
Abstract
Physisorption relying on crystalline porous materials offers prospective avenues for sustainable separation processes, greenhouse gas capture, and energy storage. However, the lack of end-to-end deep learning model for adsorption prediction confines the rapid and precise screen of crystalline porous materials. Here, we present DeepSorption, a spatial atom interaction learning network that realizes accurate, fast, and direct structure-adsorption prediction with only information of atomic coordinate and chemical element types. The breakthrough in prediction is attributed to the awareness of global structure and local spatial atom interactions endowed by the developed Matformer, which provides the intuitive visualization of atomic-level thinking and executing trajectory in crystalline porous materials prediction. Complete adsorption curves prediction could be performed using DeepSorption with a higher accuracy than Grand canonical Monte Carlo simulation and other machine learning models, a 20-35% decline in the mean absolute error compared to graph neural network CGCNN and machine learning models based on descriptors. Since the established direct associations between raw structure and target functions are based on the understanding of the fundamental chemistry of interatomic interactions, the deep learning network is rationally universal in predicting the different physicochemical properties of various crystalline materials.
Similar content being viewed by others


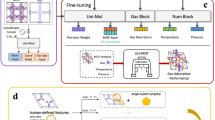
Introduction
Physisorption based on porous materials offers cost- and energy-efficient alternatives toward promising solutions to global challenges in carbon dioxide (CO2) capture1,2, energy gas storage3, separation4,5,6 and etc, which consumes 10-15% of global energy consumption7. The breakthrough of related technologies lies in the design and screening of porous materials with specific adsorption properties, a critical characteristic that determines the functions of porous materials8,9. Crystalline porous materials, including metal-organic frameworks (MOFs)10 or porous coordination polymers (PCPs)11,12, covalent-organic frameworks (COFs)13, and zeolites14, can be rationally customized via the selective self-assembly of molecular building blocks15, enabling the possibility of a bottom-up design of porous materials with envisaged functions. These materials have shown attractive potential in diverse fields, such as adsorption16, membrane separation17, and catalysis18. However, the discovery of porous materials is greatly hindered by the problems of long experimental times, high costs of conventional trial-and-error paradigms, and the limited efficiency of high-throughput simulation studies.
Machine learning affords a powerful approach for the rapid discovery of materials with desired adsorption properties by learning the knowledge of porous materials and their physisorption behaviors19,20,21,22. However, the accurate prediction of adsorption performance still remains a challenge due to the complex associations between raw material structures and functional properties that require machine learning models to understand the correlations among global atoms, local atoms with different element definitions23,24,25. Researchers have attempted to develop expert-engineered porous material descriptors that can maximally cover the key structural information to improve prediction accuracy25,26,27,28. However, since every piece of subtle structural information is crucial to the correct expression of adsorption properties, the intrinsic drawback of raw structural information loss and high computational cost during the descriptors generation and processing inevitably cause error propagation21,27,29. Even for the most commonly acknowledged structural descriptors, for example, largest cavity diameter (LCD), the Pearson correlation coefficient between the LCD and CO2 adsorption capacity is only −0.14, via the preliminary data analysis of the gas adsorption performance of porous materials (Fig. S1). End-to-end prediction is favorable for maintaining complete raw structural information, and it has great potential for accurate prediction30,31. However, three daunting challenges have yet to be addressed to realize efficient direct structure-adsorption prediction: (i) advanced models are needed for translating and transferring complete raw structural information, including both chemical element knowledge and spatial atomic arrangement; (ii) atomic-level information needs to be exchanged for the accurate cognition of spatial atomic interactions and good interpretability of the model; (iii) the efficient utilization of knowledge from field experts is required to solve the data hungry problem in solely data-driven deep learning models.
Here DeepSorption, a data-driven network with a built-in expert knowledge co-learning (KCL) module, was designed for fast and end-to-end predictions directly from the coordinates and elements of atoms to the adsorption properties of porous materials (Fig. 1) and it achieved the best prediction results on multiple data sets. The distinctive architecture of the network lies in the developed Matformer model that serves as a high-fidelity interpretation of the overall structural information of porous materials, including the atomic spatial arrangement and chemical element information. Moreover, the Multi-scale Atom-attention (MSA) mechanism within the model realizes the accurate, efficient cognition of interactions between atoms at different scales, and enables the visualization of the potential atomic interactions hidden in the encoding layers. The KCL module reduces the reliance of the end-to-end network on massive training data, and is beneficial for improving the accuracy of adsorption property prediction. DeepSorption far outperforms other available networks in adsorption uptake predictions with lowest root mean squared errors (RMSE) and highest correlation coefficients both in CO2 and acetylene (C2H2) prediction, which is essential for identifying efficient adsorbents for CO2 capture and C2H2 separation.

a The scheme of crystalline porous materials (SIFSIX-1-Cu), guest molecules (carbon dioxide) and physisorption process. b The inputs of DeepSorption, including atom coordinates and element types. c The architecture of Matformer, including 3D position encoding layer, Chemical element encoding layer, Multi-scale Atom-attention layer, and feed-forward neural network (FNN). d The outputs of DeepSorption, including gas adsorption isotherms and co-learning expert’s knowledge. e The scheme of Multi-scale Atom-attention for calculating the interaction between atom pairs in different distance scales.
