
Abstract
The Latin America and the Caribbean region is one of the most urbanized regions in the world, with a total population of around 630 million that is expected to increase by 25% by 2050. In this context, detailed and contemporary datasets accurately describing the distribution of residential population in the region are required for measuring the impacts of population growth, monitoring changes, supporting environmental and health applications, and planning interventions. To support these needs, an open access archive of high-resolution gridded population datasets was created through disaggregation of the most recent official population count data available for 28 countries located in the region. These datasets are described here along with the approach and methods used to create and validate them. For each country, population distribution datasets, having a resolution of 3 arc seconds (approximately 100 m at the equator), were produced for the population count year, as well as for 2010, 2015, and 2020. All these products are available both through the WorldPop Project website and the WorldPop Dataverse Repository.
Design Type(s) | data integration objective • database creation objective • time series design |
Measurement Type(s) | population |
Technology Type(s) | census |
Factor Type(s) | |
Sample Characteristic(s) | Homo sapiens • Antigua and Barbuda • Argentina • Belize • Bolivia • Brazil • Chile • Colombia • Costa Rica • Cuba • Dominican Republic • Ecuador • El Salvador • French Guiana Region • Guatemala • Guyana • Haiti • Honduras • Jamaica • Mexico • Nicaragua • Panama • Paraguay • Peru • Puerto Rico • Suriname • Trinidad and Tobago • Uruguay • Venezuela • anthropogenic habitat |
Machine-accessible metadata file describing the reported data (ISA-Tab format)
Similar content being viewed by others
Background & Summary
The Latin America and the Caribbean region has a population of around 630 million and is one of the most urbanized regions in the world, with 80% of its population currently living in urban areas. Its population, which increased by 1.5 times over the last 25 years, is expected to grow by another 25% and further urbanize by 2050, with 86% living in urban areas1.
According to the Pan American Health Organization2, health and demographic indicators highlight that, although with significant variation from country to country and to a far lower degree than Africa and central Asia, the region is characterized by relatively high maternal and infant mortality rates, and a lack of access to health facilities and services for a large part of its population. In addition, many endemic infectious diseases are also present and include malaria, dengue, chikungunya, chagas, and leishmaniasis3,4. Furthermore, low and middle income countries located in the region are highly vulnerable to and affected by natural and man-made disasters5 and, according to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change6, the frequency and intensity of weather- and water-related hazards are expected to rise in the upcoming decades, both globally and regionally, as a consequence of climate change. Finally, the rapid development of the region and its ongoing urbanization is expected to further exacerbate problems related to the rapid land-use change and deforestation in rural areas7 and the growth of informal settlements in urban areas8.
In this context, contemporary, spatially detailed, and comparable datasets that accurately depict the distribution of the residential human population are a fundamental prerequisite for measuring the impacts of population growth9, monitoring changes10, supporting environmental and health applications11,12, and planning interventions13. Nevertheless, for the majority of these countries, and especially for those most severely and disproportionately affected by both natural disaster and infectious disease morbidity, contemporary, spatially detailed, consistent, and open data on population distribution are often unavailable or difficult to obtain.
For these reasons, since the mid-1990s, there has been an increasing effort to create spatially-explicit population datasets by using a range of approaches, assumptions, and input data to disaggregate administrative unit-based population counts to a regular grid of fixed spatial resolution14. Current global gridded datasets depicting the distribution of human population across the Latin America and the Caribbean region include various versions of the Gridded Population of the World (GPW)15–18, the Global Rural-Urban Mapping Project (GRUMP)19, the Oak Ridge National Laboratory's LandScan20, and the United Nation Environment Programme Latin American and Caribbean Population Database21. However, these datasets present certain limitations due to their spatial resolution ranging between 30 and 150 arc seconds (approximately 1 and 5 km at the equator, respectively), the age and coarse spatial detail of the input population count data, or the lack of details on the input data and modelling approach used to produce them22,23.
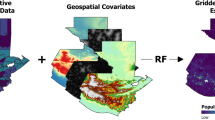
In the framework of the WorldPop Project (www.worldpop.org), an open access archive of high-resolution gridded population distribution datasets for the Latin America and the Caribbean region has been created using the most recent and finest level census and official population estimate data available at the time of writing, along with a range of ancillary geospatial datasets depicting factors known to relate to human population presence and densities. Following the Random Forest (RF)-based dasymetric mapping approach developed by Stevens et al.24 (Fig. 1), population count data and ancillary datasets for 28 countries (Tables 1 and 2) were identified, collected, assembled, and exploited in order to produce gridded population datasets with a spatial resolution of 3 arc seconds (approximately 100 m at the equator). These datasets were produced for the population count year, as well as for 2010, 2015, and 2020 using the United Nations Population Division (UNPD) rural and urban growth rates25; with national totals for 2010, 2015, and 2020 both remaining unadjusted and being adjusted to match UNPD estimates25.

