
Abstract
We use a globally consistent, time-resolved data set of CO2 emission proxies to quantify urban CO2 emissions in 91 cities. We decompose emission trends into contributions from changes in urban extent, population density and per capita emission. We find that urban CO2 emissions are increasing everywhere but that the dominant contributors differ according to development level. A cluster analysis of factors shows that developing countries were dominated by cities with the rapid area and per capita CO2 emissions increases. Cities in the developed world, by contrast, show slow area and per capita CO2 emissions growth. China is an important intermediate case with rapid urban area growth combined with slower per capita CO2 emissions growth. Urban per capita emissions are often lower than their national average for many developed countries, suggesting that urbanisation may reduce overall emissions. However, trends in per capita urban emissions are higher than their national equivalent almost everywhere, suggesting that urbanisation will become a more serious problem in the future. An important exception is China, whose per capita urban emissions are growing more slowly than the national value. We also see a negative correlation between trends in population density and per capita CO2 emissions, highlighting a strong role for densification as a tool to reduce CO2 emissions.
Similar content being viewed by others

Introduction
Cities are responsible for close to 70% of global CO2 emissions associated with energy consumption1. In North America, the proportion reaches 80% depending upon the definition of emissions scope and urban boundary2,3. Furthermore, cities could add over 2 billion people this century with global urban area tripling by 20304,5. While concern mounts over the potential lock-in of high-emitting infrastructure, many cities also have taken leadership on greenhouse gas mitigation, pledging ambitious reduction targets6,7. Quantifying trends in urban CO2 emissions is critical to understanding near-term urban emission trajectories. Identifying major contributions to these trends will help expose the factors driving emissions over the longer term. These drivers are points of mitigation leverage, a goal of several urban alliances such as the Global Covenant of Mayors or the C40 Cities Alliance8.
Given the rate of urbanisation, it is important to establish whether, on average, urbanisation contributes to increased national/global CO2 emissions. This has been a source of considerable debate with the consensus that developing cities are generally wealthier and more energy-intensive than the rural areas from which they draw their population. Thus, urban dwellers will consume more energy when compared to rural lifestyles, such that urbanisation per se, drives increased CO2 emissions9. A countervailing view is that, beyond some stage in its development, economic growth in cities comes from low-emissions service industries so that urbanisation will be a decreasing or even negative contributor to national/global CO2 emission trends10. This is a version of the Environmental Kuznets Curve (EKC)11. The more general statement of the EKC, that economic growth will first worsen but then improve environmental outcomes has been both theoretically and empirically controversial12.
To elucidate the role of urbanisation in emissions trends we would ideally like a quantitative analysis of the factors driving emissions. We could then ask whether such factors acted differently in urban and non-urban settings and during different stages of urban development. Such data is not available globally or for a long enough period for our needs. We can, however, decompose urban emissions into underlying factors and study the trajectories of different cities through the space defined by these factors. The approach is motivated by13 who performed a similar analysis for national emissions. They decomposed emissions according to the KAYA identity as [a product of population, per capita GDP and the carbon intensity of the economy. They were thus able to distinguish pathways of emissions growth undertaken by regions or countries. Our decomposition must account for changes in city area and cannot include economic data since we lack this at the needed resolution. We can track the effects of changing population density and per capita emissions in hopes of revealing the variety of development pathways.
Most previous studies of trends in urban emissions have been limited by either space or time. these studies are simplest within one country where definitions of urban boundaries and emissions are more likely to be homogeneous. Examples include: Malaysia14, Turkey15, U.S.16,17, Japan18, U.K.19. Efforts at data harmonization, either by the researcher or regional agencies, allowed multicountry studies e.g.: African region20,21, developed countries22, developing countries23,24, and Europe25.
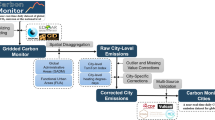
Some recent studies have been able to extend the domain of such studies to the globe. Wu et al.,26 used measurements from the Orbiting Carbon Observatory (OCO-2) to quantify emissions from 20 cities. While this platform removes some of the restrictions of self-reported or proxy emissions data it limits the spatiotemporal extent for inferences and enforces a meteorological definition of city boundaries. Crippa et al.,27 used the Emissions Database for Global Atmospheric Research (EDGAR)28 and an urban classification based on the Global Human Settlement Layer (GHSL)29 to derive longer-term trends in urban emissions. They found that CO2 emissions had grown rapidly for large cities in emerging areas while they have not in high-income countries. They also showed considerable variability in per capita emissions but noted that developed countries appear to have decoupled economic growth from emissions, at least in large cities. One limitation of this study is the spatial resolution of EDGAR (0.1o) and temporal resolution of the underlying population database (roughly five years). Here we extend the study of Crippa et al.,27 by using a higher spatial resolution (30 arc seconds) and a higher native temporal resolution (1 year). We wish to understand the contributions of bulk urban characteristics (area, population density and per capita emissions) make to trends in emissions.
