
Abstract
Western Patagonia (40–56°S) is a clear example of how the systematic lack of publicly available data and poor quality control protocols have hindered further hydrometeorological studies. To address these limitations, we present PatagoniaMet (PMET), a compilation of ground-based hydrometeorological data (PMET-obs; 1950–2020), and a daily gridded product of precipitation and temperature (PMET-sim; 1980–2020). PMET-obs was developed considering a 4-step quality control process applied to 523 hydrometeorological time series obtained from eight institutions in Chile and Argentina. Following current guidelines for hydrological datasets, several climatic and geographic attributes were derived for each catchment. PMET-sim was developed using statistical bias correction procedures, spatial regression models and hydrological methods, and was compared against other bias-corrected alternatives using hydrological modelling. PMET-sim was able to achieve Kling-Gupta efficiencies greater than 0.7 in 72% of the catchments, while other alternatives exceeded this threshold in only 50% of the catchments. PatagoniaMet represents an important milestone in the availability of hydro-meteorological data that will facilitate new studies in one of the largest freshwater ecosystems in the world.
Similar content being viewed by others


Background & Summary
High quality ground-based hydrometeorological observations contribute to the development of high quality policies and management of natural resources1. Conversely, unrepresentative, poorly collected, or incorrectly archived data introduce uncertainty into the magnitude, rate, and direction of environmental change, undermining confidence in decision-making processes2. The use of hydrometeorological variables is critical in a wide range of environmental, ecological, and hydrological applications. Therefore, there is a need for accurate datasets that include quality-controlled measurements that help address key challenges related to climate change and the impacts of hydrometeorological extremes3,4,5. In addition, hydrometeorological data must be findable, accessible, interoperable and reusable6 (FAIR data), requirements that are often not fulfilled in operational datasets7,8. Therefore, data obtained from measurements do not always represent the real behaviour of the observed processes9, and need to be corrected by homogenisation schemes10,11. Furthermore, the generation of large datasets may cross jurisdictions or institutions, lack of common standards or data formats (e.g., quality codes), require manual data collection (e.g., one time series at a time) and are more likely to suffer from spatial and temporal gaps12.
The difficulty in accessing ground-based time series has led users to rely on global hydrometeorological datasets, such as reanalyses or satellite products13,14,15. Gridded datasets are very important for deriving regional atmospheric processes for a variety of scientific applications16. However, in poorly instrumented areas, gridded datasets can have important biases that need to be corrected17 to avoid, for example, systematic underestimation of precipitation in mountainous catchments18,19. To address these limitations, different models have used vertical precipitation gradients20, precipitation (bias correction) factors21,22, or snow correction factors23,24. At the global scale, Beck et al.19 concluded that global products tend to underestimate precipitation (precipitation factors >1.5) over regions characterised by pronounced elevation gradients, low station density, and significant solid precipitation.
The recent development of the Catchment Attributes and Meteorology for Large-sample Studies25 (CAMELS) initiative has facilitated the access to hydrometeorological time series and catchment attribute data in the contiguous United States. Since then, similar country-specific datasets have been developed for Chile18, Brazil26, Australia27, Great Britain28, China29, among others, enabling important advances in large-sample hydrology12. These datasets have allowed, among other applications, the estimation of streamflow over ungauged catchments30,31, the classification of catchments by hydrological and geomorphological similarities32, the impacts related to anthropogenic activities18,33, and the analysis of hydrological model structures34,35. Despite the existence of the CAMELS initiative for Chile (CAMELS-CL), Western Patagonia is a clear example of how the systematic lack of hydrometeorological data (or open accessibility), poor quality control protocols and multiple formats between institutions36 have hindered further studies.
Western Patagonia is a vast (~400,000 km2), narrow (~200–300 km) and transboundary (Chile and Argentina) area extending from about 40°S down to the southern tip of the continent (40–56°S; Fig. 1). It is one of the largest and best preserved freshwater ecosystems in the world, encompassing numerous mountainous catchments of the southern Andes (Fig. 1a), and is surrounded by one of the most complex and extensive fjord systems in the world37. Precipitation in this region is mostly generated by disturbances embedded in the westerly flow, with strong orographic gradients38. Windward uplift leads to hyper-humid conditions along the western slope of the Andes (>5,000 mm), while downslope subsidence dries the eastern plains, leading to arid conditions39,40. The climatic gradients have determined an important climatic spatial variability (Fig. 1b), allowing the development of glaciers, different hydrological regimes41 and vegetation types (Fig. 1c).

Study area. (a) Main basins of western Patagonia (area >5,000 km2). AR indicates basins draining to the east. Elevation was obtained from NASADEM66. (b) Köppen-Geiger climate classification125. (c) Land cover in the year 2019126. NPI: Northern Patagonian Icefield. SPI: Southern Patagonian Icefield. GCN: Gran Campo Nevado. CDI: Cordillera Darwin Icefield.
Climate projections for most of Western Patagonia indicate a prolongation of the dry and warm conditions that have affected it in recent decades42. Overall, the climate impacts recorded in Western Patagonia have been attributed to the Southern Annular Mode (SAM), which has shown a significant trend towards its positive phase43. Given the heterogeneous and incomplete monitoring network of hydro-meteorological stations, most studies performed in this region have used only a very small subset of meteorological stations38,44, satellite imagery45 or climate proxies46 to study environmental changes. Despite the low use of ground-based information, the region has shown evidence of a decrease in snow cover extent47,48, an increase in forest fires49, unusual tree growth patterns50, a decrease in water availability51 and significant trends in major lakes52, rivers41,53 and glaciers54,55.
The low availability of local hydrometeorological data has hindered the development, calibration, and robust validation of regional models for western Patagonia. Krogh et al.56 implemented the physically-based Cold Regions Hydrological Model (CRHM) in the Baker River Basin (46°S; Fig. 1a) and concluded that the model forced with reanalysis data achieved better performance than the model based on scarce ground-based observations. Recent hydrological modelling efforts have benefited from the integration of local hydrometeorological data with gridded products to achieve better performance48,53,57. However, the performance metrics reported by the National Water Balance of Chile using the Variable Infiltration Capacity (VIC) model were not satisfactory in most of western Patagonia58,59. Furthermore, the variability of snow accumulation under different atmospheric forcings39 has led to divergent surface mass balances in the Patagonian Ice Fields40,60,61,62.
In this study, we present PatagoniaMet (hereafter PMET), a new dataset for Western Patagonia consisting of two datasets: i) PMET-obs, a compilation of quality-controlled ground-based hydrometeorological data, and ii) PMET-sim, a daily gridded product of precipitation, and maximum and minimum temperature. PMET-obs was developed using a 4-step quality control process applied to 523 hydro-meteorological time series (precipitation, air temperature, potential evaporation, streamflow and lake level stations) obtained from eight institutions in Chile and Argentina. In addition, the upstream area corresponding to each stream gauge in PMET-obs was delimited, and climatic and geographic attributes were derived for each catchment. Based on this dataset and currently available uncorrected gridded products, PMET-sim was developed using statistical bias correction procedures, spatial regression models (machine learning) and hydrological methods (Budyko framework). Finally, as part of the validation process, PMET-sim was compared with bias-corrected products using hydrological modelling.
