
Abstract
The simultaneous monitoring of both the process mean and dispersion has gained considerable attention in statistical process control, especially when the process follows the normal distribution. This paper introduces a novel Bayesian adaptive maximum exponentially weighted moving average (Max-EWMA) control chart, designed to jointly monitor the mean and dispersion of a non-normal process. This is achieved through the utilization of the inverse response function, particularly suitable for processes conforming to a Weibull distribution. To assess the effectiveness of the proposed control chart, we employed the average run length (ARL) and the standard deviation of run length (SDRL). Subsequently, we compared the performance of our proposed control chart with that of an existing Max-EWMA control chart. Our findings suggest that the proposed control chart demonstrates a higher level of sensitivity in detecting out-of-control signals. Finally, to illustrate the effectiveness of our Bayesian Max-EWMA control chart under various Loss Functions (LFs) for a Weibull process, we present a practical case study focusing on the hard-bake process in the semiconductor manufacturing industry. This case study highlights the adaptability of the chart to different scenarios. Our results provide compelling evidence of the exceptional performance of the suggested control chart in rapidly detecting out-of-control signals during the hard-bake process, thereby significantly contributing to the improvement of process monitoring and quality control.
Similar content being viewed by others
Introduction
Statistical process control (SPC) is an essential quality management approach ensuring efficient operations and consistent high-quality products and services. It employs statistical methods such as control charts and process capability analysis to detect and rectify production variations, fostering data-driven decision-making, process stability, and waste reduction. SPC implementation promotes proactive quality management, resulting in enhanced customer satisfaction, cost reduction, and improved operational efficiency. SPC serves as a systematic approach for managing and enhancing the quality of production processes. It primarily utilizes control charts (CCs), graphically depicting process performance by tracking data points over time. SPC aids in recognizing patterns and fluctuations, distinguishing between natural variability (common causes) and irregularities caused by specific events (special causes). By enabling early identification of process deviations, CCs empower organizations to implement timely corrective measures, ensuring consistent adherence to predefined quality standards. As a fundamental quality management tool, SPC fosters continuous improvement and operational efficiency across various industries. In the genesis of control charts (CCs), Shewhart1 laid the foundation, employing current sample data to identify significant changes in production processes. In contrast, memory-type CCs, exemplified by cumulative sum (CUSUM) and exponentially weighted moving average (EWMA) CCs, introduced by Page2 and Roberts3, respectively, incorporate both current and historical sample data. Notably, CUSUM and EWMA CCs exhibit heightened sensitivity in detecting subtle to moderate shifts in process parameters, surpassing the capabilities of traditional Shewhart CCs. These memory-type CCs, especially CUSUM and EWMA, find extensive application across diverse domains, prominently in chemical and industrial production processes. You et al.4 evaluate the performance of the EWMA median chart using EARL as a metric and show consistent performance with both EARL and ARL metrics when the deterministic shift size matches the process layer size range. Chatterjeea et al.5 introduces the TEWMA-Max CC, demonstrating its higher sensitivity compared to Max-EWMA and Max-DEWMA in detecting shifts in mean and variability, with a satisfactory overall performance for various shift combinations. Jalilibal et al.6 examines the need for continuous process monitoring emphasizing the importance of detecting changes in dispersion and location parameters of process. Yung7 highlights green manufacturing policies to minimize waste, emphasizing optimal product quality through the Qpm MQCAC for joint monitoring of mean µ and standard deviation σ, demonstrating its efficacy in quality improvement and aligning with environmental goals. Arif et al.8 proposed a new control chart integrating EWMA with the generalized likelihood ratio test statistic for joint monitoring of process mean and dispersion under double ranked set sampling. Noor-ul-Amin et al.9 introduced a Max-EWMA control chart for joint monitoring of mean and dispersion under the Weibull distribution, showcasing improved sensitivity compared to the existing Max-EWMA control chart. Evaluation