
Abstract
Deep neural networks are a powerful tool for characterizing quantum states. Existing networks are typically trained with experimental data gathered from the quantum state that needs to be characterized. But is it possible to train a neural network offline, on a different set of states? Here we introduce a network that can be trained with classically simulated data from a fiducial set of states and measurements, and can later be used to characterize quantum states that share structural similarities with the fiducial states. With little guidance of quantum physics, the network builds its own data-driven representation of a quantum state, and then uses it to predict the outcome statistics of quantum measurements that have not been performed yet. The state representations produced by the network can also be used for tasks beyond the prediction of outcome statistics, including clustering of quantum states and identification of different phases of matter.
Similar content being viewed by others


Introduction
Accurate characterization of quantum hardware is crucial for the development, certification, and benchmarking of new quantum technologies1. Accordingly, major efforts have been invested into developing suitable techniques for characterizing quantum states, including quantum state tomography2,3,4,5,6, classical shadow estimation7,8, partial state characterization9,10, and quantum state learning11,12,13,14. Recently, the dramatic development of artificial intelligence inspired new approaches on machine learning methods15. In particular, a sequence of works explored applications of neural networks to various state characterization tasks16,17,18,19,20,21,22,23,24,25,26.
In the existing quantum applications, neural networks are typically trained using experimental data generated from the specific quantum state that needs to be characterized. As a consequence, the information learnt in the training phase cannot be directly transferred to other states: for a new quantum state, a new training procedure must be carried out. This structural limitation affects the learning efficiency in applications involving multiple quantum states, including important tasks such as quantum state clustering27, quantum state classification28, and quantum cross-platform verification29.
In this paper, we develop a flexible model of neural network that can be trained offline using simulated data from a fiducial set of states and measurements, and is capable of learning multiple quantum states that share structural similarities with the fiducial states, such as being ground states in the same phase of a quantum manybody system.
Results
Quantum state learning framework
In this work we adopt a learning framework inspired by the task of “pretty good tomography”11. An experimenter has a source that produces quantum systems in some unknown quantum state ρ. The experimenter’s goal is to characterize ρ, becoming able to make predictions on the outcome statistics of a set of measurements of interest, denoted by \({{{{{{{\mathcal{M}}}}}}}}\). Each measurement \({{{{{{{\boldsymbol{M}}}}}}}}\in {{{{{{{\mathcal{M}}}}}}}}\) corresponds to a positive operator-valued measure (POVM), that is, a set of positive operators \({{{{{{{\boldsymbol{M}}}}}}}}:={({M}_{j})}_{j=1}^{{n}_{{{{{{{{\rm{o}}}}}}}}}}\) acting on the system’s Hilbert space and satisfying the normalization condition \(\mathop{\sum }\nolimits_{j=1}^{{n}_{{{{{{{{\rm{o}}}}}}}}}}{M}_{j}={\mathbb{1}}\) (without loss of generality, we assume that all the measurements in \({{{{{{{\mathcal{M}}}}}}}}\) have the same number of outcomes, denoted by no).
To characterize the state ρ, the experimenter performs a finite number of measurements Mi, i ∈ {1, …, s}, picked at random from \({{{{{{{\mathcal{M}}}}}}}}\). This random subset of measurements will be denoted by \({{{{{{{\mathcal{S}}}}}}}}={\{{{{{{{{{\boldsymbol{M}}}}}}}}}_{i}\}}_{i=1}^{s}\). Note that in general both \({{{{{{{\mathcal{M}}}}}}}}\) and \({{{{{{{\mathcal{S}}}}}}}}\) may not be informationally complete.
Each measurement in \({{{{{{{\mathcal{S}}}}}}}}\) is performed multiple times on independent copies of the quantum state ρ, obtaining a vector of experimental frequencies pi . Using this data, the experimenter attempts to predict the outcome statistics of a new, randomly chosen measurement \({{{{{{{{\boldsymbol{M}}}}}}}}}^{\prime}\in {{{{{{{\mathcal{M}}}}}}}}\setminus {{{{{{{\mathcal{S}}}}}}}}\). For this purpose, the experimenter uses the assistance of an automated learning system (e.g. a neural network), hereafter called the learner. For each measurement \({{{{{{{{\boldsymbol{M}}}}}}}}}_{i}\in {{{{{{{\mathcal{S}}}}}}}}\), the experimenter provides the learner with a pair (mi, pi), where mi is a parametrization of the measurement Mi, and pi is the vector of experimental frequencies for the measurement Mi. Here the parametrization mi could be the full description of the POVM Mi, or a lower-dimensional parametrization valid only for measurements in the set \({{{{{{{\mathcal{M}}}}}}}}\). For example, if \({{{{{{{\mathcal{M}}}}}}}}\) contains measurements of linear polarization, a measurement in \({{{{{{{\mathcal{M}}}}}}}}\) could be parametrized by the angle θ of the corresponding polarizer. The parametrization could also be encrypted, so that the actual description of the quantum hardware in the experimenter’s laboratory is concealed from the learner. In the following, we denote by enc the function mapping a POVM \({{{{{{{\boldsymbol{M}}}}}}}}\in {{{{{{{\mathcal{M}}}}}}}}\) into its parametrization enc(M). With this notation, we have mi = enc(Mi) for every i ∈ {1, …, s}.
To obtain a prediction for a new, randomly chosen measurement \({{{{{{{{\boldsymbol{M}}}}}}}}}^{\prime}\in {{{{{{{\mathcal{M}}}}}}}}\setminus {{{{{{{\mathcal{S}}}}}}}}\), the experimenter sends its parametrization \({{{{{{{{\bf{m}}}}}}}}}^{\prime}:={\mathsf{enc}}({{{{{{{{\boldsymbol{M}}}}}}}}}^{\prime})\) to the learner. The learner’s task is to predict the correct outcome probabilities \({{{{{{{{\bf{p}}}}}}}}}_{{{{{{{{\rm{true}}}}}}}}}^{\prime}={({{{{{{{\rm{tr}}}}}}}}(\rho {M}_{j}^{\prime}))}_{j=1}^{{n}_{{{{{{{{\rm{o}}}}}}}}}}\). This task includes as special case quantum state reconstruction, corresponding to the situation where the subset \({{{{{{{\mathcal{S}}}}}}}}\) is informationally complete.
