
Abstract
The worldwide fascination of da Vinci’s Mona Lisa has been dedicated to the emotional ambiguity of her face expression. In the present study we manipulated Mona Lisa’s mouth curvature as one potential source of ambiguity and studied how a range of happier and sadder face variants influences perception. In two experimental conditions we presented different stimulus ranges with different step sizes between stimuli along the happy-sad axis of emotional face expressions. Stimuli were presented in random order and participants indicated the perceived emotional face expression (first task) and the confidence of their response (second task). The probability of responding ‘happy’ to the original Mona Lisa was close to 100%. Furthermore, in both conditions the perceived happiness of Mona Lisa variants described sigmoidal functions of the mouth curvature. Participants’ confidence was weakest around the sigmoidal inflection points. Remarkably, the sigmoidal functions, as well as confidence values and reaction times, differed significantly between experimental conditions. Finally, participants responded generally faster to happy than to sad faces. Overall, the original Mona Lisa seems to be less ambiguous than expected. However, perception of and reaction to the emotional face content is relative and strongly depends on the used stimulus range.
Similar content being viewed by others

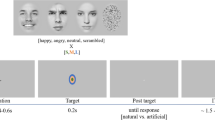
Introduction
Although our daily perceptual experience appears to us as an unambiguous and stable reflection of the world, the sensory information is inherently incomplete and ambiguous due to the limited capacity of our senses1. In order to overcome this natural limitation, the human brain has to disambiguate the sensory information and construct meaningful interpretations.
Ambiguous figures, like the famous Necker Cube2, are extreme cases, where the sensory information is maximally ambiguous, making our perception unstable, alternating spontaneously between the two most probable interpretations. This happens repeatedly, even though the physical properties of the stimulus, and its retinal projections, remain unchanged. Examples for such perceptual instabilities, resulting from ambiguous sensory input, exist at different levels of complexity, like low-level geometry (Necker Cube), figure-ground ambiguity (Rubin’s Vase-Face stimulus3), motion (e.g. von Schiller’s Stroboscopic Alternative Motion stimulus, “SAM”4,5), and also at more complex semantic levels (e.g., Boring’s Old/Young woman6,7). Ambiguity even exists in other modalities like audition and touch8. Numerous studies focused on behavioral and physiological correlates of perceptual processing of such ambiguous figures9,10,11.
Sensory ambiguity and perceptual instability can also be found at even more complex levels, e.g. in language12 and, closely related, during non-verbal aspects of communication, when the emotional content of face expressions has to be interpreted13. Indeed, configurations of facial muscles appear to be inherently ambiguous13, and in order to resolve this ambiguity and understand a facial emotional expression, the information from the face must be combined with information from speech14 and other sensory modalities15,16. One famous example of ambiguity in emotional face expressions – as discussed by experts – is Leonardo da Vinci’s (around 1503–1507) Mona Lisa painting (Fig. 1). As the English essayist and writer Walter Pater affirmed in a prominent essay, dedicated to Leonardo da Vinci17, Mona Lisa’s smile holds an “emotional ambiguity”, revealing first a “promise of an unbounded tenderness”, but soon after also a “sinister menace”. Her expression is worldwide accepted to be an emblem of emotional ambiguity. The notable English art historian Ernest Gombrich wrote in “Story of Art”18, that “sometimes she seems to mock at us, and then again we seem to catch something like sadness in her smile”.

“Mona Lisa” by Leonardo da Vinci (around 1503–1516)25.
During the recent years, the elusive quality of Mona Lisa’s painting has been object of scientific investigations19,20. So far all studies – to our best knowledge – take Mona Lisa’s emotional face expression as a priori ambiguous. The aim of the present study was to quantify the effective degree of ambiguity of da Vinci’s painting along the happy-sad axis of emotional expressions by applying a variant of the method of constant stimuli21, a well-established psychophysical method to estimate perceptual thresholds.
The facial feature, which determines the most mysterious and ambiguous character of Mona Lisa’s expression, has been found to be the mouth area19,20,22. We created a number of Mona Lisa’s variants by manipulating the curvature of the mouth in a systematic manner, in order to stepwise disambiguate them towards happy and sad face expressions.
To our great surprise the stimulus corresponding to da Vinci’s original painting was almost always perceived as unambiguously happy.
In a second experimental condition (Half-Range Condition) we reduced the range of face expressions, taking da Vinci’s variant as the most unambiguously happy face and additionally decreasing the step size between sadder face variants, in order to increase the “resolution of emotional ambiguity”.
The happiness bias of da Vinci’s original remained with this smaller range of emotional faces, but the resulting psychometric function differed from the first condition (Full-Range Condition). This indicates that the range of emotional face expressions strongly influences the perception of the individual face. The experiments described above had been aimed as pilots for a subsequent EEG study. Based on the surprising results we replicated these experiments in a more systematic manner. The here presented results confirm our earlier findings.