Methods
PMET-obs development
The ground-based measurements used to develop PMET-obs were obtained from eight Chilean and Argentinian institutions (see Table 1) for the period 1950−2020, and consist of daily precipitation data (PP), maximum and minimum temperature (Tmax and Tmin, respectively), potential evaporation (Ep), lake/reservoir levels (LL), and streamflow (Q). From the retrieved time series, we selected only those with daily resolution (e.g., the Agrarian Council of the Province of Santa Cruz in Argentina only reports monthly accumulated precipitation), with at least four years of continuous record, and that continue to operate between 2000 and 2020. Regarding the 24-hour period, the data collected correspond to the period from 12:00 to 11:59 UTC, which corresponds to 8:00 to 7:59 (UTC-4) and 9:00 to 8:59 (UTC-3) local time in Chile and Argentina (winter time zone), respectively.
Valuable information on atmospheric and hydrological processes is provided by the eight institutions listed in Table 1. However, these sources of information are subject to various types of disturbance2. Although some institutions control the quality of their records, the variety of data management protocols, recording types (automatic vs. manual) and instruments requires a standard quality control to identify and remove anomalous values. We propose a quality control system consisting of four stages, each one associated with a specific objective and time scale (Fig. 2a).
-
a)
The first step implemented the recommendations of Wilby et al.2, who identified several common errors in the information provided by hydrometeorological datasets, such as artificial influences at monitoring sites, changes in reference level, systematic observational biases (e.g., number bias and weekend under-reporting), mislocations, among others. These common errors can skew the observed frequency distribution in ways that may affect the estimation of extreme values and the correct representation of hydrological processes. If the systematic errors were not limited to a specific period, the complete time series was discarded from PMET-obs.
-
b)
The second step identified and removed daily outliers from the PMET-obs dataset. These outliers can be attributed to truncation and rounding errors, inconsistent use of missing data flags, suspicious or erroneous data recoded as zero, and data entry for records that were manually digitized. Precipitation outliers were detected using the method proposed by Sarricolea et al.63 which involves generating reference values from the 10 closest stations within a 125 km radius. We then detected inconsistent temperature measurements (Tmax < Tmin) or values outside the range of natural variability, i.e., above or below ± 3 standard deviations from the monthly mean. Finally, we detected and removed suspected repeated values in the daily streamflow and lake level time series if the coefficient of variation was less than 0.01 over a one-month window.
-
c)
The third step detected and removed monthly residual outliers of the PP, Tmax and Tmin time series using a reanalysis model as a reference. In this step, we selected the ERA5 dataset (Table 2) since it performed better than the other products (see PMET-sim methods) and does not assimilate ground-based data from the study area, as ERA5 only assimilates NCEP Stage IV, which combines NEXRAD data with ground-based precipitation over the conterminous United States. As in the previous step, we eliminated monthly residuals outside the range of natural variability (± 3 standard deviations). In this step, we only considered months with more than 20 days of records.
-
d)
The fourth step analysed the existence of (multiple) changepoints in the monthly residuals of PP, Tmax and Tmin, considering ERA5 as a reference. This was done in order to identify potential station relocations or instrumental changes, as this information was not publicly available as part of the metadata for each station. This analysis verified that the mean and variance of the residuals are constant over time, assuming that the equations/parameters that dominate the physics of the reanalysis model are constant over time. The multiple changepoints were identified using the Pruned Exact Linear Time (PELT) algorithm64 with a non-parametric cost function based on the empirical distribution of the data. Compared to the traditional parametric approach, non-parametric methods do not assume a particular distribution and are more robust to outliers, which is particularly important considering the probability distribution of precipitation. This algorithm is integrated in the changepoint.np R package v1.065, which extends the original changepoint package. Once the changepoints were identified, only a subset of the time series was selected based on its extent and consistency.

Conceptual methodological framework PMET. (a) Quality control of PMET-obs. (b) Development of PMET-sim. (c) Validation of PMET-sim.
Time series with less than four years of daily records after quality control were discarded from PMET-obs. Due to large data gaps in the raw time series, lake level time series were only reconstructed when more than one station recorded a single lake, which was common in binational lakes. Given the growing demand for large-sample datasets, the upstream area corresponding to each stream gauge was delimited using NASADEM66 and several climatic and geographic attributes were derived following current guidelines for hydrological datasets12. The list of all catchment attributes and dataset sources can be found in Table 3.
PMET-sim development
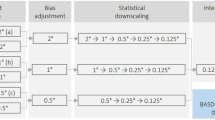
The development of PMET-sim consisted of three steps: i) the selection of the reference gridded product, ii) the downscaling of the selected product, and iii) the bias correction procedure (Fig. 2b). The reference gridded product provides a baseline for the correction in the following steps. The downscaling increases the spatial resolution (~0.5°) to a higher resolution of 0.05°, and the bias correction process addresses potential biases found in the selected reference gridded product.
Selection of the reference gridded product
Four gridded reanalysis datasets, which do not use in situ measurements from the study area, were evaluated to select the reference gridded product: ECMWF Reanalysis v567 (ERA5), Modern-Era Retrospective analysis for Research and Applications Version 268 (MERRA-2), Climate Forecast System Reanalysis69 (CFSR), and the RegCM4-CR270 (CR2REG) (Table 2). The four datasets cover the entire latitudinal gradient of Western Patagonia (40–56°S), have a minimum resolution of 0.5°, and span a minimum period of 30 years. Previous validations have shown that reanalysis products outperform satellite estimates in mid and high latitudes due to their ability to represent large-scale frontal systems14.
The selection consisted of a point-to-pixel comparison between each gridded dataset and PMET-obs. In this method, monthly precipitation and air temperature values were compared against their corresponding grid cell values71,72. Precipitation performance was measured using the modified Kling-Gupta efficiency73, which disaggregates the overall performance into three components: linear correlation (r), bias ratio (β), and variability ratio (γ). On the other hand, the temperature performance was measured using the mean bias (β’), and the standard deviation ratio (γ’). As weather stations are typically located at low elevations (i.e., valleys), each gridded alternative was compared with a pseudo-corrected version of the PMET-obs temperature time series, which was modified based on the mean elevation of the corresponding grid-cell and the lapse rate used in the downscaling procedure (see next section). All indicators were calculated using the hydroGOF R package v0.474. Considering that ERA5 achieved the best correlation for precipitation and a good representation of the annual temperature cycle (Supplementary Figure S1), we selected this alternative as the best gridded product for the next stages of development of PMET-sim.
Downscaling
To increase the spatial resolution to 0.05°, the downscaling procedure is applied to the selected gridded product (ERA5) and varied according to the variable. The temperature downscaling was based on the NASADEM66 digital elevation model, and a spatially and temporally constant environmental lapse rate of 6.5 °C km−1, a value commonly used in Western Patagonia61. Although recent studies in Patagonia have demonstrated the variability of this value75, preliminary results have shown that seasonal variation of this value does not significantly improves performance. Due to the lack of precipitation stations at high altitudes, precipitation downscaling was limited to a bilinear filter.
Bias correction
Once ERA5 was downscaled (hereafter ERA5d; Fig. 2b), the statistical bias correction process was performed. The bias correction of the maximum and minimum temperatures followed the mean and variance scaling method76,77 (Fig. 2b). This approach guarantees that the bias-corrected temperature time series of PMET-sim have the same mean and standard deviation (i.e., variance) as the ground-based time series of PMET-obs. Following the point-to-pixel comparison of the temperature, the simulated temperature obtained from ERA5d was compared with the pseudo-corrected version of PMET-obs, which takes into account the mean elevation of the grid-cell and the previously used lapse rate (6.5 °C km−1).
