
Abstract
Tacrolimus has a narrow therapeutic window and considerable variability in clinical use. Our goal was to compare the performance of multiple linear regression (MLR) and eight machine learning techniques in pharmacogenetic algorithm-based prediction of tacrolimus stable dose (TSD) in a large Chinese cohort. A total of 1,045 renal transplant patients were recruited, 80% of which were randomly selected as the “derivation cohort” to develop dose-prediction algorithm, while the remaining 20% constituted the “validation cohort” to test the final selected algorithm. MLR, artificial neural network (ANN), regression tree (RT), multivariate adaptive regression splines (MARS), boosted regression tree (BRT), support vector regression (SVR), random forest regression (RFR), lasso regression (LAR) and Bayesian additive regression trees (BART) were applied and their performances were compared in this work. Among all the machine learning models, RT performed best in both derivation [0.71 (0.67–0.76)] and validation cohorts [0.73 (0.63–0.82)]. In addition, the ideal rate of RT was 4% higher than that of MLR. To our knowledge, this is the first study to use machine learning models to predict TSD, which will further facilitate personalized medicine in tacrolimus administration in the future.
Similar content being viewed by others
Introduction
Tacrolimus is one of the most widely used immunosuppressive agents to prevent acute rejection following solid organ transplantation. More than 70% of renal transplant patients received this effective agent in 20041. However, the use of tacrolimus has to be cautious due to its narrow therapeutic index and remarkable variability of inter- and intra-individual bioavailabilities2. Insufficient dosing of tacrolimus is associated with an increased risk for acute rejection3, while overexposure with higher rate of drug-related toxicities, such as nephrotoxicity, neurotoxicity, and new-onset diabetes4,5. Daily monitoring and maintaining target concentration is important to decrease allograft rejection and toxicity6. Therefore, there is an increasing need to develop improved strategies for determining the appropriate dose in clinic.
Many factors affecting the pharmacokinetics of tacrolimus have been identified, including clinical factors such as ethnicity, age, gender, concomitant medication, hepatic and renal dysfunction, and genetic factors such as CYP3A5, CYP3A4 and ABCB1 single nucleotide polymorphisms (SNPs)7,8. Among these factors, CYP3A5 genotype is associated with a remarkable impact on the tacrolimus pharmacokinetics, while the effects of other genetic polymorphisms are rather limited or conflicting9,10,11. A number of algorithms containing clinical and/or pharmacogenomic factors have been constructed to predict tacrolimus dose; meanwhile, retrospective and prospective trials have been conducted to verify these algorithms9,12,13,14,15,16,17,18,19. Thervet et al. demonstrated that CYP3A5 genotype guided tacrolimus dosing enabled more renal recipients to achieve target tacrolimus trough (C0) levels after three days of tacrolimus treatment. In addition, these patients took less time to reach their target concentration with fewer dose modifications12. A more recent trial indicated that CYP3A4 activity and CYP3A5 genotype can explain 56–59% variability in tacrolimus dose and clearance9. These successes in clinic revealed the possibility to improve clinical outcomes of tacrolimus therapy by taking pharmacogenomic factors into account.
However, most of the algorithms for predicting tacrolimus dose were based on relatively small clinical population, and the predictive accuracy was usually uncertain. Moreover, proposed algorithms are mostly based on multiple linear regression (MLR) methods, which have some well-known limitations that may impair prediction accuracy. For example, MLR model assumes independence between variants, and the relationship between the dependent and independent variables is always complex and non-linear20. Therefore, MLR may not be the most applicable model for accurate prediction of drug outcomes.
Machine learning techniques, compared with traditional statistical models, have many advantages including high power and accuracy, ability to model non-linear effects, interpretation of large genomic data sets, robustness to parameter assumptions and dispense with normal distribution test21. Recently it has been widely used in predicting warfarin dose22. For example, Random Forest Regression (RFR), Boosted Regression Tree (BRT) and Support Vector Regression (SVR) models were utilized to predict warfarin maintenance dose in African Americans, with much higher accuracies than previous models21. Artificial neural networks (ANNs) algorithm reached high accuracy in predicting warfarin maintenance dose, more than 70% of patients in the low (≤21 mg/) and median dose (21–49 mg) subgroups have been correctly identified23. In our previous work, eight machine learning algorithms were compared with MLR in predicting warfarin dosing, results showing Bayesian additive regression trees (BART), multivariate adaptive regression splines (MARS) and SVR significantly outperformed other models; machine learning methods also performed better than MLR in the low- and high- dose ranges20.