is based on ARL and SDRL, with practical application demonstrated through two examples. Lee and Lin10 integrate adaptive techniques with Max charts for enhanced process control, utilizing a Markov chain approach to develop statistical indicators and design models. Comparing the adaptive Max charts with EWMA, CUSUM, and double-sampling charts, it demonstrates their superior ability to detect small shifts in mean and variance. Nazir et al.11 studied four robust adaptive EWMA schemes for monitoring process location parameters, examining their performance under normal and contaminated environments through comparisons of ARL, SDRL, and run length distribution percentiles, with practical examples included for implementation. Sarwar and Noor-ul-Amin12 propose an adaptive EWMA chart for monitoring the mean of a normal process, showcasing its efficacy in detecting shifts through comprehensive Monte Carlo simulations. Noor-ul-Amin et al. 9 introduces a CC for jointly identifying the variations in the process mean and dispersion, with the help of inverse response function for Weibull distribution. Previous studies indicate a prevalent dependence on traditional methods centered solely on sample data, often overlooking prior information. Conversely, the Bayesian methodology incorporates both sample data and prior knowledge to revise and construct a posterior distribution (P), thereby improving the estimation process. Menzefricke13 presents combined EWMA charts for mean and variance using Bayesian approach. Simulations compare charts for different specifications, including weighing constant and calibration sample size, and evaluate the variance-focused EWMA chart's performance. Aunali and Venkatesan14 suggested a Bayesian estimator for quick detection of small shifts in a CC assuming a normal process. It compares this estimator to classical Moving Average, CUSUM, and EWMA control charts in detecting small shifts in the process mean, utilizing a simulation study based on individual observations. Alia15 Bayesian predictive monitoring of time-between-events using CUSUM and EWMA CCs with predictive control limits, demonstrating feasibility for online process monitoring and comparison with frequentist sequential charts. Asalam and Anwar16 introduce a Bayesian Modified-EWMA chart, indicating higher performance in monitoring slight to large changes and surpassing current alternatives. Bourazasa et al.17 propose a versatile Bayesian method for online monitoring using power priors for outlier detection and accommodating diverse data distributions, showcasing superiority over frequentist approaches in an extended simulation study, with practical applications in short production runs and online Phase I monitoring. Khan et al.18 proposed a Bayesian HEWMA control chart utilizing RSS schemes, demonstrating improved sensitivity for detecting out-of-control signals compared to existing Bayesian control charts, as evidenced by extensive Monte Carlo simulations and a numerical example from semiconductor manufacturing. Noor-ul-Amin et al.19 introduce a novel Bayesian Max-EWMA control chart for simultaneous tracking of non-normal process mean and dispersion, demonstrating superior sensitivity and adaptability under different LFs for Weibull processes, particularly in semiconductor manufacturing. Iqbal et al.20 introduce a novel Bayesian Max-EWMA control chart for concurrent monitoring of mean and variance under various loss functions, demonstrating superior sensitivity and performance compared to existing methods. This is validated through Monte Carlo simulations and a practical case study in semiconductor manufacturing. Differing from prior studies exploring classical and Bayesian methods, as well as SRS and RSS schemes, for monitoring mean, variance, and their joint behavior, this article focuses uniquely on the use of Bayesian approaches for monitoring both mean and variance by adapting the value of smoothing constant that helps to adjust the value of smoothing constant according to the estimated shift size. This adaptation ensures that the monitoring process remains effective across a wide range of shift sizes, a capability not addressed in prior studies. The performance evaluation of this Bayesian Max-EWMA CC is carried out through the use of Monte Carlo simulations. The article is structured with specific segments, including a part dedicated to Bayesian theory and various LFs in Section "Bayesian approach", the proposed Bayesian adaptive Max-EWMA CC method in Section "Suggested Bayesian adaptive max-EWMA CC for Weibull process", Section "Simulation study" contains simulation study and extensive discussions and significant findings in Section "Results discussion and main findings", practical applications using real-life data in Section "Real Life application", and concluding remarks in Section "Conclusion".
