
Abstract
Classification and identification of different phases and the transitions between them is a central task in condensed matter physics. Machine learning, which has achieved dramatic success in a wide range of applications, holds the promise to bring unprecedented perspectives for this challenging task. However, despite the exciting progress made along this direction, the reliability of machine-learning approaches in experimental settings demands further investigation. Here, with the nitrogen-vacancy center platform, we report a proof-of-principle experimental demonstration of adversarial examples in learning topological phases. We show that the experimental noises are more likely to act as adversarial perturbations when a larger percentage of the input data are dropped or unavailable for the neural network-based classifiers. We experimentally implement adversarial examples which can deceive the phase classifier with a high confidence, while keeping the topological properties of the simulated Hopf insulators unchanged. Our results explicitly showcase the crucial vulnerability aspect of applying machine learning techniques in experiments to classify phases of matter, which can benefit future studies in this interdisciplinary field.
Similar content being viewed by others


Introduction
Machine learning, or more generally speaking artificial intelligence, is currently taking a technological revolution to modern society and becoming a powerful tool for fundamental research in multiple disciplines1,2. Recently, machine learning has been adopted to solve challenges in condensed matter physics3,4,5, and in particular, to classify phases of matter and identify phase transitions6,7,8,9,10,11. Within this vein, both supervised11,12,13,14,15 and unsupervised learning7,16,17,18,19,20,21 methods have been applied, enabling identifying different phases directly from raw data of local observables, such as spin textures and local correlations11,12,13. In addition, pioneering experiments have also been carried out with different platforms22,23,24,25, including electron spins in nitrogen-vacancy (NV) centers in diamond22, cold atoms in optical lattices23,24, and doped CuO225, showing unparalleled potentials of machine learning approaches compared to traditional means.
An intriguing advantage of machine learning approaches in identifying phases of matter is that they may require only a small portion of data samples, without too much prior knowledge about the phases22. Therefore, they may substantially reduce the experiment cost in practice and are particularly suitable for exploring unknown exotic phases. However, the existence of adversarial examples26,27,28,29,30, which can deceive the learning model at a high confidence level, poses a serious concern about the reliability of machine-learning approaches as well. The study of whether adversarial examples are potential obstacles in the experimental settings, and the experimental demonstration of adversarial examples in learning phases of matter, are still lacking hitherto. In this work, we find that the experimental noises are more likely to act as adversarial perturbations when a larger percentage of the input data are dropped or unavailable for the neural network-based classifiers. We present an experiment to implement adversarial examples and study their properties with a solid-state quantum simulator consisting of a single NV center in a diamond.
The NV center in diamond is a point defect31, consisting of a nitrogen atom that substitutes a carbon atom and a nearest-neighbor lattice vacancy, as shown in Fig. 1a. It has long coherence time at room temperature and can be conveniently manipulated through lasers or microwaves, making this system versatile for applications in quantum networks32,33,34,35, high-resolution sensing36,37,38,39, quantum information processing40,41,42,43,44, and quantum simulation45,46,47, etc. Here, with the NV center platform, we experimentally demonstrate adversarial examples in learning topological phases, with a focus on the peculiar Hopf insulators48,49. More concretely, we first train a phase classifier based on deep convolutional neural networks (CNNs) so that it can correctly classify experimentally implemented legitimate samples with confidence close to one. We then show even though our legitimate samples have high fidelity (99.7% on average), when some data samples are dropped randomly, the tiny experimental noise can significantly affect the performance of the classifier. We also experimentally demonstrate that even without data dropping, the phase classifier based on neural network could be unreliable: after adding a tiny amount of carefully designed perturbations to the model Hamiltonian, the phase classifier would misclassify the experimentally generated adversarial examples with a confidence level up to 99.8%. The fidelity between the legitimate and corresponding adversarial samples is large (the average fidelity is 93.4%), ensuring that the adversarial perturbations added are small indeed. In addition, we extract the topological invariant and topological links by traditional means and demonstrate that they are robust to adversarial perturbations. This sharp robustness contrast between the traditional methods and machine-learning approaches clearly showcases the vulnerability aspect of the latter, highlighting the demand for in-depth investigations about the reliability of machine-learning approaches in adversarial scenarios and for developing countermeasures.

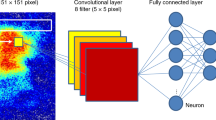
a The structure of a nitrogen-vacancy center in a diamond crystal. The blue, yellow, and gray spheres represents vacancy, nitrogen, and carbon atoms, respectively. b The structure of 3D convolutional neural network (CNN) classifier. The input data are density matrices sampled from a 10 × 10 × 10 regular grid in the momentum space, and each density matrix is represented by three real indices among the Bloch sphere. With two 3D convolution (Conv3D) layers, one max pooling layer and one fully connected layer, the classifier outputs the probabilities P(χ = 0, 1, − 2) for each phase. c The potential limitation of the CNN classifier on data with random dropping. The classifier can correctly classify the clean data of topologically trivial phase (h = 3.2, χ = 0) with more than 80% of the data samples dropped, but the adversarial ratio (Adv. ratio) also increases as the dropping ratio increases. The error bars are obtained from 100 random data dropping trials. d The ratio of adversarial perturbations around the phase transition point. The random simulated perturbations are more likely to behave as adversarial perturbations when h approaches the transition point. Even when no data samples are dropped, the simulated perturbations may mislead the classifier. The situation becomes more serious when the dropping ratio increases to 20% and 40%. e The experimental procedure for the preparation and measurement of the ground states of the Hopf Hamiltonian at each momentum k. The dashed rectangle inserted before the final measurement represents a π/2 pulse with different phases. The directions of the electron spin on the Bloch sphere at three different time points are shown below the sequence.