Note that, a priori, the learner may have no knowledge about quantum physics whatsoever. The ability to make reliable predictions about the statistics of quantum measurements can be gained automatically through a training phase, where the learner is presented with data and adjusts its internal parameters in a data-driven way. In previous works16,17,19,20,24,26, the training was based on experimental data gathered from the same state ρ that needs to be characterized. In the following, we will provide a model of learner that can be trained with data from a fiducial set of quantum states that share some common structure with ρ, but can generally be different from ρ. The density matrices of the fiducial states can be completely unknown to the learner. In fact, the learner does not even need to be provided a parametrization of the fiducial states: the only piece of information that the learner needs to know is which measurement data correspond to the same state.
The GQNQ network
Our model of learner, GQNQ, is a neural network composed of two main parts: a representation network30, producing a data-driven representation of quantum states, and a generation network31, making predictions about the outcome probabilities of quantum measurements that have not been performed yet. The combination of a representation network and a generation network is called a generative query network32. This type of neural network was originally developed for the classical task of learning 3D scenes from 2D snapshots taken from different viewpoints. The intuition for adapting this model to the quantum domain is that the statistics of a fixed quantum measurement can be regarded as a lower-dimensional projection of a higher-dimensional object (the quantum state), in a way that is analogous to a 2D projection of a 3D scene. The numerical experiments reported in this paper indicate that this intuition is indeed correct, and that GQNQ works well even in the presence of errors in the measurement data and fluctuations due to finite statistics.
The structure of GQNQ is illustrated in Fig. 1. The first step is to produce a representation r of the unknown quantum state ρ. In GQNQ, this step is carried out by a representation network, which computes a function fξ depending on parameters ξ that are fixed after the training phase (see Methods for details). The representation network receives as input the parametrization of all measurements in \({{{{{{{\mathcal{S}}}}}}}}\) and their outcome statistics on the specific state ρ that needs to be characterized. For each pair (mi, pi), the representation network produces a vector ri = fξ(mi, pi ). The vectors corresponding to different pairs are then combined into a single vector r by an aggregate function \({{{{{{{\mathcal{A}}}}}}}}\). Here, we take the aggregate function to be the average, namely \({{{{{{{\bf{r}}}}}}}}:=\frac{1}{s}\mathop{\sum }\nolimits_{i=1}^{s}{{{{{{{{\bf{r}}}}}}}}}_{i}\).

In GQNQ (a), a representation network receives as input the raw measurement data \({\{({{{{{{{{\bf{m}}}}}}}}}_{i},{{{{{{{{\bf{p}}}}}}}}}_{i})\}}_{i=1}^{s}\) and produces as output s vectors ri = fξ(mi, pi), that are combined into a single vector r by an aggregate function \({{{{{{{\mathcal{A}}}}}}}}\). The vector r serves as a concise representation of the quantum state, and is sent to a generation network gη, which predicts the outcome statistics \({{{{{{{{\bf{p}}}}}}}}}^{\prime}\) of any desired measurement \({{{{{{{{\bf{m}}}}}}}}}^{\prime}\) in the set of measurements of interest. In quantum tomography (b), the raw measurement data are fed into a statistical estimator (such as maximum likelihood), which produces a guess for the density matrix ρ. Then, the density matrix is used to predict the outcome probabilities of unperformed quantum measurements via the Born rule. Both GQNQ and quantum tomography use data to infer a representation of the quantum state.
When GQNQ is used to characterize multiple quantum states ρ(j), j ∈ {1, …, K}, the above procedure is repeated for each state ρ(j). To characterize the state ρ(j), GQNQ uses measurement data generated from a subset of s measurements \({{{{{{{{\mathcal{S}}}}}}}}}^{(j)}\subset {{{{{{{\mathcal{M}}}}}}}}\), which in general we allow to depend on j. For the the i-th measurement in \({{{{{{{{\mathcal{S}}}}}}}}}^{(j)}\), denoted by \({{{{{{{{\boldsymbol{M}}}}}}}}}_{i}^{(j)}\), GQNQ produces a representation vector \({{{{{{{{\bf{r}}}}}}}}}^{(j)}_{i}:={f}_{{{{{{{{\boldsymbol{\xi }}}}}}}}}({{{{{{{{\bf{m}}}}}}}}}_{i}^{(j)},{{{{{{{{\bf{p}}}}}}}}}_{i}^{(j)})\), where \({{{{{{{{\bf{m}}}}}}}}}_{i}^{(j)}:={\mathsf{enc}}({{{{{{{{\boldsymbol{M}}}}}}}}}_{i}^{(j)})\) is the parametrization of the measurement \({{{{{{{{\boldsymbol{M}}}}}}}}}_{i}^{(j)}\) and \({{{{{{{{\bf{p}}}}}}}}}_{i}^{(j)}\) is the measurement statistics obtained by performing \({{{{{{{{\boldsymbol{M}}}}}}}}}_{i}^{(j)}\) on the state ρ(j). The representation vectors \({{{{{{{{\bf{r}}}}}}}}}_{i}^{(j)}\) are then combined into a a single vector \({{{{{{{{\bf{r}}}}}}}}}^{(j)}:=\mathop{\sum }\nolimits_{i=1}^{s}\,{{{{{{{{\bf{r}}}}}}}}}_{i}^{(j)}/s\), which serves as a representation of the state ρ(j). Note that the vectors \({{{{{{{{\bf{r}}}}}}}}}_{i}^{(j)}\), and therefore the state representation r(j), depend only on the outcome statistics of measurements performed on the state ρ(j), and on parameters ξ that are fixed after the training phase. As a consequence, the state representation r(j) does not depend on measurement data associated to states ρ(l) with l ≠ j.
Once a state representation has been produced, the next step is to predict the outcome statistics for a new quantum measurement on that state. In quantum tomography, the prediction is generated by applying the Born rule on the estimated density matrix. In GQNQ, the task is achieved by a generation network32, which computes a function gη depending on some parameters η that are fixed after the training phase. To make predictions about the state ρ(j), the network receives as input the state representation r(j) and the parametrization \({{{{{{{{\bf{m}}}}}}}}}^{\prime}\) of the desired measurement \({{{{{{{{\boldsymbol{M}}}}}}}}}^{\prime}\in {{{{{{{\mathcal{M}}}}}}}}\setminus {{{{{{{{\mathcal{S}}}}}}}}}^{(j)}\). The output of the generation network is a vector \({{{{{{{{\bf{p}}}}}}}}}^{\prime}:={g}_{{{{{{{{\boldsymbol{\eta }}}}}}}}}({{{{{{{{\bf{r}}}}}}}}}^{(j)},{{{{{{{{\bf{m}}}}}}}}}^{\prime})\) that approximates the outcome statistics of the measurement \({{{{{{{{\boldsymbol{M}}}}}}}}}^{\prime}\) on the state ρ(j).
