
Abstract
In this paper, we propose a new type of nonlinear strict distance and similarity measures for intuitionistic fuzzy sets (IFSs). Our proposed methods not only have good properties, but also improve the drawbacks proposed by Mahanta and Panda (Int J Intell Syst 36(2):615–627, 2021) in which, for example, their distance value of \(d_{_{\textrm{MP}}}(\langle \mu , \nu \rangle , \langle 0, 0\rangle )\) is always equal to the maximum value 1 for any intuitionistic fuzzy number \(\langle \mu , \nu \rangle \ne \langle 0, 0\rangle \). To resolve these problems in Mahanta and Panda (Int J Intell Syst 36(2):615–627, 2021), we establish a nonlinear parametric distance measure for IFSs and prove that it satisfies the axiomatic definition of strict intuitionistic fuzzy distances and preserves all advantages of distance measures. In particular, our proposed distance measure can effectively distinguish different IFSs with high hesitancy. Meanwhile, we obtain that the dual similarity measure and the induced entropy of our proposed distance measure satisfy the axiomatic definitions of strict intuitionistic fuzzy similarity measure and intuitionistic fuzzy entropy. Finally, we apply our proposed distance and similarity measures to pattern classification, decision making on the choice of a proper antivirus face mask for COVID-19, and medical diagnosis problems, to illustrate the effectiveness of the new methods.
Similar content being viewed by others

Introduction
Zadeh1 introduced the concept of fuzzy sets (FSs) by using a function from the universe of discourse to [0, 1], which was called the membership function, to describe the importance of an element in the universe of discourse. Zadeh’s fuzzy set theory had been applied in different areas2,3,4. However, FSs can only deal with the situation containing two opposite responses. It fails to deal with the situation with the hesitant/neutral state of “this and also that”. As a remedy, Atanassov5 generalized Zadeh’s fuzzy set by proposing the concept of intuitionistic fuzzy sets (IFSs), characterized by a membership function and a non-membership function meeting the condition that their sum at every point is less than or equal to 1. Since then, IFSs have been widely applied to various fields, such as multiple attribute decision making (MADM)6,7,8,9,10,11, medical diagnosis12,13,14,15, similarity with pattern recognition16,17,18,19, and cluster analysis16,20,21,22.
Being a pair of dual concepts, the intuitionistic fuzzy (IF) distance measure (IFDisM) and the IF similarity measure (IFSimM) are useful for measuring the differences of IFSs under IF situations. The axiomatic definitions of IFDisMs and IFSimMs were first given by Wang and Xin23. Szmidt24 considered IFDisMs and IFSimMs and divided them into two types of IFSs according to 2-dimensional (2D) and 3-dimensional (3D) representations. However, Wu et al.25 used some examples to show that many existing 3D IFDisMs and IFSimMs, including Euclidean DisM and SimM24, Minkowski DisM and SimM26,27, do not satisfy the axiomatic definitions of IFDisMs and IFSimMs. Burillo and Bustince28 introduced the 2D Hamming IFDisM. Grzegorzewski29 and Hung and Yang30 presented some new IFSimMs and IFDisMs based on Hausdorff metric. Wang and Xin23 obtained a new IFDisM by combining the 2D Hamming IFDisM28 and the 2D Hausdorff IFDisM29. Hwang and Yang31 introduced a new IFSimM via lower, upper and middle fuzzy sets. Xiao32 obtained a 3D IFDisM based on Jensen-Shannon divergence and illustrated that it is better than the IFDisMs in33,34,35,36. However, Wu et al.37 showed some examples to illustrate that Xiao’s DisM does not satisfy the axiomatic definition of IFDisMs. Meanwhile, Wu et al.37 first introduced the concepts of strict IFDisM, and then obtained a new strict IFDisM via Jensen-Shannon divergence to more effectively compare and distinguish IFNs and IFSs.
To accurately distinguish different IFSs with high indeterminacy degrees, Mahanta and Panda38 developed a new nonlinear 2D IFDisM. However, their DisM \(d_{_{\textrm{MP}}}\) has the following two drawbacks: (1) the value of \(d_{_{\textrm{MP}}}(\langle \mu , \nu \rangle , \langle 0, 0\rangle )\) is always equal to the maximum value 1 for any IFN \(\langle \mu , \nu \rangle \ne \langle 0, 0\rangle \); (2) \(d_{_{\textrm{MP}}}(\langle \mu , 0\rangle , \langle 0, \nu \rangle )=1\) holds for all \(\mu , \nu \in (0, 1]\). These are unreasonable results. To overcome the above two drawbacks, we construct a nonlinear parametric IFDisM and show that it is a strict IFDisM, which preserves all advantages of Mahanta and Panda’s DisM38. Moreover, we prove that the dual SimM and the induced entropy of our proposed IFDisM satisfy the axiomatic definitions of IFSimM and IF entropy. Additionally, we apply the proposed IFDisM and IFSimM to pattern classification, decision making for the choice of a proper antivirus face mask for COVID-19, and medical diagnosis, to illustrate the effectiveness of the new methods.
Preliminaries
Intuitionistic fuzzy set (IFS)
Definition 2.1
(39Definition 1.1) An intuitionistic fuzzy set (IFS) I in \(\Xi \) is defined as an object in the following form
where the functions \(\mu _{_{I}}: \Xi \rightarrow [0,1]\) and \(\nu _{_{I}}: \Xi \rightarrow [0,1]\) are the degree of membership and the degree of non-membership of an element \(\vartheta \in \Xi \) to the set I, respectively; and for any \(\vartheta \in \Xi \),
Let \(\textrm{IFS}(\Xi )\) denote the set of all IFSs in \(\Xi \). For \(I\in \textrm{IFS}(\Xi )\), the indeterminacy degree \(\pi _{_{I}}(\vartheta )\) of an element \(\vartheta \) belonging to I is defined by \(\pi _{_I}(\vartheta )=1-\mu _{_I}(\vartheta )-\nu _{_I}(\vartheta )\). The pair \(\langle \mu _{_I}(\vartheta ), \nu _{_I}(\vartheta )\rangle \) is called an intuitionistic fuzzy value (IFV) or an intuitionistic fuzzy number (IFN) by Xu10. For convenience, we use \(\alpha =\langle \mu _{\alpha }, \nu _{\alpha }\rangle \) to represent an IFN \(\alpha \), which satisfies \(\mu _{\alpha }\in [0, 1]\), \(\nu _{\alpha }\in [0, 1]\), and \(0\le \mu _{\alpha }+\nu _{\alpha }\le 1\). Let \(\Theta \) be the set of all IFNs, i.e., \(\Theta =\{\langle \mu , \nu \rangle \in [0, 1]^{2} \mid \mu +\nu \le 1\}\). For \(\alpha =\langle \mu _{\alpha }, \nu _{\alpha }\rangle \in \Theta \), the complement \(\alpha ^{\complement }\) of \(\alpha \) is \(\alpha ^{\complement }=\langle \nu _{\alpha }, \mu _{\alpha }\rangle \).
Atanassov’s order ‘\(\subset \)’39, defined by the condition that \(\alpha \subset \beta \) if and only if \(\alpha \cap \beta =\alpha \), is a partial order on \(\Theta \). Clearly, \(\alpha \subset \beta \) if and only if \(\mu _{\alpha }\le \mu _{\beta }\) and \(\nu _{\alpha }\ge \nu _{\beta }\). The order ‘\(\subsetneqq \)’ on \(\Theta \) is defined by the condition that \(\alpha \subsetneqq \beta \) if and only if \(\alpha \subset \beta \) and \(\alpha \ne \beta \).
Similarity/distance measures for IFSs
Definition 2.2
10,26A mapping \(\textbf{S}: \Theta \times \Theta \longrightarrow [0, 1]\) is called an intuitionistic fuzzy similarity measure (IFSimM) on \(\Theta \) if it satisfies the following conditions: for any \(\alpha _1\), \(\alpha _2\), \(\alpha _3\in \Theta \),
-
(S1)
\(0\le \textbf{S}(\alpha _1, \alpha _2)\le 1\).
-
(S2)
\(\textbf{S}(\alpha _1, \alpha _2)=1\) if and only if \(\alpha _1=\alpha _2\).
-
(S3)
\(\textbf{S}(\alpha _1, \alpha _2)=\textbf{S}(\alpha _2, \alpha _1)\).
-
(S4)
If \(\alpha _1\subset \alpha _2\subset \alpha _3\), then \(\textbf{S}(\alpha _1, \alpha _3)\le \textbf{S}(\alpha _1, \alpha _2)\) and \(\textbf{S}(\alpha _1, \alpha _3) \le \textbf{S}(\alpha _2, \alpha _3)\).
