
Abstract
As a network of researchers we release an open-access database (EUSEDcollab) of water discharge and suspended sediment yield time series records collected in small to medium sized catchments in Europe. EUSEDcollab is compiled to overcome the scarcity of open-access data at relevant spatial scales for studies on runoff, soil loss by water erosion and sediment delivery. Multi-source measurement data from numerous researchers and institutions were harmonised into a common time series and metadata structure. Data reuse is facilitated through accompanying metadata descriptors providing background technical information for each monitoring station setup. Across ten European countries, EUSEDcollab covers over 1600 catchment years of data from 245 catchments at event (11 catchments), daily (22 catchments) and monthly (212 catchments) temporal resolution, and is unique in its focus on small to medium catchment drainage areas (median = 43 km2, min = 0.04 km2, max = 817 km2) with applicability for soil erosion research. We release this database with the aim of uniting people, knowledge and data through the European Union Soil Observatory (EUSO).
Similar content being viewed by others


Background and Summary
Soil erosion by water and sediment delivery to river systems are gaining political importance and scientific attention for their integral role in issues spanning across the domains of soil health1, food security2, environmental pollution3,4,5,6, greenhouse gas offsetting7,8,9,10, reservoir longevity11, and a range of other ecosystem services12,13,14,15,16,17,18. The scientific community has responded to these priorities with a continuingly increasing number of model-based assessments, ranging across the full spectrum of spatial scales relevant to the end-user19,20. While model applications have dominated the scientific output, the production and sharing of empirical observations haven’t necessarily kept pace21. Available summarised compilations of long-term annual average rates from monitored areas have unravelled large-scale spatial trends in soil loss by water erosion and fluvial sediment yield22,23,24,25, but often do so with a long-term annual average temporal focus that misses the high temporal variability between soil loss events26,27,28. Quantifications of net soil loss at dynamic timescales arguably form the basis of contemporary research priorities, which include, but are not limited to: (1) understanding the variable frequency-magnitude relationships of gross and net soil loss through space and time in a changing climate, (2) understanding the influences of management practices on the dynamics and magnitude of soil loss, (3) up/down-scaling soil loss by water erosion predictions to integrate soil loss by water erosion processes into Earth system models, and (4) quantifying uncertainty on model predictions and observational data.
Given the intimate coupling between empirical observations and modelling opportunities (e.g. model development, calibration and validation), the open sharing of high resolution time series data from monitoring networks is vital to confront modern research questions29,30,31,32. For example, while not without criticism33,34, typical validation routines for spatially distributed catchment models involve the routing of overland fluxes into stream channel outlets in which an integrated comparison can be made35,36,37,38,39,40. The value of small monitored catchments manifests since soil erosion and sediment delivery models require an idealised ‘goldilocks’ spatial scale for such confrontations; suitably large to incorporate catchment-scale processes, but without transitioning to scales after which fluvial processes mask and confound the signal from hillslope sediment delivery32,41. Among the spectrum of catchment drainage areas monitored in Europe, catchments potentially matching this criteria have the lowest relative abundance25.
The limited open availability of suitable catchment measurements is perhaps a key underlying reason for broad critiques of model validation efforts42. The cascading value of available centralised monitored catchment networks (e.g. USDA-ARS) is evidenced through numerous scientific and technological advancements in soil erosion research43,44,45,46. In Europe, despite a relative data-richness as a continent, the absence of a multi-national network instead requires community collaborations to systematise data in a way that can unite researchers with monitoring program operators30. This priority is compounded by the tendency of legacy research data to become increasingly unavailable through time47, emphasising the general need for European data conservation efforts.
Here we present the EUropean SEDiments collaboration (EUSEDcollab) database, a multi-source platform containing over 1600 catchment years of water discharge and sediment yield time series measurements suitable for soil erosion, sediment delivery and runoff studies. The dataset originates from collaborative efforts between a network of researchers and practitioners across the community with the goal of increasing data accessibility and usability. The data collection and harmonisation campaign was undertaken in multiple phases: (1) a call of interest for participation was made to the research community, issued by the Joint Research Centre (JRC) as part of the erosion working group within the EU Soil Observatory (EUSO), (2) interested collaborators were given (meta-)data templates to compile and share time series data to a centralised data repository, and (3) following data acquisition, a harmonisation and quality checking effort was undertaken to create a standardised database from the multiple data contributors. Following this process, we provide the first data release (EUSEDcollab.v1) of a continuing collaboration and data collation campaign through the EUSO, with the broad objective of converging scientific knowledge, people and data for research and policy-related objectives in Europe48.
Methods
Data collection: scope
The initial scope of EUSEDcollab on conception was to identify and unite high value research data in predominantly agricultural landscapes across Europe. Binary conditions were not set during the data collation phase, rather holistic criteria were made to be reflected in the compiled database, such as: (1) a significant contribution of rill and inter-rill erosion to the total sediment yield among the other relevant erosion processes (i.e. landslides, gullying and river bank erosion), and (2) a small to medium spatial scale (<1000 km2) in which the signal of hillslope sediment delivery is reflected in the sediment yield dynamics. Following this, an inclusionary approach is taken to maximise the number of catchment datasets in the repository, allowing a user to later subset the data repository based on their needs.
