
Abstract
The functional characterization of different neuronal types has been a longstanding and crucial challenge. With the advent of physical quantum computers, it has become possible to apply quantum machine learning algorithms to translate theoretical research into practical solutions. Previous studies have shown the advantages of quantum algorithms on artificially generated datasets, and initial experiments with small binary classification problems have yielded comparable outcomes to classical algorithms. However, it is essential to investigate the potential quantum advantage using real-world data. To the best of our knowledge, this study is the first to propose the utilization of quantum systems to classify neuron morphologies, thereby enhancing our understanding of the performance of automatic multiclass neuron classification using quantum kernel methods. We examined the influence of feature engineering on classification accuracy and found that quantum kernel methods achieved similar performance to classical methods, with certain advantages observed in various configurations.
Similar content being viewed by others


The field of quantum computing originated with a question posed by Feynman, namely whether it was feasible to simulate the behavior of quantum systems using a classical computer or whether a quantum computer would be required instead1. Since quantum algorithms were initially developed, scientists have been searching for their optimal applications and output. The first two quantum algorithms were published by Shor2 and Grover3, who documented that applying them to factorization and database search theoretically offers an advantage compared with classical computing. In recent years, the intersection between quantum computing and machine learning (ML) has received widespread attention and allowed the development of quantum ML algorithms4,5,6,7,8. ML and quantum computing are two technologies that may allow complex, challenging problems to be solved and progress to be accelerated in areas such as model training and pattern recognition.
Furthermore, the advances in quantum computing systems have allowed a progress in the study of quantum ML algorithms, especially with kernel methods. In classical ML, kernel methods provide a way to perform a linear classification on a highly complex data set in the framework of a support vector machine (SVM)9,10,11. Using kernel methods, quantum algorithms can be adopted through quantum kernel functions to exploit high-dimensional non-classical feature space4,12,13,14,15,16 where quantum feature maps are used to encode the datapoints into inner products or amplitudes in the Hilbert space. The number of features determined the number of qubits, and a quantum circuit used to implement the feature map was of a depth that was a linear or polylogarithmic function of the dataset’s size. Thus far, the studies that have been conducted to support the advantages of a quantum feature map have carefully selected synthetic datasets or applied it to small binary classification problems.
Despite the fact that research on cortical circuits has been conducted for over a century, determining how many classes of cortical neurons exist remains an ongoing and uncompleted task. Moreover, the continuous development of techniques and the availability of an increasing number of phenotype datasets have not led to the maintenance of a unique classification system that is easy to update and can consider the different defining features of neurons specific to a given type.
Neuron classification remains a topic in progress since how to designate a neuronal cell class and what the optimal features are for defining it are still questioned17. In this study, we demonstrate how we can apply quantum kernel methods together with classical methods for the quantitative characterization of neuronal morphologies from histological neuronal reconstructions.
Despite the inherent complexity and challenges that neuroscientists must deal with while addressing neuronal classification, numerous reasons exist for interest in this topic. Some brain diseases affect specific cell types. Neuron morphology studies may lead to the identification of genes to target for specific cell morphologies and the functions linked to them. A neuron undergoes different stages of development before acquiring its ultimate structure and function, which must be understood to identify new markers, marker combinations, or mediators of developmental choices. Understanding neuron morphology represents the basis of the modeling effort and the data-driven modeling approach for studying the impact of a cell’s morphology on its electrical behavior and function as well as on the network dynamics that the cell belongs to.
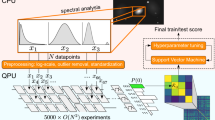
To the best of our knowledge, the present study is the first to present a methodology to utilize quantum systems for classifying neuron morphologies with the aim of improving knowledge on the performance of the automatic multiclass classification of neurons using quantum kernel methods. We explore the feasibility of classifying neurons with quantum systems and compare classical computing, quantum simulator, and real quantum hardware. We further explore the impact of feature engineering on classification accuracy.
Results
Classification using feature selection
In this study, to classify 14 classes of digitally reconstructed neuron morphologies based on the 43 morphological features described in Fig. 1, we applied several classic and quantum kernel algorithms by combining different feature rescaling and selection techniques to reduce the dataset to five features. We also considered four popular kernels to benchmark the performance of the classical SVM method (RBF, Linear, polynomial and sigmoid). Eight quantum kernel algorithms were studied. We named the first one q_kernel_zz, which applies a ZZFeatureMap and an encoding function described by Havlíček et al.,4 who defined a feature map on n-qubits generated by the unitary. The second algorithm (q_kernel_default) applies PauliFeatureMap (paulis = ['ZI','IZ','ZZ']) with a default data mapping \({\phi }_{S}\). In addition, we used five encoding functions presented by Suzuki et al.8 that we named q_kernel_8, q_kernel_9, q_kernel_10, q_kernel_11, q_kernel_12. The last quantum algorithm (q_kernel_training) trains a quantum kernel with quantum kernel alignment (QKA),16 which iteratively adapts a parametrized quantum kernel to the dataset and simultaneously converges to the maximum SVM margin. In addition, selected algorithms were run by selecting 10 and 20 features. We used up to 20 qubits. The accuracy of the classification was assessed by performing cross-validation on the training dataset.

Neuronal morphologies44,45,46,47 from the NeuroMorpho-rat dataset. Principal neurons are presented, such as (a) a pyramidal cell (layer 4, C010398B-P2) from the rat somatosensory neocortex; (b) a ganglion cell (LY8-RGC1) from the retina; (c) a granule cell (03D23APV-1) from the hippocampus; (d) a medium spiny cell (1-1-DE) from the nucleus accumbens; (e) a parachromatin cell (D20c) from the adrenal medulla; and (f) a Purkinje cell (alxP) from the cerebellum. Interneurons from the rat somatosensory neocortex are presented, such as (g) a basket cell (layer 2–3, C010398B-I4); (h) a bitufted cell (layer 4, C020600C1); (i) a chandelier cell (layer 2–3, C231001B2); (j) a double bouquet (layer 2–3, C060400B2); (k) a Martinotti cell (layer 2–3, C050398B-IA); and (l) a nitrergic cell (layer 5–6, RatS1-1-1). In addition, we demonstrated two types of glial cells: (m) a microglia cell (farsight624) from the frontal neocortex and (n) astrocyte cells (A1-CA1-L-C63x1zACR1) from the hippocampus. (o) Feature’s importance using XGBoost, decision tree, and random forest applied to the entire dataset (sample 5). (p) Definition of the 43 morphological features extracted for each neuron.They were extracted using the L-Measure tool,40 providing quantitative morphological measurement from neuronal reconstruction (http://cng.gmu.edu:8080/Lm/help/index.htm). (q) Dataset with the number of neuron morphologies for multiclass classification. From the 27,881 extracted neurons, 22,691 neurons (sample 5) remained after the application of Mahalanobis distance transformation and the suppression of all neurons with a soma surface equal to 0.
Figure 1 presents the feature’s importance using XGBoost, decision tree, and random forest.