Results
Machine learning of topological phases
To experimentally implement adversarial examples and demonstrate the vulnerability of machine learning in topological phases, we first train a phase classifier based on deep neural networks to predict topological phases with high accuracy. Concretely, we focus on an intriguing three-dimensional (3D) topological insulator called the Hopf insulator48,49, whose Hamiltonian in the momentum space reads:
where uk = (ux, uy, uz) with \({u}_{x}=2(\sin {k}_{x}\sin {k}_{z}+{C}_{{{{{{{{\bf{k}}}}}}}}}\sin {k}_{y})\), \({u}_{y}=2({C}_{{{{{{{{\bf{k}}}}}}}}}\sin {k}_{x}-\sin {k}_{y}\sin {k}_{z})\), and \({u}_{z}={\sin }^{2}{k}_{x}+{\sin }^{2}{k}_{y}-{\sin }^{2}{k}_{z}-{C}_{{{{{{{{\bf{k}}}}}}}}}^{2}\); \({\Psi }_{{{{{{{{\bf{k}}}}}}}}}^{{{{\dagger}}} }=({a}_{{{{{{{{\bf{k}}}}}}}},\uparrow }^{{{{\dagger}}} },{a}_{{{{{{{{\bf{k}}}}}}}},\downarrow }^{{{{\dagger}}} })\) are fermionic annihilation operators with pesudo-spin states \(\left|\uparrow \right\rangle\) and \(\left|\downarrow \right\rangle\) at each momentum k in the Brillouin zone (BZ); σ = (σx, σy, σz) are Pauli matrices, \({C}_{{{{{{{{\bf{k}}}}}}}}}\equiv \cos {k}_{x}+\cos {k}_{y}+\cos {k}_{z}+h\). Hopf insulators are peculiar 3D topological insulators that originate from the mathematical theory of Hopf fibration and elude the standard periodic table for topological insulators and superconductors for free fermions50,51. They can manifest the deep connection between knot theory and topological phases of matter in a visualizable fashion47,52. Their topological properties can be characterized by a topological invariant (the Hopf index) χ48,49, defined as:
where F is the Berry curvature defined as \({F}_{\mu }=\frac{1}{8\pi }{\epsilon }_{\mu \nu \tau }\hat{{{{{{{{\bf{u}}}}}}}}}\cdot ({\partial }_{\nu }\hat{{{{{{{{\bf{u}}}}}}}}}\times {\partial }_{\tau }\hat{{{{{{{{\bf{u}}}}}}}}})\) with \(\hat{{{{{{{{\bf{u}}}}}}}}}({{{{{{{\bf{k}}}}}}}})\equiv {{{{{{{\bf{u}}}}}}}}({{{{{{{\bf{k}}}}}}}})/|{{{{{{{\bf{u}}}}}}}}({{{{{{{\bf{k}}}}}}}})|\), ϵμντ being the Levi-Civita symbol, and \({\partial }_{\nu,\tau }\equiv {\partial }_{{k}_{\nu,\tau }}\)(ν, μ, τ ∈ {x, y, z}); A denotes the Berry connection obtained by Fourier transforming ∇ × A = F with the Coulomb gauge ∇ ⋅ A = 0 (see Methods). For the Hamiltonian HTI, direct calculations yield χ =−2 if ∣h∣ < 1, χ = 1 if 1 < ∣h∣ < 3, and χ = 0 otherwise.
We numerically generate 5000 samples with varying h ∈ [−5, 5] and train a 3D CNN in a supervised fashion. Figure 1b shows the structure of the CNN classifier we use. The 3D CNN model, which has three-dimensional structure and presents the translational symmetry, is suitable for learning phases with Bloch indices of density matrices in the momentum space. The input data are reconstructed density matrices in the momentum space. The classifier’s outputs are classification confidences for the phase being χ = 0, 1, or − 2, denoted by P(χ = 0), P(χ = 1), or P(χ = − 2), respectively. After training, the classifier obtains near-perfect performance on the numerically generated data, with accuracies of 99.2% and 99.6% on the validation and training sets, respectively (see Supplementary Note 5).
