
Abstract
The concept design evaluation phase of the new product launch is extremely important. However, current evaluation information relies mainly on the a priori knowledge of decision makers and is subjective and ambiguous. For this reason, a conceptual design solution decision model based on Pythagorean fuzzy sets in a big data environment is proposed. Firstly, we use the ability of big data to mine and analyze information to construct a new standard for product concept design evaluation in the big data environment. Secondly, the Pythagorean fuzzy set (PFS), Analytic Hierarchy Process (AHP), and Technique for Order Preference by Similarity to Ideal Solution (TOPSIS) are integrated into a decision model. AHP, extended by the Pythagorean fuzzy set, is used to determine the weights of new conceptual design criteria in a big data environment. The Pythagorean fuzzy TOPSIS is used to prioritize alternative conceptual design solutions. The feasibility of the approach is proven with a practical case, the generalizability of the method is confirmed with two descriptive digital cases, and the reliability, validity, and superiority of the process are demonstrated with sensitivity analysis, comparative analysis, and computational complexity analysis.
Similar content being viewed by others
Introduction
The full life cycle of a product can be divided into seven stages: “concept, detail, development, debugging, release, iteration and obsolescence”1. As such, product development begins with the design of the concept. Specifically, concept generation and evaluation are two key steps in the product design phase to achieve the best possible design outcome, with the former generating a conceptual design with possibilities and the latter determining the final choice of design candidates2. It is well known that successful concept evaluation leads to perhaps disruptive innovation and huge success, whereas poor conceptual evaluation can not only increase design costs and development cycles but also cause additional revisions, and iterations and even jeopardize overall product development success3. Given its impact on all succeeding stages in the process of product development, concept evaluation is considered to be one of the most significant activities in product design4.
Evaluation of product concept designs is a complex procedure that requires consideration of technological developments, design constraints, user satisfaction and other factors. One of the commonest methods of concept design evaluation is Multi-Criteria Decision Making (MCDM). In traditional conceptual design evaluation methods, the results depend on the subjective judgement of the decision maker, and the designer’s judgement of the conceptual design is subject to uncertainty and lag due to slow research feedback. The majority of current cases show that the evaluation criteria and performance assessment of concept designs rely more on the personal judgement and qualitative descriptions of experienced experts. However, these judgements and descriptions are often subjective, imprecise and sometimes inconsistent due to individual cultural backgrounds, life experiences, logical thinking and other factors. Unreliable decision data early in the design process will lead to almost irreparable design flaws5. Extensive research on decision making for conceptual design has found that Jing and others6 and others have summarised MCDM methods for conceptual solutions into three types, one is to build pairwise comparison matrices to obtain the weights of evaluation criteria by calculation, for example, BWM (Best Worst Method)7 and AHP (Analytic Hierarchy Process)8 can deal with the extent to which different assessment criteria influence each other, but are susceptible to the subjective preferences of decision makers. The alternate approach is to combine the assessment figures across various criteria to generate a summed assessment value for each assessment option, and to calculate the combined indicator values to derive the option ranking results, like VIKOR (Vlsekriterijumska Optimizacija I Kompromisno Resenje)9,10 and TOPSIS (Technique for Order Preference by Similarity to Ideal Solution)11, this type of method does not capture the impact of each evaluation criterion on the overall design. The third type is characterised by an order of preference, which identifies the strengths and weaknesses of different solutions to arrive at the best solution, such as ELECTRE (Elimination Et Choix Traduisant La Realité)12 and PROMETHEE (Preference Ranking Organization Method for Enrichment Evaluation)13,14, but they cannot deal directly with uncertainties and have limitations in solving realistic decision problems. To address these issues, Zadeh15 proposed a fuzzy set theory to deal with imprecise or vague information. And Yager16 proposed Pythagorean fuzzy sets (PFS) which are an extensible version of fuzzy sets and intuitionistic fuzzy sets, which can give experts much more liberty to represent judgments on uncertainty and vagueness of decision problems. Akram et al.17 combined HYBRID TOPSIS and ELECTRE I solutions with Pythagorean fuzzy information to investigate failure modes and risk factors in impact analysis, PFS extends the linguistic variable hierarchy of IFS (Intuitionistic Fuzzy Sets) to increase the fuzzy information and the acceptable space of data, Pythagorean fuzzy hybrid Order of Preference by Similarity to an Ideal Solution (PFH-TOPSIS) was proved to be a source of highly effective and simple way.
AHP and TOPSIS, due to their ease of computation, unlimited and flexible compatibility with other techniques, and their strong capabilities in analyzing complex decisions and dealing with multiple decision makers, the integrated AHP-TOPSIS approach can take full benefit of these advantages when faced with multiple evaluation criteria and contradicting parameters in product concept design evaluation. The classical AHP-TOPSIS is suitable for numerically precise scenarios, however, in real evaluation environments, many cases cannot be outlined with precise values. In the assessment process, the semantic concept is often a gradual process rather than an abrupt change. For example, if a rating of 5 is meant to be “superior”, then a rating of 5 is “excellent” and a rating of 4.9 is “not superior”, but in reality, in the user’s understanding, a rating of 5 is not very different from a rating of 4.9. In practice, there is no big gap between 5 and 4.9 in users’ understanding18. Pythagorean fuzzy sets can be used to depict linguistic variables and express fuzziness, and integrating Pythagorean fuzzy sets into AHP-TOPSIS can enhance the objectivity of product concept design evaluation results.
Technically, assessment criteria can be summarized based on expert experience, literature review4, and questionnaires18, however, the use of generic data will further increase the uncertainty and imprecision of assessment results. With the further development of social media, wearable devices, and smart manufacturing, massive quantities of databases are coming from all directions. The potential use of vast sums of data is quickly making big data and big data analytics a powerful tool for research teams to develop new applications in new fields. For example, the introduction of big data into healthcare has made a huge leap from traditional to digital healthcare. Researchers have used big data to develop large real medical data platforms19, build medical data analysis models for intelligent identification and diagnosis of diseases20, and also design medical big data ecosystems on Hadoop big data platforms to provide individualized patient health control and also facilitate the management of patients by medical staff21. The combination of data analytics and mobile cloud computing has spawned new research in the field of transportation. Studies have shown that fuzzy Markov prediction models can also be used to forecast efficient short-term traffic22,23,24, offering better route mapping and mobility of cargo and people for better informed and more efficient decisions for transport regulation or development and maintenance of transport structures. Another interesting application area is sentiment analysis, where applying big data to online learning users for sentiment analysis can optimize the learning experience25. The way decision makers make decisions are constantly changing and now relies heavily upon creating In today’s competitive environment, companies are not only interested in the technology of big data analytics, but increasingly in how they can use the data they have to create potential value and use this information effectively in their strategies, operational decisions, and innovation processes.
In summary, to attenuate the influence of subjectivity and ambiguity in product concept design evaluation and to achieve comprehensiveness and accuracy in product concept design evaluation, we propose a systematic Pythagorean fuzzy set-based group decision making method by combining Pythagorean fuzzy set-based AHP and TOPSIS in an e-business big data environment, which combines big data, Pythagorean fuzzy sets, AHP and TOPSIS. First, we use a web crawler to crawl big data of users’ online reviews, and then analyze the online reviews using a mean clustering algorithm (K-means) to establish new evaluation criteria. Then, Pythagorean fuzzy sets are fused with hierarchical analysis to calculate the weights of each evaluation criterion; finally, Pythagorean fuzzy sets are combined with ideal solutions to calculate and rank the evaluation results. Based on this method, more accurate and objective data can be obtained for the evaluation of product concept design. The method proposed in this study can also provide a quantitative reference for manufacturers and designers to screen out product design solutions with high user satisfaction.
The motivations for the study in this paper are:
-
(1)
We incorporate a thorough and efficient Pythagorean fuzzy set-based approach for product concept design evaluation under a big data environment.
-
(2)
In the proposed approach, the evaluation messages of decision makers are provided by Pythagorean fuzzy linguistic variables.
-
(3)
The suggested approach incorporates the superiority of big data in treating messages, the superiority of Pythagorean fuzzy sets in dealing with issues of uncertainty, the superiority of AHP among multiple criteria, and the superiority of TOPSIS in decision problems.