Table 1 presents the five SVMs with classical kernels that provided the best cross-validation scores when applied to sample 5. The classical algorithm that provided the best score (score = 0.91 ± 0.001) was the SVM with a radial basis function kernel and the combination of the Yeo-Johnson technique for data rescaling with the embedded decision tree classifier as a feature selection technique (selection of five features). When we used the trained model on the test dataset, the classification accuracy was 0.92. The SVM with a radial basis function used with the quantile-uniform technique for feature rescaling and an embedded decision tree classifier for feature selection also provided a cross-validation score of 0.91 ± 0.004. When we used the trained model on the test dataset, the classification accuracy was 0.91. Among all of the feature rescaling techniques, quantile transforms that map a variable’s probability distribution to another probability distribution provided the optimal classification accuracies together with Yeo-Johnson. In terms of kernel functions, SVM with a radial basis function kernel provided the optimal results. The combination that provided the minimum cross-validation score was that of the quantile-uniform technique, embedded decision tree classifier, and SVM with a sigmoid kernel, which had a cross-validation score of 0.37 ± 0.01. Table 1 also provides the cross-validation scores of SVMs with quantum kernels (QSVM-Kernel classifiers) on five qubits. The algorithm that provided the best cross-validation score (0.93 ± 0.001) was q_kernel_zz with the quantile-uniform technique for data rescaling combined with the embedded decision tree classifier for feature selection (five features). This finding indicated the slightly superior precision of quantum kernel methods compared with classical ones. When we used the trained model on the test dataset, the classification accuracy was 0.93.
Furthermore, q_kernel_training associated with the quantile-Gaussian technique and embedded decision tree classifier performed better than classical top SVMs with a cross-validation score of 0.92 ± 0.001. When we used the trained model on the test dataset, the classification accuracy was 0.92. In terms of quantum kernel methods, q_kernel_training and q_kernel_zz provided the most accurate results among the quantum algorithms. The combination that provided the minimum cross-validation score was that of MaxAbsScaler, XGBoost, and q_kernel_10, which had a cross-validation score of 0.55 ± 0.005.
Figure 2 presents the cross-validation scores of q_kernel_training run on five qubits with a combination of the quantile-Gaussian technique for data rescaling and a decision tree for feature selection; classical SVM with RBF kernel using the combination of Yeo-Johnson for data rescaling and a decision tree for feature selection; and q_kernel_zz run on five qubits using the combination of the quantile-uniform technique and a decision tree, which were applied to the samples described in Fig. 1. We observed that the three algorithms behaved the same as classical SVM, performing better on samples 1 to 4. Both q_kernel_zz and q_kernel_training performed slightly better than classical SVM on sample 5, indicating an accuracy improvement over the amount of data, such as in classical SVM.

Cross-validation scores of the different algotihms (a) Cross-validation scores of q_kernel_training run on five qubits with the combination of the quantile-Gaussian technique for data rescaling and a decision tree for feature selection; classical SVM with RBF kernel using the combination of Yeo–Johnson for data rescaling and a random forest for feature selection; and q_kernel_zz run on five qubits using the combination of the quantile-uniform technique and a decision tree, which were applied to the samples described in Fig. 1. The results were obtained by running the algorithms with five selected features. (b) Five-fold cross-validation scores obtained with the combination of the quantile-uniform technique for feature rescaling and a decision tree for feature selection to compare the performance of q_kernel_zz (five qubits) and classical SVMs with RBF, linear, polynomial, and sigmoid using five selected features on all of the samples described in Fig. 1 (sample 1 = 260 neurons, sample 2 = 626, sample 3 = 1143, sample 4 = 2080, sample 5 = 22,691). (c) Five-fold cross-validation scores obtained with a combination of the quantile-Gaussian technique for feature rescaling and a decision tree for feature selection to compare the performance of q_kernel_training (five qubits) and classical SVMs with RBF, linear, polynomial, and sigmoid kernels using five selected features on all samples. (d) Five-fold cross-validation scores obtained from the combination of the quantile-uniform and Yeo–Johnson techniques for feature rescaling and a decision tree for feature selection, comparing the performance of q_kernel_zz (20 qubits) and classical SVMs with RBF to classify neuron morphologies using 20 selected features on all of the samples described in Fig. 1 (sample 1 = 260 neurons, sample 2 = 626, sample 3 = 1143, sample 4 = 2080, sample 5 = 22,691). (e) Five-fold cross-validation scores obtained from a combination of the quantile-uniform and Yeo–Johnson techniques for feature rescaling and a decision tree for feature selection to compare the performance of q_kernel_zz (10 qubits) and classical SVMs with RBF to classify neuron morphologies using 10 selected features on all samples. (f) Cross-validation scores of q_kernel_zz run with five qubits with a combination of the quantile-uniform technique for data rescaling and a decision tree for feature selection on both quantum hardware and statevector simulation applied to the different samples described in Fig. 1.
To compare quantum and classical algorithms with the same feature rescaling and feature selection method, we combined the quantile-uniform technique for feature rescaling and decision tree for feature selection with q_kernel_zz on five qubits as well as classical SVMs with RBF, linear, polynomial, and sigmoid kernels to classify neuron morphologies using five selected features on samples 1–5 (Fig. 2). The q_kernel_zz performed better than the SVM with sigmoid on all samples as well as the SVM with linear kernels on samples 1, 4, and 5 (the score was the same on sample 3). The SVM algorithms with a polynomial and RBF kernels performed better on all samples except for sample 5. In addition, we combined the quantile-Gaussian technique for feature rescaling and a decision tree for feature selection to compare the performance of q_kernel_training (five qubits) and classical SVMs with RBF, linear, polynomial, and sigmoid kernels (Fig. 2). The q_kernel_training performed better than the SVM with sigmoid and polynomial kernels on all samples. Furthermore, the SVM algorithms with RBF and linear kernels performed better than q_kernel_training on all samples except for sample 5.
Figure 2 presents the cross-validation scores of q_kernel_zz (with the quantile-uniform technique for data rescaling and decision tree for feature selection), SVM RBF (with the quantile-uniform technique for data rescaling and decision tree for feature selection), and SVM RBF (with Yeo-Johnson for data rescaling and decision tree for feature selection) using 20 as well as 10 selected features, which were applied to all of the samples described in Fig. 1. For q_kernel_zz, we used 20 and then 10 qubits. For 20 qubits, we observed the progression of q_kernel_zz’s performance across samples to be much more pronounced compared with the classical SVMs. The cross-validation score of q_kernel_zz progressed to 0.27 between samples 1 and 2, 0.2 between samples 2 and 3, 0.09 between samples 3 and 4, and 0.15 between samples 4 and 5, reaching an equivalent cross-validation score to those of classical algorithms. For 10 qubits, as we already observed for five selected features, q_kernel_zz’s performance started behind that of the classical SVM RBF, improving across samples until it reached a similar score on sample 5. Both quantum and classical algorithms slightly improved the classification score with the increase in the number of selected features.
Neuron morphology classification using feature extraction
After rescaling data with each of the techniques described in the method section, we combined the outputs with feature extraction techniques to dimensionally reduce the number of features of the dataset to two principal components.
