
Abstract
Recognition of objects from sensory stimuli is essential for survival. To that end, sensory networks in the brain must form object representations invariant to stimulus changes, such as size, orientation and context. Although Hebbian plasticity is known to shape sensory networks, it fails to create invariant object representations in computational models, raising the question of how the brain achieves such processing. In the present study, we show that combining Hebbian plasticity with a predictive form of plasticity leads to invariant representations in deep neural network models. We derive a local learning rule that generalizes to spiking neural networks and naturally accounts for several experimentally observed properties of synaptic plasticity, including metaplasticity and spike-timing-dependent plasticity. Finally, our model accurately captures neuronal selectivity changes observed in the primate inferotemporal cortex in response to altered visual experience. Thus, we provide a plausible normative theory emphasizing the importance of predictive plasticity mechanisms for successful representational learning.
Similar content being viewed by others

Main
Recognition of invariant objects and concepts from diverse sensory inputs is crucial for perception. Watching a dog run evokes a series of distinct retinal activity patterns that differ substantially depending on the animal’s posture, lighting conditions or visual context (Fig. 1a). If we looked at a cat instead, the resulting activity patterns would be different still. That we can effortlessly distinguish dogs from cats is remarkable. It requires mapping entangled input patterns, which lie on manifolds that ‘hug’ each other like crumpled-up sheets of paper, to disentangled neuronal activity patterns, which encode the underlying factors so downstream neurons can easily read them out1. Such transformations require deep sensory networks with specific network connectivity shaped through experience-dependent plasticity (Fig. 1b). However, current data-driven plasticity models fail to establish the necessary connectivity in simulated deep sensory networks. At the same time, supervised machine-learning algorithms do yield suitable connectivity2 in deep neural networks (DNNs) that further reproduce essential aspects of the representational geometry of biological neural responses3,4. This resemblance proffers DNNs as potential tools to elucidate neural information processing in the brain5,6.

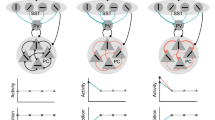
a, Schematic of an evoked response in sensory input neurons. The neuronal response patterns for distinct stimuli correspond to points in a high dimensional space spanned by the neuronal activity levels. The response patterns from different stimulus classes, for example, cats and dogs, form a low-dimensional manifold in the space of all possible response patterns. Generally, different class manifolds are entangled, which means that the stimulus identity cannot be readily decoded from a linear combination of the neuronal activities. b, Sketch of a DNN (left) that transforms inputs into disentangled internal representations that are linearly separable (right). c, Schematic of how predictive learning influences latent representations (left). Learning tries to ‘pull’ together representations that frequently co-occur close in time (bottom). However, without opposing forces, such learning dynamics lead to representational ‘collapse’, whereby all inputs are mapped to the same output and thereby become indistinguishable (right). d, SSL avoids collapse by adding a repelling force that acts on temporally distant representations that are often semantically unrelated. e, Plot of postsynaptic neuronal activity, z, over time (bottom) and a Hebbian learning rule (top33,35), which characterizes the sign and magnitude of synaptic weight change, Δw, as a function of postsynaptic activity, z. Notably, the sign of plasticity depends on whether the evoked responses are above or below the plasticity threshold θ. Using the example of neuron 1 in b, the learning rule potentiates synapses that are active when a ‘Cat’ stimulus is shown, whereas ‘Dog’ stimuli induce LTD. This effectively pushes the evoked neuronal activity levels corresponding to both stimuli away from each other, thereby preventing representational collapse.
Unfortunately, standard deep learning methods are difficult to reconcile with biology. On the one hand, they rely on backpropagation, an algorithm considered biologically implausible, although neurobiology may implement effective alternatives5,7,8,9,10. On the other hand, humans and animals cannot learn through strong label-based supervision, because this would require knowledge of a label for every input pattern.
In the present study, we show that self-supervised learning (SSL), a family of unsupervised machine-learning algorithms, may offer a remedy. SSL does not need labeled data but instead relies on prediction, a notion also supported by neurobiology11,12,13,14,15,16. Prediction can happen in the input space by, for instance, reconstructing one part of an image from another, as for autoencoders17, or by predicting the next word in a sentence, as done in language models. Alternatively, prediction can occur in latent space by requiring internal representations of related inputs to predict each other18,19. Latent space prediction is more compelling from a neuroscience perspective because it does not require an explicit decoder network that computes prediction errors at the input, that is, the sensory periphery, for which there is little experimental support. Instead, latent prediction errors are computed locally or at network outputs (compare Fig. 1) and drive learning by ‘pulling’ together related internal representations for stimuli that frequently occur close in time (Fig. 1c), similar to slow feature analysis (SFA)20,21.
However, a major issue with this strategy is that, without any forces opposing this representational pull, such learning inevitably leads to ‘representational collapse’, whereby all inputs are mapped to the same internal activity pattern that precludes linear separability (Fig. 1c). One typical solution to this issue is to add forces that ‘push’ representations corresponding to different unrelated stimuli away from each other (Fig. 1d). This is usually done by invoking so-called ‘negative samples’, which are inputs that do not frequently occur together in time. This approach has been linked to biologically plausible, three-factor learning rules22,23, but it requires constantly switching the sign of plasticity depending on whether or not two successive inputs are related to each other. Yet, it is unknown whether and how such a rapid sign switch is implemented in the brain.
Another possible solution for avoiding representational collapse without negative samples is to prevent neuronal activity from becoming constant over time, for instance, by maximizing the variance of the activity24. It is interesting that variance maximization is a known signature of Hebbian plasticity25,26, which has been found ubiquitously in the brain27,28. Although Hebbian learning is usually thought of as the primary plasticity mechanism rather than playing a supporting role, Hebbian plasticity alone has had limited success at disentangling representations in DNNs5,29,30.
This article introduces latent predictive learning (LPL), a conceptual learning framework that overcomes this limitation and reconciles SSL with Hebbian plasticity. Specifically, the local learning rules derived within our framework combine a plasticity threshold, as observed in experiments (Fig. 1e)27,31,32,33,34, with a predictive component, inspired by SSL and SFA, that renders neurons selective to temporally contiguous features in their inputs. When applied to the layers of deep hierarchical networks, LPL yields disentangled representations of objects present in natural images without requiring labels or negative samples. Crucially, LPL effectively disentangles representations as a local learning rule without requiring explicit spatial credit assignment mechanisms. Still, credit assignment capabilities can further improve its effectiveness. We demonstrate that LPL captures central findings of unsupervised visual learning experiments in monkeys and in spiking neural networks (SNNs) and naturally yields a classic spike-timing-dependent plasticity (STDP) window, including its experimentally observed firing-rate dependence27. These findings suggest that LPL constitutes a plausible normative plasticity mechanism that may underlie representational learning in biological brains.
Results
To study the interplay of Hebbian and predictive plasticity in sensory representational learning, we derived a plasticity model from an SSL objective function that is reminiscent of and extends the classic Bienenstock–Cooper–Munro (BCM) learning rule33,35 (Methods and Supplementary Note 1). According to our learning rule, the temporal dynamics of a synaptic weight Wj are given by:
where η is a small positive learning rate, xj(t) denotes the activity of the presynaptic neuron j, z(t) = f(a(t)) is the neuronal activity with the activation function f and the net input current a(t) = ∑kWkxk(t). We call the first term in parentheses the predictive term because it promotes learning of slow features20,21 by effectively ‘pulling together’ postsynaptic responses to temporally consecutive input stimuli. Importantly, it cancels when the neural activity does not change and, therefore, accurately predicts future activity. In the absence of any additional constraints, the predictive term leads to collapsing neuronal activity levels20. In our model, collapse is prevented by the Hebbian term in which \(\bar{z}(t)\), the running average of the neuronal activity, appears, reminiscent of BCM theory33,35. Its strength further depends on an online estimate of the postsynaptic variance of neuronal activity \({\sigma }_{z}^{2}(t)\). This modification posits an additional metaplasticity mechanism controlling the balance between predictive and Hebbian plasticity depending on the postsynaptic neuron’s past activity.
To make the link to BCM explicit, we rearrange the terms in equation (1) to give:
where Θ(t) corresponds to a time-dependent sliding plasticity threshold (compare Fig. 1e). Although the precise shape of the learning rule depends on the choice of neuronal activation function, its qualitative behavior remains unchanged as long as the function is monotonic (Extended Data Fig. 1). Despite the commonalities, however, there are three essential differences to the BCM model. First, in our model, the threshold depends only linearly on \(\bar{z}(t)\) (Extended Data Fig. 1b), whereas, in BCM, the threshold is typically a supralinear function of the moving average \(\bar{z}(t)\). Second, the added dependence on the predictive term \(-\frac{{{{\rm{d}}}}z}{{{{\rm{d}}}}t}\) constitutes a separate mechanism that modulates the plasticity threshold depending on the rate of change of the postsynaptic activity (Extended Data Fig. 1c,d). Third, our model adds a variance dependence that has diverse effects on the sliding threshold when the neuronal output does not accurately predict future activity and, thus, changes rapidly. We will see that these modifications are crucial to representational learning from the temporal structure in sensory inputs. As the predictive term encourages neurons to predict future activity at their output, and thus in latent space rather than the input space, we refer to equation (1) as the LPL rule.
LPL finds contiguous features in temporal data
To investigate the functional advantages of LPL over BCM and other classic Hebbian learning rules (Supplementary Note 2), we designed a synthetic two-dimensional (2D) learning task in which we parametrically controlled the proportion of predictable changes between subsequent observations (Fig. 2a and Methods). The data sequence consisted of noisy inputs from two clusters separated along the x axis. Consecutive inputs had a high probability of staying within the same cluster, thus making cluster identity a temporally contiguous feature. By varying the noise amplitude, σy, in the y direction, we controlled the amount of unpredictable changes. We simulated a single rate neuron with different datasets for varying σy, whereas the two input connections were plastic and evolved according to the LPL rule (equation (1)) until convergence. We then measured neuronal selectivity to cluster identity (Methods).

a, Illustration of the 2D synthetic data-generating process. Consecutive data points predominantly stay within the same cluster separated along the x direction and are drawn independently from the corresponding normal distribution centered in that cluster (left). These data are fed into a linear neuron that learns via LPL (right). b, Cluster selectivity of the features learned by LPL with and without the predictive term (Pred. off) and by Oja’s rule for different values of σy. By varying σy, we obtain a family of sequences with different amplitudes of within-cluster transitions (top). LPL selects temporally contiguous features and therefore ensures that the neuron always becomes selective to cluster identity. Oja’s rule finds PC1, the direction of highest variance, which switches to the noise direction at σy = 1. LPL without the predictive component shows the same behavior. Selectivity values were averaged over ten random seeds. The shaded area corresponds to 1 s.d. c, Mean output activity of the neuron over training time for σy = 1 under different versions of LPL. LPL initially increases its response and saturates at some activity level, even when the predictive term is disabled. However, without the Hebbian term (Hebb. off), the activity collapses to zero.