Results
Designing and constructing the deep learning network
Crystalline porous materials could exhibit predesigned skeletons and nanopores through the atomically precise integration of organic units, inorganic units or combinations. Physisorption reveals the different priority locations of guest molecules within nanopores that are mainly governed by interatomic interactions by exploring the potential adsorption sites and space (Fig. 1a). Here, the original data of crystalline materials, including atom coordinates and element types, are directly used as the input of DeepSorption (Fig. 1b), preventing information loss caused by using processed expert knowledge descriptors as input. Given that the characteristic of the process by which atoms form frames is inherently similar to that of natural language, different arranged atoms (words) construct the specifically defined framework (sentence), a home-made Matformer inspired by natural language processing32 is employed to process crystalline material data. The encoding of 3D atomic coordinates and the corresponding element types utilizes 3D position encoding block and Chemical element encoding block (Fig.1c). 3D position encoding is an absolute position encoding approach that endows the model with both local and global structure-aware abilities. Chemical element encoding block is initialized via chemical element knowledge graph (Fig. S2), which is built from periodic table and summarizes the most fundamental chemical properties of elements and microscopic associations among elements.
The key innovation in Matformer lies in Multi-scale Atom-attention (MSA) for understanding the interactions between different defined atoms in a spatial arrangement (Fig. 1e). Through exchanging information between atom pairs in different distances, MSA facilitates Matformer with the intuition to judge the interatomic interaction at different scales. In detail, MSA computes the atomic distance based on the input atomic coordinates, and the contribution of the atomic element type is simultaneously considered. The hyper-parameter attention distance bars are 5 Å, 8 Å, 12 Å and infinite, corresponding to bond/motif detection, adsorption site and surface decisions, pore structure detection, and global structure awareness, respectively (Fig. 1e). Interactions between atom pairs at different attention distance scales could be pointedly processed by the appointed units in Matformer, and the processed information, such as key atoms/space, would be integrated to reveal physisorption behavior of guest molecules. With regard to the data-hungry drawbacks occurred in direct data-driven learning, the strategy of knowledge co-learning (KCL) is employed (Fig. 2), and the descriptors of crystalline porous materials are set as auxiliary tasks (Fig. 1d). The results show that KCL could facilitates the convergence of the model in the structure-adsorption space establishment assisted by the expert knowledge derived from the auxiliary tasks, which is beneficial for improving the prediction accuracy of adsorption properties. It is noteworthy that the output of expert knowledge is only needed during model training, but leaving no interference with the prediction process, guaranteeing the rapid prediction speed. DeepSorption well inherits the advantages of time efficiency, decreased error propagation of end-to-end method, and the data efficiency of the expert-knowledge-driven learning method (Fig. 2).

a The scheme of Expert-knowledge-driven learning model. The raw data is transformed into corresponding descriptors via expert knowledge, serving as the input of the subsequent machine learning model. b The scheme of Data-driven learning model. Raw data is directly as the input of the model to predict the adsorption capacity. c The scheme of Data-driven knowledge co-learning model. Raw data is directly as the input of the model to predict the adsorption capacity, and the expert knowledge is used as auxiliary prediction tasks.
Model performance and validation
To train DeepSorption (Matformer+KCL) deep learning network, the data of crystalline materials collected in the CoREMOF database33 (including over 11,000 MOFs and 77 kinds of elements) and hMOF database34 (including over 300,000 MOFs and 16 kinds of elements) were used. CO2 capture is crucial to alleviate global warming, facilitating carbon conversion and utilization, and developing efficient carbon capture technologies are subjected to the discovery of adsorbents with high CO2 and low N2 capacity34,35.