To probe this question, we must separate the contributions of population growth and per capita CO2 emissions trends from total CO2 emissions growth. Such analyses require a time-series of the urban extent and CO2 emissions with global coverage and enough duration to establish trends. No direct data set allows this. In particular, integrated measures of urban emissions or energy consumption such as fuel sales or electricity flows cannot disentangle the contributions to change. There are now reliable, remotely sensed proxies of urban energy consumption or CO2 emissions which meet these criteria. By combining these with measures of urban extent and some underlying emissions contributors we can generate a global picture of the interaction of urbanisation and CO2 emissions.
Previous studies have studied the relationships between emergent and intrinsic properties of cities (such as emissions and size). Gudipudi et al.,30 used the traditional Kaya identity31 to examine the relationship between emissions and underlying drivers. Ribeiro et al.,17 used production functions to relate parameters such as population and area and emissions. Both these studies (as with most others) use static data sets. As one by-product of our approach we will test whether a fit to cross-sectional data (static in time) plus an index of urban development suffice to explain emission trends. Our target is the trend in emissions. Bettencourt et al.,32 noted that scaling properties derived from temporal and spatial (cross-sectional in their terminology) analyses were not equivalent.
Our study establishes these trends directly for a group of cities and examines drivers of these trends. For this we require a data set with global coverage and a considerable time-span. these have not, to our knowledge, been available before, at least using consistent definitions.
The other reason to monitor urban emissions directly is more practical. The United Nations Framework Convention on Climate Change33 suggests monitoring the spatiotemporal variations of GHG emissions to inform international climate change policy13,34. Atmospheric concentration measurements combined with on-ground information are emerging as the means to best achieve the combination of accurate emissions tracking and detailed source characterization of emissions in urban areas35,36,37.
The structure of this paper is as follows: The “result” section describes the analytical method, a modified form of the Kaya identity, and the data sources used in our analysis. The “discussion” section describes the resulting trends in these emission contributors and summarises our major findings, a cluster analysis to place the trends in a regional context, and placement of urban emissions within the national context to demonstrate the potential impact cities may have on future national trends. The “method” comments on the implications and caveats of the results.
Results
Trends
Figure 1 shows the emission trends for the 91 cities in our analysis (trend values of each city are provided in supplementary data as Table 1). Overall, we see rapid increases in urban CO2 emissions averaging 4.7%/yr. These averages conceal considerable variability across cities with emission trends ranging from −2.8%/yr (Madrid Spain) to 11.0%/yr (Xi’an, China). On average, the dominant contributor for CO2 emissions growth is the change in urban area, (3.5%/yr). The change in population density contributes −0.6%/yr, indicating that cities continue to sprawl as they grow. The trend in per capita CO2 emissions makes a positive contribution (averaging 2.2%/yr).

a Overall emission trends for 91 large cities b overall area trends, c overall population density trends, and d overall per capita emissions trends. Circles show the location of the chosen cities.
There are also significant relationships among the trends. Table 2 shows the correlations among the contributors across the 91 cities. It is important to stress that these are not temporal correlations but represent the relationship between trends in the three contributor variables across the 91-city sample.
The correlation of the area trend with the other two contributors is to be expected: cities that grow fast in areal extent, see declines in population density and increases in per capita CO2 emissions. More surprising is the correlation between the two intensive contributors, population density and per capita CO2 emissions. The relationship suggests that cities experiencing declines in population density, have increasing per capita CO2 emissions providing direct evidence of the impact of changing urban form on CO2 emissions.
Cluster analysis
While there is considerable spatial variability in trends and their contributors, some significant patterns emerge among classes of cities. We investigate these by performing a cluster analysis using the three contributors in Eq. 3.
