
Abstract
Design concept evaluation plays a significant role in new product development. Rough set based methods are regarded as effective evaluation techniques when facing a vague and uncertain environment and are widely used in product research and development. This paper proposed an improved rough-TOPSIS method, which aims to reduce the imprecision of design concept evaluation in two ways. First, the expert group for design concept evaluation is classified into three clusters: designers, manufacturers, and customers. The cluster weight is determined by roles in the assessment using a Multiplicative Analytic Hierarchy Process method. Second, the raw information collection method is improved with a 3-step process, and both design values and expert linguistic preferences are integrated into the rough decision matrix. The alternatives are then ranked with a rough-TOPSIS method with entropy criteria weight. A practical example is shown to demonstrate the method’s viability. The findings suggest that the proposed decision-making process is effective in product concept design evaluation.
Similar content being viewed by others
Introduction
As companies pay more attention to R&D in the current technology-driven era, new product development (NPD) has been recognized as a significant issue to deal with market competition. Design concept evaluation is a critical phase in NPD. Generally, various concepts are proposed and decision makers are assigned to select the best one for further development. Once the decision is made, the R&D of the product and over 70% of the cost are determined. Compensating for problems caused by a poor design concept at later stages is very difficult1. Because of the interconnected factors, the process for complex products is even harder2, and the loss caused by an incorrect decision will be considerable. Thus, the stage of design concept evaluation is both essential and challenging3. To reduce the subjective bias caused by individual preference, group decision-making is implemented. Meanwhile, as the evaluation attributes are multiple and complex, multiple attribute decision-making (MADM) methods are receiving considerable interest in design concept evaluation4.
Most of the studies in design concept evaluation concentrate on improving the criteria weight determination and the assessment method. In these studies, customers participate in the assessments as experts, and they give their preferences to each design scheme according to various attributes. As the customers’ preferences are usually vague and uncertain, researchers have used various means to overcome the imprecision. For instance, fuzzy method5,6 and grey theory7 are applied widely in design concept evaluation. Geng1 introduced the concept of a vague number to describe linguistic variables, and other research used an interval 2-tuple linguistic to describe the uncertainty and imprecision of the decision makers’ preferences8. Compared to the vague theory, the rough set theory is more feasible in design concept evaluation.
Rough set was introduced by Pawlak, and widely used in the MADM method after it was first proposed9. Zhai10 used rough numbers (RNs) to quantify the vagueness of raw information, and proposed an integrated method based on rough set and grey relation analysis. Zhu11, Chen4, Tiwari12 and Song13 also converted the raw data to intervals using rough set theory. Shidpour14 constructed two decision matrices using a rough set and a fuzzy set. In his study, the triangular fuzzy numbers (TFNs) and the rough numbers are converted into crisp numbers by specific methods. After the criteria weight is determined by the extent analysis method15, the design concepts are computed by measuring the distance between the alternative interval vectors and the positive and negative ideal reference vectors. Recently, rough-TOPSIS16, rough-VIKOR12 and rough-AHP13 methods have also been implemented in design concept evaluation.
Compared with the other extensions of the fuzzy set, the rough set does not need further individual judgment information in the decision matrix building4. In other words, the method is more objective compared to other fuzzy logic methods. The rough set also shows excellent performance in demonstrating the vagueness of human beings. According to cognition theory, the linguistic information of decision makers is considered as a preference close to the description (eg. close to very good, close to extremely poor). The distribution range of decision makers’ judgments can be illustrated as an interval on the axis. Furthermore, the information presents a normal distribution, and the center does not exactly correspond to the crisp integer. As is shown in Fig. 1, the fuzzy numbers are simply expanded the same distance towards each side. Unlike fuzzy numbers, the rough set method establishes the interval via a series of rigorous equations. The information treatment of the rough set is very similar to human cognition behaviors. Because of the outstanding performance in design concept evaluation, the rough-TOPSIS method is applied in our study. Focusing on the characteristic of design concept evaluation, two modifications are developed in our research: the expert weight determination and the integration of information from different sources.

Comparison of crisp number, fuzzy number and rough number approaches.
In previous studies, the method for determining the criteria weight usually plays a significant role in MADM problems. In contrast, expert weight is seldom mentioned in design concept evaluation. When the optimal product concept design must be selected from several design schemes, the decision-making organizers usually assign a group of customers to give their preferences, and the experts are viewed as a group with homogeneous weights during the assessment17. However, it does not mean that the expert weight is not important in the assessment. The expert weight determination is also an important component in the MADM structure18. Nevertheless, the design concept evaluation criteria usually include customer needs, R&D-specific parameters, and business objectives19. The expert group should include not only the customers but also professional R&D experts.
The decision matrix is integrated from the information collected according to the criteria. For some attributes, the information can be collected in two ways: the parameter value from the R&D department and the perception information from the expert preference. Taking the attribute “size” as an example, it can be judged from two perspectives: the design parameter values (such as 1.21 m) show the practical length, width, and height of the product; and the user subjective evaluation (such as “very spacious”) shows the expert individual reaction to the attribute size. Obviously, both design values and customer preference values are critical to the design concept evaluation and should be considered in the assessment.
This work attempts to mitigate the uncertainty and imprecision in the rough-TOPSIS method for product design concept evaluation. The improvements are conducted in two ways.
-
(1)
The expert group is formed by three clusters: experienced designers, manufacturers and customers. The cluster weight of each cluster is determined by the Multiplicative AHP method.
-
(2)
The raw information collection method is improved with a 3-step process, and the decision matrix is integrated by the information from both design values and customer preference values.
The remaining sections of the paper are arranged as follows. Section “State of the art” briefly reviews the related basic notions. Section “Methodology” details the proposed method. A real-life example is then given in Sect. “Case study”. Section “Conclusion” contains the concluding remarks.
State of the art
This section includes four parts. The MADM studies in design concept evaluation are generally reviewed in Sect. “MADM in design concept evaluation”, then the rough set and rough-TOPSIS method are described as the methods we apply in Sect. “Rough set and the rough-TOPSIS method”. Sections “Expert weight determination” and “The information from design values and expert preference” describe the modification we made based on the rough-TOPSIS method.
MADM in design concept evaluation
In NPD, enterprises are keen to win market share by improving their design concept. A common way to improve the design concept is to select the most appropriate concept from various suggested concepts. Hence, design concept evaluation is proposed as a significant phase to make the decision for subsequent design activities. Some simple design concept evaluation methods are proposed as quick decision-making approaches, such as SWOT analysis20, house of quality21, Pugh chart22, and screening matrix23. Nevertheless, if the product is complex, there are numerous and interconnected decision factors and it is difficult to make a correct decision relying on simple methods. Experts then implement typical MADM approaches to solve design concept selection problems. Ayağ24 introduced an analytic network process (ANP) based method in concept selection considering the needs of both customers and the company. From customer requirements and design characteristics, Lin25 proposed a hybrid method based on the Analytic Hierarchy Process (AHP) and the Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) method to help designers achieve an effective concept selection. Akay7 integrated grey theory and fuzzy set to solve both grey type and fuzzy type uncertainties in design concept evaluation. Takai26 decomposed the quality function deployment (QFD) matrices simultaneously and reconstructed a target costing and perception-based concept evaluation method for complex and large-scale systems. Moreover, other general evaluation models are also applied in design concept evaluation, such as VlseKriterijumska Optimizacija I KOmpromisno Resenje (VIKOR)27, elimination et Choice translating reality (ELECTRE)28, preference ranking organizational method for enrichment evaluation (PROMETHEE)29 and evaluation based on distance from average solution (EDAS)30.
