
Abstract
Quality control often employs memory-type control charts, including the exponentially weighted moving average (EWMA) and Shewhart control charts, to identify shifts in the location parameter of a process. This article pioneers a new Bayesian Adaptive EWMA (AEWMA) control chart, built on diverse loss functions (LFs) such as the square error loss function (SELF) and the Linex loss function (LLF). The proposed chart aims to enhance the process of identifying small to moderate as well as significant shifts in the mean, signifying a notable advancement in the field of quality control. These are implemented utilizing an informative prior for both posterior and posterior predictive distributions, employing various paired ranked set sampling (PRSS) schemes. The effectiveness of the suggested chart is appraised using average run length (ARL) and the standard deviation of run length (SDRL). Monte Carlo simulations are employed to contrast the recommended approach against other control charts. The outcomes demonstrate the dignitary performance of the recommended chart in identifying out-of-control signals, especially applying PRSS designs, in comparison to simple random sampling (SRS). Finally, a practical application was conducted in the semiconductor manufacturing context to appraise the efficacy of the offered chart using various paired ranked set sampling strategies. The results reveal that the suggested control chart performed well in capturing the out-of-control signals far better than the already in use control charts. Overall, this study interposes a new technique with diverse LFs and PRSS designs, improving the precision and effectiveness in detecting process mean shifts, thereby contributing to advancements in quality control and process monitoring.
Similar content being viewed by others
Introduction
Statistical Process Control (SPC) is a critical quality management tool employed in various industries to supervise, regulate, and improve production processes. By using statistical methodologies, SPC ensures the continuous monitoring of manufacturing operations, ensuring their effective and reliable function within predefined quality benchmarks. It involves data collection, analysis, and interpretation to identify variations and trends within the production process. Utilizing control charts (CCs), and other statistical tools, SPC aids in the timely identification of potential deviations from normal patterns, facilitating swift corrective measures to maintain desired quality levels. SPC significantly contributes to defect reduction, enhanced production efficiency, and the overall improvement of product quality, resulting in increased customer satisfaction and reduced operational costs. A CC is a fundamental component of SPC that facilitates the ongoing monitoring and evaluation of the stability and performance of manufacturing or business processes. It visually represents process data, enabling the identification of variations and trends that could potentially impact output quality. By plotting data points on a graph with predetermined control limits, it assists in recognizing common sources of variation, such as random fluctuations, as well as special causes like defects or errors. CCs enable organizations to distinguish between normal process variations and those requiring corrective actions, thereby ensuring consistent product quality and preventing defects. The effective utilization of control charts enables businesses to make informed, data-driven decisions, improve process efficiency, and achieve higher levels of customer satisfaction. Renowned engineer and statistician Walter Shewhart1 is widely recognized for pioneering the concept of memoryless type CCs. These innovative CCs are specifically engineered to swiftly and accurately identify noteworthy shifts within the production process. They achieve this by solely utilizing the most recent sample data, allowing for precise real-time monitoring and prompt corrective actions in industrial settings. Conventional memory type CCs, exemplified by the cumulative sum (CUSUM) and EWMA CCs, as proposed by Ref.2,3, are primarily applying for efficiently managing and monitoring small-to-moderate variations within processes. These traditional memory type CCs have undergone ongoing refinements and advancements, as evidenced by the developments presented in research works such as Refs.4,5,6,7,8. Haq et al.9 focuses on adaptive memory-type CCs, including AEWMA and dual CUSUM, demonstrating their superior performance in detecting mean shifts. The proposed AEWMA chart utilizes an unbiased mean shift estimator and dynamically adjusts the smoothing constant, outperforming existing AEWMA, adaptive CUSUM, and Shewhart-CUSUM charts. An illustrative example clarifies the functionality of the CCs. Sparks10 studied and proposed efficient CUSUM procedures for detecting a range of unknown location shifts, utilizing multiple CUSUM statistics with varied resetting boundaries, and an adaptive CUSUM statistic. Comparative analysis using the ARL demonstrates the relative performance of the procedures, supported by various applications. Capizzi and Masarotto11 propose an adaptive EWMA CC that balances the detection of small and large shifts, addressing limitations of a single EWMA chart. It combines Shewhart and EWMA features, offering improved protection against shifts of varying sizes, as demonstrated through average run length profiles. The current literature extensively covers various research efforts aimed at examining the utilization and effectiveness of adaptive cumulative sum (ACUSUM) and AEWMA CCs in identifying the variations in the process parameter. Key studies, such as those cited as Refs.12,13,14,15,16, contribute significantly to the comprehensive comprehension and assessment of these CC methodologies. Zaman et al.17 emphasizes the need to monitor both small and large shifts in production processes. It introduces an adaptive EWMA method with Huber and Tukey's bi-square functions, effectively monitoring various shifts, supported by real-world data analysis and performance metrics. The conventional studies have largely relied on standard methodologies that focus on analyzing sample data in isolation, disregarding any existing prior knowledge. On the other hand, the Bayesian methodology uniquely integrates both the available sample data and pre-existing information, consistently updating and refining the analysis to generate a posterior (P) distribution. This dynamic and iterative process enables a more comprehensive and nuanced estimation procedure, ultimately