustering patterns of T-T or non-T-T pairs, derived from extending and shear stress35 conditions. C Shifting of magnitude clustering pattern by removing all possible pairs below a threshold (n) in the normalized space-and-time distance, derived from tensile stress42,43 conditions.
The magnitude clustering pattern for the T-T pairs shows significantly higher probability for triggered events to be smaller magnitude (higher probability in negative M0 range). We have elucidated in previous research that, observing a smaller magnitude event is expectable for remotely triggered events35. Narrowing our focus to long distance (>10 mm) T-T pairs or long waiting time (<100 s) T-T pairs produce magnitude clustering patterns of even higher significance (Fig. 7A). Moreover, once we remove all event pairs violating the null hypothesis of GR law and preserve the pairs obeying that null hypothesis, we can even observe distinctively different types of significant magnitude clustering (Fig. 7B, C), i.e., significantly lower probability in negative M0 range (Fig. 7C). Such observation suggests a possibility that, the overlapping of different magnitude clustering patterns from obeying or violating the null hypothesis of GR law in different ratios can result in globally non-clustering or clustering observations.
Future work
The discovery that magnitude clustering is pervasive in both lab and field seismicity but with different prevalence depending on specific conditions provides tantalizing opportunities to explore physical mechanisms with future work. Hypotheses to evaluate would include (1) whether fault patches rupture with incomplete strain release such that they can rupture again soon after to form similar size events or (2) whether there are conditions controlling event size that change slowly enough between events to produce a clustering of magnitudes. For example, the increased magnitude clustering signature for long distance T-T pairs appears to be inconsistent with the identical patch rupture hypothesis, unless the incomplete strain release leads to transferred stress that promotes slip on patches of similar but smaller strength. Regardless, improving characterizations of magnitude clustering that integrate laboratory and field scale observations will narrow the possible physical mechanisms for earthquakes.
Methods
Data sources
Seismicity associated with the Ryser well pad was locally recorded between September 2013 and January 2014. Seismicity associated with the Hamilton well pad was locally recorded between August and November 2015. The seismicity catalogs were enhanced using a repeating signal detection algorithm based on waveform similarity26. Wells on the Ryser pad were stimulated sequentially (one lateral at a time), while operations on the Hamilton pad utilized a common “zipper-frac” approach where stages are alternated between two well laterals27. The Guthrie seismicity catalog was locally recorded in Logan County, Oklahoma between February and August 2014. The catalog was enhanced using a subspace detection technique28. It is well established that seismicity in central Oklahoma during this time was induced by widespread, large rate wastewater disposal53. The West Texas seismicity catalog was regionally recorded between March 2017 and December 201829. The catalog was enhanced using regional template matching30.
The investigated laboratory tests include a variety of different types of laboratory tests (3- and 4-point bending tensile tests, flawed rock compressive tests, hydraulic fracturing test; with different loading paths or protocols) under different types of stress conditions (tensile, shear, and hydraulic fracturing stress conditions) on a variety of different types of rocks (Dakota Granite, Carrara Marble, Berea sandstone, and sand-mixed cement, with different levels of homogeneity). These tests were conducted in different laboratories at different institutes (University of Minnesota-Twin Cities, Colorado School of Mines, Rock Mechanics Lab of Halliburton, and Nanyang Technological University, Singapore) spanning a decade. The energy releases from the rock fracture processes are also recorded by different types of acquisition systems. See supplementary Information for more details on specific tests.
The cumulative distribution of the probability comparison
The cumulative distribution of the difference in probability between the observed catalog and a randomized version as a function of magnitude difference shows a sinusoidal pattern for our observational catalogs. During the larger negative x-values (\({m}_{0}\)), the randomized catalogs have a larger probability of producing this larger negative \({m}_{0}\), because the real catalog is deficient in larger negative \({m}_{0}\) values as it tends to have more smaller \({m}_{0}\) values (both negative and positive). In essence, the real catalog is "trailing behind" the randomized catalogs in terms of cumulative percentage of events when we are on the negative part of the \({m}_{0}\) axis. The real catalog flips to being ahead of the randomized catalog once we enter the positive part of the \({m}_{0}\) axis as all of the small \({m}_{0}\) values allow it to surpass the relative percentage of the randomized catalogs. This pattern is not seen in Fig. 7, because only a portion of the observed catalog is being compared to a randomized version of the full catalog, such that the comparisons do not sum to the same number of events in a cumulative distribution. The consistently positive values occur due to the higher probability of observing similar magnitude events through the triggering-triggered (T-T) pairs.