Table 1 presents the SVMs’ cross-validation scores with classical and quantum (two-qubit) kernels. The results from applying the algorithms on sample 5 are displayed. We present the five algorithms that provided the best cross-validation accuracy scores. Here, the five algorithms that provided the optimal accuracy were SVMs with classical feature maps, which indicates that feature extraction techniques may not be the most suitable techniques for the quantum kernel methods used in this study. SVM RBF with Yeo-Johnson for data rescaling and LDA for feature extraction had a cross-validation score of 0.89 ± 0.002. By contrast, the best quantum algorithms (q_kernel_zz), which used MaxAbsScaler for data rescaling and LDA for feature extraction, had a cross-validation score of 0.75 ± 0.005. When we examined the application of SVM RBF with Yeo-Johnson and LDA to the different samples, we observed a cross-validation score of 0.73 for sample 4, 0.68 for sample 3, 0.59 for sample 2, and 0.48 for sample 1. By contrast, the best quantum algorithm applied to sample 4 was q_kernel_zz with MinMaxScaler and PCA with a score of 0.56. The best cross-validation scores were provided by q_kernel_zz with MaxAbsScaler and PCA for sample 3 with a score of 0.51, by q_kernel_zz with MaxAbsScaler and PCA for sample 2 with a score of 0.56, and by q_kernel_zz with Yeo-Johnson and ICA without PCA for sample 1 with a score of 0.54.
Results from quantum computer hardware
Addressing quantum ML performance on today’s noisy quantum computer hardware is of major interest. For neuron morphology classification, we used the quantum algorithm that provided the best cross-validation score on the StatevectorSimulator, namely the q_kernel_zz (five qubits for five selected features) with a combination of the quantile-uniform technique for data rescaling and the embedded decision tree classifier for feature selection. Four 27-qubit superconducting quantum computers available on the IBM Quantum Services were used to run the quantum algorithms (Fig. 3). Due to the limited access time and the running time, we performed four runs by applying the algorithms to samples 1–4 with 5 features selected (five qubits). In the future, the running time is expected to significantly reduce with hardware improvements. For every kernel entry, we used 1024 shots to reduce the statistical uncertainties in evaluating kernel entries on quantum hardware. As indicated by our results in Fig. 2, the difference in the performance achieved by the quantum computer hardware and a quantum computer simulator can be explained by the effect of quantum hardware noise and fluctuated among the hardware runs18.

Quantum Systems (a) Qubit connectivity of the four 27-qubit superconducting quantum computers. Lighter colors mean a higher T2 time for qubits and lower fidelity for coupling. (b) Characteristics of the four quantum systems.
Discussion
To understand how the brain works, the functional identification of distinct types of neurons has been and remains a crucial challenge. For over half a century, neuronal classification based on morphology alone remained a dominant theme in neurobiology; however, it fell out of fashion as physiological and molecular methods matured, and mechanistic, ‘hypothesis‐driven’ research came to be valued over projects with ‘merely descriptive’ aims19. Nevertheless, the first step in neuron taxonomy remains identifying the morphology of neurons, since they are a direct reflection of their synaptic connections, followed by understanding what they do. Identifying the different types of neurons is not only critical for understanding the microscopic anatomy of the nervous system. The different shapes and sizes of the various neuronal types are the expression of a fundamental—probably developmental—relationship among the neurons of a specific type20. Furthermore, many disease processes that affect the nervous system exhibit selectivity and may only involve certain neuronal types while sparing others. To a larger extent, the shape and extent of the dendritic tree define the neuron’s role in the organization of the nervous system as a whole, since the neuron determines the field from which it receives its input. Dendrites form relatively late in the development of neurons, and always preceded by the outgrowth of axons and axon connection. The high-throughput generation of data is expected to enable the learning of a systematic taxonomy from data by considering molecular, morphological, and electrophysiological features21; however, this huge amount of data requires appropriate storage and processing. In a transition in neuroscience over the last decade, data scientists in computational modeling and database experts have gained a major place in the field by extracting knowledge and finding regularity within the data. A central role is given to a proper digital infrastructure and the technical requirements necessary for storing, representing, and analyzing the expected deluge of data necessary for cracking the neural code22. Digital datasets in nearly all subfields of neuroscience require the right computers to be deeply integrated in daily practice. Moreover, a detailed characterization of cellular anatomy is essential for elucidating neuronal computation. Digital reconstructions increase the reliability of anatomical quantifications and enable biologically realistic computational simulations for investigating the neuronal structure–activity relationship23.
Many improvements have been achieved in neural classification based on morphology, molecules, electrophysiology, transcriptomes, genomes, and biophysics, as well as for better understanding biological structures and functions both systematically and reproducibly24. Connectivity-based neuronal classification strategies can be integrated with other cell type–specific information, such as molecular identities (mRNA expression, epigenomics, or genetic labeling), electrophysiological properties, and functional specificities. Single-cell transcriptomic signatures can be associated with specific differential electrophysiological and axon projection properties25,26. Morphological diversity also relates to the intrinsic functional differences between neuron classes27. Neuronal morphology affects network connectivity, plasticity, and information processing. Each neuron must have proper synaptic partners to function effectively and accurately28 and also for establishing the proper circuitry. Distinct neuronal cell types acquire and maintain their identity by expressing different genes. Categorizing cortical neurons into types and then studying the roles of the different types in the function of the circuit represent an essential step toward understanding how different cortical circuits produce distinct computations19. The probing of single-cell mRNA opens up new approaches for understanding brain circuitry, plasticity, and pathology, thus refining the concept of the neuronal cell type29. The increasing number of neuronal features progressively complete cell types. Computational approaches are necessary for quantifying the intricate relationship between neuronal morphology (structure) and physiology (activity)28,30.
More precise knowledge of the identity of the types of neurons that constitute the neural circuits found in different species may serve and benefit the field of comparative connectomics. When achieved, neuron classification will enable genetic access to specific neurons so that they can be marked, manipulated, and studied in diseases that involve specific cell types. A unifying definition of neuronal type should involve multiple criteria (i.e., physiological, morphological, and molecular properties). This implies that they co‐vary,19 rather than being a single ‘essential’ feature,31 and also that the criteria for defining types should be quantitative.
Moreover, studying and clarifying neuronal morphology will allow progress in the knowledge of both molecular and physiological properties. Recordings from and morphological reconstructions of thousands of neurons from cortical brain slices have been used to classify them into hundreds of morpho‐electrical types32. Here, we questioned whether quantum computers may provide the same output as classic computers for the morphological classification of neurons. The most mature, scalable, and useful technique for the molecular profiling of cell type diversity is single‐cell RNA sequencing (scRNA‐seq). This method is easily amenable to automation and, if applied at a sufficiently large scale, could drive a first “complete” cell‐type classification—a potential further application of our approach using quantum computers. By combining classical kernel methods and quantum models, quantum kernel methods such as QSVM can shape new approaches in ML4,12,13,14,15 by using the quantum state space as the feature space. From these algorithms, we expect to obtain an acceleration and increased accuracy on complex data, such as multiple-criteria neuron type classification. However, to fully exploit the computational advantage from quantum kernels, it is necessary to understand the underlying data structure to identify an optimal feature map4,15,18.
