
Abstract
The memory-type control charts, such as cumulative sum (CUSUM) and exponentially weighted moving average control chart, are more desirable for detecting a small or moderate shift in the production process of a location parameter. In this article, a novel Bayesian adaptive EWMA (AEWMA) control chat utilizing ranked set sampling (RSS) designs is proposed under two different loss functions, i.e., square error loss function (SELF) and linex loss function (LLF), and with informative prior distribution to monitor the mean shift of the normally distributed process. The extensive Monte Carlo simulation method is used to check the performance of the suggested Bayesian-AEWMA control chart using RSS schemes. The effectiveness of the proposed AEWMA control chart is evaluated through the average run length (ARL) and standard deviation of run length (SDRL). The results indicate that the proposed Bayesian control chart applying RSS schemes is more sensitive in detecting mean shifts than the existing Bayesian AEWAM control chart based on simple random sampling (SRS). Finally, to demonstrate the effectiveness of the proposed Bayesian-AEWMA control chart under different RSS schemes, we present a numerical example involving the hard-bake process in semiconductor fabrication. Our results show that the Bayesian-AEWMA control chart using RSS schemes outperforms the EWMA and AEWMA control charts utilizing the Bayesian approach under simple random sampling in detecting out-of-control signals.
Similar content being viewed by others
Introduction
Statistical process control (SPC) is considered as an effective statistical technique that are applied to track and manage variations in the production process, ensuring that any deviations from the norm are identified and addressed before they result in production of a defective item. Control charts (CCs) play a critical role in SPC as they are the primary tool for monitor the product manufacturing process. The primary aim of the CCs is to monitor and detect inconsistencies in the manufacturing process. This process ultimately stability and enhances the overall quality of the final product Montgomery1. Shewhart2 introduced the memory-less control charting theory concept, which relies solely on current sample information and disregards any prior sample information. The memory-less type CCs are effective in detecting significant variations in the manufacturing process; however, they may not be sensitive enough to detect small or moderate shifts. Thus, to identify small to moderate shifts, Page3 and Roberts4 have investigated the use of cumulative sum (CUSUM) and exponentially weighted moving average (EWMA) CCs. These particular CCs are recognized for their ability to exhibit memory characteristics, enabling them to consider not only the present but also previous samples of information. Many authors such as Lowry et al.5, Lucas and Saccucci6, and Zhao et al.7 have studied the performance of the EWMA CC for detecting small to moderate modifications in the production process. Noor-ul-Amin et al.8 and Riaz et al.9 have recently conducted studies on modifying the EWMA CC to detect small to moderate shifts more effectively. When the process mean experiences a shift, the CUSUM and EWMA CCs effectively detect the shift if the size of the shift is known beforehand or if the quality engineer can create a specific shift. However, in situations where the shift size is unknown, an adaptive version of the CC provides an advantage by improving detection for varying shift sizes. Capizzi and Masarotto10 proposed the adaptive EWMA CC to monitor fluctuations in the location parameter of process, by combining EWMA and Shewhart CCs. They show that the AEWMA CC can monitor the minor, moderate and large shifts in the production process more efficiently than optimal CUSUM, optimal EWMA, and classical Shewhart and EWMA CCs. Adaptive cumulative sum (ACUSUM) CC for supervising process mean was studied by Sparks11. This method can detect displacements of different magnitudes faster than the conventional CUSUM CC. Zaman et al.12 suggested a novel adaptive EWMA control design that utilizes the Tukey bi-square function to monitor the process mean of a location parameter. The effectiveness of this approach was assessed through various performance metrics, including ARL, extra quadratic loss, and relative ARL. The authors, such as Jiang et al.13, Wu et al.14, Huang et al.15, Aly et al.16 and Aly et al.17 worked on the AEWMA and ACUSUM CCs for monitoring variations in the production process and stability of the final product. Haq et al.18 studied adaptive EWMA CC that utilizes EWMA statistic to detect variations in the location parameter of the process. Their study found that, their suggested CC outperformed other popular CC methods, including Shewhart cumulative sum (SCUSUM), double exponentially weighted moving (DEWMA), classical CUSUM, and classical EWMA CCs, in terms of both the ARL and the SDRL performance measures.