Empirical cumulative density function for magnitudes
The ECDF was calculated by sorting the already filtered catalog magnitudes from smallest to largest and assigning a value equal to the count divided by the total number of events. The catalog was then resorted by time and the ECDF value of each event (i) was compared to the ECDF value of the subsequent event (i + 1).
Determining the time filter to address interevent incompleteness
Following the approach of prior research10, we estimated the temporary completeness magnitude mtc(t,m) at time t (in days) after a mainshock of magnitude m: mtc(t,m) = m − 4.5 − 0.75 log10(t). Thus we corrected for STAI by removing earthquakes and their magnitude differences during periods where mtc (t,m) > mc for all mainshocks with m ≥ 6. For the filtering to avoid events hidden within coda of recent event, we used a minimum interevent time of 2 min for the California catalog as in prior work10, However, when we examined seismograms associated with our induced seismicity catalogs, we identified that this time filter could be reduced to at least 30 seconds given the amplitude of small events and rates of coda decay.
Synthetic catalog processing
The stochastic synthetic catalogs were drawn from a probability density function based on the Gutenberg-Richter magnitude-frequency relation (e.g., Zhuang and Touati45). We explored issues with catalog incompleteness by artificially removing an increasing number of events towards the smaller magnitude end of the catalog. We also investigated issues with magnitude uncertainty by smearing via a normal distribution using the Box-Muller Transform. When seeking to model the observed catalogs, we generated stochastic catalogs for a range of different b-values, magnitude uncertainties, and percentage of events that were repeated. Goodness of fit to cumulative magnitude clustering curves between the real catalog and synthetic catalogs from grid search of the parameters were evaluated using a probability density function for the chi-squared statistic. We also used two different methods of simulating catalogs based on the ETAS approach that incorporate aftershock triggering. The ETAS model incorporates the Gutenberg–Richter Law, the Omori-Utsu Decay Law, and spatial clustering of aftershocks to assign an occurrence rate \({R}_{0}(m,x,y,t)\) of events with magnitudes \(m > \,{m}_{0}\) at a position \((x,y)\) during time \(t\). The first ETAS method used estimates the ETAS parameters based on the expectation maximization (EM) algorithm originally applied to the ETAS model by Veen and Schoenberg54 in 200847. The important parameters for the model are the background rate μ and the parameters k0, α, c, ω, τ, d, γ, ρ, which define the aftershock triggering rate \({R}_{0}\). We used the default estimates of the parameters.
We also applied a Bayesian approach to ETAS simulation that incorporates a maximum likelihood estimation to determine the model parameters46. Rather than using individual point estimates for the model parameters, it draws upon the posterior distribution \(p(\theta {|Y})\), where \(\theta\) equals an unknown parameter vector. This posterior distribution represents uncertainty in \(\theta\) based on observed catalogs and any prior knowledge from previous studies, which can then be incorporated into the ETAS modeling by averaging the forecast distribution over the posterior. Initially, we simulated an ETAS catalog of ~20,000 events using the default parameters. We also used the maximum likelihood estimation to fit the model parameters using the observed data in both the Southern California Catalog and the Hamilton, OH catalogs, and then created simulated catalogs using these parameters.
Data availability
The field, laboratory, and synthetic catalogs are available via https://doi.org/10.5281/zenodo.732858555.
Code availability
Codes for analyses can be available upon request by reaching out to Professor Jesse Hampton at University of Wisconsin-Madison (jesse.hampton@wisc.edu).