We found that LPL rendered the neuron selective to the cluster identity for a large range of σy values (Fig. 2b). However, without the predictive term, the selectivity to cluster identity was lost for large σy values. This behaviour was expected because omitting the predictive term renders the learning rule purely Hebbian, which biases selectivity toward directions of high variance. To illustrate this point, we repeated the same simulation with Oja’s rule, a classic Hebbian rule that finds the principal component (PC) in the input and found similar qualitative behaviour. Thus, LPL behaves fundamentally differently from purely Hebbian rules, by selecting predictable features in the input.
To confirm that the Hebbian term is essential for LPL to prevent representational collapse, we simulated learning without the Hebbian term (compare equation (1)). We observed that the neuron’s activity collapses to zero firing rate as expected (Fig. 2c). Conversely, learning with the Hebbian term but without the predictive term did not result in collapse. Therefore, LPL’s Hebbian component is essential to prevent activity collapse.
Moreover, Hebbian plasticity needs to be dynamically regulated to prevent runaway activity36. In LPL this regulation is achieved by inversely scaling the Hebbian term by a moving estimate of the variance of the postsynaptic activity \({\sigma}_{z}^{2}(t)\). Without this variance modulation, neural activity either collapsed or succumbed to runaway activity depending on which term was dominant (Supplementary Note 3). Either case precluded the neuron from developing cluster selectivity. We verified that these findings generalized to higher-dimensional tasks with more complex covariance structure (Supplementary Note 4). Hence, the combination of the predictive with variance-modulated Hebbian metaplasticity in LPL is needed to learn invariant predictive features independent of the covariance structure in the data.
LPL disentangles representations in deep hierarchical networks
As we move through the world, we see objects, animals and people under different angles and contexts (Fig. 3a). Therefore, objects themselves constitute temporally contiguous features in normal vision. We thus wondered whether training an artificial DNN with LPL on image sequences with such object permanence results in disentangled representations. To that end, we built a convolutional DNN model in which we ‘stacked’ layers with synaptic connections that evolved according to the LPL rule. In addition, we included a term to decorrelate neurons within each layer. Inhibitory plasticity presumably plays this role in biological neural networks37,38,39,40. LPL was implemented in a ‘layer-local’ manner, meaning that there was no backpropagation through layers (Methods).

a, Schematic of the DNN trained using LPL. We distinguish two learning strategies: layer-local and end-to-end learning. In layer-local LPL, each layer’s learning objective (\({{{{\mathcal{L}}}}}_{i}\)) is to predict representations within the same layer, whereas end-to-end training takes into account the output layer representations only (\({{{{\mathcal{L}}}}}_{{{{\rm{out}}}}}\)) and updates hidden-layer weights using backpropagation. b, Linear readout accuracy of object categories decoded from representations at the network output after training n = 4 networks independently on natural image data (STL-10; see Methods for details) with different learning rules in layer-local (dark) as well as end-to-end (light) configuration. Bars are averages ± s.e.m. ‘Pred. off’ corresponds to LPL but without the predictive term in the learning rule (compare equation (7)). ‘Hebb. off’ refers to the configuration without the BCM-like Hebbian term. Finally, ‘Decorr. off’ is the same as the single neuron learning rule (equation (1)) without the decorrelation term. LPL yields features with high linear readout accuracy. In contrast, when any component of LPL is disabled, linear readout accuracy drops below the pixel-decoding accuracy of ~32% (dashed line). c, Linear readout accuracy of the internal representations at different layers of the DNN after layer-local training. Data points are averages (n = 4) and error bands indicate s.e.m. LPL’s representations improve up to six layers and then settle at a high level. In contrast, readout accuracy is close to chance level without the Hebbian component and similarly remains at low levels when the decorrelating mechanism is switched off. It is interesting that, when the predictive term is off, the readout accuracy initially increases in early layers, but then ultimately decreases back below the pixel-level accuracy with further increasing depth. Finally, the full LPL learning rule applied to inputs in which temporal contingency is destroyed (LPL shuffled) behaves qualitatively like the purely Hebbian rule. d, Dimensionality ± s.e.m. of the internal representations for the different learning rule configurations shown in b. When either the Hebbian or the decorrelation term is disabled, the dimensionality of the representations collapses to 1. e, Mean neuronal activity at different layers of the DNN after training with the different learning rule variants shown in c. Data averaged over networks as in c. Error bands denote ±s.e.m. Exclusion of the Hebbian term (dotted line) leads to collapsed representations in all layers.
To simulate temporal sequences of related visual inputs, we generated pairs of images sampled from a large dataset, by applying different randomized transformations (Extended Data Fig. 2 and Methods). We trained our network model on these visual data until learning converged and evaluated the linear decodability of object categories from the learned representations using a separately trained linear classifier.
We found that, in networks trained with LPL, object categories could be linearly decoded at the output with an accuracy of (63.2 ± 0.3)% (Fig. 3b and Table 1), suggesting that the network has formed partially disentangled representations (Extended Data Fig. 3). To elucidate the roles of the different learning rule components, we conducted several ablation experiments. First, we repeated the same simulation but now excluding the predictive term. This modification resulted in an accuracy of (27.0 ± 0.2)%, which is lower than the linear readout accuracy of a classifier trained directly on the pixels of the input images (Table 1), indicating that the network did not learn disentangled representations, consistent with previous studies on purely Hebbian plasticity5,30. We measured a similar drop in accuracy when we disabled either the Hebbian or the decorrelation component during learning (Fig. 3b).
Convolutional DNNs trained through supervised learning use depth to progressively separate representations2. To understand whether networks trained with LPL similarly leverage depth, we measured the linear readout accuracy of the internal representations at every layer in the network. Crucially, we found that, in the LPL-trained networks, the readout accuracy increased with the number of layers until it gradually saturated (Fig. 3c), whereas this was not the case when any component of LPL was disabled. Similarly, readout accuracy decreased when the temporal contiguity in the input was broken by shuffling, reminiscent of experiments in developing rats15. Together, these results suggest that LPL’s combination of Hebbian, predictive and decorrelating elements is crucial for disentangling representations in hierarchical DNNs.
In SSL, the two most common causes for failure to disentangle representations are representational and dimensional collapse (Supplementary Fig. 1), owing to excessively high neuronal correlations41. To disambiguate between these two possibilities in our model, we computed the dimensionality of the representations and the mean neuronal activity at every layer (Methods). We found that disabling either the Hebbian or the decorrelation component led to a dimensionality of approximately 1, whereas the LPL rule with and without the predictive term resulted in higher dimensionality: ≈15 or ≈50, respectively (Fig. 3d). Disabling the Hebbian term silenced all layers (Fig. 3e), demonstrating representational collapse. In contrast, disabling the decorrelation term resulted in nonzero activity levels, indicating that dimensional collapse underlies its poor readout accuracy (Fig. 3e). Finally, we verified that excluding LPL’s predictive component caused neither representational nor dimensional collapse, suggesting that the decreasing linear readout accuracy with depth was due to the network’s inability to learn good internal representations. Taken together, these results show that the predictive term is crucial for disentangling object representations in DNNs (Fig. 3), whereas the other terms are essential to prevent different forms of collapse.
It is an ongoing debate whether neurobiology implements some form of credit assignment5,7,8,9,10. Above we showed that LPL, as a local learning rule, effectively disentangles representations without the need for credit assignment, provided that mechanisms exist to ensure neuronal decorrelation38. Naturally, our next question was whether a non-local LPL formulation could improve learning. To that end, we considered the fully non-local case using backpropagation. Specifically, we repeated our simulations with end-to-end training on the LPL objective defined at the network’s output (Methods). Although we do not know how the brain would implement such a non-local LPL algorithm, it provides an upper performance estimate of what is possible. End-to-end learning reproduced all essential findings of layer-local learning while increasing overall performance (Fig. 3b and Table 1). Thus, LPL’s performance improves in the non-local setting, further underscoring that biological networks could benefit from credit assignment circuit mechanisms.
The above simulations used pairs of augmented images. To check whether the key findings generalized to more realistic input paradigms and other measures of disentangling, we trained DNNs with LPL on procedurally generated videos from the 3D Shapes dataset42. The videos consisted of objects shown under a slowly changing view angle, scale or hue and occasional discontinuous scene changes, but without additional image augmentation (Extended Data Fig. 4a,b and Methods). We found that LPL-trained networks reliably disentangle object identity. In contrast, networks trained without predictive learning failed to do so (Extended Data Fig. 4c). Finally, the ground-truth latent manifold structure in the procedurally generated dataset is known. This knowledge allowed us to probe disentangling of the latent manifold directly instead of using linear classification as a proxy. This analysis revealed that LPL-trained networks faithfully disentangled the underlying objects and factors. At the same time, they also learned the topology of the data-generating manifold from the temporal sequence structure (Extended Data Figs. 4d–g and 5). Thus LPL’s ability to disentangle representations generalizes to video stimuli and other measures of disentanglement.
LPL captures invariance learning in the primate inferotemporal cortex
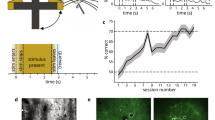
Changing the temporal contiguity structure of visual stimuli induces neuronal selectivity changes in primate inferotemporal cortex (IT), an unsupervised learning effect described by Li and DiCarlo12. In their experiment, a macaque freely viewed a blank screen, with objects appearing in the peripheral visual field at one of two alternative locations relative to the (tracked) center of its gaze, prompting the macaque to perform a saccade to this location (Fig. 4a). The experimenters differentiated between normal exposures in which the object does not change during the saccade and ‘swap exposures’ in which the initially presented object was consistently swapped out for a different one as the monkey saccaded to a specific target location Xswap. Hence, swap exposures created an ‘incorrect’ temporal association between one object at position Xswap and a different one at the animal’s center of gaze Xc. For any particular pair of swap objects, the location either above or below the center of gaze was chosen as Xswap and transitions from the opposite peripheral position Xnonswap to the center Xc were kept consistent as a control. The authors found systematic position- and object-specific changes of neuronal selectivity due to swap exposures that they attributed to unsupervised learning. Specifically, a neuron initially selective to an object P over another object N reduced or even reversed its selectivity at the swap position Xswap, while preserving its selectivity at the nonswap position Xnonswap (Fig. 4b).

