
Abstract
Control charts, including exponentially moving average (EWMA) , are valuable for efficiently detecting small to moderate shifts. This study introduces a Bayesian EWMA control chart that employs ranked set sampling (RSS) with known prior information and two distinct loss functions (LFs), the Square Error Loss function (SELF) and the Linex Loss function (LLF), for posterior and posterior predictive distributions. The chart's performance is assessed using average run length (ARL) and standard deviation of run length (SDRL) profiles, and it is compared to the Bayesian EWMA control chart based on simple random sampling (SRS). The results indicate that the proposed control chart detects small to moderate shifts more effectively. The application in semiconductor manufacturing provides concrete evidence that the Bayesian EWMA control chart, when implemented with RSS schemes, demonstrates a higher degree of sensitivity in detecting deviations from normal process behavior. Comparison to the Bayesian EWMA control chart using SRS, it exhibits a superior ability to identify and flag instances where the manufacturing process is going out of control. This heightened sensitivity is critical for promptly addressing and rectifying issues, which ultimately contributes to improved quality control in semiconductor production.
Similar content being viewed by others
Introduction
In manufacturing industries, it is common for processes to undergo variations that cannot be entirely eliminated naturally. To address this inherent challenge, control charts (CCs) are indispensable statistical tools for monitoring processes and effectively mitigating abrupt deviations from the desired target. As a result, CCs play a pivotal role in significantly reducing the likelihood of producing defective items. In the context of the production process, two distinct types of variations exist common cause and special cause. When a process exhibits common cause variation, it is perceived as being under control. Conversely, if the variation arises from a special cause, the process is deemed to be out-of-control. Shewhart1 introduced CC techniques that rely solely on current sample information to monitor the production process. These techniques have demonstrated high effectiveness in detecting significant shifts in process parameters. Furthermore, Page2 and Roberts3 have introduced alternative CCs, such as the Cumulative Sum (CUSUM) and EWMA CCs, respectively. These charts present distinct methods for monitoring and identifying deviations in a process, offering opportunities to enhance process control and ensure product quality. These specialized charts are specifically designed to improve sensitivity in detecting smaller or moderate shifts within the production process. Numerous researchers have made significant contributions to the advancement of memory-type CCs. Among them are Lucas and Crosier4, Khoo5, Khan et al.6, and Saghir et al.7. Abbas et al.8 examined CCs monitoring processes, with a focus on both location and dispersion. We investigated dispersion CCs using RSS, MRSS, and ERSS, and found that they outperform traditional methods, leading to improved process quality and efficiency. Abbas et al.9 present a dispersion control chart that utilizes NRSS, enhancing precision and resilience across diverse domains such as quality control, environmental monitoring, and process control. NRSS incorporates expert knowledge and sample selection to reduce the impact of outliers and accommodate non-normal data, with validation using real-world chemical reactor data. In Mohammadkhani et al.10 study, they explore the efficiency of RSS in statistical process monitoring and CC design, emphasizing its cost-effectiveness in obtaining representative samples. They also review the literature to identify research gaps and provide recommendations for future studies. Noor-ul-Amin and Tayyab11 enhanced the EWMA CC using cost-effective RSS methods, such as PDRSS, EPDRSS, and QPDRSS, finding that these charts outperform the SRS-based classical EWMA CC in detecting small to moderate process mean shifts, supported by an illustrative application.
Statistical inference is a fundamental process comprising two primary components: estimation and hypothesis testing. Estimation involves determining unknown population parameters, and two main approaches are used: classical and Bayesian. In the classical approach, estimators rely on data or sample information without considering prior knowledge or beliefs about the population parameter. Essentially, classical estimation relies solely on observed data to make inferences about the parameter of interest, without incorporating additional contextual information or prior understanding. In the Bayesian approach, estimators incorporate both the available sample data and prior knowledge or beliefs about the population parameter. For instance, Menzefricke12 introduced a CC within the Bayesian framework to monitor the unknown location parameter and also explored CCs for monitoring variance13. In another study, Menzefricke13 extended the use of the EWMA CC within Bayesian theory. They applied a normal distribution to model the population variance and assessed the Bayesian EWMA CC effectiveness in monitoring both the process mean and variance. The Bayesian CC construction involved leveraging the posterior (P) distribution to make informed inferences about the underlying parameter. This Bayesian approach allows for a more comprehensive and contextually informed estimation of process parameters, improving the monitoring and control of industrial processes. In the Bayesian studies, the LF plays a crucial role in minimizing the risk associated with the estimator. Tsui and Woodall14 conducted a study on multivariate CCs, assessing their effectiveness across different LFs. Wu and Tian15 introduced a CUSUM CC capable of detecting variations in both process mean and variance by utilizing a weighted LF Serel16 study delves into the economic design of EWMA-based CCs employing various LFs. Computational methods are employed to ascertain optimal chart parameters, underscoring the significance of adapting the sampling interval over sample size or control limits in response to shifts in the cost of poor quality. This observation is supported by numerical comparisons with Shewhart and S charts. Riaz et al.17 introduced a Bayesian EWMA approach to monitor process mean, utilizing three distinct LFs. their study incorporated informative conjugate and non-informative priors for both P and PP distributions. This Bayesian EWMA approach provides a robust framework for monitoring the process mean by considering various LFs and prior information. Noor et al.18 conducted research within the Bayesian framework, employing two different LFs to develop a hybrid EWMA CC for industrial process monitoring. Their study aimed to assess the performance of this chart using key metrics such as ARL and SDRL. They considered both informative and non-informative priors, demonstrating the flexibility of the Bayesian approach