
Abstract
Reservoir computing (RC) has received recent interest because reservoir weights do not need to be trained, enabling extremely low-resource consumption implementations, which could have a transformative impact on edge computing and in-situ learning where resources are severely constrained. Ideally, a natural hardware reservoir should be passive, minimal, expressive, and feasible; to date, proposed hardware reservoirs have had difficulty meeting all of these criteria. We, therefore, propose a reservoir that meets all of these criteria by leveraging the passive interactions of dipole-coupled, frustrated nanomagnets. The frustration significantly increases the number of stable reservoir states, enriching reservoir dynamics, and as such these frustrated nanomagnets fulfill all of the criteria for a natural hardware reservoir. We likewise propose a complete frustrated nanomagnet reservoir computing (NMRC) system with low-power complementary metal-oxide semiconductor (CMOS) circuitry to interface with the reservoir, and initial experimental results demonstrate the reservoir’s feasibility. The reservoir is verified with micromagnetic simulations on three separate tasks demonstrating expressivity. The proposed system is compared with a CMOS echo state network (ESN), demonstrating an overall resource decrease by a factor of over 10,000,000, demonstrating that because NMRC is naturally passive and minimal it has the potential to be extremely resource efficient.
Similar content being viewed by others

Introduction
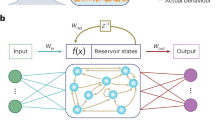
As training an artificial neural network has enormous hardware costs, reservoir computers (RCs) are promising due to their ability to provide accuracies similar to trained recurrent neural networks (RNNs) while requiring only minimal training1,2. A reservoir projects input stimuli into a higher dimensional space, enabling linearly-separable solutions to complex temporal problems. As illustrated in Fig. 1a, reservoir weights are untrained, circumventing the costs of training programmable weights; fixed physical structures can be used that do not incur the area, energy, and delay costs inherent to programmability. An early conceptualization demonstrated computation via a reservoir of water by extracting the interactions among ripples in the water3; while slow and large, the water reservoir exemplifies the ability of hardware reservoirs to naturally process information through elegant physical interactions.

a A reservoir computer (RC) is a recurrent neural network (RNN) with untrained input and hidden layer weights. A single trained linear output layer is sufficient to extract a meaningful task output. b Frustrated perpendicular magnetic anisotropy (PMA) nanomagnets. PMA nanomagnets naturally relax in the perpendicular direction ( ± z). Compass needles depict magnetization direction. The colored arrows depict a small portion of the magnetic field lines produced by that color of nanomagnet upon the other nanomagnets. (The lower half of the field lines have been omitted for space.) These nanomagnets are frustrated because they cannot all rest in their isolated lowest energy states but must instead find an equilibrium lowest energy state.
As summarized in Table 1, none of the previously proposed hardware reservoirs exhibit all of the characteristics of an ideal reservoir: “passive”—using natural physical interactions with energy only provided to the reservoir through input information; “minimal”—naturally processing information without requiring complex external circuitry or post-processing; “expressive”—demonstrating high dimensionality, nonlinearity, fading memory, and the separation property2; and “feasible”—with facile system fabrication that considers input/output interfacing, noise, scalability, and timing. While hardware reservoirs implemented in digital logic4,5,6,7,8,9 are highly expressive and clearly feasible, they are neither passive nor minimal. Promising spintronic reservoirs based on spin-waves have been proposed10, though the difficulty in probing the spin-wave states impedes practical system demonstrations. Other spintronic proposals utilize spin torque nano-oscillators with constant bias currents11,12,13,14,15,16,17 or require additional circuitry for post-processing before feeding into the output layer13,14,16,18,19,20,21, while skyrmion reservoir proposals are insufficiently mature for reliable characterization22,23,24,25. Another spintronic reservoir proposal uses arrays of nanomagnets which are actively clocked26,27,28,29, making these reservoirs neither passive nor minimal. Reservoirs with non-volatile memristors30,31,32,33,34,35,36,37 must be actively pulsed to relax the state, while photonic reservoirs2,38 process information too fast relative to the hysteretic memory time constants or require additional circuitry39,40 to maintain the information in the reservoir.
We therefore leverage frustrated nanomagnetism41,42,43 in a proposal for the first hardware RC that is passive, minimal, expressive, and feasible. Frustration between nanomagnets enables efficient and complex computation through the passive relaxation of the coupled magnetizations. We describe a complete nanomagnet reservoir computing (NMRC) system with inherent passivity and minimality, and provide an initial experimental demonstration of its feasibility. The expressivity of this frustrated nanomagnet reservoir was demonstrated through simulations for three benchmark tasks, and evaluation of hardware resource usage indicates a decrease by a factor of over ten million as compared to CMOS.
Results and discussion
Reservoir computing with frustrated nanomagnets
We propose an energy-efficient hardware reservoir in which passive coupling among frustrated nanomagnets generates high-dimensional information processing. As illustrated in Fig. 1b, each individual nanomagnet naturally relaxes along its easy axis—which in this work is the out-of-plane z − axis—resulting in two stable magnetization states. When nanomagnets are packed closely in an irregular array, they can become frustrated; that is, their coupling prevents some or all of the magnets from relaxing along an easy axis. This phenomenon can be observed in Supplementary Movie 1, where the system’s relaxation to a global minimum energy does not result in the minimization of each nanomagnet’s energy. This nanomagnetic frustration enables the system to relax to a broad range of local energy minima, producing the critical RC features of large expressivity and hysteretic memory. As opposed to regular lattice arrangements26,27,28,29,44, the reservoirs are designed with an irregular asymmetric layout that enriches the reservoir expressivity.
This nanomagnet reservoir can be readily integrated with conventional technologies in a complete system as illustrated in Fig. 2a. The input signals can be provided through spin-transfer torque (STT)45 or spin-orbit torque (SOT)46 switching of the nanomagnets, with binary input signaling due to the bistable nature of these nanomagnets. In response to this input, the reservoir passively relaxes toward an energy minimum through an exploration of a rich, temporally evolving landscape of magnetizations. To read the information in the nanomagnet reservoir, magnetic tunnel junctions (MTJs) (the central components of magnetoresistive random access memory (MRAM)47) can be formed by patterning the reservoir nanomagnets atop a tunnel barrier and pinned ferromagnetic layer. Though not arranged as a uniform crossbar, conventional wiring and transistors attached to standard MTJ electrodes enable the magnetization state to be determined through a voltage divider for classification by the memristor crossbar array (MCA) output layer.

