
Abstract
The seasonality of human occupations in archaeological sites is highly significant for the study of hominin behavioural ecology, in particular the hunting strategies for their main prey-ungulates. We propose a new tool to quantify such seasonality from tooth microwear patterns in a dataset of ten large samples of extant ungulates resulting from well-known mass mortality events. The tool is based on the combination of two measures of variability of scratch density, namely standard deviation and coefficient of variation. The integration of these two measurements of variability permits the classification of each case into one of the following three categories: (1) short events, (2) long-continued event and (3) two separated short events. The tool is tested on a selection of eleven fossil samples from five Palaeolithic localities in Western Europe which show a consistent classification in the three categories. The tool proposed here opens new doors to investigate seasonal patterns of ungulate accumulations in archaeological sites using non-destructive sampling.
Similar content being viewed by others


Introduction
The study of mortality events of large game at prehistoric archaeological sites provides significant information for the understanding of ecological management in early phases of human evolution. Among other aspects, researchers usually focus on the approximate duration of these events and their seasonality. Seasonality of the events of large game procurement in archaeological sites is often studied through the analysis of (1) the patterns of tooth eruption, wear and replacement1,2,3,4, (2) cementochronology5,6,7, or (3) stable isotope analysis of serial samples8,9. However these methods lack precision or have restrictive requirements. The first method requires large numbers of young individuals and does not take into account adults, whereas the other two methods are destructive. This makes the duration of the mortality events a parameter difficult to estimate, especially in archaeological sites.
An alternative to the above-mentioned methods is to use tooth microwear as a proxy for estimating the relative duration of these events. Tooth microwear, which analyses the microscopic features produced by food items on the surface of teeth, is known to reflect seasonal shifts in diets in ungulates10,11,12. Tooth microwear has been used in the past four decades to provide information about the dietary traits of extant and extinct mammals such as ungulates and primates, among others13,14,15,16,17,18,19. Many such studies using different methods of observation and analysis have reported a correlation between tooth microwear patterns and the dietary traits of extant species. For example, in ungulates, grazers tend to have significantly higher numbers of scratches than leaf browsers14,17,20. Each of these microwear features record unique chewing events and the food items associated with them. Consequently, the microwear patterns observed at the surface of teeth are constantly worn away and overprinted by new features as the tooth wears down. This results in a high turnover of the microwear patterns which reflects the diet of an individual recorded during a short time, such as days or weeks21,22,23. This phenomenon is known as the “Last Supper Effect”21. Consequently, teeth sampled at different times display microwear patterns related to each time frame and will reflect seasonal changes in the diet11,12,24,25.
Nevertheless, under certain circumstances, the “Last Supper Effect” might potentially bias the dietary interpretation of samples from fossil assemblages26. For example, in the case of natural mortality, fossil assemblages may accumulate over different periods of time: e.g., over long periods of attritive mortality producing assemblages of animals dead during a single year or more, seasonal accumulations (drought or winter mortality), or very short events of catastrophic mortality (e.g. volcanic eruption). This can be observed in archaeological sites where large mammal assemblages result from the accumulation of prey by hominids during events of various durations: i.e., short-term occupations, seasonal occupations or longer occupations (several seasons or longer). If an assemblage is the result of a seasonal or even a shorter mortality event, tooth microwear will only represent a snapshot of the diet of a species at that time. However, the high turnover propensity of microwear features is often an essential asset to study more typical seasonal changes in diets, especially when the depositional event that created an assemblage is short.
Building on these particularities of the “Last Supper Effect”, this paper provides insights on how to take advantage of microwear analysis of modern tooth samples to better assess the duration of mortality events in archaeological assemblages. The first objective of the paper is to test the use of variability measurements in microwear patterns as a proxy to assess the duration of the mortality events in different types of samples of ungulate teeth. We sampled and analysed tooth surfaces from extant ungulate assemblages resulting from mass mortality events and from large samples with excellent known data for each individual. The second objective is to test this application on specific cases from archaeological assemblages where previous archaeological studies defined the context of human occupations. To this end, we selected five Middle and Upper Pleistocene sites in Europe (Spain, France and Germany) with a good record of archaeological remains and where microwear data were available.
Mass mortality samples of large mammals are numerous and well-documented through many publications and reports which list the following causes for such mortality: extreme winters, droughts, starvation, violent storms, volcanic eruptions, quagmires, or natural fires27,28,29,30,31,32,33,34,35. Unfortunately, most of the animals that died during these mass mortality events were studied in the field but not collected and conserved.
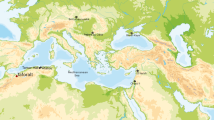
The material available in museums and collections usually consists of samples coming from various populations and different geographic areas, most of the time without very precise information available. Conversely, in this study, we analysed large samples of animals (1) coming from single populations (i.e. from a very restricted geographic area) or (2) resulting from a catastrophic death (i.e. massive and sudden) with precise records of their date of death. Such samples are unique and thus very rare to find. We have, however, located ten samples which fulfil these criteria and with mortality durations spanning from one day to a several years. The samples span a wide diversity of taxonomic groups including Cervidae (Cervus elaphus, Cervus nippon, Odocoileus hemionus, Rangifer tarandus), Antilocapridae (Antilocapra americana), Camelidae (Lama guanicoe) and Equidae (Equus quagga) as well as various geographical origins in Europe, Africa, Asia, North America and South America. The locations where these data were collected from are shown in Fig. 1 (numerical identifiers).