in adapting to different scenarios. Extensive simulations and a real-world example showcased the practicality and effectiveness of the proposed chart in real industrial applications. Asalam et al.19 introduced a novel Bayesian Modified-EWMA chart to monitor location parameters in processes and enhance statistical process control. Four different LFs and a conjugate prior distribution are employed. Performance evaluation using ARL demonstrates the proposed chart's superior performance in detecting small to moderate process shifts compared to existing methods. Real-life examples in the mechanical and sports industries further validate its significance. Noor et al.20 propose a new AEWMA CC, considering different LFs and employing conjugate priors with squared error and linex LFs. Performance assessment involves ARL and SDRL, using Monte Carlo simulations and a real-data example to compare with the existing Bayesian CC. Noor et al.21 investigated Bayesian EWMA CCs for non-normal lifetime distributions, including Exponential, Inverse Rayleigh, and Weibull distributions, with uniform priors and different LFs. Performance assessment based on ARL and SDRL favored the Weibull distribution as the most effective among the options. A practical example demonstrates the implementation of these charts. Liu et al.22 introduce a novel Bayesian AEWMA CC with multiple LFs and PRSS schemes for detecting small to moderate process mean shifts. Monte Carlo simulations and semiconductor manufacturing applications confirm its superior performance in process monitoring. Khan et al.23 introduce an innovative Bayesian AEWMA CC utilizing RSS designs, and an informative prior for effectively monitoring mean shifts in normally distributed processes. Extensive Monte Carlo simulations demonstrate its increased sensitivity when compared to the current exiting CC. Validation in real-world semiconductor fabrication confirms its effectiveness in detecting out-of-control signals.
The various aforementioned studies for monitoring the process mean under the Bayesian approach are done by using a SRS scheme. RSS designs is a cost-effective data collection method often applied in quality control contexts. RSS involves ranking units within groups and selecting a subset of these ranked units for sampling. Utilizing RSS can lead to improved CC efficiency and accuracy. By combining the EWMA CC with the Bayesian approach within the framework of RSS, it's possible to further enhance CC performance. This approach capitalizes on the efficient sampling technique offered by RSS and the adaptability of Bayesian updating, allowing control limits to be adjusted based on available data. The combination of RSS and Bayesian methods in EWMA CC proves particularly advantageous when data collection costs are high or sample sizes are limited. Therefore, we present a Bayesian CC that integrates three distinct RSS strategies: RSS, median RSS (MRSS), and extreme RSS (ERSS). These sampling methodologies are applied to both P and PP distributions, accommodating informative and non-informative priors. The proposed Bayesian CC incorporates two distinct LFs i.e., SELF and LLF. To assess the performance of this proposed CC across various ranked-based sampling approaches, we employ metrics such as ARL and SDRL. These performance measures are calculated using the Monte Carlo simulation method. The article structure is organized as follows: “Bayesian approach” provides an overview of Bayesian theory, encompassing essential terminology related to various LFs. “Ranked set sampling” discusses the RSS, MRSS, and ERSS schemes. The design of the proposed Bayesian EWMA CC is elaborated in “EWMA control-chart”. In “Simulation study”, we conduct a comprehensive simulation study. “Results, discussion and findings” includes a discussion of our findings, while “Real data application” presents an illustrative example. “Conclusion” and “Limitations of the study” outlines outline our conclusions and the study's limitations, and finally, in “Future recommendations”, we provide our recommendations.
Bayesian approach
This section presents a concise discussion of the Bayesian approach, which incorporates both sample knowledge and prior information through the P and PP distribution. The prior distribution is a pivotal element in Bayesian estimation and can be divided into two primary categories: informative and non-informative priors. Informative priors come into play when there exists prior knowledge or information regarding the population parameter, enabling the integration of this prior information into the Bayesian analysis. Conversely, non-informative priors, sometimes referred to as vague or uninformative priors, are selected when limited to no prior knowledge is accessible. This choice ensures that the prior distribution does not introduce any undue influence or bias into the Bayesian inference process. Conjugate prior distributions are employed when both the informative prior and the sampling distribution belong to the same family of probability distributions. This choice streamlines Bayesian analysis by simplifying the calculation of the P distribution. The advantage lies in the P distribution maintaining the same mathematical form as the prior distribution, making computations more straightforward. In essence, selecting a conjugate prior ensures mathematical compatibility between the prior and P distributions, facilitating efficient Bayesian estimation and belief updating when new data is introduced. In the present study, the variable under consideration X is used which follows a normal distribution with unknown mean \(\theta\) and known variance \(\delta^{2}\). We considered normal prior (conjugate prior) with hyperparameters \(\theta_{0}\) and \(\delta_{0}^{2}\) given as:
when no information is available about the prior distribution \(\theta\), it has minimum effect on the P distribution. Thus, in cases where no prior knowledge is available, it is often preferred to utilize a uniform distribution as the prior. This choice of using a non-informative prior, often referred to as a vague or uninformative prior, ensures that in the absence of prior knowledge or information, all conceivable values of the unknown population parameter are treated with equal probability or weight. In other words, the prior distribution does not favor any specific value or range of values for the parameter, effectively representing a state of maximum uncertainty. This approach is particularly useful when a researcher or analyst wants to maintain objectivity and avoid introducing any bias into the Bayesian analysis, allowing the data to exert the most significant influence on the final inference about the parameter of interest. It is a way to approach Bayesian analysis when one wants to be as neutral as possible regarding the parameter's possible values.The probability function of the uniform prior can be represented by \(p\left( \theta \right)\), and its definition is as follows:
where c represents the constant of proportionality and n is the sample size.
