
Abstract
A precise forecast of the need for blood transfusions (BT) in patients undergoing total hip arthroplasty (THA) is a crucial step toward the implementation of precision medicine. To achieve this goal, we utilized supervised machine learning (SML) techniques to establish a predictive model for BT requirements in THA patients. Additionally, we employed unsupervised machine learning (UML) approaches to identify clinical heterogeneity among these patients. In this study, we recruited 224 patients undergoing THA. To identify factors predictive of BT during the perioperative period of THA, we employed LASSO regression and the random forest (RF) algorithm as part of supervised machine learning (SML). Using logistic regression, we developed a predictive model for BT in THA patients. Furthermore, we utilized unsupervised machine learning (UML) techniques to cluster THA patients who required BT based on similar clinical features. The resulting clusters were subsequently visualized and validated. We constructed a predictive model for THA patients who required BT based on six predictive factors: Age, Body Mass Index (BMI), Hemoglobin (HGB), Platelet (PLT), Bleeding Volume, and Urine Volume. Before surgery, 1 h after surgery, 1 day after surgery, and 1 week after surgery, significant differences were observed in HGB and PLT levels between patients who received BT and those who did not. The predictive model achieved an AUC of 0.899. Employing UML, we identified two distinct clusters with significantly heterogeneous clinical characteristics. Age, BMI, PLT, HGB, bleeding volume, and urine volume were found to be independent predictors of BT requirement in THA patients. The predictive model incorporating these six predictors demonstrated excellent predictive performance. Furthermore, employing UML enabled us to classify a heterogeneous cohort of THA patients who received BT in a meaningful and interpretable manner.
Similar content being viewed by others
Introduction
Total hip arthroplasty (THA) is a common surgical intervention for treating various hip joint diseases, including osteonecrosis of the femoral head, hip ankylosis caused by ankylosing spondylitis, and hip osteoarthritis1,2. Effective blood management is a critical component of the perioperative care of THA patients3. Previous studies have indicated that blood transfusion is independently linked to higher morbidity and mortality in THA patients4,5. Strategies aimed at reducing perioperative blood loss and minimizing the need for allogeneic red blood cell transfusions encompass various measures, including addressing preoperative anemia6, administering anti-fibrinolytic therapy7, and utilizing intraoperative cell salvage techniques8,9. Effective implementation of the aforementioned measures relies on our ability to accurately predict the need for perioperative blood transfusion (BT) in THA patients. It is crucial to develop a precise predictive model to forecast the need for perioperative BT in THA, which holds significant clinical value. Furthermore, if BT events occur during the perioperative period of THA patients, clinicians need to pay closer attention to the perioperative blood management of such patients, preventing adverse events arising from hemodynamic abnormalities. Therefore, it is crucial to identify clinical heterogeneity among THA patients requiring transfusion and ascertain the presence of clusters with significantly characteristic risks among this patient population. This is essential for comprehensive perioperative blood management and the prevention of adverse events in patients undergoing THA.
In recent times, the rapid advancement of artificial intelligence has led to the increased application of machine learning (ML), a subfield of AI, in disease classification, diagnosis, and treatment. Notably, ML has been employed in addressing conditions like heart failure and pediatric dermatitis10. Precision medicine has emerged as a leading approach in modern medical practice, offering improved medical efficiency and reduced incidence of complications during medical procedures11. Precision medicine necessitates the precise identification and classification of patients, followed by the implementation of distinct medical interventions tailored to each patient's specific needs10. The incorporation of artificial intelligence and ML algorithms has ushered in a new era for precision medicine. ML comprises two principal categories, namely supervised machine learning (SML) and unsupervised machine learning (UML). SML employs large accurately labeled training datasets and iterative algorithms12; UML aims to cluster patients based on their clinical features. The integration of SML and UML techniques enables the identification of specific categories and the grouping of patients, facilitating the analysis of characteristics among similarly clustered individuals. This approach may aid in the identification of novel disease subtypes and accelerate the adoption of precision medicine.
In this study, we gathered clinical data from THA patients and utilized SML to establish a predictive model for perioperative blood transfusion requirements in these patients. Independent predictors linked to transfusion requirements were identified. We subsequently employed UML to classify THA patients who received blood transfusions during the perioperative period, ultimately identifying two distinct clusters. Finally, we conducted a differential analysis to explore the heterogeneity of these clusters. The study aims to integrate both supervised and unsupervised machine learning techniques to enhance perioperative blood management in patients undergoing THA. This integration aims to enable timely medical interventions by clinicians, mitigating the occurrence of adverse events during the perioperative period.