All these studies have been conducted to improve the classical approach; this describes a method that solely depends on the information from the current sample, disregarding any prior knowledge. The Bayesian estimation method combines both the sample and prior information that update the posterior distribution used for estimating of the unknown population mean. Girshick and Rubin19 first who suggested the Bayesian CCs. Menzefricke20 proposed a CC for monitoring the process mean of the location parameter based on Bayesian theory. Abbas et al.21 suggested DEWMA CC using the Bayesian approach, which can monitor the process mean with dissimilar shift size more quickly than the classical EWMA CC. The Bayesian CC using different symmetric and asymmetric loss functions (LFs) is studied by Ali and Riaz22. Asalam et al.23 suggested the improved Bayesian modified-EWMA CC applying posterior (P) and posterior predictive (PP) distribution, and to assess the performance of the proposed CC, both ARL as well as SDRL are employed as evaluation metrics. The findings advocate that the modified Bayesian-EWMA CC is more effective than the current CC in detecting out-of-control signals. Noor et al.24 developed the Bayesian-EWMA CC by incorporating both exponential and transformed exponential distributions and employing various LFs. Furthermore, they investigated the influence of the loss function selection on the performance of the Bayesian-EWMA CC. Lin et al.25 developed the Bayesian-EWMA CC for monitoring the variance of a distribution-free process. The proposed statistic was assessed for its sampling properties, making it well-suited for monitoring fluctuations in the time-varying process distribution. Moreover, a simulation study provides evidence of the efficacy of the CC. Khan et al.26 proposed a novel approach based Hybridized Bayesian EWMA CC for monitoring the location parameter using various RSS schemes and an informative prior. The authors evaluated the CC performance using ARL and SDRL and compared it with other Bayesian control charts, such as HEWMA and AEWMA with Bayesian theory, under SRS. Ranked-based Sampling designs is a sampling strategy that is commonly utilized in quality control applications to reduce the expense of data collection. This method involves ranking the units in each group and selecting a subset of ranked units as the sample. By utilizing RSS, the efficiency and accuracy of the CC can be improved. Moreover, the combination of RSS with the Bayesian approach and AEWMA CC can further enhance the performance of the CC. This combined approach leverages the efficient sampling method of RSS and the flexibility of Bayesian updating to adjust the control limits based on the available data. Combining RSS with the Bayesian approach in AEWMA CC can prove highly advantageous in scenarios where data collection costs are high or the sample size is limited. In this regard, we suggested Bayesian-AEWMA CC that employs three distinct ranked set sampling schemes: ranked set sampling (RSS), median ranked set sampling (MRSS), and finally extreme ranked set sampling (ERSS) based on informative prior applying two various LFs P and PP distributions. The proposed Bayesian AEWMA CCs efficacy was assessed by measuring its ARL and SDRL.
The remaining article is structured into several sections. Section "Bayesian approach" provides a brief introduction to Bayesian theory and LFs. In Section "Ranked set sampling", we discuss various RSS schemes. Section "Proposed Bayesian AEWMA CC using various LFS under RSS designs" describes a Bayesian-AEWMA CC under various RSS schemes. Section "Simulation study" contains the simulation steps and discussion and the main findings are included in section "Discussion and main findings". Section "Real-life applications" presents a numerical analysis, while the conclusion is provided in section "Conclusion".
Bayesian approach
In statistical inference, the classical and Bayesian approaches are the two estimation methods. The classical method of estimation is based on only sample information while in the Bayesian approach both types of information, i.e. prior and sample information, are utilized when estimating the unknown population parameter. The Bayesian approach is founded on the concept that probability can represent uncertainty, and permits the incorporation of prior knowledge and uncertainty into our analysis. Bayesian inference requires the use of a prior distribution, which means that both non-informative and informative priors are relevant to Bayesian analysis. On the other hand, a conjugate prior refers to a situation where the prior distribution and the sampling distribution belong to the same family of distributions. It is widely used in machine learning, finance, and medical research, where incomplete information and uncertainty are standard. In this study, we define the variable X as the study characteristic with an in-control process mean of \(\theta\) and a variance of \(\delta^{2}\) and taking normal conjugate prior under parameters \(\theta_{0}\) and \(\delta_{0}^{2}\), is mathematized as:
But if there is a lack of information regarding the population parameter, the prior is considered non-informative, which has a minimal impact on the P distribution, reflecting the Bayesian approach to incorporating prior information into the analysis. In many cases, a non-informative prior is assumed to be proportional to a uniform distribution, which assigns equal probability to all possible parameter values within a specified range. The uniform prior distribution is represented by the probability function given as:
where c represents a constant of proportionality.
When little or no prior information is available for an unknown population parameter, a non-informative prior is commonly used in Bayesian analysis. This type of prior distribution has a minimal effect on the posterior distribution. Jeffrey27 proposed a prior distribution that is proportional to the Fisher information matrix in such situations, the \(p\left( \theta \right)\) is mathematized as
In Eq. (3), \(I\left( \theta \right) = - E\left( {\frac{{\partial^{2} }}{{\partial \theta^{2} }}\log f\left( {X/\theta } \right)} \right)\) shows the Fisher information matrix and it allows for the incorporation of available information on the parameter into the analysis.