Liu and colleagues13 highlighted that quantum machine learning algorithms are capable of providing a quantum computing speed-up without assuming quantum access to data. They succeeded in attaining a substantial quantum advantage by utilizing a quantum version of a conventional support vector machine, which estimates a kernel function aided by a fault-tolerant quantum computer. The process of mapping data samples to a quantum feature space, where kernel entries can be estimated as the transitaion amplitude of a quantum circuit, bears particular relevance to our research. Similar to Liu et al., we utilize quantum kernel estimation algorithms in our methodology. However, beyond the potential speed-up, these algorithms provide the opportunity of encoding high-dimensional data that may confer a classification advantage. Given the complexity and high dimensionality of neuronal data, our methodology could outperform classical methods in more accurately classifying neuron types. We anticipate these algorithms to expedite processing and enhance accuracy on complex data, such as multi-criteria neuron type classification (morphology, electrophysiology, molecules, transcriptome, genome, biophysics), facilitating more systematic and reproducible understanding of biological structures and functions. In our study, we demonstrated the application of quantum kernel methods in classifying neuronal morphologies using quantum algorithms. We trained both classical and quantum kernel methods with varying kernels and empirically explored different combinations of feature rescaling, feature extraction, feature selection, algorithms, and counts of features and qubits to assess potential advantages of quantum kernels on our datasets. In the present study, we have successfully demonstrated a methodology how we can apply the quantum kernel methods for classifying neuron morphologies on quantum computers. The work of Glick et al.16 introduces a unique class of quantum kernels constructed for data with group structures. These quantum kernels are estimated via unitary circuits and potentially offer a quantum advantage, given certain computational hardness assumptions. Their research marks a substantial advancement in the identification of quantum kernels that provide an advantage in the classification of real-world data. Considering the potential interpretation of neuron morphology data as having a mathematical group structure (with different M-types of neurons being regarded as distinct groups), the covariant quantum kernel approach proposed by Glick et al. could prove applicable and advantageous within our framework. The incorporation of these methods and their application to broader datasets could enhance the efficacy of our approach in extracting essential features from the data, resulting in more accurate and efficient neuron type classification.
In this demonstration, we trained classical and quantum kernel methods with different kernels. We empirically studied different combinations of feature rescaling, feature extraction, feature selection, algorithms, and numbers of features and qubits to assess where quantum kernels could provide advantages on our datasets. Our results revealed that quantum kernel methods achieve high classification performance, similar to classical ML methods, with some advantages in several cases. To achieve these results, a few critical parameters must be considered regarding data manipulation, one of which is feature engineering. Depending on the method that we selected for feature rescaling, the accuracy of the classification varied significantly. Another parameter was the method that we chose for reducing the dimension of features. In our case, reducing the data from 43 to 2 dimensions using feature extraction, provided a lower classification accuracy compared with classical algorithms. On the other hand, the use of feature selection methods to reduce the number of features to 5, 10, and 20 significantly improved the accuracy of the quantum models. Another crucial parameter to specify is a suitable feature map. The heuristic application of a ZZFeatureMap and the encoding function described by Havlíček et al.4 provided better results than the others that we assessed in this study8. The quantum algorithm that trains a quantum kernel with QKA16 also improved classification results. Finally, the size of the dataset is another parameter to consider. As in the classical world, we observed that the classification accuracy significantly varied according to the sample size.
The dataset we used was a compromise between achieving sufficient statistical power and the current limitations of quantum computing resources. As quantum technology advances, we anticipate being able to process larger datasets. Additionally, neuroscience itself lacks digitized neurons. The number of available neuronal morphologies for classification is currently limited33,34,35,36. This is a challenge for the neuroscience community. This limitation indeed calls for innovative techniques to increase the variety and volume of neuronal morphologies at our disposal for more comprehensive studies, which could be addressed by generative artificial intelligence. However, we believe that our current work offers valuable preliminary insights into the capabilities and potential of quantum machine learning in the context of neuron classification. In parallel, as the field of quantum technology continues to advance, we anticipate an increased capacity to process more extensive datasets. This casts light on the capabilities and prospective benefits of employing quantum machine learning for neuron classification, acting as a stepping stone for future, more expansive research in this burgeoning field.
Huang et al.37 underscore that despite the potential advantages of quantum computing, we must concede that present-day quantum systems are beset with noise and other errors. Full-fledged, fault-tolerant quantum computers remain an aspirational goal. Another paper by Ezratty38 astutely notes that even with significant advancements, we have yet to witness the implementation of a use case that resolves actual problems faster or more energy-efficiently than classical supercomputers. We operate within the constraints of the noise and small-scale while recognizing the importance of techniques and strategies highlighted by Ezratti. These include enhancing qubit fidelities, various types of quantum error mitigation methods, and the amalgamation of analog and digital approaches. We perceive them as active research areas with the potential to increase the reliability and robustness of our methodology. A recent paper published by Kim et al.39 in Nature presents an experimental demonstration of the remarkable potential of quantum computers to surpass classical simulations by effectively leveraging error learning and mitigation techniques within the system. Their study successfully generated extensive entangled states, which were utilized to simulate the intricate dynamics of spins within a material model. The results yielded precise predictions of crucial properties such as magnetization. This notable study provides compelling evidence for the practical utility of quantum computing even in a pre-fault-tolerant era. As researchers in quantum machine learning, we maintain flexibility and readiness to evolve our methodologies as the field progresses. Methods such as variational quantum algorithms, error mitigation strategies, and quantum circuit compilation are being developed and refined to overcome challenges and maximize the utility of quantum devices. These methods, aimed at counteracting the noise and errors in quantum systems, form a crucial part of our quantum machine learning methodology. Within the context of our work, we have a particular interest in variational quantum algorithms. They allow us to design and optimize quantum circuits for better estimation of quantum kernels, even in the presence of noise. Additionally, error mitigation strategies help us to correct for quantum noise impacting our computation, thus improving the reliability of our results. Moreover, our work also involves benchmarking our quantum machine learning approach against classical algorithms to demonstrate its effectiveness.
Quantum ML can be used on real-world datasets and potentially lead to superior classification results compared with classical methods. Our primary objective was to explore the potential of quantum kernel algorithms in this particular domain of neuron morphology classification, investigate their feasibility and their impact on classification accuracy. By harnessing the capabilities of quantum systems, we seek to advance the field of neuroscience by introducing a novel approach that may offer distinct advantages over classical methods. The unique nature of neuron morphology classification presents its own set of challenges. Neuron classification is a complex task that requires capturing intricate structural details, and traditional machine learning approaches struggle to fully exploit the underlying patterns within the data. By introducing quantum kernel algorithms, we aim to harness the power of quantum computation to potentially enhance the accuracy and effectiveness of neuron morphology classification. Therefore, our contribution lies in the application and adaptation of quantum machine learning techniques to this specific problem.
Over the course of this study, we demonstrate a pathway that quantum ML can be applied to neuron morphology data. We believe that quantum ML will play a key role in the progress of neurosciences.
Methods
Datasets
Morphology‐based, whole rat brain neuron type classification is challenging, given the significant number of neuron types, limited reconstructed neuron samples, and diverse data formats. For our work on neuron morphology classification, we accessed NeuroMorpho.org, the largest collection of publicly accessible 3D neuronal reconstructions and one of the integrated resources in the Neuroscience Information Framework. It offers the opportunity to use morphological data in the context of other relevant resources and diverse subdomains of neuroscience28. The morphologies of neurons are usually described, stored, and shared digitally in two types of neuronal formats: SWC-format files (with data compressed but unstructured) and the 2D- or 3D-image format (structured but with high information dimensions)24. Digitally reconstructed neurons can be used and re-used in various research projects with different scientific aims30.