Bayesian approach
The Bayesian methodology in statistics sights probability as an indication of the plausibility or confidence in an event. It employs Bayes' theorem to revise the probability associated with a hypothesis in response to additional evidence. In contrast to frequentist statistics, which regard probability as a frequency-based limit, the Bayesian approach integrates prior knowledge or assumptions about relevant parameters during analysis. By merging prior information with fresh data, it facilitates the determination of unknown parameters and the measurement of uncertainty in a more adaptable and intuitive manner. This approach is widely applicable across a range of fields, including machine learning, decision-making, and experimental design. Let V be the random variable representing lifetimes following a Weibull distribution with both the shape parameter (λ) and scale parameter (α) being greater than zero (α > 0, λ > 0). In this scenario, the mathematical expressions for the probability density function (pdf) and cumulative distribution function (cdf) are as follows:
Squared error loss function
The SELF is a critical tool in the Bayesian framework, used to gauge the gap between predicted and actual parameter values. It computes the average squared difference between estimated and true parameter values, assessing the model's suitability. In Bayesian decision theory, it aids in choosing an optimal estimator that minimizes the expected value of the squared error loss. Additionally, this function plays a key role in Bayesian inference, helping to derive posterior distributions and evaluate model accuracy. The SELF, originally presented by Gauss21, consider the interest as X and estimator \(\hat{\theta }\) employed for the estimation of population parameter, referred to as θ. Its expression for SELF is mathematized as:
Applying SELF, Bayes estimator is mathematized as
Linex loss function
In Bayesian methodology, the linex loss function (LLF) is instrumental in gauging the difference between the estimated and true values of a parameter. It measures the absolute difference between these values, allowing for an evaluation of the model's accuracy and reliability. This function aids in the selection of an appropriate estimator to minimize the expected value of the LLF within Bayesian decision theory. Furthermore, it contributes to Bayesian inference by helping derive posterior distributions and improving the assessment of model performance and precision. Varian22 introduced the LLF to minimize risks in Bayesian estimation. The mathematical representation of the LLF is as follows:
Bayesian estimator \(\hat{\theta }\) under LLF is mathematizied as
Suggested Bayesian adaptive max-EWMA CC for Weibull process
In the context of statistical analysis, let's examine a sequence of random samples represented as Vi1, Vi2, …, Vin, derived from a Weibull distribution represented at various time instances, with i representing distinct sequences (\(i = \, 1, \, 2, \, 3\), and so forth). It is common for Weibull process that the parameters (\(\alpha\) and \(\lambda\)) to be initially unknown, prompting the need for estimation using historical data. The process of parameter estimation typically assumes the process is under control. Let \(\alpha_{0}\) and \(\lambda_{0}\) represent the estimated scale and shape parameters, respectively. The estimation of these parameters involves establishing a connection between standard normal and Weibull distribution, as elucidated Faraz et al.23 in Eq. (7), expressed as:
The properties of the above function is given as
and
Useful information about the effects of changing the parameters of a Weibull distribution on the mean and variance of a random variable with a standard normal distribution can be obtained from Eqs. (8) and (9). Essentially, these formulas express the precise influence that changes in the Weibull distribution parameters have on the features and attributes of the normal distribution.
Suppose we have a series of random samples, denoted as \(z_{i1} = W\left( {V_{i1} ,\alpha_{0} ,\lambda_{0} } \right)\), \(z_{i2} = W_{N} \left( {V_{i2} ,\alpha_{0} ,\lambda_{0} } \right)\), …, \(z_{in} = W_{N} \left( {V_{in} ,\alpha_{0} ,\lambda_{0} } \right)\), originating from a Weibull distribution and transformed to a normal distribution. In this context, the Max-EWMA Control Chart, integrating the principles of Bayesian theory, allows for the concurrent monitoring of both the mean and variance of the process that follows the normal distribution. This approach facilitates effective and simultaneous monitoring of the underlying process parameters, ensuring improved control and management of the system's performance.
In a Bayesian framework, assuming normal distributions for both the likelihood function and prior distribution, the resulting posterior distribution also adopts a normal distribution form. This distribution is characterized by its mean (θ) and variance (σ) as defining parameters. The probability density function (pdf) of the posterior distribution is articulated as:
where \(\theta_{n} = \frac{{n\overline{z} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }}\) and \(\delta_{n}^{2} = \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}\) respectively.
Selecting a sample of “n” values that represent a specific quality attribute “Z” from the production process is the first step in creating a Max-EWMA chart using Bayesian methodology. Then, using the SELF method, we calculate the transformed statistics for the mean and variance as shown below:
and
where \(\hat{\theta }_{(SELF)} = \frac{{n\overline{x} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }}\) and \(\hat{\delta }_{(SELF)}^{2} = \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}\) are the Bayes estimators applying SELF, while using LLF, the Bayes estimators are given as \(\hat{\theta }_{{\left( {_{LLF} } \right)}} = \frac{{n\overline{z} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }} - \frac{{C{\prime} }}{2}\delta_{n}^{2}\) and \(\hat{\delta }_{{\left( {LLF} \right)}}^{2} = \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}\), The mathematical description of the transformed statistic for both the process mean and variance under LLF is as follows:
and
In this context, \(H\left( {n,\nu } \right)\) represents a chi-square distribution with \(\nu\) degrees of freedom, and \(\phi^{ - 1}\) signifies the inverse function. The following is the breakdown of the calculations for the EWMA statistics related to the process mean and dispersion.
