
Abstract
In driver monitoring various data types are collected from drivers and used for interpreting, modeling, and predicting driver behavior, and designing interactions. Aim of this contribution is to introduce manD 1.0, a multimodal dataset that can be used as a benchmark for driver monitoring in the context of automated driving. manD is the short form of human dimension in automated driving. manD 1.0 refers to a dataset that contains data from multiple driver monitoring sensors collected from 50 participants, gender-balanced, aged between 21 to 65 years. They drove through five different driving scenarios in a static driving simulator under controlled laboratory conditions. The automation level (SAE International, Standard J3016) ranged from SAE L0 (no automation, manual) to SAE L3 (conditional automation, temporal). To capture data reflecting various mental and physical states of the subjects, the scenarios encompassed a range of distinct driving events and conditions. manD 1.0 includes environmental data such as traffic and weather conditions, vehicle data like the SAE level and driving parameters, and driver state that covers physiology, body movements, activities, gaze, and facial information, all synchronized. This dataset supports applications like data-driven modeling, prediction of driver reactions, crafting of interaction strategies, and research into motion sickness.
Similar content being viewed by others

Background & Summary
The first problem with machine analysis of human state is the collection of data that encompasses the entire scene1. Therefore, a robust dataset about the driver is crucial for an accurate estimation of driver state. Such a dataset should be sufficiently large to yield statistically significant conclusions, be comprehensive by encompassing all pertinent information about the driver and the driving environment, maintain accuracy in its details, and be highly reliable.
For several decades, literature has addressed the concept of driver monitoring. Initially, the primary objective of driver monitoring was to study human driving behavior in manual driving modes across various situations. As a result, datasets gathered for this purpose mainly encompassed vehicle-related information, such as the status of the pedals, steering wheel, and overall vehicle dynamics2. However, as the focus evolved, monitoring the driver state within the vehicle gained significance. This shift recognized that driver state factors, such as fatigue, could profoundly influence behavior during manual driving3,4,5. Consequently, datasets began to incorporate factors like attention and distraction, which hold relevance in both manual and automated driving contexts. While some datasets include merely RGB (color space, combination of red, green, and blue colors) images with corresponding labels6,7,8,9, others offer a more comprehensive view, integrating IR (infrared) or depth images alongside RGB images10. These visuals facilitate the extraction of insights like gaze direction, drowsiness indicators, hand-wheel interactions, and other contextual data, all of which help in assessing driver attention. A significant distraction source while driving is preoccupation with a non-driving-related task (NDRT), leading some datasets to categorize driver activities during both manual and automated driving phases11,12,13,14. Beyond camera footage, physiological data from the driver can furnish further insights, particularly about their cognitive and emotional states15,16,17,18,19. It’s essential to consider not just data about the driver but also about the vehicle, its driving dynamics, and environment to capture a holistic understanding of both the driver and the driving situation20.
Table 1 gives an overview of the characteristics of the frequently cited datasets for driver monitoring and the introduced dataset. Most datasets have notably been created to identify specific, limited factors, such as drowsiness. However, various driver state factors, including attention, workload, and emotion, can interplay and influence driving behavior. These should be assessed collectively. A comprehensive dataset should encapsulate multiple driver state factors. Additionally, elements like driving dynamics and environmental shifts, including traffic and weather conditions, can influence the driver state and should be mentioned in the dataset synchronized with other data points. These elements are invaluable for a deeper understanding and interpretation of the driver’s behavior. Hence, it’s not only beneficial but sometimes essential to incorporate these elements into the monitoring dataset. Furthermore, data should be obtained from a diverse sample, encompassing a broad range of driving scenarios and driver states, ensuring subsequent analyses and findings are holistic and representative. While creating the manD 1.0 dataset, all of the mentioned aspects are taken into account to obtain a comprehensive dataset for driver monitoring.
In the literature, a large number of varying factors are attributed to the driver state, depending on the research focus or data availability. However, many of these factors either overlap with one another or are context-dependent, rendering them not universally representative and well structured. In determining the most pertinent factors to depict the driver state for this dataset, we took into account established driver models and cognitive architectures. Adaptive Control of Thought-Rational (ACT-R)21, Queueing Network-Model Human Processor (QN-MHP)22, and CLARION23 are a few models recurrently employed for both qualitative and computational research24. ACT-R is a cognitive architecture that designates multiple modules to the driver, encompassing the goal, memory, perceptual, and motor functions. Conversely, QN-MHP offers a framework for the mathematical modeling of the driver, defining an array of interconnected queues that denote varied cognitive levels. These queues are categorized as perceptual, motor, or central, with the central queue enveloping cognitive processes like attention, memory, and decision-making. CLARION, on the other hand, outlines a cognitive architecture where modules for perception, action, motor functions, emotion, and goal synergistically interact to shape driver behavior. Considering insights from all three models results in a driver model that underpins the selection of pertinent driver state factors25. Human information processing takes place in three stages: sensory perception, decision-making, and motor response. The factors that determine the driver state are visual attention for sensory perception, emotion, attention, and workload for decision-making, and the driver’s activity and the position of body parts for motor response25. Table 2 offers a comprehensive overview of these driver state factors, the associated measuring sensors, and potential scaling features.
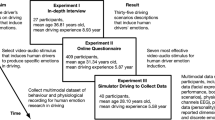
Fig. 1 shows a schema of the study and the employed sensors. The experiment was conducted using a static driving simulator in the laboratory under controlled conditions. Out of the 50 subjects who participated in the study, 11 experienced motion sickness, and their data has been reported separately in the dataset. The other participants drove through five predefined scenarios. Data related to the driver, the (simulated) vehicle, and the environment were recorded throughout the driving sessions and have been included in the presented dataset after appropriate preprocessing.

Schema of the study and the employed sensors.
manD 1.026 can support a variety of research topics concerning human drivers. These include modeling driver state factors and driving behavior, predicting reaction time and type, and exploring the correlations and interrelationships among different driver state factors, for drivers with or without motion sickness.
Methods
Experimental setup
The experiment is conducted in a driving simulator under controlled laboratory conditions at a constant temperature of 22. The driver’s cabin is separated from the rest of the environment to simulate the vehicle cabin, and distractions and disturbances have been kept to the minimum. The ambient light is turned off, but in the simulator a light is available to the driver that mimics the light source in the vehicle. The equipment used is explained below.
Driving simulator
The static driving simulator consists of a driving mockup with three 55″ displays. The displays are situated in front of the driver’s seat, each angled at 120 from one another, providing the driver perspective. The entire mockup is separated from its surroundings to reinforce the sense of presence. Automatic mode during manual driving is facilitated, obviating the need for gear and clutch engagement. During the simulation, in addition to manual driving (SAE L0), automated driving in SAE L1 to L3 is offered as well. Beside the driving equipment, an extra pedal is attached to the right of the gas pedal that serves as a communication interface to the automated system. With this pedal, drivers can robustly answer the automated system’s yes-no questions. A tablet is placed to the right of the steering wheel, providing a gaming interface as NDRT. Additionally, an extra display is positioned on the driver’s right side, playing videos to invoke specific emotional states in drivers before they embark on their ride, thus contributing to the psychological aspects of the simulation. Furthermore, a book, a bottle of water, and cookies are placed within easy reach of the drivers.
The simulator employs the SCANeR studio 2021 software (AVSimulation, Boulogne-Billancourt, France) as a real-time simulation platform. SCANeR’s connectivity with external sensors is enabled by application programming interfaces (APIs) developed using the Python programming language.
