
Abstract
The aim of this study was to investigate how background auditory processing can affect other perceptual and cognitive processes as a function of stimulus content, style and emotional nature. Previous studies have offered contrasting evidence and it has been recently shown that listening to music negatively affected concurrent mental processing in the elderly but not in young adults. To further investigate this matter, the effect of listening to music vs. listening to the sound of rain or silence was examined by administering an old/new face memory task (involving 448 unknown faces) to a group of 54 non-musician university students. Heart rate and diastolic and systolic blood pressure were measured during an explicit face study session that was followed by a memory test. The results indicated that more efficient and faster recall of faces occurred under conditions of silence or when participants were listening to emotionally touching music. Whereas auditory background (e.g., rain or joyful music) interfered with memory encoding, listening to emotionally touching music improved memory and significantly increased heart rate. It is hypothesized that touching music is able to modify the visual perception of faces by binding facial properties with auditory and emotionally charged information (music), which may therefore result in deeper memory encoding.
Similar content being viewed by others

Introduction
-
A total of 54 non-musicians listened to joyful or emotionally touching music, rain sounds, or silence while studying hundreds of faces
-
Heart rate and diastolic and systolic blood pressure were measured during face encoding
-
Except for emotionally touching music, auditory background interfered with memory recall
-
Touching music is able to bind visual properties with emotionally charged information (music), which results in enhanced memory
The effects of listening to background music on concurrent mental processing are controversial. Overall, although listening to music appears to have positive effects on emotions and especially on motor behavior (such as athletic performance), it appears to interfere with reading and memory tasks (see ref. 1 for a review). In automobile driving, listening to music appears to alleviate driver stress and reduce aggression; however, in conditions that require attention and mental concentration, driving performance is impaired2.
Two perspectives have been proposed to account for the effects of background music on cognitive processes: the Cognitive-Capacity model and the Arousal-Mood hypothesis. Kahneman’s capacity model3 postulates that only a limited pool of resources is available for cognitive processing at any given moment. When concurrent tasks compete for limited resources and their combined demands exceed the available capacity, capacity interference occurs. Only a portion of the task information is processed and therefore performance deteriorates. The interference caused by task-irrelevant information (for example, listening to music) also depends on the complexity of the information that is being processed and on the workload that is required to process task-relevant information. Indeed, increasingly complex musical distractions may result in decreased cognitive performance4.
In contrast, the Arousal-Mood hypothesis posits that listening to music affects task performance by positively influencing arousal and mood5, which is a phenomenon that is also known as the Mozart effect6. This hypothesis has been supported by several studies that have investigated the effect of listening to background music on the performance of cognitive tasks. For example, improvements in verbal memory encoding7, autobiographical memory in Alzheimer patients8, verbal and visual processing speed9, arithmetic skill10, reading11 and second language learning12 have been documented.
Conversely, reduced performance in the presence of background music has also been demonstrated (for example, see ref. 5). As noted by Kämpfe and colleagues1 in an excellent meta-analysis, background music may have a small but persistent negative effect on memory performance-related tasks, such as memorizing advertisements (e.g., ref. 13), memorizing nonsense syllables or words (especially in the presence of loud music)14,15, remembering previously read texts and reading performance16. Listening to background music vs. silence has also been reported to interfere with many additional cognitive processes, including the ability to perform arithmetic17; performance on verbal, numerical and diagrammatic analysis tests18,19; multimedia learning20; the learning of new procedures21; reading22,23,24; and inhibition of performance of the Stroop task25.
Recently, Bottiroli et al.26 found that listening to Mozart (as compared to silence and white noise) improved declarative memory tasks in the elderly. They interpreted these data in the context of the so-called “arousal and mood hypothesis”5 because performance systematically increased under conditions that induced positive mood and arousal. In contrast, Reaves et al.27 indicated that listening to music comes at a cost to concurrent cognitive functioning. In their study, both young and old adults listened to music or to silence while simultaneously studying face-name pairs. The participants’ abilities to remember the pairs were then tested as they listened to either the same or to different music. The results showed that older adults remembered 10% fewer names when listening to background music or to rain compared to silence. Therefore, although music may help to relax individuals who are trying to concentrate, it appears that it does not help them to remember what they are focusing on (new information), especially as they age.
Overall, the data are conflicting, although it appears that listening to background music most interferes with tasks that involve memory, especially for verbal items. To the best of our knowledge, the effect of listening to music on the ability to remember nonverbal or linguistic items has not been previously investigated.
To further investigate this matter, in this study, the ability to remember human faces was evaluated in the context of different types of acoustic background, including silence (as a non-interfering control), the sounds of rain and storms (generally thought to have a relaxing effect28,29) and occidental music of different emotional content and style. A previous study30 compared listening to silence with listening to music or rain during a backward digit span task and found no effect of auditory background on performance. To provide information about the effect of background noise on alertness and arousal levels, as well as possible autonomic correlates of emotional responses, heart rate and systolic and diastolic blood pressure were measured during the first part of the experiment (study phase). In this session, 300 unknown male and female faces were presented to participants in an explicit memory encoding situation. The study session was followed by a memory test that consisted of evaluating the recognition of 200 previously viewed faces that were randomly interspersed with 100 new faces, under conditions of silence. Hit and error percentages were quantified as functions of the experimental conditions (listening to emotionally touching music, to joyful music, to the sound of rain, to silence).