One challenge during classification relate to the diverse data formats, such as 2D and 3D images (structured, with high dimensions and fewer samples than the complexity of morphologies) or SWC-format files (low dimensional and unstructured)33. We accessed digitally reconstructed neurons by species, brain regions, and cell types on NeuroMorpho.org30. The database contains 173,821 cells derived from/distributed over more than 300 regions. Tools already exist that allow researchers to extract quantitative morphological characteristics from neuronal reconstructions, such as L-Measure40 and NeuroM (https://neurom.readthedocs.io/en/stable/index.html). The reconstructions are usually obtained from fluorescence microscopy preparations or brightfield, which can be synthesized through computation simulations. We extracted features from 27,881 labeled rat neurons. The data contained three main classes (principal, interneuron, and glial cells) with 14 subclasses, including six types of principal cells (ganglion, granule, medium spiny, parachromaffin, Purkinje, and pyramidal cells), six types of interneurons (basket, chandelier, Martinotti, double bouquet, bitufted, and nitrergic) and two types of glial cells (microglia and astrocytes; Fig. 1). Then, from the dataset, we extracted five samples (Fig. 1) for multiclass (ganglion, granule, medium spiny, parachromaffin, purkinje, pyramidal, basket, bitufted, chandelier, double bouquet, Martinotti, nitrergic, astrocytes, and microglia) classification. A total of 43 morphological features were extracted for each reconstructed neuron using the L-Measure tool40 (Fig. 1). We then applied our algorithms on the five samples with a Mahalanobis transformation and the suppression of a neuron when the surface of the soma equaled 0 (Fig. 1). The Mahalanobis distance is the multivariate metric that measures the distance between a point and a distribution. Applying the Mahalonobis distance allowed us to reduce the standard deviation for each feature by deleting neurons from our dataset. The datasets were preprocessed to deal with missing values. If a value within the features was missing, the neuron was deleted from the dataset. Categorical features such as morphology types were encoded, transforming each categorical feature with m possible values.
Data preprocessing
To assess the impact of feature engineering techniques on classical and quantum algorithms, we ran combinations of feature rescaling, feature extraction, and feature selection. For both feature extraction and feature selection, the following feature rescaling techniques were applied:
-
The StandardScaler, which removes the mean and scales to unit variance: \(z=\frac{x-mean\left(x\right)}{standard\, deviation \left(x\right)}\)
-
The MinMaxScaler method: \(z= \frac{{x}_{i}-\mathrm{min}\left(x\right)}{\mathrm{max}\left(x\right)-\mathrm{min}\left(x\right)}\)
-
The MaxAbsScaler method: \(z= \frac{{x}_{i}}{\mathrm{max}\left(abs\left(x\right)\right)}\)
-
The RobustScaler method: \(z= \frac{{x}_{i}- {Q}_{1}\left(x\right)}{{Q}_{3}\left(x\right)-{Q}_{1}\left(x\right)}\)
-
The l2-normalization method: y = \({\left||x\right||}_{2}=\sqrt{\sum_{i=1}^{n}{{x}_{i}}^{2}}\)
-
Logistic data transformation: \(z= \frac{1}{1+ {\mathrm{e}}^{-\mathrm{x}}}\)
-
Lognormal transformation: \(F\left(x\right)= \phi \left(\frac{\mathrm{ln}\left(x\right)}{\sigma }\right), x\ge 0 ; \sigma \ge 0\)
-
Box–Cox (for all x strictly positive): \(B\left(x,\lambda \right)=\left\{\begin{array}{c}\frac{{x}^{\lambda }-1}{\lambda } if \lambda \ne 0\\ \mathrm{log}\left(x\right) if \lambda =0\end{array}\right.\)
-
Yeo-Johnson: \(\psi \left( {\lambda ,y} \right) = \left\{ {-\!\!-} \right.\)
-
The nonparametric quantile transformation (normal and uniform distribution), which transforms the data to a certain data distribution, such as normal or uniform distribution, by applying the quantile function, an inverse function of the cumulative distribution function, to the data. Let X be a random variable following a normal distribution:
$$X \sim \mathcal{N}(\mu ,{\sigma }^{2})$$
Then, the quantile function of X is
where erf−1(x) is the inverse error function.
Let X be a random variable following a continuous uniform distribution:
Then, the quantile function of X is
After rescaling the data with each of the aforementioned methods, we combined the outputs with feature extraction techniques, which led to more than 150 possible combinations per algorithm. For feature extraction, we reduced the dataset to two features (i.e., two principal components). The following feature extraction techniques were tested: PCA, ICA, ICA with PCA, LDA, random projection, truncated SVD, Isomap, neighborhood component analysis, t-distributed stochastic neighbor embedding (t-SNE), locally linear embedding (standard LLE), Hessian locally linear embedding (Hessian LLE), MLLE, LTSA, and multidimensional scaling.
Another way to reduce the dimensionality of the dataset is to experiment with feature selection techniques that assign a score to input features based on how useful they are for predicting a target variable. This also allows an enhanced understanding of which features are crucial for classifying neurons. In this study, we combined all of the feature scaling techniques with the following three tree-based feature selection embedded methods: random forest, decision tree, and XGboost. Such tree-based algorithms are commonly used for prediction. They can also be an alternative method for selecting features by revealing which features are more important, and which are the most used, in making predictions on the target variable (classification). Take random forest for example: It is an ML technique used to solve regression and classification and consists of many decision trees; each tree of the random forest can calculate the importance of a feature. The random forest algorithm can do this because of its ability to increase the pureness of the leaves. In other words, when one trains a tree, feature importance is determined as the decrease in node impurity weighted in a tree—the higher the increment in leaf purity, the more important the feature. It is called pure when the elements belong to a single class. After normalization, the sum of the importance scores calculated is 1. The mean decreased impurity is called the Gini index (between 0 and 1), which is used in random forest to estimate a feature’s importance, measuring the degree or probability of a variable being wrongly classified when it is randomly chosen. The index is 0 when all elements belong to a certain class, 1 when the elements are randomly distributed across various classes, and 0.5 when the elements are equally distributed into some classes. The Gini index is calculated as follows:
where pi is the probability of an element being classified to a distinct class.
Kernel methods
Classifying data using quantum algorithms could provide advantages, such as faster kernel computing compared with classical computing as well as improved classification accuracy. To achieve such advantages, finding and explicitly specifying a suitable feature map is essential; however, this is not straightforward compared with classic kernel specification. Although theoretical work has demonstrated advantages on synthetically generated datasets, concrete, specific applications are required to empirically study whether quantum advantage can be achieved and for what types of datasets and applications. The challenge lies in finding quantum kernels that could provide advantages on now real-world datasets.