-
(4)
In the process of product concept design evaluation, PF-AHP-TOPSIS quantifies qualitative information, reduces the serious gap between objective assessment and subjective environment, and makes the PF-AHP-TOPSIS model more logical and useful.
The achievements of the present study are as listed below:
-
(1)
Providing a highly efficient, rational, and functional decision-making method for group multi-criteria decision making in a big data environment. Based on big data technology, user preferences and usage habits can be captured in real-time and precisely, thus driving product concept design evaluation.
-
(2)
Integrating PFAHP and PFTOPSIS (PF-AHP-TOPSIS) methods as decision models to attenuate the subjectivity and fuzziness of decision makers in the decision-making process. A wealth of expansion of the TOPSIS method in theory and practice.
-
(3)
The comparative analysis with PFAHP-FTOPSIS model and PFAHP-PFVIKOR model proves the usefulness and superiority that the raised decision model and the sensitivity analysis is executed by altering the binary weights of the evaluation criteria to ensure the stability of the proposed decision model. Through simulation experiments, it is justified that the proposed model has low computational complexity, and the applicability of the proposed method is further illustrated with the assistance of two numerical cases in addition to the example study.
The rest of this paper is structured and presented below: “Literature review” section, the introduction of proposed product concept design evaluation method in “Proposed design concept evaluation method” section, a practical case study and two illustrative numerical cases for the proposed method are in “An empirical case study” section, sensitivity analysis, comparative analysis, computational complexity analysis, advantages and discussion are in “Analysis and discussion” section, and conclusions and clarification of recommendations for future research in “Conclusion” section.
Literature review
Concept design evaluation methodology
Conceptual design evaluation can determine the final choice of alternatives and is the classical MCDM decision problem. In recent years, investigators presented diverse solutions to the concept design evaluation issue. Nghiem and Chu26 proposed to combine AHP with ELECTRE I method to solve the problem of evaluating and weighting various criteria and sub-criteria. Wang and Hsueh27 proposed a hybrid framework combining AHP, the Kano model, and DEMATEL (Decision Making Trial and Evaluation Laboratory) for incorporating client preference and sensing into product configuration. which incorporates customer preference and perception into product configuration) for discovering ideas for next-generation products. Worsdorfer28 developed an analytical model based on AHP that prior to evaluation quantifies the fitness of innovative production concepts at a given scale. The developed model was used to select more promising production alternatives, providing both a fuller and faster procedure for deciding on investments. Prabhat et al.29 assigned quantitative weights to user requirements (customer requirements) and product feature quality level (feature quality level) by using AHP assessment, assigning structured weights as opposed to the haphazard values given to designers, and then the structural weights given are applied to both PROMETHEE, which selects the best concept for product development considering both the user and manufacturer perspectives. Hayat et al.30 developed a combination of soft set, TOPSIS, and Shannon entropy in order to derive the optimal concept at a range of requirement tiers a promising framework is developed based on soft sets, TOPSIS, and the Shannon entropy. Quan et al.31 proposed the KE-GRA-TOPSIS method, which integrates KE (Kansei Engineering), AHP, entropy, game theory, and GRA-TOPSIS (Grey Relation Analysis—TOPSIS) five methods. It can help customers to select the most suitable product according to their subjective needs. Arbelaez et al.32 used crowdsourcing augmented reality environment for the evaluation of the esthetics of the product at the concept stage. Liu et al.33, in a scientific survey, reviewed breakthrough innovation research, integrated concept evaluation methods from related fields, and developed a breakthrough evaluation method to be employed for product evaluation at the concept design stage.
However, the evaluation data for the conceptual design decision process is mainly determined by the subjective judgment of the decision maker, and precise values can hardly adequately reflect the fuzzy and subjective nature of the decision process. In order to attenuate the influence of these uncertainties on conceptual design evaluation, fuzzy sets have been introduced into conceptual design decision models. Table 1 shows how fuzzy sets and their combined methods have been studied in the field of product design in recent years.
Although the methods of concept design evaluation have been continuously optimized, the evaluation criteria used in these studies are still mainly based on traditional survey methods such as expert opinion34,36,44, literature review4,34,37,41 and questionnaires18,35, which are feasible but have obvious drawbacks such as time-consuming, slow feedback, low user involvement, and small research These methods are feasible but have obvious drawbacks, such as time-consuming, slow feedback, low user participation, and small scope. A prerequisite for effective methods to obtain accurate and objective product concept evaluation results is the establishment of comprehensive and objective evaluation criteria. Without accurate assessment criteria as a basis for evaluation, the scientific validity of product concept design evaluation will be compromised. Big data provides new opportunities and research conditions for product design, and research methods that explore entirely new areas from small-scale data are being gradually replaced by big data parsing45. Studies have shown that online review data can be used as a source of information that represents a wide range of user perspectives and is more reliable than user data obtained from other sources, and that product manufacturers can also use online reviews to make quick and favorable decisions and gain a competitive edge in the marketplace46,47,48. Compared to the biases in traditional methods, web-based text mining can directly, quickly, and extensively collect user opinions and obtain a meaningful and complete vocabulary, and the vocabulary collected and the large amount of data involved can compensate for the biases in traditional methods. These words can directly and effectively reflect information about the user’s preferences for the product, which in turn facilitates the evaluation process.
Looking at the above studies, we find fewer studies applying Pythagorean fuzzy sets to product concept design evaluation, both from a fuzzy set methodology perspective (recent studies combining fuzzy sets used as shown in Table 1) and from an application perspective. Given the superior performance of Pythagorean fuzzy sets in dealing with uncertainty problems, the superiority of AHP in dealing with hierarchical relationships of evaluation criteria, the advantages of TOPSIS in decision problems, and the outstanding performance of Big Data in acquiring information and information analysis, this paper proposes a systematic, Pythagorean fuzzy set-based MCDM method in a Big Data environment to fill the gaps in existing research.
Pythagorean fuzzy set
Pythagorean fuzzy sets are extensibility of fuzzy sets and intuitionistic fuzzy sets, breaking the limitation that the total of the affiliation and insubordination degrees of intuitionistic fuzzy sets must be equal to 1, dealing with uncertainty more reliably and reducing imprecision and ambiguity in the decision making in the course16. In a Pythagorean fuzzy set, the sum of the squares of the affiliation and non-affiliation degrees is less than or equal to 1, which is defined as follows:
Definition 1
49: Let set X be a given universe of discourse, and P be a Pythagorean fuzzy set (PFS) on the universe of discourse:
where, u(x) and v(x) respectively represent the membership degree and non-membership degree of xϵP in the universe X, and satisfy \(\forall\) xϵX, u(x) and v(x)ϵ[0,1], then:
For \(\forall\) xϵX, the calculation formula of hesitation degree is:
Definition 2
49: Let p = P(u,v) be any Pythagorean fuzzy number (PFN), then:
Definition 3
50: Let α = (uα,vα) be PFN, then Eq. (6) is defined as the score function of
Definition 4
35: Let αi = (uαi,vαi)(i = 1,2) be PFN:
-
(i)
If s(α1) < s(α2) then α1 ≺α2.
-
(ii)
If s(α1) ≈ s(α2) then α1∽ α2.
Definition 5
35:Let α = (uα,vα), αi = (uαi,vαi)(i = 1,2) be PFN, then:
Industrial big data
In manufacturing, Big Data refers to a large amount of multi-source, heterogeneous data generated throughout the product lifecycle51. Since its introduction, the concept of big data has been widely used in decision-making52. It is often used in engineering research for urban planning53,54,55,56, energy management57,58,59,60, smart manufacturing61,62,63,64, and product development65,66,67. Big data can be classified into the following five categories according to data sources68: (i) management data collected from manufacturing information systems; (ii) user data collected from social networking platforms and e-commerce platforms; (iii) device data collected from smart factories; (iv) product data collected from smart products and product service system terminals; and (v) public data collected from governments and agencies. Raw data is multi-scale and highly noisy in addition to being multi-source and heterogeneous and must be processed to obtain the implied information. Partitioned clustering methods divide data objects into clusters of a single structure, and the K-means algorithm is one of the most classical partitioned clustering algorithms.