Intel RealSense: camera
An Intel RealSense D435 camera (Intel Corporation, Santa Clara, California, U.S.) is mounted on top of the front display 1.5 away from the driver to capture the facial behavior of the participants. RGB images are captured by the camera at a frame rate of 30 FPS and a resolution of 1920 × 1080 px.
SmartEye: eye tracking system
A SmartEye Aurora eye tracking system (SmartEye AB, Gothenburg, Sweden) is fixed on the driving mockup on top of the dashboard directly in front of the driver at a distance of about 0.7 from driver’s eyes. The system utilizes the dark pupil and corneal reflection as an eye tracking principle and has a sampling rate of 120. A SmartEye Pro 9.3 software is supplied with the eye tracker system, which receives data from the eye tracker via a cable and communicates the data with the SCANeR software in real time.
Empatica E4: photoplethysmogram/electrodermal activity sensor/3-axis accelerometer
In this study, a wearable Empatica E4 (Empatica Inc., Boston, Massachusetts, U.S.) wristband is applied to collect physiological data from drivers. The wristband is equipped with a photoplethysmogram (PPG) sensor to measure blood volume pulse (BVP), from which the interbeat interval (IBI), heart rate (HR), and heart rate variability (HRV) can be derived. In addition, the constantly fluctuating changes in the electrical properties of the skin can be monitored via an electrodermal activity (EDA) sensor placed in the wristband. EDA value depends on material of electrodes, position of the sensor, and environmental conditions such as temperature and humidity. Furthermore, the integrated 3-axis accelerometer and infrared thermopile record participants’ arm movement and peripheral skin temperature. The collected data from the Empatica E4 are transmitted via Bluetooth v.4.0 to the E4 Streaming Server software and from there to the SCANeR software via a Python API in real time.
BIOPAC: electroencephalogram/electrocardiogram
Participants are also asked to wear a B-ALERT X10 wireless electroencephalogram (EEG) sensor (BIOPAC, Goleta, California, U.S.) to record their brain activity during the experiment. The sensor has nine wet EEG channels (Poz, Fz, Cz, C3, C4, F3, F4, P3, P4) and an electrocardiogram (ECG) channel to capture heart activity as well. Fig. 2 illustrates the distribution of the EEG electrodes color coded according to the lobes of the brain. Two mastoid electrodes are placed behind the ears. The sensor delivers measurements via Bluetooth to AcqKnowledge 4 software and subsequently to the SCANeR in real time.

Distribution of the EEG electrodes based on International 10-10 system66.
BodiTrak: seat-pressure-sensor mats
Two BodiTrak2 Pro seat-pressure-sensor mats (Vista Medical Ltd, Winnipeg, Manitoba, Canada) are integrated into the acquisition system: one is placed on the driver’s seat and the other on the driver’s backrest. Each mat comprises 1,024 pressure sensors (arranged in a 32 × 32 grid) and spans an area of 0.45 × 0.45. For optimal performance and precision, the seat mat is calibrated to 200, while the backrest mat is set at 100. With each calibration, accuracy at the midpoint of the calibration range is maintained at 10% of the calibration maximum. Thus, for example, for the backrest mat, the highest measurable pressure stands at 100, and the accuracy at the 50 level is 10. Pressure readings are transmitted to a computer via a USB 2.0 connection, with a frequency reaching up to 150, and then forwarded to SCANeR through a Python API in real time.
Experimental procedure
The study is first approved by the ethics commission of TU Dortmund University. An informed consent is also obtained from the participants before start of the experiment. The prerequisite for participation in the experiment is basic English knowledge and the possession of a driver’s license. A couple of the participants got motion sickness during the experiment, especially right at the beginning of the experiment. Thus, they were asked to terminate the experiment. The data collected from this group are provided separately in the dataset for the case of motion sickness research.
The study lasts about two hours for each participation. As first part of the experiment, participants are adequately informed about the goals of the experiment, the procedure, and the data collection by the sensors and the signed consent form is collected. The sensors are then connected and calibrated for each driver. Next, the drivers have the opportunity to drive in the simulator, familiarize themselves with the driving and automated functions, and get used to driving in the virtual environment. Subjects drive once manually with automatic setting and then in automated mode from SAE L1 to SAE L3. They are free to drive as many times as they want until they feel comfortable with driving in the simulator. During the familiarization drive, participants experience takeover request (TOR) and familiarize themselves with the available NDRTs. The TOR has, in addition to the acoustic modality composed of warning beeps and speech, also visual modality in the form of text on the main screen and color effects on the dashboard (see Fig. 3a,b). Three activities are selected as NDRT: the auditory digit-span task27 requested by the automated system during the experiment, the n-back game28, and the Subway Surfers game (co-developed by Kiloo and SYBO Games, released 2012), which are available on the fixed tablet for the driver at any time and reminded by the automated system only on predefined occasions. Drivers are asked to drive realistic and consider the experiment as a real driving situation. Afterwards, they drive five predefined driving scenarios one after the other in alternating order with breaks in between. Before and after scenarios participants fill Differential Emotions Scale (DES)29 questionnaire to subjectively assess their emotions and they are instructed to rate their current feelings. They are also asked verbally by automated system about their emotions during the scenarios to ensure that certain previously evoked emotions are faded. Before some of the scenarios, a video clip is played to the drivers to evoke emotions in the drivers. During the driving scenarios, subjects receive instructions or cues from the automated system about the driving situation and available features, but drivers are free to accept the instructions and choose their preferred response and activity.

Visual modalities of TOR.
Design of experiment
This study aims to create a statistically reliable, multimodal dataset from drivers. A synchronized multi-sensor system is utilized to monitor the drivers, capturing an expansive set of driver state factors across diverse driving situations. This comprehensive approach guarantees a profound understanding of the driver, vehicle, and environment states. Besides, the design’s meticulous structure enhances the statistical reliability of the acquired data.
Participants are briefed on the study’s general objectives and procedures. However, the details and focus points are not disclosed until after the experiment concludes, to maximize the validity of the gathered data.
The research design incorporates various factors, including driver, vehicle, and environment states’ factors. These factors manifest in several types, spanning both qualitative (ordinal/nominal) and quantitative (continuous/discrete) variables. Covariates and potential confounding variables are accounted for as much as possible within the experiment. Age and gender, as two characteristics of the participants are considered covariates and are addressed via stratification30. Other characteristics, such as height and body mass index (BMI), are reported in the dataset but not considered as covariates, as these variables were unknown before the study. Laboratory conditions such as ambient light, noise, and temperature are control variables, which are kept constant during the experiment for all participants. The assumption is that the variables under consideration have correlations and interrelationships and that these may be modeled if a sufficient volume of data is collected in an efficient manner.
From a design perspective, the study implements a repeated measures approach. Each participant is planned to drive five scenarios, efficiently capturing varied data from the same individual across different conditions. This dual-layered approach encompasses both within-subject and between-subject variations. The dataset’s target demographic comprises licensed drivers in Germany. Of the 50 initial participants, those prone to motion sickness are excluded from the test group, however their data are separately available. The test group consists of 39 participants. Balancing the sample size and covariates is deemed crucial, especially for small trials. The covariates age and gender are handled through the stratification method, assigning two levels to each (female or male and under or over 30 years old), resulting in four blocks based on these combinations, as shown in Fig. 4. To prevent carryover effects such as learning or practice effect, fatigue effect, and context effect, counterbalancing is applied across blocks. Given the substantial participant count needed for full counterbalancing, a partial counterbalancing approach is adopted. This ensures equal representation of each scenario in the first two or last three driven scenarios in every block. Each participant goes through the experiment only once, eliminating repetition. In summary, the experimental design is methodically constructed, addressing various factors and potential confounding variables, ensuring the validity and reliability of the gathered data.

