
Abstract
Slime mold algorithm (SMA) is a nature-inspired algorithm that simulates the biological optimization mechanisms and has achieved great results in various complex stochastic optimization problems. Owing to the simulated biological search principle of slime mold, SMA has a unique advantage in global optimization problem. However, it still suffers from issues of missing the optimal solution or collapsing to local optimum when facing complicated problems. To conquer these drawbacks, we consider adding a novel multi-chaotic local operator to the bio-shock feedback mechanism of SMA to compensate for the lack of exploration of the local solution space with the help of the perturbation nature of the chaotic operator. Based on this, we propose an improved algorithm, namely MCSMA, by investigating how to improve the probabilistic selection of chaotic operators based on the maximum Lyapunov exponent (MLE), an inherent property of chaotic maps. We implement the comparison between MCSMA with other state-of-the-art methods on IEEE Congress on Evolution Computation (CEC) i.e., CEC2017 benchmark test suits and CEC2011 practical problems to demonstrate its potency and perform dendritic neuron model training to test the robustness of MCSMA on classification problems. Finally, the parameters’ sensitivities of MCSMA, the utilization of the solution space, and the effectiveness of the MLE are adequately discussed.
Similar content being viewed by others


Introduction
Meta-heuristic strategies are increasingly becoming a widespread way of working out all types of mathematical optimization problems. Unlike the preceded traditional heuristics, meta-heuristics can cope with an extensive and more complex range of problem situations because of their generality, which does not depend on the specific conditions of a particular problem1,2. ‘Meta’ can be comprehended as a kind of transcendence and extension of the original object. A meta-heuristic is more of an idea or concept developed on heuristic methods. Strictly speaking, a heuristic is a fixed solution contrived by the characteristics of a given problem to get a better solution. Meta-heuristic is a kind of abstract procedure, that constructs a set of universal process or methodology.
Nowadays, as the computational scale and complexity of various engineering application problems increase, the original traditional optimization algorithms and heuristics may no longer confront the current practical situation3,4, e.g., image classification and simulation, building load-bearing structure optimization, solar energy parameter optimization, etc5. These problems are multi-dimensional, nonlinear, multi-fitting NP-hard problems6, which have posed great challenges to the existing computing system. As a result, computer scientists expect to innovate the whole computing system from hardware and software aspects7,8. This is where meta-heuristics arise as an upgrade to algorithms from the underlying architecture. Meta-heuristics are a refinement of heuristics, which are the product of combining stochastic algorithms and local search. They create a process that can get rid of local optimum and carry out a robust search in the solution space by coordinating the interaction between local improvement and operational strategies9. During the procedure, search strategies are accustomed to acquire and master the information to find the approximate optimal solution effectively. Therefore, the operating mechanism of the meta-heuristic is not overly dependent on the organizational pattern of a certain situation. This principle can be diffusely applied to the combinatorial optimization and function calculation10,11.
In meta-heuristics, swarm intelligence has attracted considerable research interest and attention in the fields of optimization, computational intelligence, and computer science in recent years12. It exhibits computational intelligent behavior through simple cooperation between each intelligence and shows much stronger selection ability than an individual in the case of optimal selection13,14. Ant colony optimization (ACO) is a cornerstone achievement in the development of systematic swarm intelligence theory. Dorigo et al. investigated the real ant colony route planning and the use of biological pheromone mechanism, using pheromone concentration as a quality index to guide individuals to the shortest path15. The next generation population ascertains the superior route throughout the whole space according to the pheromone intensity of the previous generation. The greater the pheromone intensity in a certain route, the more presumably the individuals are to draw in that route. The route with the highest pheromone can be considered as the optimal solution sought by the algorithm16,17. ACO has good global search capability and is widely used in many combinatorial optimization areas18. For example, Gao et al. improved the k-means clustering idea into ACO and proposed a clustering ant colony algorithm which has got considerable achievements in solving dynamic location routing problems19. Particle swarm optimization (PSO) differs from ACO in that PSO pays more attention to the decision-making learning direction and collaborative information sharing when all particles traverse the solution space20,21. In per period iteration, per particle is obliged to do a learning judgment on whether to modify the route which is predicated on fitness to measure the global optimal solution and the local optimal solution. Thus, PSO accelerates the convergence rate by extracting the current best, and the particle population has a high convergence rate in terms of exploration. A wide range of PSO-based related study has now been implemented in complex systems, traditional optimization, and even large-scale engineering problems22. The above two algorithms are some of the supreme widespread and successful population intelligence algorithms. And then a whole bunch of meta-heuristic algorithms with swarm intelligence ideas emerged, including firefly algorithm23, whale optimization algorithm (WOA)24, flower pollination algorithm25, artificial bee colony algorithm26, etc.
Considering the strengths of swarm intelligence, we choose the slime mold algorithm (SMA)27 as the underlying algorithm, which is also a biological heuristic algorithm with swarm intelligence proposed recently. SMA is enlightened by the exclusive motor feedback mechanism of slime molds. This algorithm simulates the feedback mimicry of slime bacteria spreading food information, resulting in the exploration of the best pathway to obtain energy. This process considers the adaptive bidirectional feedback of the bio-information waves, allowing the algorithm to strike a counterbalance during the search process. There were also several algorithms for microbial mimicry before. For example,28 put forward a slime network founded on an ant colony system to solve the high-dimensional traveler problem. Monismith et al.29 draw on the five life forms of biological amoebae to construct an artificial neural network (ANN)-based initial lattice to solve the problems of graph theory and generative networks30. Unlike these similarly named bacterial algorithms, SMA primarily uses the adjustment of weights in the feedback to model three different biofeedback morphologies of slime molds. Extensive experimental and algorithmic variant studies demonstrate the robustness and effectiveness of this algorithm in solving optimization problems31.
Due to the outstanding performance of SMA in the field of stochastic optimization, numerous exceptional SMA variants have been widely applied to address diverse problems. Houssein et al.32 proposed a multi-objective variant of SMA that utilized an information archive to store the Pareto-optimal solutions obtained by individuals in the multi-objective search space. This approach yielded remarkable simulation results on CEC2020 multi-objective benchmark functions and the automotive spring spiral problem. Hu et al.33 addressed the issue of induced concentration in the slime molds population by employing a dispersal foraging strategy, effectively maintaining the population diversity. This improved algorithm was successfully applied to feature selection problems in data mining, efficiently identifying optimal information features while maintaining high classification accuracy. In34, a hierarchical-guided architecture was introduced to enhance SMA for solving mobile robot path planning problems. Experimental results in multiple environments demonstrated that the path constructed by the hierarchical slime molds population exhibited higher smoothness and faster computation speed. These application examples showcase the unique global stochastic optimization capabilities of SMA. By leveraging the automatic optimization capability and global exploration advantages of slime mold individuals, different improvement strategies are introduced to guide slime molds in performing efficient optimization behaviors, and there is still much ongoing work to explore its relevant properties.
Slime molds dynamically adapt their foraging behavior based on bio-wave feedback on the food. When biofeedback indicates that this area has higher food pheromones, the probability that they will stay in this area and perform a spread search becomes higher. When slime molds engage in this local search behavior, we note that this unique behavior is well aligned with the characteristics of chaotic local search. Among the existing meta-heuristic algorithms, chaotic maps are somewhat generalizable. They can be used extensively in population initialization and in adjusting cross-variance operators to perform an effective local search, thereby increasing the probability of discovering the best solution35,36. Therefore, we consider adding chaotic maps to the local search of slime molds, aiming to strengthen the capability of this algorithm in local search and further meliorate the stochasticity and ergodicity of the slime molds search behavior.