Under a big data environment, a huge amount of data can improve decision making ability and deliver well data support for decision making, while the real application generates data with unknown, blurred, and missing values due to the unpredictability of the environment, uneven environmental parameters, unstructured database architecture, and other unnecessary reasons. Pythagorean fuzzy sets help to minimize the redundancy and inconsistency of data information and reduce the hazard and decision making of big data information due to their eminent ability to handle uncertain information, missing information, and quantitative data. We discuss multi-criteria decision making in the big data environment and propose a numerical decision model based on Pythagorean fuzzy sets, which improves the accuracy of multi-criteria decision making in the big data environment.
Proposed design concept evaluation method
Concept design evaluation is designed to guide the design of a product by picking the most potential solution from among the concept solutions. In order to acquire objective and accurate evaluation outcomes, a new framework for product concept design evaluation is provided in this paper. The framework consists of two phases: in the first phase, text mining techniques are used to capture review data from user review big data and process the data information, TFIDF (Term Frequency-Inverse Document Frequency) algorithm is used to calculate text vocabulary weights, K-means algorithm is used to classify review text information, and the classified review text is sorted by designers to establish an evaluation criteria system. The details of the first phase are described in “Text data mining and clustering” section. The evaluation criteria obtained based on big data avoid the uncertainty and imprecision brought by the generic evaluation criteria and lay a solid foundation for obtaining objective evaluation results, and the selection of evaluation criteria from users’ own words is more helpful for users to understand the semantics of the evaluation criteria.
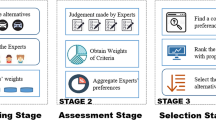
The second stage is to construct numerical models to make decisions on assessment information, and this paper integrates Pythagorean Fuzzy Hierarchical Analysis (PFAHP) and Pythagorean Fuzzy Ideal Solution (PFTOPSIS) into a new decision model. After the experts judge the assessment criteria, the weight values of the assessment criteria are calculated by PFAHP (see “Product concept evaluation weights combined with PFAHP” section for the calculation steps of PFAHP). The constructed evaluation criteria and the concept design solution are designed as a product concept design evaluation questionnaire and published to collect decision data for the concept design decision. The decision data were calculated using PFTOPSIS (see “Optimal product concept evaluation scheme combining Pythagorean fuzzy ideal solution (PFTOPSIS)” section for the calculation steps of PFTOPSIS), and the weight values calculated by PFAHP were quoted in the calculation to finally arrive at the ranking of alternatives. In decision making, Pythagorean fuzzy arrays are used instead of exact numbers, which makes the evaluation less difficult, and at the same time, fuzzy arrays are more compatible with the real-life evaluation environment. The structure of the proposed product concept design evaluation method is shown in Fig. 1.

Product concept design assessment framework diagram.
Text data mining and clustering
The effective use of user data to evaluate new concept designs is a more feasible approach than traditional user surveys. The specific steps we take to obtain information on user preferences are: first, use python’s requests library to crawl the user comment corpus data, and then use the Jieba library to segment the corpus data; secondly, introduce the Nlp Chinese stop word data set to purify the corpus, and after purification, there is still some interference information in the corpus. The top-ranked interference information is added to the deactivation dictionary, and only words that can reflect the user’s preference are retained. Term Frequency-Inverse Document Frequency (TFIDF) is a statistical algorithm that can evaluate the importance of a word to the total corpus. We use the TFIDF algorithm to obtain the weight of each vocabulary, save the weight results in the form of a matrix, and apply the k-means clustering algorithm (K-means) to classify the corpus. Finally, we perform a simple analysis of the clustering results.
Due to a large amount of data, this paper introduces the SSE (sum of the squared errors, the sum of squared errors) standard to judge the effect of data clustering, analyze the clustering results whether the data within the class is tight and whether the data between classes are separated. The algorithm is as shown in Eq. (10)69.
Among them, Ci represents the ith cluster, p represents the sample point in Ci, mi is the centroid of Ci (the mean of all samples in it), and K is the number of clusters. SSE represents the sum of squared errors of all samples after clustering and their corresponding cluster centers, indicating the accuracy of the clustering results. The higher the degree of aggregation of each class, the smaller the SSE will be, which means that the samples are divided more finely. When the value of K is less than the real category, even if K is increasing, its increase will greatly increase the degree of aggregation of each cluster, so the SSE will be greatly reduced; when the value of K reaches the real category, increase the value of K The resulting degree of aggregation decreases rapidly, so the SSE decreases sharply and then flattens as the value of K increases.
Evaluation of product concept design scheme integrating PFAHP-PFTOPSIS
The Pythagorean Fuzzy Set (PFS) is combined with Hierarchical Analysis (AHP) as Pythagorean Fuzzy Hierarchy (PFAHP) for calculating the weights of design concept evaluation criteria, and Pythagorean Fuzzy Set (PFS) is combined with Ideal Solution (TOPSISP) as Pythagorean Fuzzy Ideal Solution (PFTOPSIS). The PFTOPSIS method determines the best ranking of product design concept evaluation solutions by using the weights obtained from PFAHP.
Product concept evaluation weights combined with PFAHP
PFAHP is calculated as follows:
-
Step 1 Experts were invited to evaluate the design concept evaluation criteria, which constituted a pairwise comparison matrix A = (aik)m×m, based on the language evaluation of experts, constructed using the scale proposed by Ilbahar et al. (Table 2)70.
-
Step 2 The matrix A = (aik)m×m gives the difference matrix D = (dik)m×m by Eqs. (11) and (12).
$${d}_{ikL}={u}_{ikL}^{2}-{v}_{ikU}^{2},$$(11)$${d}_{ikU}={u}_{ikU}^{2}-{v}_{ikL}^{2}.$$(12) -
Step 3 The difference matrix D = (dik)m×m is obtained by Eqs. (13) and (14) as the interval multiplication matrix S = (sik)m×m.
$${s}_{ikL}=\sqrt{{1000}^{dL}},$$(13)$${s}_{ikU}=\sqrt{{1000}^{dU}}.$$(14) -
Step 4 Use Eq. (15) to calculate the deterministic value H=(hik)m×m.
$${h}_{ik}=1-\left({u}_{ikU}^{2}-{u}_{ikL}^{2}\right)-\left({v}_{ikU}^{2}-{v}_{ikL}^{2}\right).$$(15) -
Step 5 The determinacy value H = (hik)m×m is multiplied with the interval multi-plication matrix S = (sik)m×m according to Eq. (16) to obtain the weight matrix T = (tik)m×m before normalization.
$${t}_{ik}=\left(\frac{{S}_{ikL}+{S}_{ikU}}{2}\right){h}_{ik}.$$(16) -
Step 6 Calculate the weight of each criterion using Eq. (17):
$${w}_{i}=\frac{{\sum_{k=1}^{m}t}_{ik}}{\sum_{i=1}^{m}{\sum_{k=1}^{m}t}_{ik}}.$$(17)
Optimal product concept evaluation scheme combining Pythagorean fuzzy ideal solution (PFTOPSIS)
The weight value calculated by the PFAHP method is applied to the PFTOPSIS method, and the specific calculation steps are as follows:
-
Step 1 Construct the decision matrix R = (βi(xj))n×m under Pythagorean fuzzy sets. Let the set of assessment options be X = {x1,x2,…,xn}, (n ≥ 2), the set of assessment criteria be β = {β1,β2,…,βm}, the weight of each assessment criterion w = {w1,w2,…,wm}, 0 ≤ wi ≤ 1, and \(\sum_{i=1}^{m}{w}_{i}=1\). The assessment value βi of option xj criterion is denoted as βi(xj) = (uji,vji). Therefore, the decision matrix is:
$$R={\left({\beta }_{i}\left({x}_{j}\right)\right)}_{n\times m}=\left(\begin{array}{cccc}\left({u}_{11},{v}_{11}\right)& \left({u}_{12},{v}_{12}\right)& \cdots & \left({u}_{1m},{v}_{1m}\right)\\ \left({u}_{21},{v}_{21}\right)& \left({u}_{21},{v}_{21}\right)& \dots & \left({u}_{2m},{v}_{2m}\right)\\ \vdots & \vdots & \vdots & \vdots \\ \left({u}_{n1},{v}_{n1}\right)& \left({u}_{n2},{v}_{n2}\right)& \cdots & \left({u}_{nm},{v}_{nm}\right)\end{array}\right).$$(18) -
Step 2 The Pythagorean fuzzy positive ideal solution (PIS) and the negative ideal solution (NIS) are determined by Eqs. (19) and (20):
$$\begin{aligned} {\text{x}}^{ + } = & \left\{ {{\upbeta }_{{\text{i}}} ,{\text{max}}_{{\text{j}}} \left[ {{\text{s}}\left( {{\upbeta }_{{\text{i}}} \left( {{\text{x}}_{{\text{j}}} } \right)} \right)} \right]{\text{|i}} = 1,2 \ldots {\text{m}}} \right\} \\ = & \left\{ {\left[ {\beta_{1} ,\left( {u_{1}^{ + } ,v_{1}^{ + } } \right)} \right],\left[ {\beta_{2} ,\left( {u_{2}^{ + } ,v_{2}^{ + } } \right)} \right],...,\left[ {\beta_{m} ,\left( {u_{m}^{ + } ,v_{m}^{ + } } \right)} \right]} \right\}, \\ \end{aligned}$$(19)$$\begin{aligned} x^{ - } = & \left\{ {\beta_{i} ,{\text{min}}_{j} \left[ {s\left( {\beta_{i} \left( {x_{j} } \right)} \right)} \right]{|}i = 1,2...m} \right\} \\ = & \left\{ {\left[ {\beta_{1} ,\left( {u_{1}^{ - } ,v_{1}^{ - } } \right)} \right],\left[ {\beta_{2} ,\left( {u_{2}^{ - } ,v_{2}^{ - } } \right)} \right], \ldots ,\left[ {\beta_{m} ,\left( {u_{m}^{ - } ,v_{m}^{ - } } \right)} \right]} \right\}. \\ \end{aligned}$$(20) -
Step 3 Use Eqs. (21) and (22) to determine the distance between each evaluation scheme and the Pythagorean fuzzy PIS/NIS.