a NMRC system diagram. Write signals Wra, Wrb, etc. stimulate input nanomagnets with electrical current ± Iin through the magnetic tunnel junction (MTJ) formed by the reservoir nanomagnet, tunnel barrier, and reference layer. Rd connects readout voltage divider to power rail Vdd to deliver a reservoir voltage landscape to the memristor crossbar array (MCA) output layer. b NMRC training and inference process. Blue boxes represent an input to the reservoir via the Wr signals. Green boxes represent a read to the reservoir via the Rd signals. Red boxes represent an action performed outside of the proposed system, and yellow boxes represent a step performed by the MCA. c NMRC inference timing. Write signals are applied for length τwrite followed by a relaxation period and a read period of length τread with τwrite + τread < τ where the reservoir period τ is the reciprocal of the operating frequency f. d topography image showing a planar array of dipole coupled nanomagnets where the larger magnets can act as inputs. e Phase image showing the magnetic contrast. f Illustration of the magnetization direction (solid green arrows) and easy axis (dashed blue arrows) of the individual magnets based on the topography and the phase images, demonstrating a frustrated magnetic state.
Whereas the nanomagnet reservoir has fixed couplings that can be considered to represent synaptic weights, the single-layer MCA is trained in a supervised manner. In particular, the MCA performs the vector-matrix multiplication48,49,50,51 to produce the system output
where X is the reservoir voltage landscape and Wout is the trained output-weight vector (see the “Reservoir computing mathematics” section of the Methods). While the outputs from the nanomagnet reservoir layer are analog, the outputs of the MCA are restricted to binary to circumvent the need for an analog-to-digital converter (ADC) during inference, thereby minimizing hardware costs. All of these technologies are available in modern lithographic processes and have been experimentally demonstrated, providing a feasible path to production for an integrated NMRC. In fact, we have fabricated a reservoir layer of in-plane nanomagnets (Fig. 2d–f) exhibiting frustrated magnetization states (see the “Experimental methodology” section of the Methods) and demonstrating that the nanomagnet reservoir is feasible and has an open path to production with modern processes.
The training and inference processes are depicted in Fig. 2b. During training, linear regression can be applied to the sampled reservoir states to identify the optimal set of output weights. The crossbar can then be programmed with the output weights. A single inference operation is illustrated in Fig. 2c. Each input signal is provided through a write pulse that forces input nanomagnets to a fixed state, causing the reservoir to reach a new state that is a function of the input and the previous state (and therefore, the past inputs). To read the reservoir state X, voltage pulses are provided to the output MTJs, which directly drive the MCA to produce a task output. The reservoir is minimal and passive, as it only requires energy to be applied through the input information, thereby enabling extremely low-power computation.
Nanomagnet reservoir information processing
To evaluate the ability of frustrated nanomagnet reservoirs to support high-dimensional short-term memory, micromagnetic simulations—modeling the complete complex analog behavior of the nanomagnets—were performed with mumax352 on three benchmark RC tasks (see the “Micromagnetic simulation methodology” section of the Methods). Tasks with binary inputs and binary outputs were chosen so that task data could be directly provided to the bistable input nanomagnets without preprocessing and to preclude the need for expensive ADCs following the MCA output layer. The nanomagnet reservoir performance was compared against an RC without a reservoir layer, in which a single linear output layer with no reservoir is presented with delayed copies of the same task inputs that were provided to the nanomagnet reservoir (see the “RC without a reservoir layer” section of Methods and Supplementary Fig. S1); this network is equivalent to a single-layer perceptron network or linear classifier. For all three tasks, the NMRC achieved a significantly higher accuracy than the RC with no reservoir layer, demonstrating that passive nanomagnet reservoirs can perform complex, non-linear, temporal functions with high expressivity.
Triangle-square wave identification
The waveform identification task is a common simple benchmark task for reservoirs23,31,35,36,37, requiring the reservoir to differentiate between triangle and square waveforms presented through time. As the NMRC operates on binary inputs, triangle and square waves were quantized to two bits before being input to the reservoir as shown in Fig. 3 and Supplementary Movie 2. After training, the NMRC achieved 100% classification accuracy on input waveforms from a testing data set. The RC with no reservoir only obtained 79% accuracy, demonstrating that the frustrated nanomagnets exhibit high expressivity.

a, b Square-wave and triangle-wave input sequences, respectively, are randomly concatenated. White (black) inputs represent magnetization in the + z ( − z) direction. c Reservoir layout, with input nanomagnets A and B driving the propagation of information through the colored nanomagnets. d–f Simulation snapshots. As noted in the color wheel inset, white (black) represents magnetization along the + z ( − z) axis while the colors of the rainbow represent magnetizations in the xy plane. g Evolution of the magnetization z-components during a portion of the simulation, with the colors of each line matching the nanomagnet colors in c. Shapes below the traces indicate the input waveform, while dashed lines pointing to d–f indicate when these snapshots were taken.
Boolean function evaluation
Two of the most widely used metrics for RC are short-term-memory (STM) and parity-check (PC)11,14,15,16,17,29, which require the reservoir to, respectively, remember the previous k inputs of an input bitstream or to perform k-bit XOR on those bits. This provides gauges for the memory content (STM) and non-linear expressivity (PC). The Boolean function evaluation task illustrated in Supplementary Fig. S2 is a superset of the STM and PC tasks, requiring the RC to perform arbitrary k-bit Boolean functions including STM and PC. Accuracies for each of the \({2}^{{2}^{k}}\)k-bit functions were averaged together to calculate an overall metric for reservoir accuracy.
The nanomagnet reservoir illustrated in Fig. 4a–d and Supplementary Movie 3 performed the Boolean function evaluation task with 100% accuracy for both k = 2 and 3 bits, and 93.4% accuracy for k = 4. In contrast, the RC with no reservoir layer performed the Boolean function evaluation task with 99.6% accuracy for k = 2, 81.4% for k = 3, and 84.7% for k = 4. Furthermore, the nanomagnet reservoir achieved an STM content of 4.68 bits, which is standard for spintronic reservoirs, and a PC capability of 3.73 bits, which is close to the maximum PC reported in the literature for emerging hardware reservoirs11,14,15,16,17,29 (see the “Short-term memory and parity check capacity” section of the Methods). These results further demonstrate the ability of the NMRC to perform high-dimensional information processing with large expressivity and memory content.

