
Abstract
We study how urban quality evolves as a result of carbon dioxide emissions as urban agglomerations grow. We employ a bottom-up approach combining two unprecedented microscopic data on population and carbon dioxide emissions in the continental US. We first aggregate settlements that are close to each other into cities using the City Clustering Algorithm (CCA) defining cities beyond the administrative boundaries. Then, we use data on CO2 emissions at a fine geographic scale to determine the total emissions of each city. We find a superlinear scaling behavior, expressed by a power-law, between CO2 emissions and city population with average allometric exponent β = 1.46 across all cities in the US. This result suggests that the high productivity of large cities is done at the expense of a proportionally larger amount of emissions compared to small cities. Furthermore, our results are substantially different from those obtained by the standard administrative definition of cities, i.e. Metropolitan Statistical Area (MSA). Specifically, MSAs display isometric scaling emissions and we argue that this discrepancy is due to the overestimation of MSA areas. The results suggest that allometric studies based on administrative boundaries to define cities may suffer from endogeneity bias.
Similar content being viewed by others


Introduction
Allometry was originally introduced in the context of evolutionary theory1 to describe the correlation between relative dimensions of parts of body size, for instance brain size in mammals, with changes in overall body size. In a classical result, Kleiber showed that surface area, Y and the body mass, X, of a large range of mammal's are related by an allometric power-law Y = AXβ, where β = 3/4 is the allometric exponent and A is a constant2.
In analogy with biological systems, Bettencourt et al.3 showed that cities across US obey allometric relations with population size. Indeed, a large class of human activities can be grouped into three categories according to the value of the allometric exponent: (a) Isometric behavior (linear, non-allometric or extensive, β = 1) typically reflects the scaling with population size of individual human needs, like the number of jobs, houses and water consumption. (b) Allometric sublinear behavior (hipoallometric, non-extensive, β < 1) implies an economy of scale in the quantity of interest because its per capita measurement decreases with population size. Hipoallometry is found, for example, in the number of gasoline stations, length of electrical cables and road surfaces (material and infrastructure). (c) Superlinear behavior (hyperallometric, non-extensive, β > 1) emerges whenever the pattern of social activity has significant influence in the urban indicator. Wages, income, growth domestic product, bank deposits, as well as rates of invention measured by patents and employment in creative sectors, display a superlinear increase with population size. These superlinear scaling laws indicate that larger cities are associated with optimal levels of human productivity and quality of life; doubling the city size leads to a larger-than-double increment in productivity and life standards3,4,5.
The optimal productivity of large cities raises the question of the consequences of urban growth to environmental quality. Indeed, it is intensely debated whether large cities can be considered environmentally “green”, implying that their productivity is associated with lower than expected greenhouse gases (GHG) and pollutant emissions6,7,8,9,10,11. For instance, some of these studies report that the level of commuting has a major contributing to the relation between GHG emissions and city size6,7,8,11. As a consequence, compact cities would be more green due to the attenuation of the average commuting length. More recently, however, Gaigné et al.12 suggested that compact cities might not be as environmentally friendly as it was thought, mainly because increasing-density policies obligate firms and households to change place. This relocation of the urban system then generates a higher level of pollution. In this context, here we study the allometric laws associated with a particular type of GHG emissions from human activity by studying the relation between CO2 emissions of cities as a function of population size. We employ a bottom-up approach combining two unprecedented microscopic data on population and carbon dioxide emissions in the continental US. We first define the boundaries of cities using the City Clustering Algorithm (CCA)13,14,15,16,17,18,19,20,21 which are then used to calculate the CO2 emissions. We find a superlinear allometric scaling law between emissions and city size. We also explore different sectors and activities of the economy finding superlinear behavior in most of the sectors. Our results pertain only emissions of CO2. It will be desirable to extend it to the rest of GHGs. These results indicate that large cities may not provide as many environmental advantages as previously thought7,9,10,11.
Results
Datasets
We use two geo-referenced datasets on population and CO2 emissions in the continental US defined in a fine geometrical grid. The population dataset is obtained from the Global Rural-Urban Mapping Project (GRUMPv1)22. These data are a combination of gridded census and satellite data for population of urban and rural areas in the United States in year 2000 (Fig. 1a and Sec. 3). The GRUMPv1 data provides a high resolution gridded population data at 30 arc-second, equivalent to a grid of 0.926 km × 0.926 km at the Equator line.