To our knowledge, the development and application of machine learning algorithms to predict tacrolimus dose has not been reported. We therefore conducted this research to investigate the clinical and genetic factors significantly associated with tacrolimus stable dose as well as to identify the most feasible algorithm for prediction of the dose requirement of Chinese renal transplantation recipients.
Results
Basic Characteristics of the Study Cohorts
In total, 1,045 renal transplant recipients were enrolled in the trial, whose basic characteristics are shown in Table 1. Continuous variables are shown as mean ± standard deviation, and categorical variables are shown as number (%). No significant difference was found in the demographic, clinical and genetic data between the derivation cohort (n = 838) and the validation cohort (n = 207). All the tested SNPs were in Hardy–Weinberg equilibrium except ABCB1129TC and ABCB12677GTA, and the genotype frequencies were in accordance with previously reported data of Chinese population (Supplementary Table S1).
In the derivation cohort, the mean TSD among these patients was 3.48 ± 1.28 mg/day. Patients had an average age of 36.19 ± 10.62 years old, and 71.2% were males. The most common complication was hypertension with 561 patients (66.9%), while 19 patients were diagnosed diabetes (2.3%). The most common combined medication was calcium channel blocker (544 patients, 64.9%), in addition, 377 patients were given metoprolol (45.0%), and 246 were given omeprazole (29.4%). Among all these patients, 50.6% were carriers of CYP3A5*3 GG genotype, 9.2% were carriers of AA genotype, and 16 unknown (1.9%). The detected results of other genotypes are illustrated in Supplementary Table S1.
Patients in the validating cohort exhibited similar results in the TSD (3.50 ± 1.32 mg/day), age (35.82 ± 10.34) and sex (71.5% were males). Comparably, 134 (64.7%) patients had hypertension, and 127 (61.4%) patients were given calcium channel blocker. Genotyping data showed that 46.9% of patients were carriers of CYP3A5*3 GG genotype, 7.2% were AA genotype, with 8 (3.8%) unknown genotype (Table 1).
Identification of Clinical and Genetic Factors Significantly Associated with TSD
In order to construct a predictive model that only contains important factors, we have first investigated the relationship between each factor and the STD of patients. Univariate analysis was used to test all the clinical and genetic factors, resulted in four factors that were significantly associated with TSD: whether has hypertension, whether has diabetes, whether taking omeprazole and CYP3A5 genotype. Among them, CYP3A56986AG is the most significant influencing factor, with a P value of 2.2*10−16 in the F-test (Supplementary Table S2).
Tacrolimus stable dose was also compared among patients with different ABCB1 genotypes. The comparison was carried out for the three polymorphisms (1236 C/T, 2677 G/A/T and 3435 C/T) most studied in the literature. No statistically significant difference was found (data not shown).
Next, multivariable regression model was used to test the above four variates. It was shown that diabetes was not a significant factor in the model and thereafter excluded. The remaining three factors (hypertension, use of omeprazole and CYP3A5 genotype) were used to construct the MLR and 8 machine learning models. (Supplementary Table S3).
Overall Comparison of Predictive Algorithms
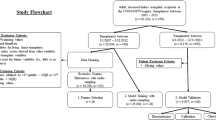
In order to determine the overall predictive accuracy, approaches including MAE and ideal rate (predictive dose fell within 20% of the actual dose) were applied. Among all the machine learning models, RT performed best in both derivation [0.71 (0.67–0.76)] and validation cohorts [0.73 (0.63–0.82)] (not statistically significant) (Fig. 1). Although MLR had similar MAE with RT, the ideal rate of RT was 4% higher than that of MLR. On the other hand, the lowest MAE was also seen using RFR model. However, as RT is a simpler and more easily understood model that fits clinical use, it was chosen for this study. The developed RT model is shown as Fig. 2.