a–d Boolean function evaluation task: a Reservoir layout. The input nanomagnet is depicted as black with white text. b Evolution of the magnetization z-components during a portion of the simulation, with the colors of each line matching the nanomagnet colors in a. Dashed lines pointing to c, d indicate when these snapshots were taken. c, d Simulation snapshots with nanomagnet magnetization indicated by the color according to the color wheel inset of c. e–h Elementary cellular automata (ECA) observer with task meta-parameter k = 4. e Reservoir layout. f Magnetization z-components during a portion of the simulation. g, h Simulation snapshots.
Elementary cellular automata observer
Observer tasks predict the internal state of a highly complex dynamical system given only an observed state, and have therefore received significant interest as an appropriate mapping to RC53. Elementary cellular automata (ECA) have demonstrated a wide range of dynamics54,55 making them a suitable candidate for a discrete-time binary system to observe. As illustrated in Supplementary Fig. S3, an ECA grid is generated with an arbitrary first row, with each successive row generated by applying ECA rule 59 to the previous row, wrapping at the edges. Rule 59—part of Wolfram class 255—was chosen because of its complex yet predictable behavior, with a period of twice the number of columns in the table. The reservoir must reproduce the entire ECA grid after receiving data from eight evenly spaced input columns from this grid provided sequentially row-by-row. After each row of inputs is received, the reservoir must fill in the values of the unseen columns based on information from the eight observed columns and the reservoir’s memory of the previous state. The spacing between successive input columns is denoted by k, and the entire grid has width 8k. For the relatively simple case of k = 4, every fourth column of the 32-column-wide ECA grid is input to the reservoir, which must reproduce the 24 unknown columns along with the eight known columns.
The 200-nanomagnet NMRC in Fig. 4e–h and Supplementary Movie 4 has a circular structure that matches the edge-wrapping of the ECA grid, with each input duplicated through two nanomagnets for increased expressivity. The reservoir attained 100% accuracy for k = 4, 98.2% for k = 8, decreasing with increasing k to provide 78.1% accuracy for k = 24; the full table of accuracies is displayed in Table 2. Due to the periodicity of ECA rule 59, the RC with no reservoir layer was restricted in memory to evaluate the reservoir’s expressivity, and it therefore achieved only 91.8% accuracy for k = 4, 79.1% for k = 8, and decreased to 73.0% for k = 24. The nanomagnet reservoir thus achieved higher accuracies than the RC with no reservoir layer for all values of k, indicating that the reservoir is performing expressive, non-linear computation.
Computing efficiency and outlook
To estimate the advantages provided by NMRC in terms of area, energy, and delay, NMRC was compared to an equivalent CMOS echo state network (ESN) (see the “Area, energy, and delay of NMRC” and “Area, energy, and delay for CMOS ESN” sections of the Methods and Supplementary Fig. S4). To ensure a fair comparison with equivalent accuracies, numerous CMOS ESNs were designed with varying numbers of neurons to achieve the same accuracies as the NMRC for each task (Table 2). As both the CMOS RC and NMRC require an MCA output layer, identical assumptions were made regarding memristor parameters.
NMRC provides massive efficiency advantages over CMOS RC in terms of area, speed, and energy. As shown in Fig. 5a, NMRC has smaller area and a delay that is a nearly constant function of task complexity, whereas the CMOS ESN needs significantly more time or area to provide equivalent accuracy. NMRC consumes significantly less energy, as can be readily observed in Fig. 5b. Importantly, a large proportion of the reservoir nanomagnets can passively contribute to the computation without being actively used as output, enabling drastic energy savings as shown in Fig. 5c.

a Scatter plot showing delay and area for NMRC and CMOS for various tasks. b Energy vs. accuracy for all three tasks with various values of task meta-parameter k when implemented in CMOS and NMRC. Solid (dashed) lines correspond with the NMRC (CMOS) system. The energy decrease between NMRC and a CMOS reservoir increases with increasing task complexity, indicating that NMRC scales better than CMOS for complex tasks. c Trade-off between accuracy and energy costs by varying the number of readout magnets, \({{{{{{{\mathcal{R}}}}}}}}\), among the 200 reservoir magnets for the ECA observer with k = 4. Inset: In resource-constrained contexts, the accuracy and energy trade-off may be optimized through the minimization of an application-dependent metric function; five such functions are shown. d Area, energy, delay, energy-delay product (EDP), and area-energy-delay-product (AEDP) of NMRC normalized according to the CMOS benchmark indicated with the dashed line at 100%. NMRC is 44,000 times more area-efficient, 60 times more energy-efficient, and four times more time-efficient, giving a combined factor of 240 for EDP, and 10,000,000 for AEDP.
Overall, as illustrated in Fig. 5d, NMRC provides a reduction in area by a factor of 44,000, in energy by a factor of 60, and in delay by a factor of four, culminating in the improvement of area-energy-delay product (AEDP) by a factor greater than 10,000,000. While these results do not consider fabrication imprecision or stray fields from the MTJ reference layer and were achieved at zero temperature, promising engineering solutions exist for all of these challenges (see the “Micromagnetic simulation methodology” section of the Methods); furthermore, the irregularity necessary for this system makes it inherently robust against concerns related to fabrication imprecision. The passivity and minimality of NMRC, coupled with its expressivity and feasibility, therefore provides a promising solution for artificial intelligence applications with extreme efficiency.