Population and emissions in US.
(a) The population map of the contiguous US from the Global Rural-Urban Mapping Project (GRUMPv1)22 dataset in logarithmic scale. (b) The CO2 emissions map of the contiguous US from the Vulcan Project (VP) dataset23 measured in log base 10 scale of metric tonnes of carbon per year. (c) Map of the mean household income per capita of 3, 092 US counties in dollars from US Census Bureau dataset24 for the year 2000.
The emissions dataset is obtained from the Vulcan Project (VP) compiled at Arizona State University23. The VP provides fossil fuel CO2 emissions in the continental US at a spatial resolution of 10 km × 10 km (0.1 deg × 0.1 deg grid) from 1999 to 2008. The data are separated according to economic sectors and activities (see Sec. 3 for details): Commercial, Industrial and Residential sectors (obtained from country-level aggregation of non-geocoded sources and non-electricity producing sources from geocoded location), Electricity Production (geolocated sources associated with the production of electricity such as thermal power stations), Onroad Vehicles (mobile transport using designated roadways such as automobiles, buses and motorcycles), Nonroad Vehicles (mobile surface sources that do not travel on roadways such as boats, trains, snowmobiles), Aircraft (Airports, geolocated sources associated with taxi, takeoff and landing cycles associated with air travel and Aircraft, gridded sources associated with the airborne component of air travel) and Cement Industry.
We analyze the annual average of emissions in 2002 for the total of all sectors combined (see Fig. 1b) and each sector separately (Fig. 2). The choice of 2002 data (rather than 2000 as in population) reflects the constraint that it is the only year for which the quantification of CO2 emissions has been achieved at the scale of individual factories, powerplants, roadways and neighborhoods and on an hourly basis23.

The CO2 emissions maps in metric tonnes of carbon per year from Vulcan Project (VP) dataset23 for each sector: (a) Aircraft, (b) Cement, (c) Commercial, (d) Industrial, (e) On-road, (f) Non-road, (g) Residential and (h) Electricity.
To define the boundary of cities, we use the notion of spatial continuity by aggregating settlements that are close to each other into cities15,16,17,18,20,21. Such a procedure, called the City Clustering Algorithm (CCA), considers cities as constituted of contiguous commercial and residential areas for which we know also the emissions of CO2 from the Vulcan Project dataset. By using two microscopically defined datasets, we are able to match precisely the population of each agglomeration to its rate of CO2 emissions by constructing the urban agglomerations from the bottom up without resorting to predefined administrative boundaries.
We also use the US income dataset available in ASCII format by US Census Bureau24 for the year 2000. This dataset provides the mean household income per capita for the 3, 092 US counties. For each county, we combined the income data and the administrative boundaries25 in order to relate them with the geolocated datasets (Fig. 1c and Sec. 3).
We first apply the CCA to construct cities aggregating population sites Di at site i. The procedure depends on a population threshold D* and a distance threshold ℓ. If Di > D*, the site i is populated. The length ℓ represents a cutoff distance between the sites to consider them as spatially contiguous, i.e. we aggregate all nearest-neighbor sites which are at distances smaller than ℓ. Thus a CCA cluster or city is defined by populated sites within a distance smaller than ℓ as seen schematically in Fig. 3. Starting from an arbitrary seed, we add all populated neighbors at distances to the cluster smaller than ℓ until no more sites can be added to the cluster. The scaling laws produced by the CCA depend weakly on D* and ℓ. and we are interested in a region of the parameters where the scaling laws are independent of these parameters.

CCA stages: We consider that if Di > D*, then the site i is populated (light blue squares).
Each site is defined by its geometric center (black circles) and the length ℓ represents a cutoff on the distance to define the nearest neighbor sites. We aggregate all nearest-neighbor sites, i.e. a CCA is defined by populated sites within a distance smaller than ℓ (red circles).
This aggregation criterion based on the geographical continuity of development was shown to provide strong evidence of Zipf's law in the US and UK15,16,17,18,20,21 in agreement with established results in urban sciences26,27,28,29. For cut-off lengths above ℓ = 5 km, it was shown that CCA clusters verify the Zipf's law and the Zipf's exponent is independent of ℓ. Next, we first present results for aggregated clusters at ℓ = 5 km and then show the robustness of the scaling laws over a larger range of parameter space.
In order to assign the total CO2 emissions to a given CCA cluster, we superimpose the obtained cluster to the CO2 emissions dataset. If a populated site composing a CCA cluster falls inside a CO2 site, we assign to the populated site the corresponding CO2 emissions proportional to its area 0.9262 km2, considering that the emissions density is constant across the CO2 site of 102 km2. For a given CCA cluster, we then calculate the population (POP) and CO2 emissions by adding the values of the constitutive sites of the cluster.
Scaling of emissions with city size
Figure 4 shows the correlation between the total annual CO2 emissions and POP for each CCA cluster for ℓ = 5 km and D* = 1000 (N = 2281). We perform a non-parametric regression with bootstrapped 95% confidence bands30,31 (see Sec. 3). We find that the emissions grow with the size of the cities, on average, faster than the expected linear behavior. The result can be approximated over many orders of magnitudes by a power-law yielding the following allometric scaling law:

where A = 2.05 ± 0.12 and β = 1.38 ± 0.03 (R2 = 0.76) is the allometric scaling exponent obtained from Ordinary Least Squares (OLS) analysis32 for this particular set of parameters ℓ = 5 km and D* = 1000 (see Sec. 3 for details on OLS and on the estimation of the exponent error, all emissions are measured in log base 10 of metric tonnes of carbon per year).