As shown in ref. 22, a well trained CNN classifier can correctly identify the phases with high (≥90%) probability even when over 90% of data are randomly dropped. This would significantly reduce the experimental cost since much fewer data samples are required. However, the existence of experimental noises is a challenge for the CNN models to showcase this advantage in reality. To test the robustness of the classifier on dropped data with noise, we numerically simulate 1000 tiny perturbations which are randomly sampled from the Gaussian distribution. We find that some of the simulated perturbations, when added into the legitimate samples, will mislead the classifier. Such perturbations, though not carefully crafted, behave like adversarial perturbations as well. As shown in Fig. 1c, although the classifier can correctly identify the phases on the clean data with more than 80% of density matrices in the discretized momentum space dropped, the ratio of adversarial perturbations also increases rapidly. This problem becomes more serious when the testing samples are closer to the phase transition point: as shown in Fig. 1d, dropping only 40% of the data will increase the ratio of adversarial perturbations to about 68%, which makes the precise identification of phase transition points unpractical.
Experimental implementation
We use a single NV center as a simulator to experimentally implement the model Hamiltonian in Eq. (1). The ground state of the NV electron spin consists of \(\left|{m}_{s}=0\right\rangle\) and degenerate \(\left|{m}_{s}=\pm 1\right\rangle\) state with zero-field splitting of 2.87 GHz53,54. Our setup is based on a home-built confocal microscope with an oil-immersed lens. To enhance photon collection efficiency, a solid immersion lens is fabricated on top of the NV center. A magnetic field of 472 Gauss is applied along the NV symmetry axis to polarize the nearby nuclear spins and remove degeneracy between states \(\left|{m}_{s}=\pm 1\right\rangle\). We use the subspace \(\left|{m}_{s}=0\right\rangle\) and \(\left|{m}_{s}=-1\right\rangle\), denoted as \(\left|0\right\rangle\) and \(\left|-1\right\rangle\) of the electron spin in the experiment. The experiment sequence is shown in Fig. 1e. The spin state is initialized to \(\left|0\right\rangle\) by optical pumping. Then, a microwave (MW) is applied to adiabatically evolve the spin state. By tuning the amplitude, frequency, and phase of MW, the electron spin is evolved to the ground state of the corresponding Hamiltonian at a given momentum point k22,55. The electron spin states at three different evolution time points are shown below the sequence in Fig. 1e. After the adiabatic evolution, quantum state tomography is performed, and the state density matrices are retrieved via maximum likelihood estimation56.
To obtain density matrices sampling of the Hamiltonian in Eq.(1), we mesh the momentum space k = (kx, ky, kz) into 10 × 10 × 10 grids with equal spacing. We use ground state density matrices of Hk with h = 0.5, 2, 3.2 as legitimate samples. These legitimate samples are used as ground truth to evaluate the topological phase classifier and latter generate corresponding adversarial examples. To alleviate the effect of experimental Gaussian noise on misleading the classifier, we implement all reconstructed states with a very high fidelity: for all three legitimate samples with h = 3.2, 2, 0.5, the average fidelities are 99.77(41)%, 99.78(41)%, and 99.77(45)%, respectively (for the fidelity on each momentum point, see Supplementary Fig. 2). The table in Table 1 presents the classifier’s output for three legitimate samples, which are all correct classifications with nearly unity confidence.
Although the experimental noises in the implemented legitimates samples are tiny, we find that they can still affect the classifier’s performance when we try to use machine learning methods to reduce experimental data. As shown in the lower panel of Fig. 2a, we randomly drop the experimentally implemented density matrices of the legitimate sample with h = 3.2. We find that the experimental noises will decrease the classification confidence P(χ = 0) as the ratio of dropped data increases, and act as adversarial perturbations when the dropping ratio increases to 60%. This result is consistent with the numerical simulation, indicating that there is a trade-off for the machine learning methods between the number of data samples used and the robustness to experimental noises. This trade-off cannot be attributed to the decreasing of the quality of the experimental data: we show the fidelity distribution in the upper panel of Fig. 2a, where the average fidelity \(\bar{F}\) and minimum fidelity Fmin are almost unchanged when the dropping ratio increases. The phenomenon that the classifier would be misled by tiny perturbations is not limited to the case where a large portion of data is dropped. Actually, with the full data, there are various kinds of tiny perturbations that can make the classifier give incorrect predictions, which is known as the vulnerability of neural networks to adversarial perturbations. This may rise severe problems for machine-learning approaches to the classification of different phases of matter, which drives us to experimentally implement these adversarial examples and study their topological properties.

a The classification confidence for experimental (Exp.) and theoretical (Theo.) data at h = 3.2 with different dropping ratios. For theoretical (experimental) data, the classifier gives correct predictions with 75% (60%) of the data samples dropped. The panels in the upper row show the fidelity distribution of the remaining data when the dropping ratios are 30%, 60%, and 75%, respectively. The average fidelity \(\bar{F}\) and minimum fidelity Fmin remain almost unchanged at different dropping ratios. b Density matrix of the experimentally implemented legitimate sample ρleg at k = (0.2π, 0.6π, 1.4π) and h = 0.5, with fidelity 99.68(31)%. c Density matrix of the experimentally implemented adversarial example ρadv at the same parameter point as in b, with fidelity 99.23(26)%. d Upper panel: the average fidelity for each kz value in the interval [0, 1.8π] with h = 2 between numerically generated and experimentally implemented adversarial examples. The angular direction represents the different values of kz and the radial direction represents the fidelity. The overall average fidelity is 99.65(46)%; Lower panel: the average fidelity between experimentally implemented legitimate samples and adversarial examples. The overall average fidelity is 93.40%.