Thus, CO2 and N2 are used as tested gases in this work, and the predicted gas uptake is consistent with the true values in all tasks, including CoREMOF-CO2 (Fig. 3a), hMOF-CO2 (Fig. 3b) and hMOF-N2 (Fig. S3). DeepSorption shows much smaller and more distributed centralized absolute errors on the CoREMOF-CO2 task than the other models, and the mean absolute error (MAE) of DeepSorption (14.39 cm3 g−1) decreased by 23–52% compared with those of Long Short-Term Memory (LSTM: 20.00 cm3 g−1), Crystal Graph Convolutional Neural Network (CGCNN: 18.94 cm3 g−1), Expert-knowledge-driven learning models (GEO_MLP: 21.78 cm3 g−1, RAC_MLP: 18.64 cm3 g−1, MBTR_MLP: 21.54 cm3 g−1, SOAP_MLP: 30.05 cm3 g−1) (Fig. 3c). Moreover, higher coefficient of determination (R2) values and lower RMSE of co-learning knowledge tasks of LCD, pore limiting diameter (PLD), density (D), accessible surface area (ASA), void fraction (VF), accessible volume (AV) are also realized (Fig. 3d and Fig. S3). The improved prediction accuracy of physisorption associated parameters is attributed to the global structure awareness ability of Matformer. On average, for the CoREMOF-CO2, hMOF-CO2 and hMOF-N2 tasks, KCL contributes to a 13% decrease in RMSE and an 18% increase in R2. These results not only indicate that DeepSorption, like human scientists, could well learn and utilize expert knowledge, but also explain why data-driven knowledge co-leaning models can achieve a better learning effect compared to the solely data-driven learning methods. In contrast to the classic EKDL model and graph neural networks, DeepSorption always exhibits the highest R2 value and the lowest MAE value (Fig. 3e, f). The R2 value of the predicted CO2 adsorption uptake in the CoREMOF dataset is over 0.70, which is increased by 38–113% than those of EKDL models (Fig. 3e and Table S1). Compared with the graph neural network CGCNN, the performance is also significantly improved, from 0.48 to 0.70 of R2 (Fig. 3e). The great advancement in prediction accuracy of DeepSorption is attributed to the unique advantages of the designed network that realizes the complete interpretation of original structural information and the comprehensive understanding of spatial atom interactions. For CGCNN, this insufficiency was attributed to the poor global structure awareness characteristic of graph neural network itself. As shown in Fig. S15, the strategy of graph neural network is to strengthen the information of atomic elements by calculating the neighbor atoms via using the spatial coordinate information. However, the information of atomic spatial coordinate would be lost in the subsequent information interaction process, which is not conducive to predict adsorption properties that are sensitive to the global spatial structure information.

a, b The correlations between true adsorption uptake and predicted adsorption uptake on test sets implemented by DeepSorption network on CoREMOF-CO2 (a), hMOF-CO2 (b) tasks. c The distribution of absolute errors on test sets between true adsorption uptake and predicted adsorption uptake on CoREMOF-CO2 based on different models, including DeepSorption (Matformer+KCL), RAC_MLP (Multilayer perceptron based on RACs descriptors), CGCNN (Crystal Graph Convolutional Neural Network47), MOFNet19, MBTR_MLP (Multilayer perceptron based on MBTR descriptors), GEO_MLP (Multilayer perceptron based on geometric structure descriptors). d The coefficient of determination R2 on test sets of co-learning knowledge, including LCD (largest cavity diameter), PLD (pore limiting diameter), D (density), ASA (accessible surface area), VF (void fraction), AV (accessible volume) on CoREMOF-CO2 using DeepSorption, CGCNN, MBTR_MLP, RAC_MLP and LSTM (Long Short-Term Memory48) models. e, f The coefficient of determination R2 and mean absolute errors (MAE) of different models on CoREMOF-CO2 (e) and hMOF-CO2 (f) tasks on test sets.
For further clarifications on the KCL (knowledge co-learning) procedure, we tested using only a subset of descriptors as KCL and analyzed the effect enhancement of different subsets (Table S10). According to the correlation coefficient between the structure descriptors and CO2 adsorption, we selected the following sets of tasks ([AD], [AD, LCD], [AD, LCD, PLD], [AD, LCD, PLD, AV], [AD, LCD, PLD, AV, ASA], [AD, LCD, PLD, AV, ASA, D], [AD, LCD, PLD, AV, ASA, D, VF]). And we found that the model achieved the best prediction results when using four descriptors (LCD, PLD, AV and ASA), slightly higher than the prediction results when using all six descriptors (R2: 0.708 vs 0.701, MSE: 419 vs 429). We also found that the difference between results of using no auxiliary tasks and incorporating any auxiliary tasks was huge. Through the following comparative experiments, it is speculated that the difference is caused by the fact that the physical structure descriptors as auxiliary tasks can activate the position-encoding module which takes absolute coordinates as the input.
To examine the sensitivity of DeepSorption toward the training-validation-test set random split of the prediction results, we performed 10 different random divisions of the CO2 adsorption data in CoREMOF dataset (Table S12) and found that the results are less affected by the division of the dataset, with R2 between 0.672– 0.712 and MAE between 13.598−15.150 cm3 g−1, proving the robustness of the model.
The ability to predict out-of-distribution data is challenging and is an important indicator of the model’s generalizability. Elements that occur less than one in a thousand times are defined as rare elements (As, Rh, Sb, Te, Ir, Pb, Np and Pu). As shown in Fig. S29 we have compared the predicted and true values of the CO2 adsorption capacity of the MOF containing the rare elements in the test set. DeepSorption still showed the best prediction performance (R2: 0.28), better than the other comparison models, CGCNN (R2: -0.23) RAC_MLP (R2: -0.15) and GEO_MLP (R2: 0.09). We attribute this good out-of-distribution prediction to the use of the Chemical Element Knowledge Graph for element coding in MatFormer. The Chemical Element Knowledge Graph coding method gives each element a vector representation containing chemical element information by learning and correlating the interrelationships between the properties of the elements. The vector representations are learnt based on Chemical Element Knowledge Graph and is independent to the training data of gas adsorption prediction, so that even if materials contain elements in the test data that do not appear in the training data or appear only a few times, the model can still give relatively accurate adsorption predictions since the out-of-distribution elements also have information-rich vector representations.