Scaling of CO2 emissions versus population.
We found a superlinear relation between CO2 (metric tonnes/year) and POP with the allometric scaling exponent β = 1.38 ± 0.03 (R2 = 0.76) for the case ℓ = 5 km, D* = 1000. The solid (black) line is the Nadaraya-Watson estimator, the dashed (black) lines are the lower and upper confidence interval and the solid (red) line is the linear regression.
In addition, we investigate the robustness of the allometric exponent as a function of the thresholds D* and ℓ. Figure 5a shows β as a function of the cut-off length ℓ for different values of population threshold D* (1000, 2000, 3000 and 4000). We observe that β increases with ℓ until a saturation value which is relatively independent of D*. Performing an average of the exponent in the plateau region with ℓ > 10 km over D*, we obtain  . Thus, we find superlinear allometry indicating an inefficient emissions law for cities: doubling the city population results in an average increment of 146% in CO2 emissions, rather than the expected isometric 100%. This positive non-extensivity suggests that the high productivity found in larger cities3,4 is done at the expense of a disproportionally larger amount of emissions compared to small cities.
. Thus, we find superlinear allometry indicating an inefficient emissions law for cities: doubling the city population results in an average increment of 146% in CO2 emissions, rather than the expected isometric 100%. This positive non-extensivity suggests that the high productivity found in larger cities3,4 is done at the expense of a disproportionally larger amount of emissions compared to small cities.

Behavior of allometric exponent β.
(a) We plot β for the total emissions for different D* as a function of ℓ. The exponent β increases with ℓ until a saturation value. (b) Allometric exponent versus ℓ for the different sectors of the economy as indicated. The scaling exponent ranges from sublinear behavior (β < 1, optimal) on the cement and aircraft sectors, to superlinear behavior (β > 1, suboptimal) on nonroad and onroad vehicles and residential emissions, up to the less efficient sectors in commercial, industrial and electricity production activities.
Figure 5b investigates the emissions of cities as deconstructed by different sectors and activities of the economy. We perform non-parametric regression with bootstrapped 95% confidence bands of β (see Fig. 6 for D* = 1000 and ℓ = 5 km by each sector) versus ℓ and we find that the exponents for different sectors saturate to an approximate constant value for ℓ > 10 km. We assign an average exponent,  over the plateau per sector as seen in Table I. The sectors with higher exponents (less efficient) are Residential, Industrial, Commercial and Electric Production with
over the plateau per sector as seen in Table I. The sectors with higher exponents (less efficient) are Residential, Industrial, Commercial and Electric Production with  , above the average for the total emissions. Onroad vehicles contribute with a superlinear exponent
, above the average for the total emissions. Onroad vehicles contribute with a superlinear exponent  , yet, below the total average. The exponent for Nonroad vehicles is also below the average at
, yet, below the total average. The exponent for Nonroad vehicles is also below the average at  , while Aircraft sector displays approximate isometric scaling with
, while Aircraft sector displays approximate isometric scaling with  . Cement Production displays sublinear scaling
. Cement Production displays sublinear scaling  , although the reported data is less significant than the rest with only 20 datapoints of cities available.
, although the reported data is less significant than the rest with only 20 datapoints of cities available.

The plot shows the CO2 behavior measured in metric tonnes of carbon per year versus POP of the CCA clusters for different sectors.
We found a superlinear relation between CO2 and POP for all the cases, except to Aircraft and Cement sectors. The solid (black) line is the Nadaraya-Watson estimator, the dashed (black) lines are the lower and upper confidence interval and the solid (red) line is the linear regression.
We further investigate the dependence of the allometric exponent β on the income per capita of cities by aggregating the CCA clusters by their income (INC) and plotting the obtained β(INC) in Fig. 7 (see also Fig. 8). We find an inverted U-shape relationship, which is analogous to the so-called environmental Kuznets curve (EKC)7,33,34. We observe that β initially increases for cities with low income per capita until an income turning point located at $ 37, 235 per capita (in 2000 US dollar). After the turning point, β decreases indicating an environmental improvement for large-income cities. However, the allometric exponent remains always larger than one regardless of the income level (except for the lowest income) indicating that almost all large cities are less efficient than small ones, no matter their income.

Dependence of allometric exponent β on the income per capita of the CCA clusters.
We found an inverted-U-shaped curve similar to an environmental Kuznets curve (EKC). In other words, we find a decrease of the allometric exponent β for the lower and higher income levels, with the following regression coefficients a0 = −247.35, a1 = 108.88 and a2 = −11.91. The income turning point is located at  .
.