Handling covariates age and gender by stratified randomization.
Driving scenarios
In the simulation, one familiarization drive and five unique driving scenarios are created. The primary aim of the familiarization drive is to give participants an opportunity to practice driving in the simulator, adjusting to the virtual environment before moving on to the main part. The objective of the main five driving scenarios is to induce different driver states, including the elicitation of distinct emotions. All of the main driving scenarios are composed of a sequence of events, subtly differentiated from each other to avoid learning effect. This variance among scenarios provides a rich spectrum of driver state factors for study. Tables 3–7 give an overview of the sequence of events for each scenario, including a duration range specified for each event. The duration of each event is different for each driver, depending on their manual driving speed, the time they change from manual to automated mode, and vice versa. The duration of the takeover event is a maximum of 10 s, which is the time budget of the TOR, and if the drivers do not react, an accident occurs and the scenario ends. The n-back games are set to have 30 s duration at each round, however this can also increase or decrease based on engagement of the drivers to the game. Some of the events are not present in the data collected from some participants because the conditions for the events are not met. For example, if the drivers do not switch to automated mode, they are not offered n-back games and data on these events are missing. In general, with the exception of the takeover situations, drivers were not forced to complete the specified tasks in order to create a more realistic ride, resulting in differences in the duration of task completion between individuals.
Each of the five specialized scenarios are designed to evoke a specific emotion, namely: no emotion, anger, surprise, sadness, and fear. Except the scenario with no emotion induction, the other four scenarios are divided into two segments. In the first segment, a particular emotion - anger, surprise, sadness, or fear - is evoked and maintained. The first segment of all scenarios starts in manual driving mode, where a pedestrian on the roadside, a car and a bicycle coming from the opposite side, and a person crossing the road are included as attention objects in the design. The other planned events in the emotional segment of the scenarios are car-following in SAE L2 with a slow car driving ahead, automated driving in SAE L3 with no task for the driver, SAE L3 combined with playing a 2-back game on the NDRT tablet, and playing auditory stimuli from outside the vehicle to attract drivers’ attention. The sequence of these events is selected based on the characteristics of the road in the simulation map, and with the exception of the attention objects at the beginning, the order of the other events is not the same in the different scenarios.
The second segment of each scenario is designed to create an emotionally neutral setting where no explicit emotional provocation occurs. This segment includes additional events such as TOR, playing auditory digit-span task, and speaking on the phone. Each scenario has been carefully designed with its own unique characteristics yet maintaining enough similarities with the other scenarios to ensure comparability of the gathered data. The “no emotion” scenario serves as a control, with no specific emotional state being induced, thereby establishing a baseline. On the other hand, the remaining four scenarios seek to elicit varying emotional states through different means. For instance, the use of emotional video clips prior to the start of the drive, as well as the implementation of monotonous and even-driven methods during the drives, have been employed to trigger the desired emotional responses31. Details on the design of each scenario are described below. The scenarios are named after the emotions that are to be evoked by emotional elements in the scenarios.
Familiarization
The familiarization drive is set along a loop of serene country roads, devoid of traffic lights or other traffic members, thereby ensuring an accident-free practice environment. The virtual drive takes place in the midday hours to provide clear visibility and allow participants to focus solely on mastering the operation of the simulator.
No emotion
In this scenario, no specific emotion is elicited from the participants. This drive also takes place during the midday, providing a neutral environment. During this scenario, participants are initially provided with 2-back game, which then reduces to 1-back game, giving them an activity that requires low cognitive load. When a TOR is presented in this scenario, it is supplemented with a visual reaction cue for drivers: a text reading “Brake” appears in red on the lower left side of the main display, near the navigation instructions, serving as an additional prompt for the driver (see Fig. 3c). Lastly, an auditory digit-span task is played towards the conclusion of the scenario, with its difficulty level fluctuating between one and five.
Anger
The scenario is designed to be driven with anger emotion. To induce this emotion, before the driving session commences, drivers watch a short clip (6′ 7″) from the film “Seven” selected from FilmStim database32 which is assumed to evoke anger feeling. The scenario is set in midday. Throughout the drive, participants are given n-back game and auditory digit-span task at difficulty level 2. TOR is exposed to drivers two times within this scenario. First time TOR has also a reaction clue in the form of a red arrow to right (see Fig. 3c). Second time, in the last part of the drive, the drivers are asked to play the Subway Surfers game when a simple TOR is exposed to them.
Surprise
The driving scenario is specifically designed to elicit a state of surprise in its first part. To accomplish this, several unexpected events are planned at the beginning of the drive. These include a sudden snowfall during sunny weather, a pedestrian who abruptly crosses the road and immediately retraces their steps, followed by an abrupt end of the snowfall31. This sequence of unexpected and rapidly changing events helps create a sense of surprise. As for cognitive tasks, the n-back game begins at difficulty level 2 and then escalates to level 3. The auditory digit-span task played during the drive has difficulty level 3. In the last part a TOR is presented, supplemented with a visual clue in the form of a red arrow pointing to the left, positioned on the lower left side of the main display near the navigation instructions (see Fig. 3c).
Sadness
This scenario is crafted to evoke and sustain a feeling of sadness in the participants in its first part. To instigate this emotion, a short clip (4′ 25″) from the film “City of angels” selected from FilmStim database32 is played for the drivers before the drive commences, which has been identified as effective in eliciting sadness. In addition, the music piece “Adagio for Organ and Strings in G Minor” plays during the first part of the drive until end of first car-following event, to help maintain the induced emotional state33,34. Furthermore, the rainy weather and dark clouds serve to augment the melancholy atmosphere. As for cognitive challenges, the n-back game begins at difficulty level 2 and then escalates to a more demanding level 4, and the auditory digit-span task is also presented at difficulty level 4. In some part of the scenario drivers are asked to read a book aloud. As the drivers’ hands are engaged with holding the book, a simple TOR is introduced due to a group of horses crossing the road.
Fear
To trigger fear, a short clip (4′ 25″) from the film “The shining” selected from FilmStim database32 is played to the drivers before the drive begins. This clip has been identified as effective in eliciting the sense of fear. The setting is further enhanced by playing “A night on the bare mountain” music during the initial part of the drive until beginning of second car-following to sustain the induced fear33. To intensify the fearful ambiance, the drive is set under dark daytime conditions, compelling drivers to switch on the vehicle’s headlights to navigate their path. As for cognitive tasks, the n-back game initiates at difficulty level 2 and then progresses to an advanced level 5, and the auditory digit-span task is held at difficulty level 5, providing high cognitive load. A unique task in this scenario requires drivers to press a communication pedal every time they spot a deer. Simultaneously, a simple TOR is issued when a deer stands in the path of the vehicle.
Computational processing
All data except videos are provided at a sampling rate of 256. However, if the data from a particular sensor is to be used separately, it can be downsampled to the acquisition frequency of the sensor. The videos provided have a sampling rate of 30 FPS.
Synchronization is carried out directly during data recording using the SCANeR studio real-time simulation software. This software has specific interfaces for the BIOPAC sensor, camera, and SmartEye system that enable reliable connection and data synchronization. In addition, the simulation software offers a communication package for self-defined communication with other sensors, which is used in this work to realize the synchronized data stream of Empatica E4 wristband and BodiTrak seat-pressure-sensor mats.