Definition 2.3
10,26A mapping \(\textbf{S}: \textrm{IFS}(\Xi )\times \textrm{IFS}(\Xi ) \longrightarrow [0, 1]\) is called an IFSimM on \(\textrm{IFS}(\Xi )\) if it satisfies the following conditions: for any \(I_1\), \(I_2\), \(I_3\in \textrm{IFS}(\Xi )\),
-
(S1)
\(0\le \textbf{S}(I_1, I_2)\le 1\).
-
(S2)
\(\textbf{S}(I_1, I_2)=1\) if and only if \(I_1=I_2\).
-
(S3)
\(\textbf{S}(I_1, I_2)=\textbf{S}(I_2, I_1)\).
-
(S4)
If \(I_1\subset I_2\subset I_3\), then \(\textbf{S}(I_1, I_3)\le \textbf{S}(I_1, I_2)\) and \(\textbf{S}(I_1, I_3)\) \(\le \textbf{S}(I_2, I_3)\).
To more effectively compare and distinguish IFNs and IFSs, the concept of strict intuitionistic fuzzy similarity/distance measures was introduced by Wu et al.37 as follows.
Definition 2.4
37A mapping \(\textbf{S}: \Theta \times \Theta \longrightarrow [0, 1]\) is called a strict IFSimM on \(\Theta \) if, for any \(\alpha _1\), \(\alpha _2\), \(\alpha _3\in \Theta \), it satisfies (Sl)–(S3) in Definition 2.2 and (S4\(^{\prime }\)) and (S5) described by
-
(S4)
(S4\(^{\prime }\)) (Strict distinctiveness) If \(\alpha _1\subsetneqq \alpha _2\subsetneqq \alpha _3\), then \(\textbf{S}(\alpha _1, \alpha _3)< \textbf{S}(\alpha _1, \alpha _2)\) and \(\textbf{S}(\alpha _1, \alpha _3) < \textbf{S}(\alpha _2, \alpha _3)\).
-
(S5)
(Extreme dissimilarity on endpoints) \(\textbf{S}(\alpha _1, \alpha _2)=0\) if and only if (\(\alpha _1=\langle 0, 1\rangle \) and \(\alpha _2=\langle 1, 0 \rangle \)) or (\(\alpha _1=\langle 1, 0\rangle \) and \(\alpha _2=\langle 0, 1 \rangle \)).
As pointed out by Wu et al.37, (1) Property (S4\(^{\prime }\)) indicates that the similarity measure \(\textbf{S}\) can strictly distinguish every pair of different IFVs under the Atanassov-order ‘\(\subset \)’; (2) Property (S5) indicates that it is extremely unsimilar (similarity measure is zero) for a pair of IFVs depending only on two endpoints.
Definition 2.5
37A mapping \(\textbf{S}: \textrm{IFS}(\Xi )\times \textrm{IFS}(\Xi ) \longrightarrow [0, 1]\) is called a strict IFSimM on \(\textrm{IFS}(\Xi )\) if, for any \(I_1\), \(I_2\), \(I_3\in \textrm{IFS}(\Xi )\), it satisfies (Sl)–(S3) in Definition 2.3 and (S4\(^{\prime }\)) and (S5) described by
- (S4\(^{\prime }\)):
-
If \(I_1\subsetneqq I_2\subsetneqq I_3\), then \(\textbf{S}(I_1, I_3)< \textbf{S}(I_1, I_2)\) and \(\textbf{S}(I_1, I_3)\) \(< \textbf{S}(I_2, I_3)\).
- (S5):
-
\(\textbf{S}(I_1, I_2)=0\) if and only if, for any \(\vartheta \in \Xi \), (\(I_1(\vartheta )=\langle 0, 1\rangle \) and \(I_2(\vartheta )=\langle 1, 0 \rangle \)) or (\(I_1(\vartheta )=\langle 1, 0\rangle \) and \(I_2(\vartheta )=\langle 0, 1 \rangle \)).
Remark 1
Property (S5) can be equivalently expressed as that \(\textbf{S}(I_1, I_2)=0\) if and only if \(I_1\) is a crisp set and \(I_{1}=I_{2}^{\complement }\).
Dually, a mapping \(d: \textrm{IFS}(\Xi )\times \textrm{IFS}(\Xi ) \longrightarrow [0, 1]\) is called a strict IFDisM on \(\textrm{IFS}(\Xi )\) if the mapping \(\textbf{S}(I_1, I_2)=1-d(I_1, I_2)\) is a strict IFSimM on \(\textrm{IFS}(\Xi )\).
Entropy measure for IFSs
Entropy is an important information measure. Szmidt and Kacprzyk15 gave the axiomatic definitions of entropy measures for IFSs as follows:
Definition 2.6
15A mapping \(E: \Theta \longrightarrow [0, 1]\) is called an intuitionistic fuzzy entropy measure (IFEM) on \(\Theta \) if it satisfies the following conditions: for any \(\alpha \), \(\beta \in \Theta \),
-
(E1)
\(E(\alpha )=0\) if and only if \(\alpha =\langle 1, 0\rangle \) or \(\alpha =\langle 0, 1\rangle \).
-
(E2)
\(E(\alpha )=1\) if and only if \(\mu _{\alpha }=\nu _{\alpha }\).
-
(E3)
\(E(\alpha )=E(\alpha ^{\complement })\).
-
(E4)
\(E(\alpha )\le E(\beta )\) whenever it holds either \(\mu _{\alpha }\le \mu _{\beta } \le \nu _{\beta } \le \nu _{\alpha }\) or \(\mu _{\alpha }\ge \mu _{\beta } \ge \nu _{\beta } \ge \nu _{\alpha }\).
Definition 2.7
15A mapping \(E: \textrm{IFS}(\Xi )\longrightarrow [0, 1]\) is called an IFEM on \(\textrm{IFS}(\Xi )\) if it satisfies the following conditions: for any \(I_1\), \(I_2 \in \textrm{IFS}(\Xi )\),
-
(E1)
\(E(I_1)=0\) if and only if \(I_1\) is a crisp sets.
-
(E2)
\(E(I_1)=1\) if and only if, for any \(\vartheta \in \Xi \), \(\mu _{I_1}(\vartheta )=\nu _{I_1}(\vartheta )\).
-
(E3)
\(E(I_1)=E(I_1^{\complement })\).
-
(E4)
\(E(I_1)\le E(I_2)\) if, for any \(\vartheta \in \Xi \), it holds either \(\mu _{I_1}(\vartheta )\le \mu _{I_2}(\vartheta )\le \nu _{I_2}(\vartheta ) \le \nu _{I_1}(\vartheta )\) or \(\mu _{I_1}(\vartheta )\ge \mu _{I_2}(\vartheta )\ge \nu _{I_2}(\vartheta ) \ge \nu _{I_1}(\vartheta )\).
The proposed nonlinear strict distance, similarity and entropy measures for IFSs
After we investigate the distance measure for IFSs proposed by Mahanta and Panda38, we find that Mahanta and Panda’s38 distance gave serious drawbacks. We present these drawbacks in next subsection.
The drawbacks of distance measure of Mahanta and Panda38
Let \(\Xi =\{\vartheta _1, \vartheta _2, \ldots , \vartheta _{\ell }\}\) be a finite UOD and \(I_1=\Big \{\frac{\langle \mu _{I_1}(\vartheta _{j}), \nu _{I_1}(\vartheta _{j})\rangle }{\vartheta _j} \mid 1\le j\le \ell \Big \}\) and \(I_2= \Big \{\frac{\langle \mu _{I_2}(\vartheta _{j}), \nu _{I_2}(\vartheta _{j})\rangle }{\vartheta _j} \mid 1\le j\le \ell \Big \}\) be two IFSs on \(\Xi \). To effectively distinguish IFSs with high degrees of hesitancy, Mahanta and Panda38 recently introduced a 2D IFDisM \(d_{_{\textrm{MP}}}\) as follows:
This subsection uses two examples to show that their IFDisM \(d_{_{\textrm{MP}}}\)38 has the following two drawbacks: (1) the distance from all IFVs except \(\langle 0, 0 \rangle \) to \(\langle 0, 0 \rangle \) obtained by the distance formula \(d_{_{\textrm{MP}}}\) is equal to the maximum value 1, i.e., \(d_{_{\textrm{MP}}} (\langle 0, 0\rangle , \alpha )=1\) holds for all \(\alpha \in \Theta \backslash \{\langle 0, 0\rangle \}\); (2) \(d_{_{\textrm{MP}}}(\langle \mu , 0\rangle , \langle 0, \nu \rangle )=1\) holds for all \(\mu , \nu \in (0, 1]\). These are unreasonable results.