In this scenario, for the EWMA statistic Pt and Qt, the initially values are denoted by \(P_{0}\) and \(Q_{0}\) respectively. Furthermore, both Pt and Qt are independent and normally distributed with a mean of zero and variances of σ2 respectively. This is expressed as follows:
Integration of adaptive approach
Subsequently, we introduce the adaptive technique. Consider \({X}_{t}\) a normally distributed random variable at time t with a sample size of n, characterized by a mean \({\upmu }_{{\text{X}}}\) and a variance \({\upsigma }_{{\text{X}}}^{2}.\mathrm{ i}.{\text{e}}.,{{\text{X}}}_{{\text{t}}}\sim {\text{N}}\left({\upmu }_{{\text{X}}}, {\upsigma }_{{\text{X}}}^{2}\right)\). Jiang et al.24 introduced an estimator for estimating the magnitude of the shift using the following expression:
The symbol ψ represents the smoothing constant, typically constrained to the range (0,1]. In real-world applications, having prior knowledge about the precise magnitude of a shift is uncommon. Consequently, we initially estimate its value. Haq et al.25 suggested an unbiased estimator, denoted as \(\hat{\delta }_{t}^{{**}}\), which can be expressed as:
where \({\text{E}}\left( {\hat{\delta }_{t}^{{**}} } \right) = {\updelta } = 0\). The process remains stable for a certain period of time, denoted as \({\text{t}}\le {{\text{t}}}_{0}\). In practical scenarios, the true magnitude is frequently unknown. Instead, δ is estimated by considering \(\tilde{\delta }_{t}^{{**}} = \left| {\hat{\delta }_{t}^{{**}} } \right|\).
The detection is accomplished through the recursive calculation of the subsequent EWMA statistic, known as the suggested chart statistic, as follows:
Setting the initializing value as \({{\text{A}}}_{0}\) = 0, we avoid using a fixed value for the smoothing constant. Instead, we adopt a function that can adjust to different values depending on the changing conditions of the process. To achieve this, we propose the following function for the self-adjusting weighting factor η(\({\tilde{\upomega }}_{{\text{t}}}^{*}\)).
The function is segmented into three parts based on the estimated shift. In the initial part, the function is constructed when the estimated shift is less than 1, resulting in a small smoothing constant to accommodate minor shifts. In the second segment, the smoothing constant takes on a larger value compared to the first part, aligning with moderate estimated shifts. For shifts categorized as large, the third part of the function assigns a smoothing constant equal to 1. Here, η(\({\tilde{\omega }}_{t}^{*}\)) represents a random variable shaped by a continuous function, optimizing the performance of our chart for shift detection. When \({\tilde{\delta }}_{t}\) ≤ 2.7, η() is specifically designed to be sensitive to small to moderate shifts. Our adaptive chart outperforms other methods by excelling in detecting shifts of any size. If the shift surpasses \({\tilde{\delta }}_{t}\) ≥ 2.7, our chart functions similarly to a Shewhart chart, effectively identifying larger shifts with \({\tilde{\delta }}_{t}\)= 2.7 serving as the pivotal point. It provides flexibility in model adjustments and the inclusion of additional factors. Instead of using a fixed value in Eqs. (10) and (11), assuming its constancy throughout the process, we utilize the self-adjusting function from Eq. (16) and iteratively update Eqs. (10) and (11) to calculate the individual EWMA under the adaptive approach. Thus, the transformed equations are mathematically described as:
Finally, these values are inserted into the Max-EWMA provided by Chen and Change26 to jointly monitor the process mean and variance in a single chart. Thus, the plotting can be expressed as:
where Max is function to get the maximum value of the given inputs.
The suggested statistic being a positive value simplifies the monitoring process. In this context, we only need to plot the UCL for the joint monitoring of the process mean and variance. The plotting statistic is then compared with the UCL threshold. If the value is above the UCL, the process is considered out of control, indicating deviations in the mean, variance, or both. On the other hand, if the value is below the UCL, the process is considered to be under control.
Simulation study
The study employs the Monte Carlo simulation method to intricately examine the effectiveness of the Bayesian adaptive Max-EWMA CC in identifying shifts in process parameters through the computation of ARLs and SDRLs, with a particular focus on the in-control process ARL set at 370. This approach is pivotal for understanding the impact of varying the smoothing constant, such as \(\gamma\) = 0.10 and 0.25, the study aims to shed light on how these adjustments can enhance the CCs responsiveness to detecting quality shifts in manufacturing processes. The Monte Carlo simulation method's comprehensive steps are crafted to provide a deep dive into the performance of the Bayesian adaptive Max-EWMA CC, evaluating its potential in improving process monitoring and control. This rigorous analysis not only highlights the adaptability and efficiency of the proposed control chart in signaling out-of-control conditions but also contributes valuable insights into optimizing process quality management strategies, thereby offering a significant advancement in the field of SPC. The following are main steps.
Step 1. setting up control limits
-
i.
We take Weibull distribution as a sampling distribution and transform to standard normal distribution. The prior distribution is also a standard normal for calculating the mean and variance of posterior distribution under different LF.
-
ii.