Environment data
Data from the driving environment is collected by SCANeR studio real-time software that initially captures this information at a rate of 20 and resamples to 256 to enhance synchronization. A vital part of the data assessment focuses on the immediate vicinity of the ego-vehicle. When an object is detected in the same lane ahead of the ego-vehicle, distance to object (DTO) is calculated as
where (xego, yego) and (xfront, yfront) denote position of the ego-vehicle and the object ahead, respectively. Furthermore, the time to collision (TTC) with any approaching object or pedestrian is determined as
where vego and vfront are speed of ego-vehicle and front vehicle, respectively.
Video
The video data is recorded using an Intel RealSense D435 camera connected to the video module of the SCANeR software, to ensure synchronization with the remaining data. The videos are captured at a frame rate of 30 FPS. While the original frames are recorded at a size of 640 × 480 px and encompass a larger area, the provided videos in the dataset have been cropped to focus specifically on the face. These cropped frames have a smaller dimension of 200 × 200 px using the OpenCV library35. The resulting videos, centered on facial expressions and reactions, are then saved in the widely compatible MP4 format, facilitating convenient viewing and analysis. The illumination of the driving scenarios is not the same, i.e. three of the scenarios take place during the day, one at night, and one in the rain, resulting in different lighting conditions in the captured videos. However, the data is not preprocessed further to keep it as much raw as possible.
Eye tracking
Eye tracking data is collected at frequency of 120. It encompasses the Percentage of Eyelid Closure (PERCLOS), which is determined from
where EO denotes eyelid opening and n in the length of the data. To ensure that the eye tracking information aligns seamlessly with remaining data, it is subsequently resampled to 256. During the resampling transition, the previous sensor readings are held constant until the new reading arrives to maintain continuity of data.
PPG/EDA
The Empatica E4 wristband sensor, worn on the participant’s dominant arm, collects data regarding wrist acceleration and various physiological indicators. The gathered data is preprocessed, resampled at a rate of 256, and provided in text files.
Acceleration data from the Empatica device is measured within a range of ±2 g, and the sensor’s output is quantified in units of 1/64 g. However, the acceleration data in manD 1.026 is already converted, rendering the unit of acceleration data as m/s2. The original sampling rate of the acceleration data is 32.
BVP is captured with units in nanoWatt (nW) at a sampling rate of 64. The Empatica measures BVP within a range of 500. From this BVP data, the instantaneous HR is calculated and presented under the column “Empatica/HR”. This is achieved by identifying the peaks in the BVP using the scipy.signal package36, taking 240 BPM as the maximum acceptable HR. The HR is then calculated following
where the sampling rate is 256 and \(BV{P}_{{\rm{peak}}}^{i}\) shows the ith peak of the BVP. EDA is sampled at 4, with the unit of measurement being microSiemens (S). The EDA data is then used to derive skin conductance level (SCL) and skin conductance response (SCR) values using the neurokit2 library37. These calculated values are included in the dataset under the columns “Empatica/SCL” and “Empatica/SCR”.
The sensor also captures peripheral skin temperature data of the participants, sampled at 4 and provided in degrees Celsius (°C).
EEG/ECG
The BIOPAC sensor system captures data through nine EEG channels and a single ECG channel, offering dynamic range of 1000. The system operates at a sampling rate of 256. According to the manufacturer’s specifications, the BIOPAC system provides a reported accuracy and resolution of 3.0 peak-to-peak and 0.038 resolution for EEG signals, and 3.0 peak-to-peak with a resolution of 0.06 for ECG signals. Initial signal processing is performed using the AcqKnowledge 4 software, which applies a 0.1 highpass filter and a 67 lowpass filter. Upon acquisition, a data preprocessing step is implemented to correct bad channels; channels presenting extreme average values are detected and interpolated using the average of neighboring channels. If all neighboring channels are similarly compromised, the defective channel is removed. Channels which exhibit a frozen (constant) value are also detected, and these unchanging segments are interpolated using the average of neighboring channels. In cases where all neighboring channels are similarly frozen, the unchanging segment of the channel is removed. In all readings, the initial 6000 steps (about 24 seconds) are discarded as the sensor requires this time to begin accurate data capture. No further preprocessing is applied to the data to keep them as much row as possible and allow the users of the dataset to apply their own data analysis and artifact removal techniques.
Instantaneous HR is also estimated based on ECG data by first calculating the IBI by identifying peaks in the ECG signal using the scipy.signal package, with a defined maximum HR of 240. HR is then computed according to Eq. 4. The “BIOPAC/HR” column demonstrates the calculated HR at a sampling rate of 256; each time a heartbeat is detected, the HR value is updated accordingly. The HR obtained from the ECG data of the BIOPAC sensor can be used as a reference compared to the instantaneous HR obtained by Empatica, because the ECG is acquired with electrodes placed directly on the heart area, so the data is acquired with less delay and noise.
Seat pressure distribution
The BodiTrak2 Pro seat-pressure-sensor mats employ pressure sensors for data acquisition at a sampling rate of 15 FPS. Despite the initial acquisition rate, the provided data is structured in an excel file at a higher sampling rate of 256 FPS synchronized with other provided data. Following data acquisition, a preprocessing phase is implemented to correct any misrecordings. Frames that are entirely zero, potentially due to network failure, are corrected by refilling them with the values from the preceding frame. Beyond the excel data file, heatmaps illustrating pressure distributions on the seat and backrest of drivers are separately provided as images and videos in PNG and MP4 formats, respectively. In creating these videos, the data are initially downsampled to 30, and a Gaussian filter is applied to smooth the data utilizing the scipy.ndimage package. Subsequently, images are plotted based on the smoothed data, and the OpenCV library is used to create videos from these images. As a result, videos of heatmaps that depict the pressure on the seat and backrest of drivers are supplied separately in MP4 format, providing a visual representation of the pressure dynamics over time.
NDRT
During the experiment, data related to NDRTs are gathered to provide comprehensive insights. Specifically, n-back data are collected separately using PsyToolkit38, a specialized toolkit tailored for the demonstration, programming, and execution of cognitive-psychological experiments. Ensuring congruence across datasets, the n-back data is then synchronized with other information at a consistent sampling rate of 256. Similarly, data derived from the digit-span task and the Subway Surfers game are also synchronized, matching the same sampling rate.
Data Records
The open access data is available for all researchers via the Harvard Dataverse repository manD 1.026. The entire dataset can be downloaded either in full or partially, according to the researcher’s requirements. The data is organized into different levels, as depicted in Fig. 5. At the root of the repository, four spreadsheets, a BIDS structure, and a python file are available:
-
“AvailableData.xlsx”, contains a report on the data availability in relation to the participant, the driving scenario, and the sensor. In addition, this file contains information about the sequence of scenarios driven by the participants.
-
“DataInfoSheet.xlsx”, gives information about the data points contained in each file, including explanation, unit, range, and interpretation of the values.
-
“DESResults.xlsx”, outlines the Z-Score of the DES assessments completed by participants before and after driving each scenario.
-
“ParticipantsCharacteristics.xlsx”, contains information about the characteristics of the participants, including biological gender, age, height, BMI, sight correction, years of driving experience, annual driving distance, and experience with assistance systems.
-
“EEG-BIDS.7z” provides the EEG data gathered from all participants in a single brain imaging data structure (BIDS)39,40. BIDS is a standard format for brain imaging data, the use of which is promoted by the neuroimaging community.
-
“DataExtraction.py” consists of functions for the extraction of files with 7z format, the derivation of HR from ECG and BVP, and the creation of heatmaps from pressure sensor readings.