Example 3.1
Let \(\Xi =\{\vartheta \}\) and \(I_1=\left\{ \frac{\langle 0, 0\rangle }{\vartheta }\right\} \in \textrm{IFS}(\Xi )\). For any \(I_2=\left\{ \frac{\langle \mu , \nu \rangle }{\vartheta }\right\} \in \textrm{IFS}(\Xi )\) with \(I_2\ne I_1\), by direct calculation and Eq. (3), we have \(d_{_{\textrm{MP}}}(I_1, I_2)= \frac{|\mu -0|+|\nu -0|}{\mu +0+\nu +0}=1\). This is obviously an unreasonable result, since all points except \(\left\{ \frac{\langle 0, 0 \rangle }{\vartheta }\right\} \) to \(\left\{ \frac{\langle 0, 0 \rangle }{\vartheta }\right\} \) is equal to the maximum value 1.
Example 3.2
Let \(\Xi =\{\vartheta \}\), \(I_1^{\prime }=\left\{ \frac{\langle \mu , 0\rangle }{\vartheta }\right\} \in \textrm{IFS}(\Xi )\), and \(I_2^{\prime }=\left\{ \frac{\langle 0, \nu \rangle }{\vartheta }\right\} \in \textrm{IFS}(\Xi )\). By direct calculation and Eq. (3), we have that, for \(0<\mu , \nu \le 1\), \(d_{_{\textrm{MP}}}(I_1^{\prime }, I_2^{\prime })=\frac{|\mu -0|+|0-\nu |}{\mu +0+0+\nu }=1\), which is also an unreasonable result.
To overcome the drawbacks of Mahanta and Panda’s distance measure mentioned above, we propose a new nonlinear strict distance measure for IFNs and IFSs in next subsection, which is proved to satisfy the axiomatic definition of IFDisM.
A new parametric distance on \(\Theta \)
We define a new parametric distance on \(\Theta \) by defining the function \(d_{\textrm{pd}}^{(\lambda )}: \Theta \times \Theta \longrightarrow \mathbb {R}^{+}\) as follows: for \(\alpha =\langle \mu _{\alpha }, \nu _{\alpha }\rangle \) and \(\beta = \langle \mu _{\beta }, \nu _{\beta }\rangle \in \Theta \),
Lemma 3.1
Let \(\lambda >0\). For \(0\le x\le y\le 2\), the following statements hold:
-
(1)
\(\frac{x}{y+\lambda }\le \frac{2}{2+\lambda }\);
-
(2)
\(\frac{x}{y+\lambda }= \frac{2}{2+\lambda }\) if and only if \(x=y=2\).
Proof
-
(1)
From \(0\le x\le y\), it follows that \(\frac{x}{y+\lambda } \le \frac{y}{y+\lambda }\). This, together with \(0\le y\le 2\), implies that \(\frac{y}{y+\lambda }\le \frac{2}{2+\lambda }\).
-
(2)
It follows directly from the proof of (1).
\(\square \)
Proposition 3.1
\(0\le d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta ) \le 1\).
Proof
Note that \(0\le |\mu _{\alpha }-\mu _{\beta }|+|\nu _{\alpha }-\nu _{\beta }| \le \mu _{\alpha }+\nu _{\alpha }+\mu _{\beta }+\nu _{\beta }\le 2\). By Lemma 3.1, it follows that \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )= \frac{|\mu _{\alpha }-\mu _{\beta }|+|\nu _{\alpha }-\nu _{\beta }|}{\mu _{\alpha }+\nu _{\alpha }+\mu _{\beta }+\nu _{\beta }+\lambda } \cdot \frac{2+\lambda }{2}\le \frac{2}{2+\lambda } \cdot \frac{2+\lambda }{2}=1\). \(\square \)
Proposition 3.2
\(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )= d_{_{\textrm{pd}}}^{(\lambda )}(\beta , \alpha )\).
Proof
It follows directly from Eq. (4). \(\square \)
Proposition 3.3
\(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )=0\) if and only if \(\alpha =\beta \).
Proof
Note that \(\lambda >0\), and by Eq. (4), it follows that \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )=0\) if and only if \(|\mu _{\alpha }-\mu _{\beta }|+|\nu _{\alpha }-\nu _{\beta }|=0\) if and only if \(\mu _{\alpha }=\mu _{\beta }\) and \(\nu _{\alpha }=\nu _{\beta }\). \(\square \)
Proposition 3.4
\(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )=1\) if and only if {\(\alpha =\langle 0, 1 \rangle \) and \(\beta =\langle 1, 0 \rangle \)}, or {\(\alpha =\langle 1, 0 \rangle \) and \(\beta =\langle 0, 1 \rangle \)}.
Proof
Sufficiency. By direct calculation and Eq. (4), it follows that \(d_{_{\textrm{pd}}}^{(\lambda )}(\langle 0, 1\rangle , \langle 1, 0\rangle ) =d_{_{\textrm{pd}}}^{(\lambda )}(\langle 1, 0\rangle , \langle 0, 1\rangle )=1\).
Necessity. By Lemma 3.1 (2), it follows that \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )=1\) if and only if \(|\mu _{\alpha }-\mu _{\beta }|+|\nu _{\alpha }-\nu _{\beta }|=2\) implying that \(|\mu _{\alpha }-\mu _{\beta }|=1\) and \(|\nu _{\alpha }-\nu _{\beta }|=1\). And thus (\(\alpha =\langle 0, 1 \rangle \) and \(\beta =\langle 1, 0 \rangle \)) or (\(\alpha =\langle 1, 0 \rangle \) and \(\beta =\langle 0, 1 \rangle \)). \(\square \)
Proposition 3.5
Let \(\alpha \), \(\beta \), \(\gamma \in \Theta \).
-
(1)
If \(\alpha \subset \beta \subset \gamma \), then \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma ) \ge d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )\) and \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma )\ge d_{_{\textrm{pd}}}^{(\lambda )}(\beta , \gamma )\).
-
(2)
If \(\alpha \subsetneqq \beta \subsetneqq \gamma \), then \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma )> d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )\) and \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma )> d_{_{\textrm{pd}}}^{(\lambda )}(\beta , \gamma )\).
Proof
-
(1)
Fix an IFV \(\alpha =\langle \mu _{\alpha }, \nu _{\alpha } \rangle \in \Theta \). For any \(\tilde{\alpha }=\langle \mu , \nu \rangle \in \Theta \) with \(\tilde{\alpha }\supset \alpha \), define a function
$$\begin{aligned} \zeta (\mu , \nu ) =d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \tilde{\alpha })=\frac{\mu -\mu _{\alpha } +\nu _{\alpha }-\nu }{\mu _{\alpha }+\nu _{\alpha }+\mu +\nu +\lambda } \cdot \frac{2+\lambda }{2}. \end{aligned}$$By direct calculation, we have
$$\begin{aligned} \frac{\partial \zeta }{\partial \mu }=\frac{2\mu _{\alpha } +2\nu +\lambda }{(\mu _{\alpha }+\nu _{\alpha }+\mu +\nu +\lambda )^{2}} \cdot \frac{2+\lambda }{2}> 0, \end{aligned}$$(5)and
$$\begin{aligned} \frac{\partial \zeta }{\partial \nu }=\frac{-2\nu _{\alpha } -2\mu -\lambda }{(\mu _{\alpha }+\nu _{\alpha }+\mu +\nu +\lambda )^{2}} \cdot \frac{2+\lambda }{2}< 0. \end{aligned}$$(6)This, together with \(\alpha \subset \beta \subset \gamma \), i.e., \(\mu _{\alpha }\le \mu _{\beta } \le \mu _{\gamma }\) and \(\nu _{\alpha } \ge \nu _{\beta } \ge \nu _{\gamma }\), implies that \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )=\zeta (\mu _{\beta }, \nu _{\beta }) \le \zeta (\mu _{\gamma }, \nu _{\beta }) \le \zeta (\mu _{\gamma }, \nu _{\gamma }) =d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma )\). Similarly, it can be verified that \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma ) \ge d_{_{\textrm{pd}}}^{(\lambda )}(\beta , \gamma )\).