$$\begin{aligned} D\left( {x_{j} ,x^{ + } } \right) = & \mathop \sum \limits_{i = 1}^{n} w_{i} d\left( {\beta_{i} \left( {x_{j} } \right),\beta_{i} \left( {x^{ + } } \right)} \right) \\ = & \frac{1}{2}\mathop \sum \limits_{i = 1}^{n} w_{i} \left( {\left| {\left( {u_{ji} } \right)^{2} - \left( {u_{i}^{ + } } \right)^{2} } \right| + \left| {\left( {v_{ji} } \right)^{2} - \left( {v_{i}^{ + } } \right)^{2} } \right| + \left| {\left( {\pi_{ji} } \right)^{2} - \left( {\pi_{i}^{ + } } \right)^{2} } \right|} \right), \\ \end{aligned}$$(21)$$\begin{aligned} D\left( {x_{j} ,x^{ - } } \right) = & \mathop \sum \limits_{i = 1}^{n} w_{i} d\left( {\beta_{i} \left( {x_{j} } \right),\beta_{i} \left( {x^{ - } } \right)} \right) \\ = & \frac{1}{2}\mathop \sum \limits_{i = 1}^{n} w_{i} \left( {\left| {\left( {u_{ji} } \right)^{2} - \left( {u_{i}^{ - } } \right)^{2} } \right| + \left| {\left( {v_{ji} } \right)^{2} - \left( {v_{i}^{ - } } \right)^{2} } \right| + \left| {\left( {\pi_{ji} } \right)^{2} - \left( {\pi_{i}^{ - } } \right)^{2} } \right|} \right). \\ \end{aligned}$$(22) -
Step 4 Use Eq. (23) to calculate the revised closeness ξ(xj) of the evaluation scheme xj.
$$\xi \left({x}_{j}\right)=\frac{D\left({x}_{j},{x}^{-}\right)}{{D}_{max}\left({x}_{j},{x}^{-}\right)}-\frac{D\left({x}_{j},{x}^{+}\right)}{{D}_{min}\left({x}_{j},{x}^{+}\right)}.$$(23) -
Step 5 Finally, the best ranking of product design concept evaluation solutions was determined, and the solution with the highest correction factor was the best.
An empirical case study
Rapid advances in drone technology and improvements in size, cost, and intelligence have led to a gradual lowering of the threshold for the use of consumer-grade drones, extending their utility in communications, photography, agriculture, surveillance, and various public services71. They are also widely sought after in major e-commerce platforms. Therefore, we choose a consumer-grade aerial photography drone as the product for our case study to validate the practicability of the proposed product design concept evaluation model.
Corresponding to the product concept design evaluation framework (Fig. 1), firstly, we crawled and analyzed the reviews of drone consumers from e-commerce platforms to construct a targeted evaluation criteria system, i.e., the content of “Get data sources” section. Second, experts in the field are invited to make independent judgments on the constructed evaluation criteria, and the relative importance of the evaluation criteria is calculated according to PFAHP, i.e., the content of “Weighted calculation of assessment criteria using PFAHP” section. Finally, the three existing drone conceptual design assessment schemes with the constructed assessment criteria system were prepared as online questionnaires and published on the Internet in anonymous form to collect questionnaire data from drone consumers, and the obtained questionnaire data were calculated using the PFTOPSIS method, i.e., the content of “Prioritization of product design concepts using PFTOPSIS” section. An illustrative numerical example is added to “Explanatory numerical examples” section to further illustrate the practicality of the method used. The example study described in detail in this section provides a clear understanding of how the proposed method works in the big data environment based on Pythagorean fuzzy set quantification for the product concept design evaluation process.
Get data sources
We collect user text data on consumer-grade aerial drones from JD.COM, one of the largest e-commerce websites in China. First, we use a crawler to crawl JD’s high-selling consumer-grade aerial drone reviews, collecting a total of 6741 web text reviews, and then process the data as described in “Text data mining and clustering” section. “Like”, “good”, “received”, “satisfied”, “Buy” and other words are high-frequency words for reviews (n = 1199; 1122; 835; 823 and 432) but they do not reflect users’ preferences for products and are not meant for the actual evaluation. Therefore, in order to avoid their interference with the final statistical results, we added the above words to the deactivated word list for secondary cleaning of the original data, and the total number of valid comments after secondary cleaning was 5697. We conducted a frequency analysis of online reviews of drones to obtain words that clearly express user preferences, and the results of the frequency analysis are summarised in Table 3. There are 24 words with high frequencies that clearly express user preferences, and they appear in the text a total of 9549 times, and the most frequent words are “texture”, “cheap”, “simple” and “clear”.
Taking effective reviews as the source of corpus data, the bag-of-words model selects the top 54 feature words (such as textured, simple, clear, and technology) that have a large TFIDF weight and can centrally reflect user preferences as the k-means clustering basis. The number of k-means user preference optimal clusters is found by the SSE standard between the cluster value of 2 and 11, as shown in Fig. 2. The abscissa of Fig. 2 is the number of clusters, and the ordinate is the average distance of each corpus, and its value can reflect the degree of aggregation of each type. It can be seen from Fig. 2 that when the review samples are divided into 8 categories, the broken line tends to be stable, so we choose 8 as the number of clusters. After determining the number of clusters, we obtained the number of clusters and their central words and sorted the results into Table 4. According to Table 4, we eliminate the comment text in category 1, which has a large amount of data and cluttered categories and merge the comment data in categories 2 and 3, which all point to operability. According to the most representative words of each category and combined with the original corpus, word frequency, and design dimensions, the results are summarized as the design concept evaluation criteria, as shown in Fig. 3.

SSE folding line chart.

Consumer drone concept design evaluation criteria system.
Evaluation of target product design concept solutions
Weighted calculation of assessment criteria using PFAHP
Ten experts in the field were invited to pairwise compare the assessment criteria system shown in Fig. 3 using the language terms of PFS (shown in Table 2). The ten experts (including five males and five females with an average age of 35.1) are engineers from different departments with a deep knowledge base in the fields of equipment manufacturing, smart technology, and product design, and they have 9 years (mean) of experience in product development to provide a valid assessment of the evaluation criteria system for this study.
In this process, linguistic terms are converted to the corresponding Pythagorean fuzzy interval values. Since these experts make different ratings, their subjective judgments need to be aggregated into a compromise pairwise comparison matrix. In this paper, the most representative data (Tertiary criteria assessment C111–C116) are used as an example to provide the relevant calculation results. Table 5 shows the compromise pairwise comparison matrices of the assessment criteria, and the compromise pairwise matrices of Table 5 are next calculated according to steps 2–6 described in “Product concept evaluation weights combined with PFAHP” section, and the results obtained are the difference matrix (Fig. 4a), the interval multiplication matrix (Fig. 4b), the deterministic value matrix (Fig. 4c), and the pre-normalization weight matrix (Fig. 4d). Figure 5 gives the final weight values calculated by the PHAHP method for C111–C116. The same calculation steps are performed in other evaluation criteria to calculate the local weights and global weights of the evaluation criteria, and the results are listed in Table 6.