Recently, studies have concentrated on the uncertainty of the decision environment. The crisp number has some limitations in expressing the vagueness of the raw data. Fuzzy set (FS) theory was proposed by Zadeh31 to deal with vagueness involved in decision-making problems, and various fuzzy data types are applied in uncertain environment identification. Zadeh32 introduced the Type-2 fuzzy sets and interval-valued fuzzy sets. Garibaldi33 revised the Type-2 fuzzy sets and proposed nonstationary fuzzy sets. Atanassov34 introduced the intuitionistic fuzzy set to describe the uncertainty of the linguistic information, and Xu35 proposed a related geometric aggregation operator. Rodríguez36 proposed the hesitant fuzzy linguistic term sets to increase the flexibility and richness of linguistic elicitation. Correspondingly, fuzzy set integrated MADM models are implemented in uncertain environments, such as fuzzy VIKOR37 and fuzzy TOPSIS38. Nevertheless, the boundary of fuzzy numbers needs to be determined subjectively before the assessment process, and this may affect the result of the evaluation17,39.
Rough set and the rough-TOPSIS method
Rough set theory is another vital mathematical data analysis approach in an uncertain environment, normally expressed as an interval named the rough number (RN). It is another extension of fuzzy sets. In contrast to the fuzzy number, rough number treats the uncertain information without an external pre-setting interval boundary or additional membership function and distribution forms4. Zhai10,40 first applied the method in design concept evaluation, where the rough set is widely used in product concept selection. Rough set theory is suitable for raw data treatment, commonly integrated with the general MADM method. We discussed the superiority of the rough set in the introduction section, and this is also true in practice. Of the top 10 papers cited from 2000 to 2022 selected from the Web of science database using the keywords “design concept evaluation”, half of them (5 papers) used the RN integrated method. Zhu27 proposed an RN based AHP criteria model and an RN-TOPSIS evaluation method in lithography tool selection. Song13, Shidpour14 and Zhu16 integrated RN with AHP or fuzzy-AHP, and Tiwari12 integrated RN with VIKOR. Here we briefly review the basic theory of RNs.
A rough set contains a lower approximation and an upper approximation, defined as two target sets. In the RN, the lower approximation and the upper approximation are represented as the conservative and liberal target set, respectively. Thus, an RN can be set as an interval. The rules of RNs are presented as follows:
The symbol \(U\) represents the universe including all the objects in the information table. Assume the object is a set \(R\) constructed by \(n\) classes. The set can be described as \(R=\left\{{C}_{1},{C}_{2},{C}_{3},\dots,{C}_{n}\right\}\), where \({C}_{1}<{C}_{2}<{C}_{3}<\cdots <{C}_{n}\). For \({C}_{i}\in R, 1\le i\le n\), \({C}_{i}\) can be expressed as an interval \({C}_{i}=[{C}_{li},{C}_{ui}]\), provided that \({C}_{li}<{C}_{ui}\) and \(1\le i\le n\). Here \({C}_{li},{C}_{ui}\) represent the lower and the upper limit, respectively. Thus \(\forall Y\in U\):
The lower approximation can be defined as the equation below.
While the upper approximation can be defined as the following equation.
The boundary region of \({C}_{i}\) is determined as:
Thus, the vague class \({C}_{i}\) in the universe \(U\) can be represented by the RN. If we use \(\underline{Lim}({C}_{i})\) and \(\overline{Lim}\left({C}_{i}\right)\) to express the upper and the lower limit of the RN, the \(RN\left({C}_{i}\right)\) can be defined as:
where \({M}_{L}\)/\({M}_{U}\) is the number of elements in \(\underline{Apr}\left({C}_{i}\right)\) / \(\overline{Apr}\left({C}_{i}\right)\), and the interval of the \(RN\left({C}_{i}\right)\) is computed as:
In a rough set, the \(RBnd\left({C}_{i}\right)\) shows the vagueness of the class. Although the rough set proposed a model dealing with the uncertain environment, the model is not a complete decision-making framework12. That is why the most frequently cited papers in design concept evaluation are RN integrated methods but not the rough set model. In our study, we integrated the rough set and TOPSIS method. The TOPSIS method is one of the most well-known and widely used methods in MADM problems41. The method is based on the idea of compromise where the alternatives are ranked by calculating the closeness index between the alternative and the ideal solution.
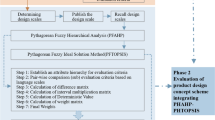
The rough-TOPSIS method is an efficient method in design concept evaluation. Song13 implemented the rough-TOPSIS method in design concept evaluation, and the criteria weight was determined by a rough AHP method. Chen4 improved the criteria weight determination method and integrated the rough entropy criteria weight, rough-TOPSIS method and the preference selection index (PSI) method in his study. We implement the rough entropy criteria and rough-TOPSIS method in our study. The process of the rough-TOPSIS method is shown in Fig. 2. There are two main steps in the design concept evaluation.

The process of the rough-TOPSIS method.
STEP 1. Determine criteria weight
Assume \(p\) experts are assigned to evaluate \(m\) alternatives according to \(n\) criteria using linguistic information. The information is converted into crisp numbers by the scale index4,13. The criteria weight determination method is proposed by Lotfi42.
After that, the crisp numbers are converted into rough numbers by Eqs. (1)–(5), and a rough decision matrix \(A\) is then constructed.
Here we use interval \([{a}_{ij}^{l},{a}_{ij}^{u}]\) to illustrate the rough number of the \(i\) th alternative and the \(j\) th attribute.
Then the interval is normalized by a linear scale transformation below:
where [\({p}_{j}^{l},{p}_{j}^{u}\)] denotes the interval relative criterion importance rating. \(\left[{Q}_{i}^{l}, {Q}_{i}^{u}\right]\) satisfies the properties for \({p}_{i}\), within estimation joint probability distribution \(P\). The lower limit \({Q}_{i}^{l}\) and the upper limit \({Q}_{i}^{u}\) can be computed by Eqs. (9) and (10).
Special conditions: If \({p}_{ij}^{l}=0\), \({p}_{ij}^{l}ln\left({p}_{ij}^{l}\right)\) is defined as 0; correspondingly if \({p}_{ij}^{u}=0\), \({p}_{ij}^{l}ln\left({p}_{ij}^{l}\right)\) is defined as 0. The criteria weight of the decision matrix can be illustrated as an interval, and the lower and the upper limit is determined by the equations below:
where \({W}_{j}^{l}\) and \({W}_{j}^{u}\) denote the lower and the upper limit respectively, the weight of attribute \(j\) can be written as \({[W}_{j}^{l}, {W}_{j}^{u}]\), \(1\le j\le n\).