a, Schematic of the simulation set-up modeled after the experiment by Li and DiCarlo12. The inputs to the model consist of images of objects presented at three different positions X1, Xc and X2 on a blank canvas. Following the original experiment, we performed a targeted perturbation in the simulated visual experience to which the model network was exposed (left and center). Specifically, we switched object identities during transitions from a specific peripheral position, say X1, to the central position Xc, while keeping transitions from the other peripheral position to the center unmodified (right). b, Evolution of object selectivity as a function of number of swap exposures in the model (top row) and observed in vivo (bottom row; data points extracted and replotted from ref. 12; see Methods for details). Data are presented as mean values ± s.e.m. We differentiate between pairs of swapped objects at the swap (left) and nonswap positions (center) as well as control objects at the swap position (right). LPL qualitatively reproduces the evolution of swap position-specific remapping of object selectivity as observed in IT. Control objects at the swap position, that is, images not used during the swap training protocol, show no selectivity changes in agreement with the experiment. a.u., arbitrary units. c, Average response to objects P and N as a function of number of swap exposures. The change in object selectivity between preferred objects P and nonpreferred objects N is due to both increased responses to N and decreased responses to P in both our model (top) and the experimental recordings (bottom). Data are mean values ± s.e.m.
We wanted to know whether LPL can account for these observations. To that end, we built a DNN model and generated input images by placing visual stimuli on a larger gray canvas to mimic central and peripheral vision as needed for the experiment (compare Fig. 4a and Methods). Importantly, we ensured that the network’s input dimension and output feature map size were large enough to avoid full translation invariance due to the network’s convolutional structure alone. To simulate the animal’s prior visual experience, we trained our network model with LPL on a natural image dataset. After training, the learned representations were invariant to object location on the canvas (Supplementary Fig. 2), a known property of neural representations in the primate IT1. Next, we simulated targeted input perturbations analogous to the original experiment. For a given pair of images from different classes, we switched object identities during transitions from a specific peripheral position, say X1, to the center Xc while keeping transitions from the other peripheral position X2 to the center unmodified. We used X1 as the swap position for half of the image pairs and X2 for the other half. Throughout, we recorded neuronal responses in the network’s output layer whereas the weights in the network model evolved according to the LPL rule.
We observed that the neuronal selectivity between preferred inputs P, as defined by their initial preference (Methods), in comparison to nonpreferred stimuli N in the model qualitatively reproduced the results of the experiment (Fig. 4b). Effectively, LPL trained the network’s output neurons to reduce their selectivity to their preferred inputs P at the swap position while preserving their selectivity at the nonswap position. Furthermore, we observed that object selectivity between pairs of control objects did not change, consistent with the experiment (Fig. 4b). Further analysis revealed that the origin of the selectivity changes between P and N stimuli at the swap position was the result of both increases in responses to N and decreases in responses to P, an effect also observed in the experiments (Fig. 4c). Thus, LPL can account for neuronal selectivity changes observed in monkey IT during in vivo, unsupervised, visual learning experiments.
SNNs with LPL selectively encode predictive inputs
So far we have considered LPL in discrete-time, rate-based, neuron models without an explicit separation of excitatory and inhibitory neurons. In contrast, cortical circuits consist of spiking neurons that obey Dale’s law and learn in continuous time. To test whether our theory would extend to such a more realistic setting, we simulated a plastic recurrent SNN model consisting of 100 excitatory and 25 inhibitory neurons (Fig. 5a and Methods). We simulated input from five Poisson populations with temporally varying firing rates (Fig. 5b and Methods). Input population P0 had a constant firing rate, whereas P1’s and P2’s firing rates followed two independent, slowly varying signals. P1ctl and P2ctl with firing rates that are temporally shuffled versions of P1 and P2 served as control populations. The input connections to the excitatory neurons evolved according to the spiking LPL rule (compare equation (1)), a fully local learning rule. Decorrelation was achieved through inhibitory STDP (Methods)38.

a, Wiring diagram of the SNN with five distinct input populations. b, Snapshot of spiking activity over 5s after LPL plasticity for the inputs (top left) and the network (bottom left) separated into excitatory (black) and inhibitory (blue) neurons. The input spikes are organized in five distinct Poisson populations with firing rates that evolve according to five different temporal input signals (top right). The population activity of two slowly varying signals (P1/2) can be linearly reconstructed (Methods) with high R2 values from the network activity whereas temporally shuffled control signals (‘ctl’; Methods) are heavily suppressed (bottom right). c, Distribution of mean afferent synaptic strength per excitatory neuron (n = 100) grouped by input population. Input connections from slowly varying signals are larger than those from the shuffle controls (left), but not when learning with the predictive term turned off (right). Error bars show minimum (min)/maximum (max) ranges. d, Signal selectivity as relative difference between signal and control pathway for networks trained with different learning rule variations (Methods; n = 100 neurons). ‘LPL’ refers to learning with the spiking LPL rule combined with inhibitory plasticity on the inhibitory-to-excitatory connections. ‘Pred. off’ corresponds to learning without the predictive term and ‘Hebb. off’ to learning without the Hebbian term. ‘Inhib. off’ refers to a setting without any inhibitory neurons, whereas ‘Inhib. fixed’ indicates a setting where the inhibitory-to-excitatory weights are held fixed. The network with LPL and inhibitory plasticity acquires high selectivity to both signals. Selectivity is lost if the predictive term, the Hebbian term or inhibitory plasticity is switched off. e, Average firing rate of excitatory neurons (n = 100) in the network for the different configurations in d. When the Hebbian (Hebb) term is off, spiking activity collapses to low activity (Act.) levels in contrast to all other configurations in which it settles at intermediate activity levels. f, Dimensionality (Dim.) of the neuronal representations (Methods) for the different configurations in d. Inhibition prevents dimensional collapse, even in cases where inhibition is not plastic. g, Averaged weight vectors of all excitatory neurons corresponding to input populations P1 and P2 (left) and the distribution of relative (Rel.) neuronal selectivities between these populations (right). Most neurons become selective to either P1 or P2, but few to both signals simultaneously. Color indicates relative preference of their weight vectors to either signal (Methods). h, Same as g, but without an inhibitory population. Most neurons develop selectivity to P2 or mixed selectivity to both signals, and their weight vectors are more correlated.
After approximately 28 h of simulated time, the network’s firing dynamics had settled into an asynchronous irregular activity regimen from which the slowly varying input signals could be decoded linearly with high fidelity (Fig. 5b). In contrast, P1ctl and P2ctl did not have high reconstruction accuracy, consistent with the idea that the network preferentially represents the slowly varying inputs in its activity. This notion was supported by the strong synaptic connectivity to P1/2 (Fig. 5c). We further computed the relative difference between the average afferent weight from each signal in comparison to its associated control pathway. As expected, we found that neuronal weights were preferentially tuned to the slow input channels (Fig. 5d). However, this selectivity was lost when we turned either the predictive or the Hebbian term off. The absence of Hebbian plasticity was further accompanied by activity collapse (Fig. 5e), as in the rate-based network.
To investigate the role of inhibition, we next removed the inhibitory population. This manipulation resulted in excessively high firing rates (Fig. 5e and Extended Data Fig. 6) and a notable reduction of the representational dimensionality (Fig. 5f and Methods). In the network with plastic inhibition, weights were more decorrelated and purely selective to either P1 or P2 (Fig. 5g). In contrast, removing inhibition resulted in fewer neurons preferentially tuned to either signal (Fig. 5h). Finally, a network with fixed inhibitory weights showed comparable dimensionality to the plastic inhibition case (Fig. 5f), but with a drop in selectivity (Fig. 5d). These results indicate that inhibition is needed to prevent correlated neuronal activity and the ensuing reduction in representational dimensionality. Furthermore, inhibitory plasticity is required to ensure that the slow signals are preferentially represented (Extended Data Fig. 6). Together, these findings illustrate that LPL learns predictive features in realistic spiking circuits with separate excitatory and inhibitory neuronal populations.
LPL qualitatively reproduces experimentally observed rate and spike-timing dependence of synaptic plasticity
Next, we wanted to examine whether the spike-based LPL rule is consistent with experimental observations of plasticity induction. Experiments commonly report intertwined rate and spike-timing dependence presumably mediated through nonlinear voltage- and calcium-dependent cellular mechanisms28,43. Theoretical work has further established conceptual links across phenomenological STDP models, SFA and BCM theory21,44,45,46,47,48.
To compare LPL to experiments, we simulated a standard STDP induction protocol. Specifically, we paired 100 pre- and postsynaptic action potentials with varying relative timing, Δt, for a range of different repetition frequencies, ρ. During the entire plasticity induction protocol, the postsynaptic cell was kept depolarized close to its firing threshold and weights evolved according to spike-based LPL. We repeated the simulated induction protocol for different initial values of the slowly moving averages of the postsynaptic firing rate \({\bar{S}}_{i}(t)\) and variance \({\sigma }_{i}^{2}(t)\) (Methods). This was done because these variables do not change much over the course of a single induction protocol owing to their slow dynamics. Their presence, however, makes LPL a form of metaplasticity, that is, plasticity depends on past neuronal activity.
We found that for small initial values of \({\sigma }_{i}^{2}\), the induced weight changes followed an antisymmetrical temporal profile consistent with STDP experiments (Fig. 6a). For larger initial values of \({\sigma }_{i}^{2}\), the STDP window changed to a more symmetrical and then ultimately an anti-Hebbian profile whereas the plasticity amplitude was suppressed, as expected owing to the variance-dependent suppression of the Hebbian term in the learning rule (Fig. 6b,c). Next we investigated the effect of different initial values for \({\bar{S}}_{i}(t)\), which acts as a moving threshold reminiscent of BCM. Specifically, we recorded plastic changes at two fixed spike-timing intervals Δt = ±10 ms for \({\sigma }_{i}^{2}(t=0)=0.1\). For intermediate threshold values \({\bar{S}}_{i}(t=0)=20\,{{{\rm{Hz}}}}\), causal spike-timing induced long-term potentiation (LTP) with a nonlinear frequency dependence (Fig. 6d), whereas acausal pre-after-post timings showed a characteristic crossover from long-term depression (LTD) to LTP, similar to that observed in experiments27. In contrast, a low initial threshold \({\bar{S}}_{i}(t=0)=0\), which would occur in circuits that have been quiescent for extended periods of time, resulted in LTP induction for both positive and negative spike timings, whereas a high initial value (\({\bar{S}}_{i}(t=0)\ge 50\,{{{\rm{Hz}}}}\)), corresponding to circuits with excessively high activity levels, led to LTD (Extended Data Fig. 7). Importantly such slow shifts in activity-dependent plasticity behavior are consistent with the metaplasticity observed in monocular deprivation experiments32,33,48. Thus, LPL qualitatively captures key phenomena observed in experiments such as STDP, the rate dependence of plasticity and metaplasticity, despite not being optimized to reproduce these phenomena. Rather our model offers a simple normative explanation for the necessity of different plasticity patterns that are also observed experimentally43.

a, Relative weight change owing to LPL in response to a standard STDP induction protocol with varying spike timing Δt for 100 pairings at a repetition frequency of ρ = 10 Hz (inset) and an initial value of σ2(t = 0) = 0.1. b, Same as a, but with an initial value of σ2(0) = 1. c, Same as a, but with σ2(0) = 100. d, Relative weight change as a function of repetition frequency, ρ, for positive and negative relative spike timings (Δt = ± 10 ms).