The uniform prior is not known for exhibiting the invariance property in Bayesian analysis. However, Jeffrey24 introduced an alternative prior distribution, called Jeffrey's prior. This prior is proportional to the Fisher information matrix, a fundamental concept in statistics that quantifies the amount of information contained in a sample from a probability distribution. Jeffrey's prior is particularly valuable because it provides a prior distribution that remains invariant under certain transformations of parameters, making it a useful choice in cases where maintaining invariance is important for robust Bayesian inference. This property ensures that the prior distribution does not change when expressing information in a different parameterization, enhancing the flexibility and applicability of Bayesian analysis. The Jeffrey’s prior for the parameter \(\theta\) is given by \(p\left( \theta \right) \propto \sqrt {I\left( \theta \right)}\), where \(I\left( \theta \right) = - E\left( {\frac{{\partial^{2} }}{{\partial \theta^{2} }}\log f\left( {X/\theta } \right)} \right)\).
The P distribution is denoted by
The The PP distribution in Bayesian analysis combines updated beliefs from the P distribution with the prior distribution to predict future data Y probabilistically, considering Bayesian process uncertainty. This aids informed, probabilistic forecasting across various fields. The PP distribution is mathematizied as
In Bayesian analysis, the risk associated with the estimator is mitigated through the use of a LF. In this study, we employed both symmetric and asymmetric LFs to address this aspect.
Square error loss function
In Bayesian analysis, the symmetric type LF SELF suggested by Gauss25. It is commonly employed to measure the disparity between a point estimate (e.g., posterior mean or median) and the true but typically unknown parameter value. It is favored in Bayesian analysis when the objective is to minimize the expected value of the squared difference between the estimate and the true parameter value, exhibiting sensitivity to larger errors. The choice of the LF in Bayesian analysis, including the SELF, depends on the specific problem and data characteristics. The SELF is mathematically defined as
The Bayesian estimator under SELF
The construction of the Bayes estimator by using SELF is included in Appendix A.
Linex loss function
Varian26 was the first to introduce the asymmetric type LF Linex LF (LLF), defined as:
When the estimator \(\hat{\theta }\) is employed to estimate the unknown population parameter, it is mathematically represented as:
Ranked set sampling
In the RSS procedure, we select m2 units randomly from the underlying population. The m2 units are distributed into m sets, with m similar set size randomly proposed by McIntyre27. The study variable Z is considered without taking into account the actual measurement and the ordering (ranking) of the m units in each set visually. The The process unfolds systematically by arranging all m sets and sequentially selecting the smallest unit from the first set for measurement. This sequential selection continues as the second smallest unit is chosen from the second set, and so on, until it culminates with the selection of the largest unit from the mth set. This constitutes a single cycle of RSS with a size of m. This cycle is then replicated r times iteratively until the desired sample size, denoted as n, is achieved. The procedure for RSS can be expressed as Zi(j), r, where i and j signify the sample set and order statistic, respectively, with values ranging from 1 to m, while r denotes the cycle number. In the case where c = 1, the mean and variance of the ranked set sample estimator can be described as follows:
The RSS mean estimator is given as
and the variance of the estimator is given by
where \(\mu\) is the overall mean.
Median ranked set sampling
Muttlak28 introduced the median ranked set sampling (MRSS) method as an estimation technique for the population mean. MRSS exhibits improved performance by minimizing ranking errors compared to the mean estimator used in RSS. Like RSS, MRSS divides the sampling units into m sets and arranges them within each set based on the study variable. If m is odd, then \(\left( {m + 1/2} \right){\text{th}}\) units are picked as a sample from all sets. When m is an even, the selection process entails choosing the smallest order units from the two middle sampling units of the first \(\left( {m/2} \right){\text{th}}\) set and selecting the highest order units from the two middle sampling units of the remaining \(\left( {m/2} \right){\text{th}}\) sets. This method involves completing a single cycle of MRSS with a size of m. If needed, the cycle can be repeated r times to reach the desired sample size \(n = mr\).
For a single cycle, the mean estimator for MRSS in case of odd sample size is given by
and the variance of the estimator is given by
In the case of an even sample size, the population mean estimator of MRSS with one cycle is
and the variance of the estimator is given by
Extreme ranked set sampling
ERSS scheme is the modified form of the RSS suggested by Samawi et al.29 and is useful in situations where the collection of ith ordered units is more difficult than extreme units. In the ERSS method, a random selection of \(m^{2}\) units is made from the underlying population, and they are then randomly distributed into m sets of equal size. The units within each set are arranged based on the study variable. When m is an odd, the procedure involves selecting the smallest units from the first \(\left( {\frac{m - 1}{2}} \right){\text{th}}\) ordered set and the highest units from the following \(\left( {\frac{m - 1}{2}} \right){\text{th}}\) ordered sets, ultimately concluding by choosing the median unit from the last set. When m is even, the process entails selecting the smallest units from the first \(\left( \frac{m}{2} \right){\text{th}}\) ordered units and the highest units from the remaining \(\left( \frac{m}{2} \right){\text{th}}\) ordered sets. This constitutes a single iteration, and if necessary, the process is repeated r times to achieve the desired sample size, denoted as n = mr.