We now consider implementing adversarial examples by adding tiny adversarial perturbations without data dropping. Choosing the loss function L as the metric to evaluate the performance of the classifier, we first search for numerical adversarial examples which can mislead the classifier by solving an optimization problem30: finding a bounded perturbation δ adding to the legitimate samples’ data to maximize the loss function L. We employ various strategies to approximately solve this optimization problem, including the fast gradient sign method (FGSM)57, projected gradient descent (PGD)57, momentum iterative method (MIM)58 and differential evolution algorithm (DEA)59,60,61. More concretely, we apply PGD and MIM to obtain continuous adversarial perturbations based on all three legitimate samples62, and apply DEA to obtain one adversarial example with discrete perturbations based on the legitimate sample with h = 3.2 (see Supplementary Note 6).
We remark that the existence of numerical adversarial examples does not guarantee that we can implement them in real experiments due to inevitable experimental imperfections—the experimental noises may wash out the bounded and carefully crafted adversarial perturbations. In fact, as shown in refs. 63,64, certain noises that are typical in experiments would nullify the adversarial examples. In the worst case, when the noise is in the opposite direction of the adversarial perturbation, the experimentally implemented adversarial examples will no longer be able to mislead the classifier. To this end, we numerically simulate the experimental noises acting on these numerically obtained adversarial examples and examine their performances on the classifier. After the simulation, for each scenario we select one example with the strongest robustness against experimental noises and reconstruct its corresponding Hamiltonian. The comparison between densities for the experimentally implemented legitimate and adversarial examples are shown in Fig. 2b, c. Figure 2d shows the average fidelity for each kz value with h = 2. All adversarial examples bear high fidelities (larger than 93%), but the classifier incorrectly predicts their phase labels with a high confidence level, as shown in Table 1.
Demonstration of adversarial examples
In the previous section, we illustrate that the experimentally implemented adversarial examples, which maintain a high fidelity with respect to original legitimate data, can mislead the topological phase classifier. In this section, we further demonstrate the effectiveness of these adversarial examples from the physical perspective. In Fig. 3a–c, with h = 3.2, we plot experimentally implemented density matrices of legitimate samples, adversarial examples with continuous perturbations, and adversarial examples with discrete perturbations. From the comparison, the obtained adversarial examples look almost the same as the original legitimate ones. It is surprising that even local discrete changes, as shown in Fig. 3c, can mislead the classifier to make incorrect prediction. This result is at variance with the physical intuition that Hopf insulators are robust to local perturbations due to their topological nature48,49, indicating that the neural network based classifier does not fully captured the underlying topological characteristics30.

a–c The first component's magnitude of the input data for h = 3.2 at kz = 0.8π, π and 1.2π. a Legitimate sample with h = 3.2 implemented in the experiment. b Adversarial examples realized in the experiment with continuous perturbations generated by the projected gradient descent method. The average fidelity between the experimentally implemented adversarial examples and legitimate samples is over 98%. c Adversarial examples realized in the experiment with discrete perturbation generated by the differential evolution algorithm. Among 1000 density matrices as input, only seven of them have been changed and successfully mislead the classifier. d–f Measured spin texture for kz = π, h = 3.2. For each subfigure, kx and ky vary from 0 to 1.8π with equal spacing of 0.2π. At each momentum k, the state can be represented on the Bloch sphere. The arrows in the plane show the direction of the Bloch vector projected to the x − y plane. The colors label the z component of the Bloch vector. d Legitimate sample with h = 3.2 implemented in experiment. e Adversarial examples implemented in the experiment with continuous perturbations generated by the momentum iterative method. f Adversarial examples implemented in the experiment with discrete perturbation generated by the differential evolution algorithm.
Focusing on classifying topological phases of Hopf insulators, we expect that the adversarial perturbations should not change the topological properties, including the integer-valued topological invariant and the topological links associated with the Hopf fibration48. We use a conventional method, which is based on the experimentally measured data, to probe the Hopf index65,66. The results are shown in Table 2 (see Supplementary Note 4). We find that each adversarial example’s Hopf index has only a negligible difference to the corresponding legitimate ones, all close to the correct integer numbers.
The momentum-space spin texture of Hopf insulators harbors a knotted structure, which is called the Hopfion67. In Fig. 3d–f, we show cross sections of the measured spin textures before and after adding continuous and discrete adversarial perturbations. The spin textures present an illustration on 3D twisting of the Hopfion, which keep original structure and are almost not affected by adversarial perturbations. A more intuitive demonstration of Hopf links can be derived if we consider the preimage of a fixed spin orientation on the Bloch sphere, which will form a closed loop in the momentum space \({{\mathbb{T}}}^{3}\). For topological nontrivial phases, the loops for different orientations are always linked47. As shown in Fig. 4, we plot the 3D preimage contours of legitimate and adversarial examples in \({{\mathbb{R}}}^{3}\) in the stereographic coordinates of \({{\mathbb{S}}}^{3}\), with h = 0.5, orientations \({{{{{{{\bf{S}}}}}}}}=(-1,-1,0)/\sqrt{2}\) and \((0,1,-1)/\sqrt{2}\) on the Bloch sphere (see Supplementary Note 7). We observe that the loops are correctly linked together as h = 0.5 corresponds to topological nontrivial χ = −2 phase, for both legitimate and adversarial examples. This result illustrates that the adversarial perturbations do not affect the Hopf link, despite the fact that they alter the predictions of the classifiers drastically.