Crucially, GQNQ does not need any parametrization of the quantum states \({\left({\rho }^{(j)}\right)}_{j=1}^{K}\), neither it needs the states to be sorted into different classes. For example, if the states correspond to different phases of matter, GQNQ does not need to be told which state belongs to which phase. This feature will be important for the applications to state clustering and classification illustrated later in this paper.
The exact form of the functions fξ and gη is determined by the internal structure of the representation and generation networks, provided in Supplementary Note 1. The purpose of the training phase is to choose appropriate values of the parameters ξ and η. In the training phase, GQNQ starts from some randomly chosen initial values ξ = ξ0 and η = η0, and then updates the values of ξ and η through a gradient descent procedure (see Methods for details). To implement this procedure, GQNQ is provided with pairs (m, p) consisting of the measurement parametrization/measurement statistics for a fiducial set of measurements \({{{{{{{{\mathcal{M}}}}}}}}}_{*}\subseteq {{{{{{{\mathcal{M}}}}}}}}\), performed on a fiducial set of quantum states \({{{{{{{{\mathcal{Q}}}}}}}}}_{*}\). In the numerical experiments provided in the Results section, we choose \({{{{{{{{\mathcal{M}}}}}}}}}_{*}={{{{{{{\mathcal{M}}}}}}}}\), that is, we provide the network with the statistics of all the measurement in \({{{{{{{\mathcal{M}}}}}}}}\). In the typical scenario, the fiducial states and measurements are known, and the training can be done offline, using computer simulated data rather than actual experimental data.
We stress that the parameters ξ and η depend only on the fiducial sets \({{{{{{{{\mathcal{M}}}}}}}}}_{*}\) and \({{{{{{{{\mathcal{Q}}}}}}}}}_{*}\) and on the corresponding measurement data, but do not depend on the unknown quantum states \({\left({\rho }^{(j)}\right)}_{j=1}^{K}\) that will be characterized later, nor on the subsets of measurements \({({{{{{{{{\mathcal{S}}}}}}}}}^{(j)})}_{j=1}^{K}\) that will be performed on these states. Hence, the network does not need to be re-trained when it is used to characterize a new quantum state ρ( j), nor to be re-trained when one changes the subset of performed measurements \({{{{{{{{\mathcal{S}}}}}}}}}^{(j)}\).
It is useful to contrast GQNQ with quantum tomography. While tomographic protocols strive to find the density matrix that fits the measurement data, GQNQ is not constrained to a specific choice of state representation. This additional freedom enables the network to construct lower-dimensional representations of quantum states with sufficiently regular structure, such as ground states in well-defined phases of matter, and to make predictions for states that did not appear in the training phase. Notice also that the tomographic reconstruction of the density matrix using statistical estimators, such as maximum likelihood and maximum entropy33, is generally more time-consuming than the evaluation of the function fξ, due to the computational complexity of the estimation procedure.
Another difference with quantum tomography is that GQNQ does not require a specific representation of quantum measurements in terms of POVM operators. Instead, a measurement parametrization is sufficient for GQNQ to make its predictions, and the parametrization can even be provided in an encrypted form. Since GQNQ does not require the description of the devices to be provided in clear, it can be used to perform data analysis on a public server, without revealing properties of the quantum hardware, such as the dimension of the underlying quantum system.
Summarizing, the main structural features of GQNQ are
-
Offline, multi-purpose training: training can be done offline using computer generated data. Once the training has been concluded, the network can be used to characterize and compare multiple states.
-
Measurement flexibility: after the training has been completed, the experimenter can freely choose which subset of measurements \({{{{{{{\mathcal{S}}}}}}}}\subset {{{{{{{\mathcal{M}}}}}}}}\) is performed on the unknown quantum states.
-
Learner-blindness: the parametrization of the measurements can be provided in an encrypted form. No parametrization of the states is needed.
Later in the paper, we will show that GQNQ can be adapted to an online version of the state learning task13, thus achieving the additional feature of
-
Online prediction: predictions can be updated as new measurement data become available.
Quantum state learning in spin systems
A natural test bed for our neural network model is provided by quantum spin systems34,35. In the following, we consider ground states of the one-dimensional transverse-field Ising model and of the XXZ model, both of which are significant for many-body quantum simulations36,37,38. These two models correspond to the Hamiltonians
and
respectively. In the Ising Hamiltonian (1), positive (negative) coupling parameters Ji correspond to ferromagnetic (antiferromagnetic) interactions. For the XXZ Hamiltonian (2), the ferromagnetic phase corresponds to coupling parameters Δi in the interval (−1, 1). If instead the coupling parameters fall in the region (−∞, −1) ∪ (1, ∞), the Hamiltonian is said to be in the XY phase39.
We start by considering a system of six qubits as example. For the ground states of the Ising model (1), we choose each coupling parameter Ji at random following a Gaussian distribution with standard deviation σ = 0.1 and mean J. For J > 0 (J < 0), this random procedure has a bias towards ferromagnetic (antiferromagnetic) interactions. For J = 0, ferromagnetic and antiferromagnetic interactions are equally likely. Similarly, for the ground states of the XXZ model (2), we choose each parameter Δi at random following a Gaussian distribution with standard deviation 0.1 and mean value Δ. When Δ is in the interval (−1, 1) ((−∞, − 1) ∪ (1, ∞)), this random procedure has a bias towards interactions of the ferromagnetic (XY) type.
In addition to the above ground states, we also consider locally rotated GHZ states, of the form \({\otimes }_{i=1}^{6}{U}_{i}\left|{{{{{{{\rm{GHZ}}}}}}}}\right\rangle\) with \(\left|{{{{{{{\rm{GHZ}}}}}}}}\right\rangle=\frac{1}{\sqrt{2}}(\left|000000\right\rangle+\left|111111\right\rangle )\) and locally rotated W states, of the form \({\otimes }_{i=1}^{6}{U}_{i}\left|{{{{{{{\rm{W}}}}}}}}\right\rangle\) with \(\left|{{{{{{{\rm{W}}}}}}}}\right\rangle=\frac{1}{\sqrt{6}}(\left|100000\right\rangle+\cdots+\left|000001\right\rangle )\), where \({({U}_{i})}_{i=1}^{6}\) are unitary matrices of the form \({U}_{i}=\exp [-{{{{{{{\rm{i}}}}}}}}{\theta }_{i,z}{\sigma }_{i,z}]\exp [-{{{{{{{\rm{i}}}}}}}}{\theta }_{i,y}{\sigma }_{i,y}]\exp [-{{{{{{{\rm{i}}}}}}}}{\theta }_{i,x}{\sigma }_{i,x}],\) where the angles θi,x, θi,y, θi,z ∈ [0, π/10] are chosen independently and uniformly at random for every i.