Using ERSS for a single cycle, the mean estimator for an odd sample size is mathematically expressed as
and the variance of the estimator is given by
The mean estimator for ERSS, in the scenario of an odd sample size and a single cycle, is defined as follows:
and the variance of the estimator is given by
EWMA control-chart
Consider a quality characteristic X that follows a normal distribution with an unknown location parameter θ and a known scale parameter σ2. In this scenario, we can express the probability density function and likelihood function of the random variable X as follows:
Let sample observation \(x_{1,} x_{2,} x_{3,} ...x_{n}\) be independently and normally distributed with mean \(\theta\) and variance \(\delta^{2}\). The statistic of EWMA CC is given by
In this context, \(\lambda\) it represents a smoothing constant that adheres to the 0 ≤ \(\lambda\) ≤ 1 constraint. The values of \(\lambda\) assign weights to both current and past sample observations. When α is set to 1, all weights are exclusively attributed to the current sample. The initial value is initialized to the mean value of the process so that \(z_{0} = \theta_{0}\).
The mean and variance of the EWMA statistic is given as
The control limits UCL, CL and LCL of EWMA CC are as follow:
In this context, the abbreviations UCL, CL, and LCL correspond to the upper control limit, center line, and lower control limit, respectively. The control constant L is employed to modify the predefined average run length ARL0. The asymptotic expression for the control limits of the EWMA statistic is presented as follows:
Proposed Bayesian-EWMA applying differnt RSS designs
The plotting statistic for the recomended Bayesian EWMA CC under different RSS schemes (RSS, MRSS, and ERSS) by using LFs and informative prior for P and PP distribution is defined as:
where RSS stands for ranked set sampling and LF is used for the loss function, the above structure is work under prior distribution given in “Utilizing normal prior the posterior distribution”.
Utilizing normal prior the posterior distribution
The P distribution is the resulting probability distribution achieved by combining the likelihood function with a normal prior distribution and mathematically expressed as
The \(P\left( {\theta |x} \right)\) is normally distributed with mean and variance are \(\theta_{n}\) and \(\delta_{n}^{2}\) respectively and given as \(\theta /X \sim N\left( {\theta_{n} ,\delta_{n}^{2} } \right)\), where \(\theta_{n} = \frac{{n\overline{x} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }}\) and \(\delta_{n}^{2} = \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}\). The construction of the P and PP distribution under normal prior is derived in Suppl. Appendix B.
The control limits for the Bayesian EWMA CC, established using both P and PP distributions and factoring in various LFs within the RSS schemes, are presented below.
Under RSS, control limits utilizing SELF
The SELF serves as a LF that facilitates the establishment of control limits for Bayesian-EWMA CCs through the utilization of RSS schemes. The estimator \(\hat{\theta }\) based on SELF is mathematizied as:
The properties of the estimator \(\hat{\theta }_{SELF}\) are mathematically expressed as:
and
In Suppl. Appendix C, we explained the process of deriving the Bayes estimator using SELF under RSS strategies for both the P and PP distributions. The asymptotic control limits of the EWMA CC under the Bayesian approach with RSS and SELF are formulated as follows:
\(\begin{aligned} {\text{where}} \quad i = 1,2,3.\quad & RSS_{1} = RSS \\ & RSS_{2} = MRSS \\ & RSS_{3} = ERSS \\ \end{aligned}\).
Under LLF, control limits utilizing RSS schemes
The LLF serves as an instance of an asymmetric LFs applied in establishing control limits for the EWMA CC within the Bayesian framework when employing RSS schemes. The estimator of \(\hat{\theta }_{LLF}\) is defined as
The properties of the estimator \(\hat{\theta }_{LLF}\) are given below:
and
The asymptotic control limits of Bayesian-EWMA CC with RSS schemes and LLF loss function are defined as
PP distribution using normal distribution
In this section, the EWMA CC utilizing Bayesian theory has been constructed using PP distribution. Let the future observation of size k are \(y_{1} ,y_{2} ,....,y_{k}\), then the PP distribution \(Y|X\)is derived as:
where \(\delta_{1}^{2} = \delta^{2} + \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}\), the Bayesian-EWMA control limits for PP distribution using various loss functions by using RSS schemes are given in subsection “Under LLF, control limits utilizing RSS schemes”.
Under LLF, control limits utilizing RSS schemes
The Bayesian-EWMA CC under asymmetric LLF and with different RSS designs, the estimator \(\hat{\theta }_{LLF}\) is mathematized as
where \(\tilde{\delta }_{1}^{2} = \frac{{\delta^{2} }}{k} + \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}\).
The properties of \(\hat{\theta }_{LLF}\) described as:
and
The control limits for Bayesian-EWMA CC under LLF and utilizing various RSS schemes are given below.
Simulation study
The The assessment of the Bayesian EWMA CCs performance in this study adheres to standard quality control methodologies, relying on ARL and SDRL as primary performance indicators. These metrics gauge the control charts efficiency across diverse ranked-based sampling designs while considering two distinct LFs and the inclusion of informative priors. Specifically, ARL0 and SDRL0 quantify the ARL and SDRL under normal, in-control conditions, while ARL1 and SDRL1 reflect scenarios where the process is out of control. The effectiveness of a CC is typically judged by its capacity to achieve a smaller ARL1 for a specific shift. To compute efficiency metrics, the Monte Carlo simulation method is employed, encompassing 20,000 iterations. The control constant is adjusted to achieve a predetermined ARL0 under varying LFs and different values of \(\lambda\), such as \(\lambda\) = 0.10 and 0.25. The simulation study encompasses the use of both the P and PP distributions to anlyze Bayesian EWMA CC using ranked-based sampling designs with sample size n = 5 and assumed standard normal distribution as prior distribution. Detailed steps for simulating ARL and SDRL are provided below.