Predicted dose within 20% of the actual dose in the train (A) and test (B) set of the derivation cohort. Mean absolute error between the predicted and actual dose in the train (C) and test (D) set. The vertical bars represent the 95% CIs of MAE. MLR: multiple linear regression; SVR: support vector regression; ANN: artificial neural network; RT: regression tree; RFR: random forest regression; BRT: boosted regression tree; MARS: multivariate adaptive regression splines; LAR: lasoo regression; BART: Bayesian additive regression trees.

N and dose represent the sample size and predicted tacrolimus dose, respectively.
Clinical Relevance
In general, RT algorithm provided more accurate prediction of TSD than other 8 algorithms. The performance of the three dose ranges, low dose (≤2.5 mg/day), intermediate dose (2.5–4 mg/day), and high dose (>4 mg/day), were compared as shown in Tables 2 and 3. Patient doses in the intermediate range were best predicted compared with the actual stable dose in both derivation and validation cohorts (MAE = 0.50 and 0.48 mg/day, respectively) (Table 2). For patients who required 2.5 mg/day or less (24.4% of the total 693 patients), 38.5% of the predicted dosage fell into ideal dose range (20% of the actual dose). While for the patients who required 4 mg/day or more (20.8% of the total patients), 44.4% of the prediction dropped into ideal dose.
Discussion
Compared with traditional dosing strategies in clinic, the current study was successful in providing a novel approach that can predict TSD more accurately and conveniently. In general, the performances of the 9 algorithms were similar in predicting TSD. While the best performance was observed in RT model in this study, comprehensive evaluation of these algorithms in various studies is needed to come to a final conclusion. It should also be noted that the current study was performed in Chinese, studies in other ethnic groups may come to different results.
The most influential factor in this study was CYP3A5 genotype. The SNP 6986 A > G on the CYP3A5 gene results in absence of function protein. Carriers of homozygous 6986 G allele (designated as CYP3A5*3) have no CYP3A5 activity, which impair the whole-blood concentration of tacrolimus24 and subsequently the time required to reach target concentration3. None of the included ABCB1 SNPs were found any significant impact on the algorithm. In fact, previous researches checking the association between ABCB1 genotypes and tacrolimus dosage have come to conflicting results24,25,26.
Our results indicated that the intermediate dose range exhibited better accuracy (lower MAE and higher ideal rate) than that in the high- and low- dose ranges. Nevertheless, patients in this dose range are less likely to benefit from statistical models based on pharmacogenomics. In practice, patients who require extreme dose administrations (or whom grouped in the high- and low- dose ranges) are more likely to face overdose or underdose and hence suffer from adverse clinical consequence22. Therefore, better prediction of extreme dose ranges are needed to present real help to those patients.
Whilst machine learning techniques demonstrated their capability in solving inferential problems by self-adjust their structure when encounter errors, as well as dealing with numerous variables simultaneously20, we should be noted that they are still far from omnipotent in clinical use. The relationship between dependent variables and independent variables are very complicated in all these statistical algorithms, and the existence of gene-gene and gene-environment interactions bring more challenge to the researchers27,28,29. Inclusion of larger number of genotypic variables in a predictive model may be helpful to obtain a better performance, but this may lead to addition of redundant data and may hinder its application in clinical practice21. The complicated situation of real patients should be well considered, as additional comorbidity and interacting drugs are always the case, which may not be completely included in the models30. Therefore, even the statistical models are utilized to increase the predictive accuracy of TSD, continuous monitoring of drug concentration is still needed at the moment.
There are some limitations in this study, no other potentially important factors were included, such as smoking, alcohol consumption and other genetic factors; secondly, data regarding tacrolimus initial doses or adverse reactions were not gathered in the study, only data about stable therapeutic doses were considered; in addition, using of p-value threshold to select significant SNPs may be not enough to generate most complementary SNP set21.