STEP 2. Rank alternatives
In this step, the rough decision matrix should be normalized before the ranking process. Vector normalization (VN), sum normalization (SN) and min–max normalization (MMN) are popularly used normalization methods. Chen43 compared the three normalization methods: among the three normalization methods, the VN and SN will not change the diversity of attribute data, and VN is suggested in the TOPSIS method. The decision matrix \(A\) can be normalized by the equations below:
where \(\left[{r}_{ij}^{-},{r}_{ij}^{+}\right]\) denotes the normalized rough number \([{a}_{ij}^{l},{a}_{ij}^{u}]\) in the decision matrix \(A\). The normalized matrix \(R\) can be written as
For the benefit attribute, the upper bound is the positive ideal solution (PIS) and the lower bound represents the negative ideal solution (NIS); for the cost attributes, the upper bound represents PIS while the lower bound means NIS. The PIS and NIS of attribute \(j\) can be shown as:
The deviation coefficient representatives of PIS and NIS are shown in Table 1.
Where the deviations to PIS and NIS are defined as \(\left[{d}_{ij}^{+l},{d}_{ij}^{+u}\right]\) and \(\left[{d}_{ij}^{-l},{d}_{ij}^{-u}\right]\).
After that, the deviation coefficient matrices need to be normalized again to compare with each other. For the PIS deviation coefficient interval \(\left[{d}_{ij}^{+l},{d}_{ij}^{+u}\right]\),
For the NIS deviation coefficient interval \(\left[{d}_{ij}^{-l},{d}_{ij}^{-u}\right]\),
where the normalized deviation coefficients to PIS and NIS are defined as \(\left[{d}_{ij}^{{+}^{\mathrm{^{\prime}}}l},{d}_{ij}^{{+}^{\mathrm{^{\prime}}}u}\right]\) and \(\left[{d}_{ij}^{{-}^{\mathrm{^{\prime}}}l},{d}_{ij}^{{-}^{\mathrm{^{\prime}}}u}\right]\).
The separation measure \({S}^{+}\) and \({S}^{-}\) are computed as the weighted deviation, denoting the dissimilarity of an information sequence of PIS and NIS values.
The crisp value of rough interval \([{S}_{i}^{-}, {S}_{i}^{+}]\) is transformed to:
where \(\alpha\) represents an optimism level, valued in the interval \([\mathrm{0,1}]\), and for a rational condition, \(\alpha = 0.5\), \(\alpha >0.5\) and \(\alpha <0.5\) denote the optimistic and the pessimistic selection of the assessment manager.
The closeness indices (\(CIs\)) are calculated to rank the alternatives:
The optimistic alternative is close to the PIS and far from the NIS, which means the value of \({S}_{i}^{+*}\) is as small as possible while \({S}_{i}^{-*}\) is as large as possible. From Eq. (22), we can select the best candidate is the alternative approach to 1. The alternatives can be ranked by the value of \(CIs\).
Expert weight determination
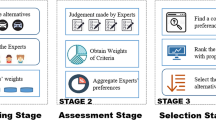
As shown in Fig. 3, expert weight determination is a critical phase in the structuring stage. However, 59% of the top cited papers in group decision-making (GDM) omitted this phase18. We examined the top cited 8 papers in design concept evaluation1,11,12,13,14,27,40. None of them mentioned expert weight, and experts are treated as homogeneous individuals.

General MADM evaluation process.
Although the rough-TOPSIS method has revealed its outstanding performance in design concept evaluation, biases may still appear in the assessment without the expert weight consideration. As experts have an important role, various studies about the expert weights are carried out in other fields of MADM problems44. The weights of experts depend on their background and experience45. Both subjective and objective methods have been applied in expert weight determination for years44. Subjective expert weights rely on the supervisors’ preferences or the pairwise comparison between experts. Multiplicative AHP46, simple multi-attribute rating technique (SMART)47 and Delphi48 are implemented to determine expert weights. All three methods are determined by comparing the attributes by experts in pairs. Objective methods for determining the expert weight depend on the proposed information. One way is to measure the expert preference for the aggregated decision49,50. The expert whose decision has minimum distance to the ideal solution gets the highest weight. Another way is to maximize the group consensus. Expert weights are given to make the judgments of experts closer51,52.
Before the assessment, the decision maker group needs to be fixed in advance. Although only customers are mentioned as experts in some studies53,54,55, it is not recommended to form the expert group with only customers. Generally, user-centered design can help companies satisfy consumers’ preferences56, and the customer plays a role as a decision maker in product development evaluation. The project manager expects to organize a decision-making group with experienced customers. However, using many customers may not work well in the assessments45. Some studies suggest that the experts in the R&D department should be selected as the experts because they are much more familiar with the criteria16, including product attractiveness, manufacturing, maintenance, cost, and time to market19. Thus, it is common to form the decision-making group with both consumers and expert producers57. In a previous study, the experts were recruited from amongst designers, manufacturers and customers, and a cluster-based expert weight determination method was proposed in the 2-tuple linguistic environment. The case study part of that paper found the variances of experts in each group were very small (Designer cluster: 0.32%, Manufacturer cluster: 0.35%, Consumer cluster: 1.15%)45, and widely considered statistically insignificant. It mainly occurs because the experts in the same cluster have a similar background and interests, and their preferences are thus probably similar. Hence, experts are divided into the customer cluster, the designer cluster and the manufacturer cluster, and to simplify the expert weight determination process, the decision makers in each cluster are viewed as homogeneous experts. In our study, the cluster weights are determined by the Multiplicative AHP method.
The information from design values and expert preference
Design values and expert preference are the two key pieces of information in design concept evaluation, especially for customer-involved products58. In terms of an attribute, the designers provide the value of the parameter of the attribute considering function, usability, cost, construction, etc., while the experts give their individual views on the attribute. Both types of information are critical and none of them can be discarded to develop a good product.