Map of location of the extant and archaeological samples.
Extant samples: (1) Rangifer tarandus (barren ground caribou) from the Qamanirjuaq population (Canada), (2) Cervus elaphus (elk) from Mount Saint Helens, Pierce County and Lewis County (Washington, USA), (3) Antilocapra americana (pronghorn) from Green River, Lamont and Rawlins (Wyoming, USA), (4) Odocoileus hemionus (mule deer) from Cache La Poudre River (Colorado, USA), (5) Cervus elaphus (red deer) from the Isle of Rum (Scotland, UK), (6) Cervus nippon (sika deer) from Kinkazan Island (Japan), (7) Lama guanicoe (guanaco) from Cardiel lake (Patagonia, Argentina) and (8) Equus quagga (plains zebra) from Mount Rumuruti (Kenya). Archaeological samples: (A) Portel-Ouest (France), (B) Abric Romaní (Spain), (C) Salzgitter Lebenstedt (Germany), (D) Taubach (Germany), (E) Caune de l’Arago (France). Source: own elaboration from maps available on Wikimedia Commons free media repository: BlankMap-World6.png (http://commons.wikimedia.org/wiki/File:BlankMap-World6.png), released into the public domain by the authors and Blank_map_of_Europe.png (http://commons.wikimedia.org/wiki/File:Blank_map_of_Europe.png), licensed under the Attribution-ShareAlike 3.0 Unported license. The license terms can be found on the following link: https://creativecommons.org/licenses/by-sa/3.0/.
We sampled fossil teeth of ungulates from archaeological sites in Europe ranging in age from the middle to late Pleistocene. The species sampled belong to the same families as those from the extant dataset: Cervidae (Cervus elaphus and Rangifer tarandus), Bovidae (Bison priscus and Bos primigenius) and Equidae (Equus ferus). The localities and species were selected following strict criteria: good stratigraphic control (sites with modern excavations which are well dated), well preserved specimens (i.e., those without weathering or chemical alteration) and those with large numbers of specimens available. The locations of the five archaeological sites are presented in Fig. 1 (alphabetical identifiers).
A comprehensive summary of all the samples is provided in the Methods section and the Supplementary Information.
Results
Once these samples were collected, we quantitatively examined the tooth microwear patterns. Following the protocol proposed by Solounias and Semprebon14 and Semprebon et al.36, we obtained the density of scratches per standard area of 0.16 mm2 on the occlusal surface of the upper or lower second molar. See the Methods section for a complete description of the analytical protocol.
The resulting dataset contains one value of density of scratches for each individual. Then, in order to address our first goal (i.e. relating the duration of a mortality event with the variability of microwear patterns among deceased individuals), we started by characterising the variability of the density of scratches in our dataset.
At first sight, one can observe that the density of scratches varies from individual to individual (even if they correspond to the same mortality event). For example, in the case of the caribou from Canada [sample #1] there is variability among animals that died on the same day (Fig. 2A). In all the analysed cases, the raw data also show this variability (Datasets are available from the Dryad Digital Repository: http://dx.doi.org/10.5061/dryad.9fp8k). Such an individual heterogeneity, which is related to characteristics such as gender, age or healthiness, can be regarded as a first source of variability. Additionally, an exploratory analysis of the results from the cases which data are available for several seasons (i.e. Rangifer tarandus [sample #1] and Odocoileus hemionus [sample #4]) revealed that the average density of scratches depended on the season within the year when the deaths occurred (Fig. 2). Specifically, independently of the species or habitat considered, the average density reached the highest values in spring (e.g. for Rangifer tarandus) or summer (e.g. for Odocoileus hemionus) and the lowest ones in fall/winter, which corresponds to an increase of the consumption of abrasive vegetation (like grass) in spring or summer for the two populations considered. Consequently, we identified two main sources of variability in the density of scratches, namely differences among individuals and season-related changes in environmental conditions.

Density of scratches as a function of the date of death (month and day) from the datasets #1 (Panel A) and #4 (Panel B).
Each data point stands for an individual. Vertically aligned points correspond to individual variability within the same mortality event. The variability range changes across seasons and colour coding highlights that the seasonal pattern is independent of the year.
We plotted and visually inspected the distribution of scratch densities of all the samples. When high resolution data were available, we also subdivided samples corresponding to long duration (e.g. a year) into shorter ones (e.g. a season, a month or a day) and compared their distributions. Interestingly, we found that the influence of these two sources of variability gets more or less relevant depending on the temporal window we are considering when analysing the data.