The aim of the present study was to determine the autonomic and cognitive correlates of non-verbal memory processing as a function of the nature of an auditory background (or the lack of it, i.e., silence). It was hypothesized that music would either increase arousal levels and therefore improve memory, as predicted by the Mozart effect5,6, or that it would interfere with memory by overloading attentional systems and therefore reduce subjects’ performance of the memory task4. The effect imparted by the emotional content of music was also explored by comparing the condition of listening to joyful music with that of listening to emotionally touching (sad) music. With respect to the effects of listening to music on autonomic parameters, it appears that although listening to music might reduce anxiety and induce mental relaxation under certain experimental conditions or clinical settings, it has little or no influence on hemodynamic parameters, except for a tendency to increase systolic blood pressure31,32,33.
In this study autonomic measures were recorded in non-musician controls since we aimed at investigating the effect of auditory background on perceptual processing in individuals not particularly specialized in music processing. Indeed, it is known that the musicians’ brain reacts differently from that of other individuals to auditory information of various nature, including phonologic stimuli, noise and sounds34. Although not a specific research aim, the effect of participants’ sex in memory for face (as a function of auditory background) was also investigated since some literature has shown gender effects on episodic memory and musical emotion processing. Indeed evidences have been provided of a female greater advantage in episodic memory tasks for emotional stimuli35 and of females’ hypersensitivity to aversive musical stimuli36.
Materials and Methods
Participants
Fifty-four healthy participants (27 males and 27 females), ranging in age between 18 and 28 years (mean age = 22.277 years), were included in this study. They were all right-handed with normal hearing and vision and none had suffered from previous or current psychiatric or neurological diseases. All participants received academic credits for their participation and provided written consent. The experiment was performed in accordance with the relevant guidelines and regulations of and was approved by the Ethical Committee of the University of Milano-Bicocca. The participants were blinded to the purpose of the experiment. None of the participants were musicians and none of them had ever studied music or played a musical instrument, or had a musical activity as a hobby or specific interest. This information was specifically ascertained through the administration of a detailed questionnaire.
Stimuli
Visual stimuli
A total if 448 colored pictures of anonymous human faces of women (N = 224) and men (N = 224) of different ages were used as visual stimuli. The faces were selected from available, open access, license-free databases. They were equally represented by sex and age ranges (children, adolescents, young adults [25–35 years], mature adults [35–60 years] and the elderly). The pictures only showed a given subject's face up to the base of the neck. The image size was 265 × 332 pixels. The characters wore various accessories (e.g., glasses, hats, earrings, etc.) and depicted various emotional expressions, ranging from joy to anger, all of which were matched across stimulus categories. The valence and arousal of each face was assessed in a preliminary validation study that was performed on 15 Psychology University students37 through the administration of a modified version of the Self Assessment Manikin (SAM)38 an affective rating system. In this system, a graphic figure depicting values along each of 2 dimensions of a continuously varying scale is used to indicate emotional reactions. Judges could select any of the 3 figures comprising each scale, which resulted in a 0–2 point rating scale for each dimension. Ratings were scored such that 2 represented a high rating on each dimension (i.e., high arousal, positivity) and 0 represented a low rating on each dimension (i.e., low arousal, negativity), with 1 representing an intermediate score. On the basis of the valence and arousal ratings that were obtained from the validation study37, faces were randomly assigned to various auditory background conditions, which were also matched for sex and age of the persons depicted, so that the average valence and arousal of faces did not differ across blocks of stimulations. Stimuli were equiluminant, as ascertained by an ANOVA that was performed on individual luminance measurements that were obtained via a Minolta luminance meter.
Auditory stimuli
Pieces of music were selected on the basis of a validation that was performed on 20 orchestra directors, composers or teachers at various Italian Conservatories (18 men and 2 women), whose mean age varied between 50 and 60 years and who freely provided lists of the most emotionally touching classic instrumental music pieces from a tonal and atonal repertoire. Tonal music was defined as a musical production having a tonal center around which melody and harmony are based, including monodic productions from the Middle Ages. Atonal music was defined as a musical production (usually dated after 1910) that did not have a tonal center or that did not use multiple tonal centers simultaneously. After an initial selection, movie soundtracks, opera pieces and highly popular pieces of music were discarded. The selected list was then re-presented to the judges while asking them to choose the 3 most emotionally touching and 3 most joyful pieces (according to their own aesthetic preferences) for the tonal and atonal categories. The pieces with the highest ratings across the tonal and atonal repertoires were considered and their similarities in structure, rhythm and in ensemble complement/instrumentation were also taken into account. In the end, the pieces that were voted to be used as stimuli in this study including the following:
-
Part, Arvo - Cantus in memoriam de Benjamin Britten (atonal, touching)
-
Hindemith, Paul - First movement from I Kammermusik (atonal, joyful)
-
Bach, Johann Sebastian - II movement from Concert in D minor for 2 violins (BWV 1043) (tonal, touching)
-
Beethoven, Ludwig van - IV Movement of Symphony (tonal, joyful)
Both rain sounds (obtained from an audio downloaded from Internet named “75 minutes of thunder and rain - relaxing noise for your ears” https://www.youtube.com/watch?v=WvRv-243Cmk&spfreload=10) and all musical excerpts were cut into 1-minute-long pieces, matched for intensity by means of MP3Gain software (89,0 dB) and faded at the end (last second) via Audacity software and were therefore transformed into MP3 files. The modulation of tonality (used to provide variety) and its possible effect on autonomic parameters were not considered in this study.