Studies combining the information from the designer and customers have been carried out recently. Yang59 proposed an assessment method that integrated fuzzy decision and fuzzy cognitive map, and evaluated the experiences of both designers and customers. Qi17,58,60 made great efforts in design concept evaluation and integrated both sources of information in decision-making, proposed an evaluation model by integrating important levels and design features, and named the rough distance to redefined ideal solution method (RD-RIS) or the integrated ideal solution definition approach (I-ISD)17. The model integrated both design values and customer preference values, and ranked the alternatives based on the compromise theory. In the Qi study, design values and expert preferences were obtained separately. Design values were provided by the designers while the expert preferences were constructed from the customers’ preferences. In the designers’ view, the best concept can satisfy the design constraints in a functional way. In expert preferences, the importance of each criteria is categorized into three levels: most important attributes, medium important attributes and less important attributes. Hence, a 6-option rule (benefit & most important, benefit & medium important, benefit & less important, cost & most important, cost & medium important, cost & less important) ideal solution method is defined integrating design values and preference values. Preference values are only relevant in option selection, where the ranking of alternatives depends on the corresponding design values. Compared with design values, expert preferences illustrate the individual subjective feeling on the corresponding attribute. On one hand, the expert preferences are obtained from their individual judgments, and they are not as precise as design values. On the other hand, expert preferences may reflect the acceptance of the design scheme, and reveal important implications for product R&D. Moreover, in real-life cases, only some of the attributes can be evaluated by the corresponding design values, as attributes such as “user acceptance” are not available to measure with design values. Last, the preference important level may be confused. In the case study section of this study, the criteria weight of expert preference information is \({W}_{j}=\left\{{W}_{1}=0.3772, {W}_{2}=0.1608,{W}_{3}= 0.2250, {W}_{4}=0.2298\right\}\), and the gaps among the criteria weights are obvious, as shown in Eq. (23).
However, if there are more attributes in the criteria index, and the deviations among the attribute weights are ambiguous, it is difficult to define the importance level of each attribute.
In our study, to maintain the information both from design values and expert preferences, data from both sources are integrated to form a new decision matrix.
Methodology
The purpose of design concept evaluation is to select an optimal design scheme from the proposed alternatives. To make the decision precise, a novel evaluation framework is proposed. The framework is constructed with three components as shown in Fig. 4. The alternatives, experts and the criteria are presented in Sect. 3.2. In phase 1, the experts are divided into three groups: the designer cluster, the manufacturer cluster and the customer cluster. The cluster weights are also determined by a Multiplicative AHP method in this phase. A 3-step information integration process is then conducted in phase 2. Both decision matrices of design values and preference values are converted into intervals according to the rough set theory, and after being normalized by the vector normalization method, the design values and preference values are integrated. By then, the pre-treated information matrix is identified. In the third phase, criteria weight is determined by a rough entropy method. The alternatives are then ranked by a rough-TOPSIS evaluation method. The details of the proposed method are presented in Sect. 3.2 to Sect. 3.4.

Framework of the proposed rough-TOPSIS method.
Assume there are \(n\) criteria \(C=\left\{{C}_{1},{C}_{2},\dots,{C}_{n}\right\}\) and \(m\) design concept alternatives \(A=\{{A}_{1},{A}_{2},\dots,{A}_{m}\}\) in an assessment. The design values of the assessment are obtained from the R&D department. The expert preference values are gathered from their preferences. Assume \(s\) expert decision makers are assigned to give their linguistic preference {extremely poor, very poor, poor, neutral, good, very good, extremely good}, and the preferences are then converted into crisp numbers \(\{1, 2, 3, 4, 5, 6, 7\}\), respectively.
Phase 1: Determine cluster weights
As introduced in Sect. “Expert weight determination”, three expert groups are established: the designer cluster (DC), the manufacturer cluster (MC) and the customer cluster (CC). We implemented the Multiplicative AHP method to determine the expert cluster weight, and we set the three clusters as the alternatives in this section. The method follows the approach of Honert61. The details of the expert cluster weight determination method in our study are as follows.
To evaluate the importance of each cluster, all the experts were asked to give their preference of the three clusters using specified words as shown in Table 2, where \({S}_{\alpha }\) and \({S}_{\beta }\) denote the preference of cluster \(\alpha\) and \(\beta\), respectively.
Assume there are z experts in the cluster \(y\), \({G}_{y}\) is defined as cluster \(y\), \({G}_{y}^{t}\) is the \(t\)th expert in cluster \(y\), \({G}_{y}\in \left\{DC,MC,CC\right\}\), \(1\le t\le z\). Then we use \({G}_{y}^{t}({G}_{\alpha }/{G}_{\beta })\) to denote the comparison \({S}_{\alpha }\) versus \({S}_{\beta }\) made by \({G}_{y}^{t}\). The average preference of the experts in \({G}_{y}\) is \({\delta }_{\alpha \beta y}\), and can be computed by the arithmetic mean:
\({r}_{\alpha \beta y}\) is defined to estimate the preference ratio \({S}_{\alpha }\) versus \({S}_{\beta }\) determined by \({G}_{y}\). The calculating equation is:
where \(\upgamma\) is a scale parameter, normally equal to \(\mathrm{ln}2\). According to Lootsma62, we determine the approximate vector \(p\) by the logarithmic least-squares method. The vector \(p\) minimizes
We define \({w}_{\alpha }=\mathrm{ln}{p}_{\alpha }\), \({w}_{\beta }=\mathrm{ln}{p}_{\beta }\) and \({q}_{\alpha \beta y}=\mathrm{ln}{r}_{\alpha \beta y}\). The function is converted into
i.e.
where \(\alpha =\mathrm{1,2},3\),\({N}_{\alpha \beta }=1\). To reduce the bias made by experts, comparisons including self-judgments are no longer valid, which means there are only two comparisons among three clusters. After the algebraic manipulation, the equation can be reduced to:
From Table 2, we can infer, for each variable, \({q}_{\alpha \beta y}=-{q}_{\beta \alpha y}\), \({G}_{\alpha \alpha }\) is empty, \({q}_{\alpha \alpha y}=0\) and \({\sum }_{\beta =1,\beta \ne \alpha }^{3}{\mathrm{w}}_{\beta }=0\). \({\mathrm{w}}_{\beta }\) can be computed as
The expert weight \({p}_{\alpha }\) is
The cluster weight \({W}_{\alpha }\) can be determined as
The weights of other clusters can be calculated accordingly.
Phase 2: Normalize and integrate decision matrices
To improve the precision of the decision, we integrated both design values and preference values. Here is the 3-step process of the proposed method.
Step 1: Establish raw matrices
While we want to get the design value and preference value of each criterion, not every criterion can be evaluated in the form of a design value. If the criterion cannot be evaluated, we mark a “N/A” in the corresponding space, with an example shown in Table 3.
Convert the design values into an interval matrix based on RNs. Equations (1)–(5) give the calculating method, and the matrix of design values is shown as follows:
where \(A\) represents the matrix of design values.\([{a}_{ij}^{l},{a}_{ij}^{u}]\) is the interval in the \(i\)th data sequence corresponding to the \(j\)th criterion of matrix \(A\). If the design value of the attribute is not available (marked N/A), we mark a symbol “−” for substitution.
For the preference values, the experts in the same cluster commonly have a similar background, thus the experts in the same cluster are regarded as homogeneous individuals of equal importance. The cluster weights were computed in Sect. 3.1. Thus, we use the weighted average operator to determine the final interval after integrating all the experts.