Matrix diagram: (a) difference matrix, (b) interval multiplication matrix, (c) deterministic value matrix, (d) weight matrix before normalization.

The weights of C111–C116.
Table 6 shows the weight values of each evaluation criterion. The results show that the five most important criteria for evaluating consumer drone design concepts are: durable (C321), cheap (C311), ingenious (C212), superior (C322), and cost performance (C312). The five least important The evaluation criteria are: textured (C113), Exquisite (C112), portable (C222), stable (C221) and professional (C125).
Prioritization of product design concepts using PFTOPSIS
An anonymous online questionnaire was published via the Internet, which was designed according to the language scale of Pérez-Domínguez et al.72 (Table 7), and three prone design concept plans were evaluated using a system of evaluation criteria, which are briefly described in Table 8. A total of seven prone consumer responses were collected. The collected response data were collated, the linguistic variables were converted to Pythagorean fuzzy numbers, and then the criteria weights calculated in the PHAHP method were applied to the calculation of the PFTOPSIS analysis. The decision matrix constructed for this evaluation is shown in Fig. 6.

Decision matrix for three design concept plans.
Using Eqs. (19) and (20), the Pythagorean fuzzy PIS and Pythagorean fuzzy NIS values are determined and the obtained results are as follows:
Using Eqs. (21) and (22), the distances of the alternatives to the Pythagorean fuzzy PIS and NIS are calculated, and the results are provided in Table 9. In addition, the revised closeness values are calculated using Eq. (23), and the results are also shown in Table 9.
According to the PFTOPSIS method, the evaluated solution with modified discount progress (xi) closest to 1 is the solution closest to the positive ideal solution and far from the negative ideal solution. Therefore, having the largest (xi) value means that the drone solution that is considered by the user to performs best in the conceptual design phase. According to Table 9, Plan 2 is the best conceptual design solution.
Explanatory numerical examples
Case 1: evaluation of the design concept of a garbage container for a kitchen
The characteristics of the kitchen waste container are in some way consistent with the evaluation criteria shown in Fig. 3, such as “the shape is exquisite”, “the structure is clear”, “the material is durable”, etc. We will follow the evaluation criteria shown in Fig. 3 and their weight values (Table 6) to apply the PFTOPSIS model to the conceptual design of kitchen waste containers discussed by Liu et al.18. Ten participants were appointed randomly to form a decision panel to express their viewpoints on the conceptual design options in linguistic terms (Table 7) after learning about the four conceptual design options for kitchen waste containers shown by Liu et al.18. Table 10 presents the collated decision matrix, Table 11 shows the corresponding Pythagorean fuzzy PIS and NIS, and Table 12 provides the distances of the conceptual design solutions from the Pythagorean fuzzy PIS and NIS, along with the revised closeness of the conceptual design solutions and the final ranking of the solutions.
The outcomes in Table 12 reveal that Design 2 is the best design and Design 1 is the second best one, which is consistent with Liu et al.’s18 ranking of the conceptual design after increasing the confidence level of managers, which indicates the universality of the method proposed in this paper. And there are many potential reasons for the inconsistent ranking of Design 3 and Design 4, for example, changes in the assessment criteria, changes in the relative importance of the assessment criteria, etc.
The method proposed by Liu et al.18 requires an extended linguistic scale (from three to five levels) if one wants to consider managers’ influence factors (self-confidence), which undoubtedly increases the subjectivity and ambiguity of the assessment process and increases the probability of distortion of the assessment results, the method proposed in this paper, which uses a uniform linguistic scale for all decision makers, ensures the uniformity of the assessment environment and attenuates the “human influence factors”, and the assessment results are more objective and reasonable.
Case 2: conceptual design selection of a smart logistics transport vehicle
At present, traditional logistics vehicles can no longer meet the operational needs of logistics enterprises, so the development of intelligent logistics transport vehicles is very necessary, and the evaluation results have a certain orientation for the development of enterprise products. Therefore, we constructed six evaluation criteria from the perspective of market demand: F1 motor-rated power, F2 wearing parts, F3 aesthetic shape, F4 operation, and maintenance cost, F5 storage capacity, and F6 distribution security. A decision team of 10 people with backgrounds in research and development, manufacturing, and use evaluated the four available options, using linguistic variables to express their views on the evaluation criteria, and the options are chosen.
The weight values θ = (0.135, 0.148, 0.132, 0.150, 0.203, 0.231) were calculated by the PFAHP model, and the final results were obtained by the PFTOPSIS model, and the best intelligent logistics transport vehicle concept design option was Option 4, and the specific calculated values are shown in Table 13.
The drone example and two illustrative numerical cases demonstrate the practicality of the approach proposed in this paper.
The decision model generated based on Pythagorean fuzzy sets can be applied in product design not only for conceptual design evaluation, but also for product sustainability selection, product modularity decision, product color evaluation, and other stages of the full product life cycle. In addition to product design, it can be applied to other fields such as material selection, robot selection, and machine tool selection in manufacturing and mechanical engineering, performance and benchmarking evaluation, personnel selection, and business investment decisions in business management, supplier selection and site selection in logistics and supply chain, wastewater management in natural environment and resources, software evaluation, network selection, and website evaluation in information science, website evaluation, etc.
Although Big Data can provide powerful data support for decision making, it cannot avoid the defects of the data itself. Pythagorean fuzzy sets, due to their own characteristics, provide a precise and superior mathematical-logical framework for expressing fuzzy information, which far exceeds the performance of fuzzy sets and intuitionistic fuzzy sets, while also excelling in handling multidimensional data. In short, the integrated method retains the advantages of the approach itself while increasing the scope of its use, and these features prove it to be a reliable method for solving multi-criteria decision problems.
Analysis and discussion
This section provides further analysis and discussions to illustrate the computational efficiency of the model proposed in this paper, the last subsection presents the advantages of the proposed approach.
Sensitivity analysis of assessment criteria
In this subsection, a sensitivity analysis of the weights of the assessment criteria is performed to test the stability of the weight calculations. This is followed by an analysis of the impact of the values of the criteria weights calculated by the PFAHP on the ranking of the assessment scenarios according to different scenarios. These scenarios are generated by changing the binary weights of the criteria73. Thus, three different scenarios are generated from a combination of three different criteria (C1–C3). The results of the sensitivity analysis calculations are given in Table 14.
The sensitivity analysis shows that even though different weights are assigned to the assessment criteria and different relative postings are obtained, the ranking results are always the same and Plan2 is the best choice in all scenarios, providing strong and reasonable data support to confirm the reliability of the proposed decision model.
Comparative analysis of decision models
In order to test the validity of the proposed decision model, the results of the model were compared and analyzed with those of the PFAHP-PFVIKOR model and the PFAHP-FTOPSIS model, and the results are shown in Table 15.
VIKOR, from the Serbian “VIsekriterijumska optimizacija i KOmpromisno Resenje”, is a decision making method based on ideal points, proposed by Opricovic and Tzeng in 1998. Like TOPSIS, the solution that is closest to the positive ideal solution and furthest from the negative ideal solution is selected as the optimal solution. Following the Pythagorean fuzzy set VIKOR method as extended by Muhammet et al.74, we take v = 0.5. The ranking order of the best solutions is determined by the minimum value of Q when the two conditions of Awasthia75 are satisfied. The first comparative analysis was performed in PFTOPSIS with PFVIKOR and Table 10 shows that it yields a consistent ranking order with the PFVIKOR method, validating the validity of the current method.