-
(2)
Suppose that, on the contrary, \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma ) \ngtr d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )\) or \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma ) \ngtr d_{_{\textrm{pd}}}^{(\lambda )}(\beta , \gamma )\). Without loss of generality, assume that \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma ) \ngtr d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )\). This, together with (1), implies that \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma ) = d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )\). From \(\beta \subsetneqq \gamma \), it follows that (\(\mu _{\beta }<\mu _{\gamma }\) and \(\nu _{\beta }\ge \nu _{\gamma }\)) or (\(\mu _{\beta }\le \mu _{\gamma }\) and \(\nu _{\beta }> \nu _{\gamma }\)). Next, we consider the following two cases: 2-1) If \(\mu _{\beta }<\mu _{\gamma }\) and \(\nu _{\beta }\ge \nu _{\gamma }\), then, by Eqs. (5) and (6), we have \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )=\zeta (\mu _{\beta }, \nu _{\beta }) <\zeta (\mu _{\gamma }, \nu _{\beta })\le \zeta (\mu _{\gamma }, \nu _{\gamma }) =d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma )\), which contradicts with \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma ) = d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )\). 2-2) If \(\mu _{\beta }\le \mu _{\gamma }\) and \(\nu _{\beta }> \nu _{\gamma }\), then, by Eqs. (5) and (6), we have \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )=\zeta (\mu _{\beta }, \nu _{\beta }) <\zeta (\mu _{\beta }, \nu _{\gamma })\le \zeta (\mu _{\gamma }, \nu _{\gamma }) =d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma )\), which contradicts with \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma ) = d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )\). Therefore, \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma )> d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )\) and \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \gamma )> d_{_{\textrm{pd}}}^{(\lambda )}(\beta , \gamma )\).
\(\square \)
Based on the defined parametric distance \(d_{\textrm{pd}}^{(\lambda )}\), we can define a similarity measure \(\textbf{S}_{\textrm{ps}}(\alpha , \beta )\) on \(\Theta \) as follows: for \(\alpha =\langle \mu _{\alpha }, \nu _{\alpha }\rangle \) and \(\beta = \langle \mu _{\beta }, \nu _{\beta }\rangle \in \Theta \),
According to Propositions 3.1 and 3.5, we have the following results.
Theorem 3.1
-
(1)
The function \(d_{_{\textrm{pd}}}^{(\lambda )}\) defined by Eq. (4) is a strict distance measure on \(\Theta \).
-
(2)
The function \(\textbf{S}_{_{\textrm{ps}}}(\alpha , \beta )\) defined by Eq. (7) is a strict similarity measure on \(\Theta \).
Similarly, we can define a new measure E on \(\Theta \) based on the parametric distance \(d_{_{\textrm{pd}}}^{(\lambda )}\) as follows:
Theorem 3.2
Let \(\lambda >0\). The measure E defined by Eq. (8) is an entropy on \(\Theta \).
Proof
(E1), (E2), and (E3) follow directly from Propositions 3.3, 3.4 and Eq. (4), respectively.
(E4) For \(\alpha \), \(\beta \in \Theta \), consider the following two cases:
(E4-1) If \(\mu _{\alpha }\le \mu _{\beta } \le \nu _{\beta } \le \nu _{\alpha }\), then \(\alpha \subset \beta \subset \beta ^{\complement } \subset \alpha ^{\complement }\). This, together with Proposition 3.5, implies that \(E(\alpha )= 1-d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \alpha ^{\complement }) \le 1-d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta ^{\complement }) \le 1-d_{_{\textrm{pd}}}^{(\lambda )}(\beta , \beta ^{\complement }) =E(\beta )\);
(E4-2) If \(\mu _{\alpha }\ge \mu _{\beta } \ge \nu _{\beta } \ge \nu _{\alpha }\), then \(\alpha ^{\complement } \subset \beta ^{\complement } \subset \beta \subset \alpha \). This, together with Proposition 3.5, implies that \(E(\alpha )= 1-d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \alpha ^{\complement }) \le 1-d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta ^{\complement }) \le 1-d_{_{\textrm{pd}}}^{(\lambda )}(\beta , \beta ^{\complement }) =E(\beta )\). \(\square \)
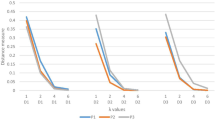
Figure 1 shows the graphs of the entropy measure E of Eq. (8) for \(\lambda =0.02, 0.04, 0.06, 0.08, 0.1\).

Entropy measure E for different values of \(\lambda \).
Mahanta and Panda38 claimed that the IFDisM \(d_{_{\textrm{MP}}}\) can deal adequately with the IF information having high uncertainty, i.e., having low values of membership and nonmembership grades. To close this section, it is shown that our proposed parametric distance \(d_{_{\textrm{pd}}}^{(\lambda )}\) can effectively distinguish different IFVs with high hesitancy.
Fix \(\lambda >0\) and give two different IFVs \(\alpha =\langle \mu _{\alpha }, \nu _{\alpha }\rangle \) and \(\beta = \langle \mu _{\beta }, \nu _{\beta }\rangle \) with \(\mu _{\alpha }+\nu _{\alpha }\le \frac{\lambda }{2}\) and \(\mu _{\beta } +\nu _{\beta }\le \frac{\lambda }{2}\). By differential mean value theorem, it can be verified that
-
(i)
If \(\mu _{\beta }\ge \mu _{\alpha }\) and \(\nu _{\beta }\ge \nu _{\alpha }\), then there exist \(\xi _1\in [\mu _{\alpha }, \mu _{\beta }]\) and \(\eta _1\in [\nu _{\alpha }, \nu _{\beta }]\) such that \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )=\frac{2\mu _{\alpha }+2\nu _{\alpha }+\lambda }{(\mu _{\alpha }+\xi _1+\nu _{\alpha }+\eta _1+\lambda )^{2}}\cdot \frac{2+\lambda }{2}\cdot (\mu _{\beta }-\mu _{\alpha })+\frac{2\mu _{\alpha }+2\nu _{\alpha }+\lambda }{(\mu _{\alpha }+\xi _1+\nu _{\alpha }+\eta _1+\lambda )^{2}}\cdot \frac{2+\lambda }{2} \cdot (\nu _{\beta }-\nu _{\alpha })\ge \frac{\lambda }{(2\lambda )^2}\cdot \frac{2+\lambda }{2} \cdot ((\mu _{\beta }-\mu _{\alpha })+(\nu _{\beta }-\nu _{\alpha })) \ge \frac{1}{4\lambda }\cdot (|\mu _{\beta }-\mu _{\alpha }|+|\nu _{\beta }-\nu _{\alpha }|)\);
-
(ii)
If \(\mu _{\alpha }\ge \mu _{\beta }\) and \(\nu _{\alpha }\ge \nu _{\beta }\), similarly to (i), it follows that there exist \(\xi _2\in [\mu _{\beta }, \mu _{\alpha }]\) and \(\eta _2\in [\nu _{\beta }, \nu _{\alpha }]\) such that \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )\ge \frac{1}{4\lambda } \cdot (|\mu _{\beta }-\mu _{\alpha }|+|\nu _{\beta }-\nu _{\alpha }|)\).
-
(iii)
If \(\mu _{\beta }\ge \mu _{\alpha }\) and \(\nu _{\beta }\le \nu _{\alpha }\), then there exist \(\xi _3\in [\mu _{\alpha }, \mu _{\beta }]\) and \(\eta _3\in [\nu _{\beta }, \nu _{\alpha }]\) such that \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta )=\frac{2\mu _{\alpha }+2\eta _3+\lambda }{(\mu _{\alpha }+\xi _3+\nu _{\alpha }+\eta _3+\lambda )^{2}}\cdot \frac{2+\lambda }{2} \cdot (\mu _{\beta }-\mu _{\alpha })+\frac{-2\xi _3-2\nu _{\alpha }-\lambda }{(\mu _{\alpha }+\xi _3+\nu _{\alpha }+\eta _3+\lambda )^{2}}\cdot \frac{2+\lambda }{2} \cdot (\nu _{\beta }-\nu _{\alpha })=\frac{2\mu _{\alpha }+2\eta _3+\lambda }{(\mu _{\alpha }+\xi _3+\nu _{\alpha }+\eta _3+\lambda )^{2}}\cdot \frac{2+\lambda }{2} \cdot (\mu _{\beta }-\mu _{\alpha })+\frac{2\xi _3+2\nu _{\alpha }+\lambda }{(\mu _{\alpha }+\xi _3+\nu _{\alpha }+\eta _3+\lambda )^{2}}\cdot \frac{2+\lambda }{2} \cdot (\nu _{\alpha }-\nu _{\beta })\ge \frac{\lambda }{(2\lambda )^2}\cdot \frac{2+\lambda }{2} \cdot ((\mu _{\beta }-\mu _{\alpha })+(\nu _{\alpha }-\nu _{\beta })) \ge \frac{1}{4\lambda }\cdot (|\mu _{\beta }-\mu _{\alpha }|+|\nu _{\beta }-\nu _{\alpha }|)\);
-
(iv)
If \(\mu _{\beta }\le \mu _{\alpha }\) and \(\nu _{\beta }\ge \nu _{\alpha }\), similarly to (iii), it follows that there exist \(\xi _4\in [\mu _{\beta }, \mu _{\alpha }]\) and \(\eta _4\in [\nu _{\alpha }, \nu _{\beta }]\) such that \(d_{_{\textrm{pd}}}^{(\lambda )}(\alpha , \beta ) \ge \frac{1}{4\lambda }\cdot (|\mu _{\beta }-\mu _{\alpha }|+|\nu _{\beta }-\nu _{\alpha }|)\).