Methods
Patients
Stable tacrolimus-treated renal recipients at The Third Xiangya Hospital of Central South University and Peking University Health Science Center between Oct 2012 and Sep 2014 were considered for enrollment. All patients were Chinese with a minimum age of 18 years old. The clinical research admission was approved by Chinese Clinical Trial Registry (registration number: ChiCTR-RNC-12002894). The study protocol was approved by the Ethics Committee of Institute of Clinical Pharmacology, Central South University (CTXY-120030-2), all methods were performed in accordance with the relevant guidelines and regulations, and written informed consent was obtained from all patients.
The demographic and clinical information of the subjects were obtained from their clinical records as well as clinical and telephone follow-ups. Information of combined diseases such as hypertension and diabetes and concomitant medications such as omeprazole, metoprolol and calcium channel blockers were collected. All the patients received tacrolimus, together with mycophenolate and glucocorticoid after transplantation. Tacrolimus was initiated at 0.05 mg/Kg every 12 h then dose adjusted to target trough concentration of 6–10 ng/ml for the first month, and then 6–8 ng/ml afterwards. Tacrolimus concentration was monitored daily during the hospital stay and in the follow-up visits. Doses were adjusted by 25% each time when it was out of the above target range. Tacrolimus stable dose (TSD) was defined as the total daily dose after 3 months of transplantation, and at least three consecutive blood concentrations were within target range and within 20% of each other19.
Genotyping
MassARRAY (Sequenom Inc., CA, USA) was used for genotyping. Detected genes included CYP3A5 (coding for tacrolimus metabolizing enzymes) and ABCB1 (coding for the drug transporter p-glycoprotein). Polymorphisms in the CYP3A5 (6986 A/G) and ABCB1 (3435 C/T, 129 T/C, 1236 C/T and 2677 G/T/A) were genotyped. The genotyping was verified by repeating 20 random samples by MassARRAY and direct sequencing of 10 random samples with Beckman Coulter CEQ800.
Model Building and Statistical Analyses
The overall modeling process is illustrated as Fig. 3. Generally, 80% (838 patients) of the eligible patients were randomly selected as the “derivation cohort” to develop dose-prediction algorithm. The remaining 20% of the patients (207 patients) constituted the “validation cohort”, which was used to test the final selected algorithm. Meanwhile, to obtain robust results, 100 times of resampling were run to minimize the overfitting problem. Next, univariate and stepwise multivariate linear regression (MLR) was used to select covariates related to tacrolimus stable dose. Covariates with statistical significance (CYP3A5 genotype, hypertension and use of omeprazole) were used to develop algorithms within derivation cohort (train set). The performances of the algorithms were evaluated and compared using the mean absolute error (MAE) and the mean percentage of patients whose predicted dose fell within 20% of the actual dose (ideal rate) in the remaining 20% of patients (test set). The MAE is defined as the average of the absolute value of actual dose minus predicted dose, while the percentage of patients within 20% of the actual dose was selected by us since this definition has been widely applied22. Descriptive statistics was utilized to determine means and standard deviations, frequency and percentage distributions. Chi-square test was used to assess deviations of allele frequencies from Hardy-Weinberg equilibrium.

MLR: multiple linear regression; SVR: support vector regression; ANN: artificial neural network; RT: regression tree; RFR: random forest regression; BRT: boosted regression tree; MARS: multivariate adaptive regression splines; LAR: lasoo regression; BART: Bayesian additive regression trees.
MLR and eight machine learning techniques, namely, support vector regression (SVR), artificial neural network (ANN), regression tree (RT), random forest regression (RFR), boosted regression tree (BRT), multivariate adaptive regression splines (MARS), lasoo regression (LAR), Bayesian additive regression trees (BART) were applied in tacrolimus dose prediction. All analyses in this study were implemented using R (Version 3.2.2)31 with related packages or our custom written functions. We used the RSNNS package for ANN32, rpart package for RT33, gbm package for BRT34, e1071 package for SVR35, randomForest package for RFR36, earth package for MARS37, glmnet package for LAR38 and bartMachine package for BART39. Default parameters were used (Supplementary Table S4).