Methods
Participants
Twelve observers (5 males, 7 females; age range = 20–33, mean age = 26 years) participated to the experiment. Nine participants were right-handed and three left-handed. All participants were naive as to the specific experimental question and gave their written informed consent. Eleven participants reported any history of neurological disease. One participant suffers from periodic migraine but was free of symptoms during the experiments. Visual acuity was tested with the Freiburg Visual Acuity Test23. Eleven participants had a normal or corrected-to-normal vision. Visual acuity of one participant was 0.5 at the right eye and 0.55 at the left eye. We repeated the below analysis without this participant. Since the effects remained, we decided to keep this participant in the analysis. The study was approved by the ethics committee of the University of Freiburg and performed in accordance with the ethical standards laid down in the Declaration of Helsinki24.
Stimuli
We used a grey-scale version of Leonardo da Vinci’s Mona Lisa25 and created 12 variants thereof by a stepwise manipulation of the curvature of Mona Lisa’s mouth in order to manipulate the emotional face expression from happy to sad. Furthermore we had to do tiny adjustments of the cheek’s shadow between stimulus variants in order to harmonize the mouth’s manipulation to the total facial expression.
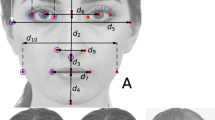
The two experimental conditions differed in the ranges of presented stimulus variants (see Procedure for details). Figure 2 displays several Mona Lisa variants with the corresponding focus on the manipulated mouth region. Red (Full-Range Condition) and blue (Half-Range Condition) arrows on the mouth region of Da Vinci’s original version (S9) indicate the trajectories on which the left and right mouth corners of the different stimulus variants were located in the two experimental conditions. The starting points of the arrows (filled circles) mark the left and right corners of the mouth of stimulus S9 (red circles for the Full-Range Condition) and stimulus S5 (blue circles for the Half-Range Condition). Stimulus S9 (da Vinci’s original) and stimulus S5 are positioned in the middle of the two ranges from the saddest to the happiest face expressions in the Full-Range Condition and the Half-Range Condition respectively. The arrow end points mark the most extreme mouth corner positions of the Mona Lisa (“ML”) variants with the most sad and most happy face expressions for the two conditions. Dotted arrows indicate manipulations towards sad face expressions, whereas continuous arrows indicate manipulations towards happy face expressions. In both conditions we used four equally sized steps along each of the four trajectories from one stimulus variant to the next.

The red and blue filled circles in S9 indicate the left and right mouth corners of the central stimulus in the Full-Range Condition (S9) and in the Half-Range Condition (S5). Arrows indicate the corresponding trajectories of the mouth corner locations of the different stimulus variants for the happy (upwards, solid lines) and sad (downwards, dashed lines) face expression.
Procedure
The experiment consisted of two conditions. In the Full-Range Condition we presented nine stimulus variants with roughly equidistant steps of mouth-manipulation from the saddest to the happiest stimulus variants. In the Half-Range Condition we again presented nine stimuli with equidistant steps, but decreased the range of stimulus variants and step sizes between individual stimuli to 50% of the Full-Range Condition respectively, in order to increase the “ambiguity resolution”. Five stimuli from the Half-Range Condition were also used in the Full-Range Condition.
Each experimental condition consisted of 30 blocks. In each block we presented a sequence of nine ML variants, ranging from the happiest to the saddest emotion. The stimulus order within each condition was randomized across blocks and participants. The two conditions were presented to the same group of subjects (within-subject design). All 30 repetitions per condition were executed in succession. The order of the two conditions was counterbalanced across participants.
The participants were seated in a chair in a dimly lit room at a distance of 114 cm from the screen and observed a series of face stimuli. The average of the luminance across five image points was 64.07 cd/m3. In a dual task paradigm stimuli were presented for a self-paced duration, which was immediately interrupted after the second of two necessary responses, but which lasted maximally 6 s in the case of missing responses. Participants first indicated in a forced-choice manner either happy or sad face perceptions or non-face perceptions by pressing one of 3 keys (“Perception Task”). Subsequently they estimated the confidence of their previous response on a scale between 1 (very unsure) and 4 (highly sure) by pressing one of four different keys (“Confidence Rating Task”). The participants’ second response started a blank screen gap of 400 ms, followed by the next stimulus (as seen in Fig. 3).

Each of the 9 Mona Lisa variants25 in a block was presented for maximal 6 seconds. Within this time window the participants were told to first indicate the perceived emotional facial expression of Mona Lisa (“Perception Task”) and to subsequently rate the confidence of their response (“Confidence Rating Task”). After the second response (or after 6 s in case of no response) the next stimulus variant appeared. Each block was repeated for 30 times and the presentation order within block was randomized. Happy and sad variants of the original Mona Lisa painting were created in Dr. Kornmeier’s lab.