reinforcing the resilience and reliability of the analysis and its outcomes. Girshick and Rubin18 are the first who researched the notion of Bayesian CC for location parameter. Saghir et al.19 introduced a Bayesian CC that utilizes the P distribution to identify fluctuations in location parameter. Their method considers different LFs, allowing flexibility in capturing the underlying process characteristics. On a similar note, Riaz et al.20 extended the Bayesian framework by proposing a Bayesian EWMA control chart. This CC incorporates the P and posterior predictive (PP) distributions and accommodates numerous LFs. Moreover, they explored the performance of the chart utilizing both informative and non-informative priors. Riaz et al.21 highlights the dominance of frequentist approaches in process monitoring, although Bayesian methodology proves advantageous, particularly with limited phase-I datasets. The study emphasizes the necessity for a corrected design of Bayesian CCs to achieve the desired in-control performance, especially with various LFs. Furthermore, the predictive CC is also introduced with simulations and real data examples illustrating the concepts. Noor et al.22 introduces Bayesian CCs for non-normal life time distributions, employing various LFs and transforming Exponential distributions. Run length profile are used for performance evaluation which indicates that the Weibull distribution demonstrates the most valuable results, validated by extensive simulations and a real-world case study. Noor-ul-Amin and Noor23 introduces a novel AEWMA CC in Bayesian theory, integrating Shewhart and EWMA CCs for effective monitoring of process mean under different LFs. Performance evaluation involves ARL and SDRL, with comparisons made against existing Bayesian EWMA CCs. Asalam et al.24 presents a novel Bayesian Modified-EWMA chart employing four LFs and a conjugate prior distribution demonstrating better efficiency in identifying slight to moderate deviations when compared to current charts. Demonstrated through practical cases: monitoring the mechanical industry's reaming process and sports industry's golf ball performance. Lin et al.25 developed the applicability of manufacturing industry quality control methods to service quality measurement in the automated service sector. It addresses challenges unique to service processes through a Bayesian Phase II EWMA CC, demonstrating robust performance via simulated and practical examples. Khan et al.26 studied a new Bayesian HEWMA CC is proposed using RSS strategies, with an informative prior and various LFs. Extensive Monte Carlo simulations demonstrate its superior performance, as evidenced by ARL and SDRL. Liu et al.27 introduces a novel Bayesian CC that utilizes different LFs and PRSS schemes, showcasing superiority in detecting out-of-control indications, especially applying PRSS compared to SRS. Monte Carlo simulations validate its effectiveness and a real-life semiconductor manufacturing application confirms its superiority over existing control charts, offering an improved approach for identifying process mean shifts. The utilization in the semiconductor manufacturing hard-bake process demonstrates the increased sensitivity of the offered HEWMA chart with RSS designs, in contrast to other CCs utilizing SRS.
The objective of this article is to introduce a new Bayesian chart that integrates distinct paired RSS (PRSS) methodologies, including PRSS, quartiles PRSS (QPRSS), and extreme PRSS (EPRSS). The methodology includes the integration of pertinent prior distributions and the P , which are established using the chosen LFs. The effectiveness evaluation of the offered CC is conducted using run length results. The study is organized into several sections, with Section "Bayesian approach" introducing Bayesian methodology, Section "Paired ranked set sampling" examining different PRSS schemes, Section "Simulation study" detailing the design of the Bayesian AEWMA CC, Section "Results and discussions" presenting results and discussions, Section "Real data applications" discussing real-world applications, and Sect. “Conclusion” offering concluding remarks.
Bayesian approach
A foundational framework for statistical inference, the Bayesian approach places a strong emphasis on the representation and manipulation of uncertainty through probabilities. The Bayesian method, named after Reverend Thomas Bayes, employs Bayes' theorem to calculate event probabilities based on prior knowledge. It combines prior beliefs with observed evidence to generate posterior probabilities, enabling dynamic belief updating. It underpins statistical inference and decision-making, enhancing understanding of complex systems. To draw conclusions about unknown quantities, the Bayesian paradigm incorporates both observed data and prior beliefs. The Bayesian approach approaches parameters as random variables with their own probability distributions, in contrast to frequentist statistics, which treats parameters as fixed but unknown values. This enables the measurement of the estimating process's uncertainty. Because they offer a flexible and natural way to incorporate past knowledge into statistical modeling and analysis, Bayesian methods are widely used in many fields, including machine learning, data analysis, and decision making under uncertainty. In situations where data is scarce or noisy, they offer a potent tool for well-informed decisions and forecasts. Additionally, a dynamic and iterative learning process is made possible by the Bayesian approach, which permits beliefs to be updated in response to new data. In the context of statistical analysis, the variable under consideration X represents an under control process with parameters θ and \(\delta^{2}\). A normal prior distribution is chosen with parameters \(\theta_{0}\) and \(\delta_{0}^{2}\) to express initial beliefs or knowledge about these parameters prior to any data observation is given by:
When there is little or no previous knowledge about an unknown population parameter, Bayesian analysis frequently applies a non-informative prior, which is typically has a negligible impact on the prior distribution. In response to this, Jeffrey28 formulated a prior distribution which is directly proportional to the Fisher information matrix, thereby addressing this particular scenario. The probability function is defined as \(p\left( \theta \right) \propto \sqrt {I\left( \theta \right)}\) where, \(I\left( \theta \right)\) is known as Fisher information matrix. This enables the analysis to incorporate any accessible information on the parameter.