References
Utsu, T., Ogata, Y. & Matsu’ura, R. S. The centenary of the Omori formula for a decay law of aftershock activity. J. Phys. Earth 43, 1–33 (1995).
Felzer, K. R. & Brodsky, E. E. Decay of aftershock density with distance indicates triggering by dynamic stress. Nature 441, 735–738 (2006).
Saichev, A. & Sornette, D. “Universal” distribution of interearthquake times explained. Phys. Rev. Lett. 97, 078501 (2006).
Davidsen, J. & Paczuski, M. Analysis of the spatial distribution between successive earthquakes. Phys. Rev. Lett. 94, 048501 (2005).
Gutenberg, B. & Richter, C. F. Frequency of earthquakes in California. Bull. Seismol. Soc. Am. 34, 185–188 (1944).
Corral, Á. Dependence of earthquake recurrence times and independence of magnitudes on seismicity history. Tectonophysics 424, 177–193 (2006).
Corral, A. Long-term clustering, scaling, and universality in the temporal occurrence of earthquakes. Phys. Rev. Lett. 92, 108501 (2004).
Lippiello, E., Godano, C. & de Arcangelis, L. Dynamical scaling in branching models for seismicity. Phys. Rev. Lett. 98, 098501 (2007).
Davidsen, J., Kwiatek, G. & Dresen, G. No evidence of magnitude clustering in an aftershock sequence of nano- and picoseismicity. Phys. Rev. Lett. 108, 038501 (2012).
Davidsen, J. & Green, A. Are earthquake magnitudes clustered? Phys. Rev. Lett. 106, 108502 (2011).
Nichols, K. & Schoenberg, F. P. Assessing the dependency between the magnitudes of earthquakes and the magnitudes of their aftershocks. Environmetrics 25, 143–151 (2014).
Spassiani, I. & Sebastiani, G. Exploring the relationship between the magnitudes of seismic events. J. Geophys. Res. Solid Earth 121, 903–916 (2016).
Field, E. H. et al. A spatiotemporal clustering model for the third uniform California earthquake rupture forecast (UCERF3‐ETAS): toward an operational earthquake forecast. Bull. Seismol. Soc. Am. 107, 1049–1081 (2017).
Nandan, S., Ouillon, G. & Sornette, D. Magnitude of earthquakes controls the size distribution of their triggered events. J. Geophys. Res. Solid Earth 124, 2762–2780 (2019).
Ogata, Y. J. Statistical models of point occurrences and residual analysis for point processes. J. Am. Stat. Assoc. 83, 9–27 (1988).
Hardebeck, J. L. Appendix S: Constraining Epidemic Type Aftershock Sequence (ETAS) Parameters from the Uniform California Earthquake Rupture Forecast, Version 3 Catalog and Validating the ETAS Model for Magnitude 6.5 or Greater Earthquakes. Report No. Open-File Report 2013-1165-S, and California Geological Survey Special Report 228-S (U.S. Geological Survey).(2013)
Lippiello, E., Godano, C. & de Arcangelis, L. The earthquake magnitude is influenced by previous seismicity. Geophys. Res. Lett. 39, n/a–n/a (2012).
Lippiello, E., de Arcangelis, L. & Godano, C. Influence of time and space correlations on earthquake magnitude. Phys. Rev. Lett. 100, 038501 (2008).
Hauksson, E., Yang, W. & Shearer, P. M. Waveform relocated earthquake catalog for Southern California (1981 to June 2011. Bull. Seismol. Soc. Am. 102, 2239–2244 (2012).
Corral, A. Comment on “Do earthquakes exhibit self-organized criticality”. Phys. Rev. Lett. 95, 159801 (2005). Discussion 159802.
Mignan, A. & Woessner, J. Estimating the magnitude of completeness for earthquake catalogs. Commun. Online Resourc. Stat. Seismicity Anal. https://doi.org/10.5078/corssa-00180805 (2012).
Wiemer, S. & Wyss, M. Minimum magnitude of completeness in earthquake catalogs, examples from Alaska, the Western United States, and Japan. Bull. Seismol. Soc. Am. 90, 859–869 (2000).