-
1
If the time window was a season or shorter, we mainly saw heterogeneity due to individual characteristics.
-
2
If the time window was longer than a season, season-dependent variability played a major role and the overall dispersion increased significantly.
This relationship between variability source and temporal window is represented on Fig. 2 for datasets #1 and #4.
Taking this into account, our next goal was to exploit the above-mentioned associations to easily determine time windows of mortality events from data on scratch densities. In order to do this, we needed to quantitatively assess variability.
Classification applying usual measures of variability
As a first approach, we applied two common measures of variability, namely the Standard Deviation (SD) and Coefficient of Variation (CV). Specifically, we calculated both magnitudes for a selection of the modern samples and compared the resulting values with the corresponding duration. Such a comparative exercise revealed that neither the SD nor the CV consistently distinguished short from long-term death events if included samples represented different seasons.
SD alone may not be able to properly distinguish death events concentrated in the warm season from those distributed during a larger time interval. In the latter case, however, the average number of marks will be smaller (See Fig. 3A). This would increase CV, making it possible to discriminate between the two scenarios. On the contrary, considering CV alone makes it difficult to separate short mortality events concentrated in the colder seasons from events distributed on a longer time interval. These two cases are easily distinguishable using SD, which is low in the former and high for the latter (See Fig. 3B).

Frequency distribution of the density of scratches in individuals that died in different mortality events.
Both standard deviation (SD) and coefficient of variation (CV) have problems distinguishing mortality time windows in certain cases. Panel (A) (left): Hypothetical scenario where SD cannot distinguish a single event in a warm season from a longer one in a colder part of the year. Panel (B) (right): Hypothetical scenario where CV cannot distinguish a single event in a cold season from a longer one in a warm part of the year.
This complementarity between SD and CV suggests that better classification accuracy could be achieved through a 2D mapping combining both variability measures. Moreover, such a bi-dimensional approach could differentiate a third sort of scenario (i.e. besides single seasonal and longer death events), namely two short events occurring in non-consecutive, different seasons (i.e. spring-autumn and winter-summer, independently of the actual year). In many cases, datasets corresponding to this sort of scenario present the same SD or CV as an equivalent longer death event, but not both variability measures simultaneously. Two illustrative examples are provided in Fig. 4.

Hypothetical scenarios illustrating how two short events concentrated in separated seasons (“EARLY FALL + SPRING” and “SEPT + FEB” in red and blue, respectively) can only be reliably differentiated from a homogeneous distribution of deaths over the whole year.
(“YEAR”, in grey) when considering both SD and CV variability measures. FIT corresponds to the Gaussian fitting implicitly applied when calculating the SD and CV of red and blue bipartite distributions. Panel (A) CV does not distinguish two concrete events occurring in spring and early fall, from a homogeneous distribution of deaths over the year. On the contrary, the SD value is different for the two scenarios. Panel (B) Opposite to example in Panel (A). In this case, only the CV value makes it possible to distinguish two short events concentrated in February and September from deaths evenly distributed through the year.
Classification applying a 2D approach combining both variability measures
In order to test the utility of combining SD and CV measures, we extracted (from the largest modern datasets) sub-samples corresponding to each one of the three scenarios described above and calculated SD and CV for all of them. Figure 5 shows the obtained values in a bidimensional map, where scenarios are identified by symbols (see the figure’s caption for details).

Coefficient of Variation versus Standard Deviation for the training set.
Circles represent seasonal or shorter events; squares stand for longer events; triangles correspond to events separated in time. Datapoints correspond to sub-samples of dataset (#1) (Rangifer tarandus (Qamanirjuaq, Canada), yellow); dataset (#3b) (Antilocapra americana (pronghorn) from Lamont and Rawlins (Wyoming, USA)); dataset (#4) (Odocoileus hemionus (Cache La Poudre River, Colorado, USA), orange); dataset (#5) (Cervus elaphus (Isle of Rum, Scotland), blue).
By visual inspection of Fig. 5, one can easily appreciate how samples appear in three groups corresponding to the three scenarios mentioned above, which are located in three different regions of the SD-CV plane:
-
A
Season-long or shorter time windows (bottom-left region in the figure)
-
B
Longer than a season (central area)
-
C
Separated events that occurred in different non-contiguous seasons (upper-right area)
Once the idea of adopting a bidimensional approach was validated, we needed to divide the whole parameter space (defined by the SD and CV values) into three regions, each one corresponding to one of the categories. This way, any new sample could be classified by positioning it on the 2D plane (using its SD and CV values as coordinates) and checking in which one of the three regions it appeared.
Taking this observation as a starting point, we have developed a classification methodology that estimates the boundaries between the three regions based on the naïve Bayes classifier37. Details on the methodology are provided in the Methods section. The resulting division of the SD-CV plane into three regions is shown in Fig. 6. This plane division allows for the classification of any new case as a function of its position in the SD-CV plane.

Boundary lines of the three regions with the error probability (heat map).