Structure of the provided dataset.
Data gathered from participants who experienced motion sickness during the experiment (withMS) and those who did not (withoutMS) are provided in two separate directories, each having the same structure. However, the number of participants who experienced motion sickness is lower and the data gathered from them is very limited, e.g., only data gathered during the familiarization drive until they clearly felt symptoms of motion sickness such as nausea and dizziness.
Each of the directories includes zipped folders of related participants (P1.7z, P2.7z, …). Each subject comprises one or more familiarization drives and five driving scenarios, which are also compressed in the dataset. Lastly, the data from each scenario is organized into three modules: “EnvironmentState”, which contains data about the surrounding situation and other traffic members provided by the simulation software; “VehicleState”, which contains data about the driving dynamics of the ego-vehicle, again given by the simulation software; and “DriverState”, which contains data about the driver gathered from all sensors.
Data in the DriverState module is further detailed into data gathered from each sensor, including physiological data, seat pressure distributions, eye tracking information, camera videos, NDRT performances, and activity labels. Below is a brief explanation of the data files included in the dataset.
xxxMS/Pxxx/<Scenario_Name>/ EnvironmentState/EnvironmentState.txt
This file provides a comprehensive snapshot of various parameters associated with the driving environment. This file captures information on prevailing weather conditions, specifics of the road including speed limits, and the relative distance to surrounding vehicles. The file also details the lateral shift, speed, and acceleration metrics of nearby vehicles. Additionally, it registers lane-crossing actions of front vehicles and provides crucial data about any objects or pedestrians ahead, including their distance and speed. Another metric included is the TTC which gives information about situation criticality. Beyond these data points “EnvironmentalEvent” column categorizes and labels the environmental scenarios, ranging from “no event” situations to specific events like attention objects, car-following, sound/scene from outside, dog on the road, takeover situation, and accident of ego-vehicle. This file ensures that every aspect of the driving environment is meticulously documented for comprehensive analysis.
xxxMS/Pxxx /<Scenario_Name > / VehicleState/VehicleState.txt
The VehicleState.txt file contains the recorded essential dynamics data, like speed, acceleration, lateral shifts, and lane crossing information. The file also provides insights into the SAE automation level of the vehicle, logs background music being played, and any interaction signals presented to the driver, which might influence their driving behavior or decision-making.
xxxMS/Pxxx /< Scenario_Name > / DriverState/Face_cropped.mp4
Face_cropped.mp4 serves as a visual record of drivers’ facial expressions during their driving experience. Captured from a camera directed at driver’s face, this file offers insights into the real-time emotional and cognitive facial responses of drivers as they navigate various road situations. Each video clip has a resolution of 200 × 200 px and is recorded at a rate of 30 FPS.
xxxMS/Pxxx /< Scenario_Name>/ DriverState/ActivityLabels.txt
The ActivityLabels.txt file stands as a detailed record of both driving and non-driving activities undertaken by drivers throughout the experiment. Generated using simulator markings, this file depicts the spectrum of actions and behaviors exhibited by drivers, providing a foundation for understanding their engagement and responses during the study. It is planned to refine and enhance the granularity of these labels in future works.
xxxMS/Pxxx /<Scenario_Name>/ DriverState/EyeTracking.txt
The EyeTracking.txt file delves into the dynamics of drivers’ ocular movements and focus during driving. A range of parameters is recorded in this file, beginning with the driver’s head position and rotation, offering insights into their overall orientation, specific eye movements like fixations (periods when the eyes are relatively stationary and gather information) and saccades (rapid eye movements between fixation points)41. Furthermore, it registers instances of blinks, providing data on the PERCLOS. The file also contains the pupil diameter, a potential indicator of cognitive load or emotional state. Additionally, the file identifies and logs the specific object or point the driver is looking at, offering a direct glimpse into their focus and attention. This combination of data helps to understanding the driver’s alertness, engagement, and possible distractions.
xxxMS/Pxxx /<Scenario_Name>/ DriverState/PhysiologicalData/PPG_EDA.txt
This file consists of physiological data captured using the Empatica E4 wristband, which drivers put on their dominant hand’s wrist. The file captures the acceleration of the wrist, giving insights into the driver’s hand movements, which can be used to improve data filtering or estimate possible gestures. Moreover, BVP and EDA, two pivotal markers of physiological arousal are recorded in this file. From these raw data, other crucial metrics are derived: HR is extracted from the BVP, while SCL and SCR are deduced from the EDA. Additionally, the file logs the skin temperature, potentially shedding light on stress levels and comfort.
xxxMS/Pxxx /<Scenario_Name>/ DriverState/PhysiologicalData/EEG_ECG.txt
The EEG_ECG.txt file provides an insight into the neural and cardiac activities of individuals, captured using the BIOPAC sensor system. This file primarily encompasses data from nine EEG channels - namely Poz, Fz, Cz, C3, C4, F3, F4, P3, and P4 - each of which maps to specific regions of the brain. These channels record the electrical activity of the brain, shedding light on cognitive processes and states of arousal. Complementing the EEG data is the ECG information, which charts the electrical activity of the heart. Also from the ECG data the HR is extracted, offering a direct measure of cardiac activity. The EEG_ECG.txt file, with its combination of neural and cardiac data, stands as a precise tool and reference for understanding both cognitive and physiological responses in real-time scenarios.
xxxMS/Pxxx /<Scenario_Name>/ DriverState/SeatPressureSensor/SeatPressureDistribution.txt
SeatPressureDistribution.txt file consists of time-stamped pressure-sensor readings from both the seat and backrest of drivers. Each frame contains 2048 readings per frame (structured as 2 × 32 × 32), to represent data from distinct pressure sensors. The columns within the file are distinctly labeled as Seat_xxx and Back_xxx for seat and backrest readings, respectively. The numbering and positioning of these sensors are visually illustrated in the Fig. 6.

Numbering of seat-pressure sensors.
xxxMS/Pxxx /<Scenario_Name>/ DriverState/SeatPressureSensor/Media/seat_xxx.png and back_xxx.png
The files seat_xxx.png and back_xxx.png offer a visual representation of pressure distribution on the two dedicated seat-pressure-sensor mats. These images, sampled at a frequency of 30 FPS, provide a real-time snapshot of how drivers adjust and shift their weight, allowing for an intuitive understanding of their comfort, positioning, and movements.
xxxMS/Pxxx /<Scenario_Name>/ DriverState/SeatPressureSensor/Media/seat_heatmap.mp4 and back_heatmap.mp4
Last components of pressure distribution are the video files seat_heatmap.mp4 and back_heatmap.mp4 with 30 FPS, visualizing the pressure distribution on the seat and backrest over time. These videos are compiled directly from the pressure distribution images housed in the same folder, offering a sequential visualization of driver’s posture and movements throughout the driving experience.
xxxMS/Pxxx /<Scenario_Name>/ DriverState/NDRT/NDRT_xxx.txt
Three NDRT_xxx.txt files provide detailed information, all timestamped, about NDRTs centered around various games. The NDRT_nback.txt captures data on the n-back game. It details the block number ranging from one to four, with each block containing between 25 to 30 digit exposures. Alongside, it records the user’s performance metrics such as score, matches, misses, false alarms, and reaction time. Additionally, the game difficulty level is also documented. The NDRT_Digit_Span.txt file is a report of the digit-span task. It captures timestamps, the playing status marked as ‘Digit_Span_Playing’ column (which turns 1 when the user is actively engaged in the game), the game difficulty level, and user responses which are marked 1 for correct answers and −1 for incorrect ones. Lastly, the NDRT_SubwaySurfers.txt is more streamlined, noting timestamps and the user’s playing status for the game Subway Surfers. Here, 1 indicates active gameplay, while 0 signifies inactivity. This file doesn’t delve into the performance metrics of the game, focusing solely on play engagement.