The Bayesian P distribution, updates our knowledge of parameters of interest by fusing prior beliefs with the likelihood function derived from the analyzed data. Considering both past knowledge and recent evidence, it represents the refined beliefs about these parameters. In order to enable a methodical approach to statistical decision-making by combining both prior beliefs and observed data, the P distribution is a crucial part of Bayesian inference. The \(p\left( {\theta |x} \right)\) is given as \(p\left( {\theta |x} \right) = \frac{{p\left( {x|\theta } \right)p\left( \theta \right)}}{{\int {p\left( {x|\theta } \right)p\left( \theta \right)d\theta } }}\). The predictive distribution in Bayesian statistics, is a key tool for predicting upcoming observations by fusing prior assumptions about parameters with likelihood derived from data. The Bayes theorem is used to update our knowledge of unknown quantities in light of fresh evidence. With parameter uncertainty and data variability taken into account, it computes the probability distribution of future observations y given observed data x. This method is useful in areas like machine learning, econometrics, and uncertainty-aware decision-making because it enables the quantification of uncertainty in complex data scenarios.The predictive distribution ensures a principled approach to prediction, integrating prior knowledge with observed data for well-informed decision-making. the \(p\left( {y|x} \right)\) is mathematically described as
Squared error loss function
In the context of the Bayesian approach, The SELF is a metric that assesses the discrepancy between the estimated and true parameters. It serves as a way to evaluate the accuracy of an estimator by considering the squared difference between the true value and the estimated value. The SELF is a fundamental component in Bayesian decision theory, where it helps to assess the quality of estimators and aids in making decisions. Specifically, it helps in quantifying the loss incurred due to the incongruity between the estimated and true values, with the aim of minimizing this loss in the decision-making process. Gauss29 suggested a SELF and mathematically described as
Using SELF the Bayes estimator is mathematized as:
Linex loss function
Within the Bayesian framework, the LLF, asymmetric measurement, evaluates the distinction between the actual and the estimated parameter. It integrates exponential and linear components, enabling the evaluation of accuracy with non-uniform preferences. This characteristic foster adaptability in decision-making and estimation, aligning with specific preferences and priorities in the Bayesian approach. Varian30 introduced an asymmetric LLF. The estimation method for the location parameter under the LLF can be described as follows:
Utilizing LLF, the Bayes estimator is given mathematically as
Paired ranked set sampling
Muttlak31 is recognized as the pioneer of the paired RSS (PRSS) method. This technique involves selecting a subset of population units for ranking, and instead of choosing only one unit from each set, two units are selected for estimation. The PRSS strategies can be implemented as follows: If the set size \(l\) is even, \(\left( {{\raise0.7ex\hbox{${l^{2} }$} \!\mathord{\left/ {\vphantom {{l^{2} } 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)\) units are randomly selected from the population. These units are then divided among \(\left( {{\raise0.7ex\hbox{$l$} \!\mathord{\left/ {\vphantom {l 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)\) sets, with each set comprising \(l\) units. The items within each set are ranked by incorporating sources, such as expert insights or auxiliary data. Subsequently, the first and \(l\)th ranked units from the initial set are chosen, followed by the second and \(\left( {l - 1} \right)th\) units from the second set, and so on, until the \(\left( {{\raise0.7ex\hbox{$l$} \!\mathord{\left/ {\vphantom {l 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)th\) and \(\left( {{\raise0.7ex\hbox{$l$} \!\mathord{\left/ {\vphantom {l 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}} + 1} \right)th\) elements taken from the last set. In the case of an odd value of l, \(\left( {{\raise0.7ex\hbox{${l\left( {l + 1} \right)}$} \!\mathord{\left/ {\vphantom {{l\left( {l + 1} \right)} 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)th\) elements are taken directly from the under study population. The PRSS procedure involves randomly distributing the selected units among \(\left( {{\raise0.7ex\hbox{${\left( {l + 1} \right)}$} \!\mathord{\left/ {\vphantom {{\left( {l + 1} \right)} 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)th\) sets, where each set consists of \(l\) units. This finalizes one cycle of the PRSS procedure. The entire method can be repeated r times if necessary to get the desired sample size \(n = lr\). The procedure for the PRSS can be described as follows: consider a specific cycle, denoted as r. within this cycle, let \(Z_{i(j),r}\), \(i,j\) = 1,2,3 … l; r = 1, 2, 3 … c, represents the jth order statistic in the ith sample, with cycle r. In this context, the RSS is used to estimate the population mean, and the estimator under PRSS approach for a single cycle is computed using the following for even l is given as
and
For odd \(l\)
and variance
Extreme pair ranked set sampling