Methods
Reservoir computing mathematics
RC can be modeled with technology-agnostic equations. Let \({{{{{{{\mathcal{N}}}}}}}}\) be the number of neurons in the reservoir, \({{{{{{{\mathcal{R}}}}}}}} < {{{{{{{\mathcal{N}}}}}}}}\) the number of readout neurons, \({{{{{{{\mathcal{I}}}}}}}}\) the number of inputs to the reservoir, and \({{{{{{{\mathcal{J}}}}}}}}\) the number of outputs from the RC. The inputs to the reservoir can be denoted by u[t], a discrete time-varying vector of length \({{{{{{{\mathcal{I}}}}}}}}\). The reservoir state can be denoted as x[t], also a discrete time-varying vector of length \({{{{{{{\mathcal{N}}}}}}}}\). In the ESN model, \({{{{{{{\bf{x}}}}}}}}[t]=f\left({{{{{{{{\bf{W}}}}}}}}}^{{{{{{{{\rm{in}}}}}}}}}{{{{{{{\bf{u}}}}}}}}[t]+{{{{{{{{\bf{W}}}}}}}}}^{{{{{{{{\rm{res}}}}}}}}}{{{{{{{\bf{x}}}}}}}}[t-1]\right)\), where f is a non-linear activation function, Win are the input weights, and \({{{{{{{{\bf{W}}}}}}}}}^{{{{{{{{\rm{res}}}}}}}}}\) are the reservoir weights. Note that at each time step, x[t] evolves according to a function of the current inputs and the previous reservoir state, specifying the reservoir’s memory and ability to process temporal signals.
In this work, the trained output layer is linear to match the capabilities of MCAs. Let \({{{{{{{\mathcal{T}}}}}}}}\) be the number of training points and x[t] be the states of the output neurons at time t. Given a desired output vector y[t] of length \({{{{{{{\mathcal{J}}}}}}}}\), the \({{{{{{{\mathcal{J}}}}}}}}\times {{{{{{{\mathcal{R}}}}}}}}\) output weight matrix, \({{{{{{{{\bf{W}}}}}}}}}^{{{{{{{{\rm{out}}}}}}}}}={{{{{{{{\bf{YX}}}}}}}}}^{\top }{({{{{{{{{\bf{XX}}}}}}}}}^{\top }+\lambda {{{{{{{\bf{I}}}}}}}})}^{-1}\), where \({{{{{{{\bf{Y}}}}}}}}=\left[{{{{{{{\bf{y}}}}}}}}[0],\ {{{{{{{\bf{y}}}}}}}}[1],\ ...,\ {{{{{{{\bf{y}}}}}}}}[{{{{{{{\mathcal{T}}}}}}}}-1]\right]\), \({{{{{{{\bf{X}}}}}}}}=\left[{{{{{{{\bf{x}}}}}}}}[0],\ {{{{{{{\bf{x}}}}}}}}[1],\ ...,\ {{{{{{{\bf{x}}}}}}}}[{{{{{{{\mathcal{T}}}}}}}}-1]\right]\), ⊤ denotes the transpose, λ is the regularization factor, and I is the \({{{{{{{\mathcal{N}}}}}}}}\times {{{{{{{\mathcal{N}}}}}}}}\) identity matrix. During reservoir operation, the RC binary output vector is computed as \(\hat{{{{{{{{\bf{y}}}}}}}}}[t]=\,{{\mbox{round}}}\,\left({{{{{{{{\bf{W}}}}}}}}}^{{{{{{{{\rm{out}}}}}}}}}{{{{{{{\bf{x}}}}}}}}[t]\right)\), rounding to either 0 or 1. During testing, the obtained RC outputs \(\hat{{{{{{{{\bf{y}}}}}}}}}[t]\) are compared against the expected outputs y[t] to determine reservoir accuracy.
Experimental methodology
Electron beam lithography was performed using a Raith 50 kV patterning tool on a Si substrate spin-coated with PMMA-495. After lithography, the substrate was developed in a MIBK:IPA (1:3) solution for 30 s. A 13 nm layer of Cobalt was deposited at a rate of 0.3 Å s−1 above a 7 nm Ti adhesion layer using an e-beam evaporator at base pressure of 2 × 10−7 Torr. Finally, lift-off was performed by soaking the sample in hot Acetone for 30 min. Magnetic force microscopy was performed using a Bruker AFM system with a high-moment tip. The nominal resonant frequency of the cantilever, the lift height, and the scan rate were 70 kHz, 80 nm, and 0.2 Hz respectively.
Micromagnetic simulation methodology
All simulations are micromagnetic simulations, performed with mumax352. Cylindrical nanomagnets (with a cell size of 2 × 2 × 2 nm for the Waveform ID and Boolean function evaluation tasks and 4 × 4 × 3 nm for the ECA observer task) were simulated with the material parameters of CoFeB: saturation magnetization Msat = 7.23 × 105 A m−1, exchange stiffness Aex = 1.3 × 10−11 J m−1, Gilbert damping factor α = 0.05, input anisotropy Kui = 3.62 × 105 J m−3, and reservoir anisotropy Kur = 1.05 × 105 J m−3. Spatial and temporal parameters were chosen to maximize reservoir expressivity: nanomagnet diameter d = 30 nm, nanomagnet thickness th = 12 nm, and reservoir period τ ∈ [25, 30] ns.
The reservoirs were designed through a combination of heuristic methods. The reservoirs for the triangle-square waveform identification and the Boolean function evaluation tasks were designed by hand through trial and error. The ECA observer reservoir was designed automatically using heuristic methods. For the ECA observer, initial reservoir nanomagnet locations were randomly chosen, and then automatically shifted according to several heuristics:
-
distancing nanomagnets from one another to avoid overlapping,
-
concentrating nanomagnets toward the center of the array, and
-
distancing nanomagnets away from fixed, reserved blockage regions to create non-uniformity (most readily observed in Fig. 4e).
Locations of the input nanomagnets were fixed. The relative strengths of the heuristics were tuned by hand to result in an array with nanomagnets sufficiently close to induce coupling and frustration, yet not overlapping. Some nanomagnet positions were changed by hand after this process if they were too near to or distant from their neighbors.
Inputs were provided to the reservoir by writing the magnetizations of the input nanomagnets to particular states; these input nanomagnets have a higher anisotropy, enhancing their ability to maintain their state after the writing force is removed. In future experimental systems, this can be achieved by providing the input nanomagnets with greater interfacial anisotropy or greater thickness. This higher anisotropy does not provide any preprocessing capability; the memory content and non-linearity emerge from the reservoir nanomagnets and not from the higher anisotropy of the input nanomagnets.