In the validation cohort, the MAE and ideal rate of the pharmacogenomic algorithm were calculated overall, also in terms of tacrolimus dose range, which was divided into three categories based on the 25% and 75% quartiles of TSD: low dose (≤2.5 mg/day), intermediate dose (2.5–4 mg/day), and high dose (>4 mg/day).
Additional Information
How to cite this article: Tang, J. et al. Application of Machine-Learning Models to Predict Tacrolimus Stable Dose in Renal Transplant Recipients. Sci. Rep. 7, 42192; doi: 10.1038/srep42192 (2017).
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Change history
29 January 2018
A correction has been published and is appended to both the HTML and PDF versions of this paper. The error has not been fixed in the paper.
30 March 2017
The original PDF version of this Article contained an error in the order of corresponding authors. This has now been corrected in the PDF version of this Article.
29 January 2018
Scientific Reports 7: Article number: 42192; published online: 08 February 2017; updated: 29 January 2018. This Article contains an error in Figure 2. For CYP3A5 *3 = AG without hypertension, “N = 31 Dose = 3.73” should read: “N = 31 Dose = 4.13” The correct Figure 2 appears below as Figure 1.
References
Meier-Kriesche, H. U. et al. Immunosuppression: evolution in practice and trends, 1994–2004. Am J Transplant 6, 1111–1131, doi: 10.1111/j.1600-6143.2006.01270.x (2006).
Wallemacq, P. et al. Opportunities to optimize tacrolimus therapy in solid organ transplantation: report of the European consensus conference. Therapeutic drug monitoring 31, 139–152, doi: 10.1097/FTD.0b013e318198d092 (2009).
MacPhee, I. A. et al. The influence of pharmacogenetics on the time to achieve target tacrolimus concentrations after kidney transplantation. Am J Transplant 4, 914–919, doi: 10.1111/j.1600-6143.2004.00435.x (2004).
The U.S. Multicenter FK506 Liver Study Group. A comparison of tacrolimus (FK 506) and cyclosporine for immunosuppression in liver transplantation. N Engl J Med 331, 1110–1115, doi: 10.1056/NEJM199410273311702 (1994).
Kershner, R. P. & Fitzsimmons, W. E. Relationship of FK506 whole blood concentrations and efficacy and toxicity after liver and kidney transplantation. Transplantation 62, 920–926 (1996).
de Jonge, H., Naesens, M. & Kuypers, D. R. New insights into the pharmacokinetics and pharmacodynamics of the calcineurin inhibitors and mycophenolic acid: possible consequences for therapeutic drug monitoring in solid organ transplantation. Therapeutic drug monitoring 31, 416–435, doi: 10.1097/FTD.0b013e3181aa36cd (2009).
Staatz, C. E., Goodman, L. K. & Tett, S. E. Effect of CYP3A and ABCB1 single nucleotide polymorphisms on the pharmacokinetics and pharmacodynamics of calcineurin inhibitors: Part I. Clinical pharmacokinetics 49, 141–175, doi: 10.2165/11317350-000000000-00000 (2010).
Staatz, C. E., Goodman, L. K. & Tett, S. E. Effect of CYP3A and ABCB1 single nucleotide polymorphisms on the pharmacokinetics and pharmacodynamics of calcineurin inhibitors: Part II. Clinical pharmacokinetics 49, 207–221, doi: 10.2165/11317550-000000000-00000 (2010).
de Jonge, H., de Loor, H., Verbeke, K., Vanrenterghem, Y. & Kuypers, D. R. In vivo CYP3A4 activity, CYP3A5 genotype, and hematocrit predict tacrolimus dose requirements and clearance in renal transplant patients. Clin Pharmacol Ther 92, 366–375, doi: 10.1038/clpt.2012.109 (2012).
Jacobson, P. A. et al. Novel polymorphisms associated with tacrolimus trough concentrations: results from a multicenter kidney transplant consortium. Transplantation 91, 300–308, doi: 10.1097/TP.0b013e318200e991 (2011).
van Gelder, T. & Hesselink, D. A. Dosing tacrolimus based on CYP3A5 genotype: will it improve clinical outcome? Clin Pharmacol Ther 87, 640–641, doi: 10.1038/clpt.2010.42 (2010).
