
Abstract
Mammals localize sounds using information from their two ears. Localization in real-world conditions is challenging, as echoes provide erroneous information and noises mask parts of target sounds. To better understand real-world localization, we equipped a deep neural network with human ears and trained it to localize sounds in a virtual environment. The resulting model localized accurately in realistic conditions with noise and reverberation. In simulated experiments, the model exhibited many features of human spatial hearing: sensitivity to monaural spectral cues and interaural time and level differences, integration across frequency, biases for sound onsets and limits on localization of concurrent sources. But when trained in unnatural environments without reverberation, noise or natural sounds, these performance characteristics deviated from those of humans. The results show how biological hearing is adapted to the challenges of real-world environments and illustrate how artificial neural networks can reveal the real-world constraints that shape perception.
Similar content being viewed by others

Main
Why do we see or hear the way we do? Perception is believed to be adapted to the world, shaped over evolution and development to help us survive in our ecological niche. Yet adaptedness is often difficult to test. Many phenomena are not obviously a consequence of adaptation to the environment, and perceptual traits are often proposed to reflect implementation constraints rather than the consequences of performing a task well. Well-known phenomena attributed to implementation constraints include aftereffects1,2, masking3,4, poor visual motion and form perception for equiluminant colour stimuli5 and limits on the information that can be extracted from high-frequency sound6,7,8.
Evolution and development can be viewed as an optimization process that produces a system that functions well in its environment. The consequences of such optimization for perceptual systems have traditionally been revealed by ideal observer models—systems that perform a task optimally under environmental constraints9,10 and whose behavioural characteristics can be compared to actual behaviour. Ideal observers are typically derived analytically, but as a result are often limited to simple psychophysical tasks11,12,13,14,15,16. Despite recent advances, such models remain intractable for many real-world behaviours. Rigorously evaluating adaptedness has thus remained out of reach for many domains. Here we extend ideas from ideal observer theory to investigate the environmental constraints under which human behaviour emerges, using contemporary machine learning to optimize models for behaviourally relevant tasks in simulated environments. Human behaviours that emerge from machine learning under a set of naturalistic environmental constraints, but not under alternative constraints, are plausibly a consequence of optimization for those natural constraints (that is, adapted to the natural environment) (Fig. 1a).

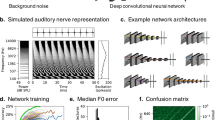
a, Illustration of the method. A variety of constraints (left) shape human behaviour. Models optimized under particular environmental constraints (right) illustrate the effect of these constraints on behaviour. Environment simulators can instantiate naturalistic environments as well as alternative environments in which particular properties of the world are altered, to examine the constraints that shape human behaviour. b, Cues to sound location available to humans: interaural time and level differences (ITDs and ILDs) (left and centre) and spectral cues to elevation (right). Time and level differences are shown for low and high-frequency sinusoids (left and centre, respectively). The level difference is small for the low frequency, and the time difference is ambiguous for the high frequency. c, Training procedure. Natural sounds (green) were rendered at a location in a room, with noises (natural sound textures, black) placed at other locations. Rendering included direction-specific filtering by the head/torso/pinnae, using head-related transfer functions from the KEMAR mannequin. Neural networks were trained to classify the location of the natural sound source (azimuth and elevation) into one of a set of location bins (spaced 5° in azimuth and 10° in elevation). d, Example neural network architectures from the architecture search. Architectures consisted of sequences of ‘blocks’ (a normalization layer, followed by a convolution layer, followed by a non-linearity layer) and pooling layers, culminating in fully connected layers followed by a classifier that provided the network’s output. Architectures varied in the total number of layers, the kernel dimensions for each convolutional layer, the number of blocks that preceded each pooling layer and the number of fully connected layers preceding the classifier. Labels indicate an example block, pooling layer and fully connected layer. The model’s behaviour was taken as the average of the results for the ten best architectures (assessed by performance on a held-out validation set of training examples). e, Recording setup for real-world test set. The mannequin was seated on a chair and rotated relative to the speaker to achieve different azimuthal positions. Sound was recorded from microphones in the mannequin ears. f, Free-field localization of human listeners, replotted from a previous publication154. Participants heard a sound played from one of 11 speakers in the front horizontal plane and pointed to the location. Graph plots kernel density estimate of participant responses for each actual location. g, Localization judgements of the trained model for the real-world test set. Graph plots kernel density estimates of response distribution. For ease of comparison with f, in which all locations were in front of the listener, positions were front–back folded. h, Localization judgements of the model without front–back folding. Model errors are predominantly at front–back reflections of the correct location.
Sound localization is one domain of perception where the relationship of behaviour to environmental constraints has not been straightforward to evaluate. The basic outlines of spatial hearing have been understood for decades17,18,19,20. Time and level differences in the sound that enters the two ears provide cues to a sound’s location, and location-specific filtering by the ears, head and torso provide monaural cues that help resolve ambiguities in binaural cues (Fig. 1b). However, in real-world conditions, background noise masks or corrupts cues from sources to be localized and reflections provide erroneous cues to direction21. Classical models based on these cues thus cannot replicate real-world localization behaviour22,23,24. Instead, modelling efforts have focused on accounting for observed neuronal tuning in early stages of the auditory system rather than behaviour25,26,27,28,29,30,31, or have modelled behaviour in simplified experimental conditions using particular cues24,30,32,33,34,35,36. Engineering systems must solve localization in real-world conditions, but typically adopt approaches that diverge from biology, using more than two microphones and/or not leveraging cues from ear/head filtering37,38,39,40,41,42,43,44. As a result, we lack quantitative models of how biological organisms localize sounds in realistic conditions. In the absence of such models, the science of sound localization has largely relied on intuitions about optimality. Those intuitions were invaluable in stimulating research, but on their own are insufficient for quantitative predictions.
Here we exploit the power of contemporary artificial neural networks to develop a model optimized to localize sounds in realistic conditions. Unlike much other contemporary work using neural networks to investigate perceptual systems45,46,47,48,49,50, our primary interest is not in potential correspondence between internal representations of the network and the brain. Instead, we aim to use the neural network as a way to find an optimized solution to a difficult real-world task that is not easily specified analytically, for the purpose of comparing its behavioural characteristics to those of humans. Our approach is thus analogous to the classic ideal observer approach, but harnesses modern machine learning in place of an ideal observer for a problem where one is not analytically tractable.
To obtain sufficient labelled data with which to train the model, and to enable the manipulation of training conditions, we used a virtual acoustic world51. The virtual world simulated sounds at different locations with realistic patterns of surface reflections and background noise that could be eliminated to yield unnatural training environments. To give the model access to the same cues available to biological organisms, we trained it on a high-fidelity cochlear representation of sound, leveraging recent technical advances52 to train the large models that are required for such high-dimensional input. Unlike previous generations of neural network models24,37,40,42,44, which were reliant on hand-specified sound features, we learn all subsequent stages of a sound localization system to obtain good performance in real-world conditions.
When tested on stimuli from classic laboratory experiments, the resulting model replicated a large and diverse array of human behavioural characteristics. We then trained models in unnatural conditions to simulate evolution and development in alternative worlds. These alternative models deviated notably from human-like hearing. The results indicate that the characteristics of human hearing are indeed adapted to the constraints of real-world localization, and that the rich panoply of sound localization phenomena can be explained as consequences of this adaptation. The approach we use is broadly applicable to other sensory modalities, providing a way to test the adaptedness of aspects of human perception to the environment and to understand the conditions in which human-like perception arises.
Results
Model construction
We began by building a system that could localize sounds using the information available to human listeners. The system thus had outer ears (pinnae), and a simulated head and torso, along with a simulated cochlea. The outer ears and head/torso were simulated using head-related impulse responses (HRIRs) recorded from a standard physical model of the human53. The cochlea was simulated with a bank of bandpass filters modelled on the frequency selectivity of the human ear54,55, whose output was rectified and low-pass filtered to simulate the presumed upper limit of phase locking in the auditory nerve56. The inclusion of a fixed cochlear front-end (in lieu of trainable filters) reflected the assumption that the cochlea evolved to serve many different auditory tasks rather than being primarily driven by sound localization. As such, the cochlea seemed a plausible biological constraint on localization.
The output of the two cochleae formed the input to a standard convolutional neural network (CNN) (Fig. 1c). This network instantiated a cascade of simple operations—filtering, pooling and normalization—culminating in a softmax output layer with 504 units corresponding to different spatial locations (spaced 5° in azimuth and 10° in elevation). The parameters of the model were tuned to maximize localization performance on the training data. The optimization procedure had two phases: an architecture search in which we searched over architectural parameters to find a network architecture that performed well (Fig. 1d), and a training phase in which the filter weights of the selected architectures were trained to asymptotic performance levels using gradient descent.
The architecture search consisted of training each one of a large set of possible architectures for 15,000 training steps with 16 1-s stimulus examples per step (240,000 total examples; see Extended Data Fig. 1 for distribution of localization performance across architectures and Extended Data Fig. 2 for the distributions from which architectures were chosen). We then chose the ten networks that performed best on a validation set of data not used during training (Extended Data Fig. 3). The parameters of these ten networks were then reinitialized and each trained for 100,000 training steps (1.6 million examples). Given evidence that internal representations can vary across different networks trained on the same task57, we present results aggregated across the top ten best-performing architectures, treated akin to different participants in an experiment58. Most results graphs present the average results for these ten networks, which we collectively refer to as ‘the model’.
The training data were based on a set of roughly 500,000 stereo audio signals with associated three-dimensional (3D) locations relative to the head (on average 988 examples for each of the 504 location bins, Methods). These signals were generated from 385 natural sound source recordings (Extended Data Fig. 4) rendered at a spatial location in a simulated room. The room simulator used a modified source-image method51,59 to simulate the reflections off the walls of the room. Each reflection was then filtered by the (binaural) HRIR for the direction of the reflection53. Five different rooms were used, varying in their dimensions and in the material of the walls (Extended Data Fig. 5). To mimic the common presence of noise in real-world environments, each training signal also contained spatialized noise. Background noise was synthesized from the statistics of a natural sound texture60, and was rendered at between three and eight randomly chosen locations using the same room simulator to produce noise that was diffuse but non-uniform, intended to replicate common real-world sources of noise. At each training step, the rendered natural sound sources were randomly paired with rendered background noises. The neural networks were trained to map the binaural audio to the location of the sound source (specified by its azimuth and elevation relative to the model’s ‘head’).
Model evaluation in real-world conditions
The trained networks were first evaluated on a held-out set of 70 sound sources rendered using the same pipeline used to generate the training data (yielding a total of around 47,000 stereo audio signals). The best-performing networks produced accurate localization for this validation set (the mean error was 5.3° in elevation and 4.4° in azimuth, front–back folded: that is, reflected about the coronal plane to discount front–back confusions).
To assess whether the model would generalize to real-world stimuli outside the training distribution, we made binaural recordings in an actual conference room using a mannequin with in-ear microphones (Fig. 1e). Humans localize relatively well in such free-field conditions (Fig. 1f). The trained networks also localized real-world recordings relatively well (Fig. 1g), on par with human free-field localization, with errors mostly limited to the front–back confusions that are common to humans when they cannot move their heads (Fig. 1h)61,62.
For comparison, we also assessed the performance of a standard set of two-microphone localization algorithms from the engineering literature63,64,65,66,67,68. In addition, we trained the same set of neural networks to localize sounds from a two-microphone array that lacked the filtering provided to biological organisms by the ears, head and torso but that included the simulated cochlea (Extended Data Fig. 6a). Our networks that had been trained with biological pinnae, head and torso filtering outperformed the set of standard two-microphone algorithms from the engineering community, as well as the neural networks trained with stereo microphone input without a head and ears (Extended Data Fig. 6b,c). This latter result confirms that the head and ears provide valuable cues for localization. Overall, performance on the real-world test set demonstrates that training a neural network in a virtual world produces a model that can accurately localize sounds in realistic conditions.
Model behavioural characteristics
To assess whether the trained model replicated the characteristics of human sound localization, we simulated a large set of behavioural experiments from the literature, intended to span many of the best-known and largest effects in spatial hearing. We replicated the conditions of the original experiments as closely as possible (for example, when humans were tested in anechoic conditions, we rendered experimental stimuli in an anechoic environment). We emphasize that the networks were not fit to human data in any way. Despite this, the networks reproduced the characteristics of human spatial hearing across this broad set of experiments.
Sensitivity to interaural time and level differences
We began by assessing whether the networks learned to use the binaural cues known to be important for biological sound localization. We probed the effect of interaural time differences (ITDs) and interaural level differences (ILDs) on localization behaviour using an experiment in which additional time and level differences are added to high- and low-frequency sounds rendered in virtual acoustic space69 (Fig. 2a). This experimental method has the advantage of using realistically externalized sounds and an absolute localization judgement (rather than the left/right lateralization judgements of simpler stimuli that are common to many other experiments70,71,72,73).

a, Schematic of stimulus generation. Noise bursts filtered into high or low-frequency bands were rendered at a particular azimuthal position, after which an additional ITD or ILD was added to the stereo audio signal. b, Schematic of response analysis. Responses were analysed to determine the amount by which the perceived location (L) was altered (∆L) by the added ITD/ILD bias, expressed as the amount by which the ITD/ILD would have changed if the actual sound’s location changed by ∆L. c, Effect of added ITD and ILD bias on human localization. The y axis plots amount by which the perceived location was altered, expressed in ITD/ILD as described above. Each dot plots a localization judgement from one trial. Data reproduced from a previous publication69. d, Effect of additional ITD and ILD on model localization. Same conventions as b. Error bars plot s.e.m., bootstrapped across the ten networks.
In the original experiment69, the change to perceived location imparted by the additional ITD or ILD was expressed as the amount by which the ITD or ILD would change in natural conditions if the actual location were changed by the perceived amount (Fig. 2b). This yields a curve whose slope indicates the efficacy of the manipulated cue (ITD or ILD). We reproduced the stimuli from the original study, rendered them in our virtual acoustic world, added ITDs and ILDs as in the original study and analysed the model’s localization judgements in the same way.
For human listeners, ITD and ILD have opposite efficacies at high and low frequencies (Fig. 2c), as predicted by classical ‘duplex’ theory17. An ITD bias imposed on low-frequency sounds shifts the perceived location of the sound substantially (bottom left), whereas an ITD imposed on high-frequency sound does not (top left). The opposite effect occurs for ILDs (right panels), although there is a weak effect of ILDs on low-frequency sound. This latter effect is inconsistent with the classical duplex story but consistent with more modern measurements indicating small but reliable ILDs at low frequencies74 that are used by the human auditory system75,76,77.
As shown in Fig. 2d, the model qualitatively replicated the effects seen in humans. Added ITDs and ILDs had the largest effect at low and high frequencies, respectively, but ILDs had a modest effect at low frequencies as well. This produced an interaction between the type of cue (ITD/ILD) and frequency range (difference of differences between slopes significantly greater than 0; P < 0.001, evaluated by bootstrapping across the ten networks). However, the effect of ILD at low frequencies was also significant (slope significantly greater than 0; P < 0.001, via bootstrap). Thus, a model optimized for accurate localization both exhibits the dissociation classically associated with duplex theory, but also its refinements in the modern era.
Azimuthal localization of broadband sounds
We next measured localization accuracy of broadband noise rendered at different azimuthal locations (Fig. 3a). In humans, localization is most accurate near the midline (Fig. 3b), and becomes progressively less accurate as sound sources move to the left or right of the listener78,79,80. One explanation is that the first derivatives of ITD and ILD with respect to azimuthal location decrease as the source moves away from the midline21, providing less information about location28. The model qualitatively reproduced this result (Fig. 3c).

a, Schematic of stimuli from experiment measuring localization accuracy at different azimuthal positions. b, Localization accuracy of human listeners for broadband noise at different azimuthal positions. Data were scanned from a previous publication80, which measured discriminability of noise bursts separated by 15° (quantified as d’). Error bars plot s.e.m. c, Localization accuracy of our model for broadband noise at different azimuthal positions. Graph plots mean absolute localization error (Mean abs. error) of the same noise bursts used in the human experiment in b. Error bars plot the s.e.m. across the ten networks. d, Schematic of stimuli from experiment measuring effect of bandwidth on localization accuracy. Noise bursts varying in bandwidth were presented at particular azimuthal locations; participants indicated the azimuthal position with a keypress. e, Effect of bandwidth on human localization of noise bursts. Accuracy was quantified as r.m.s. error. Error bars plot the s.d. Data are replotted from a previous publication82. f, Effect of bandwidth on model localization of noise bursts. Networks were constrained to report only the azimuth of the stimulus. Error bars plot s.e.m. across the ten networks.
Integration across frequency
Because biological hearing begins with a decomposition of sound into frequency channels, binaural cues are thought to be initially extracted within these channels20,25. However, organisms are believed to integrate information across frequency to achieve more accurate localization than could be mediated by any single frequency channel. One signature of this integration is improvement in localization accuracy as the bandwidth of a broadband noise source is increased (Fig. 3d,e)81,82. We replicated one such experiment on the networks and they exhibited a similar effect, with accuracy increasing with noise bandwidth (Fig. 3f).
Use of ear-specific cues to elevation
In addition to the binaural cues that provide information about azimuth, organisms are known to make use of the direction-specific filtering imposed on sound by the ears, head and torso18,83. Each individual’s ears have resonances that ‘colour’ a sound differently depending on where it comes from in space. Individuals are believed to learn the specific cues provided by their ears. In particular, if forced to listen with altered ears, either via moulds inserted into the ears84 or via recordings made in a different person’s ears85, localization in elevation degrades even though azimuthal localization is largely unaffected (Fig. 4a–c).