Input writing was considered to be instantaneous. This is justified by the fact that the reservoir relaxation time, τ ≈ 30 ns > > 3 ns ≈ τwrite56 is significantly slower than the write speeds available with modern MRAM writing techniques (STT or SOT)56. Furthermore, simulations with non-instantaneous input writing were performed on the triangle-square wave task with a write time of ~ 1 ns (see Supplementary Fig. S5 and Supplementary Movie 5). The reservoir still achieved perfect accuracy, supporting experimental feasibility. After relaxation during each cycle, the z-magnetization at the center of each nanomagnet is sampled. The output layer vector-matrix multiplication is computed in software, simulating an ideal MCA.
Reservoir functionality simulations were performed at zero temperature, and it is expected that with tuning of reservoir geometry, damping, input frequency and amplitude, and output weights, the reservoir will operate similarly at non-zero temperatures as was experimentally demonstrated with nanomagnet logic systems57. Additional micromagnetic simulations were run on individual reservoir nanomagnets, demonstrating a decoherence time greater than 10τ at 350 K; this is sufficient for robustness against thermal effects at room temperature with Joule heating. The stray magnetic field from the MTJ reference layer is neglected, as compensating nanomagnets are conventionally included in the MTJ stack to counteract these effects58,59. Perturbations of the nanomagnet state from the STT read process are similarly neglected, as any deviations in the MTJ resistance are expected to be consistent over time and are therefore incorporated into the MCA training.
RC without a reservoir layer
In order to prove that the NMRC is performing useful information processing, the RC results were compared to an RC with no reservoir layer. This network was trained to perform the tasks based on the inputs u[t], u[t − 1], . . . , u[t − (m − 1)] for some memory content m that maximizes the testing accuracy. Note that this is the same binary u[t] used in the micromagnetic simulations. This network is illustrated in Supplementary Fig. S1.
For the waveform identification task, m is 5. For the Boolean functions task, m is 2, 3, and 4 for k = 2, 3, and 4 respectively; this is intuitive as k is the number of bits upon which the output, y[t], is dependent. For the ECA observer, increasing m to an arbitrarily large value permits a feed-forward accuracy of 100% for all k due to the periodic nature of the task; therefore, to provide a fair comparison, the memory content in the comparison network was limited to that of the NMRC. As the memory content of the ECA observer NMRC was determined to be less than two bits, the time-multiplexed memory content, m, in the corresponding RC with no reservoir layer was limited to two bits.
Short-term memory and parity check capacity
STM and PC capacity are calculated according to \(C=\mathop{\sum }\nolimits_{i = 0}^{\infty }{{{\mbox{corr}}}}^{2}({{{{{{{{\bf{y}}}}}}}}}_{{{{{{{{\bf{i}}}}}}}}},{\hat{{{{{{{{\bf{y}}}}}}}}}}_{{{{{{{{\bf{i}}}}}}}}})\), where i is the delay of the STM and PC tasks with ySTM,i = u[t − i] and \({{{{{{{{\bf{y}}}}}}}}}_{{{{{{{{\rm{PC}}}}}}}},i}{ = \bigoplus }_{j = 0}^{i}{{{{{{{\bf{u}}}}}}}}[t-j]\) where ⊕ is the binary sum or XOR operation15. For this work, both sums where taken to i = 7 as both sums converged very quickly and the correlation coefficients disappeared after i = 5. The literature is inconsistent regarding whether the sum should begin from zero or one, creating a capacity differential of one; this inconsistency has been adjusted for when comparing to the literature.
Area, energy, and delay of NMRC
The area, energy, and delay metrics of the NMRC are calculated in terms of the number of reservoir nanomagnets (\({{{{{{{\mathcal{N}}}}}}}}\)), the number of output nanomagnets (\({{{{{{{\mathcal{R}}}}}}}}\)), the number of input nanomagnets (\({{{{{{{\mathcal{I}}}}}}}}\)), the length of the the output vector (\({{{{{{{\mathcal{J}}}}}}}}\)), and the reservoir operating period (τ) – which accounts for write, relaxation, and read delays as illustrated in Fig. 2c. As the output nanomagnets are a subset of the reservoir nanomagnets, there are a total of \({{{{{{{\mathcal{N}}}}}}}}+{{{{{{{\mathcal{I}}}}}}}}\) nanomagnets. For energy estimates reported in this work, \({{{{{{{\mathcal{R}}}}}}}}\) was chosen as the minimum number of output nanomagnets that achieves within 0.5% of the accuracy for \({{{{{{{\mathcal{R}}}}}}}}={{{{{{{\mathcal{N}}}}}}}}\). It is assumed that the feature size of the peripheral CMOS circuitry is 65 nm. As the MCA weights need only be trained once upon initialization (in an environment without severe energy constraints), this training cost is neglected as it is not relevant to the envisioned applications of ultra-low-energy reservoir computing at the edge. Furthermore, the crossbar programming circuitry can be power-gated after training to realize the predicted inference energy savings.
Area
The total area of the NMRC with input and output logic can be calculated as: Atotal = ANM + AMCA + ACMOS. The area each nanomagnet occupies, including the spacing between nanomagnets, is approximately 0.0035 μm2, making the total reservoir area ANM = 0.0035\(\mu {{{\mbox{m}}}}^{2}* ({{{{{{{\mathcal{N}}}}}}}}+{{{{{{{\mathcal{I}}}}}}}})\). Given an individual memristor area of 10F2, where F is the feature size, \({{{\mbox{A}}}}_{{{{{{{{\rm{MCA}}}}}}}}}=10{F}^{2}* {{{{{{{\mathcal{N}}}}}}}}* {{{{{{{\mathcal{J}}}}}}}}=0.0423\)\(\mu {{{\mbox{m}}}}^{2}* {{{{{{{\mathcal{N}}}}}}}}* {{{{{{{\mathcal{J}}}}}}}}\) for a 65 nm process. As two PMOS and one NMOS transistor will be used for each output nanomagnet, and the area of each NMOS (PMOS) transistor is 4F2 (8F2), \({{{\mbox{A}}}}_{{{{{{{{\rm{CMOS}}}}}}}}}=20{F}^{2}* {{{{{{{\mathcal{N}}}}}}}}=0.0845\)\(\mu {{{\mbox{m}}}}^{2}* {{{{{{{\mathcal{N}}}}}}}}\). In total, \({{{\mbox{A}}}}_{{{{{{{{\rm{total}}}}}}}}}=0.0035* ({{{{{{{\mathcal{N}}}}}}}}+{{{{{{{\mathcal{I}}}}}}}})+0.00423* {{{{{{{\mathcal{N}}}}}}}}* {{{{{{{\mathcal{J}}}}}}}}+0.0845* {{{{{{{\mathcal{N}}}}}}}}\)μm2.