Points correspond to the test dataset: triangles stand for seasonal or shorter events; the black square is an event of deaths distributed over a year; the white square is an unknown case. All the triangles are located in region A, while the squares are in region B and no point falls in region C. Labels refer to the samples ID (Table 1).
The tool also provides a (visual) way to easily assess the accuracy of such a classification. Real cases do not always fit perfectly in the (necessarily simplified) picture encompassed by the three scenarios. This happens, for instance, in the case of two or more short separated events that took place in consecutive seasons or any kind of uneven distribution of deaths through several months. These intermediate situations are likely to be classified both as continuously distributed deaths that occurred all year round (scenario B) or as two separated events that occurred in non-consecutive seasons (scenario C). However, in general, these types of cases will occupy positions close to region boundaries within the SD-CV plane. The closer to a boundary a particular case is, the less clear is its affiliation to any of the two corresponding neighbouring regions separated by such a boundary. More concretely, coloured bands along the boundaries in Fig. 6 indicate the probability that a case located in a particular region did not completely belong to it.
In order to test the reliability of our classification tool, we applied it to the modern samples that we did not include before. Specifically, we mapped 5 datasets (#2a, 2b, 3a, 6 and 7) of seasonal or shorter time spans (region A), one dataset (#3b) of events distributed over one year (region B) and another one whose classification was not clear (#8). As shown in Fig. 5, all the datasets whose classification was known were properly classified. The last one (whose classification was ambiguous) is located in region B, but close to the border with region A. This corresponds to a realistic scenario.
Using our 2D map approach to classify archaeological assemblages
Notice that the proposed classifier does not distinguish between years of death. Season is the only relevant aspect. This makes the proposed classification method especially suitable for the disambiguation of fossil mortality events, since the resolution of the corresponding archaeological record is of the order of centuries to millennia.
Finally, we also applied the tool to all the archaeological datasets to contrast the expected classification of each case with its positioning in the SD-CV plane. The results, presented in Fig. 7, show a significant agreement with previous interpretations of the archaeological record.

Boundary lines of the three regions with the error probability (heat map) and the fossil samples.
(A1) Rangifer tarandus from Portel-Ouest; (A2) Equus ferus from Portel-Ouest; (A3) Cervus elaphus from Portel-Ouest; (A4) Bos/Bison from Portel-Ouest; (B1) Cervus elaphus from Abric Romaní level K; (B2) Cervus elaphus from Abric Romaní level M; (C1) Rangifer tarandus from Salzgitter Lebenstedt; (D1) Bison priscus from Taubach; (E1) Equus ferus from Caune de l’Arago level G; (E2) Cervus elaphus from Caune de l’Arago level J; (E3) Rangifer tarandus from Caune de l’Arago level L.
The three samples from the Caune de l’Arago site (E1, E2 and E3) fall in different areas of the SD-CV plane. For level L (E3), the microwear pattern suggests short-term occupation, which fits with the interpretation of short stopovers of reindeer hunters as proposed by de Lumley et al.38. Remains of red deer from Level J (E2) are related to separated short events, which is consistent with the interpretation of this level as temporary seasonal occupations de Lumley et al.38. Finally, the sample of horses from level G (E1) falls on the boundary between the regions corresponding to long events and several separated short events. It is thus not possible to differentiate if this level (G) corresponds to a long-term and continuous occupation or to the recurrence of occupations through the year. This uncertainty can be explained from the context of accumulation of the archaeological record. Specifically, level G is a thick (ca. 80 cm) palimpsest (i.e., a sequence of depositional episodes in which successive layers are superimposed on preceding ones) and the distribution of species changes vertically through the level38,39.
Similarly, the various samples from Portel-Ouest (A1–A4) fall in two areas of the SD-CV plot. Interestingly, these samples correspond to four species from the same level. The accumulation of the reindeer (A1), the red deer (A3) and the large bovid (A4) correspond to seasonal (or shorter) events while the horse (A2) corresponds to a longer continued event. This differential pattern among species can be easily related to known human hunting strategies for different prey at different moments of the year.
At Salzgitter Lebenstedt (C1), the accumulation of reindeer remains corresponds to seasonal (or shorter) events which is consistent with zooarchaeological results indicating autumn hunting of reindeer40 (Gaudzinski and Roebroeks, 2000).
Finally, the remains of bison from Taubach (D1) follow a long-term pattern of accumulation which contradict previous results by Moncel and Rivals41 who characterized that accumulation as the result of a short-term occupation on the basis of the CV value only. Such results highlight the importance of combining SD and CV to properly estimate the duration of the events.
Discussion
Summarizing, we used modern data on well-known mass mortality events to develop a tool capable of easily assessing the duration of mortality events from microwear data obtained from the fossil record. Specifically, the tool indicates (with a certain probability value) to what extend a case to be classified matches each one of the following three categories: short (a season or less) events; long-continued event; and two separated short events.