Let \({\upnu }_{t}\) be the crisp value converted from the preference expert \(t\). The expert preferences \({U}_{t}\) in \({G}_{y}\) can be converted into RNs according to Eqs. (1)–(5), expressed as:
where \({U}_{t}^{l}=\overline{{\upnu }_{x}}, \forall {\upnu }_{x}\le {\upnu }_{t} 1\le x \le z\); \({U}_{t}^{u}=\overline{{\upnu }_{x}}, \forall {\upnu }_{x}\ge {\upnu }_{t} 1\le x \le z\). The interval of the cluster is:
Considering the cluster weight \({W}_{y}\), the element in the preference value matrix can be determined as:
The matrix \(B\) of preference values is shown as follows:
Step 2: Normalize matrices
A and B represent the matrix of design values and preference values, respectively. To compare and integrate A and B in the same way, we normalized both matrices with vector normalization. Equations of vector normalization are shown as follows, where [\({x}_{ij}^{-},{x}_{ij}^{+}\)] represents the normalized interval of [\({x}_{ij}^{l},{x}_{ij}^{u}\)].
Used with Eqs. (38) and (39), the normalized design value matrix \({A}^{\mathrm{^{\prime}}}={\left(\left[{a}_{ij}^{-},{a}_{ij}^{+}\right]\right)}_{m\times n}\) and the normalized preference value matrix \({B}^{\mathrm{^{\prime}}}={\left([{b}_{ij}^{-},{b}_{ij}^{+}]\right)}_{m\times n}\) are established.
Step 3: Integrate information
In this step, the normalized matrices are integrated. First, we introduce a coefficient \(\mu \in [\mathrm{0,1}]\) to illustrate the contribution of design values and preference values.
Then we have
It is obvious that when \(\mu >0.5\), the expert preference is considered to be superior in the evaluation. In contrast, \(\mu >0.5\) reveals the design value is more significant. \(\mu =0.5\) means information from both sources has equal importance.
Finally, the decision matrix is formed as
Phase 3: Determine interval entropy weight
Shannon63 proposed the entropy theory to quantify the information. In the decision-making process, information is used to rank the alternatives. Lotfi42 introduced an interval Shannon entropy approach, and implemented the interval entropy in MADM. Chen4 applied the interval entropy method in product concept evaluation. The interval weight can be calculated by the steps below.
Normalize the interval relative criterion importance rating [\({p}_{j}^{-},{p}_{j}^{+}\)] using the equations below:
We set \(\left[{H}_{j}^{-} {H}_{j}^{+}\right]\) to satisfy the properties for \({p}_{j}\). The entropy constant equals \(1/(\mathrm{ln}m)\), \({H}_{j}^{-}\) and \({H}_{j}^{+}\) can be expressed as:
In the equations above, when \({p}_{ij}^{-}=0\), we set \({p}_{ij}^{-}\mathrm{ln}\left({p}_{ij}^{-}\right)=0\). Similarly, when \({p}_{ij}^{+}=0\), \(p_{ij}^{ + } {\text{ln}}\left( {p_{ij}^{ + } } \right) = 0\).
The lower and the upper bound using the interval weight of attribute \(j\) can be computed by the following equations.
Lower bound:
Upper bound:
The criterion weight interval can be expressed as \({[w}_{j}^{-}, {w}_{j}^{+}]\).
Phase 4: Rank the alternatives by the rough-TOPSIS method
In the previous sections, the information matrix \(C\) with RNs and the interval criterion weight \({[w}_{j}^{-}, {w}_{j}^{+}]\) were prepared. In this section, the alternatives are ranked based on the rough-TOPSIS method. The steps are as follows.
Step 1: Determine the weighted normalized rough matrix \(V={\left(\left[{v}_{ij}^{-},{v}_{ij}^{+}\right]\right)}_{m\times n}\) with the equation below.
Step 2: Calculate the PIS \({v}_{P}\left(j\right)\) and the NIS \({v}_{N}\left(j\right)\) with the following equations:
Step 3: Compute the distance between the PIS and \(\left[{v}_{ij}^{-},{v}_{ij}^{+}\right]\) in the normalized matrix \([{d}_{Pij}^{-},{d}_{Pij}^{+}]\) by the equations below:
Similarly, the distance between NIS and \(\left[{v}_{ij}^{-},{v}_{ij}^{+}\right]\) in the normalized matrix \([{d}_{Nij}^{-},{d}_{Nij}^{+}]\) can be computed by the equations below:
Step 4: Determine the total distance of alternative \(i\) to PIS \({D}_{Pi}=[{D}_{Pi}^{-},{D}_{Pi}^{+}]\) and NIS \({D}_{Ni}=[{D}_{Ni}^{-},{D}_{Ni}^{+}]\) by the following equations:
Step 5: Use the optimistic indicator \(\alpha \in [\mathrm{0,1}]\) here13. A high \(\alpha\) value (\(\alpha >0.5\)) indicates that the decision makers are more optimistic; vice versa, a low value (\(\alpha <0.5\)) expresses the decision makers’ pessimism. Normally, the value \(\alpha\) is 0.5 for rational decision makers. The computing equations are:
The distance closeness indices of alternative \(i\) (\({CI}_{i}\)) can be determined by the following equation:
The alternative with a larger \({D}_{Ni}^{*}\) and a smaller \({D}_{Pi}^{*}\) is a better choice in decision-making. Hence, the alternative \(i\) whose \({CI}_{i}\) approaches 1 is an optimal candidate, and the alternatives can be ranked by the value of \(CIs\).
Informed consent
No informed consent was required, because the data are anonymized.
Case study
In our study, product concept evaluation of a cruise ship passenger cabin is used to illustrate the application of our method in a real-life case study. Three cabin design schemes \(\{{A}_{1},{A}_{2},{A}_{3}\}\) have been generated by designers as the alternatives. The evaluation objective is to select the optimal scheme out of the three alternatives.
Previous customer information45 reveals the passenger cabin should be comfortable, aesthetic and eco-friendly. Therefore, in order to meet the requirements of the passengers while considering all the aspects of the design, nine criteria are identified by the decision-making organizers.
The design criteria \({C}_{1}\) to \({C}_{9}\) are as follows. \({C}_{1}\): Size, \({C}_{2}\): User acceptance, \({C}_{3}\): Ergonomics and design humanized, \({C}_{4}\): Style and trend, \({C}_{5}\): Reasonable placement of furniture, \({C}_{6}\): Innovation and competitiveness, \({C}_{7}\): Luxurious feeling, \({C}_{8}\): Eco-friendly, and \({C}_{9}\): Cost and economical. Among the nine criteria, \({C}_{1}\) and \({C}_{9}\) are determined by both design values and preference values, \({C}_{2}\) to \({C}_{8}\) are not available to get as design values and \({C}_{9}\) is the only cost attribute.
Product concept evaluation by proposed method
Phase 1: Determine cluster weights
Thirty experts are selected as the decision makers with 10 members in each of the three clusters: the designer cluster (DC, marked as cluster 1), the manufacturer cluster (MC, marked as cluster 2) and the customer cluster (CC, marked as cluster 3). The decision makers are assigned to give their preferences according to each attribute.