Data collection: time series and metadata structure
The monitoring of suspended sediment loads (SSL) at gauging stations requires quantifications of water discharge (Q) and suspended sediment concentration (SSC) through time. These spatial and temporal extrapolation exercises inevitably associate appreciable uncertainty with the final estimated quantity49. Uncertainties depends on:(1) the proficiency of Q and SSC measurement methods in capturing lateral and vertical gradients of sediment transport rate within the stream profile, (2) the timing and frequency of these measurements, and (3) the strategy used to extrapolate discrete measurements into (nearly) continuous time series. Such extrapolation is commonly undertaken using water depth-Q and Q-SSC rating curves to continuously approximate Q and SSC respectively50,51. In the case of SSC, surrogate approximators such as water turbidity and acoustic signals are also used to proxy changes in SSC at fine temporal resolutions based on calibrated relationships52. Minimising uncertainty is context-dependent based on the system dynamics53,54,55, requiring a strategic SSC sampling technique using random, calendar-based, or flow-proportional sampling schemes. Particularly at small spatial scales, a high number of SSC samples over time and using flow-proportional sampling regimes typically associates lower uncertainties with time-integrated sediment load approximations49.
Given the method dependency of SSL quantifications, we invited data contributors to add descriptive metadata properties of the water discharge and SSC measurement methods to provide users with background context for each timeseries (Table 1). Additionally, for the popular case in which a sediment rating curve was used for the extrapolation of SSC, we invited the contributing scientists to include the original data in order for a user to reproduce the time series of SSL.
Each data entry has a standardised format with a column for the datetime, water discharge (Q: volume time−1), suspended sediment concentration (SSC: mass volume−1) and the derived suspended sediment load (SSL: mass time−1) accompanied by the relevant units. A metadata file accompanies each catchment entry to allow data contextualisation using open or categorical properties (Table 1). Input fields predominantly define descriptive properties of the catchment (e.g. monitoring station location, catchment drainage area and land cover), the data record (e.g. temporal extent) and the methods used to measure and quantify the water discharge and sediment yield. Land cover information is included as a metadata field since it gives the opportunity for data contributors to add and qualify primary descriptive catchment properties with more localised detail than is possible with auxiliary large-scale landcover datasets.
At minimum, each catchment entry contains a Q and SSL timeseries with a metadata file providing the geographic coordinates of the monitoring station location. However, for the majority of catchment entries the population of each metadata field within EUSEDcollab is relatively high (Table 1). Where possible, we also include: (1) precipitation time series data and rain gauge location information, (2) accompanying literature references from relevant publications for each dataset, and (3) a readme file to give expert-based contextual information to the end-user and qualify any necessary considerations within the time series data. For catchments without an associated English language publication, the submission of this file is emphasised in order to supplement the metadata with sufficient background information.
Data Records
The EUSEDcollab repository contains 245 catchments with time series of Q and SSL (Tables 2–4). We include a further seven catchment records with full Q time series and intermittent SSC measurements for a user to define their own extrapolation method, since no prior extrapolation was completed in these cases. These records are not considered in the subsequent summary but are included in the data release with accompanying metadata files. The combined dataset covers over 1600 catchment years of water discharge and suspended sediment load records. Based on time-structure, this repository is divided into 22 daily data records, 212 monthly records, 1 event record with a fixed timestep, 2 event records with variable timesteps, and 8 event records with event aggregations (Fig. 1). A large addition of data was made available from monitored Danish catchments56, which have a comparatively lower temporal resolution (monthly) than other individual or small collections of monitored catchments (Tables 2–4).

A statistical overview of the EUSEDcollab database. Catchment records are categorised into ‘Monthly’ data, with quantifications of sediment yield per month, and ‘Daily/event’ data, including all other data time structures with daily timesteps or time-distributed and time aggregated event data. The plotted overviews include: (a) the number of datasets belonging to each classified time-structure type, (b) the distribution of measurement record lengths within the database, (c) the number of datasets with coverage in each year, and (d) boxplot distributions of catchment drainage areas within the dataset for monthly and daily/event time series records.
The distribution of catchment drainage areas (median = 43 km2, min = 0.04 km2, max = 817 km2) included in EUSEDcollab reflects the overall focus on small to medium monitored catchment areas relevant for soil erosion and hydrological research (Fig. 1). These catchments distribute across a range of elevation settings and climatic regions but contain an overall dominance of agricultural land uses (Fig. 2). Excluding catchment entries with monthly resolution data, this median drainage area reduces to 3.6 km2 (min = 0.04 km2, max = 566 km2). The mean measurement length of all records is 6.7 years and 9.7 years for only high temporal resolution (excluding monthly data) records. These years of data coverage are predominantly concentrated from the year 1995 onwards (Fig. 1).