According to the above theoretical analysis and also the presentation in Fig. 1, we can find that, when the parameter \(\lambda \) is sufficiently small, the distance \(d_{_{\textrm{pd}}}^{(\lambda )}\) can reach very large numbers and is sensitive to small perturbations, even if the degrees of membership and nonmembership are very small. Thus, the smaller the parameter \(\lambda \) is, the stronger the sensitivity is. Therefore, the proposed parametric distance \(d_{_{\textrm{pd}}}^{(\lambda )}\) can better distinguish IFVs with small degrees of membership and nonmembership. And so, throughout this paper, the values of the parameter \(\lambda \) are chosen smaller. Meanwhile, according to Eq. (4), it is clear that the value of \(d_{_{\textrm{pd}}}^{(\lambda )}\) will be sufficiently close to \(\frac{1}{2} (|\mu _{\alpha }-\mu _{\beta }|+|\nu _{\alpha }-\nu _{\beta }|)\), when the parameter \(\lambda \) is sufficiently higher. In this case, the distance measure \(d_{_{\textrm{pd}}}^{(\lambda )}\) cannot distinguish different IFSs with high hesitancy, when the parameter \(\lambda \) is sufficiently higher. In this sense, the values of the parameter \(\lambda \) will not be chosen too high, but better with smaller values.
The proposed IFDisM, IFSisM and IFEM for IFSs
Following the newly defined function \(\textbf{d}_{_{\textrm{pd}}}^{(\lambda )}\) on \(\Theta \) in “A new parametric distance on \(\Theta \)”, we now propose the new IFDisM (distance), IFSisM (similarity) and IFEM (entropy) for IFSs as follows. Let \(\Xi =\{\vartheta _1, \vartheta _2, \ldots , \vartheta _{\ell }\}\) and \(\lambda >0\). Define the function \(\textbf{d}_{_{\textrm{New}}}^{(\lambda )}: \textrm{IFS}(\Xi )\times \textrm{IFS}(\Xi ) \longrightarrow \mathbb {R}^{+}\) for \(I_1=\{\langle \mu _{I_1}(\vartheta _i), \nu _{I_1}(\vartheta _i) \rangle \mid \vartheta _i\in \Xi \}\) and \(I_2=\{\langle \mu _{I_2}(\vartheta _i), \nu _{I_2}(\vartheta _i) \rangle \mid \vartheta _i\in \Xi \}\in \textrm{IFS}(\Xi )\),
where \(\omega =(\omega _1, \omega _2, \ldots , \omega _n)^{\top }\) is the weight vector of \(\vartheta _{i}\) (\(i=1, 2, \ldots , \ell \)) with \(\omega _i\in (0, 1]\) and \(\sum _{i=1}^{\ell }\omega _i=1\).
Based on the defined IFDisM \(\textbf{d}_{_{\textrm{New}}}^{(\lambda )}(I_1, I_2)\) for IFSs, we can define a new similarity measure \(\textbf{S}_{_{\textrm{New}}}^{(\lambda )}(I_1, I_2)\) for IFSs as follows: for \(I_1=\{\langle \mu _{I_1}(\vartheta _i), \nu _{I_1}(\vartheta _i) \rangle \mid \vartheta _i\in \Xi \}\) and \(I_2=\{\langle \mu _{I_2}(\vartheta _i), \nu _{I_2}(\vartheta _i) \rangle \mid \vartheta _i\in \Xi \}\in \textrm{IFS}(\Xi )\),
Similarly, a new entropy measure for IFSs can be defined according to the defined IFDisM \(\textbf{d}_{_{\textrm{New}}}^{(\lambda )}(I_1, I_2)\) as follows:
According to Theorems 3.1 and 3.2, we can directly obtain the following theorems.
Theorem 3.3
-
(1)
The function \(\textbf{d}_{_{\textrm{New}}}^{(\lambda )}\) defined by Eq. (9) is a strict IFDisM on \(\textrm{IFS}(\Xi )\).
-
(2)
The function \(\textbf{S}_{_{\textrm{New}}}^{(\lambda )}(I_1, I_2)\) defined by Eq. (10) is a strict IFSimM on \(\textrm{IFS}(\Xi )\).
Theorem 3.4
Let \(\lambda >0\). The measure E defined by Eq. (11) is an entropy measure on \(\textrm{IFS}(\Xi )\).
Comparative analysis with Mahanta and Panda’s distance measure
This subsection illustrates that our proposed distance measure can completely overcome Mahanta and Panda’s drawbacks mentioned in “The drawbacks of distance measure of Mahanta and Panda38”.
Example 3.3
(Continuation of Example 3.1) Take the IFSs \(I_1\) on \(\Xi =\{\vartheta \}\) as given in Example 3.1. For any \(I_2=\left\{ \frac{\langle \mu , \nu \rangle }{\vartheta }\right\} \in \textrm{IFS}(\Xi )\) with \(I_2\ne I_1\), by direct calculation and Eq. (9), we have
By varying IFS \(I_2\) within \(\textrm{IFS}(\Xi )\), Fig. 2 shows the changing trend of distances between \(I_1\) and \(I_2\) by using our proposed formula (9) for \(\lambda =0.02, 0.04, 0.06, 0.08, 0.1\). Observing from Example 3.1, Proposition 3.4, and Fig. 2, it is revealed that the distance \(\textbf{d}_{_{\textrm{New}}}^{(\lambda )}(I_1, I_2)\) between \(I_1\) and \(I_2\) is always less than 1, and changed with the change of \(I_{2}\), which are reasonable, and significantly better than the result obtained by Mahanta and Panda’s distance measure in Example 3.1.

Distance measure \(\textbf{d}_{_{\textrm{New}}}^{(\lambda )}(I_1, I_2)\) in Example 3.3 for different values of \(\lambda \).
Example 3.4
(Continuation of Example 3.2) Take the IFSs \(I_1^{\prime }\) and \(I_{2}^{\prime }\) on \(\Xi =\{\vartheta \}\) as given in Example 3.2. By direct calculation and Eq. (9), we have that, for \(0<\mu , \nu \le 1\), \( \textbf{d}_{_{\textrm{New}}}^{(\lambda )}(I_1^{\prime }, I_2^{\prime })= \frac{|\mu -0|+|0-\nu |}{\mu +0+0+\nu +\lambda }\cdot \frac{2+\lambda }{2} =\frac{\mu +\nu }{\mu +\nu +\lambda }\cdot \frac{2+\lambda }{2}. \) By varying \(\mu \) and \(\nu \) from 0 to 1, Fig. 3 shows the changing trend of distances between \(I_1^{\prime }\) and \(I_2^{\prime }\) by using our proposed formula (9) for \(\lambda =0.02, 0.04, 0.06, 0.08, 0.1\). Observing from Example 3.2, Proposition 3.4, and Fig. 3, it is revealed that the distance \(\textbf{d}_{_{\textrm{New}}}^{(\lambda )}(I_1^{\prime }, I_2^{\prime })\) between \(I_1^{\prime }\) and \(I_2^{\prime }\) is always less than 1 except for \(\mu =\nu =1\), and changes with the changed of \(I_{1}^{\prime }\) and \(I_{2}^{\prime }\), which are reasonable, and significantly better than the result obtained by Mahanta and Panda’s distance measure in Example 3.2.

Distance measure \(\textbf{d}_{_{\textrm{New}}}^{(\lambda )}(I_1^{\prime }, I_2^{\prime })\) in Example 3.4 for different values of \(\lambda \).
Applications
A pattern classification problem
Example 4.1
(32Application 2, 14Example 4.3) Consider a pattern classification problem with three classes and three attributes \({\mathfrak {A}}=\{x_1, x_2, x_3\}\), described by three patterns \({\mathfrak {P}}=\{P_1, P_2, P_3\}\) and a test sample \(S_1\) expressed by the IFSs listed in Table 1.