Bayesian statistics relies on integrating sample information based a prior distribution to obtain a P distribution that encompasses all relevant knowledge about the unknown population parameter. The P distribution is updated and provides more information than the prior distribution, as it incorporates both the sample and prior information to produce a probability distribution for the given parameter \(\theta\) is defined as
The PP distribution using P distribution as a prior distribution for novel data-set Y follows
In Bayesian methodology, the LF choice is pivotal in reducing the risks associated with the Bayes estimator. In this study, we examine two distinct LFs.
Squared error loss function
Gauss28 illustrates a symmetric loss function called SELF that can be used in statistical estimation. If we have an estimator \(\hat{\theta }\) for a population parameter (unknown) \(\theta\), then SELF can be mathematized as:
Bayes estimator using SELF is \(\hat{\theta } = E_{\theta /x} \left( \theta \right)\).
Linex loss function
Varian29 conducted a study on a specific type of loss function called the Linex Loss Function. This LFs is asymmetric and is used to minimize risks connected with the Bayesian estimator. The LLF is defined as follows:
Based on LLF, \(\hat{\theta }\) which shows the Bayesian estimator and is given by \(\hat{\theta } = - \frac{1}{c}InE_{\theta /x} \left( {e^{ - c\theta } } \right)\).
Ranked set sampling
The notion of RSS was initially presented by McIntyre30. This technique involves the following steps for selecting a sample from the population of interest:
-
1.
Select m2 random samples independently from the studied population and distributed into m sets with equal size. Array all m units by the personal judgment of the researcher or by using auxiliary variables and/or any numerical method without measurement.
-
2.
After ordering all the m sets, select 1st unit from the first set and 2nd unit is chosen from the second set and so on. Completing the steps outlined above results in a single cycle of RSS. if required, one can repeat these steps r times, resulting in a sample size of \(n = rm\)
Under the RSS scheme, the estimator for population mean with a single cycle is mathematized as
and
Median ranked set sampling
Muttlak31 introduced a revised RSS method known as the well-known Median Ranked Set Sampling (MRSS) scheme. The estimator under the MRSS scheme more efficiently estimates the population mean. The following steps provide a detailed overview of the procedure for selecting a sample using the MRSS technique. Commonly used in survey research, this technique can help ensure accurate estimates while minimizing costs and resources:
-
1.
To apply the MRSS scheme, Choose the \(m^{2}\) units from the population under study using the same method as for RSS. Next, distributed the selected elements into m similar sets and rank the elements within each set in ascending order based on the variable of interest.
-
2.
If the set size is even, select the smallest element from the middle two elements (m/2)th element and the largest elements from the middle two (m/2)th sampling elements. In case the m is odd, select median elements from ((m + 1)/2)th arranged sets. This process completes a single cycle of MRSS. If necessary, replicate the process r times to obtain a desired sample size \(n = rm\).
Utilizing MRSS, the population mean estimator for odd sample size under a single cycle is mathematized as
and
For a single cycle of MRSS, the population mean estimator for the case even sample size is given as::
with variance
Extreme ranked set sampling apporoach
A modified ranked set sampling approach, known as the extreme ranked set sampling (ERSS) scheme, was proposed by Amawi et al.32. This method is particularly useful when collecting extreme elements is difficult. The following steps provide a detailed overview of the process for selecting an ERSS sample.
-
1.
The \(m^{2}\) units are selected from the population under study and allocated randomly in m sets of equal size, assigning ranks to each unit within a set based on a particular study variable.
-
2.
For ERSS, the selection of units depends on the sample size along with the number of order sets. In case even sample size, then both the smallest and largest elements should be chosen from the first and last order sets corresponding to the middle half of the ranked units, i.e. \((m/2)\)th. In contrast, if the sample size is odd, the smallest and largest elements should be selected from the first and last order sets that correspond to the outer halves of the ranked units i.e., \((m - 1/2)th\), and the median element should be chosen from the last order set.