Histogram charts of the elevation (a) and mean annual precipitation in mm (b) of the monitoring stations included in EUSEDcollab. The distribution of the % cover of each land use type within the database is given for catchments with metadata inputs (c). Elevation is extracted from the SRTM global digital elevation layer and total annual average precipitation from Worldclim103.
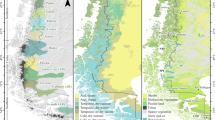
Of the total repository, 32 catchment entries contain additional time series measurements of precipitation depth at varying temporal resolutions for their respective location depending on the method employed. This precipitation file gives additional information on the rain gauge type and spatial coordinates. A total of 228 catchments have catchment boundary polygons added as additional information by the data provider (Fig. 3). Some monitored catchments, such as Kinderveld and Ganspoel35, contain additional geospatial information on land use as well as erosion surveys. In these cases we include the data in the original format and structure in which it was made available by the data producers. A full overview of all catchment locations is given in Fig. (4).

Google Earth satellite image examples of monitored catchments in EUSEDcollab with included catchment boundary polygons: (a) Kinderveld, BE (including parcel boundary information), and (b) Nučice, CZ. The point markers represent the registered monitoring locations in EUSEDcollab.

Top: A geographical overview of EUSEDcollab.v1 data entries per climate (EnZ) region in Europe104 (a). Bottom: summary-level empirical relationships found within the database entries, showing a) the relationship between catchment area (km2) and specific sediment yield (t km2 yr−1), and (b) the relationship between mean annual discharge (m3 yr−1) and the mean annual sediment yield (t yr−1) for all high temporal resolution datasets (excluding monthly data). The error bars show the variation of the annual sediment yield values around the mean annual average.
Technical Validation
Technical validation of each original record is done in a decentralised manor by the data producer. The multi-source nature of EUSEDcollab means that measurements of Q and SSL measurements were acquired with varying apparatus set-ups, temporal structures and post-processing methods (Tables 2–4). Acknowledging varying degrees of data heterogeneity requires end-users to make a judgement on the inter-comparability of catchment records for a particular use-case, based on differing measuring extents, sampling resolutions and uncertainty sources. As a data integration and harmonisation exercise, we aimed to facilitate this user-side assessment by providing necessary metadata properties, namely: (1) water discharge method descriptors, (2) sediment flux measurement and quantification methods, and (3) quality control properties describing the frequency of monitoring station checks, (4) literature references, and (5) dataset contact information (Table 1).
Data evaluation: quality and completeness assessment
To give a centralised assessment of the completeness and consistency of each submitted time series record, a ready-to-use evaluation was made of missing data inputs (Fig. 5). For example, missing inputs could be due to temporary technical issues, incomplete measurements or periodic discontinuation. Depending on the use-case, missing data may limit the applicability of a catchment dataset to a certain task and therefore may be useful for a user to know a priori.

An overview of the data quality control procedure to include an evaluation of missing data entries within each time series record. A modified evaluation is made according to the time series structure of each data record. The output of the quality control procedure provides an accompanying JSON file for each data entry within EUSEDcollab.
The compiled time series entries in EUSEDcollab contain continuous measurements (e.g. with a daily or monthly timestep) in perennial streams or episodic measurements (e.g. time-aggregated or time-distributed events) in discontinuous streams. Based on these structural data characteristics, adapted evaluation routines were used to summarise data presence/absence through time (Fig. 5). Each time series entry is initially classified into one of five structures: (1) daily data series with a fixed timestep, (2) monthly data series with a fixed timestep, (3) event data with a fixed timestep within each event, (4) event data with a variable timestep within each event, or (5) event data that is temporally-aggregated per event. Thereafter, evaluations of each time series are made to give the total % completeness of the instances for both Q and SSL. For data containing fine-resolution measurements during episodic events, within-event evaluations are additionally generated to quantify the completeness of each individual event making up the entire time series (Fig. 5). A full description of each evaluation parameter is given in S.(1) for each classified time series structure.
Usage Notes
Data opportunities
EUSEDcollab is the first database of its kind in Europe, intended as a resource for a non-exhaustive range of applications relating to runoff, soil loss by water erosion and sediment delivery research at singular or multiple sites. These opportunities can include a range of research domains seeking to understand the system dynamics of catchment-scale runoff, erosion and sediment fluxes (Figs. 4, 6). These may include modelled and analytical developments in frequency-intensity relationships26,27,57,58, spatial and temporal scale-effects25,59,60,61, or internal (e.g. topography, geology, soil characteristics), external (e.g. meteorological conditions) and anthropogenic (e.g. land use and land cover) drivers of sediment variability62.

Example syntheses of time series data from the Kinderveld catchment, BE (250 ha) and the Nučice catchment, CZ (53 ha) in the EUSEDcollab repository. Note that the data is not area-normalised and the data from the Kinderveld catchment (a) is presented in tonnes per aggregated event, while the Nučice catchment (b) is made available and presented in tonnes per day. Additionally, it is important to consider the following contextual factors: (i) The Nučice measurements include periods with baseflow carrying sediments, whereas in the Kinderveld, only runoff events are included. This difference in sediment sources (rill and interrill, bank erosion and gullying) between the two catchments, explained in the related literature (Tables 2, 3), may contribute to variations in the observed values. (ii) In Nučice, the low number of days in the data record for specific years (e.g., 2015, 2017, 2018, 2021) is due to exceptionally dry years when the discharge was zero or very low, limiting the availability of sediment data.