By taking the weight vector \(\omega \) of three attributes as \(\omega =(\frac{1}{3}, \frac{1}{3}, \frac{1}{3})^{\top }\), based on the principle of the maximum degree of SimMs, the pattern classification results obtained by using different distance measures are listed in Table 2 and Fig. 4. Observing from Table 2 and Fig. 4, we know that the test sample \(S_{1}\) is classified to the pattern \(P_3\) by our proposed DisM with \(\lambda =0.14, 0.16, 0.18\), which is consistent with the results obtained by the DisMs \(d_{_{\textrm{SK}}}^{\textrm{E}}\), \(d_{_{\textrm{G}}}\), \(d_{_{\textrm{W1}}}\), \(d_{_{\textrm{W2}}}\), \(d_{_{\textrm{P}}}\), \(d_{_{\textrm{Y}}}\), \(d_{_{\textrm{SW}}}\), \(d_{_{\textrm{SM}}}\), \(d_{_{\textrm{L}}}\), \(d_{_{\textrm{YC}}}\), and \(d_{\widetilde{\chi }}\); However, the methods using DisMs \(d_{_{\textrm{W2}}}\), \(d_{_{\textrm{H}}}^{\textrm{T}}\), \(d_{_{\textrm{H}}}^{\textrm{R}}\), \(d_{_{\textrm{H}}}^{\textrm{L}}\), \(d_{_{\textrm{H}}}^{\textrm{KD}}\), \(d_{_{\textrm{H}}}^{\textrm{M}}\), \(d_{_{\textrm{H}}}^{\textrm{LA}}\), \(d_{_{\textrm{H}}}^{\textrm{G}}\), \(d_{_{\textrm{SW}}}\), and \(d_{_{\textrm{MP}}}\) cannot determine to which pattern the test sample \(S_1\) belongs. We mention that the calculations for \(d_{_{\textrm{MP}}}\) by Mahanta and Panda38 have \(1-d_{_{\textrm{MP}}}(P_1, S_1)=0.8354\) and \(1-d_{_{\textrm{MP}}}(P_3, S_1)=0.8383\). This means that \(1-d_{_{\textrm{MP}}}(P_3, S_1)>1-d_{_{\textrm{MP}}}(P_1, S_1)\), and so it is able to distinguish between the patterns, but only a little. However, if we retain 2 digits after the decimal point, we have \(1-d_{_{\textrm{MP}}}(P_3, S_1)=0.84=1-d_{_{\textrm{MP}}}(P_1, S_1)\), and so \(d_{_{\textrm{MP}}}\) by Mahanta and Panda38 can not distinguish between the patterns.

Comparison results of different similarity measures in Example 4.1.
A TOPSIS method based on our proposed strict IFDisM and IFSimM
Suppose that there are n alternatives \({A}_{i}\) (\(i=1, 2, \ldots , n\)) evaluated with respect to m attributes \({\mathfrak {A}}_j\) (\(j=1, 2, \ldots , m\)). The sets of the alternatives and attributes are denoted by \(A=\{A_1, A_2, \ldots , A_n\}\) and \({\mathfrak {A}}=\{{\mathfrak {A}}_1, {\mathfrak {A}}_2, \ldots , {\mathfrak {A}}_m\}\), respectively. The rating (or evaluation) of each alternative \(A_i\in A\) (\(i=1, 2, \ldots , n\)) on each attribute \(o_j\) (\(j=1, 2, \ldots , m\)) is expressed with an IFS \(r_{ij}= \left\{ \frac{\langle \mu _{ij}, \nu _{ij}\rangle }{(A_i, {\mathfrak {A}}_j)}\right\} \), denoted by \(r_{ij}=\langle \mu _{ij}, \nu _{ij}\rangle \) for short, where \(\mu _{ij}\in [0, 1]\) and \(\nu _{ij}\in [0, 1]\) are respectively the satisfaction (or membership) degree and dissatisfaction (or non-membership) degree of the alternative \(A_{i}\in A\) on the attribute \(o_{j}\) satisfying the condition \(0\le \mu _{ij}+\nu _{ij}\le 1\). A multi-attribute decision-making (MADM) problem with IFSs is expressed in matrix form shown in Table 3.
For the MADM problem with IFSs, by using our proposed IFDisM \(\textbf{d}_{_{\textrm{New}}}^{(\lambda )}\) of Eq. (9), we construct a new IF TOPSIS method as follows:
Step 1: (Construct the decision matrix) Supposing that the decision-maker gave the rating (or evaluation) of each alternative \(A_i\in A\) (\(i=1, 2, \ldots , n\)) on each attribute \({\mathfrak {A}}_j\) (\(j=1, 2, \ldots , m\)) in the form of IFNs \(r_{ij}=\langle \mu _{ij}, \eta _{ij}\rangle \), construct an IF decision matrix \(R=(r_{ij})_{m\times n}\) as shown in Table 3.
Step 2: (Normalize the decision matrix) Transform the IF decision matrix \(R=(r_{ij})_{m\times n}\) to the normalized IF decision matrix \(\overline{R}=(\bar{r}_{ij})_{m\times n}=(\langle \bar{\mu }_{ij}, \bar{\nu }_{ij}\rangle )_{m\times n}\) as follows:
where \(r_{ij}^{\complement }\) is the complement of \(\gamma _{ij}\).
Step 3: (Determine the positive and negative ideal-points) Determine the IF positive ideal-point \({\mathfrak {I}}^{+}=(\langle \mu ^{+}_{1}, \nu ^{+}_{1}\rangle , \langle \mu ^{+}_{2}, \nu ^{+}_{2}\rangle ,\) \(\ldots , \langle \mu ^{+}_{m}, \nu ^{+}_{m}\rangle )^{\top }\) and IF negative ideal-point \({\mathfrak {I}}^{-}=(\langle \mu ^{-}_{1}, \nu ^{-}_{1}\rangle , \langle \mu ^{-}_{2}, \nu ^{-}_{2}\rangle , \ldots , \langle \mu ^{-}_{m}, \nu ^{-}_{m}\rangle )^{\top }\) as follows:
Step 4: (Compute the weighted similarity measures) Compute the weighted similarity measures between the alternatives \(A_i\) (\(i=1,2, \ldots ,n\)) and the IF positive ideal-point \({\mathfrak {I}}^+\), and between the alternatives \(A_i\) (\(i=1,2, \ldots ,n\)) and the IF negative ideal-point \({\mathfrak {I}}^{-}\), by using the following formulas:
and
Step 5: (Compute the relative similarity degrees) Calculate the relative similarity degrees \({\mathcal {C}}_{i}\) of the alternatives \(A_i\) (\(i=1,2, \ldots ,n\)) to the IF positive ideal-point \({\mathfrak {I}}^+\) by using the following formula:
Step 6: (Rank the alternative) Rank the alternatives \(A_i\) (\(i=1,2, \ldots ,n\)) according to the nonincreasing order of the relative closeness degrees \({\mathcal {C}}_{i}\) and select the most desirable alternative.
Comparative and sensitivity analysis
We next make a comparative and sensitivity analysis of our proposed method with the method proposed by Mahanta and Panda38.
Example 4.2
(38Example 4.3) After the outbreak of COVID-19 disease, the demand for masks has increased rapidly. There are six common types of masks on the market as follows: \({\mathscr {M}}_1\)—disposable medical masks, \({\mathscr {M}}_2\)—medical-surgical masks, \({\mathscr {M}}_3\)—particulate respirators (N95), \({\mathscr {M}}_4\)—ordinary nonmedical masks, \({\mathscr {M}}_5\)—medical protective masks, and \({\mathscr {M}}_6\)—gas masks. A citizen wants to buy a suitable mask from the above six types of masks by considering the following four attributes: \({\mathfrak {A}}_1\)—leakage rate, \({\mathfrak {A}}_2\)—recyclability, \({\mathfrak {A}}_3\)—quality of raw material, \({\mathfrak {A}}_4\)—filtration capability.
Step 1: (Construct the decision matrix) Through the market survey, the evaluations of each type of mask \({\mathscr {M}}_i\) (\(i=1, 2, 3, 4, 5, 6\)) on each attribute \({\mathfrak {A}}_j\) (\(j=1, 2, 3, 4\)) in the form of IFNs are summarized in Table 4.
Step 2: (Normalize the decision matrix) Because \({\mathfrak {A}}_1\) is a cost attribute and \({\mathfrak {A}}_2\)–\({\mathfrak {A}}_4\) are the benefit attributes, the normalized IF decision matrix is formed as shown in Table 5.
Step 3: (Determine the positive and negative ideal-points) The IF positive ideal-point is
and the IF negative ideal-point is
Steps 4 and 5: (Compute the relative similarity degrees) Take the weight vector \(\omega =(0.25, 0.25, 0.25, 0.25)^{\top }\). For \(\lambda =0.02\), 0.04, 0.06, 0.08, 0.1, calculate the relative similarity degrees \({\mathcal {C}}_{i}\) of the alternatives \({\mathscr {M}}_i\) (\(i=1, 2, 3, 4, 5, 6\)) to the IF positive ideal-point \({\mathfrak {I}}^+\) by Eqs. (12), (13), and (14). The results are presented in Table 6.