Before the start of the main experiment, the participants performed a training part, where they learned the association between keys and face expressions. In the training, we only presented the two most disambiguated versions of ML (i.e. the saddest – S1 – and the happiest – S13 – variants). This training finished, after participants had reached a threshold of at least 8 correct responses in a series of ten stimulus presentations. The training sessions lasted for about 7 minutes.
Analysis
Perception Task
For each participant and stimulus variant we calculated the percentage of happy face percepts (number of happy face responses divided by the total number of responses in the perception task). The face stimuli, which had been presented in a random order, were then numbered in increasing order from the saddest to the happiest variant and participants’ responses were sorted with respect to this order. We then fitted psychometric functions (formula 1) to the resulting response traces (see Fig. 4) and determined the stimulus number of the most ambiguous stimulus, “Samb” at the 50% response level (half-maximum, i.e. the sigmoidal inflection point with equal probability of happy and sad face percepts) and the slope of the sigmoid. The base and max values of each individual sigmoid fit were set to 0 and 1 respectively.

(b) The related reaction times (Task 1, triangles, ordinate on the right) and participants confidence ratings (Task 2, stars, ordinate on the left) of their perception responses. Happy and sad variants of the original Mona Lisa image25 (S9) were created in Dr. Kornmeier’s lab. Differences between sigmoid functions (a) are clearly visible and correspond to the differences in reaction time and confidence level traces (b).

Goodness of fit was determined individually by calculating R2 values, which were above 90% for all participants. We thus used individual Samb and slope values for statistical comparison of participants’ responses between the two conditions with t-tests.
Our results concerning perception of Mona Lisa motivated the execution of two additional ANOVAs. Here we further compared within each experimental condition the average Samb and slope values from the first five trials with the average values from the last five trials using repeated-measures ANOVAS with the factors CONDITION (two steps, Half-Range and Full-Range) and PERIOD (2 steps, average of the first five and average of the last five trials) and the variables Samb and slope. These exploratory additional analyses were not included into the repeated measures correction.
Confidence Rating Task
We calculated the mean confidence rating per participant and stimulus variant and entered these values into a repeated-measures ANOVA with polynomial contrasts with the factors CONDITION (two levels) and STIMULUS (five levels, focusing on the stimuli S1, S3, S5, S7 and S9 that were common to both conditions). Wilcoxon signed-rank tests were conducted for post-hoc tests.
Reaction Times
Reaction times were calculated as the time from stimulus onset until participant’s first response (Task 1 = Perception Task). We calculated separately for the two conditions and for each stimulus variant the mean reaction times per participant and entered the values in a repeated-measures ANOVA with polynomial contrasts with the factors CONDITION (2 levels) and STIMULUS (five levels, corresponding to the stimuli S1, S3, S5, S7 and S9, which were common to both conditions). Wilcoxon signed-rank tests were conducted for post-hoc tests.
Correlation between Confidence Ratings and Reaction Times
For each condition we calculated Pearson and Spearman correlation coefficients across stimulus variants between grand mean reaction times and grand mean confidence ratings.
Correction for multiple testing was applied with Holm’s variant of the Bonferroni correction26. In Holm’s procedure, all calculated p-values are sorted from the lowest to the highest. The first p-value is compared with an alpha corrected by the total number n of pairwise comparisons. The second p-value is compared with an alpha corrected by n-1, and so on for the following p-values. P-values that survived multiple testing corrections are reported.
Results
Perception of Emotional Face Expression
Within each condition, the perception of Mona Lisa’s emotional expression did change across variants describing a sigmoidal function of the percentage of happy face percepts, as shown in Fig. 4. For the Full-Range Condition, the average goodness of fit across participants was 0.999 ± 0.001 (thus about 100% of the variance was explained by the fit function). The average goodness of fit for the Half-Range Condition was 0.979 ± 0.018.
The sigmoid fit functions differed significantly between Conditions, with the location of the most ambiguous stimulus Samb in the Full-Range Condition being close to S5 whereas in the Half-Range Condition Samb was located close to S4 (p = 0.006, t-test, see also Fig. 4a). Further the sigmoidal fit function in the Half-Range Condition showed a steeper slope (mean slope = 0.67) than the fit function in the Full-Range Condition (mean slope = 0.87; p = 0.025, t-test, see also Fig. 4).
The present results are supported by Fig. 5, which depicts Samb and slope values of the individual participants for the Full-Range Condition and the Half-Range Condition. Ten out of twelve participants show larger Samb and slope values in the Full-Range Condition compared to the Half-Range Condition (the respective icons in Fig. 5 are above the bisection line).