Cluster analysis is a method for objectively identifying groupings in multi-dimensional data. Here we use a centroid-based technique: If each point is described by N parameters then these define its coordinate in an N-dimensional space. Clusters are defined so that the distance from every point in a cluster to its centroid (defined as the average of all the coordinates in the cluster) is less than that to the centroid of any other cluster. The number of clusters is set by the user and is generally chosen by considering the change in some metric of the analysis as a function of the chosen number of clusters. Here we use the Calinski-Harabasz score38 which is roughly the ratio of the average distance between members of a cluster to that between clusters. One seeks the maximum amount of information available before we move from delineating truly isolated clusters to partitioning randomly distributed points within clusters. For our analysis we use the KMeans function from the python scikit-learn package39.
Figure 2 shows Calinski-Harabasz metric as a function of the number of clusters. Optimal choices for the number of clusters occur at inflections in this curve, with the segments between demonstrating partition of randomly distributed points. For our case the optimal choice is four.

From the inflection in the curve, four clusters are chosen.
Henceforth we focus on our choice of four clusters. Figure 3 shows the cluster assignment for each city while Table 3 shows the cluster characteristics.

The clusters are grouped into four and their characteristics are described in Table 3.
The clusters can be classified according to their overall emission trends. This yields two high-growth clusters, one intermediate and one low-growth cluster.
Cluster 1 shows a moderate positive area trend with a larger positive per capita emissions trend. It is dominated by cities in the developing world, mostly the Asian subcontinent. Cluster 2 exchanges these contributions with the area trend contributing more than the per capita emission trend. It is dominated by Chinese cities. Clusters 3 and 4 show similar area trends but are differentiated by their per capita emissions trends. Cluster 3, with a positive per capita emissions trend, contains mostly cities throughout the developing world in addition to the two largest cities in Australia, Sydney and Melbourne. Cluster 4, with the lowest positive emissions trend, is the only cluster to show a negative per capita emissions trend. It consists almost entirely of cities in the developed world. The presence of Baghdad in this cluster suggests the role of conflict in reducing per capita emissions.
National emissions impact of urbanisation
We define the rate of urbanisation as the trend in the proportion of the population living in cities. Let us define the national population as P, the urban fraction of the population as c, the urban per capita emissions as u and the non-urban per capita emissions as n. We can write the national emissions as
Differentiating yields
The role of urbanisation in trends in national emissions is the contribution of \(\frac{{dc}}{{dt}}\) to \(\frac{{dF}}{{dt}}\), i.e., P (u − n). We also know that the national per capita emissions e are given by
Some manipulation yields the coefficient of \(\frac{{dc}}{{dt}}\) in Eq. 2 as \(P\frac{{u - e}}{{1 - c}}\). Thus, urbanisation contributes positively to the trend in national emissions if urban per capita emissions are higher than the national average and vice versa. Changes in the role of urbanisation hence depend on \(\frac{d}{{dt}}(u - e)\), the trend in urban versus national per capita emissions. We can calculate the difference in per capita emissions for a reference year and the trend in this difference over our data set. We calculate the emissions for a reference year by fitting a linear regression to the per capita emissions and calculating the value of the resulting fit at the reference year (in this case 2010.5 representing the 2010 average). Figure 4 shows both these values for 39 countries containing cities in our data set.

a Difference between reference year per capita emissions, and b percentage trend (trend divided by reference) between large cities and their host countries.
We average reference per capita emissions and trends for multiple cities in one country. The averaging is population-weighted. Egypt had too few points in its national emissions to allow calculation of trends and it is therefore excluded.
Figure 4 (panel a) shows that the current role of urbanisation is mixed. There is a tendency for developed countries to have urban per capita emissions lower than national emissions. This is by no means universal and several developing countries show the same behaviour. The case for trends in per capita emissions (panel b) is less equivocal. Here most countries show more rapid growth in urban than national emissions though again there are exceptions. There is little difference between developed and developing countries in this regard. One important exception is China whose 2010 urban per capita emissions are larger than the national value but with much slower growth. The results themselves do not shed light on whether this striking anomaly is a result of particularly emissions-efficient growth in China’s cities or the result of an explicit policy to move high-emissions industries away from cities, trading-off urban and non-urban CO2 emissions40. Cheng et al.,41 came to a similar conclusion using a traditional version of the Kaya identity and a cross-section of Chinese cities for the period 2000—2016.
Discussion
There are several caveats to the analysis presented above. First, the spatial structure of CO2 emissions calculated here is deduced from the distribution of satellite-derived nighttime lights starting in the early 1990s42,43,44. These are used to downscale country-level fossil fuel emissions provided by various national and international agencies45,46,47. When considering urban CO2 emissions, the important quantity is the proportion of nighttime lights irradiance arising from the city compared to the country as a whole. There are two potential problems with this proxy. First, trends in the proportion of urban to country nighttime lights that arise from the different penetration rates of lighting technologies in urban and rural areas will contaminate our results. We expect these to introduce noise rather than bias since the take-up of this technology is highly variable. This problem reaches its most acute with the reference emissions for 2010.