Materials and methods
Patients and data collection
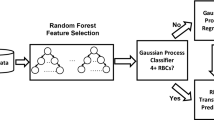
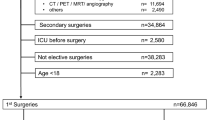
We conducted a retrospective analysis of clinical data (Table 1) collected from 224 patients who underwent total hip arthroplasty at the First People's Hospital of Nanning between 2015 and 2022. Figure 1 shows the graphical abstract of this study. Inclusion criteria were (1) age ≥ 18 years old; (2) ASA Grade II-IV13; (3) Unilateral, total hip arthroplasty had been performed. Exclusion criteria were (1) patients undergoing revision hip surgery, and (2) patients undergoing, bilateral hip replacement at the same time. We collected 44 perioperative variables in the clinical data, which were age, gender, body mass index (BMI), American Society of Anesthesiologists (ASA) grade, hypertension, pulmonary infection, diabetes, cerebral infarction, cardiovascular disease (CVD), chronic obstructive pulmonary disease (COPD), renal failure (RF), pulmonary arterial hypertension (PAH), hip fracture, operation time, bleeding volume, autotransfusion, tranexamic acid (TXA), anesthesia method, systolic pressure (SP), diastolic pressure (DP), heart rate (HR), SpO2, colloid, crystalloid, urine volume, drainage volume, red blood cell (RBC), Hemoglobin (HGB), hematocrit (HCT), platelet (PLT), total bilirubin (TBIL), total protein (TP), albumin (ALB), alanine aminotransferase (ALT), aspartate aminotransferase (AST), creatinine (CREA), blood urea nitrogen (BUN), cystatin C (Cys-C), creatinine clearance rate (Ccr), hypersensitive C-reactive protein (hs-CRP), prothrombin time (PT), activated partial thromboplastin time (APTT), fibrinogen (FIB), and D-dimer (DD). Additionally, postoperative observations and data collection were undertaken to gather clinical information from patients at 1 h, 1 day, and 1 week following total hip arthroplasty. The clinical data encompassed measurements of RBC, HGB, HCT, PLT, TBIL, TP, ALB, ALT, AST, CREA, BUN, Cys-C, Ccr, Hs-CRP, PT, APTT, FIB, and DD.

The graphical abstract of this study.
The Ethics Committee of The Fifth Affiliated Hospital of Guangxi Medical University reviewed and approved the study. All patients provided informed consent and willingly participated in the study. The clinical data involved in this study has obtained explicit authorization from the patients. The study complies with the Declaration of Helsinki.
Statistical analysis of clinical data
Concerning clinical data with missing values, we employed the expectation maximization method in SPSS Version 22.0 for imputation. The original dataset and the data with imputed missing values are available in the supplementary materials. Clinical data were presented as Mean ± SD and Median [P25, P75]. We performed statistical analyses using SPSS version 22.0, employing the Mann–Whitney U test, Student's t-test, or chi-square test as appropriate. These tests were employed to compare disparities between patients with and without blood transfusions (BT and Non-BT), depending on the data type. The significance level was set at α = 0.05. To establish a predictive model for blood transfusion in THA patients, we employed the logistic regression algorithm and created a nomogram to visualize the prediction model. The 'corrplot' package in R software was used to generate correlation heat maps illustrating the correlation between clinical data in the prediction model. The accuracy of the prediction model was determined by the ROC curve and calibration curve analyses (The 'pROC' package in R software).
LASSO-regularized linear regression
The Least Absolute Shrinkage and Selection Operator (LASSO) regression is a contraction algorithm developed to manage variables with multicollinearity. It streamlines the process of parameter estimation and generates sparse solutions, enabling efficient variable selection. Consequently, it is an appropriate method for addressing multicollinearity problems and improving test efficiency14,15,16. In this study, clinical data showing significant differences (p < 0.05) were entered into the R software to perform LASSO regression using the 'glmnet' package, which aimed to identify factors that could predict the necessity for blood transfusion in THA patients. To avoid overfitting, we employed ten rounds of tenfold cross-validation15.
Random forest
We used the "randomforest" package in R software to screen clinical data by employing the Random Forest algorithm17. The Random Forest algorithm works by assigning random values to each clinical characteristic. If a characteristic is considered more important, randomly changing its value will lead to a higher prediction error for the model18. The clinical characteristics become more significant as their value increases.
Development of a logistic regression-based predictive model
Following the initial clinical characteristics screening via supervised machine learning (SML), we proceeded to utilize univariate logistic regression analysis for the evaluation of the association between blood transfusion (BT) necessity in total hip arthroplasty (THA) patients and their clinical characteristics. Variables with p-values below 0.05 were included in the subsequent multivariate logistic regression analysis. Based on the outcomes of the multivariate logistic regression analysis, which incorporated variables with p-values less than 0.05, we constructed a predictive model for assessing the need for blood transfusion in THA patients, represented using a nomogram. Model performance was evaluated in terms of discrimination and calibration19. Calibration of the prediction model involved the creation of a visual calibration plot, which compared predicted and actual probabilities of blood transfusion (BT) requirement. The model's discriminative capability was assessed through the Area under the Curve (AUC) of the Receiver Operating Characteristic (ROC) curve, which varies from 0.5 (indicating no discrimination) to 1 (indicating perfect discrimination)20.