We further examined the performance of DeepSorption model at a wide range of conditions, including carbon dioxide (2.5 bar and 298 K), methane (35 bar and 298 K) and hydrogen (100 bar and 77 K) adsorption capacity prediction tasks. As presented in Fig. S30 and Table S13, DeepSorption model still showed better prediction performance compared with other models, and we also found that R2 of adsorption prediction tasks of high pressure was generally higher than those of low pressure. The R2 of the three tasks of CO2 (2.5 bar and 298 K), CH4 (35 bar and 298 K) and H2 (100 bar and 77 K) adsorption reached 0.96, 0.98 and 0.99 respectively via DeepSorption models, which may attribute to the fact that the adsorption capacity is mainly determined by the surface area and pore volume of the material under high pressure. This phenomenon can also be drawn from the better prediction effect of GEO_MLP on H2 (100 bar and 77 K) task (R2: 0.994), than CGCNN (R2: 0.872), since the latter is not good at capturing the overall spatial structure of materials.
The superiority of DeepSorption is further validated on the collected experimental C2H2 (EXPMOF-C2H2) as well as CO2 (EXPMOF-CO2) adsorption isotherms. C2H2 adsorption is essential to its safe storage, as well as the key technology for the production of polymer-grade ethylene36. A low RMSE is obtained using leave-one-out validation on the experimental data, where R2 reaches 0.86 for EXPMOF-C2H2 and 0.87 for EXPMOF-CO2 (Fig. 4a and b). Given the easy occurrence of severe deviations in the adsorption property prediction of porous materials with strong interaction sites, three tasks that involves typical strong polar sites, SIFSIX-2-Cu-i37 with anion sites, Zn-MOF-7438 with open metal sites, and ZJNU−103 with amino functional groups (Fig. 4c–e) are performed. It is noteworthy that DeepSorption still shows highly consistent values with the experimental ones, and moreover the prediction of C2H2 and CO2 adsorption isotherms from 0 to 1 bar could be completed within seconds using only one 3090 RTX GPU. Despite a longer computing time (tens of hours), the adsorption prediction performance of molecular simulation is still unsatisfactory in the low pressure adsorption zone (Fig. 4c–e). DeepSorption also well outperforms other exiting learning approaches for adsorption properties prediction, and its improvement is fully demonstrated in the case of known SIFSIX-2-Cu-i featured with steep C2H2 adsorption curve (Fig. 4c). Since the adsorption isotherms of C2H2 and other strong polar gases under low pressure are incline to be governed by the host-guest interactions, such as hydrogen bonding interactions between SiF62− and C2H2 in SIFSIX-2-Cu-i, instead of the pore volume and surface area, its accurate predictions require the model to gain insight into spatial interaction learning. By contrast, CGCNN and EKDL that are insensitive to either spatial information or elemental chemical information, are incapable to well evaluate interatomic interactions and fail to accurately predict steep adsorption curves. The accurate and highly-efficient prediction based on DeepSorption is believed to largely accelerate the discovery of crystalline porous materials with specific adsorption properties.

a, b The correlations between true adsorption uptake and predicted adsorption uptake from DeepSorption network on EXPMOF-C2H2 (a) and EXPMOF-CO2 (b) tasks on test sets through leave-one-out validation. c–e The experimental and predicted adsorption isotherms via different machine learning algorithms, red for DeepSorption, green for EKDL (Expert-knowledge-driven learning model), blue for CGCNN (Crystal Graph Convolutional Neural Network) and yellow for Grand canonical Monte Carlo molecular simulation of SIFSIX-2-Cu-i with SiF62−anions (c), Zn-MOF-74 with open metal sites (d), and ZJNU−103 (e) with amino functional groups.
Chemical insights at the atomic level
The interpretability of models has been a long-term concern in the field of ‘AI for science’. MSA mechanism endows DeepSorption with the logical thinking of atomic-level interactions, enabling the intuitive visualization of the execution trajectory, which is essential to deepen the understand about the learning process of the network. SIFSIX−1-Cu, one of the benchmark C2H2 adsorbents36, serves as an example (Fig. 5a). The relationship between priority attention atoms is presented in Fig. 5, and the high priority atom pairs in different attention distance scale are highlighted with lines. At the 5 Å scale bar, DeepSorption mainly focuses on the interactions between neighboring atoms, such as Cu···N, N···C and F···H, to search for the important motif and bond (Fig. 5a). At 8 Å scale bar, the local structural characteristics of the material are focused on by evaluating the interactions between F, Si atoms on the SIFSIX2− anions and H, C atoms on the organic ligands, to explore the potential adsorption sites and pore surface for gas accommodation. The deep insight into MOFs with different structures also indicates that the adjacent pairs of atoms with large electronegativity differences as the potential polar adsorption sites are preferentially concerned within small scale bars, such as Cu···O in HKUST-139 and Zn···O in UTSA-7440 (Fig. S31 and S32). At 12 Å scale bar, the interactions between atoms on the surface of the pore channel begin to be considered, which implies that the model tries to learn and calculate expert knowledge information, such as pore diameter, pore volume and surface area (Fig. 5b). As revealed in SIFSIX-1-Cu, DeepSorption not only focuses on the C···C and C···H atom pairs on the sides of square channels for PLD measurement, but also the interaction of F···C and F···H atom pairs on the diagonal of square channels to measure LCD. At the infinite scale bar, interactions between heavy atoms Si, Cu and distant atoms are highlighted, which are beneficial for model to understand and extract the overall topology and global structure information of the crystalline materials. In addition, in MOFs with open metal sites, such as MFM-18841, MOF-50542, HKUST-139 and UTSA-7440, (Figs. S33 and S34), most of the attentioned atom pairs are related to unsaturated metal sites Cu or Zn at all atom-attention distance scale bars, which verified that DeepSorption has possessed the ability to judge the critical important binding sites to give the accurate gas adsorption isotherms.