The preparation of the response variable and covariates is described in the yellow and orange panels, respectively, the RF modelling steps are outlined in in the green panels, and the disaggregation of the input population counts from administrative units into grid cells is described in the blue panel.
Methods
Random forest-based dasymetric population mapping approach
The dasymetric disaggregation of population counts from administrative units into grid cells was undertaken using a population density weighting layer generated by a RF algorithm. RF is a non-linear and non-parametric ensemble learning method that generates a large collection of unpruned decision tree models and aggregates their predictions. Each tree is independently generated by bagging (i.e., by bootstrapping with replacement)26, and each node of each tree is split using the optimal split among a randomly selected subset of covariates27. Outputs of all tree models are then aggregated by calculating either their mode or average, depending on whether the decision trees are used for classification or regression.
The RF method is robust to overfitting27 and not very sensitive, in terms of affecting prediction accuracy, to the three parameters required to be set for fitting the model28, namely (i) the number of covariates to be randomly selected at each node, (ii) the number of observations in the terminal nodes of each trees, and (iii) the number of trees in the forest. Furthermore, it is possible to accurately estimate the prediction error of the RF model. This can be done by averaging all mean squared errors calculated using the ‘out-of-bag’ (OOB) data that represent one third of the observations withheld from the bagging iteration process for each tree in the forest27. The OOB error can be also used to evaluate the importance of each covariate by considering how much the OOB error increases when only the OOB data for that given covariate are permuted28,29.
In the RF-based dasymetric population mapping approach developed by Stevens et al.24, a RF algorithm is used to generate gridded population density estimates that are subsequently used to dasymetrically disaggregate population counts from administrative units into grid cells. The same approach was used to produce the WorldPop Americas datasets described in this article. Initially, a population density response variable and a suite of covariates were calculated at the administrative unit level, and then used to fit a RF model for predicting population density at the grid cell level (i.e., to generate the dasymetric weighting layer) with those raster-based covariates having a spatial resolution of 100 m (Fig. 2).

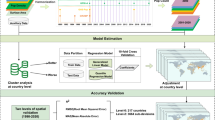
For illustrative purpose, only 4 out of the 74 covariates considered for Puerto Rico are shown here (the uninhabited Puerto Rican islands of Mona, Monito, and Desecheo are not shown).
To reduce processing time during the prediction phase, the multi-stage RF estimation technique developed by Stevens et al.24 was used. This technique first fits a model using all available covariates and the (log) population density of each administrative unit as the response. Then, a very conservative covariate selection process is performed to reduce the number of covariates that will be used for both the RF model fitting and prediction. To do this the ‘variable’ importance of each covariate27 is extracted and each covariate that has a score equal to zero is removed before re-fitting the RF model. This process is then iterated until only covariates with positive scores remain and thus results in the elimination of both redundant covariates and covariates that could negatively impact the prediction.
As in Stevens et al.24, the RF model fitting was performed by generating 500 trees in the forest and setting the number of observations in the terminal nodes equal to one. The fitted RF model was then used to predict population density using only the same reduced set of covariates. For each grid cell, each regression tree in the forest was used to predict a population density value and the average of all predictions was assigned to it as its estimated population density value. If there were not enough observations (i.e., not enough administrative unit population counts) to fit a RF model for a given country, another country located in the same ecozone30 was identified and used to fit an appropriate RF model for predicting population density at the grid cell level31.
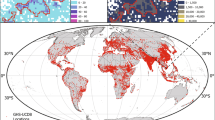
Subsequently, in both cases, the population density weighting layer was used to dasymetrically disaggregate the administrative unit-based population counts32 and produce two gridded population datasets depicting the estimated number of people per grid square and per hectare for the population count year. These datasets were then projected to 2010 (Fig. 3), 2015, and 2020 using UNPD rural and urban growth rates25 and also adjusted to match the most recent UNPD estimates at the time of writing25.

The grid cell resolution is 3 arc seconds (approximately 100 m at the equator) and coordinates refer to GCS WGS 1984. For illustrative purpose, the color ranges used are country-specific.
All tasks described above were entirely performed using the WordPop-RF code (Data Citation 1) described in the Code availability section below and publicly available through the figshare repository. In particular, the code relies on the R statistical environment (version 2.15) and the randomForest package (version 4.6–7) for fitting the RF model at the administrative unit level and predict at the grid cell level, and on the Python programming language (version 2.6; https://www.python.org/) and ArcGIS 10.1 arcpy package for performing the Geographic Information System (GIS)-specific spatial operations required for dasymetrically disaggregating the population data, projecting them to 2010, 2015 and 2020, and adjusting them to match UNPD estimates (refer to the Supplementary File 1 for a technical description of how the GIS-specific spatial operations are implemented).