a, Photographs of ear alteration in humans (reproduced from a previous publication84). b, Sound localization by human listeners with unmodified ears. Graph plots mean and s.e.m. of perceived locations for four participants, superimposed on grid of true locations (dashed lines). Data scanned from the original publication84. c, Effect of ear alteration on human localization. Same conventions as b. d, Sound localization in azimuth and elevation by the model, using the ears (HRIRs) from training, with broadband noise sound sources. Graph plots mean locations estimated by the ten networks. Tested locations differed from those in the human experiment to conform to the location bins used for network training. e, Effect of ear alteration on model sound localization. Ear alteration was simulated by substituting an alternative set of HRIRs when rendering sounds for the experiment. Graph plots average results across all 45 sets of alternative ears (averaged across the ten networks). f, Effect of individual sets of alternative ears on localization in azimuth. Graph shows results for a larger set of locations than in d and e to illustrate the generality of the effect. g, Effect of individual sets of alternative ears on localization in elevation. Bolded lines show ears at 5th, 25th, 75th and 95th percentiles when the 45 sets of ears were ranked by accuracy. h, Smoothing of HRTFs, produced by varying the number of coefficients in a discrete cosine transform. Reproduced from the original publication, ref. 86. i, Effect of spectral smoothing on human perception. Participants heard two sounds, one played from a speaker in front of them and one played through open-backed earphones, and judged which was which. The earphone-presented sound was rendered using HRTFs smoothed by various degrees. In practice, participants performed the task by noting changes in apparent sound location. Data scanned from the original publication86. Error bars plot s.e.m. Conditions with 4, 2 and 1 cosine coefficients were omitted from the experiment, but are included on the x axis to facilitate comparison with the model results in j. j, Effect of spectral smoothing on model sound localization accuracy (measured in both azimuth and elevation, as the mean absolute localization error). Conditions with 512 and 1,024 cosine components were not realizable given the length of the impulse responses we used. k, Effect of spectral smoothing on model accuracy in azimuth. l, Effect of spectral smoothing on model accuracy in elevation. m, Stimuli from experiment in n and o. Noise bursts varying in low- or high-pass cut-off were presented at particular elevations. n, Effect of low- and high-pass cut-off on accuracy in humans. Data scanned from the original publication90; error bars were not provided in the original publication. o, Effect of low- and high-pass cut-off on model accuracy. Networks were constrained to report only elevation. Here and in j, k and l, error bars plot s.e.m. across the ten networks.
To test whether the trained networks similarly learned to use ear-specific elevation cues, we measured localization accuracy in two conditions: one where sounds were rendered using the HRIR set used for training the networks, and another where the impulse responses were different (having been recorded in a different person’s ears). Because we have unlimited ability to run experiments on the networks, in the latter condition we evaluated localization with 45 different sets of impulse responses, each recorded from a different human. As expected, localization of sounds rendered with the ears used for training was good in both azimuth and elevation (Fig. 4d). But when tested with different ears, localization in elevation generally collapsed (Fig. 4e), much like what happens to human listeners when moulds are inserted in their ears (Fig. 4c), even though azimuthal localization was nearly indistinguishable from that with the trained ears. Results for individual sets of alternative ears revealed that elevation performance transferred better across some ears than others (Fig. 4f,g), consistent with anecdotal evidence that sounds rendered with head-related transfer functions (HRTFs) other than one’s own can sometimes be convincingly localized in three dimensions.
Limited spectral resolution of elevation cues
Elevation perception is believed to rely on the peaks and troughs introduced to a sound’s spectrum by the ears/head/torso18,21,83 (Fig. 1b, right). In humans, however, perception is dependent on relatively coarse spectral features—the transfer function can be smoothed substantially before human listeners notice abnormalities86 (Fig. 4h,i), for reasons that are unclear. In the original demonstration of this phenomenon, human listeners discriminated sounds with and without smoothing, a judgement that was in practice made by noticing changes in the apparent location of the sound. To test whether the trained networks exhibited a similar effect, we presented sounds to the networks with similarly smoothed transfer functions and measured the extent to which the localization accuracy was affected. The effect of spectral smoothing on the networks’ accuracy was similar to the measured sensitivity of human listeners (Fig. 4j). The effect of the smoothing was most prominent for localization in elevation, as expected, but there was also some effect on localization in azimuth for the more extreme degrees of smoothing (Fig. 4k,l), consistent with evidence that spectral cues affect azimuthal space encoding87.
Dependence on high-frequency spectral cues to elevation
The cues used by humans for localization in elevation are primarily in the upper part of the spectrum88,89. To assess whether the trained networks exhibited a similar dependence, we replicated an experiment measuring the effect of high- and low-pass filtering on the localization of noise bursts90 (Fig. 4m). Model performance varied with the frequency content of the noise in much the same way as human performance (Fig. 4n,o).
The precedence effect
Another hallmark of biological sound localization is that judgements are biased towards information provided by sound onsets21,91. The classic example of this bias is known as the precedence effect92,93,94. If two clicks are played from speakers at different locations with a short delay (Fig. 5a), listeners perceive a single sound whose location is determined by the click that comes first. The effect is often suggested to be an adaptation to the common presence of reflections off environmental surfaces (Fig. 1c)—reflections arrive from an erroneous direction but traverse longer paths and arrive later, such that basing location estimates on the earliest arriving sound might avoid errors21. To test whether our model would exhibit a similar effect, we simulated the classic precedence experiment, rendering two clicks at different locations. When clicks were presented simultaneously, the model reported the sound to be centred between the two click locations, but when a small interclick delay was introduced, the reported location switched to that of the leading click (Fig. 5b). This effect broke down as the delay was increased, as in humans, although with the difference that the model could not report hearing two sounds and so instead reported a single location intermediate between those of the two clicks.

a, Diagram of stimulus. Two clicks are played from two different locations relative to the listener. The time interval between the clicks is manipulated and the listener is asked to localize the sound(s) that they hear. When the delay is short but non-zero, listeners perceive a single click at the location of the first click. At longer delays, listeners hear two distinct sounds. b, Localization judgements of the model for two clicks at +45 and −45°. The model exhibits a bias for the leading click when the delay is short but non-zero. At longer delays, the model judgements (which are constrained to report the location of a single sound, unlike those of humans) converge to the average of the two click locations. Error bars plots s.e.m. across the ten networks. c, Error in localization of the leading and lagging clicks by humans as a function of interclick delay. SC denotes a single click at the leading or lagging location. Bars plot r.m.s. localization error. Error bars plot s.d. Data scanned from the original publication95. d, Error in localization of the leading and lagging clicks by the model as a function of interclick delay. Bars plot r.m.s. localization error. Error bars plots s.e.m. across the ten networks.
To compare the model results to human data, we simulated an experiment in which participants reported the location of both the leading and lagging click as the interclick delay was varied95. At short but non-zero delays, humans accurately localize the leading but not the lagging click (Fig. 5c, because a single sound is heard at the location of the leading click). At longer delays, the lagging click is more accurately localized and listeners start to mislocalize the leading click, presumably because they confuse which click is first95. The model qualitatively replicated both effects, in particular the large asymmetry in localization accuracy for the leading and lagging sound at short delays (Fig. 5d).
Multi-source localization
Humans are able to localize multiple concurrent sources, but only to a point96,97,98. The reasons for the limits on multi-source localization are unclear97. These limitations could reflect human-specific cognitive constraints. For instance, reporting a localized source might require attending to it, which could be limited by central factors not specific to localization. Alternatively, localization could be fundamentally limited by corruption of spatial cues by concurrent sources or other ambiguities intrinsic to the localization problem.
To assess whether the model would exhibit limitations like those observed in humans, we replicated an experiment98 in which humans judged both the number and location of a set of speech signals played from a subset of an array of speakers (Fig. 6a). To enable the model to report multiple sources we fine-tuned the final fully connected layer to indicate the probability of a source at each of the location bins, and set a probability criterion above which we considered the model to report a sound at the corresponding location (Methods). The weights in all earlier layers were ‘frozen’ during this fine-tuning, such that all other stages of the model were identical to those used in all other experiments. We then tested the model on the experimental stimuli.

a, Diagram of experiment. On each trial, between one and eight speech signals (each spoken by a different talker) was played from a subset of the speakers in a 12-speaker circular array. The lower panel depicts an example trial in which three speech signals were presented, with the corresponding speakers in green. Participants reported the number of sources and their locations. b, Average number of sources reported by human listeners, plotted as a function of the actual number of sources. Error bars plot standard deviation across participants. Here and in d, graph is reproduced from original paper98 with permission of the authors. c, Same as b, but for the model. Error bars plot standard deviation across the ten networks. d, Localization accuracy (measured as the proportion of sources correctly localized to the actual speaker from which they were presented), plotted as a function of the number of sources. Error bars plot s.d. across participants. e, Same as d, but for the model. Error bars plot s.d. across the ten networks.
Humans accurately report the number of sources up to three, after which they undershoot, only reporting about four sources in total regardless of the actual number (Fig. 6b). The model reproduced this effect, also being limited to approximately four sources (Fig. 6c). Human localization accuracy also systematically drops with the number of sources (Fig. 6d): the model again quantitatively reproduced this effect (Fig. 6e). The model–human similarity suggests that these limits on sound localization are intrinsic to the constraints of the localization problem, rather than reflecting human-specific central factors.
Effect of optimization for unnatural environments
Despite having no previous exposure to the stimuli used in the experiments and despite not being fit to match human data in any way, the model qualitatively replicated a wide range of classic behavioural effects found in humans. These results raise the possibility that the characteristics of biological sound localization may be understood as a consequence of optimization for real-world localization. However, given these results alone, the role of the natural environment in determining these characteristics is left unclear.
To assess the extent to which the properties of biological hearing are adapted to the constraints of localization in natural environments, we took advantage of the ability to optimize models in virtual worlds altered in various ways, intended to simulate the optimization that would occur over evolution and/or development in alternative environments (Fig. 1a). We altered the training environment in one of three ways (Fig. 7a): (1) by eliminating reflections (simulating surfaces that absorb all sound that reaches them, unlike real-world surfaces), (2) by eliminating background noise and (3) by replacing natural sound sources with artificial sounds (narrowband noise bursts). In each case, we trained the networks to asymptotic performance, then froze their weights and ran them on the full suite of psychophysical experiments described above. The psychophysical experiments were identical for all training conditions; the only difference was the strategy learned by the model during training, as might be reflected in the experimental results. We then quantified the dissimilarity between the model psychophysical results and those of humans as the mean squared error between the model and human results, averaged across experiments (normalized to have uniform axis limits, Methods).

a, Schematic depiction of altered training conditions, eliminating echoes or background noise or using unnatural sounds. b, Overall human–model dissimilarity for natural and unnatural training conditions. Error bars plot s.e.m., bootstrapped across networks. Asterisks denote statistically significant differences between conditions (P < 0.001, two-tailed), evaluated by comparing the human–model dissimilarity for each unnatural training condition to a bootstrapped null distribution of the dissimilarity for the natural training condition. c, Effect of unnatural training conditions on human–model dissimilarity for individual experiments, expressed as the effect size of the difference in dissimilarity between the natural and each unnatural training condition (Cohen’s d, computed between human–model dissimilarity for networks in normal and modified training conditions). Positive numbers denote a worse resemblance to human data compared to the model trained in normal conditions. Error bars plot s.e.m., bootstrapped across the ten networks d, The precedence effect in networks trained in alternative environments. e, Real-world localization accuracy of networks for each training condition. Error bars plot s.e.m., bootstrapped across the ten networks. Asterisks denote statistically significant differences between conditions (P < 0.001, two-tailed), evaluated by comparing the mean localization error for each unnatural training condition to a bootstrapped null distribution of the localization error for the natural training condition.
Figure 7b shows the average dissimilarity between the human and model results on the suite of psychophysical experiments, computed separately for each model training condition. The dissimilarity was lowest for the model trained in natural conditions, and significantly higher for each of the alternative conditions (P < 0.001 in each case, obtained by comparing the dissimilarity of the alternative conditions to a null distribution obtained via bootstrap across the ten networks trained in the naturalistic condition; results were fairly consistent across networks, Extended Data Fig. 7). The effect size of the difference in dissimilarity between the naturalistic training condition results and each of the other training conditions was large in each case (d = 2.13, anechoic; d = 2.75, noiseless; d = 3.06, unnatural sounds). This result provides additional evidence that the properties of spatial hearing are consequences of adaptation to the natural environment—human-like spatial hearing emerged from task optimization only for naturalistic training conditions.
To get an insight into how the environment influences perception, we examined the human–model dissimilarity for each experiment individually (Fig. 7c). Because the absolute dissimilarity is not meaningful (in that it is limited by the reliability of the human results, which are not perfect; Extended Data Fig. 8), we assessed the differences in human–model dissimilarity between the natural training condition and each unnatural training condition. These differences were most pronounced for a subset of experiments in each case.
The anechoic training condition produced most abnormal results for the precedence effect, but also produced substantially different results for ITD cue strength. The effect size for the difference in human–model dissimilarity between anechoic and natural training conditions was significantly greater in both these experiments (precedence effect d = 4.16; ITD cue strength d = 3.41) than in the other experiments (P < 0.001, by comparing the effect sizes of one experiment to the distribution of the effect size for another experiment obtained via bootstrap across networks). The noiseless training condition produced most abnormal results for the effect of bandwidth (d = 4.71; significantly greater than that for other experiments, P < 0.001, via bootstrap across networks). We confirmed that this result was not somehow specific to the absence of internal neural noise in our cochlear model, by training an additional model in which noise was added to each frequency channel (Methods). We found that the results of training in noiseless environments remained very similar. The training condition with unnatural sounds produced most abnormal results for the experiment measuring elevation perception (d = 4.4 for the ear alteration experiment; d = 4.28 for the high-frequency elevation cue experiment; P < 0.001 in both cases, via bootstrap across networks), presumably because without the pressure to localize broadband sounds, the model did not acquire sensitivity to spectral cues to elevation. These results indicate that different worlds would lead to different perceptual systems with distinct localization strategies.
The most interpretable example of environment-driven localization strategies is the precedence effect. This effect is often proposed to render localization robust to reflections, but others have argued that its primary function might instead be to eliminate interaural phase ambiguities, independent of reflections99. This effect is shown in Fig. 7d for models trained in each of the four virtual environments. Anechoic training completely eliminated the effect, even though it was largely unaffected by the other two unnatural training conditions. This result substantiates the hypothesis that the precedence effect is an adaptation to reflections in real-world listening conditions. See Extended Data Figs. 9 and 10 for full psychophysical results for models trained in alternative conditions.
In addition to diverging from the perceptual strategies found in human listeners, the models trained in unnatural conditions performed more poorly at real-world localization. When we ran models trained in alternative conditions on our real-world test set of recordings from mannequin ears in a conference room, localization accuracy was substantially worse in all cases (Fig. 7e, P < 0.001 in all cases). This finding is consistent with the common knowledge in engineering that training systems in noisy and otherwise realistic conditions aids performance37,42,44,100. Coupled with the abnormal psychophysical results of these alternatively trained models, this result indicates that the classic perceptual characteristics of spatial hearing reflect strategies that are important for real-world localization, in that systems that deviate from these characteristics localize poorly.
Model predictions of sound localizability
One advantage of a model that can mediate actual localization behaviour is that one can run large numbers of experiments on the model, searching for ‘interesting’ predictions that might then be tested in human listeners. Here we used the model to estimate the accuracy with which different natural sounds would be localized in realistic conditions. We chose to examine musical instrument sounds as these are both diverse and available as clean recordings in large numbers. We took a large set of instrument sounds101 and rendered them at a large set of randomly selected locations. We then measured the average localization error for each instrument.
As shown in Fig. 8a, there was reliable variation in the accuracy with which instrument sounds were localized by the model. The median error was as low as 1.06° for reed instrument no. 3 and as high as 40.02° for mallet no. 1 (folded to discount front–back confusions: without front–back folding, the overall error was larger, but the ordinal relations among instruments were similar). The human voice was also among the most accurately localized sounds in the set we examined, with a mean error of 2.39° (front–back folded).

a, Mean model localization error for each of 43 musical instruments. Each of a set of instrument notes was rendered at randomly selection locations. Graph shows letter-value plots157 of the mean azimuthal localization error across notes, measured after actual and judged positions were front–back folded. Letter-value plots are boxplots with additional quantiles. The widest box depicts the middle two quartiles (1/4) of the data distribution, as in a box plot, the second widest box depicts the next two octiles (1/8), the third widest box depicts the next two hexadeciles (1/16) and so on, up to the upper and lower 1/64 quantiles. Horizontal line plots median value and diamonds denote outliers. b, Spectrograms of an example note (middle C) for the three most and least accurately localized instruments (top and bottom, respectively).
Figure 8b displays spectrograms for example notes for the three best- and worst-localized instruments. The best-localized instruments are spectrally dense, and thus presumably take advantage of cross-frequency integration (which improve localization accuracy in both humans and the model, Fig. 3e,f). This result is consistent with the common idea that narrowband sounds are less well localized, but the model provides a quantitative metric of localizability that we would not otherwise have.
To assess whether the results could be predicted by simple measures of spectral sparsity, we measured the spectral flatness102 of each instrument sound (the ratio of the geometric mean of the power spectrum to the arithmetic mean of the power spectrum). The average spectral flatness of an instrument was significantly correlated with the model’s localization accuracy (rs = 0.77, P < 0.001), but this correlation was well below the split-half reliability of the model’s accuracy for an instrument (rs = 0.99). This difference suggests that there may be sound features above and beyond spectral sparsity that determine a sound’s localizability, and illustrates the value of an optimized system to make perceptual predictions.
We had intentions of running a free-field localization experiment in humans to test these predictions, but had to halt experiments due to COVID-19. We have hopes of running the experiment in the future. However, we note that informal observation by the authors listening in free-field conditions suggest that the sounds that are poorly localized by the model are also difficult for humans to localize.