For the set of all possible measurements \({{{{{{{\mathcal{M}}}}}}}}\), we chose the 729 six-qubit measurements consisting of local Pauli measurements on each qubit. To parameterize the measurements in \({{{{{{{\mathcal{M}}}}}}}}\), we provide the entries in the corresponding Pauli matrix at each qubit, arranging the entries in a 48-dimensional real vector. The dimension of state representation r is set to be 32, which is half of the Hilbert space dimension. In Supplementary Note 2 we discuss how the choice of dimension of r and the other parameters of the network affect the performance of GQNQ.
GQNQ is trained using measurement data from measurements in \({{{{{{{\mathcal{M}}}}}}}}\) on states of the above four types (see Methods for a discussion of the data generation techniques). We consider both the scenarios where all training data come from states of the same type, and where states of different types are used. In the latter case, we do not provide the network with any label of the state type. After training, we test GQNQ on states of the four types described above. To evaluate the performance of the network, we compute the classical fidelities between the predicted probability distributions and the correct distributions computed from the true states and measurements. For each test state, the classical fidelity is averaged over all possible measurements in \({{{{{{{\mathcal{M}}}}}}}}\setminus {{{{{{{\mathcal{S}}}}}}}}\), where \({{{{{{{\mathcal{S}}}}}}}}\) is a random subset of 30 Pauli measurements. Then, we average the fidelity over all possible test states.
The results are summarized in Table 1. Each row shows the performances of one particular trained GQNQ when tested using the measurement data from (i) 150 ground states of Ising model with J ∈ {0.1, …, 1.5}, (ii) 150 ground states of Ising model with J ∈ {−1.5, −1.4, …, −0.1}, where 10 test states are generated per value of J, (iii) 10 ground states of Ising model with J = 0, (iv) 190 ground states of XXZ model with Δ ∈ {−0.9, − 0.8, …, 0.9}, (v) 100 ground states of XXZ model with Δ ∈ {−1.5, −1.4, …, −1.1} ∪ {1.1, 1.2, …, 1.5}, where 10 test states are generated per value of Δ, (vi) all the states from (i) to (v), (vii) 200 locally rotated GHZ states (viii) 200 locally rotated W states (vii), (ix) all the states from (i) to (v), together with (vii) and (viii). In the second column, the input data given to GQNQ is the true probability distribution computed with the Born rule, while in the third and fourth columns, the input data given to GQNQ during test is the finite statistics obtained by sampling the true outcome probability distribution 50 times and 10 times, respectively.
The results shown in Table 1 indicate that the performance with finite statistics is only slightly lower than the performance in the ideal case. It is also worth noting that GQNQ maintains a high fidelity even when used on multiple types of states.
Recall that the results in Table 1 refer to the scenario where GQNQ is trained with the full set of six-qubit Pauli measurements, which is informationally complete. An interesting question is whether the learning performance would still be good if the training used a non-informationally complete set of measurements. In Supplementary Note 4, we show that fairly accurate predictions can be made even if \({{{{{{{\mathcal{M}}}}}}}}\) consists only of 72 randomly chosen Pauli measurements.
While GQNQ makes accurate predictions for state families with sufficient structure, it should not be expected to work universally well on all possible quantum states. In Supplementary Note 3, we considered the case where the network is trained and tested on arbitrary six-qubit states, finding that the performance of GQNQ drops drastically. In Supplementary Note 5, we also provide numerical experiments on the scenario where some types of states are overrepresented in the training phase, potentially causing overfitting when GQNQ is used to characterize unknown states of an underrepresented type.
We now consider multiqubit states with 10, 20, and 50 qubits, choosing the measurement set \({{{{{{{\mathcal{M}}}}}}}}\) to consist of all two-qubit Pauli measurements on nearest-neighbor qubits and \({{{{{{{\mathcal{S}}}}}}}}\) a subset containing s = 30 measurements randomly chosen from \({{{{{{{\mathcal{M}}}}}}}}\). Here the dimension of state representation r is chosen to be 24, which guarantees a good performance in our numerical experiments.
For the Ising model, we choose the coupling between each nearest-neighbor pair of spins to be either consistently ferromagnetic for J ≥ 0 or consistently antiferromagnetic for J < 0: for J ≥ 0 we replace each coupling Ji in Eq. (1) by ∣Ji∣, and for J < 0 we replace Ji by −∣Ji∣. The results are illustrated in Fig. 2. The figure shows that the average classical fidelities in both ferromagnetic and antiferromagnetic regions are close to one, with small drops around the phase transition point J = 0. The case where both ferromagnetic and anti-ferromagnetic interactions are present is studied in Supplementary Note 6, where we observe that the learning performance is less satisfactory in this scenario.

Figure a shows the average classical fidelities of predictions given by three GQNQs for ten-, twenty- and fifty-qubit ground states of Ising model (1), respectively, with respect to different values of J ∈ {−1.5, −1.4, …, 1.5}. Figure b shows the performance of another three GQNQs for ten-, twenty- or fifty-qubit ground states of XXZ model (2), respectively, with respect to different values of Δ ∈ { − 1.5, − 1.4, …, 1.5}. Given outcome probability distributions for all \({{{{{{{\bf{m}}}}}}}}\in {{{{{{{\mathcal{S}}}}}}}}\), each box shows the average classical fidelities of predicted outcome probabilities, averaged over all measurements in \({{{{{{{\mathcal{M}}}}}}}}\setminus {{{{{{{\mathcal{S}}}}}}}}\), for 10 instances.
For XXZ model, the average classical fidelities in the XY phase are lower than those in the ferromagnetic interaction region, which is reasonable due to higher quantum fluctuations in the XY phase35. At the phase transition points Δ = ± 1, the average classical fidelities drop more significantly, partly because the abrupt changes of ground state properties at the critical points make the quantum state less predictable, and partly because the states at phase transition points are less represented in the training data set.