Thervet, E. et al. Optimization of initial tacrolimus dose using pharmacogenetic testing. Clin Pharmacol Ther 87, 721–726, doi: 10.1038/clpt.2010.17 (2010).
Li, J. L. et al. Effects of diltiazem on pharmacokinetics of tacrolimus in relation to CYP3A5 genotype status in renal recipients: from retrospective to prospective. Pharmacogenomics J 11, 300–306, doi: 10.1038/tpj.2010.42 (2011).
Passey, C. et al. Validation of tacrolimus equation to predict troughs using genetic and clinical factors. Pharmacogenomics 13, 1141–1147, doi: 10.2217/pgs.12.98 (2012).
Passey, C. et al. Dosing equation for tacrolimus using genetic variants and clinical factors. British journal of clinical pharmacology 72, 948–957, doi: 10.1111/j.1365-2125.2011.04039.x (2011).
Provenzani, A. et al. Influence of CYP3A5 and ABCB1 gene polymorphisms and other factors on tacrolimus dosing in Caucasian liver and kidney transplant patients. International journal of molecular medicine 28, 1093–1102, doi: 10.3892/ijmm.2011.794 (2011).
Li, L. et al. Tacrolimus dosing in Chinese renal transplant recipients: a population-based pharmacogenetics study. Eur J Clin Pharmacol 67, 787–795, doi: 10.1007/s00228-011-1010-y (2011).
Kim, I. W. et al. Clinical and genetic factors affecting tacrolimus trough levels and drug-related outcomes in Korean kidney transplant recipients. Eur J Clin Pharmacol 68, 657–669, doi: 10.1007/s00228-011-1182-5 (2012).
Wang, P. et al. Using genetic and clinical factors to predict tacrolimus dose in renal transplant recipients. Pharmacogenomics 11, 1389–1402, doi: 10.2217/pgs.10.105 (2010).
Liu, R., Li, X., Zhang, W. & Zhou, H. H. Comparison of Nine Statistical Model Based Warfarin Pharmacogenetic Dosing Algorithms Using the Racially Diverse International Warfarin Pharmacogenetic Consortium Cohort Database. PloS one 10, e0135784, doi: 10.1371/journal.pone.0135784 (2015).
Cosgun, E., Limdi, N. A. & Duarte, C. W. High-dimensional pharmacogenetic prediction of a continuous trait using machine learning techniques with application to warfarin dose prediction in African Americans. Bioinformatics 27, 1384–1389, doi: 10.1093/bioinformatics/btr159 (2011).
Klein, T. E. et al. Estimation of the warfarin dose with clinical and pharmacogenetic data. N Engl J Med 360, 753–764, doi: 10.1056/NEJMoa0809329 (2009).
Grossi, E. et al. Prediction of optimal warfarin maintenance dose using advanced artificial neural networks. Pharmacogenomics 15, 29–37, doi: 10.2217/pgs.13.212 (2014).
Hesselink, D. A. et al. Genetic polymorphisms of the CYP3A4, CYP3A5, and MDR-1 genes and pharmacokinetics of the calcineurin inhibitors cyclosporine and tacrolimus. Clin Pharmacol Ther 74, 245–254, doi: 10.1016/S0009-9236(03)00168-1 (2003).
Macphee, I. A. et al. Tacrolimus pharmacogenetics: polymorphisms associated with expression of cytochrome p4503A5 and P-glycoprotein correlate with dose requirement. Transplantation 74, 1486–1489, doi: 10.1097/01.TP.0000045761.71385.9F (2002).
Kurzawski, M. et al. CYP3A5 and CYP3A4, but not ABCB1 polymorphisms affect tacrolimus dose-adjusted trough concentrations in kidney transplant recipients. Pharmacogenomics 15, 179–188, doi: 10.2217/pgs.13.199 (2014).