Discussion
We trained artificial neural networks to localize sounds from binaural audio rendered in a virtual world and heard through simulated ears. When the virtual world mimicked natural auditory environments, with surface reflections, background noise and natural sound sources, the trained networks replicated many attributes of spatial hearing found in biological organisms. These included the frequency-dependent use of ITDs and ILDs, the integration of spatial information across frequency, the use of ear-specific high-frequency spectral cues to elevation and robustness to spectral smoothing of these cues, localization dominance of sound onsets and limitations on the ability to localize multiple concurrent sources. The model successfully localized sounds in an actual real-world environment better than alternative algorithms that lacked ears. The model also made predictions about the accuracy with which different types of real-world sound could be localized. But when the training conditions were altered to deviate from the natural environment by eliminating surface reflections, background noise or natural sound source structure, the behavioural characteristics of the model deviated notably from human-like behaviour. The results indicate that most of the key properties of mammalian spatial hearing can be understood as consequences of optimization for the task of localizing sounds in natural environments. Our approach extends classical ideal observer analysis to new domains, where provably optimal analytic solutions are difficult to attain but where supervised machine learning can nonetheless provide optimized solutions in different conditions.
The general method involves two nested levels of computational experiments: optimization of a model under particular conditions, followed by a suite of psychophysical experiments to characterize the resulting behavioural phenotype. This approach provides an additional tool with which to examine the constraints that yield biological solutions103,104, and thus to understand evolution105. It also provides a way to link experimental results with function. In some cases, these links had been proposed but not definitively established. For example, the precedence effect was often proposed to be an adaptation to reverberation21,92, although other functional explanations were also put forth99. Our results indicate it is indeed an adaptation to reverberation (Fig. 7d). We similarly provide evidence that sensitivity to spectral cues to elevation emerges only with the demands of localizing broadband sounds106. In other cases, the model provided explanations for behavioural characteristics that previously had none. One such example is the relatively coarse spectral resolution of elevation perception (Fig. 4h–j), which evidently reflects the absence of reliable information at finer resolutions. Another is the number of sources that can be concurrently localized (Fig. 6b,c), and the dependence of localization accuracy on the number of sources (Fig. 6d,e). Without an optimized model there would be no way to ascertain whether these effects reflect intrinsic limitations of localization cues in auditory scenes or some other human-specific cognitive limit.
Previous models of sound localization required cues to be hand-coded and provided to the model by the experimenter22,23,24,36. In some cases, previous models were able to derive optimal encoding strategies for such cues28, which could be usefully compared to neural data107. In other cases, models were able to make predictions of behaviour in simplified conditions using idealized cues36. However, the idealized cues that such models work with are not well-defined for arbitrary real-world stimuli108, preventing the modelling of general localization behaviour. In addition, ear-specific spectral cues to elevation (Fig. 1b, right) are not readily hand-coded, and as a result have remained largely absent from previous models. It has thus not previously been possible to derive optimal behavioural characteristics for real-world behaviour.
Our results highlight the power of contemporary machine learning coupled with virtual training environments to achieve realistic behavioural competence in computational models. Supervised learning has traditionally been limited by the need for large amounts of labelled data, typically acquired via painstaking human annotation. Virtual environments allow the scientist to generate the data, with the labels coming for free (as the parameters used to generate the data), and have the potential to greatly expand the settings in which supervised learning can be used to develop models of the brain109. Virtual environments also allow tests of optimality that would be impossible in biological systems, because they enable environmental conditions to be controlled, and permit optimization on rapid timescales.
Our approach is complementary to the long tradition of mechanistic modelling of sound localization. In contrast with mechanistic modelling, we do not produce specific hypotheses about underlying neural circuitry. However, the model gave rise to rich predictions of real-world behaviour, and normative explanations of a large suite of perceptual phenomena. It should be possible to merge these two approaches, both by training model classes that are more faithful to biology (for example, spiking neural networks, or networks with biologically constrained weights)110,111, and by building in additional known biological structures to the neural network (for example, replicating brainstem circuitry)112,113.
One limitation of our approach is that optimization of biological systems occurs in two distinct stages of evolution and development, which are not obviously mirrored in our model optimization procedure. The procedure we used had separate stages of architectural selection and weight training, but these do not cleanly map onto evolution and development in biological systems. This limitation is shared by classical ideal observers, but limits the ability to predict effects that might be specific to one stage or the other, for instance involving plasticity114.
Our model also shares many limitations common to current deep neural network models of the brain115. The learning procedure is unlikely to have much in common with biological learning, both in the extent and nature of supervision (which involves millions of explicitly labelled examples) and in the learning algorithm, which is often argued to lack biological plausibility110. The model class is also not fully consistent with biology, and so does not yield detailed predictions of neural circuitry. The analogies with the brain thus seem most promising at the level of behaviour and representations. Our results add to growing evidence that task-optimized models can produce human-like behaviour for signals that are close to the manifold of natural sounds or images50,116,117. However, artificial neural networks also often exhibit substantial representational differences with humans, particularly for unnatural signals derived in various ways from a network118,119,120,121,122, and our model may exhibit similar divergences.
We chose to train models on a fixed representation of the ear. This choice was motivated by the assumption that the evolution of the ear was influenced by many different auditory tasks, such that it may not have been strongly influenced by the particular demands of sound localization, instead primarily serving as a constraint on biological solutions to the sound localization problem117. However, the ear itself undoubtedly reflects properties of the natural environment123. It could thus be fruitful to ‘evolve’ ears along with the rest of the auditory system, particularly in a framework with multiple tasks50. Our cochlear model also does not replicate the fine details of cochlear physiology124,125,126 due to practical constraints of limited memory resources. These differences could in principle influence the results, although the similarity of the model results to those of humans suggests that the details of peripheral physiology beyond those that we modelled do not figure critically in the behavioural traits we examined.
The virtual world we used to train our models also no doubt differs in many ways from real-world acoustic environments. The rendering assumed point sources in space, which is inaccurate for many natural sound sources. The distribution of source locations was uniform relative to the listener, and both the listener and the sound sources were static, all of which are often not true of real-world conditions. And although the simulated reverberation replicated many aspects of real-world reverberation, it probably did not perfectly replicate the statistical properties of natural environmental impulse responses127, or their distribution across environments. Our results indicate that the virtual world approximates the actual world in many of the respects that matter for spatial hearing, but the discrepancies with the real world could make a difference for some behaviours.
We also emphasize that despite presenting our approach as an alternative to ideal observer analysis9,10, the resulting model almost surely differs in some respects from a fully ideal observer. The solutions reached by our approach are not provably optimal like classic ideal observers, and the model class and optimization methods could impose biases on the solutions. It is also likely that the architecture search was not extensive enough to find the best architectures for the task. Those caveats aside, the similarity to human behaviour, along with the strong dependence on the training conditions, provides some confidence that the optimization procedure is succeeding to a degree that is scientifically useful.
Our focus in this paper has been to study behaviour, as there is a rich set of auditory localization behaviours for which normative explanations have traditionally been unavailable. However, it remains possible that the model we trained could be usefully compared to neural data. There is a large literature detailing binaural circuitry in the brainstem128 that could be compared to the internal responses of the model. The model could also be used to probe for functional organization in the auditory cortex, for instance by predicting brain responses using features from different model stages45,46,47,48,49,50, potentially helping to reveal hierarchical stages of localization circuitry.
A model that can predict human behaviour should also have useful applications. Our model showed some transfer of localization for specific sets of ears (Fig. 4g), and could be used to make predictions about the extent to which sound rendering in virtual acoustic spaces (which may need to use a generic set of HRTF) should work for a particular listener. It can also predict which of a set of sound sources will be most compellingly localized, or worst localized (Fig. 8). Such predictions could be valuable in enabling better virtual reality, or in synthesizing signals that humans cannot pinpoint in space.
One natural extension of our model would be to incorporate moving sound sources and head movements. We modelled sound localization in static conditions because most experimental data have been collected in this setting. But in real-world conditions sound sources often move relative to the listener and listeners move their heads129,130, often to better disambiguate front from back62 and more accurately localize. Our approach could be straightforwardly expanded to moving sound sources in the virtual training environment and a model that can learn to move its head42, potentially yielding explanations of auditory motion perception131,132,133. The ability to train models that can localize in realistic conditions also underscores the need for additional measurements of human localization behaviour—front–back confusions, localization of natural sounds in actual rooms, localization with head movements and so on—with which to further evaluate models.
Another natural next step is to instantiate both recognition and localization in the same model, potentially yielding insight into the segregation of these functions in the brain134, and to the role of spatial cues in the ‘cocktail party problem’135,136,137,138,139,140,141. More generally, the approach we take here—using deep learning to derive optimized solutions to perceptual or cognitive problems in different operating conditions—is broadly applicable to understanding the forces that shape complex, real-world, human behaviour.
Methods
Training data generation
Virtual acoustic simulator: image/source method
We used a room simulator51 to render binaural room impulse responses (BRIRs). This simulator used the image-source method, which approaches an exact solution to the wave equation if the walls are assumed to be rigid59, as well as an extension to that method that allowed for more accurate calculation of the arrival time of a wave142. This enabled the simulator to correctly render the relative timing between the signals received by the two simulated ears, including reflections (enabling both the direct sound and all reflections to be rendered with the correct spatial cues). Our specific implementation was identical to that used in the original paper51, except for some custom optimization to take advantage of vectorized operations and parallel computation.
The room simulator operated in three separate stages. First, the simulator calculated the positions of reflections of the source impulse forward in time for 0.5 s. For each of these positions, the simulator placed an image symmetrically reflected about the wall of last contact. Second, the simulator accounted for the absorption spectra of the reflecting walls for each image location and filtered a broadband impulse sequentially using the absorption spectrum of the simulated wall material. Third, the simulator found the direction of arrival for each image and convolved the filtered impulse with the HRIR in the recorded set whose position was closest to the computed direction. This resulted in a left and right channel signal pair for each path from the source to the listener. Last, each of these signal pairs was summed together, factoring in both the delay from the time of arrival and the level attenuation given the total distance travelled by each reflection. The original authors of the simulator previously assessed this method’s validity and found that simulated BRIRs were good physical approximations to recorded BRIRs provided that sources were rendered more than 1 m from the listener51.
We used this room simulator to render BRIRs at each of a set of listener locations in five different rooms varying in size and material (listed in Extended Data Fig. 5) for each of the source location bins in the output layer of the networks: all pairings of seven elevations (between 0° and 60°, spaced 10°) and 72 azimuths (spaced 5° in a circle around the listener), at a distance of 1.4 m. This yielded 504 source positions per listener location and room. Listener locations were chosen subject to three constraints. First, the listener location had to be at least 1.4 m from the nearest wall (because sounds were rendered 1.4 m from the listener). Second, the listener locations were located on a grid whose axes ran parallel to the walls of the room, with locations spaced 1 m apart in each dimension. Third, the grid was centred in the room. These constraints yielded four listener locations for the smallest room and 81 listener locations for the largest room. This resulted in 71,064 pairs of BRIRs, each corresponding to a possible source–listener–room spatial configuration. Each BRIR took approximately 4 min to generate when parallelized across 16 cores. We parallelized143 the generation of the full set of BRIRs across approximately 1,000 cores on the MIT OpenMind Cluster, which allowed us to generate the full set of BRIRs in approximately 4 days.
Virtual acoustic simulator: HRIRs
The simulator relied on empirically derived HRIRs to incorporate the effect of pinna filtering, head shadowing and time delays without solving wave equations for the ears, head and/or torso. Specifically, the simulator used a set of HRIRs recorded with KEMAR: a mannequin designed to replicate the acoustic effects of head and torso filtering on auditory signals. These recordings consisted of 710 positions ranging from −40° to +90° elevation at 1.4 m (ref. 53). A subset of these positions corresponded to the location bins into which the network classified source locations.
Virtual acoustic simulator: two-microphone array
For comparison with the networks trained with simulated ears, we also trained the same neural network architectures to localize sounds using audio recorded from a two-microphone array (Extended Data Fig. 6). To train these networks, we simulated audio received from a two-microphone array by replacing each pair of HRIRs in the room simulator with a pair of fractional delay filters (that is, that delayed the signal by a fraction of a sample). These filters consisted of 127 taps and were constructed via a sinc function windowed with a Blackman window, offset in time by the desired delay. Each pair of delay filters also incorporated signal attenuation from a distance according to the inverse square law, with the goal of replicating the acoustics of a two-microphone array. After substituting these filters for the HRIRs used in our main training procedure, we simulated a set of BRIRs as described above.
Natural sound sources
We collected a set of 455 natural sounds, each cut to two seconds in length. Of these sounds, 300 were drawn from a set used in previous work in the laboratory144. Another 155 sounds were drawn from the BBC Sounds Effects Database, selected by the first author to be easily identifiable. The sounds included human and animal vocalizations, human actions (chopping, chewing, clapping and so on), machine sounds (cars, trains, vacuums and so on) and nature sounds (thunder, insects, running water, etc.). The full list of sounds is given in Extended Data Fig. 4. All sounds were sampled at 44.1 kHz. Of this set, 385 sounds were used for training and another 70 were withheld for model validation and testing. To augment the dataset, each of these was bandpass-filtered with a two-octave-wide second-order Butterworth filter with centre frequencies spaced in one-octave steps starting from 100 Hz. This yielded 2,492 (2,110 training, 382 testing) sound sources in total.
Background noise sources
Background noise sources were synthesized using a previously described texture generation method that produced texture excerpts rated as highly realistic55. The specific implementation of the synthesis algorithm was that used in ref. 60, with a sampling rate of 44.1 kHz. We used 50 different source textures obtained from in-laboratory collections145. Textures were selected that synthesized successfully, both subjectively (sounding perceptually similar to the original texture) and objectively (the ratio between mean squared statistic values for the original texture and the mean squared error between the statistics of the synthesized and original texture was greater than 40 dB). We then rendered 1,000 5-s exemplars for each texture (subsequently cut to 2 s in length) for a total of 50,000 unique waveforms (1,000 exemplars × 50 textures). Background noises were created by spatially rendering between three and eight exemplars of the same texture at randomly chosen locations using the virtual acoustic simulator described above. We made this choice on grounds of ecological validity, on the basis of the intuition that noise sources are typically not completely spatially uniform96 despite being more diffuse than sounds made by single organisms or objects. By adding noises rendered at different locations we obtained background noise that was not as precisely localized as the target sound sources, which seemed a reasonable approximation of common real-world conditions.
Generating training exemplars
To reduce the storage footprint of the training data, we separately rendered the sound sources to be localized, and the background noise, and then randomly combined them to generate training exemplars. For each source, room and listener location, we randomly rendered each of the 504 positions with a probability \(P = \frac{{0.025 \times {\mathrm{no.}}\, {\mathrm{of}}\,{\mathrm{listener}}\,{\mathrm{locations}}\,{\mathrm{in}}\,{\mathrm{smallest}}\,{\mathrm{room}}}}{{{\mathrm{no.}} \,{\mathrm{of}}\,{\mathrm{listener}}\,{\mathrm{locations}}\,{\mathrm{in}}\,{\mathrm{room}}\,{\mathrm{being}}\,{\mathrm{rendered}}}}\). We used a base probability of 2.5% to limit the overall size of the training set and normalized by the number of listener locations in the room being used to render the current stimulus so that each room was represented equally in the dataset. This yielded 545,566 spatialized natural sound source stimuli in total (497,935 for training, 47,631 for testing). This resulted in 988 examples per training location, on average.
For each training example, the audio from one spatialized natural sound source and one spatialized background texture scene was combined (with a signal-to-noise ratio (SNR) sampled uniformly from 5 to 30 dB SNR) to create a single auditory scene that was used as a training example for the neural network. The resulting waveform was then normalized to have an root-mean-square (r.m.s.) amplitude of 0.1. Each training example was passed through the cochlear model before being fed to the neural network.
Stimulus preprocessing: cochlear model
Training examples were preprocessed with a cochlear model to simulate the human auditory periphery. The output of the cochlear model is a time-frequency representation intended to represent the instantaneous mean firing rates in the auditory nerve. The cochlear model was chosen to approximate the time and frequency information in the human cochlea subject to practical constraints on the memory footprint of the model and the dataset. Cochleagrams were generated using a filter bank similar to that used in previous work from our laboratory55. However, the cochleagrams we used provided fine timing information to the neural network by passing rectified subbands of the signal instead of the envelopes of the subbands. This came at the cost of substantially increasing the dimensionality of the input relative to an envelope-based cochleagram. The dimensionality was nonetheless considerably lower than what would have resulted from a spiking model of the auditory nerve, which would have been prohibitive given our hardware.
The waveforms for the left and right channels were first upsampled to 48 kHz, then separately passed through a bank of 39 bandpass filters. These filters were regularly spaced on an equivalent rectangular bandwidth scale54 with bandwidths matched to those expected in a healthy human ear. Filter centre frequencies ranged from 45 to 16,975 Hz. Filters were zero-phase, with transfer functions in the frequency domain shaped like the positive portion of a cosine function. These filters perfectly tiled the frequency axis such that the summed squared response of all filters was flat and allowed for reconstruction of the signal in the covered frequency range. Filtering was performed by multiplication in the frequency domain, yielding a set of subbands. The subbands were then transformed with a power function (0.3 exponent) to simulate the outer hair cells’ non-linear compression. The results were then half-wave rectified to simulate auditory nerve firing rates and were low-pass filtered with a cut-off frequency of 4 kHz to simulate the upper limit of phase locking in the auditory nerve56, using a Kaiser-windowed sinc function with 4,097 taps. The results of the low-pass filtering were then downsampled to 8 kHz to reduce the dimensionality of the neural network input (without information loss because the Nyquist limit matched the low-pass filter cut-off frequency). Because the low-pass filtering and downsampling were applied to rectified filter outputs, the representation retained information at all audible frequencies, just with limits on fidelity that were approximately matched to those believed to be present in the ear. We note also that the input was not divided into ‘frames’ as are common in audio engineering applications, as these do not have an obvious analogue in biological auditory systems. All operations were performed in Python but made heavy use of the NumPy and SciPy library optimization to decrease processing time. Code to generate cochleagrams in this way is available on the McDermott laboratory webpage (http://mcdermottlab.mit.edu).