Quantum state learning on a harmonic oscillator
We now test GQNQ on states encoded in harmonic oscillators, i.e. continuous-variable quantum states, including single-mode Gaussian states, as well as non-Gaussian states such as cat states and GKP states40, both of which are important for fault-tolerant quantum computing40,41. For the measurement set \({{{{{{{\mathcal{M}}}}}}}}\), we choose 300 homodyne measurements, that is, 300 projective measurements associated to quadrature operators of the form \(({e}^{i\theta }\,{\hat{a}}^{{{{\dagger}}} }+{e}^{-i\theta }\,\hat{a})/2\), where \({\hat{a}}^{{{{\dagger}}} }\) and \(\hat{a}\) are bosonic creation and annihilation operators, respectively, and θ is a uniformly distributed phase in the interval [0, π). For the subset \({{{{{{{\mathcal{S}}}}}}}}\), we pick 10 random quadratures. For the parametization of the measurements, we simply choose the corresponding phase θ. Since the homodyne measurements have an unbounded and continuous set of outcomes, here we truncate the outcomes into a finite interval (specifically, at ± 6) and discretize them, dividing the interval into 100 bins of equal width. The dimension of the representation vector r is chosen to be 16.
In Table 2 we illustrate the performance of GQNQ on (i) 200 squeezed thermal states with thermal variance V ∈ [1, 2] and squeezing parameter s satisfying ∣s∣ ∈ [0, 0.5], \(\arg (s)\in [0,\pi ]\), (ii) 200 cat states corresponding to superpositions of coherent states with opposite amplitudes \({\left|\alpha,\phi \right\rangle }_{{{{{{{{\rm{cat}}}}}}}}}:=\frac{1}{\sqrt{{{{{{{{\mathcal{N}}}}}}}}}}(\left|\alpha \right\rangle+{{{{{{{{\rm{e}}}}}}}}}^{{{{{{{{\rm{i}}}}}}}}\phi }\left|-\alpha \right\rangle )\), where \({{{{{{{\mathcal{N}}}}}}}}=2(1+{{{{{{{{\rm{e}}}}}}}}}^{-|\alpha {|}^{2}}\cos \phi )\), ∣α∣ ∈ [1, 3] and \(\phi \in \{0,\frac{\pi }{8},\ldots,\pi \}\), (iii) 200 GKP states that are superpositions of displaced squeezed states \({\left|\epsilon,\theta,\phi \right\rangle }_{{{{{{{{\rm{gkp}}}}}}}}}:={{{{{{{{\rm{e}}}}}}}}}^{-\epsilon \hat{n}}(\cos \theta {\left|0\right\rangle }_{{{{{{{{\rm{gkp}}}}}}}}}+{{{{{{{{\rm{e}}}}}}}}}^{{{{{{{{\rm{i}}}}}}}}\phi }\sin \theta {\left|1\right\rangle }_{{{{{{{{\rm{gkp}}}}}}}}})\) where \(\hat{n}={\hat{a}}^{{{{\dagger}}} }\hat{a}\) is the photon number operator, ϵ ∈ [0.05, 0.2], θ ∈ [0, 2π), ϕ ∈ [0, π], and \({\left|0\right\rangle }_{{{{{{{{\rm{gkp}}}}}}}}}\) and \({\left|1\right\rangle }_{{{{{{{{\rm{gkp}}}}}}}}}\) are ideal GKP states, and (iv) all the states from (i), (ii), and (iii).
For each type of states, we provide the network with measurement data from s = 10 random homodyne measurements, considering both the case where the data is noiseless and the case where it is noisy. The noiseless case is shown in the second and third columns of Table 2, which show the classical fidelity in the average and worst-case scenario, respectively. In the noisy case, we consider both noise due to finite statistics, and noise due to an inexact specification of the measurements in the test set. The effects of finite statistics are modeled by adding Gaussian noise to each of the outcome probabilities of the measurements in the test. The inexact specification of the test measurements is modeled by rotating each quadrature by a random angle θi, chosen independently for each measurement according to a Gaussian distribution. The fourth and the fifth columns of Table 2 illustrate the effects of finite statistics, showing the classical fidelities in the presence of Gaussian added noise with variance 0.05. In the sixth and seventh columns, we include the effect of an inexact specification of the homodyne measurements, introducing Gaussian noise with variance 0.05. In all cases, the classical fidelity of predictions are computed with respect to the ideal noiseless probability distributions.
In Supplementary Note 6 we also provide a more detailed comparison between the predictions and the corresponding ground truths in terms of actual probability distributions, instead of their classical fidelities.
Application to online learning
After GQNQ has been trained, it can be used for the task of online quantum state learning13. In this task, the various pieces of data are provided to the learner at different time steps. At the t-th time step, with t ∈ {1, …, n}, the experimenter performs a measurement Mt, obtaining the outcome statistics pt. The pair (mt, pt) is then provided to the learner, who is asked to predict the measurement outcome probabilities for all measurements in the set \({{{{{{{\mathcal{M}}}}}}}}\setminus {{{{{{{{\mathcal{S}}}}}}}}}_{t}\) with \({{{{{{{{\mathcal{S}}}}}}}}}_{t}:={\{{{{{{{{{\boldsymbol{M}}}}}}}}}_{j}\}}_{j\le t}\).
Online learning with GQNQ can be achieved with the following procedure. Initially, the state representation vector is set to r(0) = (0, …, 0). At the t-th time step, GQNQ computes the vector rt = fξ(mt, pt) and updates the state representation to r(t) = [(t − 1) r(t−1) + rt]/t. The updated state representation is then fed into the generation network, which produces the required predictions. Note that updating the state representation does not require time-consuming operations, such as a maximum likelihood analysis. It is also worth noting that GQNQ does not need to store all the measurement data received in the past: it only needs to store the state representation r(t) from one step to the next.
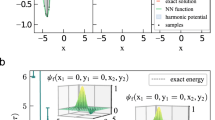
A numerical experiment on online learning of cat states is provided in Fig. 3. The figure shows the average classical fidelity at 15 subsequent time steps corresponding to 15 different homodyne measurements performed on copies of unknown cat states. The fidelity increases over time, confirming the intuitive expectation that the learning performance should improve when more measurement data are provided.

Each red point shows the classical fidelity, averaged over all the possible measurements in \({{{{{{{\mathcal{M}}}}}}}}\) and over all the cat states in the test set, which we take to be the same as in the experiments in the previous section. Each blue point is the worst-case classical fidelity over all possible query measurements, averaged over all the test states. Real outcome statistics and predicted outcome statistics at quadrature phase θ = 3/4π for an example cat state \({\left|2.22+1.41{{{{{{{\rm{i}}}}}}}},\pi /4\right\rangle }_{{{{{{{{\rm{cat}}}}}}}}}\) are plotted.