Orange squares: slope values. Green circles: Samb values. Open icons indicate grand means ± SEMs. For the majority of participants, slopes and Samb icons are above the black dashed bisection line indicating larger values for the Full-Range Condition than for the Half-Range Condition.
ANOVA comparisons of the first with the last five trials within conditions revealed a highly significant effect for the factor CONDITION (F(1,11) = 9.58, p = 0.005, uncorrected) concerning the variable Samb. We found a week tendency for an effect for the factor PERIOD concerning the variable Slope (F(1,11) = 1.4, p = 0.06) but no other significant effect (see also Fig. 6).

Sad and happy variants (S1–S8 and S10–S13) of the original Mona Lisa image (S9) were created in Dr. Kornmeier’s lab. C1 = Full-Range Condition; C2 = Half-Range Condition; Reps = Repetitions.
Confidence Rating
Perceptual confidence rating traces indicate an U-shape function with a decrease from the most unambiguous sad face stimulus towards the most ambiguous variant and an increase from the most ambiguous face stimulus towards the most happy face variant. This is indicated in the repeated-measures ANOVA as a significant quadratic effect for the factor STIMULUS (F(1,11) = 43.04, p < 0.001).
The left halves (half-ranges of sad face variants) of the two confidence rating traces mainly overlap, whereas the right half-trace (half-ranges of happy face variants) of the Full-Range Condition is shifted to the right, compared to the Half-Range Condition. This is reflected in different locations of the trace minima (lowest confidence ratings) between the Full-Range Condition (around S5) and the Half-Range Condition (around S4) and indicated in the ANOVA by a significant linear interaction between STIMULUS and CONDITION (F(1,11) = 8.28, p = 0.015).
Interestingly, the emotional content of the saddest S1 face and the happiest S13 face in the Full-Range Condition were both identified with close to 100% probability, however their confidence ratings differed, with higher values for the happiest than saddest emotional face variants. An exploratory post-hoc Wilcoxon signed-rank test indicated that this effect is significant (p = 0.0068).
Reaction Times
Reaction times from the perception task (Task 1) showed inverted U-shapes for both conditions, with increasing values from the most unambiguous sad face stimulus towards the most ambiguous variant and decreasing values from the most ambiguous face stimulus towards the happiest face variant. This is indicated in the repeated-measures ANOVA as a significant quadratic effect for the factor STIMULUS (F(1,11) = 32.65, p < 0.001).
Similar to the confidence ratings, the left halves of the reaction time traces (RTs to the sad face expression) overlap whereas the right half trace of the Full-Range Condition is shifted to the right, with a maximal reaction time of 1340 ms at stimulus S5, compared to the Half-Range Condition with a maximal reaction time value of 2025 ms at stimulus S4. This is supported by a significant linear interaction between STIMULUS and CONDITION (F(1,11) = 7.22, p = 0.021).
Also in parallel to the findings from the confidence rating, we noticed faster reaction times for the happiest face (S13) compared to the saddest face (S1) in the Full-Range Condition. A related exploratory post-hoc Wilcoxon signed-rank test indicated that this effect is significant (p = 0.0013).
Correlations between Confidence Ratings and Reaction Times
We found a significant negative correlation (Pearson and Spearman) between the grand mean reaction times and confidence ratings both in the Full-Range Condition (rPearson = −0.94 with p = 0.0013, rSpearman = −0.93) and the Half-Range Condition (rPearson = −0.941 with p = 0.0014, rSpearman = −0.9). Participants took more time for less reliable emotional face percepts (Fig. 4b).
Discussion
One of the most often described and discussed feature of Leonardo da Vinci’s Mona Lisa painting is her ambiguous emotional face expression. In the present study we quantified for the first time Mona Lisa’s ambiguity along a happy – sad axis of emotional face expressions. We presented a copy of the original Mona Lisa and variants with stepwise increasing sadness and happiness with the following results: (1) The original Mona Lisa was always perceived as happy, whereas the most ambiguous stimulus variants had a more prominent downturn of the mouth curvature, compared to Da Vinci’s original. (2) Decreasing ambiguity of the emotional face expression in either happy or sad direction increased identification rates (from chance level towards almost 100%), reaction times (by up to factor 2) and confidence rates (by up to factor 1.5). (3) The happiest stimulus variant was identified faster and with higher confidence rates than the saddest variant, despite equal identification rates for both variants close to 100%. (4) Decreasing the range of stimulus variants caused a shift of the psychometric functions of perceived happiness. As a consequence, the perception statistics of some intermediate stimulus variants differed between conditions. This indicates that the overall stimulus range within the experimental conditions determined perception of the individual.