Cao, A. & Gao, S. S. Temporal variation of seismicb-values beneath northeastern Japan island arc. Geophys. Res. Lett. 29, 48-41–48-43 (2002).
Woessner, J. & Wiemer, S. Assessing the quality of earthquake catalogues: estimating the magnitude of completeness and its uncertainty. Bull. Seismol. Soc. Am. 95, 684–698 (2005).
Maghsoudi, S., Eaton, D. W. & Davidsen, J. Nontrivial clustering of microseismicity induced by hydraulic fracturing. Geophys. Res. Lett. 43, 10,672–610,679 (2016).
Skoumal, R. J., Brudzinski, M. R. & Currie, B. S. An efficient repeating signal detector to investigate earthquake swarms. J. Geophys. Res. Solid Earth 121, 5880–5897 (2016).
Kozłowska, M. et al. Maturity of nearby faults influences seismic hazard from hydraulic fracturing. Proc. Natl Acad. Sci. USA 115, E1720–E1729 (2018).
Benz, H. M., McMahon, N. D., Aster, R. C., McNamara, D. E. & Harris, D. B. Hundreds of earthquakes per day: the 2014 Guthrie, Oklahoma, Earthquake Sequence. Seismol. Res. Lett. 86, 1318–1325 (2015).
Savvaidis, A., Young, B., Huang, G. C. D. & Lomax, A. TexNet: a statewide seismological network in Texas. Seismol. Res. Lett. https://doi.org/10.1785/0220180350 (2019).
Skoumal, R. J., Barbour, A. J., Brudzinski, M. R., Langenkamp, T. & Kaven, J. O. Induced seismicity in the Delaware Basin, Texas. J. Geophys. Res. Solid Earth https://doi.org/10.1029/2019jb018558 (2020).
Snee, J.-E. L. & Zoback, M. D. State of stress in the Permian Basin, Texas and New Mexico: implications for induced seismicity. Lead. Edge 37, 127–134 (2018).
Skoumal, R. J., Brudzinski, M. R. & Currie, B. S. Distinguishing induced seismicity from natural seismicity in Ohio: Demonstrating the utility of waveform template matching. J. Geophys. Res. Solid Earth 120, 6284–6296 (2015).
Schultz, R. et al. Hydraulic fracturing‐induced seismicity. Rev. Geophys. https://doi.org/10.1029/2019rg000695 (2020).
Lockner, D. A., Byerlee, J. D., Kuksenko, V., Ponomarev, A. & Sidorin, A. Quasi-static fault growth and shear fracture energy in granite. Nature 350, 39–42 (1991).
Xiong, Q. & Hampton, J. C. Non-local triggering in rock fracture. J. Geophys. Res. Solid Earth https://doi.org/10.1029/2020JB020403 (2020).
Reches, Z. Mechanisms of slip nucleation during earthquakes. Earth Planet. Sci. Lett. 170, 475–486 (1999).
Bares, J., Dubois, A., Hattali, L., Dalmas, D. & Bonamy, D. Aftershock sequences and seismic-like organization of acoustic events produced by a single propagating crack. Nat. Commun. 9, 1253 (2018).
Pan, X., Xiong, Q. & Wu, Z. New method for obtaining the homogeneity index m of Weibull distribution using peak and crack-damage strains. Int. J. Geomech. https://doi.org/10.1061/(ASCE)GM.1943-5622.0001146 (2018).
Xiong, Q., Lin, Q. & Hampton, J. C. Temporal evolution of a shear-type rock fracture process zone (FPZ) along continuous, sequential, and spontaneous well-separated laboratory instabilities-from intact rock to thick gouged fault. Geophys. J. Int. 226, 351–367 (2021).
Xiong, Q. & Hampton, J. C. A laboratory observation on the acoustic emission point cloud caused by hydraulic fracturing, and the post-pressure breakdown hydraulic fracturing re-activation due to nearby fault. Rock Mech. Rock Eng. 54, 5973–5992 (2021).