Procedure
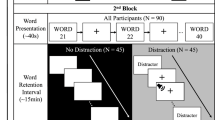
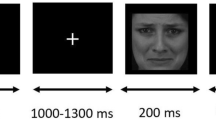
The experiment consisted of two different sessions (see fig. 1 for a schematic of the paradigm). It was preceded by a training phase in which 56 unique pictures of women and men of various ages were presented in association with an auditory background. The subjects were instructed to pay attention to the faces that were presented in the 2 training sequences, which were followed by a short old/new discrimination task in which the left and right hands were alternated between when being used to respond. The first training session consisted of presenting 20 different faces to subjects as they listened to jazz music from “Freedom: an Instrumental approach to Jazz music” (n°12, Wet atmosphere, Julian Carl, JC Records, 2014). In the second training session, in which the opposite responding hand was used, an additional 20 faces were presented with an auditory background of natural sounds (ocean waves). In both sessions, subject wore headphones and wrist devises (on the left hand) that measured heart rate and blood pressure. The third training sequence consisted of the presentation of 8 old faces and 8 new faces that were randomly mixed. In this sequence, the subjects did not wear headphones or devises that measured autonomic responses. The auditory background was complete silence. The participants were instructed to respond as accurately and quickly as possible, using the index finger to indicate old faces and the middle finger to indicate new faces.

Schematic of the experimental paradigm, which included two sessions of face encoding and memory tasks.
AMP and AZ contributed to the drawing of this figure.
After subjects were acquainted with the task requirements and experimental settings, the experimental session started.
In the study or learning session, participants sat comfortably in front of a computer screen at a distance of 114 cm in an anechoic chamber under dimly lit conditions. A total of 300 faces were randomly presented at the center of the screen for 800 ms each with an ISI of 1300 ms. The stimuli were equally divided as a function of auditory background conditions (each auditory clip lasting 60 seconds) and matched across categories for sex, age, expression, valence and arousal. Stimulus delivery was performed using Evoke software (Asa System). Subjects wore headphones and wrist devises that measured heart rate and blood pressure.
The session consisted in the presentation of 15 sequences separated by short pauses. The order of stimulus presentation was random and randomly varied across subjects. The wrist devices that measured heart rate and blood pressure was activated at the beginning of each sequence and stopped at the end. In this way it was assured a good timing of physiological responses to the cognitive stimuli.
During the memory test session, participants were presented with 300 faces (200 old and 100 new) in silent conditions and without wearing headphones or wrist devises for autonomic response measurements. The faces were presented for 800 ms each with an ISI of 1300 ms. The task requirements were the same as in the training memory task: old/new face discrimination with finger choice and response time and hits recording.
Physiological recording
Data were not sampled but continuously acquired. Since each auditory fragment lasted 1 minute, both heart rate and blood pressure were acquired and averaged as per minute value and processed after the end of recording. Xanthine intake (i.e. caffeine) was controlled. All subjects were tested in the morning and had no more than 1 breakfast coffee. None of them have been assuming medications affecting the SNC in the last 2 weeks. It was ascertained that no physical exercise was practiced by participants before the experiment and participants were required to rest sitting down before the study for about 10 minutes to achieve a basal state. At this aim, 3 sequences of training were administered to all subjects before the beginning of the recording session.
Data Analysis
The mean percentages of correct responses (arcsine transformed), response times (RTs in ms) and the mean values of heart rate and diastolic and systolic blood pressure that were measured during the learning session underwent five independent analyses of variance, with between group (sex, 2 levels: male, female) and within group (auditory background, 4 levels: joyful music, touching music, rain, silence) factors of variability.
A further analysis of variance was performed to compare the recognition rates of old and new faces that were measured during the test session. Between group (sex, 2 levels: male, female) and within group (face familiarity, 2 levels: old, new) factors of variability were included. Tukey’s test was used for post hoc comparisons of means.
Results
Figure 2 indicates the mean percentages of correct recognition of old faces (along with standard deviations) as a function of the sex of the viewers and the auditory background conditions. Although women tended to exhibit better performance on the task, sex was not a significant factor. ANOVA results indicated the significance of auditory background (F3,156 = 5.9; p < 0.0008) and higher percentages of correct facial recognition were obtained under auditory backgrounds comprised of emotionally touching music (vs. joyful music, p < 0.01; vs. rain, p < 0.007) or of silence (vs. joyful music, p < 0.03; vs. rain, p < 0.02) compared to other conditions.

Hit percentages in the memory test as a function of auditory background during the study session.
Nonverbal episodic memory recall was enhanced when study occurred either in silence or in the presence of emotionally touching music. Although women exhibited better performance on the test, especially while listening to music, the difference was not significant.
An ANOVA that was performed to compare hits of old versus new faces independent of auditory background showed a strong effect of stimulus familiarity (F1,52 = 33.3; p < 0.00001), which indicated that the test subjects had a much higher recognition of new faces (correctly rejected as unfamiliar) than old faces (correctly recognized as old), as displayed in Fig. 3. No sex differences in performance were observed.

Hit percentages in the memory test.
The data indicate that it was much easier for the participants to recognize new faces compared to old faces. Additionally, the participants were very successful at the task, despite the large number of faces that had to be remembered.
An ANOVA that was performed on RTs indicated the significance of auditory background (F3,156 = 5.1, p < 0.0022); test subjects exhibited faster RTs to faces that were studied in the presence of an auditory background of emotionally touching music (vs. joyful music, p < 0.04; vs. rain, p < 0.04) or silence (vs. joyful music, p < 0.001; vs. rain, p < 0.001) compared to other conditions. Figure 4 displays the mean RTs corresponding to correct recognition of old faces as a function of the presence of auditory background during learning.