By uniting data from across a European scientific network, we aim to: (1) release an open-access data resource hosted on the European Soil Data Centre (ESDAC) with the goal of continued database growth in a standardised manor, (2) mitigate data loss from discontinued research projects, (3) build a repository upon which a broad range of analytical and modelling methods can be built to advance scientific knowledge, and (4) allow cross-domain intercomparisons to assess the generalisation of empirical relationships and model prediction systems.
Data limitations
Data users are advised to consider the applicability of each utilised dataset for their application. These considerations range from the spatial scale (drainage area) of the catchment in its context-dependent environmental setting, to the temporal detail and measurement-richness underlying the dataset. The data quality evaluation gives additional relevant information on the time series completeness in order for initial evaluations to be made (Fig. 5).
The EUSEDcollab.v1 repository has a significant spatial bias in its coverage due to a large number of data additions from small to medium sized catchments from a national monitoring campaign in Denmark56. These data have evidenced usage in erosion modelling36 but may not meet the requirements of certain high temporal resolution research applications due to infrequent underlying suspended sediment sampling. We envisage that continued catchment data inputs from national monitoring campaigns fitting the motivations of EUSEDcollab will improve the overall spatial coverage and reduce this spatial bias.
Data platform and continued community contributions
The EUSEDcollab repository is openly accessible via the European Soil Data Centre63 (ESDAC) platform (https://esdac.jrc.ec.europa.eu/content/EUSEDcollab) and Figshare64. All files are provided in .csv format in their relevant folders and are identifiable based on the assigned ID listed in the overview file (Catchment_ID_assignment.csv). In the case of database-wide applications, users are requested to cite this article as the reference for the entire repository. In cases of individual catchment applications, users should refer to the reference studies for each catchment provided in the metadata and summarised in Tables 2–4.
EUSEDcollab.v1 is intended as the first version of a continued effort to gather and platform data through collaborative efforts from across the community. Future data collection efforts will seek to extend the size and scope of the repository through including a wider diversity of catchment types (e.g. pristine forests, badlands etc.) across a wider range of elevation settings.
Further contributions can be made to the database by downloading and completing the data and meta-data template files available in the ESDAC data portal (https://esdac.jrc.ec.europa.eu/content/EUSEDcollab). Data submissions can be included in future data releases by contacting the listed data manager through the contact details listed in the ESDAC data portal.
Code availability
All code can be found at: https://github.com/matfran/EUSEDcollab.git. We include the R language code to perform the quality control procedure on each time series entry to produce the JSON time series evaluation files for each record. Additionally, a Python language Jupyter notebook is included to demonstrate simple operations that can be undertaken using the database, such as reading and filtering the database, calculating metadata statistics and importing specific time series for analysis.
References
Montanarella, L. & Panagos, P. The relevance of sustainable soil management within the European Green Deal. Land use policy 100, 104950 (2021).
Alewell, C. et al. Global phosphorus shortage will be aggravated by soil erosion. Nature Communications 2020 11:1 11, 1–12 (2020).
Panagos, P., Jiskra, M., Borrelli, P., Liakos, L. & Ballabio, C. Mercury in European topsoils: Anthropogenic sources, stocks and fluxes. Environ Res 201, 111556 (2021).
Ulén, B., Bechmann, M., Fölster, J., Jarvie, H. P. & Tunney, H. Agriculture as a phosphorus source for eutrophication in the north-west European countries, Norway, Sweden, United Kingdom and Ireland: a review. Soil Use Manag 23, 5–15 (2007).
Mullan, D., Vandaele, K., Boardman, J., Meneely, J. & Crossley, L. H. Modelling the effectiveness of grass buffer strips in managing muddy floods under a changing climate. Geomorphology 270, 102–120 (2016).
Boardman, J., Vandaele, K., Evans, R. & Foster, I. D. L. Off-site impacts of soil erosion and runoff: Why connectivity is more important than erosion rates. Soil Use Manag 35, 245–256 (2019).
Chappell, A., Baldock, J. & Sanderman, J. The global significance of omitting soil erosion from soil organic carbon cycling schemes. Nature Climate Change 2015 6:2 6, 187–191 (2015).
Kuhn, N. J., Hoffmann, T., Schwanghart, W. & Dotterweich, M. Agricultural soil erosion and global carbon cycle: Controversy over? Earth Surf Process Landf 34, 1033–1038 (2009).
Borrelli, P. et al. Effect of Good Agricultural and Environmental Conditions on erosion and soil organic carbon balance: A national case study. Land use policy 50, 408–421 (2016).