Step 1: for in-control process
-
i.
We choice a specific value of \(\lambda\) and L smoothing constants for fixed ARL0.
-
ii.
Draw a sample with a RSS stratigies for an in-control process from normal distribution such that \(X \sim N\left( {E\left( {\hat{\theta }} \right),\delta } \right)\).
-
iii.
Computing the mean and standard deviation for the P distribution under different LFs, while assuming standard normal distributions for the sampling and prior distributions.
-
iv.
Based on Bayesian theory, the proposed Bayesian EWMA statistics are computed to evaluate the process according to the projected strategy.
-
v.
Considered Implemented the CC methodology, and in case of out-of-control process signals, documented the number of subgroups as the in-control run length.length.
-
vi.
Repeating the steps 100,000 times to estimate in-control ARL0.
Step 2: evaluation of the out-of-control process
-
i.
Draw a ranked set sample of size n from the shifted process by utilizing normal distribution, such that \(X \sim N\left( {E\left( {\hat{\theta }} \right) + \partial \frac{\delta }{\sqrt n },\delta } \right)\), where \(\partial\) represents the shift in the process mean.
-
ii.
Compute the recommended Bayesian-EWMA statistic and assess the process based on the proposed study design.
-
iii.
If out-of-control signals are detected during the process, implement the CC method and record the number of run lengths for the out-of-control process.
-
iv.
Repeating the steps 100,000 times to estimate out-of-control ARL.
Results, discussion and findings
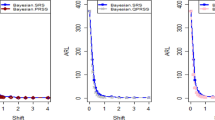
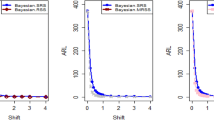
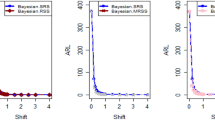
The study results, as presented in Tables 1, 2, 3, 4, 5 and 6, provide a comprehensive comparison of the Bayesian EWMA CC utilizing informative prior distributions and two distinct LFs across various ranked-based sampling designs. These findings emphasize the charts performance in comparison to the traditional Bayesian-EWMA CC designed for SRS. The analysis illuminates the strengths of the proposed Bayesian EWMA CC under diverse conditions, underscoring the importance of ranked-based sampling methods and the choice of LFs. In summary, this study demonstrates the considerable potential of the proposed method to significantly enhance process monitoring and improve quality control practices. The findings highlight a significant advantage of the suggested Bayesian EWMA CC for RSS, MRSS, and ERSS exhibits superior performance compared to the Bayesian EWMA CC for SRS at every shift. For example, Table 1 gives the values of ARLs and SDRLs of proposed Bayesian EWMA for RSS schemes (i.e. RSS, MRSS, ERSS) and Bayesian-EWMA CC by using SRS for P and PP distribution utilizing SELF as 371, 55.66, 10.36, 4.69, 1.29, 1 for RSS, 369.42, 43.99, 8.53, 3.95, 1.16, 1 for MRSS, 371, 60.05, 11.80, 5.29, 1.39, 1 for ERSS and Bayesian EWMA CC for SRS values for the same shift are 371.62, 125.58, 28.35, 13.41, 4.16, 2.12 at \(\lambda\) = 0.10. The results suggest that, for every shift value, the proposed method consistently exhibits significantly lower ARL values compared to the aviable Bayesian CC. This observation underscores the superior performance of the proposed Bayesian EWMA CC when applied to RSS strategies in comparison to the existing Bayesian EWMA CC designed for SRS. For LLF and at \(\lambda\) = 0.25, we considered Table 4 which show that the ARL results for the suggested method are 371.79, 85.76, 13.91, 5.59, 1 for RSS, 370.89, 66.78, 11.25, 4.59, 1 for MRSS, and 369.55, 100.52, 15.71, 6.33, 1 for ERSS, the values of ARL for Bayesian-EWMA SRS are 371.05, 179.81, 28.05, 15.89, 1.66. The run length profiles, which represent the number of consecutive samples required to detect an out-of-control condition, consistently exhibit smaller values for the suggested CC when compared to the considered CC. This trend suggests that the proposed CC outperforms the considered CC in terms of its ability to detect process deviations more quickly and efficiently. To further illustrate this efficiency, Figs. 1, 2 and 3 in the ARL demonstrate the effectiveness of the proposed CC when utilizing various RSS schemes. These figures provide visual evidence of the proposed CC's effectiveness in different scenarios. The comparison of the variances obtained through simulations under the considered sampling schemes is presented in Table D1 of Suppl. Appendix D. The results show that the variances under the RSS schemes are consistently lower than those of SRS. This comparison reinforces the efficiency of the suggested CC based on RSS schemes. In the following section, we will delve into the key findings and implications of the proposed CC.