Application to state clustering and classification
The state representation constructed by GQNQ can also be used to perform tasks other than predicting the outcome statistics of unmeasured POVMs. One such task is state clustering, where the goal is to group the representations of different quantum states into multiple disjoint sets in such a way that quantum states of the same type fall into the same set.
We now show that clusters naturally emerge from the state representations produced by GQNQ. To visualize the clusters, we feed the state representation vectors into a t-distributed stochastic neighbor embedding (t-SNE) algorithm42, which produces a mapping of the representation vectors into a two-dimensional plane, according to their similarities. We performed numerical experiments using the types of six-qubit states in Table 1 and the types of continuous-variable states in Table 2. For simplicity, we restricted the analysis to state representation vectors constructed from noiseless input data.
The results of our experiments are shown in Fig. 4. The figure shows that states with significantly different physical properties correspond to distant points in the two-dimensional embedding, while states with similar properties naturally appear in clusters. For example, the ground states of the ferromagnetic XXZ model and the ground states in the gapless XY phase are clearly separated in Fig. 4a, in agreement with the fact that there is an abrupt change of quantum properties at the phase transition point. On the other hand, in Fig. 4a, the ferromagnetic region of the Ising model is next to the antiferromagnetic region, both of which are gapped and short-range correlated. The ferromagnetic region of the Ising model appears to have some overlap with the region of GHZ states with local rotations, in agreement with the fact that the GHZ state is approximately a ground state of the ferromagnetic Ising model in the large J limit.

Subfigure a shows two-dimensional embeddings of state representation vectors produced by GQNQ on Ising model (ferromagnetic and antiferromagnetic) ground states, XXZ model (ferromagnetic and XY phase) ground states, locally rotated GHZ and W states. Subfigure b shows two-dimensional embeddings of the state representation vectors of squeezed thermal states, cat states and GKP states. In both subfigures, shaded areas are added to help visualize the various type of states. Note that the representation vectors generated by GQNQ of states of the same type are near to each other in the two-dimensional embeddings.
The visible clusters in the two-dimensional embedding suggest that any unsupervised clustering algorithm could effectively cluster the states according to their representation vectors. To confirm this intuition, we applied a Gaussian mixture model43 to the state representation vectors and chose the number of clusters to be equal to the actual number of state types (six for the six-qubit states, and three for the continuous-variable states). The portion of states whose types match the clusters is 94.67% for the six-qubit states, and 100% for the continuous-variable states.
The state representation produced by GQNQ can also be used to predict physical properties in a supervised model where an additional neural network is provided with labeled examples of states with a given property. In this setting, supervision can enable a more refined classification of quantum states, compared to the unsupervised clustering discussed before.
To illustrate the idea, we considered the problem of distinguishing between two different regimes in the Ising model, namely a regime where ferromagnetic interactions dominate (J > 1), and a regime both ferromagnetic and antiferromagnetic interactions are present (0 < J < 1). For convenience, we refer to these two regimes as to the pure and mixed ferromagnetic regimes, respectively. We use an additional neural network to learn whether a ground state corresponds to a Hamiltonian in the pure ferromagnetic regime or in the mixed one, using the state representation r of Ising ground states with ferromagnetic bias obtained from noiseless measurement data. The prediction reaches a success rate of 100%, 100%, and 99% for ten-qubit, twenty-qubit, and fifty-qubit ground states in our test sets, respectively. These high values can be contrasted with the clustering results in Fig. 4, where the pure ferromagnetic regime and the mixed one appear close to each other in the two-dimensional embedding.
Discussion
Many works have explored the use of generative models for quantum state characterization16,17,19,20,21, and an approach based on representation learning was recently proposed by Iten et al44. The key difference between GQNQ and previous approaches concerns the training phase. In most previous works, the neural network is trained to reconstruct a single quantum state from experimental data. While this procedure can in principle be applied to learn any state, the training is state-specific, and the information learnt by the network through training on a given state cannot be automatically transferred to the reconstruction of a different quantum state, even if that state is of the same type. In contrast, the training of GQNQ works for multiple quantum states and for states of multiple types, thus enabling a variety of tasks, such as quantum state clustering and classification.
Another difference with previous works is that the training phase for GQNQ can use classically simulated data, rather than actual experimental data. In other words, the training can be carried out in an offline mode, before the quantum states that need to be characterized become available. By moving the training to offline mode, GQNQ can be significantly faster than other data-driven approaches that need to be trained with experimental data from unknown quantum states. The flip side of this advantage, however, is that offline training requires a partial supervision, which is not required in other state reconstruction approaches 16,17,19. Indeed, the training of GQNQ requires quantum states in the same family as the tested state, and in order to implement the training offline one needs a good guess for the type of quantum state that will need to be characterized.
The situation is different if the training is done online, with actual experimental data provided from the quantum state to be characterized. In this setting, GQNQ behaves as a completely unsupervised learner that predicts the outcome statistics of unperformed measurements using measurement data obtained solely from the quantum state under consideration. Note that in this case the set of fiducial measurements \({{{{{{{{\mathcal{M}}}}}}}}}_{*}\) coincides with the set of performed measurements \({{{{{{{\mathcal{S}}}}}}}}\subset {{{{{{{\mathcal{M}}}}}}}}\). The details of the training procedure are provided in Supplementary Note 7. We performed numerical experiments in which GQNQ was trained with data from a single cat state, using data from 10 or 50 homodyne measurements. After the training, GQNQ was asked to predict the outcome statistics of a new randomly chosen homodyne measurement. The results are summarized in Table 3, where we show both the average classical fidelities averaged over all query measurements and worst-case classical fidelities over all query measurements.
Finally, we point out that our learning model shares some conceptual similarity with Aaronson’s "pretty good tomography”11, which aims at producing a hypothesis state that accurately predicts the outcome probabilities of measurements in a given set. While in pretty good tomography the hypothesis state is a density matrix, the form of the state representation in GQNQ is determined by the network itself. The flexibility in the choice of state representation allows GQNQ to find more compact descriptions for sufficiently regular sets of states. On the other hand, pretty good tomography is in principle guaranteed to work accurately for arbitrary quantum states, whereas the performance of GQNQ can be more or less accurate depending on the set of states, as indicated by our numerical experiments. An important direction of future research is to find criteria to determine a priori which quantum state families can be learnt effectively by GQNQ. This problem is expected to be challenging, as similar criteria are still lacking even in the original application of generative query networks to classical image processing.