The classification methodology is based on the quantification of the two sources of variability affecting values of scratch density in a sample: heterogeneity due to differences among individuals and variability resulting from seasonal conditions (e.g. periodic changes in the vegetation). Usual variability measures (i.e. standard deviation and coefficient of variation), calculated separately, cannot properly differentiate short and long mortality events. On the contrary, by bundling them together, the three above-mentioned scenarios can be distinguished.
By comparing the variability values (SD and CV) among the 11 populations, it became evident that variability is independent of the species considered. Samples group depending on the duration of the mortality event. Consequently, the range of CV and SD values considered in our 2D classifier can be used to frame all species of ungulates in seasonal environments.
Specifically, we have divided the space of parameters defined by SD and CV variables into three regions (each of them corresponding to one of the above-mentioned categories) through a naïve Bayesian classifier. We split the modern samples of mass mortality events (for which we knew the exact time window) into two sets. The first one was used to train the classifier and the resulting regions were checked using the second set. The agreement was perfect. Finally, the tool was applied to the archaeological mortality samples, for which we had theoretical time windows, obtained from other archaeological evidence. All the hypotheses were confirmed by the classification tool. Notice that, despite its power as a simple classifier for ‘archaeological mortality events’, the proposed tools might need to be complemented by a deeper statistical test. This will particularly be the case when sample coordinates (in terms of SD and CV values) locate the sample on a boundary. However, even in those cases, the tool provides a first, highly useful look at the nature of the mortality event.
Finally, the Bayesian nature of our classification tool should recursively allow us to use already classified cases to improve the tool’s accuracy, by informing a priori probabilities. Future efforts will be devoted to explore this possibility.
Methods
Datasets
Extant samples
After a search for large samples of extant ungulate collections with good records of the date and conditions of death, we collected specimens and established a microwear dataset made of 10 populations (Table 1). Teeth were sampled in each collection and all the moulds and casts produced are now stored in the microwear collection at the Institut Català de Paleoecologia Humana i Evolució Social (Tarragona, Spain). A more comprehensive description of each sample is available in the Supplementary Information.
Fossil samples
Fossil samples were selected from archaeological localities ranging in age from the middle Pleistocene (Marine Isotope Stages 14 to 12) and the late Pleistocene (MIS 5e to 3). Summary information of each sample is presented in Table 2. A more comprehensive summary is available in the Supplementary Information.
Microwear analysis
Microwear features of dental enamel were examined using a stereomicroscope on high-resolution epoxy casts of teeth following the cleansing, moulding, casting and examination protocol developed by Solounias and Semprebon14 and Semprebon et al.36. In short, the occlusal surface of the upper or lower second molar of each individual was cleaned using acetone and then 96% alcohol. The surface was moulded using high-resolution silicone (vinylpolysiloxane) and casts were created using clear epoxy resin. All specimens moulded were carefully screened under the stereomicroscope. Those with badly preserved enamel or taphonomic defects (features with unusual morphology and size, or fresh features made during the collecting process or during storage) were removed from the analysis, following King et al.42.
Casts were observed under incident light with a Zeiss Stemi 2000C stereomicroscope at 35× magnification, using the refractive properties of the transparent cast to reveal microfeatures on the enamel. To avoid inter-observer error, the analysis of microwear was performed by the same person for all samples (FR). We used the classification of features defined by Solounias and Semprebon14 and Semprebon et al.36 and quantified all categories of microwear features. However in this paper, we only present the results on the number of scratches because scratches are related to seasonal changes in diet14,43. Scratches are elongated microfeatures that are not merely longer than they are wide, but have straight, parallel sides. Scratches were quantified on the paracone of the M2 or the protoconid of the m2 in a standard square area of 0.16 mm2 using an ocular reticule. Two areas were analysed on each tooth and the results were averaged to be included in the dataset.
Determining region boundaries in the 2D SD-CV map using the Naive Bayes classifier
We consider three separated classes of data points corresponding to each one of the considered scenarios: (A) from one month to a season; (B) from four months to a year; (C) events occurred in non-consecutive seasons. Our goal was to determine the boundaries between the regions of the parameters’ space (CV-SD) corresponding to each one of these.
Naive Bayes classifiers are a family of simple probabilistic classifiers based on applying Bayes’ theorem with strong (naive) independence assumptions between the features (in our case, CV and SD). An advantage of naive Bayes is that it only requires a small amount of training data to estimate the parameters necessary for classification. Moreover, since we assume CV and SD to be independent, for each class only their means and variances (and not the entire covariance matrix) need to be determined.
For the construction of the training set, in order to hold a complete control over the time distribution of the events, we selected the modern datasets where the precise date of each death is known (i.e. #1, 4 and 5). We extracted from these datasets sub-samples of data such that their time distribution corresponded to one of the described scenarios with no ambiguity. As a rule of thumb, we fixed the minimum size for a sub-sample to be statistically acceptable equal to fifteen individuals. For smaller sets, we noticed that the SD values have a significant (negative) correlation with the size of the set, hence we discarded them.