It should be noted that it would be appropriate to vertically integrate nanomagnets, memristors, and CMOS in a three-dimensional heterogeneous stack. As this is prospective and has minimal impact on the comparison, this analysis considers only two-dimensional area.
Energy
The energy cost per cycle for the NMRC is Etotal = EMTJwrite + EMTJread + EMCAread. The power dissipated by a single MTJ during writing is \({{{\mbox{P}}}}_{{{{{{{{\rm{MTJwrite}}}}}}}}\_{{{{{{{\rm{single}}}}}}}}}=\frac{{{{{{{{{\rm{V\; dd}}}}}}}}}^{2}}{{{{{{{{{\rm{R}}}}}}}}}_{{{{{{{{\rm{avg}}}}}}}}}}\), where Vdd is the supply voltage and Ravg is the average resistance defined as: \({{{{{{{{\rm{R}}}}}}}}}_{{{{{{{{\rm{avg}}}}}}}}}=\frac{{{{{{{{{\rm{R}}}}}}}}}_{{{{{{{{\rm{P}}}}}}}}}+{{{{{{{{\rm{R}}}}}}}}}_{{{{{{{{\rm{AP}}}}}}}}}}{2}\), where RP (RAP) is the (anti-)parallel resistance of the MTJ. The STT writing energy is therefore \({{{{{{{{\rm{E}}}}}}}}}_{{{{{{{{\rm{MTJwrite}}}}}}}}}={{{\mbox{P}}}}_{{{{{{{{\rm{MTJwrite}}}}}}}}\_{{{{{{{\rm{single}}}}}}}}}* {{{{{{{\mathcal{I}}}}}}}}* {\tau }_{{{{{{{{\rm{write}}}}}}}}}\), where τwrite is the write pulse length. For this work, Vdd = 1.7 V, RP = 25 kΩ, RAP = 35 kΩ, and τwrite = 3 ns56. Thus, \({{{{{{{{\rm{E}}}}}}}}}_{{{{{{{{\rm{MTJwrite}}}}}}}}}=\frac{{{{{{{{{\rm{V\; dd}}}}}}}}}^{2}}{{{{{{{{{\rm{R}}}}}}}}}_{{{{{{{{\rm{avg}}}}}}}}}}* {{{{{{{\mathcal{I}}}}}}}}* {\tau }_{{{{{{{{\rm{write}}}}}}}}}=289\) fJ*I. IMTJwrite = Vdd/RAP is multiple times larger than the current needed to switch > 10 nm thick free layers60, so EMTJwrite is a conservative upper bound. The reference resistance will be RAP, thus read energy through the voltage divider is \({{{{{{{{\rm{E}}}}}}}}}_{{{{{{{{\rm{MTJread}}}}}}}}}=\frac{{{{{{{{{\rm{V\; dd}}}}}}}}}^{2}}{{{{{{{{{\rm{R}}}}}}}}}_{{{{{{{{\rm{avg}}}}}}}}}+{{{{{{{{\rm{R}}}}}}}}}_{{{{{{{{\rm{AP}}}}}}}}}}* {{{{{{{\mathcal{R}}}}}}}}* {\tau }_{{{{{{{{\rm{read}}}}}}}}}=311\) fJ\(* {{{{{{{\mathcal{R}}}}}}}}\), assuming τread = 7 ns. Memristor resistance must be significantly greater than RAP for proper voltage divider functionality. An average resistance of 1 MΩ is assumed, which is within the standard range for memristors48. On average, the voltage across each memristor will be Vdd/2, applied for time τread. Thus, \({{{{{{{{\rm{E}}}}}}}}}_{{{{{{{{\rm{MCAread}}}}}}}}}=\frac{{({{{{{{{\rm{V\; dd}}}}}}}}/2)}^{2}}{1M\Omega }* {\tau }_{{{{{{{{\rm{read}}}}}}}}}* {{{{{{{\mathcal{R}}}}}}}}* {{{{{{{\mathcal{J}}}}}}}}=5.05\) fJ\(* {{{{{{{\mathcal{R}}}}}}}}* {{{{{{{\mathcal{J}}}}}}}}\), giving \({{{{{{{{\rm{E}}}}}}}}}_{{{{{{{{\rm{total}}}}}}}}}=(289* {{{{{{{\mathcal{I}}}}}}}}+311* {{{{{{{\mathcal{R}}}}}}}}+5.05* {{{{{{{\mathcal{R}}}}}}}}* {{{{{{{\mathcal{J}}}}}}}})\) fJ.
Delay
The delay of the NMRC is simply τ: D = τ.
Area, energy, and delay for CMOS ESN
The area, energy, and delay of a CMOS ESN was evaluated based on analysis of a design synthesized in a 65 nm process with Cadence Genus Synthesis Suite. Supplementary Fig. S4 depicts the digital ESN system with a 16-bit fixed-point vector-vector multiplier. For a fair comparison between the NMRC and CMOS reservoirs, the output layers of both were implemented with MCAs.
The number of neurons in the synthesized ESN for each task was tuned to match the accuracy obtained with the NMRC. For each task and number of neurons, ten samples of 20 networks each were generated with random weights and evaluated on the task. The accuracy of the best network in each sample was recorded as the sample accuracy, and these accuracies were averaged across the ten samples to give the reported accuracies in Table 2.
Area
The CMOS area was obtained directly after synthesis using the syn_gen command in Genus. The MCA area was determined similarly to the NMRC MCA. The total area is the sum of the CMOS and MCA areas.
Energy
Energy was calculated using the total power dissipation reported by Genus (both static and dynamic) in concert with the input switching rates of random data. To determine the energy, the power dissipation was multiplied by the delay per RC operation (calculated below). The energy consumed by the MCA was calculated and added to the total, in the manner described above for NMRC.