Before the preference data is treated, the experts are required to make a pairwise comparison among the clusters. Then we calculated the cluster judgment by the arithmetic mean. The cluster pairwise comparisons are shown in Table 4, where cells shaded in grey mean being unable to compare against itself, and the symbol “N/A” means the corresponding cell is not permitted to compare with others.
Equations (26)–(28) can be simplified as:
In Eq. (29), \({\mathrm{q}}_{\alpha \beta y}=\upgamma {\updelta }_{\alpha \beta y}\), we have the equation set
\({\mathrm{w}}_{1}\) to \({\mathrm{w}}_{3}\) are calculated as:
The cluster weights are:
Phase 2: Normalize and integrate decision matrices
Next, after the linguistic preferences are transformed into crisp numbers on the 7-level scale listed in Sect. 3.2, the crisp numbers are converted into rough numbers by Eqs. (1)–(5). Taking the first expert in the designer cluster as an example, the corresponding data are shown in Table 5.
Similarly, the preferences of the three clusters (DC, MC and CC) are converted into rough numbers, and the integrated interval of alternative \({A}_{1}\) is determined, as shown in Table 6.
The matrix of preference values and normalized data based on Eqs. (38) and (39) are shown in Table 7.
In this case, the attributes \({C}_{1}\) and \({C}_{9}\) are available to obtain the corresponding design values. The design values are normalized by Eqs. (1) to (5), and the design value matrix is shown as Table 8.
Using Eqs. (40) and (41), let \(\mu =0.5\), the decision matrix can be determined.
Phase 3: Determine interval entropy weight
Subsequently, the entropy weights are determined by Eqs. (42) to (47), the weight of criteria calculated. The decision matrix and criteria are shown in Table 9.
Phase 4: Rank the alternatives by the rough-TOPSIS method
Finally, the relative variables and CIs are computed by Eqs. (36) to (42), indicated in Table 10. The best design concept based on design values and expert preferences is A2, and the ranking of the alternatives can be calculated by the CIs, which is \(A2\succ A3\succ A1\).
Further analysis
To show the influence of the modifications, we made comparisons on the proposed method, the rough-TOPSIS method without the expert weight consideration and the rough-TOPSIS method without the information integration. In our study, the rough-TOPSIS method with rough-entropy criteria weight is applied in the assessment process. This process has been proven effective in design concept evaluation4,12,13,16,53. Hence, in this section, we focus on the sensitivity analysis of the proposed method.
Firstly, a comparison is proposed to reveal the effectiveness of the proposed method. In our study, a rough-entropy criteria weight-based assessment is implemented, and the differences between the original rough-TOPSIS method and the proposed method are the criteria weights, which are shown in Table 11. The CIs of the original rough-TOPSIS method with entropy criteria weight and the proposed method are calculated, as shown in Fig. 5. It is obvious the CI of \(A1\) is inferior compared to the other two design concepts, no matter whether using the proposed method or the original rough-TOPSIS method. However, the optimal alternative in the rankings varies because of the different criteria weights. In the original rough-TOPSIS method, the ranking is \(A3\succ A2\succ A1\) while the ranking in the proposed method is \(A2\succ A3\succ A1\). In the design concept evaluation, the rough number information shows the uncertainty of the experts’ preference, which means the data may fluctuate in an interval. Thus, the entropy weight which is generated from the decision maker’s preference is preferred to be an interval as well. Hence, the rough-entropy criteria weight-based assessment is more practical for design concept evaluation.

The comparison between the original rough-TOPSIS method and the proposed method.
In Phase 3, the integrated matrix is determined by the coefficient \(\mu\). The coefficient shows the contribution of design values and preference values in the decision matrix, and the relative coefficient \(\mu\) and the corresponding CI are shown in Fig. 6. When \(\mu =0\), the element decision matrix is only determined by design values. Similarly, when \(\mu =1\), the element decision matrix is only determined by preference values. We can infer from the figure that the ranking of alternatives does not change as while the contribution coefficient \(\mu\) changes from 0 to 0.9, the preference remains \(A2\succ A3\succ A1\). It is obvious that while \(\mu\) increases from 0 to 1, \(A1\) and \(A2\) decline while \(A3\) increases. What we need to notice is that, when \(\mu\) equals 0.9, the CI of \(A1\) and \(A3\) are very close, with a value of 0.521 and 0.524, respectively. When the coefficient reaches 1, the result is calculated by all the preference values, and the ranking of the alternatives changes to \(A2\succ A1\succ A3\).

Closeness indices (CIs) of alternatives by different coefficient μ.
We also compared the different optimism levels (α) of decision makers. The alternative ranking is calculated as shown in Fig. 7. While α increases from 0.1 to 0.9, the design alternative ranking remains in the same sequence, \(A2\succ A3\succ A1\). From the variance tendency, we can see that as the optimism level increases, both \(A2\) and \(A3\) increase. On the contrary, the most negative alternative \(A1\) declines, and the gap between \(A1\) and the other two alternatives increases in this process.

Closeness indices (CIs) of alternatives by different coefficient α.
As a comparison, we applied the same rough-TOPSIS method without cluster weight determination. The experts are regarded as homogeneous individuals, and the ranking of the alternatives is shown in Table 12. Without cluster weight, the sequence of the alternatives may vary. In our case, when the contribution α chooses 0.1 or 0.3, alternative 3 is the optimal option, which is different from the result considering cluster weight.
Hence, we can infer from the comparative analysis that integrating design values and preference values makes the evaluation more accurate. Ignoring design values or expert preferences may lead to a different ranking. Moreover, considering the cluster weight can also help the project manager to eliminate or reduce the influence of the different backgrounds of various experts.
Conclusion
As an effective approach in design concept evaluation the rough-TOPSIS method reveals excellent performance in the ambiguity and imprecision of the evaluation of complicated product design concepts. This paper provides a modified rough-TOPSIS method. Two modifications are presented in this study:
-
(1)
Consideration of expert weight. We classified the experts into three clusters: the designer cluster, the manufacturer cluster and the customer cluster. The expert weights are considered by a cluster weight determination method. The cluster weights are determined by a Multiplicative AHP method.
-
(2)
Preservation of information from the design values and the expert preferences. We introduced a 3-step process with a coefficient \(\mu\) to represent the contribution of the two sources. Both information sources are integrated and formed a hybrid decision matrix.
Application and comparison based on the proposed method were implemented. The result shows it is a feasible method for design concept evaluation. Further analysis indicates both cluster weight and the source of the information may affect the result of the decision making, and our modifications in design concept evaluation may improve the precision of the result.
Although the proposed method is shown to be an effective MADM model in design concept evaluation, some improvements can be made in future study. The coefficient \(\mu\) for information integration may not represent different attributes, and a dynamic variable can better illustrate real situations. Applications in other fields also need to be verified by real-world applications.
Ethics approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Data availablity
The data that supports the findings of this study are available in the supplementary material of this article.
References
Geng, X., Chu, X. & Zhang, Z. A new integrated design concept evaluation approach based on vague sets. Expert Syst. Appl. 37, 6629–6638. https://doi.org/10.1016/j.eswa.2010.03.058 (2010).