If essential, the complete method of ERSS is repeated r time to get the required sample size n = mr. For odd sample size, under ERSS the mean estimator for the population mean (unknown) using ERSS using single cycle can be written as:
with
Utilizing ERSS with an even sample size, the mean estimator utilizing single cycle is follows as:
and
Proposed Bayesian AEWMA CC using various LFS under RSS designs
This section describes the suggested AEWMA CC for monitoring variation and detecting the small, moderate and large shifts of a normally distributed manufacturing process using different RSS schemes. Consider the study variable X that following a normal distribution with \(\theta\) and \(\delta^{2}\) as a mean and variance respectively. The probability function for X can be expressed as
Let the \(\widehat{{\delta_{t}^{*} }}\) be the sequence of EWMA statistic applying \(\left\{ {X_{t} } \right\}\), given by:
where \(\psi\) is a smoothing constant and \(\widehat{{\delta_{0}^{*} }} = 0\). The estimator \(\widehat{{\delta_{t}^{*} }}\) is unbiased for the in-control process and biased for the out-of-control process. Haq et al.18 proposed an unbiased estimator \(\delta\) for both the case of in-control and out-of-control situations, which is given by
They suggested to use \(\widehat{{\delta_{t} }} = |\widehat{{\delta_{t}^{**} }}|\), to estimate \(\delta\).
The proposed AEWMA CC under Bayesian theory applying various ranked-based sampling designs for the process mean using the sequence \(\hat{\theta }_{{\left( {RSS_{i} } \right)LF}}\) is given by
Such that i = 1, 2, 3. \(\begin{gathered} RSS_{1} = RSS \hfill \\ RSS_{2} = MRSS \hfill \\ RSS_{3} = ERSS \hfill \\ \end{gathered}\), \(v\left( {\hat{\delta }_{t} } \right) \in \left( {0,\left. 1 \right]} \right.\) and \(W_{0} = 0\) such that
In case, if the plotting statistic cross the threshold value \(h\) then the process is said to be out-of-control otherwise the process is in control.
In case the prior and sampling distribution are both normal distributions than P distribution will also be a normal distribution. The mean and standard deviation of the P distribution are given by \(\theta_{n}\) and \(\delta_{n}\) respectively. The \(P\left( {\theta /x} \right)\) can be demonstrated as follows:
where \(\theta_{n} = \frac{{n\overline{x} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }}\) and \(\delta_{n} = \sqrt {\frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}}\) respectively.
Under SELF, the Bayes estimator using various RSS schemes is mathematized as
The properties of the \(\hat{\theta }_{{\left( {SELF} \right)}}\) is given as
\(E\left( {\hat{\theta }_{{\left( {SELF} \right)}} } \right) = \frac{{n\theta_{1} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }}\) and \(sd\left( {\hat{\theta }_{{\left( {SELF} \right)}} } \right) = \sqrt {\frac{{n\delta_{{(RSS_{i} )}}^{2} \delta_{0}^{4} }}{{\delta^{2} + n\delta_{0}^{2} }}}\) respectively. The Bayes estimator \(\hat{\theta }_{{RSS_{i} \left( {_{LLF} } \right)}}\) for suggested Bayesian CC using LLF applying ranked-based sampling methods is derived as
The mean and standard deviation of \(\hat{\theta }_{{\left( {_{LLF} } \right)}}\) is given by
\(E\left( {\hat{\theta }_{LLF} } \right) = \frac{{n\theta_{1} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }} - \frac{{C^{^{\prime}} }}{2}\) and \(sd\left( {\hat{\theta }_{LLF} } \right) = \sqrt {\frac{{n\delta_{{(RSS_{i} )}}^{2} \delta_{0}^{4} }}{{\left( {\delta^{2} + n\delta_{0}^{2} } \right)^{2} }}}\) respectively.
The suggested Bayesian-AEWMA CC, which utilizes various RSS schemes for the P and PP distributions, is defined based on a set of feature observations of size h denoted as \(y_{1} ,y_{2} ,....,y_{h}\) is given by
which is normally distributed with mean and variance \(\theta_{n}\) and \(\delta_{1}\) respectively, derived as \(\delta_{1} = \sqrt {\delta^{2} + \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}}\). The estimator \(\hat{\theta }\) for PP distribution utilizing LLF under different RSS schemes is defined as
where \(\tilde{\delta }_{1}^{2} = \frac{{\delta^{2} }}{k} + \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}\). The mean and standard deviation of \(\hat{\theta }_{LLF}\) is given as
\(E\left( {\hat{\theta }_{LLF} } \right) = \frac{{n\theta_{1} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }} - \frac{{C^{^{\prime}} }}{2}\tilde{\delta }_{1}^{2}\) and \(sd\left( {\hat{\theta }_{LLF} } \right) = \sqrt {\frac{{n\delta_{{(RSS_{i} )}}^{2} \delta_{0}^{4} }}{{\left( {\delta^{2} + n\delta_{0}^{2} } \right)^{2} }}}\) respectively.