Total CO2 emissions in metric tonnes of carbon per year versus POP of CCA clusters for different income's range as indicated.
We found a superlinear relation between CO2 and POP for all the cases except for the lowest income below $ 25, 119. The solid (black) line is the Nadaraya-Watson estimator, the dashed (black) lines are the lower and upper confidence interval and the solid (red) line is the linear regression. The resulting exponent β(INC) is plotted in Fig. 7.
Comparison with MSA
A further important issue in the scaling of cities is the dependence on the way they are defined15,16,17,18,20,21,35. Thus, it is of interest to compare our results with definitions based on administrative boundaries such as the commonly used Metropolitan Statistical Areas (MSA)36 provided by the US Census Bureau37. MSAs are constructed from administrative boundaries aggregating neighboring counties which are related socioeconomically via, for instance, large commuting patterns. A drawback is that MSAs are available only for a subset (274 cites) of the most populated cities in the US and therefore can represent only the upper tail of the distribution17,21,35 (see Sec. 3 for details).
Furthermore, we find that the MSA construction violates the expected extensivity3,17 between the land area occupied by the MSA and their population since MSA overestimates the area of the small agglomerations17. This is indicated in Fig. 9, where we find the regression:

with aMSA = 0.81 ± 0.36 and bMSA = 0.51 ± 0.06 (R2 = 0.48). This approximate square-root law implies that the density is not constant across the MSAs:

On the contrary, CCA clusters capture precisely the occupied area of the agglomeration leading to the expected extensive relation between land area and population as seen also in Fig. 9:

with aCCA = −2.86 ± 0.06 and bCCA = 0.94 ± 0.01, with small dispersion R2 = 0.99, implying that the density of population of CCA clusters is well-defined (extensive), i.e. it is constant across population sizes,

In summary, while the CCA displays almost isometric relation between population and area, the MSA shows a sublinear scaling between these two measures. As a consequence, the emission of CCA is independent of the population density, as expected. On the other hand, from Eq. 2 and Eq. 6, the MSA leads to a superlinear scaling between them,  .
.

Scaling of the occupied land area versus population for MSAs and CCA clusters.
Two problems are evident from this comparison. First, the range of population obtained by MSA is two decades smaller than that of CCA since CCA captures all city sizes while MSA is defined only for the top 274 cities. Second, the MSA violates the extensivity between land area and population while CCA does not. This is due to the fact that MSA agglomerates together many small cities into a single administrative boundary with a large area which can be largely unpopulated, as can be see in the examples of Fig. 10. This results in an overestimation of the size of the areas of small cities compared with large cities, resulting in the violation of extensivity shown in the figure. This endogenous bias is absent in the CCA definition. This bias in the small cities ultimately affects the allometric exponent yielding a βMSA smaller than the one obtained using the CCAs.
The non-extensive character of the MSA areas is due to the fact that many MSAs are constituted by aggregating small disconnected clusters resulting in large unpopulated areas inside the MSA. This is exemplified in some typical MSAs plotted in Fig. 10, such as Las Vegas, Albuquerque, Flagstaff and others. The plots show that a large MSA area is associated to a series of disconnected small counties, like it is seen, for instance, in the region near Las Vegas. This clustering of disconnected small cities inside a MSA results into an overestimation of the emissions associated with the Las Vegas MSA, for instance. The same pattern is verified for many small cities, specially in the mid-west of US, as seen in the other panels. For some large cities, like NY, the agglomeration captures similar shapes as in the occupied areas obtained with CCA, although it is also clearly seen that the area of the NY MSA contains many unoccupied regions. Therefore, the occupied area of a typical MSA is overestimated in comparison to the area that is actually populated as captured by the CCA, the bias is larger for small cities than larger ones. This endogeneity bias leads to an overestimation of the CO2 emissions of the small cities as compared to large cities. Consequently, we find a smaller allometric exponent for MSA than CCA with an almost extensive relation:

with AMSA = 1.08 ± 0.38 and βMSA = 0.92 ± 0.07 (R2 = 0.71, see Fig. 11). This result is consistent with previous studies of scaling emissions of MSA by Fragkias et al.36, who used MSAs and found a linear scaling between emissions and size of the cities and also Rybski et al.38, who used administrative boundaries to define 256 cities in 33 countries. Table II and III summarize the results of CCA and MSA cities.