Discussion
We introduced LPL, a local plasticity rule that combines Hebbian and predictive elements. We demonstrated that LPL disentangles object representations in DNNs through mere exposure to temporal data in which object identity varies slowly. Crucially, we showed that predictive and Hebbian learning are both required to achieve this effect. Moreover, we demonstrated that LPL qualitatively captures the representational changes observed in unsupervised learning experiments in monkey IT12. Finally, we found that LPL in SNNs naturally reproduces STDP and its experimentally observed rate dependence, while further predicting a new form of metaplasticity with distinct variance dependence of the STDP window.
The idea that sensory networks use temporal prediction as a learning objective has been studied extensively in both machine learning and neuroscience. The model in this article combines elements of classic BCM theory with central ideas of SFA and more recent SSL approaches from machine learning. Although SSL has shown great promise in representational learning without labeled data, it is typically formulated as a contrastive learning problem requiring negative samples18,19 to prevent representational collapse. As negative samples break temporal contiguity, they are not biologically plausible. LPL does not require negative samples. Instead, it relies on variance regularization as proposed previously to prevent collapse24. Our model uses virtually the same mechanism, albeit with a logarithmic variance dependence (Supplementary Note 3), and builds a conceptual bridge from variance regularization to Hebbian metaplasticity. Similar to most SSL approaches, Bardes et al.24 used end-to-end learning whereby the objective function is formulated on the embeddings at the network’s output. In contrast, we studied the case of greedy learning in which the objective is applied to each layer individually. Doing so alleviates the need for backpropagation and permitted us to formulate the weight updates as local learning rules, similar to work that combined contrastive objectives with greedy training29. Furthermore, recent work showed that greedy contrastive learning is directly linked to plasticity rules that rapidly switch between Hebbian and anti-Hebbian learning through a global third factor22. However, both these models required implausible negative samples, whereas LPL requires neither end-to-end training nor negative samples.
LPL shares its basic shape with the BCM rule, which has been qualitatively confirmed in numerous experimental studies both in vitro27,32,33 and in vivo34. Furthermore, BCM has been linked to STDP28 and informed numerous phenomenological plasticity models44,45,46,47,49. However, unequivocal evidence for the predicted supralinear behavior of the firing rate dependence of the BCM-sliding threshold remains scarce32 and the fast-sliding threshold required for network stability seems at odds with experiments36,48. In contrast, LPL does not require a rapid nonlinear sliding threshold for stability. Instead, it posits a fast-acting variance dependence of Hebbian plasticity that ensures stability. This suppressive effect allows the sliding threshold, possibly implemented through neuronal or circuit mechanisms32,50, to catch up slowly, more consistent with experiments48. Hence, LPL offers a possible explanation for the current gap between theory and experiment.
The notion of slowness learning has been studied extensively in the context of the trace rule51, optimal stability52 and SFA20,40, which have conceptual ties to STDP21. However, the first enforces a hard constraint on the norm of the weight vector to prevent collapse, whereas the latter two rely on hard variance constraints on the activity. In contrast, LPL implements a soft variance constraint24 to the same effect. A similar soft constraint on the variance can be derived from statistical independence arguments53 within a mutual information view of SSL18. However, these studies used negative samples, assumed rapid global sign switching of the learning rule and did not connect their work to biological plasticity mechanisms.
Our study has several limitations that we aim to address in future work. First, our study is limited to visual tasks of core object recognition, whereas other sensory modalities may use LPL as a mechanism to form disentangled representations of the external world. For computational feasibility, we restricted ourselves to artificial data augmentation techniques borrowed from SSL and procedurally generated videos with a simple structure, which are only crude proxies of rich real-world stimuli. Finally, there remains a performance gap in classification performance compared with less plausible, fully supervised and contrastive approaches (Supplementary Table 1), showing that there remains room for improvement, possibly by incorporating biological circuit mechanisms and top-down feedback connections into the model. It is left as future work to show how LPL can be extended to the circuit level and to more ethologically realistic sensory modalities54 and video input while further combining them with plausible models of saccadic eye movement.
Despite the limitations, our model makes several concrete predictions. First, modulation of the strength of Hebbian plasticity as a function of the postsynaptic variance is essential to LPL. Therefore, the predictive contribution to plasticity should be best observable for highly variable neuronal activity. Although our model does not make quantitative predictions about the time scale of variance estimation, we expect that a quiescent neuron shows stronger Hebbian plasticity than neurons with highly irregular activity. Moreover, LPL should manifest in metaplasticity experiments as a transition from an asymmetrical Hebbian STDP window, via a symmetrical window to, ultimately, an anti-Hebbian window (compare Fig. 6) when priming the postsynaptic neuron with increasing output variance. Specifically, we expect a neuron that has remained quiescent for a long period of time to display a classic STDP window, whereas a neuron with activity that has undergone substantial fluctuations in the recent past should show an inverted STDP window. Such metaplasticity may account for the diversity of different shapes of STDP windows observed in experiments43.
To fathom how established data-driven plasticity models are related to theoretically motivated learning paradigms such as SFA and SSL is essential to understanding the brain. A central open question in neuroscience remains: how do the different components of such learning rules interact with the rich local microcircuitry to yield useful representations at the network level? In this article, we have only scratched the surface by proposing a local plasticity rule and illustrating its aptitude for disentangling internal representations. However, a performance gap remains compared with learning algorithms that can leverage top-down feedback. We expect that extending predictive learning to the circuit and network level will narrow this gap and generate deep mechanistic insights into the underlying principles of neural plasticity.
Methods
Plasticity model
The LPL rule is derived from an objective function approach. It consists of three distinct parts, each stemming from a different additive term in the following combined objective function:
First, the predictive component \({{{{\mathcal{L}}}}}_{{{{\rm{pred}}}}}\) minimizes neuronal output fluctuations for inputs that occur close in time. Second, a Hebbian component, \({{{{\mathcal{L}}}}}_{{{{\rm{Hebb}}}}}\), maximizes variance and thereby prevents representational collapse. Finally, \({{{{\mathcal{L}}}}}_{{{{\rm{decorr}}}}}\) is a decorrelation term that we use in all nonspiking network simulations to prevent excessive correlations between neurons within the same layer in a network. In SNNs decorrelation is achieved without this term through lateral inhibition and inhibitory plasticity.
In the following, we consider a network layer with N input units and M output units trained on batches of B pairs of consecutive stimuli. In all simulations we approximate the temporal derivative dz/dt that appears in equation (1) by finite differences z(t) − z(t − Δt) assuming a discrete time step, Δt, while absorbing all constants into the learning rate. In this formulation, the LPL rule has a time horizon of two time steps, in the sense that only one temporal transition enters into the learning rule directly. We used this insight to efficiently train our models using mini-batches of paired consecutive input stimuli that approximate learning on extended temporal sequences consisting of many time steps. Let \(\mathbf{x}^{b}(t)\in {{\mathbb{R}}}^{N}\) be the input to the network at time \(t, {W} \in {{\mathbb{R}}}^{M\times N}\) the weight matrix to be learned, \(\mathbf{a}^{b}(t)= {W}\mathbf{x}^{b}(t)\in {{\mathbb{R}}}^{M}\) the pre-activations and \({z}_{i}^{b}(t)=f({a}_{i}^{b}(t))\), the activity of the ith output neuron at time t. Finally, b indexes the training example within a mini-batch of size B.
Predictive component
We define the predictive objective \({{{{\mathcal{L}}}}}_{{{{\rm{pred}}}}}\) as the mean squared difference between neuronal activity in consecutive time steps:
where SG denotes the Stopgrad function, which signifies that the gradient is not evaluated with respect to quantities in the past.
Hebbian component
To avoid representational collapse, we rely on the Hebbian plasticity rule that results from minimizing the negative logarithm of the variance of neuronal activity:
where \({\bar{z}}_{i}(t)={{{\rm{SG}}}}\left(\frac{1}{B}\mathop{\sum }\nolimits_{b = 1}^{B}{z}_{i}^{b}(t)\right)\) and \({\sigma }_{i}^{2}(t)=\frac{1}{B-1}\mathop{\sum }\nolimits_{b = 1}^{B}{\left({z}_{i}^{b}(t)-{\bar{z}}_{i}(t)\right)}^{2}\) are the current estimates of the mean and variance of the activity of the ith output neuron. Note that we do not compute gradients with respect to the mean estimate, which would require backpropagation through time. Assuming that the mean is fixed allows formulation of LPL as a temporally local learning rule (compare equation (3)). To minimize the computational burden in DNN simulations, we performed all necessary computations on mini-batches, which includes estimating the mean and variance. However, these quantities could also be estimated using stale estimates from previous inputs, a requirement for implementing LPL as an online learning rule. Using stale mean and variance estimates from previous mini-batches in our DNN simulations did cause a drop in readout performance (Supplementary Table 2). Still, such a drop could possibly be avoided using larger mini-batch sizes, by further reducing the learning rate or by computing the estimates as running averages over past inputs. All of the above manipulations result in essentially the same learning rule (Supplementary Note 1).
Decorrelation component
Finally, we use a decorrelation objective to prevent excessive correlation between different neurons in the same layer, as suggested previously24,37,55. The decorrelation loss function is the sum of the squared off-diagonal terms of the covariance matrix between units within the same layer, which is given as:
with a scaling factor that keeps the objective invariant to the number of units in the population.
The full learning rule
We obtain the LPL rule as the negative gradient of the total objective, \({{{{\mathcal{L}}}}}_{{{{\rm{LPL}}}}}\), plus an added weight decay. For a single network layer, this yields the layer-local LPL rule in which we omitted the time argument t from all present quantities for brevity:
where λ1 and λ2 are parameters that control the relative strengths of each objective, α and β are the appropriate normalizing constants for batch size and number of units and ηw is a parameter controlling the strength of the weight decay.
Numerical optimization methods
We implemented all network model learning with LPL using gradient descent on the equivalent objective function in PyTorch (v.1.11.0) with the Lightning framework (v.1.6.1). DNN simulations were run on five Linux workstations equipped with Nvidia Quadro RTX 5000 graphics processing units (GPUs) and a compute cluster with Nvidia V100 and A100 GPUs. In the case of the DNNs, we used the Adam optimizer to accelerate learning. Parameter values used in all simulations are summarized in Supplementary Table 3. All simulations were run using Python (v.3.8). We used Jupyter notebooks (v.1.0.0) for all data analysis and plotting. The simulation and analysis codes are available online56.
Learning in the single neuron set-up
We considered a simple linear rate-based neuron model with an output firing rate, z, given by the weighted sum of the firing rates, xj, of the input neurons, that is, z = ∑jWjxj, where Wj corresponds to the synaptic weight of input j. We trained the neuron using stochastic gradient descent (SGD) on the corresponding objective function:
Here, and in all following simulations, we fixed the Hebbian coefficient λ1 = 1. We also added a small constant ϵ = 10−6 to the estimate of the variance σz for numerical stability. In the case of a single rate neuron, the LPL rule (equation (7)) simplifies to equation (1) without the decorrelation term.