Methods
Data generation procedures
Here we discuss the training/test dataset generation procedures. In the numerical experiments for ground states of Ising models and XXZ models, the training set is composed of 40 different states for each value of J and Δ, while the test set is composed of 10 different states for each value of J and Δ. For GHZ and W states with local rotations, we generate 800 states for training and 200 states for testing.
In the continuous-variable experiments, we randomly generate 10000 different states for each of the three families of squeezed thermal states, cat states, and GKP states. We then split the generated states into a training set and testing set, with a ratio of 4 : 1.
In the testing stage, the noiseless probability distributions for one-dimensional Ising models and XXZ models are generated by solving the ground state problem, either exactly (in the six qubit case) or approximately by density-matrix renormalization group (DMRG) algorithm45 (for 10, 20, and 50 qubits). The data of continuous-variable quantum states are generated by simulation tools provided by Strawberry Fields46.
Network training
The training data set of GQNQ includes measurement data obtained from a fiducial set of quantum measurements \({{{{{{{{\mathcal{M}}}}}}}}}_{*}\) performed on a fiducial set of quantum states \({{{{{{{{\mathcal{Q}}}}}}}}}_{*}={\{({\sigma }^{(k)})\}}_{k=1}^{N}\). The fiducial states are divided into N/B batches of B states each. For each state in the b-th batch, a subset of fiducial measurements \({{{{{{{{\mathcal{M}}}}}}}}}_{{{{{{{{\rm{train}}}}}}}}}^{(b)}\subset {{{{{{{{\mathcal{M}}}}}}}}}_{*}\) is randomly picked, and the network is provided with all the pairs (m, p(k)), where m is the parametrization of a measurement in \({{{{{{{{\mathcal{M}}}}}}}}}_{{{{{{{{\rm{train}}}}}}}}}^{(b)}\) and p(k) is the corresponding vector of outcome probabilities on the state σ(k). The network is then asked to make predictions on the outcome probabilities of the rest of the measurements in \({{{{{{{{\mathcal{M}}}}}}}}}_{*}\setminus {{{{{{{{\mathcal{M}}}}}}}}}_{{{{{{{{\rm{train}}}}}}}}}^{(b)}\), and the loss is computed from the difference between the real outcome probabilities (computed with the Born rule) and GQNQ’s predictions (see Supplementary Note 1 for the specific expression of the loss function). For each batch, we optimize the parameters ξ and η of GQNQ by updating them along the opposite direction of the gradient of the loss function with respect to ξ and η, using Adam optimizer47 and batch gradient descent. The pseudocode for the training algorithm is also provided in Supplementary Note 1.
The training is repeated for E epochs. In each epoch of the training phase, we iterate the above procedure over the N/B batches of training data. For the numerical experiments in this paper, we typically choose B = 30 and E = 200.
Network testing
After training, the parameters ξ and η are fixed. Then, the performance of GQNQ is tested on a set of test states \({\left({\rho }^{(j)}\right)}_{j=1}^{K}\). For each test state ρ(j), we randomly select an s-element subset \({{{{{{{{\mathcal{S}}}}}}}}}^{(j)}\) from the set \({{{{{{{\mathcal{M}}}}}}}}\) of possible POVM measurements. We then input the measurement data to the trained representation network, generate the state representation r(j), and feed r(j) into the trained generation network, asking it to predict the outcome probabilities for all the measurements in \({{{{{{{\mathcal{M}}}}}}}}\setminus {{{{{{{{\mathcal{S}}}}}}}}}^{(j)}\). Then we calculate the classical fidelity between each output prediction and the corresponding ground truth, and we average the fidelity over all possible measurements in \({{{{{{{\mathcal{M}}}}}}}}\setminus {{{{{{{{\mathcal{S}}}}}}}}}^{(j)}\).
Hardware
Our neural networks are implemented by the pytorch48 framework and trained on four NVIDIA GeForce GTX 1080 Ti GPUs.
Data availability
The training and test data generated in this study have been deposited in the Figshare database, which can be accessed by https://doi.org/10.6084/m9.figshare.21211283.v2.
Code availability
The codes that support the findings of this study are available in https://github.com/yzhuqici/GQNQ.
References
Eisert, J. et al. Quantum certification and benchmarking. Nat. Rev. Phys. 2, 382–390 (2020).
Tóth, G. et al. Permutationally invariant quantum tomography. Phys. Rev. Lett. 105, 250403 (2010).
Gross, D., Liu, Y.-K., Flammia, S. T., Becker, S. & Eisert, J. Quantum state tomography via compressed sensing. Phys. Rev. Lett. 105, 150401 (2010).
Cramer, M. et al. Efficient quantum state tomography. Nat. Commun. 1, 1–7 (2010).
Lanyon, B. P. et al. Efficient tomography of a quantum many-body system. Nat. Phys. 13, 1158–1162 (2017).
Cotler, J. & Wilczek, F. Quantum overlapping tomography. Phys. Rev. Lett. 124, 100401 (2020).
Huang, H.-Y., Kueng, R. & Preskill, J. Predicting many properties of a quantum system from very few measurements. Nat. Phys. 16, 1050–1057 (2020).
Huang, H.-Y., Kueng, R., Torlai, G., Albert, V. V. & Preskill, J. Provably efficient machine learning for quantum many-body problems. Science 377, eabk3333 (2022).
Flammia, S. T. & Liu, Y.-K. Direct fidelity estimation from few pauli measurements. Phys. Rev. Lett. 106, 230501 (2011).
da Silva, M. P., Landon-Cardinal, O. & Poulin, D. Practical characterization of quantum devices without tomography. Phys. Rev. Lett. 107, 210404 (2011).
Aaronson, S. The learnability of quantum states. Proc. R. Soc. A 463, 3089–3114 (2007).
Aaronson, S. Shadow tomography of quantum states. SIAM J. Comput. 49, STOC18–368 (2019).
Aaronson, S., Chen, X., Hazan, E., Kale, S. & Nayak, A. Online learning of quantum states. J. Stat. Mech.: Theory Exp. 2019, 124019 (2019).
Arunachalam, S., Grilo, A. B. & Yuen, H. Quantum statistical query learning. arXiv https://doi.org/10.48550/arXiv.2002.08240 (2020).