To minimize artificial onset cues at the beginning and end of the cochleagram that would not be available to a human listener in everyday listening conditions, we removed the first and last 0.35 s of the computed cochleagram and then randomly excerpted a 1-s segment from the remaining 1.3 s. The neural network thus received 1 s of input from the cochlear model, as a 39 × 8,000 × 2 tensor (39 frequency channels × 8,000 samples at 8 kHz × 2 ears).
For reasons of storage and implementation efficiency, the cochlear model stage was in practice implemented as follows, taking advantage of the linearity of the filter bank. First, the audio from each spatialized natural sound source and each spatialized background texture scene was run through the cochlear filter bank. Second, we excerpted a 1-s segment from the resulting subbands as described in the previous paragraph. Third, the two sets of subbands were stored in separate data structures. Fourth, during training, the subbands for a spatialized natural sound source and a spatialized background scene were loaded, scaled to achieve the desired SNR (sampled uniformly from 5 to 30 dB), summed and scaled to correspond to a waveform with r.m.s. amplitude of 0.1. The resulting subbands were then half-wave rectified, raised to the power of 0.3 to simulate cochlear compression, and downsampled to 8 kHz to simulate the upper limit of auditory nerve phase locking. This ‘cochleagram’ was the input to the neural networks.
Environment modification for unnatural training conditions
In each unnatural training condition, one aspect of the training environment was modified.
Anechoic environment
All echoes and reflections in this environment were removed. This was accomplished by setting the room material parameters for the walls, floor and ceiling to completely absorb all frequencies. This can be conceptualized as simulating a perfect anechoic chamber.
Noiseless environment
In this environment, the background noise was removed by setting the SNR of the scene to 85 dB. No other changes were made.
Unnatural sound sources
In this environment, we replaced the natural sound sources with unnatural sounds consisting of repeating bandlimited noise bursts. For each 2-s sound source, we first generated a 200 ms 0.5 octave-wide noise burst with a 2 ms half-Hanning window at the onset and offset. We then repeated that noise burst separated by 200 ms of silence for the duration of the signal. The noise bursts in a given source signal always had the same centre frequency. The centre frequencies (the geometric mean of the upper and lower cut-offs) across the set of sounds were uniformly distributed on a log scale between 60 and 16.8 kHz.
Neural network models
The 39 × 8,000 × 2 cochleagram representation (representing 1 s of binaural audio) was passed to a CNN, which instantiated a feedforward, hierarchically organized set of linear and non-linear operations. The components of the CNNs were standard; they were chosen because they have been shown to be effective in a wide range of sensory classification tasks. In our CNNs, there were four different kinds of layer, each performing a distinct operation: (1) convolution with a set of filters, (2) a point-wise non-linearity, (3) batch normalization and (4) pooling. The first three types of layer always occurred in a fixed order (batch normalization, convolution and a point-wise non-linearity). We refer to a sequence of these three layers in this order as a ‘block’. Each block was followed by either another block or a pooling layer. Each network ended with either one or two fully connected layers feeding into the final classification layer. Below, we define the operations of each type of layer.
Convolutional layer
A convolutional layer consists of a bank of K linear filters, each convolved with the input to produce K separate filter responses. Convolution performs the same operation at each point in the input, which in our case was the cochleagram. Convolution in time is natural for models of sensory systems as the input is a temporal sequence whose statistics are translation invariant. Convolution in frequency is less obviously natural, as translation invariance does not hold in frequency. However, approximate translation invariance holds locally in the frequency domain for many types of sound signal, and convolution in frequency is often present, implicitly or explicitly, in auditory models146,147. Moreover, imposing convolution greatly reduces the number of parameters to be learned, and we have found that neural network models train more readily when convolution in frequency is used, suggesting that it is a useful form of model regularization.
The input to a convolutional layer is a three-dimensional array with shape (nin, min, din) where nin and min are the spectral and temporal dimensions of the input, respectively, and din is the number of filters. In the case of the first convolutional layer, nin = 39 and min = 8,000, corresponding to the spectral and temporal dimensions of the cochleagram, and din = 2, corresponding to the left and right audio channels.
A convolution layer is defined by five parameters:
-
1.
nk, the height of the convolutional kernels (that is, their extent in the frequency dimension)
-
2.
mk, the width of the convolutional kernels (that is, their extent in the time dimension)
-
3.
K, the number of different kernels
-
4.
W, the kernel weights for each of the K kernels; this is an array of dimensions (nk, mk, din, K)
-
5.
B, the bias vector, of length K
For any input array X of shape (nin, min, din), the output of this convolutional layer is an array Y of shape (nin, min − mk + 1,K) (due to the boundary handling choices described below):
where i ranges from (1, …, nin), j ranges (1, …, min) and ⊙ represents point-wise array multiplication.
Boundary handling via valid padding in time
There are several common choices for boundary handling during convolution operations. For the output of a convolution to be the same dimensionality as the input, the input signal is typically padded with zeros. This approach—often termed ‘same’ convolution—has the downside of creating an artificial onset in the data that would not be present in continuous audio in the natural world, and that might influence the behaviour of the model. To avoid this possibility, we used ‘valid’ convolution in the time dimension. This type of convolution only applies the filter at positions where every element of the kernel overlaps with the actual input. This eliminates artificial onsets at the start/end of the signal but means that the output of the convolution will be slightly smaller than its input, as the filters cannot be centred over the first and last positions in the input without having part of the filter not overlap with the input data. We used ‘same’ convolution in the frequency dimension because the frequency dimension has lower and upper limits in the cochlea, such that boundary effects are less obviously inconsistent with biology. In addition, the frequency dimension was much smaller than the time dimension, such that it seemed advantageous to preserve channels at each convolution stage.
Point-wise non-linearity
If a neural network consists of only convolution layers, it can be mathematically reduced to a single matrix operation. A non-linearity is needed for the neural network to learn more complex functions. We used rectified linear units (a common choice in current deep neural networks) that operate point wise on every element in the input map according to a piecewise linear function:
Normalization layer
The normalization layer applied batch normalization148 in a point-wise manner to the input map. Specifically, for a batch B of training examples, consisting of examples \(\left\{ {X_1, \ldots ,X_M} \right\}\), with shape (nin, min, din), each example is normalized by the mean and variance of the batch:
where \(\hat X_i\) is the normalized three-dimensional matrix of the same shape as the input matrix and \({\it{\epsilon }} = 0.001\) to prevent division by zero.
Throughout training, the batch normalization layer maintains a cumulative mean and variance across all training examples, μTotal and \(\sigma _{{\mathrm{Total}}}^2\). At test time \(\hat X_i\) is calculated using μTotal and \(\sigma _{{\mathrm{Total}}}^2\) in place of μB and \(\sigma _B^2\).
Pooling layer
A pooling layer allows downstream layers to aggregate information across longer periods of time and wider bands of frequency. It downsamples its input by aggregating values across nearby time and frequency bins. We used max pooling, which is defined via four parameters:
-
1.
ph, the height of the pooling kernel
-
2.
pw, the width of the pooling kernel
-
3.
sh, the stride in the vertical dimension
-
4.
sw, the stride in the horizontal dimension
A pooling layer takes array X of shape (nin, min, din) and returns array Y with shape (nin/sw, min/sh, din) according to:
where \(N_{p_{\mathrm{w}}p_{\mathrm{h}}}\left( {X,i,j,k} \right)\) i s a windowing function that takes a (pw, ph) excerpt of X of centred at (i,j) from filter k. The maximum is over all elements in the resulting excerpt.
Fully connected layer
A fully connected layer, also often called a dense layer, does not use the weight sharing found in convolutional layers, in which the same filter is applied to all positions within the input. Instead, each (input unit, output unit) pair has its own learned weight parameter and each output unit has its own bias parameter. Given input X with shape (nin, min, din), a fully connected layer produces output Y with shape (nout). It does so in two steps:
-
1.
Flattens the input dimensions, creating an input Xflat of shape \((n_{{\mathrm{in}}} \times m_{{\mathrm{in}}} \times d_{{\mathrm{in}}})\)
-
2.
Multiplies Xflat by weight and bias matrices of shape \((n_{{\mathrm{out}}},n_{{\mathrm{in}}} \times m_{{\mathrm{in}}} \times d_{{\mathrm{in}}})\) and (nout), respectively. This is implemented as:
where B(nout) is the bias vector, W(nout,l) is the weight matrix and l ranges from 1 to \((n_{{\mathrm{in}}} \times m_{{\mathrm{in}}} \times d_{{\mathrm{in}}})\) and indexes all positions in the flattened input matrix.
Softmax classifier
The final layer of every network was a classification layer, which consists of a fully connected layer where nout is the number of class labels (in our case 504). The output of that fully connected layer was then passed through a normalized exponential (softmax) function. Together this was implemented as:
The vector y sums to one and all entries are greater than zero. This is often interpreted as a vector of label probabilities conditioned on the input.
Dropout during training
For each new batch of training data, dropout was applied to all fully connected layers of a network. Dropout consisted of randomly choosing 50% of the weights in the layer and temporarily setting them to zero, thus effectively not allowing the network access to the information at those positions. The other 50% of the weights were scaled up such that the expected value of the sum over all inputs was unchanged. This was implemented as:
Dropout is common in neural network training and can be viewed as a form of model averaging where exponentially many models using different subsets of the input vector are being trained simultaneously149. During evaluation, dropout was turned off (and no weight scaling was performed) so that all weights were used.
Neural network optimization
Architecture search: overview
When neural networks are applied to a new problem it is common to use architectures that have previously produced good results on similar problems. However, most standard CNN architectures that operate on two-dimensional inputs have been designed for visual tasks and make assumptions based on the visual world. For example, most architectures assume that the units in the x and y dimension are equivalent, such that square filter kernels are a reasonable choice. However, in our problem the two input dimensions are not comparable (frequency versus time). Additionally, our input dimensionality was several orders of magnitude larger than standard visual stimuli (70,000 versus 1.1 million), even though some relevant features occur on the scale of a few samples. For example, an ITD of 400 µs (a typical value) corresponds to only a six-sample offset between channels. Given that our problem was distinct from many previous applications of standard neural network architectures, we performed an architecture search to find architectures that were well-suited to our task. First, we defined a space of architectures described by a small number of hyperparameters. Next, we defined discrete probability distributions for each hyperparameter. Last, we independently sampled from these hyperparameter distributions to generate architectures. We then trained each architecture for a brief period and selected the architectures that performed best on our task for further training.
Architecture search: distribution over hyperparameters
To search over architectures, we defined a space of possible architectures that were encoded via a set of hyperparameters. The space had the following constraints:
-
There could be between three and eight pooling layers for any given network.
-
A pooling layer was preceded by between one and three blocks. Each block consisted of batch normalization, followed by convolution, followed by a rectified linear layer.
-
The number of channels (filters) in the network was always 32 in the first convolutional layer and could either double or remain the same in each successive convolutional layer.
-
The penultimate stage of each network consisted of one or two fully connected layers containing 512 units each. Each of these was followed by a dropout layer.
-
The final stage of each network was always a Softmax Classifier with 504 output units, corresponding to the 504 locations the network could report.
We picked the pooling and convolutional kernel parameters at each layer by uniformly sampling from the lists of values in Extended Data Fig. 2. We chose these distributions to skew toward smaller values at deeper layers, approximately in line with the downsampling that resulted from pooling operations. Multiple copies of the same number increased the probability of that value being chosen for the kernel size. Note that differences between the time and frequency dimensions of the cochlear input motivate the use of filters that are not square.
Filter weight training
Throughout training, the parameters in each convolutional kernel and all weights from fully connected layers were iteratively adjusted to improve task accuracy via mini-batch stochastic gradient descent (SGD)150. Training was performed with 1.6 million sounds (100,000 training steps each with a batch of 16 training examples) generated by looping over the 500,000 foreground sounds and combining each with a randomly selected background sound. Networks were assessed via a held-out set of 50,000 test stimuli created by looping over the 48,000 sound sources in the validation set in the same manner. We used a Softmax Cross-Entropy loss function. The trainable weights in the convolutional layers and fully connected layers were updated using the gradient of the loss function, computed using backpropagation.
Gradient checkpointing
The dimensionality of our input was sufficiently large (due to the high sampling rates needed to preserve the fine timing information in the simulated auditory periphery) as to preclude training neural networks using standard methodology. For example, consider training a network consisting of four pooling layers (2 × 1 kernel), each preceded by one block. If there are 32 convolutional filters in the first layer, and double the number of filters in each successive layer, this network would require approximately 80 GB of memory at peak usage, which exceeded the maximum memory of graphical processing units (GPUs) that were standard at the time of model training (available GPUs varied between 12 and 32 GB). We addressed this problem using a previously proposed solution called gradient checkpointing52.
In the standard backpropagation algorithm, we must retain the output from each layer of a network in memory because it is needed to calculate gradients for each updatable parameter. The gradient checkpointing algorithm we used trades speed for lower memory usage by not retaining each layer’s output during the forward pass, instead recomputing it a second time during the backward pass when gradients are computed. In the most extreme version, this would result in laboriously recomputing each layer starting with the original network input. Instead, the algorithm creates sparse, evenly spaced checkpoints throughout the network that save the output of selected layers. This strategy allows recomputation during backpropagation to start from one of these checkpoints, saving compute time. In practice, it also provides users with a parameter that allows them to select a speed/memory trade-off that will maximize speed subject to a network fitting onto the available GPU. We created checkpoints at every pooling layer and found it kept our memory use below the 16-GB limit of the hardware we used for all networks in the architecture search.
Network architecture selection and training
We performed our architecture search on the Department of Energy’s Summit Supercomputer at Oak Ridge National Laboratory. First, we randomly drew 1,500 architectures from our hyperparameter distribution. Next, we trained each architecture (that is, optimized the weights of the convolutional and fully connected layers) using mini-batch SGD for 15,000 steps, each with a batch size of 16, for a total of 240,000 unique training examples, randomly drawn from the training set described above. We then evaluated the performance of each architecture on left-out data. The length of this training period was determined by the job limits on Summit; however, it was long enough to see substantial reductions in the loss function for many networks. We considered the procedure adequate for architecture selection given that performance early in training is a good predictor of training performance late in training151. In total, this architecture search took 2.05 GPU years and 45.2 CPU years.
We selected the ten best-performing architectures. They varied significantly, ranging from four to six pooling layers. We then retrained these ten architectures until a point where performance on the withheld validation set began to decrease, evaluating every 25,000 iterations. This occurred at 100,000 iterations for the naturalistic, anechoic and noiseless training conditions and at 150,000 iterations for the unnatural sounds training condition. Model architectures and the trained weights for each model are available online in the associated codebase: www.github.com/afrancl/BinauralLocalizationCNN.
Real-world evaluation
We tested the model in real-world conditions to verify generalization from the virtual training environment. We created a series of spatial recordings in an actual conference room (part of our laboratory space, with dimensions distinct from the rooms in our virtual training environment) and then presented those to the trained networks. We also made recordings of the same source sounds and environment with a two-microphone array to test the importance of naturally induced binaural cues (from the ears, head and/or torso).
Sound sources
We used 100 sound sources in total: 50 sound sources were from our validation set of withheld environmental sounds, and the remaining 50 sound sources were taken from the GRID dataset of spoken sentences152. For the examples from the GRID dataset, we used five sentences from each of ten speakers (five male and five female). The model performed similarly for stimuli from the GRID dataset as for our validation set stimuli. All source signals were normalized to the same peak amplitude before the recordings were made.
Recording setup
We made the set of real-world evaluation recordings using a KEMAR head and torso simulator mannequin built by Knowles Electronics to replicate the shape and absorbency of a human head, upper body and pinna. The KEMAR mannequin contains a microphone in each ear, recording audio similar to that which a human would hear in natural conditions. The audio from these microphones was then passed through Etymotic Research preamplifiers designed for the KEMAR mannequin before being passed to a Zoom 8 USB to Audio Converter. Finally, it was passed to Audacity where the left and right channels were simultaneously recorded at 48 kHz.
We made recordings of all 100 sounds at every azimuth (relative to the KEMAR mannequin) from 0° to 360° in 30° increments. This led to 1,200 recordings in total. All source sounds were played 1.5 m from the vertical axis of the mannequin using a KRK ROKIT 7 speaker positioned at approximately 0° elevation. The audio was played using Audacity and converted to an analogue signal using a Zoom 8 USB to Audio Converter.
Recordings were made in our main laboratory space in building 46 on the MIT campus, in a room that was roughly 7 × 6 × 3 m. The room was filled with furniture and shelves, and had multiple windows and doors (Fig. 1e). This setup was substantially different from any of the simulated rooms in the virtual training environment, in which all rooms were convex, empty and had smooth walls. During the recordings, there was low-level background noise from the ventilation system, the refrigerator and laboratory members talking in surrounding offices. For all recordings, the mannequin was seated in an office chair, with the head approximately 1 m from the ground.
Two-microphone array baseline
We made a second set of recordings using the same sound sources, room and recording equipment as above, but with the KEMAR mannequin replaced with a two-microphone array consisting of two Beyerdynamic MM-1 Omnidirectional Microphones separated by 15 cm (the same distance separating the two microphones in the mannequin ears). The microphone array was also elevated approximately 1 m from the floor using a microphone stand (Extended Data Fig. 6a).