Unsupervised machine learning for clinical heterogeneity identification
To ascertain whether there are distinct risk-characterized clusters among patients requiring BT in THA, we employed UML to further identify clinical heterogeneity. To conduct UML, we used R software version 4.1.3. We normalized the clinical data of THA patients who received BT during the perioperative period (n = 61) by utilizing the Scale Function in the "factoextra" package21. To determine the optimal clustering number (K value), we used the "Fpc" package, which utilizes the Silhouette Coefficient (SC)11,22,23. The K-means clustering algorithm is a well-known unsupervised learning technique in machine learning. In this study, we utilized the K-means algorithm to group patients into clusters23,24,25. The clusters derived from the K-means algorithm were visually presented using clustergram and radargram.
The K-means algorithm is an Unsupervised Machine Learning algorithm that can categorize and identify data11. The K-means clustering algorithm can effectively group clinical data based on their characteristics, even if their labels are unknown. These groups, or "clusters," are represented by a central point called a "centroid." To initiate the clustering process, the clinical data is normalized using the Scale Function, and the K-means algorithm is applied through the following steps: (I) K initial centroids are randomly chosen, and each sample point is assigned to the nearest centroid to form K clusters. (II) A new centroid is calculated for each cluster by computing the average coordinate value of all points within the cluster. (III) This process is repeated until the position of the centroids remains stable. The optimal value of K is determined in this study using the Silhouette Coefficient (SC).
The formula employed in this study uses a(i) to represent the average distance between a sample point and all other points within the same cluster. b(i), on the other hand, refers to the average distance between the sample point and all points within the second closest cluster26. The main objective of the K-means clustering algorithm is to decrease the within-cluster variation and increase the between-cluster variation. The Silhouette Coefficient is used to assess the quality of clustering, with values ranging from –1 to 1. A higher value closer to 1 suggests better clustering performance, while a value closer to –1 indicates poor results.
We employed the K-means algorithm to cluster patients undergoing THA who received BT based on six independent predictive factors from the predictive model, aiming to identify clinical heterogeneity. We employed radargram for visualizing the heterogeneity between the two patient clusters and compared differences in Age, BMI, HGB, PLT, Bleeding Volume, and Urine Volume. Additionally, box plots were used to visually represent the data variances, offering an intuitive presentation of the clinical heterogeneity among patients.
Ethical approval
The study got approval by Ethics Department of the Fifth Affiliated Hospital of Guangxi Medical University (No. 2021-064-01). All subjects of this study are volunteered and signed informed consent forms. The clinical data involved in this study has obtained explicit authorization from the patients. The study complies with the Declaration of Helsinki.
Result
Results of SML: tenfold cross-validation LASSO regression and random forest
Table 1 presents the clinical data of 224 patients who underwent total hip arthroplasty. Among them, 61 patients received blood transfusions (BT) during the perioperative period, while 163 did not. Statistical significance (P < 0.05) was observed in 15 clinical characteristics between the BT and non-BT patients, including Age, BMI, CVD, Bleeding volume, autotransfusion, TXA, HR, colloid, urine volume, RBC, HGB, HCT, PLT, Cys-C, and Ccr.
To identify predictive factors of perioperative blood transfusion, LASSO regression analysis was conducted on the clinical data with significant differences. The results are shown in Supplementary Fig. 1A and Fig. 2A, which displays the 12 predictive factors of perioperative blood transfusion: Age, BMI, Bleeding volume, HR, colloid, urine volume, HCT, PLT, Ccr, HGB, CVD, and TXA.

The results of LASSO regression (A). 14 predictive factors were screened by Random Forest algorithms (B). The pattern diagram for five iterations of tenfold cross validation (C). Intersection of predictive factors screened using LASSO regression and Random Forest algorithm (D).
In a similar vein, we utilized the Random Forest algorithm to identify predictive factors for patients with BT during the perioperative period by analyzing the clinical data with significant differences in Table 1. We set the number of decision trees to 20,000 and observed that the error rate of the model became stable (Supplementary Fig. 1B). From the eight clinical characteristics, we selected the top 14 factors with the highest importance (Fig. 2B). These factors were Age, HCT, Bleeding Volume, HGB, PLT, Autotransfusion, Cys-C, RBC, Ccr, BMI, Urine Volume, HR, Colloid, and TXA.
To avoid overfitting, we conducted ten rounds of tenfold cross-validation for the outcomes of LASSO regression and Random Forest algorithm. Figure 2C demonstrates the graphical representation of this approach. The intersection of the 11 predictors identified through LASSO regression and Random Forest algorithm are Age, BMI, Bleeding Volume, HR, Colloid, Urine Volume, HCT, PLT, Ccr, HGB, and TXA, as shown in Fig. 2D.