Stimulus manipulation
Livingstone discussed the role of image statistics for the perception of Mona Lisa’s emotional face expression. Her image manipulations showed that low-pass filtered images uncover cheerful faces, whereas the high frequencies promote sad face expressions22. Kontsevich and Tyler20 found that the mouth region has a central role for the perception of Mona Lisa’s face expression. In the present study we restricted our stimulus manipulation to a parametric change in mouth curvature in order to create different Mona Lisa variants along the happy-sad axis of emotional face expression.
Happy faces can be identified faster and with more confidence
In the Full-Range Condition with the larger range of stimulus variants we found faster reaction times and higher confidence ratings for the happiest compared to the saddest Mona Lisa variants. Such a reaction time difference was also visible as a tendency in the Half-Range Condition. This finding confirms previous studies, showing that observers recognize positive facial expressions faster than negative expressions27,28,29. An innate happy-face advantage for facial emotional recognition is discussed as possible explanation28 for this effect.
Mona Lisa is always happy…
Several experts from art and history of art have discussed the fascination that emanates from da Vinci’s painting as a result of the inherent emotional ambiguity17,18. The present study tested this ambiguity for the first time by quantifying it with the well-established method of constant stimuli21. To our great surprise all of our participants identified the original Mona Lisa variant as happy. However, for interpretations of the current findings, one has to keep in mind the following limitation. We restricted our focus to one emotional dimension, namely the happy – sad axis of emotional face expressions. However, the “space” of emotions and emotional face expressions has more dimensions30 that may contribute to Mona Lisa’s ambiguity. Further our three-alternative forced-choice paradigm (happy, sad and non-face percepts) filters out any intermediate perception or any other perceptual aspects (e.g. neutral face percepts) than the binary happy vs. sad decision. Despite these limitations, our results clearly indicate that positive emotions prevail the perception of Mona Lisa.
… but only sometimes sad
The present two experimental conditions differed in the extent of emotional face expressions with a twice as large range in the Full-Range Condition than in the Half-Range Condition. With the Half-Range Condition we aimed to identify more precisely the most ambiguous Mona Lisa variant by reducing the range and concurrently decreasing the step size between variants, thus increasing the “ambiguity resolution”. However, the smaller range did not increase the resolution of ambiguity, but instead changed the psychometric function of perceptual identification. Consequences of this were, for example, that stimulus variant S5 was identified as most ambiguous in the Full-Range Condition, but the identical stimulus was identified as happy in about 70% of the cases in the Half-Range Condition (see Fig. 4a). Further, the most ambiguous stimulus variant in the Half-Range Condition was S4. However, S4 would have been less often rated as sad in the Full-Range Condition (about 25%), as predicted by the corresponding psychometric function.
About the potential role of adaptation
A huge amount of literature provides evidence for visual aftereffects, like priming and adaptation (for a specific example in the context of classical ambiguous figures see refs 31 and 32). In the case of adaptation, the focused observation for several seconds of an adapting stimulus containing certain stimulus features, biases perception of the subsequent test stimulus towards the opposite of the adaptation stimulus. Earlier adaptation studies showed effects for lower-level stimulus features like colour, contrast, orientation, size or motion33. More recent studies demonstrated very similar adaptation effects for high-level stimuli like faces, their identity, gender, ethnicity or emotional expression33,34,35.
Can adaptation explain the difference between the psychometric functions found in the present experiment? The present paradigm deviates fundamentally from typical adaptation paradigms: (1) Our maximal possible stimulus presentation duration is 6 s. However, the average observation time ranged between one and two seconds (see reaction times in Fig. 4). Although this is enough to reach some degree of adaptation36, it is shorter than typical times for full face adaptation effects (between 15 and 20 s35). This takes the adaptive power of our experimental procedure into question. (2) Typical adaptation experiments used one certain adaptation stimulus and one or more test stimuli within an experimental block. Each combination of adaptation and test stimuli was then repeated several times in order to get enough data for statistics. In the present experiment a series of nine Mona Lisa variants was presented in an order that was randomized between experimental blocks and participants. Therefore, any adaptation effect of a perceived stimulus by its precursor must be averaged out.
However, adaptation mechanisms can be understood in a more general sense beyond time constants from the classical experimental paradigms, as Webster and MacLeod discussed in their seminal review paper33. A convincing example is the other race effect37, which provides clear evidence for adaptation effects with time constants in the range of long-term memory. The reduction of this other race effect in people who spend some time (months or years) in other-race countries shows adaptation effects with intermediate time constants34.