The approach is based on two parameters (βT and αT), which scale the mean and variance of the temperature, respectively. In a first step, βT is calculated as the difference between the mean (µ) of the simulated time series from ERA5d (TS) and the mean of the pseudo-corrected version of PMET-obs (To) (Eq. 1).
Thereafter, the mean-corrected simulated time series (TS - βT) is shifted to a zero mean (TS1, Eq. 2).
The variance scaling parameter (αT) was then calculated from the ratio between the standard deviations (σ) of To and TS1 (Eq. 3).
In a final step, the corrected temperature (TS2; Eq. 4) was obtained using the parameters βT and αT and TS1 of Eq. 2. To account for seasonal biases, the parameters βT (Eq. 1) and αT (Eq. 3) are calculated independently for each month.
The bias correction of PMET-sim precipitation followed a quantile mapping approach (Fig. 2b), which has been used in several meteorological datasets78,79,80. This method attempts to find a “transfer function” between the simulated (PPs) and observed (PPo; PMET-obs) cumulative distribution functions. In this case, the transfer function was based on a linear parametric transformation81,82 (Eq. 5).
In Eq. 5, PPo* indicates the best estimate of PPo, and αPP and βPP are the monthly parameters subjected to calibration. Following Piani et al.81, the linear parametric transformation was fitted to the fraction of the cumulative distribution function (CDF) corresponding to observed wet days (PPo > 0 mm d−1) by minimising the residual sum of squares. Other transformation functions, such as power and exponential, showed similar performance despite having more parameters. The bias correction was performed in the qmap R package v1.082,83.
For the three variables (PP, Tmax and Tmin), two parameters (α and β) were obtained for each time series and month (36 parameters in total). We used random forest (RF) regression models to derive regional gap-free maps for each parameter (Fig. 2b). RF regression models generate predictions using an adaptation of Leo Breiman’s RF algorithm, a supervised machine learning method84,85. These models have been successfully applied in several water resources studies using numerous climatic and geographic predictors19,86,87. In each RF model, 500 regression trees were used as an ensemble, with each tree having a minimum leaf size of five. At each split, two variables were randomly selected as candidates. From the full list of predictors (Table 4), we used backward selection (i.e., recursive feature elimination) with external validation to select the best predictors for each parameter and month. For external validation, we used leave-one-group-out cross-validation (LOGTCV) with 100 samples distributed across groups, with each group containing 90% of the data. Leaving out one group at a time and repeating the process for all groups provides a robust assessment of the model’s ability to generalise across groups. This procedure was performed using the R packages randomForest v4.788 and caret v6.089. Overall, the climate predictors, such as mean precipitation or temperature, were more important than geographic predictors (Supplementary Figure S2). To avoid abrupt discontinuities in the gridded precipitation, the resulting maps for αPP and βPP were subsequently smoothed with a Gaussian filter with a sigma size equal to the spatial resolution of PMET-sim (0.05°).
Once the gridded parameters were derived from the RF procedure, we used the proposed bias correction methods to obtain the corrected values of precipitation, and maximum and minimum temperature for PMET-sim over 1980–2020. In addition, to correct precipitation undercatch, we followed the methodology proposed by Beck et al.19 (Fig. 2b), where the true long-term precipitation is inferred using the Budyko framework90,91,92. The Budyko framework93 is a parsimonious first-order empirical equation relating long-term precipitation (PP), potential evaporation (Ep), and actual evaporation (E) that assumes: long-term PP is the sum of long-term E and long-term runoff (R); long-term changes in water storage (ΔW) can be neglected; and PP is the only water input, and R and E are the only outputs19. To address these assumptions, we discarded catchments with dams (n = 5) and used the modified curve proposed by Liu et al.94 that includes glacier mass balance in the water balance:
where w is an empirical parameter representing catchment characteristics (unitless), and ΔW is the change in storage expressed as the average glacier mass balance in equivalent water column height (mm). We estimated the mass change for each catchment from geodetic mass balances for 2000–201955. Note that Western Patagonia has a large native forest cover, low population density and many protected areas, so other implicit assumptions, such as the natural flow regime, can be reasonably assumed in the study area.
We first estimated long-term PP for each interstation catchment from long-term runoff (R) and potential evaporation (Ep). We then calculated interstation R for all catchments without dams in the PMET-obs dataset (n = 104). Long-term Ep was obtained directly from GLEAM v3.6a95, a process-based but semi-empirical model that calculates total evaporation and its individual components from satellite and reanalysis data (MSWX net radiation and air temperature). In preliminary stages, GLEAM 3.6a showed an adequate performance with respect to the ground-based data from the INIA institution (Table 1; Supplementary Figure S3). In both cases, long-term averages of R and Ep were calculated for the period 1980–2020. The empirical parameter w was estimated from previous results of the Chilean Water Balance for 1985–201558,59. To date, this water balance is the largest hydrological modelling effort performed in Chile, including the binational catchments with Argentina. Specifically, we use the median w estimated for the selected catchments (w = 1.2), assuming that there are no significant differences between the two periods.
Once the true long-term precipitation was calculated, we calculated bias correction factors (BCFs) for each interstation catchment. Approximately 40% of the catchments had a BCF greater than 1.3, suggesting a significant underestimation of the precipitation necessary to generate the observed streamflows over the last decades (Supplementary Figure S4). The mean BCF obtained from the full dataset was 1.04 ± 0.45 ( ± 1 standard deviation). We then used RF regression models to derive regional gap-free BCF maps. Interstation regions with BCF > 2.5 (n = 2) were considered erroneous and were discarded from the training set (n = 102). Predictors were selected using backward selection and LOGTCV as external validation (Table 4). Based on this approach, the most important predictors of the RF regression were mean annual precipitation, elevation and aridity index (Supplementary Figure S2). The areas characterised by high BCFs were located on the western side of the Andes and were described by pronounced elevation gradients, high altitude and precipitation above 3,000 mm (Supplementary Figure S4). Following Beck et al.19, the BCFs were truncated at a lower bound of 1 because precipitation is more likely to be under than overestimated due to gauge undercatch96,97 and the low-elevation bias in gauge placement98,99. Finally, the BCFs were applied to the previously bias-corrected precipitation to obtain the final gridded PMET-sim precipitation.
Data Records
The complete PatagoniaMet dataset (v1.1) can be found at: https://doi.org/10.5281/zenodo.7992760100.
PMET-obs dataset
The quality-controlled data of each variable of PMET-obs are stored in separate.csv files with the following naming convention: variable_PMETobs_timeperiod_version.csv. Each variable has an additional.csv file with the metadata for each station (variable_PMETobs_version_metadata.csv). The metadata file contains the station name (gauge_name), the institution, the station location (gauge_lat and gauge_lon), the NASADEM elevation (gauge_alt) and the total number of daily records (length). In addition, the precipitation and temperature metadata include the number of monthly outliers (third step in the methods) and the number of changepoints (fourth step in the methods). In order to make transparent the possible erroneous data discarded from the quality-controlled version, a.zip file with the raw data of all variables is included in the dataset (raw_data_PMETobs_version.zip). Regarding the catchment dataset, the set of catchment boundaries is stored in shapefiles (each with a gauge_id), which are compiled into a.zip file (basins_PMETobs_version.zip). The attributes calculated for each catchment can be found in the corresponding metadata file (Q_PMETobs_version_metadata.csv; Table 3). In addition, the file Q_PMETobs_version_water_balance.csv contains the water balance for the catchments that were part of the hydrological modeling validation (next section).