A modified version of the PRSS method, proposed by Balci et al.32 and referred to as extreme PRSS (EPRSS), introduces an innovative approach to sample selection. EPRSS is particularly valuable in cases where the population follows a heavy-tailed distribution, a scenario more common than a normal distribution. This modification addresses the limitations of standard sampling techniques, which often struggle to capture extreme values in datasets with heavy-tailed distributions. By identifying and accounting for these extreme values, EPRSS aids in producing more accurate and representative estimates, thereby mitigating potential biases that could arise from skewed estimations. The EPRSS method entails the following steps: If l is even, a certain number of sampling units, specified as \(\left( {{\raise0.7ex\hbox{${l^{2} }$} \!\mathord{\left/ {\vphantom {{l^{2} } 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)\), are taken from the population concerned. These units are divided into \(\left( {{\raise0.7ex\hbox{$l$} \!\mathord{\left/ {\vphantom {l 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)\) sets of comparable size. Following this, elements in each group are arranged in ascending sequence, and measurements are obtained from the initial and final elements in each ordered group. However, if the value of l is odd, an alternative method is implemented. In this case, a total of \(\left( {{\raise0.7ex\hbox{${l\left( {l + 1} \right)}$} \!\mathord{\left/ {\vphantom {{l\left( {l + 1} \right)} 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)\) elements taken from population under study. These units are randomly distributed into \(\left( {{\raise0.7ex\hbox{${l - 1}$} \!\mathord{\left/ {\vphantom {{l - 1} 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)\) sets, and all elements in each set are ranked accordingly. This comprehensive process enables the identification and collection of specific data points from the population, facilitating a more nuanced and inclusive analysis within the EPRSS framework. If vital, the entire EPRSS technique is recurrent r times to get a sample of size \(n = lr\). The technique for estimating the mean and variance in EPRSS for a one rotation is given as follows: In case of l being even, the estimator is given by:
with variance
If \(l\) is odd then
and
Quartile pair ranked set sampling
Tayyab et al.33 proposed the Quartile Paired RSS (QPRSS) design as an approach for estimating population parameters. The QPRSS technique can be summarized as follows: if l is an even number, \(\left( {{\raise0.7ex\hbox{${l^{2} }$} \!\mathord{\left/ {\vphantom {{l^{2} } 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)\) elements are randomly drawn from the available population and allocated to \(\left( {{\raise0.7ex\hbox{$l$} \!\mathord{\left/ {\vphantom {l 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)\) sets, with each set having a size of l. The elements selected within each set are ranked using cost-effective sources. Subsequently, the \(\left( {{\raise0.7ex\hbox{${\left( {l + 1} \right)}$} \!\mathord{\left/ {\vphantom {{\left( {l + 1} \right)} 4}}\right.\kern-0pt} \!\lower0.7ex\hbox{$4$}}} \right)th\) and \(\left( {{\raise0.7ex\hbox{${3\left( {l + 1} \right)}$} \!\mathord{\left/ {\vphantom {{3\left( {l + 1} \right)} 4}}\right.\kern-0pt} \!\lower0.7ex\hbox{$4$}}} \right)th\) ordered elements from each set are chosen. If l is an odd number, \(\left( {{\raise0.7ex\hbox{${l\left( {l + 1} \right)}$} \!\mathord{\left/ {\vphantom {{l\left( {l + 1} \right)} 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)\) ordered elements are randomly taken from the population and allocated to \(\left( {{\raise0.7ex\hbox{${\left( {l + 1} \right)}$} \!\mathord{\left/ {\vphantom {{\left( {l + 1} \right)} 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)\) sets. After ordering the units in each set, the \(\left( {{\raise0.7ex\hbox{${\left( {l + 1} \right)}$} \!\mathord{\left/ {\vphantom {{\left( {l + 1} \right)} 4}}\right.\kern-0pt} \!\lower0.7ex\hbox{$4$}}} \right)th\) and \(\left( {{\raise0.7ex\hbox{${3\left( {l + 1} \right)}$} \!\mathord{\left/ {\vphantom {{3\left( {l + 1} \right)} 4}}\right.\kern-0pt} \!\lower0.7ex\hbox{$4$}}} \right)th\) ordered units from the \(\left( {{\raise0.7ex\hbox{${\left( {l - 1} \right)}$} \!\mathord{\left/ {\vphantom {{\left( {l - 1} \right)} 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)\) sets, along with the \(\left( {{\raise0.7ex\hbox{${\left( {l + 1} \right)}$} \!\mathord{\left/ {\vphantom {{\left( {l + 1} \right)} 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)th\) unit from the enduring last set, are quantified to complete a single cycle. If essential, repeat the preceding procedures r times to obtain the needed sample size n = lr.
The mean estimator for QPRSS for a single series is specified as follows: In case l is an even number, mean estimator is mathematized as
and if \(l\) is odd then
respective variances are
and
Suggested AEWMA CC applying with various PRSS schemes utilizing Bayesian methodology
The section discusses the recommended CC applying distinct PRSS strategies for monitoring the process parameter of a normally distribution. Consider the independently and identically normally distributed variable i.e., \(X_{1} ,X_{2} ,...X_{n}\) with θ and \(\sigma^{2}\) respectively. As a result, the probability function can be expressed as:
The estimation of the mean shift is denoted by \({\widehat{\delta }}_{t}^{*}\) and is considered as the sequence of EMWA statistics using \(\left\{ {X_{t} } \right\}\). Mathematically, this is expressed as
where \(\hat{\delta }_{0}^{*} = 0\) and \(\psi\) denotes the smoothing constant, the estimator \(\hat{\delta }_{0}^{*}\) exhibits bias for out-of-control processes and is unbiased for in-control processes. Haq et al.9 have contributed an equitable approximation of σ that is suitable for both processes within control and those that are out of control. This impartial estimation can be mathematically articulated as:
It is offered to use \(\hat{\delta }_{t} = \left| {\hat{\delta }_{t}^{**} } \right|\) for \(\delta\) estimation.