Delay
Genus reported the longest path in the design, which was between 2 ns and 3 ns over the three tasks. The maximum clock frequency is therefore between 300 MHz and 500 MHz. The minimum delay per operation is calculated by multiplying the minimum clock period (Tclk) by the number of clock cycles per reservoir operation: \({{{\mbox{D}}}}_{{{{{{{{\rm{CMOS}}}}}}}}}=({{{{{{{\mathcal{N}}}}}}}}+6)* {{{\mbox{T}}}}_{{{{{{{{\rm{clk}}}}}}}}}\).
Code availability
The code that supports the finding within this manuscript is available from the corresponding authors upon reasonable request.
References
Jaeger, H. & Haas, H. Harnessing nonlinearity: predicting chaotic systems and saving energy in wireless communication. Science 304, 78–80 (2004).
Tanaka, G. et al. Recent advances in physical reservoir computing: a review. Neural Netw. 115, 100–123 (2019).
Fernando, C. & Sojakka, S. Pattern recognition in a bucket. In Banzhaf, W., Ziegler, J., Christaller, T., Dittrich, P. & Kim, J. T. (eds.) Adv. Artif. Life. 588–597 (Springer Berlin Heidelberg, Berlin, Heidelberg, 2003).
Snyder, D., Goudarzi, A. & Teuscher, C. Computational capabilities of random automata networks for reservoir computing. Phys. Rev. E 87, 042808 (2013).
McDonald, N. Reservoir computing extreme learning machines using pairs of cellular automata rules. In 2017 International Joint Conference on Neural Networks (IJCNN), 2429–2436 (2017).
Morán, A., Frasser, C. F. & Rosselló, J. L. Reservoir computing hardware with cellular automata (2018). ArXiv:1806.04932 [cs.NE].
Honda, K. & Tamukoh, H. A hardware-oriented echo state network and its fpga implementation. Journal of Robotics, Networking and Artificial Life7 (2020).
Liao, Y.Real-Time Echo State Network Based on FPGA and Its Applications, chap. 2 (IntechOpen, 2020).
Alomar, M. L., Canals, V., Perez-Mora, N., Martínez-Moll, V. & Rosselló, J. L. Fpga-based stochastic echo state networks for time-series forecasting. Comput. Intellig Neurosci. 2016, 3917892 (2016).
Nakane, R., Tanaka, G. & Hirose, A. Reservoir computing with spin waves excited in a garnet film. IEEE Access 6, 4462–4469 (2018).
Furuta, T. et al. Macromagnetic simulation for reservoir computing utilizing spin dynamics in magnetic tunnel junctions. Phys. Rev. Appl. 10, 034063 (2018).
Marković, D. et al. Reservoir computing with the frequency, phase, and amplitude of spin-torque nano-oscillators. Appl. Phys. Lett. 114, 012409 (2019).
Riou, M. et al. Temporal pattern recognition with delayed-feedback spin-torque nano-oscillators. Phys. Rev. Appl. 12, 024049 (2019).
Tsunegi, S. et al. Physical reservoir computing based on spin torque oscillator with forced synchronization. Appl. Phys. Lett. 114, 164101 (2019).
Kanao, T. et al. Reservoir computing on spin-torque oscillator array. Phys. Rev. Appl. 12, 024052 (2019).
Yamaguchi, T. et al. Periodic structure of memory function in spintronics reservoir with feedback current. Phys. Rev. Res. 2, 023389 (2020).
Yamaguchi, T. et al. Step-like dependence of memory function on pulse width in spintronics reservoir computing. Sci. Rep. 10, 19536 (2020).
Dawidek, R. W. et al. Dynamically driven emergence in a nanomagnetic system. Adv. Funct. Mater. 31, 2008389 (2021).
Gartside, J. C. et al. Reconfigurable training and reservoir computing in an artificial spin-vortex ice via spin-wave fingerprinting. Nat. Nanotechnol. 17, 460–469 (2022).
Vidamour, I. T. et al. Quantifying the computational capability of a nanomagnetic reservoir computing platform with emergent magnetisation dynamics. Nanotechnology 33, 485203 (2022).
Stenning, K. D. et al. Neuromorphic few-shot learning: Generalization in multilayer physical neural networks (2023).
Prychynenko, D. et al. Magnetic skyrmion as a nonlinear resistive element: a potential building block for reservoir computing. Phys. Rev. Appl. 9, 014034 (2018).
Pinna, D., Bourianoff, G. & Everschor-Sitte, K. Reservoir computing with random skyrmion textures. Phys. Rev. Appl. 14, 054020 (2020).
Love, J., Mulkers, J., Bourianoff, G., Leliaert, J. & Everschor-Sitte, K. Spatial analysis of physical reservoir computers (2021).
Rajib, M. M., Misba, W. A., Chowdhury, M. F. F., Alam, M. S. & Atulasimha, J. Skyrmion based energy-efficient straintronic physical reservoir computing. Neuromorph. Comput. Eng. 2, 044011 (2022).
Nomura, H. et al. Reservoir computing with dipole-coupled nanomagnets. Jpn J. App. Phys. 58, 070901 (2019).
Nomura, H. et al. Reservoir computing with two-bit input task using dipole-coupled nanomagnet array. Jpn J. App. Phys. 59, SEEG02 (2020).
Nomura, H., Kubota, H. & Suzuki, Y. Reservoir Computing with Dipole-Coupled Nanomagnets, 361–374 (Springer Singapore, Singapore, 2021).
Hon, K. et al. Numerical simulation of artificial spin ice for reservoir computing. Appl. Phys. Exp. 14, 033001 (2021).
Bennett, C. H., Querlioz, D. & Klein, J.-O. Spatio-temporal learning with arrays of analog nanosynapses. In 2017 IEEE/ACM International Symposium on Nanoscale Architectures (NANOARCH), 125–130 (2017).
Bürger, J. & Teuscher, C. Variation-tolerant computing with memristive reservoirs. In 2013 IEEE/ACM International Symposium on Nanoscale Architectures (NANOARCH), 1–6 (2013).
Bürger, J., Goudarzi, A., Stefanovic, D. & Teuscher, C. Hierarchical composition of memristive networks for real-time computing. In Proceedings of the 2015 IEEE/ACM International Symposium on Nanoscale Architectures (NANOARCH’15), 33–38 (2015).