Synthetic 2D dataset generation
The 2D synthetic data sequence (Fig. 2a) consists of two clusters of inputs, one centered at x = −1 and the other at x = +1. Pairs of consecutive data points were drawn independently from normal distributions centered at their corresponding cluster. To generate a family of different datasets, we kept the s.d. in the x direction fixed at σx = 0.1 and varied σy. In addition, to account for occasional transitions between clusters with probability P, we included a corresponding fraction of such ‘crossover pairs’ in the training batch. For each value of σy, we simulated the evolution of the input connections of a single linear model neuron that received the x and y as its two inputs, and updated its input weights according to LPL. In the simulations in Fig. 2 we assumed P → 0; however, the qualitative behavior remained unchanged for noise levels below P = 0.5, that is, as long as the ‘noisy’ pairs of points from different clusters were rare in each training batch (Extended Data Fig. 8).
Neuronal selectivity measure
After training weights to convergence, we measured the neuron’s selectivity to the x input as the normalized difference between mean responses to stimuli coming from the two respective input clusters. Concretely, let \(\langle {z}_{1} \rangle\) be the average output caused by inputs from the x = 1 cluster and \(\langle {z}_{2} \rangle\) from the x = −1 cluster, then the selectivity χ is defined as:
with \({z}_{\max }\) the maximum and \({z}_{\min }\) the minimum response across all inputs.
Learning in deep CNNs
For all network simulations, we used a convolutional DNN based on the VGG-11 architecture57 (see Supplementary Note 5 for details). We trained this network on STL-10 and CIFAR-10 (Extended Data Fig. 9), two natural image datasets (see Supplementary Table 3 for hyperparameters). To simulate related consecutive inputs, we used two differently augmented versions of the same underlying image, a typical approach in vision-based SSL methods. Specifically, we first standardized the pixel values to zero mean and unit s.d. within each dataset before using the set of augmentations originally suggested in ref. 19, which includes random crops, blurring, color jitter and random horizontal flips (see Extended Data Fig. 2 for examples).
Synthetic video generation
To study LPL in settings with more naturalistic transitions between consecutive images and without relying on image augmentation, we procedurally generated videos using images from the 3D Shapes dataset42. The dataset has a known latent manifold structure spanned by view angle, object scale, hue and object type, and is commonly used to measure disentangling in variational autoencoders. Using the knowledge of the ground-truth factors, we generated a continuous video composed of 17-frame clips during which the object shape remained fixed and a randomly chosen factor changed gradually. Specifically, we proceeded as follows: we randomly chose one factor and changed it frame by frame such that transitions between adjacent factor values were more likely. For instance, one such clip shows a cube under a smoothly varying camera angle (Extended Data Fig. 4a). Furthermore, we randomly permuted the order of all three hue factors. This was done to break the orderly ring topology of the hue mappings in the original dataset, which allowed us to test that the structure is restored through LPL, but not other methods (Extended Data Fig. 4g). After 17 frames we randomly chose another shape and factor and repeated the above procedure. This sequence generation resulted in a video with many consecutive latent manifold traversals as captured by the empirical transition matrices (Extended Data Fig. 5a). Importantly, due to the nature of the video, which switches between objects periodically, the resulting input sequence also included occasional transitions between different objects that the LPL rule interprets as positive samples. Such transitions also appear in real-world stimuli when objects leave or enter the scene. Despite these ‘false positives’, LPL learned disentangled representations of shapes and the underlying factors.
Network training
We trained our network models on natural image data by minimizing the equivalent LPL objective function. For both datasets, we trained the DNN using the Adam optimizer with default parameters and a cosine learning rate schedule that drove the learning rate to zero after 800 epochs. We distinguished between two cases: layer-local and end-to-end learning. End-to-end learning corresponds to training the network by optimizing \({{{{\mathcal{L}}}}}_{{{{\rm{LPL}}}}}^{({{{\rm{out}}}})}\) at the network’s output while using backpropagation to train the hidden layer weights. This is the standard approach used in deep learning. In contrast, in layer-local learning, we minimized the LPL objective, \({{{{\mathcal{L}}}}}_{{{{\rm{LPL}}}}}\), at each layer in the network independently without backpropagating loss gradients between layers similar to previous work22,29. In this case, every layer greedily learns predictive features of its own inputs, that is, its previous layer’s representations. To achieve this behavior, we prevented PyTorch from backpropagating gradients between layers by detaching the output of every layer in the forward pass and optimizing the sum of per-layer losses \({\sum }_{l}{{{{\mathcal{L}}}}}_{{{{\rm{LPL}}}}}^{(l)}\).
Unless mentioned otherwise, we used global average pooling (GAP) to reduce feature maps to a single vector before applying the learning objective at the output of every convolutional layer for layer-local training, or just at the final output in the case of end-to-end training. Although pooling was not strictly necessary and LPL could be directly applied on the feature maps (Extended Data Fig. 10), it substantially sped up learning and led to an overall improved linear readout accuracy on CIFAR-10 (Supplementary Table 2). However, we observed that GAP was essential on the STL-10 dataset for achieving readout accuracy levels above the pixel-level baseline (compare Table 1). This discrepancy was presumably the result of the larger pixel dimensions of this dataset and the resulting smaller relative receptive field size in early convolutional layers. Concretely, feature pixels in the first convolutional layer of VGG-11 have a receptive field of 3 × 3 pixels covering a larger portion of the 32 × 32 CIFAR-10 images, compared with the 96 × 96 STL-10 inputs. This hypothesis was corroborated by the fact that, when we subsampled STL-10 images to a 32 × 32 resolution, the dependence on GAP was removed and LPL was effective directly on the feature maps (Supplementary Table 2).
Baseline models
As baseline models for comparison (Supplementary Table 1), we trained the same CNN architecture either with a standard crossentropy supervised objective, which requires labels, or with a contrastive objective, which relies on negative samples. To implement contrastive learning, the network outputs z(t) were passed through two additional dense projection layers, v(t) = fproj(z(t)), which is considered crucial in contrastive learning to avoid dimensional collapse41. Finally, the following contrastive loss function was applied to these projected outputs:
where \({{{\rm{sim}}}}(\mathbf{v}_{1},\mathbf{v}_{2})=\frac{\mathbf{v}_{1}^{{{{\rm{T}}}}}\mathbf{v}_{2}}{\parallel \mathbf{v}_{1}\parallel \parallel \mathbf{v}_{2}\parallel }\) is the cosine similarity between two representations, v1 and v2. The second term in the loss function is a sum over all pairwise similarities between inputs in a given mini-batch. These pairs correspond to different underlying base images and therefore constitute negative samples. During training the network is therefore optimized to reduce the representational similarity between them.
For training the layer-local versions of the supervised and contrastive models, we followed the same procedure as with LPL of optimizing the respective loss function at the output of every convolutional layer, l, of the DNN without backpropagation between the layers. As projection networks are necessary for avoiding dimensional collapse in case of contrastive learning, we included two additional dense layers to obtain the projected representations, \(\mathbf{v}^{l}(t)={f}_{{{{\rm{proj}}}}}^{\;l}(\mathbf{z}^{l}(t))\), at every level of the DNN before calculating the layer-wise contrastive loss, \({{{{\mathcal{L}}}}}_{{{{\rm{contrast}}}}}^{l}\). This meant that gradients were backpropagated through each of these dense layers for training the corresponding convolutional layers of the DNN, but consecutive convolutional layers were still trained independent of each other.
Population activity analysis
We adopted two different metrics to analyze the representations learned by the DNN after unsupervised training with LPL on the natural image datasets.
Linear readout accuracy
To evaluate how well the LPL rule trained the DNN to disentangle and identify underlying latent factors in a given image, we measured linear decodability by training a linear classifier on the network outputs in response to a set of training images. Crucially, during this step we trained only the readout weights while keeping the weights of the LPL-pretrained DNN frozen. We then evaluated the linear readout accuracy (Fig. 3b) on a held-out test set of images. We used the same procedure to evaluate the representations at intermediate layers (Fig. 3c) and for the baseline models.
Representational similarity analysis
To visualize the latent manifold structure in learned network embeddings, we computed average representational similarity matrices (RSMs). To obtain the RSM for one factor, say object hue, we first fixed the values of all the other factors and calculated the cosine similarity between the network outputs as the object hue was changed. We repeated this procedure for many different values for the other factors to get the final averaged RSM for object hue (Extended Data Fig. 4f).
Metric for disentanglement
To quantitatively measure disentanglement, we used the metric proposed by Kim and Mnih42. This measure requires full knowledge of the underlying latent factors, as was the case for our procedurally generated videos. In brief, to compute the measure one first identifies the most insensitive neuron to all except one factor. Next, using the indices of these neurons, one trains a simple majority-vote classifier that predicts which factor is being coded for. The accuracy of this classifier on held-out data is the disentanglement score.
Dimensionality and activity measures
To characterize mean activity levels in the network models, we averaged neuronal responses over all inputs in the validation set. To quantify the dimensionality of the learned representations, we computed the participation ratio58. Concretely, if \({Z} \in {{{{\mathbb{R}}}}}^{B\times N}\) are N-dimensional representations of B input images, and λi, 1 ≤ i ≤ N is the set of eigenvalues of ZTZ, then the participation ratio is given by:
Model of unsupervised learning in IT
Network model and pre-training dataset
To simulate the experimental set-up of Li and DiCarlo12, we modeled the animal’s ventral visual pathway with a convolutional DNN. To that end, we used the same network architecture as before, except that we removed all biases in the convolutional layers to prevent boundary effects. This modification resulted in a drop in linear readout accuracy (Supplementary Table 2). Pre-training of the network model proceeded in two steps as follows. First, we performed unsupervised pre-training for 800 epochs on STL-10 using augmented image views exactly as before. Next, we added a fully connected dense layer at the network’s output and trained it for ten epochs with the LPL objective while keeping the weights of the convolutional layers frozen. During this second pre-training phase, we used augmented STL-10 inputs that were spatially extended to account for the added spatial dimension of different canvas positions in the experiment12. The expanded inputs consisted of images placed on a large black canvas at either the center position, Xc, or one of two peripheral positions, X1/2, at the upper or lower end of the canvas. Concretely, these images had dimensions (13 × 96) × 96 which resulted in an expanded feature map at the output of the convolutional DNN with spatial dimensions 13 × 1 (see Supplementary Note 5 for details). Note that we expanded the canvas only in the vertical dimension instead of using a set-up with a 13 × 13 feature map because it resulted in a substantial reduction in computational and memory complexity. During this second stage of pre-training, the network was exposed only to ‘true’ temporal transitions wherein the image was not altered between time steps apart from changing position on the canvas.