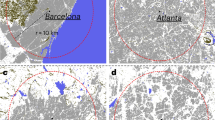
Examples of MSA and CMSA combining the datasets from Global Rural-Urban Mapping Project (GRUMPv1), Vulcan Project (VP) and US Census Bureau22,23,37: (a)–(c) MSA of Albuquerque (Albuquerque, NM); (d)–(f) MSA of Flagstaff (Flagstaff, AZ–UT); (g)–(i) CMSA of Los Angeles (Los Angeles–Riverside–Orange County, CA); (j)–(l) MSA of Reno (Reno, NV); and (m)–(o) MSA of Las Vegas (Las Vegas, NV–AZ).
In the first column, we plot the population as given by the GRUMPv1 dataset inside the administrative boundary of the MSA as provided by the US Census Bureau. The grey regions show the large unpopulated areas considered inside the MSA. The large MSA areas thus put together different populated clusters into one large administrative boundary. In the second column we plot the CO2 emissions dataset inside the boundary of each MSA. The population and the CO2 emissions are plotted in logarithmic scale according to the color bar at the bottom of the plot. In the third column, we plot the CCA clusters inside the corresponding MSA. Different from the MSA, the CCA captures the contiguous occupied area of a city.

CO2 emissions in metric tonnes/year versus POP using the MSA/CMSA definition of cities for the total CO2 emissions.
We found almost extensive relation between CO2 and POP with the allometric scaling exponent βMSA = 0.92 ± 0.07 (R2 = 0.71) The solid (black) line is the Nadaraya-Watson estimator, the dashed (black) lines are the lower and upper confidence interval and the solid (red) line is the linear regression.
Thus, the measurement bias in the MSAs leads to smaller β found for MSA as compared with CCA, since low-density MSAs have relatively large areas. Hence, the CCA results, which are not subject to that endogeneity bias, should be considered the main source of information on emissions. They show a positive link between emissions and population size as well as the expected extensive behavior of the occupied land. This analysis calls the attention to use the proper definition of cities when the scaling behavior of small cities needs to be accurately represented. Indeed, this issue arises in the controversy regarding the distribution of city size for small cities since the distribution of administrative cities (such as US Places) are found broadly lognormal (that is, a power law in the tail that deviates into a log-Gaussian for small cities)21,39,40,41,42, while the distribution of geography-based agglomerations like CCA is found to be Zipf distributed along all cities (power-law for all cities)13,14,15,16,17,18,20.
Discussion
In general, we expect that when the scaling obtained by CCA is extensive, then any agglomeration of CCA such as MSA, should give rise to extensive scaling too. However, when there are intrinsic long-range spatial correlations in the data (like in non-extensive systems with β ≠ 1), agglomerating populated clusters (as done with MSA) may give different allometric exponents depending on the particular administrative boundary used to define cities. It is of interest to note that, beyond MSA36, there are other administrative boundaries used in the literature to define cities, like for instance US-Places studied in39,40,41. This measurement bias is a generic property of any non-extensive system, such as a physical system at a critical point. Thus, scaling laws obtained using administrative boundaries to define cities which cluster data in a somehow arbitrary manner may need to be taken with caution.
In summary, we find that CCA urban clusters in the US have sub-optimal CO2 emissions as measured by a superlinear allometric exponent β > 1. The exponent β decreases for cities with low and high income per capita in agreement with an EKC hypothesis7. From the point of view of allometry, larger cities may not represent an improvement of CO2 emissions as compared with smaller cities.
Methods
Population dataset
The United States population dataset for the year 2000 is a part of the Global Rural-Urban Mapping Project (GRUMPv1). The GRUMPv1 is available in shapefile format on the Latitude-Longitude projection (Fig. 12a) and it was developed by the International Earth Science Information Network (CIESIN) in collaboration with the International Food Policy Research Institute (IFPRI), the World Bank and the Centro Internacional de Agricultura Tropical (CIAT)22 (Fig. 1a). The GRUMPv1 combines data from administrative units and urban areas by applying a mass-conserving algorithm named Global Rural Urban Mapping Programme (GRUMPe) that reallocates people into urban areas, within each administrative unit, while reflecting the United Nations (UN) national rural-urban percentage estimates as closely as possible22. The administrative units (more than 70, 000 units with population > 1, 000 inhabitants) are based on population census data and their administrative boundaries. The urban areas (more than 27, 500 areas with population > 5, 000 inhabitants) are based on night-time lights data from the National Oceanic and Atmospheric Administration (NOAA) and buffered settlement centroids (in the cases where night lights are not sufficiently bright). In order to provide a higher resolution gridded population data (30 arc-second, equivalent to a grid of 0.926 km × 0.926 km at the Equator line), the GRUMPv1 assumes that the population density of the administrative units are constant and the population of each site is proportional to the administrative unit areas located inside of that site. We exported the original data to the ASCII format on Lambert Conformal Conic projection (Fig. 12b), available to download at http://jamlab.org. Both projections parameters are defined as follow:
-
Projection name: Latitude–Longitude (LL)
-
Horizontal datum name: WGS84
-
Ellipsoid name: WGS84
-
Semi-major axis: 6378137
-
Denominator of flattening ratio: 298.257224
-
Projection name: Lambert Conformal Conic (LCC)
-
Standard parallels: 33, 45
-
Central meridian: –97
-
Latitude of projection origin: 40
-
False easting: 0
-
False northing: 0
-
Geographic coordinate system: NAD83