Step 6: (Rank the alternative) For any \(\lambda \in \{0.02, 0.04, 0.06, 0.08, 0.1\}\), because it always holds \({\mathcal {C}}_3> {\mathcal {C}}_6> {\mathcal {C}}_4> {\mathcal {C}}_5> {\mathcal {C}}_1> {\mathcal {C}}_2\), the ranking of these types of masks \({\mathscr {M}}_i\) (\(i=1, 2, 3, 4, 5, 6\)) is:
Therefore, the most desirable mask type is \({\mathscr {M}}_3\)—particulate respirators (N95).
Mahanta and Panda38, Example 4.3 showed that the most desirable mask type is \({\mathscr {M}}_1\)—disposable medical masks, which is different from our result. The main reason for this is lack of normalization step (Step 2) in Mahanta and Panda’s TOPSIS method38. This may yield counter-intuitive results, because the smaller the score for cost attribute is, the better the attribute on this attribute is. To illustrate the effectiveness of the proposed TOPSIS method, we give a comparison of the preference orders of the alternatives in Example 4.2 for different TOPSIS methods as follows.
From Table 7, which shows a comparison of the preference orders of the alternatives in Example 4.2 for different TOPSIS methods, we observe that although our ranking result is different from these obtained by the TOPSIS method in25,35,43, the most desirable mask type is always \({\mathscr {M}}_3\)–particulate respirators (N95). Note that the scores of \({\mathscr {M}}_3\) on the attributes \({\mathfrak {A}}_2\), \({\mathfrak {A}}_3\), and \({\mathfrak {A}}_4\) (by Table 5) are much greater than that of \({\mathscr {M}}_1\). This gives a reason to support the conclusion that \({\mathscr {M}}_{3}\) is better than \({\mathscr {M}}_1\). Therefore, our method is more reasonable than that of Mahanta and Panda38.
To study the changing tendency of the relative similarity degrees and the rankings for \({\mathscr {M}}_1\), \({\mathscr {M}}_2\), \(\ldots \), \({\mathscr {M}}_6\) with the variation of the parameter \(\lambda \) from 0 to 1, Fig. 5 is used for illustration. Observing from Fig. 5, it is revealed that the rankings for \({\mathscr {M}}_1\), \({\mathscr {M}}_2\), \(\ldots \), \({\mathscr {M}}_6\) remain unchange with the variation of the parameter \(\lambda \) from 0 to 1. As a result, N95 is always the most desirable type of marks.

Relative similarity degrees for different values of \(\lambda \) for \(\omega =(0.25, 0.25, 0.25, 0.25)^{\top }\).
In the above analysis, we assume that four attributes \({\mathfrak {A}}_1\)–\({\mathfrak {A}}_4\) have the same weight. To study the impact of the weights of attributes on the decision process, Fig. 6 is used for illustration. Observing from Fig. 6, it is revealed that although the most desirable mask type is always \({\mathscr {M}}_3\)–particulate respirators (N95), the rankings of \({\mathscr {M}}_1\) and \({\mathscr {M}}_2\) may change, when changing the weights of attributes and the parameter \(\lambda \).
A medical diagnosis problem
Example 4.3
(38Example 4.4,14) Consider a medical diagnosis problem for 4 patients \(\mathbb {P}=\{\mathbb {P}_1, \mathbb {P}_2, \mathbb {P}_3, \mathbb {P}_4\}\) with the symptoms \({\mathfrak {S}}=\{\text {Temperature, Headache, Stomach pain, Cough, Chest pain}\}\) represented by using IFNs, as listed in Table 8. The symptom characteristics for diagnosis \({\mathfrak {D}}=\{\text {Viral fever, Malaria, Typhoid, Stomach problem, Chest problem}\}\) are represented by using IFNs, as shown in Table 9.

Relative similarity degrees for different values of \(\lambda \) and weight vectors \(\omega \).
By taking the weight vector \(\omega \) of the 5 symptoms attributes as \(\omega =(0.2, 0.2, 0.2, 0.2, 0.2)^{\top }\), based on the principle of the maximum degree of SimMs, the diagnosis results obtained by using different SimMs are listed in Table 10 with \(\lambda =0.02\).
To study the changing tendency of the diagnostic results for different patients \(\mathbb {P}_1\), \(\mathbb {P}_2\), \(\mathbb {P}_3\), \(\mathbb {P}_4\) with the variation of the parameter \(\lambda \) from 0 to 1, Fig. 7 is used for illustration. Observing from Fig. 7, it is revealed that when the parameter \(\lambda \) changes from 0 to 1, the diagnostic results for \(\mathbb {P}_1\), \(\mathbb {P}_2\), \(\mathbb {P}_3\), and \(\mathbb {P}_4\) are perfectly consistent with the result for \(\lambda =0.02\), i.e., \(\mathbb {P}_1\) suffers from ‘Malaria’, \(\mathbb {P}_2\) suffers from ‘Stomach problem’, \(\mathbb {P}_3\) suffers from ‘Typhoid’, and \(\mathbb {P}_4\) suffers from ‘Viral fever’.

The diagnostic results of different patients for different \(\lambda \in [0, 1]\).
Conclusion
To overcome the two drawbacks of Mahanta and Panda’s DisM38 mentioned in “The drawbacks of distance measure of Mahanta and Panda38”, we propose a new nonlinear parametric DisM for IFSs, which is proved to satisfy the axiomatic definition of a strict IFDisM and effectively distinguish different IFSs with high hesitancy when the parameter is sufficiently small. Moreover, we prove that the dual SimM and the induced entropy of the proposed DisM are a strict IFSimM and an IF entropy, respectively. Finally, to illustrate the effectiveness of our method, we apply our proposed DisM/SimM to the following three problems:
-
(1)
Considering an IF pattern classification problem from14, our proposed DisM can accurately determine to which pattern the test sample belongs. The test result shows that our proposed DisM is better than the DisMs in23,36,38,41;
-
(2)
To deal with an IF MADM problem on the decision making about the choice of a proper antivirus face mask for COVID-19, we propose a TOPSIS method based on our proposed strict IFSimM. The comparative analysis shows that the most desirable choice obtained by our proposed TOPSIS method with the variation of the parameter \(\lambda \) from 0 to 1 is consistent with the results obtained by the TOPSIS methods in25,35,43. The comparative analysis also shows that the TOPSIS method in38 is unreasonable, because it does not consider the cost attributes for normalization;
-
(3)
We use our proposed SimM to solve an IF medical diagnosis problem. Our diagnostic results are consistent with the results in15,38,44,46,47.
In the paper, we had demonstrated these relative similarity degrees for different values of the parameter \(\lambda \) and weights \(\omega \) with the conclusion that, the ranking results in the MCDM application may change, when changing the values of the parameter \(\lambda \) and weights \(\omega \) of attributes. This parameter dependency becomes the drawback of the proposed method. To find a better combination of the parameter \(\lambda \) and weight \(\omega \) in the MCDM application becomes important, and will be a further research topic. In the future, we shall further extend our constructive methods of strict IFDisM, IFSimM and IFEM to Pythagorean fuzzy sets, q-rung orthopair fuzzy sets, T-spherical fuzzy sets, and some other interval-valued fuzzy sets.
Data availability
All data generated or analysed during this study are included in this published article.
References
Zadeh, L. A. Fuzzy sets. Inf. Control 8(3), 338–353 (1965).
Chang, S. T., Lu, K. P. & Yang, M. S. Fuzzy change-point algorithms for regression models. IEEE Trans. Fuzzy Syst. 23(6), 2343–2357 (2015).
Kabir, S. & Papadopoulos, Y. A review of applications of fuzzy sets to safety and reliability engineering. Int. J. Approx. Reason. 100, 29–55 (2018).
Lu, K. P., Chang, S. T. & Yang, M. S. Change-point detection for shifts in control charts using fuzzy shift change-point algorithms. Comput. Ind. Eng. 93, 12–27 (2016).
Atanassov, K. T. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 20(1), 96–97 (1986).
Enginoglu, S. & Arslan, B. Intuitionistic fuzzy parameterized intuitionistic fuzzy soft matrices and their application in decision-making. Comput. Appl. Math. 39, article no. 325 (2020).
Liu, X. et al. Analysis of distance measures in intuitionistic fuzzy set theory: A line integral perspective. Expert Syst. Appl. 226(120), 221 (2023).
Patel, A., Jana, S. & Mahanta, J. Intuitionistic fuzzy EM-SWARA-TOPSIS approach based on new distance measure to assess the medical waste treatment techniques. Appl. Soft Comput. 20, 110521 (2023).
Senapati, T., Chen, G. & Yager, R. R. Aczel–Alsina aggregation operators and their application to intuitionistic fuzzy multiple attribute decision making. Int. J. Intell. Syst. 37(2), 1529–1551 (2022).