The other problem is that the time-averaged spatial distribution of emissions might not be perfectly represented by nighttime lights. If this misrepresentation occurs, the temporal variation driven by urban growth will be incorrect. This problem highlights the need for better spatial proxies for individual emission sectors but at the moment these are not available. Recent advances in the EDGAR emissions product28 may provide a path forward but will require extreme care in how proxies are used to downscale national statistics. Analysis by Doll et al.,42 suggests that nighttime lights are a reasonable proxy for temporal snapshots of spatial emissions but there are few independent data sets to assess trends.
There is also some ambiguity in the quantity represented by the ODIAC results displayed in Fig. 4. The intensity of nighttime lights is a mixed indicator of emissions (scope 1) and energy consumption (scope 2). The comparisons with bottom-up inventories carried out by Asefi-Najafabady et al.,45 suggest this is not a major limitation for this application. Furthermore, the role of urban development in overall emissions is also a mixed scope 1 and scope 2 problem, so it is likely the nighttime lights distribution captures the relevant dynamics.
The results of this study have implications both for CO2 emissions projections and preferred modes of urban development. First, we note the range of trends in per capita emissions. The per capita CO2 emissions trend is the largest single contributor to the urban CO2 emissions trend explaining, alone, 75% of the variance. Reducing this trend in the developing world seems, from our analysis, to be a general and powerful mitigation pathway. Cluster 2 (largely China) offers evidence that this is possible. In developed countries, our analysis suggests that the evolution of urban density is an opportunity for mitigation. Figure 4 does not show clear differences between developed and developing countries in the current role of urbanisation. The comparison of trends does not suggest any simple relationship as in the UKC. If there are discernible contributors of per capita CO2 emissions trends, these might be valuable points of policy intervention to limit emissions growth. Possible candidates include an urban form48 and economic specialisations.
The correlations among contributors of urban emissions also contain pointers for policy intervention. Table 1 shows that far from densifying, rapidly growing cities are generally thinning. This is associated with a growth in per capita CO2 emissions. There is also a direct correlation between trends in population density and per capita emissions. Cities choosing a development path with greater population density are also minimising their growth in per capita CO2 emissions. The historical link between urban planning and carbon efficiency should motivate city managers to strengthen policies on urban density.
Figure 4 also carries an important lesson for studies of urban development and emissions. The panel a describes a snapshot in time. The snapshot suggests that per capita emissions decrease relative to national totals as cities develop. The trend analysis (panel b) suggests this is not the case. This highlights again the importance of data sets that can probe the temporal and spatial aspects of urban development and the risks of using a static view to predict evolution. The complex relationship between size and emissions trend is support by Crippa et al.,27, showing that different urban categories had different trends.
This work is an opening exploration of a potentially rich data set. While we have captured most of the world’s largest cities, some are missing due to incomplete Landsat data or the impossibility of determining an urban boundary in a large agglomeration such as the U.S. East Coast. Nonetheless, we should broaden the coverage of the data, in particular to include the mass of smaller cities which are also changing rapidly.
We stress that this analysis is descriptive rather than casual. Trends in multiple contributors may have common underlying drivers. Also, we do not consider energy flows (either embodied or direct) between urban and non-urban regions. An important future task is to investigate the underlying drivers of the relationships exhibited here. For example, how important is the trend in per capita GDP as an explanatory variable and can we learn anything about the carbon efficiency of the economies of different cities. This requires considerable care since many of the data sets attempting to spatially allocate economic activity also use nighttime lights as proxies, confounding the required independence of the explanatory variable.
We analysed trends of CO2 emissions for 91 of the world’s largest cities using algorithmically generated urban boundaries overlaid on gridded fossil fuel CO2 emissions data. The average growth rate of 4.4%/yr reflects rising CO2 per capita emissions globally and the growth in our chosen cities. With a modified Kaya identity as a framework, we decomposed urban CO2 emissions into three contributing variables: area, population density and per capita CO2 emissions. The trend in area contributes to CO2 emissions growth across almost all cities while the trend in per capita CO2 emissions makes a large contribution in most developing countries. Population density and per capita CO2 emissions trends correlate negatively, suggesting a relationship between changing urban form and per capita CO2 emissions. For our reference year of 2010, the per capita emissions in developed countries are generally lower than the national average, while those in developing countries are generally higher. With the strong exception of China, emissions trends are generally larger for our chosen cities than the national averages suggesting that urbanisation will play an increasing role in driving national emissions and highlighting the importance of mitigation policies for cities.