Schalekamp, T. et al. VKORC1 and CYP2C9 genotypes and phenprocoumon anticoagulation status: interaction between both genotypes affects dose requirement. Clin Pharmacol Ther 81, 185–193, doi: 10.1038/sj.clpt.6100036 (2007).
Hunter, D. J. Gene-environment interactions in human diseases. Nature reviews. Genetics 6, 287–298, doi: 10.1038/nrg1578 (2005).
Cao, R. & Cheng, J. Deciphering the association between gene function and spatial gene-gene interactions in 3D human genome conformation. BMC genomics 16, 880, doi: 10.1186/s12864-015-2093-0 (2015).
Shin, J. & Cao, D. Comparison of warfarin pharmacogenetic dosing algorithms in a racially diverse large cohort. Pharmacogenomics 12, 125–134, doi: 10.2217/pgs.10.168 (2011).
Laboratories, B. The R Project for Statistical Computing, https://www.r-project.org/(2016).
Bergmeir, C. & Benitez, J. M. Neural Networks in R Using the Stuttgart Neural Network Simulator: RSNNS. Journal of Statistical Software 46, 1–26 (2012).
Therneau, T., Atkinson, B. & Ripley, B. Rpart: Recursive Partitioning and Regression Trees, https://CRAN.R-project.org/package=rpart (2015).
Ridgeway, G. Gbm: Generalized Boosted Regression Models, https://CRAN.R-project.org/package=gbm (2015).
Meyer, D. et al. e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien, https://cran.r-project.org/web/packages/e1071/ (2015).
Breiman, L., Cutler, A., Liaw, A. & Wiener, M. Randomforest: Breiman and Cutler’s Random Forests for Classification and Regression, https://CRAN.R-project.org/package=randomForest (2015).
Milborrow, S., Hastie, T., Tibshirani, R., Miller, A. & Lumley, T. Earth: Multivariate Adaptive Regression Splines, https://CRAN.R-project.org/package=earth (2015).
Friedman, J., Hastie, T. & Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. Journal of Statistical Software 33, 1–22 (2010).
Kapelner, A. & Bleich, J. bartMachine: Machine Learning with Bayesian Additive Regression Trees. Journal of Statistical Software 70, 1–40, doi: 10.18637/jss.v070.i04 (2016).
Acknowledgements
This research was supported by grants from the National Key Research and Development Program (No. 2016YFC0905000, 2016YFC0905001), National High Technology Research and Development Program of China, “863” Project (No. 2012AA02A518), National Natural Scientific Foundation of China (No. 81403018, 81522048, 81573511 and 81273595) and Innovation Driven Project of Central South University (No. 2016CX024).
Author information
Authors and Affiliations
Contributions
J.T. wrote the manuscript, R.L. performed statistical analysis and provided figures and tables, Y.L.Z. conducted laboratory experiments, M.Z.L. and M.J.S. contributed to genotyping, Y.F.H., L.J.Z., H.W.X., G.W.F., W.J.S., X.G.M., L.R.Z. and Y.Z.M. contributed to collection of subjects, W.Z. designed the study. All authors edited the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Supplementary information
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Tang, J., Liu, R., Zhang, YL. et al. Application of Machine-Learning Models to Predict Tacrolimus Stable Dose in Renal Transplant Recipients. Sci Rep 7, 42192 (2017). https://doi.org/10.1038/srep42192
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep42192
This article is cited by
-
Predicting quetiapine dose in patients with depression using machine learning techniques based on real-world evidence
Annals of General Psychiatry (2024)
-
Automated screening of potential organ donors using a temporal machine learning model
Scientific Reports (2023)
-
A Real-World Exploration into Clinical Outcomes of Direct Oral Anticoagulant Dosing Regimens in Morbidly Obese Patients Using Data-Driven Approaches
American Journal of Cardiovascular Drugs (2023)
-
Development and evaluation of uncertainty quantifying machine learning models to predict piperacillin plasma concentrations in critically ill patients
BMC Medical Informatics and Decision Making (2022)
-
Models to predict the short-term survival of acute-on-chronic liver failure patients following liver transplantation
BMC Gastroenterology (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