The map projections from Global Rural-Urban Mapping Project (GRUMPv1)22.
(a) Latitude-Longitude projection and (b) Lambert Conformal Conic projection of the population map of continental US.
Emissions dataset
The second dataset used in this study is the annual mean of the United States fossil fuel carbon dioxide emissions with the grid of 10 km × 10 km for the year 2002. Full documentation is available at http://vulcan.project.asu.edu/pdf/Vulcan.documentation.v2.0.online.pdf. This dataset was compiled by the Vulcan Project (VP) and it is already available in binary format on the Lambert Conformal Conic projection defined above. The VP was developed by the School of Life Science at Arizona State University in collaboration with investigators at Colorado State University and Lawrence Berkeley National Laboratory23. The VP dataset is created from five primary datasets, constituting eight data types: The National Emissions Inventory (NEI) containing the Non-road data (county-level aggregation of mobile surface sources that do not travel on roadways such as boats, trains, ATVs, snowmobiles, etc), the Non-point data (county-level aggregation of non-geocoded sources), the Point data (non electricity-producing sources identified as a specific geocoded location) and the Airport data (geolocated sources associated with taxi, takeoff and landing cycles associated with air travel); The Emissions Tracking System/Continuous Emissions Monitoring (ETS/CEM) containing the Electricity production data (geolocated sources associated with the production of electricity); The National Mobile Inventory Model (NMIM) containing the On-road data (county-level aggregation of mobile road-based sources such as automobiles, buses and motorcycles); The Aero2k containing the Aircraft data (gridded sources associated with the airborne component of air travel) and finally, the Portland Cement containing the cement production data (geolocated sources associated with cement production).
These data types supply the CO2 emissions sectors: Aircraft, Cement, Commercial, Industrial, Non-road, On-road, Residential and Electricity. In order to represent all the sectors in a 10 km × 10 km grid, the VP assumes that the CO2 emissions of each site is given by the contributions of the geocoded and non-geocoded (via area-weighted proportions) sources located inside of that site. We exported the original data to the ASCII format, available to download at http://lev.ccny.cuny.edu/~hmakse/soft_data (Fig. 1b and Fig. 2).
Income per capita dataset
We also use the US income dataset available in ASCII format by US Census Bureau24 for the year 2000. This dataset provides the mean household income per capita for the 3, 092 US counties. For each county, we combined the income data and the administrative boundaries (Fig. 1c) in order to relate them with the geolocated datasets. The US county boundaries are also available to download in ASCII format by the US Census Bureau25. However, we already joined these datasets and provided them to download at http://lev.ccny.cuny.edu/~hmakse/soft_data.
Superimposing the datasets
We superimposed the population and CO2 datasets on the Lambert Conformal Conic projection in order to estimate the CO2 emissions on a higher grid level (0.926 km × 0.926 km). We checked if each population site is inside of a CO2 site. If so, we assigned the CO2 value as proportional to its area (0.9262 km2), considering that the CO2 density is constant in each CO2 site. For the population and income datasets, we checked if each population site (actually, the center of mass) is inside of some US county boundary. If so, we assigned the income value for that site equal to the income value for the county. We performed this test taking into account that a horizontal line (in the polygon direction), starting in a point that is inside of a polygon, hits on it an odd number of times, while a point that is outside of the polygon, hits on it an even number of times.
MSA
The definitions of Metropolitan Statistical Area (MSA), Primary Metropolitan Statistical Area (PMSA) and Consolidated Metropolitan Statistical Area (CMSA) are provided by the US Census Bureau37. The MSAs are geographic entities defined by some counties socioeconomically related with population larger than 50, 000. The PMSAs are analogous to MSAs, however they are defined by just one or two counties also socioeconomically related with population larger than 1, 000, 000. Finally, the CMSA are large metropolitan region defined by some PMSAs close to each other. In order to set a relation between the definition of MSA/CMSA cities and CCA cities, we show the 15 most populated MSA/CMSA cities and the largest CCA cities associated to them in Table I and II. The largest CCA city associated to a given MSA/CMSA is defined by the most populated CCA city whose center of mass is inside of that MSA/CMSA boundary. All datasets are available to download from37, including the population and administrative boundaries of MSA/CMSA. Additionally, we make them available at http://lev.ccny.cuny.edu/~hmakse/soft_data.
Nadaraya-Watson method
In order to calculate the allometric scaling exponents, we performed well-known statistic methods31. For one data distribution {Xi, Yi}, we apply the Nadaraya-Watson method43,44 to construct the kernel smoother function,

where N is the number of points and Kh(x − Xi) is a Gaussian kernel of the form,

where the h is the bandwidth estimated by least squares cross-validation method45,46. We compute the 95% (α = 0.05) confidence interval (CI) by the so-called α/2 quantile function over 500 random bootstrapping samples with replacement.
For our case, the distribution is the set of values {Xi, Yi} = {log(POPi), log(CO2i)}, where i is from 1 to the number of CCA cities N. Furthermore, we calculate the exponents by the ordinary least square (OLS) method47. Let us to consider the terms,