Chose the initial value of h with a specific value of \(\gamma\) at fixed \({ARL}_{0}\)= 370.
-
iii.
Random samples of size n is generated for the in-control process from the normal distribution such that \(X\sim N\left( {E(\hat{\theta }),E\left( {\hat{\delta }} \right)} \right)\).
-
iv.
Compute the plotting statistic of the offered Bayesian adaptive Max-EWMA CC and evaluate the process according to the suggested design.
-
v.
If the process declared in-control, then repeat steps (iii-iv) until the process is showed to be out-of-control. When the process is declared as out-of-control then record the in-control number as run length.
-
vi.
Repeat the steps (iii-v) 50,000 times and calculate the in-control ARL.
-
vii.
If \({ARL}_{0}=370\), then go to Step 2 with the same value of \(\gamma\), and h. Otherwise, repeat steps (ii-vi) with the change value of L.
Step 2. Evaluate the out-of-control ARL
-
i.
Select random sample for the shifted process from the normal distribution such that \(X\sim N\left( {E(\hat{\theta }) + \sigma \frac{{E\left( {\hat{\delta }} \right)}}{\sqrt n },E\left( {\hat{\delta }} \right)} \right),\) where \(\sigma\) is the amount of shift in the process parameter.
-
ii.
Calculate plotting statistic and appraise the process according to the design of the recommended CC.
-
iii.
If the plotted statistic lies within the UCL, repeat steps (i–ii). Otherwise, record the number of generated points, indicating a single out-of-control run length.
-
iv.
Repeat the aforementioned process (steps i–iii) 50,000 times to determine the ARL1 and SDRL1 for out-of-control scenarios.
Results discussion and main findings
In this examination, Tables 1, 2, 3 and 4 play a pivotal role in presenting the extensive findings resulting from the implementation suggested CC in the context of the Weibull process. The study conducts a detailed exploration of the implications of two different LFs, highlighting the significance of the posterior distribution. In the context of informative priors, these assessments are conducted by incorporating pre-existing knowledge and beliefs into the analytical procedures. This integration aims to augment the overall understanding of the results, recognizing and leveraging prior information to inform the Bayesian analysis. The use of 50,000 replicates ensures robust statistical findings, enhancing the reliability of the ARL and SDRL calculations. Careful selection of smoothing constants demonstrates a commitment to precision, refining the analysis and enabling a thorough evaluation of the suggested Bayesian CC performance in diverse scenarios. Additionally, the study comprehensively explores a wide range of combinations, spanning from 0.00 to 3.00 of shift values (a) and from 0.25 to 3.00 for variance shift values (b). In this comprehensive study, we thoroughly examine the efficacy of the offered CC designed for jointly identifying both the process mean and dispersion. The study's findings unequivocally highlight the exceptional sensitivity of the method in detecting deviations from established norms within production processes. This underscores the significant potential of the proposed CC as a reliable tool for continuous monitoring and quality control across various industrial sectors. It is crucial to continuously confirm during the analysis that the plotting statistic was computed stays less than the UCLi. The outcome of each trial is determined by the plotting statistic exceeding the UCLi, which indicates a substantial change in the process mean and standard deviation. These observed changes are associated with variations in the parameters of the Weibull distribution, indicating potential deviations from the expected norms in the production process. In our examination, we specifically investigate shifts in shape parameters within the range of 0.25 to 4.00 and shifts in scale parameters within the range of 0.0 to 5.00. For W(1, 1.5), the process initially adheres to control limits, following a N(0,1) normal distribution. The ARL under in-control conditions was determined as 370 for two distinct values of λ. The findings presented in Tables 1 and 2 robustly affirm the performance of offered CC, particularly when employed in conjunction with SELF applying posterior distribution. This combined approach showcases an impressive capability to detect shifts in both process mean and variance concurrently, ensuring process stability and product quality. Notably, a trend that consistently shows up in the data indicates that ARLs decrease as mean shift magnitude increases. ARLs exhibit a decline in response to variance shifts as well. These consistent patterns strongly emphasize the recommended CC's ability to promptly recognize and indicate process shifts, enabling timely intervention and process control. This characteristic positions it as an invaluable instrument for comprehensive production process monitoring, ensuring the swift identification and resolution of deviations from established norms. The ultimate goal of implementing these control charts is to enhance product quality and improve process efficiency, rendering them valuable assets across diverse industries. For instance, when scrutinizing the ARL results for the suggested Bayesian Max-EWMA CC, emphasis is placed on the application of the SELF. In this context, a smoothing parameter of λ = 0.10 and a sample size of n = 5 are employed. In particular, our exploration involves examining different Weibull distribution shape parameter shift values, spanning from 1.50 to 5.00, while keeping the scale parameter shift constant at 1.0. The corresponding