Baseline algorithms
We evaluated our trained neural networks against a variety of baseline algorithms. These comprised: steered-response power phase transform (SRP)65, multiple signal classification (MUSIC)64, the coherent signal-subspace method (CSSM)63, weighted average of signal subspaces (WAVES)66, test of orthogonality of projected subspaces (TOPS)67 and the WavLoc neural network68. With the exception of the WavLoc model, in each case we used the previously validated and published algorithm implementations in Pyroomacoustics153. For the WavLoc model, we used a reference GitHub implementation and confirmed that we could reproduce the results of the original paper68 before testing with our KEMAR mannequin recordings. We also created a baseline model trained using a simulation of the two-microphone array described in the previous section within the virtual training environment (the same ten neural network architectures used for our primary model were trained to localize sounds using audio recorded from simulated a two-microphone array).
The results shown in Extended Data Fig. 6b,c for the baselines (aside from our two-microphone array baseline neural network model) all plot localization of the KEMAR mannequin recordings. We found empirically that the baseline methods performed better for the KEMAR recordings than for the two-microphone array recordings, presumably because the mannequin head increases the effective distance between the microphones. The baseline algorithms require previous knowledge of the intermicrophone distance. To make the baselines as strong as possible relative to our method, we searched over all distances shorter than 50 cm and found that an assumed distance of 26 cm yielded the best performance. We then evaluated the baselines at that assumed distance. This optimal assumed distance is greater than the actual intermicrophone distance of 15 cm, consistent with the idea that the mannequin head increases the effective distance between microphones.
Comparison with human listeners
To provide an example of free-field human sound localization, Fig. 1f plots the results of an experiment by Yost and colleagues154. In that experiment, humans were presented with noise bursts (low-pass filtered white noise with a cut-off of 6 kHz, 200 ms in duration, with 20 ms cosine onset and offset ramps) played from one of 11 speakers in an anechoic chamber. The speakers were spaced every 15°, with the array centred on the midline. Speakers were visible to participants. Participants indicated the speaker from which the sound was played by entering a number corresponding to the speaker. Results are shown for 45 participants (34 female), ages 21–49. Because the human experiment was restricted to speakers in front of the participants, for ease of comparison Fig. 1g plots model results after front–back folding of actual and judged positions (Fig. 1h shows model results without front–back folding). Figure 1f–h display kernel density estimates of the response distributions, generated using the seaborn statistical data visualization library.
Psychophysical evaluation of model
Overview
We simulated a suite of classic psychoacoustic experiments on the ten trained neural networks, using the same stimuli for each network. We then calculated the mean response across networks for each experimental condition and calculated error bars by bootstrapping across the ten networks. This approach can be interpreted as marginalizing out uncertainty over architectures in a situation in which there is no single obviously optimal architecture (and where the space of architectures is so large that it is probably not possible to find the optimum even if it exists). Moreover, recent work suggests that internal representations across different networks trained on the same task can vary considerably57, so this approach aided in mitigating the individual idiosyncrasies of any given network. The approach could also be viewed as treating every network as an individual experimental participant, calculating means and error bars as one would in a standard human psychophysical experiment.
In each experiment, stimuli were run through our cochlear model and passed to each of the networks, whose localization responses were recorded for each stimulus. Stimuli were generated as 2 s sound signals, normalized to have an r.m.s. amplitude of 0.1. The output of the cochlear model was then cropped to 1 s (by excerpting the middle 1 s), which provided the input to the networks.
Front–back folding
For experiments in which human participants judged locations within the frontal hemifield, we front–back folded the model responses to enable a fair comparison. This consisted of treating each model response in the rear hemifield as though it was a response in the corresponding front hemifield. For example, the 10° and 170° azimuthal positions were considered equivalent.
Sensitivity to ITDs and ILDs: stimuli
We reproduced the experimental stimuli from ref. 69, in which ITDs and ILDs were added to 3D spatially rendered sounds. In the original experiment, participants stood in a dark anechoic room and were played spatially rendered stimuli with modified ITDs or ILDs via a set of headphones. After each stimulus presentation, participants oriented their head towards the perceived location of the stimulus and pressed a button. The experiment included 13 participants (five male) ranging in age from 18–35 years old.
Stimulus generation for the model experiment was identical to that in the original experiments apart from using our acoustic simulator to render the sounds. First, we generated high- and low-pass noise bursts with passbands of 4–16 and 0.5–2 kHz, respectively (44.1 kHz sampling rate). Each noise burst was 100 ms long with a 1-ms squared-cosine ramp at the beginning and end of the stimulus. We randomly jittered the starting time of the noise burst by padding the signal to 2,000 ms in total length, constrained such that the entire noise burst was contained in the middle second of the 2-s audio signal (the noise onset was uniformly distributed subject to this constraint). These signals were then rendered at 0° elevation, with azimuth varied from 0 to 355° (in 5° steps) for a total of 72 locations. All signals were rendered using our virtual acoustic simulator in an anechoic environment without any background noise.
Next, we created versions of each signal with an added ITD or ILD bias. ITD biases were ±300 and ±600 µs and ILD biases were ±10 and ±20 dB (Fig. 2a). As in the original publication69, we prevented presentation of stimuli outside the physiological range by restricting the 400 µs/10 dB biases to signals rendered less than 40° away from the midline and restricting the 600 µs/20 dB biases to signals rendered less than 20° away from the midline. In total, there were four stimulus sets (2 passbands × 2 types of bias) of 266 stimuli (72 locations with no bias, 52 locations at ±medium bias, 45 locations ± large bias). We replicated the above process 20 times with different exemplars of bandpass noise, increasing each stimulus set size to 5,320 (20 exemplars of 266 stimuli).
Sensitivity to ITDs and ILDs: analysis
We measured the perceptual bias induced by the added ITD or ILD bias in the same manner as the published analysis of human listeners69.
We first calculated the naturally occurring ITD and ILD for each sound source position (varying in azimuth, at 0° elevation) from the HRTFs used to train our networks. For ITDs, we ran the HRTFs for a source position through our cochlear model and found the ITD by cross-correlating the cochlear channels whose centre frequency was closest to 600, 700 and 800 Hz and taking the median ITD from the three channels. For ILDs, we computed power spectral density estimates via Welch’s method (29 samples per window, 50% overlap, Hamming windowed) for each of the two HRTFs for a source position and integrated across frequencies in the stimulus passband. We expressed the ILD as the ratio between the energy in the left and right channel in decibels, with positive values corresponding to more power in the right ear. This set of natural ILDs and ITDs allowed us to map the judged position onto a corresponding ITD/ILD.
For each stimulus with added ITD, we used the response mapping described above to calculate the ITD of the judged source position. Next, we calculated the ITD for the judged position of the unaltered stimulus using the same response mapping. The perceptual effect of the added ITD was calculated as the difference between these two ITD values, quantifying (in microseconds) how much the added stimulus bias changed the response of the model. The results graphs plot the added stimulus bias on the x axis and the resulting response bias on the y axis. The slope of the best-fitting regression line (the ‘bias weight’ shown in the subplots of Fig. 2c,d) provides a unitless measure of the extent to which the added bias affects the judged position. We repeated an analogous process for ILD bias using the natural ILD response mapping, yielding the bias in decibels. The graphs in Fig. 2d plot the mean response across the ten networks with standard error of the mean (s.e.m.) computed via bootstrap over networks.
Azimuthal localization of broadband sounds: stimuli
We reproduced the stimulus generation from ref. 80. In the original experiment, participants were played six broadband white noise bursts, with three noise bursts (15 ms in duration, 5-ms cosine ramps, repeated at 10 Hz) played from a reference speaker followed by three noise bursts played from one of two target speakers, located 15° to the left or right of the reference speaker. The reference speaker position ranged from –97.5° to +97.5° azimuth in 15° intervals. Participants reported whether the last three noise bursts were played to the left or the right of the reference speaker, and performance was expressed as d’. 18 speakers arranged at 15° intervals from –127.5° to +127.5° azimuth simultaneously played white noise during all trials, producing spatially diffuse background noise that served to bring performance below ceiling. The SNR of the stimulus was set individually for each participant. To determine the SNR, stimuli were played from the speakers at +90 or –90 azimuth and participants judged if each stimulus was to their right or left. This procedure was repeated at different SNRs and the SNR where the participant performed at 95% accuracy was chosen for the main experiment. The experiment included 16 participants between the ages of 18 and 35 years old.
We measured network localization performance using the same stimuli as in the original paper, but for simplicity rendered the stimulus at a single location and measured performance with an absolute, instead of relative, localization task. The stimuli presented to the networks consisted of three pulses of broadband white noise. Each noise pulse was 15 ms in duration and repeated at 10 Hz. A 5-ms cosine ramp was applied to the beginning and end of each pulse. We generated 100 exemplars of this stimulus using different samples of white noise (44.1 kHz sampling rate). The stimuli were zero-padded to 2,000 ms in length, with the temporal offset of the three-burst sequence randomly sampled from a uniform distribution such that all three noise bursts were fully contained in the middle second of audio. We then rendered all 100 stimuli at 0° elevation and azimuthal positions ranging from −90° to +90° in 15° steps. All stimuli were rendered in an anechoic environment without any background noise using our virtual acoustic simulator. This led to 7,200 stimuli in total (100 exemplars at each of 72 locations). The stimuli were presented in spatially diffuse background noise, generated by presenting white noise from 19 positions at 15° intervals from –135° to +135°. The SNR was set for each network individually by measuring its left/right accuracy on stimuli rendered at +90 or –90 degrees at a range of SNRs spaced in 1 dB increments, and then selecting the highest SNR at which the network performed below 95% accuracy. The SNRs selected in this way ranged from –8 dB to –14 dB depending on the network.
Azimuthal localization of broadband sounds: analysis
Because human participants in the analogous experiment judged relative position in the frontal hemifield, before calculating the model’s accuracy we eliminated front–back confusions by mirroring model responses of each stimulus across the coronal plane. We then calculated the difference in degrees between the rendered azimuthal position and the position judged by the model. We calculated the mean absolute error for each rendered azimuth for each network. The graph in Fig. 3c plots the mean error across networks. Error bars are s.e.m., bootstrapped over networks.
Integration across frequency: stimuli
We reproduced stimuli from ref. 82. In the original experiment, human participants were played a single noise burst, varying in bandwidth and centre frequency, from one of eight speakers spaced 15° in azimuth. Participants judged which speaker the noise burst was played from. The experimenters then calculated the localization error in degrees for each bandwidth and centre frequency condition. The experiment included 33 participants (26 female) between the ages of 18 and 36 years old.
The stimuli varied in bandwidth (pure tones, and noise bursts with bandwidths of 1/20, 1/10, 1/6, 1/3, 1 and 2 octaves wide; all with 44.1 kHz sampling rate). All sounds were 200 ms long with a 20-ms squared-cosine ramp at the beginning and end of the sound. All pure tones had random phase. All other sounds were bandpass-filtered white noise with the geometric mean of the passband cut-offs set to 250, 2,000 or 4,000 Hz (as in the original paper82).
For the model experiment, the stimuli were zero-padded to 2,000 ms in length, with the temporal offset of the noise burst randomly sampled from a uniform distribution such that the noise burst was fully contained in the middle second of audio. We generated 30 exemplars of each bandwidth–frequency pair using different exemplars of white noise (or of random phase for the pure tone stimuli). Next, we rendered all stimuli at 0° elevation and azimuthal positions ranging from 0° to 355° in 5° steps. All stimuli were rendered in an anechoic environment without any background noise using the virtual acoustic simulator. This led to 45,360 stimuli in total (30 exemplars × 72 positions × 3 centre frequencies × 7 bandwidths).
Integration across frequency: analysis
Because human participants in the original experiment judged position in the frontal hemifield, before calculating the model’s accuracy, we again eliminated front–back confusions by mirroring model responses of each stimulus across the coronal plane. We then calculated the difference in degrees between the rendered azimuthal position and the azimuthal position judged by the model. For each network, we calculated the r.m.s. error for each bandwidth. The graph in Fig. 3f plots the mean of this quantity across networks. Error bars are s.e.m., bootstrapped over networks.
Use of ear-specific cues to elevation: stimuli
We simulated a change of ears for our networks, analogous to the ear mould manipulation in ref. 84). In the original experiment in ref. 84, participants sat in a dark anechoic room and were played broadband white noise bursts from a speaker on a robotic arm that moved ±30° in azimuth and elevation. Participants reported the location of each noise burst by saccading to the perceived location. After collecting a baseline set of measurements, participants were fitted with plastic ear moulds (Fig. 4a), which modified the location-dependent filtering of their pinnae. Participants then performed the same localization task a second time. The experimenters plotted the mean judged location for each actual location before and after fitting participants with the plastic ear moulds (Fig. 4b,c). The experiment included four participants between the ages of 22 and 44 years old.
For the model experiment, instead of ear moulds we substituted HRTFs from the CIPIC dataset155. The CIPIC dataset contains 45 sets of HRTFs, each of which is sampled at azimuths from −80 to +80 in 25 steps of varying size, and elevations from 0 to 360 in 50 steps of varying size. For the sound sources to be localized, we generated 500 ms broadband (0.2–20 kHz) noise bursts sampled at 44.1 kHz (as in ref. 84). We then zero-padded these sounds to 2,000 ms, with the temporal offset of the noise burst randomly sampled from a uniform distribution such that it was fully contained in the middle second of audio. We generated 20 such exemplars using different samples of white noise. We then rendered each stimulus at ±20 and ±10° azimuths, and 0°, 10°, 20° and 30° elevation for all 45 sets of HRTFs as well as the standard set of HRTFs (that is, the one used for training the model). This led to a total of 14,720 stimuli (46 HRTFs × 4 azimuths × 4 elevations). The rendered locations were slightly different from those used in ref. 84 as we were constrained by the locations that were measured for the CIPIC dataset.
Use of ear-specific cues to elevation: analysis
The results graphs for this experiment (Fig. 4b–e) plot the judged source position for each of a set of rendered source positions, either for humans (Fig. 4b,c) or the model (Fig. 4d,e). For the model results, we first calculated the mean judged position for each network for all stimuli rendered at each source position. The graphs plot the mean of this quantity across networks. Error bars are the s.e.m., bootstrapped over networks. In Fig. 4d we plot model responses for stimuli rendered using the HRTFs used during network training. In Fig. 4e we plot the average model responses for stimuli rendered with 45 sets of HRTFs from the CIPIC database (none of which were used during network training). In Fig. 4f,g we plot the results separately for each alternative set of HRTFs, averaged across elevation or azimuth. The thickest bolded line denotes the mean performance across all HRTFs, and thinner bolded lines denote HRTFs at the 5th, 25th, 75th and 95th percentiles order by error. Each line plots the mean over the ten networks.
Limited spectral resolution of elevation cues: stimuli
We ran a modified version of the spectral smoothing experiment in ref. 86 on our model using the training HRTFs. The original experiment86 measured the effect of spectral detail on human sound localization. The experimenters first measured HRTFs for each participant. Participants then sat in an anechoic chamber and were played broadband white noise bursts presented in one of two ways. The noise burst was either played directly from a speaker in the room or virtually rendered at the position of the speaker using the participant’s HRTF and played from a set of open-backed earphones worn by the participant. The experimenters manipulated the spectral detail of the HRTFs as described below. On each trial, two noise bursts (one for each of the two presentation methods) were played in random order and participants judged which of the two noise bursts were played via earphones. In practice, this judgement was performed by noticing changes in the apparent sound position that occurred when the HRTFs were sufficiently degraded. The results of the experiment were expressed as the accuracy in discriminating between the two modes of presentation as a function of the amount of spectral detail removed (Fig. 4i). The experiment included four participants.
The HRTF is obtained from the Fourier transform of the HRIR, and thus can be expressed as:
where x is the HRIR, N is the number of samples in the HRTF and k = [0,N − 1]. To smooth the HRTF, we first compute the log-magnitude of H[k]. This log-magnitude HRTF can be decomposed into frequency components via the discrete cosine transform:
where C(n) is the nth cosine coefficient of log|H[k]| and M = N/2.
As in the original experiment86, we smoothed the HRTF by reconstructing it with M < N/2. We used the same set of previously recorded HRTFs used in the room simulator53. In the most extreme case where M = 0, the magnitude spectrum was perfectly flat at the average value of the HRTF. Increasing M increases the number of cosines used for reconstruction, leading to more spectral detail (Fig. 4h). After smoothing, we calculated the minimum phase filter from the smoothed magnitude spectrum, adding a frequency-independent time delay consistent with the original HRIR. Our HRIRs consisted of 512 time points, corresponding to a maximum of 256 points in its cosine series.
We repeated this smoothing process for each left and right HRTF at each spatial position. We then generated 20 exemplars of broadband white noise (0.2–20 kHz, 2,000 ms in length) with a 10 ms cosine ramp at the beginning and end of the signal. Each exemplar was rendered using each smoothed set of HRTFs. The exemplars were rendered at elevations between 0° and 60° in 10° steps and a set of azimuths ranging from 0° to 355°, the spacing of which varied with elevation due to the locations in the original set of HRTFs. This yielded 74,340 stimuli (nine smoothed sets of HRTFS × 20 exemplars × 413 locations).
Limited spectral resolution of elevation cues: analysis
For the model, the effect of the smoothing was measured as the average absolute difference in degrees between the judged position and the rendered position for each stimulus. Figure 4j plots the mean error across networks for each smoothed set of HRTFs. Error bars are s.e.m., bootstrapped over networks. Figure 4k,l plot the mean judged azimuth (left) and elevation (right) versus the actual rendered azimuth and elevation, plotted separately for each smoothing level. Each line is the mean response pooled across networks. Error bars are shown as bands around the line and show s.e.m., bootstrapped over networks.