Du, C. et al. Reservoir computing using dynamic memristors for temporal information processing. Nat. Commun. 8, 2204 (2017).
Hassan, A. M., Li, H. H. & Chen, Y. Hardware implementation of echo state networks using memristor double crossbar arrays. In 2017 International Joint Conference on Neural Networks (IJCNN), 2171–2177 (2017).
Kulkarni, M. S. & Teuscher, C. Memristor-based reservoir computing. In 2012 IEEE/ACM International Symposium on Nanoscale Architectures (NANOARCH), 226–232 (2012).
Tanaka, G. et al. Waveform classification by memristive reservoir computing. In Liu, D., Xie, S., Li, Y., Zhao, D. & El-Alfy, E.-S. M. (eds.) Neural Information Processing, 457–465 (Springer International Publishing, Cham, 2017).
Zhong, Y. et al. Dynamic memristor-based reservoir computing for high-efficiency temporal signal processing. Nat. Commun. 12, 408 (2021).
der Sande, G. V., Brunner, D. & Soriano, M. C. Advances in photonic reservoir computing. Nanophotonics 6, 561–576 (2017).
Schneider, B., Dambre, J. & Bienstman, P. Using digital masks to enhance the bandwidth tolerance and improve the performance of on-chip reservoir computing systems. IEEE Trans. Neural Netw. Learn. Syst. 27, 2748–2753 (2016).
Antonik, P., Haelterman, M. & Massar, S. Brain-inspired photonic signal processor for generating periodic patterns and emulating chaotic systems. Phys. Rev. Appl. 7, 054014 (2017).
Ramirez, A. Chapter 4 geometrical frustration. Handbook Magn. Mater. 13, 423–520 (2001).
Wang, R. F. et al. Artificial ‘spin ice’ in a geometrically frustrated lattice of nanoscale ferromagnetic islands. Nature 439, 303–306 (2006).
Jensen, J. H., Folven, E. & Tufte, G. Computation in artificial spin ice. ALIFE 2018: The 2018 Conference on Artificial Life 15–22 (2018).
Jensen, J. H. & Tufte, G. Reservoir computing in artificial spin ice. ALIFE 2020: The 2020 Conference on Artificial Life 376–383 (2020).
Ralph, D. & Stiles, M. Spin transfer torques. J. Magnet. Magnet. Mater. 320, 1190–1216 (2008).
Lee, J. M. et al. Field-free spin–orbit torque switching from geometrical domain-wall pinning. Nano Lett. 18, 4669–4674 (2018).
Tehrani, S. Status and prospect for mram technology. In 2010 IEEE Hot Chips 22 Symposium (HCS), 1–23 (2010).
Li, Y., Wang, Z., Midya, R., Xia, Q. & Yang, J. J. Review of memristor devices in neuromorphic computing: materials sciences and device challenges. J. Phys. D: Appl. Phys. 51, 503002 (2018).
Hu, M. et al. Memristor-based analog computation and neural network classification with a dot product engine. Adv. Mater. 30, 1705914 (2018).
Cai, F. et al. A fully integrated reprogrammable memristor-CMOS system for efficient multiply-accumulate operations. Nat. Electron. 2, 290–299 (2019).
Chen, W.-H. et al. Cmos-integrated memristive non-volatile computing-in-memory for ai edge processors. Nat. Electron. 2, 420–428 (2019).
Vansteenkiste, A. et al. The design and verification of MuMax3. AIP Adv. 4, 107133 (2014).
Lu, Z. et al. Reservoir observers: Model-free inference of unmeasured variables in chaotic systems. Chaos: Interdiscip. J. Nonlinear Sci. 27, 041102 (2017).
Wolfram, S. Statistical mechanics of cellular automata. Rev. Mod. Phys. 55, 601–644 (1983).
Wolfram, S. A New Kind of Science (Wolfram Media, 2002). https://www.wolframscience.com.
Lim, H., Lee, S. & Shin, H. Switching time and stability evaluation for writing operation of stt-mram crossbar array. IEEE Trans. Electron Dev. 63, 3914–3921 (2016).
Niemier, M. T. et al. Nanomagnet logic: progress toward system-level integration. J. Phys.: Condens. Matter 23, 493202 (2011).
Liu, B. et al. On-chip readout circuit for nanomagnetic logic. IET Circ. Dev. Syst. 8, 65–72 (2014).
Shah, F. A. et al. Compensation of orange-peel coupling effect in magnetic tunnel junction free layer via shape engineering for nanomagnet logic applications. J. Appl. Phys. 115, 17B902 (2014).
Watanabe, K., Jinnai, B., Fukami, S., Sato, H. & Ohno, H. Shape anisotropy revisited in single-digit nanometer magnetic tunnel junctions. Nat. Commun. 9, 663 (2018).
Acknowledgements
Any opinions, findings, conclusions, or recommendations expressed in this material are those of the authors, and do not necessarily reflect the views of the US Government, the Department of Defense, or the Air Force Research Lab. Approved for Public Release; Distribution Unlimited: AFRL-2022-4420. The authors thank E. Laws, J. McConnell, N. Nazir, L. Philoon, and C. Simmons for technical support, S. Luo for fruitful discussion, and the Texas Advanced Computing Center at The University of Texas at Austin, Austin, TX, USA, for providing computational resources. F.G.S. acknowledges support from project No. PID2020117024GB-C41 funded by Ministerio de Ciencia e Innovacion from the Spanish government.
Author information
Authors and Affiliations
Contributions
A.J.E. and P.Z. performed the simulations; A.J.E. designed and analyzed the circuits and system; D.B., W.A.M., M.F.C., and J.A. performed the experiment and provided experimental guidance; N.R.M., L.L., and C.D.T. provided guidance regarding RC; F.G.S., N.H., and X.H. contributed to the simulations and analysis; J.S.F. conceived of the system and supervised the research; A.J.E. and J.S.F. prepared the manuscript, to which all authors contributed.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Communications Physics thanks the anonymous reviewers for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Edwards, A.J., Bhattacharya, D., Zhou, P. et al. Passive frustrated nanomagnet reservoir computing. Commun Phys 6, 215 (2023). https://doi.org/10.1038/s42005-023-01324-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s42005-023-01324-8
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