Technical Validation
In the present contribution, the technical validation included two steps: quality control to check the availability and reliability of the data and experimental validation to check the scope of the data.
Quality control of collected dataset
In the dataset, certain data points are absent due to technical problems. To provide clarity on this, the “DataAvailability.xlsx” file offers an overview of the available data. For environmental data, both the range of data and the sequence of the recorded environmental events are rigidly monitored. Fig. 7 shows example sequences of events for the 5 scenarios.

Sample event sequences for the driving scenarios. 0: no event; 1: attention objects; 2: car-following; 3: sound/scene from outside; 4: dog on the road; 5: takeover situation.
The vehicle data has also undergone the validation. Specifically, the order of interaction signals (see Fig. 8), automation mode, and plots of specific vehicle dynamics parameters, such as travelled distance, have been verified.

Example sequence of interaction signals. 0: no signal; 1: I don’t know; 2: autonomous mode available; 3: TOR; 4: engagement of communication pedal; 5: read the book; 6: looking for a car; 7: car found; 8: a dog on the road; 9: unknown object on the road; 10: a tollgate ahead; 11: unknown objects on the road side; 12: end of the ride; 13: an accident detected; 14: game available on the iPad; 15: phone call; 16: auditory digit-span task.
One of the unique attributes of the driver activity data is its multi-labeling feature, signifying that multiple activities can occur simultaneously. Within the validation process the plausibility of these overlaps are examined.
A few participants opted not to include their videos in the dataset. To further ensure the dataset’s integrity, both face videos and pressure heatmap videos are played back to confirm that they are correctly encoded, contain the requisite information, and are free from playback issues.
In the realm of eye tracking data, any unavailable column is excised. Supplementary columns are provided for the confidence of the head position, head rotation, and pupil diameter. These columns represent the average data quality, with values spanning from zero to one, given directly from the sensor.
The physiological data, procured using the Empatica E4, has been validated by checking the data range for parameters such as BVP, SCL, and Skin temperature. Figs. 9–11 depict the range of gathered data.

BVP [μV] data collected from all participants using Empatica E4 during five driving scenarios.

SCL [μS] data of all participants during five driving scenarios extracted from the EDA.

Skin temperature [°C] of all participants measured with Empatica E4 during five driving scenarios.
When collecting EEG data, before start of the study the resistance between each electrode and scalp of each participant is checked to be less than 80, which shows good quality of connection and data collection according to the manufacturer. After the experiment, for the EEG and ECG datasets, the availability of channels has been confirmed and the pattern of the ECG data is controlled. The primary check was visual observation to ensure that the heartbeats are recognizable and clear anomalies such as constant values or white noise are removed. Later, during the extraction of the HR from the ECG data, the data is checked again by means of a code to make the same corrections if required.
The seat-pressure-sensor mats data is investigated for pressure reading ranges, and any void frames have been populated with preceding frame values.
Engagement with infotainment is confined to either the n-back task or the Subway Surfers game. Thorough checks are implemented to ensure the “Infotainment_Engagement” activity label accurately covers the timestamps when these games are in play, and that there’s no overlapping between the two.
By leveraging video data and following detailed noted protocols, there’s an ambition to craft more nuanced and refined activity labels in the future. This evolution aims to allow future analyses to delve deeper, offering richer insights into behavioral patterns.
Experimental validation
A variety of effects and events were incorporated into the driving scenarios to vary the driver state. One element to elicit different emotions in participants was to play emotional video clips before the start of the three scenarios to elicit the emotions of anger, sadness, and fear. Participants were instructed to watch the video clips, then complete the DES, and drive off. After a one-way ANOVA test42, significant differences were found regarding the average of the rated emotions, enjoyment (F(4, 145) = 11.008, P = 7.9 E-08), surprise (F(4, 145) = 4.88, P = 1.0E-03), sadness (F(4, 145) = 13.86, P = 1.3E-09), anger (F(4, 145) = 9.17, P = 1.2E-06), disgust (F(4, 145) = 18.93, P = 1.5E-12), contempt (F(4, 145) = 4.44, P = 2.1E-03), and fear (F(4, 145) = 5.16, P = 6.4E-04), across all driving scenarios, where F denotes the ratio of between group variation and within group variation and P is the probability of obtaining an F-ratio as large or larger than the one observed, assuming that the null hypothesis of no difference amongst group means is true. Fig. 12 shows subjective ratings of participants. Post hoc analyses (T-test43) reveal that all three video clips evoked intended emotions as well as other emotions. Table 8 shows the significant (P < 0.05) emotions elicited by each video clip. This analysis does not control for the increase in the familywise error rate in the reported statistical analyses. Therefore, replication is recommended.

Z-Score [] of participants’ subjectively rated emotions (DES) immediately before the start of the driving scenarios.
To capture drivers by surprise, unexpected events happen right at the beginning of the respective scenario. The system then verbally asks the drivers about their feelings. The subjects are free whether or not to answer the question with any word of their own choice. Later, when the drivers’ surprise has completely worn off, they are asked again about their feelings. Here again, subjects are free not to answer or to answer with any word they choose. Fig. 13 shows the drivers’ ratings of these two verbal questions. The initial χ2 test44 shows no significant difference between the two ratings (χ2 = 7.23, P = 0.20), however replication is encouraged.

Verbal emotion rating of drivers immediately after surprising events and later on in surprise scenario.
Usage Notes
The dataset comprises about 600. To facilitate the upload and download process, the dataset has been compressed to almost 45 in the 7z format. Files with the 7z extension are compressed archive files created with 7-Zip software, which reduces the file size while preserving quality. Most common file archiving software, such as WinRAR or 7-Zip, can unpack these files. Also, in the DataExtraction.py file, the function find_and_extract_7z_files() can be used to extract the zipped files.
The scope of the dataset is provided in *.txt format, which is suitable for most text viewing programs that can process large files and analyze the data. All data files have header and time stamps. By integrating this dataset with any other dataset the used sensor for collection of the data and the sampling rate should be considered.
The broad coverage of the manD 1.0 dataset makes it suitable for various research questions. The dataset can be used to train driving behavior models using data collected from drivers during manual driving. It can be used to predict the reaction time and type of drivers in critical situations by using the data from takeover situations. Since all participants go through the same driving scenarios, the differences between individuals can be investigated. There are also some similarities between the scenarios, which provides the opportunity to compare the effects of different emotions on individuals’ driving behavior. In addition, the dataset contains data from multiple sensors that allow for the measurement of several synchronized psychophysiological factors. These measurements, along with vehicle and environmental state data, can be used to develop and train cognitive architectures and mental state models. In addition, the scenarios contain various interaction signals whose effect on the participants’ behavior can be investigated and evaluated for the development of new interaction concepts. The inclusion of data collected from participants with motion sickness experience during the experiment may be helpful for research towards this concept in the simulator. The data is mainly collected in manual driving mode and includes all sensor readings. Some examples of research questions that can be investigated using this part of dataset are the research on similarities in driving behavior of drivers with motion sickness, and the early detection of motion sickness based on physiological and behavioral data before the onset of the annoying symptoms such as headache and dizziness.