Mean RTs for correctly recognized old faces as a function of the auditory background present during the study session.
Nonverbal episodic memory recall was significantly faster if study occurred in silent conditions or in conditions of emotionally touching music.
An ANOVA that was performed to assess heart rate measurements indicated the significance of auditory background (F3,156 = 3.5; p < 0.018). Post hoc comparisons showed that the test subjects exhibited significantly faster heart rates while listening to emotionally touching music compared to rain (p < 0.026) or silence (p < 0.006); this was also true in the case of listening to emotionally touching versus joyful music (p < 0.06). Listening to joyful music also tended to enhance heart rate (p < 0.06) compared to silence, as displayed in Fig. 5.

Mean heart rate (beats per minute) measurements recorded during different auditory background conditions.
Participants exhibited significantly faster heart rates while listening to music (especially emotionally touching music) compared to rain sounds or silence. The intensity of auditory background (in dB) was matched across conditions and therefore the changes in heart rate possibly reflected increased cognitive and emotional processing.
A statistical analysis of diastolic blood pressure (diaBLP) measurements demonstrated an effect of sex (F1, 52 = 11.1; p < 0.0016), with lower diaBLP values in women (74.5 mmHg; SE 1.36) than men (8.1 mmHg; SE = 1.36). The effect of auditory background did not reach statistical significance (F3.156 = 0.08) but diaBLP tended to increase when subjects listened to emotionally touching (p < 0.07) and joyful (p < 0.08) music, as compared to sounds of rain or silence. The means and standard deviations corresponding to the above analyses are shown in Fig. 6.

Diastolic (minim) blood pressure (diaBDP) values recorded as a function of auditory background.
Music listening tended to increase diaBDP (p < 0.08).
An ANOVA that was performed on systolic blood pressure (sysBDP) measurements indicated a significant effect corresponding to sex (F1,52 = 32.3; p < 0.000001), with much lower sysBDP values in women (112.6 mmHg, SE = 1.96) than men (128.5 mmHg, SE = 1.96) and no significant effect caused by auditory background, as displayed in Fig. 7.

Systolic (maximal) blood pressure (sysBDP) values recorded as a function of auditory background.
No effect was found between listening to music or rain sounds compared to silence.
Discussion
The aim of this study was to investigate how exposing subjects to varying auditory backgrounds while they engaged in a memory task affected later recognition performance. Response times were significantly faster and the recognition rate was higher for faces that were studied either in complete silence or in the presence of emotionally touching background music. Behavioral data demonstrated a higher recognition rate for new faces (correctly rejected as unfamiliar in 77.3% of hits with a 22.7% rate of error) than old faces (correctly recognized as familiar in 55.5% of hits with a 44.5% rate of error). This pattern is in accordance with previous literature and it indicates that regardless of the large number of faces that were presented (N = 448), participants were able to accurately reject approximately 4 out of 5 new faces on the basis of a lack of familiarity. In a previously conducted electrophysiological study39, the recognition rate of 200 total faces was compared to that of 100 new faces and produced 79.3% correct hits for the former and 66.3% for the latter. Similarly, Yovel and Paller40 obtained hit rates of 87.8% for new faces and 65.3% for old faces. In the ERP study that was conducted by Currand and Hancock41 and included 360 faces, the memory recognition rates were approximately 90% for new faces and 81% for old faces. Considering that there were a greater number of stimuli in the present study, the performance was satisfactory, especially with respect to new faces. Overall, the recognition rate for old faces was a little bit lower in this than in other studies not featuring an interfering auditory background. Learning conditions were purposely made difficult to overload cognitive and perceptual systems and to determine whether the effects of listening to music and rain on visual learning were disruptive or enhancing.
Overall, the results of this study demonstrated that subjects more accurately encoded faces while listening to emotionally touching music compared to listening to rain or joyful music, similarly to conditions of silence. The most plausible explanation for this enhancement (or lack of interference) is that listening to emotionally touching music increased the arousal of the listeners, which was indicated by their increased heart rates. However, the arousal hypothesis does not hold true in this case per se because heart rates were also increased while listening to joyful music (which was associated with an increased number of facial recognition errors). Furthermore, listening to music generally tended to increase blood pressure compared to listening to rain sounds. The significant cost of listening to joyful music, which had the same intensity (in dB) as the emotionally touching music and rain sounds, must therefore not be interpreted as a lack of arousal activation but rather as lacking the beneficial effect that is imparted by musically-induced emotions on the ability to encode faces. Therefore, a hypothesis can be proposed that suggests that listening to emotionally touching music leads to emotionally-driven audiovisual encoding that strengthens memory engrams for faces that are visualized in this context, whereas listening to either rain or joyful music produces interfering effects by overloading perceptual channels during face encoding, as predicted by numerous studies that have described the persistent negative effects of listening to music on memory performance1,4,13,14,15,17,18,19,20,21,22,23,24,25. Indeed, according to Jancke42 (2008), “nostalgic music” has a strong influence on episodic memory. A recent study by Gold et al.43 investigated the effects of music on mnemonic capacity. In this study, music that was considered to be pleasant by subjects was contrasted with emotionally neutral music; both types of music were listened to by musician and non-musician subjects. During music listening, participants were engaged in encoding and later recalling Japanese ideograms. The results showed that subjects with musical expertise exhibited better performance on memory tasks while listening to neutral music, whereas subjects with no musical training (as in our study) more successfully memorized the studied ideograms while listening to emotionally touching music. These group differences might be interpreted by assuming that musicians dedicate more cognitive and attentional resources to the technical analysis of a preferred song and its musical properties. Conversely, the better performance at ideogram recall that was exhibited by non-musically trained participants as they listened to emotionally pleasant music might be due to increased attentional and arousal levels that were stimulated by the music. Indeed, numerous studies support the hypothesis that musical perception is able to modify how the brain processes visual information, which is the same principle that underlies the concept of the movie soundtrack44,45,46,47,48. In this case, music can strongly influence the interpretation of a film narrative by becoming integrated into the memory along with visual information and therefore it provides continuation, directs attention, induces mood, communicates meaning, cues memory, creates a sense of reality and contributes to the aesthetic experience44. Furthermore, music can convey various types of emotional information via its harmony, rhythm, melody, timbre and tonality, which can inspire multiple types of emotions in the listener, both simultaneously and in succession49.