a The 3D attention maps of SIFSIX−1-Cu at different attention distance scale bars, including 5 Å, 8 Å, 12 Å, and infinite. b The structure of SIFSIX−1-Cu, including bond, motif, pore size and adsorption surface (LCD: largest cavity diameter, PLD: pore limiting diameter). (Color code: C, Gray-50%; Si, Cyan; H, Gray-25%; N, Blue; Cu, Green; F, Pink; The attention between atom pairs, Red).
Discussion
DeepSorption presents the spatial atom interaction learning network that realizes the accurate and fast prediction of complex adsorption properties of crystalline porous materials with benchmark prediction accuracy. Benefiting from the Multi-scale Atom-attention mechanism, DeepSorption is able to perform an accurate evaluation of interactions between atoms to achieve physisorption behavior prediction and offer an intuitive visualization of the thinking and executing trajectory which has not been realized in the existing networks for adsorption prediction. The remarkable advancement in the prediction of complex physicochemical properties highlights the importance of the global structure awareness, the coupling transfer and interaction of the atomic-level spatial structure information and the chemical element information. The spatial atom interaction learning network reveals the intrinsic chemistry that determines the expressed function of crystalline porous materials, and is a promising powerful tool for the prediction of various physicochemical and surface properties of other crystalline materials with accessible atomic coordinates, such as perovskite and crystalline catalysts.
Methods
DeepSorption network
DeepSorption network is mainly composed of Matformer and KCL modules. During training of DeepSorption network, the cartesian three-dimensional coordinates and corresponding element types of atoms in crystalline porous materials are input. In order to assign a representation to each atom in crystalline porous materials, three-dimensional coordinate information and element type information of atoms are first encoded through 3D position encoding layer and Chemical element encoding layer respectively, and the spatial and element information are then added up to get the atomic representation. The obtained atomic representation in the crystalline porous materials are transferred and interacted among atoms through the Multi-scale Atom-attention layer (MSA) in Matformer model. After the computation of Matformer module with six layers, DeepSorption outputs the predicted value of adsorption capacity as the target task and expert knowledge (largest cavity diameter, pore limiting diameter, density, accessible surface area, void fraction, accessible volume) as the auxiliary tasks simultaneously based on the KCL module. More details of DeepSorption network are available in supporting information.
MSA
Multi-scale Atom-attention (MSA), a scale-aware multi-head attention mechanism (Fig. S4), is designed to recognize the interactions between atoms at different scales. Its input is a sequence of atom vectors, and the output is a sequence of updated atom vectors in the same order as the input. For each attention head, we assign a visible distance \({{{{{{\rm{\tau }}}}}}}_{{{{{{\rm{s}}}}}}}\) to make atoms within \({{{{{{\rm{\tau }}}}}}}_{{{{{{\rm{s}}}}}}}\) visible to each other during attention calculation in this head. With the input atom representation sequence \(({x}_{1},{x}_{2},{x}_{3},\ldots,{x}_{i},\ldots,{x}_{N})\), each head of MSA first generates a key, value and query based on each atom vector \({x}_{i}\):
where \({q}_{i}\), \({k}_{i}\), \({v}_{i}\) are query, key and value vector with dimension \({d}_{k}\). Then an attention score is calculated based on the similarity between query \({q}_{i}\) to key of atoms whose distance to atom \(i\) is within \({{{{{{\rm{\tau }}}}}}}_{{{{{{\rm{s}}}}}}}\). Specifically, the attention that the atom \(i\) pays to \(j\) can be formulated as:
where \({d}_{{ij}}={{||}{p}_{i}-{p}_{j}{||}}_{2}\) is the Euclidean distance between atom \(i\) and \(j\), \({1}_{\{{d}_{{ij}} < {{{{{{\rm{\tau }}}}}}}_{{{{{{\rm{s}}}}}}}\}}\) is the indicator function that makes the score between two atoms beyond distance \({{{{{{\rm{\tau }}}}}}}_{{{{{{\rm{s}}}}}}}\) to 0, and \(\frac{1}{\sqrt{{{{{{{\rm{d}}}}}}}_{{{{{{\rm{k}}}}}}}}}\) is a scaling factor. The output vector of atom \(i\) at this attention head is:
here \(\sigma\) denotes the softmax function. For each attention head, we specify distinct distances to enable the model to capture knowledge at different scales. Then vectors of atom \(i\) from different heads are concatenated resulting a multi-scale vector \({{{{{{\boldsymbol{z}}}}}}}_{i}\), followed by a feed-forward network to map it to dimension \({d}_{{model}}\).