In summary, the PMET-obs dataset consists of 231, 129, 31, 109 and 23 time series of precipitation, air temperature, potential evaporation, stream gauges and lake levels, respectively (Fig. 3). Considering the area of Western Patagonia (~400,000 km2), the spatial density of precipitation, temperature and streamflow stations is one station per 1,700 km2, 3,100 km2 and 3,600 km2, respectively. The catchment area covered by all stream gauges is only one third of the total area of Western Patagonia (Fig. 3a). At the temporal scale, the median number of years (≥11 months of data) with precipitation, temperature and streamflow data is 18, 10 and 28 years, respectively. Only 17% of all time series have more than 30 years of data. Most stations with long-term records are located near major human settlements (e.g., Bariloche, Coyhaique and Punta Arenas; Fig. 1c) and near some rivers of hydroelectric interest (e.g., Puelo, Pascua and Baker; Fig. 1a).

Spatial distribution of hydrometeorological stations in the PMET-obs dataset. (a) Stream gauges and lake level stations. (b) Precipitation. (c) Air temperature. The size of the circles is proportional to the number of years with records of each time series. The coloured areas in (a) indicate the catchments delimited by the stream gauges.
PMET-sim dataset
The gridded data of PMET-sim are stored in netcdf files with the following naming convention: variable_PMETsim_timeperiod_version.nc. All variables (precipitation and maximum and minimum temperature) have a spatial resolution of 0.05°, and cover the period 1980–2020.
The PMET-sim spatial patterns of precipitation show a clear distinction between the western (>4,000 mm yr−1) and the eastern (<1,000 mm yr−1) side of the Andes (Fig. 4a). The maximum annual values were located in the Northern and Southern Patagonian Icefields (NPI and SPI) with mean values of 6,090 mm and 6,080 mm, respectively. These values are in agreement with Sauter39, who found that the icefield-wide precipitation averages (period 2010–2016) are likely to be within 5.38 ± 0.59 and 6.09 ± 0.64 m w.e. yr−1 on the NPI and 5.06 ± 0.51 and 5.99 ± 0.59 m w.e. yr−1 on the SPI according to the regional moisture flux. The catchments located in the northern area (Puelo to Cisnes) had a mean annual precipitation of 2100 mm, while the catchments located in the southeastern area had a mean annual precipitation lower than 500 mm (Gallegos and Río Grande). Most of the main catchments had mean annual temperatures between 3.0 °C and 7.0 °C (Fig. 4b). Considering the daily variation of air temperature and a melting threshold of 0 °C, the Pascua and Santa Cruz Rivers catchments had the highest annual snow accumulation amounts, with mean values of 500 mm and 285 mm, respectively (~25% of the total precipitation in both cases). The comparison between mean annual precipitation and potential evaporation (Fig. 4c) suggests that all major catchments are limited by available energy.

Long-term annual mean climate obtained from PMET-sim (1990–2020). (a) Precipitation (PP). (b) Air temperature (T2M). (c) Potential evaporation (Ep). Ep was calculated using the Hargreaves equation. Dotted areas in (a) show the glacier areas from RGI v6.0123. The white outlines indicate the main basins.
Technical Validation
Validation approach
The validation of PMET-sim consisted of a comparison with four gridded datasets using two approaches: a point-to-pixel comparison with PMET-obs (monthly precipitation and temperature), and a performance assessment by hydrological modelling (Fig. 2c). In the first case, the performance was measured using the metrics previously used in the selection of the reference gridded product (KGE, β’ and γ’), while the second approach used the performance obtained from the calibration of the TUWmodel23. For both approaches, a 10-fold cross-validation was added to avoid overestimating the performance achieved by PMET-sim. Each group (i.e., PMET-sim version) was developed using only 90% of all the stations, and the performance was measured in the remaining 10% of the stations.
The four benchmarks selected for the validation of PMET-sim were the Center for Climate and Resilience Research Meteorological dataset version 2.5 (CR2MET v2.5), Multi-Source Weighted-Ensemble Precipitation v2.8 (MSWEP) and W5E5 v2.0 (Table 2). These products have shown a good performance over the study area due to the use of local and/or regional data in their development (e.g., data from DGA, DMC and SMN, Table 1). CR2MET is currently a widely used reference dataset for PP and T2M in Chile18,31,57,70, including the National Water Balance in southern Chile58,59. MSWEP v2.8 is a multi-source precipitation-only product that merges gauge, satellite and reanalysis data to reduce temporal mismatches between satellite reanalysis estimates and gauge observations. Previous versions of MSWEP have recently outperformed other state-of-the-art precipitation products over Chile101. Precipitation data from MSWEP v2.8 were complemented with air temperature from Multi-Source Weather (MSWX), a bias-corrected compatible meteorological product. The W5E5 v2.0 dataset is part of the Inter-Sectoral Impact Model Intercomparison Project (ISIMIP3b) and merges local data with bias-corrected reanalysis data102 (WFDE5). The downscaled version of ERA5 (ERA5d) was also included in the comparison to measure the performance before the inclusion of PMET-obs in the bias correction procedure.
The hydrological modelling validation used the TUWmodel23, which is a daily conceptual rainfall-runoff model that follows the structure of the Hydrologiska Byråns Vattenbalansavdelning (HBV) model103. The model consists of three routines: a snow routine, a soil moisture routine, and a flow routing routine, which use precipitation, temperature and potential evaporation as input variables. The snow routine incorporates a temperature-index model to capture the accumulation and melting of snow104, assuming an empirical relationship between air temperatures and melt rates. In this approach, the melting is based on a degree-day factor (mm d−1 C−1) and a specific temperature threshold, while the calculation of snowfall and snow accumulation considers the temperatures at which snow and rain occur. The soil moisture routine accounts for changes in root zone moisture content caused by evapotranspiration and runoff generation. Estimation of actual evapotranspiration is based on potential evaporation. In addition, a model parameter is used to determine the soil moisture level at which actual evapotranspiration equals potential evaporation. Finally, the runoff routing module handles the movement of water across hillslopes and streams. It uses a runoff response function consisting of two reservoirs representing upper and lower storage zones. Runoff from the reservoirs in each elevation zone is aggregated and directed through a triangular transfer function for routing purposes. We selected the TUWmodel because of its extensive use in hydrological applications in snow-dominated catchments105,106,107,108.For example, Baez-Villanueva et al.31 used this model to calibrate a set of 100 near-natural catchments with a diverse hydroclimatic and geomorphological characteristics from the CAMELS-CL dataset, achieving a good overall performance (median KGE > 0.77).
The spin-up, calibration and validation periods of the hydrological modelling were 1987–1989 (3 years), 1990–2005 (16 years) and 2006–2020 (15 years), respectively. In contrast to central Chile, western Patagonia has not experienced consecutive dry years, and therefore both periods (calibration and validation) include dry and wet years. Based on the PMET-obs dataset, we selected 71 catchments with more than two-thirds of the records during the calibration period and no dams. Following the CemaNeige model106, each selected catchment was divided into equal-area elevation zones. The number of elevation zones (EZ) was defined as EZ = (Hmax − Hmin)/300, where H is the elevation obtained from NASADEM (Table 4). If EZ > 5, EZ was set to 5 to be consistent with the spatial resolution of the different atmospheric forcings (≥0.05°) in mountainous areas. Based on the maximum and minimum daily temperature of each dataset, Ep was calculated using the Hargreaves equation and the PyEt package109. To maximise the KGE between observed and simulated streamflow, the automatic calibration was performed for each combination of atmospheric forcing (n = 6) and each independent catchment using the hydroPSO R package v0.574,110. HydroPSO is a global optimization R package that implements a state-of-the-art version of the Particle Swarm Optimization (PSO). This algorithm has been successfully used in several hydrological modelling applications31,111,112. The parameter ranges of the TUWmodel were based on Parajka et al.106 (Supplementary Table S1).