At the same time, we focus on the essential property of chaotic maps – the maximum Lyapunov exponent (MLE). This coefficient is a crucial criterion for determining whether a system is performing a chaotic motion. We select the most appropriate chaotic map based on the value of MLE, giving the chance for a second selection of chaotic local operator, and ameliorating the overall capability of the entire algorithm in local exploration. In this study, we creatively put forward an MLE-based multiple chaotic slime mold algorithm (MCSMA). We for the first time select suitable chaotic maps according to their MLE relevance and use a multi-chaotic roulette wheel to incorporate these maps into the local search pattern of slime molds, thus realizing a better balance of exploitation and exploration. To verify the performance of MCSMA, extensive experiments are conducted based on 29 IEEE CEC2017 benchmark function optimization problems, 22 IEEE CEC2011 practical applications, and 7 real-world classification problems. Statistical results show that MCSMA significantly outperforms its peers. Additionally, the parameters’ sensitivities of MCSMA, the utilization of the solution space, and the effectiveness of the MLE are systematically discussed to show more insights into MCSMA.
The remaining part is set up by follows: “Brief description of SMA” section roughly introduces the behavioral pattern and search features of slime molds in the underlying algorithm SMA. In “Multi-chaotic local search operator” section, we describe the nature and features of the chaotic local operator in detail. In “MLE‑based multiple chaotic SMA” section, we explain exhaustively how to adapt the MLE-based weight adjustment mechanism into the chaotic operator. In addition, the whole running process of MCSMA is introduced. The experimental data and results of MCSMA on several test function sets are given and analyzed in “Experimental analysis” section. “Discussion” section conducts a sufficient discussion on the optimal parameters of MCSMA, the movement pattern of the population, and the effectiveness of the MLE-based adjustment mechanism. Finally, we summarize and outline the work done in “Conclusion” section, giving some thoughts on future development.
Brief description of SMA
Biologists discovered early on that slime molds, as single-celled organisms, exhibit incredible intelligence. Nakagaki et al.37 devised an interesting maze experiment in which oats were placed at certain points in the maze, and it was found that the slime molds always chose the path that required the least amount of energy and obtained a sufficient amount of food. Tero et al.38 later used slime molds to simulate the railway network throughout the Tokyo area. Experiments showed that in complex combinatorial optimization problems, the network formed by the connection of slime molds approximated the optimal path in engineering. Therefore, the scientists believe that this intelligence of the slime molds can be used in the design of transport networks as well as in complex large-scale simulation experiments.
SMA has thoroughly analyzed the mechanisms of cytoplasmic flow and venous structure change as the slime molds search for food. Slime molds sense food through a tight network of veins, and when the veins sense a food source, a biofeedback wave is propagated by a biological oscillator. When the molds sense this feedback wave, they increase the cytoplasmic concentration in the vein, and the thickness of the vein is positively correlated with the cytoplasmic concentration. The more abundant the food signal, the greater the cytoplasmic concentration and the richer the network of veins leading to food, thus establishing the optimal pathway for foraging. Moreover, when faced with different quality food sources, the slime molds can also rationalize the veins leading to food according to the optimal theory. This algorithm learns the adaptive feedback search strategy and special mechanisms of the slime molds and constructs an efficient mathematical optimization model. SMA includes seek nutrition, wrap up nutrition, and biological oscillator processes.

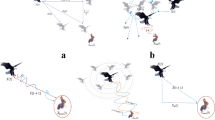
Visualization schematic of SMA in 2D and 3D.
Seek nutrition
Microbes generally seek nutrition through residual pheromones in the air and along the pathways. Figure 1 is illustrated to understand the visual model of slime molds in seeking nutrition. The asymptotic search behavior of slime molds for nutrition can be formulated by:
where each M can be considered as an individual slime mold, and these individuals refresh their positions in compliance with the contemporary optimal individual \(M^{*}\), and three related parameters \(\alpha\), \(\beta\) and W. \(M_{i}(t)\), \(M_{j}(t)\) represent two randomly selected slime individuals, t implies the number of iterations, and W is a weight learned from the foraging behavior of the slime. \(\alpha\) is calculated as a balanced parameter based on the number of iterations, and \(\beta\) is a decreasing linear coefficient from 1 to 0. r is a random value in [0,1]. q is defined by \(q=\tanh \vert F_i-F^{*}\vert\). \(F_i\) indicates the fitness value of M. \(F^{*}\) denotes the optimal fitness of the entire iterations.
The distribution of \(\alpha\) is in the range \([-a, a]\). The value of a is derived from an inverse hyperbolic tangent function regarding the number of iterations, taking values in the range (-1, 1). a can be expressed by:
where \(t_{max}\) is the maximum iteration number. Through this approach, an approximate activity range is assigned to slime molds in each generation.
From Fig. 1, we can see the updated changes in the search position of the slime individuals in the two-dimensional and three-dimensional space. By adjusting the parameters of Eq. (1), the slime molds can investigate in random directions within the search space, forming a free-angle search vector that enhances the probability and capacity of individuals to find the optimal solution. This process stimulates the wrapped venous network formed by the slime bacteria as they approach the food source, searching for everything possible about the food.
Wrap up nutrition
When the venous network receives enough nutrition information, the bio-oscillator begins to fluctuate information that can regulate the concentration of cytoplasm and biological structure. This process is dedicated to learning about this feedback pattern of slime molds that regulates the structure of biological tissues. W in Eq. (1) is expressed mathematically as a positive and negative feedback coefficient between venous tissues and food pheromone concentrations. The definition of W is outlined as follows:
where \(F_{b}\) means the fitness of the best contemporary individual and \(F_{w}\) means the fitness of the worst contemporary individual. The logarithmic function is accustomed to balancing the rate of change of the values and preventing extreme values of the frequency of change. Because of the uncertainty of slime mold’s biological activity, a rand factor is attached to model randomness. \(Case-Half\) means the case where \(F_i\) is at the hand half ranking of the population. Obviously, when the concentration and quality of nutrition are high, the likelihood of a slime mold individual staying in the region for an all-encompassing search becomes greater; when the concentration and quality of nutrition are low, the individual moves to another region.
Biological oscillator
To better understand the changes in the slime molds of mucilaginous bacteria upon receipt of bio-waves, SMA uses W, \(\alpha\) and \(\beta\) to go for the regulation mechanism of the oscillator. \(\alpha\) and \(\beta\) are two coefficients that both oscillate randomly within a certain interval and converge to zero. The mutual modulation of these two parameters gives a good indication of the biological stochastic selection behavior of the mucilage. When an individual has found the optimal solution in space, the slime molds may still allocate part of their population to other areas, enhancing the probability of finding the missing food source. It is also an instinct of the organism to find all food sources possible, rather than getting stuck in a localized food area. Furthermore, by adjusting the bidirectional feedback coefficients W, the frequency of the bio-wave in the presence of different concentrations of food pheromones can be changed. When good quality food sources founded by venous tissues, W will be cranked up to change the cytoplasmic concentration and approach the food source more efficiently; when the quality and concentration of food are not good in some areas, W will be lessened to slow down the tissue extension of the region and save energy, so as to choose food sources more efficiently.
The SMA intuitively visualizes the efficient foraging biological activity of slime molds. Nevertheless, the journey to find the best food source is not straightforward and influenced by various factors that may inevitably lead to the trap of local optimal. Therefore, we need to consider adding a number of mechanisms to correct this trend and remedy some of the algorithm’s flaws.