Construction of a prediction model for blood transfusion in patients undergoing THA
In this research study, we conducted univariate and multivariate logistic regression analyses on 11 factors to develop a clinical prediction model for patients who underwent total hip arthroplasty with perioperative blood transfusion. Table 2 presents the outcomes of the univariate and multivariate logistic regression, which showed that six independent variables were selected as predictors, namely Age, Body Mass Index (BMI), Hemoglobin (HGB), Platelet count (PLT), Bleeding Volume, and Urine Volume. A heatmap in Fig. 3A illustrates the correlation between these six independent variables. The area under the curve (AUC) values for each of these six independent variables in predicting the need for blood transfusion were 0.653 for age, 0.622 for BMI, 0.688 for HGB, 0.603 for PLT, 0.791 for Bleeding Volume, and 0.607 for Urine Volume (Fig. 3B). A nomogram was utilized to visualize the prediction model based on these six independent variables (Fig. 3C), which displays a sample of a patient who underwent total hip arthroplasty and required perioperative blood transfusion (Fig. 3D). Calibration curves were generated to validate the accuracy of the nomogram's predicted probabilities, and these curves revealed a satisfactory level of agreement between the predicted and actual probabilities (Fig. 3E). The ROC curve for the nomogram is shown in Fig. 3F, with an AUC value of 0.899.

Six independent predictors were evaluated using univariate and multivariate logistic regression. Red color piece indicates a positive correlation, while blue color piece indicates a negative correlation. The strength of the correlation increases with the increase in color intensity (A). The diagnostic ability of six clinical characteristics was assessed using ROC curves in the clinical data (B). Nomogram for predicting of patient who received BT (C). A nomogram represents a BT patient in THA. Red dots indicate the patient's score and total score for each clinical characteristic, and arrows indicate the probability BT (D). Calibration curves for predicting a BT patient in THA (E). AUC of the nomogram (F).
Postoperative observation of independent predictors of blood transfusion after THA
In this study, Fig. 4A displays the alterations in preoperative and postoperative Hemoglobin (HGB) levels at 1 h, 1 day, and 1 week among patients who received Blood Transfusion (BT) during the perioperative period. Similarly, Fig. 4B portrays the modifications in preoperative and postoperative Platelet (PLT) levels at 1 h, 1 day, and 1 week in patients who received BT during the perioperative period. Furthermore, Fig. 4C illustrates the variations in preoperative and postoperative HGB levels at 1 h, 1 day, and 1 week among patients who did and did not receive BT transfusions during the perioperative period. Finally, Fig. 4D depicts the fluctuations in preoperative and postoperative PLT levels at 1 h, 1 day, and 1 week for patients who received BT transfusions during the perioperative period and those who did not.

The alterations in preoperative and HGB levels at 1 h, 1 day, and 1 week among patients who received BT during the perioperative period (A). The alterations in preoperative and postoperative PLT levels at 1 h, 1 day, and 1 week in patients who received BT during the perioperative period (B). The variations in preoperative and postoperative HGB levels at 1 h, 1 day, and 1 week among patients who did and did not receive BT during the perioperative period (C). The variations in preoperative and postoperative PLT levels at 1 h, 1 day, and 1 week for patients who received BT during the perioperative period and those who did not (D). HGB: Hemoglobin, BT: Blood, PLT: Platelet.
Results of unsupervised machine learning
To cluster patients based on six independent predictors, we utilized the K-means algorithm. The optimal number of clusters was determined using the Silhouette Coefficient value, and Fig. 5A shows that the highest point on the broken line corresponds to the optimal value of 2 on the X-axis. This result indicates that the K-means clustering algorithm identified two clusters as optimal. The clinical data of 61 patients were successfully divided into two clusters (Fig. 5B), where each dot represents a patient, with the orange dot representing cluster 1 and the blue dot representing cluster 2. The K-means clustering algorithm's outcome is presented in Supplementary Table S1.

Silhouette Coefficient (SC) of K-means clustering algorithm which was determined the optimal clustering result. Peak of the broken line is the optimal value for Silhouette Coefficient (Y Axis), the optimal clustering results were equal to 2 (X Axis) (A). Scatter plot of 61 THA patients who received BT. Each dot in the figure represents a patient. The orange scatter represents cluster 1 and the blue scatter represents cluster 2 (B).