a Topological link, obtained from two spin states with Bloch sphere representations \({{{{{{{\bf{S}}}}}}}}=(-1,-1,0)/\sqrt{2}\) (blue) and \((0,1,-1)/\sqrt{2}\) (orange), for a legitimate sample in the stereographic coordinates of \({{\mathbb{S}}}^{3}\), between two spin states on the Bloch sphere. Solid lines are curves from numerically calculated directions Sth and the stars are experimentally measured spin orientations Sexp. The deviation ∣Sexp − Sth∣≤0.25(0.35) for the blue (orange) curve. b The topological link for an adversarial example with deviation ∣Sexp − Sth∣≤0.25 for blue and orange curves.
A possible defense strategy against adversarial perturbations is adversarial training. The basic idea is to retrain the classifier with a new training set that contains both legitimate and adversarial samples28. Here, we retrain the phase classifier with both carefully crafted adversarial examples and samples with experimental noises. We find that this adversarial training strategy can indeed substantially enhance the robustness of the classifier against adversarial perturbations and experimental noises. Yet, after adversarial training the classifier’s performance near the phase transition points becomes poorer. This is attributed to the fact that adversarial training will flatten weight parameters in general (See Supplementary Note 8).
Discussion
The above sections showcase that the adversarial perturbations do not affect the topological properties of topological phases. The incorrect predictions given by the classifier indicate that the classifier does not learn the accurate and robust physical criterion for identifying topological phases, which is consistent with the theoretical prediction in the recent paper30. How to exploit the experimental data to make the classifier better learn physical principles, and balance the trade-off between the number of data samples used and the classification accuracy in real experiments, is an interesting and important problem worth further investigation. In addition, recent experiments have demonstrated the simulation of non-Hermitian topological phases with the NV platform68 and a theoretical work on learning non-Hermitian phases with exotic skin effect in an unsupervised fashion has also been reported17. In the future, it would be interesting and desirable to study adversarial examples for unsupervised learning of topological phases, both in theory and in experiment.
In summary, we have experimentally demonstrated the adversarial examples in learning topological phases with a solid-state simulator. Our result showcases that neural network-based classifiers are vulnerable to tiny adversarial perturbations, which may originate from experimental noises, or be carefully designed. In the former case, we showed that there is a trade-off between the number of data sample used and the robustness to tiny experimental noises. For the latter case, we implemented the adversarial examples in experiment and studied their properties, such as the high fidelity, unchanged topological invariant, and topological link. These results reveal that current machine learning methods do not fully capture the underlying physical principles and thus are especially vulnerable to adversarial perturbations, and inevitable experimental noises when only a small portion of data are accessible.
Methods
Experimental setup
Our experiment is implemented on a home-built confocal microscope at room temperature. The 532 nm diode laser passes through an acoustic optical modulator setting in a double-pass configuration. The laser can be switched on and off on the time scale of ~20 ns with on-off ratio to 10,000:1. A permanent magnetic provides the static magnetic field of 472 Gauss. The magnetic field is precisely aligned parallel to the symmetry axis of the NV center by observing the emitted photon numbers69. With this magnetic field, a level anticrossing in the electronic state allows electron-nuclear spin flip-flops, which polarizes the nuclear spin70. The magnetic field also removes the degeneracy between \(\left|{m}_{s}=\pm 1\right\rangle\) states. The spin state is initialized by a 3μs laser excitation, then a MW modulation is implemented by programming two orthogonal 100 MHz carrier signals, which are generated by arbitrary waveform generator. The MW is amplified and guided through coaxial cables to gold coplanar waveguide close to the NV center. The emitted photons are collected through an oil -immersed objective lens (NA = 1.49) and detected by an avalance photodiode. The spin state is readout by counting the spin-dependent number of photons. To enhance collection efficiency, a solid immersion lens with 6.74 μm diameter is fabricated. The fluorescence count is about 260 kcps under 0.25 mW laser excitation, with the signal-noise ratio about 100:1. The sequence is repeated 7.5 × 105 times, collecting about 3.9 × 104 photons.