The ability of emotional sounds to influence visual perception has been shown experimentally for stimuli such as complex IAPS (International Affective Picture System) scenes50,51, photographs of faces and landscapes52, emotional facial expressions53 and schematics of faces embedded in noise54. In particular, with regard to faces, it has been shown that subjects were more accurate at detecting sub-threshold happy faces while listening to happy music and vice versa for sad faces and sad music. This suggests that music is able to modulate visual perception by altering early visual cortex activity and sensory processing in a binding modality54. In a separate study53, participants rated photographs of crying, smiling, angry and yawning faces while concurrently being exposed to happy, angry, sad and calm music, or no music and the results indicated that the participants made more favorable judgments about a crying face when listening to either sad or calm background music. Based on the current literature, it can be hypothesized that listening to music, especially emotionally touching music, might alter the visual perception of faces by making perceived faces (that were balanced for intensity and valence as uni-sensory visual stimuli) more emotionally charged and arousing to the viewer via a mechanism of audiovisual encoding. The higher arousal value of faces that were perceived in the presence of emotionally touching music (and to a lesser extent joyful music) was indicated by the increased heart rates of the participants that were measured under this condition. The result that higher hit rates were achieved with respect to emotive faces when participants were listening to emotionally touching music is compatible with current neuroscientific literature on facial memory. For example, untrustworthy faces are better remembered than trustworthy faces55; disgusting faces are better remembered than non-disgusting faces56; and faces expressing negative emotions are better remembered than neutral faces57,58. It is thought that this type of enhanced facial memory is due to a more general advantage that is imparted by remembering faces that are representative of negative or threatening contexts and it is associated with increased activity in the amygdala, hippocampus, extrastriate and frontal and parietal cortices during facial encoding58. A similar phenomenon might occur when faces are perceived in an arousing or emotional context (e.g., in a thriller movie with a scary soundtrack or in our study on listening to emotionally touching music). In others words, music might strengthen memory engrams by enhancing affective coding and enabling multimodal, redundant audiovisual memory encoding.
Although auditory background heavily affected memory accuracy and heart rate, it appeared to have little effect on blood pressure, except for a slight tendency to increase it during music listening. With regard to the effect of music listening on autonomic responses (blood pressure, heart rate and respiratory rate), the literature is very conflicting. Although it has been shown that listening to music can reduce pain intensity and systolic blood pressure in patients during postoperative recovery59 and can reduce stress levels and heart rate in patients with coronary heart disease and cancer60, a reduction in heart rate or blood pressure caused by listening to music has not been demonstrated in healthy controls. For example, in a study conducted by Radstaak and colleagues31, healthy participants had to perform a mental arithmetic task while being exposed to harassment to induce stress. Afterward, participants were assigned to one of several “recovery” conditions in which they either (1) listened to self-chosen relaxing or happy music, listened to an audio book, or sat in silence. Systolic blood pressure, diastolic blood pressure and heart rate were continuously monitored. The results indicated that although listening to both relaxing and happy music improved subjects moods, it did not diminish stress-enhanced systolic blood pressure. Therefore, mental relaxation was not associated with an improvement in autonomic parameters. In another interesting study32, systolic and diastolic blood pressure (BPsys, BPdia) were monitored as participants sat in silence and as they listened to 180-second-long recordings of two different “relaxing” and two different “aggressive” classical music excerpts. The results showed that listening to relaxing classical music and listening to aggressive classical music both increased BPsys, whereas autonomic modulation was lower under conditions of silence. Furthermore, in a study by Tan et al.33, the effect of relaxing music on heart rate recovery after exercise was investigated. Twenty-three healthy young volunteers underwent treadmill exercise and were then assessed for heart rate recovery and subjected to saliva analysis. The participants were either exposed to sedating music or to silence during the recovery period immediately following the exercise. No differences were found between exposure to music or silence with respect to heart rate recovery, resting pulse rate, or salivary cortisol. Overall, it appeared that although listening to music reduced anxiety under certain experimental settings, it did not seem to strongly influence hemodynamic parameters, except for a tendency to increase systolic blood pressure, which is consistent with the results of the present study.