Heterogeneous clinical characteristics of the patients by unsupervised machine learning
Table 3 presents six independent predictors of two clusters identified using the K-means clustering algorithm. As shown in Table 3, the values of Age, BMI, and PLT in cluster 1 are significantly greater than those in cluster 2 (Age: cluster 1/cluster 2 = 74.98 ± 8.81/52.94 ± 14.41, P < 0.001; BMI: cluster 1/cluster 2 = 23.05 ± 16.73/42.06 ± 22.84, P < 0.001; PLT: cluster 1/cluster 2 = 279.33 ± 83.84/221.56 ± 59.59, p = 0.022). In contrast, both Bleeding Volume and Urine Volume are significantly higher in cluster 2 compared to cluster 1 (Bleeding Volume: cluster 1/cluster 2 = 452.27 ± 146.53/658.82 ± 240.24, P = 0.002; Urine Volume: cluster 1/cluster 2 = 682.95 ± 374.31/975.29 ± 584.21, P = 0.046). HGB did not exhibit significant differences between the two clusters (HGB: cluster 1/cluster 2 = 110.28 ± 17.01/115.21 ± 17.40, P = 0.250). A radargram, depicted in Fig. 6A, was employed to visualize the heterogeneity of the two clusters. ROC curves were employed to assess the predictive performance of six independent predictive factors for Cluster 1, and the predictive efficiency was demonstrated using AUCs (based on logistic regression from the "pROC" package in R software). The AUCs of the six independent predictive factors for predicting Cluster 1 were as follows: 0.895 for age, 0.891 for BMI, 0.597 for HGB, 0.691 for PLT, 0.749 for bleeding volume, and 0.666 for Urine Volume (Fig. 6B). Figure 7A–F displays the differences in age, BMI, HGB, PLT, bleeding volume, and urine volume between the two clusters using a box-line scatter plot.

Radargram of 6 independent predictors in patients who were received blood transfusion during THA in two clusters based on K-means clustering algorithm (A). The AUCs of the six independent predictors for predicting Cluster 1 (B). BMI: Body Mass Index, HGB: Hemoglobin, PLT: Platelet.

Box-line scatter plots of Age, Bleeding Volume, BMI, HGB, PLT, and Urine Volume between the two clusters (A–F). BMI: Body Mass Index, HGB: Hemoglobin, PLT: Platelet.
Discussion
Construction of a prediction model for blood transfusion in patients undergoing THA, based on SML and its clinical significance
LASSO regression and the Random Forest algorithm are extensively utilized for selecting predictive factors in disease data analysis. Liang et al. discovered that the platelet-to-lymphocyte ratio was an autonomous risk factor and had a correlation with the severity of AS. They used LASSO regression to conduct statistical analysis27. Gao et al. employed the Random Forest regression model to forecast distant metastases subsequent to stereotactic body radiation therapy for early-stage non-small cell lung cancer28. In this research, we employed LASSO regression and the Random Forest algorithm to identify predictive factors of patients undergoing THA who received blood transfusions in the perioperative phase. We identified 11 predictive factors that intersected, including Age, BMI, Bleeding Volume, HR, Colloid, Urine Volume, HCT, PLT, Ccr, HGB, and TXA (Fig. 2D). We constructed predictive models utilizing univariate and multivariate logistic regression techniques. Finally, six independent predictive factors were revealed, including Age, BMI, Bleeding Volume, Urine Volume, and PLT. As mentioned in the introduction section of this paper, blood transfusion is independently associated with increased morbidity and mortality in THA. The constructed model demonstrated good accuracy in predicting whether patients would receive a blood transfusion, with an AUC of 0.899 (Fig. 3F). The model allows clinicians to clinically anticipate whether patients undergoing THA will require blood transfusions during the perioperative phase using preoperative data such as Age, BMI, Bleeding Volume, Urine Volume, and PLT. With the aid of this prediction model, clinicians can effectively assess the necessity of blood transfusions in patients undergoing THA during the perioperative phase and make appropriate preparations for potential adverse effects, thereby facilitating the implementation of precision medicine.
The orientation and interpretability of unsupervised machine learning
This study employed unsupervised machine learning, specifically K-means clustering, to categorize patients undergoing total hip replacement who received blood transfusions in the perioperative phase. Our decision to utilize K-means clustering was rooted in its suitability for this particular context. K-means clustering has several advantages that make it well-suited for our research objectives. Firstly, it is computationally efficient and capable of handling large datasets, a vital consideration in clinical studies where data can be extensive. Secondly, it is relatively straightforward to implement, making it accessible to researchers without extensive machine learning expertise29.
In our analysis, K-means demonstrated remarkable data separation between the two patient clusters, as evident in the radargram (Fig. 6A). This separation allows for the identification of distinctive patient groups with varying clinical characteristics, which can have significant implications for personalized treatment plans. This methodological choice aligns with the ultimate goal of our research, which is to seamlessly integrate inherently diverse and heterogeneous clinical data without supervision30.
While we have discussed the strengths of K-means clustering, it is important to acknowledge its limitations. K-means is sensitive to the initial cluster centers, and different starting points may lead to different cluster results31. This challenge underscores the importance of careful preprocessing and initialization strategies, which we meticulously addressed in our study. Furthermore, K-means clustering may not be the optimal choice for datasets with irregularly shaped or non-convex clusters, and in such cases, alternative approaches like density-based clustering or hierarchical clustering may be considered.