The traditional TOPSIS method is only able to be used in numerically accurate situations and the FTOPSIS method is an extension of the TOPSIS method under fuzzy sets. A second comparative analysis was performed between the currently proposed decision model and PFAHP-FTOPSIS76. The results show that the ranking order derived using the PFAHP-FTOPSIS model is slightly different from the current integrated approach, with the top ranking still being Plan 2, but Plan 1 and Plan 3 being ranked differently. Some of the reasons for the difference in ranking may be that (i) the subordination of Pythagorean fuzzy sets is more detailed than the subordination of fuzzy sets; (ii) in some cases, intuitionistic fuzzy sets cannot satisfy the condition when the subordination and non-subordination are greater than 1, whereas Pythagorean fuzzy sets can, in the case of Pythagorean fuzzy sets, the sum of squares cannot exceed 1, whereas the sum of subordination and non-subordination can This makes Pythagorean fuzzy sets more sensitive, flexible and powerful in dealing with uncertainty.
The above results demonstrate the validity and reliability of the proposed decision model, which can be used to evaluate product concept designs by taking advantage of the Pythagorean fuzzy set, which has significant advantages over other fuzzy sets in terms of sensitivity in the face of data and in dealing with the uncertainty of the problem, providing more reasonable and accurate results.
Computational complexity analysis of decision models
In this section, the computational complexity of the proposed decision model is discussed in terms of time complexity and space complexity through simulation experiments. The experimental studies performed are all based on Python 3.7 on an ordinary PC with 12th Gen Intel(R) Core(TM) i7-12700H 2.30 GHz, 16 GB RAM.
As can be seen from Table 16, the computational complexity of PFAHP-PFTOPSIS is simpler than PFAHP-PFVIKOR and Z-AHP-TOPSIS and more complex than PFAHP-FTOPSIS. This is because the Pythagorean fuzzy set divides the linguistic terms more carefully and achieves dimensionality reduction for the data.
Advantages of the proposed work
In real-world problems, big data and Pythagorean fuzzy sets are more appropriate design decision tools to address vagueness, subjectivity, and imprecision in concept design evaluation. Pythagorean fuzzy sets provide a reliable mathematical framework in which vague conceptual factors in the product design evaluation process in big data environments can be studied precisely and rigorously. This paper combines AHP, TOPSIS, and PFS to convert qualitative evaluation criteria into quantitative parameters evaluated through product concept design, which is advanced in generating evaluation criteria and evaluating alternatives, showing a distinctive innovation in the design evaluation process, and the advantages of the proposed concept design evaluation method are summarized as follows.
-
(1)
The proposed method uses TFIDF and K-means to analyze user review data collected from e-commerce platforms, enabling designers and manufacturers to clarify user preferences and usage habits of products in a comprehensive, real-time, and precise manner, facilitating the analysis and construction of product concept design evaluation criteria that meet user needs and corporate interests, mitigating the impact of cognitive biases of design/manufacturing experts It can also reduce the impact of the cognitive bias of design/manufacturing experts, instead of relying on the experience and intuition of experts.
-
(2)
The PF-AHP-TOPSIS decision model uses generalized triangular intuitive fuzzy numbers instead of precise quantitative numbers to express the quantitative assessment of decision makers in the concept design evaluation process, increasing the space for accommodating uncertain information and data, weakening the ambiguity and subjectivity of decision makers, and enhancing the objectivity of evaluation results while avoiding the precise rating of product concept design evaluation criteria. makes the evaluation easier and more flexible.
-
(3)
This study provides an effective and practical solution to the complexity of the fuzzy multi-criteria decision-making problem in the industrial big data environment, which is more targeted and more in line with the current decision-making environment, considering both the inherent uncertainty of individual evaluation information and the subjectivity within the decision-making group; the credibility of the ranking results is well enhanced, ultimately providing manufacturers and designers with reasonable and objective evaluation The credibility of the ranking results is well enhanced, ultimately providing manufacturers and designers with reasonable and objective evaluation results.
Conclusion
Based on fuzzy mathematical theory and the characteristics of online review big data, this study proposes a group decision model applying Pythagorean fuzzy sets for product concept design evaluation, which is investigated in an example with an aerial photography drone. In the flow of the proposed method, user preference data of users for the product are mined and segmented for application to evaluation criteria, and the raw, subjective and uncertain perceptions of decision makers are captured and represented as fuzzy values. In the process of concept design evaluation, individual verbal assessments are converted into fuzzy values, criteria weights are determined through a hierarchical analysis fused with Pythagorean fuzzy sets, and alternatives are ranked through an ideal solution based on Pythagorean fuzzy sets. One of the main features of the proposed approach, which attempts to solve the problem of product concept design evaluation based on the analysis of consumer reviews, is that it does not only attenuate the influence of uncertainties from the perspective of a decision model, but the entire process, the entire product concept design evaluation framework, serves the purpose of achieving more objective and reasonable evaluation results.
Although the proposed method provides a quantitative and reliable objective decision model for the evaluation of product concept design in the example study, there are certain limitations in this study. When the object of application changes, the assessment criteria may follow suit, requiring once again textual information mining, clustering, etc. The second is that there are various e-commerce websites in each country/region, but this study only selected JD.COM reviews, and the evaluation criteria established have limited application. The subjective evaluation of the evaluation criteria and product concept design solutions relies on the experience of experts and users, which may make the evaluation results variable. Further research is, therefore, necessary to capture the expression of user preferences for product attributes in various regions and cultures; it is also possible to weigh up experts or users and set risk parameters to reduce the interference of subjective factors. The PF-AHP-TOPSIS decision model is still somewhat challenging to compute for non-specialists, and subsequent software programs can be developed and promoted to simplify the computation process. When the decision makers’ views tend to be neutral, the evaluation results calculated by the PF-AHP-TOPSIS decision model are difficult to distinguish obviously.
Other methods used to solve the product concept design evaluation problem are VIKOR, ELECTRE, PROMETHEE, BWM, FMEA, etc. These methods have their own characteristics, for example, VIKOR considers the subjective preferences of decision makers, while TOPSIS, which does not consider the subjective preferences of decision makers in the decision making process, has a more powerful performance in excluding humans (experts, consumers, decision makers, etc.) errors and is more in line with the original intention of obtaining objective evaluation results in this paper.
In future research, the construction of evaluation criteria can be further discussed, other methods can be combined with Pythagorean fuzzy sets according to the purpose of decision making to develop more decision models for big data environments, and the proposed methods can be applied to other fields to process multidimensional data so as to obtain reliable decisions. Further extensions of TOPSISI to more complex spherical fuzzy sets can also be investigated, and the advantages and disadvantages of the extensions are discussed to explore their practical applications.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Li, L. et al. Multidisciplinary collaborative design modeling technologies for complex mechanical products based on digital twin. Comput. Integr. Manuf. Syst. 25(6), 1307–1319. https://doi.org/10.13196/j.cims.2019.06.001 (2019).
Wang, T. A novel approach of integrating natural language processing techniques with fuzzy TOPSIS for product evaluation. Symmetry 14(1), 0120. https://doi.org/10.3390/sym14010120 (2022).
Guo-Niu, Z., Jie, H. & Hongliang, R. A fuzzy rough number-based AHP-TOPSIS for design concept evaluation under uncertain environments. Appl. Soft Comput. J. https://doi.org/10.1016/j.asoc.2020.106228 (2020).
Sena, A. et al. Concept design evaluation by using Z-axiomatic design. Comput. Ind. 122, 103278. https://doi.org/10.1016/j.compind.2020.103278 (2020).
Junfeng, M., Gül, E. O. K. & Charles, D. R. A comprehensive end-of-life strategy decision making approach to handle uncertainty in the product design stage. Res. Eng. Des. https://doi.org/10.1007/s00163-017-0277-0 (2018).
Jing, L. et al. An integrated product conceptual scheme decision approach based on shapley value method and fuzzy logic for economic-technical objectives trade-off under uncertainty. Comput. Ind. Eng. 156, 107281. https://doi.org/10.1016/j.cie.2021.107281 (2021).
Guang, Y., Wenqiang, L. & Changfu, W. Core-problem oriented system cause identification method and innovative design research. Chin. J. Mech. Eng. 15(33), 007. https://doi.org/10.3969/i.issn.1004-132X.2022.15.007 (2022).
He, W. Y., Zhang, J. H. & Wang, J. A comprehensive evaluation method of diesel engine sound quality based on paired comparison, uniform design sampling, and improved analytic hierarchy process. J. Zhejiang Univ. Sci. A 18(7), 531. https://doi.org/10.1631/jzus.A1600025 (2017).
Jing, L. T. et al. Conceptual scheme decision model for mechatronic products driven by risk of function failure propagation. Sustainability 12(17), 7134. https://doi.org/10.3390/su12177134 (2020).