Multi-chaotic local search operator
The order of the macro universe is built on the disorder of the micro world. This harmony contains underlying laws that existing paradigms cannot describe, explain, or predict. Chaos theory is to study the local uncertainty and the stability of the whole, the order hidden in the unpredictable phenomenon. Most scenarios we encounter in reality are non-linear systems that cannot be solved by conventional experience and theory, with complex interactions between elements within the system that are difficult to quantify. Chaotic systems generally have the following three typical characteristics:
-
(1)
If a system makes a chaotic motion, the orbit of the system is disproportionately sensitive to tiny changes in the initial state, or a small change produced in one part of the system can lead to a violent reaction in the whole system.
-
(2)
Chaotic systems have fractal properties, that is, the system is irregular in its overall structure from the beginning, but the degree of irregularity of the system is repetitive at different scales.
-
(3)
Systems always exhibit a state of mutual antagonism and coupling between static equilibrium features and the tendency to fall into non-predetermined patterns.
Chaotic maps
Chaotic map can be conceived as a function used to generate random chaotic arrays. In the field of evolutionary computation, algorithms often require pseudo-random number generators for population initialization, but sometimes the results are not satisfactory. It is found that due to the unpredictability and ergodicity of chaotic maps, better results are attained by replacing pseudo-random generators with chaotic maps39. In our study, 12 representative chaotic maps are chosen, taking one of the well-known maps Chebyshev as an example, whose chaotic map formula is:
where x and n belongs to the set of integers. O denotes the order of the Chebyshev map. When O is greater than or equal to 2, no matter how approximate the initial value is selected, the resulting iterated sequence has no correlation, i.e., the system is in chaos. Figure 2 shows the histogram of the distribution produced by 12 different chaotic maps.

The histogram of the distribution produced by 12 different chaotic maps.
Maximum Lyapunov exponent
The maximum Lyapunov exponent is an essential quantitative indicator for measuring and determining whether a non-linear system is undergoing chaotic motion. For chaotic systems, trajectories initiated by two enormously close initial variables produce exponential separation over time, and the MLE is defined to quantify the quantity that describes this separation rate.
Assume a 1-dimensional discrete dynamical system: \(x_{n+1}=\textrm{f}\left( x_{n}\right)\). After n iterations, whether the initial two points are separated or close in space depends on the derivative \(\left| \frac{d f (x_{n})}{d x_{n}}\right|\). For an initial variable point \(x_{0}\), we set the change in position caused by each iteration to have an exponential separation rate of \(\Lambda\). Then the initial distance \(\Delta\) between the two points after iteration becomes:
Taking the limits \(\Delta \rightarrow 0\), \(n \rightarrow \infty\), then Eq. (5) can be deformed to
The above equation can be simplified as:
From this we can generalize this definition to all problems and obtain the defining equation for the maximum Lyapunov exponent as:
where \(\delta \textbf{Y} (t)\) and \(\delta \textbf{Y} _ {0}\) represent the trajectories of motion caused by two initial values in the dynamical system, respectively. It is intuitive to see that if \(\Lambda\) is greater than or equal to 0, that means that no matter how close the initial two tracks are, the difference in their trajectories will be exponentially magnified in space with time. So we can draw two conclusions: (1) If a system has at least one MLE greater than 0, the system does the chaotic motion. (2) The MLE of periodic motion or steady state must be at least non-positive.
According to the above definitions, we can obtain the MLE of each chaotic map separately, and the value of numbers are summarized in Table 1. We consider the MLE as a fundamental characteristic of the different chaotic sequences and will discuss later how this fundamental property can be incorporated into the consideration of the local operators.
Chaotic local search operator
Meta-heuristic algorithms are an interactive association of global explore strategy and local search operator in essence. The research and improvement of search strategies over the years are essential to allow the algorithm to explore the solution space more rationally and get free from the problem of being induced by local optima. Following the chaotic properties introduced earlier, the offspring generated by a chaotic map are randomly and irregularly varying. If an algorithm is assigned enough computational time and computational resources, we can approximately believe that the algorithm is able to travel the whole search area and find the target solution we want. But once the problem is of high dimensionality and high computational complexity, it will require a huge amount of resources and optimization time, which is not in line with the aim of computer science to pursue efficiency. Thus, the utilization of chaotic search operators in small search spaces and specific phases can be a significant way to enhance search performance. To date, this operator has been applied to extensive algorithms for global search strategies, and many fruitful achievements have been realized.
Alatas et al.40 proposed an improved harmony search algorithm by replacing the random sequence in the initialization of harmony search algorithm with each of seven different chaotic maps and tests the performance of seven chaotic combination algorithms in solving optimization problems. It was found that this approach improved the performance of the algorithms in global search. Yuan et al.41 combined the quantum thinking and chaotic local search in traditional artificial bee colony algorithm. In contemporary iterations, the swarm performs a disorderly search around the vicinity of the current best food source found, which can well circumvent the algorithm being captured by the local optimum through the jumpiness of chaos. Gao et al.42 reformed the local search-based differential evolution by chaos, embedding multi-chaos local search operator based on success probability in the mutation process. It effectively improves the inherent defects of most differential evolution variants, namely premature convergence and unstable performance. In addition, four chaotic variants are proposed based on different applications of chaotic local search, and the effectiveness of multi-chaos is demonstrated on a sufficient number of test problems.
Many examples prove that chaotic local search has a comprehensive and successful application in meta-heuristic algorithms. Scholars have used chaotic local search in a variety of ways to help algorithms improve the capacity of exploring and exploiting the search space, avoid the interference of local optima, and perform efficient and accurate convergence behavior.
MLE-based multiple chaotic SMA
In this section, we specify the sources of inspiration for MCSMA and the operation mechanism of the algorithm. The three questions of how to include a chaotic local search in SMA, which way to call chaotic maps, and how to improve the local operator are explained in detail. The flowchart and pseudo-code of MCSMA are also introduced.
Inspiration
In the previous section, we have described the biological mechanisms and mathematical modeling process of SMA in detail. The biological activities of single-celled organisms appear to be disorderly and random, but there are also characteristic laws behind them. For a microscopic individual such as a slime mold, the most challenging task is how to find food information accurately in a vast space. Similarly, for a good algorithm, the most critical problem to be solved is how to efficiently find that optimal solution over the entire solution space8,43. In SMA, the individuals of the population update and judge their position by employing positive and negative feedback coefficients. From Eq. (1), we can assume that the individuals perform two kinds of ordered activities in the solution space under the adaptation of the feedback parameters. When no food information is detected temporarily, individuals adjust their corresponding positions to each other, move and search towards the region of the angle between two individuals, or possibly continue exploring along the direction of their own vector. However, in this process, the globally optimal solution we need may be hidden in the vacant solution space of these two alternative paths. We cannot rule out this possibility, so the question of how to allow individuals of the population to search more fully through the entire solution space is an urgent problem to be solved. The tremendous advantage of chaotic motion is that completely disordered motion in a given region can significantly compensate for the algorithm’s weakness in local exploration. From the perspective of exploration and exploitation of the overall search space, the slime mold individuals in SMA demonstrate satisfactory exploration capabilities, allowing the population to explore all potential regions. However, SMA lacks strong exploitation of specific regions, which increases the risk of search stagnation and premature convergence. Considering the advantages of chaotic search, we contemplate how to incorporate chaotic local search operator into the feedback mechanism of slime individuals for food information. By incorporating chaotic local search operators to perturb individual trajectories in an unordered manner, we aim to enhance the algorithm’s specialized exploitation capabilities in promising regions, aiding in achieving desired optimization results.