Borrelli, P. et al. A step towards a holistic assessment of soil degradation in Europe: Coupling on-site erosion with sediment transfer and carbon fluxes. Environ Res 161, 291–298 (2018).
Graf, W. L., Wohl, E., Sinha, T. & Sabo, J. L. Sedimentation and sustainability of western American reservoirs. Water Resour Res 46, 12535 (2010).
Borrelli, P. et al. Policy implications of multiple concurrent soil erosion processes in European farmland. Nature Sustainability 2022 1–10, https://doi.org/10.1038/s41893-022-00988-4 (2022).
Borrelli, P. & Panagos, P. An indicator to reflect the mitigating effect of Common Agricultural Policy on soil erosion. Land use policy 92, 104467 (2020).
Panagos, P. & Katsoyiannis, A. Soil erosion modelling: The new challenges as the result of policy developments in Europe. Environmental Research vol. 172, 470–474, https://doi.org/10.1016/j.envres.2019.02.043 (2019).
Panagos, P. et al. Projections of soil loss by water erosion in Europe by 2050. Environ Sci Policy 124, 380–392 (2021).
Quinton, J. N., Govers, G., Van Oost, K. & Bardgett, R. D. The impact of agricultural soil erosion on biogeochemical cycling. Nature Geoscience 2010 3:5 3, 311–314 (2010).
Lal, R. Soil conservation and ecosystem services. International Soil and Water Conservation Research 2, 36–47 (2014).
Issaka, S. & Ashraf, M. A. Impact of soil erosion and degradation on water quality: a review. 1, 1–11, https://doi.org/10.1080/24749508.2017.1301053 (2017).
Tang, T. et al. Bridging global, basin and local-scale water quality modeling towards enhancing water quality management worldwide. Curr Opin Environ Sustain 36, 39–48 (2019).
Borrelli, P. et al. Soil erosion modelling: A global review and statistical analysis. Science of The Total Environment 780, 146494 (2021).
Vörösmarty, C. et al. Global water data: A newly endangered species. Eos (Washington DC) 82, (2001).
Syvitski, J. et al. Earth’s sediment cycle during the Anthropocene. Nature Reviews Earth & Environment 2022 3:3 3, 179–196 (2022).
García-Ruiz, J. M. et al. A meta-analysis of soil erosion rates across the world. Geomorphology 239, 160–173 (2015).
Maetens, W. et al. Effects of land use on annual runoff and soil loss in Europe and the Mediterranean: A meta-analysis of plot data. 36, 599–653, https://doi.org/10.1177/0309133312451303 (2012).
Vanmaercke, M., Poesen, J., Verstraeten, G., de Vente, J. & Ocakoglu, F. Sediment yield in Europe: Spatial patterns and scale dependency. Geomorphology 130, 142–161 (2011).
Gonzalez-Hidalgo, J. C., de Luis, M. & Batalla, R. J. Effects of the largest daily events on total soil erosion by rainwater. An analysis of the USLE database. Earth Surf Process Landf 34, 2070–2077 (2009).
Gonzalez-Hidalgo, J. C., Batalla, R. J. & Cerda, A. Catchment size and contribution of the largest daily events to suspended sediment load on a continental scale. Catena (Amst) 102, 40–45 (2013).
Vercruysse, K., Grabowski, R. C. & Rickson, R. J. Suspended sediment transport dynamics in rivers: Multi-scale drivers of temporal variation. Earth Sci Rev 166, 38–52 (2017).
Vereecken, H. et al. Soil hydrology: Recent methodological advances, challenges, and perspectives. Water Resour Res 51, 2616–2633 (2015).
Bogena, H. R. et al. Toward Better Understanding of Terrestrial Processes through Long-Term Hydrological Observatories. Vadose Zone Journal 17, 1–10 (2018).
Lefèvre, C., Cruse, R. M., Cunha dos Anjos, L. H., Calzolari, C. & Haregeweyn, N. Guest editorial – soil erosion assessment, tools and data: A special issue from the Global Symposium on soil Erosion 2019. International Soil and Water Conservation Research 8, 333–336 (2020).
Latron, J. & Lana-Renault, N. The relevance of hydrological research in small catchments- a perspective from long-term monitoring sites in. Europe. Geographical Research Letters 44, 387–395 (2018).
Brazier, R. E., Beven, K. J., Freer, J. & Rowan, J. S. Equifinality and uncertainty in physically based soil erosion models: application of the GLUE methodology to WEPP–the Water Erosion Prediction Project–for sites in the UK and USA. https://doi.org/10.1002/1096-9837.
Beven, K. & Binley, A. The future of distributed models: Model calibration and uncertainty prediction. Hydrol Process 6, 279–298 (1992).
van Oost, K. et al. Spatially distributed data for erosion model calibration and validation: The Ganspoel and Kinderveld datasets. Catena (Amst) 61, 105–121 (2005).
Onnen, N. et al. Distributed water erosion modelling at fine spatial resolution across Denmark. Geomorphology 342, 150–162 (2019).