Code availability
The custom code “DataExtraction.py” is available26 from the same repository, (https://doi.org/10.7910/DVN/SG9TMD). The code consists of functions to generate HR from BVP and ECG as well as functions to create images and videos of seat pressure distribution heatmaps. It also includes functions for extracting zipped files of the dataset. The code is tested and run with Python 3.1145.
References
Vinciarelli, A., Pantic, M. & Bourlard, H. Social signal processing: survey of an emerging domain. Image and Vision Computing 27, 1743–1759, https://doi.org/10.1016/j.imavis.2008.11.007 (2009).
Zhang, Y., Li, J. & Guo, Y. Vehicle driving behavior. IEEE Dataport https://doi.org/10.21227/qzf7-sj04 (2018).
Petrellis, N. et al. Nitymed. IEEE Dataport https://doi.org/10.21227/85xe-3f88 (2022).
Abtahi, S., Omidyeganeh, M., Shirmohammadi, S. & Hariri, B. Yawdd: Yawning detection dataset. IEEE Dataport https://doi.org/10.21227/e1qm-hb90 (2020).
Nasri, I., Karrouchi, M., Snoussi, H., Kassmi, K. & Messaoudi, A. Detection and prediction of driver drowsiness for the prevention of road accidents using deep neural networks techniques. In Bennani, S., Lakhrissi, Y., Khaissidi, G., Mansouri, A. & Khamlichi, Y. (eds.) WITS 2020, 57–64, https://doi.org/10.1007/978-981-33-6893-4_6 (Springer, Singapore, 2022).
Ezzouhri, A., Charouh, Z., Ghogho, M. & Guennoun, Z. Howdrive 3d: driver distraction dataset. IEEE Dataport https://doi.org/10.21227/f9z3-0438 (2021).
Montoya, A., Holman, D., SF_data_science, Smith, T. & Kan, W. State farm distracted driver detection. Kaggle https://kaggle.com/competitions/state-farm-distracted-driver-detection (2016).
Yang, D. et al. All in one network for driver attention monitoring. In 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2258–2262, https://doi.org/10.1109/ICASSP40776.2020.9053659 (2020).
Eraqi, H. M., Abouelnaga, Y., Saad, M. H. & Moustafa, M. N. Driver distraction identification with an ensemble of convolutional neural networks. Journal of Advanced Transportation 2019, https://doi.org/10.1155/2019/4125865 (2019).
Ortega, J. D. et al. Dmd: A large-scale multi-modal driver monitoring dataset for attention and alertness analysis. In Bartoli, A. & Fusiello, A. (eds.) Computer Vision – ECCV 2020 Workshops, 387–405, https://doi.org/10.1007/978-3-030-66823-5_23 (Springer International Publishing, Cham, 2020).
Yuksel, A. S. & Atmaca, S. Driving behavior dataset. Mendeley Data https://doi.org/10.17632/jj3tw8kj6h.2 (2020).
Schwarz, A., Haurilet, M., Martinez, M. & Stiefelhagen, R. Driveahead - a large-scale driver head pose dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 1–10, https://doi.org/10.1109/cvprw.2017.155 (2017).
Jegham, I., Ben Khalifa, A., Alouani, I. & Mahjoub, M. A. A novel public dataset for multimodal multiview and multispectral driver distraction analysis: 3mdad. Signal Processing: Image Communication 88, https://doi.org/10.1016/j.image.2020.115960 (2020).
Martin, M. et al. Drive & Act: A multi-modal dataset for fine-grained driver behavior recognition in autonomous vehicles. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), https://doi.org/10.1109/iccv.2019.00289 (2019).
Abril, J. D., Castillo-Castaneda, E. & Avilés, O. F. Physiological and emotional states during virtual driving. IEEE Dataport https://doi.org/10.21227/9fmc-nw22 (2022).
Healey, J. & Picard, R. Detecting stress during real-world driving tasks using physiological sensors. IEEE Transactions on Intelligent Transportation Systems 6, 156–166, https://doi.org/10.1109/TITS.2005.848368 (2005).
Taylor, P. et al. Warwick-jlr driver monitoring dataset (dmd): statistics and early findings. In Proceedings of the 7th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, AutomotiveUI ‘15, 89–92, https://doi.org/10.1145/2799250.2799286 (Association for Computing Machinery, New York, NY, USA, 2015).
Othman, W., Kashevnik, A., Ali, A. & Shilov, N. Drivermvt: in-cabin dataset for driver monitoring including video and vehicle telemetry information. Data 7, https://doi.org/10.3390/data7050062 (2022).
Dcosta, M. Simulator study i: a multimodal dataset for various forms of distracted driving. OSF https://doi.org/10.17605/OSF.IO/C42CN (2017).
Jha, S. et al. The multimodal driver monitoring database: a naturalistic corpus to study driver attention. IEEE Transactions on Intelligent Transportation Systems 23, 10736–10752, https://doi.org/10.1109/TITS.2021.3095462 (2022).
Anderson, J. R. & Lebiere, C. J. The Atomic Components of Thought (Psychology Press, 2014).
Liu, Y., Feyen, R. & Tsimhoni, O. Queueing network-model human processor (qn-mhp): a computational architecture for multitask performance in human-machine systems. ACM Trans. Comput.-Hum. Interact. 13, 37–70, https://doi.org/10.1145/1143518.1143520 (2006).
Sun, R. Anatomy of the Mind: Exploring Psychological Mechanisms and Processes with the Clarion Cognitive Architecture (Oxford University Press, 2016).
Park, J. & Zahabi, M. A review of human performance models for prediction of driver behavior and interactions with in-vehicle technology. Human Factors 0, https://doi.org/10.1177/00187208221132740. PMID: 36259529 (2022).
Dargahi Nobari, K., Albers, F., Bartsch, K., Braun, J. & Bertram, T. Modeling driver-vehicle interaction in automated driving. Forschung im Ingenieurwesen 86, 65–79, https://doi.org/10.1007/s10010-021-00576-6 (2022).
Dargahi Nobari, K. & Bertram, T. manD 1.0. Harvard Dataverse https://doi.org/10.7910/DVN/SG9TMD (2023).
Daneman, M. & Merikle, P. M. Working memory and language comprehension: a meta-analysis. Psychonomic Bulletin & Review 3, 422–433, https://doi.org/10.3758/bf03214546 (1996).
Kirchner, W. K. Age differences in short-term retention of rapidly changing information. Journal of Experimental Psychology 55, 352–358, https://doi.org/10.1037/h0043688 (1958).
Izard, C., Dougherty, F., Bloxom, B. & Kotsch, N. The differential emotions scale: a method of measuring the subjective experience of discrete emotions. Nashville (1974).
Kernan, W. N., Viscoli, C. M., Makuch, R. W., Brass, L. M. & Horwitz, R. I. Stratified randomization for clinical trials. Journal of Clinical Epidemiology 52, 19–26, https://doi.org/10.1016/s0895-4356(98)00138-3 (1999).
Dargahi Nobari, K., Velasquez, C. & Bertram, T. Emotion induction strategies in driving simulator for validated experiments. In Human Systems Engineering and Design (IHSED2021) Future Trends and Applications, https://doi.org/10.54941/ahfe1001156 (AHFE International, 2021).
Schaefer, A., Nils, F., Sanchez, X. & Philippot, P. Assessing the effectiveness of a large database of emotion-eliciting films: a new tool for emotion researchers. Cognition & Emotion 24, 1153–1172, https://doi.org/10.1080/02699930903274322 (2010).