The proposed statistic applying PRSS designs utilizing Bayesian technique for estimating the process mean using the sequence \(\left\{ {X_{t} } \right\}\) is provided by:
where \(i = 1,2,3,\)\(RSS_{1} = PRSS\), \(RSS_{2} = QPRSS\), \(RSS_{3} = EPRSS\),\(g\left( {\hat{\delta }_{t} } \right) \in \left( {0,\left. 1 \right]} \right.\) and \(F_{0} = 0\) such that g
Atif et al.34 presented a function, labeled as (23), aimed at adjusting the smoothing constant while factoring shift estimated. The recommended constants utilized in \(g\left( {\hat{\delta }_{t} } \right)\) is \(a = 7\) and \(c = 1\), when \(1 < \hat{\delta }_{t} \le 2.7\), the value of \(c = 2\) for \(\hat{\delta }_{t} \le 1\). When the Bayesian AEWMA plotting statistic exceeds the predetermined threshold value h, it signals an out-of-control process. And if the statistic remains lower than the assigned threshold value, it signifies a process under control.
In scenarios where probability function and the prior distribution adhere to a normal distribution, the subsquent posterior distribution also conforms to a normal distribution, characterized by θn and σ2n, mean and variance respectively. The \(P\left( {\theta /x} \right)\) can be mathematically represented as:
where, \(\theta_{n} = \frac{{n\overline{x} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }}\) and \(\delta_{n}^{2} = \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}\).
The estimator for the suggested approach, which incorporates the Bayesian methodology under various PRSS designs utilizes the SELF, can be expressed as follows:
The estimator for the offered approach, which integrates Bayesian methodology across various PRSS designs employs the SELF, is mathematically represented as follows:
The properties of the \(\hat{\theta }_{{_{{\left( {SELF} \right)}} }}\) is expressed, \(E\left( {\hat{\theta }_{{\left( {SELF} \right)}} } \right) = \frac{{n\theta_{1} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }}\) and \(sd\left( {\hat{\theta }_{{\left( {SELF} \right)}} } \right) = \sqrt {\frac{{n\delta_{{(PRSS_{i} )}}^{2} \delta_{0}^{4} }}{{\delta^{2} + n\delta_{0}^{2} }}}\). The Bayes estimator utilizing the LLF and with PRSS, can be calculated as follows:
The mean of \(\hat{\theta }_{{\left( {LLF} \right)}}\) is mathematized as \(E\left( {\hat{\theta }_{LLF} } \right) = \frac{{n\theta_{1} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }} - \frac{{C{\prime} }}{2}\).
Suppose there are future observations of size h, denoted as y1, y2, …, yn. In context of Bayesian methodology, employing different RSS strategies for posterior predictive distribution, the P(y/x) can be represented as:
where \({\raise0.7ex\hbox{$y$} \!\mathord{\left/ {\vphantom {y x}}\right.\kern-0pt} \!\lower0.7ex\hbox{$x$}}\) is normally distributed having mean \(\theta_{n}\) and the standard deviation \(\delta_{1}\), mathematized as \(\delta_{1} = \sqrt {\delta^{2} + \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}}\). Then \(\theta\) is estimated for posterior predictive distribution applying LLF with different PRSS designs by
where, \(\tilde{\delta }_{1}^{2} = \frac{{\delta^{2} }}{k} + \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}\), \(E\left( {\hat{\theta }_{LLF} } \right) = \frac{{n\theta_{1} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }} - \frac{{C{\prime} }}{2}\tilde{\delta }_{1}^{2}\) and \(sd\left( {\hat{\theta }_{LLF} } \right) = \sqrt {\frac{{n\delta_{{(PRSS_{i} )}}^{2} \delta_{0}^{4} }}{{\left( {\delta^{2} + n\delta_{0}^{2} } \right)^{2} }}}\) are the mean and standard deviation of \(\hat{\theta }_{LLF}\).
Simulation study
The effectiveness of the AEWMA CC, which incorporates Bayesian methodology and is applicable to various PRSS designs, is evaluated using Monte Carlo simulation. The evaluation process encompasses various measures, including the ARL and the SDRL. To evaluate the impact of the proposed CC with different LFs, smoothing constants of \(\psi\) = 0.10 and 0.25 are utilized. The state of an in-control process is indicated at 370. Hereafter, we present a summary of the essential simulation steps required to implement the offered CC.
Step 1: Setting in-control ARL
-
The prior and sampling distribution are assumed to follow a standard normal distribution, from which the properties are determined for different LFs. i.e., \(E\left( {\hat{\theta }_{{\left( {_{LLF} } \right)}} } \right)\) and \(\delta_{LLF}\).
-
The determination of the threshold value 'h' is grounded on a particular chosen smoothing constant value.
-
For an in-control process, generate a random samples from a normal distribution of size n, \(X \sim N\left( {E\left( {\hat{\theta }} \right),\delta^{2} } \right)\).
-
Compute the recommended AEWMA statistic and assess the process in line with the predetermined design specifications.
-
Repeat the preceding three stages indefinitely as long as the process stays under control, and maintain track of the number of run lengths for the under-control process until it is identified as out-of-control.
Step 2: For out-of-control ARL
-
In the case of a shifted process, draw samples from a Gaussian distribution. i.e., \(X \sim N\left( {E\left( {\hat{\theta }_{{_{LF} }} } \right) + \sigma \frac{\delta }{\sqrt n },\delta } \right)\).
-
Compute the statistic Ft for the AEWMA using a Bayesian approach, and assess the process under the offered design.
-
Continue to repeat the above-mentioned steps as long as the process remains within control, while keeping a record of the run length for the in-control process.
-
Perform iterations of steps (i–iii) for a total of 100,000 times, and compute the ARL and SDRL.