Data collection
For each country listed in Table 1, population counts were extracted from the most detailed and recent official population count data and matched to their corresponding administrative units in a GIS environment. Both population counts and the corresponding administrative units were either publicly available (e.g., from GeoHive33 and GADM34, respectively) or contributed by National Statistical Offices such as the Instituto Brasileiro de Geografia e Estatística (IBGE). Table 1 also provides summary information about the input population count data and administrative unit datasets used to produce the WorldPop Americas datasets.
It is well known that human population density is highly correlated with environmental and physical factors35 that can plausibly impact the spatial distribution of population and/or be related to it. These may include continuous variables such as intensity of night-time lights36, energy productivity of plants37, topographic elevation and slope38,39, and climatic factors40, as well as categorical variables such as land-cover type41 and presence/absence of roads42, waterways and waterbodies43, human settlements and urban areas44, and protected areas45. Thus, twelve global raster and vector datasets (described below) were identified, collected, assembled, and processed into a set of default covariates (Table 2) used for model fitting and prediction.
The spatial variation of factors related to population distribution, such as night-light intensity and plant energy productivity, was measured using the NOAA Suomi National Polar-orbiting Partnership Visible Infrared Imaging Radiometer Suite (VIIRS)46,47 and the NASA TERRA/Moderate Resolution Imaging Spectroradiometer (MODIS) Net Primary Productivity (NPP)48,49 raster dataset, respectively. The spatial variation of climatic factors affecting population distribution was considered by including the WorldClim Annual Mean Temperature (BIO1) and Annual Precipitation (BIO12) raster datasets50,51. The World Wildlife Fund (WWF) HydroSheds raster dataset52,53, based on the NASA’s Shuttle Radar Topography Mission (SRTM) Digital Elevation Model54, was used to represent the spatial variation of elevation and slope. The European Space Agency (ESA) ENVISAT/MERIS-based GlobCover raster dataset55,56, and the MODIS 500-m map of global urban extent57,58 were used to identify different land-cover types and distinguish between urban and rural areas. Finally, the World Database on Protected Areas (WDPA)59 was used to obtain vector polygons representing protected areas, while the National Geospatial-Intelligence Agency (NGA) Vector Map Level 0 (VMAP0) dataset60 was used to obtain features representing populated places, roads, rivers, and waterbodies.
Where available, additional country-specific datasets were used to integrate and/or replace the default datasets outlined above and the corresponding default covariates in the analysis. For example, for most of the countries, the Landsat TM-based EarthSat GeoCover-LC raster dataset61,62 was combined with the GlobCover raster dataset to refine the extent of urban areas and identify rural settlements. Similarly, OpenStreetMap (OSM) vector datasets63 were regularly used to integrate the VMAP0 settlement dataset and account for land-use types, building sites, and locations of points of interest that may be strongly correlated with population presence (e.g., health clinics, schools, and police stations). Furthermore, OSM road and river data were often deemed to be more complete than the corresponding VMAP0 data and, thus, were used to increase the precision and accuracy of the gridded population outputs64.
For each country, all assembled vector and raster datasets, including the country specific ones, are described in the metadata file accompanying the corresponding gridded population datasets and viewable in any web-browser (refer to the Data Record section below for a more detailed description of the metadata file content).
Data preparation
For each country, the vector dataset representing its administrative units, used to match to population counts, was projected using the most appropriate country-specific projected coordinate system that minimized linear and areal distortion. It was then buffered by 10 km, and rasterized at a spatial resolution of 100 m. This was done in order to (i) generate a dataset representing the population density response variable, (ii) obtain a raster dataset, representing the study area, for co-registering all raster covariates, and (iii) produce a number of raster ‘distance to’ covariates that were unaffected by edge effects due to the fact that the study area is artificially bounded while spatial processes are not65. The population density response variable was obtained through dividing population counts by the area of the corresponding administrative units, and log-transforming the results to normalize the response variable distribution.
Covariates for input to the RF method were derived as follows. First, a continuous raster dataset representing the spatial variation of topographic slope was derived from the USGS HydroSheds dataset (Table 2). Then, all raster datasets representing continuous variables, including the latter, were projected, resampled to 100 m resolution, co-registered and matched to the rasterized buffered study area. For all covariates, ‘NoData’ grid cells overlapping the rasterized buffered study area were filled with the values of the nearest neighbours (using the Nibble tool available in ArcGIS 10.1). All vector and raster datasets representing categorical variables were projected, rasterized to or resampled to 100 m resolution, co-registered, matched to the rasterized buffered study area, and converted into a number of binary raster covariates, representing presence/absence of a given feature, that were subsequently used to produce continuous ‘distance to’ and ‘proportion of’ raster covariates (Table 2); with the latter representing, within a 500 m buffer from each grid cell, the proportion of grid cells where the given feature is present.