run length outcomes for mentioned shifts are enumerated as follows: 369.15, 80.19, 24.05, 13.71, 10.14, 8.16, 7.12, 4.88, and 4.13. Notably, as shift magnitude increases, a distinct reduction in the corresponding ARL values is observed. This finding underscores the heightened efficiency of the proposed Bayesian Max-EWMA CC in promptly identifying shifts in the shape parameter. Practically, this increased sensitivity implies that the control chart can swiftly identifying minor variations in the process mean, facilitating a rapid response—a critical aspect in upholding process quality and consistency. The analysis extends to evaluating the influence of varying scale parameter values, ranging from 1.0 to 4.00, while keeping the shape parameter constant at a = 1.50. The resultant run length are: 369.51, 24.90, 16.82, 7.16, 5.08, 3.60, 2.60, 2.11, and 1.50. Notably, these results exhibit a distinct trend—as the shape parameter diverges from its baseline value of 1, there is a noticeable decrease in ARL values. This pattern demonstrates how the recommended Control Chart can effectively identify changes in process dispersion quickly. It is crucial to underscore a key observation from Table 2. In assessing the performance of the recommended CC, it becomes apparent that the effectiveness of the CC diminishes with higher values of the smoothing constant. According to this realization, there are some situations where choosing a smaller smoothing constant might be more beneficial for getting the best results. ARL results for the proposed CC using the LLF with a consistent λ = 0.25 and n = 5 are similarly presented in Tables 3 and 4. 370.09, 20.34, 6.34, 2.81, 1.99, 1.57, and 1.17 were The ARL values that resulted from several trials that involved shifting the shape parameter from 1.50 to 5.00 and corresponding shifts in the scale parameter kept at 1.0. The key findings indicate a noticeable pattern: as process shifts become more significant, ARL values show a steep decrease, underlining the remarkable accuracy of the provided control chart in quickly detecting deviations in both process mean and dispersion. It is also important to recognize that the effectiveness of the suggested CC in concurrently identifying process mean and dispersion is impacted by the sample size. The results consistently show that as the sample size grows, ARL values decrease, demonstrating the improved precision of the recommended control chart in promptly identifying deviations from the anticipated process parameters:
-
The analysis of the ARL and SDRL across Tables 1, 2, 3 and 4 associated with proposed CC using Weibull process highlights its effectiveness in identifying both process mean and variance, particularly in the detection of minor to moderate shifts. These profiles demonstrate the CC's performance across various scenarios, with a consistent trend indicating its proficiency in swiftly identifying variations in process mean and dispersion, thus establishing its significance and consistency.
-
Simulation outcomes clearly show reducing the smoothing constant enhances effectiveness of the recommended Bayesian CC for simultaneous process monitoring. Essentially, decreasing the \(\lambda\) makes CC more responsive and adept at swiftly identifying changes in both the process mean and variance. This insight suggests that, in particular situations or applications, opting for a lower \(\lambda\) can result in more streamlined monitoring, leading to faster identification of deviations from expected process parameters and ultimately improving the quality and reliability of the process.
-
In our investigation, a critical aspect that we have thoroughly examined is the variation in sample size. Our analysis reveals a crucial and compelling insight. Clearly, the efficacy and performance of the proposed CC improve noticeably and significantly with increasing sample size. In practical terms, this suggests that when utilizing larger sample sizes, the CC becomes more skilled at accurately and swiftly detecting changes in both the process mean and variance. This development holds particular significance as it has the potential to improve process monitoring's dependability and resilience, thereby leading to an overall improvement in process consistency and quality.
Real Life application
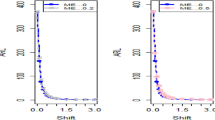
The article provides a practical illustration of the proposed CC by applying it to data obtained from Montgomery's research27, which focuses on the hard-bake process in semiconductor manufacturing. The dataset used in this application comprises 45 samples, with each sample containing 5 wafers, resulting in a total of 225 data points measured in microns. The measurements were taken at regular one-hour intervals during the data collection. Within the dataset, the initial 30 samples, totaling 150 observations, represent a well-controlled process referred to as the phase I dataset. This phase serves as a baseline for the controlled state of the manufacturing process. On the other hand, the subsequent 15 samples, comprising 75 observations, depict an out-of-control process and are identified as the phase II dataset. This phase is characterized by variations or deviations from the expected or controlled behavior in the semiconductor manufacturing process. The differentiation between phase I and phase II datasets allows for the assessment of the proposed CC's effectiveness in identifying and responding to variations, providing insights into its practical utility in monitoring and maintaining the quality of the manufacturing process (Figs. 1, 2).