Dependence on high-frequency spectral cues to elevation: stimuli
In the original experiment90, human participants were played high- and low-pass noise bursts. The high-pass cut-off frequencies took on one of six values: 3.8, 5.8, 7.5, 10.0, 13.2 and 15.3 kHz; low-pass cut-off frequencies took on one of seven values: 3.9, 6.0, 8.0, 10.3, 12.0, 14.5 and 16.0 kHz (imposed with an analogue Cauer–Chebychev filter). The sampling rate was 44.1 kHz. Each noise burst was 1,000 ms in duration, with a 5-ms squared-cosine ramp at the beginning and end. Each stimulus was presented from one of nine speakers spaced along the midline at 30° increments in elevation from −30° to 210°, with 0° being frontal horizontal. Participants judged which speaker the noise burst was played from, indicating their judgement with a keypress. The results graph (Fig. 4n) plots the proportion correct for each condition (error bars were not plotted in the original publication, and the raw data were no longer available). The experiment included ten participants.
Stimuli for the model experiment were similar to those from the human experiment apart from being presented from a subset of elevations used in the human experiment due to the constraints of the HRTF set in the model. We generated 50 exemplars of each cut-off frequency used in the human experiment, each with a different exemplar of white noise. Filtering was performed in the frequency domain by setting Fourier coefficients beyond the cut-off to zero. We then rendered all 650 noise bursts at one of six locations along the midline: 0°, 30°, 60°, 120°, 150° and 180°, with 0° being frontal horizontal. This led to 3,900 stimuli in total (650 noise bursts at each of six locations). All stimuli were rendered in an anechoic environment without any background noise using the virtual acoustic simulator.
Dependence on high-frequency spectral cues to elevation: analysis
We determined the model’s response in the experiment to be the elevation in the stimulus set that was closest to the elevation of the softmax class bin with the maximum activation. Figure 4o plots the proportion of correct responses for each high-pass and low-pass cut-off frequency, averaged across the ten networks. Error bars are s.e.m., bootstrapped over networks.
Precedence effect: stimuli
For the basic demo of the precedence effect (Fig. 5b) we generated a click consisting of a single sample at +1 surrounded by zeros. We then rendered that click at ±45 azimuth and 0° elevation in an anechoic room without background noise using the virtual acoustic simulator. We added these two rendered signals together, temporally offsetting the −45° click behind the 45° click by an amount ranging from 1 to 50 ms. We then zero-padded the signal to 2,000 ms, sampled it at 44.1 kHz and randomly varied the temporal offset of the click sequence, constrained such that all non-zero samples occurred in the middle second of the stimulus. For each delay value, we created 100 exemplars with different start times.
To quantitatively compare the precedence effect in our model with that in human participants, we reproduced the stimuli from ref. 95. In the original experiment, participants were played two broadband pink noise bursts from two different locations. The leading noise burst came from one of six locations (±20°, ±40° or ±60°) and the lagging noise burst came from 0°. The lagging noise burst was delayed relative to the leading noise burst by 5, 10, 25, 50 or 100 ms. For each pair of noise bursts, participants reported whether they perceived one or two sounds and the judged location for each perceived sound. The experimenters then calculated the mean localization error separately for the leading and lagging click for each time delay (Fig. 5c). The experiment included ten participants (all female) between the ages of 19 and 26 years old.
For both the human and model experiments, stimuli were 25-ms pink noise bursts, sampled at 44.1 kHz, with a 2-ms cosine ramp at the beginning and end of the burst. For the model experiment, we generated two stimuli for each pair of noise burst positions, one where the 0° noise burst was the lead click and another where it was the lag click. For each delay value, location and burst order, we created 100 exemplars with different start times. This was achieved by zero-padding the signal to 2,000 ms and randomly varying the temporal offset, constrained such that all non-zero samples occurred in the middle second of the stimulus.
Precedence effect: analysis
Because human experiments on the precedence effect typically query participants about positions in the frontal hemifield, we corrected for front–back confusions in the analysis of both the precedence effect demo and the Litovsky and Godar experiment by mirroring model responses of each stimulus across the coronal plane. Figure 5b plots the mean judged position at each interclick delay, averaged across the means of the ten individual networks. Error bars are s.e.m., bootstrapped over networks.
To generate Fig. 5d (plotting the results of the model version of the Litovsky and Godar experiment) we calculated errors for each stimulus between the model’s judged position and the positions of the leading and lagging clicks. We calculated the average lead click error and average lag click error for each network at each delay. Figure 5d plots the mean of these quantities across the ten networks. Error bars are s.e.m., bootstrapped over networks.
Multi-source localization: stimuli
We reproduced stimuli from the original experiment98, in which human participants were played between one and eight concurrent speech stimuli. Each stimulus was played from a different location (out of 12 possible, evenly spaced in azimuth). Participants judged the number of stimuli as well as the locations at which stimuli were presented in each trial. The experimenters then plotted the mean number of sources perceived versus the actual number of sources presented (Fig. 6b) and localization accuracy (proportion correct) versus the number of sources presented (Fig. 6d). The experiment included eight normal-hearing participants.
Stimuli were 10 s in duration and consisted of a concatenation of ten 1-s recordings of a person saying the name of a country (randomly drawn without replacement from a list of 24 countries). Each stimulus used recordings from a single talker (out of 12 possible talkers, six were female). Each stimulus was presented from one of 12 speakers at 0° elevation, spaced 30° apart in azimuth (Fig. 6a). On each trial, between one and eight stimuli were simultaneously presented, each spoken by a different talker and presented from a different speaker.
The model experiment used the same 1-s recordings used in the original experiment (kindly provided by W. Yost), but presented a single 1-s recording (of a speaker saying a single country name, rather than the sequence of ten such recordings used in the human experiment) at each location, to accommodate the 1-s input length of the model. For each number of sources (one to eight) we computed each possible spatial source configuration and rendered 20 scenes for each configuration, randomly sampling talkers and country names for each trial (without replacement). All stimuli were rendered in an anechoic environment without any background noise using the virtual acoustic simulator. This led to 75,920 stimuli in total (20 exemplars in each of 3,796 spatial configurations).
Multi-source localization: output layer fine-tuning
To enable the model to perform the multi-source localization experiment, we altered the softmax output layer, which was designed to report one source at a time. We replaced the softmax function with independent sigmoid functions for each output unit. This allowed the model to independently report the probability of a source at each location. To allow our model to use this new output representation, we retrained this new final model stage. We froze all weights in each network except for those in the final fully connected layer, which we then trained using gradient descent for 10,000 steps (‘fine-tuning’). The fine-tuning used a dataset consisting of auditory scenes generated and rendered in the same manner as the original training data (as described in Training data generation above), with two exceptions. First, each scene contained between one and eight natural sounds, each rendered at a different location. Second, the scenes did not contain background noise. This process was repeated for each network to allow the model to use its features on the multi-source localization task.
To measure accuracy after fine-tuning, we created a multi-source validation set using the natural sounds from the main model validation set. We measured the area under the curve for the receiver operator characteristic curve over the entire multi-source validation set. The average area under the curve across fine-tuned networks after fine-tuning was 0.73.
Multi-source localization: analysis
The output layer of the multi-source model contained a unit for each location, as for the main single-source localization model, but differed in that the unit activation represented the judged probability that a source was present at that location. To enable the model to perform the multi-source experiment, we implemented a decision rule whereby the model would determine a source to be present at a location if the probability for that location exceeded a criterion. We set this criterion such that the model would correctly estimate the number of sources when a single source was present. We found empirically that the absolute activations resulting from the sigmoid output units varied considerably across sounds, presumably because the networks were trained with a softmax output layer that normalizes the output activations (which was no longer present in the multi-source decision layer). We thus adopted a criterion that was a proportion of the maximum probability across all output units and found that this yielded results that were stable across stimuli. Using all the experiment stimuli containing one source, we successively lowered the criterion from 1, each time running through the full set of scenes and estimating confidence intervals on the average predicted number of sources, until the 95% confidence interval for the predicted number of sources (after front–back folding) included 1. This yielded a decision criterion of 0.09 times the maximum probability across all output unit activations for the stimulus.
To perform a trial in the experiment, we first selected the model’s location bins whose probability exceeded the criterion of 0.09 times the maximum probability across all output unit activations for the stimulus. We then mapped these locations to the 12 possible speaker locations in the experiment (for each output location bin, we selected the speaker location closest in azimuth). The number of sources was calculated as the number of these 12 speaker locations to which a localized source was mapped (Fig. 6c). The proportion correct was calculated as the hit rate: the fraction of the 12 speaker locations at which the model correctly judged there to be a source (Fig. 6e).
Evaluation of models trained in unnatural conditions
Once trained, each alternative model was run on each of the psychophysical experiments. The exception was the multi-source localization experiment, which was omitted because it was not clear how to incorporate the background noise training manipulation into the fine-tuning of the model output layer. The psychophysical experiments were identical for all training conditions.
Analysis of results of unnatural training conditions
Human–model dissimilarity
We assessed the effect of training condition on model behaviour by quantifying the extent of the dissimilarity between the model psychophysical results and the human results. For each results graph, we measured human–model dissimilarity as the r.m.s. error between corresponding y axis values in the human and model experiments. To compare results between experiments, before measuring this error, we min–max normalized the y axis to range from 0 to 1. For experiments with the same y axis for human and model results, we normalized the model and human data together (that is, taking the min and max values from the pooled results). For experiments where the y axes were different for human and model results (because the tasks were different, as in Figs. 3b,c and 4i,j), we normalized the data individually for human and model results.
The one exception was the ear alteration experiment (Fig. 4a–g), in which the result of primary interest was the change in judged location relative to the rendered location, and for which the locations were different in the human and model experiments (due to constraints of the HRTF sets that we used). To measure the human–model dissimilarity for this experiment, we calculated the error between the judged and rendered location for each point on the graph, for humans and the model. We then calculated human–model dissimilarity between these error values, treating the two grids of locations as equivalent. This approach would fail to capture some patterns of errors but was sufficient to capture the main effects of preserved azimuthal localization along with the collapse of elevation localization.
This procedure yielded a dissimilarity measure that varied between zero and one for each experiment, where zero represents a perfect fit to the human results. For Fig. 7b, we then calculated the mean of this dissimilarity measure over the seven experiments. To generate error bars, we bootstrapped across the ten networks, recalculating all results graphs and the corresponding mean normalized error for each bootstrap sample. Error bars in Fig. 7b plot the s.d. of this distribution (that is, the standard error of the mean). Additionally, we plotted the mean normalized error individually for each of the ten networks (Extended Data Fig. 7).
Between-human dissimilarity
The dissimilarity that would result between different samples of human participants puts a lower bound on human–model dissimilarity, and would thus be useful to compare to the dissimilarity plotted in Fig. 7b. This between-human dissimilarity could be estimated using data from the original individual human participants. Unfortunately, the individual participant data were unavailable for nearly all of the experiments that we modelled, many of which were conducted several decades ago. Instead, we used the error bars in the published results figures to simulate different samples of human participants given the variability observed in the original experiments. Error bars were provided for only some of the original experiments (the exceptions being the experiments in Figs. 2 and 4n), so we were only able to estimate the between-human dissimilarity for this subset. We then compared the estimated between-human dissimilarity to the human–model dissimilarity for the same subset of experiments (Extended Data Fig. 8).
We assumed that human data for each experimental condition were independently normally distributed with a mean and variance given by the mean and error bars for that condition. Depending on the experiment, the error bars in the original graphs plotted the standard deviation, the s.e.m., or the 95% confidence interval of the data. In each case we estimated the variance from the mean of the upper and lower error bar (for s.d. the square of the error bar; for s.e.m.: \({\mathrm{variance}} = (\sqrt N \times {\mathrm{s.e.m.}})^2\); for 95% confidence interval: \({\mathrm{variance}} = (\sqrt N \times ({\mathrm{error}}\,{\mathrm{bar}}\,{\mathrm{width}})/1.96)^2\), where N is the number of participants). To obtain behavioural data for one simulated human participant, we sampled from the Gaussian distribution for each condition. We sampled data for the number of participants run in the original experiment, and obtained mean results for this set of simulated participants. We then calculated the r.m.s. error (described in the previous section) between the simulated human data and actual human data (normalized as described in the previous section for the human–model dissimilarity). We repeated this process 10,000 times for each experiment, yielding a distribution of dissimilarities for each experiment. We then calculated the mean dissimilarity across experiments and samples. Extended Data Fig. 8 plots this estimated between-human dissimilarity (with confidence intervals obtained from the distribution of between-human dissimilarity) alongside the human–model dissimilarity for the same subset of experiments.
Models with internal noise
To test for the possibility that the noiseless training environments might have had effects that were specific to the lack of internal noise in the cochlear model used as input to our networks, we trained an alternative model with internal noise added to the output of the cochlear stage. This alternative model was identical to the main model used throughout the paper except that independent Gaussian noise was added to each frequency channel before the rectification stage of the cochlear model. The noise was sampled from a standard normal distribution and then scaled so that its power was on average 60.6 dB below the average power in the subbands of the input signal (intended to produce noise at 9.4 dB SPL assuming sources at 70 dB SPL156). In practice, we pregenerated 50,000 noise arrays, sampled one at random on each trial, and added it to the output of the cochlear filters at the desired SNR.
Cohen’s d
To assess how training conditions affected individual psychophysical effects, we measured the effect size of the difference between human–model dissimilarity in the naturalistic and unnatural training conditions for each psychophysical effect. Specifically, we measured Cohen’s d for each experiment:
where μ and σ2 are the mean and variance, respectively, of the human–model dissimilarity across our ten networks for the naturalistic or unnatural training condition. We calculated error bars on Cohen’s d by bootstrapping across the ten networks, computing the effect size for each bootstrap sample. Figure 7c plots the mean and s.e.m. of this distribution.
Instrument note localization
Instrument note localization: stimuli
To assess the ability of the model to predict localization behaviour for natural sounds, we rendered a set of instruments playing notes at different spatial positions. Instruments were sourced from the Nsynth Dataset101, which contains a large number of musical notes from a wide variety of instruments. We used the validation set component of the dataset, which contained 12,678 notes sampled from 53 instruments. For each note, room in our virtual environment, and listener location within each room, we randomly rendered each of the 72 possible azimuthal positions (0° elevation, 0°–355° azimuth in 5° steps) with a probability \(P = \frac{{0.025 \times {\mathrm{no.}}\, {\mathrm{of}}\,{\mathrm{locations}}\,{\mathrm{in}}\,{\mathrm{smallest}}\,{\mathrm{room}}}}{{{\mathrm{no.}}\, {\mathrm{of}}\,{\mathrm{locations}}\,{\mathrm{in}}\,{\mathrm{current}}\,{\mathrm{room}}}}\). We used a base probability of 2.5% to limit the overall size of the test set and normalized by the number of locations in the current room so that each room was represented equally in the test set. This yielded a total of 456,580 stimuli.
Instrument note localization: analysis
We anticipated performing a human instrument note localization experiment in an environment with speakers in the frontal hemifield, so we corrected for front–back confusions by mirroring model responses of each stimulus across the coronal plane. Different instruments in the dataset contained different subsets of pitches. To ensure that differences in localization accuracy would not be driven solely by the instrument’s pitch range, we limited analysis to instruments for which the dataset contained all notes in the octave around middle C (MIDI note 55 to 66) and performed all analysis on notes in that range. This yielded 43 instruments and 1,860 unique notes. We calculated the mean localization error for each network judgement by calculating the absolute difference, in degrees, between the judged and rendered azimuthal location. We then averaged the error across networks and calculated the mean error for each of the 1,860 remaining notes from the original dataset. We plotted the distributions of the mean error over notes for each instrument (8 A) using letter-value plots157.
To characterize the density of the spectrum we computed its spectral flatness. We first estimated the power spectrum x(n) using Welch’s method (window size of 2,000 samples, 50% overlap). The spectral flatness was computed for each note of each instrument as:
We averaged the spectral flatness across all notes of an instrument and then computed the Spearman correlation of this measure with the network’s mean accuracy for that instrument.
Statistics
Real-world localization
For plots comparing real-world localization across models (Extended Data Fig. 6b,c), error bars are s.e.m., bootstrapped over stimuli (because there was only one version of the baseline models).
Psychophysical experiments
For plots assessing duplex theory (Fig. 2d), azimuth sensitivity (Fig. 3c), bandwidth sensitivity (Fig. 3f), ear alteration (Fig. 4d,e), spectral smoothing (Fig. 4j), sensitivity to low-pass and high-pass filtering (Fig. 4o), the precedence effect (Fig. 5b,d) and multi-source localization (Fig. 6c,e) error bars are s.e.m., bootstrapped across networks. In some cases, the graph of human results used s.d. rather than s.e.m. for error bars because that is what was used in the original paper, the results of which were scanned from the original figure. We opted to use s.e.m. error bars for all model results for the sake of consistency.
To assess the significance of the interaction between the stimulus frequency range and the magnitude of the ITD/ILD bias weights (Fig. 2d), we calculated the difference of differences in bias weights across the four stimulus or cue-type conditions:
where B denotes the bias weight for each condition). We calculated the difference of differences bootstrapped across models with 10,000 samples, and compared it to 0. As this difference of differences exceeded 0 for all 10,000 bootstrap samples, we fit a Gaussian distribution to the histogram of values for the 10,000 bootstrap samples and calculated the P value (two-tailed) for a value of 0 or smaller from the fitted Gaussian.
We assessed the significance of the low-pass ILD bias weight (Fig. 2d) by bootstrapping across networks, again fitting a Gaussian distribution to the histogram of bias weights from each bootstrap sample and calculating the P value (two-tailed) for a value of 0 or smaller from the fitted Gaussian.
Statistical significance of unnatural training conditions
We assessed the statistical significance of the effect of individual unnatural training conditions (Fig. 7b) by comparing the human–model dissimilarity for each unnatural training condition to a null distribution of the dissimilarity for the natural training condition. The null distribution was obtained by bootstrapping the human–model dissimilarity described above across networks. We fit a Gaussian distribution to the histogram of the dissimilarity for each bootstrap sample and calculated the P value (two-tailed) of obtaining the value of the dissimilarity measure (or smaller) for each unnatural training condition under the fitted Gaussian. The effect size of the difference in dissimilarity between training conditions was quantified as Cohen’s d (calculated as described above for individual experiments, but with the dissimilarity aggregated across experiments, as is plotted in Fig. 7b).