MCSMA
Herein, we present an ameliorated algorithm MCSMA based on the predatory behavior of slime molds and multiple chaotic local operators for the first time. The underlying algorithm SMA has proven to be a strong global search algorithm. As the number of iterations increases, the distribution of populations in the search space exhibits a cross-searching motion track. Especially in the earlier phase of the iterations, the renewal of individual positions fluctuates very sharply in the early stages because of the parameters \(\alpha\) and W. Thus SMA can rapidly converge at an early stage and explore a significant portion of the entire exploration space. Subsequent iterations of individuals converge in regions that are likely to be globally optimal and conduct disordered exploration. This ensures the global search capability of the algorithm. But when \(r \ge q\), the population will engage in selective behavior, with some of the slime heading towards other regions, and some other individuals keeping their original direction for oscillatory search. Along this search trajectory, there is a possibility that the optimal solution may be neglected in space, or captured by a local optimum in a small region. We therefore consider the insertion of a powerful exploitation mechanism in this process, namely the chaotic local operator.
In a local operator using a single map, the operator generates the next generation of new individuals, employing a contemporary globally optimal individual \(E_{k}\). The formula for chaotic search can be expressed as:
where \(\widetilde{E_{k}}\) denotes the potential individual to replace the contemporary globally optimal. \(V_{U}\) is the upper bound vector of the population, and \(V_{L}\) is the lower bound vector. \(\phi\) can be understood as a spatial scale that can represent the chaotic search. \(\omega _{k}\) represents the distribution variables generated by the chaotic map in this iteration. In the contemporary iteration, if \(\widetilde{E_{k}}\) has a superior fitness than \(E_{k}\), it renews \(E_{k}\) in the next generation of search behavior. This renewal reflects the behavior of an individual, which performs a chaotic expansion in space.
From42, we learn that using multiple chaotic maps can often achieve better results than using single chaos. The combinations of plural chaotic maps can incorporate different dynamical properties and keep the dynamics changing in space. There are various combinations in the algorithm including parallel, sequential, and permutation, and so on. In this study, we use the traditional roulette wheel idea, where the selection probability of each individual is proportional to its fitness value, and choose 12 chaotic maps with different dynamics to form a probabilistic roulette wheel. However, different from the preceding methods, we take the ideology of meritocracy as the guide to determine the chaotic map used in the iterations. For a given problem, if a particular chaotic map selected by the meritocracy improves the algorithm more in a certain iteration, then we can assume that this chaotic map may have good compatibility with the problem and its dynamics can better help the algorithm access this problem. In the next iteration, the probability of selecting this superior map in the previous generation is incremented to find the most suitable chaotic search operator.
Using this roulette strategy based on the principle of meritocracy enables the algorithm to find the best chaotic operator to solve the test problem quickly. However, parts of the chaotic maps may be given great weight in the initial iteration, resulting in a lack of competition for other chaotic maps in subsequent iterations. This will lead to the algorithm missing some relatively superior maps and suffering from the waste of computational resources and poor robustness. Based on this consideration, we focus on the maximum Lyapunov exponent, a property of chaos itself, aiming to investigate the best chaotic local operator from the fundamental properties of chaotic maps. A probabilistic compensation mechanism is introduced to give the operator a second chance to choose the suitable map based on a meritocratic roulette wheel selection.
The maximum Lyapunov exponent is an index that measures the tendency of a chaotic system to move over time. Twelve different chaotic maps have their MLE values. We can define a correlation coefficient \(C_{i j}\) based on the MLE, formulated as:
where rand is a random coefficient; \(L_{i}\) and \(L_{j}\) represent the MLE values of two distinct random chaotic mappings. \(C_{i j}\) is the correlation coefficient normalized to the MLE values of any two chaotic maps with values distributed in (0, 1). Based on this, we can construct a 12*12 matrix as shown as follows:
This matrix represents the nature of the association between the individual chaotic maps. Once we have chosen the most appropriate contemporary chaotic map, it is reasonable to believe that the chaotic map with the closest value of its MLE also has a better improvement on the target problem. Therefore, we give the optimal and sub-optimal maps a conditioning weight in the probability adjustment of roulette selection. The adjustment weights \(W_{k}\) are defined as follows:
where s is a parity ordinal number that takes the value 1 or 2. index(s) represents the index position in the roulette wheel of the chosen optimal and sub-optimal maps. \(\xi\) is a distribution of chaotic weights in interval (0, 2). When adjusting the weights for the optimal chaotic map, as it is the highest priority map, s takes the value of 1. When adjusting the weights for the sub-optimal map, as viewed as a sub-optimal chaotic choice, this map is compensated with a smaller adjustment weight, s takes the value of 2. Figure 3 illustrates this weight adjustment process. Relying on adjusting s and the correlation \(C_{i j}\) values, we can rationalize the span of roulette weights to select the most appropriate chaotic map and avoid premature formulation of the map map by the chaotic local operator.

The process of adjusting the span of the weighted wheel.
The schematic pseudo-code of MCSMA is illustrated in Algorithm 1. The general flowchart of MCSMA is depicted in Fig. 4. The entire operation flow of MCSMA can be generally summarized as follows:
-
(1)
MCSMA starts to generate the slime molds \(M_i\) and evaluate the fitness.
-
(2)
Initialize twelve equivalent spans of roulette and generate correlation coefficient matrix C, mutation probability z.
-
(3)
According to the feedback mechanism of slime molds, the algorithm selects and updates \(M_i\) based on Eq. (1).
-
(4)
When the algorithm matches the pre-defined scenario, MCSMA enters the phase of chaotic local search and utilizes roulette wheel selection to select the chaos operator by Eq. (9).
-
(5)
Update the span of roulette by Eq. (12) and re-tune the chaotic local operator.
-
(6)
Repeat the above steps until reaching the terminal condition.
In summary, we establish a selection weight adjustment mechanism based on the connection of MLE to optimize the chaotic local operator. Based on the kinematic properties of chaotic behavior, a plausible screening mechanism is established to guide the search pattern of the local operator. In addition, considering the search behaviors and trajectories of slime mold individuals in MCSMA, we expect to explore a general way to refine the underlying search logic of the algorithm and guide the algorithm to improve its reliability throughout the search process44,45.
Ethical approval
No human or animal subjects were involved in this experiment.


A general flow chart of MCSMA.
Experimental analysis
To evince the capability of the proposed algorithm MCSMA, numerous test sets were selected for experimentation. To validate the effectiveness of MCSMA on different kinds of optimization problems in different dimensions, 29 problems from CEC2017 were elected to run experiments and data analysis. CEC2017 contains 2 unimodal problems (F1, F2), 7 multimodal problems (F3-F9), 10 mixed-state problems (F10-F19) and 10 combinatorial optimisation problems (F20- F29). The Wilcoxon rank-sum test, the convergence curve graph, and the box-and-whisker chart were applied to analyze the experimental data in a multifaceted way. Meanwhile, for the propose of examining the algorithm’s ability to handle real-world problems, we experiment with 22 real-world problems from CEC2011 and ANN training.
Experimental set up
For CEC2017: The proportion of population N is regulated by 100, The dimension of problems D is designed with three sets of data, i.e., 30, 50, and 100, respectively. This operation is to examine the effectiveness of MCSMA when facing high-dimensional problems and whether it have defects such as overfitting. The maximum number of fitness evaluation is determined as \(10000*D\). To obtain a more credible experimental result, we position the number of independent runs at 51. The search range is arranged in the interval \([-100, 100]\).