Adiabatic passage approach
Consider the electron subspace spanned by the \(\left|0\right\rangle\) and \(\left|-1\right\rangle\) states, in a rotating frame, the effective Hamiltonian with variable time t reads
where Ω(t) is the MW amplitude, φ is the MW phase, Δω(t) = ω0 − ωMW, and ω0 and ωMW are NV resonant frequency and MW frequency, respectively. In the matrix form, the Hamiltonian Hk reads:
We terminate the adiabatic evolution at time tc to satisfy \({{\Delta }}\omega ({t}_{c})/{{\Omega }}({t}_{c})={u}_{z}/\sqrt{{u}_{x}^{2}+{u}_{y}^{2}}\). Phase \(\varphi=-\arctan ({u}_{y}/{u}_{x})\) is kept constant in the adiabatic evolution. To satisfy the adiabatic condition22:
where \(\left|{\psi }^{g}\right\rangle\) and \(\left|{\psi }^{e}\right\rangle\) are ground and excited states of the Hamiltonian HTI, and Eg and Ee are energies of the ground and excited states, respectively. We use \({{{\Omega }}}_{\max }=2\pi \times 7.81\) MHz and \({{\Delta }}{\omega }_{\max }=2\pi \times 10\) MHz during the adiabatic passage process for a total time of 1500 ns.
Conventional method to obtain the Hopf index with experimental data
We use the discretization scheme introduced in refs. 65,66 and applied in ref. 47 to calculate the Hopf index directly from experimental data. The Hopf index can be written as:
where F is the Berry curvature with and A is the associated Berry connection satisfying ∇ × A = F. To avoid the arbitrary phase problem, we can use a discretized version of the Berry curvature65,66:
The U(1)-link is defined as
with \({{{\hat{{{{{\boldsymbol{\nu }}}}}}}}}\in \{{{{\hat{{{{{\boldsymbol{x}}}}}}}}},{{{\hat{{{{{\boldsymbol{y}}}}}}}}},{{{\hat{{{{{\boldsymbol{z}}}}}}}}}\}\), which is a unit vector in the corresponding direction. This discretized version of F can be calculated after performing quantum state tomography at all points kJ on the momentum grid. We can also obtain the Berry connection A by Fourier transforming ∇ × A = F with the Coulomb gauge ∇ ⋅ A = 0. Finally, instead of doing the integral, we sum over all points on the momentum grid to obtain the Hopf index χ. It is shown in22,47 that for a 10 × 10 × 10 grid, this method is quite robust to various perturbations and can extract the Hopf index with high accuracy.
The simulation of experimental noise and random dropping trials
To test the robustness of the neural network-based classifier against experimental noises and random data dropping, we numerically simulated 1000 tiny experimental noises and 100 different data point dropping sequences on the theoretically calculated data with h = 3.2 and χ = 0. Each experimental noise is simulated by the 10 × 10 × 10 × 3 independent variables sampled from the normal distribution:
The noise is directly added on the Bloch vector for each density matrix. After this, we normalize the obtained vector so that it still represent a pure state on the Bloch sphere. The noise is tiny enough to keep the high fidelity (\(\overline{F}=0.9899\)). The data dropping is implemented by sequentially replacing the Bloch vectors \(({n}_{x}^{({{{{{{{\boldsymbol{k}}}}}}}})},{n}_{y}^{({{{{{{{\boldsymbol{k}}}}}}}})},{n}_{z}^{({{{{{{{\boldsymbol{k}}}}}}}})})\) at randomly selected k point by a zero vector (0, 0, 0).
Data availability
The data generated in this study have been deposited in the zenodo database under accession code https://doi.org/10.5281/zenodo.6830983.
Code availability
The data analysis and numerical simulation codes are available at https://doi.org/10.5281/zenodo.6811855.
References
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Jordan, M. I. & Mitchell, T. M. Machine learning: trends, perspectives, and prospects. Science 349, 255–260 (2015).
Carleo, G. et al. Machine learning and the physical sciences. Rev. Mod. Phys. 91, 045002 (2019).
Das Sarma, S., Deng, D.-L. & Duan, L.-M. Machine learning meets quantum physics. Phys. Today 72, 48–54 (2019).
Dunjko, V. & Briegel, H. J. Machine learning & artificial intelligence in the quantum domain: a review of recent progress. Rep. Prog. Phys. 81, 074001 (2018).
Li, L.-L. et al. Machine learning–enabled identification of material phase transitions based on experimental data: exploring collective dynamics in ferroelectric relaxors. Sci. Adv. 4, eaap8672 (2018).
Wang, L. Discovering phase transitions with unsupervised learning. Phys. Rev. B 94, 195105 (2016).
Carrasquilla, J. & Melko, R. G. Machine learning phases of matter. Nat. Phys. 13, 431–434 (2017).
van Nieuwenburg, E. P. L., Liu, Y.-H. & Huber, S. D. Learning phase transitions by confusion. Nat. Phys. 13, 435–439 (2017).
Ch’ng, K., Carrasquilla, J., Melko, R. G. & Khatami, E. Machine learning phases of strongly correlated fermions. Phys. Rev. X 7, 031038 (2017).
Zhang, Y. & Kim, E.-A. Quantum loop topography for machine learning. Phys. Rev. Lett. 118, 216401 (2017).
Zhang, Y., Melko, R. G. & Kim, E.-A. Machine learning Z2 quantum spin liquids with quasiparticle statistics. Phys. Rev. B 96, 245119 (2017).
Zhang, P.-F., Shen, H.-T. & Zhai, H. Machine learning topological invariants with neural networks. Phys. Rev. Lett. 120, 066401 (2018).