Validation results
The development of PMET-sim improved several metrics with respect to ground-based observations (Fig. 5). For precipitation, PMET-sim achieved correlation values similar to ERA5d (Fig. 5a). MSWEP v2.8 reached the best correlation (median value = 0.87), while W5E5 showed the worst. PMET-sim reduced the median precipitation bias (β) from 2.1 in ERA5d to 1.3 (Fig. 5b), which represents an overestimation of 30% with respect to observations from meteorological stations (usually unshielded tipping bucket rain gauges). All models underestimate precipitation variability (Fig. 5c). CR2MET and W5E5 showed better median values (γ), but W5E5 presented a higher spread. CR2MET showed the best overall precipitation performance expressed by the KGE (Fig. 5d). Compared to ERA5d and PMET-sim, CR2MET showed a better KGE due to lower biases and a better reproduction of the precipitation variability. The temperature bias correction reduced the bias spread (standard deviation of β’) from 1.0 °C in ERA5d to 0.4 °C in PMET-sim (Fig. 5e). W5E5, CR2MET and MSWEP showed a warm bias lower than 1 °C. All models were able to reproduce the variability of the annual cycle expressed by γ’, with median values close to 1.0 in all cases (Fig. 5e). The results of the 10-fold cross-validation achieved similar values to the PMET-sim version developed with all available data (Fig. 5), which could be attributed to the fact that the predictors in the RF spatial regression were previously selected using LOGTCV as an external validation.

Performance metrics of precipitation (a–d) and air temperature (e,f) for ERA5d (downscaled version of ERA5), W5E5 v2.0, MSWEP v2.8 (WSWX for air temperature), CR2MET v2.5 and PMET-sim. The PMET-sim (CV) corresponds to the summarized results (“unseen” stations) from the 10-fold cross-validation. The different performance metrics were obtained using a point-to-pixel analysis using PMET-obs as the reference (period 1990–2020). The dotted line in each box plot represents the mean value. The horizontal dotted line in each panel represents the optimal value.
Good performance obtained from the comparison with meteorological stations did not always translate into a good hydrological performance (Fig. 6). All forcing datasets showed median correlations values greater than 0.7 during the calibration and validation stages (Fig. 6a), with PMET-sim, ERA5d and CR2MET being the best forcing datasets (r > 0.8 during calibration). The bias (β) was the metric that showed the most variability among the forcing datasets. Despite the high biases of ERA5d and PMET-sim in Fig. 5b,both models achieved biases close to the optimum with a small spread (Fig. 6b). In terms of variability (γ), most datasets slightly underestimated the ground-based observations (Fig. 6c). Considering the performance during the calibration phase, PMET-sim achieved KGEs greater than 0.7 in 72% of the catchments compared to CR2MET, MSWEP and W5E5, which achieved 53%, 29% and 38% in the calibration period, respectively (Fig. 6d). In all metrics, the performance achieved in the “unseen” catchments of the 10-fold cross-validation was similar to that achieved with all available data.

Hydrological model performance (on a monthly basis) under different atmospheric alternatives (ERA5d, MSWEP v2.8/MSWX, CR2MET v2.5, W5E5 v2.0 and PMET-sim). The PMET-sim (CV) corresponds to the summarized results (“unseen” stations) from the 10-fold cross-validation. The calibration (dark colours) and validation (light colours) periods were 1990–2005 and 2006–2020, respectively. The horizontal dotted line in each panel represents the optimal value.
Usage Notes
This regional dataset contributes to the hydrological and atmospheric sciences by providing a novel dataset for Western Patagonia, which will improve data availability113 and research reproducibility114, and can be used to advance our understanding of the effects of climate change in this unique water reservoir for South America. Although the time series available in PMET-obs represent a clear advance for a variety of scientific applications, it is important to note that the density of precipitation stations (Fig. 3b) is still seven times lower than the one recommended by the WMO115 for mountainous areas (1 per 250 km2). On the other hand, the density of stream gauges is almost four times lower than recommended (1 per 1,000 km2). The best spatial density of gauging stations is found in the vicinity of the main human settlements (where different institutions measure the same meteorological variable), while in the western fjord zone there are large regions with few or no observations (Fig. 3). Taking this into account, it is important to note that there are large areas in PMET-sim without local validation. Nevertheless, PMET currently performs better hydrologically than any other regional and global gridded product available to date.
PatagoniaMet is envisioned as an open collaborative dataset that will be regularly updated with new records, incorporating additional meteorological variables, institutions and time-steps as they become available. This will provide a foundation for future hydrometeorological studies in Western Patagonia, which can be accessed and reviewed by anyone in the community.
Code availability
The complete repository can be found at: https://github.com/rodaguayo/PatagoniaMet116.
References
Doherty, S. J. et al. Lessons Learned from IPCC AR4: Scientific Developments Needed to Understand, Predict, and Respond to Climate Change. Bulletin of the American Meteorological Society 90, 497–514 (2009).
Wilby, R. L. et al. The ‘dirty dozen’ of freshwater science: detecting then reconciling hydrological data biases and errors. Wiley Interdisciplinary Reviews: Water 4, e1209 (2017).
Begert, M., Schlegel, T. & Kirchhofer, W. Homogeneous temperature and precipitation series of Switzerland from 1864 to 2000. International Journal of Climatology 25, 65–80 (2005).
McRoberts, D. B. & Nielsen-Gammon, J. W. A New Homogenized Climate Division Precipitation Dataset for Analysis of Climate Variability and Climate Change. Journal of Applied Meteorology and Climatology 50, 1187–1199 (2011).
Noone, S. et al. Homogenization and analysis of an expanded long-term monthly rainfall network for the Island of Ireland (1850–2010). International Journal of Climatology 36, 2837–2853 (2016).
Wilkinson, M. D. et al. The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data 3, 160018 (2016).
Hannah, D. M. et al. Large-scale river flow archives: importance, current status and future needs. Hydrological Processes 25, 1191–1200 (2011).
Crochemore, L. et al. Lessons learnt from checking the quality of openly accessible river flow data worldwide. Hydrological Sciences Journal 65, 699–711 (2020).
Li-Juan, C. & Zhong-Wei, Y. Progress in Research on Homogenization of Climate Data. Advances in Climate Change Research 3, 59–67 (2012).
Yan, Z., Li, Z. & Xia, J. Homogenization of climate series: The basis for assessing climate changes. Science China Earth Sciences 57, 2891–2900 (2014).
Venema, V. K. C. et al. Benchmarking homogenization algorithms for monthly data. Climate of the Past 8, 89–115 (2012).
Addor, N. et al. Large-sample hydrology: recent progress, guidelines for new datasets and grand challenges. Hydrological Sciences Journal 65, 712–725 (2020).
Muñoz-Sabater, J. et al. ERA5-Land: A state-of-the-art global reanalysis dataset for land applications. Earth System Science Data 13,4349–4383, https://doi.org/10.5194/essd-13-4349-2021 (2021).