In this study, accuracy and RT data indicated that participants committed more errors and were much slower when learning occurred under a background of rain sounds (vs. emotional music or silence). Although it is thought that listening to natural sounds (e.g., sounds of a rippling ocean, a small stream, soft wind, or a bird twittering) may produce relaxing and anxiety-reducing effects61, it has not been demonstrated that benefits to the learning process are imparted by listening to such sounds while studying and memory encoding. For example, a study that compared listening to silence versus listening to music or rain sounds during a backward digit span task found that auditory background produced no effect on performance whatsoever30. A study on the perception of white noise62, which shares several auditory properties with rain sounds (expect for artificiality), showed that listening to natural sounds (a running horse) and music tones decreased the ability of subjects to recall memories of scenes from their daily lives (compared to a condition of silence), whereas listening to white noise improved memory performance by improving connectivity between brain regions that are associated with visuospatial processing, memory and attention modulation. These results can be interpreted by assuming that the perception of recognizable and structured auditory objects (natural or musical sounds) interferes with memory processing, which is in agreement with the cognitive capacity model4. Conversely, listening to unstructured white noise does not produce such interference and alternatively increases cerebral arousal levels, in agreement with the arousal hypothesis5. In this context, the rain sounds and types of music that were used in the present investigation overloaded the perceptual systems of the participants, as shown by their reduced levels of performance on the assigned tasks compared to a condition of silence. However, listening to emotionally touching music benefitted concurrent emotional processing (associated with significantly increased heart rate), in agreement with a study conducted by Gold et al.43 and Quarto et al.63 In support of this hypothesis, several studies have provided evidence that listening to pleasant or emotionally arousing music can increase the heart rate of the listener64,65,66. Overall, the data indicate that perception of emotionally touching music can modify visual perception by binding visual inputs with emotionally charged musical information, resulting in deeper memory encoding.
One of the possible study’s limits is the existence of a culturally-mediated difference in the aesthetic musical preference between the judges and naïve participants who listened to the selected pieces. Indeed, while music evaluation resulting in the “touching and “joyful” characterization was performed by professional musicians that, as a result of their specific profession, have developed a quite positive aesthetic preference for classical music, naïve subjects (selected on the basis of their limited interest in music of whatever style) might have potentially found it boring or not interesting. Although aesthetics is based on liking or not an artwork, we assumed that touching and joyful music excerpts carried in their compositional structure some universal properties able to affect auditory processing of people not particularly skilled in music processing. The data strongly support this initial assumption, that music aesthetical preference is not only culturally, but also biologically based.
Additional Information
How to cite this article: Proverbio, A. M. et al. The effect of background music on episodic memory and autonomic responses: listening to emotionally touching music enhances facial memory capacity. Sci. Rep. 5, 15219; doi: 10.1038/srep15219 (2015).
Change history
14 December 2015
A correction has been published and is appended to both the HTML and PDF versions of this paper. The error has been fixed in the paper.
References
Kämpfe, J., Sedlmeier, P. & Renkewitz, F. The impact of background music on adult listeners: a meta-analysis. Psychol. Music. 39, 424–448 (2010).
Dalton, B. H. & Behm, D. G. Effects of noise and music on human and task performance: A systematic review. Occup. Ergonomics. 7, 143–152 (2007).
Kahneman, D. Attention and Effort. Englewood Cliffs. NJ: (Prentice-Hall 1973).
Furnham, A. & Allass, K. The influence of musical distraction of varying complexity on the cognitive performance of extroverts and introverts. Eur. J. Pers. 13 (1), 27–38 (1999).
Thompson, W. F., Schellenberg, E. G. & Husain, G. Arousal, mood and the Mozart effect. Psychol. Sci. 12, 248–251 (2001).
Cassidy, G. & MacDonald, R. A. R. The effect of background music and background noise on the task performance of introverts and extroverts. Psychol. Music. 35 (3), 515–537 (2007).
Ferreri, L., Aucouturier, J. J., Muthalib, M., Bigand, E. & Bugaiska, A. Music improves verbal memory encoding while decreasing prefrontal cortex activity: an fNIRS study. Front. Hum. Neurosci. 7, 779 (2013).
El Haj, M., Postal, V. & Allain, P. Music enhances autobiographical memory in mild Alzheimer’s disease. Educ. Gerontol. 38, 30–41 (2012).
Angel, L. A., Polzella, D. J. & Elvers, G. C. Background music and cognitive performance. Percept. Mot. Skills. 11, 1059–1064 (2010).
Hallam, S., Price, J. & Katsarou, G. The effect of background music on primary school pupils’ task performance. Educ. Stud. 28, 111–122 (2002).
Liu, B., Huang, Y., Wang, Z. & Wu, G. The influence of background music on recognition processes of Chinese characters: an ERP study. Neurosci Lett. 518 (2), 80–5 (2012).
Kang, H. J. & J. W. Williamson Background can aid second language learning. Psychol. Music. 42, 728–747 (2013).
Oakes, S. & North, A. C. The impact of background musical tempo and timbre congruity upon ad content recall and affective response. Appl. Cognitive Psych. 20, 505–520 (2006).
Woo, E. W. & Kanachi, M. The effects of music type and volume on short-term memory. Tohoku Psychol. Folia. 64, 68–76 (2005).
Iwanaga, M. & Ito, T. Disturbance effect of music on processing of verbal and spatial memories. Percept. Mot. Skills. 94, 1251–1258 (2002).
Furnham, A. & Allass, K. The influence of musical distraction of varying complexity on the cognitive performance of extroverts and introverts. Eur. J. Pers. 13, 27–38 (1999).
Bloor, A. The rhythm’s gonna get ya’—background music in primary classrooms and its effect on behaviour and attainment. J. Emot. Behav. Disord. 14, 261–274 (2009)
Avila, C., Furnham, A. & McClelland, A. The influence of distracting familiar vocal music on cognitive performance of introverts and extraverts Psychol. Music. 40, 84–93 (2011).