Simulation study
To appraise the efficacy of the suggested AEWMA CC with different ranked-based designs applying the Bayesian approach under an informative prior distribution using the Monte Carlo simulation technique. We take two different values of smoothing constants i.e., \(\psi = 0.10\) and \(\psi = 0.25\) to study the effectiveness of smoothing constants on the suggested Bayesian-AEWMA CC. The complete simulation steps follow as:
Estimating the threshold for an in-control ARL
-
i.
When calculating the mean as well as variance of both the P distribution and PP distribution under different LFs, we employed the standard normal distribution as prior and sampling distribution. i.e., \(E\left( {\hat{\theta }_{{\left( {RSS_{i} } \right)LF}} } \right)\) and \(\delta_{{\left( {RSS_{i} } \right)LF}}\).
-
ii.
For an unchangeable value of smoothing constant \(\psi\) choose a value of h.
-
iii.
From normal distribution, select a ranked set sample of size n for in-control process i.e., \(X \sim N\left( {E\left( {\hat{\theta }} \right),\delta^{2} } \right)\).
-
iv.
Compute the suggested Bayesian-AEWMA statistic given in Eq. (21), and evaluate the process accordingly.
-
v.
If the process is determined to be in-control, continue with the steps above until an out-of-control signal is observed, and make a record of the number of consecutive in-control run lengths.
Setting the threshold for out-of-control ARL
-
i.
Create a random sample drawn from a normal distribution, but with a mean that has been shifted. i.e., \(X \sim N(E(\hat{\theta }_{LF} ) + \delta \frac{\sigma }{\sqrt n },\delta )\).
-
ii.
Calculate \(W_{t}\) and assess the procedure using the proposed AEWMA CC under the Bayesian approach applying various RSS designs.
-
iii.
If the process is deemed to be in control, the two steps mentioned earlier should be repeated until the process is declared out-of-control. It is also essential to keep track of the number of in-control runs for record-keeping purposes.
-
iv.
Execute the previously described steps repeatedly for 100,000 iterations to determine the run-length profiles.
Discussion and main findings
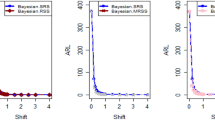
Tables 1, 2, 3, 4, 5 and 6 display a comparison between the Bayesian-AEWMA CC under SRS and the proposed Bayesian CC based on various RSS designs under an informative prior. The comparison is performed using two distinct LFs at different values of the smoothing constant \(\psi\). The outcomes presented in Tables 1 and 2 indicate the effectiveness of the EWMA and adaptive EWMA CC applying Bayesian approach using SRS, and proposed CC utilizing RSS, MRSS, and ERSS schemes for P and PP distribution based on SELF. The findings demonstrate that the proposed CC utilizing RSS schemes is more efficient in detecting out-of-control signals compared to the existing EWMA and AEWMA CC under Bayesian methodology utilizing SRS. i.e., the ARL outcomes of the EWMA CC under Bayesian theory, using SELF at smoothing constant \(\psi = 0.10\) and different shifts i.e., \(\sigma\) = 0.0, 0.30, 0.50, 0.80, 1.50, 4 are 370.63, 115.00, 28.51, 13.38, 5.82 and 2.13, and for Bayesian-AEWMA CC the ARL results are 370.16, 35.40, 13.55, 5.62, 2.25 and 1.02. Utilizing analogous condition ARL outcomes of proposed AEWMA CC applying RSS, MRSS and ERSS are 370.25, 20.53, 8.87, 3.07, 1.26, 1 and the values under MRSS are 371.55, 19.83, 8.34, 2.86, 1.18, 1 and 370.13, 22.38, 9.52, 3.36, 1.37 and 1 are the \(ARL\) values for ERSS. In the same way, Table 6 shows the comparison of EWMA and AEWMA CC with Bayesian approach using SRS with the proposed CC using RSS schemes under LLF, the ARL results of Bayesian-EWMA CC utilizing SRS at \(\psi = 0.25\) and shifts \(\sigma\) = 0.0, 0.30, 0.50, 0.80, 1.50, 4 are 370.23, 103.68, 41.26, 15.79, 5.18, and 1.66, and 369.58, 54.92, 25.97, 12.79, 4.94 and 1.09 are the respective numeric of ARL for Bayesian-AEWMA CC, for proposed AEWMA CC under RSS the \(ARL\) values with same smoothing constant and shifts are 371.18, 23.55, 8.64, 3.92, 2.46, 1 for MRSS the \(ARL\) values are 370.56, 18.70, 7.15, 2.66, 1.20, 1 and \(ARL\) values for the ERSS are 369.23, 30.52, 11.15, 4.45, 2.01, and 1. At the larger shift the \(ARL\) values decrease rapidly which shows the superiority of the proposed CC applying Bayesian theory with various ranked-based sampling designs, and more quickly detect the out-of-control signals than the existing Bayesian-EWMA and Bayesian-AEWMA CC. and the ARL Figs. 1, 2 and 3 also show the efficiency of the proposed Bayesian AEWMA CC under RSS schemes. The following are key discoveries of the suggested CC using distinct LFs and under various ranked-based sampling designs using P and PP distribution:
-
The run length profiles result of suggested AEWMA CC Bayesian theory utilizing ranked-based sampling designs using SELF decrease quickly with increases in the mean shift are presented in Tables 1 and 2, which indicate that the proposed Bayesian AEWMA CC can quickly detect the shifts in the mean process. For example, at \(ARL_{0} = 370\) and \(\psi = 0.10\) with shift δ = 0.20 and 0.70, the ARL values are 38.40 and 3.93 for RSS, and for MRSS 32.19 and 3.14 while 39.45 and 3.92 are the ARL results of ERSS.