Beck, H. E. et al. MSWEP V2 Global 3-Hourly 0.1° Precipitation: Methodology and Quantitative Assessment. Bulletin of the American Meteorological Society 100, 473–500 (2019).
Harris, I., Osborn, T. J., Jones, P. & Lister, D. Version 4 of the CRU TS monthly high-resolution gridded multivariate climate dataset. Scientific. Data 7, 109 (2020).
Tarek, M., Brissette, F. P. & Arsenault, R. Evaluation of the ERA5 reanalysis as a potential reference dataset for hydrological modelling over North America. Hydrology and Earth System Sciences 24, 2527–2544 (2020).
Beguería, S., Vicente-Serrano, S. M., Tomás-Burguera, M. & Maneta, M. Bias in the variance of gridded data sets leads to misleading conclusions about changes in climate variability. International Journal of Climatology 36, 3413–3422 (2016).
Alvarez-Garreton, C. et al. The CAMELS-CL dataset: Catchment attributes and meteorology for large sample studies-Chile dataset. Hydrology and Earth System Sciences 22, 5817–5846 (2018).
Beck, H. E. et al. Bias correction of global high-resolution precipitation climatologies using streamflow observations from 9372 catchments. Journal of Climate 33, 1299–1315 (2020).
Hamman, J. J., Nijssen, B., Bohn, T. J., Gergel, D. R. & Mao, Y. The Variable Infiltration Capacity model version 5 (VIC-5): infrastructure improvements for new applications and reproducibility. Geoscientific Model. Development 11, 3481–3496 (2018).
Maussion, F. et al. The Open Global Glacier Model (OGGM) v1.1. Geoscientific Model Development 12, 909–931 (2019).
Huss, M. & Hock, R. Global-scale hydrological response to future glacier mass loss. Nature Climate Change 8, 135–140 (2018).
Viglione, A. & Parajka, J. TUWmodel: Lumped/Semi-Distributed Hydrological Model for Education Purposes. (2020).
Mayr, E., Hagg, W., Mayer, C. & Braun, L. Calibrating a spatially distributed conceptual hydrological model using runoff, annual mass balance and winter mass balance. Journal of Hydrology 478, 40–49 (2013).
Addor, N., Newman, A. J., Mizukami, N. & Clark, M. P. The CAMELS data set: catchment attributes and meteorology for large-sample studies. Hydrology and Earth System Sciences 21, 5293–5313 (2017).
Chagas, V. B. P. et al. CAMELS-BR: Hydrometeorological time series and landscape attributes for 897 catchments in Brazil. Earth System Science Data 12, 2075–2096 (2020).
Fowler, K. J. A., Acharya, S. C., Addor, N., Chou, C. & Peel, M. C. CAMELS-AUS: hydrometeorological time series and landscape attributes for 222 catchments in Australia. Earth System Science Data 13, 3847–3867 (2021).
Coxon, G. et al. CAMELS-GB: hydrometeorological time series and landscape attributes for 671 catchments in Great Britain. Earth System Science Data 12, 2459–2483 (2020).
Hao, Z. et al. CCAM: China Catchment Attributes and Meteorology dataset. Earth System Science Data 13, 5591–5616 (2021).
Ma, K. et al. Transferring Hydrologic Data Across Continents – Leveraging Data‐Rich Regions to Improve Hydrologic Prediction in Data‐Sparse Regions. Water Resources Research 57, (2021).
Baez-Villanueva, O. M. et al. On the selection of precipitation products for the regionalisation of hydrological model parameters. Hydrology and Earth System Sciences 25, 5805–5837 (2021).
Jehn, F. U., Bestian, K., Breuer, L., Kraft, P. & Houska, T. Using hydrological and climatic catchment clusters to explore drivers of catchment behavior. Hydrology and Earth System Sciences 24, 1081–1100 (2020).
Bloomfield, J. P., Gong, M., Marchant, B. P., Coxon, G. & Addor, N. How is Baseflow Index (BFI) impacted by water resource management practices? Hydrology and Earth System Sciences 25, 5355–5379 (2021).
Knoben, W. J. M., Freer, J. E., Peel, M. C., Fowler, K. J. A. & Woods, R. A. A Brief Analysis of Conceptual Model Structure Uncertainty Using 36 Models and 559 Catchments. Water Resources Research 56, e2019WR025975 (2020).
Lees, T. et al. Hydrological concept formation inside long short-term memory (LSTM) networks. Hydrology and Earth System Sciences 26, 3079–3101 (2022).
Somos-Valenzuela, M. & Manquehual-Cheuque, F. Evaluating Multiple WRF Configurations and Forcing over the Northern Patagonian Icecap (NPI) and Baker River Basin. Atmosphere 11, 815 (2020).
Iriarte, J. L., Pantoja, S. & Daneri, G. Oceanographic Processes in Chilean Fjords of Patagonia: From small to large-scale studies. Progress in Oceanography 129, 1–7 (2014).
Garreaud, R., Lopez, P., Minvielle, M. & Rojas, M. Large-scale control on the Patagonian climate. Journal of Climate 26, 215–230 (2013).
Sauter, T. Revisiting extreme precipitation amounts over southern South America and implications for the Patagonian Icefields. Hydrology and Earth System Sciences 24, 2003–2016 (2020).
Lenaerts, J. T. M. et al. Extreme Precipitation and Climate Gradients in Patagonia Revealed by High-Resolution Regional Atmospheric Climate Modeling. Journal of Climate 27, 4607–4621 (2014).
Masiokas, M. H. et al. Streamflow variations across the Andes (18°–55°S) during the instrumental era. Scientific Reports 9, 17879 (2019).
Pabón-Caicedo, J. D. et al. Observed and Projected Hydroclimate Changes in the Andes. Frontiers in Earth Science 8, 61 (2020).
Fogt, R. L. & Marshall, G. J. The Southern Annular Mode: Variability, trends, and climate impacts across the Southern Hemisphere. WIREs Climate Change 11, (2020).
Boisier, J. P. et al. Anthropogenic drying in central-southern Chile evidenced by long-term observations and climate model simulations. Elementa: Science of the Anthropocene 6, 74 (2018).
Lo Vecchio, A. et al. MODIS Image-derived ice surface temperature assessment in the Southern Patagonian Icefield. Progress in Physical Geography: Earth and Environment 43, 754–776 (2019).
Roig, F. A. & Villalba, R. Understanding Climate from Patagonian Tree Rings. in Developments in Quaternary Sciences (ed. Rabassa, J.) vol. 11, 411–435 (Elsevier, 2008).
Aguirre, F. et al. Snow Cover Change as a Climate Indicator in Brunswick Peninsula, Patagonia. Frontiers in Earth Science 6, (2018).
Aguayo, R. et al. The glass half-empty: climate change drives lower freshwater input in the coastal system of the Chilean Northern Patagonia. Climatic Change 155, 417–435 (2019).
Mundo, I. A. et al. Fire history in southern Patagonia: Human and climate influences on fire activity in Nothofagus pumilio forests. Ecosphere 8, e01932 (2017).
Villalba, R. et al. Unusual Southern Hemisphere tree growth patterns induced by changes in the Southern Annular Mode. Nature Geoscience 5, 793–798 (2012).
Pessacg, N., Flaherty, S., Solman, S. & Pascual, M. Climate change in northern Patagonia: critical decrease in water resources. Theoretical and Applied Climatology 140, 807–822 (2020).