Miller, L. K. & Schyb, M. Facilitation and interference by background music. J. Music Ther. 26 (1), 42–54 (1989).
Moreno, R. & Mayer, R. E. A coherence effect in multimedia learning: the case for minimizing irrelevant sounds in the design of multimedia instructional messages. J. Educ. Psychol. 92, 117–125 (2000).
Miskovic, D., Rosenthal, R., Zingg, U., Oertli, D., Metzger, U. & Jancke, L. Randomized controlled trial investigating the effect of music on the virtual reality laparoscopic learning performance of novice surgeons. Surg. Endosc. 22, 2416–2420 (2008).
Kallinen, K. Reading news from a pocket computer in a distracting environment: Effects of the tempo of background music. Comput. Human Behav. 18, 537–551 (2002).
Thompson, W. F., Schellenberg, E. G. & Letnic, A. K. Fast and loud background music disrupts reading comprehension. Psychol. Music. 40, 1–9 (2011).
Madsen, C. K. Background music: competition for focus of attention in Applications of Research in Music Behavior (eds. Madsen, C. K. & Prickett, C. A. ) 315–325 (The University of Alabama Press, 1987).
Parente, J. A. Music preference as a factor of music distraction. Percept. Mot. Skills. 43, 337–338 (1976).
Bottiroli, S., Rosi, A., Russo, R., Vecchi, T. & Cavallini, E. The cognitive effects of listening to background music on older adults: processing speed improves with upbeat music, while memory seems to benefit from both upbeat and downbeat music. Front. Aging Neurosci. 10.3389/fnagi.2014.00284 (2014).
Reaves, S., Graham, B., Grahn, J., Rabannifard, P. & Duarte, A. Turn Off the Music! Music Impairs Visual Associative Memory Performance in Older Adults. The Gerontologist, 10.1093/geront/gnu113 (2015).
Mackrill, J., Jennings, P. & Cain, R. Exploring positive hospital ward soundscape interventions. Appl. Ergon. 45 (6), 1454–60 (2014).
Garza Villarreal, E. A., Brattico, E., Vase, L., Østergaard, L. & Vuust, P. (2012). Superior Analgesic Effect of an Active Distraction versus Pleasant Unfamiliar Sounds and Music: The Influence of Emotion and Cognitive Style. PLoS One 7 (1), e29397 (2012).
Steele, K. M., Ball, T. N. & Runk, R. Listening to Mozart does not enhance backwards digit span performance. Percept. Mot. Skills. 84, 1179–1184 (1997).
Radstaak, M., Geurts, S. A., Brosschot, J. F. & Kompier, M. A. Music and psychophysiological recovery from stress. Psychosom Med. 76 (7), 529–37 (2014).
Hilz, M. J., Stadler, P., Gryc, T., Nath, J., Habib-Romstoeck, L., Stemper, B., Buechner, S., Wong, S. & Koehn, J. Music induces different cardiac autonomic arousal effects in young and older persons. Auton Neurosci. 183, 83–93 (2014).
Tan, F., Tengah, A., Nee, L. Y. & Fredericks, S. A study of the effect of relaxing music on heart rate recovery after exercise among healthy students. Complement Ther Clin Pract. 20 (2), 114–7 (2014).
Kraus, N. & Chandrasekaran, B. Music training for the development of auditory skills. Nat. Rev. Neurosci. 11 (8), 599–605 (2010).
Spalek, K., Fastenrath, M., Ackermann, S., Auschra, B., Coynel, D., Frey, J., Gschwind, L., Hartmann, F., van der Maarel, N., Papassotiropoulos, A., de Quervain, D. & Milnik, A. Sex-dependent dissociation between emotional appraisal and memory: a large-scale behavioral and fMRI study. J Neurosci. 35 (3), 920–35 (2015).
Nater, U. M., Abbruzzese, E., Krebs, M. & Ehlert, U. Sex differences in emotional and psychophysiological responses to musical stimuli. Int. J. Psychophysiol. 62 (2), 300–8 (2006).
Proverbio, A. M. & Lozano Nasi, V. (in revision) Sex differences in the evaluation of human faces along the arousal and valence dimensions. Cogn. Emot.
Lang, P. J., Bradley, M. M. & Cuthbert, B. N. International Affective Picture System (IAPS): Technical Manual and Affective Ratings. (NIMH Center for the Study of Emotion and Attention, 1997).
Proverbio, A. M., La Mastra, F., Adorni, R. & Zani, A. How social bias (prejudice) affects memory for faces: An electrical neuroimaging study (Society for Neuroscience Abstracts, 2014 Annual Meeting of SFN, Washington, D.C. 2014).
Yovel, G. & Paller, K. A. The neural basis of the butcher-on-the-bus phenomenon: when a face seems familiar but is not remembered. NeuroImage. 21, 789–800 (2004).
Curran, T. & Hancock, J. The FN400 indexes familiarity-based recognition of face. Neuroimage. 36 (2), 464–471 (2007).
Jäncke, L. Music, memory and emotion. J. Biol. 7:21 10.1186/jbiol82 (2008).
Gold, B. P., Frankm, M. J., Bogertm, B. & Brattico, E. Pleasurable music affects reinforcement learning according to the listener. Front Psychol. 21, 4, 541 (2013).
Cohen A. J. Music as a source of emotion in film In Music and emotion: Theory and research (eds. Juslin, P. N. & Sloboda, J. A. ) 249–272 (Oxford University Press, 2001).
Iwamiya, S. Interaction between auditory and visual processing when listening to music in an audio visual context. Psychomusicology. 13, 133–53 (1994).