For CEC2011: The size of population N is regulated by 100. Because the optimization model is learned from the actual problem, each problem has its adapted dimension. The specific situation is summarized in Table 7. We set 30 as the number of runs because the optimization time required for the test problems is time-consuming.
The experimental equipment is configured with 16GB RAM and a 3.00 GHz Intel(R) Core(TM) i5-7400 CPU, and the test platform was MATLAB.
Comparison analysis on CEC2017
In this set of benchmark experiments, we select HHO46, WOA, MFO47, SSA48, SCA49 and GLPSO50 as the comparison targets in addition to the underlying algorithm SMA. These meta-heuristic algorithms are inspired by the biological phenomena in nature or mathematical laws in recent years. For example, HHO simulates the teamwork and chase patterns of a falcon hunting a rabbit, and has excellent advantages in solving single-target problems. We expect to test the performance of MCSMA under different circumstances with these algorithms that possess different comparative advantages. The particular parameter setting is listed in Table 2.
The first assessment criterion is the Wilcoxon rank-sum test, which is a two-sample t-test51. The median confidence interval is set to \(95\%\) to infer the distribution of the overall values when comparing two mutually independent data sets. Table 3 exhibits the final compared experimental data of the seven control groups in 30 dimensions. “MEAN” describes the median of the data sample set. “STD” refers to the standard deviation, which is an important statistic to measure the degree of dispersion of the data. The Wilcoxon test generally has three types of ranking comparison results: “\(+\)”, “\(\approx\)”, and “−”, indicating MCSMA performs better, tied, or worse than it comparison algorithms, respectively. In this table, the symbols “W/T/L” indicate the total number of three results of win, tied, and lose, respectively. The data group in bold means that the data is the optimal value for the same group under this test function. The comparison result between MCSMA and the basic algorithm SMA is 19/6/4, which indicates that this improved method we proposed has a great advancement on the algorithm. The comparison results between MCSMA and the other six meta-heuristic algorithms are 28/1/0, 29/0/0, 29/0/0, 20/3/6, 29/0/0, and 16/7/6, respectively. This positive result indicates that MCSMA achieves superior performance on most of the tested problems. We compare the p-values obtained from the Wilcoxon rank-sum test with the significant level of 0.05 to determine the presence of significant differences in the experimental results. Table 4 provides a detailed comparison of p-values for the 30-dimensional case. The symbols following the specific p-values represent the final outcome of the experimental comparison. It is evident that the obtained p-values compared with the original and other powerful meta-heuristic are substantially lower, indicating a significant improvement in the performance. In addition, we examine the stability and performance of MCSMA in both 50 dimensions and 100 dimensions, summarized in Table 5 and Table 6, respectively. It is noticeable that the MCSMA’s prime value and the number of wins increases as the dimensionality magnifies. This trend proves the stability of MCSMA on high-dimensional problems. When other algorithms fall into overfitting or local optimum, MCSMA still maintains stronger robustness.
The second assessment criterion is the convergence diagram of different algorithms52. This test is mainly to visually match the convergence speed with performance of the algorithm. As displayed in Fig. 5, the horizontal coordination represents the number of evaluations on different function problems, and the vertical coordination represents the average optimization error that the algorithm can achieve. We choose six different types of functions F11, F12, F16, F23, F24, and F29 to show the convergence ability of MCSMA. The curve slope of MCSMA is the smallest in the first period of evaluation, which indicates that MCSMA is able to converge to desired solutions at a faster rate. The lowest point of the MCSMA curve is always the smallest of the six functions, verifying that MCSMA has the capability of grasping the best solution. In summary, MCSMA possesses a fast convergence speed and excellent performance.
The third evaluation criterion is the box-and-whisker chart. This chart is mainly used to evaluate the quality of the solutions obtained by the algorithm. It can visually furnish the distribution characteristics between different data groups and manifest their differences. As displayed in Fig. 6, the lines inside the box depict the median of the data, and the upper and lower edges represent the quartile spacing boxes. The smaller spacing between the edges of the box indicates that the overall distribution of the data is in a confidence interval, which suggests the better robustness of the algorithm. The upper and lower black lines outside the box refer to the maximum and minimum values of the algorithm’s solution, respectively. The box is located in the lower space, suggesting the better solution quality of the algorithm. The red crosses are the outliers in the data, and the fewer outliers indicate the more stable performance of the algorithm and the higher confidence of the data. Since outliers often have an opposing influence on the distribution and characteristics of a set of data and affect the analysis and judgment of the data, we have to consider this factor cautiously. On the six test functions we selected, it is clear that MCSMA consistently has the lowest spatial position and the smallest spacing. This illustrates that MCSMA has the highest solution quality and the strongest stability in this control group.
In summary, we carry out a series of comparison experiments under different dimensions on the CEC2017 standard test set and analyze the experimental results using three distinct data evaluation methods53. The analysis shows that MCSMA is quite competitive in terms of the overall solution quality, convergence rate, performance stability and robustness of the algorithm.

The exhibition of convergence comparison on Functions 11, 12, 16, 23, 24, and 29.

The exhibition of box-and-whisker diagrams on Functions 11, 12, 16, 23, 24, and 29.
Engineering practical problem test
In the past, the research of intelligent algorithms mainly focused on mathematical theory and simulation modeling. With the rising productivity needs of society, whether an algorithm is superior should also focus on its ability to solve real engineering problems and create social value54,55,56. To test the capability of MCSMA on some large-scale complex real-world problems, we choose CEC2011 as a test set. CEC2011 contains 22 test functions, encompassing real-world problems in various domains. Table 7 reveals the details of these real-world problems, including dimensions, constraint types, and modeling processes.
Table 8 shows the comparison results between MCSMA and the other six meta-heuristic algorithms. The comparison result of “W/T/L” with the original SMA is 8/8/6. Although MCSMA does not achieve a significant advantage, it obtains the most number of optimal values, indicating that the method we proposed for improvement still has some performance boost in solving complex real-world problems. Compared with other meta-heuristic algorithms, MCSMA shows considerably satisfactory comparison results. In particular, MCSMA achieves the most optimal values for some multimodal high-dimensional test problems, indicating that MCSMA has considerable potential and advantages for some complex application problems. Therefore, MCSMA can be applied to the present engineering and practical fields with desirable results tentatively in the future57,58.
Performance test on artificial neural model training
Currently, neural networks have become a cornerstone technology in solving image processing and classification prediction problems. Starting from the most primitive linear threshold artificial neural network models, many new network models with innovative structures and simulations of human brain structures have emerged59,60. Dendritic neuron model(DNM) is a single neural network model that simulates the primitive dendritic structure of a nerve cell. This model uses logical operators and sigmoid functions to transmit signals and simulates the connections and propagation between neurons. Because of its specific synaptic hierarchy, DNM can circumvent some common defects of traditional propagation networks61. In this section, we use DNM to examine the feasibility and performance of MCSMA on some general classification problems.
The network structure of DNM is simulated from the cytosolic conformation of human brain neurons, which consists of four levels: synapse, dendrite, cell membrane, and soma. Figure 7 illustrates the general structure of a simple fully connected dendritic neural network. Similar to actual brain cells, the main role of synapses is to receive and hold messages. In DNM, the sigmoid function is selected as the activation function for each synapse. The sigmoid function protects the integrity of the data while compressing it. Thus, setting the sigmoid function as the activation function in the synaptic layer can effectively protect and process the data signal to a large extent62. Similar to brain potential signals, there are two states of cellular potentials depending on the input signal received by the synaptic layer: inhibition and excitation. The two states are represented and regulated by two learnable parameters in the sigmoid function.