In recent years, SVMs have been widely used as binary classifiers and applied to solve multiclass problems. In binary SVMs, the objective is to create a hyperplane that linearly divides n-dimensional data points into two components by searching for an optimal margin, which correctly segregates the data into different classes. The hyperplane that divides the input dataset into two groups can either be in the original feature space or in a higher dimensional kernel space. The selected optimal hyperplane among many hyperplanes that might classify the data corresponds to the one that has the largest margin and that allows the largest separation between classes. This is an optimization problem under constraints, where the distance between the nearest data point and the optimal hyperplane (on each side) is maximized. The hyperplane is then called the maximum-margin hyperplane, which allows one to create a maximum-margin classifier. The closest data points are known as support vectors, while the margin is an area that generally does not contain any data points. If the hyperplane defined as optimal is too close to data points and the margin is too small, predicting new data will be difficult and the model will fail to generalize well.
Studies have built multiclass SVMs based on a binary SVM, such as the all-pair approach, where a binary classification problem for each pair of classes is used41. In addition to linear classification, it is also possible to compute a nonlinear classification using what is commonly called the kernel trick (kernel function), which maps inputs into high-dimensional feature spaces. The kernel function corresponds to an inner product of vectors in a potentially high-dimensional Euclidian space, which is referred to as the feature space. The objective of a nonlinear SVM is to gain separation by mapping the data to a higher dimensional space, as many classification or regression problems are not linearly separable or regressable in the space of the inputs \({\varvec{x}}\). The aim is to use the kernel trick to move to a higher-dimensional feature space given a suitable mapping \({\varvec{x}}\to \phi ({\varvec{x}})\).
Compared with classical ML, one of the present study’s objectives is to find better data patterns within ML processes by leveraging quantum systems that map data to higher dimensions for training purposes and for use by the scientific community. In 2014, Rebentrost et al.42 proposed a theoretically feasible quantum kernel approach based on SVM. In 2019, Havlíček et al.4 as well as Schuld and Killoran14 presented two mplementations of quantum kernel methods. Recently, Havlíček et al.4 experimentally implemented two quantum algorithms in a superconducting processor. The quantum variational classifier, as in conventional SVM, uses a variational quantum circuit to classify data, while the quantum kernel estimator estimates the kernel function and optimizes the classical SVM. The principle, considering a classical data vector \({\varvec{x}}\in{\varvec{\chi}}\), is to map \({\varvec{x}}\) to a n-qubit quantum feature state \(|\phi ({\varvec{x}})\rangle\) by a unitary encoding circuit \(U\left( {\varvec{x}} \right)\), such as \(\phi \left( {\varvec{x}} \right) = U\left( {\varvec{x}} \right)|0^{n} 0^{n} |U^{\dag } \left( {\varvec{x}} \right)\). For two samples \({\varvec{x}},\widetilde{{\varvec{x}}}\), the quantum kernel function K12 is defined as the inner products of two quantum feature states in the Hilbert–Schmidt space \(K\left( {{\varvec{x}},\tilde{\user2{x}}} \right) = tr\left[ {\phi^{\dag } \left( {\varvec{x}} \right)\phi \left( {\tilde{\user2{x}}} \right)} \right]\) and translates as the transition amplitude \(K\left( {{\varvec{x}},\tilde{\user2{x}}} \right) = \left| {0^{n} \left| {U^{\dag } \left( {\varvec{x}} \right)U\left( {\tilde{\user2{x}}} \right)} \right|0^{n} } \right|^{2}\). For instance, the kernel function can be estimated on a quantum computer through a procedure called quantum kernel estimation (QKE), which consists of evolving the initial state \(|0^{n}\) with \(U^{\dag } \left( {\varvec{x}} \right)U\left( {\tilde{\user2{x}}} \right)\) and recording the frequency of the all-zero outcome \({0}^{n}\)16. The constructed kernel is then injected into a standard SVM. By replacing the classical kernel function with QKE, it is possible to classify data in a quantum feature space with SVM.
Quantum kernel method
Although the principle is almost the same as the classical kernel method, the quantum kernel method is a kernel method based on quantum computing properties that maps the data point from an original space to a quantum Hilbert space. The quantum mapping function is critical in quantum kernel methods and has a direct impact on the model’s performance. Finding a suitable feature map in the context of gate-based quantum computers is less trivial than just specifying a suitable kernel on classical algorithms. In quantum kernel ML, a classical feature vector \(\overrightarrow{x}\) is mapped to a quantum Hilbert space using a quantum feature map \({\Phi }\left( {\vec{x}} \right)\), such that \(K_{ij} = \left| {{\Phi }^{\dag } \left( {\vec{x}_{j} } \right)|{\Phi }\left( {\vec{x}_{i} } \right)} \right|^{2}\). There are crucial factors to evaluate when one considers a feature map, such as the feature map circuit depth, the data map function for encoding classical data, the quantum gate set, and the order expansion. One can also find different types of feature maps. One example is the ZFeatureMap, which implements a first-order diagonal expansion where \(\left|S\right|=1\). One must set up various parameters: (i) feature dimensions (the dimensionality of the data, which equals the number of required qubits); (ii) the number of times the feature map circuit is repeated (reps); and (iii) a function that encodes the classical data. Here, no entanglement occurs as there are no interactions between features. Another example is the ZZFeatureMap, which is a second-order Pauli-Z evolution circuit that allows \(\left|S\right| \le 2\) and \(\Phi\) a classical nonlinear function. Here, interactions in the data are encoded in the feature map according to the connectivity graph and the classical data map. Similar to ZFeatureMap, ZZFeatureMap requires the same parameters as well as an additional one, namely the entanglement that generates connectivity (‘full’, ‘linear’, or own entanglement structure). The PauliFeatureMap is the general form that allows one to create feature maps using different gates. It transforms input data \(\overrightarrow{x}\in {\mathbb{R}}^{n}\) as follows:
where \({P}_{i}\in \left\{I, X, Y, Z\right\}\) denotes the Pauli matrices, and S the connectivities between different qubits or datapoints: \(S\in \left\{\left(\genfrac{}{}{0pt}{}{n}{k}\right)combinations, k=1, \dots , n\right\}\). For k = 1 and \({P}_{0}\), we can refer to ZFeatureMap and ZZFeatureMap for k = 2 and \({P}_{0}=Z\) and \({P}_{\mathrm{0,1}}=ZZ\)4.
Eight algorithms were used in the present study. The first one we named q_kernel_zz, which applies a ZZFeatureMap. As described by Havlíček et al.,4 we defined a feature map on n-qubits generated by the unitary:
where H denotes the conventional Hadamard gate, and \(U_{{\phi \left( {\vec{x}} \right)}}\) is a diagonal gate in the Pauli-Z basis.
Taking an example with two qubits, the general expression is as follows:
where
The encoding function that transforms the input data into a higher dimensional feature space was given by
To create a feature map and test different encoding functions, we used the encoding function from Havlíček et al.4 as follows:
For q_kernel_zz, we used the ZZFeatureMap with full entanglement, a different feature dimension depending on the dimensionality reduction techniques (we used two qubits when using feature extraction techniques and five with feature selection techniques); moreover, we repeated the data encoding step two times.
The second algorithm that we tested was q_kernel_default, which applies a PauliFeatureMap (paulis = [‘ZI’,’IZ’,’ZZ’]) with the default data mapping \({\phi }_{S}\):
For q_kernel_default, we used the PauliFeatureMap with full entanglement, a different feature dimension depending on the dimensionality reduction techniques, and we repeated the data encoding step two times.