Methods
Datasets and exceptions
Our task is to calculate trends in fossil fuel emissions for major cities, decompose these into their dominant contributors and investigate possible patterns in these contributors. Our chosen contributors are population, area and per capita emissions. Our analysis requires data for urban extent, fossil fuel CO2 emissions and population. Urban extent is generated from the Built-up, Nighttime lights and Travel Time for Urban Size (BUNTUS) algorithm of Luqman et al.,49. This algorithm defines a metric based on land cover classification, nighttime lights intensity and travel time to an urban centroid. All contiguous 30 arc-second pixels scoring above a threshold are included and the algorithm accounts for non-urban islands such as large parks or open space inside cities. We commenced our analysis with 91 cities chosen mainly by population50. The 91 cities span 39 countries with nineteen in China, twelve in the United States and nine in India. All other countries represented have three or fewer cities. Our study period covers 2000–2018, the longest period for which all our required data sets exist.
Some large cities are excluded from the study. There are two reasons for this. Firstly, the necessary imagery may not exist across enough of our study period. The usual gap is the Landsat imagery necessary to characterise the urban boundary. The second is that some cities exist as parts of such large agglomerations that their boundaries cannot be defined by physical data. The clearest example is New York City which forms part of a larger agglomeration on the East Coast of the U.S. The excluded cities are listed in Table 1. There is a problem of land cover classification for some cities. As noted by Luqman et al.,49, a common trajectory for growing cities is that two regions defined as urban by BUNTUS fuse to a single region. This obviously changes area and consequently total emissions suddenly, complicating trend analysis. Where this occurs we carry out the analysis for the whole period and include any city defined within the largest boundary of our chosen city (usually 2018). For example, Beijing commences with 13 cities in 1998 and finishes with one in 2018. The name we assign to the final city is its name in 2018.
Gridded population estimates come from the LandScan product51. LandScan is a global population database depicting an ambient (24-hour average) population distribution. The LandScan methodology disaggregates subnational census information through a suite of dynamically adaptable algorithms using spatial data, imagery-derived spatial products, and manual corrections. LandScan exploits spatial data and imagery analysis technologies in a multi-variable asymmetric modeling approach52. LandScan data represents an average, or ambient, population that integrates diurnal movements and collective travel habits into a single measure52. This is different from purely residential population maps but is better suited for comparison with emissions which include both residential and nonresidential activities of the target population.
CO2 emissions are taken from The Open-Data Inventory for Anthropogenic Carbon dioxide (ODIAC)53. ODIAC is a global high resolution (1 km × 1 km) fossil fuel CO2 emission data product53,54. ODIAC is based on spatial disaggregation of CO2 emission estimates made by the Carbon Dioxide Information Analysis Center (CDIAC)55. CDIAC emissions are estimated by fuel type (solid, gas, and liquid fuels, bunker fuel, and gas flares) plus cement production, rather than the emission sector that is often used for the national inventory compilation56. The ODIAC spatial disaggregation is done in two steps. First, emissions from point sources (mainly power plants) are estimated and mapped using the power plant emission estimates and geolocation taken from a global power plant database. The rest of the emissions (country total minus point source emissions), which we refer to a non-point source emissions, are distributed using the spatial distribution of satellite-observed nighttime lights (NTL) intensities53,54. Non-point source emissions are disaggregated to a 1 km × 1 km spatial resolution using Defense Meteorological Satellite Program (DMSP) calibrated radiance and Visible Infrared Imaging Radiometer Suite (VIIRS) NTL datasets, with mitigated saturation effect, developed by National Oceanic and Atmospheric Administration’s (NOAA) Earth Observation Group57. The calibrated radiance NTL data is a merged product of the regular DMSP NTL product and benefits from reduced gain observations58. Oda et al.,53 show an improved spatial emissions distribution from the original publication by Oda and Maksyutov,54 due to the use of the calibrated radiance data. We calculate emissions for each city in each year by summing all emissions from ODIAC for that year which lie within the polygon defined by BUNTUS. All the data values are provided as Supplementary Table 2.