Molignini, P., Zegarra, A., van Nieuwenburg, E., Chitra, R. & Chen, W. A supervised learning algorithm for interacting topological insulators based on local curvature. SciPost Phys. 11, 73 (2021).
Maskara, N., Buchhold, M., Endres, M. & van Nieuwenburg, E. Learning algorithm reflecting universal scaling behavior near phase transitions. Phys. Rev. Res. 4, L022032 (2022).
Rodriguez-Nieva, J. F. & Scheurer, M. S. Identifying topological order through unsupervised machine learning. Nat. Phys. 15, 790–795 (2019).
Yu, L.-W. & Deng, D.-L. Unsupervised learning of non-hermitian topological phases. Phys. Rev. Lett. 126, 240402 (2021).
Scheurer, M. S. & Slager, R.-J. Unsupervised machine learning and band topology. Phys. Rev. Lett. 124, 226401 (2020).
Long, Y., Ren, J. & Chen, H. Unsupervised manifold clustering of topological phononics. Phys. Rev. Lett. 124, 185501 (2020).
Lidiak, A. & Gong, Z. Unsupervised machine learning of quantum phase transitions using diffusion maps. Phys. Rev. Lett. 125, 225701 (2020).
Käming, N. et al. Unsupervised machine learning of topological phase transitions from experimental data. Mach. Learn.: Sci. Technol. 2, 035037 (2021).
Lian, W.-Q. et al. Machine learning topological phases with a solid-state quantum simulator. Phys. Rev. Lett. 122, 210503 (2019).
Rem, B. S. et al. Identifying quantum phase transitions using artificial neural networks on experimental data. Nat. Phys. 15, 917–920 (2019).
Bohrdt, A. et al. Classifying snapshots of the doped Hubbard model with machine learning. Nat. Phys. 15, 921–924 (2019).
Zhang, Y. et al. Machine learning in electronic-quantum-matter imaging experiments. Nature 570, 484–490 (2019).
Huang, L., Joseph, A. D., Nelson, B., Rubinstein, B. I. & Tygar, J. D. Adversarial machine learning. In Proc. 4th ACM Workshop on Security and Artificial Intelligence, 43 (2011).
Papernot, N. et al. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. Preprint at https://arxiv.org/abs/1605.07277 (2016).
Biggio, B. & Roli, F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recogn. 84, 317–331 (2018).
Goodfellow, I., Shlens, J. & Szegedy, C. Explaining and harnessing adversarial examples. In International conference on learning representations (2015).
Jiang, S., Lu, S. & Deng, D.-L.Adversarial machine learning phases of matter. Preprint at https://arxiv.org/abs/1910.13453 (2019).
Doherty, M. W. et al. The nitrogen-vacancy colour centre in diamond. Phys. Rep. 528, 1–45 (2013).
Hensen, B. et al. Loophole-free Bell inequality violation using electron spins separated by 1.3 kilometres. Nature 526, 682–686 (2015).
Kalb, N. et al. Entanglement distillation between solid-state quantum network nodes. Science 356, 928–932 (2017).
Humphreys, P. C. et al. Deterministic delivery of remote entanglement on a quantum network. Nature 558, 268–273 (2018).
Pompili, M. et al. Realization of a multinode quantum network of remote solid-state qubits. Science 372, 259–264 (2021).
Barry, J. F. et al. Sensitivity optimization for NV-diamond magnetometry. Rev. Mod. Phys. 92, 015004 (2020).
Hsieh, S. et al. Imaging stress and magnetism at high pressures using a nanoscale quantum sensor. Science 366, 1349–1354 (2019).
Grinolds, M. S. et al. Nanoscale magnetic imaging of a single electron spin under ambient conditions. Nat. Phys. 9, 215–219 (2013).
Zaiser, S. et al. Enhancing quantum sensing sensitivity by a quantum memory. Nat. Commun. 7, 1–11 (2016).
Yao, N. Y. et al. Scalable architecture for a room temperature solid-state quantum information processor. Nat. Commun. 3, 1–8 (2012).
Van der Sar, T. et al. Decoherence-protected quantum gates for a hybrid solid-state spin register. Nature 484, 82 (2012).
Zhang, J., Hegde, S. S. & Suter, D. Efficient implementation of a quantum algorithm in a single nitrogen-vacancy center of diamond. Phys. Rev. Lett. 125, 030501 (2020).
Bradley, C. et al. A ten-qubit solid-state spin register with quantum memory up to one minute. Phys. Rev. X 9, 031045 (2019).
Wrachtrup, J., Kilin, S. Y. & Nizovtsev, A. Quantum computation using the 13C nuclear spins near the single NV defect center in diamond. Opt. Spectrosc. 91, 429–437 (2001).
Georgescu, I. M., Ashhab, S. & Nori, F. Quantum simulation. Rev. Mod. Phys. 86, 153 (2014).
Choi, J. et al. Probing quantum thermalization of a disordered dipolar spin ensemble with discrete time-crystalline order. Phys. Rev. Lett. 122, 043603 (2019).
Yuan, X.-X. et al. Observation of topological links associated with hopf insulators in a solid-state quantum simulator. Chin. Phys. Lett. 34, 060302 (2017).