KCL
Knowledge co-learning (KCL), a module of DeepSorption network, is utilized to guide the model to better and faster converge during training by learning to predict target tasks and auxiliary tasks closely related to target tasks synchronously. The selection of auxiliary tasks commonly depends on the expert knowledge in the field. It is worth mentioning that the expert knowledge only needs to be used as a data label during model training. The prediction of crystalline porous adsorbents does not require expert knowledge, only the coordinates and corresponding element types of atoms in crystalline porous adsorbents are required as input (Fig. 2c). In this way, the simplicity and speed of the prediction process will not be damaged. Expert knowledge such as pore size and pore volume used in this study can be obtained by high-throughput calculation using automated high-throughput analysis software Zeo + +43. Zeo + + uses crystal structure information files of crystalline porous materials as input, which can calculate the expert knowledge of materials at high throughput without manual annotation by chemical experts. Zeo + + are based on the Voronoi decomposition, which for a given arrangement of atoms in a periodic domain provides a graph representation of the void space44. After having the representations of crystalline porous materials \({\{{{{{{{\boldsymbol{z}}}}}}}_{i}\}}_{i=1,\ldots,N}\), we feed them into a fully connected layer to conduct prediction.
Training details
To train DeepSorption, we use the crystalline materials collected in the CoREMOF, hMOF, EXPMOF-CO2 and EXPMOF-C2H2 datasets. We split the CoREMOF and hMOF datasets with a ratio for train/validation/test as 0.7:0.15:0.15. For CoREMOF, we simultaneously predict the following 7 targets: LCD, PLD, D, ASA, VF, AV and ADCO2 (adsorption uptake of CO2). For hMOF, the following 7 targets are predicted at the same time: ADCO2, ADN2 (adsorption uptake of N2), LCD, PLD, D, VF and ASA. We use leave-one-out method to evaluate the performance of our model in EXPMOF-CO2 and EXPMOF-C2H2 datasets. In details, when predicting the adsorption performance of material X (X refers to any material in the EXPMOF database) in the test set, any adsorption data of material X will not appear in the training set for model training. For EXPMOF-CO2, we predict the following targets at the same time: adsorption uptakes of CO2 at different pressures (0.01–0.92 bar, spaced at 0.1 bar), LCD, PLD, D, ASA and AV. For EXPMOF-C2H2, we predict the following targets at the same time: adsorption uptakes of C2H2 at different pressures (0.06–0.95 bar, spaced at 0.1 bar), LCD, PLD, D, ASA and AV. In details DeepSorption is trained to minimize the MSE loss, which is the mean of the squared errors between true and predicted values on training data. We evaluate the performance of our model on test dataset.
3D attention visualization of DeepSorption
With the help of the Multi-scale Atom-attention mechanism, the interpretability at multiple scales is clearly presented in this study, weights are extracted from Multi-scale Atom-attention layers. Atom pair interactions with higher weight ranking are displayed by connecting lines to show the atomic interactions that the model pays more attention to in the predicting process. Taking 5 Å distance scale bar as an example, we first draw the structure of crystalline porous material by using atomic coordinate information and chemical element type information. Then, the Atom-attention weight parameters for each atom pair of Matformer with distance bar of 5 Å are extracted and sorted from largest to smallest. The top 20 atomic pairs in weight order of each layer of Matformer in the distance bar of 5 Å are highlighted with red lines.
Dataset
CoREMOF, hMOF and EXPMOF datasets were used in this study. hMOF dataset includes over 300,000 hypothetical MOFs containing 16 elements, which are built with rigid organic and inorganic struts called secondary building units (SBU)s. hMOF dataset includes 3D Cartesian coordinates and the corresponding element types of MOFs, and corresponding adsorption performances of carbon dioxide (CO2), nitrogen (N2) determined by Grand canonical Monte Carlo (GCMC) simulations, and their corresponding expert knowledge, including LCD, PLD, D, ASA, and VF. CoREMOF (Computation-Ready, Experimental MOF33) dataset includes over 11,000 computation-ready, experimental three-dimensional metal-organic frameworks (MOFs) that contains more than 77 elements. The dataset contains 3D Cartesian coordinates and the corresponding element types of MOFs, and the corresponding adsorption performance of carbon dioxide (CO2) determined by Grand canonical Monte Carlo (GCMC) simulations45, and their corresponding expert knowledge, including LCD, PLD, D, ASA, VF and AV (Fig. S3). It is worth mentioning that the expert knowledge is only needed during training process, but is not required in the prediction of crystalline porous adsorbents. The EXPMOF dataset constructed by ourselves is composed of EXPMOF-CO2 and EXPMOF-C2H2. The adsorption data of EXPMOF dataset is from experiments. The 3D Cartesian coordinates and the corresponding element types of crystals are collected from reported literature or our lab. EXPMOF-CO2 contains 112 data, and EXPMOF-C2H2 contains 140 data. In more details, adsorption isotherms are extracted from the figures of literature and then are interpolated for data alignment. The expert knowledge of MOFs, including LCD, PLD, D, ASA, and AV, are calculated using Zeo + + programs.