The regression exponents (A and β in the equation Y = A + βX) are given by,

If the errors are normally and independently distributed, the standard error of each exponent is given by32,

where tα/2,N−2 is the Student-t distribution with α/2 = 0.025 of CI and N − 2 degrees of freedom and the variances σA and σβ are given by,

Finally, we show the value of the regression exponents as,

R-squared
The R2 is the coefficient of determination or R-squared and is calculated as following:

The R2 by emission sector and the average  are in Table I.
are in Table I.
Change history
04 March 2014
A correction has been published and is appended to both the HTML and PDF versions of this paper. The error has not been fixed in the paper.
References
Huxley, J. S. & Tessier, G. Terminology of relative growth. Nature 137, 780–781 (1936).
Kleiber, M. The fire of life: An introduction to animal energetic (John Wiley, New York, 1961).
Bettencourt, L. M. A., Lobo, J., Helbing, D., Kühnert, C. & West, G. B. Growth, innovation, scaling and the pace of life in cities. Proc. Natl. Acad. Sci. USA 104, 7301–7306 (2007).
Bettencourt, L. M. A. & West, G. B. A unified theory of urban living. Nature 467, 912–913 (2010).
Bettencourt, L. M. A., Lobo, J., Strumsky, D. & West, G. B. Urban scaling and its deviations: Revealing the structure of wealth, innovation and crime across cities. PLoS One 5, e13541 (2010).
Bento, A. M., Franco, S. F. & Kaffine, D. The efficiency and distributional impacts of alternative anti-sprawl policies. J. Urban Econ. 59, 121–141 (2006).
Kahn, M. E. Green cities: Urban growth and the environment (Brookings Institution Press, Michigan, 2006).
Brownstone, D. & Golob, T. F. The impact of residential density on vehicle usage and energy consumption. J. Urban Econ. 65, 91–98 (2009).
Dodman, D. Blaming cities for climate change? An analysis of urban greenhouse gas emissions inventories. Environ. Urban. 21, 185–201 (2009).
Puga, D. The magnitude and causes of agglomeration economies. J. Regional Sci. 50, 203–219 (2010).
Glaeser, E. L. & Kahn, M. E. The greenness of cities: Carbon dioxide emissions and urban development. J. Urban Econ. 67, 404–418 (2010).
Gaigné, D., Riou, S. & Thisse, J. F. Are compact cities environmentally friendly? J. Urban Econ. 72, 123–136 (2012).
Makse, H. A., Havlin, S. & Stanley, H. E. Modeling urban growth patterns. Nature 377, 608–612 (1995).
Makse, H. A., Andrade, J. S., Batty, M., Havlin, S. & Stanley, H. E. Modeling urban growth patterns with correlated percolation. Phys. Rev. E 58, 7054 (1998).
Rozenfeld, H. D. et al. Laws of population growth. Proc. Natl. Acad. Sci. USA 105, 18702–18707 (2008).
Giesen, K., Zimmermann, A. & Suedekum, J. The size distribution across all cities Double Pareto lognormal strikes. J. Urban Econ. 68, 129–137 (2010).
Rozenfeld, H. D., Rybski, D., Gabaix, X. & Makse, H. A. The area and population of cities: new insights from a different perspective on cities. Am. Econ. Rev. 101, 2205–2225 (2011).
Duranton, G. & Puga, D. The growth of cities (Work in progress, University of Toronto, 2012).
Gallos, L. K., Barttfeld, P., Havlin, S., Sigman, M. & Makse, H. A. Collective behavior in the spatial spreading of obesity. Sci. Rep. 2, 454 (2012).
Duranton, G. Delineating metropolitan areas: Measuring spatial labour market networks through commuting patterns (Processed, Wharton School, University of Pennsylvania, 2013).
Ioannides, Y. M. & Skouras, S. Gibrat's law for (all) cities: A rejoinder (2009). Accessed 30-01-2014. http://ase.tufts.edu/econ/research/documents/2009/ioannidesGibratsLaw.pdf; Ioannides, Y. & Skouras, S. US city size distribution: Robustly Pareto, but only in the tail J. Urban Econ. 73, 18–29 (2013).
Center for International Earth Science Information Network (CIESIN)/Columbia University, International Food Policy Research Institute (IFPRI), The World Bank & Centro Internacional de Agricultura Tropical (CIAT). Global Rural-Urban Mapping Project Version 1 (2011). Accessed 18-07-2013. http://sedac.ciesin.columbia.edu.
Vulcan Project. School of Life Science, Arizona State University (2013). Accessed 18-07-2013. http://vulcan.project.asu.edu.