Moore, J. E., Ran, Y. & Wen, X.-G. Topological surface states in three-dimensional magnetic insulators. Phys. Rev. Lett. 101, 186805 (2008).
Deng, D.-L., Wang, S.-T., Shen, C. & Duan, L.-M. Hopf insulators and their topologically protected surface states. Phys. Rev. B 88, 201105 (2013).
Kitaev, A.Periodic table for topological insulators and superconductors. In AIP conference proceedings, vol. 1134, 22 (American Institute of Physics, 2009).
Schnyder, A. P., Ryu, S., Furusaki, A. & Ludwig, A. W. W. Classification of topological insulators and superconductors in three spatial dimensions. Phys. Rev. B 78, 195125 (2008).
Deng, D.-L., Wang, S.-T., Sun, K. & Duan, L.-M. Probe knots and hopf insulators with ultracold atoms. Chin. Phys. Lett. 35, 013701 (2018).
Childress, L. et al. Coherent dynamics of coupled electron and nuclear spin qubits in diamond. Science 314, 281–285 (2006).
Bar-Gill, N., Pham, L. M., Jarmola, A., Budker, D. & Walsworth, R. L. Solid-state electronic spin coherence time approaching one second. Nat. Commun. 4, 1–6 (2013).
Xu, K. et al. Experimental adiabatic quantum factorization under ambient conditions based on a solid-state single spin system. Phys. Rev. Lett. 118, 130504 (2017).
James, D. F., Kwiat, P. G., Munro, W. J. & White, A. G. Measurement of qubits. Phys. Rev. A 64, 052312 (2001).
Madry, A., Makelov, A., Schmidt, L., Tsipras, D. & Vladu, A. Towards deep learning models resistant to adversarial attacks. In 6th International Conference on Learning Representations (2018).
Dong, Y.-P. et al. Boosting adversarial attacks with momentum. In Proc. IEEE Conference on Computer Vision and Pattern Recognition, 9185-9193 (2018).
Storn, R. & Price, K. Differential evolution - a simple and efficient heuristic for global optimization over continuous spaces. J. Global Optimization 11, 341–359 (1997).
Das, S. & Suganthan, P. N. Differential evolution: a survey of the state-of-the-art. IEEE Trans. Evol. Comput. 15, 4–31 (2011).
Su, J., Vargas, D. V. & Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 23, 828–841 (2019).
Papernot, N. et al. Technical report on the cleverhans v2. 1.0 adversarial examples library. Preprint at https://arxiv.org/abs/1610.00768 (2018).
Cohen, J. M., Rosenfeld, E. & Kolter, J. Z. Certified adversarial robustness via randomized smoothing. In Proc. 36th International Conference on Machine Learning, vol. 97 of Proc. Machine Learning Research, 1310-1320 (2019).
Li, B., Chen, C., Wang, W. & Carin, L .Certified adversarial robustness with additive noise. In eds Wallach, H. et al. Advances in Neural Information Processing Systems, vol. 32 (Curran Associates, Inc., 2019).
Fukui, T., Hatsugai, Y. & Suzuki, H. Chern numbers in discretized brillouin zone: efficient method of computing (spin) hall conductances. J. Phys. Soc. Jpn. 74, 1674–1677 (2005).
Deng, D.-L., Wang, S.-T. & Duan, L.-M. Direct probe of topological order for cold atoms. Phys. Rev. A 90, 041601 (2014).
Faddeev, L. & Niemi, A. J. Stable knot-like structures in classical field theory. Nature 387, 58–61 (1997).
Zhang, W. et al. Observation of non-Hermitian topology with non-unitary dynamics of solid-state spins. Phys. Rev. Lett. 127, 090501 (2021).
Epstein, R. J., Mendoza, F. M., Kato, Y. K. & Awschalom, D. D. Anisotropic interactions of a single spin and dark-spin spectroscopy in diamond. Nat. Phys. 1, 94–98 (2005).
Jacques, V. et al. Dynamic polarization of single nuclear spins by optical pumping of nitrogen-vacancy color centers in diamond at room temperature. Phys. Rev. Lett. 102, 057403 (2009).
Acknowledgements
This work was supported by the Frontier Science Center for Quantum Information of the Ministry of Education of China, Tsinghua University Initiative Scientific Research Program, and the Beijing Academy of Quantum Information Sciences. D.-L.D. also acknowledges additional support from the Shanghai Qi Zhi Institute.
Author information
Authors and Affiliations
Contributions
H.Z. and X.W. carried out the experiment under the supervision of L.-M.D. and D.-L.D. S.J. did the numerical simulations and analyzed the experimental data together with H.Z. W.Z., X.O., X.H., Y.Y., and Y.L. contributed to the fabrication of the diamond sample, and helped with the experimental measurements. All authors contributed to the experimental set-up, the discussions of the results and the writing of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks the anonymous reviewers for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, H., Jiang, S., Wang, X. et al. Experimental demonstration of adversarial examples in learning topological phases. Nat Commun 13, 4993 (2022). https://doi.org/10.1038/s41467-022-32611-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-022-32611-7
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