Full algorithm details
Full explanations and details of deep learning model algorithm and hyper-parameter details (including Matformer and LSTM) are available in supporting information.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
All data supporting the findings of this study are available within the main text and the Supplementary Information. The data that support the findings of this study are available in https://doi.org/10.5281/zenodo.769971946. Source data are provided with this paper.
Code availability
The code repository is stored at https://doi.org/10.5281/zenodo.769971946 and https://github.com/DeepSorption/DeepSorption1.0.
References
Nugent, P. et al. Porous materials with optimal adsorption thermodynamics and kinetics for CO 2 separation. Nature 495, 80–84 (2013).
Datta, S. J. et al. CO2 capture from humid flue gases and humid atmosphere using a microporous coppersilicate. Science 350, 302–306 (2015).
Chen, Z. et al. Balancing volumetric and gravimetric uptake in highly porous materials for clean energy. Science 368, 297–303 (2020).
Li, J. R. et al. Porous materials with pre-designed single-molecule traps for CO2 selective adsorption. Nat. Commun. 4, 1538 (2013).
Zhao, X., Wang, Y., Li, D. S., Bu, X. & Feng, P. Metal–organic frameworks for separation. Adv. Mater. 30, 1705189 (2018).
Yang, S. et al. Selectivity and direct visualization of carbon dioxide and sulfur dioxide in a decorated porous host. Nat. Chem. 4, 887–894 (2012).
Liu, G. et al. Mixed matrix formulations with MOF molecular sieving for key energy-intensive separations. Nat. Mater. 17, 283–289 (2018).
Lin, J. Y. S. Molecular sieves for gas separation. Science 353, 121–122 (2016).
Han, X., Yang, S. & Schröder, M. Porous metal–organic frameworks as emerging sorbents for clean air. Nat. Rev. Chem. 3, 108–118 (2019).
Furukawa, H., Cordova, K. E., O’Keeffe, M. & Yaghi, O. M. The chemistry and applications of metal-organic frameworks. Science 341, 1230444 (2013).
Kim, C. R., Uemura, T. & Kitagawa, S. Inorganic nanoparticles in porous coordination polymers. Chem. Soc. Rev. 45, 3828–3845 (2016).
Duan, J. et al. Density gradation of open metal sites in the mesospace of porous coordination polymers. J. Am. Chem. Soc. 139, 11576–11583 (2017).
Diercks, C. S. & Yaghi, O. M. The atom, the molecule, and the covalent organic framework. Science 355, 923 (2017).
Bereciartua, P. J. et al. Control of zeolite framework flexibility and pore topology for separation of ethane and ethylene. Science 358, 1068–1071 (2017).
Kalmutzki, M. J., Hanikel, N. & Yaghi, O. M. Secondary building units as the turning point in the development of the reticular chemistry of MOFs. Sci. Adv. 4, 1–16 (2018).
Cadiau, A., Adil, K., Bhatt, P. M., Belmabkhout, Y. & Eddaoudi, M. A metal-organic framework-based splitter for separating propylene from propane. Science 353, 137–140 (2016).
Zhou, S. et al. Asymmetric pore windows in MOF membranes for natural gas valorization. Nature 606, 706–712 (2022).
Lee, J. et al. Metal–organic framework materials as catalysts. Chem. Soc. Rev. 38, 1450–1459 (2009).
Chen, P. et al. Interpretable Graph Transformer Network for Predicting Adsorption Isotherms of Metal−Organic Frameworks. J. Chem. Inf. Model. 62, 5446–5456 (2022).
Jablonka, K. M., Ongari, D., Moosavi, S. M. & Smit, B. Using collective knowledge to assign oxidation states of metal cations in metal-organic frameworks. Nat. Chem. 13, 771–777 (2021).
Yao, Z. et al. Inverse design of nanoporous crystalline reticular materials with deep generative models. Nat. Mach. Intell. 3, 76–86 (2021).
Burger, B. et al. A mobile robotic chemist. Nature 583, 237–241 (2020).
Anderson, R., Rodgers, J., Argueta, E., Biong, A. & Gomez-Gualdron, D. A. Role of pore chemistry and topology in the CO2 capture capabilities of MOFs: From molecular simulation to machine learning. Chem. Mater. 30, 6325–6337 (2018).
Simon, C. M., Mercado, R., Schnell, S. K., Smit, B. & Haranczyk, M. What are the best materials to separate a xenon/krypton mixture? Chem. Mater. 27, 4459–4475 (2015).
Wu, Y., Duan, H. & Xi, H. Machine learning-driven insights into defects of zirconium Metal–Organic Frameworks for enhanced ethane–ethylene separation. Chem. Mater. 32, 2986–2997 (2020).