Alatorre, L. C., Beguería, S. & García-Ruiz, J. M. Regional scale modeling of hillslope sediment delivery: A case study in the Barasona Reservoir watershed (Spain) using WATEM/SEDEM. J Hydrol (Amst) 391, 109–123 (2010).
Jetten, V., de Roo, A. & Favis-Mortlock, D. Evaluation of field-scale and catchment-scale soil erosion models. Catena (Amst) 37, 521–541 (1999).
Refsgaard, J. C. Parameterisation, calibration and validation of distributed hydrological models. J Hydrol (Amst) 198, 69–97 (1997).
Baartman, J. E. M., Jetten, V. G., Ritsema, C. J. & de Vente, J. Exploring effects of rainfall intensity and duration on soil erosion at the catchment scale using openLISEM: Prado catchment, SE Spain. Hydrol Process 26, 1034–1049 (2012).
de Vente, J. & Poesen, J. Predicting soil erosion and sediment yield at the basin scale: Scale issues and semi-quantitative models. Earth Sci Rev 71, 95–125 (2005).
Batista, P. V. G., Davies, J., Silva, M. L. N. & Quinton, J. N. On the evaluation of soil erosion models: Are we doing enough? Earth Sci Rev 197, 102898 (2019).
Harmel, R. D., Bonta, J. V. & Richardson, C. W. The Original USDA-ARS Experimental Watersheds in Texas and Ohio: Contributions from the Past and Visions for the Future. Trans ASABE 50, 1669–1675 (2007).
Owens, L. B., Bonta, J. V. & Shipitalo, M. J. USDA-ARS North Appalachian Experimental Watershed: 70-Year Hydrologic, Soil Erosion, and Water Quality Database. Soil Science Society of America Journal 74, 619–623 (2010).
Goodrich, D. C. et al. The USDA‐ARS Experimental Watershed Network – Evolution, Lessons Learned, Societal Benefits, and Moving Forward. Water Resour Res https://doi.org/10.1029/2019wr026473 (2020).
Nearing, M. A., Foster, G. R., Lane, L. J. & Finkner, S. C. A Process-Based Soil Erosion Model for USDA-Water Erosion Prediction Project Technology. Transactions of the ASAE 32, 1587–1593 (1989).
Vines, T. H. et al. The Availability of Research Data Declines Rapidly with Article Age. Current Biology 24, 94–97 (2014).
Panagos, P. et al. Soil priorities in the European Union. Geoderma Regional 29, e00510 (2022).
Horowitz, A. J., Clarke, R. T. & Merten, G. H. The effects of sample scheduling and sample numbers on estimates of the annual fluxes of suspended sediment in fluvial systems. Hydrol Process 29, 531–543 (2015).
Horowitz, A. J. An evaluation of sediment rating curves for estimating suspended sediment concentrations for subsequent flux calculations. Hydrol Process 17, 3387–3409 (2003).
Asselman, N. E. M. Fitting and interpretation of sediment rating curves. J Hydrol (Amst) 234, 228–248 (2000).
Navratil, O. et al. Global uncertainty analysis of suspended sediment monitoring using turbidimeter in a small mountainous river catchment. J Hydrol (Amst) 398, 246–259 (2011).
Rode, M. & Suhr, U. Uncertainties in selected river water quality data. Hydrol Earth Syst Sci 11, 863–874 (2007).
Skarbøvik, E., Stålnacke, P., Bogen, J. & Bønsnes, T. E. Impact of sampling frequency on mean concentrations and estimated loads of suspended sediment in a Norwegian river: Implications for water management. Science of The Total Environment 433, 462–471 (2012).
de Girolamo, A. M. & di Pillo, R. lo Porto, A., Todisco, M. T. & Barca, E. Identifying a reliable method for estimating suspended sediment load in a temporary river system. Catena (Amst) 165, 442–453 (2018).
Thodsen, H. et al. Suspended matter and associated contaminants in Danish streams: a national analysis. J Soils Sediments 19, 3068–3082 (2019).
Gonzalez-Hidalgo, J. C., Batalla, R. J., Cerdá, A. & de Luis, M. Contribution of the largest events to suspended sediment transport across the USA. Land Degrad Dev 21, 83–91 (2010).
Gonzalez-Hidalgo, J. C., Peña-Monné, J. L. & de Luis, M. A review of daily soil erosion in Western Mediterranean areas. Catena (Amst) 71, 193–199 (2007).
Parsons, A. J., Brazier, R. E., Wainwright, J. & Powell, D. M. Scale relationships in hillslope runoff and erosion. Earth Surf Process Landf 31, 1384–1393 (2006).
Kirkby, M. J. Distance, time and scale in soil erosion processes. Earth Surf Process Landf 35, 1621–1623 (2010).
Cerdan, O. et al. Scale effect on runoff from experimental plots to catchments in agricultural areas in Normandy. J Hydrol (Amst) 299, 4–14 (2004).
Peña-Angulo, D. et al. Spatial variability of the relationships of runoff and sediment yield with weather types throughout the Mediterranean basin. J Hydrol (Amst) 571, 390–405 (2019).