A special case of a categorical raster dataset is the land-cover data. Indeed, in this case land-cover classes must be aggregated (if needed) and recoded to match the ten WorlPop Americas classes derived from the GlobCover dataset (i.e., from class 11 to 230 in the 4th column of Supplementary Table 1). By default, the recoded GlobCover dataset was ‘Nibbled’, to fill in any missing grid cell, and then mosaicked with the MODIS 500 m Global Urban Extent dataset to delineate the extent of urban and non-urban built-up areas (i.e., class 190 and 240 respectively in Supplementary Table 1). When using the GeoCover-LC dataset, it was first recoded and mosaicked with the GlobCover dataset, to fill missing grid cell, and with the MODIS 500 m Global Urban Extent dataset. Similarly to the other raster datasets representing categorical variables, the processed land-cover raster dataset obtained as described above was projected, resampled to 100 m resolution, co-registered, matched to the rasterized buffered study area, and converted into twelve binary raster covariates including the combined built-up areas class (BLT) obtained by combining classes 190 and 240. Binary raster covariates were subsequently used to produce continuous ‘distance to’ and ‘proportion of’ raster covariates (Table 2). Finally, average and modal values for continuous and binary covariates, respectively, were calculated for each administrative unit and used for fitting the RF model.
The preparation of the population density response variable and raster covariates was entirely performed using the WordPop-RF code (Data Citation 1) described in the Code availability section below and publicly available through the figshare repository. In particular, the code relies on the Python programming language (version 2.6; https://www.python.org/) and ArcGIS 10.1 arcpy package for performing the GIS-specific spatial operations required for preparing both the response variable and raster covariates (refer to the Supplementary File 1 for a technical description of how the GIS-specific spatial operations are implemented). For each country, all derived covariates are listed in the metadata file accompanying the corresponding gridded population datasets (refer to the Data Record section below for a more detailed description of the metadata file contents).
Code availability
The WordPop-RF code (Data Citation 1), used to produce the WorldPop Americas datasets, as well as the metadata and the KML files associated with them (refer to the Data Records section for a description of the latter), is publicly available through the figshare repository. The code consists of two Python (version 2.6; https://www.python.org/) and four R (version 2.15.3) programming language scripts that must be run sequentially in the following order: 1) 01.0—Configuration.py.R; 2) Metadata.R; 3) 01.1—Data Preparation, R.r; 4) 01.2—Data Preparation, Python.py; 5) 01.3—More Complex Random Forest Regression, Full Covariate Set and Data Preparation.r; 6) 01.4—Process Density Weights to Population Maps.py; 7) 01.5—Generate KML.r; 8) 01.6—Generate Metadata Report.r. Each script is also internally documented in order to both explaining its purpose (including a detailed description of the GIS-specific spatial operations that it performs) and, when required, guiding the user through its customization.
Data Records
The high-resolution WorldPop Americas datasets described in this article referring to the 28 countries listed in Table 1, are publicly and freely available both through the WorldPop Dataverse Repository (Data Citation 2) and the WorldPop project website (http://www.worldpop.org.uk/data/). However, while the WorldPop Americas datasets stored in the Dataverse Repository represent a static version of the datasets produced at the time of writing and will be preserved stably in their published form, the datasets stored in the project website (Supplementary Table 2) will be expanded by including additional countries located in the region and updated as better and more recent official population count data and covariates become available.
Both through the Dataverse Repository and the project website, the WorldPop Americas can be download as 7-Zip archives (7-Zip.org) containing the population distribution datasets of the country it is associated with for the population count year, as well as for 2010, 2015, and 2020, and a RF model metadata report (Table 3).
Additionally, from the Data Availability page available on the WorldPop project website (http://www.worldpop.org.uk/data/data_sources/) it is also possible to browse the 7-Zip archives described above, download individual GeoTIFF datasets from them, and view the HTML files containing the RF model metadata reports. For each country, the metadata report illustrates the datasets and the related derived covariates used as input in the RF model, the population density response variable, the gridded population density dataset used to dasymetrically disaggregate the population from administrative unit to grid cell level, and basic information about the RF model that includes (i) the country on which it is based, (ii) its prediction error, (iii) the relative importance of each covariate, (iv) the prediction intervals using the OOB data (refer to the Methods section for additional information about the latter features).