The dendritic hierarchy is the core structure of the entire network model, where each node on each neural branch receives signals from the synapse. The process can be considered as a nonlinear mapping. According to brain science, the processing and responses produced by each response center in the cerebral cortex after receiving signals from neuronal stimuli can be regarded as a primitive multiplicative law. Between each dendritic node, multiplicative logic operations are used to prepare the signal for subsequent processing. After this, the signals from each dendritic branch are concentrated at the membrane-layer structure. At the membrane layer structure, all signals are summed linearly and the total signal is then transmitted to the cytosol for the nucleus to make the final decision. In the soma layer, a threshold exists within the cell body to determine whether the neuron emits an electrical signal. After the total potential signal processed by the first three layers exceeds the value, the neuron generates an excitation potential and transmits that excitation potential to other neural units. That is a complete single-neuron processing process63.
Potential signals in the dendritic layer will be selectively pruned according to the hierarchical structure and functional properties of DNM. When the output of any nerve node is 0, that dendritic nerve is considered an invalid dendrite to retain the robust unit with the strongest impact on the soma body. Due to the electrical principle of the system, the operation of DNM can be well represented using logic circuit symbols as shown in Fig. 8. Figure 8 illustrates a complete structural process of DNM training. When the input data is fed into the model as activation potentials, the final soma output is obtained through filtering, pruning, and other operations.
We pick 7 different types of classification problems from the UC Irvine machine learning repository, containing medical, biological, physical, and other fields. Table 9 summarizes the relevant properties about the data sets and the training. In this training experiment, we choose MCSMA, SMA, HHO, SSA, and a classical back-propagation algorithm(BP) as the comparison training algorithms. BP is the most popular and successful neural network learning algorithm. It utilizes two phases of forward and backward propagation to achieve a predetermined target outcome64. To ensure reliable and fair experimental results, the number of evaluations is 30000, the sample ratio of training samples to test samples is 1:1. Table 10 lists the results of the four compared algorithms on the training and test sets. The experimental data are measured by the overall accuracy. From the comparison results, MCSMA achieves the best accuracy on the five test sets, indicating that the proposed algorithm achieves the most correct sample classifications on multiple classification problems.
Through the above real-world problem test sets and neural network training experiments, we can conclude that MCSMA can cope well with some real-world practical optimization problems and classification problems.

A schematic diagram of the fully connected dendritic neuron model.

The general learning procedure of dendritic neural network model.
Discussion
In this section, we perform a comprehensive discussion about the parameter and properties of MCSMA. Furthermore, an analysis regarding the effectiveness of our proposed MLE-based selection mechanism is presented, comparing it with traditional chaotic improvement methods. We hope to have a valid analysis and discussion of the underlying operational structure of the algorithm.
Parameter discussion
In MCSMA, whether the algorithm performs a chaotic local search is determined by an evaluation value. When \(rand \le \eta\), the mold individuals move forward or backward along the original trajectory; when \(rand \ge \eta\), the population starts a chaotic local search and performs a chaotic oscillatory motion along the original motion trajectory. With the complementarity of such different search behaviors, the omission of the solution space is complemented and the local trap is jumped out. \(\eta\) is a random value that can take the value of (0, 1], and it may have an impact on the performance of the algorithm. We could not determine the specific value of \(\eta\) that would result in the maximum improvement in the ability of MCSMA, so we designed a set of controlled experiments. Ten real values of \(\eta\) are taken at 0.1 intervals and tested on the CEC2017 problem set.
Table 11 reveals the performance under 10 different parameters of MCSMA on CEC2017 test sets. We perform a Friedman test on ten sets of data to arrive at a final ranking. When \(\eta\) takes 0.5, the algorithm has the first Friedman rank and performs the best. By analyzing the data, we can conclude that the algorithm performs relatively well when \(\eta\) takes 0.4, 0.5, and 0.6. This indicates that taking values for the median allows for a good coupling of the chaos operator and the slime mold search. Therefore, we set the parameter \(\eta\) of MCSMA as 0.5 in this study.
Population movement trajectory analysis
For meta-heuristics, the algorithm maintains the population updates and motions to perform a probe in the solution space. The size and motion of the population make a direct difference in the robustness and performance of the algorithm. Individuals in the population intelligence first explore the space extensively, looking for more information to decide whether they can obtain sufficient rewards. When many individuals always choose a certain region or follow a specific trajectory, it is likely to be trapped into a local optimum. At this point, intelligent individuals are needed to develop optimal solutions or decisions around known search regions in which to help the algorithm escape the trap of local optimal. The issue of how to reasonably design the algorithm’s strategy at different stages is a critical issue.

The population movement trajectory on F6, F10 and F26.
We visually observe the different stages of the algorithm by the search trajectory of the population. Figure 9 shows the trajectory and trend of the MCSMA on the three typical problems (F6, F10, and F26) of the CEC2017 test set for the slime population. On the multi-peaked function F6, we can see that the slime molds are randomly spread throughout the space at the beginning of the iteration. This is a search process, with the population searching aimlessly for information about possible food. When the number of iterations reaches 5, we can see that the mucilaginous population rapidly clusters into areas of possible optimal solutions. As the number of iterations increases, the individual slime bacteria arrange their search strategy according to the available information and implement a chaotic local search around this region. From \(t = 5\) to \(t = 10\), this process interprets the exploitation of a particular region by a population of slime bacteria. We can clearly see the population-specific search strategy of MCSMA in the two different types of test functions, F10 and F26. This indicates that the search strategy of MCSMA rationally designs the trajectory of the population to achieve the coordination of search and exploitation.
Validity of MLE
When algorithms use multiple improvement mechanisms, it is difficult to determine which of these improvements on the algorithm is beneficial. Each algorithm has extremely complex mathematical workings behind it, and there is a degree of black box effect. In this section, we hope to prove that this new MLE-based probabilistic adjustment mechanism we proposed has a genuine improvement on the algorithm.
To investigate the impact of MLE of interest on the chaotic behavior perturbation of the search system, we design a group of controlled ablation experiments. In this set of experiments, we verify the effectiveness of this MLE-based roulette selection mechanism by using MCSMA and a multi-chaotic slime mold algorithm (CSMA) as control groups. CSMA also uses a success probability roulette mechanism to involve chaotic maps, but there is no quadratic weight probability adjustment based on MLE. The local search operator selects chaotic maps based solely on the quality of solutions without considering the guiding significance of the mathematical properties of chaotic maps on the selection weights. Table 12 manifests the comparative outcomes between MCSMA and CSMA on CEC2017. From Table 12, it can be observed that in the case of unimodal problems F1 and F2, the inclusion of MLE seems to have a negative effect, indicating that excessive chaotic perturbations are not beneficial for the evolutionary search of the population in extremely low-dimensional unimodal problems. However, in almost all multimodal and complex hybrid problems, MCSMA achieves optimal values and demonstrates significantly prior performance compared to CSMA without the MLE-based optimization of weights. The consequence of “W/T/L” shows the validity of the design of MLE-based roulette. This can prove that the proposed strategy of reasonably choosing the best chaotic local operator based on the inherent properties of chaos, i.e., MLE, is genuinely valid.
Analysis of time complexity
The evaluation of algorithmic time complexity aims to estimate how the execution time and resource usage of a program increase with the growth of input size. In initial setting, N denotes the population size; D is the dimension scale; T represents the number of iterations. The time complexity of MCSMA can be calculated by follows:
-
(1)
The process of initializing population needs \(O(N\times D)+O(N)\).