Results and discussions
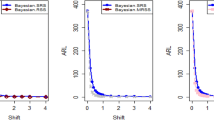
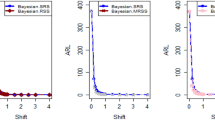
Tables 1, 2, 3, 4, 5 and 6 present a detailed comparison between the proposed methodology and the existing chart that employs Bayesian approach using SRS. The suggested CC is developed through the implementation of distinct PRSS strategies, each utilizing two distinct LFs. The observations suggest that the suggested CC demonstrates a more pronounced ability to effectively monitor the mean of the process when compared with available Bayesian chart that utilizes SRS based on the analysis of performance measures such as the ARL and the SDRL values of the offered CC, which are derived from the PRSS schemes utilizing the SELF under an informative prior. This performance is notably superior to that of the Bayesian AEWMA CC, which employs SRS. As an illustration, consider the results obtained from the available Bayesian chart applying SRS with a specific \(\psi\) = 0.10. The ARL values for distinct shifts, such as 0.0, 0.30, 0.50, 0.80, 1.50, and 4, are 370.16, 43.59, 18.90, 7.90, 2.56, and 1.01, respectively. In a similar scenario, the ARL values of offered CC, employing PRSS are 370.51, 23.55, 9.20, 3.73, 1.45, and 1, while those under QPRSS are 369.17, 22.46, 8.73, 3.55, 1.40, and 1. Furthermore, the run length outcomes of the offered CC under EPRSS are 371.14, 24.20, 9.52, 3.94, 1.49, and 1. As an illustration, consider the results obtained from the existing CC using SRS, with SELF under \(\psi\) = 0.10. ARL values for various shifts, such as 0.0, 0.30, 0.50, 0.80, 1.50, and 4, are 370.16, 43.59, 18.90, 7.90, 2.56, and 1.01, respectively. In a similar scenario, the ARL values for the offered chart, employing PRSS, are 370.51, 23.55, 9.20, 3.73, 1.45, and 1, while those under QPRSS are 369.17, 22.46, 8.73, 3.55, 1.40, and 1. Furthermore, ARL output of recommended chart utilizing EPRSS are 371.14, 24.20, 9.52, 3.94, 1.49, and 1. The findings illustrate the effectiveness of the offered chart when applying PRSS designs. Additionally, a comparison is made between the effectiveness of the Bayesian chart applying SRS and the suggested CC under PRSS methods, which include an informative prior and two distinct LFs at \(\psi\) = 0.25. These comparisons are conducted across different shift values such as 0.0, 0.30, 0.50, 0.80, 1.50, and 4, revealing ARLs of 369.50, 55.71, 27.40, 12.96, 4.08, and 1.08, respectively. ARL outcomes of recommended method utilizing PRSS demonstrate values of 371.18, 28.96, 14.91, 6.24, 2.02, and 1 for various shift magnitudes. In contrast, employing QPRSS yields ARL output are 370.56, 31.82, 14.12, 5.83, 1.93, and 1. Furthermore, when utilizing EPRSS, the ARL outputs are 369.23, 21.93, 11.03, 6.41, 1.37, and 1 for shifts of differing magnitudes. In contrast to AEWMA chart, which uses Bayesian approach under SRS, the results suggest that the proposed methodology shows a rapid decay in values under PRSS systems, especially at larger shifts. This bearish trend is a testament to the system's superior ability to effectively detect runaway signals within the monitored process. These findings can be summarized briefly and succinctly in the following key points.
-
Analysis of the ARL results for the proposed CC applying SELF across distinct PRSS designs shows a consistent and rapid decrease in values with increasing shift in the process mean. This trend designates that the offered technique remains unbiased, as shown in Tables 1 and 2. For example, looking at the results in Table 1 with an ARL = 370 and a smoothing constant (δ) set to various shifts such as 0.20 and 0.70, the ARL values are 44.39 and 4 for PRSS 0.70, for QPRSS at 46.01 and 4.77 and for EPRSS at 42.81 and 4.78.
-
From Tables 3 and 4, it can be seen that the performance of the offered technique is susceptible to variations in the value of \(\psi\), which are given as 0.10 and 0.25. Considering the LLF, ARL and SDRL outcomes for the offered method with emphasis on the P distribution are presented in Tables 3 and 4. These tables illustrate a decrease in efficiency as the smoothing constant increases for offered chart. For example, with ARL = 370 and \(\psi\) = 0.10 along with a shift of 0.20, respective ARL outputs of suggested chart using PRSS, QPRSS, and EPRSS are 46.17, 44.18, and 47.89, respectively. Furthermore, the ARL values for the same displacement (δ) of 0.20 are 54.76 for PRSS, 52.23 for QPRSS, and 56.82 for EPRSS, respectively.
-
The run length output of the offered chart under various PRSS schemes are presented in Tables 5 and 6. These tables offer valuable information on how the proposed chart performs when employing PRSS methodologies with the LLF. Specifically, at ARL = 370, with a shift (δ) value of 0.50 and a smoothing constant (sci) set at 0.10, the ARL value is 9.35. Similarly, when the smoothing constant (sci) is set to 0.25, the ARL value is 14.81. Comparatively, for the same scenario, the ARL values using QPRSS are 9.05 and 13.00, while those obtained using EPRSS are 9.90 and 14.90, respectively.