The current two experimental conditions differ in the range of stimulus variants and thus in the “average happiness” across stimuli within conditions. The average happiness-value from one condition may have adapted the participants perceptual system, resulting in the shift of the psychometric function found in our data. However, the order of conditions was randomized across subjects, i.e. half of the subjects started with the Full-Range Condition and the other half with the Half-Range Condition. We should thus observe opposite adaptation effects for the two half groups but we did not.
About the potential role of serial dependency effects
Serial dependence is a mechanism, which assures that our perception of the physical environment from one moment to another can be regarded as continuous. In fact, positive serial dependence would assimilate the information of the previous and present stimulus to build up a perception38,39. It has been described for facial identity40 and attractiveness41. Very recently, a negative serial dependency effect has been described for the emotional face perception42. In this case the perception of the previous emotional face expression wouldn’t be integrated in the current percept, but rather has contrastive effects on the current percept, probably to maximize the detection of naturally quick changes of expressions41. In the Half-Range Condition of the present experiment the net number of face stimuli with downwards pointing endpoints of the mouth curvature is larger than in the Full-Range Condition. This may have increased the happy-percept-probability of some intermediate stimuli, compared to the Full-Range Condition. Negative serial dependency may thus explain the sigmoid shift between conditions.
About the potential role of anchoring
Another possible explanation for the observed shift of psychometric functions may be the following: Each stimulus sequence was presented 30 times and participants may have learned about the range of stimulus variants and calibrated their internal happy-sad scale to this exogenously presented range. We tested this hypothesis by taking the participants’ mean across the first 5 stimulus sequences and comparing them with the participants’ mean across the last 5 sequences. No significant difference between the sigmoidal functions of the first and the last 5 sequences within conditions was found, although there is some tendency visible for a difference in the slope variable. Most importantly, the shift of the sigmoidal functions between the two conditions is already visible in the average of the first five sequences (Fig. 6) and statistically indicated. The proposed calibration of the endogenous happy-sad scale must thus have taken place surprisingly rapid, possibly during the first sequence of stimulus presentation. Such a quick recalibration is reminiscent of anchoring effects in the range of rating scales43,44, where one stimulus or a given stimulus range can serve as an anchor in the sense of a standard reference for “stimuli under consideration”43. Anchoring effects have been shown at lower and higher complexity levels of sensory input44,45. In particular it has been shown that one or few initial stimulus examples are enough to induce an anchoring effect45.
Whether the sigmoid shift can be explained by adaptation or serial dependency on the sensory level, or anchoring on the decision level has to be shown in further experiments.
About Ambiguity
Ambiguity of a piece of sensory information means that two or more interpretations are possible. The ambiguity of the classical visually ambiguous figures, like the famous Necker cube2 or Rubin’s famous Vase/Face figure3, is mainly binary in nature. Typically the perceptual system oscillates between two most probable interpretations (two different 3D configurations of the Necker cube; or either a vase of a face in Rubin’s figure), although other – less probable – interpretations may also exist. Things are more complicated in the case of higher-level ambiguity, e.g. the emotional expression of face stimuli. As in the current experiments, often a number of equidistant stimulus variants along one certain feature dimension are created, resulting in unambiguous perceptual interpretations at the extreme points (like happy and sad face expressions in the current study). The presentation of the stimulus sample is typically combined with a binary forced choice task (e.g. happy vs. sad percept). The stimulus at the mid point along the feature axis may then be labelled as ambiguous, given that the probabilities of the two response options are both at about 50%. However, the binary task hides the possibility of other perceptual interpretations, like that of a neutral face. In terms of perceptual probabilities it may thus be necessary to differ between binary (e.g. Necker cube) and non-binary situations (e.g. face morphing along the happy-sad or gender axes), when using the term “ambiguous”.
Da Vinci’s Mona Lisa is special in this context, because there seems to be a general agreement about the painting’s ambiguity. Assuming this, it is unlikely that any of our variants has been perceived as neutral, although we did not ask explicitly about that.
Conclusions
Given the present ranges of Mona Lisa variants, Leonardo da Vinci’s original was always perceived as happy. We were able to identify Mona Lisa variants in our selection of stimuli, with roughly equal numbers of happy and sad face identifications and labelled them as ‘ambiguous’. Whether perception of them is really ambiguous, in the sense of classical binary ambiguous figures, has to be shown in future experiments. The identity of the most ‘ambiguous’ stimulus variant in our study depended on and changed with the underlying range of happy and sad stimulus variants in the two experimental conditions. Our data demonstrate that visual perception is highly adaptive and a recalibration of a complex, cognitive feature, like the emotional face expression, seems to take place rapidly within the first few exposures to the whole stimuli range.
The present data suggest that “ambiguity” along the happy-sad axis of emotional face expressions is not the central feature making da Vinci’s painting as famous as it is, because perception of da Vinci’s original stayed happy across the two experimental conditions. However, perception of and reaction to emotional face content is relative and strongly depends on the stimulus context.