-
(2)
Generating correlation coefficient matrix C needs O(N).
-
(3)
The fitness evaluation and sorting of individuals costs \(O(N\times T\times (1+log N))\).
-
(4)
Updating the \(M_{i}\) requires \(O(N\times T\times D)\).
-
(5)
The phase of chaotic local search costs \(O(N\times T\times D)\).
So the time complexity of MCSMA can be summarized as \(O((N+2N\times T)\times D+2N+N\times T\times (1+logN))\). According to27, the original SMA’s time complexity is \(O((1+N\times T)\times D+N\times T\times (1+logN))\). It can be observed that the time complexity of both algorithms remain at the linear-logarithmic order, indicating that our proposed improvement method does not lead a significant increase in program complexity and does not require sacrificing computational resources for performance improvements.
Conclusion
In this paper, we propose a novel algorithm, MCSMA, that incorporates a multi-chaotic local operator while retaining the unique sticky bacteria feedback search in SMA. We consider for the first time the fundamental property of chaotic motion, i.e., the maximum Lyapunov exponent, and add it as an evaluation criterion to the meritocratic multi-chaotic roulette wheel. By constructing the MLE correlation matrix of the chaotic map as a moderating factor for probabilistic adjustment, the most efficient and suitable chaotic operator for the algorithm is screened. We compare the performance of MCSMA on three different types of test sets, i.e., IEEE CEC2017, CEC2011, and a challenging neural network learning task. Experimental results verify the effectiveness and feasibility of MCSMA.
It has been a pressing challenge for computational intelligence to effectively address the need of compensating for some specific drawbacks of algorithms while avoiding compromising their advantages12,65. We aspire to construct a general enhancement mechanism to improve the local exploitation capability of existing algorithms, and the issue of how to optimize and generalize the structure of such chaotic local operators is a focus of future work. It is also worthwhile to apply MCSMA to other areas, such as control scheduling, industrial modeling, and data processing66,67.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Cully, A. & Demiris, Y. Quality and diversity optimization: A unifying modular framework. IEEE Trans. Evol. Comput. 22, 245–259 (2017).
Miikkulainen, R. & Forrest, S. A biological perspective on evolutionary computation. Nat. Mach. Intell. 3, 9–15 (2021).
Tang, J., Liu, G. & Pan, Q. A review on representative swarm intelligence algorithms for solving optimization problems: Applications and trends. IEEE/CAA J. Autom. Sinica 8, 1627–1643 (2021).
Hua, Y., Liu, Q., Hao, K. & Jin, Y. A survey of evolutionary algorithms for multi-objective optimization problems with irregular Pareto fronts. IEEE/CAA J. Autom. Sinica 8, 303–318 (2021).
Abualigah, L. et al. Meta-heuristic optimization algorithms for solving real-world mechanical engineering design problems: A comprehensive survey, applications, comparative analysis, and results. Neural Comput. Appl. 34, 4081–4110 (2022).
Mohamed, M. A. E., Nasser Ahmed, S. & Eladly Metwally, M. Arithmetic optimization algorithm based maximum power point tracking for grid-connected photovoltaic system. Sci. Rep. 13, 5961 (2023).
Li, B., Wu, G., He, Y., Fan, M. & Pedrycz, W. An overview and experimental study of learning-based optimization algorithms for the vehicle routing problem. IEEE/CAA J. Autom. Sinica 9, 1115–1138 (2022).
Yu, Y. et al. Scale-free network-based differential evolution to solve function optimization and parameter estimation of photovoltaic models. Swarm Evol. Comput. 2022, 101142 (2022).
Wang, Y., Yu, Y., Gao, S., Pan, H. & Yang, G. A hierarchical gravitational search algorithm with an effective gravitational constant. Swarm Evol. Comput. 46, 118–139 (2019).
Wang, J. et al. Multiobjective multiple neighborhood search algorithms for multiobjective fleet size and mix location-routing problem with time windows. IEEE Trans. Syst. Man Cybern.: Syst. 51, 2284–2298 (2019).
Lei, Z., Gao, S., Gupta, S., Cheng, J. & Yang, G. An aggregative learning gravitational search algorithm with self-adaptive gravitational constants. Expert Syst. Appl. 152, 113396 (2020).
Dokeroglu, T., Sevinc, E., Kucukyilmaz, T. & Cosar, A. A survey on new generation metaheuristic algorithms. Comput. Ind. Eng. 137, 106040 (2019).
Lei, Z., Gao, S., Zhang, Z., Zhou, M. & Cheng, J. MO4: A many-objective evolutionary algorithm for protein structure prediction. IEEE Trans. Evol. Comput. 26, 417–430 (2021).
Aboud, A. et al. DPb-MOPSO: A dynamic Pareto bi-level multi-objective particle swarm optimization algorithm. Appl. Soft Comput. 129, 109622 (2022).
Bonabeau, E., Dorigo, M. & Theraulaz, G. Inspiration for optimization from social insect behaviour. Nature 406, 39–42 (2000).
Dorigo, M. Optimization, learning and natural algorithms. Ph. D. Thesis, Politecnico di Milano (1992).
Dorigo, M., Di Caro, G. & Gambardella, L. M. Ant algorithms for discrete optimization. Artif. Life 5, 137–172 (1999).
Wang, Z., Gao, S., Zhang, Y. & Guo, L. Symmetric uncertainty-incorporated probabilistic sequence-based ant colony optimization for feature selection in classification. Knowl.-Based Syst. 256, 109874 (2022).
Gao, S., Wang, Y., Cheng, J., Inazumi, Y. & Tang, Z. Ant colony optimization with clustering for solving the dynamic location routing problem. Appl. Math. Comput. 285, 149–173 (2016).
Lei, Z., Gao, S., Wang, Y., Yu, Y. & Guo, L. An adaptive replacement strategy-incorporated particle swarm optimizer for wind farm layout optimization. Energy Convers. Manage. 269, 116174 (2022).
Nguyen, T. A. A novel approach with a fuzzy sliding mode proportional integral control algorithm tuned by fuzzy method (FSMPIF). Sci. Rep. 13, 7327 (2023).
Xia, X. et al. Triple archives particle swarm optimization. IEEE Trans. Cybern. 50, 4862–4875 (2020).
Yang, X.-S. Firefly algorithm, stochastic test functions and design optimisation. Int. J. Bio-inspired Comput. 2, 78–84 (2010).
Mirjalili, S. & Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67 (2016).
Yang, X.-S. Flower pollination algorithm for global optimization. In International Conference on Unconventional Computing and Natural Computation, 240–249 (Springer, 2012).
Karaboga, D. & Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Global Optim. 39, 459–471 (2007).
Li, S., Chen, H., Wang, M., Heidari, A. A. & Mirjalili, S. Slime mould algorithm: A new method for stochastic optimization. Futur. Gener. Comput. Syst. 111, 300–323 (2020).
Qian, T., Zhang, Z., Gao, C., Wu, Y. & Liu, Y. An ant colony system based on the physarum network. In International Conference in Swarm Intelligence, 297–305 (Springer, 2013).
Monismith, D. R. & Mayfield, B. E. Slime mold as a model for numerical optimization. In 2008 IEEE Swarm Intelligence Symposium, 1–8 (IEEE, 2008).
Uncuoglu, E. et al. Comparison of neural network, Gaussian regression, support vector machine, long short-term memory, multi-gene genetic programming, and M5 Trees methods for solving civil engineering problems. Appl. Soft Comput. 129, 109623 (2022).