-
From An examination of Tables 1, 2, 3, 4, 5 and 6 reveals that the suggested chart displays a relatively higher susceptibility in identifying out-of-control with the comparison to the Bayesian CC that utilizes SRS. This decision is drawn from the Figs. 1, 2, 3, 4, 5, 6 and 7, which provides clear evidence of the offered Bayesian AEWMA CC comparatively limited effectiveness in identifying deviations from the expected process behavior. The r codes for the proposed design are included in the Appendix A.

Using SELF, Plots for P and PP distribution.

ARL graphs for P distribution applying LLF with PRSS designs.

Graphs for PP distribution with LLF using PRSS schemes.

Based on SRS, the ARL graph for the Bayesian chart with SELF.

Using PRSS, ARL graph for Bayesian CC under SELF.

Using QPRSS, the graph shows Bayesian AEWMA CC based on SELF.

Using EPRSS, graph shows AEWMA chart utilizing SELF.
Real data applications
In the realm of research, the utilization of real datasets and simulated examples is a standard practice aimed at illustrating the practical application and effectiveness of proposed charts. In the context of this particular study, a real dataset is used to showcase the operational dynamics and the practical utility of the charts. The investigation focuses on semiconductor manufacturing, particularly the integration of the hard-bake process with photolithography. The central objective revolves around establishing statistical control over the resist flow width within this process, employing both the existing and recommended chart. To achieve this, a dataset obtained from Montgomery35 is employed, comprising forty-five samples, each involving 5 wafers derived from the manufacturing process. These samples are taken at hourly intervals, with the measurements of flow width recorded in microns. The initial 30 samples are presumed to reflect data from an in-control process, constituting the phase 1 dataset, while the subsequent 15 samples represent data from an out-of-control process, forming the phase 2 dataset. for both the P and PP distributions.
Figure 4 depicts the application of Bayesian chart under SRS, identifying an out-of-control signal on the 40th sample. This method utilizes the SELF for P distributions, employing SRS. In contrast, Figs. 5, 6, 7 demonstrate the usage of the recommended chart that integrating P distribution applying SELF and different stratigies for the PRSS. According to the figures, the suggested CC detects out-of-control signals for PRSS, QPRSS, and EPRSS on the 36th, 33rd, and 35th samples, respectively. In summary, Figs. 1, 2, 3, 4, 5, 6 and 7 collectively emphasize the increased sensitivity of the suggested CC in detecting out-of-control signals.
Conclusion
The implementation of the recommended CC applying PRSS schemes for both P and PP distribution has been proposed to effectively monitor process mean. This innovative methodology is meticulously compared to the availiable CC under SRS, and the comprehensive analysis is documented in Tables 1, 2, 3, 4, 5 and 6. Notably, the results obtained from the recommended approach demonstrate a superior performance compared to the conventional CC. To exemplify the practical implementation of the proposed technique, a real-world dataset is utilized, showcasing its efficacy in precisely tracking the location parameter and promptly identifying any deviations from the desired target. In order to further enhance the Bayesian AEWMA CC, the study suggests several promising research avenues. These research avenues involve delving into the method's adaptability and resilience when dealing with non-normal distributions. Additionally, they encompass an examination of alternative sampling techniques, such as consecutive sampling, to improve the precision of the control chart. By focusing on these areas of investigation, the proposed methodology can be customized to various scenarios, ultimately bolstering its efficacy in overseeing processes and ensuring quality control. This research highlights the importance of these developments in managing varied datasets and provides valuable guidance for future studies, thereby making ongoing contributions to the enhancement of process monitoring and quality management practices.
Data availability
Should anyone make a reasonable request, they can directly access the datasets used or analyzed in this study from the corresponding author.
References
Shewhart, W. A. The application of statistics as an aid in maintaining quality of a manufactured product. J. Am. Stat. Assoc. 20(152), 546–548 (1925).
Page, E. S. Continuous inspection schemes. Biometrika 41(1/2), 100–115 (1954).
Roberts, S. Control chart tests based on geometric moving averages. Technometrics 42(1), 97–101 (1959).
Lu, C.-W. & Reynolds, M. R. Jr. EWMA control charts for monitoring the mean of autocorrelated processes. J. Qual. Technol. 31(2), 166–188 (1999).
Knoth, S. Accurate ARL computation for EWMA-S2 control charts. Stat. Comput. 15(4), 341–352 (2005).
Maravelakis, P. E. & Castagliola, P. An EWMA chart for monitoring the process standard deviation when parameters are estimated. Comput. Stat. Data Anal. 53(7), 2653–2664 (2015).
Chiu, J.-E. & Tsai, C.-H. Monitoring high-quality processes with one-sided conditional cumulative counts of conforming chart. J. Ind. Prod. Eng. 32(8), 559–565 (2015).
Noor-ul-Amin, M. & Tayyab, M. Enhancing the performance of exponential weighted moving average control chart using paired double ranked set sampling. J. Stat. Comput. Simul. 90(6), 1118–1130 (2020).
Haq, A., Gulzar, R. & Khoo, M. B. An efficient adaptive EWMA control chart for monitoring the process mean. Qual. Reliab. Eng. Int. 34(4), 563–571 (2018).
Sparks, R. S. CUSUM charts for signaling varying location shifts. J. Qual. Technol. 32(2), 157–171 (2000).
Capizzi, G. & Masarotto, G. An adaptive exponentially weighted moving average control chart. Technometrics 45(3), 199–207 (2003).
Jiang, W., Shu, L. & Apley, D. W. Adaptive CUSUM procedures with EWMA-based shift estimators. IIE Trans. 40(10), 992–1003 (2008).