Chang, S. C. & Tsai, P. H. Evaluating the competitive strategy of tablet PC industry by using fuzzy group decision making techniques. J. Test. Eval. 45(2), 671–686. https://doi.org/10.1520/JTE20150373 (2017).
Arbabi, H. et al. A data-driven multi-criteria decision-making approach for assessing new product conceptual designs. Proc. Inst. Mech. Eng. B. https://doi.org/10.1177/0954405421991418 (2021).
Elbishari, E. et al. An Integrated Approach for Facilities Planning by ELECTRE Method. https://doi.org/10.1088/1757-899X/290/1/012021 (2018).
Chen, Y. F. et al. Meta-action reliability-based mechanical product optimization design under uncertainty environment. Eng. Appl. Artif. Intell. https://doi.org/10.1016/j.engappai.2021.104174 (2021).
Vinodh, S. & Girubha, R. J. PROMETHEE based sustainable concept selection. Appl. Math. Model. 36(11), 5301–5308. https://doi.org/10.1016/j.apm.2011.12.030 (2012).
Zadeh, L. A. Special issue on fuzzy sets and systems dedicated to the 90th birthday of Prof. Lotfi A-Zadeh foreword. Int. J. Comput. Commun. Control. 6(3), 385–386. https://doi.org/10.15837/ijccc.2011.3.2123 (2011).
Ronald, R. Y. Pythagorean membership grades in multicriteria decision making. IEEE Trans. Fuzzy Syst. 22(4), 78989. https://doi.org/10.1109/TFUZZ.2013.2278989 (2014).
Akram, M., Luqman, A. & Alcantud, J. Risk evaluation in failure modes and effects analysis: Hybrid TOPSIS and ELECTRE I solutions with Pythagorean fuzzy information. Neural Comput. Appl. 33(11), 5675–5703. https://doi.org/10.1007/s00521-020-05350-3 (2021).
Liu, Q. et al. Conceptual design evaluation considering confidence based on Z-AHP-TOPSIS method. Appl. Sci. 11(16), 7400. https://doi.org/10.3390/app11167400 (2021).
Wang, M. Y. et al. Big data health care platform with multisource heterogeneous data integration and massive high-dimensional data governance for large hospitals: Design, development, and application. JMIR Med. Inform. 10(4), 196–210. https://doi.org/10.2196/36481 (2022).
Sun, H. Q. et al. Intelligent analysis of medical big data based on deep learning. IEEE Access. 7, 142022–142037. https://doi.org/10.1109/ACCESS.2019.2942937 (2019).
Zhang, X. F. & Wang, Y. M. Research on intelligent medical big data system based on Hadoop and blockchain. EURASIP J. Wirel. Commun. Netw. https://doi.org/10.1186/s13638-020-01858-3 (2021).
Bouyahia, Z. et al. Traffic state prediction using conditionally Gaussian observed Markov fuzzy switching model. J. Intell. Transp. Syst. https://doi.org/10.1080/15472450.2022.2069498 (2022).
Govindan, K., Ramalingam, S. & Broumi, S. Traffic volume prediction using intuitionistic fuzzy Grey-Markov model. Neural Comput. Appl. 33(19), 12905–12920. https://doi.org/10.1007/s00521-021-05940-9 (2021).
Chen, C. et al. A short-term traffic prediction model in the vehicular cyber-physical systems. Future Gener. Comput. Syst. Int. J. Esci. 105, 894–903. https://doi.org/10.1016/j.future.2017.06.006 (2020).
Jena, R. K. Sentiment mining in a collaborative learning environment: Capitalising on big data. Behav. Inf. Technol. 38(9), 986–1001. https://doi.org/10.1080/0144929X.2019.1625440 (2019).
Nghiem, T. B. H. & Chu, T. Evaluating sustainable conceptual designs using an AHP-based ELECTRE I method. Int. J. Inf. Technol. Decis. Mak. 20(04), 1121–1152. https://doi.org/10.1142/S0219622021500280 (2021).
Wang, C. & Hsueh, O. A novel approach to incorporate customer preference and perception into product configuration: A case study on smart pads. Comput. Stand. Interfaces 35(5), 549–556. https://doi.org/10.1016/j.csi.2013.01.002 (2013).
Worsdorfer, D., Lier, S. & Grunewald, M. Potential analysis model for case specific quantification of the degree of eligibility of innovative production concepts in the process industry. Chem. Eng. Process. Process Intensif. 98, 123–136. https://doi.org/10.1016/j.cep.2015.10.005 (2015).
Kumar, P. & Tandon, P. Design decision in the manufacturing environment using an improved multiple-criteria performance evaluation method. Arab. J. Sci. Eng. 47(3), 3751–3762. https://doi.org/10.1007/s13369-021-06049-w (2022).
Hayat, K. et al. Design concept evaluation using soft sets based on acceptable and satisfactory levels: An integrated TOPSIS and Shannon entropy. Soft. Comput. 24(3), 2229–2263. https://doi.org/10.1007/s00500-019-04055-7 (2020).
Quan, H. F. et al. Personalized product evaluation based on GRA-TOPSIS and Kansei engineering. Symmetry-Basel 11(7), 0867. https://doi.org/10.3390/sym11070867 (2019).
Arbelaez, J. C. & Osorio-Gomez, G. Crowdsourcing augmented reality environment (CARE) for aesthetic evaluation of products in conceptual stage. Comput. Ind. 99, 241–252. https://doi.org/10.1016/j.compind.2018.03.028 (2018).
Liu, W. et al. A proposed radicality evaluation method for design ideas at conceptual design stage. Comput. Ind. Eng. 132, 141–152. https://doi.org/10.1016/j.cie.2019.04.027 (2019).
Liang, X. D. et al. A hybrid fuzzy BWM-VIKOR MCDM to evaluate the service level of bike-sharing companies: A case study from Chengdu, China. J. Clean. Prod. https://doi.org/10.1016/j.jclepro.2021.126759 (2021).
Liu, A. J. et al. An empirical study on design partner selection in green product collaboration design. Sustainability 10(1), 133. https://doi.org/10.3390/su10010133 (2018).
Mistarihi, M. Z., Okour, R. A. & Mumani, A. A. An integration of a QFD model with fuzzy-ANP approach for determining the importance weights for engineering characteristics of the proposed wheelchair design. Appl. Soft Comput. 90, 106136. https://doi.org/10.1016/j.asoc.2020.106136 (2020).
Jing, L. et al. A rough set-based interval-valued intuitionistic fuzzy conceptual design decision approach with considering diverse customer preference distribution. Adv. Eng. Inform. https://doi.org/10.1016/j.aei.2021.101284 (2021).
Li, M. & Zhang, J. Integrating kano model, AHP, and QFD methods for new product development based on text mining, intuitionistic fuzzy sets, and customers satisfaction. Math. Probl. Eng. https://doi.org/10.1155/2021/2349716 (2021).
Feng, C., Huang, S. & Bai, G. A group decision making method for sustainable design using intuitionistic fuzzy preference relations in the conceptual design stage. J. Clean. Prod. 243, 118640. https://doi.org/10.1016/j.jclepro.2019.118640 (2020).
Hayat, K. et al. Best concept selection in design process: An application of generalized intuitionistic fuzzy soft sets. J. Intell. Fuzzy Syst. 35, 5707–5720. https://doi.org/10.3233/JIFS-172121 (2018).
Buyukozkan, G. & Guleryuz, S. A new integrated intuitionistic fuzzy group decision making approach for product development partner selection. Comput. Ind. Eng. 102, 383–395. https://doi.org/10.1016/j.cie.2016.05.038 (2016).
Li, Y. et al. An integrated approach to evaluate module partition schemes of complex products and systems based on interval-valued intuitionistic fuzzy sets. Int. J. Comput. Integr. Manuf. 27(7), 675–689. https://doi.org/10.1080/0951192X.2013.834471 (2014).
Chen, R. A problem-solving approach to product design using decision tree induction based on intuitionistic fuzzy. Eur. J. Oper. Res. 196(1), 266–272. https://doi.org/10.1016/j.ejor.2008.03.009 (2009).
Garcia Aguirre, P. A. et al. PFDA-FMEA, an integrated method improving FMEA assessment in product design. Appl. Sci.-Basel 11(4), 1406. https://doi.org/10.3390/app11041406 (2021).