ARL plot for the offered CC under SELF.

ARL plot for suggested CC utilizing LLF.
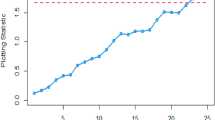
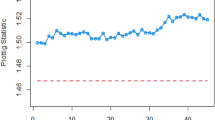
Figures 3 and 4 visually demonstrate the application of the existing Bayesian Max-EWMA CC, which is specifically designed to monitor both process mean and dispersion simultaneously, utilizing the SELF and LLF methods. A detailed examination of these charts clearly indicates instances where the process has deviated from the expected control state, notably in the 38th and 39th samples, particularly when considering a smoothing constant of 0.25, while Figs. 5 and 6 identifying the out-of-control signals for both the process mean and dispersion on the 35th and 36th samples for the proposed CC. These changes in process behavior are closely related to changes in process mean and dispersion of the Weibull distribution. In reliability and survival analysis, the Weibull distribution is a statistical model often used to describe the distribution of data. Changes in the shape and scale parameters directly influence the distribution's characteristics, resulting in the observed discrepancies in the control charts. In essence, the identified deviations in the 36th and 35th samples can be traced back to shifts in the fundamental parameters of the underlying statistical distribution, impacting the overall behavior of the manufacturing process and triggering the out-of-control conditions reflected in the CCs.

Existing Max-EWMA CC under Weibull process for jointly monitoring with \(\lambda = 0.25\).

Utilizing LLF, Max-EWMA CC applying Weibull process for jointly monitoring at \(\lambda = 0.25\).

plot for the suggested CC Using SELF, for jointly monitoring with \(\lambda = 0.25\).

Plot using LLF, for recommended CC for jointly monitoring with \(\lambda = 0.25\).
Conclusion
In this research, we present an innovative Bayesian CC specifically designed for monitoring Weibull processes, enabling simultaneous tracking of process mean and variance. This CC includes informative prior distributions and integrates two different LFs within the framework of the posterior distribution. To thoroughly assess the performance of this novel approach, we conducted an extensive analysis, presenting detailed results in Tables 1, 2, 3 and 4 . ARL and SDRL were used as evaluation metrics These evaluations utilized key metrics such as ARL and SDRL and ARL plots i.e., Figs. 1 and 2 also show efficient performance of the suggested CC. A useful case study was also carried out, with an emphasis on the hard bake procedure used in the production of semiconductors. Importantly, when applied to posterior distributions, the proposed CC demonstrated significant proficiency in detecting out-of-control signals within the process. The insights gained from this study hold promise for extending these principles to the development of other memory-type Control Charts, enhancing their effectiveness across diverse industrial applications. Expanding the application of this innovative technique beyond non-normal distributions to various types of Control Charts contributes to a more comprehensive understanding of underlying data patterns. This increased effort reduces the likelihood of costly errors and defects by facilitating early detection of potential quality issues in multiple areas and enabling timely remedial action. This method is essential to quickly detect irregularities in patient data, enable rapid interventions, and improve patient care outcomes in real-world settings, particularly healthcare settings. Applying this methodology to non-normal distributions and various types of control charts in the manufacturing industry helps detect process variations, which in turn leads to improved product quality and waste reduction.
Data availability
If there is a reasonable request, interested individuals can directly obtain the datasets that were utilized and/or analyzed in the present study from the corresponding author.
References
Shewhart, W. A. The application of statistics as an aid in maintaining quality of a manufactured product. J. Am. Stat. Assoc. 20(152), 546–548 (1925).
Page, E. S. Continuous inspection schemes. Biometrika 41(1/2), 100–115 (1954).
Roberts, S. W. Control chart tests based on geometric moving averages. Technometrics 42(1), 97–101 (2000).
You, H., Shahrin, M., & Mustafa, Z. (2021). Design of EWMA-type control chart. Paper presented at the IOP Conference Series: Materials Science and Engineering.
Chatterjee, K., Koukouvinos, C. & Lappa, A. A joint monitoring of the process mean and variance with a TEWMA-Max control chart. Commun. Stat.-Theory Methods 52(22), 8069–8095 (2023).
Jalilibal, Z., Amiri, A. & Khoo, M. B. A literature review on joint control schemes in statistical process monitoring. Qual. Reliab. Eng. Int. 38(6), 3270–3289 (2022).
Yang, C.-M. An improved multiple quality characteristic analysis chart for simultaneous monitoring of process mean and variance of steering knuckle pin for green manufacturing. Qual. Eng. 33(3), 383–394 (2021).