Technical Validation
Root mean square error (RMSE) and mean absolute error (MAE)
Six countries, located in different parts of the Latin American and the Caribbean region were selected to assess the increased accuracy of the RF-based dasymetric mapping approach with respect to a simple areal-weighting (SAW) approach66 (Table 4). For each selected country, population counts were aggregated within the next coarser administrative level boundary than the finest for which they were available (e.g., if admin level 4 population count data were available, these were aggregated to admin level 3). The coarser, aggregated population counts were then used to produce gridded population count datasets, with a resolution of 100 m, using both the SAW and the RF approach outlined here. Finally, the two different population estimates produced using these approaches within each of the finest administrative unit were calculated, and compared with observed population figure referring to the same higher resolution unit.
Results, summarized in Table 4, show how both the RMSE, the %RMSE (RMSE expressed as a percentage of the average population of the finest administrative unit level), and the MAE values (5th, 6th, and 7th column of Table 4, respectively) calculated using the RF-based outputs are consistently lower than the corresponding values calculated for the SAW outputs. These statistics can be used to compare the accuracy of the two approaches when downscaling the estimates.
Out-of-bag (OOB) error estimation
The OOB error estimate (3rd column of Table 4), as already briefly described in the Methods section, is internally calculated during the RF model fitting and can be considered a robust and unbiased measurement of the prediction accuracy of the model itself27.
Nevertheless, it is important to note that since the RF model is fitted at the administrative unit level and then is used to predict at the grid cell level, the OOB error estimate should not be interpreted as the prediction error at the grid cell level. Similarly, it does not represent the prediction error that could be expected to be observed at the administrative unit level by summing all final grid cell values within each administrative unit and comparing it to the observed population count referring to the same administrative unit. However, referring to the six countries mentioned in the previous section, by comparing the OOB error estimates calculated at the aggregate lower administrative unit level than the highest available (3rd column of Table 4) with the corresponding RMSE and MAE values (5th and 7th column of Table 3, respectively), it is reasonable to expect that higher accuracy of predicted values at the administrative unit level results in a higher accuracy of the final gridded population distribution datasets24.
Usage Notes
The WorldPop Americas datasets can be used both to support applications for planning interventions, measuring progress, and to predict response variables intrinsically dependent on the population distribution. However, considering that they represent modelling outputs generated using ancillary covariate datasets in the disaggregation process, to avoid circularity, they should not be used to make predictions or explore relationships about any of these ancillary datasets14. Thus, before using WorldPop Americas datasets in correlation analyses against factors which are included in the process of their construction (e.g., correlating population distribution with land-cover), ideally the population modelling process should be re-run using the WordPop-RF code (Data Citation 1) with the covariate of interest being removed to avoid issues relating to endogeneity.
Additional Information
How to cite this article: Sorichetta, A. et al. High-resolution gridded population datasets for Latin America and the Caribbean in 2010, 2015, and 2020. Sci. Data 2:150045 doi: 10.1038/sdata.2015.45 (2015).
References
References
United Nations, Department of Economic and Social Affairs, Population Division (UNPD). World Urbanization Prospects: The 2014 Revision, Highlights. (United Nations, 2014).
Pan American Health Organization (PAHO). Health in the Americas, 2012 Edition: Regional Volume,http://www2.paho.org/saludenlasamericas/dmdocuments/hia-2012-chapter-4.pdf (2012).
World Health Organisation (WHO). The Global Burden of Disease: 2004 Update. (World Health Organisation, 2008).
World Health Organisation (WHO). The World Health Report 2013: Research for Universal Health Coverage. (World Health Organisation, 2013).
International Federation of Red Cross and Red Crescent Societies (IFRC). World Disaster Report 2014: Focus on Culture and Risk. (Imprimerie Chirat, 2014).
Intergovernmental Panel on Climate Change (IPCC). Climate Change 2014: Synthesis Report. Contribution of Working Groups I, II and III to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change. (IPCC, 2014).
Grau, H. R. & Aide, M. Globalization and land-use transitions in Latin America. Ecology and Society 13, 16 (2008).
United Nations Human Settlements Programme (UN-Habitat). State of the world’s cities 2012/2013: Prosperity of cities. (Routledge, 2012).
McDonald, R. I. et al. Urban growth, climate change, and freshwater availability. Proc. Natl. Acad. Sci 108, 6312–6317 (2011).
Brown, M. L., Donovan, T. M., Schwenk, W. S. & Theobald, D. M. Predicting impacts of future human population growth and development on occupancy rates of forest-dependent birds. Biol. Conser 170, 311–320 (2014).