Ng, K., Lee, C. K., Chan, F. T. & Lv, Y. Review on meta-heuristics approaches for airside operation research. Appl. Soft Comput. 66, 104–133 (2018).
Houssein, E. H. et al. An efficient slime mould algorithm for solving multi-objective optimization problems. Expert Syst. Appl. 187, 115870 (2022).
Hu, J. et al. Dispersed foraging slime mould algorithm: Continuous and binary variants for global optimization and wrapper-based feature selection. Knowl.-Based Syst. 237, 107761 (2022).
Hu, G., Du, B. & Wei, G. HG-SMA: Hierarchical guided slime mould algorithm for smooth path planning. Artif. Intell. Rev. 56, 1–61 (2023).
Liu, Y. et al. Chaos-assisted multi-population SALP swarm algorithms: Framework and case studies. Expert Syst. Appl. 168, 114369 (2021).
Jia, D., Zheng, G. & Khan, M. K. An effective memetic differential evolution algorithm based on chaotic local search. Inf. Sci. 181, 3175–3187 (2011).
Nakagaki, T., Yamada, H. & Tóth, Á. Maze-solving by an amoeboid organism. Nature 407, 470–470 (2000).
Tero, A. et al. Rules for biologically inspired adaptive network design. Science 327, 439–442 (2010).
Caponetto, R., Fortuna, L., Fazzino, S. & Xibilia, M. G. Chaotic sequences to improve the performance of evolutionary algorithms. IEEE Trans. Evol. Comput. 7, 289–304 (2003).
Alatas, B. Chaotic harmony search algorithms. Appl. Math. Comput. 216, 2687–2699 (2010).
Yuan, X., Wang, P., Yuan, Y., Huang, Y. & Zhang, X. A new quantum inspired chaotic artificial bee colony algorithm for optimal power flow problem. Energy Convers. Manage. 100, 1–9 (2015).
Gao, S. et al. Chaotic local search-based differential evolution algorithms for optimization. IEEE Trans. Syst. Man Cybern.: Syst. 51, 3954–3967 (2019).
Yu, K. et al. A correlation-guided layered prediction approach for evolutionary dynamic multiobjective optimization. IEEE Trans. Evol. Comput. 2022, 1–1. https://doi.org/10.1109/TEVC.2022.3193287 (2022).
Siddique, A., Vai, M. I. & Pun, S. H. A low cost neuromorphic learning engine based on a high performance supervised SNN learning algorithm. Sci. Rep. 13, 6280 (2023).
Azizi, M., Baghalzadeh Shishehgarkhaneh, M., Basiri, M. & Moehler, R. C. Squid game optimizer (SGO): A novel metaheuristic algorithm. Sci. Rep. 13, 1–24 (2023).
Heidari, A. A. et al. Harris hawks optimization: Algorithm and applications. Futur. Gener. Comput. Syst. 97, 849–872 (2019).
Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl.-Based Syst. 89, 228–249 (2015).
Mirjalili, S. et al. SALP swarm algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 114, 163–191 (2017).
Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 96, 120–133 (2016).
Gong, Y.-J. et al. Genetic learning particle swarm optimization. IEEE Trans. Cybern. 46, 2277–2290 (2015).
Carrasco, J., García, S., Rueda, M., Das, S. & Herrera, F. Recent trends in the use of statistical tests for comparing swarm and evolutionary computing algorithms: Practical guidelines and a critical review. Swarm Evol. Comput. 54, 100665 (2020).
Wang, K. et al. Spherical search algorithm with adaptive population control for global continuous optimization problems. Appl. Soft Comput. 132, 109845 (2022).
Tosa, Y., Omae, R., Matsumoto, R., Sumitani, S. & Harada, S. Data-driven automated control algorithm for floating-zone crystal growth derived by reinforcement learning. Sci. Rep. 13, 1–9 (2023).
Liang, J. et al. A survey on evolutionary constrained multi-objective optimization. IEEE Trans. Evol. Comput. 27, 1–1 (2022).
Ma, L. et al. Learning to optimize: Reference vector reinforcement learning adaption to constrained many-objective optimization of industrial copper burdening system. IEEE Trans. Cybern. 52, 12698–12711 (2021).
Yu, Y. et al. A population diversity-controlled differential evolution for parameter estimation of solar photovoltaic models. Sustain. Energy Technol. Assess. 51, 101938 (2022).
Pham, M., Yuan, Y., Rana, A., Osher, S. & Miao, J. Accurate real space iterative reconstruction (RESIRE) algorithm for tomography. Sci. Rep. 13, 5624 (2023).
Wang, Y., Gao, S., Zhou, M. & Yu, Y. A multi-layered gravitational search algorithm for function optimization and real-world problems. IEEE/CAA J. Autom. Sinica 8, 94–109 (2020).
Gao, S. et al. Fully complex-valued dendritic neuron model. IEEE Trans. Neural Netw. Learn. Syst. 34, 1–14 (2023).
Lee, C., Hasegawa, H. & Gao, S. Complex-valued neural networks: A comprehensive survey. IEEE/CAA J. Autom. Sinica 9, 1406–1426 (2022).
Xu, Z. et al. Dendritic neuron model trained by information feedback-enhanced differential evolution algorithm for classification. Knowl.-Based Syst. 233, 107536 (2021).
Yu, Y. et al. Improving dendritic neuron model with dynamic scale-free network-based differential evolution. IEEE/CAA J. Autom. Sinica 9, 99–110 (2021).
Gao, S. et al. Dendritic neuron model with effective learning algorithms for classification, approximation, and prediction. IEEE Trans. Neural Netw. Learn. Syst. 30, 601–614 (2018).
Kassaymeh, S. et al. Backpropagation Neural Network optimization and software defect estimation modelling using a hybrid SALP Swarm optimizer-based Simulated Annealing Algorithm. Knowl.-Based Syst. 244, 108511 (2022).
Wang, Z. et al. Information-theory-based nondominated sorting ant colony optimization for multiobjective feature selection in classification. IEEE Trans. Cybern. 53, 1–14. https://doi.org/10.1109/TCYB.2022.3185554 (2022).
Eiben, A. E. & Smith, J. From evolutionary computation to the evolution of things. Nature 521, 476–482 (2015).
Zhan, Z.-H., Shi, L., Tan, K. C. & Zhang, J. A survey on evolutionary computation for complex continuous optimization. Artif. Intell. Rev. 55, 59–110 (2022).
Acknowledgements
This research was partially supported by the Japan Society for the Promotion of Science (JSPS) KAKENHI under Grant JP22H03643, Japan Science and Technology Agency (JST) Support for Pioneering Research Initiated by the Next Generation (SPRING) under Grant JPMJSP2145, and JST through the Establishment of University Fellowships towards the Creation of Science Technology Innovation under Grant JPMJFS2115.
Author information
Authors and Affiliations
Contributions
J.Y.: Writing—original draft, methodology, conceptualization, software. Y.Z.: Formal analysis, writing—review and editing, conceptualization. T.J.: Methodology, visualization. Z.L.: Data curation, writing—reviewing and editing. Y.T.: Formal analysis, validation. S.G.: Writing—review and editing, resources, project administration, supervision.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, J., Zhang, Y., Jin, T. et al. Maximum Lyapunov exponent-based multiple chaotic slime mold algorithm for real-world optimization. Sci Rep 13, 12744 (2023). https://doi.org/10.1038/s41598-023-40080-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-40080-1
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