This emphasis on unsupervised machine learning (UML) in our study is a deliberate choice. UML prioritizes the intrinsic characteristics of the data, enabling us to delve deeper into the fundamental features and emphasize the diversity of clinical traits that are relevant to medical research hypotheses32. By doing so, we uncover latent structures within our data that might not be apparent using traditional, supervised machine learning methods. This approach not only enriches our understanding of patient diversity but also contributes to the evolving landscape of medical research.
In conclusion, the choice of K-means clustering in our study was driven by its appropriateness for our research objectives and data characteristics. It is important to consider the specific research goals and data properties when selecting the most suitable method. The application of UML techniques, as seen in our research, has the potential to yield valuable insights in the field of medical research and can serve as a powerful tool for uncovering hidden patterns within clinical data. Future research may further explore the use of alternative clustering methods and deep learning techniques to enhance our understanding of patient diversity and improve medical decision-making.
Heterogeneity of clinical characteristics based on the classification of unsupervised machine learning
Using the clustering outcomes, we compared the variation of six independent predictors between the two clusters to confirm the effectiveness of unsupervised machine learning (UML) clustering. As demonstrated in Fig. 6A, the dissimilarity of Age, BMI, PLT, Bleeding Volume, and Urine Volume between the two clusters is substantial and can effectively differentiate between them (Fig. 6B). UML can efficiently categorize patients based on their clinical characteristic heterogeneity, offering an understandable and significant classification of a diverse cohort33. In our research, this intelligibility was reflected in the heterogeneity of Age, BMI, PLT, Bleeding Volume, and Urine Volume.
To conclude, UML was able to sufficiently classify 61 patients undergoing total hip replacement who received blood transfusions in the perioperative phase into two clusters according to their fundamental clinical attributes. A thorough comprehension of patient heterogeneity can detect and manage complications during the perioperative period and provide beneficial guidance for the implementation of precision medicine.
Clinical significance of the combination of supervised machine learning and unsupervised machine learning
In this study, we developed an SML predictive model to assess the need for blood transfusion in THA patients, identifying six predictive factors: Age, BMI, Bleeding Volume, Urine Volume, PLT, and HGB. Based on the SML model, attention should be focused on these six BT-related predictive factors during the perioperative management of THA patients, aiming to enhance preoperative preparation and improve the quality of perioperative care. Furthermore, to explore clinical heterogeneity in THA patients requiring BT, we applied the UML algorithm based on K-means clustering. The results indicate that the UML algorithm clustered THA patients into two groups based on these six predictive factors. Patients in Cluster 2 exhibited significantly higher Bleeding Volume and Urine Volume compared to Cluster 1, while their PLT was significantly lower (Table 3). Bleeding Volume, Urine Volume, and PLT precisely reflect crucial indicators of effective circulating blood volume in THA patients. This suggests that patients in Cluster 2 may have a poorer effective circulating blood volume. The above results enlighten us that, in the perioperative management of THA patients requiring blood transfusion, there is a subset with inadequate circulating blood volume characterized by high Bleeding Volume and Urine Volume and low PLT. Such patients in this cluster may have unstable hemodynamics, warranting special attention from clinicians. In the perioperative management of patients, clinicians should first evaluate the likelihood of blood transfusion based on the six predictive factors from the SML model, improving preoperative preparation and enhancing perioperative care quality. Subsequently, post-blood transfusion in THA patients, attention should be directed to Bleeding Volume, Urine Volume, and PLT using the UML algorithm results, allowing timely medical intervention to prevent adverse perioperative events.
Surgeon's influence and limitations
In this section, we will discuss the study’s limitations, with a specific focus on how a surgeon's individual preferences and prior experiences may have impacted our results. Factors specific to the surgeon can introduce data variability and influence result interpretation34. Our research constructed a predictive model for blood transfusion and primarily examined the clinical diversity among patients undergoing THA surgery and receiving blood transfusions. Nevertheless, it is essential to recognize that the surgeons' distinct surgical techniques, implant preferences, and perioperative practices, influenced by their experiences, can unintentionally contribute to clinical diversity35. The influence of surgeon-specific factors on our findings constitutes a noteworthy limitation. Future research should delve more comprehensively into this aspect, possibly through collaborations with surgical teams and additional data gathering. The development of standardized procedures and guidelines for specific surgical aspects could potentially mitigate the impact of surgeon-specific variables3. In conclusion, while our study illustrates patient clinical diversity, we recognize the constraints linked to surgeon preferences and experiences. Addressing these limitations and integrating these factors into data analysis and interpretation is crucial for a more profound comprehension of patient outcomes.
Additionally, there are other limitations in our current study that need to be acknowledged. First, the participants were recruited exclusively from a single center. Second, given that this is a retrospective study, there is the potential for selection bias. Furthermore, it is possible that the surgeon's individual preferences and prior experiences could have influenced the study's outcomes.