Zhang, Y. et al. A review of researches of manufacturing-service integration and PSS with new ICT. China Mech. Eng. 29(18), 2164–2176. https://doi.org/10.3969/j.issn.1004-132X.2018.18.002 (2018).
Cheng, F. et al. User experience evaluation method based on online product reviews. J. Intell. Fuzzy Syst. 41(1), 210564. https://doi.org/10.3233/JIFS-210564 (2021).
Yu, Q. et al. Feature extraction and correlation model construction of online product reviews and its applications. China Mech. Eng. 28(22), 2714–2721. https://doi.org/10.3969/j.issn.1004-132X.2017.22.011 (2017).
Mohammad, S. & Dan, J. K. Predicting the performance of online consumer reviews: A sentiment mining approach to big data analytics. Decis. Support Syst. https://doi.org/10.1016/j.dss.2015.10.006 (2016).
Li, M. & Lu, J. Pythagorean fuzzy TOPSIS based on novel score function and cumulative prospect theory TOPSIS. Control Decis. 37(2), 483–492. https://doi.org/10.13195/j.kzyjc.2020.0926 (2022).
He, X., Liu, W. & Chang, J. Multiplicative consistent Pythagorean fuzzy preference relation. Control Decis. 36(4), 1010–1016. https://doi.org/10.13195/j.kzyjc.2019.0967 (2021).
Li, J. R. et al. Big data in product lifecycle management. Int. J. Adv. Manuf. Technol. 81(1–4), 667–684. https://doi.org/10.1007/s00170-015-7151-x (2015).
Tang, M. & Liao, H. From conventional group decision making to large-scale group decision making: What are the challenges and how to meet them in big data era? A state-of-the-art survey. Omega Int. J. Manag. Sci. 100, 102141. https://doi.org/10.1016/j.omega.2019.102141 (2021).
Li, X., Zhou, J. D. & Pedrycz, W. Linking granular computing, big data and decision making: A case study in urban path planning. Soft Comput. 24(10), 7435–7450. https://doi.org/10.1007/s00500-019-04369-6 (2020).
Yu, W. C. et al. Implementation Evaluation of Beijing Urban Master Plan Based on Subway Transit Smart Card Data (2014).
Martelli, C. & Bellini, E. Using Value Network Analysis to Support Data Driven Decision Making in Urban Planning, 998–1003. https://doi.org/10.1109/SITIS.2013.161 (2013).
Silva, B. N. et al. Urban planning and smart city decision management empowered by real-time data processing using big data analytics. Sensors 18(9), 2994. https://doi.org/10.3390/s18092994 (2018).
Marino, C. A. & Marufuzzaman, M. A microgrid energy management system based on chance-constrained stochastic optimization and big data analytics. Comput. Ind. Eng. 143, 106392. https://doi.org/10.1016/j.cie.2020.106392 (2020).
Koseleva, N. & Ropaite, G. Big data in building energy efficiency: Understanding of big data and main challenges. Procedia Eng. 172, 544–549. https://doi.org/10.1016/j.proeng.2017.02.064 (2017).
Refaat, S. S., Abu-Rub, H. & Mohamed, A. Big Data, Better Energy Management and Control Decisions for Distribution Systems in Smart Grid, 3115–3120. https://doi.org/10.1109/BigData.2016.7840966 (2016).
Melville, N. P. & Zik, O. Energy Points: A New Approach to Optimizing Strategic Resources by Leveraging Big Data, 1030–1039. https://doi.org/10.1109/HICSS.2016.132 (2016).
Li, C. Q., Chen, Y. Q. & Shang, Y. L. A review of industrial big data for decision making in intelligent manufacturing. Eng. Sci. Technol. Int. J. 29, 101021. https://doi.org/10.1016/j.jestch.2021.06.001 (2022).
Zhou, G. H. et al. Knowledge-driven digital twin manufacturing cell towards intelligent manufacturing. Int. J. Prod. Res. 58(4), 1034–1051. https://doi.org/10.1080/00207543.2019.1607978 (2020).
Yang, Y. H. et al. High-Performance Computing Based Big Data Analytics for Smart Manufacturing (2018).
Zhong, R. Y. et al. Big data analytics for physical internet-based intelligent manufacturing shop floors. Int. J. Prod. Res. 55(9), 2610–2621. https://doi.org/10.1080/00207543.2015.1086037 (2017).
Reinhold, D. & Michael, T. Estimating aggregate consumer preferences from online product reviews. Int. J. Res. Mark. 27(4), 001. https://doi.org/10.1016/j.ijresmar.2010.09.001 (2010).
Hou, T. J. et al. Mining changes in user expectation over time from online reviews. J. Mech. Des. 141(9), 4042793. https://doi.org/10.1115/1.4042793 (2019).
Ireland, R. & Liu, A. Application of data analytics for product design: Sentiment analysis of online product reviews. CIRP J. Manuf. Sci. Technol. 23, 128–144. https://doi.org/10.1016/j.cirpj.2018.06.003 (2018).
Tao, F. et al. Data-driven smart manufacturing. J. Manuf. Syst. 48, 157–169. https://doi.org/10.1016/j.jmsy.2018.01.006 (2018).
Yuan, G. et al. Short-term wind power prediction based on deep belief network. Acta Energiae Solaris Sin. 43(2), 451–457. https://doi.org/10.19912/j.0254-0096.tynxb.2020-0405 (2022).
Esra Ilbahar, A. K. S. C. A novel approach to risk assessment for occupational health and safety using Pythagorean fuzzy AHP & fuzzy inference system. Saf. Sci. 103, 124–136. https://doi.org/10.1016/j.ssci.2017.10.025 (2018).
Alwateer, M., Loke, S. W. & Fernando, N. Enabling drone services: Drone crowdsourcing and drone scripting. IEEE Access. 7, 110035–110049. https://doi.org/10.1109/ACCESS.2019.2933234 (2019).
Luis, P. et al. MOORA under Pythagorean fuzzy set for multiple criteria decision making. Complexity https://doi.org/10.1155/2018/2602376 (2018).
Colak, M. & Kaya, İ. Multi-criteria evaluation of energy storage technologies based on hesitant fuzzy information: A case study for Turkey. J. Energy Storage 28, 101211. https://doi.org/10.1016/j.est.2020.101211 (2020).
Muhammet, G., Ak, M. F. & Ali, F. G. Pythagorean fuzzy VIKOR-based approach for safety risk assessment in mine industry. J. Saf. Res. https://doi.org/10.1016/j.jsr.2019.03.005 (2019).
Anjali, A. & Govindan, K. Green supplier development program selection using NGT and VIKOR under fuzzy environment. Comput. Ind. Eng. https://doi.org/10.1016/j.cie.2015.11.011 (2016).
Muhammet, G. & Ak, M. F. A comparative outline for quantifying risk ratings in occupational health and safety risk assessment. J. Clean. Prod. https://doi.org/10.1016/j.jclepro.2018.06.106 (2018).
Acknowledgements
This work is supported by Guizhou Provincial Science and Technology Projects ([2020]1Y262).
Funding
This research was funded by Science and Technology Foundation of Guizhou Province ([2020]1Y262), Youth Science and Technology Talent Growth Project by Department of Education of Guizhou Province (Grant Number KY (2018)112) and Talent Introduction Project by Guizhou University (Grant Number GDRJHZ (2018) No. 16).
Author information
Authors and Affiliations
Contributions
Conceptualization, W.-X.W. and L.-D.M.; Data curation, L.-D.M.; Formal analysis, L.-D.M. and J.-W.X.; Funding acquisition, W.-X.W.; Investigation, L.-D.M., J.-W.X., N.Z., N.-F.H. and Z.-A.W.; Methodology, L.-D.M.; Project administration, W.-X.W.; Resources, L.-D.M.; Software, L.-D.M. and J.-W.X.; Writing—original draft, L.-D.M.; Writing—review and editing, L.-D.M., N.Z. and N.-F.H. All authors have read and agreed to the published version of the manuscript. All the authors are agreed to publish this manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ma, LD., Wang, WX., Xie, JW. et al. Evaluation of product conceptual design based on Pythagorean fuzzy set under big data environment. Sci Rep 12, 22387 (2022). https://doi.org/10.1038/s41598-022-26873-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-26873-w
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