We also assessed the statistical significance of the effect size of the change to individual experiment results (relative to other experiments) when training in alternative conditions (Fig. 7c). We first measured Cohen’s d as described above for 10,000 bootstrap samples of the ten networks, leading to a distribution over Cohen’s d for each experiment and each training condition. For each experiment of interest, we assessed the probability under its bootstrap distribution that a value at or below the mean Cohen’s d of each other experiment could have occurred. The histogram of bootstrap samples was non-Gaussian so we calculated this probability by counting the number of values at or below the mean for each condition and reported the proportion of such values as the P value (two-tailed).
We assessed the statistical significance of the effect of training condition on real-world localization performance (Fig. 7e) by bootstrapping the r.m.s. localization error across networks. We fit a Gaussian distribution to the histogram of the r.m.s. error for the normal training condition. The reported P value (two-tailed) is the probability that a value could have been drawn from that Gaussian at or above the mean r.m.s. error for each alternative training condition.
Reporting Summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
Data used to train and analyse the main model in this paper, as well as the weights of the trained networks in the model, are available at: www.github.com/afrancl/BinauralLocalizationCNN. Training data for the unnatural training conditions are not posted publicly as their overall size is prohibitive, but will be shared on request to the corresponding authors. Source data are provided with this paper.
Code availability
Code used to train and analyse the model in this paper is available at: www.github.com/afrancl/BinauralLocalizationCNN
Change history
14 September 2022
A Correction to this paper has been published: https://doi.org/10.1038/s41562-022-01448-x
References
Coltheart, M. Visual feature-analyzers and the aftereffects of tilt and curvature. Psychological Rev. 78, 114–121 (1971).
Jin, D. Z., Dragoi, V., Sur, M. & Seung, H. S. Tilt aftereffect and adaptation-induced changes in orientation tuning in visual cortex. J. Neurophysiol. 94, 4038–4050 (2005).
Delgutte, B. Physiological mechanisms of psychophysical masking: observations from auditory-nerve fibers. J. Acoustical Soc. Am. 87, 791–809 (1990).
Macknik, S. L. & Martinez-Conde, S. The role of feedback in visual masking and visual processing. Adv. Cogn. Psychol. 3, 125–152 (2007).
Livingstone, M. S. & Hubel, D. H. Psychophysical evidence for separate channels for perception of form, color, movement and depth. J. Neurosci. 7, 3416–3468 (1987).
Attneave, F. & Olson, R. K. Pitch as a medium: a new approach to psychophysical scaling. Am. J. Psychol. 84, 147–166 (1971).
Javel, E. & Mott, J. B. Physiological and psychophysical correlates of temporal processes in hearing. Hearing Res. 34, 275–294 (1988).
Jacoby, N. et al. Universal and non-universal features of musical pitch perception revealed by singing. Curr. Biol. 29, 3229–3243 (2019).
Geisler, W. S. in The Visual Neurosciences (eds Chalupa, L. M. & Werner, J. S.) 825–837 (MIT Press, 2003).
Geisler, W. S. Contributions of ideal observer theory to vision research. Vis. Res. 51, 771–781 (2011).
Siebert, W. M. Frequency discrimination in the auditory system: place or periodicity mechanisms? Proc. IEEE 58, 723–730 (1970).
Heinz, M. G., Colburn, H. S. & Carney, L. H. Evaluating auditory performance limits: I. One-parameter discrimination using a computational model for the auditory nerve. Neural Comput. 13, 2273–2316 (2001).
Weiss, Y., Simoncelli, E. P. & Adelson, E. H. Motion illusions as optimal percepts. Nat. Neurosci. 5, 598–604 (2002).
Girshick, A. R., Landy, M. S. & Simoncelli, E. P. Cardinal rules: visual orientation perception reflects knowledge of environmental statistics. Nat. Neurosci. 14, 926–932 (2011).
Burge, J. & Geisler, W. S. Optimal defocus estimation in individual natural images. Proc. Natl Acad. Sci. USA 108, 16849–16854 (2011).
Burge, J. Image-computable ideal observers for tasks with natural stimuli. Annu. Rev. Vis. Sci. 6, 491–517 (2020).
Rayleigh, L. On our perception of sound direction. Philos. Mag. 3, 456–464 (1907).
Batteau, D. W. The role of pinna in human localization. Proc. R. Soc. B. 168, 158–180 (1967).
Carlile, S. Virtual Auditory Space: Generation and Applications (Landes, 1996).
Grothe, B., Pecka, M. & McAlpine, D. Mechanisms of sound localization in mammals. Physiological Rev. 90, 983–1012 (2010).
Blauert, J. Hearing: The Psychophysics of Human Sound Localization (MIT Press: 1997).
Bodden, M. & Blauert, J. in Speech Processing in Adverse Conditions 147–150 (Cannes-Mandelieu, 1992).
Gaik, W. Combined evaluation of interaural time and intensity differences: psychoacoustic results and computer modeling. J. Acoustical Soc. Am. 94, 98–110 (1993).
Chung, W., Carlile, S. & Leong, P. A performance adequate computational model for auditory localization. J. Acoustical Soc. Am. 107, 432–445 (2000).
Jeffress, L. A. A place theory of sound localization. J. Comp. Physiological Psychol. 41, 35–39 (1948).
Colburn, H. S. Theory of binaural interaction based on auditory-nerve data. I. General strategy and preliminary results on interaural discrimination. J. Acoustical Soc. Am. 54, 1458–1470 (1973).
Blauert, J. & Cobben, W. Some consideration of binaural cross correlation analysis. Acta Acoustica 39, 96–104 (1978).
Harper, N. S. & McAlpine, D. Optimal neural population coding of an auditory spatial cue. Nature 430, 682–686 (2004).
Zhou, Y., Carney, L. H. & Colburn, H. S. A model for interaural time difference sensitivity in the medial superior olive: interaction of excitatory and inhibitory synaptic inputs, channel dynamics, and cellular morphology. J. Neurosci. 25, 3046–3058 (2005).
Stern, R. M., Brown, G. J. & Wang, D. in Computational Auditory Scene Analysis: Principles, Algorithms, and Applications (eds Wang, D. & Brown, G. J.) (John Wiley & Sons Inc., 2006).
Dietz, M., Wang, L., Greenberg, D. & McAlpine, D. Sensitivity to interaural time differences conveyed in the stimulus envelope: estimating inputs of binaural neurons through the temporal analysis of spike trains. J. Assoc. Res. Otolaryngol. 17, 313–330 (2016).
Sayers, B. M. & Cherry, E. C. Mechanism of binaural fusion in the hearing of speech. J. Acoustical Soc. Am. 29, 973–987 (1957).
Raatgever, J. On the Binaural Processing of Stimuli with Different Interaural Phase Relations. Thesis, Technische Hogeschool (1980).
Stern, R. M., Zeiberg, A. S. & Trahiotis, C. Lateralization of complex binaural stimuli: a weighted-image model. J. Acoustical Soc. Am. 84, 156–165 (1988).
Trahiotis, C., Bernstein, L. R., Stern, R. M. & Buell, T. N. in Sound Source Localization 238–271 (Springer, 2005).
Fischer, B. J. & Peña, J. L. Owl’s behavior and neural representation predicted by Bayesian inference. Nat. Neurosci. 14, 1061–1066 (2011).
May, T., Van De Par, S. & Kohlrausch, A. A probabilistic model for robust localization based on a binaural auditory front-end. IEEE Trans. Audio, Speech, Lang. Process. 19, 1–13 (2011).
Woodruff, J. & Wang, D. Binaural localization of multiple sources in reverberant and noisy environments. IEEE Trans. Audio, Speech, Lang. Process. 20, 1503–1512 (2012).
Xiao, X. et al. A learning-based approach to direction of arrival estimation in noisy and reverberant environments. In Proc. International Conference on Acoustics, Speech, and Signal Processing (eds Gray, D. & Cochran, D.) https://doi.org/10.1109/ICASSP.2015.7178484 (IEEE, 2015).
Roden, R., Moritz, N., Gerlach, S., Weinzierl, S. & Goetze, S. On sound source localization of speech signals using deep neural networks. DAGA: Dtsch. Ges. für. Akust. https://doi.org/10.14279/depositonce-8779 (2015).
Chakrabarty, S. & Habets, E. A. P. Broadband DOA estimation using convolutional neural networks trained with noise signals. In Proc. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) (eds Mysore, G. & Christensen, M.) https://doi.org/10.1109/WASPAA.2017.8170010 (IEEE, 2017).
Ma, N., May, T. & Brown, G. J. Exploiting deep neural networks and head movements for robust binaural localization of multiple sources in reverberant environments. IEEE/ACM Trans. Audio, Speech, Lang. Process. 25, 2444–2453 (2017).
Adavanne, S., Politis, A. & Virtanen, T. Direction of arrival estimation for multiple sound sources using convolutional recurrent neural network. In Proc. 2018 26th European Signal Processing Conference (EUSIPCO) (eds Barbarossa, S. et al.) https://doi.org/10.23919/EUSIPCO.2018.8553182 (IEEE, 2018).
Jiang, S., Wu, L., Yuan, P., Sun, Y. & Liu, H. Deep and CNN fusion method for binaural sound source localisation. J. Eng. 2020, 511–515 (2020).
Khaligh-Razavi, S.-M. & Kriegeskorte, N. Deep supervised, but not unsupervised, models may explain IT cortical representation. PLoS Computational Biol. 10, e1003915 (2014).
Güçlü, U. & van Gerven, M. A. J. Deep neural networks reveal a gradient in the complexity of neural representations across the ventral stream. J. Neurosci. 35, 10005–10014 (2015).
Yamins, D. L. K. & DiCarlo, J. J. Using goal-driven deep learning models to understand sensory cortex. Nat. Neurosci. 19, 356–365 (2016).
Cichy, R. M., Khosla, A., Pantazis, D., Torralba, A. & Oliva, A. Comparison of deep neural networks to spatio-temporal cortical dynamics of human visual object recognition reveals hierarchical correspondence. Sci. Rep. 6, 27755 (2016).
Eickenberg, M., Gramfort, A., Varoquaux, G. & Thirion, B. Seeing it all: convolutional network layers map the function of the human visual system. Neuroimage 152, 184–194 (2017).
Kell, A. J. E., Yamins, D. L. K., Shook, E. N., Norman-Haignere, S. & McDermott, J. H. A task-optimized neural network replicates human auditory behavior, predicts brain responses, and reveals a cortical processing hierarchy. Neuron 98, 630–644 (2018).
Shinn-Cunningham, B. G., Desloge, J. G. & Kopco, N. Empirical and modeled acoustic transfer functions in a simple room: effects of distance and direction. In Proc. 2001 IEEE Workshop on the Applications of Signal Processing to Audio and Acoustics (ed. Slaney, M.) https://doi.org/10.1109/ASPAA.2001.969573 (IEEE, 2001).
Chen, T., Xu, B., Zhang, C. & Guestrin, C. Training deep nets with sublinear memory cost. Preprint at https://arxiv.org/abs/1604.06174 (2016).
Gardner, W. G. & Martin, K. D. HRTF measurements of a KEMAR. J. Acoustical Soc. Am. 97, 3907–3908 (1995).
Glasberg, B. R. & Moore, B. C. J. Derivation of auditory filter shapes from notched-noise data. Hearing Res. 47, 103–138 (1990).
McDermott, J. H. & Simoncelli, E. P. Sound texture perception via statistics of the auditory periphery: evidence from sound synthesis. Neuron 71, 926–940 (2011).
Palmer, A. R. & Russell, I. J. Phase-locking in the cochlear nerve of the guinea-pig and its relation to the receptor potential of inner hair-cells. Hearing Res. 24, 1–15 (1986).
Mehrer, J., Spoerer, C. J., Kriegeskorte, N. & Kietzmann, T. C. Individual differences among deep neural network models. Nat. Commun. 11, 1–12 (2020).
Wilson, A. G. & Izmailov, P. Bayesian deep learning and a probabilistic perspective of generalization. In Advances in Neural Information Processing Systems (NeurIPS) (eds Larochelle, H. et al.) (Curran Associates, Inc., 2020).
Allen, J. B. & Berkley, D. A. Image method for efficiently simulating small-room acoustics. J. Acoustical Soc. Am. 65, 943–950 (1979).
McWalter, R. I. & McDermott, J. H. Adaptive and selective time-averaging of auditory scenes. Curr. Biol. 28, 1405–1418 (2018).
Young, P. T. The role of head movements in auditory localization. J. Exp. Psychol. 14, 95–124 (1931).
Wallach, H. The role of head movements and vestibular and visual cues in sound localization. J. Exp. Psychol. 27, 339–368 (1940).
Wang, H. & Kaveh, M. Coherent signal-subspace processing for the detection and estimation of angles of arrival of multiple wide-band sources. IEEE Trans. Acoust., Speech, Signal Process. 33, 823–831 (1985).
Schmidt, R. Multiple emitter location and signal parameter estimation. IEEE Trans. Antennas Propag. 34, 276–280 (1986).
DiBiase, J. H. A High-accuracy, Low-latency Technique for Talker Localization in Reverberant Environments Using Microphone Arrays. Thesis, Brown Univ. (2000).
Di Claudio, E. D. & Parisi, R. WAVES: weighted average of signal subspaces for robust wideband direction finding. IEEE Trans. Signal Process. 49, 2179–2191 (2001).
Yoon, Y.-S., Kaplan, L. M. & McClellan, J. H. TOPS: new DOA estimator for wideband signals. IEEE Trans. Signal Process. 54, 1977–1989 (2006).
Vecchiotti, P., Ma, N., Squartini, S. & Brown, G. J. End-to-end binaural sound localisation from the raw waveform. In Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (eds Mandic, D. et al.) 451–455 (IEEE, Brighton, 2019).
Macpherson, E. A. & Middlebrooks, J. C. Listener weighting of cues for lateral angle: the duplex theory of sound localization revisited. J. Acoustical Soc. Am. 111, 2219–2236 (2002).
Zwislocki, J. & Feldman, R. S. Just noticeable differences in dichotic phase. J. Acoustical Soc. Am. 28, 860–864 (1956).
Hafter, E. R., Dye, R. H. & Gilkey, R. H. Lateralization of tonal signals which have neither onsets nor offsets. J. Acoustical Soc. Am. 65, 471–477 (1979).
Henning, G. B. Lateralization of low-frequency transients. Hearing Res. 9, 153–172 (1983).
Brughera, A., Dunai, L. & Hartmann, W. M. Human interaural time difference thresholds for sine tones: the high-frequency limit. J. Acoustical Soc. Am. 133, 2839–2855 (2013).
Cai, T., Rakerd, B. & Hartmann, W. M. Computing interaural differences through finite element modeling of idealized human heads. J. Acoustical Soc. Am. 138, 1549–1560 (2015).
Hafter, E. R., Dye, R. H., Neutzel, J. M. & Aronow, H. Difference thresholds for interaural intensity. J. Acoustical Soc. Am. 61, 829–834 (1977).
Yost, W. A. & Dye, R. H. Jr. Discrimination of interaural differences of level as a function of frequency. J. Acoustical Soc. Am. 83, 1846–1851 (1988).
Hartmann, W. M., Rakerd, B., Crawford, Z. D. & Zhang, P. X. Transaural experiments and a revised duplex theory for the localization of low-frequency tones. J. Acoustical Soc. Am. 139, 968–985 (2016).
Sandel, T. T., Teas, D. C., Feddersen, W. E. & Jeffress, L. A. Localization of sound from single and paired sources. J. Acoustical Soc. Am. 27, 842–852 (1955).
Mills, A. W. On the minimum audible angle. J. Acoustical Soc. Am. 30, 237–246 (1958).
Wood, K. C. & Bizley, J. K. Relative sound localisation abilities in human listeners. J. Acoustical Soc. Am. 138, 674–686 (2015).
Butler, R. A. The bandwidth effect on monaural and binaural localization. Hearing Res. 21, 67–73 (1986).
Yost, W. A. & Zhong, X. Sound source localization identification accuracy: bandwidth dependencies. J. Acoustical Soc. Am. 136, 2737–2746 (2014).
Wightman, F. & Kistler, D. J. Headphone simulation of free-field listening. II: psychophysical validation. J. Acoustical Soc. Am. 85, 868–878 (1989).
Hofman, P. M., Van Riswick, J. G. A. & van Opstal, A. J. Relearning sound localization with new ears. Nat. Neurosci. 1, 417–421 (1998).
Wenzel, E. M., Arruda, M., Kistler, D. J. & Wightman, F. L. Localization using nonindividualized head-related transfer functions. J. Acoustical Soc. Am. 94, 111–123 (1993).
Kulkarni, A. & Colburn, H. S. Role of spectral detail in sound-source localization. Nature 396, 747–749 (1998).
Ito, S., Si, Y., Feldheim, D. A. & Litke, A. M. Spectral cues are necessary to encode azimuthal auditory space in the mouse superior colliculus. Nat. Commun. 11, 1087 (2020).
Langendijk, E. H. A. & Bronkhorst, A. W. Contribution of spectral cues to human sound localization. J. Acoustical Soc. Am. 112, 1583–1596 (2002).
Best, V., Carlile, S., Jin, C. & van Schaik, A. The role of high frequencies in speech localization. J. Acoustical Soc. Am. 118, 353–363 (2005).
Hebrank, J. & Wright, D. Spectral cues used in the localization of sound sources on the median plane. J. Acoustical Soc. Am. 56, 1829–1834 (1974).