-
The robustness of the suggested AEWMA CC based on Bayesian approach applying various RSS designs by using a normal prior distribution with LLF at \(\psi = 0.10\) and \(0.25\). Tables 3 and 4 present run-length profiles of the proposed AEWMA CC based on Bayesian approach, which indicates that the strength of the suggested CC is inversely proportional to the values of the smoothing constant. For example, at \(ARL_{0} = 370\), \(\psi = 0.10\) and shift δ = 0.30, ARL value for the proposed CC using RSS is 19.78, for MRSS the ARL value are 15.88 and 21.95 for ERSS. For the mean shift δ = 0.30 and \(\psi = 0.25\) the ARL results for using RSS is 29.15, for MRSS 23.39 is the ARL value and the ARL value for the ERSS is 31.99.
-
Tables 5 and 6 show the ARL as well as SDRL values for the offered AEWMA CC utilizing RSS designs applying LLF based on informative prior using P and PP distribution. The outcomes indicate that the ARL values of offered AEWMA with Bayesian approach CC applying RSS at \(ARL_{0} = 370\), δ = 0.20 and \(\psi = 0.10\) is 39.15, and the ARL value in the same case at \(\psi = 0.25\) is 51.42, similarly for MRSS the ARL values is 30.55 and 36.48 and in the similar case, ARL values for ERSS is 38.96 and 54.59.

Under SELF, ARL plots using P and PP distribution with different ranked-based sampling schemes.

Utilizing LLF, ARL plots of suggested AEWMA CC under RSS, MRSS, and ERSS.

Under LLF, ARL plots using PP distribution applying distinct RSS schemes.
The findings displayed in Tables 1, 2, 3, 4, 5 and 6 regarding the Bayesian-AEWMA CC, which utilized different LFs and RSS schemes for both P and PP distribution, indicate that this method is highly effective in identifying out of control signals when contrasted to other sampling schemes analyzed in this study. Specifically, the Bayesian-AEWMA CC with MRSS stands out as the most efficient in identifying such signals. These results demonstrate the superiority of the suggested Bayesian-AEWMA CC method when it comes to identifying out-of-control signals, and its effectiveness in ensuring that prompt corrective measures can be taken.
Real-life applications
Many analysts in the field of SPC use both actual and simulated datasets to evaluate the performance of CCs. In the current study, we have utilized real-dataset obtained from Montgomery33 to demonstrate the functioning and carrying out of the Bayesian AEWMA CC utilizing various ranked-based sampling designs based on P and PP distributions applying two distinct LFs. The dataset contains 45 samples, with each sample containing 5 wafers. The semiconductor production process involves photolithography in conjunction with the hard bake process, and measurements are taken in microns. Samples were collected at hourly intervals, with the first thirty samples representing in controlled process (Phase I), and the next fifteen samples representing the process that is out-of-control (Phase II). It is important to note that all observations in the Phase-II dataset have been adjusted by adding 0.017, indicating an upward shift in the core process mean.
Figures 4 and 5 depict the EWMA and AEWMA CCs utilizing Bayesian theory applying P and PP distribution based on SRS utilizing SELF. For Fig. 4, the CC indicates that the process cannot detect out of control signals, while for Fig. 5 the process becomes out of control on 40th sample. Figures 6, 7, and 8 display the offered Bayesian CC applying SELF with different RSS methods using P and PP distribution. Figures 6, 7 and 8 indicate that the process detect out of control signals for RSS on the 37th sample, for MRSS on 34th, and for ERSS on 36th sample. It can be illustrate from plots 1–8, that the Bayesian-AEWMA CC under RSS methods, as proposed, is more effective in pointing the out-of-control signals than both the Bayesian-EWMA and Bayesian-AEWMA CC using SRS.