Krumhansl, C. L. An exploratory study of musical emotions and psychophysiology. Canadian Journal of Experimental Psychology/Revue canadienne de psychologie expérimentale 51, 336–353, https://doi.org/10.1037/1196-1961.51.4.336 (1997).
Peretz, I. Music and emotion: perceptual determinants, immediacy, and isolation after brain damage. Cognition 68, 111–141, https://doi.org/10.1016/s0010-0277(98)00043-2 (1998).
Bradski, G. The OpenCV Library. Dr. Dobb’s Journal: software tools for the professional programmer 25, 120–123 (2000).
Virtanen, P. et al. SciPy 1.0: fundamental algorithms for scientific computing in python. Nature Methods 17, 261–272, https://doi.org/10.1038/s41592-019-0686-2 (2020).
Makowski, D. et al. NeuroKit2: a python toolbox for neurophysiological signal processing. Behavior Research Methods 53, 1689–1696, https://doi.org/10.3758/s13428-020-01516-y (2021).
Stoet, G. PsyToolkit. Teaching of Psychology 44, 24–31, https://doi.org/10.1177/0098628316677643 (2016).
Gorgolewski, K. J. et al. The brain imaging data structure, a format for organizing and describing outputs of neuroimaging experiments. Scientific Data 3, https://doi.org/10.1038/sdata.2016.44 (2016).
Pernet, C. R. et al. Eeg-bids, an extension to the brain imaging data structure for electroencephalography. Scientific Data 6, https://doi.org/10.1038/s41597-019-0104-8 (2019).
Fischer, B. & Weber, H. Express saccades and visual attention. Behavioral and Brain Sciences 16, 553–567, https://doi.org/10.1017/s0140525x00031575 (1993).
Girden, E. R. ANOVA: Repeated Measures. 84 (Sage Publications, Inc., 1992).
Student. The probable error of a mean. Biometrika 6, 1–25 (1908).
Pearson, K. X. on the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science 50, 157–175, https://doi.org/10.1080/14786440009463897 (1900).
Van Rossum, G. & Drake, F. L. Python 3 Reference Manual (CreateSpace, Scotts Valley, CA, 2009).
Kopuklu, O., Zheng, J., Xu, H. & Rigoll, G. Driver anomaly detection: A dataset and contrastive learning approach. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 91–100, https://doi.org/10.1109/WACV48630.2021.00014 (2021).
Li, L. & Zhang, W. A driving fatigue dataset of driver’s facial features and heart rate features. 2020 IEEE International Conference on Information Technology,Big Data and Artificial Intelligence (ICIBA) 1, 293–298, https://doi.org/10.1109/ICIBA50161.2020.9277178 (2020).
Li, W. et al. A spontaneous driver emotion facial expression (defe) dataset for intelligent vehicles: Emotions triggered by video-audio clips in driving scenarios. IEEE Transactions on Affective Computing 14, 747–760, https://doi.org/10.1109/TAFFC.2021.3063387 (2023).
Bradley, M. M. & Lang, P. J. Measuring emotion: The self-assessment manikin and the semantic differential. Journal of Behavior Therapy and Experimental Psychiatry 25, 49–59, https://doi.org/10.1016/0005-7916(94)90063-9 (1994).
Solovey, E. T., Zec, M., Perez, E. A. G., Reimer, B. & Mehler, B. Classifying driver workload using physiological and driving performance data. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, https://doi.org/10.1145/2556288.2557068 (ACM, 2014).
Gable, T. M., Kun, A. L., Walker, B. N. & Winton, R. J. Comparing heart rate and pupil size as objective measures of workload in the driving context. In Adjunct Proceedings of the 7th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, https://doi.org/10.1145/2809730.2809745 (ACM, 2015).
Lee, H. B. et al. Nonintrusive biosignal measurement system in a vehicle. In 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, https://doi.org/10.1109/iembs.2007.4352786 (IEEE, 2007).
Yamakoshi, T. et al. A preliminary study on driver’s stress index using a new method based on differential skin temperature measurement. In 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, 722–725, https://doi.org/10.1109/IEMBS.2007.4352392 (IEEE, 2007).
Hassib, M., Pfeiffer, M., Schneegass, S., Rohs, M. & Alt, F. Emotion actuator. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, https://doi.org/10.1145/3025453.3025953 (ACM, 2017).
Dong, Y., Hu, Z., Uchimura, K. & Murayama, N. Driver inattention monitoring system for intelligent vehicles: a review. IEEE Transactions on Intelligent Transportation Systems 12, 596–614, https://doi.org/10.1109/tits.2010.2092770 (2011).
Recarte, M. Á., Pérez, E., Conchillo, Á. & Nunes, L. M. Mental workload and visual impairment: differences between pupil, blink, and subjective rating. The Spanish Journal of Psychology 11, 374–385, https://doi.org/10.1017/s1138741600004406 (2008).
Victor, T. W., Harbluk, J. L. & Engström, J. A. Sensitivity of eye-movement measures to in-vehicle task difficulty. Transportation Research Part F: Traffic Psychology and Behaviour 8, 167–190, https://doi.org/10.1016/j.trf.2005.04.014 (2005).
Young, K. & Regan, M. Driver distraction: a review of the literature. Distracted driving 2007, 379–405 (2007).
Kahneman, D., Tursky, B., Shapiro, D. & Crider, A. Pupillary, heart rate, and skin resistance changes during a mental task. Journal of Experimental Psychology 79, 164–167, https://doi.org/10.1037/h0026952 (1969).
Itoh, M. Individual differences in effects of secondary cognitive activity during driving on temperature at the nose tip. In 2009 International Conference on Mechatronics and Automation, https://doi.org/10.1109/icma.2009.5246188 (IEEE, 2009).
Marquart, G., Cabrall, C. & de Winter, J. Review of eye-related measures of drivers’ mental workload. Procedia Manufacturing 3, 2854–2861, https://doi.org/10.1016/j.promfg.2015.07.783 (2015).
Wang, Y., Reimer, B., Dobres, J. & Mehler, B. The sensitivity of different methodologies for characterizing drivers’ gaze concentration under increased cognitive demand. Transportation Research Part F: Traffic Psychology and Behaviour 26, 227–237, https://doi.org/10.1016/j.trf.2014.08.003 (2014).
Nocera, F. D., Camilli, M. & Terenzi, M. Using the distribution of eye fixations to assess pilots’ mental workload. Proceedings of the Human Factors and Ergonomics Society Annual Meeting 50, 63–65, https://doi.org/10.1177/154193120605000114 (2006).
Dargahi Nobari, K., Hugenroth, A. & Bertram, T. Position classification and in-vehicle activity detection using seat-pressure-sensor in automated driving. In AmE 2022-Automotive meets Electronics; 13. GMM-Symposium, 1–6 (VDE, 2022).
Dargahi Nobari, K. & Bertram, T. Generalized model for driver activity recognition in automated vehicles using pressure sensor array. In AHFE International, https://doi.org/10.54941/ahfe1002733 (AHFE International, 2022).
Chatrian, G. E., Lettich, E. & Nelson, P. L. Ten percent electrode system for topographic studies of spontaneous and evoked EEG activities. American Journal of EEG Technology 25, 83–92, https://doi.org/10.1080/00029238.1985.11080163 (1985).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
K.D.N. and T.B. discussed and conceived the experiment. K.D.N. conducted the experiment and analyzed the results. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dargahi Nobari, K., Bertram, T. A multimodal driver monitoring benchmark dataset for driver modeling in assisted driving automation. Sci Data 11, 327 (2024). https://doi.org/10.1038/s41597-024-03137-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03137-y