Pasquini, A. I., Lecomte, K. L. & Depetris, P. J. Climate change and recent water level variability in Patagonian proglacial lakes, Argentina. Global and Planetary Change 63, 290–298 (2008).
Aguayo, R., León-Muñoz, J., Garreaud, R. & Montecinos, A. Hydrological droughts in the southern Andes (40–45°S) from an ensemble experiment using CMIP5 and CMIP6 models. Scientific Reports 11, 5530 (2021).
Davies, B. J. & Glasser, N. F. Accelerating shrinkage of Patagonian glaciers from the Little Ice Age (~AD 1870) to 2011. Journal of Glaciology 58, 1063–1084 (2012).
Hugonnet, R. et al. Accelerated global glacier mass loss in the early twenty-first century. Nature 592, 726–731 (2021).
Krogh, S. A., Pomeroy, J. W. & McPhee, J. Physically Based Mountain Hydrological Modeling Using Reanalysis Data in Patagonia. Journal of Hydrometeorology 16, 172–193 (2014).
Vásquez, N. et al. Catchment-Scale Natural Water Balance in Chile. in Water Resources of Chile 189–208, https://doi.org/10.1007/978-3-030-56901-3_9 (2021).
DGA. Application of the Methodology for Updating the National Water Balance in the Basins of the Southern Macrozone and the Northern Part of the Southern Macrozone. https://snia.mop.gob.cl/sad/REH5850v4.pdf (2018).
DGA. Application of the Methodology for Updating the National Water Balance in the Basins of the Southern Part of the Southern Macro Zone and Easter Island. https://snia.mop.gob.cl/sad/REH5889v4.pdf (2019).
Mernild, S. H., Liston, G. E., Hiemstra, C. & Wilson, R. The Andes Cordillera. Part III: glacier surface mass balance and contribution to sea level rise (1979–2014). International Journal of Climatology 37, 3154–3174 (2017).
Schaefer, M., MacHguth, H., Falvey, M., Casassa, G. & Rignot, E. Quantifying mass balance processes on the Southern Patagonia Icefield. Cryosphere 9, 25–35 (2015).
Bravo, C., Bozkurt, D., Ross, A. N. & Quincey, D. J. Projected increases in surface melt and ice loss for the Northern and Southern Patagonian Icefields. Scientific Reports 11, 1–13 (2021).
Serrano-Notivoli, R., de Luis, M. & Beguería, S. An R package for daily precipitation climate series reconstruction. Environmental Modelling and Software 89, 190–195 (2017).
Killick, R., Fearnhead, P. & Eckley, I. A. Optimal Detection of Changepoints With a Linear Computational Cost. Journal of the American Statistical Association 107, 1590–1598 (2012).
Killick, R. & Eckley, I. A. changepoint: An R Package for Changepoint Analysis. Journal of Statistical Software 58, (2014).
NASA JPL. NASADEM Merged DEM Global 1 arc second V00. Earth Observing System Data and Information System https://doi.org/10.5067/MEaSUREs/NASADEM/NASADEM_HGT.001 (2020).
Hersbach, H. et al. The ERA5 global reanalysis. Quarterly Journal of the Royal Meteorological Society 146, 1999–2049 (2020).
Gelaro, R. et al. The Modern-Era Retrospective Analysis for Research and Applications, Version 2 (MERRA-2). Journal of Climate 30, 5419–5454 (2017).
Saha, S. et al. The NCEP Climate Forecast System Version 2. Journal of Climate 27, 2185–2208 (2014).
Bozkurt, D. et al. Dynamical downscaling over the complex terrain of southwest South America: present climate conditions and added value analysis. Climate Dynamics 53, 6745–6767 (2019).
Zambrano-Bigiarini, M., Nauditt, A., Birkel, C., Verbist, K. & Ribbe, L. Temporal and spatial evaluation of satellite-based rainfall estimates across the complex topographical and climatic gradients of Chile. Hydrology and Earth System Sciences 21, 1295–1320 (2017).
Baez-Villanueva, O. M. et al. Temporal and spatial evaluation of satellite rainfall estimates over different regions in Latin-America. Atmospheric Research 213, 34–50 (2018).
Kling, H., Fuchs, M. & Paulin, M. Runoff conditions in the upper Danube basin under an ensemble of climate change scenarios. Journal of Hydrology 424–425, 264–277 (2012).
Zambrano-Bigiarini, M. hydroGOF: Goodness-of-fit functions for comparison of simulated and observed hydrological time series., Zenodo, https://doi.org/10.5281/zenodo.839854 (2020).
Bravo, C. et al. Air Temperature Characteristics, Distribution, and Impact on Modeled Ablation for the South Patagonia Icefield. Journal of Geophysical Research: Atmospheres 124, 907–925 (2019).
Teutschbein, C. & Seibert, J. Bias correction of regional climate model simulations for hydrological climate-change impact studies: Review and evaluation of different methods. Journal of Hydrology 456–457, 12–29 (2012).
Chen, J., Brissette, F. P. & Leconte, R. Uncertainty of downscaling method in quantifying the impact of climate change on hydrology. Journal of Hydrology 401, 190–202 (2011).
Mishra, V., Bhatia, U. & Tiwari, A. D. Bias-corrected climate projections for South Asia from Coupled Model Intercomparison Project-6. Sci Data 7, 338 (2020).
Tang, G. et al. SCDNA: a serially complete precipitation and temperature dataset for North America from 1979 to 2018. Earth System Science Data 12, 2381–2409 (2020).
Prudhomme, C. et al. Future Flows Climate: an ensemble of 1-km climate change projections for hydrological application in Great Britain. Earth System Science Data 4, 143–148 (2012).
Piani, C., Haerter, J. O. & Coppola, E. Statistical bias correction for daily precipitation in regional climate models over Europe. Theoretical and Applied Climatology 99, 187–192 (2010).
Gudmundsson, L., Bremnes, J. B., Haugen, J. E. & Engen-Skaugen, T. Technical Note: Downscaling RCM precipitation to the station scale using statistical transformations – a comparison of methods. Hydrology and Earth System Sciences 16, 3383–3390 (2012).
Gudmundsson, L. qmap: Statistical transformations for post-processing climate model output. (2016).
Breiman, L. Random Forests. Machine Learning 45, 5–32 (2001).
Svetnik, V. et al. Random Forest: A Classification and Regression Tool for Compound Classification and QSAR Modeling. Journal of Chemical Information and Computer Sciences 43, 1947–1958 (2003).
Tyralis, H., Papacharalampous, G. & Langousis, A. A Brief Review of Random Forests for Water Scientists and Practitioners and Their Recent History in Water Resources. Water 11, 910 (2019).
Baez-Villanueva, O. M. et al. RF-MEP: A novel Random Forest method for merging gridded precipitation products and ground-based measurements. Remote Sensing of Environment 239, 111606 (2020).
Liaw, A. & Wiener, M. Classification and Regression by randomForest. R News 2, 18–22 (2002).
Kuhn, M. Building Predictive Models in R Using the caret Package. Journal of Statistical Software 28, 1–26 (2008).
Donohue, R. J., Roderick, M. L. & McVicar, T. R. On the importance of including vegetation dynamics in Budyko’s hydrological model. Hydrology and Earth System Sciences 11, 983–995 (2007).
Wang, C., Wang, S., Fu, B. & Zhang, L. Advances in hydrological modelling with the Budyko framework. Progress in Physical Geography: Earth and Environment 40, 409–430 (2016).
Budyko, M. I. Climate and Life. (Academic Press, 1974).