For the first two scenarios, we took into account groups of events evenly distributed, avoiding long blank periods or high concentrations of deaths in short time spans. Since none of the three considered datasets includes deaths dated in all the months of the year, we had to relax the requirements in a few cases to obtain a more balanced training set (see Supplementary Information-Table of the dataset sub-samples included in the training set). We discarded the sub-sample corresponding to the summer dates in dataset #4 because it was too small. On the contrary, we included three large-enough sub-samples extracted from dataset #3b despite the fact that its time resolution is lower than the general one (i.e. we know the month of the death, but not always the day).
As for the third scenario, we built each sub-sample as two groups of data corresponding to deaths that occurred in two opposite seasons. However, seasons are hardly equally represented within the same dataset. For instance, in the largest one (#1), winter is completely missing, while in #4, summer is under-represented. Consequently, available sub-samples for this scenario are scarce. Hence, we decided to assemble new ones by replicating data corresponding to one of the two considered seasons, thus altering their relative frequencies. In this way, we have been able to obtain up to nine sub-samples with different proportions of events in the cold and in the warm season, theoretically covering all the spectrum of possibilities within the definition of the third scenario (see Supplementary Information–Table of the dataset sub-samples included in the training set for further details).
Assuming that the values associated with each class are normally distributed, we associate to each scenario a bidimensional Gaussian distribution. Its parameters are determined as the mean and the standard deviation of the x and the y values, being x and y coordinates in the parameter space we want to divide into regions (i.e. SD and CV, respectively, in our case).



In principle, each distribution should be weighted with a prior probability given by the fraction of cases belonging to the corresponding class. In our case, since there is no a priori information about real (fossils) case frequencies at hand, we gave each distribution the same weight PA = PB = PC = p = 1/3.
Since there is almost no overlap between distribution GA and distribution GC, we looked for the boundary between class A and class B and then between class B and class C as separated situations. In this way, we had two binary classification problems (class 0 vs. class 1) and the boundaries could be determined by equating the corresponding distribution functions:
 and
and  , respectively.
, respectively.
Thus, we are dividing the plane into three regions such that the distribution taking the larger value is GA in region A, GB in region B and GC in region C. The class of any new data point can be therefore easily determined from its position in the parameter space.
The uncertainty of the classification, represented in the heat map of Figs 6 and 7, can be estimated from the variance of the classifier. Its expression is

where  is the total probability distribution for a new mortality event to be found at position
is the total probability distribution for a new mortality event to be found at position  in the SD-CV plane.
in the SD-CV plane.
We computed three contour lines of  corresponding to a total probability of 68%, 95% and 99.5%, respectively, of finding a datapoint within the region of the SD-CV plane delimitated by such curves. Notice that all the fossil datasets fall inside the second curve (See Fig. 8). There is no difference between extant and fossil samples in terms of range of SD and CV values and this is precisely, from a statistical point of view, what allows us to use the former to develop a classifier for the latter.
corresponding to a total probability of 68%, 95% and 99.5%, respectively, of finding a datapoint within the region of the SD-CV plane delimitated by such curves. Notice that all the fossil datasets fall inside the second curve (See Fig. 8). There is no difference between extant and fossil samples in terms of range of SD and CV values and this is precisely, from a statistical point of view, what allows us to use the former to develop a classifier for the latter.

Isolines of G(x,y), the total probability distribution for a mortality event to be found at position (x, y) in the SD-CV plane, corresponding to, from the most internal one, a total probability equal to 68%, 95%, 99.7%.
Datapoints correspond both to the extant samples (triangles, squares, circles) and the fossil ones (diamonds).
The expected total error is given by the sum of the integrals of each distribution outside the region of the corresponding class (beyond the boundary)

being the overlap of GA and Gc negligible.
Additional Information
How to cite this article: Rivals, F. et al. A tool for determining duration of mortality events in archaeological assemblages using extant ungulate microwear. Sci. Rep. 5, 17330; doi: 10.1038/srep17330 (2015).
References
Guillien, Y. & Henri-Martin, G. Croissance du renne et saison de chasse: Le Moustérien à denticulés et le Moustérien de tradition acheuléenne de La Quina. Inter-Nord 13–14, 119–127 (1974).
Todd, L. C., Hofman, J. L. & Schultz, C. B. Seasonality of the Scottsbluff and Lipscomb bison bonebeds: Implications for modeling Paleoindian ubsistence. Am. Antiquity 55, 813–827 (1990).
Carter, R. J. Reassessment of seasonality at the Early Mesolithic site of Star Carr, Yorkshire based on radiographs of mandibular tooth development in red deer (Cervus elaphus). J. Archaeol. Sci. 25, 851–856 (1998).
Lubinski, P. M. Estimating age and season of death of pronghorn antelope (Antilocapra americana Ord) by means of tooth eruption and wear. Int. J. Osteoarchaeol. 11, 218–230 (2001).
Lieberman, D. E. Life history variables preserved in dental cementum microstructure. Science 261, 1162–1164 (1993).
Lieberman, D. E., Deacon, T. W. & Meadow, R. H. Computer image enhancement and analysis of cementum increments as applied to teeth of Gazella gazella. J. Archaeol. Sci. 17, 519–533 (1990).