Stecker, G. C. & Hafter, E. R. Temporal weighting in sound localization. J. Acoustical Soc. Am. 112, 1046–1057 (2002).
Wallach, H., Newman, E. B. & Rosenzweig, M. R. The precedence effect in sound localization. Am. J. Psychol. 42, 315–336 (1949).
Litovsky, R. Y., Colburn, H. S., Yost, W. A. & Guzman, S. J. The precedence effect. J. Acoustical Soc. Am. 106, 1633–1654 (1999).
Brown, A. D., Stecker, G. C. & Tollin, D. J. The precedence effect in sound localization. J. Assoc. Res. Otolaryngol. 16, 1–28 (2015).
Litovsky, R. Y. & Godar, S. P. Difference in precedence effect between children and adults signifies development of sound localization abilities in complex listening tasks. J. Acoustical Soc. Am. 128, 1979–1991 (2010).
Santala, O. & Pulkki, V. Directional perception of distributed sound sources. J. Acoustical Soc. Am. 129, 1522–1530 (2011).
Kawashima, T. & Sato, T. Perceptual limits in a simulated ‘cocktail party’. Atten., Percept., Psychophys. 77, 2108–2120 (2015).
Zhong, X. & Yost, W. A. How many images are in an auditory scene? J. Acoustical Soc. Am. 141, 2882–2892 (2017).
Zurek, P. M. The precedence effect and its possible role in the avoidance of interaural ambiguities. J. Acoustical Soc. Am. 67, 952–964 (1980).
Hannun, A. et al. Deep speech: scaling up end-to-end speech recognition. Preprint at https://arxiv.org/abs/1412.5567 (2014).
Engel, J. et al. Neural audio synthesis of musical notes with wavenet autoencoders. In Proc. 34th International Conference on Machine Learning-Volume 70 1068–1077 (JMLR.org, 2017).
Johnston, J. D. Transform coding of audio signals using perceptual noise criteria. IEEE J. Sel. Areas Commun. 6, 314–323 (1988).
Cheung, B., Weiss, E. & Olshausen, B. A. Emergence of foveal image sampling from learning to attend in visual scenes. In Proc. International Conference on Learning Representations (eds Larochelle, H. et al.) https://openreview.net/forum?id=SJJKxrsgl (2017).
Kell, A. J. E. & McDermott, J. H. Deep neural network models of sensory systems: windows onto the role of task constraints. Curr. Opin. Neurobiol. 55, 121–132 (2019).
Schnupp, J. W. & Carr, C. E. On hearing with more than one ear: lessons from evolution. Nat. Neurosci. 12, 692–697 (2009).
Middlebrooks, J. C. Narrow-band sound localization related to external ear acoustics. J. Acoustical Soc. Am. 92, 2607–2624 (1992).
Stecker, G. C., Harrington, I. A. & Middlebrooks, J. C. Location coding by opponent neural populations in the auditory cortex. PLoS Biol. 3, 0520–0528 (2005).
Mlynarski, W. & Jost, J. Statistics of natural binaural sounds. PLoS ONE 9, e108968 (2014).
Gan, C. et al. ThreeDWorld: a platform for interactive multi-modal physical simulation. in Proc. Neural Information Processing Systems (NeurIPS) (eds Beygelzimer, A. et al.) https://openreview.net/forum?id=db1InWAwW2T (Neural Information Processing Systems Foundation, 2021).
Guerguiev, J., Lillicrap, T. P. & Richards, B. A. Towards deep learning with segregated dendrites. eLife 6, e22901 (2017).
Tschopp, F. D., Reiser, M. B. & Turaga, S. C. A connectome based hexagonal lattice convolutional network model of the Drosophila visual system. Preprint at https://arxiv.org/abs/1806.04793 (2018).
Joris, P. X., Smith, P. H. & Yin, T. C. Coincidence detection in the auditory system: 50 years after Jeffress. Neuron 21, 1235–1238 (1998).
Brughera, A., Mikiel-Hunter, J., Dietz, M. & McAlpine, D. Auditory brainstem models: adapting cochlear nuclei improve spatial encoding by the medial superior olive in reverberation. J. Assoc. Res. Otolaryngol. 22, 289–318 (2021).
Kacelnik, O., Nodal, F. R., Parsons, C. H. & King, A. J. Training-induced plasticity of auditory localization in adult mammals. PLoS Biol. 4, e71 (2006).
Lake, B. M., Ullman, T. D., Tenenbaum, J. B. & Gershman, S. J. Building machines that learn and think like people. Behav. Brain Sci. 40, e253 (2017).
Kubilius, J., Bracci, S. & Op de Beeck, H. P. Deep neural networks as a computational model for human shape sensitivity. PLoS Comput. Biol. 12, e1004896 (2016).
Saddler, M. R., Gonzalez, R. & McDermott, J. H. Deep neural network models reveal interplay of peripheral coding and stimulus statistics in pitch perception. Nat. Commun. in press (2021).
Goodfellow, I. J., Shlens, J. & Szegedy, C. Explaining and harnessing adversarial examples. In Proc. International Conference on Learning Representations (eds Kingsbury, B. et al.) (2015).
Feather, J., Durango, A., Gonzalez, R. & McDermott, J. H. Metamers of neural networks reveal divergence from human perceptual systems. In Proc. Advances in Neural Information Processing Systems (NeurIPS) (eds Larochelle, H. et al.) (2019).
Geirhos, R. et al. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. In Proc. International Conference on Learning Representations (eds Levine, S. et al.) (2019).
Jacobsen, J.-H., Behrmann, J., Zemel, R. & Bethge, M. Excessive invariance causes adversarial vulnerability. In Proc. International Conference on Learning Representations (ICLR) (eds Levine, S. et al.) (2019).
Golan, T., Raju, P. C. & Kriegeskorte, N. Controversial stimuli: pitting neural networks against each other as models of human recognition. Proc. Natl Acad. Sci. USA 117, 29330–29337 (2020).
Lewicki, M. S. Efficient coding of natural sounds. Nat. Neurosci. 5, 356–363 (2002).
Zilany, M. S. A., Bruce, I. C. & Carney, L. H. Updated parameters and expanded simulation options for a model of the auditory periphery. J. Acoustical Soc. Am. 135, 283–286 (2014).
Bruce, I. C., Erfani, Y. & Zilany, M. S. A. A phenomenological model of the synapse between the inner hair cell and auditory nerve: implications of limited neurotransmitter release sites. Hearing Res. 360, 40–54 (2018).
Baby, D., Broucke, A. V. D. & Verhulst, S. A convolutional neural-network model of human cochlear mechanics and filter tuning for real-time applications. Nat. Mach. Intell. 3, 134–143 (2021).
Traer, J. & McDermott, J. H. Statistics of natural reverberation enable perceptual separation of sound and space. Proc. Natl Acad. Sci. USA 113, E7856–E7865 (2016).
Devore, S., Ihlefeld, A., Hancock, K., Shinn-Cunningham, B. & Delgutte, B. Accurate sound localization in reverberant environments is mediated by robust encoding of spatial cues in the auditory midbrain. Neuron 62, 123–134 (2009).
Thurlow, W. R., Mangels, J. W. & Runge, P. S. Head movements during sound localization. J. Acoustical Soc. Am. 42, 489–493 (1967).
Brimijoin, W. O., Boyd, A. W. & Akeroyd, M. A. The contribution of head movement to the externalization and internalization of sounds. PLoS ONE 8, e83068 (2013).
Grantham, D. W. & Wightman, F. L. Detectability of varying interaural temporal differences. J. Acoustical Soc. Am. 63, 511–523 (1978).
Carlile, S. & Leung, J. The perception of auditory motion. Trends Hearing 20, 1–20 (2016).
Zuk, N. & Delgutte, B. Neural coding and perception of auditory motion direction based on interaural time differences. J. Neurophysiol. 122, 1821–1842 (2019).
Bizley, J. K. & Cohen, Y. E. The what, where and how of auditory-object perception. Nat. Rev. Neurosci. 14, 693–707 (2013).
Culling, J. F. & Summerfield, Q. Perceptual separation of concurrent speech sounds: absence of across-frequency grouping by common interaural delay. J. Acoustical Soc. Am. 98, 785–797 (1995).
Darwin, C. J. & Hukin, R. W. Perceptual segregation of a harmonic from a vowel by interaural time difference and frequency proximity. J. Acoustical Soc. Am. 102, 2316–2324 (1997).
Bronkhorst, A. W. The cocktail party phenomenon: a review of research on speech intelligibility in multiple-talker conditions. Acustica 86, 117–128 (2000).
Hawley, M. L., Litovsky, R. Y. & Culling, J. F. The benefit of binaural hearing in a cocktail party: effect of location and type of interferer. J. Acoustical Soc. Am. 115, 833–843 (2004).
Kidd, G., Arbogast, T. L., Mason, C. R. & Gallun, F. J. The advantage of knowing where to listen. J. Acoustical Soc. Am. 118, 3804–3815 (2005).
McDermott, J. H. The cocktail party problem. Curr. Biol. 19, R1024–R1027 (2009).
Schwartz, A., McDermott, J. H. & Shinn-Cunningham, B. Spatial cues alone produce innaccurate sound segregation: the effect of interaural time differences. J. Acoustical Soc. Am. 132, 357–368 (2012).
Peterson, P. M. Simulating the response of multiple microphones to a single acoustic source in a reverberant room. J. Acoustical Soc. Am. 80, 1527–1529 (1986).
Tange, O. GNU Parallel 2018 (Zenodo, 2018).
Norman-Haignere, S., Kanwisher, N. & McDermott, J. H. Distinct cortical pathways for music and speech revealed by hypothesis-free voxel decomposition. Neuron 88, 1281–1296 (2015).
McDermott, J. H., Schemitsch, M. & Simoncelli, E. P. Summary statistics in auditory perception. Nat. Neurosci. 16, 493–498 (2013).
Dau, T., Kollmeier, B. & Kohlrausch, A. Modeling auditory processing of amplitude modulation. I. Detection and masking with narrow-band carriers. J. Acoustical Soc. Am. 102, 2892–2905 (1997).
Chi, T., Ru, P. & Shamma, S. A. Multiresolution spectrotemporal analysis of complex sounds. J. Acoustical Soc. Am. 118, 887–906 (2005).
Ioffe, S. & Szegedy, C. Batch normalization: accelerating deep network training by reducing internal covariate shift. In Proc. International Conference on Machine Learning (eds Bach, F. & Blei, D.) 448–456 (PMLR, 2015).
Hinton, G. E., Srivastava, N., Krizhevsky, A., Sutskever, I. & Salakhutdinov, R. R. Improving neural networks by preventing co-adaptation of feature detectors. Preprint at https://arxiv.org/abs/1207.0580 (2012).
Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proc. COMPSTAT'2010 (eds Aguilera, A. M. et al.) 177–186 (Physica-Verlag HD, 2010).
Zhou, D. et al. EcoNAS: finding proxies for economical neural architecture search. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (eds Liu, C. et al.) 11393–11401 (IEEE, 2020).
Barker, J., Cooke, M., Cunningham, S. & Shao, X. The GRID audiovisual sentence corpus https://doi.org/10.5281/zenodo.3625687 (Zenodo, 2013).
Scheibler, R., Bezzam, E. & Dokmanić, I. Pyroomacoustics: a python package for audio room simulation and array processing algorithms. In Proc. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (eds Hayes, M. & Ko, H.) 351–355 (IEEE, 2018).
Yost, W. A., Loiselle, L., Dorman, M., Burns, J. & Brown, C. A. Sound source localization of filtered noises by listeners with normal hearing: a statistical analysis. J. Acoustical Soc. Am. 133, 2876–2882 (2013).
Algazi, V. R., Duda, R. O., Thompson, D. M. & Avendano, C. The CIPIC HRTF database. In Proc. IEEE Workshop on Applications of Signal Processing to Audio and Electroacoustics (ed. Slaney, M.) 99–102 (IEEE, 2001).
Breebaart, J., Van De Par, S. & Kohlrausch, A. Binaural processing model based on contralateral inhibition. I. Model structure. J. Acoustical Soc. Am. 110, 1074–1088 (2001).
Hofmann, H., Wickham, H. & Kafadar, K. Value plots: boxplots for large data. J. Computational Graph. Stat. 26, 469–477 (2017).
Acknowledgements
We thank J. Cohn for assistance securing computing resources, W. Yost for sharing data, R. Gonzalez for writing the cochleagram generation codebase, J. Feather and M. Saddler for their support and technical advice, members of the McDermott laboratory for their comments on the paper (especially D. Boebinger, M. Cusimano, J. Feather, M. McPherson, M. Saddler and J. Traer), participants in the Binaural Bash for advice and feedback, and S. Colburn for lending us his KEMAR mannequin and for advice throughout the project. This research used resources of the Oak Ridge Leadership Computing Facility, which is a Department of Energy Office of Science User Facility supported under contract no. DE-AC05-00OR22725. This work was supported by a National Science Foundation Graduate Research Fellowship to A.F., NSF grant no. BCS-1634050 to J.H.M. and National Institutes of Health grant no. R01DC017970 to J.H.M. The funders had no role in study design, data collection and analysis, decision to publish or preparation of the paper.
Author information
Authors and Affiliations
Contributions
A.F. designed the experiments, collected and analysed data and wrote the paper. J.H.M. designed the experiments and wrote the paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature Human Behaviour thanks Ning Ma, Piotr Majdak and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 Architecture search results.
a. Histogram of validation set accuracies (proportion correct) for neural network architectures after 15k steps of training during architecture search. Here and in B, histograms include the 897 architectures that remained (out of the initial set of 1500) at this point in the architecture search. b. Histogram of validation set losses for neural network architectures after 15k steps of training during architecture search.
Extended Data Fig. 2 Discrete prior distributions used for architecture search.
Pooling and convolutional kernel parameters at each layer were uniformly sampled from the lists of values.
Extended Data Fig. 3 Summary of the 10 network architectures.
These architectures performed best in the architecture search and were used as ‘the model’ in all experiments in this paper.
Extended Data Fig. 4 Natural sounds used in training.
The set of sources contained multiple exemplars of some of the sound classes, denoted with the numeral at the end of the source name.
Extended Data Fig. 5 Room configurations used in virtual training environment.
Dimensions of rooms are given in meters.
Extended Data Fig. 6 Comparison of our model to alternative two-microphone localization systems.
a. Photo of two-microphone array. Microphone spacing was the same as that in the KEMAR mannequin (shown in Fig. 1e) used to record our real-world test set, but the recordings lacked the acoustic effects of the pinnae, head, and torso. b. Localization accuracy of standard two-microphone localization algorithms, our neural network localization model trained with ear/head/torso filtering effects (same data as plotted in Fig. 1g,h), and neural networks trained instead with simulated input from the two-microphone array. Localization judgements are front-back folded. Error bars here and in C plot SEM, obtained by bootstrapping across stimuli. c. Front-back confusions by each of the algorithms from B. Chance level is 50%. Our main model (that is, the one trained with ears) is the only model whose front-back confusions are substantially below chance levels, confirming the utility of head-related transfer function cues for partially resolving front-back ambiguity.
Extended Data Fig. 7
Human-model dissimilarity for natural and unnatural training conditions for each of the 10 individual neural networks.
Extended Data Fig. 8 Human-model dissimilarity and human-human dissimilarity.
Human-model dissimilarity and human-human dissimilarity (root-mean-square error; RMSE) calculated over the subset of experiments for which across-participant variability could be estimated (typically from error bars in the original results graphs).
Extended Data Fig. 9 Model psychophysical results across training conditions for first three psychophysical experiments.
a. Model sensitivity to interaural time and level differences (Fig. 2d). b. Model accuracy for broadband noise at different azimuthal positions (Fig. 3c). c. Effect of bandwidth on model localization of noise bursts (Fig. 3f). All plotting conventions are the same as in the corresponding figures in the main text.
Extended Data Fig. 10 Model psychophysical results across training conditions for fourth through seventh psychophysical experiments.
a. Sound localization by the model in azimuth and elevation before and after ear alteration (Fig. 4d,e). b. Effect of spectral smoothing on model localization accuracy (Fig. 4j). c. Effect of low-pass and high-pass cutoff on model localization accuracy for elevation (Fig. 4o). d. Model error in localization of the leading and lagging clicks in the precedence effect experiment, as a function of delay (Fig. 5d). All plotting conventions are the same as in the corresponding figures in the main text.
Supplementary information
Source data
Source Data Fig. 1
Statistical source data.
Source Data Fig. 2
Statistical source data.
Source Data Fig. 3
Statistical source data.
Source Data Fig. 4
Statistical source data.
Source Data Fig. 5
Statistical source data.
Source Data Fig. 6
Statistical source data.
Source Data Fig. 7
Statistical source data.
Source Data Fig. 8
Statistical source data.
Source Data Extended Data Fig. 1
Statistical source data.
Source Data Extended Data Fig. 2
Table source data.
Source Data Extended Data Fig. 3
Table source data.
Source Data Extended Data Fig. 4
Table source data.
Source Data Extended Data Fig. 5
Table source data.
Source Data Extended Data Fig. 6
Statistical source data.
Source Data Extended Data Fig. 7
Statistical source data.
Source Data Extended Data Fig. 8
Statistical source data.
Source Data Extended Data Fig. 9
Statistical source data.
Source Data Extended Data Fig. 10
Statistical source data.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Francl, A., McDermott, J.H. Deep neural network models of sound localization reveal how perception is adapted to real-world environments. Nat Hum Behav 6, 111–133 (2022). https://doi.org/10.1038/s41562-021-01244-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41562-021-01244-z
This article is cited by
-
Alignment of brain embeddings and artificial contextual embeddings in natural language points to common geometric patterns
Nature Communications (2024)
-
Model metamers reveal divergent invariances between biological and artificial neural networks
Nature Neuroscience (2023)
-
Deep learning in alternate reality
Nature Human Behaviour (2022)