Kaya Identity
We proceed by analogy with economics which frequently decomposes Gross Domestic Product (GDP) as a product of three terms
Raupach et al.,13 used a decomposition for national emissions. We write urban CO2 emissions using a modified Kaya identity59 as a product of urban area, population density and per capita CO2 emissions.
where E is the total CO2 emissions, A the urban area, p the population density (persons per unit area) and e the per capita CO2 emissions (tons carbon per person). We use upper case for extensive and lower case for intensive variables. Following Raupach et al.,13 we use a logarithmic transformation to decompose the proportional trend in CO2 emissions as
where δ represents a proportional trend defined by
and is usually expressed as a percentage per year. For a quantity x we calculate \(\delta x\) as follows:
-
1.
We start with a time-series x(t) which is often sparse since some years lack urban boundary data (see Luqman et al.,49 for an explanation).
-
2.
Fit a linear regression L(t) = a + bt to x(t)
-
3.
Calculate \(\bar x\) as \(L(t_{{{{\mathrm{ref}}}}})\) where \(t_{{{{\mathrm{ref}}}}}\) midpoint of our study period. \(\bar x\) is hence an estimate of the average assuming linearity with time.
-
4.
We repeat this procedure for E, A, p and e.
We stress that while expressions like Eq. 5 are mathematical identities they are not statement of causality but may elucidate underlying causes. We apply the modified Kaya identity to our 91 cities.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
We used the data from the following sources in our analysis. The city boundary data (BUNTUS) is available at http://thebuntus.com/paper_page.html. The gridded population data (LandScan) is available at ref. 51 and gridded fossil fuel CO2 emission dataset (ODIAC) is available at ref. 53. All the calculated values are provided as Supplementary Table 2.
References
Seto, K. C. et al. Human settlements, infrastructure and spatial planning. (Cambridge University Press, 2014).
Gurney, K. R. et al. The Vulcan Version 3.0 High-Resolution Fossil Fuel CO2 Emissions for the United States. J. Geophys. Res. Atmospheres 125, e2020JD032974 (2020).
Jones, C. & Kammen, D. M. Spatial Distribution of U.S. Household Carbon Footprints Reveals Suburbanization Undermines Greenhouse Gas Benefits of Urban Population Density. Environ. Sci. Technol. 48, 895–902 (2014).
Nations, U. World Urbanization Prospects 2018 - Population Division - United Nations. (2018).
Seto, K. C., Güneralp, B. & Hutyra, L. R. Global forecasts of urban expansion to 2030 and direct impacts on biodiversity and carbon pools. Proc. Natl. Acad. Sci. 109, 16083–16088 (2012).
C40, Arup & University of Leeds. The Future of Urban Consumption in a 1.5C World. https://www.arup.com/perspectives/publications/research/section/the-future-of-urban-consumption-in-a-1-5c-world (2019).
Seto, K. C. et al. Carbon lock-in: types, causes, and policy implications. Annu. Rev. Environ. Resour. 41, 425–452 (2016).
Wang, R. et al. High resolution mapping of combustion processes and implications for CO2 emissions. Atmospheric Chem. Phys. Discuss. 12, 21211–21239 (2012).
Little, W., McGivern, R. & Kerins, N. Introduction to Sociology-2nd Canadian Edition. (BC Campus, 2016).
Uchiyama, K. Environmental Kuznets Curve Hypothesis and Carbon Dioxide Emissions. (Springer Japan, 2016). https://doi.org/10.1007/978-4-431-55921-4.
Grossman, G. M. & Krueger, A. B. Environmental impacts of a North American free trade agreement. (1991).
Stern, D. I. The environmental Kuznets curve after 25 years. J. Bioeconomics 19, 7–28 (2017).
Raupach, M. R. et al. Global and regional drivers of accelerating CO2 emissions. Proc. Natl. Acad. Sci. 104, 10288–10293 (2007).
Shahbaz, M., Loganathan, N., Muzaffar, A. T., Ahmed, K. & Jabran, M. A. How urbanization affects CO2 emissions in Malaysia? The application of STIRPAT model. Renew. Sustain. Energy Rev. 57, 83–93 (2016).
Katircioğlu, S. & Katircioğlu, S. Testing the role of urban development in the conventional environmental Kuznets curve: evidence from Turkey. Appl. Econ. Lett. 25, 741–746 (2018).
Dogan, E. & Turkekul, B. CO2 emissions, real output, energy consumption, trade, urbanization and financial development: testing the EKC hypothesis for the USA. Environ. Sci. Pollut. Res. 23, 1203–1213 (2016).
Ribeiro, H. V., Rybski, D. & Kropp, J. P. Effects of changing population or density on urban carbon dioxide emissions. Nat. Commun. 10, 1–9 (2019).