Zhang, Z. & Chu, X. A new integrated decision-making approach for design alternative selection for supporting complex product development. 22, 179-198 (2009).
Lai, Z., Fu, S. Q., Yu, H., Lan, S. L. & Yang, C. A data-driven decision-making approach for complex product design based on deep learning. Int. C Comp. Supp. Coop. https://doi.org/10.1109/Cscwd49262.2021.9437761 (2021).
Chen, Z., Zhong, P., Liu, M., Sun, H. & Shang, K. A novel hybrid approach for product concept evaluation based on rough numbers, Shannon entropy and TOPSIS-PSI. J. Intell. Fuzzy Syst. 40, 12087–12099. https://doi.org/10.3233/jifs-210184 (2021).
Zhang, J. M., Wei, X. P., Wang, J. Evaluating design concepts by ranking fuzzy numbers. Proceedings of the 2003 International Conference on Machine Learning and Cybernetics (IEEE Cat. No. 03EX693), 2596–2600 (2003).
Carnahan, J., Thurston, D. & Liu, T. Fuzzing ratings for multiattribute design decision-making. J. Mech. Design (1994).
Akay, D. & Kulak, O. Evaluation of product design concepts using grey-fuzzy information axiom. IEEE International Conference on Grey Systems and Intelligent Services. 1040–1045 (2007).
Geng, X. L., Gong, X. M. & Chu, X. N. Component oriented remanufacturing decision-making for complex product using DEA and interval 2-tuple linguistic TOPSIS. Int. J. Comput. Intell. Syst. 9, 984–1000. https://doi.org/10.1080/18756891.2016.1237195 (2016).
Pawlak, Z. Rough set theory and its applications to data analysis. Cybern. Syst. 29, 661–688 (1998).
Zhai, L.-Y., Khoo, L.-P. & Zhong, Z.-W. Design concept evaluation in product development using rough sets and grey relation analysis. Expert Syst. Appl. 36, 7072–7079. https://doi.org/10.1016/j.eswa.2008.08.068 (2009).
Zhu, G.-N., Hu, J. & Ren, H. A fuzzy rough number-based AHP-TOPSIS for design concept evaluation under uncertain environments. Appl. Soft Comput. https://doi.org/10.1016/j.asoc.2020.106228 (2020).
Tiwari, V., Jain, P. K. & Tandon, P. Product design concept evaluation using rough sets and VIKOR method. Adv. Eng. Inform. 30, 16–25. https://doi.org/10.1016/j.aei.2015.11.005 (2016).
Song, W., Ming, X. & Wu, Z. An integrated rough number-based approach to design concept evaluation under subjective environments. J. Eng. Des. 24, 320–341 (2013).
Shidpour, H., Da Cunha, C. & Bernard, A. Group multi-criteria design concept evaluation using combined rough set theory and fuzzy set theory. Expert Syst. Appl. 64, 633–644. https://doi.org/10.1016/j.eswa.2016.08.022 (2016).
Chang, D. Y. Applications of the extent analysis method on fuzzy AHP. Eur. J. Oper. Res. 95, 649–655 (1996).
Zhu, G., Hu, J. & Ren, H. A fuzzy rough number-based AHP-TOPSIS for design concept evaluation under uncertain environments. Appl. Soft Comput. 91, 106228 (2020).
Qi, J., Hu, J. & Peng, Y. A customer-involved design concept evaluation based on multi-criteria decision-making fusing with preference and design values. Adv. Eng. Inf. https://doi.org/10.1016/j.aei.2021.101373 (2021).
Kabak, Ö. & Ervural, B. Multiple attribute group decision making: A generic conceptual framework and a classification scheme. Knowl.-Based Syst. 123, 13–30 (2017).
Ullah, R., Zhou, D. & Zhou, P. Design concept evaluation and selection: A decision making approach. 2nd International Conference on Mechanical Engineering and Green Manufacturing (MEGM 2012). 1122–1126 (2012).
Shinno, H., Yoshioka, H., Marpaung, S. & Hachiga, S. Quantitative SWOT analysis on global competitiveness of machine tool industry. J. Eng. Des. 17, 251–258 (2006).
Shvetsova, O. A., Park, S. C. & Lee, J. H. Application of quality function deployment for product design concept selection. Appl. Sci.-Basel 11, 2681 (2021).
Lønmo, L. & Muller, G. in INCOSE International Symposium. 583–598 (Wiley Online Library).
Ulrich, K. & Eppinger, S. Product design and development (McGraw-Hill Inc, 2000).
Ayağ, Z. & özdemr, R. G. An analytic network process-based approach to concept evaluation in a new product development environment. J. Eng. Design 18, 209–226 (2007).
Lin, M. C., Wang, C. C., Chen, M. S. & Chang, C. A. Using AHP and TOPSIS approaches in customer-driven product design process. Comput. Ind. 59, 17–31 (2008).
Takai, S. & Ishii, K. Integrating target costing into perception-based concept evaluation of complex and large-scale systems using simultaneously decomposed QFD. J. Mech. Des. 128, 1186–1195 (2006).
Zhu, G.-N., Hu, J., Qi, J., Gu, C.-C. & Peng, Y.-H. An integrated AHP and VIKOR for design concept evaluation based on rough number. Adv. Eng. Inform. 29, 408–418. https://doi.org/10.1016/j.aei.2015.01.010 (2015).
Pang, J., Zhang, G. & Chen, G. ELECTRE I decision model of reliability design scheme for computer numerical control machine. J. Softw. 6, 895 (2011).
Vinodh, S. & Girubha, R. J. PROMETHEE based sustainable concept selection. Appl. Math. Model. 36, 5301–5308 (2012).
Zhang, S., Gao, H., Wei, G., Wei, Y. & Wei, C. Evaluation based on distance from average solution method for multiple criteria group decision making under picture 2-tuple linguistic environment. Mathematics 7 (2019).
Zadeh, L. A. Fuzzy sets. Inf. Control 8, 338–353 (1965).
Zadeh, L. A. The concept of a linguistic variable and its application to approximate reasoning—I. Inf. Sci. 8, 199–249 (1975).
Garibaldi, J. M., Jaroszewski, M. & Musikasuwan, S. Nonstationary fuzzy sets. IEEE Trans. Fuzzy Syst. 16, 1072–1086 (2008).
Atanassov, K. & Gargov, G. Interval valued intuitionistic fuzzy sets. Fuzzy Sets Syst. Eng. 31, 343–349 (1989).
Xu, Z. & Yager, R. R. Some geometric aggregation operators based on intuitionistic fuzzy sets. Int. J. Gen Syst 35, 417–433 (2006).
Rodríguez, R. M., Martínez, L., Torra, V., Xu, Z. S. & Herrera, F. Hesitant fuzzy sets: State of the art and future directions. Int. J. Intell. Syst. 29, 495–524. https://doi.org/10.1002/int.21654 (2014).