An interesting next step would be, to quantify observers’ perception of da Vinci’s Mona Lisa presented in isolation, without any adapting influence nor any reference system of happier and sadder stimulus variants in the immediate spatio-temporal vicinity. In this case the number of observers need to be increased and each observer should be asked only once, simply because the perception process obviously changes the perceptual system – another interesting analogy of cognitive functions to a core feature in quantum physics46. Further, other spatial and temporal contexts of the individual observer need to be controlled as well.
Additional Information
How to cite this article: Liaci, E. et al. Mona Lisa is always happy – and only sometimes sad. Sci. Rep. 7, 43511; doi: 10.1038/srep43511 (2017).
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
Kornmeier, J. & Mayer, G. The alien in the forest OR when temporal context dominates perception. Perception 43, 1270–1274 (2014).
Necker, L. A. Observations on some remarkable optical phaenomena seen in Switzerland; and on an optical phaenomenon which occurs on viewing a figure of a crystal or geometrical solid. Lond. Edinb. Philos. Mag. J. Sci. 1, 329–337 (1832).
Rubin, E. Visuell wahrgenommene Figuren. (Gyldendals, 1921).
Schiller, P. V. Stroboskopische Alternativversuche. Psychol. Forsch. 17, 179–214 (1933).
Kornmeier, J., Wörner, R. & Bach, M. Can I trust in what I see? – EEG Evidence for a Cognitive Evaluation of Perceptual Constructs. Psychophysiology 53, 1507–1523 (2016).
Boring, E. G. A new ambiguous figure. Am J Psychol 42, 444–445 (1930).
Kornmeier, J. & Bach, M. EEG correlates of perceptual reversals in Boring’s ambiguous old/young woman stimulus. Perception 0, 0–0 (2014).
Liaci, E., Bach, M., Tebartz van Elst, L., Heinrich, S. P. & Kornmeier, J. Ambiguity in Tactile Apparent Motion Perception. PLOS ONE 11, e0152736 (2016).
Blake, R. & Logothetis, N. K. Visual competition. Nat. Rev Neurosci 3, 13–21 (2002).
Kornmeier, J. & Bach, M. Ambiguous figures – what happens in the brain when perception changes but not the stimulus. Front. Hum. Neurosci. 6, 1–23 (2012).
Long, G. M. & Toppino, T. C. Enduring interest in perceptual ambiguity: alternating views of reversible figures. Psychol. Bull. 130, 748–68 (2004).
Wildgen, W. In Ambiguity in Mind and Nature (eds Kruse, P. & Stadler, M. ) 64, 221–240 (Springer Berlin Heidelberg, 1995).
Hassin, R. R., Aviezer, H. & Bentin, S. Inherently Ambiguous: Facial Expressions of Emotions, in Context. Emot. Rev. 5, 60–65 (2013).
Busso, C. & Narayanan, S. S. Interrelation Between Speech and Facial Gestures in Emotional Utterances: A Single Subject Study. IEEE Trans. Audio Speech Lang. Process. 15, 2331–2347 (2007).
Mower, E., Mataric, M. J. & Narayanan, S. Human Perception of Audio-Visual Synthetic Character Emotion Expression in the Presence of Ambiguous and Conflicting Information. IEEE Trans. Multimed. 11, 843–855 (2009).
De Silva, L. C., Miyasato, T. & Nakatsu, R. Facial emotion recognition using multi-modal information. In 1, 397–401 (IEEE, 1997).
Pater, W. & Hill, D. L. The Renaissance: studies in art and poetry: the 1893 text. (University of California Press, 1980).
Gombrich, E. H. The story of art. (Phaidon Press, 2011).
Bohrn, I., Carbon, C.-C. & Hutzler, F. Mona Lisa’s Smile–Perception or Deception? Psychol. Sci. 21, 378–380 (2010).
Kontsevich, L. L. & Tyler, C. W. What makes Mona Lisa smile? Vision Res. 44, 1493–1498 (2004).
Gescheider, G. A. Psychophysics: the fundamentals. (L. Erlbaum Associates, 1997).
Livingstone, M. S. Is It Warm? Is It Real? Or Just Low Spatial Frequency? Science 290, 1299b–1299 (2000).
Bach, M. The Freiburg Visual Acuity test-variability unchanged by post-hoc re-analysis. Graef Arch Clin Exp 245, 965–971 (2007).
World Medical Association. Declaration of Helsinki: ethical principles for medical research involving human subjects. JAMA 284, 3043–3045 (2000).
High Resolution Art. Mona Lisa. Mona Lisa by Leonardo da Vinci. Available at: http://www.highresolutionart.com/2013/11/mona-lisa-by-leonardo-da-vinci.html (2015).