Conclusion
Age, BMI, PLT, HGB, Bleeding Volume, and Urine Volume were identified as independent predictors of whether a THA patient requires a blood transfusion. The predictive model constructed based on these six independent predictors displayed remarkable predictive performance. Unsupervised machine learning (UML) can offer a clear and meaningful classification of a diverse cohort of THA patients who received BT.
Data availability
The original contributions presented in this study are available in the article/supplementary material. More inquiries can be directed to the corresponding authors.
Abbreviations
- BT:
-
Blood transfusions
- THA:
-
Total hip arthroplasty
- ML:
-
Machine learning
- SML:
-
Supervised machine learning
- UML:
-
Unsupervised machine learning
- RF:
-
Random forest
- LASSO:
-
Least absolute shrinkage and selection operator
- BMI:
-
Body mass index
- HGB:
-
Hemoglobin
- PLT:
-
Platelet
- ASA:
-
American society of anesthesiologists
- CVD:
-
Cardiovascular disease
- COPD:
-
Chronic obstructive pulmonary disease
- PAH:
-
Pulmonary arterial hypertension
- TXA:
-
Tranexamic acid
- SP:
-
Systolic pressure
- DP:
-
Diastolic pressure
- HR:
-
Heart rate
- RBC:
-
Red blood cell
- HGB:
-
Hemoglobin
- HCT:
-
Hematocrit
- PLT:
-
Platelet
- TBIL:
-
Total bilirubin
- TP:
-
Total protein
- ALB:
-
Albumin
- ALT:
-
Alanine aminotransferase
- AST:
-
Aspartate aminotransferase
- CREA:
-
Creatinine
- BUN:
-
Blood urea nitrogen
- Cys-C:
-
Cystatin C
- Ccr:
-
Creatinine clearance rate
- Hs-CRP:
-
Hypersensitive C-reactive protein
- PT:
-
Prothrombin time
- APTT:
-
Activated partial thromboplastin time
- FIB:
-
Fibrinogen
- DD:
-
D-Dimer
- SC:
-
Silhouette coefficient
- AUC:
-
Area under the curve
References
Yu, C. et al. Mechanism of hip arthropathy in ankylosing spondylitis: abnormal myeloperoxidase and phagosome. Front. Immunol. 12, 572592 (2021).
Ali, A., Loeffler, M., Aylin, P. & Bottle, A. Factors associated with 30-day readmission after primary total hip arthroplasty: analysis of 514 455 procedures in the UK national health service. JAMA Surg. 152(12), e173949 (2017).
van Bodegom-Vos, L. et al. Cell Salvage in hip and knee arthroplasty: a meta-analysis of randomized controlled trials. J. Bone Joint Surg. Am. 97(12), 1012–1021 (2015).
Goel, R., Buckley, P., Sterbis, E. & Parvizi, J. Patients with infected total hip arthroplasty undergoing 2-stage exchange arthroplasty experience massive blood loss. J. Arthroplasty 33(11), 3547–3550 (2018).
Kim, J., Park, J., Han, S., Cho, I. & Jang, K. Allogeneic blood transfusion is a significant risk factor for surgical-site infection following total hip and knee arthroplasty: a meta-analysis. J. Arthroplasty 32(1), 320–325 (2017).
Muñoz, M. et al. International consensus statement on the peri-operative management of anaemia and iron deficiency. Anaesthesia. 72(2), 233–247 (2017).
Peck, J. et al. The effect of preoperative administration of intravenous tranexamic acid during revision hip arthroplasty: a retrospective study. J. Bone Joint Sur. Am. 100(17), 1509–1516 (2018).
Sullivan, I. & Ralph, C. Obstetric intra-operative cell salvage: a review of an established cell salvage service with 1170 re-infused cases. Anaesthesia. 74(8), 976–983 (2019).
Kelleher, A. et al. A quality assurance programme for cell salvage in cardiac surgery. Anaesthesia. 66(10), 901–906 (2011).
Cikes, M. et al. Machine learning-based phenogrouping in heart failure to identify responders to cardiac resynchronization therapy. Eur. J. Heart Fail. 21(1), 74–85 (2019).
Zhou, C. et al. Machine learning-based clustering in cervical spondylotic myelopathy patients to identify heterogeneous clinical characteristics. Front. Surg. 9, 935656 (2022).
Gulshan, V. et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA. 316(22), 2402–2410 (2016).
Horvath, B., Kloesel, B., Todd, M., Cole, D. & Prielipp, R. The evolution, current value, and future of the American society of anesthesiologists physical status classification system. Anesthesiology. 135(5), 904–919 (2021).
Wang, S. et al. An Eight-CircRNA assessment model for predicting biochemical recurrence in prostate cancer. Front. Cell Dev. Biol. 8, 599494 (2020).
Zhu, J. et al. Development and validation of a machine learning-based nomogram for prediction of ankylosing spondylitis. Rheumatol. Therapy. 9(5), 1377–97 (2022).
Zhang, M. et al. An Immune-related signature predicts survival in patients with lung adenocarcinoma. Front. Oncol. 9, 1314 (2019).