Sayadi, M. K., Heydari, M. & Shahanaghi, K. Extension of VIKOR method for decision making problem with interval numbers. Appl. Math. Model. 33, 2257–2262 (2009).
Toosi, S. R. & Samani, J. A new integrated MADM technique combined with ANP, FTOPSIS and fuzzy max-min set method for evaluating water transfer projects. Water Resour. Manage 28, 4257–4272 (2014).
Sinani, F., Erceg, Z. & Vasiljević, M. An evaluation of a third-party logistics provider: The application of the rough Dombi-Hamy mean operator. Decis. Mak.: Appl. Manag. Eng. 3, 92–107 (2020).
Zhai, L.-Y., Khoo, L.-P. & Zhong, Z.-W. A rough set enhanced fuzzy approach to quality function deployment. Int. J. Adv. Manuf. Technol. 37, 613–624 (2008).
Behzadian, M., Otaghsara, S. K., Yazdani, M. & Ignatius, J. A state-of the-art survey of TOPSIS applications. Expert Syst. Appl. 39, 13051–13069 (2012).
Lotfi, F. H. & Fallahnejad, R. Imprecise Shannon's entropy and multi attribute decision making. Entropy 12 (2010).
Chen, P. Effects of normalization on the entropy-based TOPSIS method. Expert Syst. Appl. 136, 33–41 (2019).
Koksalmis, E. & Kabak, Ö. Deriving decision makers’ weights in group decision making: An overview of objective methods. Inf. Fusion 49, 146–160 (2019).
Chen, Z., Zhong, P., Liu, M., Ma, Q. & Si, G. An integrated expert weight determination method for design concept evaluation. Sci. Rep. 12, 6358. https://doi.org/10.1038/s41598-022-10333-6 (2022).
Ramanathan, R. & Ganesh, L. Group preference aggregation methods employed in AHP: An evaluation and an intrinsic process for deriving members’ weightages. Eur. J. Oper. Res. 79, 249–265 (1994).
Barzilai, J. & Lootsma, F. Power relations and group aggregation in the multiplicative AHP and SMART. Journal of Multi-Criteria Decision Analysis 6, 155–165 (1997).
Azadfallah, M. The extraction of expert weights from pair wise comparisons in Delphi method. J. Appl. Inform. Sci. 3, 1–5 (2015).
Yue, Z. Deriving decision maker’s weights based on distance measure for interval-valued intuitionistic fuzzy group decision making. Expert Syst. Appl. 38, 11665–11670 (2011).
Yue, Z. Approach to group decision making based on determining the weights of experts by using projection method. Appl. Math. Model. 36, 2900–2910 (2012).
Xu, X., Zhang, Q. & Chen, X. Consensus-based non-cooperative behaviors management in large-group emergency decision-making considering experts’ trust relations and preference risks. Knowl.-Based Syst. 190, 105108 (2020).
Pang, J., Liang, J. & Song, P. An adaptive consensus method for multi-attribute group decision making under uncertain linguistic environment. Appl. Soft Comput. 58, 339–353. https://doi.org/10.1016/j.asoc.2017.04.039 (2017).
Tiwari, V., Jain, P. K. & Tandon, P. An integrated Shannon entropy and TOPSIS for product design concept evaluation based on bijective soft set. J. Intell. Manuf. 30, 1645–1658. https://doi.org/10.1007/s10845-017-1346-y (2017).
Hayat, K., Ali, M. I., Karaaslan, F., Cao, B.-Y. & Shah, M. H. Design concept evaluation using soft sets based on acceptable and satisfactory levels: An integrated TOPSIS and Shannon entropy. Soft. Comput. 24, 2229–2263. https://doi.org/10.1007/s00500-019-04055-7 (2020).
Hayat, K., Ali, M. I., Alcantud, J. C. R., Cao, B.-Y. & Tariq, K. U. Best concept selection in design process: An application of generalized intuitionistic fuzzy soft sets. J. Intell. Fuzzy Syst. 35, 5707–5720. https://doi.org/10.3233/jifs-172121 (2018).
Mirtalaie, M. A., Hussain, O. K., Chang, E. & Hussain, F. K. A decision support framework for identifying novel ideas in new product development from cross-domain analysis. Inf. Syst. 69, 59–80. https://doi.org/10.1016/j.is.2017.04.003 (2017).
Crilly, N., Moultrie, J. & Clarkson, P. J. Seeing things: Consumer response to the visual domain in product design. Des. Stud. 25, 547–577 (2004).
Qi, J., Hu, J. & Peng, Y. Modified rough VIKOR based design concept evaluation method compatible with objective design and subjective preference factors. Appl. Soft Comput. https://doi.org/10.1016/j.asoc.2021.107414 (2021).
Rui-Yang, C. Fuzzy dual experience-based design evaluation model for integrating engineering design into customer responses. Int. J. Interact. Design Manuf. 10, 439–458 (2016).
Qi, J., Hu, J. & Peng, Y. New design concept evaluation method involving customer preferences based on rough distance to redefined ideal solution. Comput. Ind. Eng. 147, 106677 (2020).
Van den Honert, R. Decisional power in group decision making: A note on the allocation of group members’ weights in the multiplicative AHP and SMART. Group Decis. Negot. 10, 275–286 (2001).
Lootsma, F. A. Scale sensitivity in the multiplicative AHP and SMART. J. Multi-Crit. Decis. Anal. 2, 87–110 (1993).
Shannon, C. E. A mathematical theory of communication. ACM Sigmobile Mobile Comput. Commun. Rev. 27, 379–423. https://doi.org/10.1002/j.1538-7305.1948.tb01338.x (1948).
Acknowledgements
This work was supported by the Key Research and Development Plan of Shandong Province (2019GGX104102) awarded to Peisi Zhong, Natural Science Foundation of Shandong Province (ZR2017MEE066) awarded to Peisi Zhong, High-tech Ship project of China’s Ministry of Industry and Information Technology awarded to Qing Ma (MC-201917-C09), and the Culture and Tourism Research Project of Shandong Province (21WL(H)64) awarded to Zhe Chen.
Author information
Authors and Affiliations
Contributions
Conceptualization: All authors; Methodology: P.Z., Z.C. and M.L.; Data collection: Q.M.; Data Analysis: Z.C., Q.M. and G.S.; Writing – original draft preparation: Z.C.; Writing – review and editing: Z.C., P.Z. and G. S.; Funding acquisition: P.Z., Q.M. and Z. C.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, Z., Zhong, P., Liu, M. et al. A novel integrated MADM method for design concept evaluation. Sci Rep 12, 15885 (2022). https://doi.org/10.1038/s41598-022-20044-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-20044-7
This article is cited by
-
An integrated design concept evaluation model based on interval valued picture fuzzy set and improved GRP method
Scientific Reports (2024)
-
A Novel Decision-Making Approach for Product Design Evaluation Using Improved TOPSIS and GRP Method Under Picture Fuzzy Set
International Journal of Fuzzy Systems (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