McGranahan, G., Balk, D. & Anderson, B. The rising tide: assessing the risks of climate change and human settlements in low elevation coastal zones. Environ. Urban. 19, 17–37 (2007).
Tatem, A. J., Campiz, N., Gething, P. W., Snow, R. W. & Linard, C. The effects of spatial population dataset choice on estimates of population at risk of disease. Population Health Metrics 9, 4 (2011).
Taramelli, A., Melelli, L., Pasqui, M. & Sorichetta, A. Modelling risk hurricane elements in potentially affected areas by a GIS system. Geomatics, Natural Hazards and Risk 1, 349–373 (2010).
Balk, D. L., Deichmann, U., Yetman, G., Pozzi, F., Hay, S. I. & Nelson, A. Determining Global Population Distribution: Methods, Applications and Data. Adv. Parasit 62, 119–156 (2006).
Tobler, W., Deichmann, U., Gottsegen, J. & Maloy, K. World population in a grid of spherical quadrilaterals. International Journal of Population Geography 3, 203–225 (1997).
Deichmann, U., Balk, D. & Yetman, G. Transforming Population Data for Interdisciplinary Usages: From Census to Grid http://sedac.ciesin.org/gpw-v2/GPWdocumentation.pdf (Center for International Earth Science Information Network (CIESIN), Columbia University, 2001).
Balk, D. & Yetman, G . The Global Distribution of Population: Evaluating the gains in resolution refinement http://sedac.ciesin.columbia.edu/downloads/docs/gpw-v3/gpw3_documentation_final.pdf (Center for International Earth Science Information Network (CIESIN), Columbia University, 2004).
Doxsey-Whitfield, E. et al. Taking Advantage of the Improved Availability of Census Data: A First Look at the Gridded Population of the World, Version 4. Papers in Applied Geography 1, 226–234 (2015).
Balk, D., Pozzi, F., Yetman, G., Deichmann, U. & Nelson, A. The distribution of people and the dimension of place: methodologies to improve the global estimation of urban extents. In Proc. of 2005 Urban Remote Sensing Conferenceftp://ftp.ecn.purdue.edu/jshan/proceedings/URBAN_URS05/balk-etal.pdf (2005).
Dobson, J. E., Bright, E. A., Coleman, P. R., Durfee, R. C. & Worley, B. A. LandScan: a global population database for estimating populations at risk. Photogramm. Eng. Rem. S 66, 849–857 (2000).
Centro Internacional de Agricultura Tropical (CIAT) United Nations Environment Program (UNEP) Center for International Earth Science Information Network (CIESIN) Columbia University the World Bank. Latin America and the Caribbean Population Database http://gisweb.ciat.cgiar.org/population/download/report.pdf (CIAT, 2000).
Linard, C., Gilbert, M., Snow, R. W., Noor, A. M. & Tatem, A. J. Population Distribution, Settlement Patterns and Accessibility across Africa in 2010. PLoS ONE 7, e31743 (2012).
Gaughan, A. E., Stevens, F. R., Linard, C., Jia, P. & Tatem, A. J. High Resolution Population Distribution Maps for Southeast Asia in 2010 and 2015. PLoS ONE 8, e55882 (2013).
Stevens, F. R., Gaughan, A. E., Linard, C. & Tatem, A. J. Disaggregating Census Data for Population Mapping Using Random Forests with Remotely-Sensed and Ancillary Data. PLoS ONE 10, e0107042 (2015).
United Nations Department of Economic and Social Affairs Population Division (UNPD). World Urbanization Prospects: The 2014 Revision. CD-ROM Edition http://esa.un.org/unpd/wup/CD-ROM/ (2014).
Breiman, L. Bagging predictors. Mach. Learn. 24, 123–140 (1996).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Liaw, A. & Wiener, M. Classification and Regression by randomForest. R News 2, 18–22 (2002).
Breiman, L. Manual on setting up, using, and understanding random forests v3.1http://www.stat.berkeley.edu/~breiman/Using_random_forests_V3.1.pdf (2002).
Kottek, M., Grieser, J., Beck, C., Rudolf., B. & Rubel, F. World map of the Koppen-Geiger climate classification updated. Meteorol. Z. 15, 259–263 (2006).
Gaughan, A. E., Stevens, F. R., Linard, C., Patel, N. N. & Tatem, A. J. Exploring nationally and regionally defined models for large area population mapping. Int. J. Digit. Earth. 10.1080/17538947.2014.965761 (2014).
Mennis, J. Generating Surface Models of Population Using Dasymetric Mapping. The Professional Geographer 55, 31–42 (2003).
GEOHIVE. Global Population Statisticshttp://www.geohive.com/cntry/ (2014).
GADM. Database of Global Administrative Areashttp://www.gadm.org/ (2012).