Utilizing SRS, Bayesian-EWMA CC using SELF.

Using SRS, the Bayesian AEWMA CC based on SELF.

Utilizing SELF, Bayesian AEWMA CC based on RSS design.

Based on SELF, the Bayesian AEWMA CC utilizing MRSS.

Based on ERSS, the Bayesian-AEWMA CC applying SELF.
Conclusion
This study proposes a novel Bayesian AEWMA CC that applies different ranked-based sampling designs under informative prior and two different LFs using P and PP distributions for the process mean. The outcomes presented in Tables 1, 2, 3, 4, 5 and 6 demonstrate the performance of the proposed CC applying RSS designs compared to the Bayesian-AEWMA CC utilizing SRS. The ARL plots (Figs. 1, 2 and 3) demonstrate the superiority of the proposed Bayesian CC. Additionally, to evaluate the performance of the suggested CC under various ranked-based sampling designs, a numerical example was applied to the hard bake process in semiconductor manufacturing. Moreover, the proposed Bayesian-AEWMA CC for both P and PP distributions was more effective at pointing the out-of-control signals compared to the EWMA and AEWMA CCs using the Bayesian approach under SRS. The Bayesian AEWMA CC utilizing various ranked-based sampling designs proposed in this study can be extended to other memory-type CCs. Additionally, it is worth noting that this approach is not restricted to normal distributions and can be adapted to accommodate data that follows a binomial distribution or Poisson. Nevertheless, to incorporate Bayesian updating, the likelihood function would require modification. Expanding this proposed technique to non-normal distributions and other types of control charts (CCs) could provide a more comprehensive picture of the underlying data and help detect subtle variations that may not be evident using conventional statistical methods. This could, in turn, help organizations identify potential quality concerns earlier, take corrective actions more quickly, and reduce the likelihood of costly errors and defects. For instance, in the healthcare sector, extending this approach to CCs could help detect anomalies in patient data, enabling healthcare providers to intervene promptly and provide timely care to patients. Similarly, this technique could be used in the finance industry to identify fraudulent activities and potential errors in financial transactions. In manufacturing, expanding this approach to non-normal distributions and other types of CCs could help detect variations in the production process, enabling manufacturers to improve their product quality and reduce waste.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request. Further, no experiments on humans and/or the use of human tissue samples involved in this study.
References
Montgomery, D. C. Introduction to statistical quality control: John Wiley & Sons (2009).
Shewhart, W. A. The application of statistics as an aid in maintaining quality of a manufactured product. J. Am. Stat. Assoc. 20(152), 546–548 (1925).
Page, E. S. Continuous inspection schemes. Biometrika 41(1/2), 100–115 (1954).
Roberts, S. Control chart tests based on geometric moving averages. Technometrics 42(1), 97–101 (2000).
Lowry, C. A. & Montgomery, D. C. A review of multivariate control charts. IIE transactions 27(6), 800–810 (1995).
Lucas, J. M. & Saccucci, M. S. Exponentially weighted moving average control schemes: properties and enhancements. Technometrics 32(1), 1–12 (1990).
Zhao, Y. et al. Detection of intermittent faults based on an optimally weighted moving average T2 control chart with stationary observations. Automatica 123, 109298 (2020).
Noor-ul-Amin, M., Riaz, A. & Safeer, A. Exponentially weighted moving average control chart using auxiliary variable with measurement error. Communications in Statistics-Simulation and Computation 51(3), 1002–1014 (2020).
Riaz, S., Riaz, M., Nazeer, A. & Hussain, Z. On Bayesian EWMA control charts under different loss functions. Qual. Reliab. Eng. Int. 33(8), 2653–2665 (2017).
Capizzi, G., & Masarotto, G. An adaptive exponentially weighted moving average control chart. Technometrics 45(3), 199–207 (2003).
Sparks, R. S. CUSUM charts for signalling varying location shifts. J. Qual. Technol. 32(2), 157–171 (2000).
Zaman, B., Lee, M. H., Riaz, M. & Abujiya, M. An adaptive approach to EWMA dispersion chart using Huber and Tukey functions. Qual. Reliab. Eng. Int. 35(6), 1542–1581 (2019).
Jiang, W., Shu, L. & Apley, D. W. Adaptive CUSUM procedures with EWMA-based shift estimators. IIE Trans. 40(10), 992–1003 (2008).
Wu, Z., Jiao, J., Yang, M., Liu, Y. & Wang, Z. An enhanced adaptive CUSUM control chart. IIE Trans. 41(7), 642–653 (2009).