Data generation for simulated swap exposures
To simulate the experiment by Li and DiCarlo12, we exposed the network to normal and swap temporal transitions. In the latter case the image was consistently switched to one belonging to a different object category at the specific swap position. The swap position for a given pair of images was randomly pre-selected to be either X1 or X2, whereas the other nonswap position was used as a control. Specifically, we switched object identities during transitions from one peripheral swap position, say X1, to the central position Xc, while keeping transitions from the other peripheral position X2 to the center unmodified. As in the experiment, we chose several pairs of images as swap pairs and fixed X1 as the swap position for half the pairs of images and X2 as the swap position for the other half. To simulate ongoing learning during exposure to these swap and nonswap input sequences, we continued fine-tuning the convolutional layers. To that end, we used the Adam optimizer used during pre-training with its internal state restored to the state at the end of pre-training. Moreover, we used a learning rate of 10−7 during fine-tuning, which was approximately 100× larger than the learning rate reached by the cosine learning rate schedule during pre-training (4 × 10−9, after 800 epochs). Finally, we trained the newly added dense layers with vanilla SGD with a learning rate of 0.02.
Neuronal selectivity analysis
Before training on the swap exposures, for each output neuron in the dense layer, we identified the preferred and nonpreferred members of each swap image pair, based on which image drove higher activity in that neuron. This allowed us to quantify object selectivity on a per-neuron basis as P − N, where P is the neuron’s response to its initially preferred image and N to its nonpreferred image at the same position on the canvas. Note that, by definition, the initial object selectivity for every neuron is positive. Finally, we measured the changes in object selectivity P − N during the swap training regimen, at the swap and nonswap positions, averaging over all output neurons for all image pairs. As a control, we included measurements of the selectivity between pairs of control images that were not part of the swap set.
Comparison to experimental data
To compare our model with experiments, we extracted the data from Li and DiCarlo12 using the Engauge Digitizer software (v.12.1) and replotted it in Fig. 4b.
Spiking neural network simulations
We tested a spiking version of LPL in networks of conductance-based, leaky, integrate-and-fire neurons. Specifically, we simulated a recurrent network of 125 spiking neurons (100 excitatory and 25 inhibitory neurons) receiving afferent connections from 500 input neurons. In all simulations the input connections evolved according to the spike-based LPL rule described below. In our model, neurons actively decorrelated each other through locally connected inhibitory interneurons with connectivity shaped by inhibitory plasticity.
Neuron model
The neuron model was based on previous work26,59 in which the membrane potential Ui of neuron i evolves according to the ordinary differential equation:
where τmem denotes the membrane time constant, Ux is the synaptic reversal potential (Supplementary Table 4) and \({g}_{i}^{x}(t)\) the corresponding synaptic conductances expressed in units of the neuronal leak conductance. The excitatory conductance is the sum of NMDA (N-methyl-d-aspartate) and AMPA (α-amino-3-hydroxy-5-methyl-4-isoxazolepropionic acid) conductances: \({g}_{i}^{{{{\rm{exc}}}}}(t)=0.5({g}_{i}^{{{{\rm{ampa}}}}}(t)+{g}_{i}^{{{{\rm{nmda}}}}}(t))\). Their dynamics are described by the following differential equations:
whereas the inhibitory γ-aminobutyric acid (GABA) conductance, \({g}_{i}^{{{{\rm{inh}}}}}={g}_{i}^{{{{\rm{gaba}}}}}\), evolves as:
In the above expressions, \({S}_{j}(t)={\sum }_{k}\delta ({t}_{j}^{k}-t)\) refers to the afferent spike train emitted by neuron j, in which \({t}_{j}^{k}\) is the corresponding firing times and τx denotes the individual neuronal and synaptic time constants (Supplementary Table 4). Neuron i fires an output spike whenever its membrane potential reaches the dynamic firing threshold, ϑi(t), which evolves according to:
to implement an absolute and relative refractory period. Specifically, ϑi jumps by Δϑ = 100 mV every time an output spike is triggered, after which it exponentially decays back to its rest value of ϑrest = −50 mV. All neuronal spikes are delayed by 0.8 ms to simulate axonal delay and to allow efficient parallel simulation before they trigger postsynaptic potential in other neurons.
Time-varying spiking input model
Inputs were generated from 500 input neurons divided into 5 populations of 100-Poisson neurons each. All inputs, where implemented as independent Poisson processes with the same average firing rate of 5 Hz and neurons within the same group, shared the same instantaneous firing rate. Concretely, neurons in P0 had a fixed firing rate of 5 Hz, whereas the firing rates in groups P1 and P2 changed slowly over time. Specifically, we generated periodic template signals x(t) from a Fourier basis:
with random uniformly drawn coefficients 0 ≤ θk, ϕk < 1. The spectral decay constant α = 1.1 biased the signals toward slow frequencies and thus slowly varying temporal structure. We chose the period T = 3 s for P1 and (3 + 1/13) s for P2, respectively. The different periods were chosen to avoid phase-locking between the two signals. Both signals were then sampled at 10-ms intervals, centered on 5 Hz, variance normalized and clipped below at 0.1 Hz before using them as periodic time-varying firing rates for P1 and P2. In addition, we simulated control inputs P1/2ctl of the two input signals by destroying their slowly varying temporal structure. To that end, we repeated the original firing rate profile for 13 periods before shuffling it on a time grid with 10-ms temporal resolution.
Spike-based LPL
To extend LPL to the spiking domain, we build on SuperSpike60, a previously published online learning rule, which had been used only in the context of supervised learning in SNNs thus far. In this article, we replaced the supervised loss with the LPL loss (equation (3)) without the decorrelation term. The resulting spiking LPL online rule for the weight wij is given by:
with the learning rate η = 10−2 and a small positive constant ξ = 10−3 to avoid division by zero. Furthermore, the * denotes a temporal convolution and α is a double exponential, causal filter kernel applied to the neuronal spike train Si(t). Similarly, ϵ is a causal filter kernel that captures the temporal shape of how a presynaptic spike influences the postsynaptic membrane potential. For simplicity, we assumed a fixed kernel and ignored any conductance-based effects and NMDA dependence. Furthermore, we added the transmitter-triggered plasticity term with δ = 10−5 to ensure that weights of quiescent neurons slowly potentiate in the absence of activity to ultimately render them active59. Finally, λ = 1 is a constant that modulates the strength of the Hebbian term. We set it to zero to switch off the predictive term where this is mentioned explicitly.
Furthermore, \({f}^{\,{\prime} }({U}_{i})=\beta {\left(1+\beta \left\vert {U}_{i}-{\vartheta }^{{{{\rm{rest}}}}}\right\vert \right)}^{-2}\) is the surrogate derivative with β = 1 mV−1, which renders the learning rule voltage dependent. Finally, \({\bar{S}}_{i}(t)\) and \({\sigma }_{i}^{2}(t)\) are slowly varying quantities obtained online as exponential moving averages with the following dynamics:
with τmean = 600 s and τvar = 20 s. These quantities confer the spiking LPL rule with elements of metaplasticity32.
In our simulations, we computed the convolutions with α and ϵ by double exponential filtering of all quantities. Generally, for the time-varying quantity c(t) we computed:
which yields the convolved quantity \(\bar{\bar{c}}\). Specifically, we used \({\tau }_{\alpha }^{{{{\rm{rise}}}}}=2\,{{{\rm{ms}}}}\), \({\tau }_{\alpha }^{{{{\rm{fall}}}}}=10\,{{{\rm{ms}}}}\), \({\tau }_{\epsilon }^{{{{\rm{rise}}}}}={\tau }_{{{{\rm{ampa}}}}}=5\,{{{\rm{ms}}}}\) and \({\tau }_{\epsilon }^{{{{\rm{fall}}}}}={\tau }_{{{{\rm{mem}}}}}=20\,{{{\rm{ms}}}}\).
Overall, one can appreciate the resemblance of equation (18) to the nonspiking equivalent (compare equation (1)). As in the nonspiking case, the learning rule is local in that it depends only on pre- and postsynaptic quantities. The predictive term in the learning rule can be seen as an instantaneous error signal, which is minimized when the present output spike train Si(t) is identical to a delayed version of the same spike train Si(t − Δt) with Δt = 20 ms. In other words, the past output serves as a target spike train (compare ref. 60).
Microcircuit connectivity
Connections from the input population to the network neurons and recurrent connections were initialized with unstructured random sparse connectivity and different initial weight values (Supplementary Table 5). One exception to this rule was the excitatory-to-inhibitory connectivity which was set up with a Gaussian connection probability profile:
with c(i) = 0.25i and σ2 = 20 to mimic the dense local connectivity on to inhibitory neurons as a result of which inhibitory neurons inherit some of the tuning of their surrounding excitatory cells.
Inhibitory plasticity
Inhibitory-to-excitatory synapses were plastic unless mentioned otherwise. We modeled inhibitory plasticity according to a previously published inhibitory STDP model38:
using pre- and postsynaptic traces:
with time constant τSTDP = 20 ms, learning rate ζ = 1 × 10−3 and target firing rate κ = 10 Hz.
Reconstruction of input signals from network activity
To reconstruct the input signals, we first computed input firing rates of the 5 input populations by binning their spikes emitted during the last 100 s of the simulation in 25-ms bins. We further averaged the binned spikes over input neurons to provide the regression targets. Similarly, we computed the binned firing rates of the network neurons but without averaging over neurons. We then performed Lasso regression using SciKit-learn with default parameters to predict each target input signal from the network firing rates. Specifically, we trained on the first 95 s of the activity data and computed R2 scores on the Lasso predictions over the last 5 s of held-out data (Fig. 5b).
Signal selectivity measures
We measured signal selectivity of each neuron to the two slow signals relative to their associated shuffled controls (Fig. 5d), using the following relative measure defined on the weights:
where \({w}_{{\rm{P}}}^{i}\) is the average synaptic connection strength from the signal pathways P1/2 on to excitatory neuron i and \({w}_{{{\rm{P}}}_{{{{\rm{ctl}}}}}}^{i}\) is the same but from the control pathways P1/2ctl.
Representational dimension
To quantify the dimensionality of the learned neuronal representations (Fig. 5f), we binned network spikes in 25-ms bins and computed the participation ratio (equation (11)) of the binned data.
Neuronal tuning analysis of the learned weight profiles
To characterize the receptive fields of each neuron (Fig. 5g,h), we plotted wP1 against wP2 for every neuron in the excitatory population (Fig. 5g,h, left), and colored the resulting weight vectors by mapping the cosine of the vectors with the x axis (wP2) to a diverging color map. Furthermore, we calculated the relative tuning index as follows:
STDP induction protocols
To measure STDP curves, we simulated a single neuron using the spiking LPL rule (equation (18)) with a learning rate of η = 5 × 10−3. In all cases, we measured plasticity outcomes from 100 pairings of pre- and postsynaptic spikes at varying repetition frequencies, ρ. The postsynaptic neuron’s membrane voltage was held fixed between spikes at −51 mV for the entire duration of the protocol. To measure STDP curves, we set the initial synaptic weight at 0.5 and simulated 100 different pre–post time delays, Δt, chosen uniformly from the interval [−50, 50] ms with ρ = 10 Hz. To measure the rate dependence of plasticity, we repeated the simulations for fixed Δt = ±10 ms while varying the repetition frequency ρ.