Sloboda, I. A. Empirical studies of emotional response to music In Cognitive bases of musical communication (eds. Iones, M. R. & Holleran, S. ), 33–46 (Washington, DC, American Psychological Association, 1992)
Rigg, M. G. The mood effects of music: A comparison of data from four investigations. J. Psychol. 58, 427–38 (1964).
Thayer, J. F. & Levenson, R. Effects of music on psychophysiological responses to a stressful film. Psychomusicology. 3, 44–54 (1983).
Kalinak, K. Settling the score. Madison, WI (University of Wisconsin Press, 1992).
Baumgartner, T., Lutz, K., Schmidt, C. F. & Jäncke, L. The emotional power of music: how music enhances the feeling of affective pictures, Brain Res. 1075 (1), 151–64 (2006).
Gerdes, A. B. M., Wieser, M. J., Bublatzky, F., Kusay, A., Plichta, M. M. & Alpers, G. W. Emotional sounds modulate early neural processing of emotional pictures. Front. Psychol. 4, 741 (2013).
Jomori, I., Hoshiyama, M., Uemura, J., Nakagawa, Y., Hoshino, A. & Iwamoto, Y. Effects of emotional music on visual processes in inferior temporal area. Cogn. Neurosci. 4 (1), 21–30 (2013).
Hanser, W. E., Mark, R. E., Zijlstra, W. P. & Vingerhoets, Ad J. J. M. The effects of background music on the evaluation of crying faces. Psychol. Music. 43, 75–85 (2015).
Jolij, J. & Meurs, M. Music alters visual perception. PLoS One. 21, 6(4), e18861 (2011).
Rule, N. O., Slepian, M. L. & Ambady, N. A Memory advantage for untrustworthy faces. Cognition. 125, 207–218 (2012).
Bell, R. & Buchner, A. Valence modulates source memory for faces. Mem. Cognit. 38, 29–41 (2010).
Johansson, M., Mecklinger, A. & Treese, A. C. Recognition memory for emotional and neutral faces: an event-related potential study. J. Cogn. Neurosci. 16 (10), 1840–1853 (2004).
Keightley, M. L., Chiew, K. S., Anderson, J. A. E. & Grady, C. L. Neural correlates of recognition memory for emotional faces and scenes. Soc. Cogn. Affect. Neurosci. 6 (1), 24–37 (2011).
Chen, H. J., Chen, T. Y., Huang, C. Y., Hsieh, Y. M. & Lai, H. L. Effects of music on psychophysiological responses and opioid dosage in patients undergoing total knee replacement surgery. Jpn. J. Nurs. Sci., Mar 9. 10.1111/jjns.12070 (2015).
Tan, Y. Z., Ozdemir, S., Temiz, A. & Celik, F. The effect of relaxing music on heart rate and heart rate variability during ECG GATED-myocardial perfusion scintigraphy. Complement. Ther. Clin. Pract., Feb 14. pii: S1744-3881(15)00002-X (2015).
Tsuchiya, M., Asada, A., Ryo, K., Noda, K., Hashino, T., Sato, Y., Sato, E. F. & Inoue, M. Relaxing intraoperative natural sound blunts haemodynamic change at the emergence from propofol general anaesthesia and increases the acceptability of anaesthesia to the patient. Acta Anaesthesiol. Scand. 47(8), 939–43 (2003).
Rauscher, F. H., Shaw, G. L. & Ky, K. N. Music and spatial task performance. Nature 365, 611 (1993).
Quarto, T. Blasi, G., Pallasen, K. J., Bertolino, A. & Brattico, E. Implicit Processing of Visual Emotions Is Affected by Sound-Induced Affective States and Individual Affective Traits. PLoS ONE 9 (7), e103278 (2014).
Etzel, J. A., Johnsen, E. L., Dickerson, J., Tranel, D. & Adolphs, R. Cardiovascular and respiratory responses during musical mood induction. Int. J. Psychophysiol. 61(1) 57–69 (2006).
Khalfa, S., Roy, M., Rainville, P., Dalla Bella, S. & Peretz, I. Role of tempo entrainment in psychophysiological differentiation of happy and sad music? Int. J. Psychophysiol. 68 (1), 17–26 (2008).
Withvliet, C. V. O. & Vrana, S. R. Play it again Sam: Repeated exposure to emotionally evocative music polarises liking and smiling responses and influences other affective reports, facial EMG and heart rate. Cogn. Emot. 21 (1), 1–23 (2006).
Acknowledgements
The authors are very grateful to all of the subjects for their generous participation and to the judges for kindly completing the initial survey and responding to the questionnaire on aesthetic musical preferences. Additionally, we wish to express our gratitude to M° Aldo Ceccato, Domenico Morgante, Andrea Pestalozza, Renato Rivolta, Mario Guido Scappucci and Luigi Verdi for their valuable suggestions on the selection of musical pieces.
Author information
Authors and Affiliations
Contributions
A.M.P: Conception and design; Analysis and interpretation of data; Wrote the paper. V.L.N., L.A.A., F.D., M.G. and M.G.: Acquisition and analysis of data; A.Z.: Contributed useful comments to an earlier version of manuscript; revised the article.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Mado Proverbio, A., Lozano Nasi, V., Alessandra Arcari, L. et al. The effect of background music on episodic memory and autonomic responses: listening to emotionally touching music enhances facial memory capacity. Sci Rep 5, 15219 (2015). https://doi.org/10.1038/srep15219
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep15219
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