Errington, N. et al. A diagnostic miRNA signature for pulmonary arterial hypertension using a consensus machine learning approach. EBioMedicine. 69, 103444 (2021).
Zhang, H., Wang, W., Haggerty, J. & Schuster, T. Predictors of patient satisfaction and outpatient health services in China: evidence from the WHO SAGE survey. Family Practice. 37(4), 465–472 (2020).
Iasonos, A., Schrag, D., Raj, G. & Panageas, K. How to build and interpret a nomogram for cancer prognosis. J. Clin. Oncol.: Off. J. Am. Soc. Clin. Oncol. 26(8), 1364–1370 (2008).
Bandos, A., Rockette, H., Song, T. & Gur, D. Area under the free-response ROC curve (FROC) and a related summary index. Biometrics. 65(1), 247–256 (2009).
Wu, S. et al. Genome-wide identification of immune-related alternative splicing and splicing regulators involved in abdominal aortic aneurysm. Front. Gene. 13, 816035 (2022).
Sebastian A, Cistulli P, Cohen G, de Chazal P. Association of snoring characteristics with predominant site of collapse of upper airway in obstructive sleep apnea patients. Sleep.44(12) (2021).
Ahlqvist, E. et al. Novel subgroups of adult-onset diabetes and their association with outcomes: a data-driven cluster analysis of six variables. Lancet Diabetes Endocrinol. 6(5), 361–369 (2018).
Brusco, M., Shireman, E. & Steinley, D. A comparison of latent class, K-means, and K-median methods for clustering dichotomous data. Psychol. Methods. 22(3), 563–580 (2017).
Kobayashi, M. et al. Machine learning-derived echocardiographic phenotypes predict heart failure incidence in asymptomatic individuals. JACC Cardiovasc. Imaging. 15(2), 193–208 (2022).
Rousseeuw, P. J. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65 (1984).
Liang, T. et al. Platelet-to-lymphocyte ratio as an independent factor was associated with the severity of ankylosing spondylitis. Front. Immunol. 12, 760214 (2021).
Gao, S., Jin, L., Meadows, H., Shafman, T., Gross, C., Yu, J., et al. Prediction of distant metastases after stereotactic body radiation therapy for early stage non-small cell lung cancer: development and external validation of a multi-institutional model. J. Thoracic Oncol.: Off. Publ. Int. Assoc. Study Lung Cancer (2022).
Benito-León, J. et al. Using unsupervised machine learning to identify age- and sex-independent severity subgroups among patients with COVID-19: observational longitudinal study. J. Med. Internet Res. 23(5), e25988 (2021).
Bakker, D. et al. Unraveling heterogeneity in pediatric atopic dermatitis: Identification of serum biomarker based patient clusters. J. Allergy Clin. Immunol. 149(1), 125–134 (2022).
Kalscheur, M. et al. Machine learning algorithm predicts cardiac resynchronization therapy outcomes: lessons from the COMPANION trial. Circ. Arrhythmia Electrophysiol. 11(1), e005499 (2018).
Kwong, A. et al. Machine learning to predict waitlist dropout among liver transplant candidates with hepatocellular carcinoma. Cancer Med. 11(6), 1535–1541 (2022).
Wang, Z. et al. AD risk score for the early phases of disease based on unsupervised machine learning. Alzheimer’s Dementia: J. Alzheimer’s Assoc. 16(11), 1524–1533 (2020).
Takenaka, S. et al. Risk factor analysis of surgery-related complications in primary cervical spine surgery for degenerative diseases using a surgeon-maintained database. Bone Joint J. 1, 157–163 (2021).
Nystad, T. et al. Hip replacement surgery in patients with ankylosing spondylitis. Annals Rheumatic Dis. 73(6), 1194–1197 (2014).
Acknowledgements
We are very grateful to Prof. Yubo Xie (Department of Anesthesiology, The First Affiliated Hospital of Guangxi Medical University) for support in all stages of this study.
Funding
Guangxi Clinical Research Center for Anesthesiology (No. GK AD22035214), the Key Project of Natural Science Foundation of Guangxi (No. 2020GXNSFDA238025) sponsored this study. Funding bodies had not participated in the design of the study, collection, interpretation, and analysis of the data or in writing the manuscript.
Author information
Authors and Affiliations
Contributions
J.D. and C.Z. contributed equally to this work. J.D. and C.Z. participated conceptualization and methodology design of the study. F.X. in charge of data curation and investigation. J.C. and C.L. analyzed and visualized the data. Y.X.: Writing- Reviewing and Editing. All authors contributed to the article and approved the submitted version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Deng, J., Zhou, C., Xiao, F. et al. Construction of a predictive model for blood transfusion in patients undergoing total hip arthroplasty and identification of clinical heterogeneity. Sci Rep 14, 724 (2024). https://doi.org/10.1038/s41598-024-51240-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-51240-2
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