Wu, Z., Jiao, J., Yang, M., Liu, Y. & Wang, Z. An enhanced adaptive CUSUM control chart. IIE Trans. 41(7), 642–653 (2009).
Huang, W., Shu, L. & Su, Y. An accurate evaluation of adaptive exponentially weighted moving average schemes. IIE Trans. 46(5), 457–469 (2014).
Aly, A. A., Saleh, N. A., Mahmoud, M. A. & Woodall, W. H. A reevaluation of the adaptive exponentially weighted moving average control chart when parameters are estimated. Qual. Reliab. Eng. Int. 31(8), 1611–1622 (2015).
Aly, A. A., Hamed, R. M. & Mahmoud, M. A. Optimal design of the adaptive exponentially weighted moving average control chart over a range of mean shifts. Commun. Stat.-Simul. Comput. 46(2), 890–902 (2017).
Zaman, B., Lee, M. H., Riaz, M. & Abujiya, M. A. R. An adaptive approach to EWMA dispersion chart using Huber and Tukey functions. Qual. Reliab. Eng. Int. 35(6), 1542–1581 (2019).
Girshick, M. A. & Rubin, H. A Bayes approach to a quality control model. Ann. Math. Stat. 23(1), 114–125 (1952).
Saghir, A., Lin, Z. & Chen, C.-W. The properties of the geometric-Poisson exponentially weighted moving control chart with estimated parameters. Cogent Math. 2(1), 992381 (2015).
Riaz, S., Riaz, M., Nazeer, A. & Hussain, Z. On Bayesian EWMA control charts under different loss functions. Qual. Reliab. Eng. Int. 33(8), 2653–2665 (2017).
Ali, S. & Riaz, M. On designing a new Bayesian dispersion chart for process monitoring. Arab. J. Sci. Eng. 45(3), 2093–2111 (2020).
Noor, S., Noor-ul-Amin, M. & Abbasi, S. A. Bayesian EWMA control charts based on exponential and transformed exponential distributions. Qual. Reliab. Eng. Int. 37(4), 1678–1698 (2021).
Noor-ul-Amin, M. & Noor, S. An adaptive EWMA control chart for monitoring the process mean in Bayesian theory under different loss functions. Qual. Reliab. Eng. Int. 37(2), 804–819 (2021).
Aslam, M. & Anwar, S. M. An improved Bayesian modified-EWMA location chart and its applications in mechanical and sport industry. PLoS ONE 15(2), e0229422 (2020).
Lin, C.-H., Lu, M.-C., Yang, S.-F. & Lee, M.-Y. A Bayesian control chart for monitoring process variance. Appl. Sci. 11(6), 2729 (2021).
Khan, I. et al. Hybrid EWMA control chart under bayesian approach using ranked set sampling schemes with applications to hard-bake process. Appl. Sci. 13(5), 2837 (2023).
Liu, B., Noor-ul-Amin, M., Khan, I., Ismail, E. A. & Awwad, F. A. Integration of Bayesian adaptive exponentially weighted moving average control chart and paired ranked-based sampling for enhanced semiconductor manufacturing process monitoring. Processes 11(10), 2893 (2023).
Jeffreys, H. An invariant form for the prior probability in estimation problems. Proc. R. Soc. Lond. Ser. A Math. Phys. Sci. 186(1007), 453–461 (1946).
Gauss, C. (1955). Methods Moindres Carres Memoire sur la Combination des Observations, 1810 Translated by J. In: Bertrand.
Varian, H. R. (1975). A Bayesian approach to real estate assessment. Studies in Bayesian econometric and statistics in Honor of Leonard J. Savage, 195–208.
Muttlak, H. A. Pair rank set sampling. Biom. J. 38(7), 879–885 (1996).
Balci, S., Akkaya, A. D. & Ulgen, B. E. Modified maximum likelihood estimators using ranked set sampling. J. Computat. Appl. Math. 238, 171–179 (2013).
Tayyab, M., Noor-ul-Amin, M. & Hanif, M. Exponential weighted moving average control charts for monitoring the process mean using pair ranked set sampling schemes. Iran. J. Sci. Technol. Trans. A Sci. 43(4), 1941–1950 (2019).
Sarwar, M. A. & Noor-ul-Amin, M. Design of a new adaptive EWMA control chart. Qual. Reliabil. Eng. Int. https://doi.org/10.1002/qre.3141 (2022).
Montgomery, D. C. Introduction to statistical quality control (Wiley, 2009).
Acknowledgements
This work was supported by Research Supporting Project Number (RSPD2024R585), King Saud University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
I.K. and Y.W. wrote the manuscript, conducted mathematical analyses, and undertook numerical simulations. M.N.A and S.A.A initiated the core problem, conducted data analyses, and contributed to restructuring the manuscript. I.K. and B.A. rigorously validated the findings, revised the manuscript, and secured funding. Moreover, Y.W. and M.N.A. enhanced the manuscript's language and carried out additional numerical simulations. All authors collaborated and unanimously agreed on the final version of the manuscript intended for submission.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, Y., Khan, I., Noor-ul-Amin, M. et al. Monitoring of semiconductor manufacturing process on Bayesian AEWMA control chart under paired ranked set sampling schemes. Sci Rep 13, 22703 (2023). https://doi.org/10.1038/s41598-023-49843-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-49843-2
This article is cited by
-
Use of improved memory type control charts for monitoring cancer patients recovery time censored data
Scientific Reports (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