Nagle, N. N., Buttenfield, B. P., Leyk, S. & Spielman, S. Dasymetric Modeling and Uncertainty. Ann. Assoc. Am. Geogr 104, 80–95 (2014).
Briggs, D. J., Gulliver, J., Fecht, D. & Vienneau, D. M. Dasymetric modelling of small-area population distribution using land cover and light emissions data. Remote Sens. Environ. 108, 451–466 (2007).
Luck, J. W. The relationships between net primary productivity, human population density and species conservation. J. Biogeogr. 34, 201–212 (2007).
Cohen, J. E. & Small, C. Hypsographic demography: The distribution of human population by altitude. Proc. Natl. Acad. Sci 95, 14009–14014 (1998).
Schumacher, J. V., Redmond, R. L., Hart, M. M. & Jensen, M. E. Mapping patterns of human use and potential resource conflicts on public lands. Environ. Monit. Assess. 64, 127–137 (2000).
Small, C. & Cohen, J. E. Continental physiography, climate, and the global distribution of human population. Curr. Anthropol. 45, 269–277 (2004).
Linard, C., Gilbert, M. & Tatem, A. J. Assessing the use of global land cover data for guiding large area population distribution modelling. GeoJ 76, 525–538 (2011).
Reibel, M. & Bufalino, M. E. Street-weighted interpolation techniques for demographic count estimation in incompatible zone systems. Environ. Plann. A 27, 127–139 (2005).
Kummu, M., de Moel, H., Ward, P. J. & Varis, O. How Close Do We Live to Water? A Global Analysis of Population Distance to Freshwater Bodies. PLoS ONE 6, e20578 (2011).
Tatem, A. J., Noor, A. M., von Hagen, C., Di Gregorio, A. & Hay, S. I. High Resolution Population Maps for Low Income Nations: Combining Land Cover and Census in East Africa. PLoS ONE 2, e1298 (2007).
Luck, G. W. A review of the relationships between human population density and biodiversity. Biol. Rev. 82, 607–645 (2007).
National Oceanic and Atmospheric Administration (NOAA). Visible Infrared Imaging Radiometer Suite (VIIRS) Nighttime Lights-2012 (Two months composite)http://ngdc.noaa.gov/eog/viirs/download_viirs_ntl.html (2013).
Elvidge, C. D., Baugh, K. E., Zhizhi, M. & Hsu, F.-C. Why VIIRS data are superior to DMSP for mapping nighttime lights. Proc. Asia Pac. Adv. Netw 35, 62–19 (2013).
National Aeronautics and Space Administration (NASA). Terra/MODIS Net Primary Production Yearly L4 Global 1 km MOD17A3https://lpdaac.usgs.gov/dataset_discovery/modis/modis_products_table/mod17a3 (2015).
Turner, D. P. et al. Evaluation of MODIS NPP and GPP products across multiple biomes. Remote Sens. Environ. 102, 282–292 (2006).
Hijmans, R. J., Cameron, S. E., Parra, J. L., Jones, P. G., Jarvis, A. & Richardson, K. WorldCli m Annual Mean Temperature (BIO1) and Annual Precipitation (BIO12) 30 arc-seconds (~1 km)http://www.worldclim.org/current (2005).
Hijmans, R. J., Cameron, S. E., Parra, J. L., Jones, P. G. & Jarvis, A. Very high resolution interpolated climate surfaces for global land areas. Internat. J. Climatol. 25, 1965–1978 (2005).
World Wildlife Fund (WWF). 3 s GRID: Void-filled DEMhttp://hydrosheds.cr.usgs.gov/dataavail.php (2006).
Lehner, B., Verdin, K. & Jarvis, A. New Global Hydrography Derived From Spaceborne Elevation Data. Eos Trans. AGU 89, 93–94 (2008).
Farr, T. G. et al. The shuttle radar topography mission. Rev. Geophys. 45 10.1029/2005RG000183 (2007).
European Space Agency (ESA). GlobCover 2009 (Global Land Cover Map)http://due.esrin.esa.int/page_globcover.php (2010).
Bontemps, S., Defourny, P., van Bogaert, E., Kalogirou, V. & Arino, O. GlobCover 2009: Products description and validation report http://due.esrin.esa.int/files/GLOBCOVER2009_Validation_Report_2.2.pdf (2011).
Schneider, A., Friedl, M. A. & Potere, D. Mapping global urban areas using MODIS 500-m data: New methods and datasets based on ‘urban ecoregions’. Remote Sens. Environ. 114, 1733–1746 (2010).
Schneider, A., Friedl, M. A. & Potere, D. A new map of global urban extent from MODIS satellite data. Environ. Res. Lett. 4, 044003 (2009).