In addition, we used the five encoding functions presented by Suzuki et al.,8 which are presented as follows for a two-qubit example:
For q_kernel_8, q_kernel_9, q_kernel_10, q_kernel_11, and q_kernel_12, we used the PauliFeatureMap (paulis = ['ZI','IZ','ZZ']) with full entanglement and repeated the data encoding step two times.
It is also possible to train a quantum kernel with QKA,16 which iteratively adapts a parametrized quantum kernel to a dataset, converging to the maximum SVM margin at the same time. We named this q_kernel_training. The algorithm introduced by Glick et al.16 allows a quantum kernel to be learned from a family of kernels (covariant quantum kernels that are related to covariant quantum measurements) and simultaneously converge to the maximum SVM margin, optimizing the parameters in a quantum circuit. To implement it, we prepared the dataset as mentioned previously and defined the quantum feature map. Then, we used the QuantumKernelTrained.fit method to train the kernel parameters and pass them to an ML model. In covariant quantum kernels, the feature map is defined by a unitary representation D(\({\varvec{x}})\) for \({\varvec{x}}\in{\varvec{\chi}}\) and a state \(|\psi \rangle\) = \(U|{0}^{n}\rangle\). The kernel matrix is given as follows43:
For a given group, QKA is used to find the optimal fiducial state.16 In the context of covariant quantum kernels, the equation can be extended to the following:
where quantum kernel alignment learns an optimal fiducial state parametrized by \(\lambda\) for a given group.
To train the quantum kernel, we used QuantumKernel, holding the feature map and its parameters. For all of the trained quantum kernels, we passed them to an ML model (fit and test) using the Qiskit’s QVC for classification (https://qiskit.org). For q_kernel_training, we used QuantumKernel and QuantumKernelTrainer to manage the training process. We selected the kernel loss function (SVCLoss) as input for the QuantumKernelTrainer. Furthermore, we selected the simultaneous perturbation stochastic approximation as the optimizer with 10 as the maximum number of iterations, 0.05 as the learning rate, and 0.05 for the magnitude of the perturbation for the finite difference approximation of the gradients.
Support vector machine
For comparison purposes, we used classical SVMs to classify neuron morphologies. We used the “kernel trick” to move to a higher-dimensional feature space given a suitable mapping \({\varvec{x}}\to \phi ({\varvec{x}})\). In the present study, we implemented SVMs with the following kernels:
-
Linear: \(K\left({x}_{i},{x}_{j}\right)={x}_{i}^{T}{x}_{j}\)
-
Gaussian radial basis function: \(K\left({x}_{i},{x}_{j}\right)={e}^{-\frac{{\Vert {x}_{i}-{x}_{j}\Vert }^{2}}{2{\sigma }^{2}}}\)
-
Polynomial: \(K\left({x}_{i},{x}_{j}\right)=({{\varvec{x}}}_{i}\cdot {{\varvec{x}}}_{j}+a{)}^{b}\)
-
Sigmoidal: \({K\left({x}_{i},{x}_{j}\right)=tanh(a{\varvec{x}}}_{i}\cdot {{\varvec{x}}}_{j}-b)\)
The scikit-learn svm.SVC algorithm (http://scikit-learn.org) was also used. All algorithms were run with all of the different combinations of feature rescaling/feature extraction and feature rescaling/feature selection techniques.
Quantum simulator
The quantum simulations were run on StatevectorSimulator, which is available on Qiskit and IBM Quantum Services. Each circuit was run with 1024 shots. The statevector_simulator was run on Nvidia GPUs.
Classical hardware
We ran the algorithms on a computer with a 12-core (24-thread) AMD Ryzen 9 3900X 12-Core Processor, 32 GB of memory, and Nvidia GeForce RTX 3070 (Driver version: 510.85.02, CUDA version: 11.6).
Quantum hardware
The following four 27-qubit superconducting quantum computers available on IBM Quantum Services were used to run the quantum algorithms: ibmq_kolkota, ibmq_montreal, ibmq_mumbai, and ibmq_auckland. The qubit connectivity and the system characteristics are provided in Fig. 3.
Software
The algorithms were implanted in Python 3 (http://www.python.org) using the scikit-learn (https://scikit-learn.org/stable/) open-source python library. Morphological features were extracted for each neuron using the L-Measure tool,40 allowing the extraction of quantitative morphological measurements from neural reconstructions. The open-source SDK Qiskit (https://qiskit.org) was used to work with quantum algorithms. Based on the aim of the present study, we developed an open-source framework that allowed us to run all of the pipelines; it is available on GitHub: https://github.com/xaviervasques/hephaistos.
Classification assessment and selection
For each experiment, to assess whether patterns were identifiable, we trained the supervised classification algorithms using 80% of the data sample described in Fig. 1, which was randomly chosen, and we assessed the accuracy of predicting the remaining 20%. This method provided an indication of how well algorithms perform on data used for training; however, overfitting and underfitting may have occurred, thereby limiting our understanding of how well the learner would generalize to independent and unseen data. To optimally fit the model, we also applied the k-fold cross-validation test to better estimate accuracy. We computed the scores five consecutive times. The mean score and the 95% confidence interval are presented. Supervised algorithms were tested on neurons gathered by m-types in young and adult rat populations. We selected the top five algorithms where we applied feature extraction techniques and where data were dimensionally reduced to two features. The algorithms were chosen according to the classification accuracy scores based on k-fold cross-validation for both classical and quantum simulation algorithms (two qubits) applied to sample 5 (Fig. 1). To understand the behavior of the chosen algorithms, we then compared the results with the accuracy of the selected algorithms applied to other samples (Samples 1, 2, 3, and 4). In addition, we selected the top five algorithms where we applied feature selection techniques to use the five most important features. The algorithms were chosen according to the classification accuracy scores, which were based on k-fold cross-validation scores for both classical and quantum algorithms (five qubits) applied to sample 5 (Fig. 1). Finally, the quantum simulation algorithms that provided the highest accuracy were run on real quantum hardware on samples 1, 2, 3, and 4, allowing us to run the algorithms in a reasonable computing time.
Data availability
The data that support the findings of this study are available from the corresponding author, X.V., upon reasonable request.
References
Feynman, R. Simulating physics with computers. In International Journal of Theo- retical Physics (1981).
Shor, P. Algorithms for quantum computation: Discrete logarithms and factoring. In Proc. 35th annual symposium on findations of computer science Ieee, 124–134 (1994).
Grover, L. K. A fast quantum mechanical algorithm for database search. In Proc. of the twenty-eighth annual ACM symposium on Theory of computing 212–219 (1996).
Havlíček, V. et al. Supervised learning with quantum-enhanced feature spaces. Nature 567, 209–212 (2019).
Coles, P. J. Seeking quantum advantage for neural networks. Nat. Comput. Sci. 1, 389–390 (2021).
Farhi, E. & Neven, H. Classification with Quantum Neural Networks on Near Term Processors. http://arxiv.org/abs/1802.06002 (2018).
Biamonte, J. et al. Quantum machine learning. Nature 549, 195–202 (2017).