Numerical simulations
All SNN simulations were implemented in customized C++ code56 using the Auryn SNN simulator (v.0.8.2-dev, commit 36b3c197). Throughout we used a 0.1-ms simulation time step. Simulations were run on seven Dell Precision workstations with eight-core Intel Xeon central processing units.
Statistics and reproducibility
This article is a simulation study. No statistical method was used to predetermine sample size. No data were excluded from the analyses. The experiments were not randomized. The Investigators were not blinded to allocation during experiments and outcome assessment.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The deep learning tasks used the STL-10 and CIFAR-10 datasets, typically available through all major machine-learning libraries. The original releases for these datasets can be found at http://ai.stanford.edu/%7Eacoates/stl10 and https://www.cs.toronto.edu/~kriz/cifar.html, respectively. For the Extended Data figures and Supplementary figures, we further used the 3D Shapes dataset42 available at https://github.com/deepmind/3d-shapes and the MNIST dataset available at http://yann.lecun.com/exdb/mnist.
Code availability
The simulation code to reproduce the key results is publicly available at https://github.com/fmi-basel/latent-predictive-learning. PyTorch and the Lightning framework are freely available at https://pytorch.org and https://www.pytorchlightning.ai, respectively. The Auryn spiking network simulator is available at https://github.com/fzenke/auryn. The Engauge Digitizer is available at http://markummitchell.github.io/engauge-digitizer.
References
DiCarlo, J. J., Zoccolan, D. & Rust, N. C. How does the brain solve visual object recognition? Neuron 73, 415–434 (2012).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Yamins, D. L. K. et al. Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proc. Natl Acad. Sci. USA 111, 8619–8624 (2014).
Nayebi, A. et al. Explaining heterogeneity in medial entorhinal cortex with task-driven neural networks. Adv. Neural Inform. Process. Systems 34, 12167–12179 (2021).
Richards, B. A. et al. A deep learning framework for neuroscience. Nat. Neurosci. 22, 1761–1770 (2019).
Chung, S. & Abbott, L. F. Neural population geometry: an approach for understanding biological and artificial neural networks. Curr. Opin. Neurobiol. 70, 137–144 (2021).
Guerguiev, J., Lillicrap, T. P. & Richards, B. A. Towards deep learning with segregated dendrites. eLife 6, e22901 (2017).
Sacramento, J., Ponte Costa, R., Bengio, Y. & Senn, W. Dendritic cortical microcircuits approximate the backpropagation algorithm. Adv. Neural Inform. Process. Systems https://doi.org/10.48550/arXiv.1810.11393 (2018).
Lillicrap, T. P., Santoro, A., Marris, L., Akerman, C. J. & Hinton, G. Backpropagation and the brain. Nat. Rev. Neurosci. 21, 335–346 (2020).
Payeur, A., Guerguiev, J., Zenke, F., Richards, B. A. & Naud, R. Burst-dependent synaptic plasticity can coordinate learning in hierarchical circuits. Nat. Neurosci. 24, 1010–1019 (2021).
Rao, R. P. & Ballard, D. H. Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nat. Neurosci. 2, 79–87 (1999).
Li, N. & DiCarlo, J. J. Unsupervised natural experience rapidly alters invariant object representation in visual cortex. Science 321, 1502–1507 (2008).
Keller, G. B. & Mrsic-Flogel, T. D. Predictive processing: a canonical cortical computation. Neuron 100, 424–435 (2018).
Singer, Y. et al. Sensory cortex is optimized for prediction of future input. eLife 7, e31557 (2018).
Matteucci, G. & Zoccolan, D. Unsupervised experience with temporal continuity of the visual environment is causally involved in the development of v1 complex cells. Sci. Adv. 6, eaba3742 (2020).
Gillon, C. J. et al. Learning from unexpected events in the neocortical microcircuit. Preprint at bioRxiv https://doi.org/10.1101/2021.01.15.426915 (2021).
He, K. et al. Masked autoencoders are scalable vision learners. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition 15979–15988 (IEEE, 2022).
Oord, A. v. d., Li, Y. & Vinyals, O. Representation learning with contrastive predictive coding. Preprint at https://doi.org/10.48550/arXiv.1807.03748 (2018).
Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning Vol. 119 (eds Ill, H. D. & Singh, A.) 1597–1607 (PMLR, 2020).
Wiskott, L. & Sejnowski, T. J. Slow feature analysis: unsupervised learning of invariances. Neural Comput. 14, 715–770 (2002).
Sprekeler, H., Michaelis, C. & Wiskott, L. Slowness: an objective for spike-timing-dependent plasticity? PLoS Comput. Biol. 3, e112 (2007).
Illing, B., Ventura, J., Bellec, G. & Gerstner, W. Local plasticity rules can learn deep representations using self-supervised contrastive predictions. Adv. Neural Inform. Process. Systems https://doi.org/10.48550/arXiv.2010.08262 (2021).
Kusmierz, L., Isomura, T. & Toyoizumi, T. Learning with three factors: modulating Hebbian plasticity with errors. Curr. Opin. Neurobiol. 46, 170–177 (2017).
Bardes, A., Ponce, J. & LeCun, Y. VICReg: variance-invariance-covariance regularization for self-supervised learning. In ICLR 2022-International Conference on Learning Representations, 6481 (ICLR, 2022).
Oja, E. Simplified neuron model as a principal component analyzer. J.Math. Biol. 15, 267–273 (1982).
Gerstner, W. & Kistler, W. Spiking Neuron Models (Cambridge Univ. Press, 2002).
Sjöström, P. J., Turrigiano, G. G. & Nelson, S. B. Rate, timing, and cooperativity jointly determine cortical synaptic plasticity. Neuron 32, 1149–1164 (2001).
Feldman, D. E. The spike-timing dependence of plasticity. Neuron 75, 556–571 (2012).
Löwe, S., O’Connor, P. & Veeling, B. S. Putting an end to end-to-end: gradient-isolated learning of representations. Adv. Neural Inform. Process. Systems https://doi.org/10.48550/arXiv.1905.11786 (2019).
Miconi, T. Multi-layer hebbian networks with modern deep learning frameworks. Preprint at https://doi.org/10.48550/arXiv.2107.01729 (2021).
Artola, A., Bröcher, S. & Singer, W. Different voltage-dependent thresholds for inducing long-term depression and long-term potentiation in slices of rat visual cortex. Nature 347, 69–72 (1990).
Abraham, W. C. Metaplasticity: tuning synapses and networks for plasticity. Nat. Rev. Neurosci. 9, 387–387 (2008).
Cooper, L. N. & Bear, M. F. The BCM theory of synapse modification at 30: interaction of theory with experiment. Nat. Rev. Neurosci. 13, 798–810 (2012).
Lim, S. et al. Inferring learning rules from distributions of firing rates in cortical neurons. Nat. Neurosci. 18, 1804–1810 (2015).
Bienenstock, E. L., Cooper, L. N. & Munroe, P. W. Theory of the development of neuron selectivity: orientation specificity and binocular interaction in visual cortex. J. Neurosci. 2, 32–48 (1982).
Zenke, F. & Gerstner, W. Hebbian plasticity requires compensatory processes on multiple timescales. Philosoph. Transact. R. Soc. B 372, 20160259 (2017).
Földiak, P. Forming sparse representations by local anti-Hebbian learning. Biol. Cybernetics 64, 165–170 (1990).
Vogels, T. P., Sprekeler, H., Zenke, F., Clopath, C. & Gerstner, W. Inhibitory plasticity balances excitation and inhibition in sensory pathways and memory networks. Science 334, 1569–1573 (2011).
King, P. D., Zylberberg, J. & DeWeese, M. R. Inhibitory interneurons decorrelate excitatory cells to drive sparse code formation in a spiking model of V1. J. Neurosci. 33, 5475–5485 (2013).
Lipshutz, D., Windolf, C., Golkar, S. & Chklovskii, D. A biologically plausible neural network for slow feature analysis. Adv. Neural Inform. Process. Systems 33, 14986–14996 (2020).
Jing, L., Vincent, P., LeCun, Y. & Tian, Y. Understanding dimensional collapse in contrastive self-supervised learning. In International Conference on Learning Representations, 6792 (ICLR, 2022).
Kim, H. & Mnih, A. Disentangling by factorising. In Proceedings of the 35th International Conference on Machine Learning Vol. 80 (eds Dy, J. & Krause, A.) 2649–2658 (PMLR, 2018).
Inglebert, Y., Aljadeff, J., Brunel, N. & Debanne, D. Synaptic plasticity rules with physiological calcium levels. Proc. Natl Acad. Sci. USA 117, 33639–33648 (2020).
Shouval, H. Z., Bear, M. F. & Cooper, L. N. A unified model of NMDA receptor-dependent bidirectional synaptic plasticity. Proc. Natl Acad. Sci. USA 99, 10831–10836 (2002).
Pfister, J.-P. & Gerstner, W. Triplets of spikes in a model of spike timing-dependent plasticity. J. Neurosci. 26, 9673–9682 (2006).
Clopath, C., Büsing, L., Vasilaki, E. & Gerstner, W. Connectivity reflects coding: a model of voltage-based STDP with homeostasis. Nat. Neurosci. 13, 344–352 (2010).
Gjorgjieva, J., Clopath, C., Audet, J. & Pfister, J.-P. A triplet spike-timing-dependent plasticity model generalizes the Bienenstock–Cooper–Munro rule to higher-order spatiotemporal correlations. Proc. Natl Acad. Sci. USA 108, 19383–19388 (2011).
Toyoizumi, T., Kaneko, M., Stryker, M. P. & Miller, K. D. Modeling the dynamic interaction of Hebbian and homeostatic plasticity. Neuron 84, 497–510 (2014).
Graupner, M. & Brunel, N. Calcium-based plasticity model explains sensitivity of synaptic changes to spike pattern, rate, and dendritic location. Proc. Natl Acad. Sci. USA 109, 3991–3996 (2012).
Hennequin, G., Agnes, E. J. & Vogels, T. P. Inhibitory plasticity: balance, control, and codependence. Annu. Rev. Neurosci. 40, 557–579 (2017).
Rolls, E. T. & Stringer, S. M. Invariant visual object recognition: a model, with lighting invariance. J. Physiol. 100, 43–62 (2006).
Wyss, R., König, P. & Verschure, P. F. M. J. A model of the ventral visual system based on temporal stability and local memory. PLOS Biol. 4, e120 (2006).