-
The The appraisal of the offered CC involved analyzing its performance across various smoothing constant (λ) values. Tables 1 and 2 provided comprehensive results on the ARL and SDRL for the both P and PP distributions, with a normal prior and the SELF. These tables illuminated how the Bayesian-EWMA CCs efficiency varied with different λ values. The key finding was that the Bayesian EWMA CC achieved its optimal performance at the smallest λ value. In essence, when the smoothing constant was set to its minimum, the CC exhibited the highest sensitivity in detecting process deviations. This observation underscores the critical role of selecting an appropriate λ value, as a smaller λ enhances the ability to detect process changes promptly—an essential aspect of quality control and process monitoring.For example, at \(ARL_{0} = 370\), δ = 0.30, and \(\lambda\) = 0.1, the ARL value is 25.63 and for \(\lambda\) = 0.25, the ARL result is 40.81 for RSS, 21.10 and 31.19 are the ARL values using MRSS and the ARL results using ERSS is 29.31 and 46.44.
-
With an increase in the magnitude of the shift, the ARL values of the suggested Bayesian EWMA CC for RSS schemes decrease faster than the considered Bayesian-EWMA CC. For example, from Tables 1 and 2, we can observe that at \(ARL_{0} = 370\), and with \(\lambda\) = 0.1, the ARL value for δ = 0.20 is 55.66 and for δ = 0.50 is 10.36 using RSS, 43.99 and 8.53 utilizing MRSS and under the similar condition, the ARL result using ERSS is 60.05 and 11.80, which shows that the suggested design is unbiased.
-
The outcomes presented in Tables 3 and 4 show the run length results under LLF for Pdistribution for \(ARL_{0} = 370\), \(\lambda = 0.10\) and for δ = 0.50 the ARL value is 10.43 and 13.91 for \(\lambda = 0.25\), 8.47 and 11.25 for MRSS and in the same case, the run length outcomes using ERSS is 11.81 and 15.71, which clearly shows that as the value of \(\lambda\) increases the performance of the recommended CC distribution decreases.
-
The results for PP distribution under LLF are presented in Tables 5 and 6, which show that the ARL values at \(ARL_{0} = 370\), δ = 0.20 and 54.68 and the ARL values for \(\lambda = 0.25\) is 85.76 using RSS, In the identical situation the ARL results are 44.30 and 71.03. Under ERSS the ARL outcomes are 62.82 and 97.99. The results presented in Tables 3, 4, 5 and 6 indicate that the proposed Bayesian-EWMA CC for the Pdistribution utilizing LLF yields a similar performance to the PP distribution under LLF.
-
After a comprehensive analysis of the outcomes provided in Tables 1, 2, 3, 4, 5 and 6, which detail the performance of the proposed CC utilizing both P and PP distributions, and considering both SELF and LLF, it becomes apparent that the Bayesian EWMA CC incorporating MRSS excels in terms of efficiency when it comes to detecting shifts in the monitored process. When compared to other sampling design strategies, the offered CC utilizing MRSS consistently demonstrates a higher level of effectiveness in promptly and accurately identifying and responding to shifts in the process. This superior performance suggests that MRSS is a particularly suitable approach when aiming to enhance the efficiency of process monitoring and quality control through the Bayesian EWMA CC framework.

Flow chart for the suggested CC applying RSS schems.

Employing SELF, ARL plots for the recommended CC applying the RSS, MRSS, and ERSS schemes.

Utlizing LLF, ARL plots of the suggested CC under RSS, MRSS, and ERSS for P distribution.
Real data application
In the field of SPC, it is a customary approach for researchers to evaluate the effectiveness of CC by employing a combination of simulated and real datasets. For this study, we utilized a dataset obtained from Montgomery30, consisting of flow width during the hard-bake process. The primary focus of this study is to assess the performance of the newly proposed Bayesian CCs within the context of ranked-based sampling strategies. Our primary objective revolves around the development of a robust statistical CC tailored to effectively monitor variations in the flow width of the resist. The flow width measurements were taken in microns at hourly intervals. The dataset comprises 45 samples, each consisting of measurements from five wafers, totaling 225 observations. It's important to note that we designate the first 30 samples as representing the in-control process, constituting the phase-I dataset, which includes 150 observations. Control limits are established based on this phase-I dataset, assuming a standard normal distribution. The remaining 15 samples are categorized as part of the out-of-control process, involving an ascending shift of 0.017 added to the central process mean, thus forming the phase-II dataset. The subsequent steps delineate the procedure for implementing the proposed Bayesian EWMA CC under various ranked-based sampling schemes.
Step 1: Select twenty-five observations by SRS from 150 control observations and divide them into five groups of equal size randomly at the time t. Note that the sample from the in-control dataset is generated for t = 1, 2, …., 30.
Step 2: Rank the observations within each group and select the five observations for measurement purposes by following the sampling schemes such as RSS, MRSS, and ERSS. For instance, the diagonal elements will be selected for the RSS scheme.
Step 3: Compute the sample means such as \(\overline{Z}_{SRS}\), \(\overline{Z}_{RSS}\), \(\overline{Z}_{MRSS}^{O}\) and \(\overline{Z}_{ERSS}^{O}\) for \(t = 1,2,...,45\). The shifted dataset is used for t = 31, 32, ..., 45.
Step 4: Compute the Bayes estimator and its standard deviation using different loss functions such as (SELF and LLF) from the sample means (\(\overline{Z}_{SRS}\), \(\overline{Z}_{RSS}\), \(\overline{Z}_{MRSS}^{O}\) and \(\overline{Z}_{ERSS}^{O}\)).