United Nations Environment Programme's World Conservation Monitoring Centre (UNEP-WCMC) & International Union for Conservation of Nature (IUCN). World Database on Protected Areas (WDPA)http://www.protectedplanet.net/ (2012).
National Geospatial-Intelligence Agency (NGA). VMAP0http://geoengine.nga.mil/geospatial/SW_TOOLS/NIMAMUSE/webinter/rast_roam.html (2005).
MDA Federal Inc. EarthSat GeoCover-LC Year 2000http://www.mdafederal.com/geocover (2005).
Cunningham, D., Melican, J. E., Wemmelmann, E. & Jones, T. B. GeoCover LC-A moderate resolution global land cover database. In Proc. of 2002 Esri International User Conferencehttp://proceedings.esri.com/library/userconf/proc02/pap0811/p0811.htm (2002).
OpenStreetMap contributors. OpenStreetMaphttp://www.openstreetmap.org/ (2014).
Linard, C. et al. Use of active and passive VGI data for population distribution modelling: experience from the WorldPop project. In Proc. of the Eighth International Conference on Geographic Information Sciencehttps://web.ornl.gov/registration_resumes/CFP_VGI%20Workshop_Linard.pdf (2014).
Fotheringham, A. S. & Rogerson, P. A. GIS and spatial analytical problems. Int. J. Geogr. Inf. Syst 7, 3–19 (1993).
Flowerdew, R. & Green, M. Areal interpolation and types of data. Spatial analysis and GIS (Taylor and Francis Ltd., 1994).
Instituto Geográfico Nacional de la República Argentina (IGN). Departamentoshttp://www.ign.gob.ar/NuestasActividades/sigign (2013).
Meerman, J. Belize Basemap (boundaries, districts)http://www.biodiversity.bz/mapping/warehouse/ (2010).
Valle-Jones, D. Shapefiles of Mexico (AGEBs, Manzanas, etc)https://blog.diegovalle.net/2013/06/shapefiles-of-mexico-agebs-manzanas-etc.html (2013).
Data Citations
Stevens, F. R. WorldPop-RF, Version 2b.1.1. figshare http://dx.doi.org/10.6084/m9.figshare.1491490 (2015)
Sorichetta, A., Hornby, G. M., Stevens, F. R., Gaughan, A. E., Linard, C., & Tatem, A. J. Americas Datasets, V1. Harvard Dataverse http://dx.doi.org/10.7910/DVN/PUGPVR (2015)
Acknowledgements
A.S. is supported by funding from the Bill & Melinda Gates Foundation (OPP1106427, 1032350). A.J.T. is supported by funding from NIH/NIAID (U19AI089674), the Bill & Melinda Gates Foundation (OPP1106427, 1032350), and the RAPIDD program of the Science and Technology Directorate, Department of Homeland Security, and the Fogarty International Center, National Institutes of Health. This work forms part of the WorldPop Project (www.worldpop.org). The funders had no role in study design, data collection and analysis, decision to publish, and preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
A.S. drafted the manuscript. A.S., G.M.H., and F.R.S. undertook data collection, assembly, and analyses, produced the datasets, and performed their technical validation. F.R.S. developed the Random Forests-based dasymetric mapping approach and the multi-stage Random Forests estimation technique used for producing the datasets. G.M.H., F.R.S., A.E.G., and C.L. edited the manuscript. A.E.G. and C.L. aided with data collection. A.J.T. conceived the study, aided with data collection and drafting the manuscript. All authors read and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The Authors declare that they have no competing financial interests that might have influenced the presentation of the WorldPop Americas datasets and the description of the methods used to produce and assess them.
ISA-Tab metadata
Supplementary information
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0 Metadata associated with this Data Descriptor is available at http://www.nature.com/sdata/ and is released under the CC0 waiver to maximize reuse.
About this article

Cite this article
Sorichetta, A., Hornby, G., Stevens, F. et al. High-resolution gridded population datasets for Latin America and the Caribbean in 2010, 2015, and 2020. Sci Data 2, 150045 (2015). https://doi.org/10.1038/sdata.2015.45
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/sdata.2015.45
This article is cited by
-
Comparing the suitability of global gridded population datasets for local landslide risk assessments
Natural Hazards (2024)
-
Gridded Datasets for Japan: Total, Male, and Female Populations from 2001–2020
Scientific Data (2023)
-
Human footprint is associated with shifts in the assemblages of major vector-borne diseases
Nature Sustainability (2023)
-
High-resolution gridded population datasets for Latin America and the Caribbean using official statistics
Scientific Data (2023)
-
Modeling place-based nature-based solutions to promote urban carbon neutrality
Ambio (2023)