Fu, B. P. On the Calculation of the Evaporation from Land Surface. Scientia Atmospherica Sinica 5, 23–31 (1981).
Liu, S.-W. et al. Effect of glaciers on the annual catchment water balance within Budyko framework. Advances in Climate Change Research 13, 51–62 (2022).
Martens, B. et al. GLEAM v3: satellite-based land evaporation and root-zone soil moisture. Geoscientific Model Development 10, 1903–1925 (2017).
Rasmussen, R. et al. How Well Are We Measuring Snow: The NOAA/FAA/NCAR Winter Precipitation Test Bed. Bull. Amer. Meteor. Soc. 93, 811–829 (2012).
Sevruk, B., Ondrás, M. & Chvíla, B. The WMO precipitation measurement intercomparisons. Atmospheric Research 92, 376–380 (2009).
Schneider, U. et al. GPCC’s new land surface precipitation climatology based on quality-controlled in situ data and its role in quantifying the global water cycle. Theor Appl Climatol 115, 15–40 (2014).
Kidd, C. et al. So, How Much of the Earth’s Surface Is Covered by Rain Gauges? Bulletin of the American Meteorological Society 98, 69–78 (2017).
Aguayo, R. et al. PatagoniaMet: A multi-source hydrometeorological dataset for Western Patagonia., Zenodo, https://doi.org/10.5281/ZENODO.7992760 (2023).
Zambrano-Bigiarini, M. Temporal and spatial evaluation of long-term satellite-based precipitation products across the complex topographical and climatic gradients of Chile. in Remote Sensing and Modeling of the Atmosphere, Oceans, and Interactions VII. https://doi.org/10.1117/12.2513645 (2018).
Cucchi, M. et al. WFDE5: bias-adjusted ERA5 reanalysis data for impact studies. Earth System Science Data 12, 2097–2120 (2020).
Lindström, G., Johansson, B., Persson, M., Gardelin, M. & Bergström, S. Development and test of the distributed HBV-96 hydrological model. Journal of Hydrology 201, 272–288 (1997).
Hock, R. Temperature index melt modelling in mountain areas. Journal of Hydrology 282, 104–115 (2003).
Tong, R. et al. The value of ASCAT soil moisture and MODIS snow cover data for calibrating a conceptual hydrologic model. Hydrology and Earth System Sciences 25, 1389–1410 (2021).
Parajka, J. et al. Uncertainty contributions to low-flow projections in Austria. Hydrology and Earth System Sciences 20, 2085–2101 (2016).
Astagneau, P. C. et al. Technical note: Hydrology modelling R packages – a unified analysis of models and practicalities from a user perspective. Hydrology and Earth System Sciences 25, 3937–3973 (2021).
Széles, B. et al. The Added Value of Different Data Types for Calibrating and Testing a Hydrologic Model in a Small Catchment. Water Resources Research 56, (2020).
Vremec, M., Collenteur, R. A. & Birk, S. Technical note: Improved handling of potential evapotranspiration in hydrological studies with PyEt. Hydrology and Earth System Sciences Discussions 1–23 https://doi.org/10.5194/hess-2022-417 (2023).
Zambrano-Bigiarini, M. & Rojas, R. A model-independent Particle Swarm Optimisation software for model calibration. Environmental Modelling & Software 43, 5–25 (2013).
Galleguillos, M. et al. Disentangling the effect of future land use strategies and climate change on streamflow in a Mediterranean catchment dominated by tree plantations. Journal of Hydrology, 595, 126047 https://doi.org/10.1016/j.jhydrol.2021.126047 (2021).
Althoff, D. & Rodrigues, L. N. Goodness-of-fit criteria for hydrological models: Model calibration and performance assessment. Journal of Hydrology 600, 126674 (2021).
Stagge, J. H. et al. Assessing data availability and research reproducibility in hydrology and water resources. Sci Data 6, 190030 (2019).
Hutton, C. et al. Most computational hydrology is not reproducible, so is it really science? Water Resources Research 52, 7548–7555 (2016).
WMO. Guide to Hydrological Practices, Volume I: Hydrology – From Measurement to Hydrological Information. (2008).
Aguayo, R. rodaguayo/PatagoniaMet: v1.1. Zenodo https://doi.org/10.5281/ZENODO.8374542 (2023).
Boisier, J. P. CR2MET: A high-resolution precipitation and temperature dataset for the period 1960–2021 in continental Chile. https://doi.org/10.5281/zenodo.7529682 (2023).
Lange, S. et al. WFDE5 over land merged with ERA5 over the ocean (W5E5 v2.0). https://doi.org/10.48364/ISIMIP.342217 (2021).
Beck, H. E. et al. MSWX: Global 3-Hourly 0.1° Bias-Corrected Meteorological Data Including Near-Real-Time Updates and Forecast Ensembles. Bulletin of the American Meteorological Society 103, E710–E732 (2022).
Messager, M. L., Lehner, B., Grill, G., Nedeva, I. & Schmitt, O. Estimating the volume and age of water stored in global lakes using a geo-statistical approach. Nat Commun 7, 13603 (2016).
Hansen, M. C. et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 342, 850–853 (2013).
Mao, J. & Yan, B. Global Monthly Mean Leaf Area Index Climatology, 1981–2015. ORNL DAAC https://doi.org/10.3334/ORNLDAAC/1653 (2019).
RGI Consortium. Randolph Glacier Inventory - A Dataset of Global Glacier Outlines, Version 6. https://doi.org/10.7265/4M1F-GD79 (2017).
Wilson, A. M. & Jetz, W. Remotely Sensed High-Resolution Global Cloud Dynamics for Predicting Ecosystem and Biodiversity Distributions. PLOS Biology 14, e1002415 (2016).
Beck, H. E. et al. Present and future Köppen-Geiger climate classification maps at 1-km resolution. Scientific Data 5, 180214 (2018).
Buchhorn, M. et al. Copernicus Global Land Service: Land Cover 100m: collection 3: epoch 2019: Globe. Zenodo https://doi.org/10.5281/ZENODO.3939050 (2020).
Acknowledgements
We thank Paul Sandoval and Benjamin Alarcon for their help in compiling and updating the ground-based data for PMET-obs. We thank Alejandro Dussaillant and Wilson Hernandez for providing the data from ENDESA and DIRECTEMAR, respectively. We thank the ANID-FONDAP 1522A0001 Centre for Climate and Resilience Research (CR2) for compiling the data from the DGA and DMC institutions. This research was supported by ANID PFCHA/DOCTORADO NACIONAL/2019 - 21190544 and FONDECYT 1221102. AF received financial support from ANILLO 210080, FONDECYT 1201429, and Programa CIMASur-UdeC. JL received financial support from FSEQ. 210030, FONDAP INCAR 1522A0004 and FONDECYT 1221102.
Author information
Authors and Affiliations
Contributions
R.A. collected the data and performed the core data analysis and validation. J.L. and M.A. helped design the computational framework and analysed the data. O.B. and M.Z. helped to refine the validation approach and assisted with the analyses. A.F. and M.J. contributed to the analysis of the results and to the drafting of the manuscript. All authors revised the manuscript, provided feedback, and contributed to the preparation of the figures and tables. All authors approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Aguayo, R., León-Muñoz, J., Aguayo, M. et al. PatagoniaMet: A multi-source hydrometeorological dataset for Western Patagonia. Sci Data 11, 6 (2024). https://doi.org/10.1038/s41597-023-02828-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-02828-2