Step 5: Calculate the Bayesian-EWMA statistic by following the design of the CC and plotting the graph with the control limits.
The Bayes estimator using SELF for P and PP distribution utilizing informative prior is 1.5056 for the in-control dataset. The control limits such as LCL and UCL are 1.46 and 1.54 respectively using SRS. The LCL and UCL for RSS are 1.47 and 1.53, LCL and UCL for MRSS are 1.48 and 1.51 respectively. The respective control limits for the Bayesian-EWMA for ERSS are 1.47 and 1.53. Figure 5 presents the Bayesian-EWMACC under SRS for P and PP distribution in which all the points are within the control limits. Figures 6, 7, and 8 present visual representations of the Bayesian EWMA CC as applied to various RSS strategies, including RSS, MRSS, and ERSS schemes. These charts serve as visual indicators of instances where the process exhibits out-of-control behavior, with such deviations occurring at the 37th, 34th, and 36th samples, respectively. Upon a comprehensive analysis of all Figs. 1, 2, 3, 4, 5, 6, 7 and 8, it becomes evident that the Bayesian EWMA CC, particularly when employed within the RSS frameworks displays superior efficiency in promptly identifying out-of-control signals in comparison to the pre-existing Bayesian CC. These findings underscore the enhanced capabilities of the proposed CC in the context of process monitoring and quality control practices.

Using LLF, ARL plots of the suggested CC under different RSS strategies for PP distribution.

Applying SRS, Bayesian EWMA CC with SELF.

Under RSS, Bayes EWMA CC utilizing SELF.

Under MRSS, Bayes EWMA CC applying SELF.

Utilizin SELF, Bayesian EWMA CC using ERSS.
Conclusion
The present study uses the ranked-based sampling designs to improve Bayesian CC. The suggested CC applying P and PP distribution is constructed to evaluate the variations in the production process. The run length findings were adapted to asses the effectiveness of recomended CC using RSS schemes. The simulation study was conducted to assess the comparative effectiveness of the Bayesian CC using RSS schemes in contrast to the established Bayesian EWMA CC using SRS. The results presented in Tables 1, 2, 3, 4, 5 and 6 consistently indicate that the proposed Bayesian CC, when employed in conjunction with RSS, MRSS, and ERSS and utilizing both LFs for both P and PP distributions, outperforms the traditional Bayesian EWMA CC based on SRS in terms of its ability to promptly and accurately detect out-of-control signals. This underscores the excellence of the suggested Bayesian CC in the realm of quality control and process monitoring. Furthermore, the superiority of the proposed CC becomes evident when examining the ARL plots (Fig. 1, 2, and 3). These plots provide a visual representation of how quickly the CC can detect out-of-control signals. Additionally, apart from the ARL plots, we demonstrate the effectiveness of the recommended CC through a practical example involving the hard bake process in semiconductor manufacturing. The results of this real-world application affirm that the Bayesian EWMA CC, when deployed under RSS schemes, displays a heightened sensitivity in promptly identifying out-of-control signals in comparison to its counterpart operating under the SRS framework. This heightened sensitivity underscores the practical advantages of implementing the proposed Bayesian EWMA CC in the context of quality control and process monitoring within semiconductor manufacturing.
Limitations of the study
In scenarios involving large sample sizes, the implementation of Bayesian CCs under RSS designs may encounter computational challenges. This complexity stems from the necessity of conducting Bayesian updates for both the process mean and variance at each individual sample point. As a result, this procedure can become computationally intensive and time-consuming due to the substantial computational workload it entails, rendering it resource-intensive.
Another limitation is that the Bayesian approach specifies prior distributions for the process mean and variance. If the prior distributions are not chosen carefully, the performance of the CC may be affected. Moreover, the selection of prior distributions can be subjective and may require expert knowledge, potentially introducing bias into the analysis.
Finally, using RSS in the Bayesian-EWMA CC assumes that the data is exchangeable. If the data is not exchangeable, the CC may not perform as expected, and the results may be unreliable. Therefore, it is important to assess the exchangeability of the data before using RSS in the Bayesian-EWMA CC.
Future recommendations
The proposed Bayesian EWMA CCs under RSS schemes can be applied to other memory-type CCs. This approach is also versatile enough to handle distributions beyond the normal distribution, including Poisson or binomial distributions, with the requirement of appropriate adjustments to the likelihood function in Bayesian updating. This extension of the approach to cover diverse types of CCs and non-normal distributions has the potential to enhance the effectiveness and efficiency of quality control processes across various industries, such as healthcare, finance, and manufacturing.
Data availability
The corresponding author is available to provide the datasets used or analyzed in this study upon a reasonable request.
References
Shewhart, W. A. The application of statistics as an aid in maintaining quality of a manufactured product. J. Am. Stat. Assoc. 20(152), 546–548 (1925).
Page, E. S. Continuous inspection schemes. Biometrika 41(1/2), 100–115 (1954).
Roberts, S. Control chart tests based on geometric moving averages. Technometrics 42(1), 97–101 (1959).
Lu, C.-W. & Reynolds, M. R. Jr. EWMA control charts for monitoring the mean of autocorrelated processes. J. Qual. Technol. 31(2), 166–188 (1999).
Khoo, M. B. A moving average control chart for monitoring the fraction of non-conforming. Qual. Reliab. Eng. Int. 20(6), 617–635 (2004).