U.S. Census Bureau. Small Area Income and Poverty Estimates (2013). Accessed 18-07-2013. http://www.census.gov.
U.S. Census Bureau. Cartographic Boundary Files (2013). Accessed 18-07-2013. http://www.census.gov.
Gabaix, X. Zipf's law for cities: An explanation. Q. J. Econ. 114, 738–767 (1999).
Ioannides, Y. M. & Overman, H. G. Zipf's law for cities: An empirical examination. Reg. Sci. Urban. Econ. 33, 127–137 (2003).
Giesen, K. & Suedekum, J. Zipf's Law for Cities in the Regions and the Country. Econ. Geogr. 11, 667–686 (2011).
Giesen, K. & Suedekum, J. The French Overall City Size Distribution (2012). 30-01-2014. http://region-developpement.univ-tln.fr/fr/pdf/R36/6_GiesenSudekum.pdf.
Silverman, B. W. Density estimation for statistics and data analysis (Chapman and Hall, New York, 1986).
Hardle, W. Applied nonparametric regression (Cambridge University Press, Cambridge, 1990).
Montgomery, D. C., Peck, E. A. & Vining, G. G. Introduction to linear regression analysis (Wiley, Sons, New York, 2006).
Kuznets, S. Economic growth and income inequality. Am. Econ. Rev. 45, 1–28 (1955).
Grossman, G. M. & Krueger, A. B. Economic growth and the environment. Q. J. Econ. 110, 353–378 (1995).
Krugman, P. R. The self organizing economy (Blackwell Publishers, Cambridge, 1996).
Fragkias, M., Lobo, J., Strumsky, D. & Seto, K. C. Does size matter? Scaling of CO2 emissions and U.S. urban areas. PLoS One 8, e64727 (2013).
U.S. Census Bureau. Pre-2010 Cartographic Boundary File Naming Conventions and Download Access (2013). Accessed 18-07-2013. http://www.census.gov.
Rybski, D., Sterzel, T., Reusser, D. E., Fichtner, C. & Kropp, J. P. Cities as nuclei of sustainability? (2013). Accessed 19-11-2013. http://arxiv.org/abs/1304.4406.
Eeckhout, J. Gibrat's law for (All) cities. Am. Econ. Rev. 94, 1429–1451 (2004).
Levy, M. Gibrat's law for (all) cities: Comment. Am. Econ. Rev. 99, 1672–1675 (2009).
Eeckhout, J. Gibrat's law for (all) cities: Reply. Am. Econ. Rev. 99, 1676–1683 (2009).
Glaeser, E. L. Agglomeration Economics (University of Chicago Press, Chicago, 2010).
Nadaraya, E. On estimating regression. Theor. Probab. Appl. 9, 141–142 (1964).
Watson, G. S. Smooth regression analysis. Sankhya Ser. A 26, 359–372 (1964).
Racine, J. & Li, Q. Nonparametric estimation of regression functions with both categorical and continuous data. J. Econometrics 119, 99–130 (2004).
Li, Q. & Racine, J. Cross-validated local linear nonparametric regression. Stat. Sinica 14, 485–512 (2004).
Press, W. H., Teukolsky, S. A., Vetterling, W. T. & Flannery, B. P. Numerical recipes: The art of scientific computing (Cambridge University Press, New York, 2007).
Acknowledgements
We gratefully acknowledge funding by NSF, CNPq, CAPES and FUNCAP. We also thank the US Census Bureau, Global Rural-Urban Mapping Project and Vulcan Project teams for the datasets provided. Furthermore, we would like to thank X. Gabaix and S. Alarcon for helpful discussions.
Author information
Authors and Affiliations
Contributions
E.A.O., J.S.A. and H.A.M. designed research, performed research and wrote the manuscripts.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Rights and permissions
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-nd/3.0/
About this article
Cite this article
Oliveira, E., Andrade, J. & Makse, H. Large cities are less green. Sci Rep 4, 4235 (2014). https://doi.org/10.1038/srep04235
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep04235
This article is cited by
-
Evaluation of carbon emission efficiency based on urban scaling law: take 308 cities in China as an example
Environmental Science and Pollution Research (2023)
-
Impact of population agglomeration in big cities on carbon emissions
Environmental Science and Pollution Research (2022)
-
The Impacts of City Size and Density on CO2 Emissions: Evidence from the Yangtze River Delta Urban Agglomeration
Applied Spatial Analysis and Policy (2022)
-
Access to mass rapid transit in OECD urban areas
Scientific Data (2020)
-
Effects of changing population or density on urban carbon dioxide emissions
Nature Communications (2019)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