Suzuki, Y. et al. Analysis and synthesis of feature map for kernel-based quantum classifier. Quantum Mach. Intell. 2, 9 (2020).
Cortes, C. & Vapnik, V. Support-vector networks. Mach. Leaming 20, 237–297 (1995).
Vapnik, V. The nature of statistical learning theory. (1995).
Boser, B. E., Guyon, I. M. & Vapnik, V. N. A training algorithm for optimal margin classifiers. 144–152 (ACM Press, 1992). https://doi.org/10.1145/130385.130401.
Schuld, M. Supervised quantum machine learning models are kernel methods. https://doi.org/10.48550/ARXIV.2101.11020 (2021).
Liu, Y., Arunachalam, S. & Temme, K. A rigorous and robust quantum speed-up in supervised machine learning. Nat. Phys. 17, 1013–1017 (2021).
Schuld, M. & Killoran, N. Quantum machine learning in feature Hilbert spaces. https://doi.org/10.48550/ARXIV.1803.07128 (2018).
Hubregtsen, T. et al. Training quantum embedding kernels on near-term quantum computers. https://doi.org/10.48550/ARXIV.2105.02276 (2021).
Glick, J. R.et al. Covariant quantum kernels for data with group structure. https://doi.org/10.48550/ARXIV.2105.03406 (2021).
DeFelipe, J. et al. New insights into the classification and nomenclature of cortical GABAergic interneurons. Nat. Rev. Neurosci. 14, 202–216 (2013).
Wu, S. L. et al. Application of quantum machine learning using the quantum kernel algorithm on high energy physics analysis at the LHC. Phys. Rev. Res. 3, 033221 (2021).
Zeng, H. & Sanes, J. R. Neuronal cell-type classification: challenges, opportunities and the path forward. Nat. Rev. Neurosci. 18, 530–546 (2017).
Gillespie, T. H., Tripathy, S. J., Sy, M. F., Martone, M. E. & Hill, S. L. The Neuron phenotype ontology: A FAIR approach to proposing and classifying neuronal types. Neuroinform https://doi.org/10.1007/s12021-022-09566-7 (2022).
Petilla Interneuron Nomenclature Group et al. Petilla terminology: nomenclature of features of GABAergic interneurons of the cerebral cortex. Nat. Rev. Neurosci. 9, 557–568 (2008).
Tiesinga, P., Bakker, R., Hill, S. & Bjaalie, J. G. Feeding the human brain model. Curr. Opin. Neurobiol. 32, 107–114 (2015).
Ascoli, G. A., Maraver, P., Nanda, S., Polavaram, S. & Armañanzas, R. Win-win data sharing in neuroscience. Nat Methods 14, 112–116 (2017).
Zhang, T. et al. Neuron type classification in rat brain based on integrative convolutional and tree-based recurrent neural networks. Sci Rep 11, 7291 (2021).
Tasic, B. et al. Adult mouse cortical cell taxonomy revealed by single cell transcriptomics. Nat. Neurosci. 19, 335–346 (2016).
Tasic, B. et al. Shared and distinct transcriptomic cell types across neocortical areas. Nature 563, 72–78 (2018).
Stiefel, K. M. & Sejnowski, T. J. Mapping function onto neuronal morphology. J. Neurophysiol. 98, 513–526 (2007).
Halavi, M. et al. NeuroMorpho.Org implementation of digital neuroscience: Dense coverage and integration with the NIF. Neuroinform 6, 241 (2008).
Nelson, S. B., Hempel, C. & Sugino, K. Probing the transcriptome of neuronal cell types. Curr. Opin. Neurobiol. 16, 571–576 (2006).
Ascoli, G. A., Donohue, D. E. & Halavi, M. NeuroMorpho.Org: A central resource for neuronal morphologies. J. Neurosci. 27, 9247–9251 (2007).
Tyner, C. F. The naming of neurons: Applications of taxonomic theory to the study of cellular populations. Brain Behav. Evol. 12, 75–96 (1975).
Markram, H. et al. Reconstruction and simulation of neocortical microcircuitry. Cell 163, 456–492 (2015).
Vasques, X., Vanel, L., Villette, G. & Cif, L. Morphological neuron classification using machine learning. Front. Neuroanat. 10, 102 (2016).
Gouwens, N. W. et al. Classification of electrophysiological and morphological neuron types in the mouse visual cortex. Nat. Neurosci. 22, 1182–1195 (2019).
Santana, R., McGarry, L. M., Bielza, C., Larrañaga, P. & Yuste, R. Classification of neocortical interneurons using affinity propagation. Front. Neural Circuits 7, 185 (2013).
McGarry,. Quantitative classification of somatostatin-positive neocortical interneurons identifies three interneuron subtypes. Front. Neural Circuits https://doi.org/10.3389/fncir.2010.00012 (2010).
Huang, H. -L. et al. Near-term quantum computing techniques: variational quantum algorithms, error mitigation, circuit compilation, benchmarking and classical simulation. https://doi.org/10.48550/ARXIV.2211.08737 (2022).
Ezratty, O. Where are we heading with NISQ? https://doi.org/10.48550/ARXIV.2305.09518 (2023).
Kim, Y. et al. Evidence for the utility of quantum computing before fault tolerance. Nature 618, 500–505 (2023).
Scorcioni, R., Polavaram, S. & Ascoli, G. A. L-Measure: A web-accessible tool for the analysis, comparison and search of digital reconstructions of neuronal morphologies. Nat. Protoc. 3, 866–876 (2008).
Bishwas, A. K., Mani, A. & Palade, V. An all-pair quantum SVM approach for big data multiclass classification. Quantum Inf. Process. 17, 282 (2018).
Rebentrost, P., Mohseni, M. & Lloyd, S. Quantum support vector machine for big data classification. https://doi.org/10.48550/ARXIV.1307.0471 (2013).
IBM. Quantum Kernel Alignment with Qiskit Runtime. https://qiskit.org/documentation/partners/qiskit_ibm_runtime/tutorials/qka.html.
Toledo-Rodriguez, M., Goodman, P., Illic, M., Wu, C. & Markram, H. Neuropeptide and calcium-binding protein gene expression profiles predict neuronal anatomical type in the juvenile rat: Predicting anatomical type from gene expression. J. Physiol. 567, 401–413 (2005).
Wang, Y. Anatomical, physiological, molecular and circuit properties of nest basket cells in the developing somatosensory cortex. Cereb. Cortex 12, 395–410 (2002).
Wang, Y. et al. Anatomical, physiological and molecular properties of Martinotti cells in the somatosensory cortex of the juvenile rat. J. Physiol. 561, 65–90 (2004).
Martone, M. E. et al. The cell-centered database: A database for multiscale structural and protein localization data from light and electron microscopy. Neuroinformatics 1, 379–396 (2003).
Acknowledgements
We would like to thank Anna Lelorieux for her support on the data preparation phase.
Author information
Authors and Affiliations
Contributions
All co-authors have contributed to the concept design and/or drafting of the manuscript. All authors have read and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Vasques, X., Paik, H. & Cif, L. Application of quantum machine learning using quantum kernel algorithms on multiclass neuron M-type classification. Sci Rep 13, 11541 (2023). https://doi.org/10.1038/s41598-023-38558-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-38558-z
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