Khan, N., Aslam, M. & Jun, C. H. Design of a control chart using a modified EWMA statistic. Qual. Reliab. Eng. Int. 33(5), 1095–1104 (2017).
Saghir, A., Ahmad, L. & Aslam, M. Modified EWMA control chart for transformed gamma data. Commun. Stat.-Simul. Comput. 50(10), 3046–3059 (2021).
Abbas, T., Zaman, B., Atir, A., Riaz, M. & Akbar Abbasi, S. On improved dispersion control charts under ranked set schemes for normal and non-normal processes. Qual. Reliab. Eng. Int. 35(5), 1313–1341 (2019).
Abbas, T., Riaz, M., Javed, B. & Abujiya, M. A new scheme of dispersion charts based on neoteric ranked set sampling. AIMS Math. 8(8), 17996–18020 (2023).
Mohammadkhani, A., Amiri, A., & Khoo, M. B. A review of ranked set sampling and modified methods in designing control charts. Qual. Reliabil. Eng. Int. (2023).
Noor-ul-Amin, M. & Tayyab, M. Enhancing the performance of exponential weighted moving average control chart using paired double ranked set sampling. J. Stat. Comput. Simul. 90(6), 1118–1130 (2020).
Menzefricke, U. On the evaluation of control chart limits based on predictive distributions. Commun. Stat.-Theory Methods 31(8), 1423–1440 (2002).
Menzefricke, U. Combined exponentially weighted moving average charts for the mean and variance based on the predictive distribution. Commun. Stat.-Theory Methods 42(22), 4003–4016 (2013).
Tsui, K.-L. & Woodall, W. H. Multivariate control charts based on loss functions. Seq. Anal. 12(1), 79–92 (1993).
WuTian, Z. Y. Weighted-loss-function CUSUM chart for monitoring mean and variance of a production process. Int. J. Prod. Res. 43(14), 3027–3044 (2005).
Serel, D. A. Economic design of EWMA control charts based on loss function. Math. Comput. Model. 49(3–4), 745–759 (2009).
Riaz, S., Riaz, M., Nazeer, A. & Hussain, Z. On Bayesian EWMA control charts under different loss functions. Qual. Reliab. Eng. Int. 33(8), 2653–2665 (2017).
Noor, S., Noor-ul-Amin, M., Mohsin, M. & Ahmed, A. Hybrid exponentially weighted moving average control chart using Bayesian approach. Commun. Stat.-Theory Methods 51(12), 3960–3984 (2022).
Aslam, M. & Anwar, S. M. An improved Bayesian modified-EWMA location chart and its applications in mechanical and sport industry. PLoS ONE 15(2), e0229422 (2020).
Noor-ul-Amin, M. & Noor, S. An adaptive EWMA control chart for monitoring the process mean in Bayesian theory under different loss functions. Qual. Reliab. Eng. Int. 37(2), 804–819 (2021).
Noor, S., Noor-ul-Amin, M. & Abbasi, S. A. Bayesian EWMA control charts based on exponential and transformed exponential distributions. Qual. Reliab. Eng. Int. 37(4), 1678–1698 (2021).
Liu, B., Noor-ul-Amin, M., Khan, I., Ismail, E. A. A. & Awwad, F. A. Integration of Bayesian adaptive exponentially weighted moving average control chart and paired ranked-based sampling for enhanced semiconductor manufacturing process monitoring. Processes 11, 2893. https://doi.org/10.3390/pr11102893 (2023).
Khan, I. et al. Hybrid EWMA control chart under bayesian approach using ranked set sampling schemes with applications to hard-bake process. Appl. Sci. 13(5), 2837 (2023).
Jeffreys, H. An invariant form for the prior probability in estimation problems. Proc. R. Soc. Lond. Ser. A Math. Phys. Sci. 186(1007), 453–461 (1946).
Gauss, C. Methods Moindres Carres Memoire sur la Combination des Observations, 1810 Translated by J. Bertrand (1955).
Varian, H. R. A Bayesian approach to real estate assessment. In Studies in Bayesian Econometric and Statistics in Honor of Leonard J. Savage. 195–208 (1975).
McIntyre, G. A method for unbiased selective sampling, using ranked sets. Aust. J. Agric. Res. 3(4), 385–390 (1952).
Muttlak, H. Median ranked set sampling. J. Appl. Stat. Sci. 6, 245–255 (1997).
Samawi, H. M., Ahmed, M. S. & Abu-Dayyeh, W. Estimating the population mean using extreme ranked set sampling. Biometric. J. 38(5), 577–586 (1996).
Montgomery, D. C. Introduction to Statistical Quality Control (Wiley, 2009).
Acknowledgements
Researchers Supporting Project number (RSPD2023R1060), King Saud University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
I.K. conducted thorough numerical simulations, and rigorously validated all mathematical results. The original manuscript was a collaborative effort involving I.K., M.N.A., and D.M.K., who collectively conducted mathematical analyses and numerical simulations and W.S., improved the manuscript's language. E.A.A.I conducted comprehensive verification of all findings, restructured the manuscript, and played a key role in securing project support and funding. The final version of the submission garnered unanimous approval from all authors.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Khan, I., Noor-ul-Amin, M., Khan, D.M. et al. Monitoring of manufacturing process using bayesian EWMA control chart under ranked based sampling designs. Sci Rep 13, 18240 (2023). https://doi.org/10.1038/s41598-023-45553-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-45553-x
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