Wang, S., Li, Y., Dai, S. & Jiang, D. E. Prediction by convolutional neural networks of CO2 /N2 selectivity in porous carbons from N2 adsorption isotherm at 77 K. Angew. Chem. Int. Ed. 59, 19645–19648 (2020).
Fernandez, M., Woo, T. K., Wilmer, C. E. & Snurr, R. Q. Large-scale quantitative structure–property relationship (QSPR) analysis of methane storage in Metal–Organic Frameworks. J. Phys. Chem. C. 117, 7681–7689 (2013).
Ye, W., Chen, C., Wang, Z., Chu, I. H. & Ong, S. P. Deep neural networks for accurate predictions of crystal stability. Nat. Commun. 9, 3800 (2018).
Wu, X., Xiang, S., Su, J. & Cai, W. Understanding quantitative relationship between methane storage capacities and characteristic properties of Metal–Organic Frameworks based on machine learning. J. Phys. Chem. C. 123, 8550–8559 (2019).
Degrave, J. et al. Magnetic control of tokamak plasmas through deep reinforcement learning. Nature 602, 414–419 (2022).
Jung, S.-M. et al. Selective electrocatalysis imparted by metal–insulator transition for durability enhancement of automotive fuel cells. Nat. Catal. 3, 639–648 (2020).
Ashish, V. et al. Attention Is All You Need. In Advances in Neural Information Processing Systems 30, (2017).
Chung, Y. G. et al. Advances, updates, and analytics for the Computation-Ready, Experimental Metal−Organic Framework database: CoRE MOF 2019. J. Chem. Eng. Data 64, 5985–5998 (2019).
Boyd, P. G. et al. Data-driven design of metal-organic frameworks for wet flue gas CO2 capture. Nature 576, 253–256 (2019).
Zhou, Y. et al. Self-assembled iron-containing mordenite monolith for carbon dioxide sieving. Science 373, 315–320 (2021).
Cui, X. L. et al. Pore chemistry and size control in hybrid porous materials for acetylene capture from ethylene. Science 353, 141–144 (2016).
Nugent, P. et al. Porous materials with optimal adsorption thermodynamics and kinetics for CO2 separation. Nature 495, 80–84 (2013).
Bloch, E. D. et al. Hydrocarbon Separations in a Metal-Organic Framework with Open Iron(II) Coordination Sites. Science 335, 1606–1610 (2012).
Chui, StephenS. Y. et al. Chemically functionalizable nanoporous material [Cu3(TMA)2(H2O)3]n. Science 283, 1148–1150 (1999).
Luo, F. et al. UTSA-74: a MOF-74 isomer with two accessible binding sites per metal center for highly selective gas separation. J. Am. Chem. Soc. 138, 5678–5684 (2016).
Moreau, F. et al. Unravelling exceptional acetylene and carbon dioxide adsorption within a tetra-amide functionalized metal-organic framework. Nat. Commun. 8, 14085 (2017).
Chen, B., Ockwig, N. W., Millward, A. R., Contreras, D. S. & Yaghi, O. M. High H2 adsorption in a microporous metal-organic framework with open metal sites. Angew. Chem. Int. Ed. 44, 4745–4749 (2005).
Pinheiro, M., Martin, R. L., Rycroft, C. H. & Haranczyk, M. High accuracy geometric analysis of crystalline porous materials. Cryst. Eng. Comm. 15, 7531 (2013).
Willems, T. F., Rycroft, C. H., Kazi, M., Meza, J. C. & Haranczyk, M. Algorithms and tools for high-throughput geometry-based analysis of crystalline porous materials. Micropor. Mesopor. Mater. 149, 134–141 (2012).
Korolev, V. V. et al. Transferable and extensible machine learning-derived atomic charges for modeling hybrid nanoporous materials. Chem. Mater. 32, 7822–7831 (2020).
Cui, J. Y. et al. Direct prediction of gas adsorption via spatial atom interaction learning. Zenodo, https://doi.org/10.5281/zenodo.7699719 (2023).
Xie, T. & Grossman, J. C. Crystal graph convolutional neural networks for an accurate and interpretable prediction of material properties. Phys. Rev. Lett. 120, 145301 (2018).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735–1780 (1997).
Acknowledgements
This work was financially supported by the National Natural Science Foundation of China 22122811 (X.C.), 22227812 (H.X.), and 21938011 (H.X.).
Author information
Authors and Affiliations
Contributions
H.X., H.C., and J.C. conceived of the project. J.C., L.Y., J.H., X.S. collected and cleaned the dataset. F.W., J.C., P.Y. and W.Z. designed the models. F.W., P.Y., Y.F. and J.C. ran the experiments. Y.M., Q.Z., X.C., X.S. and L.Y. analysis the results and provided advice. H.X., H.C. and W.Z. directed and managed the project. J.C. and L.Y. wrote the paper with help and feedback from H.X., H.C., W.Z., Y.M., Q.Z., X.C., X.S.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks the anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cui, J., Wu, F., Zhang, W. et al. Direct prediction of gas adsorption via spatial atom interaction learning. Nat Commun 14, 7043 (2023). https://doi.org/10.1038/s41467-023-42863-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-023-42863-6
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