Ouyang, X. & Lin, B. Carbon dioxide (CO2) emissions during urbanization: A comparative study between China and Japan. J. Clean. Prod. 143, 356–368 (2017).
Baiocchi, G. & Minx, J. C. Understanding Changes in the UK’s CO2 Emissions: A Global Perspective. Environ. Sci. Technol. 44, 1177–1184 (2010).
Al-Mulali, U., Fereidouni, H. G., Lee, J. Y. & Sab, C. N. B. C. Exploring the relationship between urbanization, energy consumption, and CO2 emission in MENA countries. Renew. Sustain. Energy Rev. 23, 107–112 (2013).
Salahuddin, M., Ali, M. I., Vink, N. & Gow, J. The effects of urbanization and globalization on CO2 emissions: evidence from the Sub-Saharan Africa (SSA) countries. Environ. Sci. Pollut. Res. 26, 2699–2709 (2019).
Liddle, B. & Lung, S. Age-structure, urbanization, and climate change in developed countries: revisiting STIRPAT for disaggregated population and consumption-related environmental impacts. Popul. Environ. 31, 317–343 (2010).
Martínez-Zarzoso, I. & Maruotti, A. The impact of urbanization on CO2 emissions: evidence from developing countries. Ecol. Econ. 70, 1344–1353 (2011).
Sadorsky, P. The effect of urbanization on CO2 emissions in emerging economies. Energy Econ 41, 147–153 (2014).
Khoshnevis Yazdi, S. & Shakouri, B. The effect of renewable energy and urbanization on CO2 emissions: A panel data. Energy Sources Part B Econ. Plan. Policy 13, 121–127 (2018).
Wu, D., Lin, J. C., Oda, T. & Kort, E. A. Space-based quantification of per capita CO2 emissions from cities. Environ. Res. Lett. 15, 035004 (2020).
Crippa, M. et al. Global anthropogenic emissions in urban areas: patterns, trends, and challenges. Environ. Res. Lett. 16, 074033 (2021).
Janssens-Maenhout, G. et al. EDGAR v4. 3.2 Global Atlas of the three major Greenhouse Gas Emissions for the period 1970–2012. Earth Syst. Sci. Data 11, 959–1002 (2019).
Pesaresi, M. et al. Operating procedure for the production of the Global Human Settlement Layer from Landsat data of the epochs 1975, 1990, 2000, and 2014. Publ. Off. Eur. Union 1–62 (2016).
Gudipudi, R. et al. The efficient, the intensive, and the productive: Insights from urban Kaya scaling. Appl. Energy 236, 155–162 (2019).
Nakicenovic, N. Socioeconomic driving forces of emissions scenarios 62 (Island Press, Washington, DC, 2004).
Bettencourt, L. M. et al. The interpretation of urban scaling analysis in time. J. R. Soc. Interface 17, 20190846 (2020).
UNFCCC, V. Adoption of the Paris Agreement. Propos. Pres. Draft Decis. U. N. Off. Geneva Switz. (2015).
Figueres, C. et al. Emissions are still rising: ramp up the cuts. Nature 564, 27–30 (2018).
Gurney, K. R. et al. Under-reporting of greenhouse gas emissions in US cities. Nat. Commun. 12, 1–7 (2021).
Gurney, K. R. et al. Climate change: Track urban emissions on a human scale. Nat. News 525, 179 (2015).
Lauvaux, T. et al. Policy-Relevant Assessment of Urban CO2 Emissions. Environ. Sci. Technol. 54, 10237–10245 (2020).
Calinski, T. A dendrite method for cluster analysis. Commun. Stat. 3, 1–27 (1974).
Arthur, D. & Vassilvitskii, S. k-means++: The advantages of careful seeding. (2006).
Wang, C., Lin, J., Cai, W. & Zhang, Z. Policies and practices of low carbon city development in China. Energy Environ 24, 1347–1372 (2013).
Cheng, L., Mi, Z., Sudmant, A. & Coffman, D. Bigger cities better climate? Results from an analysis of urban areas in China. Energy Econ 107, 105872 (2022).
Doll, Christopher, N. H., Muller, J.-P. & Elvidge, C. D. Night-time Imagery as a Tool for Global Mapping of Socioeconomic Parameters and Greenhouse Gas Emissions. AMBIO J. Hum. Environ. 29, 157–162 (2000).
Elvidge, C. D. et al. Night-time lights of the world: 1994–1995. J. Photogramm. Remote Sens. 56, 81–99 (2001).