Hampton, J., Gutierrez, M. & Matzar, L. Microcrack damage observations near coalesced fractures using acoustic emission. Rock Mech. Rock Eng. 52, 3597–3608 (2019).
Lin, Q., Wan, B., Wang, S., Li, S. & Fakhimi, A. Visual detection of a cohesionless crack in rock under three-point bending. Eng. Fract. Mech. 211, 17–31 (2019).
Lin, Q., Wan, B., Wang, Y., Lu, Y. & Labuz, J. F. Unifying acoustic emission and digital imaging observations of quasi-brittle fracture. Theor. Appl. Fract. Mech. 103, 102301 (2019).
Lin, Q., Yuan, H., Biolzi, L. & Labuz, J. F. Opening and mixed mode fracture processes in a quasi-brittle material via digital imaging. Eng. Fract. Mech. 131, 176–193 (2014).
Zhuang, J. & Touati, S. Stochastic simulation of earthquake catalogs. Commun. Online Resourc. Stat. Seismicity Anal. https://doi.org/10.5078/corssa-43806322 (2015).
Ross, G. J. Bayesian estimation of the ETAS model for earthquake occurrences. Bull. Seismol. Soc. Am. 111, 1473–1480 (2021).
Mizrahi, L., Nandan, S. & Wiemer, S. Embracing data incompleteness for better earthquake forecasting. J. Geophys. Res. Solid Earth https://doi.org/10.1029/2021jb022379 (2021).
Baiesi, M. & Paczuski, M. Scale-free networks of earthquakes and aftershocks. Phys. Rev. E Stat. Nonlin. Soft Matter Phys. 69, 066106 (2004).
Zaliapin, I., Gabrielov, A., Keilis-Borok, V. & Wong, H. Clustering analysis of seismicity and aftershock identification. Phys. Rev. Lett. 101, 018501 (2008).
Davidsen, J. et al. Triggering processes in rock fracture. Phys. Rev. Lett. 119, 068501 (2017).
Zaliapin, I. & Ben-Zion, Y. Earthquake clusters in southern California I: Identification and stability. J. Geophys. Res. Solid Earth 118, 2847–2864 (2013).
Zaliapin, I. & Ben-Zion, Y. Earthquake clusters in southern California II: Classification and relation to physical properties of the crust. J. Geophys. Res. Solid Earth 118, 2865–2877 (2013).
Keranen, K. M., Weingarten, M., Abers, G. A., Bekins, B. A. & Ge, S. Sharp increase in central Oklahoma seismicity since 2008 induced by massive wastewater injection. Science 345, 448–451 (2014).
Veen, A. & Schoenberg, F. P. Estimation of space–time branching process models in seismology using an EM–type algorithm. J. Am. Stat. Assoc. 103, 614–624 (2012).
Xiong, Q., Brudzinski, M. R., Gossett, D., Lin, Q., & Hampton, J. C. Seismic magnitude clustering is prevalent in field and laboratory catalogs [DATA] [Data set]. zenodo. https://doi.org/10.5281/zenodo.7328586 (2020).
Acknowledgements
We thank Professor Joseph F. Labuz of University of Minnesota for permission to publish data on the three-point bending tests experiments. All other experimental data have been collected by the authors. The authors also would like to thank the Wisconsin Alumni Research Foundation at the University of Wisconsin-Madison for partially supporting the work.
Author information
Authors and Affiliations
Contributions
All authors contributed equally to this work. Q.X. performed experimental analyses, methods, and code development. M.R.B. and D.G. performed field-scale seismicity investigations, analyses, methods, and code development. M.R.B. supervised field-scale seismicity analyses. Q.L. provided a subset of the experimental data and method discussions with Q.X. J.C.H. contributed to idea conception, interpretation, and supervised experimental work and article generation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Xiaowei Chen and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xiong, Q., Brudzinski, M.R., Gossett, D. et al. Seismic magnitude clustering is prevalent in field and laboratory catalogs. Nat Commun 14, 2056 (2023). https://doi.org/10.1038/s41467-023-37782-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-023-37782-5
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