Pike-Tay, A. L. ’ analyse du cément dentaire chez les cerfs: l’application en préhistoire. Paléo 3, 149–166 (1991).
Sharp, Z. D. & Cerling, T. E. Fossil isotope records of seasonal climate and ecology: Straight from the horse’s mouth. Geology 26, 219–222 (1998).
Drucker, D., Bocherens, H., Pike-Tay, A. & Mariotti, A. Isotopic tracking of seasonal dietary change in dentine collagen: preliminary data from modern caribou. C. R. Acad. Sci. Paris, ser. IIa 333, 303–309 (2001).
Merceron, G., Escarguel, G., Angibault, J.-M. & Verheyden-Tixier, H. Can dental microwear textures record inter-individual dietary variations? PLoS ONE 5, e9542 (2010).
Merceron, G., Viriot, L. & Blondel, C. Tooth microwear pattern in roe deer (Capreolus capreolus L.) from Chizé (Western France) and relation to food composition. Small Ruminant Res. 53, 125–132 (2004).
Rivals, F. & Deniaux, B. Investigation of human hunting seasonality through dental microwear analysis of two Caprinae in late Pleistocene localities in Southern France. J. Archaeol. Sci. 32, 1603–1612 (2005).
Merceron, G., Blondel, C., de Bonis, L., Koufos, G. D. & Viriot, L. A new method of dental microwear: application to extant primates and Ouranopithecus macedoniensis (Late Miocene of Greece). Palaios 20, 551–561 (2005).
Solounias, N. & Semprebon, G. Advances in the reconstruction of ungulate ecomorphology with application to early fossil equids. Am. Mus. Novitates 3366, 1–49 (2002).
Ungar, P. S. Dental microwear of European Miocene catarrhines: evidence for diets and tooth use. J. Hum. Evol. 31, 335–366 (1996).
Walker, A., Hoek, H. N. & Perez, L. Microwear of mammalian teeth as an indicator of diet. Science 201, 908–910 (1978).
Solounias, N., Teaford, M. & Walker, A. Interpreting the diet of extinct ruminants: The case of a non-browsing giraffid. Paleobiology 14, 287–300 (1988).
Teaford, M. F. A review of dental microwear and diet in modern mammals. Scanning Microscopy 2, 1149–1166 (1988).
Mainland, I. L., Dental microwear and diet in domestic sheep (Ovis aries) and goats (Capra hircus): Distinguishing grazing and fodder-fed ovicaprids using a quantitative analytical approach. J. Archaeol. Sci. 25, 1259–1271 (1998).
Fraser, D., Mallon, J. C., Furr, R. & Theodor, J. M. Improving the repeatability of low magnification microwear methods using high dynamic range imaging. Palaios 24, 818–825 (2009).
Grine, F. E. Dental evidence for dietary differences in Australopithecus and Paranthropus: a quantitative analysis of permanent molar microwear. J. Hum. Evol. 15, 783–822 (1986).
Teaford, M. F. & Oyen O. J. In vivo and in vitro turnover in dental microwear. Am. J. Phys. Anthropol. 80, 447–460 (1989).
Teaford, M. F. & Glander, K. E. Dental microwear in live, wild-trapped Alouatta palliata from Costa Rica. Am. J. Phys. Anthropol. 85, 313–319 (1991).
Teaford, M. F. & Robinson, J. G. Seasonal or ecological differences in diet and molar microwear in Cebus nigrivittatus. Am. J. Phys. Anthropol. 80, 391–401 (1989).
Mainland, I. L. The potential of dental microwear for exploring seasonal aspects of sheep husbandry and management in Norse Greenland. Archaeozoologia 11, 79–99 (2000).
Gogarten, J. F. & Grine, F. E. Seasonal mortality patterns in primates: Implications for the interpretation of dental microwear. Evol. Anthropol. 22, 9–19 (2013).
Berger, J. Ecology and catastrophic mortality in wild horses: Implications for interpreting fossil assemblages. Science 220, 1403–1404 (1983).
Lyman, R. L. Taphonomy of cervids killed by the May 18, 1980, volcanic eruption of Mount St. Helens, Washington, USA In: Bone modification (eds Bonnichsen, R., Sorg, M. H. ) 149–167 (Center for the Study of the First Americans, University of Maine, 1989).
Young, T. P. Natural die-offs of large mammals: Implications for conservation. Conserv. Biol. 8, 410–418 (1994).
French, M. G. & French, S. P. Large mammal mortality in the 1988 Yellowstone fires. In: Ecological implications of fire in Greater Yellowstone. Proceedings of the Second Biennial Conference on the Greater Yellowstone ecosystem, Yellowstone National Park, September 19-21, 1993 (eds Greenlee J. M.) 113-115 (International association of Wildland Fire, 1996).
Aguirre, A., Bröjer, C. & Mörner, T. Descriptive epidemiology of roe deer mortality in Sweden. J. Wildlife Dis. 35, 753–762 (1999).