Huang, W., Shu, L. & Su, Y. An accurate evaluation of adaptive exponentially weighted moving average schemes. IIE Trans. 46(5), 457–469 (2014).
Aly, A. A., Saleh, N. A., Mahmoud, M. A. & Woodall, W. H. A reevaluation of the adaptive exponentially weighted moving average control chart when parameters are estimated. Qual. Reliab. Eng. Int. 31(8), 1611–1622 (2015).
Aly, A. A., Hamed, R. M. & Mahmoud, M. A. Optimal design of the adaptive exponentially weighted moving average control chart over a range of mean shifts. Commun. Stat. Simul. Comput. 46(2), 890–902 (2017).
Haq, A., Gulzar, R. & Khoo, M. B. An efficient adaptive EWMA control chart for monitoring the process mean. Qual. Reliab. Eng. Int. 34(4), 563–571 (2018).
Girshick, M. A. & Rubin, H. A Bayes approach to a quality control model. The Annals of mathematical statistics 23(1), 114–125 (1952).
Menzefricke, U. On the evaluation of control chart limits based on predictive distributions. Commun. Stat. Theory Methods 31(8), 1423–1440 (2002).
Abbas, N. Homogeneously weighted moving average control chart with an application in substrate manufacturing process. Comput. Ind. Eng. 120, 460–470 (2018).
Ali, S. & Riaz, M. On designing a new Bayesian dispersion chart for process monitoring. Arab. J. Sci. Eng. 45(3), 2093–2111 (2020).
Aslam, M. & Anwar, S. M. An improved Bayesian Modified-EWMA location chart and its applications in mechanical and sport industry. PLoS ONE 15(2), e0229422 (2020).
Noor, S., Noor-ul-Amin, M. & Abbasi, S. A. Bayesian EWMA control charts based on exponential and transformed exponential distributions. Qual. Reliab. Eng. Int. 37(4), 1678–1698 (2021).
Lin, C.-H., Lu, M.-C., Yang, S.-F. & Lee, M.-Y. A bayesian control chart for monitoring process variance. Appl. Sci. 11(6), 2729 (2021).
Khan, I. et al. Hybrid EWMA control chart under bayesian approach using ranked set sampling schemes with applications to hard-bake process. Appl. Sci. 13(5), 2837 (2023).
Jeffreys, H. (1946). An invariant form for the prior probability in estimation problems. Proc. R. Soc. Lond. Ser. A. Math. Phys. Sci. 186(1007), 453–461.
Gauss, C. Method des Moindres Carres Memoire sur la Combination des Observations, 1810 Translated by J. In: Bertrand (1955).
Varian, H. R. A Bayesian approach to real estate assessment. Studies in Bayesian econometric and statistics in Honor of Leonard J. Savage, 195–208 (1975).
McIntyre, G. A method for unbiased selective sampling, using ranked sets. Australian Journal of agricultural research 3(4), 385–390 (1952).
Muttlak, H. Median ranked set sampling. J. Appl. Stat. Sci. 6, 245–255 (1997).
Amawi, H. M., Ahmed, M. S. & Abu-Dayyeh, W. Estimating the population mean using extreme ranked set sampling. Biom. J. 38(5), 577–586 (1996).
Montgomery, D. C. Introduction to statistical quality control: John Wiley & Sons (2007).
Acknowledgements
This Research is funded by Research Supporting Project Number (RSPD2023R585), King Saud University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
I.K. and M.N.A. wrote the original manuscript, performed mathematical results and numerical simulations. D.M.K. conceptualized the main problem and perform data analysis. S.A.A. and W.S. validate all the results with care, restructured the manuscript and funding acquisition. W.S. improve the language of the manuscript and performed numerical simulations. All authors are agreed on the final draft of the submission file.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Khan, I., Noor-ul-Amin, M., Khan, D.M. et al. Adaptive EWMA control chart using Bayesian approach under ranked set sampling schemes with application to Hard Bake process. Sci Rep 13, 9463 (2023). https://doi.org/10.1038/s41598-023-36469-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-36469-7
This article is cited by
-
An adaptive Bayesian approach for improved sensitivity in joint monitoring of mean and variance using Max-EWMA control chart
Scientific Reports (2024)
-
Memory type Max-EWMA control chart for the Weibull process under the Bayesian theory
Scientific Reports (2024)
-
A novel Bayesian Max-EWMA control chart for jointly monitoring the process mean and variance: an application to hard bake process
Scientific Reports (2023)
-
Adaptive multivariate dispersion control chart with application to bimetal thermostat data
Scientific Reports (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