Panagos, P. et al. European Soil Data Centre 2.0: Soil data and knowledge in support of the EU policies. Eur J Soil Sci 73, e13315 (2022).
Matthews, F. et al. EUSEDcollab.v1. Figshare https://doi.org/10.6084/m9.figshare.22117559 (2023).
Cantreul, V., Pineux, N., Swerts, G., Bielders, C. & Degré, A. Performance of the LandSoil expert-based model to map erosion and sedimentation: application to a cultivated catchment in central Belgium. Earth Surf Process Landf 45, 1376–1391 (2020).
Pineux, N. et al. Diachronic soil surveys: A method for quantifying long-term diffuse erosion? Geoderma Regional 10, 102–114 (2017).
Steegen, A. et al. Sediment export by water from an agricultural catchment in the Loam Belt of central Belgium. Geomorphology 33, 25–36 (2000).
Steegen, A. et al. Factors Controlling Sediment and Phosphorus Export from Two Belgian Agricultural Catchments. J Environ Qual 30, 1249–1258 (2001).
Steegen, A. & Govers, G. Correction factors for estimating suspended sediment export from loess catchments. Earth Surf Process Landf 26, 441–449 (2001).
Pak, L. T. et al. Observatoire Pesticeros des transferts de substances actives phytosanitaires dans les eaux de ruissellement d’un bassin versant agricole représentatif des régions limoneuses en grandes cultures. in 48th congress of French pesticides Group (2018).
Ouvry, J.-F. et al. Erosion des sols à l’échelle du bassin versant agricole de Bourville. in Journée d’Etudes des Sols (‘Journée d’Etudes des Sols’ conference, 2018).
Grangeon, T. et al. Les observatoires du ruissellement: comprendre les processus pour améliorer les modélisations. La Houille Blanche - Revue internationale de l’eau 6, 7–16 (2020).
Grangeon, T. et al. Dynamic parameterization of soil surface characteristics for hydrological models in agricultural catchments. Catena (Amst) 214, 106257 (2022).
Richet, J.-B., Ouvry, J.-F. & Pak, L. T. Quantification des ruissellements sur les petits bassins versants limoneux et karstiques de Normandie. in SHF scientific research congress Lyon 30 nov-2 déc 2020 (SHF scientific research congress Lyon 30 nov-2 déc 2020, 2020).
Patault, E., Alary, C., Franke, C., Gauthier, A. & Abriak, N. E. Assessing temporal variability and controlling factors of the sediment budget of a small agricultural catchment in Northern France (the Pommeroye). Heliyon 5, e01407 (2019).
Licciardello, F., Barbagallo, S. & Gallart, F. Hydrological and erosional response of a small catchment in Sicily. Journal of Hydrology and Hydromechanics 67, 201–212 (2019).
Carollo, F. G., di Stefano, C., Ferro, V. & Pampalone, V. New Stage-Discharge Equation for the SMBF Flume. Journal of Irrigation and Drainage Engineering 142, 04016005 (2016).
Ferro, V., di Stefano, C., Giordano, G. & Rizzo, S. Sediment delivery processes and the spatial distribution of caesium-137 in a small Sicilian basin. Hydrol Process 12, 701–711 (1998).
Zumr, D., Dostál, T. & Devátý, J. Identification of prevailing storm runoff generation mechanisms in an intensively cultivated catchment. J. Hydrol. Hydromech 63, 246–254 (2015).
Zumr, D. et al. Experimental determination of the flood wave transformation and the sediment resuspension in a small regulated stream in an agricultural catchment. Hydrol Earth Syst Sci 21, 5681–5691 (2017).
Li, T., Jeřábek, J., Noreika, N., Dostál, T. & Zumr, D. An overview of hydrometeorological datasets from a small agricultural catchment (Nučice) in the Czech Republic. Hydrol Process 35, e14042 (2021).
Gamvroudis, C., Nikolaidis, N. P., Tzoraki, O., Papadoulakis, V. & Karalemas, N. Water and sediment transport modeling of a large temporary river basin in Greece. Science of The Total Environment 508, 354–365 (2015).
Tzoraki, O. et al. Flood generation and classification of a semi-arid intermittent flow watershed: Evrotas river. 11, 77–92, https://doi.org/10.1080/15715124.2013.768623 (2013).
Smolska, E. Soil erosion and sediment supply to a fluvial system in the last-glacial area on the example of the upper Szeszupa river catchment (NE Poland). in Zeitschrift für Geomorphologie (2012).
Smolska, E. Soil erosion and fluvial transport monitoring in the Upper Szeszupa catchment (NE Poland). in Quaestiones Geographicae 73–83 (Adam Mickiewicz University Press, 2008).
Smolska, E. Extreme rainfalls and their impact on slopes based on soil erosion measurements (as exemplified by the Suwalki Lakeland, Poland). Geogr Pol 80 (2007).
Smolska, E. Channel response to flood flows on example of the Szeszupa river in the last-glacial area (NE Poland). in Quaestiones Geographicae 63–72 (Adam Mickiewicz University Press, 2008).