Holm, S. A simple sequentially rejective multiple test procedure. Scand J Stat. 6, 65–70 (1979).
Feyereisen, P., Malet, C. & Martin, Y. In Aspects of Face Processing (eds Ellis, H. D., Jeeves, M. A., Newcombe, F. & Young, A. ) 349–355 (Springer: Netherlands, 1986).
Kirita, T. & Endo, M. Happy face advantage in recognizing facial expressions. Acta Psychol. (Amst.) 89, 149–163 (1995).
Leppänen, J. M., Tenhunen, M. & Hietanen, J. K. Faster Choice-Reaction Times to Positive than to Negative Facial Expressions. J. Psychophysiol. 17, 113–123 (2003).
Ekman, P. An argument for basic emotions. Cogn. Emot. 6, 169–200 (1992).
Long, G. M., Toppino, T. C. & Mondin, G. W. Prime time: fatigue and set effects in the perception of reversible figures. Percept Psychophys 52, 609–16 (1992).
Toppino, T. C. & Long, G. M. Time for a change: What dominance durations reveal about adaptation effects in the perception of a bi-stable reversible figure. Atten. Percept. Psychophys. 77, 867–882 (2015).
Webster, M. A. & MacLeod, D. I. A. Visual adaptation and face perception. Philos. Trans. R. Soc. B Biol. Sci. 366, 1702–1725 (2011).
Webster, M. A., Kaping, D., Mizokami, Y. & Duhamel, P. Adaptation to natural facial categories. Nature 428, 557–561 (2004).
Leopold, D. A., Rhodes, G., Muller, K.-M. & Jeffery, L. The dynamics of visual adaptation to faces. Proc. R. Soc. B Biol. Sci. 272, 897–904 (2005).
Xu, H., Dayan, P., Lipkin, R. M. & Qian, N. Adaptation across the Cortical Hierarchy: Low-Level Curve Adaptation Affects High-Level Facial-Expression Judgments. J. Neurosci. 28, 3374–3383 (2008).
Behrman, B. W. & Davey, S. L. Eyewitness identification in actual criminal cases: An archival analysis. Law Hum. Behav. 25, 475–491 (2001).
St. John-Saaltink, E., Kok, P., Lau, H. C. & de Lange, F. P. Serial Dependence in Perceptual Decisions Is Reflected in Activity Patterns in Primary Visual Cortex. J. Neurosci. 36, 6186–6192 (2016).
Fischer, J. & Whitney, D. Serial dependence in visual perception. Nat. Neurosci. 17, 738–743 (2014).
Liberman, A., Fischer, J. & Whitney, D. Serial Dependence in the Perception of Faces. Curr. Biol. 24, 2569–2574 (2014).
Taubert, J., Van der Burg, E. & Alais, D. Love at second sight: Sequential dependence of facial attractiveness in an on-line dating paradigm. Sci. Rep. 6, 22740 (2016).
Taubert, J., Alais, D. & Burr, D. Different coding strategies for the perception of stable and changeable facial attributes. Scientific Reports. 6, 32239, https://doi.org/10.1038/srep32239 (2016).
Brown, D. R. Stimulus-Similarity and the Anchoring of Subjective Scales. Am. J. Psychol. 66, 199 (1953).
Chapman, G. B. & Johnson, E. J. Anchoring, Activation, and the Construction of Values. Organ. Behav. Hum. Decis. Process. 79, 115–153 (1999).
Furnham, A. & Boo, H. C. A literature review of the anchoring effect. J. Socio-Econ. 40, 35–42 (2011).
Atmanspacher, H. & Römer, H. Order effects in sequential measurements of non-commuting psychological observables. J. Math. Psychol. 56, 274–280 (2012).
Acknowledgements
Financial support from the Deutsche Forschungsgemeinschaft (KO 4764/1-1, TE 280/8-1) is gratefully acknowledged. Thanks to High Resolution Art for allowing us to use their variant of the Mona Lisa image and to Karin Moos for helpful comments and suggestions. We also thank two anonymous reviewers for their helpful comments and suggestions.
Author information
Authors and Affiliations
Contributions
E.L. and J.K. conceived research; E.L., A.F. and J.K. performed research; E.L. and J.K. analyzed data; E.L., A.F., L.T.v.E., M.H., J.K. wrote the paper; E.L., A.F., L.T.v.E., M.H. and J.K. provided critical revisions.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Liaci, E., Fischer, A., Heinrichs, M. et al. Mona Lisa is always happy – and only sometimes sad. Sci Rep 7, 43511 (2017). https://doi.org/10.1038/srep43511
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep43511
This article is cited by
-
The Mona Lisa - A Prototype for Multidisciplinary Science Education
Science & Education (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