Xu, Z. & Cai, X. Intuitionistic Fuzzy Information Aggregation: Theory and Applications, Mathematics Monograph Series, Vol. 20 (Science Press, 2012).
Yang, M. S., Hussain, Z. & Ali, M. Belief and plausibility measures on intuitionistic fuzzy sets with construction of belief-plausibility topsis. Complexity 7849686, 1–12 (2020).
De, S. K., Biswas, R. & Roy, A. R. An application of intuitionistic fuzzy sets in medical diagnosis. Fuzzy Sets Syst. 117(2), 209–213 (2001).
Jiang, Q. et al. A lightweight multimode medical image fusion method using similarity measure between intuitionistic fuzzy sets joint laplacian pyramid. IEEE Trans. Emerg. Top. Comput. Intell. 7(3), 631–647 (2023).
Luo, M. & Zhao, R. A distance measure between intuitionistic fuzzy sets and its application in medical diagnosis. Artif. Intell. Med. 89, 34–39 (2018).
Szmidt, E. & Kacprzyk, J. Intuitionistic fuzzy sets in intelligent data analysis for medical diagnosis. In International Conference on Computational Science-ICCS 2001 (eds Alexandrov, V. N., Dongarra, J. J., Juliano, B. A. et al.) 263–271 (Springer, 2001).
Ejegwa, P. A. & Ahemen, S. Enhanced intuitionistic fuzzy similarity operators with applications in emergency management and pattern recognition. Granul. Comput. 8(2), 361–372 (2023).
Singh, A. & Kumar, S. A novel dice similarity measure for IFSs and its applications in pattern and face recognition. Expert Syst. Appl. 149(113), 245 (2020).
Chen, Z. & Liu, P. Intuitionistic fuzzy value similarity measures for intuitionistic fuzzy sets. Comput. Appl. Math. 41, article no. 45 (2022).
Gupta, R. & Kumar, S. Intuitionistic fuzzy similarity-based information measure in the application of pattern recognition and clustering. Int. J. Fuzzy Syst. 24, 2493–2510 (2022).
Mujica-Vargas, D., Kinani, J. M. V. & Rubio, J. J. Color-based image segmentation by means of a robust intuitionistic fuzzy c-means algorithm. Int. J. Fuzzy Syst. 22, 901–916 (2020).
Varshney, A. K., Muhuri, P. K. & Lohani, Q. D. Density-based IFCM along with its interval valued and probabilistic extensions, and a review of intuitionistic fuzzy clustering methods. Artif. Intell. Rev. 56(4), 3755–3795 (2023).
Wang, Z. et al. Direct clustering analysis based on intuitionistic fuzzy implication. Appl. Soft Comput. 23, 1–8 (2014).
Wang, W. & Xin, X. Distance measure between intuitionistic fuzzy sets. Pattern Recogn. Lett. 26(13), 2063–2069 (2005).
Szmidt, E. Distances and Similarities in Intuitionistic Fuzzy Sets, Studies in Fuzziness and Soft Computing Vol. 307 (Springer, 2014).
Wu, X. et al. A monotonous intuitionistic fuzzy TOPSIS method with linear orders under two novel admissible distance measures. IEEE Trans. Fuzzy Syst. 31, 1552–1565 (2023).
Li, D. F. Decision and Game Theory in Management with Intuitionistic Fuzzy Sets, Studies in Fuzziness and Soft Computing Vol. 308 (Springer, 2014).
Xu, Z. Some similarity measures of intuitionistic fuzzy sets and their applications to multiple attribute decision making. Fuzzy Optim. Decis. Mak. 6(2), 109–121 (2007).
Burillo, P. & Bustince, H. Entropy on intuitionistic fuzzy sets and on interval-valued fuzzy sets. Fuzzy Sets Syst. 78(3), 305–316 (1996).
Grzegorzewski, P. Distances between intuitionistic fuzzy sets and/or interval-valued fuzzy sets based on the Hausdorff metric. Fuzzy Sets Syst. 148(2), 319–328 (2004).
Hung, W. L. & Yang, M. S. Similarity measures of intuitionistic fuzzy sets based on Hausdorff distance. Pattern Recogn. Lett. 25(14), 1603–1611 (2004).
Hwang, C. M. & Yang, M. S. New construction for similarity measures between intuitionistic fuzzy sets based on lower, upper and middle fuzzy sets. Int. J. Fuzzy Syst. 15, 359–3661 (2013).
Xiao, F. A distance measure for intuitionistic fuzzy sets and its application to pattern classification problems. IEEE Trans. Syst. Man. Cybern. Syst. 51(6), 3980–3992 (2021).
Szmidt, E. & Kacprzyk, J. Distances between intuitionistic fuzzy sets. Fuzzy Sets Syst. 114(3), 505–518 (2000).
Yang, Y. & Chiclana, F. Consistency of 2D and 3D distances of intuitionistic fuzzy sets. Expert Syst. Appl. 39(10), 8665–8670 (2012).
Shen, F. et al. An extended intuitionistic fuzzy TOPSIS method based on a new distance measure with an application to credit risk evaluation. Inf. Sci. 428, 105–119 (2018).
Song, Y. et al. A new approach to construct similarity measure for intuitionistic fuzzy sets. Soft Comput. 23(6), 1985–1998 (2019).
Wu, X., Wang, T. & Chen, G. et al Strict intuitionistic fuzzy distance/similarity measures based on Jensen-Shannon divergence. IEEE Trans. Syst. Man Cybern. Syst. arxiv:2207.06980 (2022).
Mahanta, J. & Panda, S. A novel distance measure for intuitionistic fuzzy sets with diverse applications. Int. J. Intell. Syst. 36(2), 615–627 (2021).
Atanassov, K. T. Intuitionistic Fuzzy Sets: Theory and Applications, Studies in Fuzziness and Soft Computing Vol. 35 (Springer, 1999).
Park, J. H., Lim, K. M. & Kwun, Y. C. Distance measure between intuitionistic fuzzy sets and its application to pattern recognition. J. Korean Inst. Intell. Syst. 19(4), 556–561 (2009).
Hatzimichailidis, A. G., Papakostas, G. A. & Kaburlasos, V. G. A novel distance measure of intuitionistic fuzzy sets and its application to pattern recognition problems. Int. J. Intell. Syst. 27(4), 396–409 (2012).
Yang, Y. & Chiclana, F. Intuitionistic fuzzy sets: Spherical representation and distances. Int. J. Intell. Syst. 24(4), 399–420 (2009).
Chen, S. M., Cheng, S. H. & Lan, T. C. Multicriteria decision making based on the TOPSIS method and similarity measures between intuitionistic fuzzy values. Inf. Sci. 367, 279–295 (2016).
Cheng, C., Xiao, F. & Cao, Z. A new distance for intuitionistic fuzzy sets based on similarity matrix. IEEE Access 7, 70,436-70,446 (2019).
Own, C. M. Switching between type-2 fuzzy sets and intuitionistic fuzzy sets: An application in medical diagnosis. Appl. Intell. 31(3), 283–291 (2009).
Wei, C. P., Wang, P. & Zhang, Y. Z. Entropy, similarity measure of interval-valued intuitionistic fuzzy sets and their applications. Inf. Sci. 181(19), 4273–4286 (2011).
Mondal, K. & Pramanik, S. Intuitionistic fuzzy similarity measure based on tangent function and its application to multi-attribute decision making. Glob. J. Adv. Res. 2(2), 464–471 (2015).
Szmidt, E. & Kacprzyk, J. A similarity measure for intuitionistic fuzzy sets and its application in supporting medical diagnostic reasoning. In International Conference on Artificial Intelligence and Soft Computing-ICAISC 2004 (eds Rutkowski, L., Siekmann, J. H., Tadeusiewicz, R. et al.) 388–393 (Springer, 2004).
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Nos. 11601449 and 71771140), the Key Natural Science Foundation of Universities in Guangdong Province (No. 2019KZDXM027), the Natural Science Foundation of Sichuan Province (No. 2022NSFSC1821), and the Ministry of Science and Technology of Taiwan under Grant MOST 111-2118-M-033-001.
Author information
Authors and Affiliations
Contributions
X.W., H.T., Z.Z. and L.L. give conceptualization. H.T., L.L., G.C. and M.S.Y give methodology. X.W., H.T. and Z.Z. have formal analysis. X.W., H.T., Z.Z. and L.L. write the original draft preparation. X.W., G.C. and M.S.Y. give review and editing. G.C. and M.S.Y are supervision. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wu, X., Tang, H., Zhu, Z. et al. Nonlinear strict distance and similarity measures for intuitionistic fuzzy sets with applications to pattern classification and medical diagnosis. Sci Rep 13, 13918 (2023). https://doi.org/10.1038/s41598-023-40817-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-40817-y
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