Dau, J. Two caribou mortality events in Northwest Alaska: possible causes and management implications. Rangifer Special Issue 16, 37–50 (2005).
Scorolli, A. L., Lopez Cazorla, A. C. & Tejera, L. A. Unusual mass mortality of feral horses during a violent rainstorm in Parque Provincial Tornquist, Argentina. Mast. Neotrop. 13, 255–258 (2006).
Islam, M. Z., Ismail, K. & Boug, A. Catastrophic die-off of globally threatened Arabian Oryx and Sand Gazelle in the fenced protected area of the arid central Saudi Arabia. J. Threat. Taxa 2, 677–684 (2010).
Fey, S. B. et al. Recent shifts in the occurrence, cause and magnitude of animal mass mortality events. Proc. Natl Acad. Sci. USA 112, 1083–1088 (2015).
Semprebon, G. M., Godfrey, L. R., Solounias, N., Sutherland, M. R. & Jungers, W. L. Can low-magnification stereomicroscopy reveal diet? J. Hum. Evol. 47, 115–144 (2004).
Rish, I. An empirical study of the naive Bayes classifier. IJCAI 2001 workshop on empirical methods in artificial intelligence 3, 41–46 (2001).
de Lumley, H. et al. Habitat et mode de vie des chasseurs paléolithiques de la Caune de l’Arago (600 000–400 000 ans). L’Anthropologie 108, 159–184 (2004).
Moigne, A.-M. et al. Les faunes de grands mammifères de la Caune de l’Arago (Tautavel) dans le cadre biochronologique des faunes du Pléistocène moyen italien. L’Anthropologie 110, 788–831 (2006).
Gaudzinski, S. & Roebroeks, W. Adults only. Reindeer hunting at the Middle Palaeolithic site Salzgitter Lebenstedt, Northern Germany. J. Hum. Evol. 38, 497–521 (2000).
Moncel, M.-H. & Rivals, F. On the question of short-term Neanderthal site occupations: Payre, France (MIS 8-7) and Taubach/Weimar, Germany (MIS 5). J. Anthropol. Res. 67, 47–75 (2011).
King, T., Andrews, P. & Boz, B. Effect of taphonomic processes on dental microwear. Am. J. Phys. Anthropol. 108, 359–373 (1999).
Rivals, F., Schulz, E. & Kaiser, T. M. A new application of dental wear analyses: estimation of duration of hominid occupations in archaeological localities. J. Hum. Evol. 56, 329–339 (2009).
Acknowledgements
We acknowledge the following persons for granting us access to the collections: Diego Rindel (CONICET and Instituto Nacional de Antropología y Pensamiento Latinoamericano), Juan Bautista Belardi (CONICET-Universidad Nacional de la Patagonia Austral), Josephine Pemberton (University of Edinburgh), Seiki Takatsuki (Azabu University), Jeff Bradley (Burke Museum), Danny Walker (Wyoming Department of State Parks and Cultural Resources), Gerald Oetelaar (University of Calgary), Michel Gosselin and Kamal Khidas (Canadian Museum of Nature). Maria Gema Chacón and Edgard Camarós are acknowledged for their help in sampling in Patagonia and the Isle of Rum, respectively. This work was supported by the research grants from the Ministerio de Economia y Competitividad (MINECO grants HAR2010-19957 and HAR2013-48784-C3-1-P) and the Agència de Gestió d’Ajuts Universitaris i de Recerca (AGAUR 2012-BE-DGR-93 and 2014-SGR-900). S. L. is supported by the Ramón y Cajal programme through the grant RYC-2012-01043.
Author information
Authors and Affiliations
Contributions
G.M.S. and F.R. undertook the sampling; F.R. undertook the microwear analysis; L.P. and S.L. processed the data and developed the classifier; All authors contributed significantly to the manuscript’s writing.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Electronic supplementary material
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Rivals, F., Prignano, L., Semprebon, G. et al. A tool for determining duration of mortality events in archaeological assemblages using extant ungulate microwear. Sci Rep 5, 17330 (2015). https://doi.org/10.1038/srep17330
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep17330
This article is cited by
-
Dietary traits of the ungulates from the Middle Pleistocene sequence of Lazaret Cave: palaeoecological and archaeological implications
Archaeological and Anthropological Sciences (2023)
-
Seasonality and mobility of Epipaleolithic groups in the north-east of the Iberian Peninsula: tooth wear analysis of ungulates from Balma del Gai
Archaeological and Anthropological Sciences (2023)
-
Too good to go? Neanderthal subsistence strategies at Prado Vargas Cave (Burgos, Spain)
Archaeological and Anthropological Sciences (2023)
-
Browsing into a Panamanian tropical rainforest: micro- and mesowear study of Central American red brocket deer
Mammal Research (2023)
-
Neanderthals’ hunting seasonality inferred from combined cementochronology, mesowear, and microwear analysis: case studies from the Alpine foreland in Italy
Archaeological and Anthropological Sciences (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.

{kind=link}
{kind=link}