Li, Y., Pogodin, R., Sutherland, D. J. & Gretton, A. Self-supervised learning with kernel dependence maximization. Adv. Neural Inform. Process. Systems 34 (2021).
Mehrer, J., Spoerer, C. J., Jones, E. C., Kriegeskorte, N. & Kietzmann, T. C. An ecologically motivated image dataset for deep learning yields better models of human vision. Proc. Natl Acad. Sci. USA 118, e2011417118 (2021).
Zbontar, J., Jing, L., Misra, I., LeCun, Y. & Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. In Proceedings of the 38th International Conference on Machine Learning Vol. 139 (eds Meila, M. & Zhang, T.) 12310–12320 (PMLR, 2021).
Halvagal, M. & Zenke, F. fmi-basel/latent-predictive-learning: LPL, v1.0. Zenodo https://doi.org/10.5281/zenodo.8252888 (2023).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. Preprint at https://doi.org/10.48550/arXiv.1409.1556 (2014).
Litwin-Kumar, A., Harris, K. D., Axel, R., Sompolinsky, H. & Abbott, L. F. Optimal degrees of synaptic connectivity. Neuron 93, 1153–1164.e7 (2017).
Zenke, F., Agnes, E. J. & Gerstner, W. Diverse synaptic plasticity mechanisms orchestrated to form and retrieve memories in spiking neural networks. Nat. Commun. 6, 6922 (2015).
Zenke, F. & Ganguli, S. Superspike: supervised learning in multilayer spiking neural networks. Neural Comput. 30, 1514–1541 (2018).
Acknowledgements
We thank all members of the Zenke Group for comments and discussions that shaped this project and A. K. Sinha for many helpful suggestions. We are particularly grateful to J. Rossbroich for providing invaluable insights throughout the course of this work. This project was supported by the Swiss National Science Foundation (grant no. PCEFP3_202981 to F.Z.) and the Novartis Research Foundation (to M.S.H. and F.Z.). The funders had no role in study design, data collection and analysis, decision to publish or preparation of the paper.
Author information
Authors and Affiliations
Contributions
F.Z. conceived the study. M.S.H. and F.Z. developed the theory. M.S.H. wrote DNN code and performed simulations and analysis. F.Z. developed SNN code and performed simulations. M.S.H. and F.Z. wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Neuroscience thanks the anonymous reviewers for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 LPL extends BCM theory by adding a variance- and rate-of-change dependence.
(a) Example of a typical neuronal input-output function with postsynaptic activity z. (b) Weight change induced by the LPL rule for co-varying input and the postsynaptic activity z for different values of the plasticity threshold Θ, with \({\sigma }_{z}^{2}=1\) and dz/dt = 0. The functional shift of the threshold is reminiscent of the BCM rule. (c) Same as (b) but for different values of the variance of the postsynaptic activity with zero prediction error dz/dt = 0 and fixed mean activity \(\bar{z}=30\). (d) Same as (c) but with a positive prediction error dz/dt = + 10. (e) Same as (a), but for a rectified linear unit (ReLU) activation function with positive threshold. (f) Same as (b) but for ReLU. (g) Same as (c) but for ReLU. (h) Same as in (d) but for ReLU and a negative prediction error dz/dt = − 10.
Extended Data Fig. 2 Image augmentation model.
Illustration of the image transformations used to generate natural image sequences as suggested by Chen et al.19.
Extended Data Fig. 3 Disentangling of object representations in the DNN.
(a) Data distribution of the STL-10 validation set along the first two principal components in pixel-space. Data corresponding to different object classes are highly entangled. (b) Same as (a) but along the principal components of representations in Layer 3 of the DNN after learning with LPL. Object classes are somewhat disentangled. (c) Same as (a) but along the principal components of representations in Layer 8 of the DNN. Object classes are highly disentangled.
Extended Data Fig. 4 LPL finds latent manifold structure of simulated video data.
(a) Input frames from the procedurally generated video using the 3D Shapes dataset42. (b) The empirically measured transition matrix of object hue with latent structure (see Extended Data Fig. 5 for the complete set of transition matrices). (c) Object classification accuracy of a linear classifier trained on network outputs of a network with LPL, without the predictive term (Pred. off), and the randomly initialized network (Random). Values represent averages from cross validation (n = 10 folds). Error bars indicate ± SEM. The accuracy is close to 100% for LPL, but lower at initialization or when trained without the predictive term. (d) Disentanglement scores computed according to the metric proposed by Kim and Mnih42 for the final-layer representations of the three networks in (c) compared to the input pixels (Pixels). LPL yields close to maximum scores (95.0% ± 0.8%), higher than a randomly initialized network or after training without the predictive term. However, evaluating the metric on the pixels directly also yields high scores (93.0% ± 0.0%), albeit still slightly lower than LPL. The high scores in pixel space can partially be explained by the high input dimension and the small number of classes in the dataset. Importantly, the metric is insensitive to the manifold topology (see below). Different data points correspond to averages over n = 10 independent evaluations of the metric, with error bars ± SEM. (e) Projections of the representations onto the first two principal components before (Random) and after training (LPL). Each point corresponds to one input image, and the color represents the object type. The object class is entangled at initialization and disentangled after learning. (f) Averaged RSM computed from representations of different object colors in (d). LPL’s RSM closely resembles the transition structure shown in (b). Without the predictive term, the RSM becomes diagonal, while the random network’s RSM does not have this structure and roughly follows the input pixel similarity structure. (g) Network output projected onto the first two principal components for changing hue sequentially while keeping all other factors fixed. The two lines correspond to two different object sizes. The trajectories are disentangled for LPL and preserve the topology of the data manifold (cf. b), whereas this is not the case when the predictive term is off, at initialization (random), or at the input (pixels).
Extended Data Fig. 5 Transition matrices and RSMs for all latent factors of the 3D shapes dataset.
(a) Transition probabilities estimated from the generated video. The high values on the diagonal reflect the fact that within a 17-frame clip, only one factor changes while the others remain fixed. The off-diagonal values reflect the transition probabilities when a specific factor is changing. For instance, within a clip cycling through all the object hues, the color may only change to the next or previous assignments in the color map with a smaller probability for a two-step transition. The hue mapping was randomly chosen with respect to the original dataset to ensure an entangled topology at the input (cf. Fig. 4g). The orientation and scale factors are not allowed to transition from the smallest to the largest values, and vice versa. Furthermore, the direction of change for any factor is fixed within a given clip, but may reverse for orientation and scale at the extreme values (cf. Fig. 4a). (b) Same as Fig. 4f, but for all factors at the pixel level. RSM values represent average cosine similarity between the pixels of images differing only in one factor with all other factors fixed. Some similarity structure exists along the scale and orientation factors only. (c) Same as (b) but for the final-layer representations learned by LPL. The RSM closely resembles the transition probability structure that characterizes the temporal properties of the video sequence. (d) Same as (c) but for learning without the predictive term. The RSM is diagonal, which shows that the network represents different factors in almost orthogonal directions. (e) Same as (b), but at random initialization before training. The RSM for all factors is reflective of the pixel RSM.
Extended Data Fig. 6 Same as Fig. 5 but with detailed controls.
(a) Snapshot of spiking activity (left) and underlying firing rate signals or their reconstructions (right) over 100 ms for the input and network populations. (b) Same as Fig. 5d showing signal selectivity learned with the different variations of spiking LPL given in (a). (c) Average synaptic connection strength grouped by input population for the different configurations in (a). LPL with plastic inhibition results in higher weights on the slowly varying signals relative to the shuffled controls, but not when the predictive or Hebbian term are disabled. Without inhibition or without inhibitory plasticity, connections from all populations are strong with a small preference for P2. (d) Average firing rates over 100 s bins throughout training for the configurations in (a). Firing rates saturate with the inhibitory neurons settling at a higher firing rate when learning with spiking LPL with inhibition, even when the predictive term is disabled or the inhibition is not plastic. Activity collapses without the Hebbian term, whereas firing rates diverge without inhibition. (e) Averaged weight vectors from populations P1 and P2 onto each excitatory neuron (left) and distribution of the excitatory neurons’ relative selectivity between the two populations (right). Different neurons are exclusively selective to either P1 or P2 under spiking LPL with inhibitory plasticity. Without the predictive term, or the Hebbian term, few if any neurons are selective to one population over the other. Moreover, weights collapse to small values without the Hebbian term. When inhibition is removed altogether, a few neurons become exclusively selective to P2, but the weight vectors are not well-decorrelated. Without inhibitory plasticity, a few weight vectors are well-decorrelated, but most neurons are not preferentially selective to either signal.
Extended Data Fig. 7 Learning threshold determines the sign of plasticity.
(a) Weight changes as a function of repetition frequency ρ for positive and negative relative spike timings (Δt = ± 10 ms) with σ2 (t = 0) = 0 and \({\bar{S}}_{i}(t=0)=0\). (b) Same as (a) but for \({\bar{S}}_{i}(t=0)=50\).
Extended Data Fig. 8 LPL is robust to noise.
(a) Same as Fig. 1b but for high rates of noisy transitions between clusters in the training data sequence with ρ = 0.2 (Methods). A neuron learning with LPL still consistently becomes selective to cluster identity even with noisy transitions. Data are averages ± SEM (n = 10 random seeds). (b) Cluster selectivity as a function of the probability of noisy cross-cluster transitions in the data sequence with σy = 1. LPL drives selectivity to cluster identity only below ρ = 0.5, i.e, only as long as cluster identity remains the slow feature. Values are averages xy5SEM (n = 10 random seeds).
Extended Data Fig. 9 Same as Fig. 3 but for the CIFAR-10 dataset.
(a) Linear readout accuracy of object categories decoded from representations at the network output after training it on natural image data for different learning rules in layer-local (dark) as well as the end-to-end configuration (light). (b) Linear readout accuracy of the internal representations at different layers of the DNN after layer-local training. (c) Dimensionality of the internal representations for the different learning rule configurations shown in (b). (d) Mean neuronal activity at different layers of the DNN after training for the different learning rule variants shown in (b).
Extended Data Fig. 10 Evaluating readout accuracy without pooling.
(a) Same as Extended Data Fig. 9b above, but with linear readout accuracies evaluated from the full feature map at each layer instead of after pooling. Results are qualitatively the same as before, but the starting accuracy at early layers is substantially higher. (b) Effective representation size that would be the input to the linear classifier at each layer with or without pooling. Without pooling, the number of features at early layers is very large, and may explain the higher early-layer accuracies in (b).
Supplementary information
Supplementary Information
Supplementary Tables 1–5, Figs. 1–4 and Notes 1–5.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Halvagal, M.S., Zenke, F. The combination of Hebbian and predictive plasticity learns invariant object representations in deep sensory networks. Nat Neurosci 26, 1906–1915 (2023). https://doi.org/10.1038/s41593-023-01460-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41593-023-01460-y