Święchowicz, J. Linkage of slope wash and sediment and solute export from a foothill catchment in the Carpathian Foothills of South Poland. Earth Surf Process Landf 27, 1389–1413 (2002).
Święchowicz, J. The influence of plant cover and land use on slope–channel decoupling in a foothill catchment: a case study from the Carpathian Foothills, southern Poland. Earth Surf Process Landf 27, 463–479 (2002).
Nunes, J. P. et al. Hydrological and Erosion Processes in Terraced Fields: Observations from a Humid Mediterranean Region in Northern Portugal. Land Degrad Dev 29, 596–606 (2018).
Nunes, J. P. et al. Impacts of wildfire and post-fire land management on hydrological and sediment processes in a humid Mediterranean headwater catchment. Hydrol Process 34, 5210–5228 (2020).
Wu, J., Baartman, J. E. M. & Nunes, J. P. Comparing the impacts of wildfire and meteorological variability on hydrological and erosion responses in a Mediterranean catchment. Land Degrad Dev 32, 640–653 (2021).
Bezak, N., Šraj, M. & Mikoš, M. Analyses of suspended sediment loads in Slovenian rivers. Hydrological Sciences Journal 61, 1094–1108 (2016).
Durán, Z. V. H. et al. Runoff and sediment yield from a small watershed in southeastern Spain (Lanjarón): implications for water quality. Hydrological Sciences Journal 57, 1610–1625 (2012).
Merchán, D. et al. Dissolved solids and suspended sediment dynamics from five small agricultural watersheds in Navarre, Spain: A 10-year study. Catena (Amst) 173, 114–130 (2019).
Casalí, J. et al. Runoff, erosion, and water quality of agricultural watersheds in central Navarre (Spain). Agric Water Manag 95, 1111–1128 (2008).
Merchán, D. et al. Runoff, nutrients, sediment and salt yields in an irrigated watershed in southern Navarre (Spain). Agric Water Manag 195, 120–132 (2018).
Chahor, Y. et al. Evaluation of the AnnAGNPS model for predicting runoff and sediment yield in a small Mediterranean agricultural watershed in Navarre (Spain). Agric Water Manag 134, 24–37 (2014).
Giménez, R. et al. Factors controlling sediment export in a small agricultural watershed in Navarre (Spain). Agric Water Manag 110, 1–8 (2012).
Casalí, J. et al. Sediment production and water quality of watersheds with contrasting land use in Navarre (Spain). Agric Water Manag 97, 1683–1694 (2010).
Outeiro, L., Úbeda, X. & Farguell, J. The impact of agriculture on solute and suspended sediment load on a Mediterranean watershed after intense rainstorms. Earth Surf Process Landf 35, 549–560 (2010).
Farguell, J., Úbeda, X. & Pacheco, E. Shrub removal effects on runoff and sediment transport in a mediterranean experimental catchment (Vernegà River, NE Spain). Catena (Amst) 210, 105882 (2022).
Fick, S. E. & Hijmans, R. J. WorldClim 2: new 1-km spatial resolution climate surfaces for global land areas. International Journal of Climatology 37, 4302–4315 (2017).
Metzger, M. J., Bunce, R. G. H., Jongman, R. H. G., Mücher, C. A. & Watkins, J. W. A climatic stratification of the environment of Europe. Global Ecology and Biogeography 14, 549–563 (2005).
Acknowledgements
All data included in EUSEDcollab is all open-access to the user-community. The authors gratefully acknowledge network of funding agencies, monitoring station operators and data managers required to maintain the sediment monitoring programs that underwrite the existence of this data compilation. The first author acknowledges the financial support provided for this research provided from the Collaborative Doctoral Partnerships (CDP) initiative of the Joint Research Centre (JRC) grant number 35332 and the Fonds Wetenschappelijk Onderzoek (Research Foundation Flanders -application S003017N). Further acknowledgements corresponding to individual datasets are included in the readme files associated with each catchment.
Author information
Authors and Affiliations
Contributions
F.M. was involved in all stages from project conceptualisation, project coordination, data harmonisation and manuscript writing. P.P., G.V., M.V., P.B. and J.P. contributed to project conceptualisation, project coordination and manuscript recommendations. H.T., V.P., V.H.D., N.B., J.C., E.N.R., N.S.L.R., F.L., J.C.N., J.O., M.D., E.S., D.Z., T.L., J.F., X.Ú., A.D., E.P., M.D., C.A. and R.T. were all involved in data coordination, preparation and harmonisation, and manuscript recommendations. All other authors were involved in key roles in the significant amount of work done at institutions involved in this project.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Matthews, F., Verstraeten, G., Borrelli, P. et al. EUSEDcollab: a network of data from European catchments to monitor net soil erosion by water. Sci Data 10, 515 (2023). https://doi.org/10.1038/s41597-023-02393-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-02393-8
This article is cited by
-
Assessment properties of Tannur reservoir sediments for agricultural use
Arabian Journal of Geosciences (2023)