Elvidge, C. D., Baugh, K. E., Kihn, E. A., Kroehl, H. W. & Davis, E. R. Mapping city lights with Nighttime data from the DSMP Operational LineScan System. Photogramm. Eng. Remote Sens. 63, 727–734 (1997).
Asefi-Najafabady, S. A multiyear, global gridded fossil fuel CO2 emission data product: Evaluation and analysis of results. J Geophys Res Atmos 119, 10213–10231 (2014).
Raupach, M. R., Rayner, P. J. & Paget, M. Regional variations in spatial structure of nightlights, population density and fossil-fuel CO2 emissions. Energy Policy 38, 4756–4764 (2010).
Rayner, P. J., Raupach, M. R., Paget, M., Peylin, P. & Koffi, E. A new global gridded data set of CO2 emissions from fossil fuel combustion. Methodol. Eval. J. Geophys. Res. 115, 19 (2010).
Thompson, J. et al. A global analysis of urban design types and road transport injury: an image processing study. Lancet Planet. Health 4, e32–e42 (2020).
Luqman, M., Rayner, P. J. & Gurney, K. R. Combining Measurements of Built-up Area, Nighttime Light, and Travel Time Distance for Detecting Changes in Urban Boundaries: Introducing the BUNTUS Algorithm. Remote Sens 11, 2969 (2019).
Demographia. WORLD MEGACITIES Urban Areas with More than 10,000,000 Population. (2015).
Bhaduri, B., Bright, E., Coleman, P. & Urban, M. L. LandScan USA: a high-resolution geospatial and temporal modeling approach for population distribution and dynamics. GeoJournal 69, 103–117 (2007).
Dobson, J. E., Bright, E. A., Coleman, P. R., Durfee, R. C. & Worley, B. A. LandScan: a global population database for estimating populations at risk. Photogramm. Eng. Remote Sens. 66, 849–857 (2000).
Oda, T., Maksyutov, S. & Andres, R. J. The Open-source Data Inventory for Anthropogenic CO2, version 2016 (ODIAC2016): a global monthly fossil fuel CO2 gridded emissions data product for tracer transport simulations and surface flux inversions. Earth Syst. Sci. Data 10, 87–107 (2018).
Oda, T. & Maksyutov, S. A very high-resolution (1 km × 1 km) global fossil fuel CO2 emission inventory derived using a point source database and satellite observations of nighttime lights. Atmos Chem Phys 11, 543–556 (2011).
Boden, T. A., Marland, G. & Andres, R. J. National CO2 emissions from fossil-fuel burning, cement manufacture, and gas flaring: 1751–2014. Carbon Dioxide Inf. Anal. Cent. Oak Ridge Natl. Lab. US Dep. Energy (2017).
Marland, G. & Rotty, R. M. Carbon dioxide emissions from fossil fuels: a procedure for estimation and results for 1950-1982. Tellus B Chem. Phys. Meteorol 36, 232–261 (1984).
Oda, T., Maksyutov, S. & Elvidge, C. D. Disaggregation of national fossil fuel CO2 emissions using a global power plant database and DMSP nightlight data. Proc. Asia-Pac. Adv. Netw. 30, 219–228 (2010).
Ziskin, D., Baugh, K., Hsu, F. C., Ghosh, T. & Elvidge, C. Methods used for the 2006 radiance lights. Proc. Asia-Pac. Adv. Netw. 30, 131–142 (2010).
Kaya, Y., Yokobori, K. & others. Environment, energy, and economy: strategies for sustainability. (United Nations University Press Tokyo, 1997).
Acknowledgements
We acknowledge Oak Ridge National Community (ORNL) for LandScan datasets, DMSP-OLS, VIIRS products, and Google Earth. M.L. is thankful to the University of Melbourne for Melbourne Research Scholarship. He also acknowledges the Albert Shimmins Fund. We would like to thank the anonymous reviewers for their useful comments, which allowed us to improve the quality of the manuscript.
Author information
Authors and Affiliations
Contributions
M.L., P.R., and K.G. conceived and developed the idea for this article. M.L. wrote the initial draft of the paper. M.L., P.R., and K.G. edited the manuscript and wrote the subsequent and final drafts.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Luqman, M., Rayner, P.J. & Gurney, K.R. On the impact of urbanisation on CO2 emissions. npj Urban Sustain 3, 6 (2023). https://doi.org/10.1038/s42949-023-00084-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s42949-023-00084-2