Arif, F., Noor-ul-Amin, M. & Hanif, M. Joint monitoring of mean and variance under double ranked set sampling using likelihood ratio test statistic. Commun. Stat.-theory methods 51(17), 6032–6048 (2022).
Noor-ul-Amin, M., Aslam, I. & Feroze, N. Joint monitoring of mean and variance using Max-EWMA for Weibull process. Commun. Stat.-Simulat. Comput. 52(7), 3257–3272 (2023).
Lee, P. H. & Lin, C. S. Adaptive Max charts for monitoring process mean and variability. J. Chin. Inst. Ind. Eng. 29(3), 193–205 (2012).
Nazir, H. Z., Hussain, T., Akhtar, N., Abid, M. & Riaz, M. Robust adaptive exponentially weighted moving average control charts with applications of manufacturing processes. Int. J. Adv. Manuf. Technol. 105, 733–748 (2019).
Sarwar, M. A. & Noor-ul-Amin, M. Design of a new adaptive EWMA control chart. Qual. Reliab. Eng. Int. 38(7), 3422–3436 (2022).
Menzefricke, U. Combined exponentially weighted moving average charts for the mean and variance based on the predictive distribution. Commun. Stat.-Theory Methods 42(22), 4003–4016 (2013).
Aunali, A. S. & Venkatesan, D. Comparison of bayesian method and classical charts in detection of small shifts in the control charts. Int. J. 6(2), 101–114 (2017).
Ali, S. A predictive Bayesian approach to EWMA and CUSUM charts for time-between-events monitoring. J. Stat. Comput. Simul. 90(16), 3025–3050 (2020).
Aslam, M. & Anwar, S. M. An improved Bayesian Modified-EWMA location chart and its applications in mechanical and sport industry. PLoS ONE 15(2), e0229422 (2020).
Bourazas, K., Kiagias, D. & Tsiamyrtzis, P. Predictive control charts (PCC): a Bayesian approach in online monitoring of short runs. J. Quality Technol. 54(4), 367–391 (2022).
Khan, I. et al. Hybrid EWMA control chart under bayesian approach using ranked set sampling schemes with applications to hard-bake process. Appl. Sci. 13(5), 2837 (2023).
Noor-ul-Amin, M. et al. Memory type Max-EWMA control chart for the Weibull process under the Bayesian theory. Sci. Rep. 14(1), 3111 (2024).
Iqbal, J. et al. A novel Bayesian Max-EWMA control chart for jointly monitoring the process mean and variance: an application to hard bake process. Sci. Rep. 13(1), 21224 (2023).
Gauss, C. (1955). Methods Moindres Carres Memoire sur la Combination des Observations, 1810 Translated by J. In: Bertrand.
Varian, H. R. Bayesian approach to real estate assessment. Stud. Bayesian Econ. Stat. Honor Leonard J. Savage 35(2), 115–135 (1975).
Faraz, A., Saniga, E. M. & Heuchenne, C. Shewhart control charts for monitoring reliability with Weibull lifetimes. Quality Reliability Eng. Int. 31(8), 1565–1574 (2015).
Jiang, W., Shu, L. & Apley, D. W. Adaptive CUSUM procedures with EWMA-based shift estimators. Iie Transact. 40(10), 992–1003 (2008).
Haq, A., Gulzar, R. & Khoo, M. B. An efficient adaptive EWMA control chart for monitoring the process mean. Qual. Reliability Eng. Int. 34(4), 563–571 (2018).
Chen, G., Cheng, S. W. & Xie, H. Monitoring process mean and variability with one EWMA chart. Journal of Quality Technology 33(2), 223–233 (2001).
Montgomery, D. C. (2009). Introduction to statistical quality control: John Wiley & Sons.
Acknowledgements
The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University, Saudi Arabia for funding this work through Large Groups Project under grant number R.G.P2/186/44.
Author information
Authors and Affiliations
Contributions
I.K. and A.A.Z. contributed to the manuscript through mathematical analyses and numerical simulations. A.R. and A.A.A. conceptualized the primary idea, analyzed data, and assisted in restructuring the manuscript. B.A. and A.A.Z. rigorously validated the findings, revised the manuscript, and secured funding. Additionally, A.A.Z. and A.A.A. enhanced the manuscript's language and performed additional numerical simulations. The final version of the manuscript, ready for submission, represents a consensus reached by all authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
A. Zaagan, A., Khan, I., Ayari-Akkari, A. et al. Memory type Bayesian adaptive max-EWMA control chart for weibull processes. Sci Rep 14, 8923 (2024). https://doi.org/10.1038/s41598-024-59680-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-59680-6
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