Carleo, G. et al. Machine learning and the physical sciences. Rev. Mod. Phys. 91, 045002 (2019).
Torlai, G. et al. Neural-network quantum state tomography. Nat. Phys. 14, 447–450 (2018).
Torlai, G. & Melko, R. G. Latent space purification via neural density operators. Phys. Rev. Lett. 120, 240503 (2018).
Xu, Q. & Xu, S. Neural network state estimation for full quantum state tomography. arXiv https://doi.org/10.48550/arXiv.1811.06654 (2018).
Carrasquilla, J., Torlai, G., Melko, R. G. & Aolita, L. Reconstructing quantum states with generative models. Nat. Mach. Intell. 1, 155–161 (2019).
Tiunov, E. S., Tiunova, V. V., Ulanov, A. E., Lvovsky, A. I. & Fedorov, A. K. Experimental quantum homodyne tomography via machine learning. Optica 7, 448–454 (2020).
Ahmed, S., Sánchez Muñoz, C., Nori, F. & Kockum, A. F. Quantum state tomography with conditional generative adversarial networks. Phys. Rev. Lett. 127, 140502 (2021).
Ahmed, S., Sánchez Muñoz, C., Nori, F. & Kockum, A. F. Classification and reconstruction of optical quantum states with deep neural networks. Phys. Rev. Res. 3, 033278 (2021).
Rocchetto, A., Grant, E., Strelchuk, S., Carleo, G. & Severini, S. Learning hard quantum distributions with variational autoencoders. NPJ Quant. Inf. 4, 28 (2018).
Quek, Y., Fort, S. & Ng, H. K. Adaptive quantum state tomography with neural networks. NPJ Quant. Inf. 7, 105 (2021).
Palmieri, A. M. et al. Experimental neural network enhanced quantum tomography. NPJ Quant. Inf. 6, 20 (2020).
Smith, A. W. R., Gray, J. & Kim, M. S. Efficient quantum state sample tomography with basis-dependent neural networks. PRX Quantum 2, 020348 (2021).
Sentís, G., Monràs, A., Muñoz Tapia, R., Calsamiglia, J. & Bagan, E. Unsupervised classification of quantum data. Phys. Rev. X 9, 041029 (2019).
Gao, J. et al. Experimental machine learning of quantum states. Phys. Rev. Lett. 120, 240501 (2018).
Elben, A. et al. Cross-platform verification of intermediate scale quantum devices. Phys. Rev. Lett. 124, 010504 (2020).
Bengio, Y., Courville, A. & Vincent, P. Representation learning: a review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 35, 1798–1828 (2013).
Foster, D. Generative Deep Learning: Teaching Machines To Paint, Write, Compose, and Play (O’Reilly Media, 2019).
Eslami, S. M. A. et al. Neural scene representation and rendering. Science 360, 1204–1210 (2018).
Teo, Y. S., Zhu, H., Englert, B.-G., Reháček, J. & ěk Hradil, Z. Quantum-state reconstruction by maximizing likelihood and entropy. Phys. Rev. Lett. 107, 020404 (2011).
Schollwöck, U., Richter, J., Damian, J. J.& Farnell, R. F. Bishop. Quantum Magnetism, Vol. 645 (Springer, 2008)
Samaj, L. Introduction to the Statistical Physics Of Integrable Many-body Systems (Cambridge University Press, 2013).
Friedenauer, A., Schmitz, H., Glueckert, J. T., Porras, D. & Schätz, T. Simulating a quantum magnet with trapped ions. Nat. Phys. 4, 757–761 (2008).
Kim, K. et al. Quantum simulation of frustrated ising spins with trapped ions. Nature 465, 590–593 (2010).
Islam, R. et al. Onset of a quantum phase transition with a trapped ion quantum simulator. Nat. Commun. 2, 1–6 (2011).
Yang, C. N. & Yang, C. P. One-dimensional chain of anisotropic spin-spin interactions. i. proof of bethe’s hypothesis for ground state in a finite system. Phys. Rev. 150, 321–327 (1966).
Gottesman, D., Kitaev, A. & Preskill, J. Encoding a qubit in an oscillator. Phys. Rev. A 64, 012310 (2001).
Albert, V. V. et al. Performance and structure of single-mode bosonic codes. Phys. Rev. A 97, 032346 (2018).
Van der Maaten, L. & Hinton, G. Visualizing Data Using t-sne. J. Mach. Learn. Res. 9 (2008).
Bishop, C. M. & Nasrabadi, N. M. Pattern recognition and machine learning, Vol. 4 (Springer, 2006)
Iten, R., Metger, T., Wilming, H., del Rio, L. & Renner, R. Discovering physical concepts with neural networks. Phys. Rev. Lett. 124, 010508 (2020).
Schollwöck, U. The density-matrix renormalization group. Rev. Mod. Phys. 77, 259 (2005).
Killoran, N. et al. Strawberry fields: A software platform for photonic quantum computing. Quantum 3, 129 (2019).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980 (2014).
Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural. Inf. Process. Syst. 32, 8026–8037 (2019).
Williamson, D. F., Parker, R. A. & Kendrick, J. S. The box plot: a simple visual method to interpret data. Ann. Intern. Med. 110, 916–921 (1989).
Acknowledgements
This work was supported by funding from the Hong Kong Research Grant Council through grants no. 17300918 and no. 17307520, through the Senior Research Fellowship Scheme SRFS2021-7S02, the Croucher Foundation, and by the John Templeton Foundation through grant 61466, The Quantum Information Structure of Spacetime (qiss.fr). Y.X.W. acknowledges funding from the National Natural Science Foundation of China through grants no. 61872318. Research at the Perimeter Institute is supported by the Government of Canada through the Department of Innovation, Science and Economic Development Canada and by the Province of Ontario through the Ministry of Research, Innovation and Science. The opinions expressed in this publication are those of the authors and do not necessarily reflect the views of the John Templeton Foundation.
Author information
Authors and Affiliations
Contributions
Y.Z., Y.-D.W., and G.C. established the key idea in the paper. Y.Z. developed the neural network model and did the numerical experiments. Y.-D.W. wrote the draft paper. G.B., D.-S.W., and Y.W. contributed to the design and the implementation of numerical experiments. All the authors contributed to the preparation of the paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Yihui Quek, Gael Sentís and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhu, Y., Wu, YD., Bai, G. et al. Flexible learning of quantum states with generative query neural networks. Nat Commun 13, 6222 (2022). https://doi.org/10.1038/s41467-022-33928-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-022-33928-z
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
